Embed Size (px)
Citation preview

Eur. J. Biochem. 160,77 - 82 (1986) 0 FEBS 1986
Nucleotide sequence of the structural gene for dihydroorotase of Escherichia coli K12 Dan BACKSTROM, Rose-Marie SJOBERG and Lennart G. LUNDBERG Department of Biochemistry and Biophysics, Chalmers University of Technology, Goteborg
(Received April 30,1986) - EJB 86 0428
The nucleotide sequence of the dihydroorotase structural gene, pyrC, of Escherichia coli K12 has been determined. The DNA sequence predicts a polypeptide chain of 347 amino acid residues corresponding in size and composition to the previously purified dihydroorotase subunit. Nuclease S1 mapping indicated that transcription of pyrC is initiated around 40 base pairs upstream from the translational start, The transcriptional leader region contains a region of dyad symmetry, which allows a stable hairpin to be formed. This sequence may have regulatory functions since similar structures are found in other pyr genes. The nucleotide sequence also contains a 186-codon open reading frame in front of pyrC. Nuclease Bal31-deletion derivatives of pyrC plasmids indicate that this gene does not affect the expression of pyrC. The predicted polypeptide chain shows a putative signal sequence. Downstream from the structural gene a sequence similar to a rho-independent transcriptional terminator is found. This unknown gene may thus encode a membrane protein of unknown function.
Dihydroorotase is an enzyme involved in the pyrimidine nucleotide metabolism. The structural genes for enzymes taking part in this metabolism are scattered on the Escherichia coli chromosome. The expression of thepyr genes is controlled in a complex manner. Thus, pyrB, pyrE and pyrF appear to be controlled by a uridine nucleotide, while pyrC and pyrD are repressed primarly by a cytidine nucleotide [l]. Guanine nucleotides also appear to have effects on the level ofpyr gene activity [2,3]. Recently the primary structure of thepyrBZ[4- 71 and the pyrE operon [8,9] suggested an additional feature of regulation. The transcriptional regulation is thought to be modulated by a coupled transcriptional/translational model ,where the transcribing RNA polymerase is regulated by the supply of UTP in an attenuation mechanism [lo]. The codon usage of the leader peptide in this model strongly affects the pyrE expression [l 11. Trans-acting regulatory factors (re- pressors or activators) have also been suggested in the regula- tion of the pyrC gene [12, 131 but so far no protein factors have been isolated.
The structural gene for dihydroorotase, pyrC, maps at 23.4 minutes on the E. coli linkage map [14]. The transcription of pyrC is counter-clockwise on the E. coli genetic map [15]. The only genes mapped in the neighbourhood of the pyrC gene are rpmF and rimJ, both genes involved in ribosome assembly and modification [16]. The pyrC gene has been cloned on different plasmids [15]. The dihydroorotase enzyme has been purified to homogeneity by several groups [17 - 191 and its amino acid composition has been determined [19].
In this investigation we have determined the nucleotide sequence of the pyrC region to allow access to the amino
Correspondence to L. G. Lundberg, Institutionen for Biokemi och Biofysik, Chalmers Tekniska Hogskola, Fack, S-412 96 Goteborg, Sweden
Abbreviations. bp, base pairs of DNA; kb, lo3 base pairs in DNA; ORF, open reading frame.
Enzyme. Dihydroorotase or 4,5-~-dihydroorotate amidohydro- lase (EC 3.5.2.3).
acid sequence of dihydroorotase, a prerequisite for further enzymological studies of dihydroorotase, and to see if the DNA sequence may shed some light on how the pyrC gene is regulated.
MATERIALS AND METHODS
Bacterial strains and plasmids
used in this study are also listed in Table 1. All E. coli K12 strains are listed in Table 1. Plasmid vectors
Growth media
The growth medium was M9 minimal medium supple- mented with the required metabolites and glycerol (0.4%) as the carbon source [20] or L-broth medium [21].
D N A techniques
The methods used for isolation and restriction endonu- clease digestions have been described previously [22]. DNA sequence determination was employed using the method of Maxam and Gilbert [23] and the method of Sanger et al. [24], as modified by Biggin et al. [25].
Ba131 treatment
Plasmid pCLL4 (20 pg) was digested with SalI, diluted fivefold and treated with 5 units of Ba131 exactly as described by Maarse et al. [26]. After ethanol precipitation DNA samples were digested with EcoRI and a small part analyzed by agaraose electrophoresis (1 -2% w/v). The remainder was extracted with phenol and ethanol-precipitated. About 10% of this DNA was ligated into M13mp8 (restricted with EcoRI and SmaI). White plaques were scored and insert sizes were determined by digestion with EcoRI and Sun followed by gel electrophoresis.

