Embed Size (px)
Citation preview

OCULOMOTOR CAPTURE BY IRRELEVANT LTM

Devue, Belopolsky, and Theeuwes, 2012 • Examined whether or not oculomotor capture can occur in a bottom-up fashion by making faces irrelevant to the task.
• Examined if faces capture eye movements because of low-level features (by using inverted faces) or if capture depends on extracting meaning from the face (up right faces).

Methods• The Fixation cross varied from
600 to 1000 ms (in order to prevent anticipatory eye movements.
• 200 ms blank screen (in order to ease attentional disengagement).
• The search display was presented for 1000 ms.
• 500 ms blank screen. • The position of the critical item was non-predictive
of the position of the target circle.

• Displays used 6 grayscale objects which were surrounded by 6 colored circles.
• One object was a critical object (upright face, inverted face, or a butterfly).
• The other 5 objects were inanimate filler objects chosen from 6 categories (toys, vegetables, domestic devices, dishes, clothes, and musical instruments).
• The circles were all the same color except for the target circle which was a different color. 20 blocks X 54 trials = 1080 total trials
Participants were to make a saccade to the uniquely colored circle as quickly and as accurately as possible.
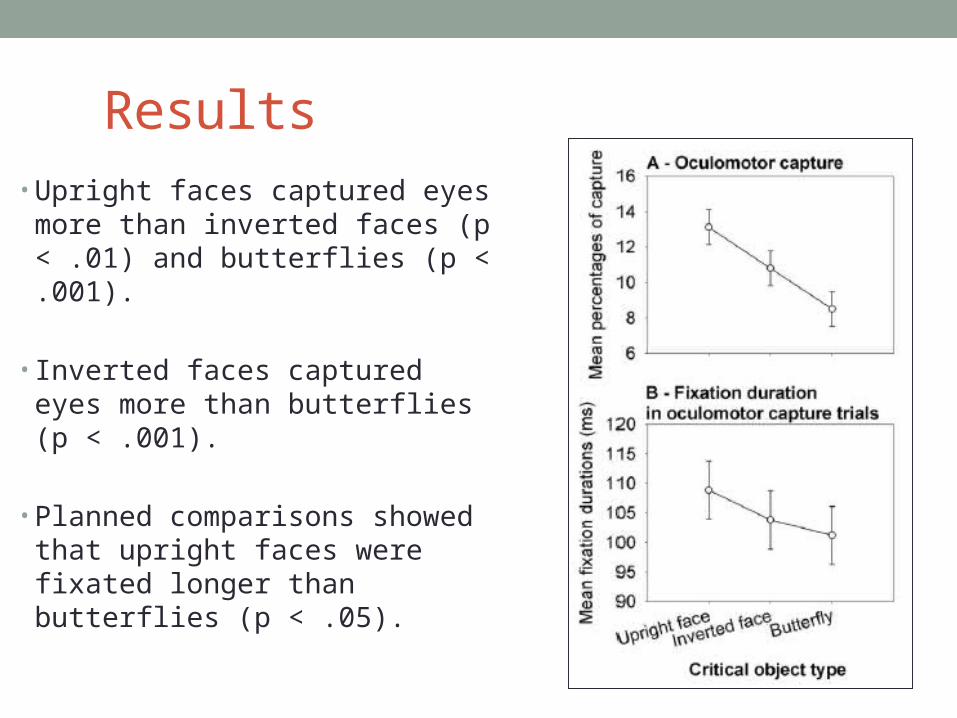
Results• Upright faces captured eyes
more than inverted faces (p < .01) and butterflies (p < .001).
• Inverted faces captured eyes more than butterflies (p < .001).
• Planned comparisons showed that upright faces were fixated longer than butterflies (p < .05).
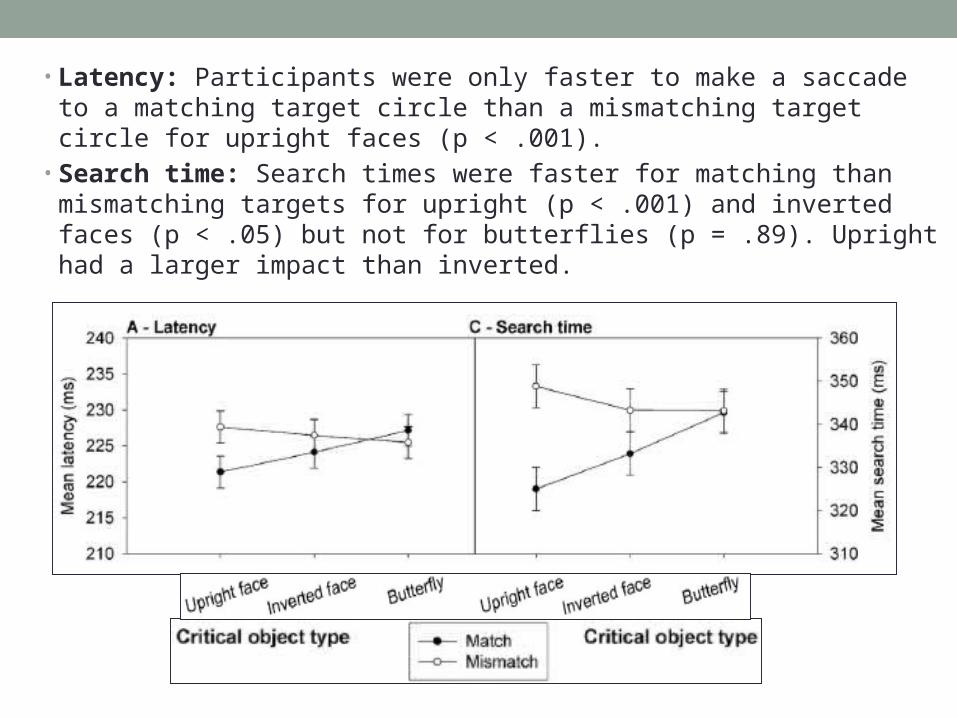
• Latency: Participants were only faster to make a saccade to a matching target circle than a mismatching target circle for upright faces (p < .001).
• Search time: Search times were faster for matching than mismatching targets for upright (p < .001) and inverted faces (p < .05) but not for butterflies (p = .89). Upright had a larger impact than inverted.

