Embed Size (px)
Citation preview

One-class classifier ensemble pruning and weightingwith firefly algorithm
Bartosz KrawczykDepartment of Systems and Computer Networks, Wroclaw University of Technology, Wybrzeze Wyspianskiego 27, 50-370 Wroclaw, Poland
a r t i c l e i n f o
Article history:Received 1 January 2014Received in revised form19 May 2014Accepted 7 July 2014
Keywords:One-class classificationClassifier ensemblesEnsemble pruningWeighted fusionFirefly algorithmDiversity
a b s t r a c t
This paper introduces a novel technique for forming efficient one-class classifier ensembles. It combinesan ensemble pruning algorithm with weighted classifier fusion module. The ensemble pruning isrealized as a search problem and implemented through a swarm intelligence approach. A fireflyalgorithm is selected as the framework for managing the process of reducing the size of the classifierpool. Input classifiers are coded as population members. The interactions between fireflies are realizedthrough the consistency measure, which describes the effectiveness of individual one-class classifiers. Anew pairwise diversity measure, based on calculating the intersections between spherical one-classclassifiers, is used for controlling the movements of fireflies. With this, we indirectly implement a multi-objective optimization, as selected classifiers have at the same time high individual accuracy and aremutually diverse. The fireflies form groups and for each group the best representative is selected – thusrealizing the pruning task. Additionally, a classifier weight calculation scheme based on the brightness offireflies is applied for weighted fusion. Experimental analysis, backed-up with statistical tests, proves thequality of the proposed method and its ability to outperform state-of-the-art algorithms for selectingone-class classifiers for the classification committees.
& 2014 Elsevier B.V. All rights reserved.
1. Introduction
Machine learning techniques have found themselves a plethoraof applications in modern world over the last few decades [21].However, with ongoing advancement of the technology, we arefaced with novel problems that cannot be handled by standardclassification method. Big data, data streams, social networks orreal-time computer vision are popular examples of contemporarychallenging areas for machine learning society. All of these areasrely on the assumption that representative data from all possibleclasses is easily available during the classifier building step.However, in many real-life situations we are unable to satisfy thisassumption. That is why a new paradigm in machine learning,called one-class classification (OCC) has arisen.
One-class classification assumes that during the classifiertraining stage objects coming from only a single distribution areat disposal [25]. Therefore, it aims at creating a description ofavailable data that will allow to characterize its unique properties.During the exploitation of the classifier new, unseen objects mayappear. They can origin from the target concept, or from someunknown distributions. Such instances are called outliers and
must be detected by one-class classifiers. OCC can be seen as adichotomization between the known and unknown samples. Thisfinds numerous applications in situations, where we can easilygather positive examples but gathering a representative collectionof counterexamples is costly, unethical, time-consuming or simplyimpossible [16,22]. Due to the specific nature of OCC task (lack ofcounterexamples), methods that improve the discrimination abil-ities of the recognition system (robustness to outliers), withoutsacrificing its generalization abilities (avoiding overfitting on thetarget class) are an important research track in this area [44].Recently, the possibility of applying ensemble methods for OCC isgaining increasing attention [30].
Currently, most of the classifier committees for OCC are basedon existing methods originally designed for multi-class problems,such as boosting, bagging or random forest [9,10,48]. However,they do not take into consideration the specific nature of OCCproblems which results in their varied performance. There is still alack of dedicated methods for building OCC ensembles [47]. Thereare some works done on introducing pruning to OCC ensembles[6] and dedicated diversity measures (as the standard ones tend tofail in this task) [28]. Yet to execute them, one needs an effectivemethod for checking all the possible combinations of ensemblemembers, as simple ordering methods do not deliver satisfactoryresults. Therefore, an accurate search engine must be proposed to
Contents lists available at ScienceDirect
journal homepage: www.elsevier.com/locate/neucom
Neurocomputing
http://dx.doi.org/10.1016/j.neucom.2014.07.0680925-2312/& 2014 Elsevier B.V. All rights reserved.
E-mail address: [email protected]
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i
Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎

tackle OCC ensemble pruning in a reasonable computational time.Additionally, there is a need for designing combination methodsthat will allow to aggregate effectively individual outputs ofensemble members. So far, only simple methods based on majorityvoting or averaging support values of individual learners are used.Sophisticated fusion blocks had been proven to significantlyimprove the ensemble performance in multi-class problems, soone may suspect that this may be a promising direction for OCC.One may identify pruning and weighting methods as importantproblems in forming OCC ensembles, which require a thoroughinvestigation.
In this paper, we propose a novel method for constructing OCCensembles that has built-in pruning and weighting modules. Itconducts simultaneously a classifier selection and weighted com-bination to fully exploit the potential of given pool of classifiers. Aswe aim at finding the best possible subset of classifiers, wepropose to apply a metaheuristic optimization procedure to finda good solution in a reasonable amount of time – an importantproblem for large pool of available learners. We implement theoptimization task as a swarm-based search method by using fireflyalgorithm. Final, reduced population of fireflies represent thepruned ensemble. For selecting one-class classifiers, we utilize acombined criterion consisting in individual classifier's consistency(a dedicated measure for evaluating quality of one-class classifiers)and a pairwise diversity of classifiers in the pool. We propose anovel method for calculating weights of classifier, based on theoutput of firefly algorithm.
Below, let us list the main contributions of this paper:
� We propose a new approach for pruning ensembles of one-class classifiers. We utilize the swarm intelligence approach,implemented as firefly algorithm. We encode the given initialpool of classifiers as a population of fireflies. The fireflies formgroups, based on their initial brightness. By applying a com-bined criterion that checks both accuracy and diversity, weensure that formed groups are mutually diverse and comple-mentary. We select single representatives for each group, thusreducing the number of classifiers in the committee.
� We modify the firefly algorithm, in order to adapt it to thespecific nature of forming one-class classifier committees. Thebrightness of fireflies is expressed by the consistency measure,which is a dedicated performance measure for one-class clas-sifiers. This is motivated by the fact, that due to the lack ofcounterexamples during the training process one cannot usestandard measures, such as accuracy. To measure the locationof a single firefly, we do not use distance measures, as they do
not give any insight into the performance of the ensemble.Instead, we suggest to use a novel diversity measure based ongeometric intersection between decision boundaries, that isdedicated to one-class problems. As we show further in thepaper, it satisfies all the conditions imposed upon distancemeasures, while giving a valuable information about the classi-fiers under consideration.
� We introduce a weighting scheme for modifying the influenceof the selected classifiers on the fusion step. Weights arecalculated according to the average lightness of fireflies in thegiven group. Then, the averaged value is assigned to therepresentative of this group and used as its weight in thefusion process. This way, we ensure that the final weight doesnot reflect the single classifier, but the entire group. With thiswe do not lose the information from the remaining classifiers,while reducing the quantity of learners in the ensemble.
The remaining parts of the manuscript are organized as follows.In the next Section necessary background in the problem if one-class classification is presented. Section 3 describes in detail all thecomponents of the introduced firefly-based one-class ensemblepruning algorithm. Section 4 presents the experimental investiga-tions carried on a set of benchmark databases, and comparisonwith several state-of-the-art ensembles for one-class problems.The final Section concludes the paper.
2. One-class classification
OCC aims to distinguish the target concept objects from thesepossible outliers, hence it is often referred to as learning in theabsence of counter-examples. The OCC is quite similar to binaryclassification but the primary difference is how the one-classclassifier is trained. In the standard dichotomy problems we mayexpect objects from the other classes to predominantly come fromone direction. Here, the available class should be separated fromall the possible outliers – this leads to a situation in which adecision boundary should be estimated in all directions in thefeature space around the target class. An example of a OCCproblem is depicted in Fig. 1.
OCC is a solution to many real-life problems where data from asingle class is abundant but is hard or even impossible to obtainfor other objects. This is often the case in problems such asintrusion detection [18], machine fault diagnosis [2], or solid-state fermentation [22].
Fig. 1. The idea of one-class classification. (Left) Boundary one-class classifier with volume enclosing all the relevant samples from the target class. (Right) outlier objects(red) that appear during the exploitation of the model. (For interpretation of the references to color in this figure caption, the reader is referred to the web version of thispaper.)
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎2
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i

Several methods dedicated to solving OCC problems have beenrecently introduced. In the relevant literature two mainapproaches can be distinguished:
� Methods based on density estimation of a target class, whichcan be simple and effective in some cases. However, thisapproach has limited applications, as it requires a high numberof available samples and the assumption of a flexible densitymodel [39]. Among the most popular density methods for OCCthe Gaussian model, the mixture of Gaussians [55], and theParzen density [8] can be mentioned.