78
Table 1 . E. coli strains andplasmids
Designation Bacterium Plasmid Relevant genotype Source or reference
s01539 S01263 pEClO AP',PYrC + ~ 5 1 S01606 S01263 pEC135 Ap'mrC + [I51 LL102 RRIAMIS pCLL2 Ap',pyrC + a this study LL103 RRIAMIS pCLL3 Ap',pyrC + a this study LL104 RRIAMIS pCLL4 Ap',pyrC + a this study LL112 S01263 pCLL2 Ap',pyrC + a this study LL113 S01263 pCLL3 AP',PYrC + a this study LL114 S01263 pCLL4 Ap',pyrC + a this study S01263 - - RRIAM15 - - PYrC WI
l a d M 1 5 1291
a Mutant dihydroorotase monomer expressed.
Digestion with S1 nuclease
Total cellular RNA was extracted by hot phenol from exponentially growing cells of S01263 harbouring a pyrC plasmid (pEC10, pEC135 or pCLL4) as described by Valentin- Hansen et al. [27]. A 32P-labeled fragment was hybridized to cellular RNA, treated for various times and amounts of S1 nuclease (Boehringer) and analyzed by electrophoresis on a standard 8% sequencing gel as described by Poulsen et al. [9].
RESULTS
Subcloning ojthe pyrC gene region
The plasmids pEClO and pECl35 carry the structural gene for dihydroorotase, pyrC, as earlier reported [15] (see Fig. 1). In order to sequence the pyre gene more easily we subcloned a 1.8 x lo3 base-pair Ban-HincII fragment from pEC13.5 into both plasmid pUC8 and pUC9 [28] using SmaI digestion of the vector. The host for these transformations was RRIdM15 I291 and the clones were scored as white colonies on X-Gal/ IPTG indicator plates [20]. The resulting vectors, pCLL2 and pCLL4, are shown in Fig. 1. A third vector was also constructed in this cloning experiment having the small (0.2 kb) Ban-HincII fragment from plasmid pEC135 inserted as an extra fragment. This vector is called pCLL3. The purified plasmids were also transformed into strain S01263@yrCp) and the resulting clones were tested for growth on minimal plates without supplementation of uracil. All three plasmid clones were positive in this test, indicating that the DNA cloned in these vectors contained at least most of the structural gene for dihydroorotase.
Isolation of the pyrC gene region
Our starting material for the nucleotide sequencing of the pyrC gene was the four plasmids presented in Fig. 1. From these plasmids the following DNA fragments were prepared and later used for subcutting with different restriction endo- nucleases for mapping the pyrC gene region, and also for labeling in DNA sequence determinations: from pEClO a 1.6- kb PvuII-BstEII fragment, a 2.0-kb HincII fragment, a 1.8-kb BssHII fragment, a 1.1-kb NdeI-NruI fragment, a 0.9-kb BssHII-BstEII fragment; from pEC135 a 1.4-kb AvaII frag- ment. The following restriction sites were directly used for labeling and sequencing: BssHII, BstEII and also the SalI site in the multilinker region of pCLL4. For sequencing some gaps in the sequence we also used Bul31-generated DNA fragments
obtained by deleting DNA sequences from the SuR site in pCLL4 and clone (after restriction with EcoRI) into an Eco- RI-SmuI-digested M13mp8 vector. The clone bank thus obtained was sequenced using the M13 universal sequencing primer. Besides the Bal31-generated clones for sequencing with the dideoxy-DNA method some fragments were directly cloned (in both directions) into a appropriately digested M13mp8: a 0.7-kb BamHI fragment and a 0.8-kb TaqI frag- ment from pCLL4. The 1.6-kb PvuII-BstEII fragment from pEClO was also cloned into SmuI-digested M13mp8, so that using the universal sequencing primer the sequence was read from the PvuII site towards the Bs~Ell site.
