Embed Size (px)
Citation preview

November 2005 Distributed systems: shared data 1
Distributed Systems:
Shared Data

November 2005 Distributed systems: shared data 2
Overview of chapters
• Introduction• Co-ordination models and languages• General services• Distributed algorithms• Shared data
– Ch 13 Transactions and concurrency control, 13.1-13.4
– Ch 14 Distributed transactions
– Ch 15 Replication

November 2005 Distributed systems: shared data 3
Overview• Transactions and locks
• Distributed transactions
• Replication

November 2005 Distributed systems: shared data 4
Overview• Transactions
• Nested transactions
• Locks
• Distributed transactions
• Replication
Known material!
November 2005 Distributed systems: shared data 5
Transactions: Introduction
• Environment– data partitioned over different servers on
different systems– sequence of operations as individual unit– long-lived data at servers (cfr. Databases)
• transactions = approach to achieve consistency of data in a distributed environment
November 2005 Distributed systems: shared data 6
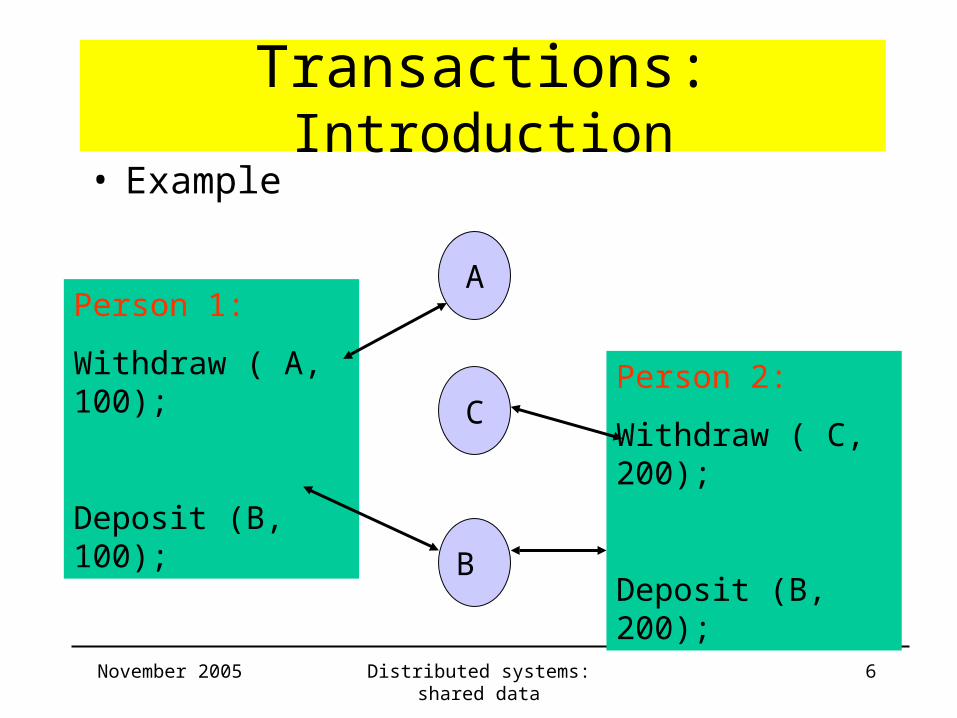
Transactions: Introduction• Example
Person 1:
Withdraw ( A, 100);
Deposit (B, 100);
Person 2:
Withdraw ( C, 200);
Deposit (B, 200);
A
C
B

November 2005 Distributed systems: shared data 7
Transactions: Introduction• Critical section
– group of instructions indivisible block wrt other cs
– short duration
• atomic operation (within a server)– operation is free of interference from operations being
performed on behalf of other (concurrent) clients
– concurrency in server multiple threads
– atomic operation <> critical section
• transaction

November 2005 Distributed systems: shared data 8
Transactions: Introduction• Critical section• atomic operation• transaction
– group of different operations + properties
– single transaction may contain operations on different servers
– possibly long duration
ACID properties

November 2005 Distributed systems: shared data 9
Transactions: ACID• Properties concerning the sequence of operations
that read or modify shared data:
A tomicity
C onsistency
I solation
D urability

November 2005 Distributed systems: shared data 10
Transactions: ACID• Atomicity or the “all-or-nothing” property
– a transaction
• commits = completes successfully or
• aborts = has no effect at all
– the effect of a committed transaction
• is guaranteed to persist
• can be made visible to other transactions
– transaction aborts can be initiated by
• the system (e.g. when a node fails) or
• a user issuing an abort command

November 2005 Distributed systems: shared data 11
Transactions: ACID• Consistency
– a transaction moves data from one consistent state to another
• Isolation– no interference from other transactions
– intermediate effects invisible to other transactions
The isolation property has 2 parts:
– serializability: running concurrent transactions has the same effect as some serial ordering of the transactions
– Failure isolation: a transaction cannot see the uncommitted effects of another transaction

November 2005 Distributed systems: shared data 12
Transactions: ACID
• Durability– once a transaction commits, the effects of the
transaction are preserved despite subsequent failures
November 2005 Distributed systems: shared data 13
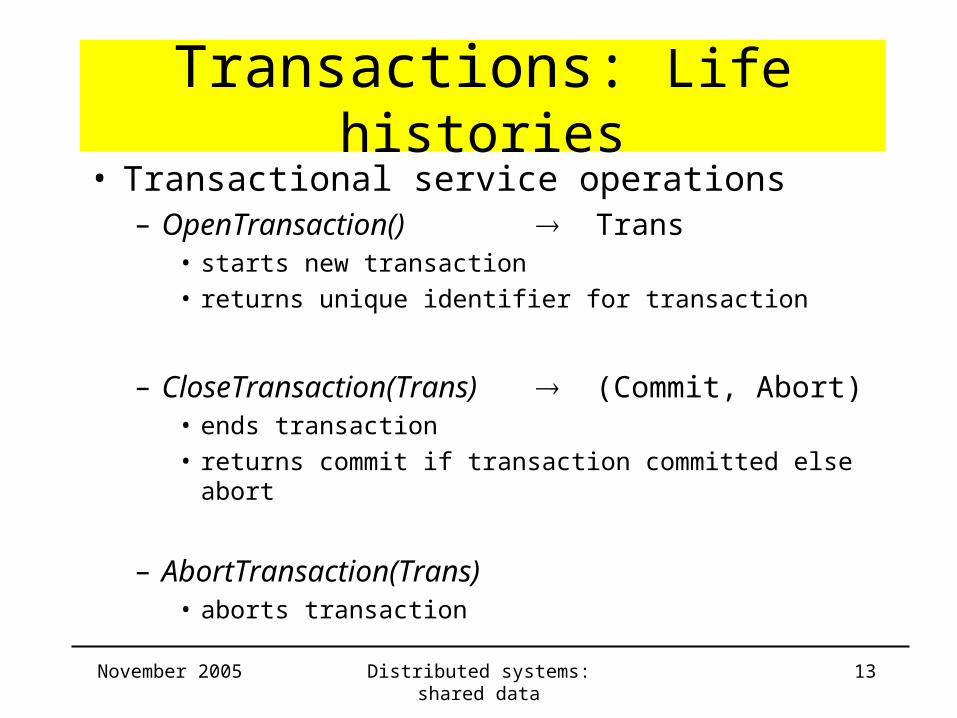
Transactions: Life histories• Transactional service operations
– OpenTransaction() Trans• starts new transaction
• returns unique identifier for transaction
– CloseTransaction(Trans) (Commit, Abort)• ends transaction
• returns commit if transaction committed else abort
– AbortTransaction(Trans)• aborts transaction
November 2005 Distributed systems: shared data 14
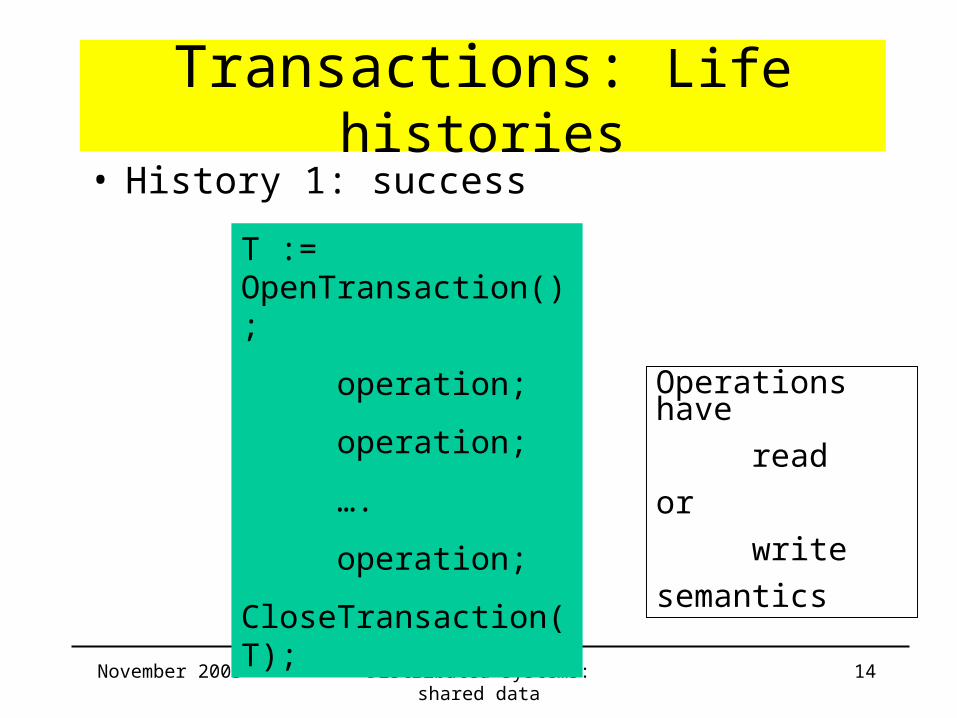
Transactions: Life histories• History 1: success
T := OpenTransaction();
operation;
operation;
….
operation;
CloseTransaction(T);
Operations have
read
or
write
semantics

November 2005 Distributed systems: shared data 15
Transactions: Life histories• History 2: abort by client
T := OpenTransaction();
operation;
operation;
….
operation;
AbortTransaction(T);
November 2005 Distributed systems: shared data 16
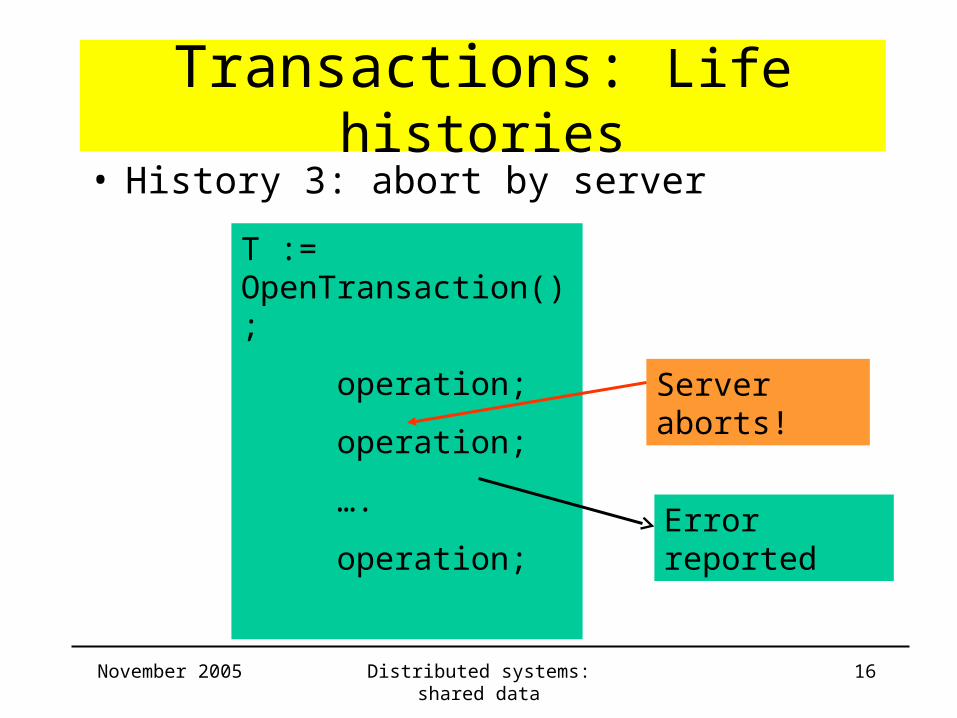
Transactions: Life histories• History 3: abort by server
T := OpenTransaction();
operation;
operation;
….
operation;
Server aborts!
Error reported

November 2005 Distributed systems: shared data 17
Transactions: Concurrency• Illustration of well known problems:
– the lost update problem
– inconsistent retrievals
• operations used + implementations
– Withdraw(A, n)
– Deposit(A, n)
b := A.read();
A.write( b - n);
b := A.read();
A.write( b + n);

November 2005 Distributed systems: shared data 18
Transactions: Concurrency• The lost update problem:
Transaction T
Withdraw(A,4);
Deposit(B,4);
Transaction U
Withdraw(C,3);
Deposit(B,3);
Interleaved execution of operations on B ?

November 2005 Distributed systems: shared data 19
Transactions: Concurrency• The lost update problem:
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4);A: 100
B: 200
C: 300

November 2005 Distributed systems: shared data 20
Transactions: Concurrency• The lost update problem:
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4); bu := C.read();
C.write(bu-3);
A: 96
B: 200
C: 300

November 2005 Distributed systems: shared data 21
Transactions: Concurrency• The lost update problem:
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4); bu := C.read();
C.write(bu-3);
A: 96
B: 200
C: 297
bt := B.read();
bt=200 bu := B.read();
B.write(bu+3);

November 2005 Distributed systems: shared data 22
Transactions: Concurrency• The lost update problem:
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4); bu := C.read();
C.write(bu-3);
A: 96
B: 203
C: 297
bt := B.read();
bt=200 bu := B.read();
B.write(bu+3);B.write(bt+4);

November 2005 Distributed systems: shared data 23
Transactions: Concurrency• The lost update problem:
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4); bu := C.read();
C.write(bu-3);
A: 96
B: 204
C: 297
bt := B.read();
bt=200 bu := B.read();
B.write(bu+3);B.write(bt+4);
Correct B = 207!!
November 2005 Distributed systems: shared data 24
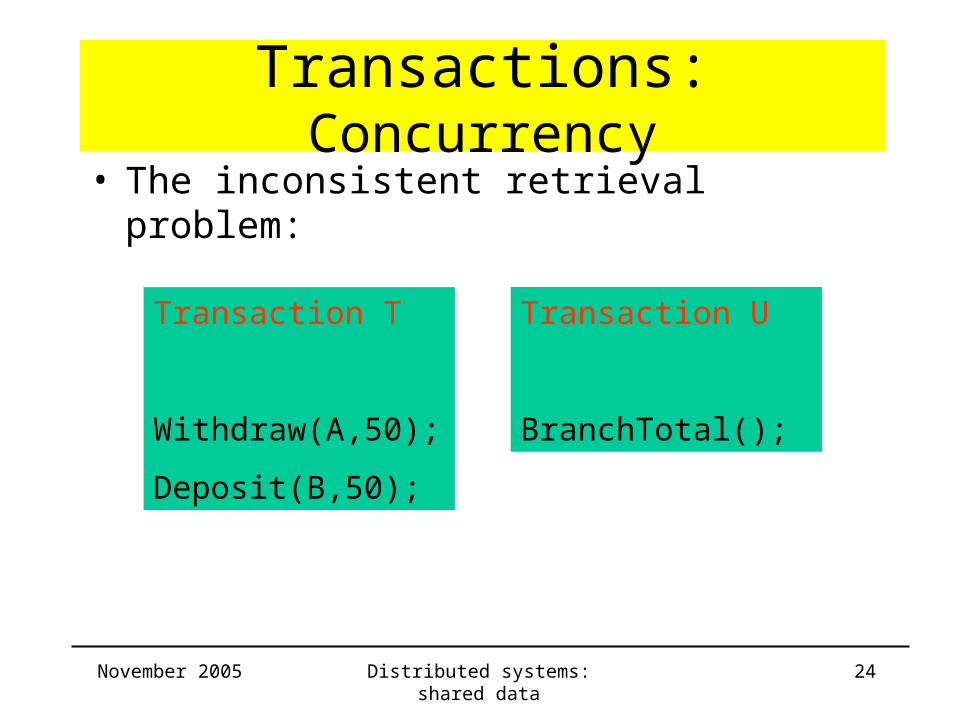
Transactions: Concurrency• The inconsistent retrieval problem:
Transaction T
Withdraw(A,50);
Deposit(B,50);
Transaction U
BranchTotal();
November 2005 Distributed systems: shared data 25
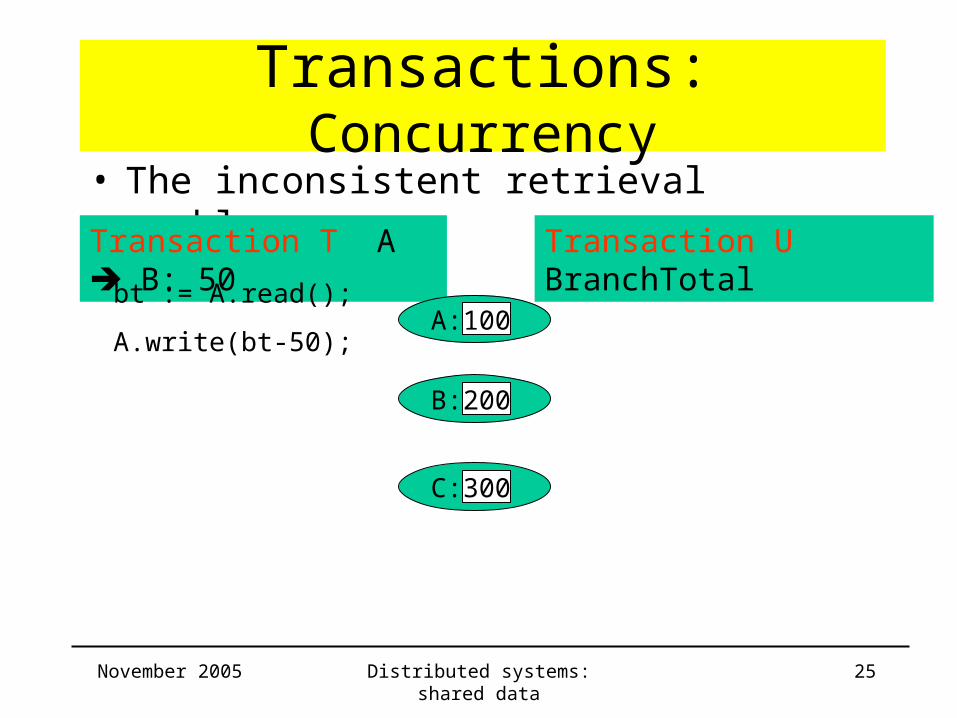
Transactions: Concurrency• The inconsistent retrieval problem :
Transaction T A B: 50 Transaction U BranchTotal
bt := A.read();
A.write(bt-50);A: 100
B: 200
C: 300
November 2005 Distributed systems: shared data 26
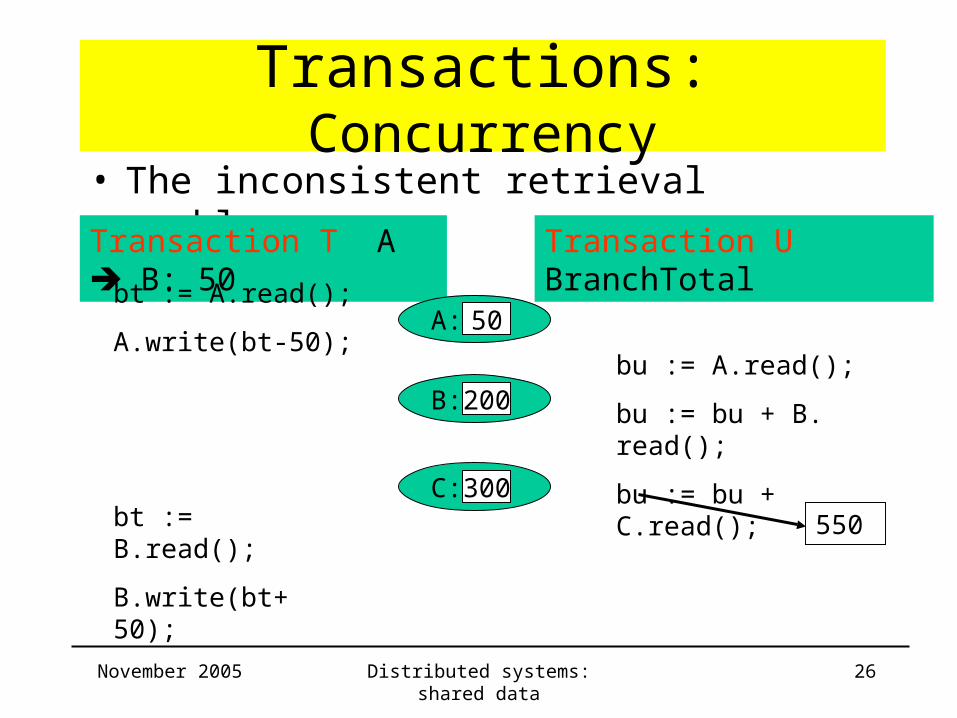
Transactions: Concurrency• The inconsistent retrieval problem :
Transaction T A B: 50 Transaction U BranchTotal
bt := A.read();
A.write(bt-50);A: 50
B: 200
C: 300
bu := A.read();
bu := bu + B. read();
bu := bu + C.read();
550bt := B.read();
B.write(bt+50);
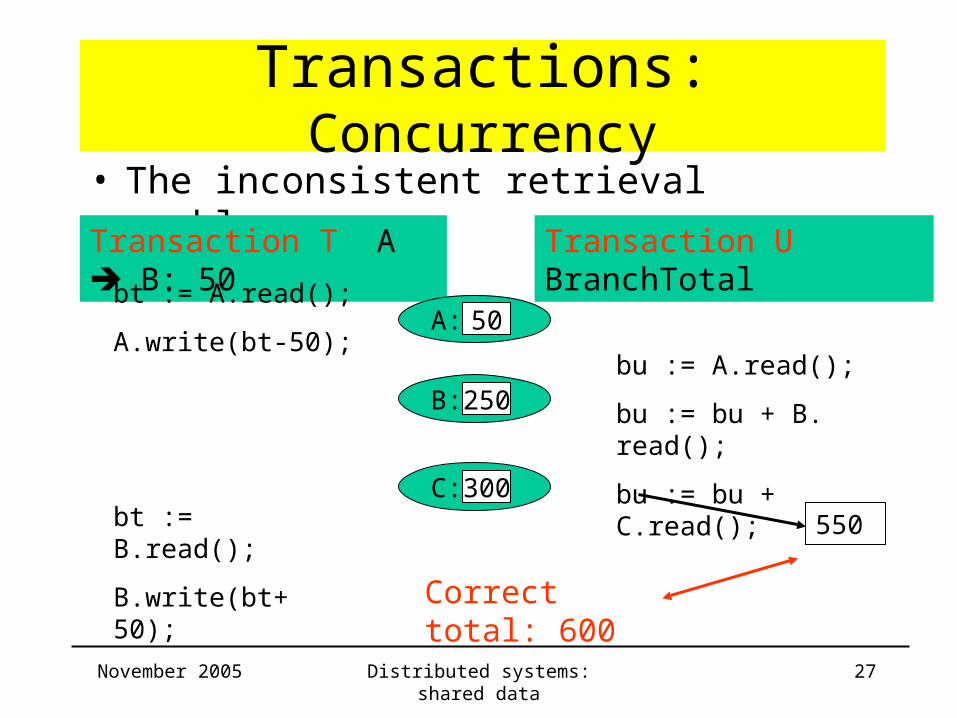
November 2005 Distributed systems: shared data 27
Transactions: Concurrency• The inconsistent retrieval problem:
Transaction T A B: 50 Transaction U BranchTotal
bt := A.read();
A.write(bt-50);A: 50
B: 250
C: 300
bu := A.read();
bu := bu + B. read();
bu := bu + C.read();
550bt := B.read();
B.write(bt+50);Correct total: 600

November 2005 Distributed systems: shared data 28
Transactions: Concurrency• Illustration of well known problems:
– the lost update problem
– inconsistent retrievals
• elements of solution– execute all transactions serially?
• No concurrency unacceptable
– execute transactions in such a way that overall execution is equivalent with some serial execution
• sufficient? Yes
• how? Concurrency control

November 2005 Distributed systems: shared data 29
Transactions: Concurrency• The lost update problem: serially equivalent interleaving
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4);A: 100
B: 200
C: 300

November 2005 Distributed systems: shared data 30
Transactions: Concurrency• The lost update problem: serially equivalent interleaving
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4); bu := C.read();
C.write(bu-3);
A: 96
B: 200
C: 300

November 2005 Distributed systems: shared data 31
Transactions: Concurrency• The lost update problem: serially equivalent interleaving
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4); bu := C.read();
C.write(bu-3);
A: 96
B: 200
C: 297
bt := B.read();
B.write(bt+4);

November 2005 Distributed systems: shared data 32
Transactions: Concurrency• The lost update problem: serially equivalent interleaving
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4); bu := C.read();
C.write(bu-3);
A: 96
B: 204
C: 297
bt := B.read();
B.write(bt+4); bu := B.read();
B.write(bu+3);

November 2005 Distributed systems: shared data 33
Transactions: Concurrency• The lost update problem: serially equivalent interleaving
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
A.write(bt-4); bu := C.read();
C.write(bu-3);
A: 96
B: 207
C: 297
bt := B.read();
B.write(bt+4); bu := B.read();
B.write(bu+3);

