Embed Size (px)
Citation preview

chapter
Nucleotides have a variety of roles in cellular metab-olism. They are the energy currency in metabolic
transactions, the essential chemical links in the re-sponse of cells to hormones and other extracellular stim-uli, and the structural components of an array of en-zyme cofactors and metabolic intermediates. And, lastbut certainly not least, they are the constituents of nu-cleic acids: deoxyribonucleic acid (DNA) and ribonu-cleic acid (RNA), the molecular repositories of geneticinformation. The structure of every protein, and ulti-mately of every biomolecule and cellular component, isa product of information programmed into the nu-cleotide sequence of a cell’s nucleic acids. The ability tostore and transmit genetic information from one gener-ation to the next is a fundamental condition for life.
This chapter provides an overview of the chemicalnature of the nucleotides and nucleic acids found inmost cells; a more detailed examination of the functionof nucleic acids is the focus of Part III of this text.
8.1 Some BasicsNucleotides, Building Blocks of Nucleic Acids The amino acid
sequence of every protein in a cell, and the nucleotidesequence of every RNA, is specified by a nucleotide se-
quence in the cell’s DNA. A segment of a DNA moleculethat contains the information required for the synthesisof a functional biological product, whether protein orRNA, is referred to as a gene. A cell typically has manythousands of genes, and DNA molecules, not surpris-ingly, tend to be very large. The storage and transmis-sion of biological information are the only known func-tions of DNA.
RNAs have a broader range of functions, and sev-eral classes are found in cells. Ribosomal RNAs
(rRNAs) are components of ribosomes, the complexesthat carry out the synthesis of proteins. Messenger
RNAs (mRNAs) are intermediaries, carrying geneticinformation from one or a few genes to a ribosome,where the corresponding proteins can be synthesized.Transfer RNAs (tRNAs) are adapter molecules thatfaithfully translate the information in mRNA into a specific sequence of amino acids. In addition to thesemajor classes there is a wide variety of RNAs with spe-cial functions, described in depth in Part III.
Nucleotides and Nucleic Acids Have CharacteristicBases and Pentoses
Nucleotides have three characteristic components:(1) a nitrogenous (nitrogen-containing) base, (2) a pen-tose, and (3) a phosphate (Fig. 8–1). The molecule with-out the phosphate group is called a nucleoside. Thenitrogenous bases are derivatives of two parent com-pounds, pyrimidine and purine. The bases and pentosesof the common nucleotides are heterocyclic compounds.The carbon and nitrogen atoms in the parent structuresare conventionally numbered to facilitate the namingand identification of the many derivative compounds.The convention for the pentose ring follows rules out-lined in Chapter 7, but in the pentoses of nucleotides
NUCLEOTIDES AND NUCLEIC ACIDS8.1 Some Basics 273
8.2 Nucleic Acid Structure 279
8.3 Nucleic Acid Chemistry 291
8.4 Other Functions of Nucleotides 300
A structure this pretty just had to exist.—James Watson, The Double Helix, 1968
8
273

and nucleosides the carbon numbers are given a prime(�) designation to distinguish them from the numberedatoms of the nitrogenous bases.
The base of a nucleotide is joined covalently (at N-1of pyrimidines and N-9 of purines) in an N-�-glycosylbond to the 1� carbon of the pentose, and the phosphateis esterified to the 5� carbon. The N-�-glycosyl bond isformed by removal of the elements of water (a hydroxylgroup from the pentose and hydrogen from the base),as in O-glycosidic bond formation (see Fig. 7–31).
Both DNA and RNA contain two major purine bases,adenine (A) and guanine (G), and two major pyrim-idines. In both DNA and RNA one of the pyrimidines iscytosine (C), but the second major pyrimidine is notthe same in both: it is thymine (T) in DNA and uracil
(U) in RNA. Only rarely does thymine occur in RNA oruracil in DNA. The structures of the five major basesare shown in Figure 8–2, and the nomenclature of theircorresponding nucleotides and nucleosides is summa-rized in Table 8–1.
Nucleic acids have two kinds of pentoses. The re-curring deoxyribonucleotide units of DNA contain 2�-deoxy-D-ribose, and the ribonucleotide units of RNAcontain D-ribose. In nucleotides, both types of pentosesare in their �-furanose (closed five-membered ring)form. As Figure 8–3 shows, the pentose ring is not pla-nar but occurs in one of a variety of conformations gen-erally described as “puckered.”
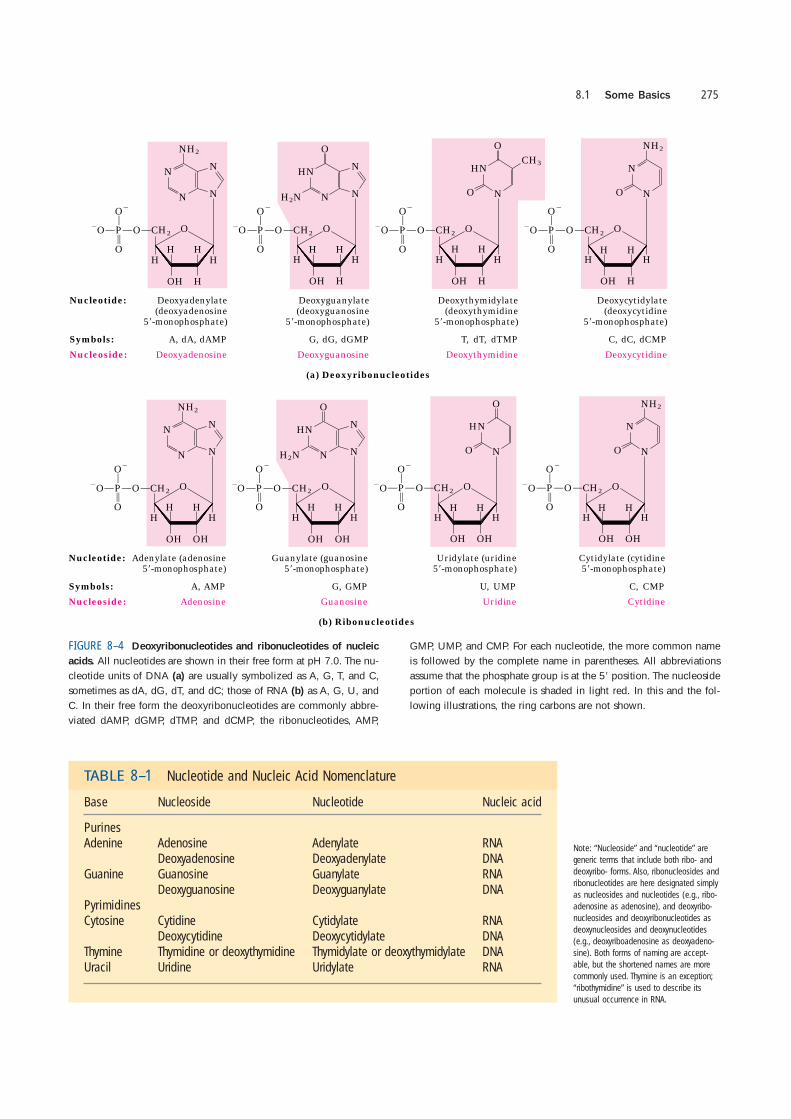
Figure 8–4 gives the structures and names of thefour major deoxyribonucleotides (deoxyribonucleo-side 5�-monophosphates), the structural units of DNAs,and the four major ribonucleotides (ribonucleoside 5�-monophosphates), the structural units of RNAs. Specific
long sequences of A, T, G, and C nucleotides in DNA arethe repository of genetic information.
Although nucleotides bearing the major purines andpyrimidines are most common, both DNA and RNA also
Chapter 8 Nucleotides and Nucleic Acids274
FIGURE 8–1 Structure of nucleotides. (a) General structure showingthe numbering convention for the pentose ring. This is a ribonu-cleotide. In deoxyribonucleotides the OOH group on the 2� carbon(in red) is replaced with OH. (b) The parent compounds of the pyrim-idine and purine bases of nucleotides and nucleic acids, showing thenumbering conventions.
(b)
(a)
FIGURE 8–2 Major purine and pyrimidine bases of nucleic acids.
Some of the common names of these bases reflect the circumstancesof their discovery. Guanine, for example, was first isolated from guano(bird manure), and thymine was first isolated from thymus tissue.
FIGURE 8–3 Conformations of ribose. (a) In solution, the straight-chain (aldehyde) and ring (�-furanose) forms of free ribose are in equi-librium. RNA contains only the ring form, �-D-ribofuranose. Deoxy-ribose undergoes a similar interconversion in solution, but in DNAexists solely as �-2�-deoxy-D-ribofuranose. (b) Ribofuranose rings innucleotides can exist in four different puckered conformations. In allcases, four of the five atoms are in a single plane. The fifth atom (C-2� or C-3�) is on either the same (endo) or the opposite (exo) sideof the plane relative to the C-5� atom.
8.1 Some Basics 275
CH2O�O
OH
H
P
CH3
O�
HN
N
HH
H
H
O
T, dT, dTMP
Deoxythymidine
Nucleotide: Deoxyadenylate(deoxyadenosine
5�-monophosphate)
Deoxyguanylate(deoxyguanosine
5�-monophosphate)
Deoxythymidylate(deoxythymidine
5�-monophosphate)
Deoxycytidylate(deoxycytidine
5�-monophosphate)
Symbols: A, dA, dAMP
Nucleoside: Deoxyadenosine
O
G, dG, dGMP
Deoxyguanosine
O
C, dC, dCMP
Deoxycytidine
(a) Deoxyribonucleotides
OO
CH2
N
O�O
OH
H
P
NH2
O�
N
NN
HH
H
H
O
O
CH2O�O
OH
H
P
HN
H2NO�
N
NN
HH
H
H
O
O
CH2O�O
OH
H
P
NH2
O�
N
N
HH
H
H
O
O
O
O
CH2
N
O�O
OH
H
P
NH2
O�
N
NN
HH
H
O
O
CH2O�O
OH
H
P
HN
H2NO�
N
NN
HH
H
O
O
CH2O�O
OH
H
P
O�
N
N
H
H
H
O
O
(b) Ribonucleotides
U, UMP C, CMP
Uridine
Nucleotide: Adenylate (adenosine5�-monophosphate)
Guanylate (guanosine5�-monophosphate)
Uridylate (uridine5�-monophosphate)
Cytidylate (cytidine5�-monophosphate)
Symbols: A, AMP
Nucleoside: Adenosine
G, GMP
Guanosine Cytidine
CH2O�O
OH
H
P
NH2
O�
N
N
HH
H
O
O
O
OH OH OH OH
H
O
O
FIGURE 8–4 Deoxyribonucleotides and ribonucleotides of nucleic
acids. All nucleotides are shown in their free form at pH 7.0. The nu-cleotide units of DNA (a) are usually symbolized as A, G, T, and C,sometimes as dA, dG, dT, and dC; those of RNA (b) as A, G, U, andC. In their free form the deoxyribonucleotides are commonly abbre-viated dAMP, dGMP, dTMP, and dCMP; the ribonucleotides, AMP,
GMP, UMP, and CMP. For each nucleotide, the more common nameis followed by the complete name in parentheses. All abbreviationsassume that the phosphate group is at the 5� position. The nucleosideportion of each molecule is shaded in light red. In this and the fol-lowing illustrations, the ring carbons are not shown.
TABLE 8–1 Nucleotide and Nucleic Acid Nomenclature
Base Nucleoside Nucleotide Nucleic acid
PurinesAdenine Adenosine Adenylate RNA
Deoxyadenosine Deoxyadenylate DNAGuanine Guanosine Guanylate RNA
Deoxyguanosine Deoxyguanylate DNAPyrimidinesCytosine Cytidine Cytidylate RNA
Deoxycytidine Deoxycytidylate DNAThymine Thymidine or deoxythymidine Thymidylate or deoxythymidylate DNAUracil Uridine Uridylate RNA
Note: “Nucleoside” and “nucleotide” are
generic terms that include both ribo- and
deoxyribo- forms. Also, ribonucleosides and
ribonucleotides are here designated simply
as nucleosides and nucleotides (e.g., ribo-
adenosine as adenosine), and deoxyribo-
nucleosides and deoxyribonucleotides as
deoxynucleosides and deoxynucleotides
(e.g., deoxyriboadenosine as deoxyadeno-
sine). Both forms of naming are accept-
able, but the shortened names are more
commonly used. Thymine is an exception;
“ribothymidine” is used to describe its
unusual occurrence in RNA.