Nucleotide sequence
Since a BamHI site in the pyrC gene region had been found to be important for expression of dihydroorotase activity [15] we concentrated on sequencing the DNA region around the BumHI site. Fig. 2 presents the sequencing strategy and a restriction endonuclease map covering the pyrC gene region. The nucleotide sequence is presented in Fig. 3, where the numbering of the DNA sequence starts from the BalI site used for cloning and extends 2046 base pairs (bp) (to the PvuII site used for cloning). The nucleotide sequence contains two open reading frames downstream from the Ban site. One starts with an ATG at position 881 and ends with a TAA at position 1925. The corresponding polypeptide chain with the amino acid sequence indicated in Fig. 3 has a calculated M, of 38 773. The amino acid composition as well as the N-terminal sequence corresponds very closely to the one determined for purified dihydroorotase [19]. The other open reading frame starts with an ATG at position 21 5 and ends with TAA at position 773. Assigned regions of interest have been listed in Table 2.
Mapping the transcriptional start of pyrC Nuclease S1 mapping of the pyrC gene region with RNA
preparations from strain S01263, harbouring different pyrC plasmids (pEC10, pEC135 and pCLL4) and hybridized to different DNA fragments, gave some interesting results. The probes used were a RsuI fragment (positions 1079-581), a BstNII fragment (positions 895-743) and also a 1.6-kb BurnHI fragment from plasmid pEC163 [15] labeled in posi- tion 1135 in the presented DNA sequence. First, the protected bands with RNA preparations from pCLL4 were always weaker than the same bands from the other plasmids in- dicating that the mutant mRNA transcribed in th s case is unstable. Secondly, there were always two areas of protected

79
AvaI
HincII
A v a I l
BamHl \\\SalI/HincII
SalI/HincII
EcoRI Hincll
pEC135 Pstl
EcoRV
AvaIl
AvaII
BssHII EcoRV
BamHl
4.5kb BstEII Nrul EcoRV
EcoRI
Fig. 1. Restriction endonucleuse maps ofplasmids utilized. Plasmids pEClO and pEC135 have been described [15]. The E. coli DNA in plasmid pEC135 ends at nucleotide position 1936 in the pyrC DNA sequence. The construction of pCLL2 and pCLL4 is described in the text. The different origins of plasmid DNA are indicated. The positions of various genes are shown and the directions of transcription have been indicated by arrows
Hae Bss
Fig. 2. Sequencing strulegy for the pyrC region. Arrows indicate sequenced fragments and the extent of sequence information. Restriction endonuclease sites unique to the region have been indicated. For a complete map see the DNA sequence listed in Fig. 3. The pyrC gene is indicated as a black box
Table 2. Assigned regions of' interest in the nucleotide sequence determined
Gene Assigned feature Position Sequence ~ ~~
PYrC promoter: -44 region Pribnow box transcription start leader transcript: stem-loop structures Shine-Dalgarno structural gene proposed repressor site
open reading frame transcription termination structure
Predicted unknown gene Shine-Dalgarno
798-807 831 -838 840 - 841 843 - 867 873 - 877 881 - 1927 838 - 856 205 - 209 215-775 781 - 806
~~
TTTATTTTTC TATCCTT see Fig. 3 see Fig. 3 AGAGA see Fig. 3 see Fig. 3 GAGGA see Fig. 3 see Fig. 3

80
bands on the gels, in contrast to data from S1 nuclease mapping of Salmonella typhimurum pyrC [30]. The upper area (data not shown) corresponds to a transcriptional start around position 808. Since the sequence in this region is (A + T)-rich, the bands seen here can be artefacts due to S1 nuclease cutting of (A + T)-rich sequences [27]. It should be pointed out that this region is situated around 40 bp upstream of the proposed transcriptional start for pyrC (see below). The main transcriptional start for pyrC was identified in S1 nuclease mapping experiments to be positions 840 - 841 with minor protected bands appearing at positions 839 and 842. Since most E. coli genes have a purine base in the first ribonucleotide at transcriptional start sites, position 841 seems to be the most likely one and also corresponds to the mRNA start identified in S. typhimurum pyrC [30].
DISCUSSION
We have determined the nucleotide sequence of the pyrC gene region. Two long open reading frames are revealed in the sequence. The second has been identified as the structural gene for dihydroorotase, pyrC, by comparing the derived amino acid sequence with the composition of the purified dihydroorotase subunit [19]. The N-terminal sequence of dihydroorotase (the first eleven amino acids) was also deter- mined in this study [19] and these corresponds exactly to the sequence derived from the DNA sequence except that the native protein does not have the N-terminal formylmethio- nine. Comparison (from the DNA sequence predicted) with the amino acid sequence of S. typhimurum dihydroorotase [30] shows a >88% homology where 306 out of 347 amino acids are identical. On the nucleotide level the homology is around 11%. The codon usage in the pyrC gene resemble these of weakly expressed genes [31].