November 2005 Distributed systems: shared data 34
Transactions: Recovery• Illustration of well known problems:
– a dirty read
– premature write
• operations used + implementations
– Withdraw(A, n)
– Deposit(A, n)
b := A.read();
A.write( b - n);
b := A.read();
A.write( b + n);
November 2005 Distributed systems: shared data 35
Transactions: Recovery• A dirty read problem:
Transaction T
Deposit(A,4);
Transaction U
Deposit(A,3);
Interleaved execution and abort ?
November 2005 Distributed systems: shared data 36
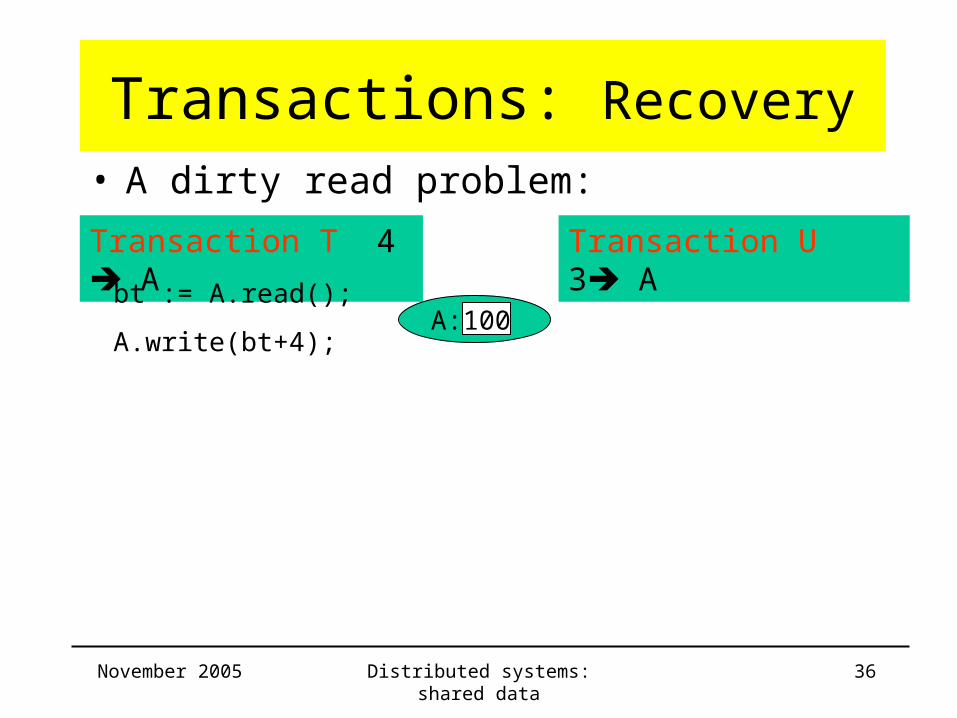
Transactions: Recovery• A dirty read problem:
Transaction T 4 A Transaction U 3 A
bt := A.read();
A.write(bt+4);A: 100
November 2005 Distributed systems: shared data 37
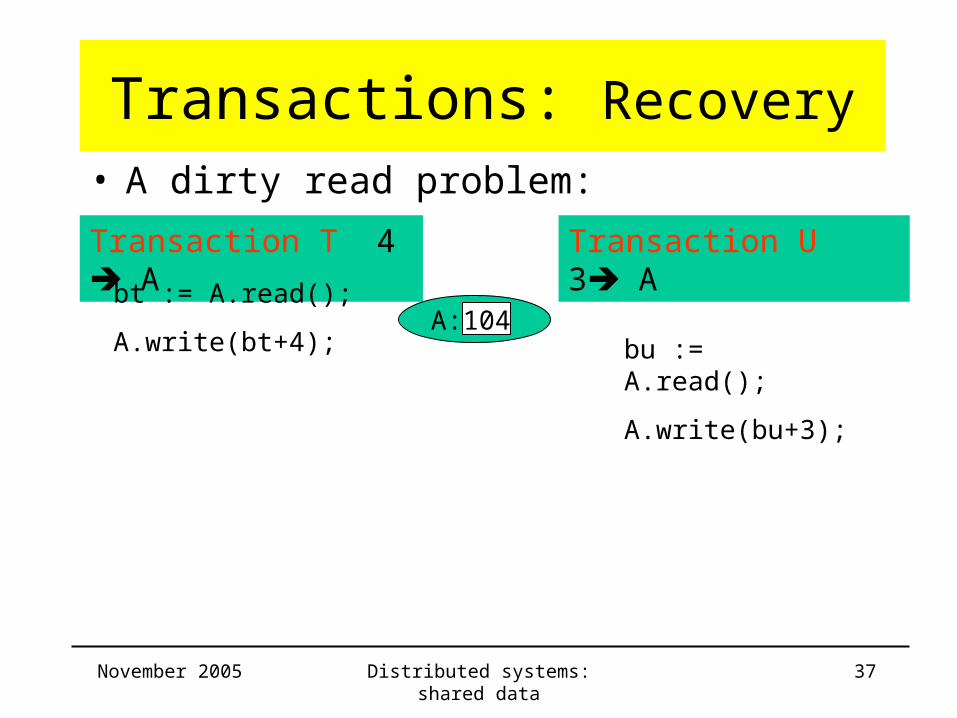
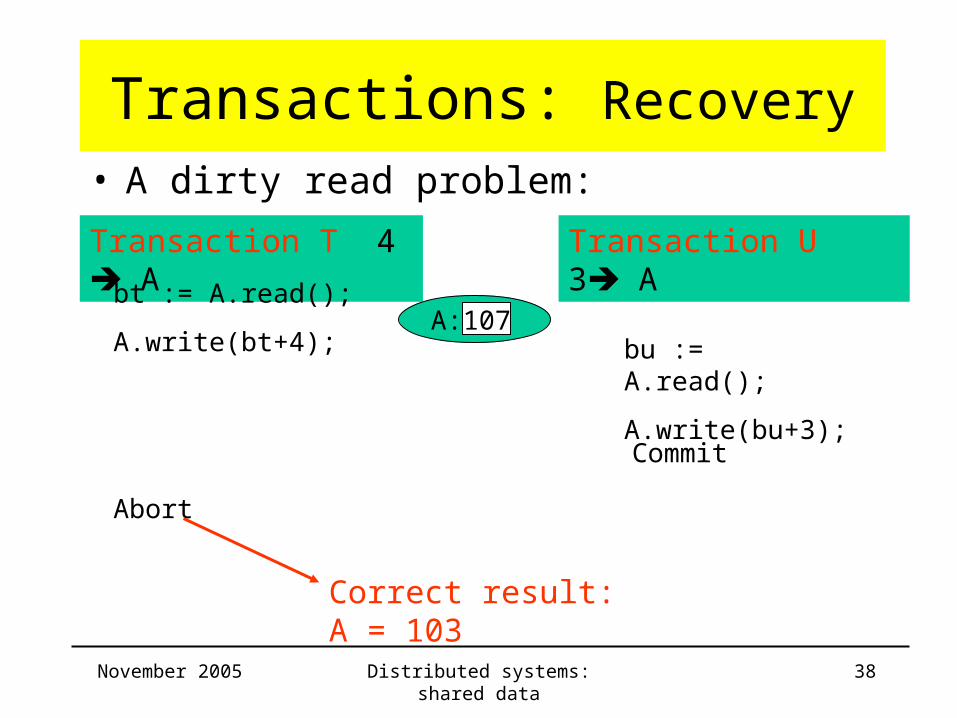
Transactions: Recovery• A dirty read problem:
Transaction T 4 A Transaction U 3 A
bt := A.read();
A.write(bt+4); bu := A.read();
A.write(bu+3);
A: 104
November 2005 Distributed systems: shared data 38
Transactions: Recovery• A dirty read problem:
Transaction T 4 A Transaction U 3 A
bt := A.read();
A.write(bt+4); bu := A.read();
A.write(bu+3);
A: 107
Commit
Abort
Correct result: A = 103
November 2005 Distributed systems: shared data 39
Transactions: Recovery• Premature write or
Over-writing uncommitted values :
Transaction T
Deposit(A,4);
Transaction U
Deposit(A,3);
Interleaved execution and Abort ?

November 2005 Distributed systems: shared data 40
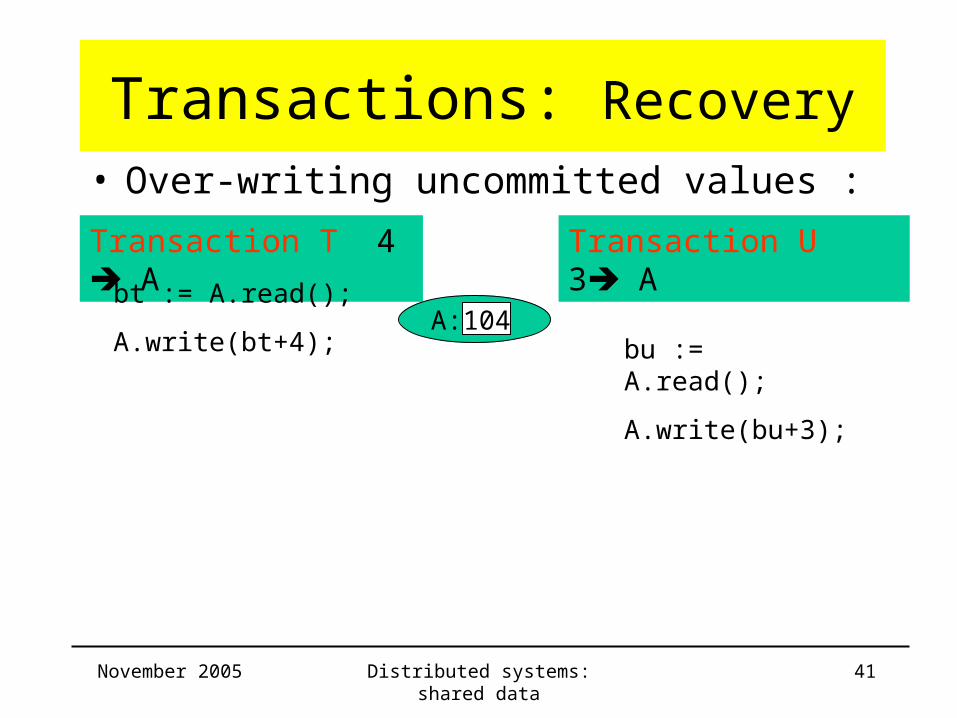
Transactions: Recovery• Over-writing uncommitted values :
Transaction T 4 A Transaction U 3 A
bt := A.read();
A.write(bt+4);A: 100
November 2005 Distributed systems: shared data 41
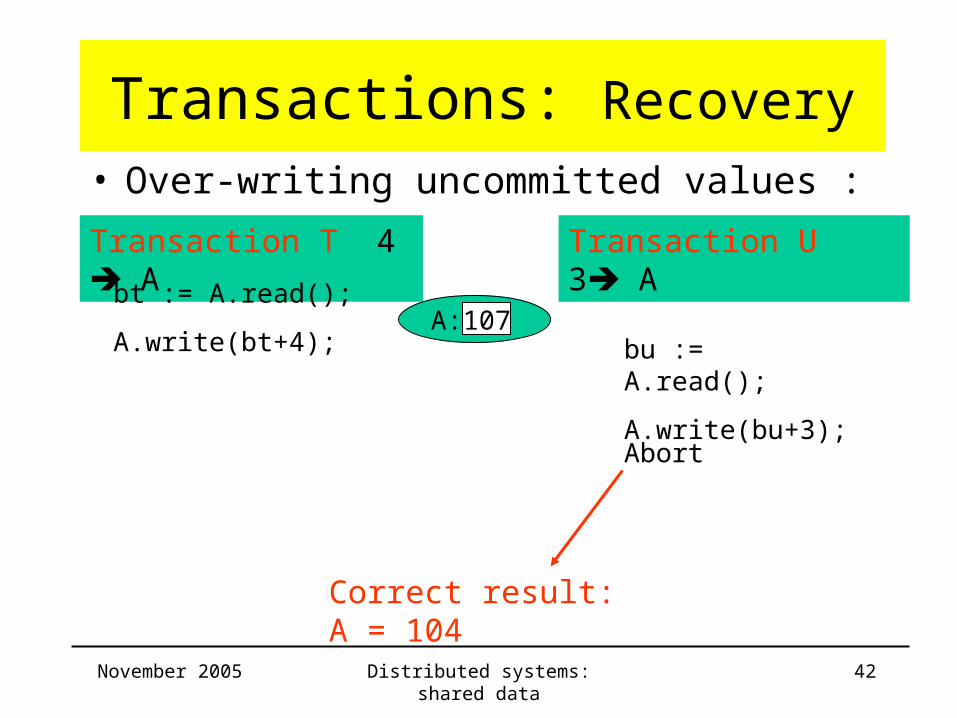
Transactions: Recovery• Over-writing uncommitted values :
Transaction T 4 A Transaction U 3 A
bt := A.read();
A.write(bt+4); bu := A.read();
A.write(bu+3);
A: 104
November 2005 Distributed systems: shared data 42
Transactions: Recovery• Over-writing uncommitted values :
Transaction T 4 A Transaction U 3 A
bt := A.read();
A.write(bt+4); bu := A.read();
A.write(bu+3);
A: 107
Abort
Correct result: A = 104

November 2005 Distributed systems: shared data 43
Transactions: Recovery• Illustration of well known problems:
– a dirty read
– premature write
• elements of solution:– Cascading Aborts: a transaction reading uncommitted
data must be aborted if the transaction that modified the data aborts
– to avoid cascading aborts, transactions can only read data written by committed transactions
– undo of write operations must be possible

November 2005 Distributed systems: shared data 44
Transactions: Recovery
• how to preserve data despite subsequent failures?– usually by using stable storage
• two copies of data stored – in separate parts of disks
– not decay related (probability of both parts corrupted is small)

November 2005 Distributed systems: shared data 45
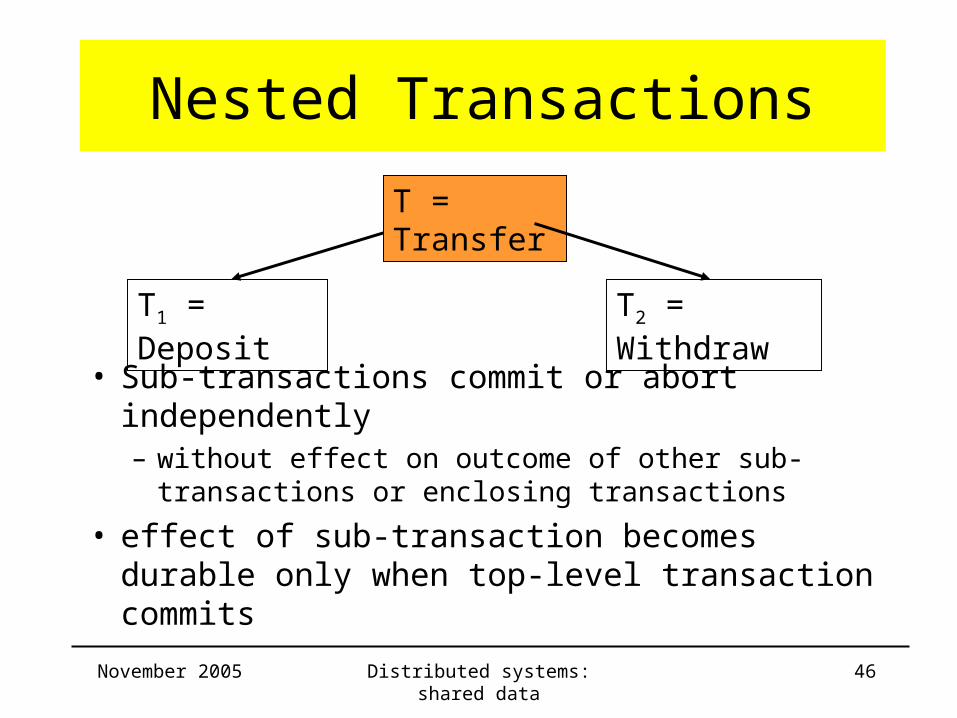
Nested Transactions• Transactions composed of several
sub-transactions
• Why nesting?– Modular approach to structuring transactions in
applications
– means of controlling concurrency within a transaction• concurrent sub-transactions accessing shared data are
serialized
– a finer grained recovery from failures• sub-transactions fail independent
November 2005 Distributed systems: shared data 46
Nested Transactions
• Sub-transactions commit or abort independently– without effect on outcome of other sub-transactions or
enclosing transactions
• effect of sub-transaction becomes durable only when top-level transaction commits
T = Transfer
T1 = Deposit T2 = Withdraw

November 2005 Distributed systems: shared data 47
Concurrency control: locking• Environment
– shared data in a single server (this section)– many competing clients
• problem:– realize transactions– maximize concurrency
• solution: serial equivalence
• difference with mutual exclusion?

November 2005 Distributed systems: shared data 48
Concurrency control: locking
• Protocols:– Locks– Optimistic Concurrency Control– Timestamp Ordering

November 2005 Distributed systems: shared data 49
Concurrency control: locking• Example:
– access to shared data within a transaction lock (= data reserved for …)
– exclusive locks• exclude access by other transactions

November 2005 Distributed systems: shared data 50
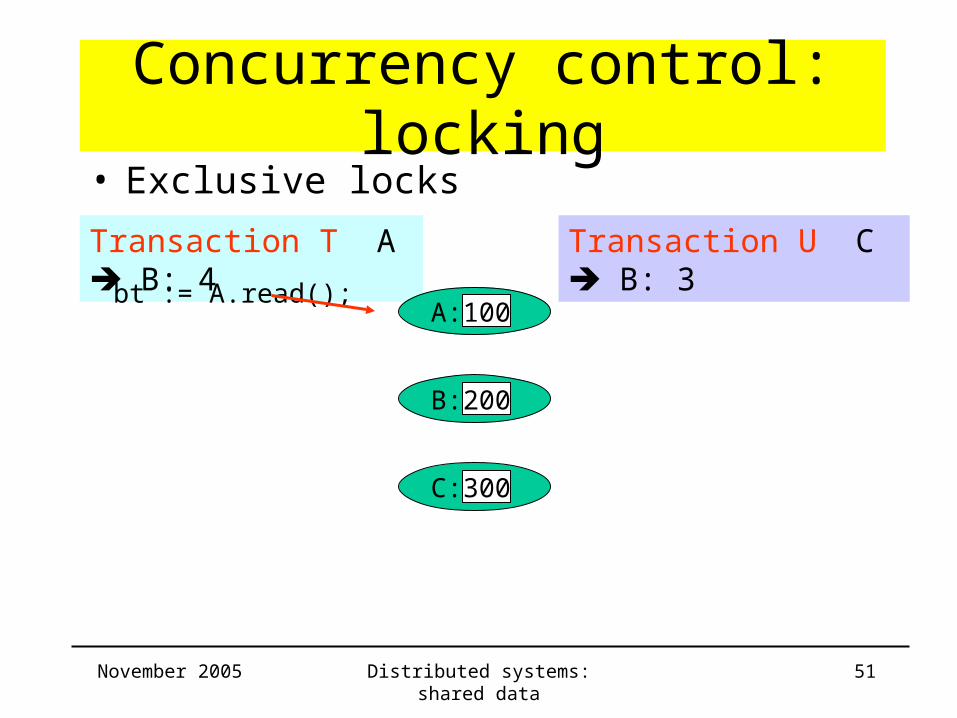
Concurrency control: locking• Same example (lost update) with locking
Transaction T
Withdraw(A,4);
Deposit(B,4);
Transaction U
Withdraw(C,3);
Deposit(B,3);
Colour of data show owner of lock
November 2005 Distributed systems: shared data 51
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 300
• Exclusive locks
A: 100
November 2005 Distributed systems: shared data 52
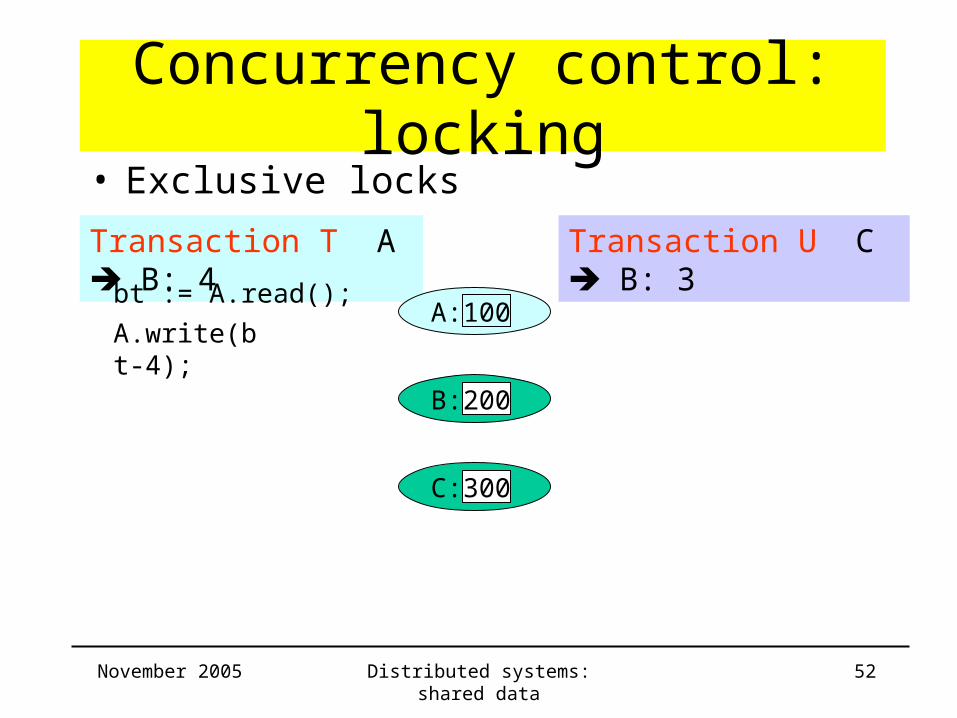
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 300
• Exclusive locks
A: 100A.write(bt-4);
November 2005 Distributed systems: shared data 53
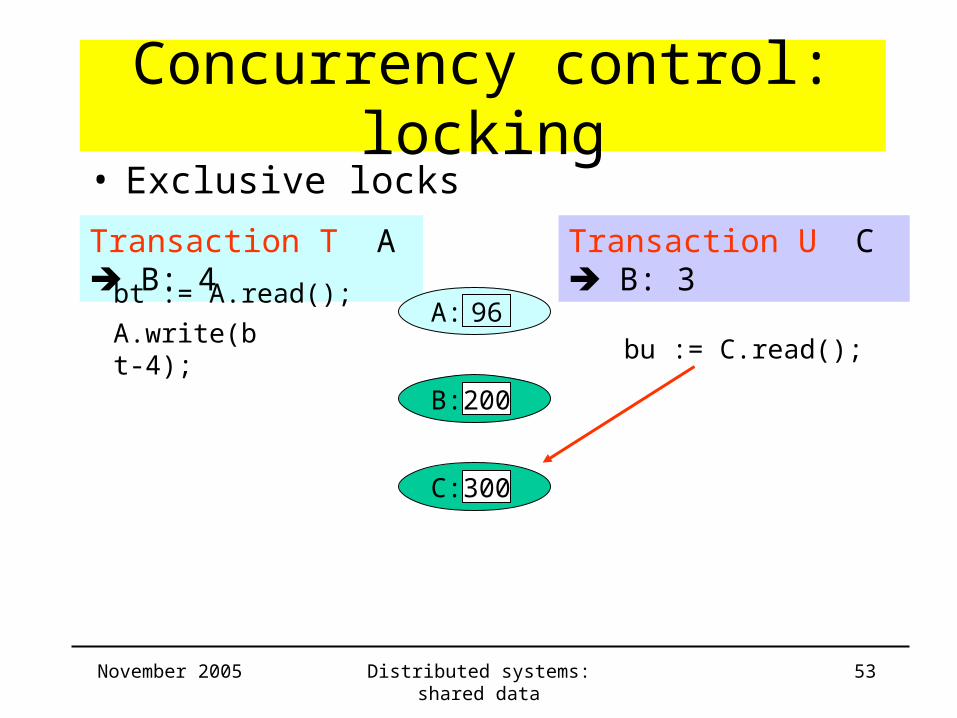
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 300
• Exclusive locks
A: 96A.write(bt-4);
bu := C.read();
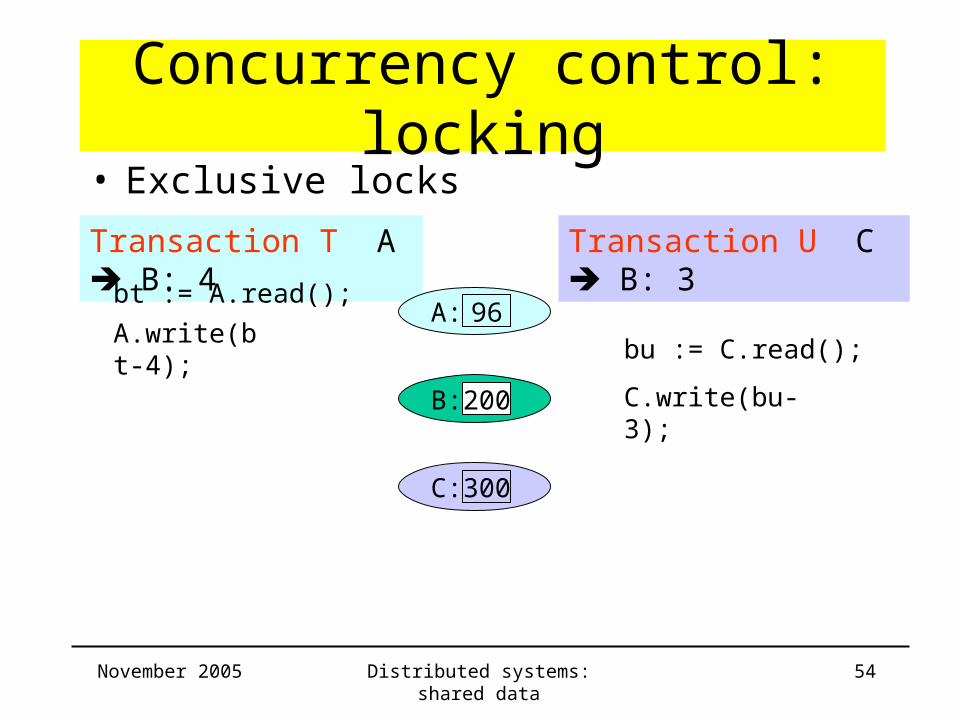
November 2005 Distributed systems: shared data 54
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 300
• Exclusive locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
November 2005 Distributed systems: shared data 55
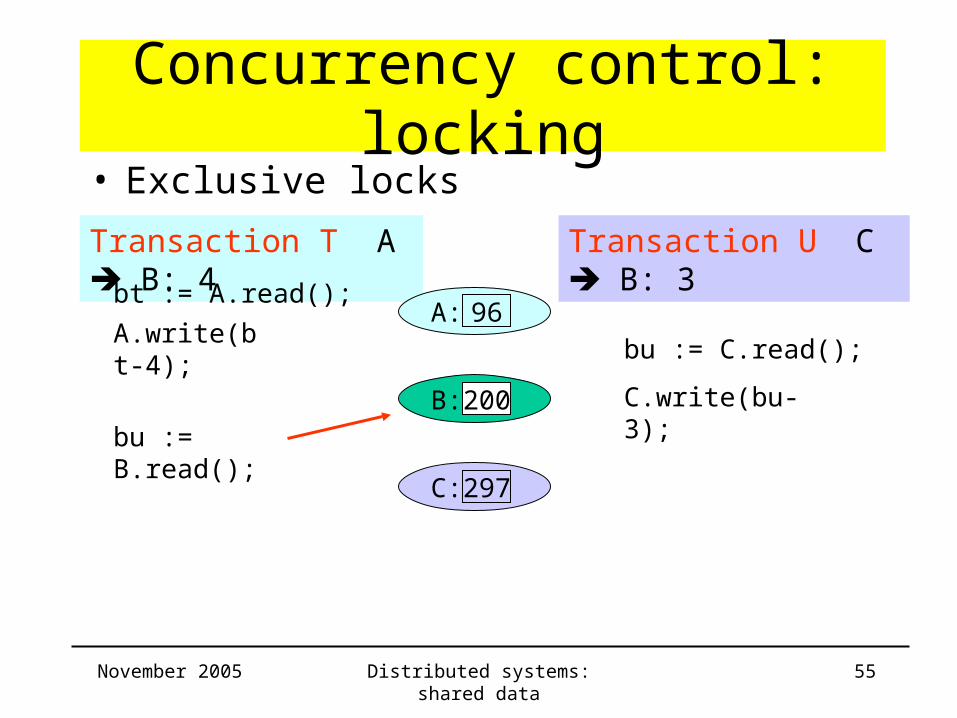
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 297
• Exclusive locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bu := B.read();
November 2005 Distributed systems: shared data 56
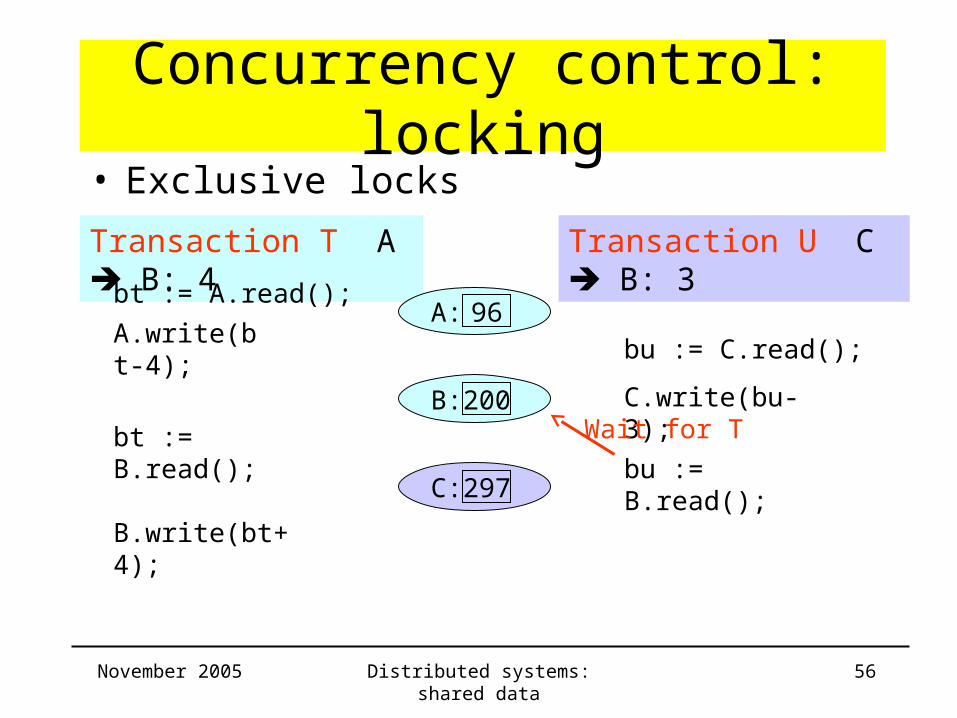
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 297
• Exclusive locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
Wait for T
B.write(bt+4);
November 2005 Distributed systems: shared data 57
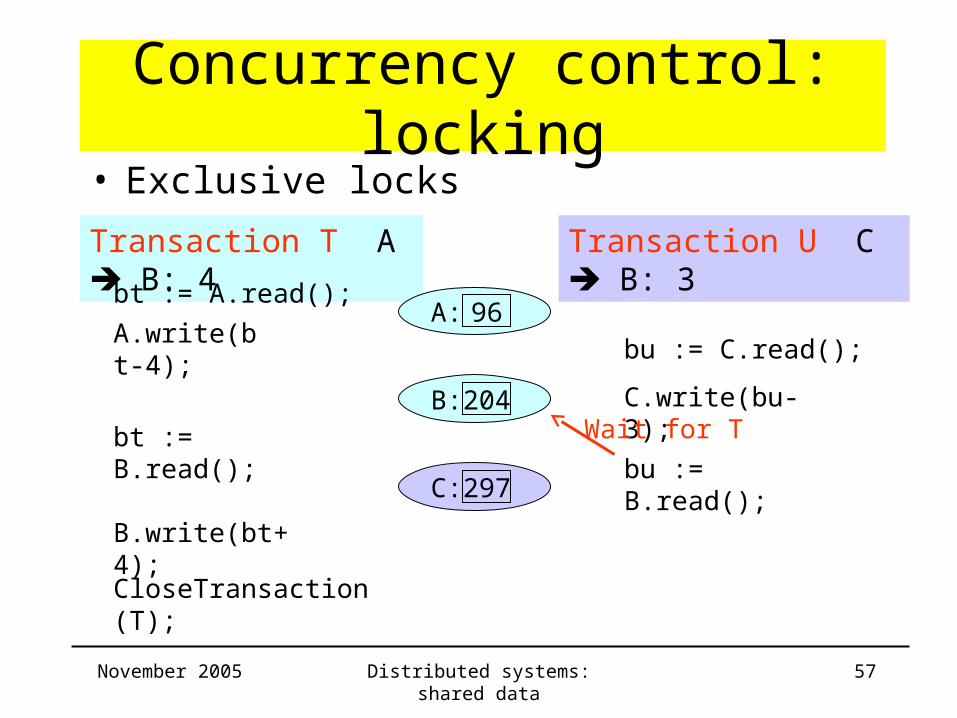
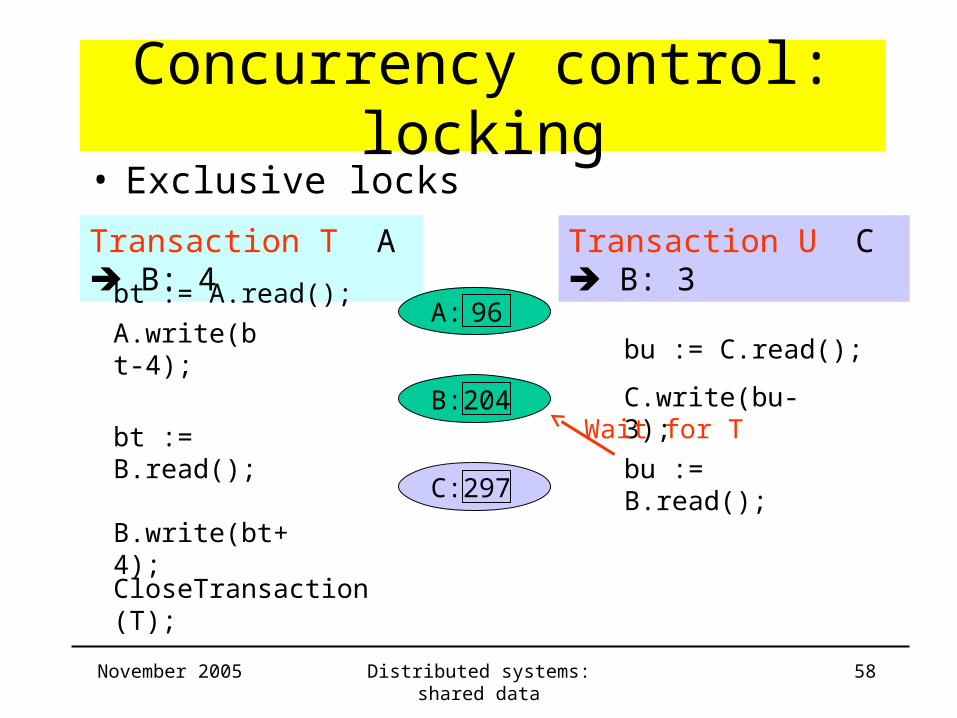
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 204
C: 297
• Exclusive locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
Wait for T
B.write(bt+4);
CloseTransaction(T);
November 2005 Distributed systems: shared data 58
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 204
C: 297
• Exclusive locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
Wait for T
B.write(bt+4);
CloseTransaction(T);
November 2005 Distributed systems: shared data 59
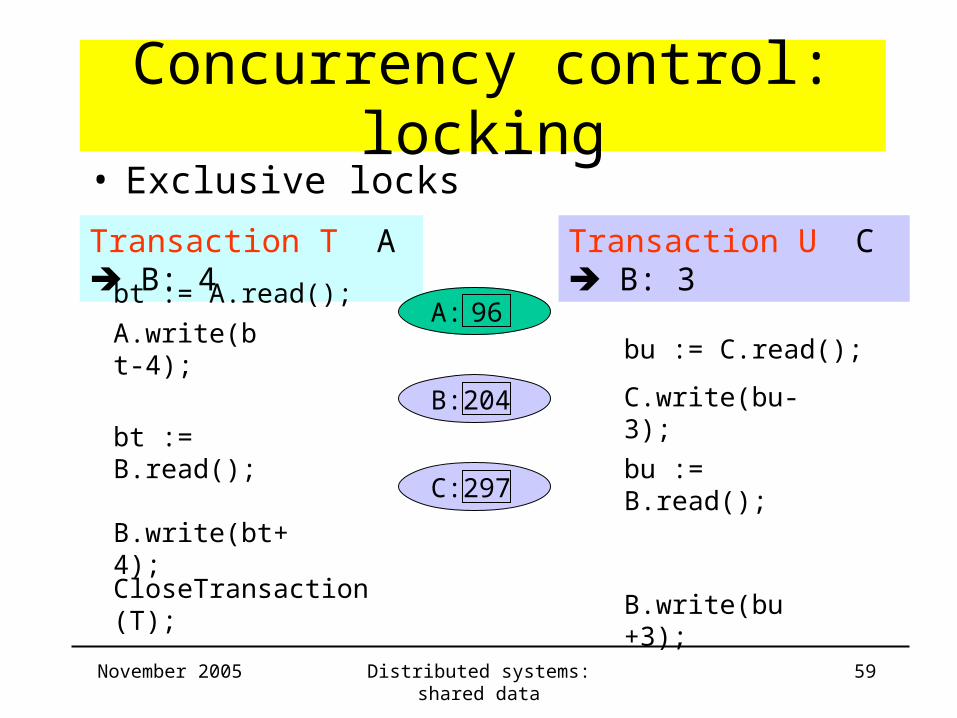
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 204
C: 297
• Exclusive locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
B.write(bt+4);
CloseTransaction(T);B.write(bu+3);

