Embed Size (px)
Citation preview

Object-Proposal Evaluation Protocol is ‘Gameable’(Supplement)
Neelima Chavali*† Harsh Agrawal* Aroma Mahendru* Dhruv BatraVirginia Tech
{gneelima, harsh92, maroma, dbatra}@vt.edu
Abstract
The main paper demonstrated how the object proposal eval-uation protocol is ‘gameable’ and performed some experi-ments to detect this ‘gameability’. In this supplement, wepresent additional details and results which support the ar-guments presented in the main paper.In section 1, we list and briefly describe the different objectproposal algorithms which we used for our experiments.Following this, details of instance-level PASCAL Contextare discussed in section 2. Then we present the results onnearly-fully annotated dataset, cross dataset evaluation onother evaluation metrics in section 3. We also show theper category performance of various methods on MS COCOand PASCAL Context in section 4.
1. Overview of Object Proposal Algorithms
Table 1 provides an overview of some popular object pro-posal algorithms. The symbol ∗ indicates methods we haveevaluated in this paper. Note that a majority of the ap-proaches are learning based.
2. Details of PASCAL Context Annotation
As explained in section 5.1 of the main paper, PASCALContext provides full annotations for PASCAL VOC 2010dataset in the form of semantic segmentations. A total of459 classes have labeled in this dataset. We split these intothree categories namely Objects/Things, Background/Stuffand Ambiguous as shown in Tables 2, 4 and 3. Most classes(396) were put in the ‘Objects’ category. 20 of these arePASCAL categories. Of the remaining 376, we selected themost frequently occurring 60 categories and manually cre-ated instance level annotations for the same.