The constructed plasmid vectors pCLL2, pCLL3 and pCLLA have the DNA sequence in the structural gene for pyrC changed at position 1802, where pUC vector sequences [32] have been inserted. The mutant protein, expressed from strains carrying these vectors, has only about 1% of the ex- pected dihydroorotase activity [19].
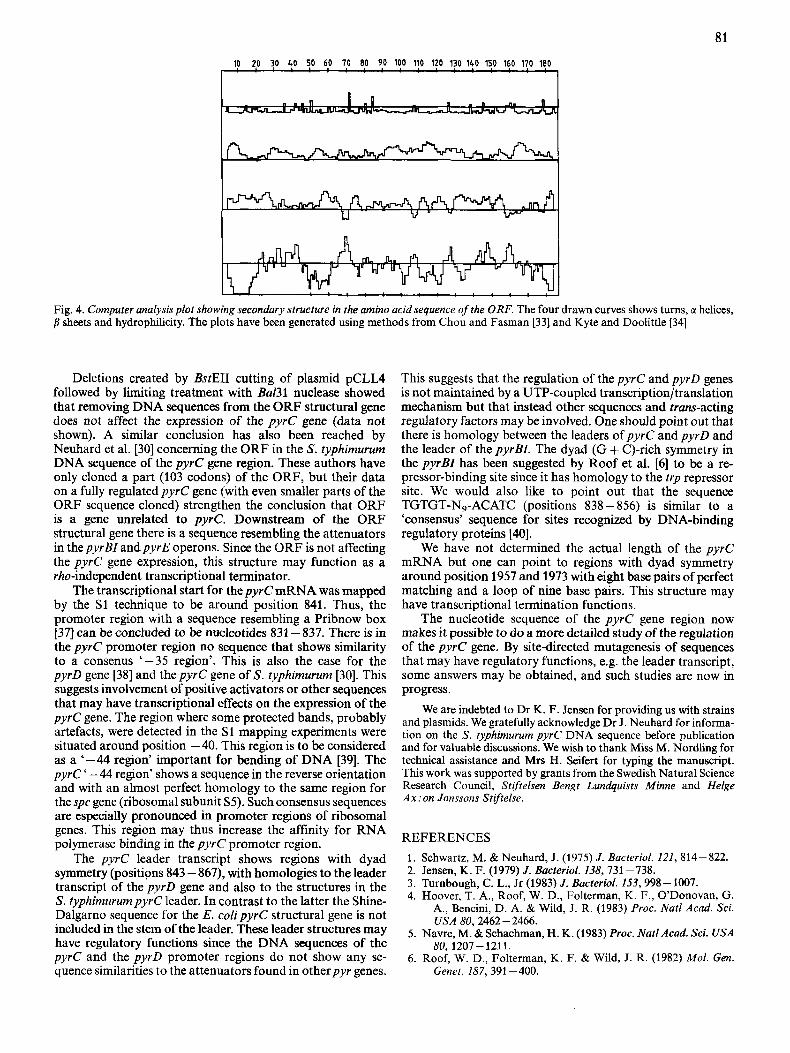
The first open reading frame (ORF) encodes a 186-amino- acid polypeptide of unknown function. Secondary-structure predictions by computer analysis [33] and a hydrophilicity plot [34] Fig. 4, show some remarkable features. First, there is an extensive hydrophobic region in the N-terminal part of the protein. Analysis by the method of von Hejne I351 suggests that there is a signal sequence of 21 amino acids very similar in sequence to the Ipp protein signal sequence [36]. It can not be concluded from the amino acid sequence that the signal sequence is cleaved. There are, in addition, other domains of hydrophobicity in the predicted protein sequence suggesting membrane-spanning or binding parts of the protein (see Fig. 4). Minicell and maxicell experiments withpyrC plasmids [15] (A. L. Sivertsen, personal communication) show three protein bands of size 16- 19 kDa that apparently are coded by the ORF DNA sequence region. These polypeptides may correspond to different processed ORF polypeptides. The 186-amino-acid open reading frame may thus encode an un- known membrane protein.