November 2005 Distributed systems: shared data 60
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 207
C: 297
• Exclusive locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
B.write(bt+4);
CloseTransaction(T);B.write(bu+3); CloseTransaction(U);

November 2005 Distributed systems: shared data 61
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 207
C: 297
• Exclusive locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
B.write(bt+4);
CloseTransaction(T);B.write(bu+3); CloseTransaction(U);

November 2005 Distributed systems: shared data 62
Concurrency control: locking• Basic elements of protocol
1 serial equivalence• requirements
– all of a transaction’s accesses to a particular data item should be serialized with respect to accesses by other transactions
– all pairs of conflicting operations of 2 transactions should be executed in the same order
• how?– A transaction is not allowed any new locks after it has
released a lock
Two-phase locking

November 2005 Distributed systems: shared data 63
Concurrency control: locking• Two-phase locking
– Growing Phase• new locks can be acquired
– Shrinking Phase• no new locks
• locks are released

November 2005 Distributed systems: shared data 64
Concurrency control: locking• Basic elements of protocol
1 serial equivalence two-phase locking 2 hide intermediate results
• conflict between– release of lock access by other transactions possible
– access should be delayed till commit/abort transaction
• how?– New mechanism?
– (better) release of locks only at commit/abort
strict two-phase locking– locks held till end of transaction

November 2005 Distributed systems: shared data 65
Concurrency control: locking• How increase concurrency and preserve
serial equivalence?– Granularity of locks
– Appropriate locking rules

November 2005 Distributed systems: shared data 66
Concurrency control: locking• Granularity of locks
– observations• large number of data items on server• typical transaction needs only a few items• conflicts unlikely
– large granularitylimits concurrent access• example: all accounts in a branch of bank are
locked together
– small granularity overhead
November 2005 Distributed systems: shared data 67
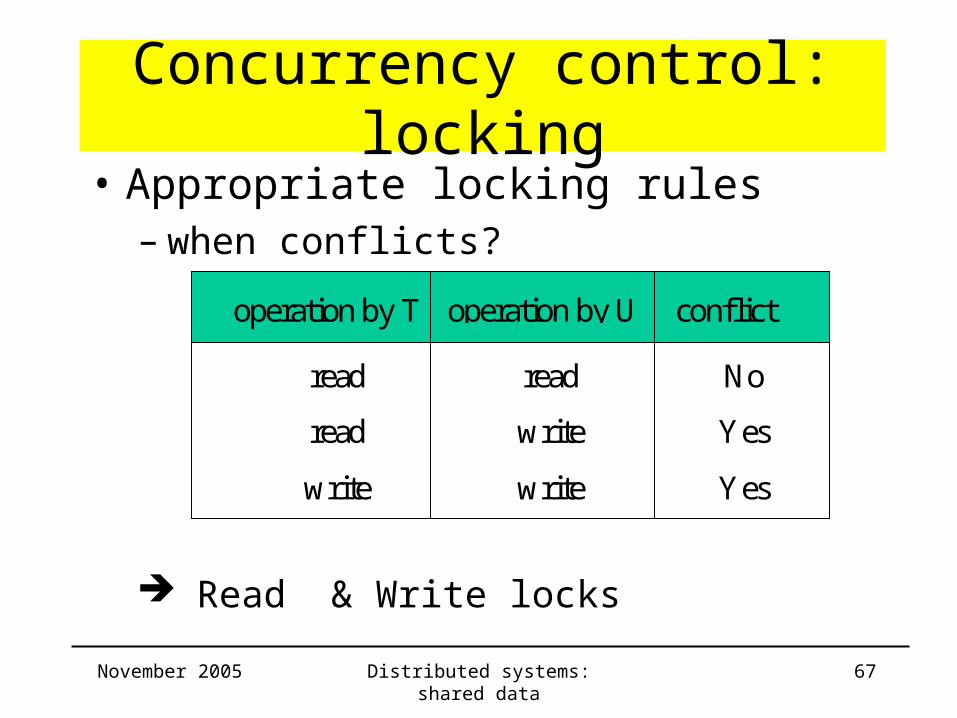
Concurrency control: locking• Appropriate locking rules
– when conflicts?
Read & Write locks
operation by T operation by U conflict
read read No
read write Yes
write write Yes
November 2005 Distributed systems: shared data 68
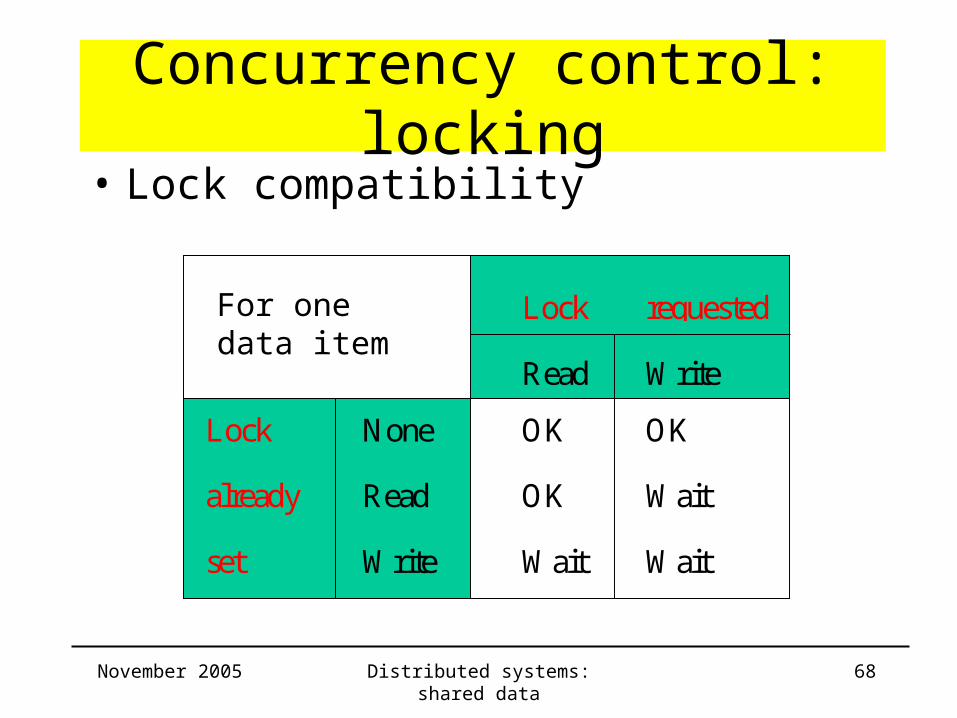
Concurrency control: locking• Lock compatibility
Lock requested
Read Write
Lock None OK OK
already Read OK Wait
set Write Wait Wait
For one data item

November 2005 Distributed systems: shared data 69
Concurrency control: locking• Strict two-phase locking
– locking• done by server (containing data item)
– unlocking• done by commit/abort of the transactional service
November 2005 Distributed systems: shared data 70
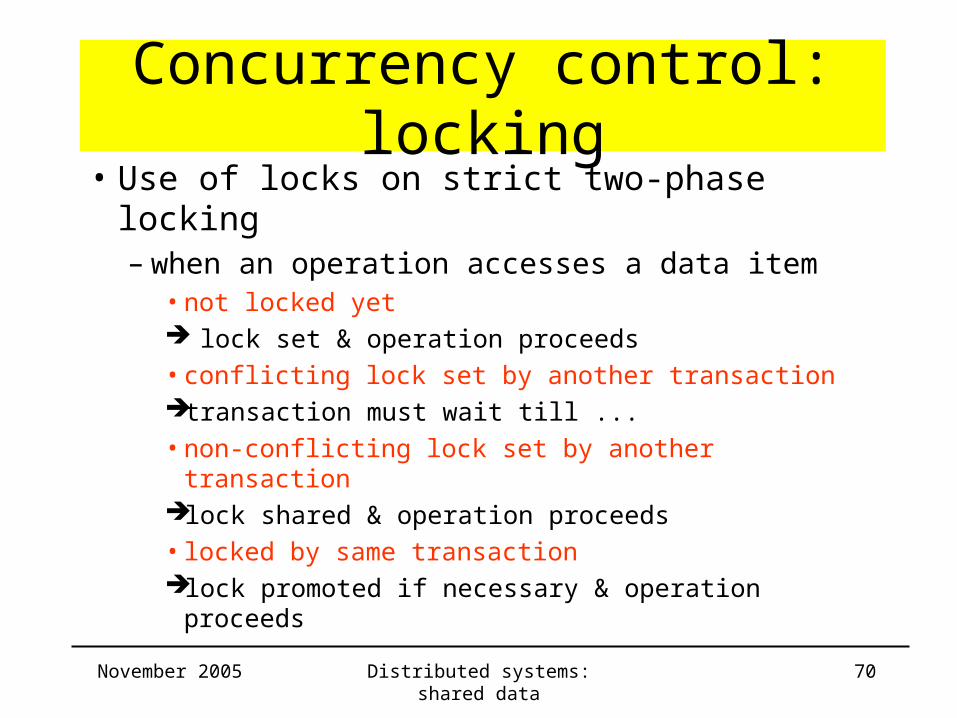
Concurrency control: locking• Use of locks on strict two-phase locking
– when an operation accesses a data item• not locked yet lock set & operation proceeds
• conflicting lock set by another transactiontransaction must wait till ...
• non-conflicting lock set by another transactionlock shared & operation proceeds
• locked by same transactionlock promoted if necessary & operation proceeds
November 2005 Distributed systems: shared data 71
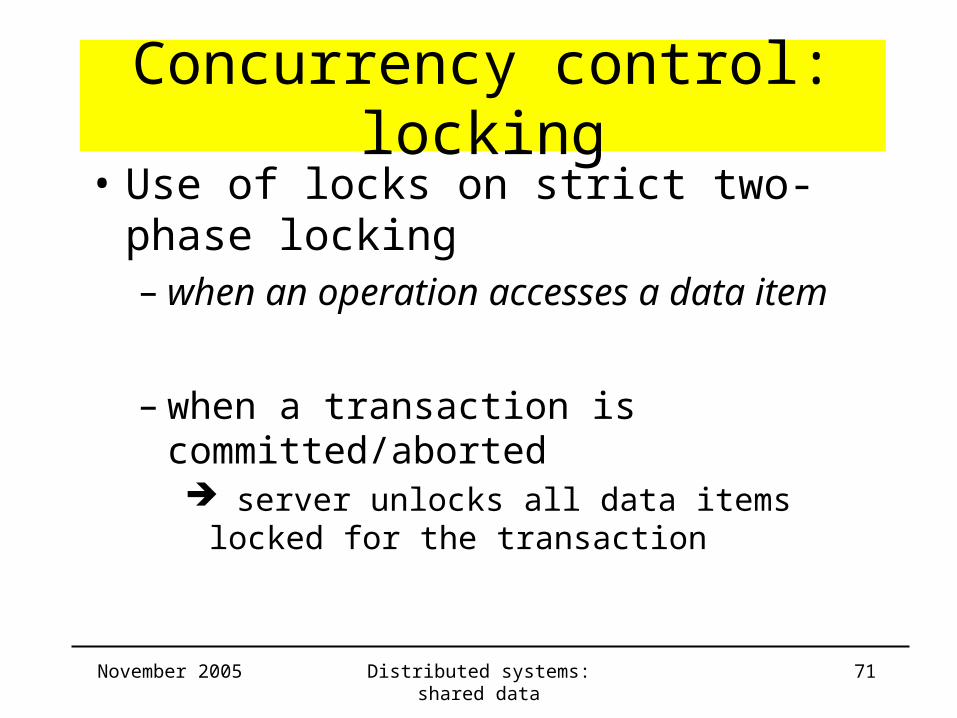
Concurrency control: locking• Use of locks on strict two-phase locking
– when an operation accesses a data item
– when a transaction is committed/aborted server unlocks all data items locked for the
transaction

November 2005 Distributed systems: shared data 72
Concurrency control: locking• Lock implementation
– lock manager– managing table of locks:
• transaction identifiers
• identifier of (locked) data item
• lock type
• condition variable– for waiting transactions

November 2005 Distributed systems: shared data 73
Concurrency control: locking• Deadlocks
– a state in which each member of a group of transactions is waiting for some other member to release a lock
no progress possible!
– Example: with read/write locks