contain some minor bases (Fig. 8–5). In DNA the mostcommon of these are methylated forms of the majorbases; in some viral DNAs, certain bases may be hy-droxymethylated or glucosylated. Altered or unusualbases in DNA molecules often have roles in regulatingor protecting the genetic information. Minor bases ofmany types are also found in RNAs, especially in tRNAs(see Fig. 26–24).
The nomenclature for the minor bases can be con-fusing. Like the major bases, many have common names—hypoxanthine, for example, shown as its nucleoside ino-sine in Figure 8–5. When an atom in the purine orpyrimidine ring is substituted, the usual convention (used
here) is simply to indicate the ring position of the sub-stituent by its number—for example, 5-methylcytosine, 7-methylguanine, and 5-hydroxymethylcytosine (shownas the nucleosides in Fig. 8–5). The element to which the substituent is attached (N, C, O) is not identified. The convention changes when the substituted atom is exocyclic (not within the ring structure), in which casethe type of atom is identified and the ring position to which it is attached is denoted with a superscript. Theamino nitrogen attached to C-6 of adenine is N
6; simi-larly, the carbonyl oxygen and amino nitrogen at C-6 and C-2 of guanine are O6 and N
2, respectively. Examplesof this nomenclature are N
6-methyladenosine and N2-
methylguanosine (Fig. 8–5).Cells also contain nucleotides with phosphate
groups in positions other than on the 5� carbon (Fig.8–6). Ribonucleoside 2�,3�-cyclic monophosphatesare isolatable intermediates, and ribonucleoside 3�-monophosphates are end products of the hydrolysisof RNA by certain ribonucleases. Other variations areadenosine 3�,5�-cyclic monophosphate (cAMP) andguanosine 3�,5�-cyclic monophosphate (cGMP), consid-ered at the end of this chapter.
Phosphodiester Bonds Link Successive Nucleotidesin Nucleic Acids
The successive nucleotides of both DNA and RNA arecovalently linked through phosphate-group “bridges,” inwhich the 5�-phosphate group of one nucleotide unit is
Chapter 8 Nucleotides and Nucleic Acids276
(a)
(b)
FIGURE 8–5 Some minor purine and pyrimidine bases, shown as the
nucleosides. (a) Minor bases of DNA. 5-Methylcytidine occurs in theDNA of animals and higher plants, N6-methyladenosine in bacterialDNA, and 5-hydroxymethylcytidine in the DNA of bacteria infectedwith certain bacteriophages. (b) Some minor bases of tRNAs. Inosinecontains the base hypoxanthine. Note that pseudouridine, like uridine,contains uracil; they are distinct in the point of attachment to theribose—in uridine, uracil is attached through N-1, the usual attach-ment point for pyrimidines; in pseudouridine, through C-5.
FIGURE 8–6 Some adenosine monophosphates. Adenosine 2�-monophosphate, 3�-monophosphate, and 2�,3�-cyclic monophosphateare formed by enzymatic and alkaline hydrolysis of RNA.
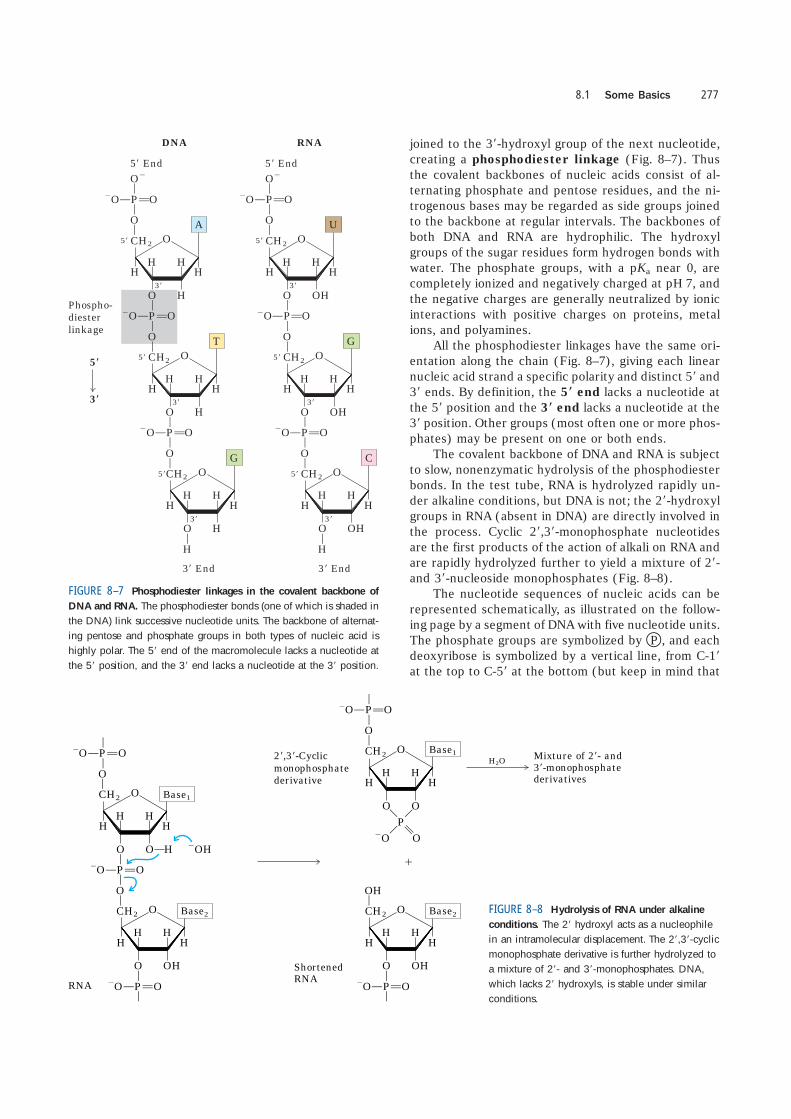
joined to the 3�-hydroxyl group of the next nucleotide,creating a phosphodiester linkage (Fig. 8–7). Thusthe covalent backbones of nucleic acids consist of al-ternating phosphate and pentose residues, and the ni-trogenous bases may be regarded as side groups joinedto the backbone at regular intervals. The backbones ofboth DNA and RNA are hydrophilic. The hydroxylgroups of the sugar residues form hydrogen bonds withwater. The phosphate groups, with a pKa near 0, arecompletely ionized and negatively charged at pH 7, andthe negative charges are generally neutralized by ionicinteractions with positive charges on proteins, metalions, and polyamines.
All the phosphodiester linkages have the same ori-entation along the chain (Fig. 8–7), giving each linearnucleic acid strand a specific polarity and distinct 5� and3� ends. By definition, the 5� end lacks a nucleotide atthe 5� position and the 3� end lacks a nucleotide at the3� position. Other groups (most often one or more phos-phates) may be present on one or both ends.
The covalent backbone of DNA and RNA is subjectto slow, nonenzymatic hydrolysis of the phosphodiesterbonds. In the test tube, RNA is hydrolyzed rapidly un-der alkaline conditions, but DNA is not; the 2�-hydroxylgroups in RNA (absent in DNA) are directly involved inthe process. Cyclic 2�,3�-monophosphate nucleotidesare the first products of the action of alkali on RNA andare rapidly hydrolyzed further to yield a mixture of 2�-and 3�-nucleoside monophosphates (Fig. 8–8).
The nucleotide sequences of nucleic acids can berepresented schematically, as illustrated on the follow-ing page by a segment of DNA with five nucleotide units.The phosphate groups are symbolized by P�, and eachdeoxyribose is symbolized by a vertical line, from C-1�at the top to C-5� at the bottom (but keep in mind that
8.1 Some Basics 277
O�
RNA
CH2
O�O
H
P
H
OH
H
O
3�
5�
U
H
O
CH2
O�O
H
P
HH
O
O
3�
5�
G
H
O
CH2
O�O
H
P
HH
O
O
3�
5�
H
O
H
O
5� EndO�
CH2
O�O
H
P
H
H
H
O
3�
5�
A
H
O
CH2
O�O
H
P
H
H
H
O
O
3�
5�
T
H
O
CH2
O�O
H
P
H
H
H
O
O
3�
5�
G
H
O
H
O
5� End
3� End3� End
C
5�
3�
DNA
Phospho-diesterlinkage
OH
OH
FIGURE 8–7 Phosphodiester linkages in the covalent backbone of
DNA and RNA. The phosphodiester bonds (one of which is shaded inthe DNA) link successive nucleotide units. The backbone of alternat-ing pentose and phosphate groups in both types of nucleic acid ishighly polar. The 5� end of the macromolecule lacks a nucleotide atthe 5� position, and the 3� end lacks a nucleotide at the 3� position.
H
P
HH
H
O
�OH
2�,3�-Cyclicmonophosphatederivative
O
OCH2
O
H
P
H
H
H
O
O
Base1
O
O�O
H
CH2
O
H
P
H
H
H
O
O
Base2
O
�O
H
OP�O
CH2
HH
H
H
O
O
Base2
O
H
OP�O
OH
�
Base1
OP
O
�O Mixture of 2�- and3�-monophosphatederivatives
CH2
�O
O
RNA ShortenedRNA
H2O
O
RNA
ShortenedRNA
FIGURE 8–8 Hydrolysis of RNA under alkaline
conditions. The 2� hydroxyl acts as a nucleophilein an intramolecular displacement. The 2�,3�-cyclicmonophosphate derivative is further hydrolyzed toa mixture of 2�- and 3�-monophosphates. DNA,which lacks 2� hydroxyls, is stable under similarconditions.
the sugar is always in its closed-ring �-furanose form innucleic acids). The connecting lines between nucleotides(which pass through P�) are drawn diagonally from themiddle (C-3�) of the deoxyribose of one nucleotide tothe bottom (C-5�) of the next.
By convention, the structure of a single strand of nu-cleic acid is always written with the 5� end at the leftand the 3� end at the right—that is, in the 5� n 3� di-rection. Some simpler representations of this pentade-oxyribonucleotide are pA-C-G-T-AOH, pApCpGpTpA,and pACGTA.
A short nucleic acid is referred to as an oligonu-cleotide. The definition of “short” is somewhat arbi-trary, but polymers containing 50 or fewer nucleotidesare generally called oligonucleotides. A longer nucleicacid is called a polynucleotide.
The Properties of Nucleotide Bases Affect the Three-Dimensional Structure of Nucleic Acids
Free pyrimidines and purines are weakly basic com-pounds and are thus called bases. They have a varietyof chemical properties that affect the structure, andultimately the function, of nucleic acids. The purinesand pyrimidines common in DNA and RNA are highlyconjugated molecules (Fig. 8–2), a property with im-portant consequences for the structure, electron distri-bution, and light absorption of nucleic acids. Resonanceamong atoms in the ring gives most of the bonds par-tial double-bond character. One result is that pyrim-idines are planar molecules; purines are very nearly
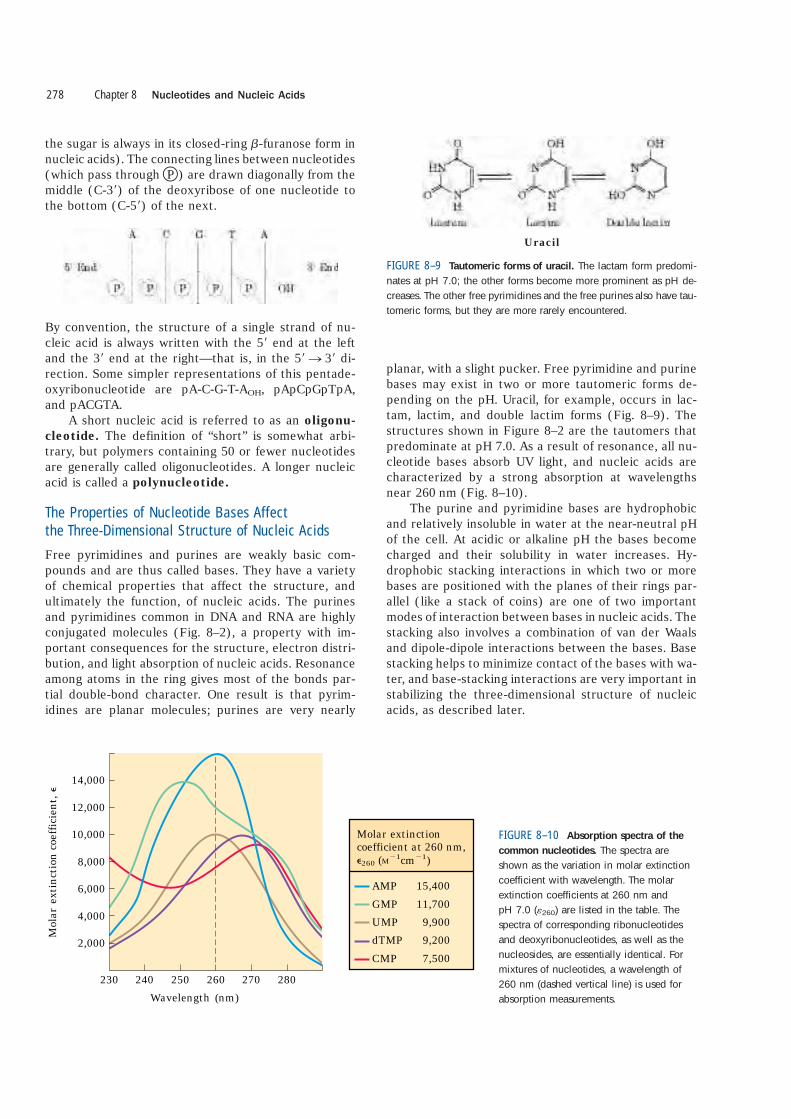
planar, with a slight pucker. Free pyrimidine and purinebases may exist in two or more tautomeric forms de-pending on the pH. Uracil, for example, occurs in lac-tam, lactim, and double lactim forms (Fig. 8–9). Thestructures shown in Figure 8–2 are the tautomers thatpredominate at pH 7.0. As a result of resonance, all nu-cleotide bases absorb UV light, and nucleic acids arecharacterized by a strong absorption at wavelengthsnear 260 nm (Fig. 8–10).
The purine and pyrimidine bases are hydrophobicand relatively insoluble in water at the near-neutral pHof the cell. At acidic or alkaline pH the bases becomecharged and their solubility in water increases. Hy-drophobic stacking interactions in which two or morebases are positioned with the planes of their rings par-allel (like a stack of coins) are one of two importantmodes of interaction between bases in nucleic acids. Thestacking also involves a combination of van der Waalsand dipole-dipole interactions between the bases. Basestacking helps to minimize contact of the bases with wa-ter, and base-stacking interactions are very important instabilizing the three-dimensional structure of nucleicacids, as described later.
Chapter 8 Nucleotides and Nucleic Acids278
Uracil
FIGURE 8–9 Tautomeric forms of uracil. The lactam form predomi-nates at pH 7.0; the other forms become more prominent as pH de-creases. The other free pyrimidines and the free purines also have tau-tomeric forms, but they are more rarely encountered.
14,000
12,000
10,000
8,000
6,000
4,000
2,000
280
Mol
ar e
xtin
ctio
n co
effic
ient
, �
Wavelength (nm)230 240 250 260 270
Molar extinctioncoefficient at 260 nm, �260 (M�1cm�1)
AMPGMPUMPdTMPCMP
15,40011,700
9,9009,2007,500
FIGURE 8–10 Absorption spectra of the
common nucleotides. The spectra areshown as the variation in molar extinctioncoefficient with wavelength. The molar extinction coefficients at 260 nm and pH 7.0 (�260) are listed in the table. The spectra of corresponding ribonucleotidesand deoxyribonucleotides, as well as thenucleosides, are essentially identical. Formixtures of nucleotides, a wavelength of260 nm (dashed vertical line) is used forabsorption measurements.