• Accuracy: Participants were more accurate for matching targets than mismatching targets for upright faces (p < .001) and inverted faces (p < .005) but not for butterflies (p = .7).
• Number of saccades: Upright faces required significantly fewer saccades for matching targets than mismatching targets ( p < .001) whereas inverted faces (p = .071) and butterflies (p = .88) did not reach significance.

Conclusions
• Oculomotor capture occurs in a bottom-up fashion for irrelevant faces.
• Faces help guide search when they are next to the target.
• Faces interfere with search when they are away from the target.
• Inverted faces created similar but smaller effects (low-level features of faces can impact visual selection).

If an irrelevant faces can capture eye movements, is it possible that irrelevant LTMs can also capture eye movements?
• Using the same display used by Devue, Belopolsky, and Theeuwes, (2012), we will examine whether or not encoding manipulations can capture eye movements.
• Faces and houses will serve as critical objects and will be studied during the encoding trials.
• Following encoding trials, participants will follow the same procedure used by Devue, Belopolsky, and Theeuwes, (2012).
• Finally, participants will make judgments on recognition and confidence.

Encoding Trials• Participants will study
30 faces and 30 houses twice each for 4 s.
• Participants will be asked to commit these pictures to memory for later on in the recognition trials.

Attention Trials• The Fixation cross will vary from
600 to 1000 ms (in order to prevent anticipatory eye movements.
• 200 ms blank screen (in order to ease attentional disengagement).
• The search display will be presented for 1000 ms.
• 500 ms blank screen.

Recognition Trials
seen during:• encoding trials • attention trials • not seen
Confidence rating:• guess • low confidence• high confidence.
Critical objects from the encoding trials and the attention trials will be presented as well as faces and houses that were not seen.

Predictions• Memory for studied objects should be better (more
accurate and confident) than for objects that only appeared in the attention task.
• Accuracy and confidence will be used to back-sort eye movement data from the attention task.
• Studied objects are expected to capture attention more than objects that only appeared during the attention trials.
• When capture due to LTM occurs, it should be more difficult to disengage.

Why should we expect an irrelevant LTM can capture eye movements in the same way an irrelevant face does?
• Irrelevant color associations stored in LTM can interfere with attentional guidance (Olivers, 2011).
• Distractors with semantic associations in LTM capture attention and eye movements more than objects without semantic associations in LTM (Moores, Laiti, and Chelazzi, 2003).