November 2005 Distributed systems: shared data 74
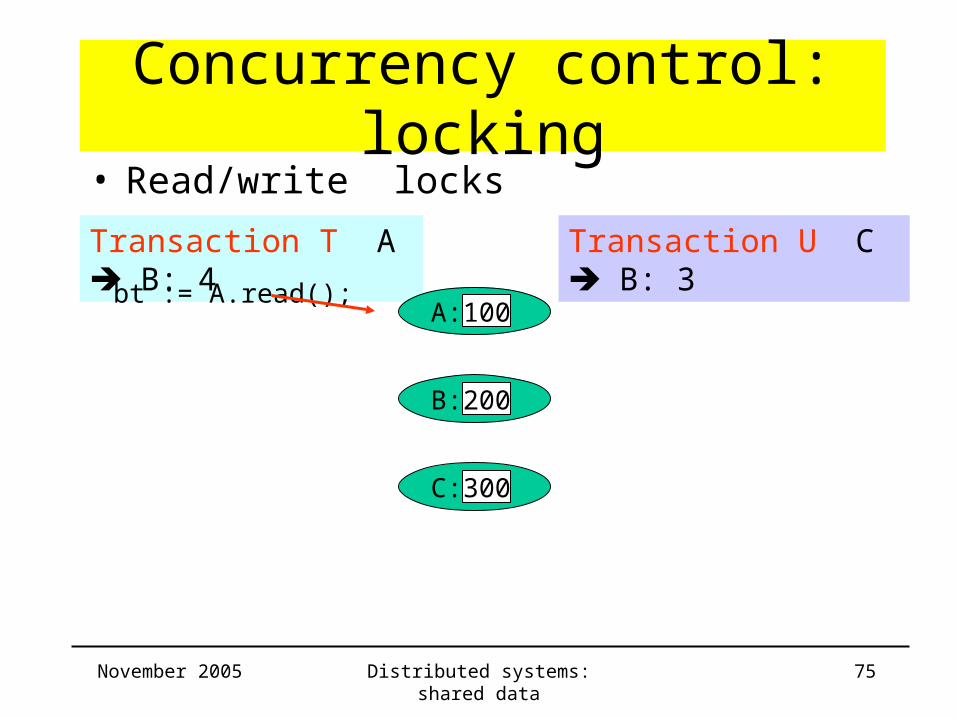
Concurrency control: locking• Same example (lost update) with locking
Transaction T
Withdraw(A,4);
Deposit(B,4);
Transaction U
Withdraw(C,3);
Deposit(B,3);
Colour of data show owner of lock
November 2005 Distributed systems: shared data 75
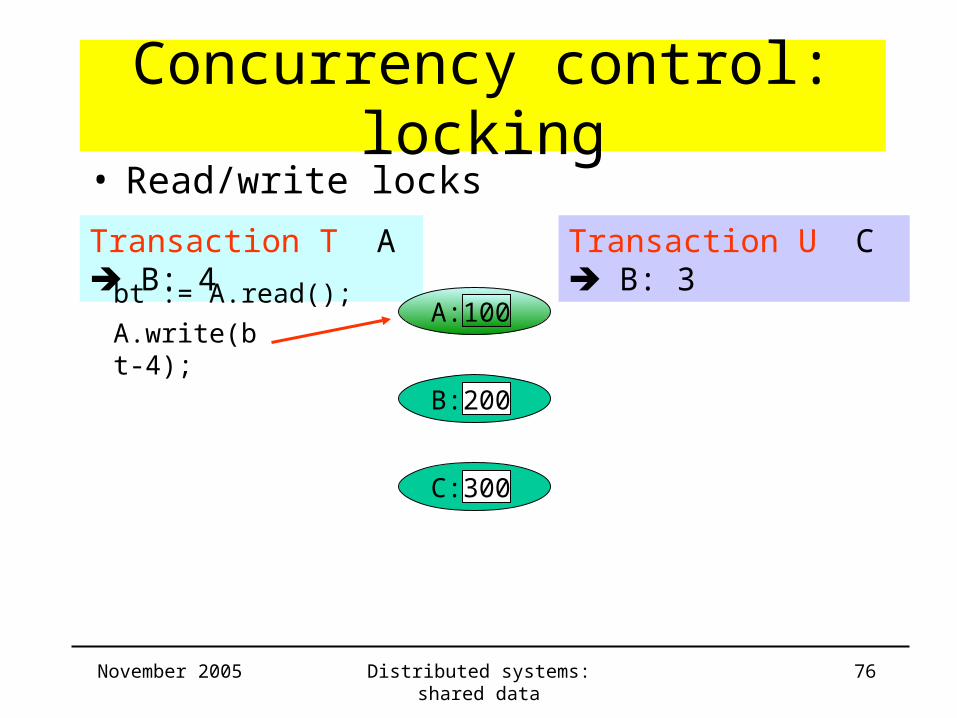
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 300
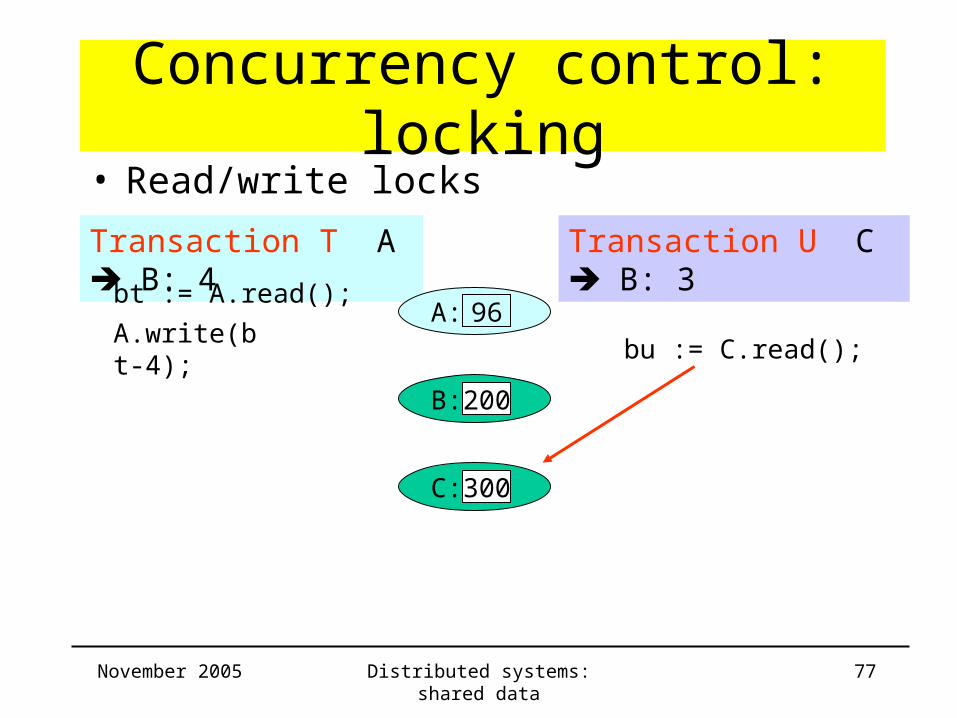
• Read/write locks
A: 100
November 2005 Distributed systems: shared data 76
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 300
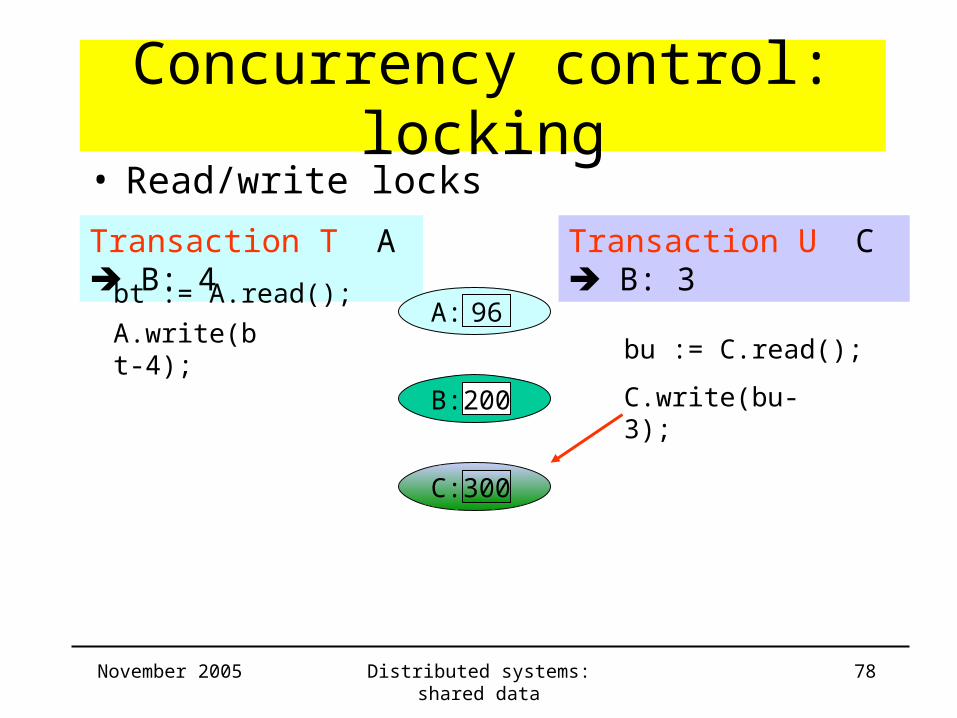
• Read/write locks
A: 100A.write(bt-4);
November 2005 Distributed systems: shared data 77
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 300
• Read/write locks
A: 96A.write(bt-4);
bu := C.read();
November 2005 Distributed systems: shared data 78
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 300
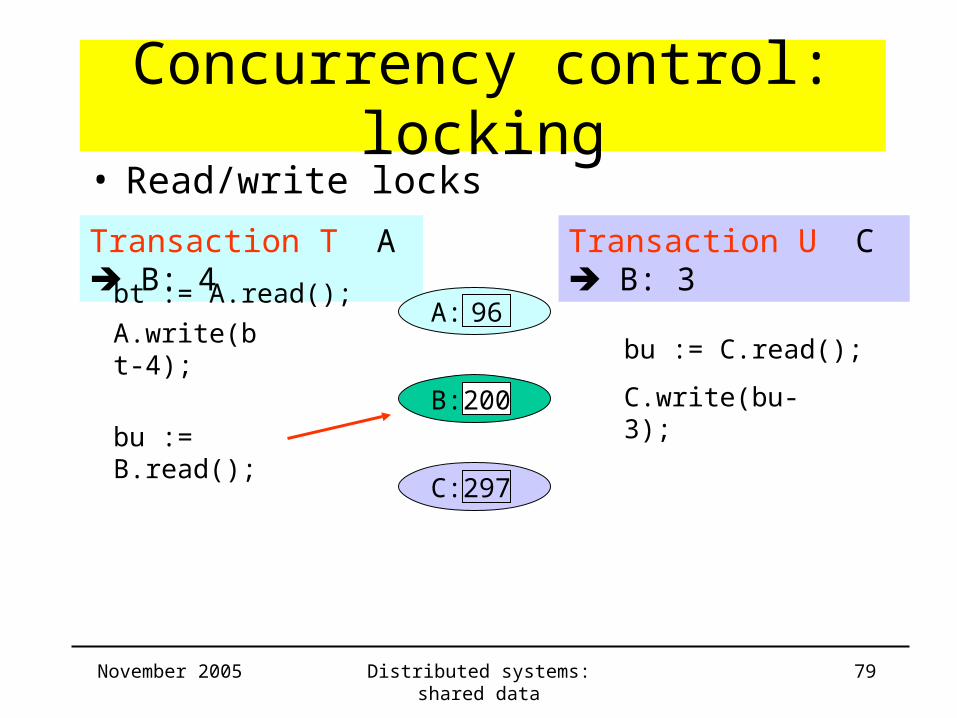
• Read/write locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
November 2005 Distributed systems: shared data 79
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 297
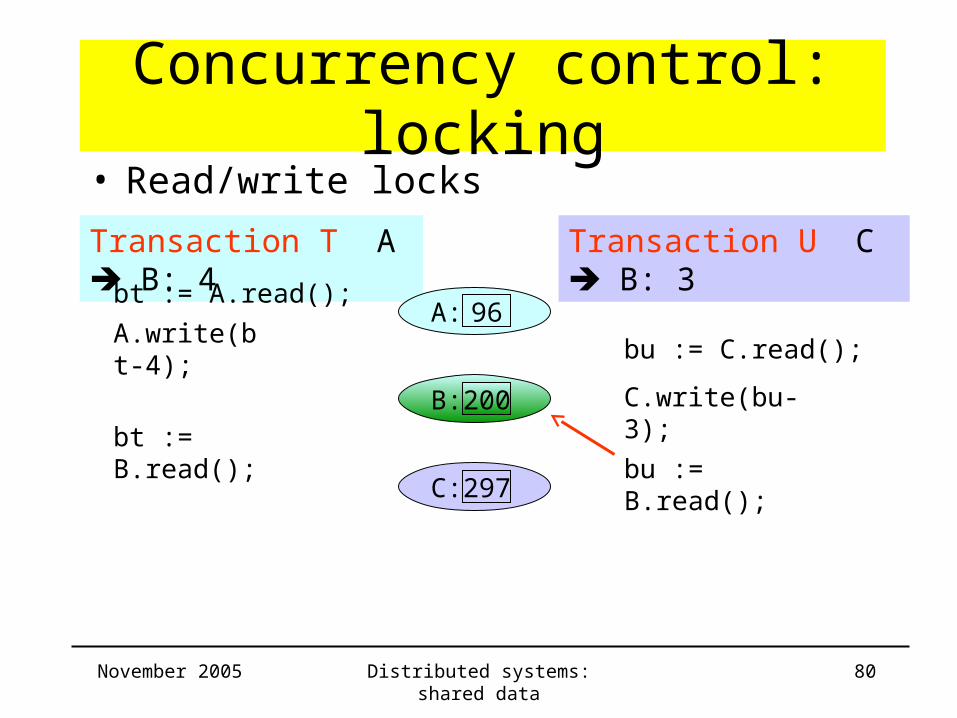
• Read/write locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bu := B.read();
November 2005 Distributed systems: shared data 80
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 297
• Read/write locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
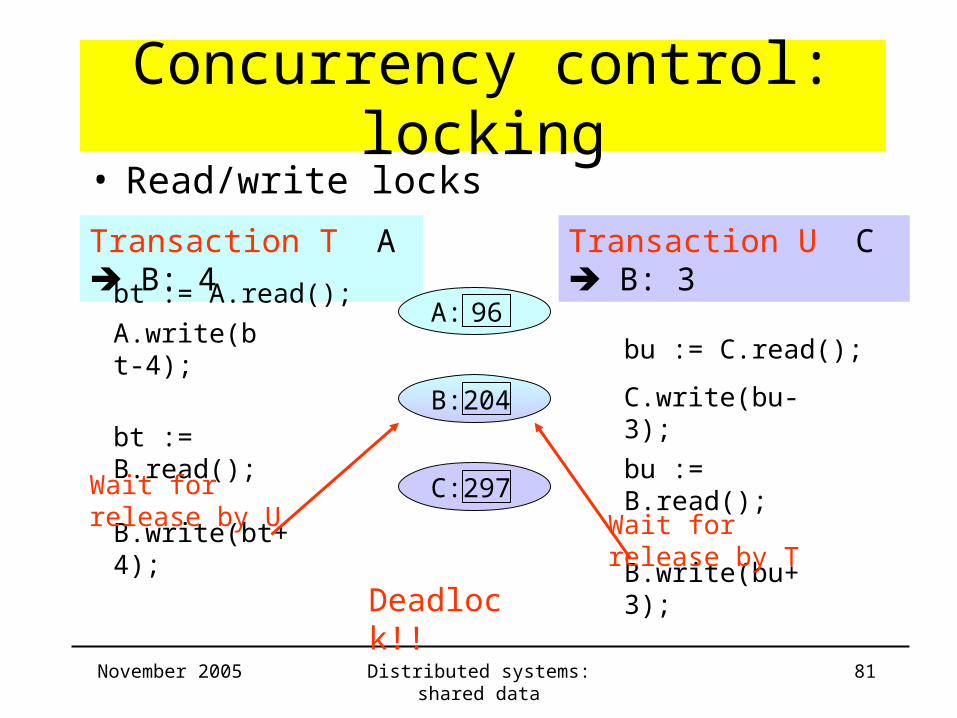
November 2005 Distributed systems: shared data 81
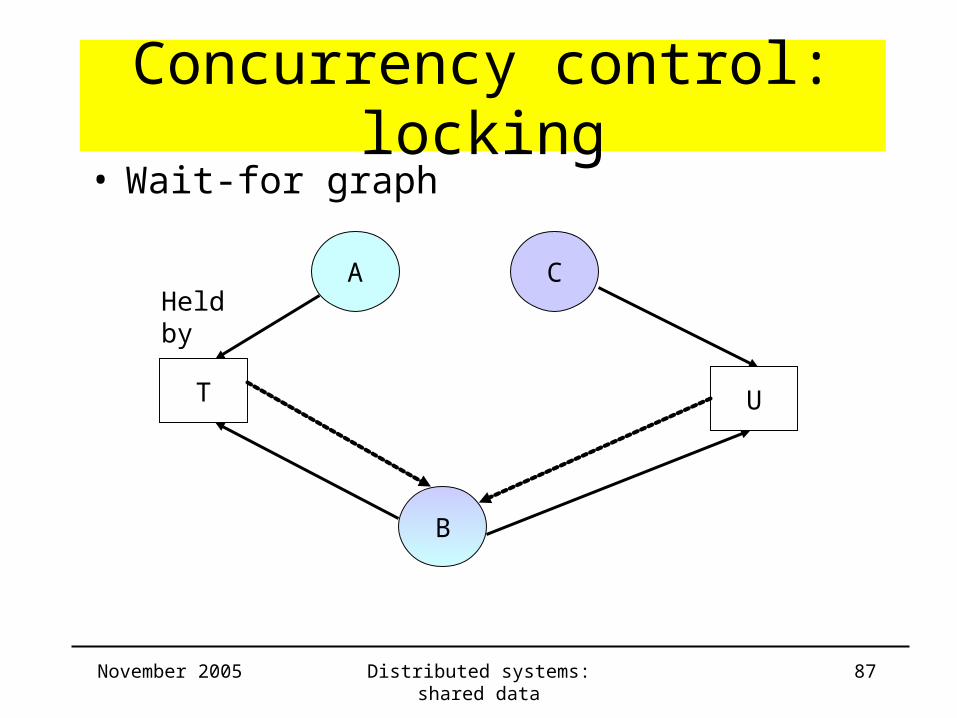
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 204
C: 297
• Read/write locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
B.write(bt+4);
Wait for release by U
B.write(bu+3);
Wait for release by T
Deadlock!!

November 2005 Distributed systems: shared data 82
Concurrency control: locking• Solutions to the Deadlock problem
– Prevention• by locking all data items used by a transaction
when it starts
• by requesting locks on data items in a predefined order
Evaluation• impossible for interactive transactions
• reduction of concurrency

November 2005 Distributed systems: shared data 83
Concurrency control: locking• Solutions to the Deadlock problem
– Detection• the server keeps track of a wait-for graph
– lock: edge is added
– unlock: edge is removed
• the presence of cycles may be checked– when an edge is added
– periodically
– example

November 2005 Distributed systems: shared data 84
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 200
C: 297
• Read/write locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
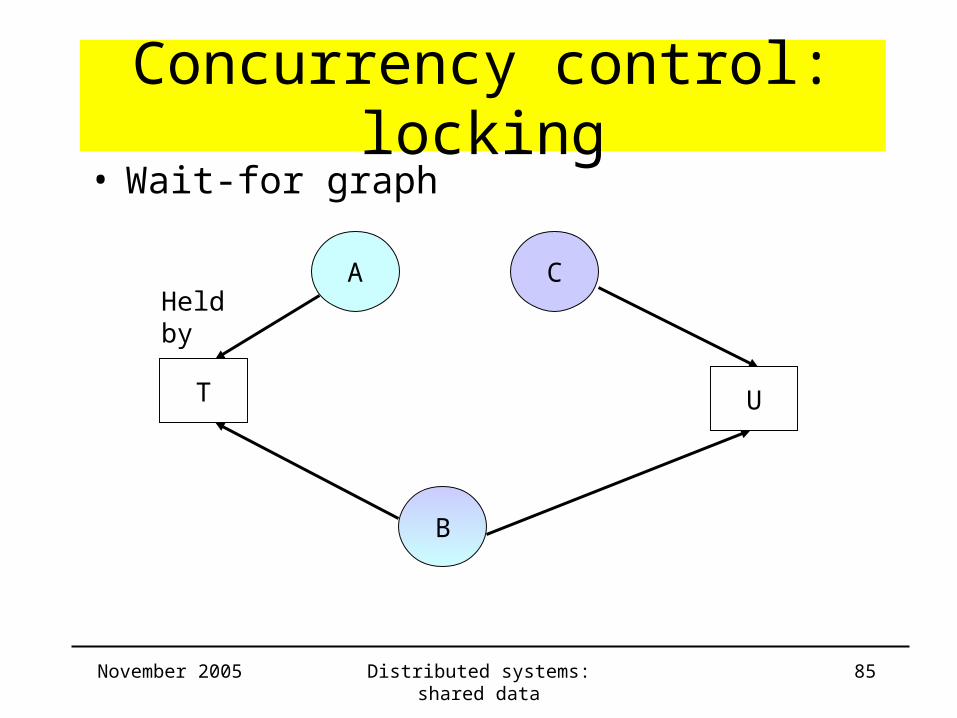
November 2005 Distributed systems: shared data 85
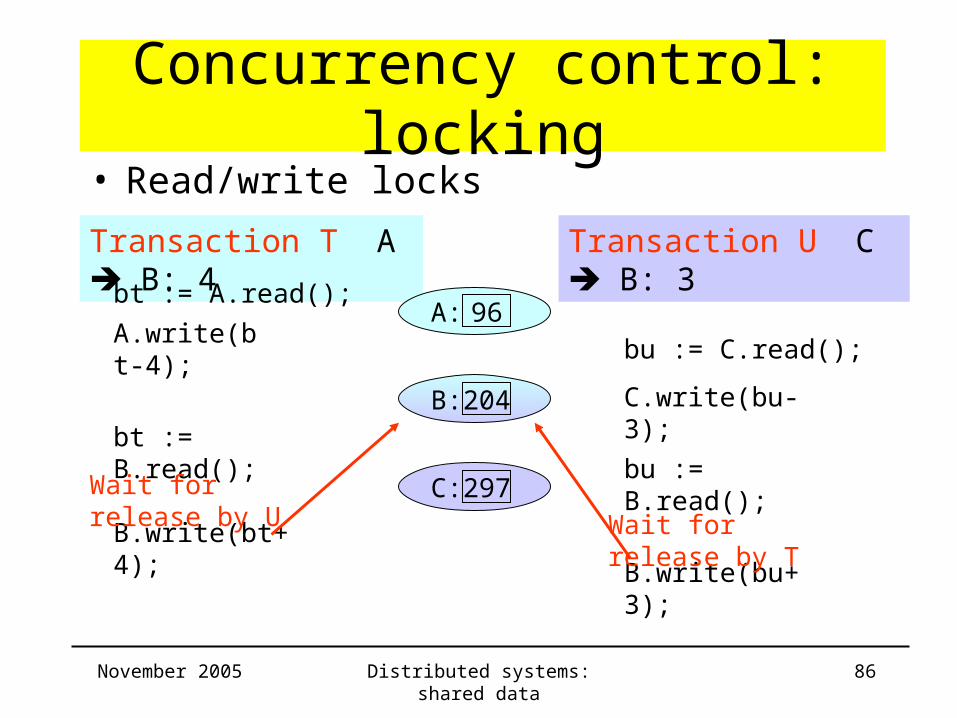
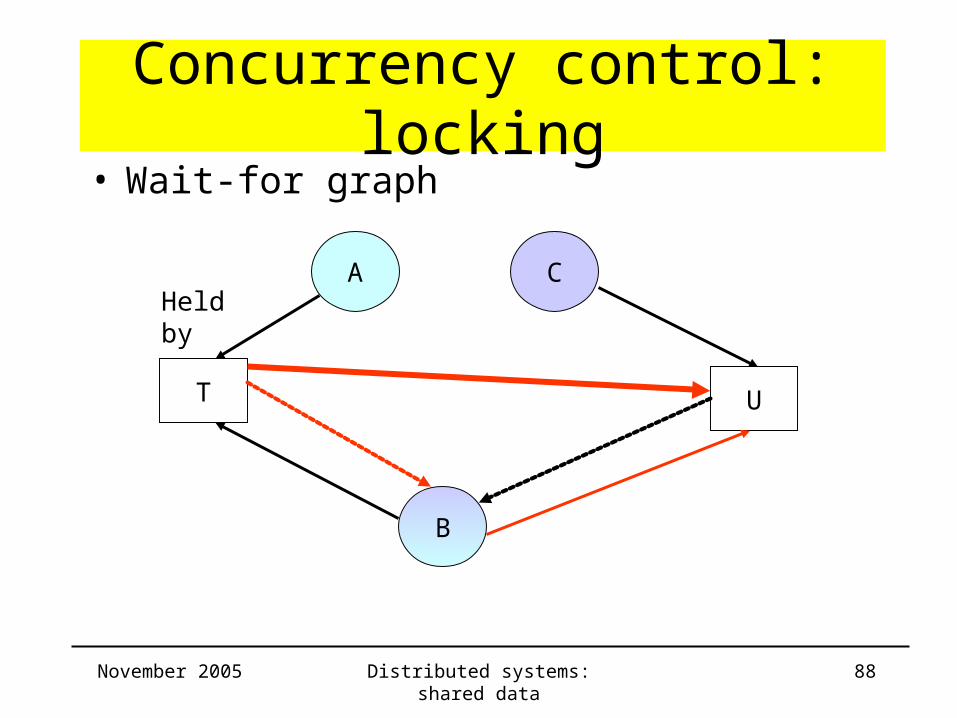
Concurrency control: locking• Wait-for graph
A
B
C
T U
Held by
November 2005 Distributed systems: shared data 86
Concurrency control: locking
Transaction T A B: 4 Transaction U C B: 3
bt := A.read();
B: 204
C: 297
• Read/write locks
A: 96A.write(bt-4);
bu := C.read();
C.write(bu-3);
bt := B.read();bu := B.read();
B.write(bt+4);
Wait for release by U
B.write(bu+3);
Wait for release by T
November 2005 Distributed systems: shared data 87
Concurrency control: locking• Wait-for graph
A
B
C
T U
Held by
November 2005 Distributed systems: shared data 88
Concurrency control: locking• Wait-for graph
A
B
C
T U
Held by
November 2005 Distributed systems: shared data 89
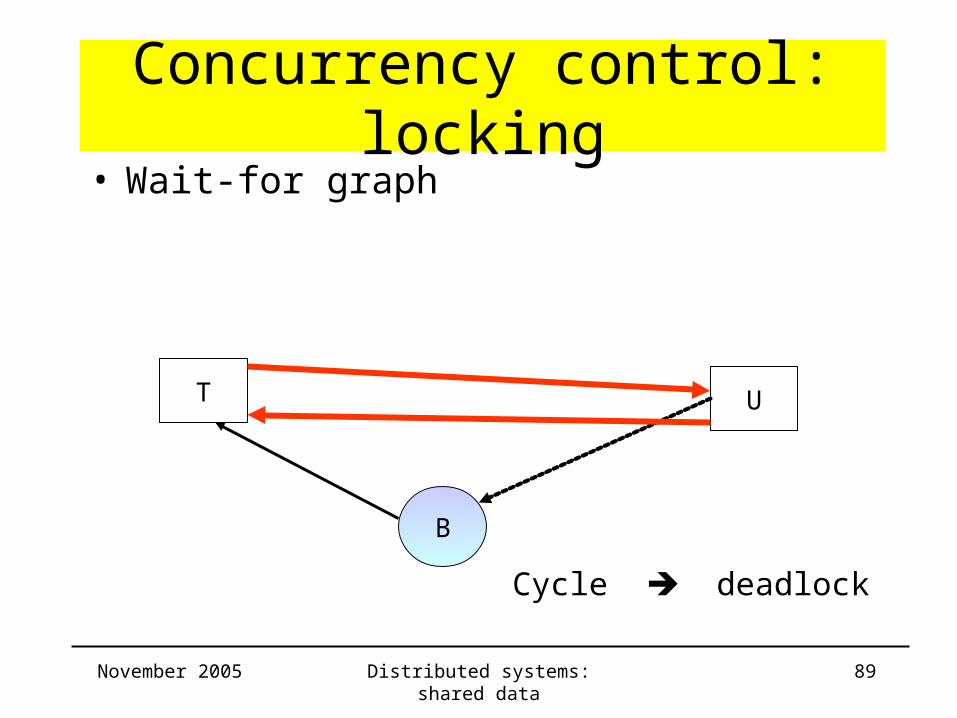
Concurrency control: locking• Wait-for graph
B
T U
Cycle deadlock

November 2005 Distributed systems: shared data 90
Concurrency control: locking• Solutions to the Deadlock problem
– Detection• the server keeps track of a wait-for graph
• the presence of cycles must be checked
• once a deadlock detected, the server must select a transaction and abort it (to break the cycle)
• choice of transaction? Important factors– age of transaction
– number of cycles the transaction is involved in

November 2005 Distributed systems: shared data 91
Concurrency control: locking• Solutions to the Deadlock problem
– Timeouts• locks granted for a limited period of time
– within period: lock invulnerable
– after period: lock vulnerable

November 2005 Distributed systems: shared data 92
Overview• Transactions
• Distributed transactions– Flat and nested distributed transactions– Atomic commit protocols– Concurrency in distributed transactions– Distributed deadlocks– Transaction recovery
• Replication