Statistics of New Annotations: We made the following ob-servations on our new annotations:
*Equal contribution.†Now at Amgen Inc.
• The number of instances we annotated for the extra60 categories were about the same as the number ofinstances for annotated for 20 PASCAL categories inthe original PASCAL VOC. This shows that about halfthe annotations were missing and thus a lot of genuineproposal candidates are not being rewarded.
• Most non-PASCAL categories occupy a small percent-age of the image. This is understandable given that thedataset was curated with these categories. The othercategories just happened to be in the pictures.
3. Evaluation of Proposals on Other Metrics
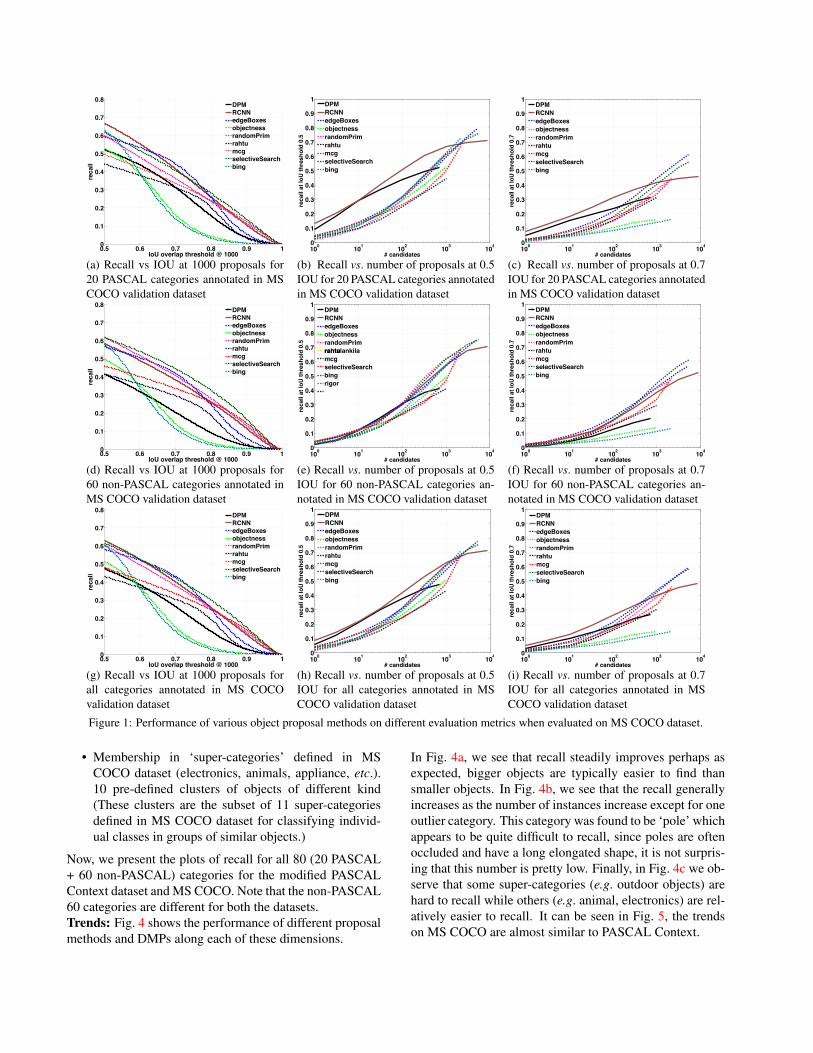
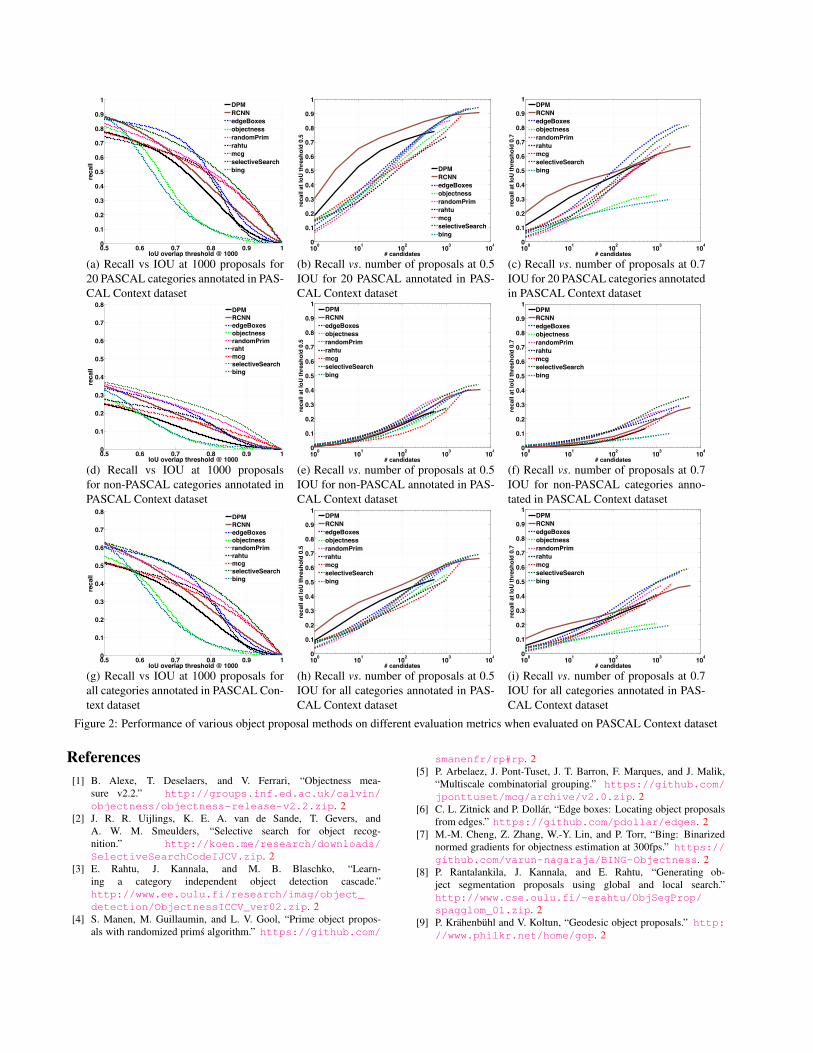
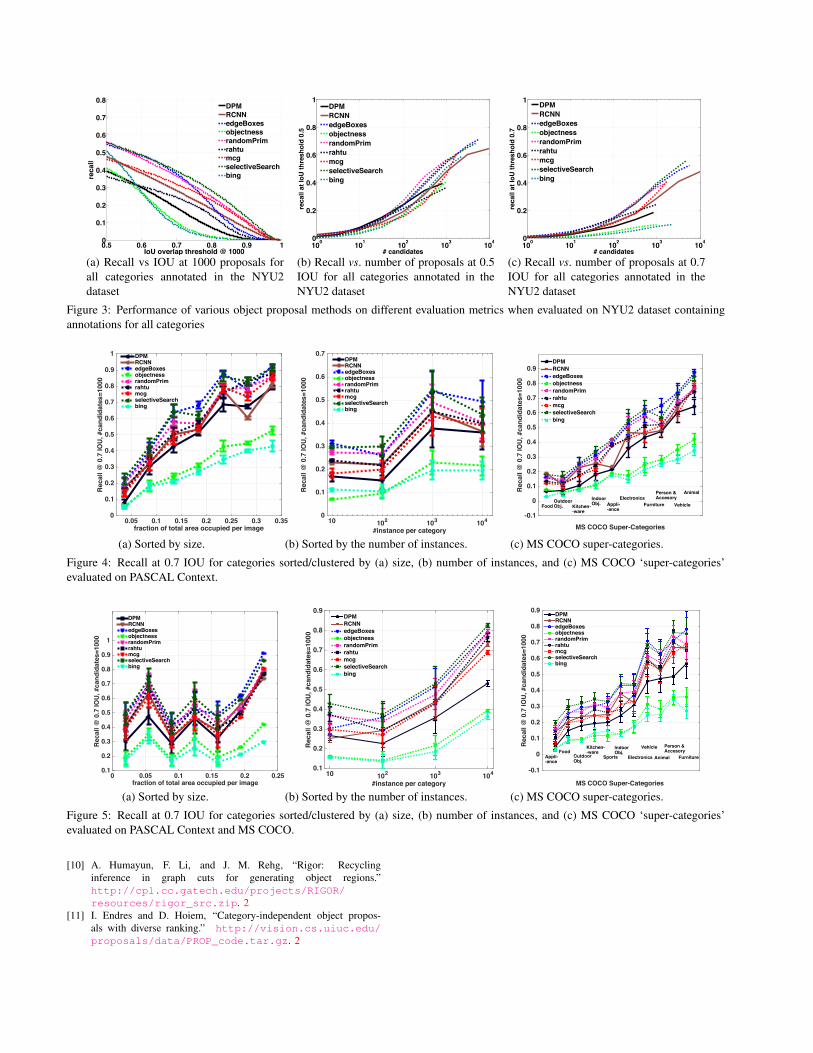
In this section, we show the performance of different pro-posal methods and DMPs on MS COCO dataset on variousmetrics. Fig. 1a shows performance on Recall-vs-IOU met-ric at 1000 #proposals on PASCAL 20 categories. Fig. 1b,Fig. 1c show performance on Recall-vs.-#proposals metricat 0.5 and 0.7 IOU respectively. Similarly in Figs. 1d,1e, 1fand Figs. 1g,1h, 1i, we can see the performance of all pro-posal methods and DMPs on these three metrics where 60non-PASCAL and all categories respectively are annotatedin the MS COCO dataset.These metrics also demonstrate the same trend as shownby the AUC-vs.