The most important functional groups of pyrim-idines and purines are ring nitrogens, carbonyl groups,and exocyclic amino groups. Hydrogen bonds involvingthe amino and carbonyl groups are the second impor-tant mode of interaction between bases in nucleic acidmolecules. Hydrogen bonds between bases permit acomplementary association of two (and occasionallythree or four) strands of nucleic acid. The most impor-tant hydrogen-bonding patterns are those defined byJames D. Watson and Francis Crick in 1953, in which Abonds specifically to T (or U) and G bonds to C (Fig.8–11). These two types of base pairs predominate indouble-stranded DNA and RNA, and the tautomersshown in Figure 8–2 are responsible for these patterns.It is this specific pairing of bases that permits the du-plication of genetic information, as we shall discuss laterin this chapter.
SUMMARY 8.1 Some Basics
■ A nucleotide consists of a nitrogenous base(purine or pyrimidine), a pentose sugar, andone or more phosphate groups. Nucleic acidsare polymers of nucleotides, joined together byphosphodiester linkages between the 5�-hydroxyl group of one pentose and the 3�-hydroxyl group of the next.
■ There are two types of nucleic acid: RNA andDNA. The nucleotides in RNA contain ribose,and the common pyrimidine bases are uraciland cytosine. In DNA, the nucleotides contain2�-deoxyribose, and the common pyrimidinebases are thymine and cytosine. The primarypurines are adenine and guanine in both RNAand DNA.
8.2 Nucleic Acid Structure
The discovery of the structure of DNA by Watson andCrick in 1953 was a momentous event in science, anevent that gave rise to entirely new disciplines and in-fluenced the course of many established ones. Our pres-ent understanding of the storage and utilization of acell’s genetic information is based on work made possi-ble by this discovery, and an outline of how genetic in-formation is processed by the cell is now a prerequisitefor the discussion of any area of biochemistry. Here, weconcern ourselves with DNA structure itself, the events
8.2 Nucleic Acid Structure 279
3�
C
C
C
CG
G
G
G
A
A
A
A
A
T
T
T
T
T
5�
5� 3�
10.8 Å
NC
O
C
N
C
H
CC
H
C
N
C
NC
11.1 Å
2.8 Å
3.0 Å
HN
C O
CH3
CO
N
H
N
C
HC
CH
N
C
C
N
C
H
NC
N
O
N
H
H
H
H
2.9 Å
3.0 Å
2.9 Å
Adenine
Thymine
Guanine
Cytosine
N
H
C-1�
C-1�
C-1�
H
HN
C
NC-1�
FIGURE 8–11 Hydrogen-bonding patterns in the base pairs defined
by Watson and Crick. Here as elsewhere, hydrogen bonds arerepresented by three blue lines.
James Watson Francis Crick

that led to its discovery, and more recent refinementsin our understanding. RNA structure is also introduced.
As in the case of protein structure (Chapter 4), itis sometimes useful to describe nucleic acid structurein terms of hierarchical levels of complexity (primary,secondary, tertiary). The primary structure of a nucleicacid is its covalent structure and nucleotide sequence.Any regular, stable structure taken up by some or all ofthe nucleotides in a nucleic acid can be referred to assecondary structure. All structures considered in the re-mainder of this chapter fall under the heading of sec-ondary structure. The complex folding of large chro-mosomes within eukaryotic chromatin and bacterialnucleoids is generally considered tertiary structure; thisis discussed in Chapter 24.
DNA Stores Genetic Information
The biochemical investigation of DNA began withFriedrich Miescher, who carried out the first systematicchemical studies of cell nuclei. In 1868 Miescher isolateda phosphorus-containing substance, which he called“nuclein,” from the nuclei of pus cells (leukocytes) ob-tained from discarded surgical bandages. He found nuclein to consist of an acidic portion, which we knowtoday as DNA, and a basic portion, protein. Miescherlater found a similar acidic substance in the heads ofsperm cells from salmon. Although he partially purifiednuclein and studied its properties, the covalent (pri-mary) structure of DNA (as shown in Fig. 8–7) was notknown with certainty until the late 1940s.
Miescher and many others suspected that nuclein(nucleic acid) was associated in some way with cell in-heritance, but the first direct evidence that DNA is thebearer of genetic information came in 1944 through adiscovery made by Oswald T. Avery, Colin MacLeod, andMaclyn McCarty. These investigators found that DNAextracted from a virulent (disease-causing) strain of thebacterium Streptococcus pneumoniae, also known aspneumococcus, genetically transformed a nonvirulentstrain of this organism into a virulent form (Fig. 8–12).
Chapter 8 Nucleotides and Nucleic Acids280
(a)
(b)
(c)
(d)
(e)
FIGURE 8–12 The Avery-MacLeod-McCarty experiment. (a) Wheninjected into mice, the encapsulated strain of pneumococcus is lethal,(b) whereas the nonencapsulated strain, (c) like the heat-killed en-capsulated strain, is harmless. (d) Earlier research by the bacteriolo-gist Frederick Griffith had shown that adding heat-killed virulent bac-teria (harmless to mice) to a live nonvirulent strain permanentlytransformed the latter into lethal, virulent, encapsulated bacteria.(e) Avery and his colleagues extracted the DNA from heat-killed vir-ulent pneumococci, removing the protein as completely as possible,and added this DNA to nonvirulent bacteria. The DNA gained en-trance into the nonvirulent bacteria, which were permanently trans-formed into a virulent strain.

Avery and his colleagues concluded that the DNA ex-tracted from the virulent strain carried the inheritable ge-netic message for virulence. Not everyone accepted theseconclusions, because protein impurities present in theDNA could have been the carrier of the genetic informa-tion. This possibility was soon eliminated by the findingthat treatment of the DNA with proteolytic enzymes didnot destroy the transforming activity, but treatment withdeoxyribonucleases (DNA-hydrolyzing enzymes) did.
A second important experiment provided inde-pendent evidence that DNA carries genetic information.In 1952 Alfred D. Hershey and Martha Chase used ra-dioactive phosphorus (32P) and radioactive sulfur (35S)tracers to show that when the bacterial virus (bacterio-phage) T2 infects its host cell, Escherichia coli, it isthe phosphorus-containing DNA of the viral particle, notthe sulfur-containing protein of the viral coat, that en-ters the host cell and furnishes the genetic informationfor viral replication (Fig. 8–13). These important earlyexperiments and many other lines of evidence haveshown that DNA is the exclusive chromosomal compo-nent bearing the genetic information of living cells.
DNA Molecules Have Distinctive Base Compositions
A most important clue to the structure of DNA camefrom the work of Erwin Chargaff and his colleagues inthe late 1940s. They found that the four nucleotidebases of DNA occur in different ratios in the DNAs ofdifferent organisms and that the amounts of certainbases are closely related. These data, collected fromDNAs of a great many different species, led Chargaff tothe following conclusions:
1. The base composition of DNA generally variesfrom one species to another.
2. DNA specimens isolated from different tissues ofthe same species have the same base composition.
3. The base composition of DNA in a given speciesdoes not change with an organism’s age,nutritional state, or changing environment.
4. In all cellular DNAs, regardless of the species, thenumber of adenosine residues is equal to thenumber of thymidine residues (that is, A � T),and the number of guanosine residues is equal tothe number of cytidine residues (G � C). Fromthese relationships it follows that the sum of thepurine residues equals the sum of the pyrimidineresidues; that is, A � G � T � C.
These quantitative relationships, sometimes called“Chargaff’s rules,” were confirmed by many subsequentresearchers. They were a key to establishing the three-dimensional structure of DNA and yielded clues to howgenetic information is encoded in DNA and passed fromone generation to the next.
32P experiment 35S experiment
RadioactiveDNA
Nonradioactivecoat
NonradioactiveDNA
Radioactivecoat
Injection
Blendertreatmentshears off
viral heads
Separationby
centrifugation
Radioactive Not radioactive
Phage
RadioactiveNotradioactive
Bacterialcell
FIGURE 8–13 The Hershey-Chase experiment. Two batches of iso-topically labeled bacteriophage T2 particles were prepared. One waslabeled with 32P in the phosphate groups of the DNA, the other with35S in the sulfur-containing amino acids of the protein coats (capsids).(Note that DNA contains no sulfur and viral protein contains no phos-phorus.) The two batches of labeled phage were then allowed to in-fect separate suspensions of unlabeled bacteria. Each suspension ofphage-infected cells was agitated in a blender to shear the viral cap-sids from the bacteria. The bacteria and empty viral coats (called“ghosts”) were then separated by centrifugation. The cells infected withthe 32P-labeled phage were found to contain 32P, indicating that thelabeled viral DNA had entered the cells; the viral ghosts contained noradioactivity. The cells infected with 35S-labeled phage were found tohave no radioactivity after blender treatment, but the viral ghosts con-tained 35S. Progeny virus particles (not shown) were produced in bothbatches of bacteria some time after the viral coats were removed, in-dicating that the genetic message for their replication had been in-troduced by viral DNA, not by viral protein.
DNA Is a Double Helix
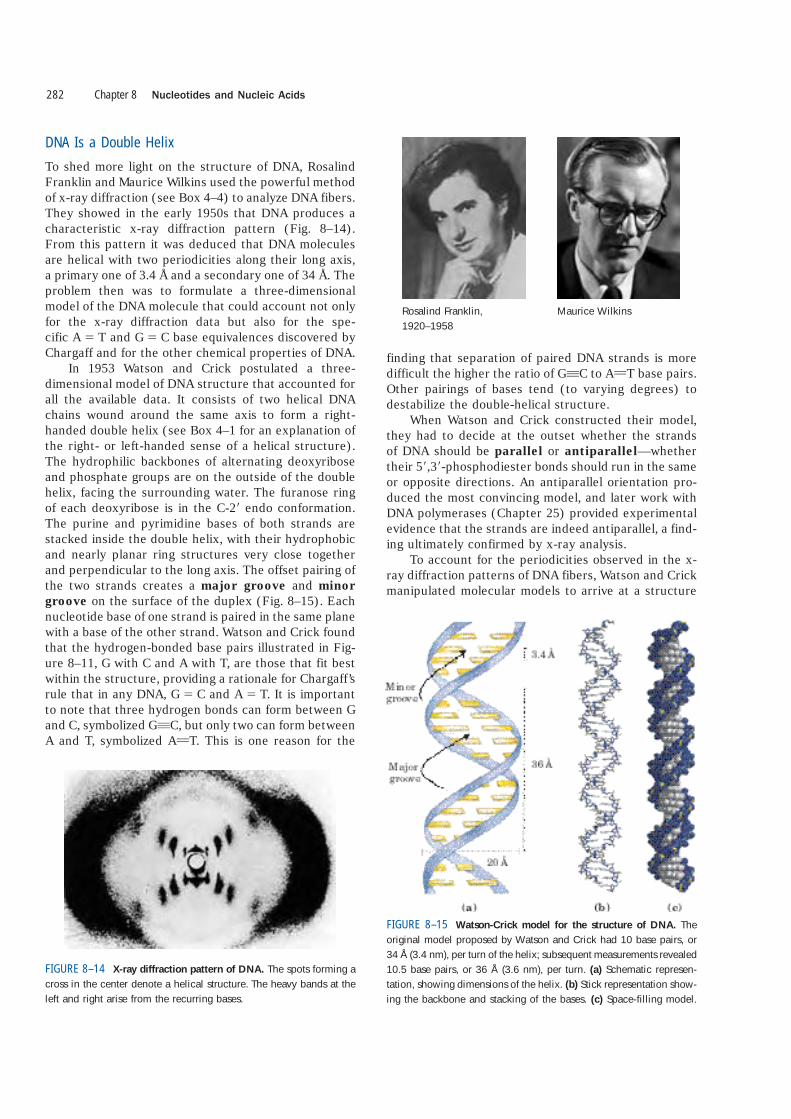
To shed more light on the structure of DNA, RosalindFranklin and Maurice Wilkins used the powerful methodof x-ray diffraction (see Box 4–4) to analyze DNA fibers.They showed in the early 1950s that DNA produces acharacteristic x-ray diffraction pattern (Fig. 8–14).From this pattern it was deduced that DNA moleculesare helical with two periodicities along their long axis,a primary one of 3.4 Å and a secondary one of 34 Å. Theproblem then was to formulate a three-dimensionalmodel of the DNA molecule that could account not onlyfor the x-ray diffraction data but also for the spe-cific A � T and G � C base equivalences discovered byChargaff and for the other chemical properties of DNA.
In 1953 Watson and Crick postulated a three-dimensional model of DNA structure that accounted forall the available data. It consists of two helical DNAchains wound around the same axis to form a right-handed double helix (see Box 4–1 for an explanation ofthe right- or left-handed sense of a helical structure).The hydrophilic backbones of alternating deoxyriboseand phosphate groups are on the outside of the doublehelix, facing the surrounding water. The furanose ringof each deoxyribose is in the C-2� endo conformation.The purine and pyrimidine bases of both strands arestacked inside the double helix, with their hydrophobicand nearly planar ring structures very close togetherand perpendicular to the long axis. The offset pairing ofthe two strands creates a major groove and minorgroove on the surface of the duplex (Fig. 8–15). Eachnucleotide base of one strand is paired in the same planewith a base of the other strand. Watson and Crick foundthat the hydrogen-bonded base pairs illustrated in Fig-ure 8–11, G with C and A with T, are those that fit bestwithin the structure, providing a rationale for Chargaff’srule that in any DNA, G � C and A � T. It is importantto note that three hydrogen bonds can form between Gand C, symbolized GqC, but only two can form betweenA and T, symbolized AUT. This is one reason for the
finding that separation of paired DNA strands is moredifficult the higher the ratio of GqC to AUT base pairs.Other pairings of bases tend (to varying degrees) todestabilize the double-helical structure.
When Watson and Crick constructed their model,they had to decide at the outset whether the strands of DNA should be parallel or antiparallel—whethertheir 5�,3�-phosphodiester bonds should run in the sameor opposite directions. An antiparallel orientation pro-duced the most convincing model, and later work withDNA polymerases (Chapter 25) provided experimentalevidence that the strands are indeed antiparallel, a find-ing ultimately confirmed by x-ray analysis.
To account for the periodicities observed in the x-ray diffraction patterns of DNA fibers, Watson and Crickmanipulated molecular models to arrive at a structure
Chapter 8 Nucleotides and Nucleic Acids282
FIGURE 8–14 X-ray diffraction pattern of DNA. The spots forming across in the center denote a helical structure. The heavy bands at theleft and right arise from the recurring bases.
FIGURE 8–15 Watson-Crick model for the structure of DNA. Theoriginal model proposed by Watson and Crick had 10 base pairs, or34 Å (3.4 nm), per turn of the helix; subsequent measurements revealed10.5 base pairs, or 36 Å (3.6 nm), per turn. (a) Schematic represen-tation, showing dimensions of the helix. (b) Stick representation show-ing the backbone and stacking of the bases. (c) Space-filling model.
Rosalind Franklin, 1920–1958
Maurice Wilkins

in which the vertically stacked bases inside the doublehelix would be 3.4 Å apart; the secondary repeat dis-tance of about 34 Å was accounted for by the presenceof 10 base pairs in each complete turn of the doublehelix. In aqueous solution the structure differs slightlyfrom that in fibers, having 10.5 base pairs per helicalturn (Fig. 8–15).
As Figure 8–16 shows, the two antiparallel polynu-cleotide chains of double-helical DNA are not identicalin either base sequence or composition. Instead they arecomplementary to each other. Wherever adenine oc-curs in one chain, thymine is found in the other; simi-larly, wherever guanine occurs in one chain, cytosine isfound in the other.
The DNA double helix, or duplex, is held togetherby two forces, as described earlier: hydrogen bondingbetween complementary base pairs (Fig. 8–11) andbase-stacking interactions. The complementarity be-tween the DNA strands is attributable to the hydrogenbonding between base pairs. The base-stacking interac-tions, which are largely nonspecific with respect to theidentity of the stacked bases, make the major contribu-tion to the stability of the double helix.
The important features of the double-helical modelof DNA structure are supported by much chemical and
biological evidence. Moreover, the model immediatelysuggested a mechanism for the transmission of geneticinformation. The essential feature of the model is thecomplementarity of the two DNA strands. As Watson andCrick were able to see, well before confirmatory data be-came available, this structure could logically be replicatedby (1) separating the two strands and (2) synthesizinga complementary strand for each. Because nucleotidesin each new strand are joined in a sequence specified bythe base-pairing rules stated above, each preexistingstrand functions as a template to guide the synthesis ofone complementary strand (Fig. 8–17). These expecta-tions were experimentally confirmed, inaugurating a rev-olution in our understanding of biological inheritance.
DNA Can Occur in Different Three-Dimensional Forms
DNA is a remarkably flexible molecule. Considerable ro-tation is possible around a number of bonds in thesugar–phosphate (phosphodeoxyribose) backbone, andthermal fluctuation can produce bending, stretching, andunpairing (melting) of the strands. Many significant de-viations from the Watson-Crick DNA structure are foundin cellular DNA, some or all of which may play impor-tant roles in DNA metabolism. These structural varia-tions generally do not affect the key properties of DNAdefined by Watson and Crick: strand complementarity,
8.2 Nucleic Acid Structure 283
FIGURE 8–16 Complementarity of strands in the DNA double helix.
The complementary antiparallel strands of DNA follow the pairingrules proposed by Watson and Crick. The base-paired antiparallelstrands differ in base composition: the left strand has the compositionA3 T2 G1 C3; the right, A2 T3 G3 C1. They also differ in sequence wheneach chain is read in the 5� n 3� direction. Note the base equiva-lences: A � T and G � C in the duplex.
FIGURE 8–17 Replication of DNA as suggested by Watson and Crick.
The preexisting or “parent” strands become separated, and each is thetemplate for biosynthesis of a complementary “daughter” strand (in red).

