Embed Size (px)
Citation preview

Object-Relational Database Systems:
Evolution Beats Revolution
Michael J. CareyIBM Almaden Research Center
Smalltalk
Navi-
gation
Queries
Java
C++
Appl.
Dev.
Tools
New
Data
Types
SQL

Plan for the Talk
The relational DBMS revolution Relational model and query language Why relational succeeded Why relational isn't enough, and some options
The object-oriented DBMS revolution Object-oriented model(s) and query language(s) Why object-oriented "failed" Why wrappers will fail as well
The object-relational DBMS evolution The object-relational model and query language Current products and examples Performance and other challenges

The Relational DBMS Revolution
The pre-relational era (1970's) Graph-based data models
Hierarchical model (e.g., IMS) Network model (e.g., Codasyl)
Low-level, navigational interfaces Labor-intensive and error-prone
The relational era (1980's) Simple, abstract data model
Database = set of relations ("tables") 3 schema levels: views, base tables, physical schema Algebra of set-oriented operations
High-level, declarative interfaces SQL, Quel, QBE Embedded languages, 4GLs

The Relational Model (by example)
Employees and departments
Department dno name 10 Toy 20 Shoe
Employee eno name salary dept 1 Lou 10000000 10 7 Laura 150000 20 22 Mike 80000 20
select E.name, E.salary, D.nofrom Employee E, Department Dwhere E.salary < 100000
and D.name = 'Shoe'and E.dept = D.dno
?

Relational DBMS "Goodies"
Relational query processing Queries range over tables and/or views Programmers use a declarative language (SQL)
Query optimizer picks the lowest-cost query plan
Alternative access paths, join orders, join methods, and so on (based on indices and database characteristics)
Result: data independenceSupport for (shared) business logic
Integrity constraints Check constraints, referential integrity constraints
Triggers, stored procedures, views, authorization
Performance and robustness Buffering, locking, crash recovery, replication, ...

We've Achieved Nirvana ... Right?
Relations are surely the answer! Simple, high-level model for programmers
Easy to distribute data and parallelize queries
But what was the question? Sometimes difficult to model "real world" data
Entities and relationships (versus tables) Variance among entities (versus homogeneity)
Set-valued attributes (versus normalization)Demanding new database applications
New applications bring new data types Complex objects are problematic
"A relational database is like a garage which forces you to take your car apart and store the pieces in little drawers..."

What are the Options?
Throw in the towel OOPL + your favorite file system
Object-oriented DBMS Tightly integrated: OOPL w/built-in DBMS
Object-oriented client wrapper Loosely integrated: OOPL + relational DBMS
Object-relational DBMS Newly integrated: Relational model + OO features
Which solution is the "right" one...?
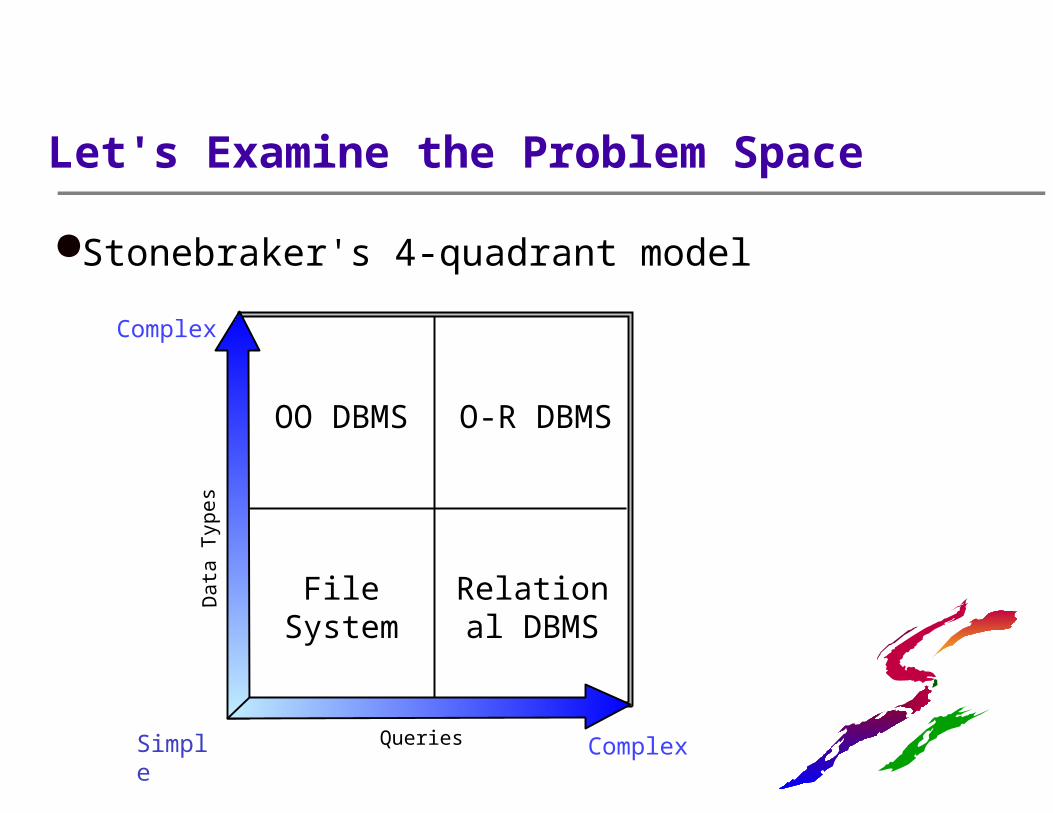
Let's Examine the Problem Space
Simple Complex
Stonebraker's 4-quadrant model
Complex
OO DBMS O-R DBMS
Relational DBMS
File System
Queries
Da
ta T
ype
s