-#proposals in the main paper. When onlyPASCAL categories are annotated (Figs. 1a,1b, 1c ), DMPsoutperform all proposal methods. However, when othercategories are also annotated (Figs. 1g,1h, 1i) or the per-formance is evaluated specifically on the other categories(Figs. 1d,1e, 1f), DMPs cease to be the top performers.Finally, we also report results on different metrics PASCALContext (Fig. 2) and NYU-Depth v2 (Fig. 3). They alsoshow similar trends, supporting the claims made in the pa-per.
4. Measuring Fine-Grained Recall
We also looked at a more fine-grained per-category perfor-mance of proposal methods and DMPs. Fine grained recallcan be used to answer if some proposal methods are opti-mized for larger or frequent categories i.e. if they perform
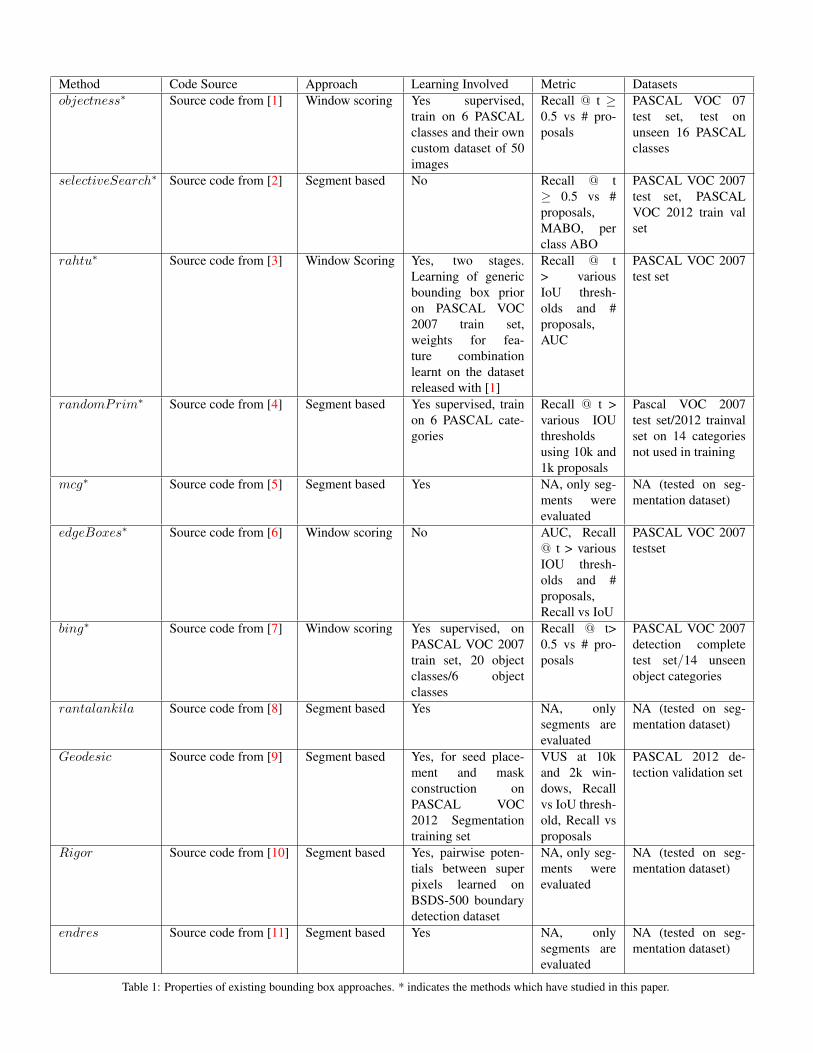
Method Code Source Approach Learning Involved Metric Datasetsobjectness∗ Source code from [1] Window scoring Yes supervised,
train on 6 PASCALclasses and their owncustom dataset of 50images
Recall @ t ≥0.5 vs # pro-posals
PASCAL VOC 07test set, test onunseen 16 PASCALclasses
selectiveSearch∗ Source code from [2] Segment based No Recall @ t≥ 0.5 vs #proposals,MABO, perclass ABO
PASCAL VOC 2007test set, PASCALVOC 2012 train valset
rahtu∗ Source code from [3] Window Scoring Yes, two stages.Learning of genericbounding box prioron PASCAL VOC2007 train set,weights for fea-ture combinationlearnt on the datasetreleased with [1]
Recall @ t> variousIoU thresh-olds and #proposals,AUC