� Estimating the complete density or structure of a targetconcept in one-class problems may very often be too demand-ing or even impossible. Therefore, boundary methods havebeen proposed in recent years [40,41]. They concentrate onestimating only the close boundary for a given data, assumingthat such a boundary will describe sufficiently the target class[24]. The main aim of these methods is to find the optimal sizeof the volume enclosing given training points [43], because onethat is too small can lead to an overtrained model, while onethat is too big may lead to an extensive acceptance of outliersinto the target class. These methods rely strongly on thedistance between objects, therefore proper feature scaling is avery important data pre-processing step. On the other hand,boundary methods require a smaller number of objects toproperly estimate the decision criterion in comparison withtwo previous groups of methods. The most popular methods ofthis group include the Support Vector Data Description [41]and the One-class Support Vector Machine [5].
In the literature a third group of methods is mentioned some-times. It is known as reconstruction methods. They were originallyintroduced as a tool for data modeling [7]. This group of algo-rithms makes assumptions about the object distribution. Use ofreconstruction methods for OCC is based on the idea that possiblythe unknown outliers do not satisfy those assumptions about thestructure of objects under consideration. The most popular tech-niques are the k-means [4], the self-organizing maps [45] and theauto-encoder networks [33]. However, one can notice that thebasis of operation for this group of algorithms is similar to thedensity-based methods estimating some distribution/structure ofthe data). That is why it can be considered as a sub-group of thisfamily of one-class classifiers.
There are several papers dealing with a combination of one-class classifiers [35,37,47,3,31] and their practical application[18,27]. Ensembles are a promising research direction for OCCproblems [30], as they allow us to train less complex individualclassifiers, thereby reducing the risk of model overfitting which isone of the major concerns in OCC. Additionally, they are an idealsolution for implementation in a distributed environment. Most ofthe OCC classifiers (especially the boundary-based ones) arecomputationally expensive, and therefore relying on several weakmodels that run independently may significantly reduce thetraining cost of the recognition system. It has been shown thatMCS for OCC, designed on the basis of the random subspacemethod [20,15], can outperform a single-model approach [29] andcan introduce novel diversity measures dedicated to pruning theOCC ensembles [26]. These approaches assume dimensionalityreduction of the base classifiers.
3. Firerfly-based one-class classifier ensemble
When forming ensembles of classifiers, efficient methods forchoosing the best individual learners from the pool are of thehighest importance. Although a plethora of approaches have been
proposed for multi-class classification [17,36,13,48], there is still alack of methods dedicated to the specific nature of one-classclassification [30]. It should be noted that due to the lack ofcounterexamples during the training procedure, one cannot applycanonical ensemble pruning methods. They rely on the notions ofaccuracy (which requires information about samples from all theclasses) or diversity (which are mainly based on checking theperformance of two or more classifiers on a class assignment task)– and these measures cannot be obtained in one-class problemsduring the model selection phase [23]. That is why there is a needfor introducing novel methods tuned to the nature of OCC.
When designing an ensemble pruning procedure there are twomain tracks that can be chosen: criteria-based or criteria-free [48].In the first case, we aim at finding a subset of classifiers accordingto some pre-defined criteria reflecting the quality of the formedensemble. This is often realized as an optimization problem, due towell-defined search space and given criteria which may serve as afitness function [36]. The second approach is based on utilizingalternative methods that can give an outlook on the similarity/performance of classifiers in the pool. Among them, clustering theavailable classifiers is considered as one of the most popular ones[17].
In this paper, we decided to use the criteria-based approach forpruning one-class classifier committees. This is based on ourprevious experience with simple genetic algorithms for one-classclassifier selection which returned satisfactory results [29].
When selecting a proper optimization procedure, one shouldhave in mind the area of applicability – in this case ensemblepruning. It is common in real-life applications that the initial poolof classifiers consists of dozens, or even hundreds of base learners.In such cases there is a need for a method that is able to efficientlyexplore the search space. Our previous experiments with geneticalgorithms [29] showed that for large sizes of classifier pools, thisoptimization method requires a significant computational cost toexecute and tends to get attracted to local minimals. Therefore, wewere interested in finding an alternative search method for ourproblem.
As the pool of classifiers can be viewed as a population, witheach base classifier as a single member, population-based methodscome to mind. Recently, swarm intelligence has gained an atten-tion of the research community [34]. It is inspired from thecollective behavior of social swarms of ants, termites, bees, andworms, flock of birds, and fish. Although these swarms consist ofquite simple individuals, they exhibit coordinated behavior thatdirects the swarms to their desired goals. This usually results intheir self-organizing behavior, and collective intelligence or swarmintelligence is in essence the self-organization of such multi-agentsystems, based on simple interaction rules. This coordinatedbehavior is performed due to interaction between individuals inreaching common goals. They can easily deal with large popula-tions in a reduced computational time.
Among plethora of swarm intelligence methods, we havedecided to chose the firefly algorithm (FA) [53]. In our previousworks, we have successfully applied it in a medical imagesegmentation task for detecting cell nuclei [27]. This served as amotivation for transferring this algorithm to the ensemblepruning field.
The next section describes the basic notations of the used FA.
3.1. Basis of firefly algorithm
FA is a kind of stochastic, nature-inspired, meta-heuristic algo-rithm that can be applied for solving the most difficult optimizationtasks (such as NP-hard problems) [52]. As it is a stochastic approach,it uses a randomization in searching for a set of solutions. It isinspired by the flashing lights of fireflies.
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎ 3
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i

Each firefly in the population is characterized by its brightnessand position. Lightness represents the individual fitness of thefirefly – ‘stronger’ lightness corresponds to the better fitness of theindividual. Position determines the current location of the fireflyin the search space, and is used for checking the distance betweentwo fireflies.
The FA procedure is based on interactions between individualfireflies. The level of interaction is modeled by the strength of thisevent. Each firefly has its attractiveness, which is used to attractother fireflies to it. Attractiveness depends on the light intensity,so each firefly is attracted to the neighbor that glows brighter. Thelight intensity I(r) is dependent on the environment in which thefireflies are located, and is modeled according to the inversesquare law:
IðrÞ ¼ Isr2; ð1Þ
where Is is the light intensity exhibited by the source (theattracting firefly) and r is the distance between the consideredtwo fireflies (the attracting firefly and attracted firefly).
Light is absorbed in the firefly's environment according to thegiven absorption coefficient γ. The absorption level is used tocontrol the influence of distance between fireflies on the level oftheir interaction. With the increase of the absorption level, theinteractions strength decreases over the same distance.
To properly model the interactions between the populationmembers, one need to use both the distance and absorption of theenvironment. The combination of the inverse square law and theabsorption level can be calculated according to the followingsolution (its worth noticing that such approach allows to avoidsingularity at r¼0 in Is=r2Þ:IðrÞ ¼ Ioe� γr2 ; ð2Þwhere Io is the original light intensity.
The attractiveness of each firefly is proportional to its bright-ness, as seen by its neighbor. Therefore, we may calculate theattractiveness value as follows:
βðrÞ ¼ βoe� γr2 ; ð3Þ
where βo is the attractiveness at r¼0.From the above, one may see that the distance between the
two fireflies plays a major role on the performance of the FA. Tocalculate the location of i-th and j-th fireflies, the Euclideandistance is used. The movement of the i-th population memberfrom location xi towards the j-th member at location xj, isexpressed by
xiðtþ1Þ ¼ xiðtÞþβoe� γr2 ðxj�xiÞ; ð4Þ
where t stands for the number of current FA iteration.Iterations of FA are conducted until one of the two termination
conditions are met:
� the maximum number of iterations Ni has been performed;� the maximum movement of fireflies in the population is lower
than given stop parameter ϵ.
The result of the FA are fireflies gathered around the points ofinterest. Finally, the fireflies that lay closer to each other than agiven parameter Φ are merged together. Remaining populationmembers indicate the found solutions.
3.2. Encoding the ensemble as a firefly population
To use the full potential of the FA, one need to tune it to theproblem at hand. In our case, we need to adjust it for the one-classensemble pruning procedure.
We propose that each firefly in the population will represent aone-class classifier from the pool. Hence, if we have a given pool ofK one-class classifiers assigned to the target class:
ΠωT ¼ fΨ ð1ÞωT;Ψ ð2Þ
ωT;…;Ψ ðKÞ
ωTg: ð5Þ
then our FA population is represented by K individual fireflies.As for the pruning procedure, we associate it with the process
of merging fireflies at the end of the FA. We get in result N groupsof fireflies, located closer than Φ to each other. As our populationmembers represent classifiers, we propose to select a singlerepresentative for each group. The criteria for selection is basedon choosing a member with highest value of lightness. Therefore,we reduce the number of classifiers in the pool and select the mostvaluable representatives.
Finally, we need to establish how to measure the lightness ofeach firefly (as to represent the quality of each classifier) and howto measure the distance between the fireflies (in order to checkthe differences between two classifiers).
3.2.1. Measuring the lightness of firefliesThe brightness of fireflies represents their individual fitness
and influences the interaction level between the populationmembers. Therefore, it is crucial to chose a proper representationfor the brightness function.