The Object-Oriented DBMS Revolution
Motivated by new database applications, e.g.:
Computer-aided engineering Document management
Geographic data managementEngineering applications were early drivers
Complex data structures ("pointer spaghetti")
Navigational data access required Tight coupling between applications and data
Version management support neededApproach: OOPL + DBMS = OO-DBMS
Commonly based on C++ or Smalltalk Persistence, collections, versions, queries, ...

No OO "Ted Codd" Stepped Forward
Object-Oriented Database System Manifesto
Mandatory features Complex objects, identity, encapsulation Inheritance w/substitutability and late binding Computationally complete methods Extensible type system, persistence Secondary storage, concurrency and recovery Ad hoc queries
Optional features Multiple inheritance, static type checking Distribution, long transactions, versions
Individual choices Programming paradigm/language Details and uniformity of object model

OO-DBMS Technology Today
Lots of research results Object data models and features OO query languages and processing techniques
Client-server architectures and performanceSignificant commercial progress
Important and innovative systems E.g., O2, ObjectStore, ODE
Quite a few commercial product offerings GemStone, Objectivity, ObjectStore, Ontos, O2, Matisse, Poet, Versant, others
The ODMG-93 standard (release 2.0) Consortium of OO-DBMS startups Three key parts: ODL, OQL, C++ binding

But the Revolution "Failed" ($0B)
Lingering OO-DBMS differences Query power, API details, implementation twists
Piecewise ODMG standard conformance (ex: OQL!)
Still behind R-DBMSs in important ways Codasyl-like schema compilation cycle Schema evolution painful, if supported Typically missing many useful "goodies"
Support for multiple application languages Query optimization, views, authorization, constraints, triggers, multi-user scalability and robustness, ...
Other factors (niche market) SQL-based application building tools Architecturally biased towards "fat clients"

OO Client Wrappers are the Answer...
Available from a number of vendors Persistence Software, Ontologic, HP, Next, ...
Language-specific relational wrappers Proxy classes for C++ or Smalltalk (or Java)
Mapping of row data into language objects Client-side (or middle-tier) object caching and method execution
Why is this approach attractive? Can develop OO applications today, against existing enterprise data, for "business objects"

...Not!
Paradigm mismatch for querying C++ or Smalltalk for simple business logic and navigation, against object-oriented schema
SQL for queries, against relational schema
Choice forced for business logic & rules
Do on server, using DBMS facilities? Check constraints, referential integrity constraints, triggers, stored procedures, authorization
Do on client, using OO wrapper facilities? C++ or Smalltalk (or Java) programming
This had better be a stop-gap solution
R-DBMS could become a storage manager, throwing away 20+ years of successful R&D!