PASCAL VOC 2007test set
randomPrim∗ Source code from [4] Segment based Yes supervised, trainon 6 PASCAL cate-gories
Recall @ t >various IOUthresholdsusing 10k and1k proposals
Pascal VOC 2007test set/2012 trainvalset on 14 categoriesnot used in training
mcg∗ Source code from [5] Segment based Yes NA, only seg-ments wereevaluated
NA (tested on seg-mentation dataset)
edgeBoxes∗ Source code from [6] Window scoring No AUC, Recall@ t > variousIOU thresh-olds and #proposals,Recall vs IoU
PASCAL VOC 2007testset
bing∗ Source code from [7] Window scoring Yes supervised, onPASCAL VOC 2007train set, 20 objectclasses/6 objectclasses
Recall @ t>0.5 vs # pro-posals
PASCAL VOC 2007detection completetest set/14 unseenobject categories
rantalankila Source code from [8] Segment based Yes NA, onlysegments areevaluated
NA (tested on seg-mentation dataset)
Geodesic Source code from [9] Segment based Yes, for seed place-ment and maskconstruction onPASCAL VOC2012 Segmentationtraining set
VUS at 10kand 2k win-dows, Recallvs IoU thresh-old, Recall vsproposals
PASCAL 2012 de-tection validation set
Rigor Source code from [10] Segment based Yes, pairwise poten-tials between superpixels learned onBSDS-500 boundarydetection dataset
NA, only seg-ments wereevaluated
NA (tested on seg-mentation dataset)
endres Source code from [11] Segment based Yes NA, onlysegments areevaluated
NA (tested on seg-mentation dataset)
Table 1: Properties of existing bounding box approaches. * indicates the methods which have studied in this paper.