antiparallel strands, and the requirement for APT andGqC base pairs.
Structural variation in DNA reflects three things:the different possible conformations of the deoxyribose,rotation about the contiguous bonds that make up thephosphodeoxyribose backbone (Fig. 8–18a), and freerotation about the C-1�–N-glycosyl bond (Fig. 8–18b).Because of steric constraints, purines in purine nu-cleotides are restricted to two stable conformations withrespect to deoxyribose, called syn and anti (Fig. 8–18b).Pyrimidines are generally restricted to the anti confor-mation because of steric interference between the sugarand the carbonyl oxygen at C-2 of the pyrimidine.
The Watson-Crick structure is also referred to as B-form DNA, or B-DNA. The B form is the most stablestructure for a random-sequence DNA molecule underphysiological conditions and is therefore the standardpoint of reference in any study of the properties of DNA.Two structural variants that have been well character-ized in crystal structures are the A and Z forms. Thesethree DNA conformations are shown in Figure 8–19,with a summary of their properties. The A form is fa-vored in many solutions that are relatively devoid of wa-ter. The DNA is still arranged in a right-handed doublehelix, but the helix is wider and the number of base pairsper helical turn is 11, rather than 10.5 as in B-DNA. The
Chapter 8 Nucleotides and Nucleic Acids284
FIGURE 8–18 Structural variation in DNA. (a) The conformation of a nucleotide inDNA is affected by rotation about seven different bonds. Six of the bonds rotate freely.The limited rotation about bond 4 gives rise to ring pucker, in which one of the atoms inthe five-membered furanose ring is out of the plane described by the other four. Thisconformation is endo or exo, depending on whether the atom is displaced to the sameside of the plane as C-5� or to the opposite side (see Fig. 8–3b). (b) For purine bases innucleotides, only two conformations with respect to the attached ribose units aresterically permitted, anti or syn. Pyrimidines generally occur in the anti conformation.
FIGURE 8–19 Comparison of A, B, and Z forms of DNA. Each struc-ture shown here has 36 base pairs. The bases are shown in gray, thephosphate atoms in yellow, and the riboses and phosphate oxygensin blue. Blue is the color used to represent DNA strands in later chap-ters. The table summarizes some properties of the three forms of DNA.
A form B form Z form
Helical sense Right handed Right handed Left handedDiameter �26 Å �20 Å �18 ÅBase pairs per helical
turn 11 10.5 12Helix rise per base pair 2.6 Å 3.4 Å 3.7 ÅBase tilt normal to the
helix axis 20° 6° 7°Sugar pucker conformation C-3� endo C-2� endo C-2� endo for
pyrimidines;C-3� endo for purines
Glycosyl bond conformation Anti Anti Anti for pyrimidines;syn for purines

plane of the base pairs in A-DNA is tilted about 20� withrespect to the helix axis. These structural changesdeepen the major groove while making the minor grooveshallower. The reagents used to promote crystallizationof DNA tend to dehydrate it, and thus most short DNAmolecules tend to crystallize in the A form.
Z-form DNA is a more radical departure from the Bstructure; the most obvious distinction is the left-handed helical rotation. There are 12 base pairs per hel-ical turn, and the structure appears more slender andelongated. The DNA backbone takes on a zigzag ap-pearance. Certain nucleotide sequences fold into left-handed Z helices much more readily than others. Promi-nent examples are sequences in which pyrimidinesalternate with purines, especially alternating C and G or5-methyl-C and G residues. To form the left-handed helix in Z-DNA, the purine residues flip to the syn conformation, alternating with pyrimidines in the anticonformation. The major groove is barely apparent in Z-DNA, and the minor groove is narrow and deep.
Whether A-DNA occurs in cells is uncertain, but thereis evidence for some short stretches (tracts) of Z-DNAin both prokaryotes and eukaryotes. These Z-DNA tractsmay play a role (as yet undefined) in regulating the ex-pression of some genes or in genetic recombination.
Certain DNA Sequences Adopt Unusual Structures
A number of other sequence-dependent structural vari-ations have been detected within larger chromosomesthat may affect the function and metabolism of the DNAsegments in their immediate vicinity. For example,bends occur in the DNA helix wherever four or moreadenosine residues appear sequentially in one strand.Six adenosines in a row produce a bend of about 18�.
The bending observed with this and other sequences maybe important in the binding of some proteins to DNA.
A rather common type of DNA sequence is a palin-drome. A palindrome is a word, phrase, or sentencethat is spelled identically read either forward or back-ward; two examples are ROTATOR and NURSES RUN.The term is applied to regions of DNA with invertedrepeats of base sequence having twofold symmetryover two strands of DNA (Fig. 8–20). Such sequencesare self-complementary within each strand and there-fore have the potential to form hairpin or cruciform(cross-shaped) structures (Fig. 8–21). When the in-verted repeat occurs within each individual strand ofthe DNA, the sequence is called a mirror repeat.Mirror repeats do not have complementary sequenceswithin the same strand and cannot form hairpin or cru-ciform structures. Sequences of these types are found
8.2 Nucleic Acid Structure 285
FIGURE 8–20 Palindromes and mirror repeats. Palindromes are se-quences of double-stranded nucleic acids with twofold symmetry. Inorder to superimpose one repeat (shaded sequence) on the other, itmust be rotated 180� about the horizontal axis then 180� about thevertical axis, as shown by the colored arrows. A mirror repeat, on theother hand, has a symmetric sequence within each strand. Superim-posing one repeat on the other requires only a single 180� rotationabout the vertical axis.
FIGURE 8–21 Hairpins and cruciforms. Palindromic DNA (or RNA)sequences can form alternative structures with intrastrand base pair-ing. (a) When only a single DNA (or RNA) strand is involved, thestructure is called a hairpin. (b) When both strands of a duplex DNAare involved, it is called a cruciform. Blue shading highlights asym-metric sequences that can pair with the complementary sequence ei-ther in the same strand or in the complementary strand.
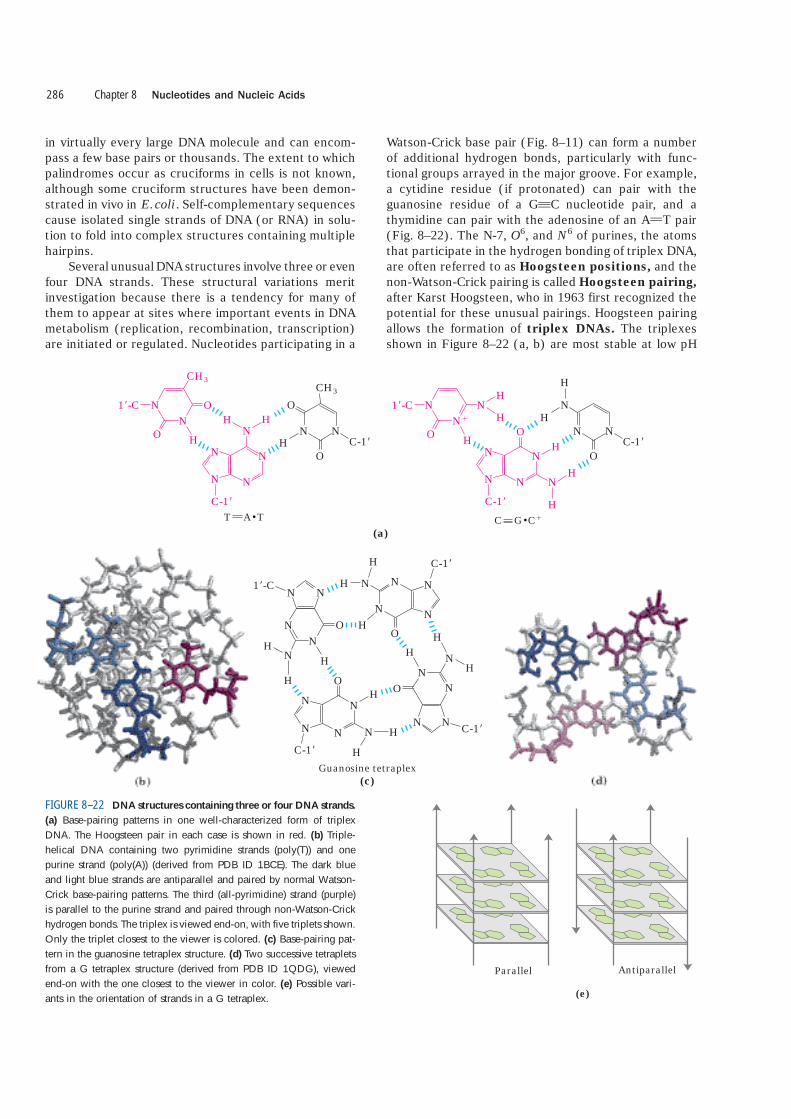
in virtually every large DNA molecule and can encom-pass a few base pairs or thousands. The extent to whichpalindromes occur as cruciforms in cells is not known,although some cruciform structures have been demon-strated in vivo in E.coli. Self-complementary sequencescause isolated single strands of DNA (or RNA) in solu-tion to fold into complex structures containing multiplehairpins.
Several unusual DNA structures involve three or evenfour DNA strands. These structural variations meritinvestigation because there is a tendency for many ofthem to appear at sites where important events in DNAmetabolism (replication, recombination, transcription)are initiated or regulated. Nucleotides participating in a
Watson-Crick base pair (Fig. 8–11) can form a numberof additional hydrogen bonds, particularly with func-tional groups arrayed in the major groove. For example,a cytidine residue (if protonated) can pair with theguanosine residue of a GqC nucleotide pair, and athymidine can pair with the adenosine of an AUT pair(Fig. 8–22). The N-7, O6, and N6 of purines, the atomsthat participate in the hydrogen bonding of triplex DNA,are often referred to as Hoogsteen positions, and thenon-Watson-Crick pairing is called Hoogsteen pairing,after Karst Hoogsteen, who in 1963 first recognized thepotential for these unusual pairings. Hoogsteen pairingallows the formation of triplex DNAs. The triplexesshown in Figure 8–22 (a, b) are most stable at low pH
Chapter 8 Nucleotides and Nucleic Acids286
CH3CH3
ON
O H
N
NH H
NH
NN
C-1�
1�-C
C-1�N
N N
O
O
T A T(a)
NN�
O H
N
OH
H
H
NH
NN
C-1�
1�-C
C-1�N
H
H
N
N N
OH
N
C G C�
H
Guanosine tetraplex(c)
H
H
NN
O
C-1�
N
NN
HH
H
NN
N N1�-C
N O
C-1�
NN
N N
O
N H
H
H O
C-1�
N
HH
N
NN
NH
Parallel Antiparallel
(e)
FIGURE 8–22 DNA structures containing three or four DNA strands.
(a) Base-pairing patterns in one well-characterized form of triplexDNA. The Hoogsteen pair in each case is shown in red. (b) Triple-helical DNA containing two pyrimidine strands (poly(T)) and onepurine strand (poly(A)) (derived from PDB ID 1BCE). The dark blueand light blue strands are antiparallel and paired by normal Watson-Crick base-pairing patterns. The third (all-pyrimidine) strand (purple)is parallel to the purine strand and paired through non-Watson-Crickhydrogen bonds. The triplex is viewed end-on, with five triplets shown.Only the triplet closest to the viewer is colored. (c) Base-pairing pat-tern in the guanosine tetraplex structure. (d) Two successive tetrapletsfrom a G tetraplex structure (derived from PDB ID 1QDG), viewedend-on with the one closest to the viewer in color. (e) Possible vari-ants in the orientation of strands in a G tetraplex.