Fig. 3. DNA sequence of the pyrC gene region. The sequence is written in 5'+3' direction of the non-coding strand. The deduced amino acid sequence for the dihydroorotase monomer and the ORF gene product are shown below. Special regions of interest are listed in Table 2
81
10 2,O !O $0 !O 60 70 80 90 100 110 120 130 140 150 160 170 180
I " ' - . ! ' - . ' 1
Fig. 4. Computer analysis plot showing secondary structure in the amino acid sequence of the ORF. The four drawn curves shows turns, G( helices, p sheets and hydrophilicity. The plots have been generated using methods from Chou and Fasman [33] and Kyte and Doolittle [34]
Deletions created by BstEII cutting of plasmid pCLL4 followed by limiting treatment with Ba131 nuclease showed that removing DNA sequences from the ORF structural gene does not affect the expression of the pyrC gene (data not shown). A similar conclusion has also been reached by Neuhard et al. [30] concerning the ORF in the S. typhimurum DNA sequence of the pyrC gene region. These authors have only cloned a part (103 codons) of the ORF, but their data on a fully regulated pyrC gene (with even smaller parts of the ORF sequence cloned) strengthen the conclusion that ORF is a gene unrelated to pyrC. Downstream of the ORF structural gene there is a sequence resembling the attenuators in the pyrBZ andpyrE operons. Since the ORF is not affecting the pyrC gene expression, this structure may function as a rho-independent transcriptional terminator.
The transcriptional start for the pyrC mRNA was mapped by the S1 technique to be around position 841. Thus, the promoter region with a sequence resembling a Pribnow box [37] can be concluded to be nucleotides 831 - 837. There is in the pyrC promoter region no sequence that shows similarity to a consenus '-35 region'. This is also the case for the pyrD gene [38] and thepyrC gene of S. typhimurum [30]. This suggests involvement of positive activators or other sequences that may have transcriptional effects on the expression of the pyrC gene. The region where some protected bands, probably artefacts, were detected in the S1 mapping experiments were situated around position -40. This region is to be considered as a '-44 region' important for bending of DNA [39]. The pyrC ' -44 region' shows a sequence in the reverse orientation and with an almost perfect homology to the same region for the spc gene (ribosomal subunit S5). Such consensus sequences are especially pronounced in promoter regions of ribosomal genes. This region may thus increase the affinity for RNA polymerase binding in the pyrC promoter region.
The pyrC leader transcript shows regions with dyad symmetry (positions 843 - 867), with homologies to the leader transcript of the pyrD gene and also to the structures in the S. typhimurumpyrC leader. In contrast to the latter the Shine- Dalgarno sequence for the E. colipyrC structural gene is not included in the stem of the leader. These leader structures may have regulatory functions since the DNA sequences of the pyrC and the pyrD promoter regions do not show any se- quence similarities to the attenuators found in otherpyr genes.
This suggests that the regulation of the pyrC and pyrD genes is not maintained by a UTP-coupled transcription/translation mechanism but that instead other sequences and trans-acting regulatory factors may be involved. One should point out that there is homology between the leaders of pyrC and pyrD and the leader of the pyrBI. The dyad (G + C)-rich symmetry in the pyrBZ has been suggested by Roof et al. [6] to be a re- pressor-binding site since it has homology to the trp repressor site. We would also like to point out that the sequence TGTGT-N9-ACATC (positions 838 - 856) is similar to a 'consensus' sequence for sites recognized by DNA-binding regulatory proteins [40].
We have not determined the actual length of the pyrC mRNA but one can point to regions with dyad symmetry around position 1957 and 1973 with eight base pairs of perfect matching and a loop of nine base pairs. This structure may have transcriptional termination functions.
The nucleotide sequence of the p y r e gene region now makes it possible to do a more detailed study of the regulation of the pyrC gene. By site-directed mutagenesis of sequences that may have regulatory functions, e.g. the leader transcript, some answers may be obtained, and such studies are now in progress.
We are indebted to Dr K. F. Jensen for providing us with strains and plasmids. We gratefully acknowledge Dr J . Neuhard for informa- tion on the S. typhimurum pyrC DNA sequence before publication and for valuable discussions. We wish to thank Miss M. Nordling for technical assistance and Mrs H. Seifert for typing the manuscript. This work was supported by grants from the Swedish Natural Science Research Council, Stiftelsen Bengt Lundquists Minne and Helge Ax :on Jonssons Stifelse.
REFERENCES 1. Schwartz, M. & Neuhard, J . (1975) J . Bacteriol. 121, 814-822. 2. Jensen, K. F. (1979) J . Bacteriol. 138, 731 -738. 3. Turnbough, C. L., Jr (1983) J. BucterioI. 153,998-1007. 4. Hoover, T. A., Roof, W. D., Folterman, K. F., O'Donovan, G.
A,, Bencini, D. A. &Wild, J. R. (1983) Proc. Natl Acad. Sci.