The Object-Relational DBMS Evolution
Third Generation Database System Manifesto
Support rich object structures and rules Rich type system, inheritance, encapsulation Functions, optional unique ids, rules/trigggers
Subsume second generation database systems
High-level query-oriented interface Stored and virtual collections Updatable views Data model/performance feature separation
Open to other subsystems (tools, middleware) Accessible from multiple languages Layered persistence-oriented language bindings SQL support ("intergalactic dataspeak") Query-shipping architecture

"Not Your Father's Employee Type"
Beyond name, rank, and serial number Several new attribute types
Location (2-d point), job description (text), photo (image), ...
Associated functions Distance(point, point), contains(text, string), ...
Beyond your basic employee record Employees come in different flavors
Emp, RSM, Programmer, Manager, Temp, ... Employees have many known relationships
Manager, department, projects, ... Employees have behavior
Age(Emp), qualified(Emp, Job), hire(Emp), ...
An Employee is a "business object"

Two Flavors of O-R Object Extensions
Object extension #1: Abstract data types (ADTs)
New column types and functions E.g.,text, image, audio, video, time series, point, line, OLE...
For modeling new kinds of facts about enterprise entities
Object extension #2: Row types Types and functions for rows of tables
Includes inheritance, references, set-valued attributes
For modeling business objects with relationships & behavior
Impact on schemas and query language: SQL3
Schemas: tables at the top, OO richness within Queries: extensions to support the added richness
Structured types: support both ADT and row type object modeling needs (unified type system)

ADTs (Black Box)
To define and use a "black box ADT", a user will
Implement its internal structure and functions in an external programming language (e.g., C/C++, Java)
Use the DDL to register the type with the DBMS Size of an instance of the type Input (constructor) and output functions Other functions and operators, including signatures and linkable implementations
Costs and other properties for query optimizer Use the new type like a built-in data type
Now available for defining columns of tables Functions and operators become available in queries

Example: Illustra Black Box ADT
Point as a "black box ADT" (written in C)
create type Point(
internallength = 16; -- typedef struct {double x, double y} pointinput = point_in; -- for reading in Point constantsoutput = point_out; -- for displaying Point results
);
create function point_in(Text) returns Point asexternal name 'MI_HOME/functions/point.so'language C;
create function point_out(Point) returns Text asexternal name 'MI_HOME/functions/point.so'language C;

Example: Illustra Black Box ADT (cont.)
Now we can put an end to "Pointless" queries...!
create function further_west(Point, Point) returns Boolean asexternal name 'MI_HOME/functions/pointfuns.so'language C;
select E1.name, E1.locationfrom Emp E1, Emp E2where further_west(E1.location, E2.location) and E2.name = 'Mike';
create binary operator binding to further_west;
select E1.name, E1.locationfrom Emp E1, Emp E2where E1.location >> E2.location and E2.name = 'Mike';

ADTs (White Box)
To define and use a "white box ADT", a user will
Describe its internal structure using SQL3 DDL Attribute definitions are column-like Advantages: heterogeneity, nulls, nesting, constraints, ...
Implement its functions either directly in SQL or in his/her favorite external programming language
Utilize system-generated accessors and mutators Finish explaining the type to the DBMS using DDL
For query optimizer, as before Use the new type like a built-in data type
In tables and queries, as before Note: this is just a SQL3 structured type definition that's primarily intended for use in columns

Example: DB2 UDB/OSF White Box ADT
Point as a "white box ADT" (written in SQL3)create type Point as
(x double,y double,
);
create function distance(p1 Point, p2 Point) returns Pointlanguage SQL inline not variantreturn sqrt((p2..y-p1..y)*(p2..y-p1..y) + (p2..x-p1..x)*(p2..x-p1..x));
select E.namefrom Emp E, City Cwhere C.name = 'San Jose'
and distance(E.location, C.center) < 25;

Of Extenders, Blades, and Cartridges
High performance demands "deep" integration
Optimizer must know about an ADT operator's...
Execution cost (especially for expensive functions) Logical properties (e.g., transitivity, negator, ...) Selectivity estimates (i.e., filtering/matching power) Relationship to access methods (both old and new)
DBMS runtime must invoke functions efficiently
Static vs. dynamic loading, fenced vs. unfenced execution
Partnerships and third-party packages E.g., DB2's text, image, and spatial extenders Package contains types, functions, access methods, optimizer information, and SQL DDL statements for all of the above