because the CqG � C� triplet requires a protonated cy-tosine. In the triplex, the pKa of this cytosine is �7.5,altered from its normal value of 4.2. The triplexes alsoform most readily within long sequences containing onlypyrimidines or only purines in a given strand. Sometriplex DNAs contain two pyrimidine strands and onepurine strand; others contain two purine strands andone pyrimidine strand.
Four DNA strands can also pair to form a tetraplex(quadruplex), but this occurs readily only for DNA se-quences with a very high proportion of guanosineresidues (Fig. 8–22c, d). The guanosine tetraplex, or Gtetraplex, is quite stable over a wide range of condi-tions. The orientation of strands in the tetraplex canvary as shown in Figure 8–22e.
A particularly exotic DNA structure, known asH-DNA, is found in polypyrimidine or polypurine tractsthat also incorporate a mirror repeat. A simple exampleis a long stretch of alternating T and C residues (Fig.8–23). The H-DNA structure features the triple-strandedform illustrated in Figure 8–22 (a, b). Two of the threestrands in the H-DNA triple helix contain pyrimidinesand the third contains purines.
In the DNA of living cells, sites recognized by manysequence-specific DNA-binding proteins (Chapter 28)are arranged as palindromes, and polypyrimidine orpolypurine sequences that can form triple helices oreven H-DNA are found within regions involved in theregulation of expression of some eukaryotic genes. Inprinciple, synthetic DNA strands designed to pair withthese sequences to form triplex DNA could disrupt geneexpression. This approach to controlling cellular me-tabolism is of growing commercial interest for its po-tential application in medicine and agriculture.
Messenger RNAs Code for Polypeptide Chains
We now turn our attention briefly from DNA structureto the expression of the genetic information that it con-tains. RNA, the second major form of nucleic acid incells, has many functions. In gene expression, RNA actsas an intermediary by using the information encoded inDNA to specify the amino acid sequence of a functionalprotein.
Given that the DNA of eukaryotes is largely con-fined to the nucleus whereas protein synthesis occurson ribosomes in the cytoplasm, some molecule otherthan DNA must carry the genetic message from the nu-cleus to the cytoplasm. As early as the 1950s, RNA wasconsidered the logical candidate: RNA is found in boththe nucleus and the cytoplasm, and an increase in pro-tein synthesis is accompanied by an increase in theamount of cytoplasmic RNA and an increase in its rateof turnover. These and other observations led severalresearchers to suggest that RNA carries genetic infor-mation from DNA to the protein biosynthetic machin-
ery of the ribosome. In 1961 François Jacob and JacquesMonod presented a unified (and essentially correct) pic-ture of many aspects of this process. They proposed thename “messenger RNA” (mRNA) for that portion of thetotal cellular RNA carrying the genetic information fromDNA to the ribosomes, where the messengers providethe templates that specify amino acid sequences inpolypeptide chains. Although mRNAs from differentgenes can vary greatly in length, the mRNAs from a par-ticular gene generally have a defined size. The processof forming mRNA on a DNA template is known as transcription.
In prokaryotes, a single mRNA molecule may code forone or several polypeptide chains. If it carries the codefor only one polypeptide, the mRNA is monocistronic;
8.2 Nucleic Acid Structure 287
FIGURE 8–23 H-DNA. (a) A sequence of alternating T and C residuescan be considered a mirror repeat centered about a central T or C.(b) These sequences form an unusual structure in which the strandsin one half of the mirror repeat are separated and the pyrimidine-containing strand (alternating T and C residues) folds back on the otherhalf of the repeat to form a triple helix. The purine strand (alternatingA and G residues) is left unpaired. This structure produces a sharpbend in the DNA.

if it codes for two or more different polypeptides, themRNA is polycistronic. In eukaryotes, most mRNAsare monocistronic. (For the purposes of this discussion,“cistron” refers to a gene. The term itself has historicalroots in the science of genetics, and its formal geneticdefinition is beyond the scope of this text.) The mini-mum length of an mRNA is set by the length of thepolypeptide chain for which it codes. For example, apolypeptide chain of 100 amino acid residues requiresan RNA coding sequence of at least 300 nucleotides, be-cause each amino acid is coded by a nucleotide triplet(this and other details of protein synthesis are discussedin Chapter 27). However, mRNAs transcribed from DNAare always somewhat longer than the length needed sim-ply to code for a polypeptide sequence (or sequences).The additional, noncoding RNA includes sequences thatregulate protein synthesis. Figure 8–24 summarizes thegeneral structure of prokaryotic mRNAs.
Many RNAs Have More Complex Three-Dimensional Structures
Messenger RNA is only one of several classes of cellu-lar RNA. Transfer RNAs serve as adapter molecules inprotein synthesis; covalently linked to an amino acid atone end, they pair with the mRNA in such a way thatamino acids are joined to a growing polypeptide in thecorrect sequence. Ribosomal RNAs are components ofribosomes. There is also a wide variety of special-func-tion RNAs, including some (called ribozymes) that haveenzymatic activity. All the RNAs are considered in de-tail in Chapter 26. The diverse and often complex func-tions of these RNAs reflect a diversity of structure muchricher than that observed in DNA molecules.
The product of transcription of DNA is alwayssingle-stranded RNA. The single strand tends to assumea right-handed helical conformation dominated by base-stacking interactions (Fig. 8–25), which are stronger be-tween two purines than between a purine and pyrimi-dine or between two pyrimidines. The purine-purineinteraction is so strong that a pyrimidine separating twopurines is often displaced from the stacking pattern so
that the purines can interact. Any self-complementarysequences in the molecule produce more complex struc-tures. RNA can base-pair with complementary regionsof either RNA or DNA. Base pairing matches the pat-tern for DNA: G pairs with C and A pairs with U (or withthe occasional T residue in some RNAs). One differenceis that base pairing between G and U residues—unusualin DNA—is fairly common in RNA (see Fig. 8–27). Thepaired strands in RNA or RNA-DNA duplexes are an-tiparallel, as in DNA.
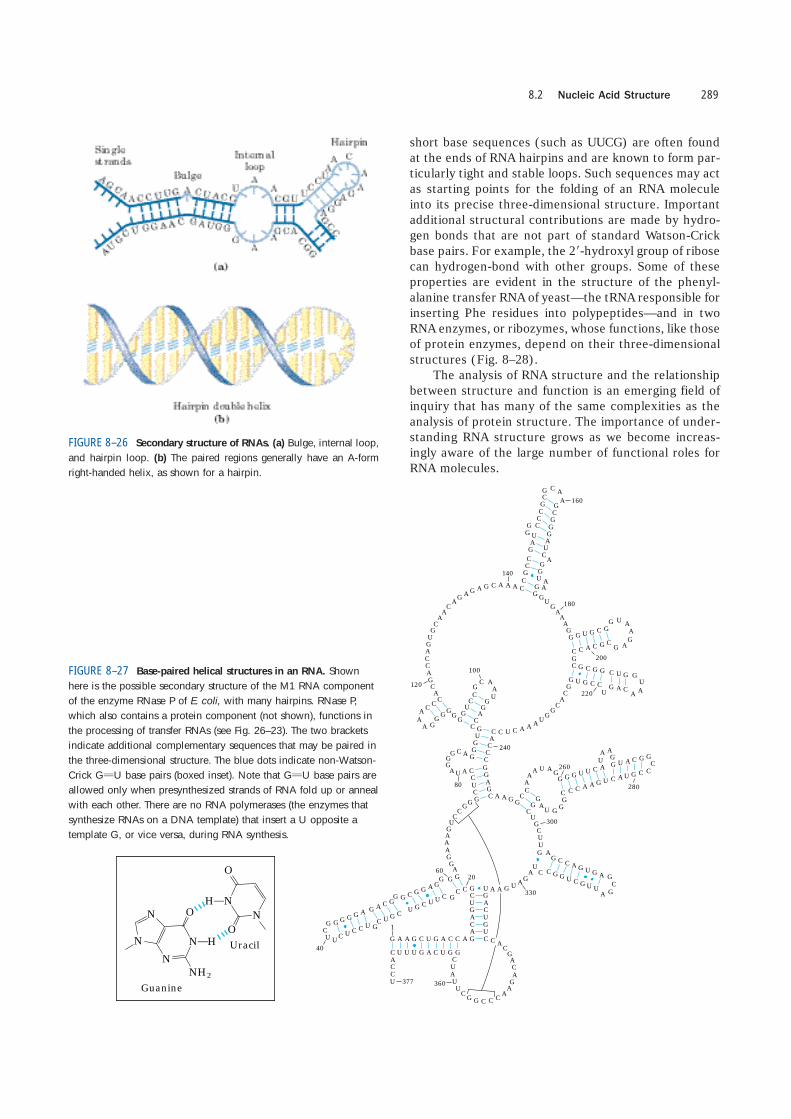
RNA has no simple, regular secondary structurethat serves as a reference point, as does the double he-lix for DNA. The three-dimensional structures of manyRNAs, like those of proteins, are complex and unique.Weak interactions, especially base-stacking interactions,play a major role in stabilizing RNA structures, just asthey do in DNA. Where complementary sequences arepresent, the predominant double-stranded structure isan A-form right-handed double helix. Z-form heliceshave been made in the laboratory (under very high-saltor high-temperature conditions). The B form of RNAhas not been observed. Breaks in the regular A-form he-lix caused by mismatched or unmatched bases in oneor both strands are common and result in bulges or in-ternal loops (Fig. 8–26). Hairpin loops form betweennearby self-complementary sequences. The potential forbase-paired helical structures in many RNAs is exten-sive (Fig. 8–27), and the resulting hairpins are the mostcommon type of secondary structure in RNA. Specific
Chapter 8 Nucleotides and Nucleic Acids288
FIGURE 8–24 Prokaryotic mRNA. Schematic diagrams show (a)
monocistronic and (b) polycistronic mRNAs of prokaryotes. Red seg-ments represent RNA coding for a gene product; gray segments rep-resent noncoding RNA. In the polycistronic transcript, noncoding RNAseparates the three genes.
FIGURE 8–25 Typical right-handed stacking pattern of single-
stranded RNA. The bases are shown in gray, the phosphate atoms inyellow, and the riboses and phosphate oxygens in green. Green is usedto represent RNA strands in succeeding chapters, just as blue is usedfor DNA.
short base sequences (such as UUCG) are often foundat the ends of RNA hairpins and are known to form par-ticularly tight and stable loops. Such sequences may actas starting points for the folding of an RNA moleculeinto its precise three-dimensional structure. Importantadditional structural contributions are made by hydro-gen bonds that are not part of standard Watson-Crickbase pairs. For example, the 2�-hydroxyl group of ribosecan hydrogen-bond with other groups. Some of theseproperties are evident in the structure of the phenyl-alanine transfer RNA of yeast—the tRNA responsible forinserting Phe residues into polypeptides—and in twoRNA enzymes, or ribozymes, whose functions, like thoseof protein enzymes, depend on their three-dimensionalstructures (Fig. 8–28).
The analysis of RNA structure and the relationshipbetween structure and function is an emerging field ofinquiry that has many of the same complexities as theanalysis of protein structure. The importance of under-standing RNA structure grows as we become increas-ingly aware of the large number of functional roles forRNA molecules.
8.2 Nucleic Acid Structure 289
GU
C
A
C
C
A G
U
G
C
A
AC
A
G
AG
A
G
C
A
A
C
A
G
U
G
A
180
A
G
G
C
G
C
120
A
C
G
G
GCG
CC
C
A
240
A
UG
G
C
C
A
G
CG
C
CG
A
U
C
CC
G
C
C
G
G
GG
A
U
C
G
G
U
G
GC
A
160A
G
G
140
A
A
A
G
C C CG
G C GG
UG
G
A
220
A
A
U
GGC G
G
C
U
G
UG
C
C G
A
C GG
U
A
200
A
A
C
CGG
100
AA G G
C
A
G
G
80
C
CC
U A
A
G
A
A
U
G
GG
C
CC
A
CG
A
U
A
AA
G
U
C
C
G
G
G
C
A
G
G
C
U
G
C
U
U
G
UAG
AU
GAA
G
G
A
G
GAG
G
C
UU
C
GGG
C
A
A
CA
U A
C
U
G
A
C
A
G
A
C
U
G
U
C
GG
G
A
C
G
G
C
A
GG
CG
C
U
U C
G
U
G
GGG
C
CCC
GO
ON H
O
NH2
N
NN
N
ON
H
O
Guanine
Uracil
CC
G GA
AA
U
A
G
G
C
C
CA
A
G GU
U
CA
G
UG
CU
A
A
C
GU G
C
GC C
280
A260 G U
G
GG
U
A
300
C
AAG C G
U
GC
C
GG G
U
A
G U
U
G A
C
330
U
A
C
C
A G
U
C G
A
A GG
U
CA
G
U
U
U
C
G A C
C
U
377 360
1 CU
A
U
U
CG
GC
C C
A
A
G
A
C
AG
CA
C
2060
GCG
UA
U
U
GG
GC U
U
40
A
C
FIGURE 8–26 Secondary structure of RNAs. (a) Bulge, internal loop,and hairpin loop. (b) The paired regions generally have an A-formright-handed helix, as shown for a hairpin.
FIGURE 8–27 Base-paired helical structures in an RNA. Shownhere is the possible secondary structure of the M1 RNA componentof the enzyme RNase P of E. coli, with many hairpins. RNase P,which also contains a protein component (not shown), functions inthe processing of transfer RNAs (see Fig. 26–23). The two bracketsindicate additional complementary sequences that may be paired inthe three-dimensional structure. The blue dots indicate non-Watson-Crick GUU base pairs (boxed inset). Note that GUU base pairs areallowed only when presynthesized strands of RNA fold up or annealwith each other. There are no RNA polymerases (the enzymes thatsynthesize RNAs on a DNA template) that insert a U opposite atemplate G, or vice versa, during RNA synthesis.

SUMMARY 8.2 Nucleic Acid Structure
■ Many lines of evidence show that DNA bearsgenetic information. In particular, the Avery-MacLeod-McCarty experiment showed that DNAisolated from one bacterial strain can enter andtransform the cells of another strain, endowingit with some of the inheritable characteristicsof the donor. The Hershey-Chase experiment
showed that the DNA of a bacterial virus, but not its protein coat, carries the genetic message for replication of the virus in a host cell.
■ Putting together much published data, Watsonand Crick postulated that native DNA consistsof two antiparallel chains in a right-handeddouble-helical arrangement. Complementarybase pairs, AUT and GqC, are formed byhydrogen bonding within the helix. The base
Chapter 8 Nucleotides and Nucleic Acids290
FIGURE 8–28 Three-dimensional structure in RNA. (a) Three-dimensional structure of phenylalanine tRNA of yeast (PDB ID 1TRA).Some unusual base-pairing patterns found in this tRNA are shown.Note also the involvement of the oxygen of a ribose phosphodiesterbond in one hydrogen-bonding arrangement, and a ribose 2�-hydroxylgroup in another (both in red). (b) A hammerhead ribozyme (so namedbecause the secondary structure at the active site looks like the headof a hammer), derived from certain plant viruses (derived from PDB
ID 1MME). Ribozymes, or RNA enzymes, catalyze a variety of reac-tions, primarily in RNA metabolism and protein synthesis. The com-plex three-dimensional structures of these RNAs reflect the complexityinherent in catalysis, as described for protein enzymes in Chapter 6.(c) A segment of mRNA known as an intron, from the ciliated proto-zoan Tetrahymena thermophila (derived from PDB ID 1GRZ). Thisintron (a ribozyme) catalyzes its own excision from between exons inan mRNA strand (discussed in Chapter 26).