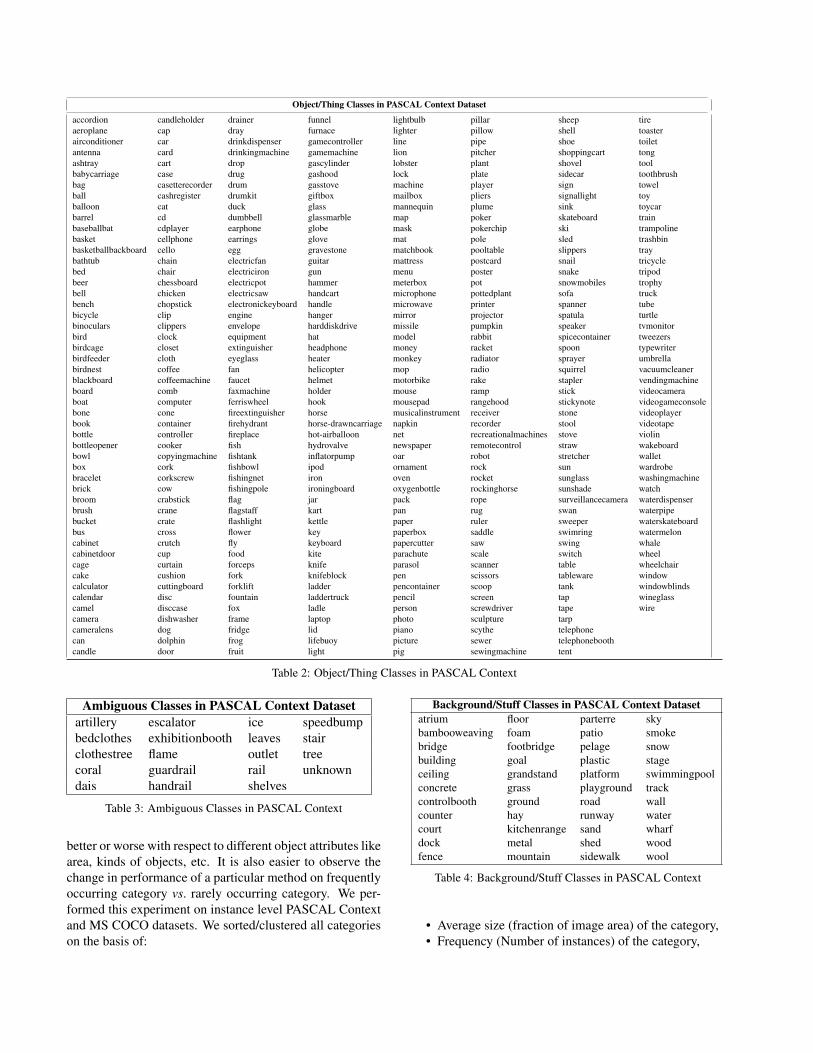
Object/Thing Classes in PASCAL Context Dataset
accordion candleholder drainer funnel lightbulb pillar sheep tireaeroplane cap dray furnace lighter pillow shell toasterairconditioner car drinkdispenser gamecontroller line pipe shoe toiletantenna card drinkingmachine gamemachine lion pitcher shoppingcart tongashtray cart drop gascylinder lobster plant shovel toolbabycarriage case drug gashood lock plate sidecar toothbrushbag casetterecorder drum gasstove machine player sign towelball cashregister drumkit giftbox mailbox pliers signallight toyballoon cat duck glass mannequin plume sink toycarbarrel cd dumbbell glassmarble map poker skateboard trainbaseballbat cdplayer earphone globe mask pokerchip ski trampolinebasket cellphone earrings glove mat pole sled trashbinbasketballbackboard cello egg gravestone matchbook pooltable slippers traybathtub chain electricfan guitar mattress postcard snail tricyclebed chair electriciron gun menu poster snake tripodbeer chessboard electricpot hammer meterbox pot snowmobiles trophybell chicken electricsaw handcart microphone pottedplant sofa truckbench chopstick electronickeyboard handle microwave printer spanner tubebicycle clip engine hanger mirror projector spatula turtlebinoculars clippers envelope harddiskdrive missile pumpkin speaker tvmonitorbird clock equipment hat model rabbit spicecontainer tweezersbirdcage closet extinguisher headphone money racket spoon typewriterbirdfeeder cloth eyeglass heater monkey radiator sprayer umbrellabirdnest coffee fan helicopter mop radio squirrel vacuumcleanerblackboard coffeemachine faucet helmet motorbike rake stapler vendingmachineboard comb faxmachine holder mouse ramp stick videocameraboat computer ferriswheel hook mousepad rangehood stickynote videogameconsolebone cone fireextinguisher horse musicalinstrument receiver stone videoplayerbook container firehydrant horse-drawncarriage napkin recorder stool videotapebottle controller fireplace hot-airballoon net recreationalmachines stove violinbottleopener cooker fish hydrovalve newspaper remotecontrol straw wakeboardbowl copyingmachine fishtank inflatorpump oar robot stretcher walletbox cork fishbowl ipod ornament rock sun wardrobebracelet corkscrew fishingnet iron oven rocket sunglass washingmachinebrick cow fishingpole ironingboard oxygenbottle rockinghorse sunshade watchbroom crabstick flag jar pack rope surveillancecamera waterdispenserbrush crane flagstaff kart pan rug swan waterpipebucket crate flashlight kettle paper ruler sweeper waterskateboardbus cross flower key paperbox saddle swimring watermeloncabinet crutch fly keyboard papercutter saw swing whalecabinetdoor cup food kite parachute scale switch wheelcage curtain forceps knife parasol scanner table wheelchaircake cushion fork knifeblock pen scissors tableware windowcalculator cuttingboard forklift ladder pencontainer scoop tank windowblindscalendar disc fountain laddertruck pencil screen tap wineglasscamel disccase fox ladle person screwdriver tape wirecamera dishwasher frame laptop photo sculpture tarpcameralens dog fridge lid piano scythe telephonecan dolphin frog lifebuoy picture sewer telephoneboothcandle door fruit light pig sewingmachine tent
Table 2: Object/Thing Classes in PASCAL Context
Ambiguous Classes in PASCAL Context Datasetartillery escalator ice speedbumpbedclothes exhibitionbooth leaves stairclothestree flame outlet treecoral guardrail rail unknowndais handrail shelves
Table 3: Ambiguous Classes in PASCAL Context
better or worse with respect to different object attributes likearea, kinds of objects, etc. It is also easier to observe thechange in performance of a particular method on frequentlyoccurring category vs. rarely occurring category. We per-formed this experiment on instance level PASCAL Contextand MS COCO datasets. We sorted/clustered all categorieson the basis of:
Background/Stuff Classes in PASCAL Context Datasetatrium floor parterre skybambooweaving foam patio smokebridge footbridge pelage snowbuilding goal plastic stageceiling grandstand platform swimmingpoolconcrete grass playground trackcontrolbooth ground road wallcounter hay runway watercourt kitchenrange sand wharfdock metal shed woodfence mountain sidewalk wool
Table 4: Background/Stuff Classes in PASCAL Context
• Average size (fraction of image area) of the category,• Frequency (Number of instances) of the category,
0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
IoU overlap threshold @ 1000
reca
ll
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(a) Recall vs IOU at 1000 proposals for20 PASCAL categories annotated in MSCOCO validation dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
5
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(b) Recall vs. number of proposals at 0.5IOU for 20 PASCAL categories annotatedin MS COCO validation dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
7
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(c) Recall vs. number of proposals at 0.7IOU for 20 PASCAL categories annotatedin MS COCO validation dataset
0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
IoU overlap threshold @ 1000
reca
ll
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(d) Recall vs IOU at 1000 proposals for60 non-PASCAL categories annotated inMS COCO validation dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
5
DPMRCNNedgeBoxesobjectnessrandomPrimrantalankilarahtumcgselectiveSearchbingrigor
(e) Recall vs. number of proposals at 0.5IOU for 60 non-PASCAL categories an-notated in MS COCO validation dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
7
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(f) Recall vs. number of proposals at 0.7IOU for 60 non-PASCAL categories an-notated in MS COCO validation dataset
0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
IoU overlap threshold @ 1000
reca
ll
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(g) Recall vs IOU at 1000 proposals forall categories annotated in MS COCOvalidation dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
5
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(h) Recall vs. number of proposals at 0.5IOU for all categories annotated in MSCOCO validation dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
7
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(i) Recall vs. number of proposals at 0.7IOU for all categories annotated in MSCOCO validation dataset
Figure 1: Performance of various object proposal methods on different evaluation metrics when evaluated on MS COCO dataset.
• Membership in ‘super-categories’ defined in MSCOCO dataset (electronics, animals, appliance, etc.).10 pre-defined clusters of objects of different kind(These clusters are the subset of 11 super-categoriesdefined in MS COCO dataset for classifying individ-ual classes in groups of similar objects.)
Now, we present the plots of recall for all 80 (20 PASCAL+ 60 non-PASCAL) categories for the modified PASCALContext dataset and MS COCO. Note that the non-PASCAL60 categories are different for both the datasets.Trends: Fig. 4 shows the performance of different proposalmethods and DMPs along each of these dimensions.
In Fig. 4a, we see that recall steadily improves perhaps asexpected, bigger objects are typically easier to find thansmaller objects. In Fig. 4b, we see that the recall generallyincreases as the number of instances increase except for oneoutlier category. This category was found to be ‘pole’ whichappears to be quite difficult to recall, since poles are oftenoccluded and have a long elongated shape, it is not surpris-ing that this number is pretty low. Finally, in Fig. 4c we ob-serve that some super-categories (e.g. outdoor objects) arehard to recall while others (e.g. animal, electronics) are rel-atively easier to recall. It can be seen in Fig. 5, the trendson MS COCO are almost similar to PASCAL Context.