As our FA represents the classification problem, we shouldchose such a function that will allow us to evaluate the individualquality of analyzed classifiers in the pool. There are a plethora ofperformance measures used in machine learning such as accuracy,F-measure, AUC or G-mean [21]. However, these measures requireinformation about both positive and negative examples. In case ofOCC, we do not have any information about the counterexamplesduring the training phase. As our pruning procedure will beconducted only with the use of the target class ωT , we need analternative measure for ranking the quality of one-class classifiers.
The consistency measure indicates how consistent a pool ofclassifiers is in rejecting fraction f of the target data [42]. One maycompute it by comparing the rejected fraction f with an estimateof the error on the target class bεt :ConsðΨ lÞ ¼ jbεt � f j; ð6Þwhere Ψl is the tested one-class classifier. To get an independentestimation of consistency measure, one must repeat several runswith different values of f to see how the classifier performs withdifferent error thresholds, and average results. This is an unsu-pervised measure well suitable for OCC problems as we need onlythe estimation of error on the target class – no information aboutoutliers is required.
In the proposed approach, we associate the consistency of agiven classifier with the lightness of a firefly that represents it:
Ilo ¼ ConsðΨ lÞ: ð7Þ
3.2.2. Measuring the distance between firefliesTo properly model the interactions between the classifiers, one
need to select a proper environment, in which the distancebetween the fireflies will be measured. In our previous work[27], we have used the pixel location as we were dealing withmedical images.
Here FA is used for pruning one-class ensembles and firefliesrepresent classifiers in the pool. Hence, it is not trivial on how todescribe the ‘location’ of a classifier. Additionally, we would likethat the used measure will be meaningful and give an outlook onthe differences between two classifiers (in a way, that classifiersthat are ‘closer’ to each other are more similar).
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎4
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i

Here, we propose to use the diversity of classifiers to measuretheir distance from each other. By this, classifiers that are locatedfurther from each other are at the same time more diverse.Diversity measure fulfills all the requirements of the FA environ-ment and gives us a meaningful information about the classifier‘locations’ in the competence space.
At the same time it allows us to transform our FA-basedpruning algorithm into a kind of multi-objective optimization.The lightness of fireflies will reflect their individual quality, whilethe distance between them their diversity in the pool. This willlead to a selection of mutually accurate and diverse ensemblemembers.
In FA, we need to calculate the distance between two fireflies(classifiers) at once. Therefore, we must use a pairwise diversitymeasure that will give an information about the differencesbetween a pair of one-class learners.
Diversity is a novel concept in OCC. In our previous works, weshowed that standard diversity measures fail when applied to one-class problems [26] and that there is a need for novel methodsdedicated to the specific nature of OCC [30].
Intuitively a high diversity of an ensemble may be achievedwhen each of the classifiers has a different area of competence.From this one may easily see that two classifiers with similar areasof competence will not contribute much to the quality of thecommittee. Taking into consideration the specific nature ofboundary one-class classifiers we may assume that two predictorswith high overlap of decision boundaries may be deemed as oneswith a low diversity. Therefore we propose a diversity measuredesigned specifically for spherical one-class classifiers (such asconsidered in this paper boundary methods), based on a degree ofoverlap between individual classifiers [23].
In case of classifier overlapping there may be two situations –
where classifiers overlap pairwise and when more than a pair ofclassifiers overlap.
We propose to measure the diversity of the ensemble bymeasuring the overall degree of overlap between all classifiers inthe pool. Firstly we need to calculate the volume of a singlespherical classifier:
VSða;RÞ ¼2πD=2RD
ΓðD=2þ1Þ; ð8Þ
where D is the dimensionality of the training set TS, a is the centerof the sphere, R is the radius of the sphere and Γ is the gammafunction.
Therefore the volume of all L classifiers from the pool is equalto the sum of their individual volumes:
Vsum ¼ ∑L
i ¼ 1VSðai;RiÞ: ð9Þ
In case of a lack of overlap between the spheres in the committeethe volume of an ensemble is equal to the sum of the volumes ofall individual classifiers:
Vens ¼ Vsum3 8 ia j i;j ¼ 1;…;L
VSðai;RiÞ \ VSðaj;RjÞ ¼∅: ð10Þ
We assume that maximum diversity is achieved for the situationpresented in (10) i.e. when no overlap between individualclassifiers exist.
In case of E pairwise overlaps the volume of an ensemble isgiven by the following formulae:
Vens ¼ ∑L
i ¼ 1VSðai;RiÞ� ∑
E
e ¼ 1VOe
3 ( ia j i;j ¼ 1;…;L VSðai;RiÞ \ VSðaj;RjÞa∅: ð11Þ
The spherical cap [19] is a part of a hypersphere defined by itsheight hcA ½0;2R� and its radius rcA ½0;2R�. In [23] equation for Ddimensional spherical cap has been proposed as follows:
VcapðR;hc;DÞ ¼πðD�1Þ=2RD�1
ΓððD�1Þ=2þ1ÞZβmaxðR;hcÞ
0
sin D�1ðβÞ dβ; ð12Þ
where
βmaxðR;hcÞ ¼ arcsinðffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffið2R�hcÞðhc=R2Þ
qÞ: ð13Þ
From this we may write the volume of a single pairwise overlapVOe as a sum of their spherical caps:
VOe ðR;hcÞ ¼ Vcap1þVcap2: ð14ÞThe idea of the pairwise overlap is presented in Fig. 2.With presented above equations we propose to measure the
diversity by comparing the volume of the pairwise overlap to thesum of the individual classifiers volumes, assuming that withincrease of the intersection degree the diversity falls down:
DIVSIðS1;S2Þ ¼VOe
VS1 þVS2
: ð15Þ
We use the given pairwise sphere intersection diversity mea-sure as the distance between the fireflies representing the twoconsidered classifiers:
distðxi; xjÞ ¼DIVSIðS1;S2Þ: ð16Þ
3.3. Calculating weights assigned to selected classifiers
As an output of FA, we receive a pruned pool of classifiers. Fromgroups of fireflies that are close to each other, a single representa-tive will be selected. Reduced pool of classifiers will consist of one-class learners that display high individual quality (due to theirhighest brightness/consistency) and that are diverse to each other(due to the used way of measuring their location).
However, we further extend this concept by introducing anovel weighting scheme for controlling the fusion process.
One-class boundary methods are based on computing thedistance between the object x and the decision boundary thatencloses the target class ωT . To apply fusion methods we requirethe support function of object x for a given class.
Fig. 2. The intersection (volume overlap) of two spherical one-class classifiers, asdenoted by the gray area. As two classifiers cover the same space, they will make anidentical decision within the overlap area and cannot be deemed as diverse.
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎ 5
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i

We propose to use the following heuristic solution:
Fðx;ωT Þ ¼1c1expð�dðx ωT Þ=c2Þ;
�� ð17Þ
which models a Gaussian distribution around the classifier, wheredðxjωT Þ is an Euclidean distance metric between the consideredobject and a decision boundary around the target class, c1 is thenormalization constant and c2 is the scale parameter. Parametersc1 and c2 should be fitted to the target class distribution.
To combine the outputs of individual one-class classifiers, weuse a following weighted combination method:
ymwvðxÞ ¼1K∑kWkIðFkðx;ωT ÞZθkÞþð1�WkÞIðFkðx;ωT ÞrθkÞ; ð18Þ
where Fkðx;ωT is a value of k-th classifiers' support function forobject x, Ið�Þ is the indicator function, θk is a classification threshold(usually 0.5 is used) and Wk is weight assigned to the k-th one-class classifier.
As one may see, weights play an important role in the fusionprocess. They control how strongly the given individual classifieraffects the collective decision. Although there is a significantnumber of works on how to use weighted fusers for multi-classproblems [32,12,50,51], the idea of establishing weights for one-class learners has, best to our knowledge, yet not been explored.
We propose to use the lightness function as a basis for weightcalculation. As our ensemble will select a single representative foreach of N groups of fireflies, we are interested in calculatingweights only for the selected classifiers.
We introduce a novel weighting scheme that assigns a weightfor a selected classifier equal to the average lightness of fireflies inits n-th group:
Wnr ¼
I1oþ I2oþ⋯þ Ilol
; ð19Þ
where Wrn is the weight assigned to the representative classifier
from n-th group of fireflies and l is the number of fireflies(classifiers) in n-th group. Weights are then normalized to theinterval [0;1].
By this, each representative classifier will also store someinformation about the quality of all classifiers in its group. Thiswill be encoded in its weight. This approach allows to maintainsome of the information from discarded classifiers (as they maygive an outlook on the competence space of the problem).
3.4. Firefly-based one-class ensemble pruning summary
To give an outlook of the firefly-based pruning algorithm thepseudocode of the proposed method is given in Algorithm 1.