pairs are stacked perpendicular to the long axisof the double helix, 3.4 Å apart, with 10.5 basepairs per turn.
■ DNA can exist in several structural forms. Twovariations of the Watson-Crick form, or B-DNA,are A- and Z-DNA. Some sequence-dependentstructural variations cause bends in the DNAmolecule. DNA strands with appropriate se-quences can form hairpin/cruciform structuresor triplex or tetraplex DNA.
■ Messenger RNA transfers genetic informationfrom DNA to ribosomes for protein synthesis.Transfer RNA and ribosomal RNA are also involved in protein synthesis. RNA can bestructurally complex; single RNA strands canbe folded into hairpins, double-stranded re-gions, or complex loops.
8.3 Nucleic Acid Chemistry
To understand how nucleic acids function, we must un-derstand their chemical properties as well as their struc-tures. The role of DNA as a repository of genetic infor-mation depends in part on its inherent stability. Thechemical transformations that do occur are generally veryslow in the absence of an enzyme catalyst. The long-termstorage of information without alteration is so importantto a cell, however, that even very slow reactions that alter DNA structure can be physiologically significant.Processes such as carcinogenesis and aging may be intimately linked to slowly accumulating, irreversible al-terations of DNA. Other, nondestructive alterations also occur and are essential to function, such as the strandseparation that must precede DNA replication or tran-scription. In addition to providing insights into physio-logical processes, our understanding of nucleic acidchemistry has given us a powerful array of technologiesthat have applications in molecular biology, medicine, andforensic science. We now examine the chemical proper-ties of DNA and some of these technologies.
Double-Helical DNA and RNA Can Be Denatured
Solutions of carefully isolated, native DNA are highlyviscous at pH 7.0 and room temperature (25 �C). Whensuch a solution is subjected to extremes of pH or to tem-peratures above 80 �C, its viscosity decreases sharply,indicating that the DNA has undergone a physicalchange. Just as heat and extremes of pH denature glob-ular proteins, they also cause denaturation, or melting,of double-helical DNA. Disruption of the hydrogenbonds between paired bases and of base stacking causesunwinding of the double helix to form two single strands,completely separate from each other along the entire
length or part of the length (partial denaturation) of themolecule. No covalent bonds in the DNA are broken(Fig. 8–29).
Renaturation of a DNA molecule is a rapid one-stepprocess, as long as a double-helical segment of a dozenor more residues still unites the two strands. When thetemperature or pH is returned to the range in whichmost organisms live, the unwound segments of the twostrands spontaneously rewind, or anneal, to yield theintact duplex (Fig. 8–29). However, if the two strandsare completely separated, renaturation occurs in twosteps. In the first, relatively slow step, the two strands“find” each other by random collisions and form a shortsegment of complementary double helix. The secondstep is much faster: the remaining unpaired bases suc-cessively come into register as base pairs, and the twostrands “zipper” themselves together to form the dou-ble helix.
The close interaction between stacked bases in anucleic acid has the effect of decreasing its absorptionof UV light relative to that of a solution with the sameconcentration of free nucleotides, and the absorption isdecreased further when two complementary nucleicacids strands are paired. This is called the hypochromiceffect. Denaturation of a double-stranded nucleic acidproduces the opposite result: an increase in absorption
8.3 Nucleic Acid Chemistry 291
FIGURE 8–29 Reversible denaturation and annealing (renaturation)
of DNA.

called the hyperchromic effect. The transition fromdouble-stranded DNA to the single-stranded, denaturedform can thus be detected by monitoring the absorptionof UV light.
Viral or bacterial DNA molecules in solution dena-ture when they are heated slowly (Fig. 8–30). Eachspecies of DNA has a characteristic denaturation tem-perature, or melting point (tm): the higher its contentof GqC base pairs, the higher the melting point of theDNA. This is because GqC base pairs, with three hy-drogen bonds, require more heat energy to dissociatethan AUT base pairs. Careful determination of the melt-ing point of a DNA specimen, under fixed conditions ofpH and ionic strength, can yield an estimate of its basecomposition. If denaturation conditions are carefullycontrolled, regions that are rich in AUT base pairs willspecifically denature while most of the DNA remains
double-stranded. Such denatured regions (called bub-bles) can be visualized with electron microscopy (Fig.8–31). Strand separation of DNA must occur in vivo dur-ing processes such as DNA replication and transcrip-tion. As we shall see, the DNA sites where theseprocesses are initiated are often rich in AUT base pairs.
Duplexes of two RNA strands or of one RNA strandand one DNA strand (RNA-DNA hybrids) can also bedenatured. Notably, RNA duplexes are more stable thanDNA duplexes. At neutral pH, denaturation of a double-helical RNA often requires temperatures 20 �C or morehigher than those required for denaturation of a DNAmolecule with a comparable sequence. The stability ofan RNA-DNA hybrid is generally intermediate betweenthat of RNA and that of DNA. The physical basis forthese differences in thermal stability is not known.
Nucleic Acids from Different Species Can Form Hybrids
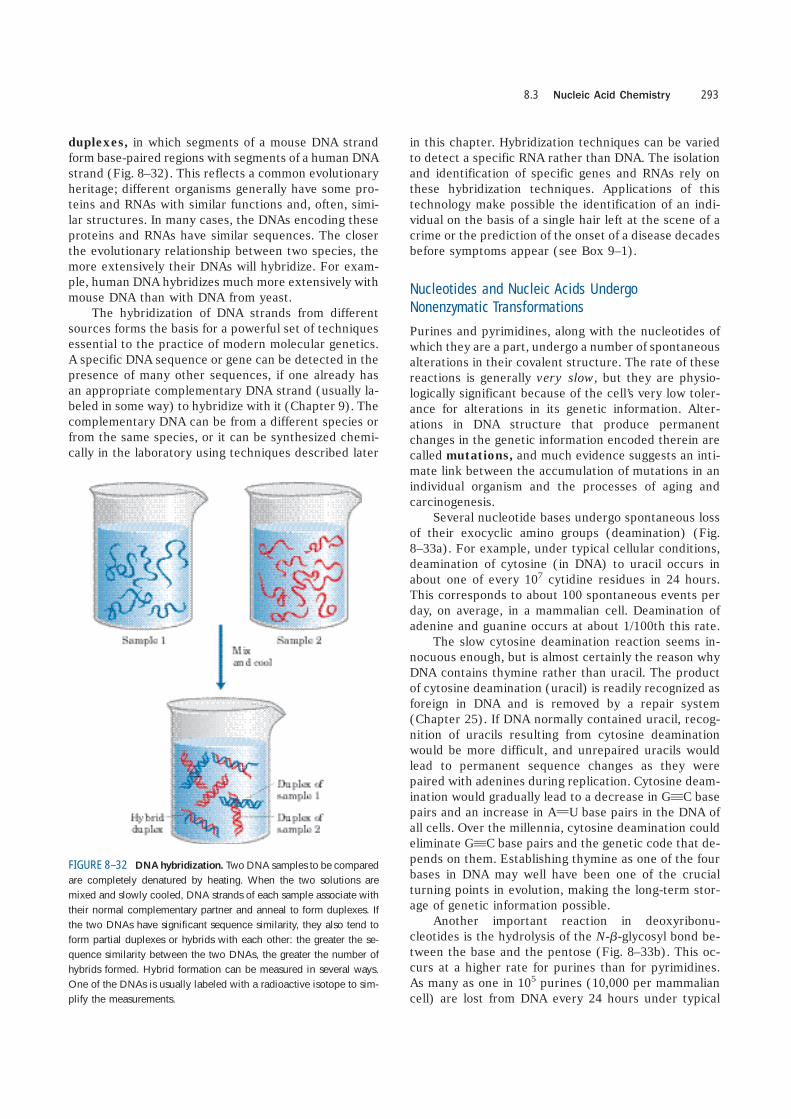
The ability of two complementary DNA strands to pairwith one another can be used to detect similar DNA se-quences in two different species or within the genomeof a single species. If duplex DNAs isolated from humancells and from mouse cells are completely denatured byheating, then mixed and kept at 65 �C for many hours,much of the DNA will anneal. Most of the mouse DNAstrands anneal with complementary mouse DNA strandsto form mouse duplex DNA; similarly, most humanDNA strands anneal with complementary human DNAstrands. However, some strands of the mouse DNA willassociate with human DNA strands to yield hybrid
Chapter 8 Nucleotides and Nucleic Acids292
100
G�
C (
% o
f to
tal n
ucl
eoti
des) 80
070 80 90
tm (°C)11060 100
60
40
20
100
Den
atu
rati
on (
%)
50
075 80 85
Temperature (°C)
tm tm
FIGURE 8–30 Heat denaturation of DNA. (a) The denaturation, ormelting, curves of two DNA specimens. The temperature at the mid-point of the transition (tm) is the melting point; it depends on pH andionic strength and on the size and base composition of the DNA.(b) Relationship between tm and the GqC content of a DNA.
(a)
(b)
FIGURE 8–31 Partially denatured DNA. This DNA was partially de-natured, then fixed to prevent renaturation during sample preparation.The shadowing method used to visualize the DNA in this electron mi-crograph increases its diameter approximately fivefold and obliteratesmost details of the helix. However, length measurements can be ob-tained, and single-stranded regions are readily distinguishable fromdouble-stranded regions. The arrows point to some single-strandedbubbles where denaturation has occurred. The regions that denatureare highly reproducible and are rich in AUT base pairs.
duplexes, in which segments of a mouse DNA strandform base-paired regions with segments of a human DNAstrand (Fig. 8–32). This reflects a common evolutionaryheritage; different organisms generally have some pro-teins and RNAs with similar functions and, often, simi-lar structures. In many cases, the DNAs encoding theseproteins and RNAs have similar sequences. The closerthe evolutionary relationship between two species, themore extensively their DNAs will hybridize. For exam-ple, human DNA hybridizes much more extensively withmouse DNA than with DNA from yeast.
The hybridization of DNA strands from differentsources forms the basis for a powerful set of techniquesessential to the practice of modern molecular genetics.A specific DNA sequence or gene can be detected in thepresence of many other sequences, if one already hasan appropriate complementary DNA strand (usually la-beled in some way) to hybridize with it (Chapter 9). Thecomplementary DNA can be from a different species orfrom the same species, or it can be synthesized chemi-cally in the laboratory using techniques described later
in this chapter. Hybridization techniques can be variedto detect a specific RNA rather than DNA. The isolationand identification of specific genes and RNAs rely onthese hybridization techniques. Applications of thistechnology make possible the identification of an indi-vidual on the basis of a single hair left at the scene of acrime or the prediction of the onset of a disease decadesbefore symptoms appear (see Box 9–1).
Nucleotides and Nucleic Acids UndergoNonenzymatic Transformations
Purines and pyrimidines, along with the nucleotides ofwhich they are a part, undergo a number of spontaneousalterations in their covalent structure. The rate of thesereactions is generally very slow, but they are physio-logically significant because of the cell’s very low toler-ance for alterations in its genetic information. Alter-ations in DNA structure that produce permanentchanges in the genetic information encoded therein arecalled mutations, and much evidence suggests an inti-mate link between the accumulation of mutations in anindividual organism and the processes of aging and carcinogenesis.
Several nucleotide bases undergo spontaneous lossof their exocyclic amino groups (deamination) (Fig.8–33a). For example, under typical cellular conditions,deamination of cytosine (in DNA) to uracil occurs inabout one of every 107 cytidine residues in 24 hours.This corresponds to about 100 spontaneous events perday, on average, in a mammalian cell. Deamination ofadenine and guanine occurs at about 1/100th this rate.
The slow cytosine deamination reaction seems in-nocuous enough, but is almost certainly the reason whyDNA contains thymine rather than uracil. The productof cytosine deamination (uracil) is readily recognized asforeign in DNA and is removed by a repair system(Chapter 25). If DNA normally contained uracil, recog-nition of uracils resulting from cytosine deaminationwould be more difficult, and unrepaired uracils wouldlead to permanent sequence changes as they werepaired with adenines during replication. Cytosine deam-ination would gradually lead to a decrease in GqC basepairs and an increase in AUU base pairs in the DNA ofall cells. Over the millennia, cytosine deamination couldeliminate GqC base pairs and the genetic code that de-pends on them. Establishing thymine as one of the fourbases in DNA may well have been one of the crucialturning points in evolution, making the long-term stor-age of genetic information possible.
Another important reaction in deoxyribonu-cleotides is the hydrolysis of the N-�-glycosyl bond be-tween the base and the pentose (Fig. 8–33b). This oc-curs at a higher rate for purines than for pyrimidines.As many as one in 105 purines (10,000 per mammaliancell) are lost from DNA every 24 hours under typical
8.3 Nucleic Acid Chemistry 293
FIGURE 8–32 DNA hybridization. Two DNA samples to be comparedare completely denatured by heating. When the two solutions aremixed and slowly cooled, DNA strands of each sample associate withtheir normal complementary partner and anneal to form duplexes. Ifthe two DNAs have significant sequence similarity, they also tend toform partial duplexes or hybrids with each other: the greater the se-quence similarity between the two DNAs, the greater the number ofhybrids formed. Hybrid formation can be measured in several ways.One of the DNAs is usually labeled with a radioactive isotope to sim-plify the measurements.
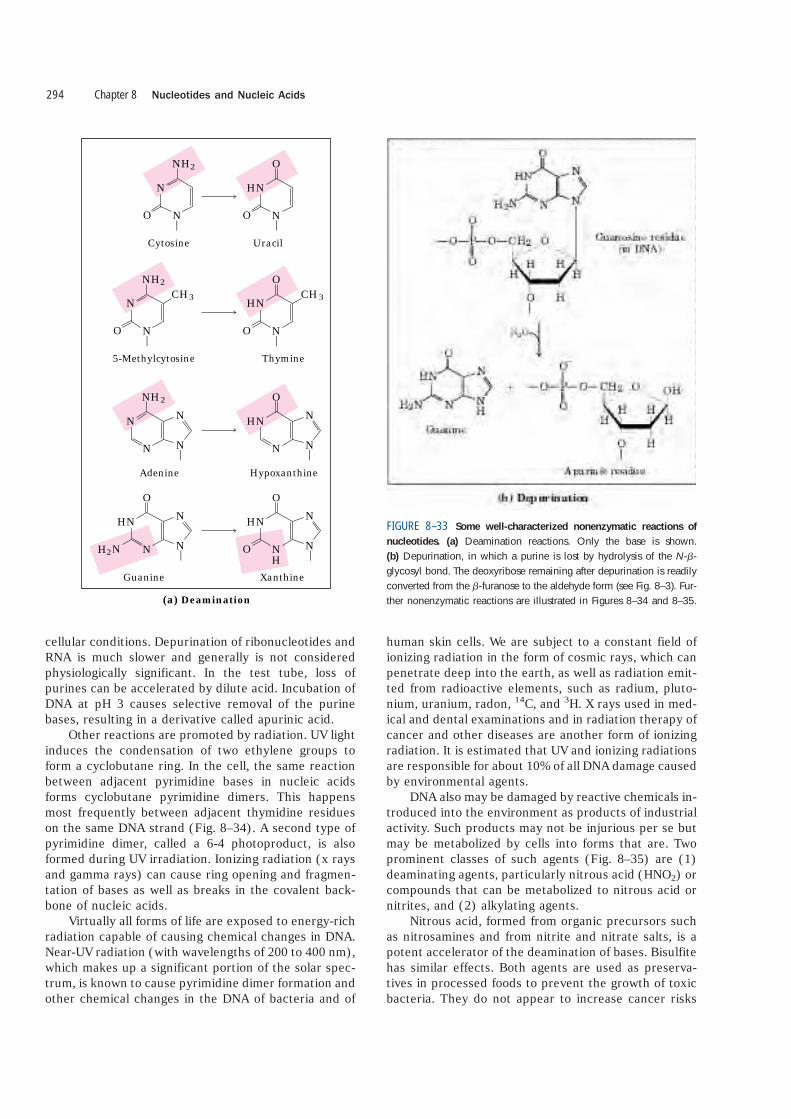
cellular conditions. Depurination of ribonucleotides andRNA is much slower and generally is not consideredphysiologically significant. In the test tube, loss ofpurines can be accelerated by dilute acid. Incubation ofDNA at pH 3 causes selective removal of the purinebases, resulting in a derivative called apurinic acid.
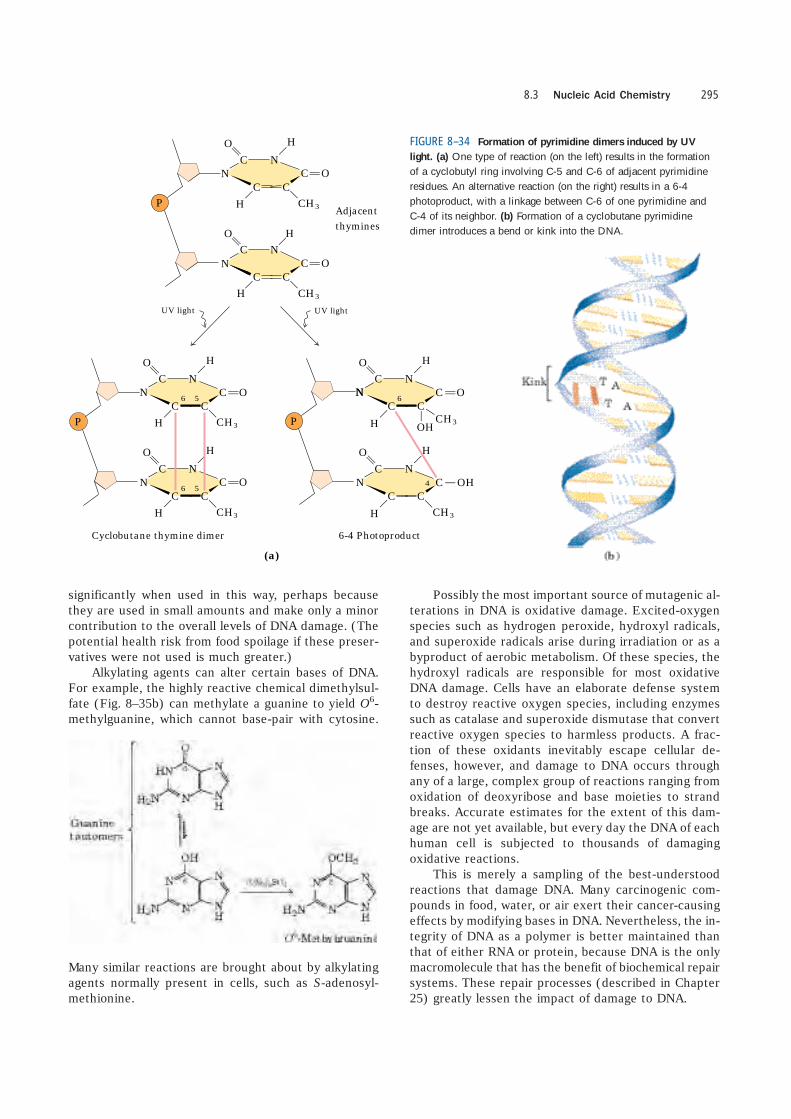
Other reactions are promoted by radiation. UV lightinduces the condensation of two ethylene groups toform a cyclobutane ring. In the cell, the same reactionbetween adjacent pyrimidine bases in nucleic acidsforms cyclobutane pyrimidine dimers. This happensmost frequently between adjacent thymidine residueson the same DNA strand (Fig. 8–34). A second type ofpyrimidine dimer, called a 6-4 photoproduct, is alsoformed during UV irradiation. Ionizing radiation (x raysand gamma rays) can cause ring opening and fragmen-tation of bases as well as breaks in the covalent back-bone of nucleic acids.
Virtually all forms of life are exposed to energy-richradiation capable of causing chemical changes in DNA.Near-UV radiation (with wavelengths of 200 to 400 nm),which makes up a significant portion of the solar spec-trum, is known to cause pyrimidine dimer formation andother chemical changes in the DNA of bacteria and of
human skin cells. We are subject to a constant field ofionizing radiation in the form of cosmic rays, which canpenetrate deep into the earth, as well as radiation emit-ted from radioactive elements, such as radium, pluto-nium, uranium, radon, 14C, and 3H. X rays used in med-ical and dental examinations and in radiation therapy ofcancer and other diseases are another form of ionizingradiation. It is estimated that UV and ionizing radiationsare responsible for about 10% of all DNA damage causedby environmental agents.
DNA also may be damaged by reactive chemicals in-troduced into the environment as products of industrialactivity. Such products may not be injurious per se butmay be metabolized by cells into forms that are. Twoprominent classes of such agents (Fig. 8–35) are (1)deaminating agents, particularly nitrous acid (HNO2) orcompounds that can be metabolized to nitrous acid ornitrites, and (2) alkylating agents.
Nitrous acid, formed from organic precursors suchas nitrosamines and from nitrite and nitrate salts, is apotent accelerator of the deamination of bases. Bisulfitehas similar effects. Both agents are used as preserva-tives in processed foods to prevent the growth of toxicbacteria. They do not appear to increase cancer risks
Chapter 8 Nucleotides and Nucleic Acids294
3
(a) Deamination
3
2
2
2
2
CH
N
HN
Hypoxanthine
Uracil
N
Cytosine
O
CH
NO
N
Xanthine
NO
N
O
HN
NH
NH
N
N
N
NH
Thymine5-Methylcytosine
O
HN
O
O
NN
N N
Adenine
Guanine
O NH
N
N
O
N
N
NH N
O
HNHN FIGURE 8–33 Some well-characterized nonenzymatic reactions of
nucleotides. (a) Deamination reactions. Only the base is shown.(b) Depurination, in which a purine is lost by hydrolysis of the N-�-glycosyl bond. The deoxyribose remaining after depurination is readilyconverted from the �-furanose to the aldehyde form (see Fig. 8–3). Fur-ther nonenzymatic reactions are illustrated in Figures 8–34 and 8–35.
significantly when used in this way, perhaps becausethey are used in small amounts and make only a minorcontribution to the overall levels of DNA damage. (Thepotential health risk from food spoilage if these preser-vatives were not used is much greater.)
Alkylating agents can alter certain bases of DNA.For example, the highly reactive chemical dimethylsul-fate (Fig. 8–35b) can methylate a guanine to yield O6-methylguanine, which cannot base-pair with cytosine.
Many similar reactions are brought about by alkylatingagents normally present in cells, such as S-adenosyl-methionine.
Possibly the most important source of mutagenic al-terations in DNA is oxidative damage. Excited-oxygenspecies such as hydrogen peroxide, hydroxyl radicals,and superoxide radicals arise during irradiation or as abyproduct of aerobic metabolism. Of these species, thehydroxyl radicals are responsible for most oxidativeDNA damage. Cells have an elaborate defense systemto destroy reactive oxygen species, including enzymessuch as catalase and superoxide dismutase that convertreactive oxygen species to harmless products. A frac-tion of these oxidants inevitably escape cellular de-fenses, however, and damage to DNA occurs throughany of a large, complex group of reactions ranging fromoxidation of deoxyribose and base moieties to strandbreaks. Accurate estimates for the extent of this dam-age are not yet available, but every day the DNA of eachhuman cell is subjected to thousands of damagingoxidative reactions.
This is merely a sampling of the best-understoodreactions that damage DNA. Many carcinogenic com-pounds in food, water, or air exert their cancer-causingeffects by modifying bases in DNA. Nevertheless, the in-tegrity of DNA as a polymer is better maintained thanthat of either RNA or protein, because DNA is the onlymacromolecule that has the benefit of biochemical repairsystems. These repair processes (described in Chapter25) greatly lessen the impact of damage to DNA.
8.3 Nucleic Acid Chemistry 295
OHC
N
H
OH
CO
CC
H
N
OC
N
H CH3
CO
CC
H
N
UV lightUV light
Adjacentthymines
Cyclobutane thymine dimer 6-4 Photoproduct
OC
N
H CH3
CO
CC
HN
OC
N
H CH3
CO
CC
H
N
OC
N
H CH3
CO
CC
H
N
OC
N
H CH3
CO
CC
H
N
46
CH3
5
66 5
(a)
N
P P
P
FIGURE 8–34 Formation of pyrimidine dimers induced by UV
light. (a) One type of reaction (on the left) results in the formationof a cyclobutyl ring involving C-5 and C-6 of adjacent pyrimidineresidues. An alternative reaction (on the right) results in a 6-4photoproduct, with a linkage between C-6 of one pyrimidine andC-4 of its neighbor. (b) Formation of a cyclobutane pyrimidinedimer introduces a bend or kink into the DNA.