November 2005 Distributed systems: shared data 93
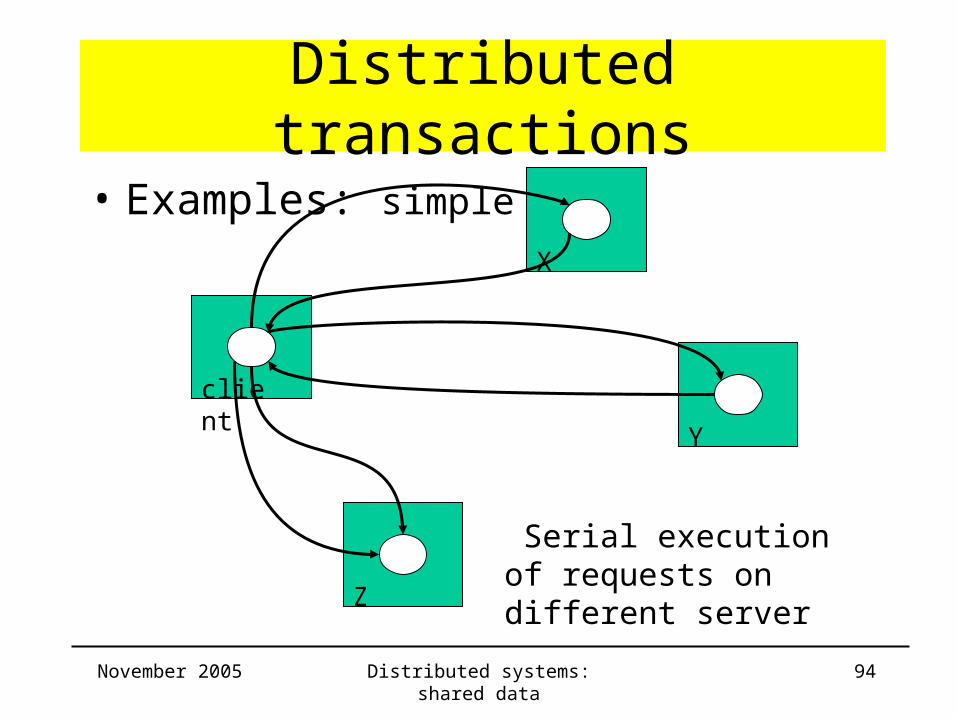
Distributed transactions
• Definition
Any transaction whose activities involve
multiple servers
• Examples
– simple: client accesses several servers
– nested: server accesses several other servers
November 2005 Distributed systems: shared data 94
Distributed transactions
• Examples: simple
client
Y
X
Z
Serial execution of requests on different server
November 2005 Distributed systems: shared data 95
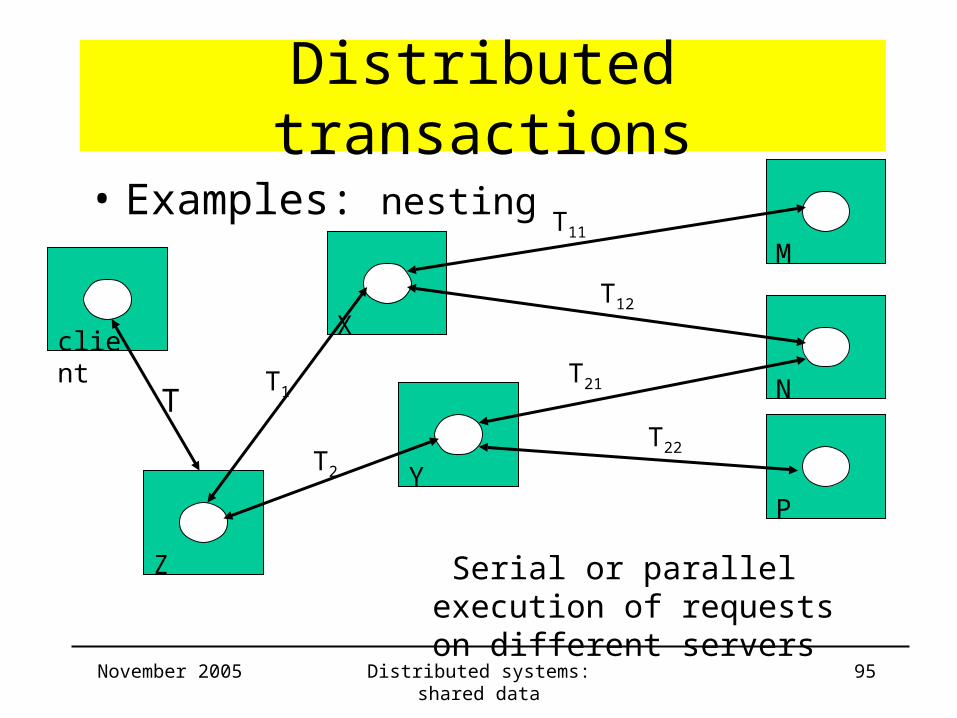
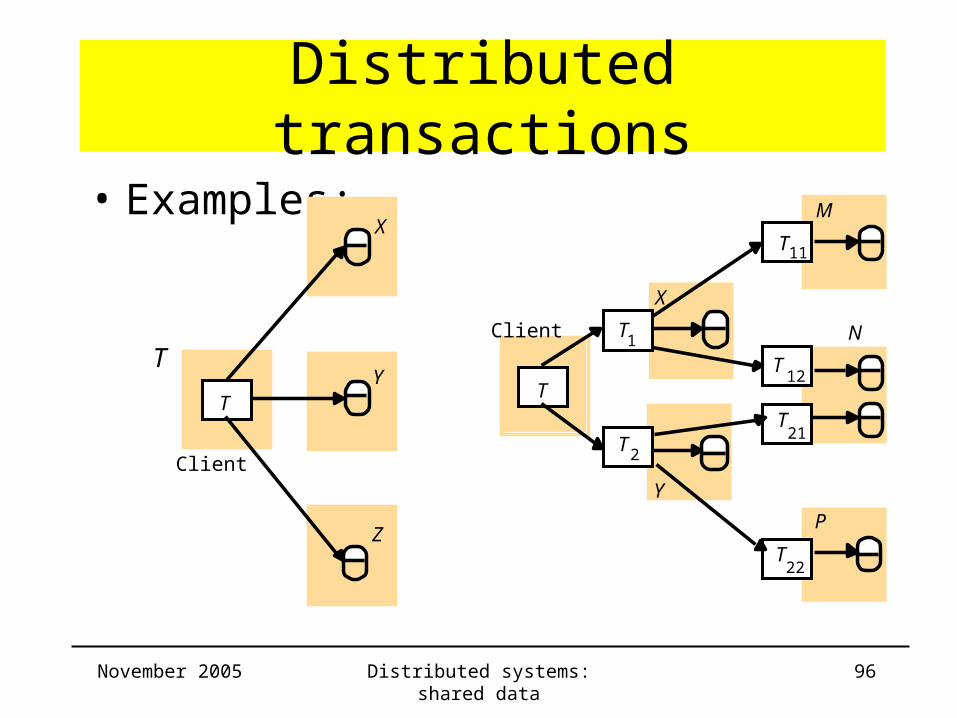
Distributed transactions
• Examples: nesting
Serial or parallel execution of requests on different servers
client
Y
X
Z
P
N
M
TT1
T2
T11
T12
T22
T21
November 2005 Distributed systems: shared data 96
Distributed transactions
• Examples:
Client
X
Y
Z
X
Y
M
NT1
T2
T11
Client
P
TT
12
T21
T22
T
T

November 2005 Distributed systems: shared data 97
Distributed transactions• Commit: agreement between all servers involved
• to commit• to abort
• take one server as coordinatorsimple (?) protocol
– single point of failure?
• tasks of the coordinator– keep track of other servers, called workers
– responsible for final decision

November 2005 Distributed systems: shared data 98
Distributed transactions• New service operations:
– AddServer( TransID, CoordinatorID)• called by clients
• first operation on server that has not joined the transaction yet
– NewServer( TransID, WorkerID)• called by new server on the coordinator
• coordinator records ServerID of the worker in its workers list
November 2005 Distributed systems: shared data 99
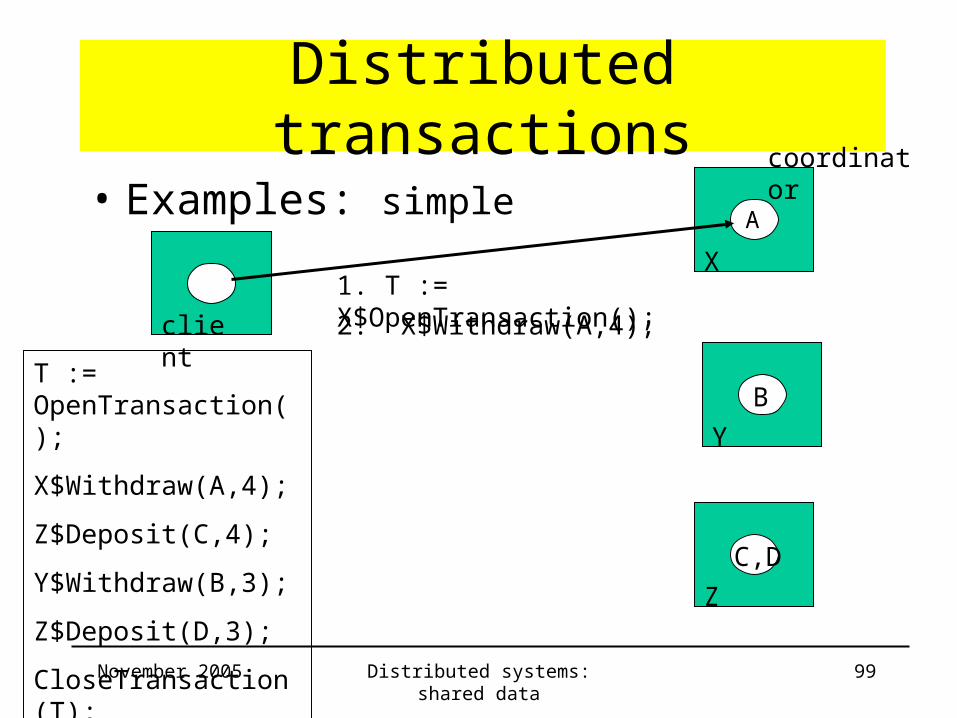
Distributed transactions
• Examples: simple
client
Y
X
Z
T := OpenTransaction();
X$Withdraw(A,4);
Z$Deposit(C,4);
Y$Withdraw(B,3);
Z$Deposit(D,3);
CloseTransaction(T);
1. T := X$OpenTransaction();
2. X$Withdraw(A,4);
coordinator
A
B
C,D
November 2005 Distributed systems: shared data 100
Distributed transactions
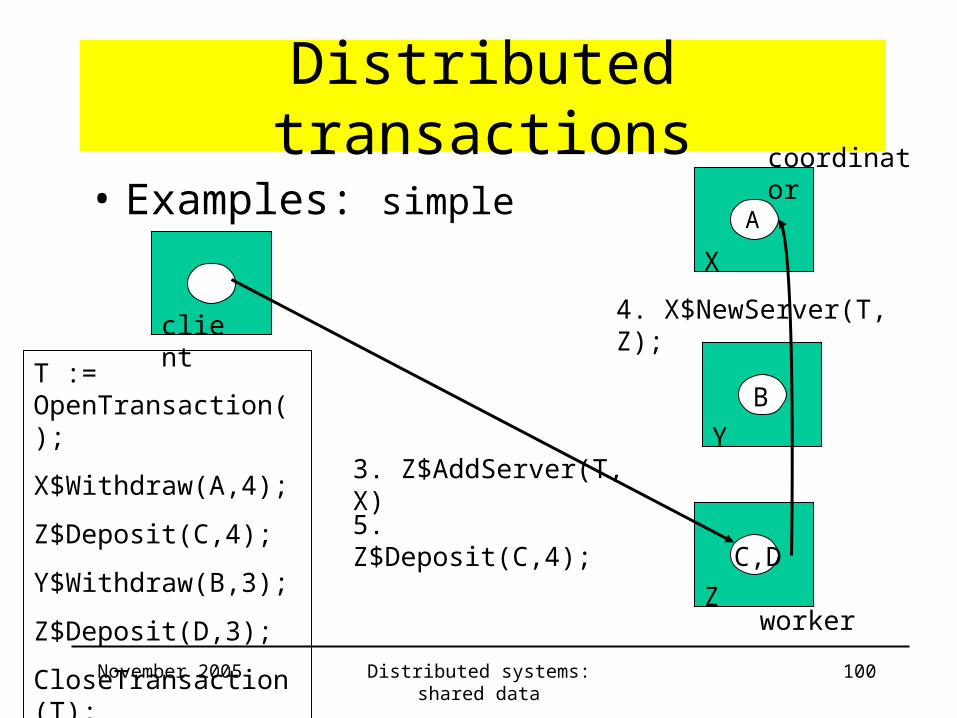
• Examples: simple
client
Y
X
Z
T := OpenTransaction();
X$Withdraw(A,4);
Z$Deposit(C,4);
Y$Withdraw(B,3);
Z$Deposit(D,3);
CloseTransaction(T);
coordinator
A
B
C,D
3. Z$AddServer(T, X)
4. X$NewServer(T, Z);
5. Z$Deposit(C,4);
worker
November 2005 Distributed systems: shared data 101
Distributed transactions
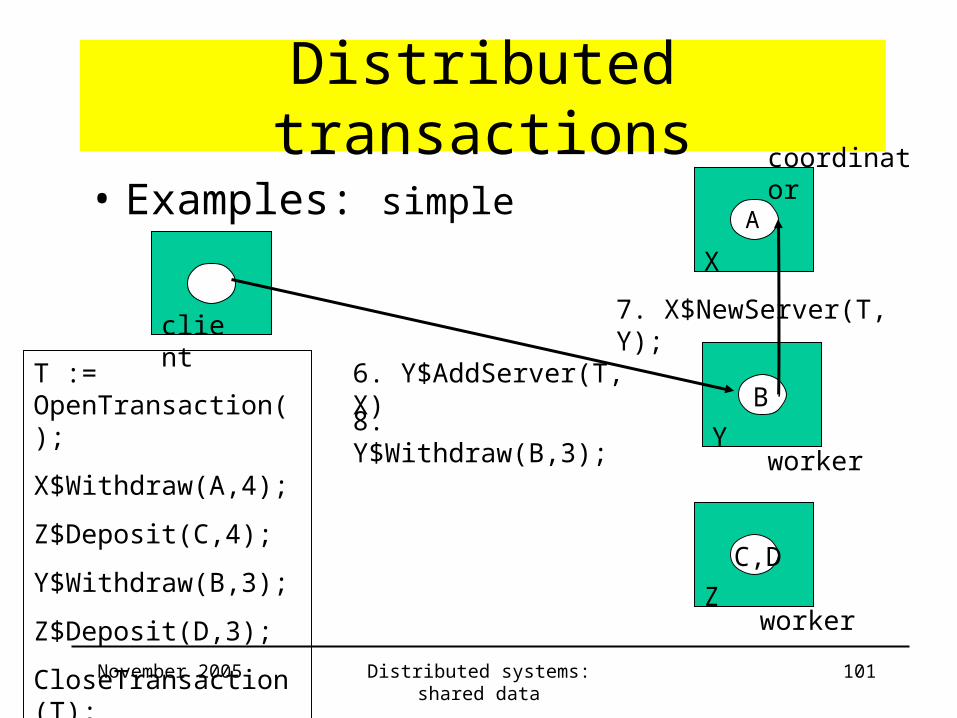
• Examples: simple
client
Y
X
Z
T := OpenTransaction();
X$Withdraw(A,4);
Z$Deposit(C,4);
Y$Withdraw(B,3);
Z$Deposit(D,3);
CloseTransaction(T);
coordinator
A
B
C,D
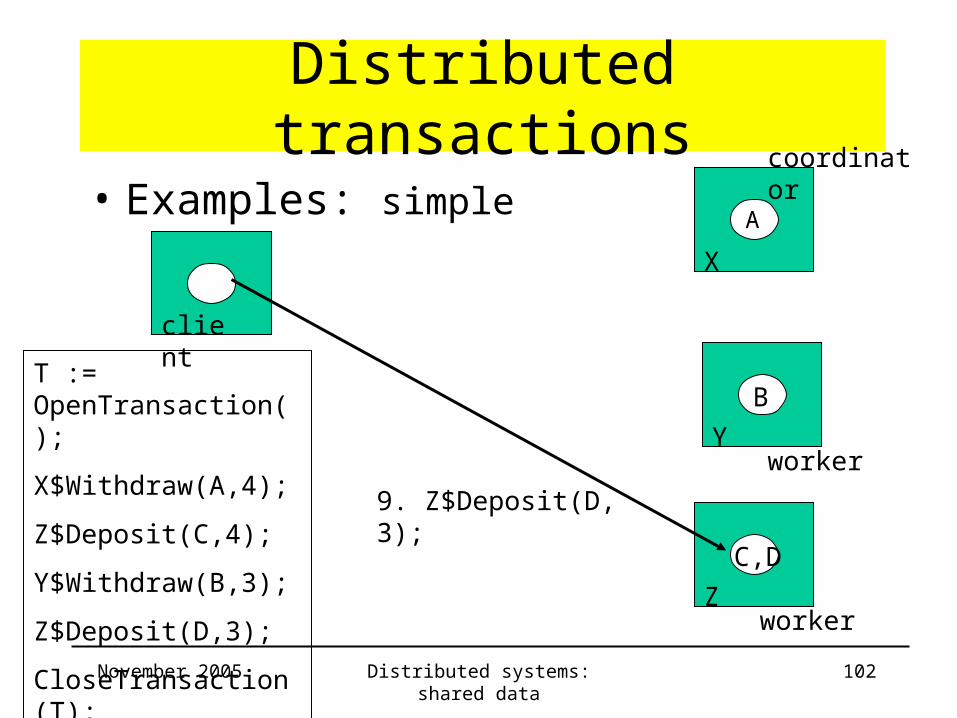
6. Y$AddServer(T, X)
7. X$NewServer(T, Y);
8. Y$Withdraw(B,3);
worker
worker
November 2005 Distributed systems: shared data 102
Distributed transactions
• Examples: simple
client
Y
X
Z
T := OpenTransaction();
X$Withdraw(A,4);
Z$Deposit(C,4);
Y$Withdraw(B,3);
Z$Deposit(D,3);
CloseTransaction(T);
coordinator
A
B
C,D
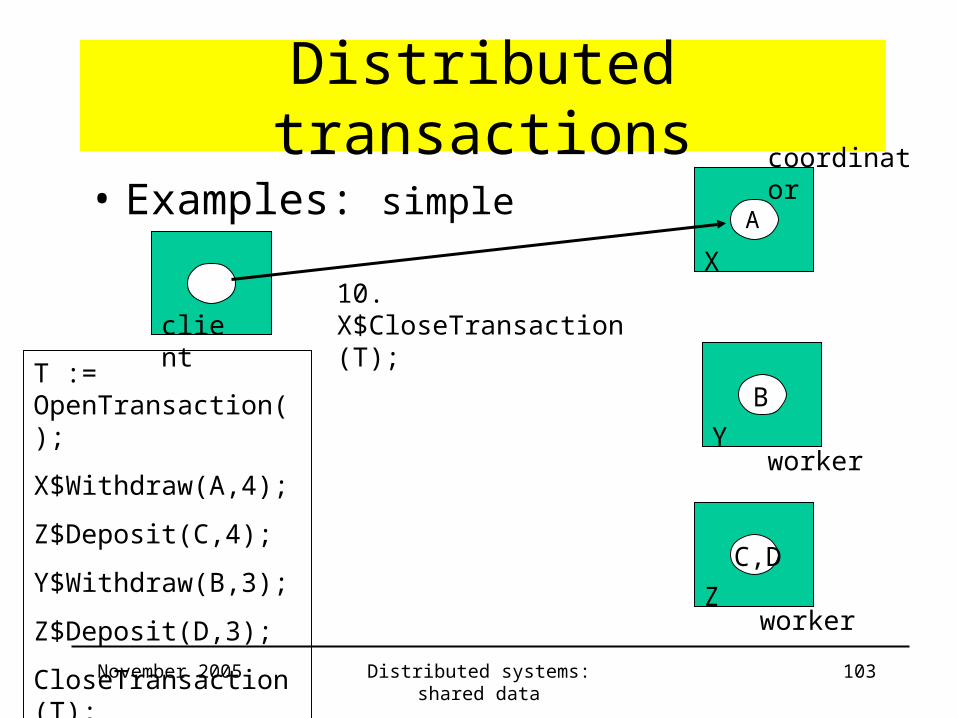
9. Z$Deposit(D, 3);
worker
worker
November 2005 Distributed systems: shared data 103
Distributed transactions
• Examples: simple
client
Y
X
Z
T := OpenTransaction();
X$Withdraw(A,4);
Z$Deposit(C,4);
Y$Withdraw(B,3);
Z$Deposit(D,3);
CloseTransaction(T);
coordinator
A
B
C,D
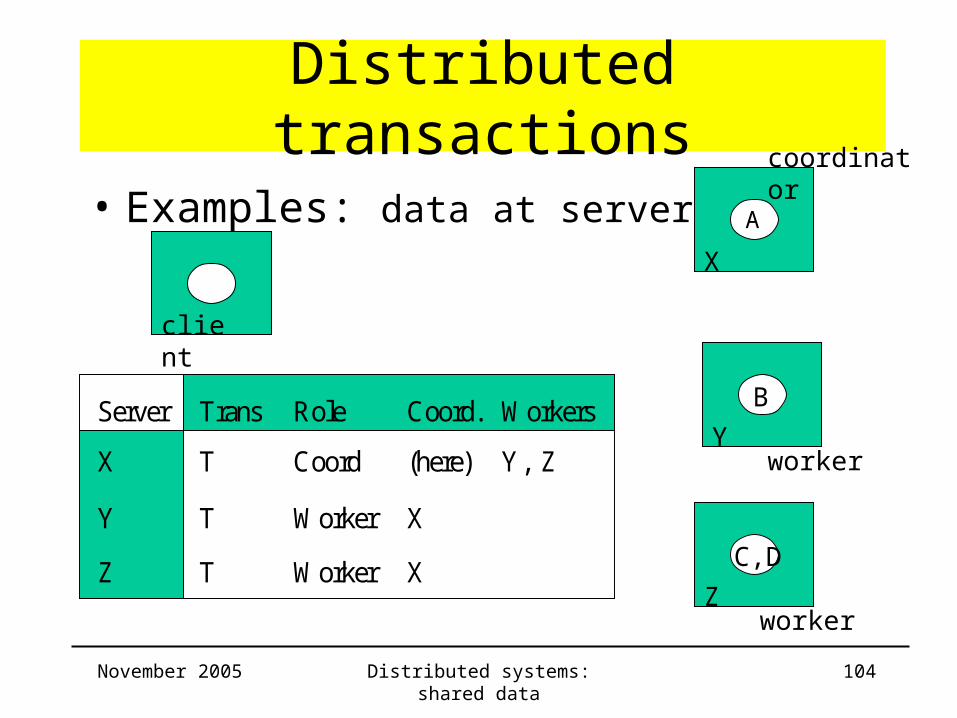
10. X$CloseTransaction(T);
worker
worker
November 2005 Distributed systems: shared data 104
Distributed transactions
• Examples: data at servers
client
Y
X
Z
coordinator
A
B
C,D
worker
worker
Server Trans Role Coord. Workers
X T Coord (here) Y, Z
Y T Worker X
Z T Worker X

November 2005 Distributed systems: shared data 105
Overview• Transactions
• Distributed transactions– Flat and nested distributed transactions– Atomic commit protocols– Concurrency in distributed transactions– Distributed deadlocks– Transaction recovery
• Replication

November 2005 Distributed systems: shared data 106
Atomic Commit protocol
• Elements of the protocol– each server is allowed to abort its part of a transaction
– if a server votes to commit it must ensure that it will
eventually be able to carry out this commitment
• the transaction must be in the prepared state
• all altered data items must be on permanent storage
– if any server votes to abort, then the decision must be
to abort the transaction

November 2005 Distributed systems: shared data 107
Atomic Commit protocol• Elements of the protocol (cont.)
– the protocol must work correctly, even when
• some servers fail
• messages are lost
• servers are temporarily unable to communicate

November 2005 Distributed systems: shared data 108
Atomic Commit protocol• Protocol:
– Phase 1: voting phase
– Phase 2: completion according to outcome of vote
November 2005 Distributed systems: shared data 109
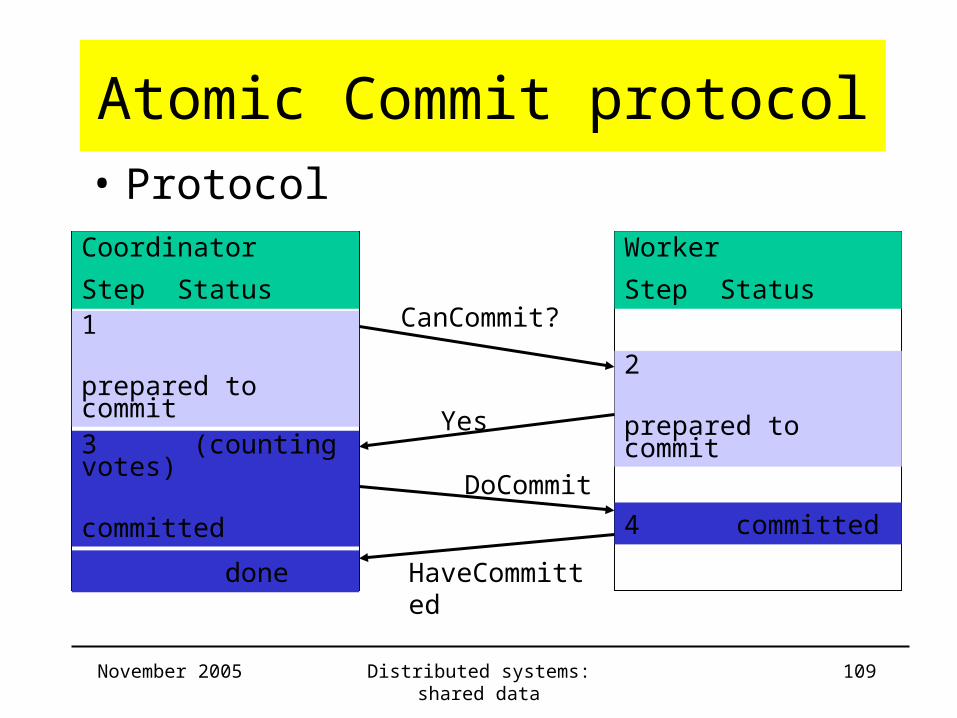
Atomic Commit protocol• Protocol
Coordinator
Step Status1
prepared to commit
Worker
Step Status
2
prepared to commit
3 (counting votes)
committed
CanCommit?
Yes
4 committed
done
DoCommit
HaveCommitted

November 2005 Distributed systems: shared data 110
Atomic Commit protocol• Protocol: Phase 1 voting phase
– Coordinator: for operation CloseTransaction• sends CanCommit to each worker• behaves as worker in phase 1• waits for replies from workers
– Worker: when receiving CanCommit• if for worker transaction can commit
– saves data items– sends Yes to coordinator
• if for worker transaction cannot commit– sends No to coordinator– clears data structures, removes locks

November 2005 Distributed systems: shared data 111
Atomic Commit protocol• Protocol: Phase 2
– Coordinator: collecting votes• all votes Yes:
commit transaction; send DoCommit to workers
• one vote No:abort transaction
– Worker: voted yes, waits for decision of coordinator• receives DoCommit
– makes committed data available; removes locks
• receives AbortTransaction– clears data structures; removes locks
Point of decision!!