Algorithm 1. Firefly-based one-class ensemble pruning andweighting
Require: pool of classifiers Π,max. number of iterations Ni,absorption coefficient γmovement threshold ϵdistance threshold Φ
1: i’02: encode Π as a population of fireflies3: repeat4: calculate the original light intensity of each firefly
(according to Eq. (7))5: calculate the brightness of each firefly (according to
Eq. (2))6: calculate the attractiveness of each firefly (according to
Eq. (3))
7: calculate the movements of each firefly (according toEqs. (4) and (16))
8: until i¼Ni or max movement oϵ9: create N groups of fireflies (distance between fireflies in
each group lower than Φ)10: for all nAN do11: for n-th group select a single firefly with highest
brightness12: calculate a weight assigned to the selected firefly
(classifier) according to Eq. (18)13: end for14: Apply the weighted combination of selected classifiers
(according to Eq. (18))
We summarize properties of the proposed firefly-based one-class ensemble pruning approach. We also identify the advan-tages of applying FA for this task and using the proposedencoding form embedding the classifier selection procedure intothe FA scheme.
� We propose to represent one-class classifiers in the pool asmembers of a population, in order to apply nature-inspiredsearch algorithms. As in real-life problems the number oflearners at our disposal is often very high, we decided toinvestigate swarm algorithms. FA was selected due to itsproven effectiveness. Usage of FA allows us to deal with largenumber of base classifiers and check their possible combina-tions with reduced computational complexity (in comparisonto genetic-based algorithms).
� The output of the FA are groups of fireflies gathered together.From these groups, we select a single representative withhighest brightness (and hence, highest fitness). By this werealize the ensemble pruning procedure, having reduced thenumber of classifiers in the pool.
� We introduced a novel method for measuring the lightness offireflies. As we are dealing with the one-class ensemble form-ing problem, we selected a measure that reflects the perfor-mance of individual classifiers. By using the consistencymeasure as lightness function, we are able to efficiently modelthe interactions between the fireflies and promote the bestindividual classifiers in the pool.
� To measure the location of fireflies in the environment (andhence classifiers in the decision space), we proposed to utilize anew pairwise diversity measure, based on the intersection levelof spherical one-class classifiers. This measure is suitable forproblems, where counterexamples are not available. Usingdiversity for measuring the location of fireflies allows us tocreate meaningful groups of classifiers - one-class learnersinside a group will be similar to each other (and hence mostof them can be discarded), while each group will be diverse incomparison to other.
� Our FA-based ensemble pruning algorithm realizes indirectly amulti-objective optimization task. For grouping fireflies, weconsider the diversity of learners, while for selecting the bestrepresentatives from each group we consider their consistency.This allows to select one-class classifiers from the pool, that aredisplay at the same time a high individual discriminatorypower and are mutually complementary.
� Finally, we enhance our pruning method with a scheme forcalculating weights for selected classifiers. As weighted fusionoften improves the performance of ensembles in multi-classtasks, we can assume that this will hold for one-class problems.Weight calculation is directly correlated with the output of the
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎6
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i

FA pruning procedure and allows us to further boost the qualityof the proposed multiple classifier system.
� The proposed method can be seen as one originating in the idea ofclustering-based ensemble pruning [54]. It aims at discoveringgroups of similar classifiers and replacing them with a singlerelevant representative. It should be noted that there are manymethods on how such a grouping can be performed - k-means orself-organizing neural networks to name a few [46]. Using fireflyalgorithm has two additional benefits. Firstly, it does not require apre-defined number of clusters, as fireflies self-organize them-selves. Secondly, it offers the proposed weighted fusion mechanismon the basis of fireflies lightness.
4. Experimental investigations
The aims of the experiment was to check the quality of theproposed method on several benchmark datasets and compare theproposed FA-based pruning algorithm with other existing classi-fier selection methods, dedicated to OCC problems. We alsochecked, if applying a weighted fusion procedure for combiningoutputs of individual one-class classifiers leads to a significantlybetter performance of the entire ensemble.
4.1. Datasets
We have chosen 10 binary datasets in total - 9 coming from UCIRepository and an additional one, originating from chemoinfor-matics domain and describing the process of discovering pharma-ceutically useful isoforms of CYP 2C19 molecule. The dataset isavailable for download at [38]. Details of the chosen datasets aregiven in Table 1.
Due to the lack of one-class benchmarks we use the canonicalmulti-class ones.
We used a method for testing one-class classifiers, presented in[26]. The training set was composed from the part of objects fromthe target class (according to cross-validation rules), while thetesting set consisted of the remaining objects from the target classand outliers (to check both the false acceptance and false rejectionrates). As the behavior of used one-class methods may differsignificantly in respect to used dataset, we decided to utilize eachbenchmark twice - once using majority class as the target conceptand once using the minority class as the target concept. This intotal gives us 20 different one-class benchmarks.
For the experiment a Support Vector Data Description [41] with apolynomial kernel is used as a base classifier. The kernel parameterswere set as follows: degree of polynomial kernel d¼2 and softmargin constant C¼10.
The pool of classifiers was homogeneous, i.e. consisted ofclassifiers of the same type, built on the basis of Random Subspacemethod.
The pool of classifiers was created in a fixed way to allow a properexploitation of properties of different classifier selection criteria. Itconsisted in total of 60 models for each of the classes – 20 were buildon the basis of a Random Subspace [20] approach with eachsubspace consisting of 10%, 20 were build on the basis of a RandomSubspace approach with each subspace consisting of 90% of originalfeatures and 20 of which were build on the basis of a RandomSubspace approach with each subspace consisting of 60% of originalfeatures. This way our pool consisted of models displaying highdiversity but low accuracy, high accuracy but low diversity and ofmodels build on a standard Random Subspace settings (which wereproven to provide good OCC models for ensembles, maintaining agood individual accuracy and introducing diversity [28]).
To put the obtained results into context, we compared ourproposed method with the following reference approaches and thefollowing state-of-the-art methods for selecting one-class classifiers:
� a single SVDD classifier;� a Parzen Density Data Description (one-class density-based
method);� an unpruned pool of classifiers (to check, if classifier selection will
lead to any improvement over using all available classifiers);� a genetic algorithm pruning procedure, that uses diversity
measure as fitness function with settings from [29];� a consistency-based one-class ensemble pruning [6];� an AUC-based ensemble pruning [6];� the proposed FA pruning scheme using simple majority voting,
without the weighting module (to check if the weighted fusionleads to any improvement over standard combination methodin one-class classification).
Each pruning method worked on the same pool of classifiers.In order to present a detailed comparison among a group of
machine learning algorithms, one must use statistical tests toprove that the reported differences among classifiers are signifi-cant [14]. We use both pairwise and multiple comparison tests.Pairwise tests give as an outlook on the specific performance ofmethods for a given dataset, while multiple comparison allows usto gain a global perspective on the performance of the algorithmsover all benchmarks. With this, we get a full statistical informationabout the quality of the examined classifiers.
� For a pairwise comparison, we use a 5�2 combined CV F-test[1]. It repeats five-time two fold cross-validation so that in eachof the folds the size of the training and testing sets is equal. Thistest is conducted by comparison of all versus all. As a test scorethe probability of rejecting the null hypothesis is adopted, i.e.that classifiers have the same error rates. As an alternativehypothesis, it is conjectured that tested classifiers have differ-ent error rates. A small difference in the error rate implies thatthe different algorithms construct two similar classifiers withsimilar error rates; thus, the hypothesis should not be rejected.For a large difference, the classifiers have different error ratesand the hypothesis should be rejected.
� For assessing the ranks of classifiers over all examined bench-marks, we use a Friedman ranking test [11]. It checks, if theassigned ranks are significantly different from assigning to eachclassifier an average rank.
� We use the Shaffer post-hoc test to find out which of thetested methods are distinctive among an n x n comparison.The post-hoc procedure is based on a specific value of thesignificance level α. Additionally, the obtained p-values shouldbe examined in order to check how different given twoalgorithms are.
We fix the significance level α¼0.05 for all comparisons.
Table 1Details of datasets used in the experimental investigation. Numbers in parenthesesindicate the number of objects in the minor class in case of binary problems.