Some Bases of DNA Are Methylated
Certain nucleotide bases in DNA molecules are enzy-matically methylated. Adenine and cytosine are methy-lated more often than guanine and thymine. Methyla-tion is generally confined to certain sequences orregions of a DNA molecule. In some cases the functionof methylation is well understood; in others the func-tion remains unclear. All known DNA methylases use S-adenosylmethionine as a methyl group donor. E. coli
has two prominent methylation systems. One serves aspart of a defense mechanism that helps the cell to dis-tinguish its DNA from foreign DNA by marking its own DNA with methyl groups and destroying (foreign)DNA without the methyl groups (this is known as a restriction-modification system; see Chapter 9). Theother system methylates adenosine residues within thesequence (5�)GATC(3�) to N
6-methyladenosine (Fig.8–5a). This is mediated by the Dam (DNA adeninemethylation) methylase, a component of a system thatrepairs mismatched base pairs formed occasionally dur-ing DNA replication (see Fig. 25–20).
In eukaryotic cells, about 5% of cytidine residues inDNA are methylated to 5-methylcytidine (Fig. 8–5a).Methylation is most common at CpG sequences, pro-ducing methyl-CpG symmetrically on both strands of theDNA. The extent of methylation of CpG sequencesvaries by molecular region in large eukaryotic DNA mol-ecules. Methylation suppresses the migration of seg-ments of DNA called transposons, described in Chapter25. These methylations of cytosine also have structuralsignificance. The presence of 5-methylcytosine in an al-ternating CpG sequence markedly increases the ten-dency for that segment of DNA to assume the Z form.
The Sequences of Long DNA Strands Can Be Determined
In its capacity as a repository of information, a DNA mol-ecule’s most important property is its nucleotide se-
quence. Until the late 1970s, determining the sequenceof a nucleic acid containing even five or ten nucleotideswas difficult and very laborious. The development of twonew techniques in 1977, one by Alan Maxam and WalterGilbert and the other by Frederick Sanger, has made pos-sible the sequencing of ever larger DNA molecules withan ease unimagined just a few decades ago. The tech-niques depend on an improved understanding of nu-cleotide chemistry and DNA metabolism, and on elec-trophoretic methods for separating DNA strands differingin size by only one nucleotide. Electrophoresis of DNA issimilar to that of proteins (see Fig. 3–19). Polyacrylamideis often used as the gel matrix in work with short DNAmolecules (up to a few hundred nucleotides); agarose isgenerally used for longer pieces of DNA.
In both Sanger and Maxam-Gilbert sequencing, thegeneral principle is to reduce the DNA to four sets of la-beled fragments. The reaction producing each set isbase-specific, so the lengths of the fragments correspondto positions in the DNA sequence where a certain baseoccurs. For example, for an oligonucleotide with the se-quence pAATCGACT, labeled at the 5� end (the left end),a reaction that breaks the DNA after each C residue willgenerate two labeled fragments: a four-nucleotide and aseven-nucleotide fragment; a reaction that breaks theDNA after each G will produce only one labeled, five-nucleotide fragment. Because the fragments are radio-actively labeled at their 5� ends, only the fragment to the5� side of the break is visualized. The fragment sizes cor-respond to the relative positions of C and G residues inthe sequence. When the sets of fragments correspondingto each of the four bases are electrophoretically sepa-rated side by side, they produce a ladder of bands fromwhich the sequence can be read directly (Fig. 8–36). Weillustrate only the Sanger method, because it has provento be technically easier and is in more widespread use.It requires the enzymatic synthesis of a DNA strand com-plementary to the strand under analysis, using a radio-actively labeled “primer” and dideoxynucleotides.
Chapter 8 Nucleotides and Nucleic Acids296
FIGURE 8–35 Chemical agents that cause
DNA damage. (a) Precursors of nitrous acid,which promotes deamination reactions.(b) Alkylating agents.

8.3 Nucleic Acid Chemistry 297
(a)
P
PdATP
dGTP
3�
P
P
P
OH
A
P
P P P
P
P PP
A TCGGC
OH
A
OH
G
P
C
P
C
P
G
P
T
5�
Primerstrand
Templatestrand
PP
TC
FIGURE 8–36 DNA sequencing by the Sanger method. This methodmakes use of the mechanism of DNA synthesis by DNA polymerases(Chapter 25). (a) DNA polymerases require both a primer (a shortoligonucleotide strand), to which nucleotides are added, and a templatestrand to guide selection of each new nucleotide. In cells, the 3�-hy-droxyl group of the primer reacts with an incoming deoxynucleosidetriphosphate (dNTP) to form a new phosphodiester bond. (b) The Sangersequencing procedure uses dideoxynucleoside triphosphate (ddNTP)analogs to interrupt DNA synthesis. (The Sanger method is also knownas the dideoxy method.) When a ddNTP is inserted in place of a dNTP,strand elongation is halted after the analog is added, because it lacks
the 3�-hydroxyl group needed for the next step. (c) The DNA to be sequenced is used as the tem-
plate strand, and a short primer, radioactivelyor fluorescently labeled, is an-nealed to it. By addition of smallamounts of a single ddNTP, for example ddCTP, to an otherwise
normal reaction system, the synthesizedstrands will be prematurely terminated at some lo-
cations where dC normally occurs. Given the excess ofdCTP over ddCTP, the chance that the analog will be incorporatedwhenever a dC is to be added is small. However, ddCTP is present insufficient amounts to ensure that each new strand has a high proba-bility of acquiring at least one ddC at some point during synthesis. Theresult is a solution containing a mixture of labeled fragments, each end-ing with a C residue. Each C residue in the sequence generates a setof fragments of a particular length, such that the different-sized frag-ments, separated by electrophoresis, reveal the location of C residues.This procedure is repeated separately for each of the four ddNTPs, andthe sequence can be read directly from an autoradiogram of the gel.Because shorter DNA fragments migrate faster, the fragments near thebottom of the gel represent the nucleotide positions closest to the primer(the 5� end), and the sequence is read (in the 5� n 3� direction) frombottom to top. Note that the sequence obtained is that of the strandcomplementary to the strand being analyzed.