November 2005 Distributed systems: shared data 112
Atomic Commit protocol• Timeouts:
– worker did all/some operations and waits for CanCommit
• unilateral abort possible– coordinator waits for votes of workers
• unilateral abort possible– worker voted Yes and waits for final decision
of coordinator• wait unavoidable• extensive delay possible• additional operation GetDecision can be used to get
decision from coordinator or other workers

November 2005 Distributed systems: shared data 113
Atomic Commit protocol• Performance:
– C W: CanCommit N-1 messages– W C: Yes/No N-1 messages– C W: DoCommit N-1 messages– W C: HaveCommitted N-1 messages
+ (unavoidable) delays possible

November 2005 Distributed systems: shared data 114
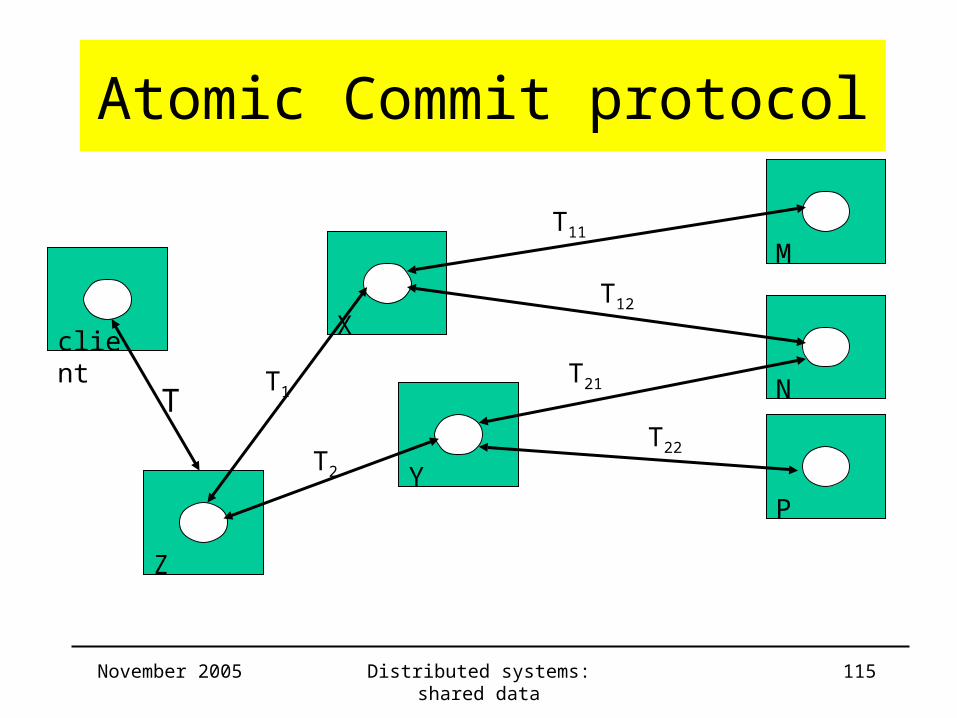
Atomic Commit protocol• Nested Transactions
– top level transaction & subtransactions
transaction tree
November 2005 Distributed systems: shared data 115
Atomic Commit protocol
client
Y
X
Z
P
N
M
TT1
T2
T11
T12
T22
T21

November 2005 Distributed systems: shared data 116
Atomic Commit protocol• Nested Transactions
– top level transaction & subtransactions
transaction tree
– coordinator = top level transaction
– subtransaction identifiers• globally unique
• allow derivation of ancestor transactions(why necessary?)

November 2005 Distributed systems: shared data 117
Atomic Commit protocol• Nested Transactions: Transaction IDs
TID in example actual TID
T Z, nz
T1 Z, nz ; X, nx
T11 Z, nz ; X, nx ; M, nm
T2 Z, nz ; Y, ny

November 2005 Distributed systems: shared data 118
Atomic Commit protocol• Upon completion of a subtransaction
– independent decision to commit or abort– commit of subtransaction
• only provisionally• status (including status of descendants) reported to
parent• final outcome dependant on its ancestors
– abort of subtransaction• implies abort of all its descendants• abort reported to its parent (always possible?)

November 2005 Distributed systems: shared data 119
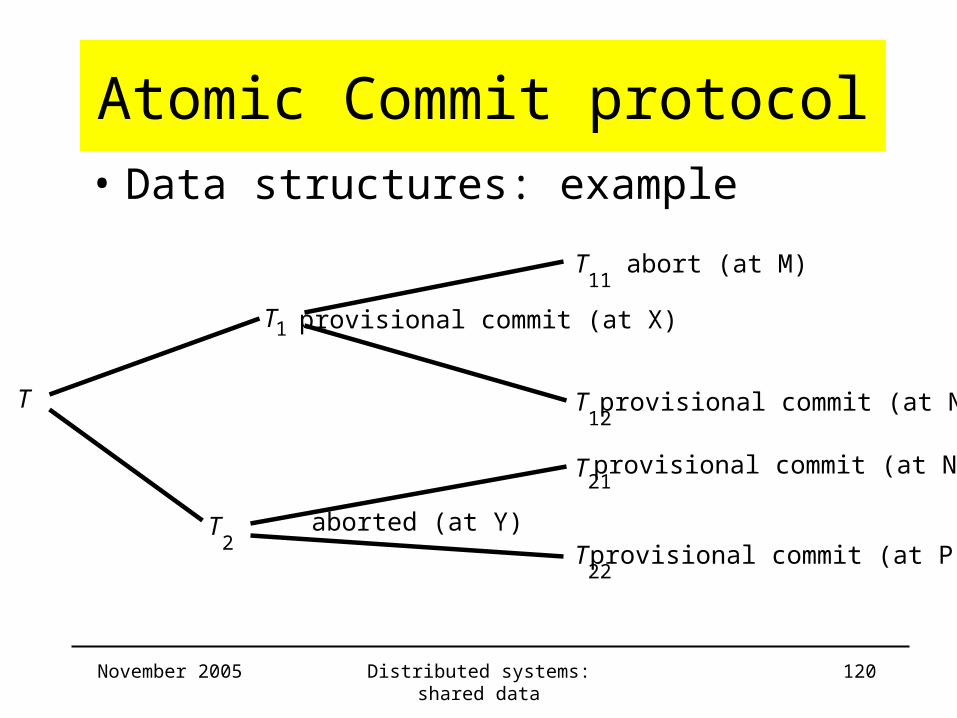
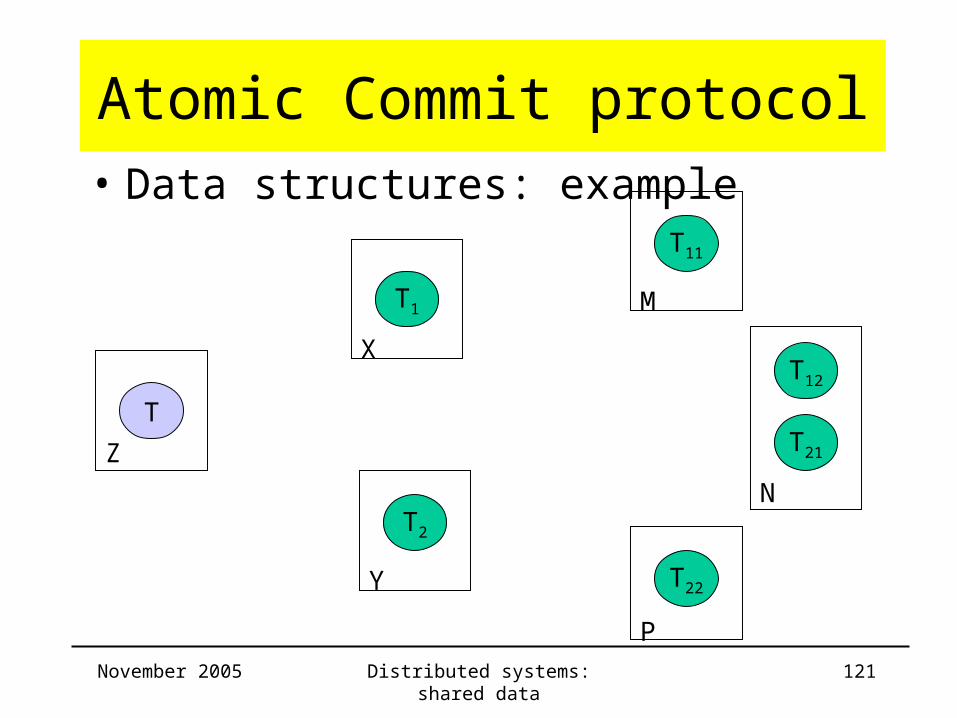
Atomic Commit protocol• Data structures
– commit list: list of all committed (sub)transactions
– aborts list: list of all aborted (sub)transactions
– example
November 2005 Distributed systems: shared data 120
Atomic Commit protocol• Data structures: example
1
2
T11
T12
T22
T21
abort (at M)
provisional commit (at N)
provisional commit (at X)
aborted (at Y)
provisional commit (at N)
provisional commit (at P)
T
T
T
November 2005 Distributed systems: shared data 121
Atomic Commit protocol• Data structures: example
T22
P
T1
T2
T12
T21
X
Y
T11
M
N
T
Z
November 2005 Distributed systems: shared data 122
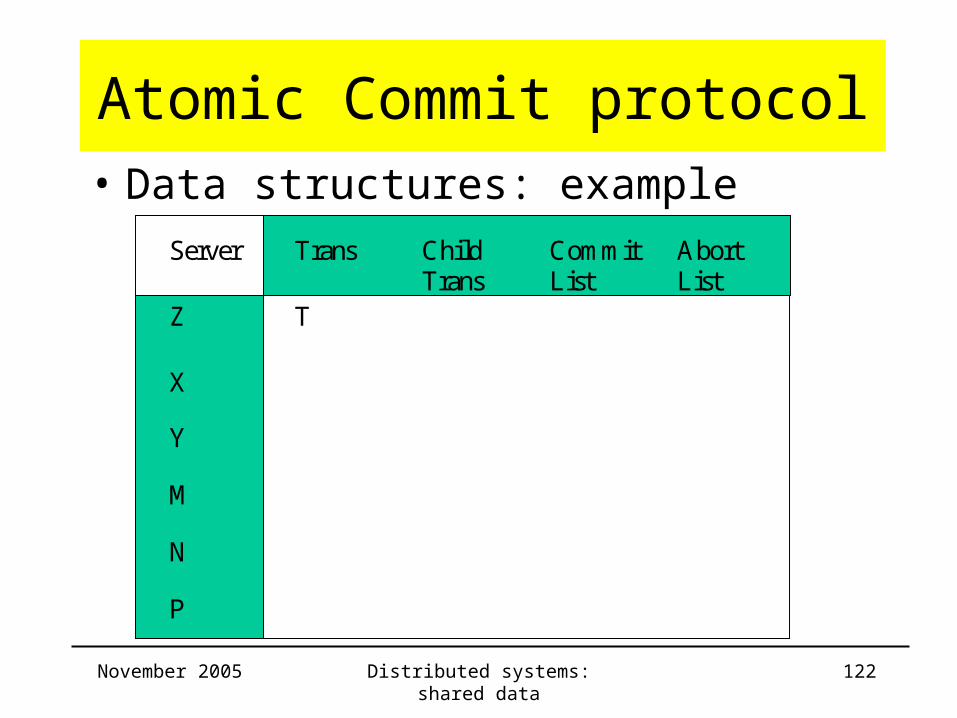
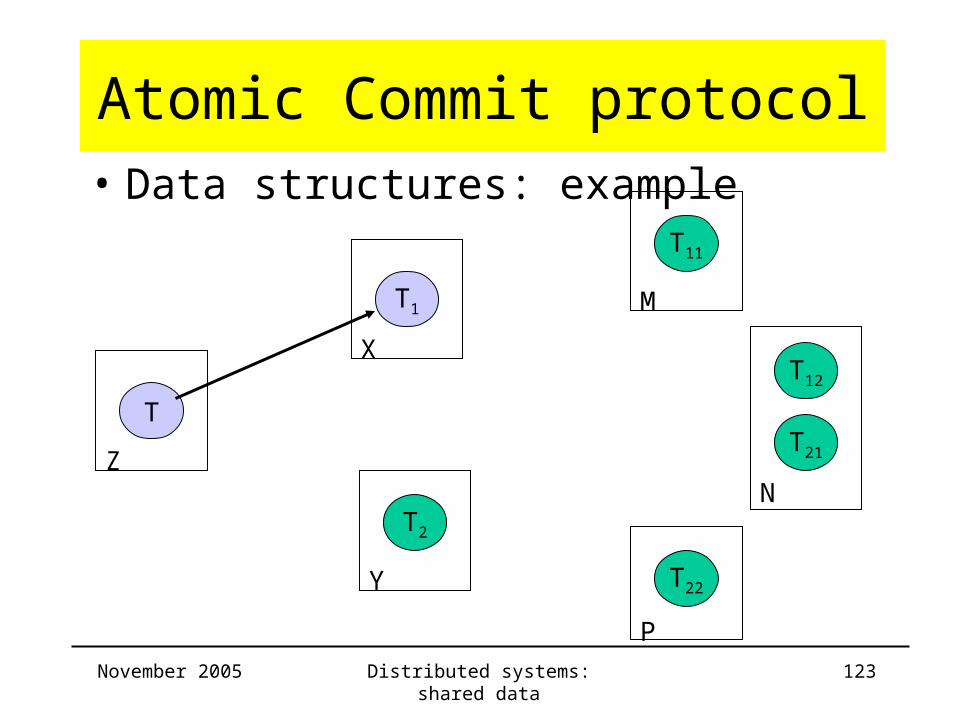
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T
X
Y
M
N
P
November 2005 Distributed systems: shared data 123
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
November 2005 Distributed systems: shared data 124
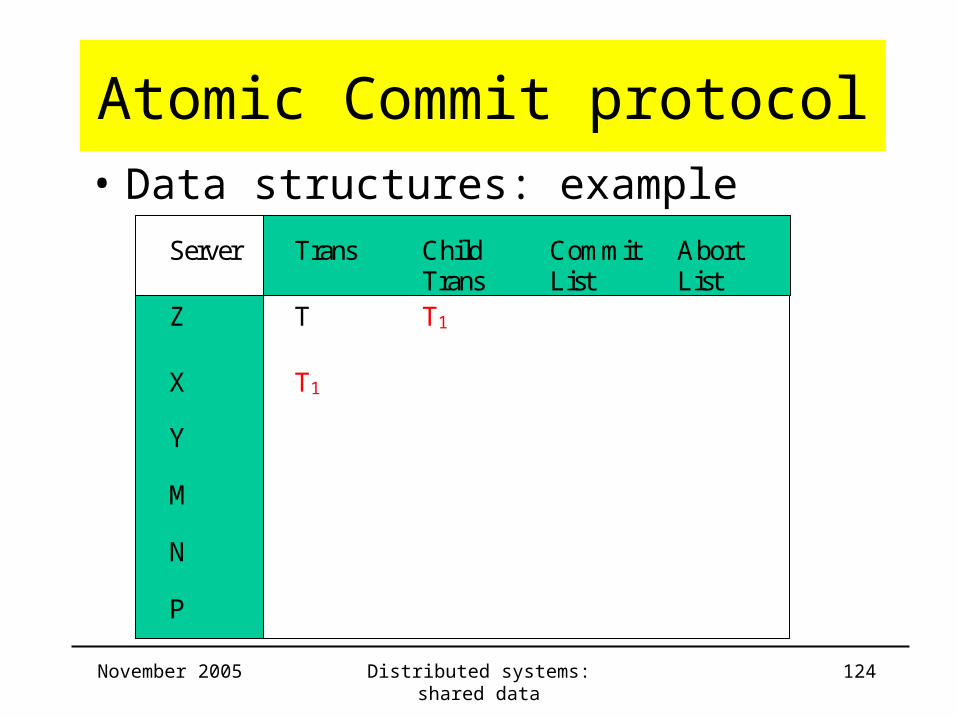
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1
X T1
Y
M
N
P
November 2005 Distributed systems: shared data 125
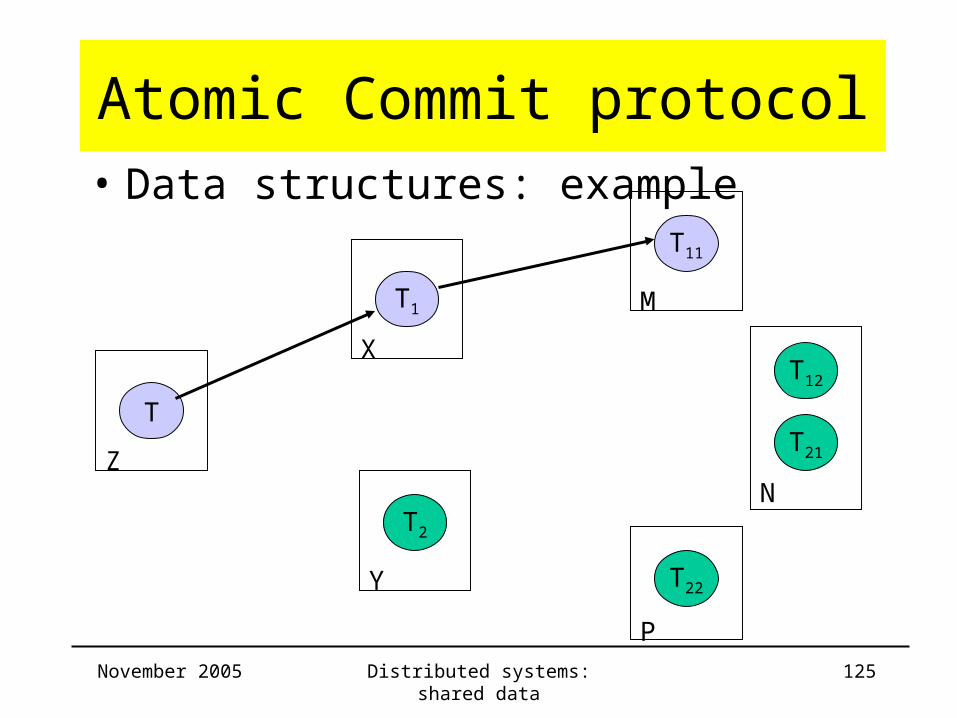
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ

November 2005 Distributed systems: shared data 126
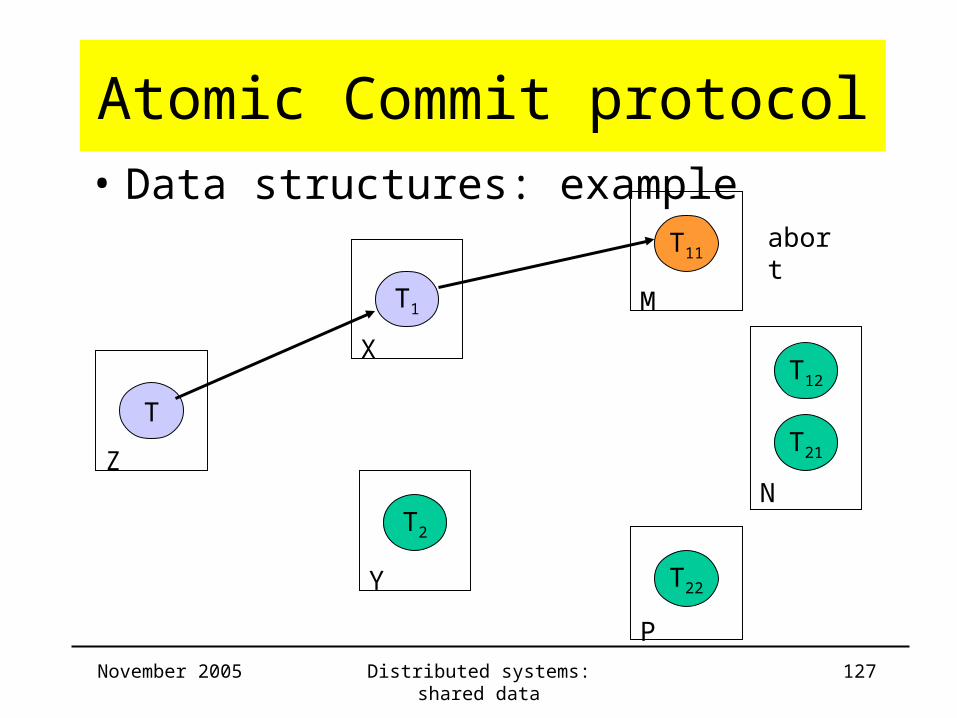
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1
X T1 T11
Y
M T11
N
P
November 2005 Distributed systems: shared data 127
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort

November 2005 Distributed systems: shared data 128
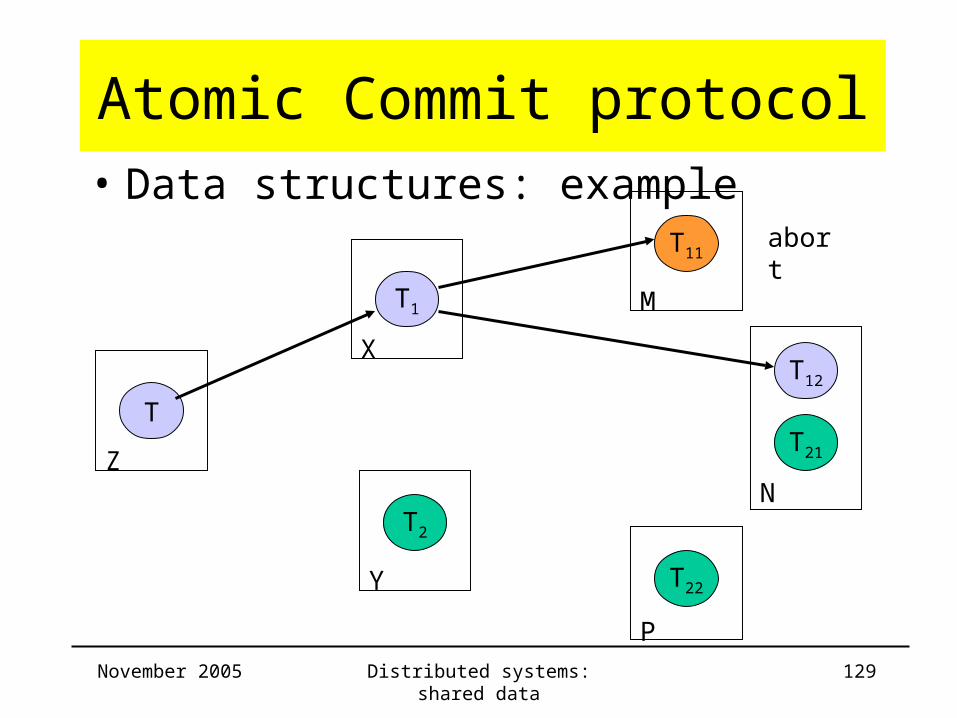
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1
X T1 T11 T11
Y
M T11 T11
N
P
November 2005 Distributed systems: shared data 129
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort

November 2005 Distributed systems: shared data 130
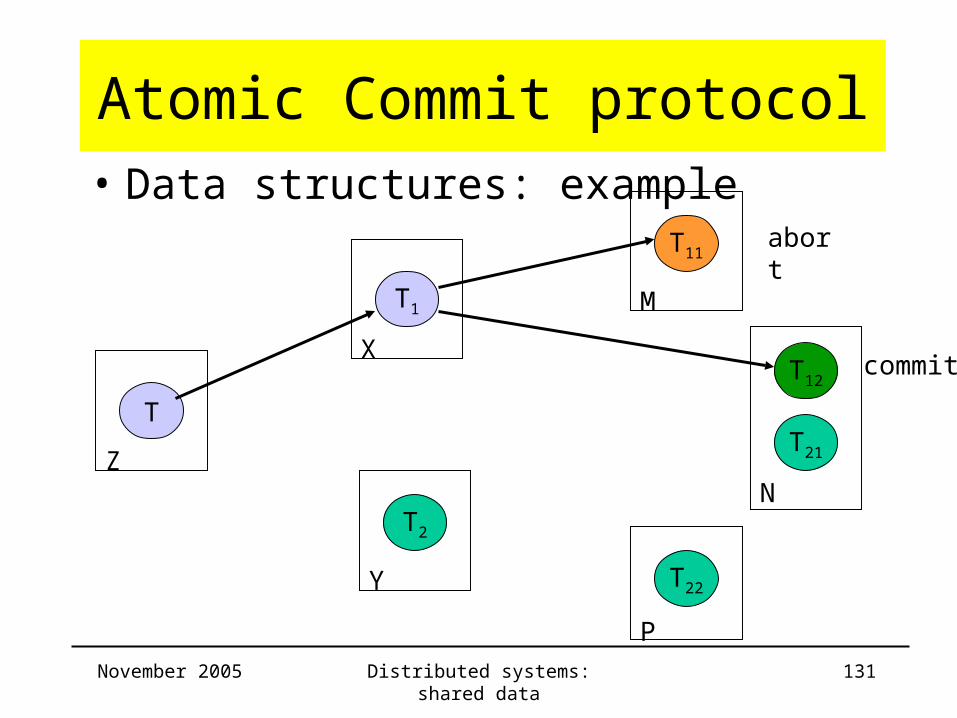
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1
X T1 T11 ,T12 T11
Y
M T11 T11
N T12
P
November 2005 Distributed systems: shared data 131
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort
commit

November 2005 Distributed systems: shared data 132
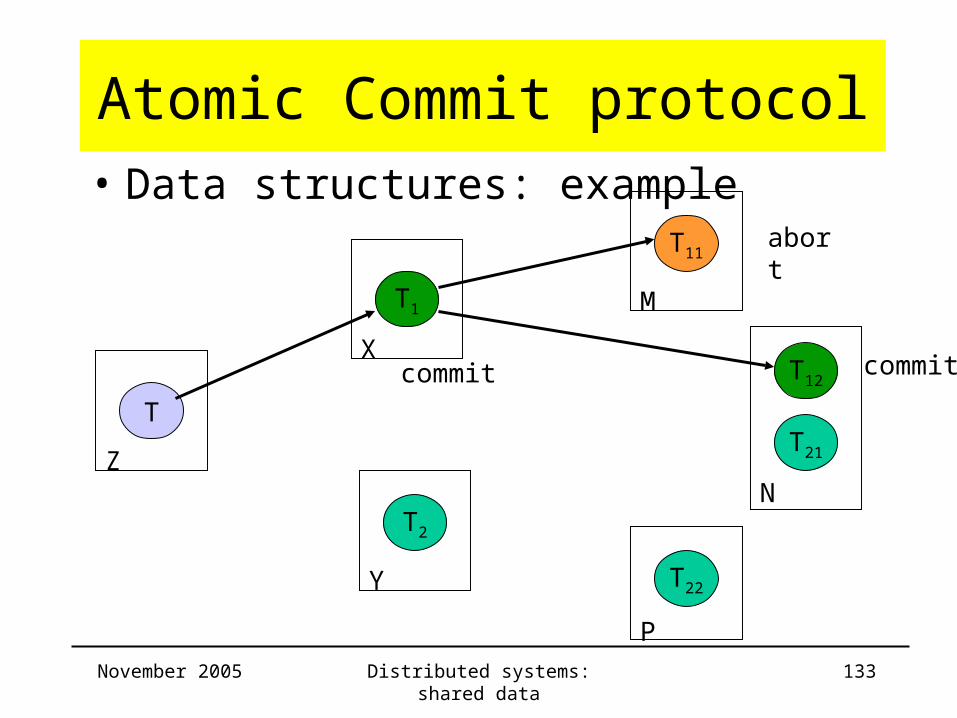
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1
X T1 T11 ,T12 T12 T11
Y
M T11 T11
N T12 T12
P
November 2005 Distributed systems: shared data 133
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort
commitcommit

November 2005 Distributed systems: shared data 134
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1
X T1 T11 ,T12 T12 , T1 T11
Y
M T11 T11
N T12 T12
P