No. Name Objects Features Classes
1 Breast-cancer 286 (85) 9 22 Breast-Wisconsin 699 (241) 9 23 Colic 368 (191) 22 24 Diabetes 768 (268) 8 25 Heart-statlog 270 (120) 13 26 Hepatitis 155 (32) 19 27 Ionosphere 351(124) 34 28 Sonar 208 (97) 60 29 Voting records 435 (168) 16 2
10 CYP2C19 isoform 837 (181) 242 2
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎ 7
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i
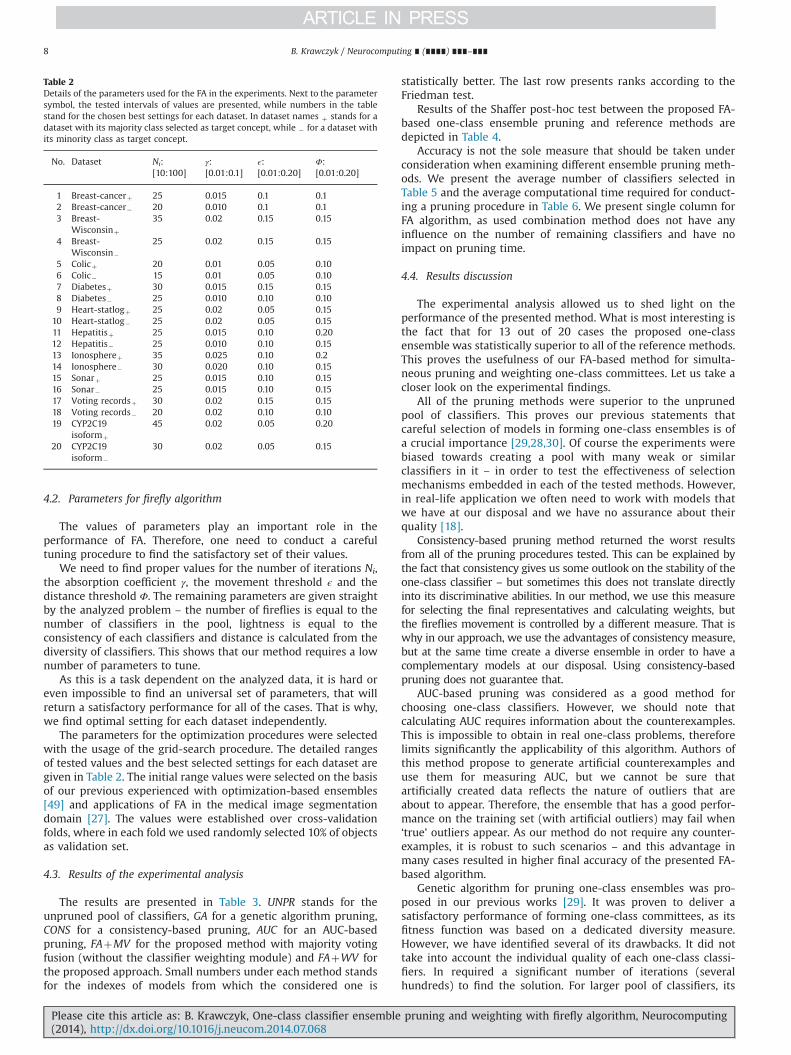
4.2. Parameters for firefly algorithm
The values of parameters play an important role in theperformance of FA. Therefore, one need to conduct a carefultuning procedure to find the satisfactory set of their values.
We need to find proper values for the number of iterations Ni,the absorption coefficient γ, the movement threshold ϵ and thedistance threshold Φ. The remaining parameters are given straightby the analyzed problem – the number of fireflies is equal to thenumber of classifiers in the pool, lightness is equal to theconsistency of each classifiers and distance is calculated from thediversity of classifiers. This shows that our method requires a lownumber of parameters to tune.
As this is a task dependent on the analyzed data, it is hard oreven impossible to find an universal set of parameters, that willreturn a satisfactory performance for all of the cases. That is why,we find optimal setting for each dataset independently.
The parameters for the optimization procedures were selectedwith the usage of the grid-search procedure. The detailed rangesof tested values and the best selected settings for each dataset aregiven in Table 2. The initial range values were selected on the basisof our previous experienced with optimization-based ensembles[49] and applications of FA in the medical image segmentationdomain [27]. The values were established over cross-validationfolds, where in each fold we used randomly selected 10% of objectsas validation set.
4.3. Results of the experimental analysis
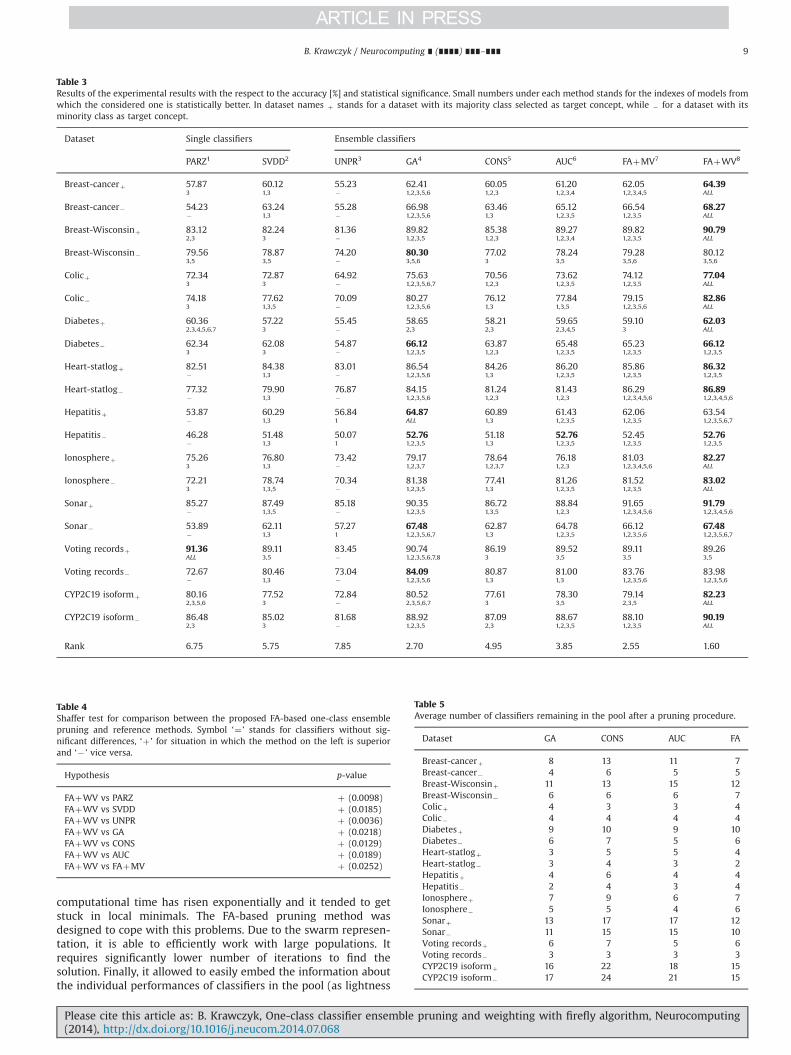
The results are presented in Table 3. UNPR stands for theunpruned pool of classifiers, GA for a genetic algorithm pruning,CONS for a consistency-based pruning, AUC for an AUC-basedpruning, FAþMV for the proposed method with majority votingfusion (without the classifier weighting module) and FAþWV forthe proposed approach. Small numbers under each method standsfor the indexes of models from which the considered one is
statistically better. The last row presents ranks according to theFriedman test.
Results of the Shaffer post-hoc test between the proposed FA-based one-class ensemble pruning and reference methods aredepicted in Table 4.
Accuracy is not the sole measure that should be taken underconsideration when examining different ensemble pruning meth-ods. We present the average number of classifiers selected inTable 5 and the average computational time required for conduct-ing a pruning procedure in Table 6. We present single column forFA algorithm, as used combination method does not have anyinfluence on the number of remaining classifiers and have noimpact on pruning time.
4.4. Results discussion
The experimental analysis allowed us to shed light on theperformance of the presented method. What is most interesting isthe fact that for 13 out of 20 cases the proposed one-classensemble was statistically superior to all of the reference methods.This proves the usefulness of our FA-based method for simulta-neous pruning and weighting one-class committees. Let us take acloser look on the experimental findings.
All of the pruning methods were superior to the unprunedpool of classifiers. This proves our previous statements thatcareful selection of models in forming one-class ensembles is ofa crucial importance [29,28,30]. Of course the experiments werebiased towards creating a pool with many weak or similarclassifiers in it – in order to test the effectiveness of selectionmechanisms embedded in each of the tested methods. However,in real-life application we often need to work with models thatwe have at our disposal and we have no assurance about theirquality [18].
Consistency-based pruning method returned the worst resultsfrom all of the pruning procedures tested. This can be explained bythe fact that consistency gives us some outlook on the stability of theone-class classifier – but sometimes this does not translate directlyinto its discriminative abilities. In our method, we use this measurefor selecting the final representatives and calculating weights, butthe fireflies movement is controlled by a different measure. That iswhy in our approach, we use the advantages of consistency measure,but at the same time create a diverse ensemble in order to have acomplementary models at our disposal. Using consistency-basedpruning does not guarantee that.
AUC-based pruning was considered as a good method forchoosing one-class classifiers. However, we should note thatcalculating AUC requires information about the counterexamples.This is impossible to obtain in real one-class problems, thereforelimits significantly the applicability of this algorithm. Authors ofthis method propose to generate artificial counterexamples anduse them for measuring AUC, but we cannot be sure thatartificially created data reflects the nature of outliers that areabout to appear. Therefore, the ensemble that has a good perfor-mance on the training set (with artificial outliers) may fail when‘true’ outliers appear. As our method do not require any counter-examples, it is robust to such scenarios – and this advantage inmany cases resulted in higher final accuracy of the presented FA-based algorithm.
