Embed Size (px)
Citation preview

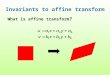
Object Localization using affine invariant substructure constraintsIshani Chakraborty and Ahmed Elgammal, Dept. of Computer Science, Rutgers University
{ishanic,elgammal}@cs.rutgers.edu
Background
Objects are complex shapes composed of simple geometric structures.
Introduction
Approach
Results
Motivation
- Complex geometrical shape can’t be represented as a single structure.
- Substructure based representation can handle articulation.
- Substructures can be occluded and yet object can be localized.
- Common substructures form shape alphabet to form different objects shape vocabulary.
- Simple models can be learnt to recognize real world objects.
Training phase
Substructure = quadruplet of edge-linesRepresentation: Canonical affine invariant descriptor[1].
Substructure probabilities
Graph Partitioning
Search model distributions using k-NN approach w*
(I1,I2,I3,I4) ↔ (l1,l2,l3,l4)
Label Consistency
-Add robustness to correspondences.-Based on Cyclic Invariance.
If correspondence is correct, labeling decisions should be equivalent for cyclic permutations.
(e1|e2,e3,e4)≡(e4|e1,e2,e3) ≡(e3|e4,e1,e2) ≡(e2|e3,e4,e1)
•Substructures -may not be unique -can occur in the background.
Mug object coexists with the alphabets that form the background clutter.
Alphabet structures U and G together are similar to mug object.
•How to identify object Consider interaction between substructures. Substructures belonging to the object will have higher affinity amongst
themselves than background clutter. ie. - View substructure interaction as a graph partitioning problem. - Consider object structure as comprising of lines from the higher connection density.
Comparing object and background cluster densities. Left image: density of mug object cluster = 1.76, density of background cluster = 1.56. The small difference in values is due to the structural similarities between mug shape and the background (e.g. alphabet U, G etc.). Right image: density of mug
object cluster = 2.37, density of background cluster = 0.06 - the object forms a much denser cluster than the background. Graph partitioning using
metis[5].
Figure1. Training shapes for star, mug and SUV shapes. An important advantage in our approach is that hand-drawn models can be used for object localization in real images. Real object edges can also be used but they would require manual labeling of edges.
Figure2. Left: Edge lines of star object and background letters. .Middle: High density cluster (black lines) separates the object from thethe low density letters background (grey lines). Right: Clusters in an affinetransformed version.
Training data
References1. F. Tsai. A probabilistic approach to geometric hashing using line features. 1993.2. E. Rivlin and I.Weiss. Deformation invariants in object recognition. 65(1):95–108, January 1997.3. J. Mundy and A. Zisserman. Geometric Invariance in Computer Vision. MIT Press, 1992.4. Y. Lamdan, J. Schwartz, and H. Wolfson. Object recognition by affine invariant matching. pages 335–344, 1988.5. E. Karypis and V. Kumar. hmetis: A hypergraph partitioning package. Technical report, Department of Computer Science, University
of Minnesota, MN, 1998.6. H.J. Wolfson and I. Rigoutsos. Geometric Hashing: An Overview. IEEE Computational Science and Engineering, 4(4), pages10-21,
1997. 7. S. Mahamud, L. Williams, K. Thornber, and K. Xu, “Segmentation of multiple salient closed contours from real images,” IEEE Trans.
Pattern Anal. Mach. Intell., vol. 25, no. 4, pp. 433–444, Apr. 2003.8. I.Chakraborty and A. Elgammal, “Combining Low and High Level Features for Object Recognition”, Accepted for Oral Presentation,
ICPR 2006.
Deformation Invariant canonical representation[2] Keypoint representation on a global shape basis.[8] Connected-component based edge grouping.[7]
Basic Framework
Related Work combine
substructuresobject
(e1,e2,e3,e4)Basis = (e1,e2,e3)
(r,θ) of e4
(e1,e2,e3) (x=0, y=0, x+y=1)T
Find T and hence find T(e4)

![Learning The Right Metric on The Right Feature … · Learning The Right Metric on The Right Feature Babak Saleh, Ahmed Elgammal ... [cs.CV] 5 May 2015. 2 Babak Saleh, Ahmed Elgammal](https://img.pdfslide.us/doc/110x75/5af9dca87f8b9ae92b8cf6ae/learning-the-right-metric-on-the-right-feature-the-right-metric-on-the-right.jpg)




![a arXiv:1503.06813v2 [cs.CV] 13 Apr 2015 · tgaaly@cs.rutgers.edu (Tarek El-Gaaly), elgammal@cs.rutgers.edu (Ahmed Elgammal), jiangzg@buaa.edu.cn (Zhiguo Jiang) Accepted in Computer](https://img.pdfslide.us/doc/110x75/5f52e6395067e32266202638/a-arxiv150306813v2-cscv-13-apr-2015-tgaalycs-tarek-el-gaaly-elgammalcs.jpg)