0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
IoU overlap threshold @ 1000
reca
ll
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(a) Recall vs IOU at 1000 proposals for20 PASCAL categories annotated in PAS-CAL Context dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
5
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(b) Recall vs. number of proposals at 0.5IOU for 20 PASCAL annotated in PAS-CAL Context dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
7
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(c) Recall vs. number of proposals at 0.7IOU for 20 PASCAL categories annotatedin PASCAL Context dataset
0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
IoU overlap threshold @ 1000
reca
ll
DPMRCNNedgeBoxesobjectnessrandomPrimrahtmcgselectiveSearchbing
(d) Recall vs IOU at 1000 proposalsfor non-PASCAL categories annotated inPASCAL Context dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
5
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(e) Recall vs. number of proposals at 0.5IOU for non-PASCAL annotated in PAS-CAL Context dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
7
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(f) Recall vs. number of proposals at 0.7IOU for non-PASCAL categories anno-tated in PASCAL Context dataset
0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
IoU overlap threshold @ 1000
reca
ll
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(g) Recall vs IOU at 1000 proposals forall categories annotated in PASCAL Con-text dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
5
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(h) Recall vs. number of proposals at 0.5IOU for all categories annotated in PAS-CAL Context dataset
100 101 102 103 1040
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
7
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(i) Recall vs. number of proposals at 0.7IOU for all categories annotated in PAS-CAL Context dataset
Figure 2: Performance of various object proposal methods on different evaluation metrics when evaluated on PASCAL Context dataset
References[1] B. Alexe, T. Deselaers, and V. Ferrari, “Objectness mea-
sure v2.2.” http://groups.inf.ed.ac.uk/calvin/objectness/objectness-release-v2.2.zip. 2
[2] J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, andA. W. M. Smeulders, “Selective search for object recog-nition.” http://koen.me/research/downloads/SelectiveSearchCodeIJCV.zip. 2
[3] E. Rahtu, J. Kannala, and M. B. Blaschko, “Learn-ing a category independent object detection cascade.”http://www.ee.oulu.fi/research/imag/object_detection/ObjectnessICCV_ver02.zip. 2
[4] S. Manen, M. Guillaumin, and L. V. Gool, “Prime object propos-als with randomized prims algorithm.” https://github.com/
smanenfr/rp#rp. 2[5] P. Arbelaez, J. Pont-Tuset, J. T. Barron, F. Marques, and J. Malik,
“Multiscale combinatorial grouping.” https://github.com/jponttuset/mcg/archive/v2.0.zip. 2
[6] C. L. Zitnick and P. Dollár, “Edge boxes: Locating object proposalsfrom edges.” https://github.com/pdollar/edges. 2
[7] M.-M. Cheng, Z. Zhang, W.-Y. Lin, and P. Torr, “Bing: Binarizednormed gradients for objectness estimation at 300fps.” https://github.com/varun-nagaraja/BING-Objectness. 2
[8] P. Rantalankila, J. Kannala, and E. Rahtu, “Generating ob-ject segmentation proposals using global and local search.”http://www.cse.oulu.fi/~erahtu/ObjSegProp/spagglom_01.zip. 2
[9] P. Krähenbühl and V. Koltun, “Geodesic object proposals.” http://www.philkr.net/home/gop. 2
0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
IoU overlap threshold @ 1000
reca
ll
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(a) Recall vs IOU at 1000 proposals forall categories annotated in the NYU2dataset
100 101 102 103 1040
0.2
0.4
0.6
0.8
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
5
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(b) Recall vs. number of proposals at 0.5IOU for all categories annotated in theNYU2 dataset
100 101 102 103 1040
0.2
0.4
0.6
0.8
1
# candidates
reca
ll at
IoU
thre
shol
d 0.
7
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(c) Recall vs. number of proposals at 0.7IOU for all categories annotated in theNYU2 dataset
Figure 3: Performance of various object proposal methods on different evaluation metrics when evaluated on NYU2 dataset containingannotations for all categories
fraction of total area occupied per image0.05 0.1 0.15 0.2 0.25 0.3 0.35
Rec
all @
0.7
IOU
, #ca
ndid
ates
=100
0
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1 DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(a) Sorted by size.#instance per category
10 102 103 104
Rec
all @
0.7
IOU
, #ca
ndid
ates
=100
0
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(b) Sorted by the number of instances.
MS COCO Super-CategoriesR
ecal
l @ 0
.7 IO
U, #
cand
idat
es=1
000
-0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
OutdoorObj. Kitchen-
-ware
IndoorObj. Appli-
-ance
ElectronicsFurniture
Person &Accesory
Animal
VehicleFood
(c) MS COCO super-categories.