Genetic algorithm for pruning one-class ensembles was pro-posed in our previous works [29]. It was proven to deliver asatisfactory performance of forming one-class committees, as itsfitness function was based on a dedicated diversity measure.However, we have identified several of its drawbacks. It did nottake into account the individual quality of each one-class classi-fiers. In required a significant number of iterations (severalhundreds) to find the solution. For larger pool of classifiers, its
Table 2Details of the parameters used for the FA in the experiments. Next to the parametersymbol, the tested intervals of values are presented, while numbers in the tablestand for the chosen best settings for each dataset. In dataset names þ stands for adataset with its majority class selected as target concept, while � for a dataset withits minority class as target concept.
No. Dataset Ni:[10:100]
γ:[0.01:0.1]
ϵ:[0.01:0.20]
Φ:[0.01:0.20]
1 Breast-cancerþ 25 0.015 0.1 0.12 Breast-cancer� 20 0.010 0.1 0.13 Breast-
Wisconsinþ
35 0.02 0.15 0.15
4 Breast-Wisconsin�
25 0.02 0.15 0.15
5 Colicþ 20 0.01 0.05 0.106 Colic� 15 0.01 0.05 0.107 Diabetesþ 30 0.015 0.15 0.158 Diabetes� 25 0.010 0.10 0.109 Heart-statlogþ 25 0.02 0.05 0.15
10 Heart-statlog� 25 0.02 0.05 0.1511 Hepatitisþ 25 0.015 0.10 0.2012 Hepatitis� 25 0.010 0.10 0.1513 Ionosphereþ 35 0.025 0.10 0.214 Ionosphere� 30 0.020 0.10 0.1515 Sonarþ 25 0.015 0.10 0.1516 Sonar� 25 0.015 0.10 0.1517 Voting recordsþ 30 0.02 0.15 0.1518 Voting records� 20 0.02 0.10 0.1019 CYP2C19
isoformþ
45 0.02 0.05 0.20
20 CYP2C19isoform�
30 0.02 0.05 0.15
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎8
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i
computational time has risen exponentially and it tended to getstuck in local minimals. The FA-based pruning method wasdesigned to cope with this problems. Due to the swarm represen-tation, it is able to efficiently work with large populations. Itrequires significantly lower number of iterations to find thesolution. Finally, it allowed to easily embed the information aboutthe individual performances of classifiers in the pool (as lightness
Table 3Results of the experimental results with the respect to the accuracy [%] and statistical significance. Small numbers under each method stands for the indexes of models fromwhich the considered one is statistically better. In dataset names þ stands for a dataset with its majority class selected as target concept, while � for a dataset with itsminority class as target concept.
Dataset Single classifiers Ensemble classifiers
PARZ1 SVDD2 UNPR3 GA4 CONS5 AUC6 FAþMV7 FAþWV8
Breast-cancerþ 57.87 60.12 55.23 62.41 60.05 61.20 62.05 64.393 1,3 � 1,2,3,5,6 1,2,3 1,2,3,4 1,2,3,4,5 ALL
Breast-cancer� 54.23 63.24 55.28 66.98 63.46 65.12 66.54 68.27� 1,3 � 1,2,3,5,6 1,3 1,2,3,5 1,2,3,5 ALL
Breast-Wisconsinþ 83.12 82.24 81.36 89.82 85.38 89.27 89.82 90.792,3 3 � 1,2,3,5 1,2,3 1,2,3,4 1,2,3,5 ALL
Breast-Wisconsin� 79.56 78.87 74.20 80.30 77.02 78.24 79.28 80.123,5 3,5 � 3,5,6 3 3,5 3,5,6 3,5,6
Colicþ 72.34 72.87 64.92 75.63 70.56 73.62 74.12 77.043 3 � 1,2,3,5,6,7 1,2,3 1,2,3,5 1,2,3,5 ALL
Colic� 74.18 77.62 70.09 80.27 76.12 77.84 79.15 82.863 1,3,5 � 1,2,3,5,6 1,3 1,3,5 1,2,3,5,6 ALL
Diabetesþ 60.36 57.22 55.45 58.65 58.21 59.65 59.10 62.032,3,4,5,6,7 3 � 2,3 2,3 2,3,4,5 3 ALL
Diabetes� 62.34 62.08 54.87 66.12 63.87 65.48 65.23 66.123 3 � 1,2,3,5 1,2,3 1,2,3,5 1,2,3,5 1,2,3,5
Heart-statlogþ 82.51 84.38 83.01 86.54 84.26 86.20 85.86 86.32� 1,3 � 1,2,3,5,6 1,3 1,2,3,5 1,2,3,5 1,2,3,5
Heart-statlog� 77.32 79.90 76.87 84.15 81.24 81.43 86.29 86.89� 1,3 � 1,2,3,5,6 1,2,3 1,2,3 1,2,3,4,5,6 1,2,3,4,5,6
Hepatitisþ 53.87 60.29 56.84 64.87 60.89 61.43 62.06 63.54� 1,3 1 ALL 1,3 1,2,3,5 1,2,3,5 1,2,3,5,6,7
Hepatitis� 46.28 51.48 50.07 52.76 51.18 52.76 52.45 52.76� 1,3 1 1,2,3,5 1,3 1,2,3,5 1,2,3,5 1,2,3,5
Ionosphereþ 75.26 76.80 73.42 79.17 78.64 76.18 81.03 82.273 1,3 � 1,2,3,7 1,2,3,7 1,2,3 1,2,3,4,5,6 ALL
Ionosphere� 72.21 78.74 70.34 81.38 77.41 81.26 81.52 83.023 1,3,5 � 1,2,3,5 1,3 1,2,3,5 1,2,3,5 ALL
Sonarþ 85.27 87.49 85.18 90.35 86.72 88.84 91.65 91.79� 1,3,5 � 1,2,3,5 1,3,5 1,2,3 1,2,3,4,5,6 1,2,3,4,5,6
Sonar� 53.89 62.11 57.27 67.48 62.87 64.78 66.12 67.48� 1,3 1 1,2,3,5,6,7 1,3 1,2,3,5 1,2,3,5,6 1,2,3,5,6,7
Voting recordsþ 91.36 89.11 83.45 90.74 86.19 89.52 89.11 89.26ALL 3,5 � 1,2,3,5,6,7,8 3 3,5 3,5 3,5
Voting records� 72.67 80.46 73.04 84.09 80.87 81.00 83.76 83.98� 1,3 � 1,2,3,5,6 1,3 1,3 1,2,3,5,6 1,2,3,5,6
CYP2C19 isoformþ 80.16 77.52 72.84 80.52 77.61 78.30 79.14 82.232,3,5,6 3 � 2,3,5,6,7 3 3,5 2,3,5 ALL
CYP2C19 isoform� 86.48 85.02 81.68 88.92 87.09 88.67 88.10 90.192,3 3 � 1,2,3,5 2,3 1,2,3,5 1,2,3,5 ALL
Rank 6.75 5.75 7.85 2.70 4.95 3.85 2.55 1.60
Table 4Shaffer test for comparison between the proposed FA-based one-class ensemblepruning and reference methods. Symbol ‘¼ ’ stands for classifiers without sig-nificant differences, ‘þ ’ for situation in which the method on the left is superiorand ‘� ’ vice versa.
Hypothesis p-value
FAþWV vs PARZ þ (0.0098)FAþWV vs SVDD þ (0.0185)FAþWV vs UNPR þ (0.0036)FAþWV vs GA þ (0.0218)FAþWV vs CONS þ (0.0129)FAþWV vs AUC þ (0.0189)FAþWV vs FAþMV þ (0.0252)
Table 5Average number of classifiers remaining in the pool after a pruning procedure.
Dataset GA CONS AUC FA
Breast-cancerþ 8 13 11 7Breast-cancer� 4 6 5 5Breast-Wisconsinþ 11 13 15 12Breast-Wisconsin� 6 6 6 7Colicþ 4 3 3 4Colic� 4 4 4 4Diabetesþ 9 10 9 10Diabetes� 6 7 5 6Heart-statlogþ 3 5 5 4Heart-statlog� 3 4 3 2Hepatitisþ 4 6 4 4Hepatitis� 2 4 3 4Ionosphereþ 7 9 6 7Ionosphere� 5 5 4 6Sonarþ 13 17 17 12Sonar� 11 15 15 10Voting recordsþ 6 7 5 6Voting records� 3 3 3 3CYP2C19 isoformþ 16 22 18 15CYP2C19 isoform� 17 24 21 15
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎ 9
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i

function). Experiments show, that for most datasets, our newalgorithm was superior to its predecessor.