November 2005 Distributed systems: shared data 135
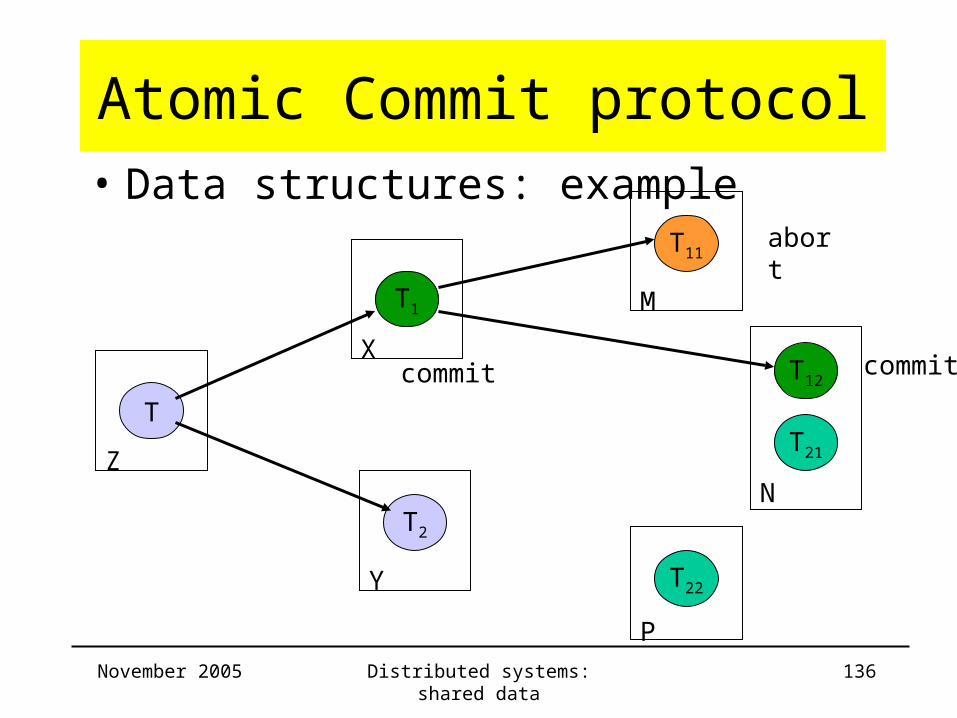
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1 T12 , T1 T11
X T1 T11 ,T12 T12 , T1 T11
Y
M T11 T11
N T12 T12
P
November 2005 Distributed systems: shared data 136
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort
commitcommit

November 2005 Distributed systems: shared data 137
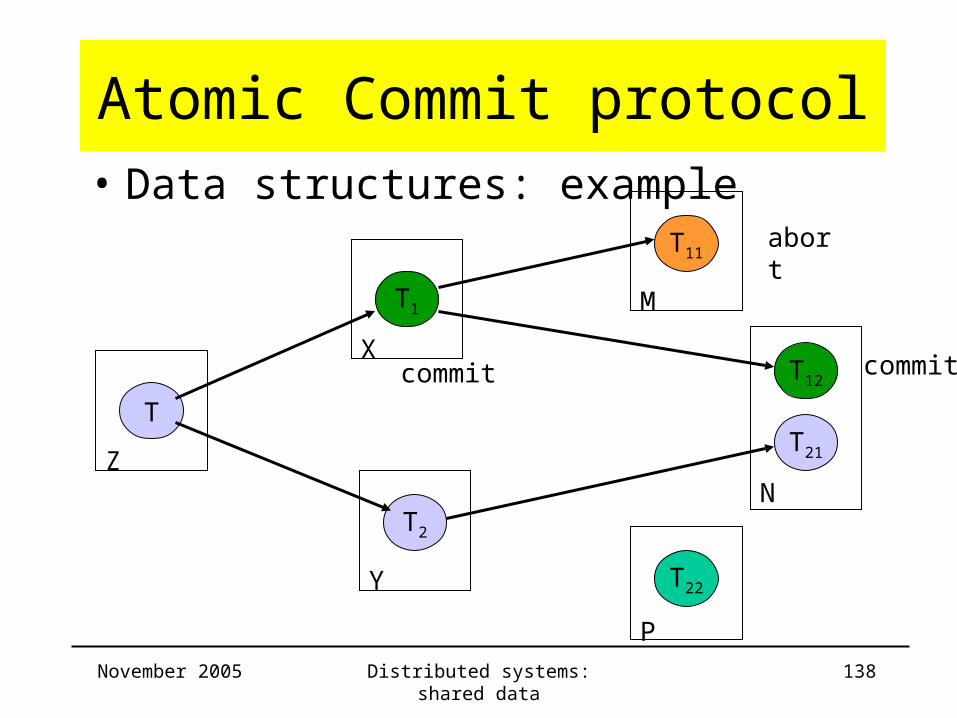
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1 ,T2 T12 , T1 T11
X T1 T11 ,T12 T12 , T1 T11
Y T2
M T11 T11
N T12 T12
P
November 2005 Distributed systems: shared data 138
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort
commitcommit

November 2005 Distributed systems: shared data 139
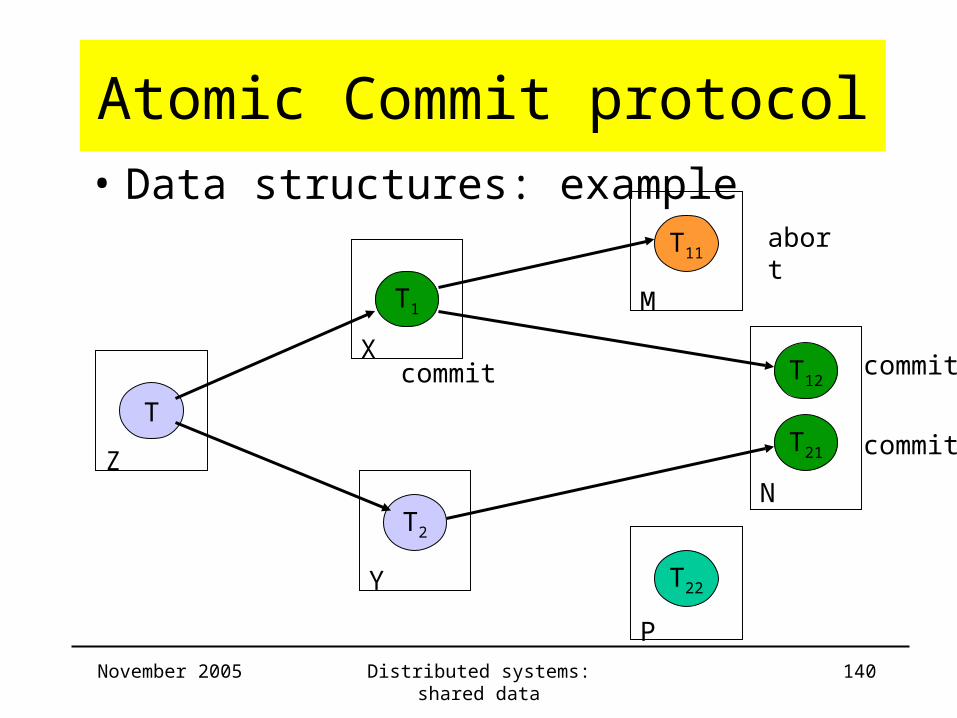
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1 ,T2 T12 , T1 T11
X T1 T11 ,T12 T12 , T1 T11
Y T2 T21
M T11 T11
N T12 ,T21 T12
P
November 2005 Distributed systems: shared data 140
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort
commitcommit
commit

November 2005 Distributed systems: shared data 141
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1 ,T2 T12 , T1 T11
X T1 T11 ,T12 T12 , T1 T11
Y T2 T21 T21
M T11 T11
N T12 ,T21 T12 ,T21
P
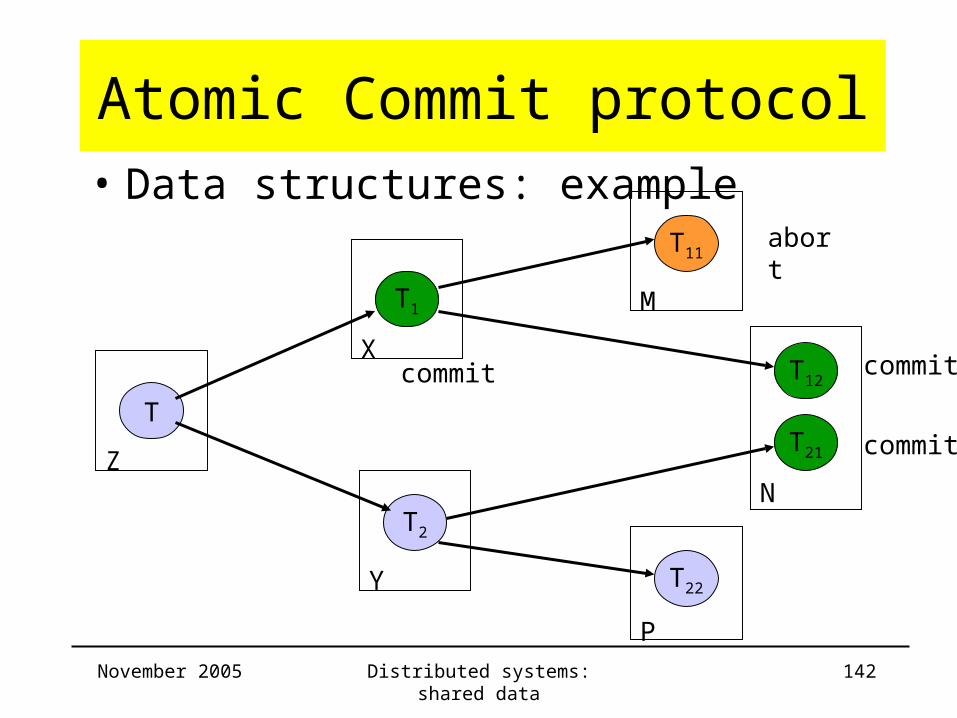
November 2005 Distributed systems: shared data 142
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort
commitcommit
commit

November 2005 Distributed systems: shared data 143
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1 ,T2 T12 , T1 T11
X T1 T11 ,T12 T12 , T1 T11
Y T2 T21 ,T22 T21
M T11 T11
N T12 ,T21 T12 ,T21
P T22
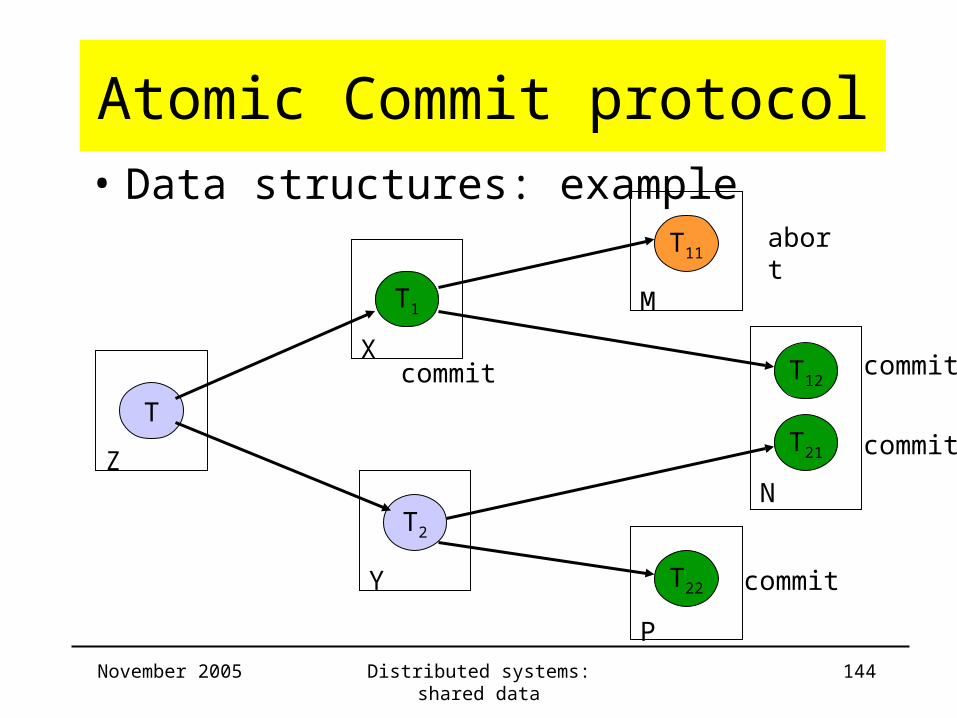
November 2005 Distributed systems: shared data 144
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort
commitcommit
commit
commit

November 2005 Distributed systems: shared data 145
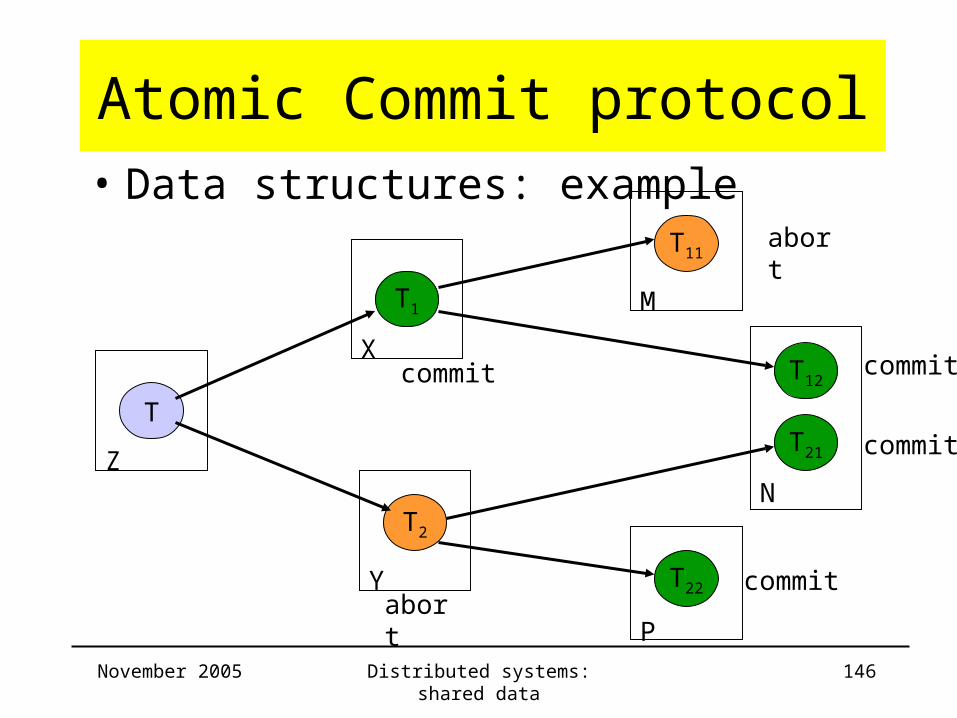
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1 ,T2 T12 , T1 T11
X T1 T11 ,T12 T12 , T1 T11
Y T2 T21 ,T22 T21 ,T22
M T11 T11
N T12 ,T21 T12 ,T21
P T22 T22
November 2005 Distributed systems: shared data 146
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort
commitcommit
commit
commitabort

November 2005 Distributed systems: shared data 147
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1 ,T2 T12 , T1 T11
X T1 T11 ,T12 T12 , T1 T11
Y T2 T21 ,T22 T21 ,T22 T2
M T11 T11
N T12 ,T21 T12 ,T21
P T22 T22

November 2005 Distributed systems: shared data 148
Atomic Commit protocol• Data structures: example
Server Trans ChildTrans
CommitList
AbortList
Z T T1 ,T2 T12 , T1 T11 ,T2
X T1 T11 ,T12 T12 , T1 T11
Y T2 T21 ,T22 T21 ,T22 T2
M T11 T11
N T12 ,T21 T12 ,T21
P T22 T22

November 2005 Distributed systems: shared data 149
Atomic Commit protocol• Data structures: final data
Server Trans Child Trans
Commit List
Abort List
Z T T12 , T1
N, X T11 ,T2
X T1 T12 , T1 T11
Y
M
N T12 ,T21 T12 ,T21
P T22 T22
November 2005 Distributed systems: shared data 150
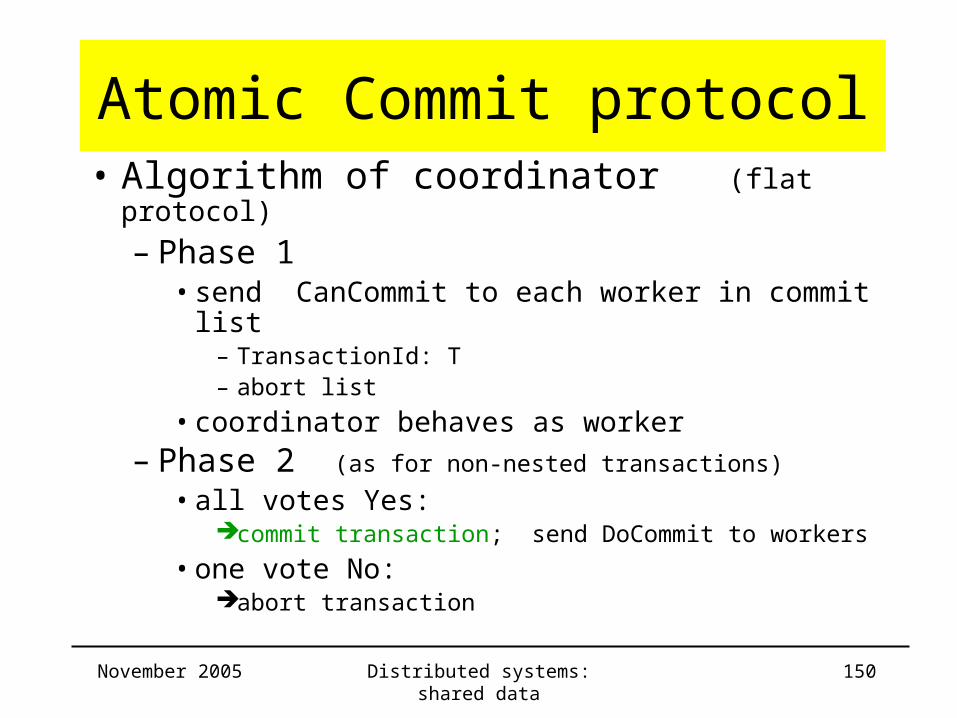
Atomic Commit protocol• Algorithm of coordinator (flat protocol)
– Phase 1• send CanCommit to each worker in commit list
– TransactionId: T– abort list
• coordinator behaves as worker– Phase 2 (as for non-nested transactions)
• all votes Yes:commit transaction; send DoCommit to workers
• one vote No:abort transaction

November 2005 Distributed systems: shared data 151
Atomic Commit protocol• Algorithm of worker (flat protocol)
– Phase 1 (after receipt of CanCommit)
• at least one (provisionally) committed descendant of top level transaction:
– transactions with ancestors in abort list are aborted
– prepare for commit of other transactions
– send Yes to coordinator
• no (provisionally) committed descendant– send No to coordinator
– Phase 2 (as for non-nested transactions)

November 2005 Distributed systems: shared data 152
Atomic Commit protocol• Algorithm of worker (flat protocol)
– Phase 1 (after receipt of CanCommit)
– Phase 2 voted yes, waits for decision of coordinator• receives DoCommit
– makes committed data available; removes locks
• receives AbortTransaction– clears data structures; removes locks

November 2005 Distributed systems: shared data 153
Atomic Commit protocol• Timeouts:
– same 3 as above:• worker did all/some operations and waits for
CanCommit• coordinator waits for votes of workers • worker voted Yes and waits for final decision of
coordinator– provisionally committed child with an aborted
ancestor:• does not participate in algorithm• has to make an enquiry itself• when?

November 2005 Distributed systems: shared data 154
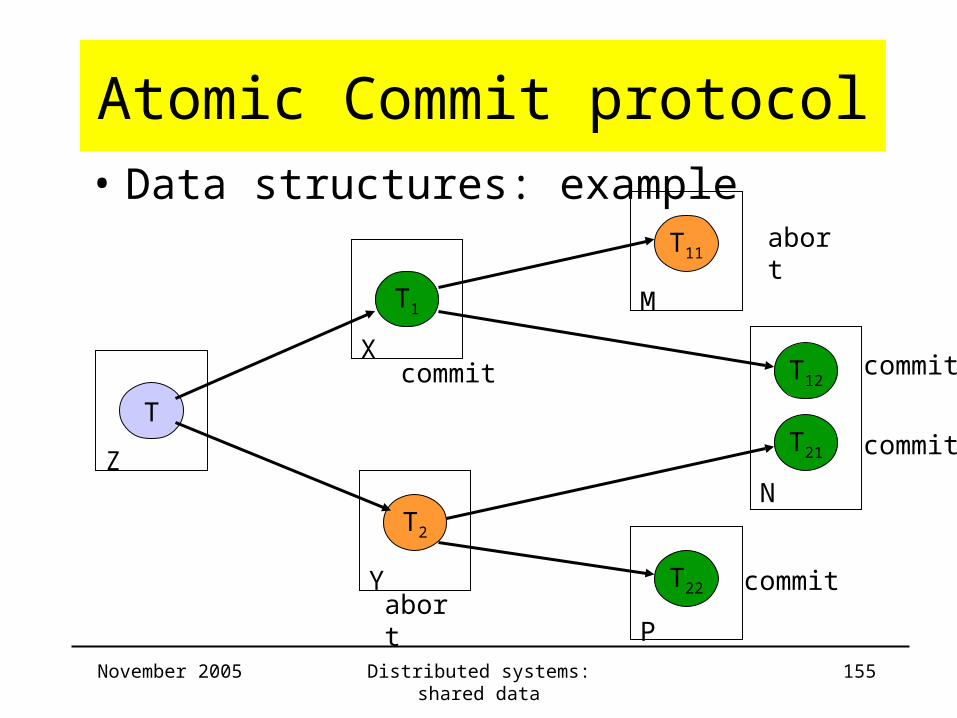
Atomic Commit protocol• Data structures: final data
Server Trans ChildTrans
CommitList
AbortList
Z T T12 , T1
N, XT11 ,T2
X T1 T12 , T1 T11
Y
M
N T12 ,T21 T12 ,T21
P T22 T22
November 2005 Distributed systems: shared data 155
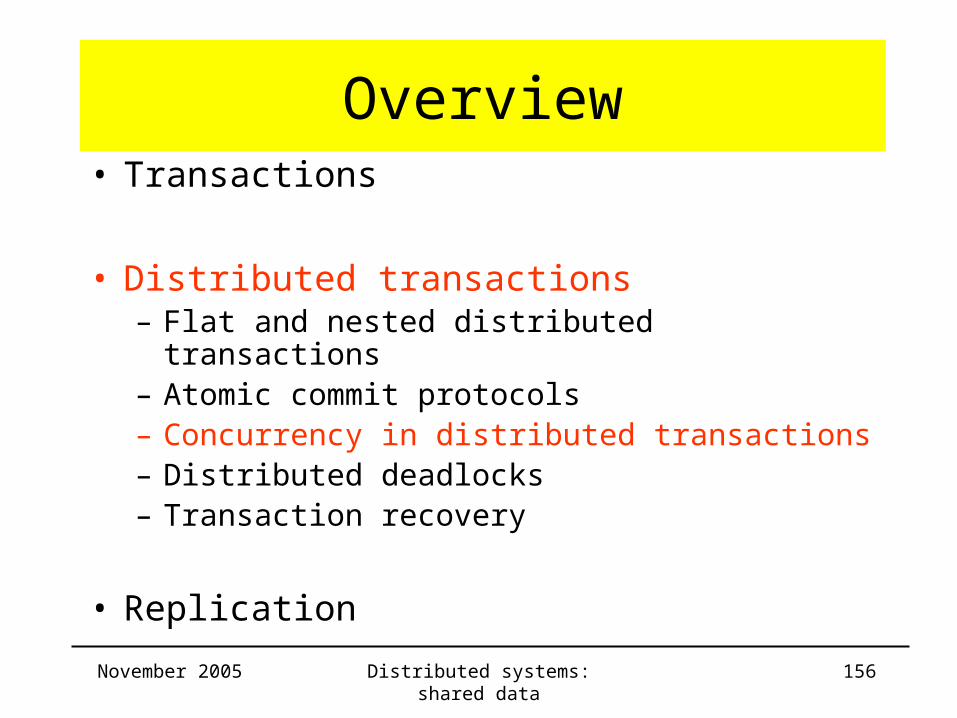
Atomic Commit protocol• Data structures: example
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
abort
commitcommit
commit
commitabort
November 2005 Distributed systems: shared data 156
Overview• Transactions
• Distributed transactions– Flat and nested distributed transactions– Atomic commit protocols– Concurrency in distributed transactions– Distributed deadlocks– Transaction recovery
• Replication

November 2005 Distributed systems: shared data 157
Distributed transactions Locking
• Locks are maintained locally (at each server)
– it decides whether• to grant a lock
• to make the requesting transaction wait
– it cannot release the lock until it knows whether the transaction has been
• committed
• aborted
at all servers– deadlocks can occur

November 2005 Distributed systems: shared data 158
Distributed transactions Locking
• Locking rules for nested transactions– child transaction inherits locks from parents
– when a nested transaction commits, its locks are inherited by its parents
– when a nested transaction aborts, its locks are removed
– a nested transaction can get a read lock when all the holders of write locks (on that data item) are ancestors
– a nested transaction can get a write lock when all the holders of read and write locks (on that data item) are ancestors
November 2005 Distributed systems: shared data 159
Distributed transactions Locking
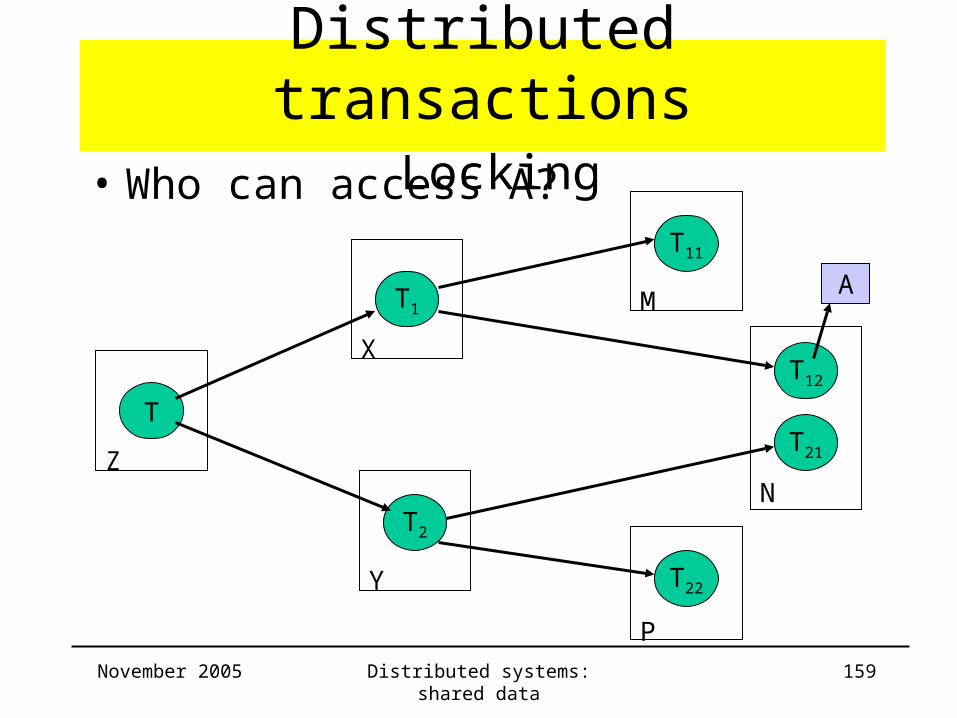
• Who can access A?
T
T1
T2
T12
T21
X
Y
T11
M
T22
P
NZ
A