5. Navre, M. & Schachman, H. K. (1983) Proc. Nut1 Acad. Sci. USA
6. Roof, W. D., Folterman, K. F. & Wild, J. R. (1982) Mol. Gen.
USA 80,2462 - 2466.
80, 3207-1211.
Genet. 187, 391 -400.

7. Turnbough, C. L., Jr, Hicks, H. L. & Donahue, J. P. (1983) Proc. Natl Acad. Sci. USA 80, 368 - 372.
8. Poulsen, P., Jensen, K. F., Valentin-Hansen, P., Carlsson, P. & Lundberg, L. G. (1983) Eur. J. Biochem. 135,223-229.
9. Poulsen, P., Bonekamp, F. & Jensen, K. F. (1984) EMBO J. 3,
10. Bonekamp, F., Clemmesen, K., Karlstrom, 0. & Jensen, K. F.
11. Bonekamp, F., Andersen, H. D., Christensen, T. & Jensen, K. F.
12. Bussey, L. B. & Ingraham, J. L. (1982) J. Bucteriol. 151, 144-
13. Nowlan, S. F. & Kantrowitz, E. R. (1983) Mol. Gen. Genet. 192,
14. Bdchman, B. J. (1983) Microhiol. Rev. 47, 180-230. 15. Jensen, K. F., Larsen, J. N., Schack, L. & Sivertsen, A. (1984)
16. Janda, I., Kitakawa, M. & Isono, K. (1985) MoZ. Gen. Genet. 201,
17. Sander, E. G. & Heeb, M. J. (1971) Biochim. Biophys. Acta 227,
18. Washabaugh, M. W. & Collins, K. D. (1984) J. Biol. Chem. 259,
19. Unpublished results. 20. Miller, J. H. (1972) Experiments in moleculargenetics, Cold Spring
21. Bertani, G. (1951) J. Bacteriol. 62, 293-300. 22. Lundberg, L. G., Thoresson, H.-O., Karlstrom, 0. H. & Nyman,
1783 - 1790.
(1984) EMBO J . 3,2857-2861.
(1985) Nucleic Acids Res. 13,4113-4123.
152.
264- 271.
Eur. J . Biochem. 140, 343 - 352.
433-436.
442 - 452.
3293 - 3298.
Harbor Laboratory Press, NY.
P. 0. (1983) EMBO J . 2,967-971.
23. Maxam, A. & Gilbert, W. (1977) Proc. Natl Acad. Sci. USA 74,
24. Sanger, F., Nicklen, S. & Coulson, A. R. (1977) Proc. Natl Acad.
25. Biggin, M. D., Gibson, T. J. & Hong, G. F. (1983) Proc. Natl
26. Maarse, A. C., Van Loon, A. P. G. M., Riezman, H., Gregor, I.,
27. Valentin-Hansen, P., Aiba, H. & Schumperli, D. (1982) EMBO
28. Viera, J. & Messing, J. (1982) Gene 19, 259-268. 29. Rulher, U. (1982) Nucleic Acids Res. 10, 5765-5772. 30. Neuhard, J., Kelln, R. A. & Stauning, E. (1986) Eur. J . Biochem.
31. Grosjedn, H. & Fiers, W. (1982) Gene 18, 199-209. 32. Yanisch-Perron, C., Viera, J. & Messing, J. (1985) Gene 33, 103-
33. Chou, P. Y. & Fasman, G. I). (1978) Annu. Rev. Biochem. 47,
34. Kyte, J. & Doolittle, R. F. (1982) J. Mol. Biol. 157, 105-132. 35. Von Hejne, G. (1983) Eur. J . Biochem. 133,17-21. 36. Nakamura, K. & Tnouye, M. (1979) Cell 18,1109-1117. 37. Rosenberg, M. & Court, D. (1979) Annu. Rev. Genet. 13, 319-
38. Larsen, J. N. & Jensen, K. F. (1985) Eur. J . Biochem. 151, 59-
39. Galas, D. J., Eggert, M. & Waterman, M. S. (1985) J. Mol. Biol.
40. Gicquel-Sanzey, B. & Cossart, P. (1 982) EMBO J. I, 591 - 595.
560 - 564.
Sci. USA 74, 5463 - 5467.
Acad. Sci. USA 80,3963 - 3965.
Schatz, G. & Grivell, L. A. (1984) EMBO J . 3, 2831 -2837.
J. I, 317-322.
157,335 - 342.
109.
251 -276.
353.
65.
186,117-128.