Comparison with simplified version of our FA-based pruningscheme (which used majority voting) showed that a weighted fusionis a promising research direction for one-class ensembles. In 10 out of20 datasets, the weights assigned to classifiers allowed us to furtherboost the recognition rate of constructed compound system. Theproposed method for weight calculation is simple, yet effective. As itis embedded in the pruning algorithm, it requires no additionalparameters, nor does it increases the complexity of the system.
Shaffer test for multiple comparisons showed that the proposedmethod is statistically better than all of the reference algorithms,when considering its performance over all of the datasets.
When considering the reduction rate of tested pruning meth-ods (see Table 5), one can see that all of examined algorithmsdisplayed a satisfactory performance. Most of the classifiers in thepool were irrelevant and pruning methods were able to cope withsuch situations. Interestingly, there are few cases in which FAcreated a slightly larger pool of classifiers, yet displaying superiorperformance. This can be explained by the fact that FA pruningoptimizes both consistency and diversity. So it was possible, that alarger number of highly specialized classifiers were selected, thatafter combination gave an efficient ensemble.
Looking at the Table 6 allows us to notice that the proposed FApruning has the lowest computational time requirements from allof tested pruning approaches. It is significantly faster than con-sistency and AUC based methods, as they carry a full search overall of possible combinations. What is worth noticing is the fact thatthe proposed scheme is faster than genetic approach – as itrequires significantly lower number of iterations to meet one ofstop criteria. Operations within FA (brightness calculation andfirefly movement) are more time consuming than within GA(simple cross-over and mutation), but a low number of iterationsrequired for FA overcompensates this.
5. Conclusions
In this paper a novel technique for forming efficient one-classclassifier ensembles was presented. It combines an ensemble pruningalgorithm for discarding irrelevant learners with weighted fusionmodule for controlling the influence of selected classifier over thefinal committee decision. The ensemble pruning was realized as a
search problem and implemented through a swarm intelligenceapproach. A firefly algorithm was selected as the framework formanaging the process of reducing the size of the pool and inputclassifiers were coded as its population members. The interactionsbetween fireflies were realized through the consistency measure,which describes the effectiveness of individual one-class classifiers. Anew pairwise diversity measure, based on calculating the intersec-tions between spherical one-class classifiers, was used for controllingthe movement of fireflies. With this, we indirectly implemented amulti-objective optimization, as selected classifiers have at the sametime high individual accuracy and are mutually diverse. The firefliesform groups and for each group the best representative was selected– thus realizing the pruning task. Additionally, a classifier weightcalculation scheme based on the brightness of fireflies was appliedfor weighted fusion.
Experimental results carried on the diverse set of benchmarksprove the usefulness of our approach. For most cases it out-performed all of the state-of-the-art pruning algorithms, dedi-cated to one-class classification. Three statistical tests (pairwise,ranking and post-hoc) were carried to back-up the experimentalfindings. They all showed that the proposed pruning and weight-ing algorithm for one-class ensembles based on firefly optimiza-tion is able to form efficient committees of one-class classifiers.
Our method is easy to use, as it requires relatively smallnumber of parameters to establish. It has a lower computationalcomplexity in comparison with our previous works and is able todeal with larger pools of classifiers. We showed that it works wellwith spherical boundary-based one-class classifiers. However, weshould note that the proposed method is elastic and canwork withany type of one-class learner. The end-user just needs to use adifferent diversity measure for one-class classification [30], as theone used in this paper can work only with spherical models.
Acknowledgment
This work was supported by The Polish National Science Centreunder the grant PRELUDIUM number DEC-2013/09/N/ST6/03504.
References
[1] Ethem Alpaydin, Combined 5�2 cv f test for comparing supervised classifica-tion learning algorithms, Neural Comput. 11 (8) (1999) 1885–1892.
[2] A. Bartkowiak, R. Zimroz, Outliers analysis and one class classificationapproach for planetary gearbox diagnosis, J. Phys. Conf. Ser. 305 (1) (2011).
[3] P. Casale, O. Pujol, P. Radeva, Approximate polytope ensemble for one-classclassification, Pattern Recognit. 47 (2) (2014) 854–864.
[4] B. Chen, A. Feng, S. Chen, B. Li, One-cluster clustering based data description,Jisuanji Xuebao/Chin. J. Comput. 30 (8) (2007) 1325–1332.
[5] Y. Chen, X.S. Zhou, T.S. Huang, One-class svm for learning in image retrieval,in: IEEE International Conference on Image Processing, vol. 1, 2001, pp. 34–37.
[6] V. Cheplygina, D.M.J. Tax, Pruned random subspace method for one-classclassifiers, in: Multiple Classifier Systems, LNCS of Lecture Notes in ComputerScience, vol. 6713, 2011, pp. 96–105.
[7] K.F. Cheung, Fuzzy one-mean algorithm: formulation, convergence analysis,and applications, J. Intell. Fuzzy Syst. 5 (4) (1997) 323–332.
[8] G. Cohen, H. Sax, A. Geissbuhler, Novelty detection using one-class parzendensity estimator an application to surveillance of nosocomial infections, in:Studies in Health Technology and Informatics, vol. 136, 2008, pp. 21–26.
[9] B. Cyganek, Image segmentation with a hybrid ensemble of one-class supportvector machines, LNAI of Lecture Notes in Computer Science (includingsubseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinfor-matics), vol. 6076, 2010, pp. 254–261.
[10] B. Cyganek, One-class support vector ensembles for image segmentation andclassification, J. Math. Imaging Vis. 42 (2–3) (2012) 103–117.
[11] J. Demsar, Statistical comparisons of classifiers over multiple data sets, J. Mach.Learn. Res. 7 (2006) 1–30.
[12] R.P.W. Duin, The combining classifier: to train or not to train? in: Proceedingsof Sixteenth International Conference on Pattern Recognition, 2002, vol. 2,2002, pp. 765–770.
[13] Mikel Galar, Alberto Fernández, Edurne Barrenechea Tartas, HumbertoBustince Sola, Francisco Herrera, Dynamic classifier selection for one-vs-one
Table 6Average time complexity of the pruning procedure in seconds [s].
Dataset GA CONS AUC FA
Breast-cancerþ 92.43 167.32 221.45 68.37Breast-cancer� 87.23 143.56 160.94 55.49Breast-Wisconsinþ 126.34 189.02 234.63 84.05Breast-Wisconsin� 98.56 156.82 182.37 60.89Colicþ 72.43 104.56 120.87 45.92Colic� 71.12 100.89 113.52 44.39Diabetesþ 130.58 210.93 244.43 80.49Diabetes� 93.76 118.74 140.39 55.24Heart-statlogþ 82.35 98.74 104.32 58.94Heart-statlog� 65.23 78.97 92.11 44.38Hepatitisþ 43.25 58.94 65.42 32.98Hepatitis� 32.15 41.10 50.07 20.36Ionosphereþ 93.98 130.43 196.89 62.30Ionosphere� 87.98 116.52 178.90 61.89Sonarþ 73.49 120.43 155.68 62.11Sonar� 79.87 124.20 158.16 64.53Voting recordsþ 52.35 78.66 89.03 41.92Voting records� 51.18 73.42 85.67 38.44CYP2C19 isoformþ 189.43 262.18 311.18 110.63CYP2C19 isoform� 146.23 224.33 275.19 87.72
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎10
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i

strategy: avoiding non-competent classifiers, Pattern Recognit. 46 (12) (2013)3412–3424.
[14] Salvador García, Alberto Fernández, Julián Luengo, Francisco Herrera,Advanced nonparametric tests for multiple comparisons in the design ofexperiments in computational intelligence and data mining: experimentalanalysis of power, Inf. Sci. 180 (10) (2010) 2044–2064.
[15] N. Garcia-Pedrajas, J. Maudes-Raedo, C. García-Osorio, J.J. Rodriguez-Diez,Supervised subspace projections for constructing ensembles of classifiers,Inf. Sci. 193 (2012) 1–21.
[16] A.B. Gardner, A.M. Krieger, G. Vachtsevanos, B. Litt, One-class novelty detec-tion for seizure analysis from intracranial eeg, J. Mach. Learn. Res. 7 (2006)1025–1044.
[17] G. Giacinto, F. Roli, G. Fumera, Design of effective multiple classifier systems byclustering of classifiers, in: Proceedings of Fifteenth International Conferenceon Pattern Recognition, 2000, vol. 2, 2000, pp. 160–163.
[18] Giorgio Giacinto, Roberto Perdisci, Mauro Del Rio, Fabio Roli, Intrusiondetection in computer networks by a modular ensemble of one-class classi-fiers, Inf. Fusion 9 (January) (2008) 69–82.
[19] J.W. Harris, H. Stocker, Handbook of Mathematics and Computational Science,Springer-Verlag, New York, 1998.
[20] Tin Kam Ho, The random subspace method for constructing decision forests,IEEE Trans. Pattern Anal. Mach. Intell. 20 (August) (1998) 832–844.