DNA sequencing is readily automated by a varia-tion of Sanger’s sequencing method in which thedideoxynucleotides used for each reaction are labeledwith a differently colored fluorescent tag (Fig. 8–37).This technology allows DNA sequences containing thou-sands of nucleotides to be determined in a few hours.Entire genomes of many organisms have now been se-quenced (see Table 1–4), and many very large DNA-sequencing projects are in progress. Perhaps the mostambitious of these is the Human Genome Project, inwhich researchers have sequenced all 3.2 billion basepairs of the DNA in a human cell (Chapter 9). Dideoxy
Sequencing of DNA
The Chemical Synthesis of DNA Has Been Automated
Another technology that has paved the way for manybiochemical advances is the chemical synthesis ofoligonucleotides with any chosen sequence. The chem-ical methods for synthesizing nucleic acids were devel-oped primarily by H. Gobind Khorana and his colleaguesin the 1970s. Refinement and automation of these meth-ods have made possible the rapid and accurate synthe-sis of DNA strands. The synthesis is carried out with thegrowing strand attached to a solid support (Fig. 8–38),using principles similar to those used by Merrifield inpeptide synthesis (see Fig. 3–29). The efficiency of eachaddition step is very high, allowing the routine labora-tory synthesis of polymers containing 70 or 80 nu-cleotides and, in some laboratories, much longerstrands. The availability of relatively inexpensive DNApolymers with predesigned sequences is having a pow-erful impact on all areas of biochemistry (Chapter 9).
Chapter 8 Nucleotides and Nucleic Acids298
FIGURE 8–37 Strategy for automating DNA sequencing reactions.
Each dideoxynucleotide used in the Sanger method can be linked toa fluorescent molecule that gives all the fragments terminating in thatnucleotide a particular color. All four labeled ddNTPs are added to asingle tube. The resulting colored DNA fragments are then separatedby size in a single electrophoretic gel contained in a capillary tube (arefinement of gel electrophoresis that allows for faster separations). Allfragments of a given length migrate through the capillary gel in a singlepeak, and the color associated with each peak is detected using a laserbeam. The DNA sequence is read by determining the sequence ofcolors in the peaks as they pass the detector. This information is feddirectly to a computer, which determines the sequence.

Nucleosideattached tosilica support
1
42Repeat steps to until all residues are added
CH2
H
O
HH H
Base1O
OH H3�
5�
DMTNucleosideprotectedat 5� hydroxyl
R
Si
O
H
O
HH H
Base1O
H
CH2
H
DMT
O
CH2
H
O
HH
Base1O
H
R
Si
H
O
H
O P
HH
Base2O
R
Si
CH2
H
O
HHH H
Base1OCH2
H
O
O
O
H
2NC (CH2)
DMT
O
H
O P
HH H
Base2O
R
Si
CH2
H
O
HHH H
Base1OCH2
H
O
O
2NC (CH2)
DMT
Oxidation to form triester4
DMT
Protectinggroup removed
2
2H
Next nucleotideadded
3
N� CH2CH
2HN CH(CH3)2CH
(CH3)
H
O P
HH H
Base2O
Nucleotideactivated
at 3� position
CH2
H
O
O
(CH3)
(CH3)
2NC (CH2)
Cyanoethylprotecting group
Diisopropylamine byproduct
DMT
Diisopropylamino activating group
Remove protecting groups from bases
Remove cyanoethyl groups from phosphates
Cleave chain from silica support7
5
6
5� 3�
Oligonucleotide chain
8.3 Nucleic Acid Chemistry 299
FIGURE 8–38 Chemical synthesis of DNA. Automated DNA synthe-sis is conceptually similar to the synthesis of polypeptides on a solidsupport. The oligonucleotide is built up on the solid support (silica),one nucleotide at a time, in a repeated series of chemical reactionswith suitably protected nucleotide precursors. 1 The first nucleoside(which will be the 3� end) is attached to the silica support at the 3�
hydroxyl (through a linking group, R) and is protected at the 5� hy-droxyl with an acid-labile dimethoxytrityl group (DMT). The reactivegroups on all bases are also chemically protected. 2 The protectingDMT group is removed by washing the column with acid (the DMTgroup is colored, so this reaction can be followed spectrophotomet-rically). 3 The next nucleotide is activated with a diisopropylamino
group and reacted with the bound nucleotide to form a 5�,3� linkage,which in step 4 is oxidized with iodine to produce a phosphotri-ester linkage. (One of the phosphate oxygens carries a cyanoethyl pro-tecting group.) Reactions 2 through 4 are repeated until all nu-cleotides are added. At each step, excess nucleotide is removed beforeaddition of the next nucleotide. In steps 5 and 6 the remainingprotecting groups on the bases and the phosphates are removed, andin 7 the oligonucleotide is separated from the solid support and pu-rified. The chemical synthesis of RNA is somewhat more complicatedbecause of the need to protect the 2� hydroxyl of ribose without ad-versely affecting the reactivity of the 3� hydroxyl.

SUMMARY 8.3 Nucleic Acid Chemistry
■ Native DNA undergoes reversible unwindingand separation of strands (melting) on heatingor at extremes of pH. DNAs rich in GqC pairshave higher melting points than DNAs rich inAUT pairs.
■ Denatured single-stranded DNAs from twospecies can form a hybrid duplex, the degreeof hybridization depending on the extent ofsequence similarity. Hybridization is the basisfor important techniques used to study andisolate specific genes and RNAs.
■ DNA is a relatively stable polymer. Spontaneousreactions such as deamination of certain bases,hydrolysis of base-sugar N-glycosyl bonds, radiation-induced formation of pyrimidinedimers, and oxidative damage occur at very lowrates, yet are important because of cells’ verylow tolerance for changes in genetic material.
■ DNA sequences can be determined and DNApolymers synthesized with simple, automatedprotocols involving chemical and enzymaticmethods.
8.4 Other Functions of Nucleotides
In addition to their roles as the subunits of nucleic acids,nucleotides have a variety of other functions in everycell: as energy carriers, components of enzyme cofac-tors, and chemical messengers.
Nucleotides Carry Chemical Energy in Cells
The phosphate group covalently linked at the 5� hy-droxyl of a ribonucleotide may have one or two addi-tional phosphates attached. The resulting molecules arereferred to as nucleoside mono-, di-, and triphosphates(Fig. 8–39). Starting from the ribose, the three phos-
phates are generally labeled �, �, and �. Hydrolysis ofnucleoside triphosphates provides the chemical energyto drive a wide variety of cellular reactions. Adenosine5�-triphosphate, ATP, is by far the most widely used forthis purpose, but UTP, GTP, and CTP are also used insome reactions. Nucleoside triphosphates also serve asthe activated precursors of DNA and RNA synthesis, asdescribed in Chapters 25 and 26.
The energy released by hydrolysis of ATP and theother nucleoside triphosphates is accounted for by thestructure of the triphosphate group. The bond betweenthe ribose and the � phosphate is an ester linkage. The�,� and �,� linkages are phosphoanhydrides (Fig.8–40). Hydrolysis of the ester linkage yields about 14kJ/mol under standard conditions, whereas hydrolysisof each anhydride bond yields about 30 kJ/mol. ATP hy-drolysis often plays an important thermodynamic rolein biosynthesis. When coupled to a reaction with a pos-itive free-energy change, ATP hydrolysis shifts the equi-librium of the overall process to favor product forma-
Chapter 8 Nucleotides and Nucleic Acids300
Abbreviations of ribonucleoside5�-phosphates
Base Mono- Di- Tri-
Adenine
Guanine
Cytosine
Thymine
AMP
GMP
CMP
UMP
ADP
GDP
CDP
UDP
ATP
GTP
CTP
UTP
Abbreviations of deoxyribonucleoside
Base Mono- Di- Tri-
Adenine
Guanine
Cytosine
Uracil
dAMP
dGMP
dCMP
dTMP
dADP
dGDP
dCDP
dTDP
dATP
dGTP
dCTP
dTTP
5�-phosphatesO�O CH2
H
O�
P
O� O�
O
P
O
OOP
OOH
H
H
H
BaseO
OH
�
NMP
NDP
NTP
FIGURE 8–39 Nucleoside phosphates. General structure of the nucleoside5�-mono-, di-, and triphosphates (NMPs, NDPs, and NTPs) and their standardabbreviations. In the deoxyribonucleoside phosphates (dNMPs, dNDPs, anddNTPs), the pentose is 2�-deoxy-D-ribose.
FIGURE 8–40 The phosphate ester and phosphoanhydride bonds of
ATP. Hydrolysis of an anhydride bond yields more energy than hy-drolysis of the ester. A carboxylic acid anhydride and carboxylic acidester are shown for comparison.

tion (recall the relationship between equilibrium con-stant and free-energy change described by Eqn 6–3 onp. 195).
Adenine Nucleotides Are Components of ManyEnzyme Cofactors
A variety of enzyme cofactors serving a wide range ofchemical functions include adenosine as part of theirstructure (Fig. 8–41). They are unrelated structurallyexcept for the presence of adenosine. In none of thesecofactors does the adenosine portion participate directlyin the primary function, but removal of adenosine gen-erally results in a drastic reduction of cofactor activi-ties. For example, removal of the adenine nucleotide(3�-phosphoadenosine diphosphate) from acetoacetyl-
CoA, the coenzyme A derivative of acetoacetate, re-duces its reactivity as a substrate for �-ketoacyl-CoAtransferase (an enzyme of lipid metabolism) by a factorof 106. Although this requirement for adenosine has notbeen investigated in detail, it must involve the bindingenergy between enzyme and substrate (or cofactor) thatis used both in catalysis and in stabilizing the initialenzyme-substrate complex (Chapter 6). In the case of�-ketoacyl-CoA transferase, the nucleotide moiety ofcoenzyme A appears to be a binding “handle” that helpsto pull the substrate (acetoacetyl-CoA) into the activesite. Similar roles may be found for the nucleoside por-tion of other nucleotide cofactors.
Why is adenosine, rather than some other large mol-ecule, used in these structures? The answer here mayinvolve a form of evolutionary economy. Adenosine is
8.4 Other Functions of Nucleotides 301
�O
H
O�
P
O�
O
O
O
P
HH
H
O OH
CH2 O
OCH3
C
N
CH2
NH2
N
N
N
N C CC
N
CH2
C
NCH2CH2
H
H H
H
CH3
HS
O
OO H
CH35�
P
O
O
O�
O�
3�-Phosphoadenosine diphosphate(3�-P-ADP)
Pantothenic acidb-Mercaptoethylamine
Coenzyme A
CH2
CHOH
CHOH
CHOH
CH2
O
O
P
�
O
O
O P O�
CH2
H
O
HH
N
NH2
N N
N
H
O H2�
4� 1�
3�
CH2 O
H
ONO
N
N
CH3
NH2
Riboflavin
Nicotinamide adenine dinucleotide (NAD�)
H
O
HH
N
N N
N
H
HO H
CH2 O
NH2
Flavin adenine dinucleotide (FAD)
H
O
HH
N
H
HO H
CH2 O
Nicotinamide
OP�O
O
O
O P O�
O
O
FIGURE 8–41 Some coenzymes containing adenosine. Theadenosine portion is shaded in light red. Coenzyme A (CoA) functions in acyl group transfer reactions; the acyl group (such asthe acetyl or acetoacetyl group) is attached to the CoA through athioester linkage to the �-mercaptoethylamine moiety. NAD� func-tions in hydride transfers, and FAD, the active form of vitamin B2
(riboflavin), in electron transfers. Another coenzyme incorporatingadenosine is 5�-deoxyadenosylcobalamin, the active form of vita-min B12 (see Box 17-2), which participates in intramoleculargroup transfers between adjacent carbons.

certainly not unique in the amount of potential bindingenergy it can contribute. The importance of adenosineprobably lies not so much in some special chemical char-acteristic as in the evolutionary advantage of using onecompound for multiple roles. Once ATP became the uni-versal source of chemical energy, systems developed tosynthesize ATP in greater abundance than the other nu-cleotides; because it is abundant, it becomes the logicalchoice for incorporation into a wide variety of struc-tures. The economy extends to protein structure. A sin-gle protein domain that binds adenosine can be used ina wide variety of enzymes. Such a domain, called anucleotide-binding fold, is found in many enzymesthat bind ATP and nucleotide cofactors.
Some Nucleotides Are Regulatory Molecules
Cells respond to their environment by taking cues fromhormones or other external chemical signals. The in-teraction of these extracellular chemical signals (“firstmessengers”) with receptors on the cell surface oftenleads to the production of second messengers insidethe cell, which in turn leads to adaptive changes in the cell interior (Chapter 12). Often, the second mes-senger is a nucleotide (Fig. 8–42). One of the most common is adenosine 3�,5�-cyclic monophosphate
(cyclic AMP, or cAMP), formed from ATP in a reac-tion catalyzed by adenylyl cyclase, an enzyme associ-ated with the inner face of the plasma membrane. CyclicAMP serves regulatory functions in virtually every celloutside the plant kingdom. Guanosine 3�,5�-cyclic mono-phosphate (cGMP) occurs in many cells and also hasregulatory functions.
Another regulatory nucleotide, ppGpp (Fig. 8–42),is produced in bacteria in response to a slowdown inprotein synthesis during amino acid starvation. This nu-cleotide inhibits the synthesis of the rRNA and tRNAmolecules (see Fig. 28–24) needed for protein synthe-sis, preventing the unnecessary production of nucleicacids.
SUMMARY 8.4 Other Functions of Nucleotides
■ ATP is the central carrier of chemical energy incells. The presence of an adenosine moiety in avariety of enzyme cofactors may be related tobinding-energy requirements.
■ Cyclic AMP, formed from ATP in a reactioncatalyzed by adenylyl cyclase, is a commonsecond messenger produced in response tohormones and other chemical signals.
Chapter 8 Nucleotides and Nucleic Acids302
FIGURE 8–42 Three regulatory nucleotides.
Key Terms
gene 273ribosomal RNA (rRNA) 273messenger RNA (mRNA) 273transfer RNA (tRNA) 273nucleotide 273nucleoside 273pyrimidine 273purine 273deoxyribonucleotides 274ribonucleotide 274phosphodiester linkage 277
Terms in bold are defined in the glossary.
5� end 2773� end 277oligonucleotide 278polynucleotide 278base pair 279major groove 282minor groove 282B-form DNA 284A-form DNA 284Z-form DNA 284palindrome 285
hairpin 285cruciform 285triplex DNA 286G tetraplex 287H-DNA 287monocistronic mRNA 287polycistronic mRNA 288mutation 293second messenger 302adenosine 3�,5�-cyclic monophos-
phate (cyclic AMP, cAMP) 302




