Figure 4: Recall at 0.7 IOU for categories sorted/clustered by (a) size, (b) number of instances, and (c) MS COCO ‘super-categories’evaluated on PASCAL Context.
fraction of total area occupied per image0 0.05 0.1 0.15 0.2 0.25
Rec
all @
0.7
IOU
, #ca
ndid
ates
=100
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(a) Sorted by size.#instance per category
10 102 103 104
Rec
all @
0.7
IOU
, #ca
ndid
ates
=100
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
(b) Sorted by the number of instances.MS COCO Super-Categories
Rec
all @
0.7
IOU
, #ca
ndid
ates
=100
0
-0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9 DPMRCNNedgeBoxesobjectnessrandomPrimrahtumcgselectiveSearchbing
OutdoorObj.
FoodKitchen--ware
IndoorObj.
Electronics
Vehicle Person &Accesory
Animal FurnitureAppli--ance
Sports
(c) MS COCO super-categories.
Figure 5: Recall at 0.7 IOU for categories sorted/clustered by (a) size, (b) number of instances, and (c) MS COCO ‘super-categories’evaluated on PASCAL Context and MS COCO.
[10] A. Humayun, F. Li, and J. M. Rehg, “Rigor: Recyclinginference in graph cuts for generating object regions.”http://cpl.cc.gatech.edu/projects/RIGOR/resources/rigor_src.zip. 2
[11] I. Endres and D. Hoiem, “Category-independent object propos-als with diverse ranking.” http://vision.cs.uiuc.edu/proposals/data/PROP_code.tar.gz. 2





![[MS-PUBCSOM]: Publishing Client-Side Object Model Protocol · 2018. 12. 11. · Publishing Client-Side Object Model Protocol Intellectual Property Rights Notice for Open Specifications](https://img.pdfslide.us/doc/110x75/602f8024edffbf182878f3b1/ms-pubcsom-publishing-client-side-object-model-protocol-2018-12-11-publishing.jpg)
![[MS-OXOSMMS]: SMS and MMS Object Protocol SpecificationM… · [MS-OXOSMMS]: SMS and MMS Object Protocol Specification Intellectual Property Rights Notice for Open Specifications](https://img.pdfslide.us/doc/110x75/5f40cc1f6d079a401070633f/ms-oxosmms-sms-and-mms-object-protocol-specification-m-ms-oxosmms-sms-and.jpg)
![[MS-DCOM]: Distributed Component Object Model (DCOM ...... · [MS-DCOM]: Distributed Component Object Model (DCOM) Remote Protocol ... Additionally, overview documents cover inter-protocol](https://img.pdfslide.us/doc/110x75/5e9787271edd026c3e6d6efe/ms-dcom-distributed-component-object-model-dcom-ms-dcom-distributed.jpg)


![Atmel AT42QT1085 Object Protocol Guideww1.microchip.com/downloads/en/DeviceDoc/Atmel... · Object Protocol Guide. AT42QT1085 [DATASHEET] 2 9626C–AT42–05/3013 Figure 2-1. Generic](https://img.pdfslide.us/doc/110x75/5ea1e6fcb11ed5192f682d62/atmel-at42qt1085-object-protocol-object-protocol-guide-at42qt1085-datasheet-2.jpg)


![[MC-COMQC]: Component Object Model Plus (COM+) Queued ... · The Component Object Model Plus (COM+) Queued Components Protocol (COMQC) is a protocol for persisting method calls made](https://img.pdfslide.us/doc/110x75/5e93eaabe8c30106dc0db82e/mc-comqc-component-object-model-plus-com-queued-the-component-object-model.jpg)
![[MS-COM]: Component Object Model Plus (COM+) Protocol... · 2018-09-11 · Component Object Model Plus (COM+) Protocol Intellectual Property Rights Notice for Open Specifications](https://img.pdfslide.us/doc/110x75/5f478de3cf4db86df541cda3/ms-com-component-object-model-plus-com-protocol-2018-09-11-component.jpg)

![[MS-OXSHARE]: Sharing Message Object Protocol Specification](https://img.pdfslide.us/doc/110x75/61c731583d6dec4ca60c9c3a/ms-oxshare-sharing-message-object-protocol-specification.jpg)


![[MS-OXCMSG]: Message and Attachment Object Protocol](https://img.pdfslide.us/doc/110x75/6199f1fa2535f2292f559c5e/ms-oxcmsg-message-and-attachment-object-protocol-.jpg)


![[MS-OXOMSG]: E-mail Object Protocol Specification](https://img.pdfslide.us/doc/110x75/626c82ab04afa4133612c0e8/ms-oxomsg-e-mail-object-protocol-specification.jpg)