[21] A.K. Jain, R.P.W. Duin, Jianchang Mao, Statistical pattern recognition: a review,IEEE Trans. Pattern Anal. Mach. Intell. 22 (January (1)) (2000) 4–37.
[22] H. Jiang, G. Liu, X. Xiao, C. Mei, Y. Ding, S. Yu, Monitoring of solid-statefermentation of wheat straw in a pilot scale using ft-nir spectroscopy andsupport vector data description, Microchem. J. 102 (2012).
[23] P. Juszczak, Learning to recognise. A study on one-class classification andactive learning (Ph.D. thesis), Delft University of Technology, 2006.
[24] P. Juszczak, D.M.J. Tax, E. Pekalska, R.P.W. Duin, Minimum spanning tree basedone-class classifier, Neurocomputing 72 (7–9) (2009) 1859–1869.
[25] M.W. Koch, M.M. Moya, L.D. Hostetler, R.J. Fogler, Cueing, feature discovery,and one-class learning for synthetic aperture radar automatic target recogni-tion, Neural Netw. 8 (7–8) (1995) 1081–1102.
[26] B. Krawczyk, Diversity in ensembles for one-class classification, in:Mykola Pechenizkiy, Marek Wojciechowski (Eds.), New Trends in Databasesand Information Systems, Advances in Intelligent Systems and Computing, vol.185, Springer, Berlin, Heidelberg, 2012, pp. 119–129.
[27] B. Krawczyk, P. Filipczuk, Cytological image analysis with firefly nucleidetection and hybrid one-class classification decomposition, Eng. Appl. Artif.Intell. 31 (2014) 126–135.
[28] B. Krawczyk, M. Wozniak, Accuracy and diversity in classifier selection forone-class classification ensembles, in: Proceedings of the 2013 IEEE Sympo-sium on Computational Intelligence and Ensemble Learning, CIEL 2013 – 2013IEEE Symposium Series on Computational Intelligence, SSCI 2013, 2013,pp. 46–51.
[29] B. Krawczyk, M. Woźniak, Combining diverse one-class classifiers, in:Emilio Corchado, Vaclav Snasel, Ajith Abraham, Michal Wozniak,Manuel Grana, Sung-Bae Cho (Eds.), Hybrid Artificial Intelligent Systems,Lecture Notes in Computer Science, vol. 7209, Springer, Berlin/Heidelberg,2012, pp. 590–601.
[30] B. Krawczyk, M. Woźniak, Diversity measures for one-class classifier ensem-bles, Neurocomputing 126 (2014) 36–44.
[31] B. Krawczyk, M. Woźniak, B. Cyganek, Clustering-based ensembles for one-class classification, Inf. Sci. 264 (2014) 182–195.
[32] L.I. Kuncheva, L.C. Jain, Designing classifier fusion systems by genetic algo-rithms, IEEE Trans. Evol. Comput. 4 (November (4)) (2000) 327–336.
[33] L. Manevitz, M. Yousef, One-class document classification via neural networks,Neurocomputing 70 (7–9) (2007) 1466–1481.
[34] R.S. Parpinelli, H.S. Lopes, New inspirations in swarm intelligence: a survey,Int. J. Bio-Inspir. Comput. 3 (1) (2011) 1–16.
[35] G. Ratsch, S. Mika, B. Scholkopf, K. Muller, Constructing boosting algorithmsfrom svms: an application to one-class classification, IEEE Trans. Pattern Anal.Mach. Intell. 24 (9) (2002) 1184–1199.
[36] Dymitr Ruta, Bogdan Gabrys, Classifier selection for majority voting, Inf.Fusion 6 (1) (2005) 63–81.
[37] A.D. Shieh, D.F. Kamm, Ensembles of one class support vector machines, in:Multiple Classifier Systems, 8th International Workshop, MCS 2009, LectureNotes in Computer Science, vol. 5519, Springer, 2009, pp. 181–190.
[38] SIAM. Proceedings of the Eleventh SIAM International Conference on DataMining, SDM 2011, April 28–30, 2011, Mesa, Arizona, USA. SIAM Omnipress,2011. ⟨http://tunedit.org/challenge/QSAR⟩.
[39] S. Sonnenburg, G. Rtsch, C. Schfer, andB. Schlkopf, Large scale multiple kernellearning, J. Mach. Learn. Res. 7 (2006) 1531–1565.
[40] D.M.J. Tax, R.P.W. Duin, Support vector domain description, Pattern Recognit.Lett. 20 (11–13) (1999) 1191–1199.
[41] D.M.J. Tax, R.P.W. Duin, Support vector data description, Mach. Learn. 54 (1)(2004) 45–66.
[42] D.M.J. Tax, K. Müller, A consistency-based model selection for one-classclassification, in: Proceedings – International Conference on Pattern Recogni-tion, vol. 3, 2004, Cited By (since 1996):12, pp. 363–366.
[43] David M.J. Tax, Piotr Juszczak, Elzbieta Pekalska, Robert P.W. Duin, Outlierdetection using ball descriptions with adjustable metric, in: Proceedings ofthe 2006 joint IAPR international conference on Structural, Syntactic, andStatistical Pattern Recognition SSPR'06/SPR'06, Springer-Verlag, Berlin,Heidelberg, 2006, pp. 587–595.
[44] D.M.J. Tax, Robert P.W. Duin, Characterizing one-class datasets, in: Proceedingsof the Sixteenth Annual Symposium of the Pattern Recognition Association ofSouth Africa, 2005, pp. 21–26.
[45] O. Taylor, J. MacIntyre, Adaptive local fusion systems for novelty detection anddiagnostics in condition monitoring, in: Proceedings of SPIE – The Interna-tional Society for Optical Engineering, vol. 3376, 1998, pp. 210–218.
[46] G. Tsoumakas, I. Partalas, I.P. Vlahavas, An ensemble pruning primer, in:Applications of Supervised and Unsupervised Ensemble Methods, 2009, pp.1–13.
[47] T. Wilk, M. Woźniak, Soft computing methods applied to combination of one-class classifiers, Neurocomputing 75 (January) (2012) 185–193.
[48] M. Woźniak, M. Grana, E. Corchado, A survey of multiple classifier systems ashybrid systems, Inf. Fusion 16 (1) (2014) 3–17.
[49] M. Woźniak, B. Krawczyk, Combined classifier based on feature spacepartitioning, J. Appl. Math. Comput. Sci. 22 (4) (2012) 855–866.
[50] Michal Wozniak, Experiments with trained and untrained fusers, in:Emilio Corchado, Juan Corchado, Ajith Abraham (Eds.), Innov. Hybrid Intell. Syst.Adv. Soft Comput., vol. 44, Springer, Berlin/Heidelberg, 2007, pp. 144–150.
[51] Michal Wozniak, Marcin Zmyslony, Combining classifiers using trained fuser—analytical and experimental results, Neural Netw. World 13 (7) (2010)925–934.
[52] X. Yang, Engineering optimization: an introduction with metaheuristic appli-cations, 2010.
[53] X. Yang, Firefly algorithm, stochastic test functions and design optimization,Int. J. Bio-Inspir. Comput. 2 (2) (2010) 78–84.
[54] H. Zhang, L. Cao, A spectral clustering based ensemble pruning approach,Neurocomputing 139 (2014) 289–297.
[55] H. Zuo, O. Wu, W. Hu, B. Xu, Recognition of blue movies by fusion of audio andvideo, in: 2008 IEEE International Conference on Multimedia and Expo, ICME2008 – Proceedings, 2008, pp. 37–40.
Bartosz Krawczyk received a BSc Engineering degreein Computer Science in 2011 and MSc degree withdistinctions in 2012 from Wroclaw University of Tech-nology, Poland. He was awarded as the best MScgraduate by the Rector of Wroclaw University of Tech-nology. He is currently a Research Assistant and a Ph.D.Candidate in the Department of Systems and ComputerNetworks at the same university. His research isfocused on machine learning, multiple classifier sys-tems, one-class classification, class imbalance, datastreams and interdisciplinary applications of thesemethods. So far, he has published more than 80 papersin international journals and conferences. Mr Krawczyk
was awarded with numerous prestigious awards for his scientific achievements likeIEEE Richard E. Merwin Scholarship, PRELUDIUM and ETIUDA grants from PolishNational Science Center, Scholarship of Polish Minister of Sciene and HigherEducation or START award from Foundation for Polish Science among others. Heis a member of Program Committees for over 40 international conferences and areviewer for over a dozen of journals.
B. Krawczyk / Neurocomputing ∎ (∎∎∎∎) ∎∎∎–∎∎∎ 11
Please cite this article as: B. Krawczyk, One-class classifier ensemble pruning and weighting with firefly algorithm, Neurocomputing(2014), http://dx.doi.org/10.1016/j.neucom.2014.07.068i





