Row Types
To define and use a "row type", a user will Create the desired structured type using SQL3 DDL
Columns, plus (optional) specification of a supertype Create functions/methods involving the type
Arguments of the new type, w/overloading in the case of methods Create one or more tables of the indicated type
Type hierarchy (if any) yields corresponding table hierarchies
Em p_t K id_t
Pe rson_t
IB M _E m ps IB M _K ids
IB M _P eop le
Type Hierarchy Table Hierarchy

Example: SQL3 Row Types (plus Sets...)
Employees are people, so ...
create type Emp_tunder Person_t as (
salary Float,job_description Varchar(100),department ref(Dept),projects set(ref(Project)
);
create table IBM_Emps of Emp_tunder IBM_People (...);
create type Person_t as(name Varchar(20),birthdate Date)
method age( ) returns Integer language SQL;
create method age( ) for Person_treturn year(current date) - year(birthdate);
create table IBM_People of Person_t (ref is self);
(**Note: this is approximate SQL3 syntax)

Queries Over Row Types
SQL's query constructs, extended with the ability to access these features (a la SQL3 plus sets)
User-defined functions in queries (w/late method binding)
Dereferencing of references (path expressions) Queries over nested collections (table expressions)
For example, find unexplainable discrepencies between employees' and managers' salaries:
select E.name, E.manager->name, display(E.photo)from IBM_Emps Ewhere E.salary > E.department->manager->salaryand E.department->manager->age( ) > E.self->age( )and not contains(E.job_description, "Java")

Other OR-Related Features
Support for large objects Multimedia data types aren't small (e.g., video) Special handling required for efficiency
Minimal copying, piecewise retrieval, optional logging, movement to/from files, separate storage area from other attributes
DB2 has blob, clob, and dbclob types (up to 2GB)Support for active data (triggers and constraints)
Ex: create trigger me_tooafter insert on IBM_Empsreferencing new as newempforeach row mode db2sqlwhen salary > department->manager->salarybegin atomic
set newemp.department->manager->salary= newemp.salary;
end

OR-DBMS Technology Status
Many OR-DBMS research results Postgres, EXODUS, Starburst, ... OODB query processing research
Commercial systems exist today IBM DB2 CS (V2.1) and CA-Ingres
User-defined types & functions, large objects, triggers Illustra, UniSQL/X
Early providers of ADTs, row objects, inheritance IBM DB2 UDB, Informix, Oracle
"Universal server" products contain subsets of all this stuff
Standards right around the corner SQL3 is "hardening" and has an object part with structured types, table hierachies, user-defined functions and methods, object views, ....

Some OR-DBMS Performance Issues
Bucky OR-DBMS benchmark from UW-Madison
Based on a hypothetical university schema Exercised a range of OR-DBMS features
Row types, inheritance, late binding, subtables Queries involving path expressions and/or sets ADTs (black or white box) and functions
In Proc. 1997 ACM SIGMOD ConferenceTested a first-generation OR-DBMS product
OR versus relational simulation, same DB engine
Showed benefits of (complex) ADTs, indexes on functions
Indicated areas where query optimization needs schema support: scope for path expressions, inverse relationships
Turned up bugs and performance problems (e.g., sets)

Object-relational server managing the database
ADTs w/inheritance and multi-language support Row types, integrated with all of SQL (OO views, authorization, triggers, constraints, etc.)
High-function, OO, caching front-ends Support for desktop and middle-tier (web!) applications
OR object model at all levels, for queries and navigation
Clean bindings for OOPLs (Java, C++, Smalltalk) Methods/queries running on client or server Likewise for triggers and constraints
Business rules specified & implemented once! In SQL (+ OOPL), running where appropriate
OR Enterprise Scenerio (w/Challenges)

Multi-Tier Integration Challenges
Good mappings and interfaces to provide object-relational objects to OOPLs
Java, C++, Smalltalk, others Full query support in addition to navigation
Challenges in querying and caching Intelligent querying over cache + database Correct and efficient caching of view objects
Update-related challenges Triggers and constraints of all types View objects (both directions)
Method execution on client or server Java should be very useful here

Legacy Data Access Challenges
Some data will live outside the OR-DBMS Older DBMSs (both relational & pre-relational) Specialized data stores (documents, images, ...)
Applications (i.e., legacy transactions)Object-relational middleware is the answer!
Table functions can handle simple cases now Distributed OR query engine (a la DataJoiner) can mediate between new applications and legacy data
Resulting appearance is that of an integrated OR database, accessible via SQL3 APIs and OO tools
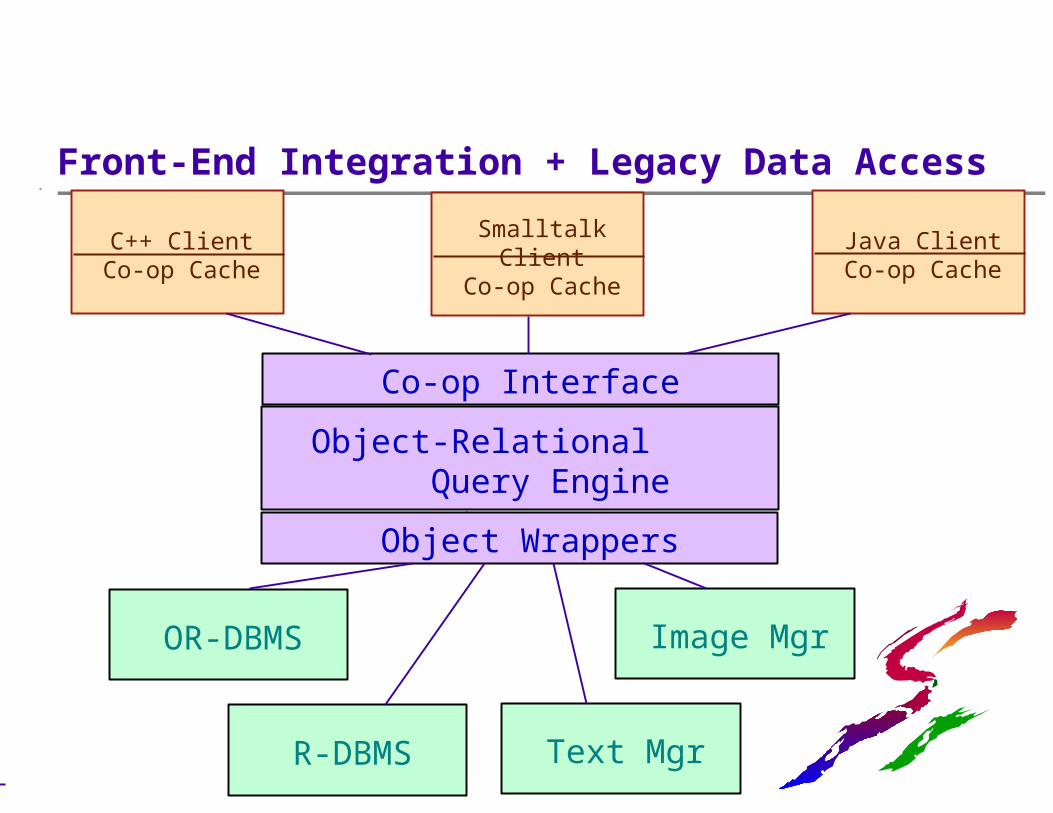
Front-End Integration + Legacy Data Access
Co-op Interface
OR-DBMS
R-DBMS
Image Mgr
C++ ClientCo-op Cache
Smalltalk ClientCo-op Cache
Java ClientCo-op Cache
Text Mgr
Object Wrappers
Object-Relational Query Engine

Conclusions
Relational DBMS era: 1980's, early 1990's. Significantly raised the levels of abstraction & productivity
Only "real" parallel computing success story to date, too!
Object DBMS era: Should have been early 1990's...
Never made it out of the (mainstream) starting gateObject-relational DBMS era: You are there!
Object enhancements to relational DBMSs ADTs (white box, black box) and functions Row types with inheritance, references, sets, ...
Vastly reduces the "impedence mismatch" w/OOPLs Today's OO wrappers are an interim solution Possibilities abound for nice OO/OR tools
Will have OR middleware as well as engines





