November 2005 Distributed systems: shared data 160
Overview• Transactions
• Distributed transactions– Flat and nested distributed transactions– Atomic commit protocols– Concurrency in distributed transactions– Distributed deadlocks– Transaction recovery
• Replication

November 2005 Distributed systems: shared data 161
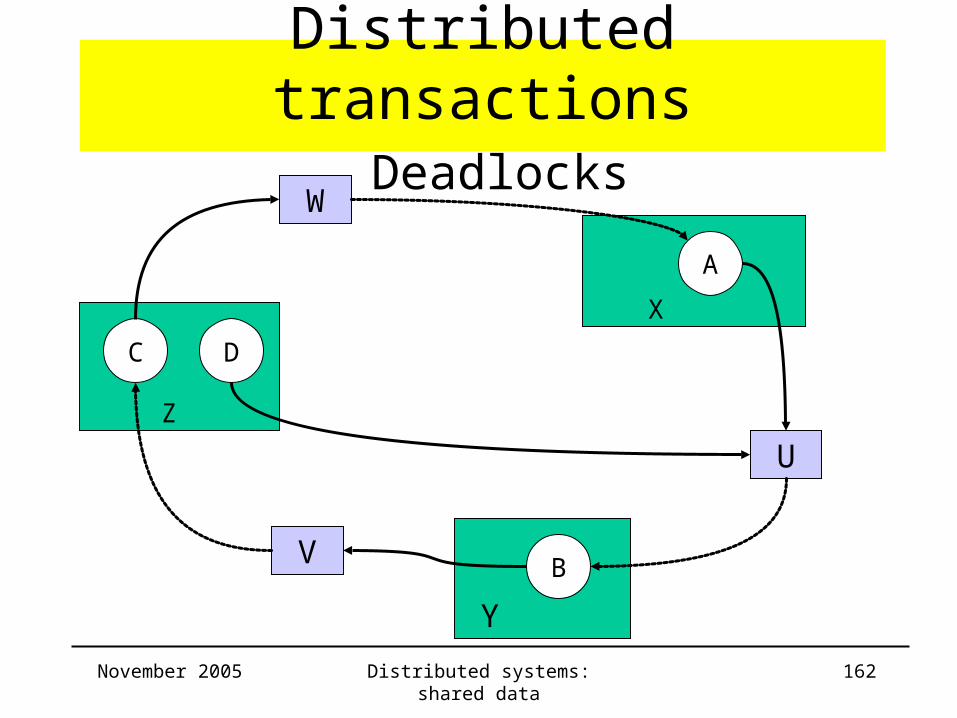
Distributed deadlocks
• Single server approaches– prevention: difficult to apply
– timeouts: value with variable delays?
Detection
• global wait-for-graph can be constructed from local
ones
• cycle in global graph possible without cycle in local
graph
November 2005 Distributed systems: shared data 162
Distributed transactions Deadlocks
C D
Z
A
X
B
Y
W
V
U

November 2005 Distributed systems: shared data 163
Distributed transactions Deadlocks
• Algorithms:
– centralised deadlock detection: not a good idea
• depends on a single server
• cost of transmission of local wait-for graphs
– distributed algorithm:
• complex
• phantom deadlocks
edge chasing approach

November 2005 Distributed systems: shared data 164
Distributed transactions Deadlocks
• Phantom deadlocks
– deadlock detected that is not really a deadlock
– during deadlock detection
• while constructing global wait-for graph
• waiting transaction is aborted

November 2005 Distributed systems: shared data 165
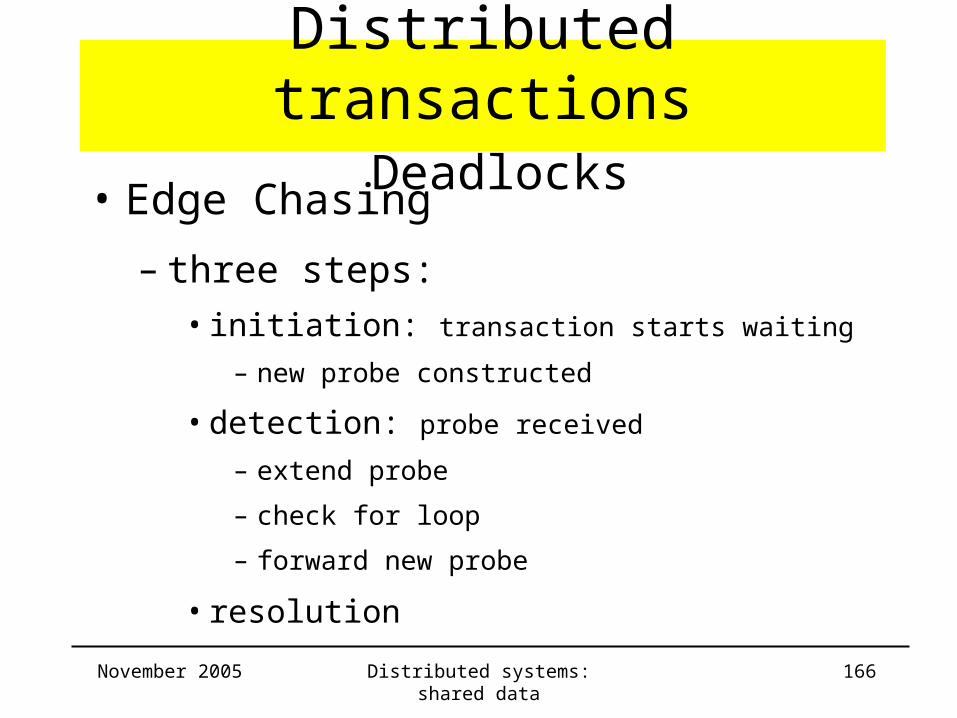
Distributed transactions Deadlocks
• Edge Chasing
– distributed approach to deadlock detection:
• no global wait-for graph is constructed
– servers attempt to find cycles
• by forwarding probes (= messages) that follow
edges of the wait-for graph throughout the
distributed system
November 2005 Distributed systems: shared data 166
Distributed transactions Deadlocks
• Edge Chasing
– three steps:
• initiation: transaction starts waiting
– new probe constructed
• detection: probe received
– extend probe
– check for loop
– forward new probe
• resolution

November 2005 Distributed systems: shared data 167
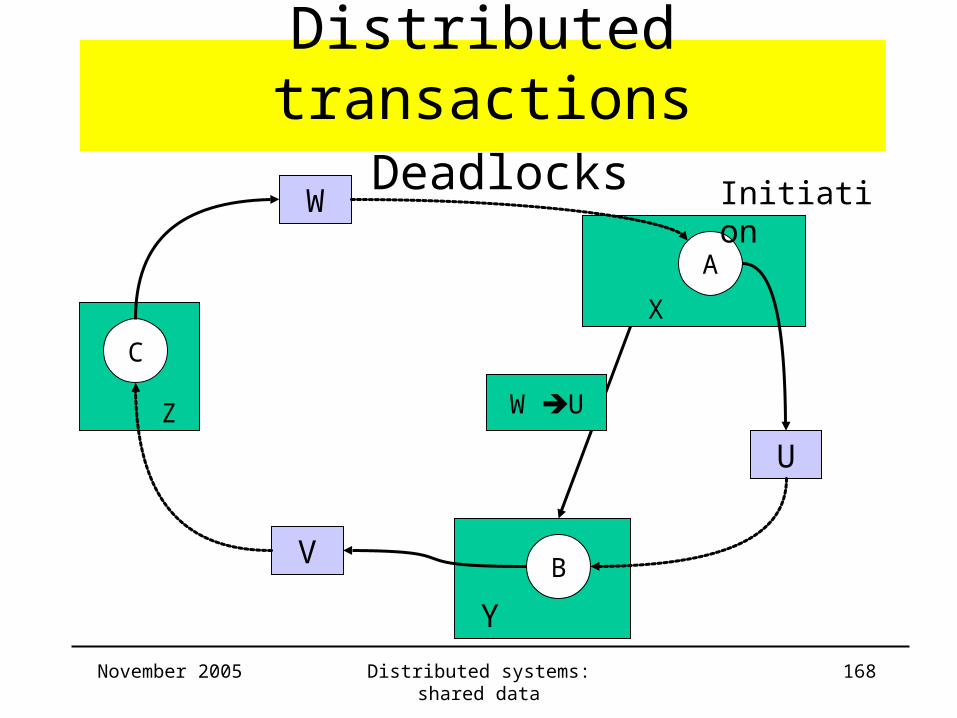
• Edge Chasing: initiation
– send out probe
when transaction T starts waiting for U (and U
is already waiting for …)
– in case of lock sharing, different probes are
forwarded
Distributed transactions Deadlocks
T U
November 2005 Distributed systems: shared data 168
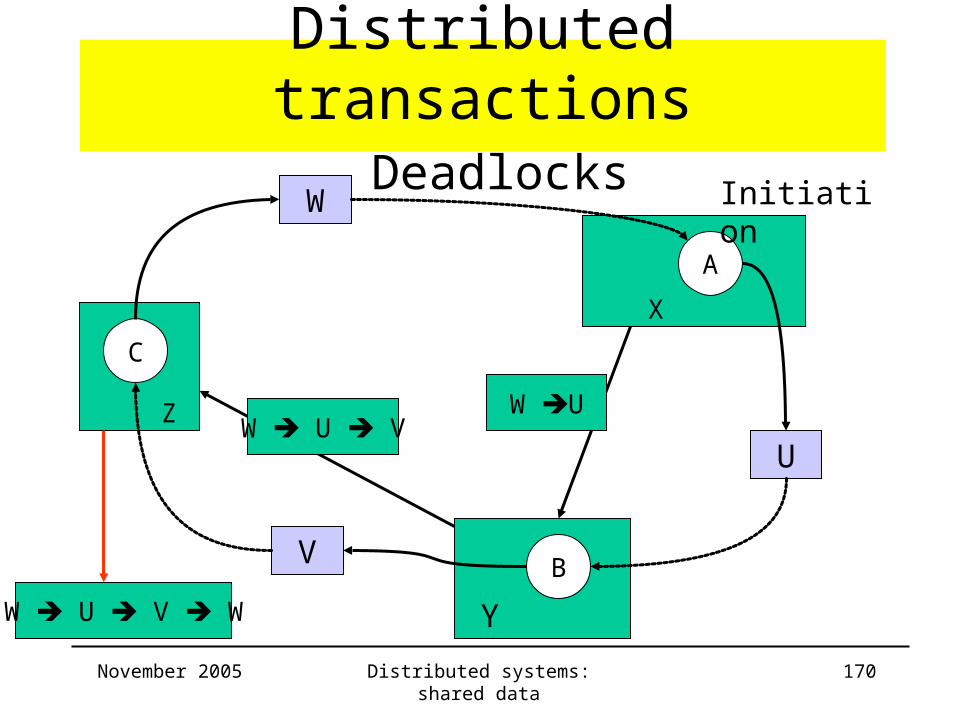
Distributed transactions Deadlocks
C
Z
A
X
B
Y
W
V
U
W U
Initiation
November 2005 Distributed systems: shared data 169
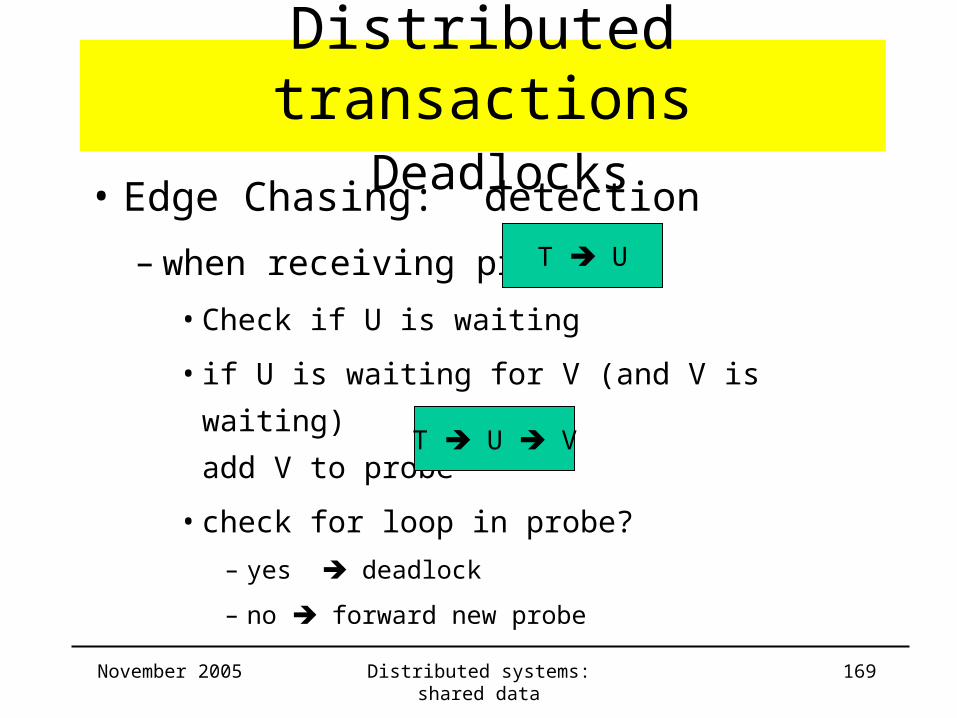
• Edge Chasing: detection
– when receiving probe
• Check if U is waiting
• if U is waiting for V (and V is waiting)
add V to probe
• check for loop in probe?
– yes deadlock
– no forward new probe
Distributed transactions Deadlocks
T U
T U V
November 2005 Distributed systems: shared data 170
Distributed transactions Deadlocks
C
Z
A
X
B
Y
W
V
U
W U
Initiation
W U V
W U V W

November 2005 Distributed systems: shared data 171
• Edge Chasing: resolution
– abort one transaction
– problem?
• Every waiting transaction can initiate deadlock
detection
• detection may happen at different servers
• several transactions may be aborted
– solution: transactions priorities
Distributed transactions Deadlocks

November 2005 Distributed systems: shared data 172
• Edge Chasing: transaction priorities
– assign priority to each transaction, e.g. using
timestamps
– solution of problem above:
• abort transaction with lowest priority
• if different servers detect same cycle, the same
transaction will be aborted
Distributed transactions Deadlocks

November 2005 Distributed systems: shared data 173
• Edge Chasing: transaction priorities
– other improvements
• number of initiated probe messages – detection only initiated when higher priority transaction
waits for a lower priority one
• number of forwarded probe messages – probes travel downhill -from transaction with high
priority to transactions with lower priorities
– probe queues required; more complex algorithm
Distributed transactions Deadlocks

November 2005 Distributed systems: shared data 174
Overview• Transactions
• Distributed transactions– Flat and nested distributed transactions– Atomic commit protocols– Concurrency in distributed transactions– Distributed deadlocks– Transaction recovery
• Replication

November 2005 Distributed systems: shared data 175
Transactions and failures• Introduction
– Approaches to fault-tolerant systems• replication
– instantaneous recovery from a single fault
– expensive in computing resources
• restart and restore consistent state– less expensive
– requires stable storage
– slow(er) recovery process

November 2005 Distributed systems: shared data 176
Transactions and failures• Overview
– Stable storage
– Transaction recovery
– Recovery of the two-phase commit protocol

November 2005 Distributed systems: shared data 177
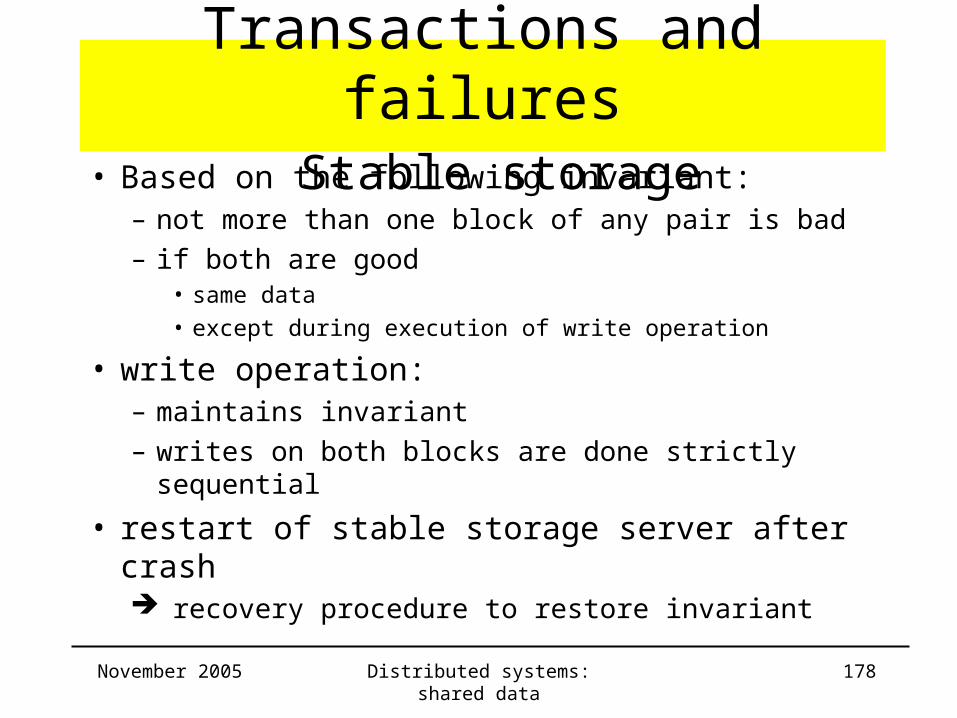
Transactions and failures Stable storage
• Ensures that any essential permanent data will be recoverable after any single system failure
• allow system failures: – during a disk write
– damage to any single disk block
• hardware solution RAID technology• software solution:
– based on pairs of blocks for same data item
– checksum to determine whether block is good or bad
November 2005 Distributed systems: shared data 178
Transactions and failures Stable storage
• Based on the following invariant:– not more than one block of any pair is bad
– if both are good• same data
• except during execution of write operation
• write operation:– maintains invariant
– writes on both blocks are done strictly sequential
• restart of stable storage server after crash recovery procedure to restore invariant

November 2005 Distributed systems: shared data 179
Transactions and failures Stable storage
• Recovery for a pair:– both good and the same ok
– one good, one bad copy good block to bad block
– both good and different copy one block to the other

November 2005 Distributed systems: shared data 180
Transactions and failures• Overview
– Stable storage
– Transaction recovery
– Recovery of the two-phase commit protocol

November 2005 Distributed systems: shared data 181
Transactions and failures Transaction recovery
• atomic property of transaction implies:– durability
• data items stored in permanent storage
• data will remain available indefinitely
– failure atomicity• effects of transactions are atomic even when servers
fail
• recovery should ensure durability and failure atomicity

November 2005 Distributed systems: shared data 182
Transactions and failures Transaction recovery
• Assumptions about servers– servers keep data in volatile storage
– committed data recorded in a recovery file
• single mechanism: recovery manager– save data items in permanent storage for committed
transactions
– restore the server’s data items after a crash
– reorganize the recovery file to improve performance of recovery
– reclaim storage space in the recovery file

November 2005 Distributed systems: shared data 183
Transactions and failures Transaction recovery
• Elements of algorithm:– each server maintains an intention list for all of its
active transactions: pairs of
• name• new value
– decision of server: prepared to commit a transaction intention list saved in the recovery file (stable storage)
– server receives DoCommit commit recorded in recovery file
– after a crash: based on recovery file
• effects of committed transactions restored (in correct order)
• effects of other transactions neglected

November 2005 Distributed systems: shared data 184
Transactions and failures Transaction recovery
• Alternative implementations for recovery file:
– logging technique
– shadow versions
• (see book for details)

November 2005 Distributed systems: shared data 185
Transactions and failures• Overview
– Stable storage
– Transaction recovery
– Recovery of the two-phase commit protocol

November 2005 Distributed systems: shared data 186
Transactions and failures two-phase commit protocol
• Server can fail during commit protocol
• each server keeps its own recovery file
• 2 new status values:– done– uncertain

November 2005 Distributed systems: shared data 187
Transactions and failures two-phase commit protocol
• meaning of status values:– committed:
• coordinator: outcome of votes is yes
• worker: protocol is complete
– done• coordinator: protocol is complete
– uncertain:• worker: voted yes; outcome unknown

November 2005 Distributed systems: shared data 188
Transactions and failures two-phase commit protocol
• Recovery actions: (status@…) in recovery file
– prepared@coordinator• no decision before failure of server
• send AbortTransaction to all workers
– aborted@coordinator• send AbortTransaction to all workers
– committed@coordinator• decision to commit taken before crash
• send DoCommit to all workers
• resume protocol

November 2005 Distributed systems: shared data 189
Transactions and failures two-phase commit protocol
• Recovery actions: (status@…) in recovery file
– committed@worker• send HaveCommitted to coordinator
– uncertain@worker• send GetDecision to coordinator to get status
– prepared@worker• not yet voted yes• unilateral abort possible
– done@coordinator• no action required

November 2005 Distributed systems: shared data 190
Overview• Transactions
• Distributed transactions
• Replication– System model and group communication– Fault-tolerant services– Highly available services– Transactions with replicated data

November 2005 Distributed systems: shared data 191
Replication• A technique for enhancing services
– Performance enhancement– Increased availability– Fault tolerance
• Requirements– Replication transparency– Consistency

November 2005 Distributed systems: shared data 192
Overview• Transactions
• Distributed transactions
• Replication– System model and group communication– Fault-tolerant services– Highly available services– Transactions with replicated data
November 2005 Distributed systems: shared data 193
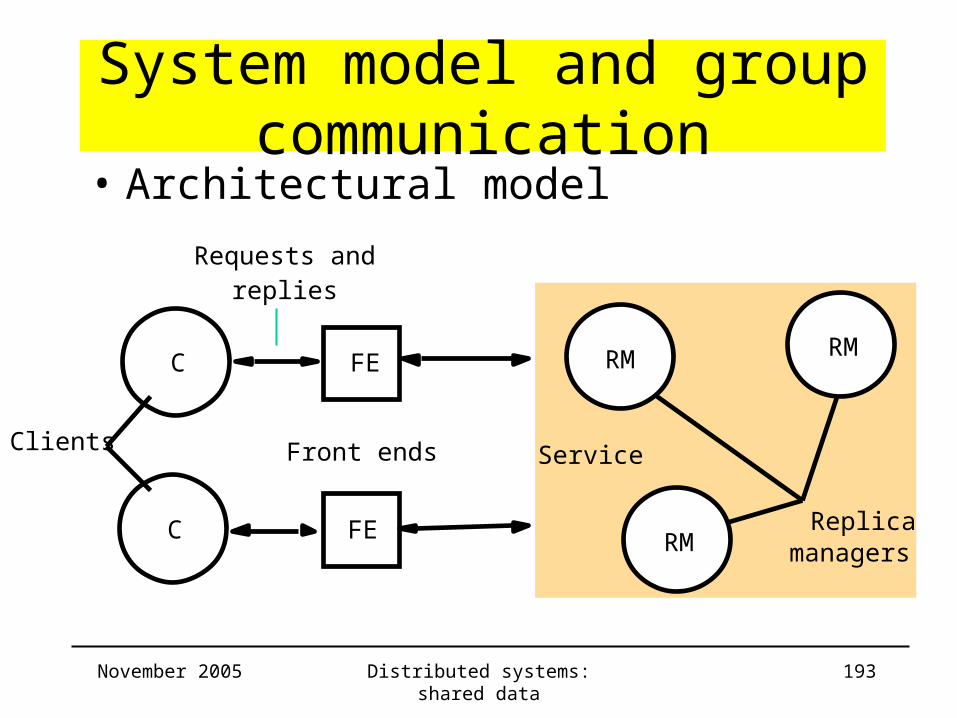
System model and group communication
• Architectural model
FE
Requests andreplies
C
ReplicaC
ServiceClients Front ends
managers
RM
RMFE
RM

November 2005 Distributed systems: shared data 194
System model and group communication
• 5 phases in the execution of a request:
– FE issues requests to one or more RMs
– Coordination: needed to execute requests consistently
• FIFO
• Causal
• Total
– Execution: by all managers, perhaps tentatively
– Agreement
– Response

November 2005 Distributed systems: shared data 195
System model and group communication
• Need for dynamic groups!
• Role of group membership service– Interface for group membership changes: create/destroy groups, add process
– Implementing a failure detector: monitor group members
– Notifying members of group membership changes
– Performing group address expansion
• Handling network partitions: group is
– Reduced: primary-partition
– Split: partitionable
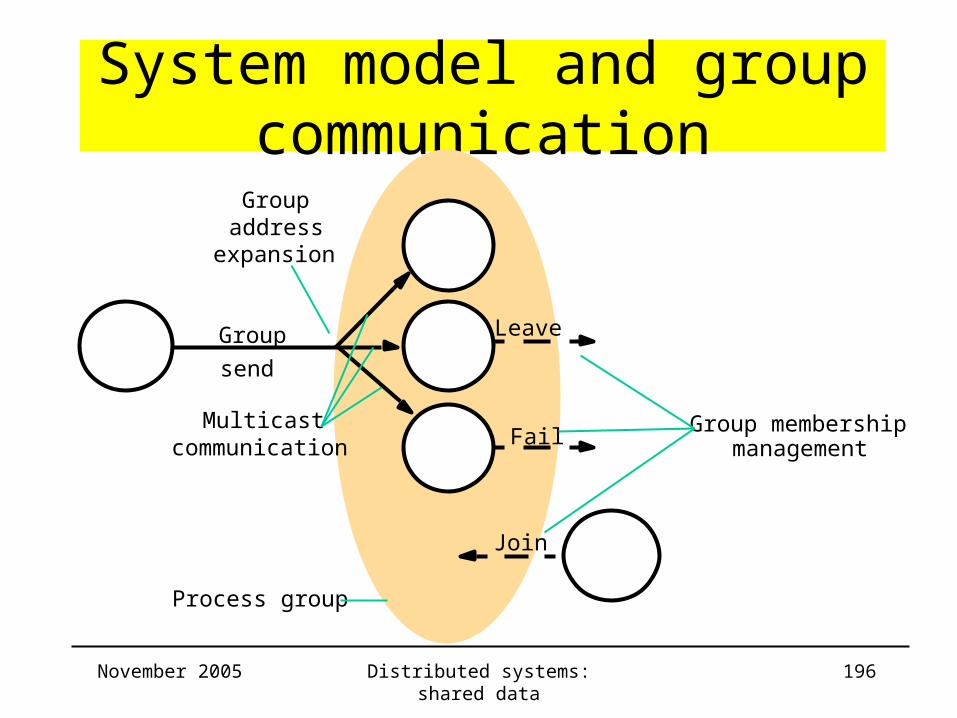
November 2005 Distributed systems: shared data 196
System model and group communication
Join
Groupaddress
expansion
Multicastcommunication
Group
send
FailGroup membership
management
Leave
Process group
November 2005 Distributed systems: shared data 197
System model and group communication
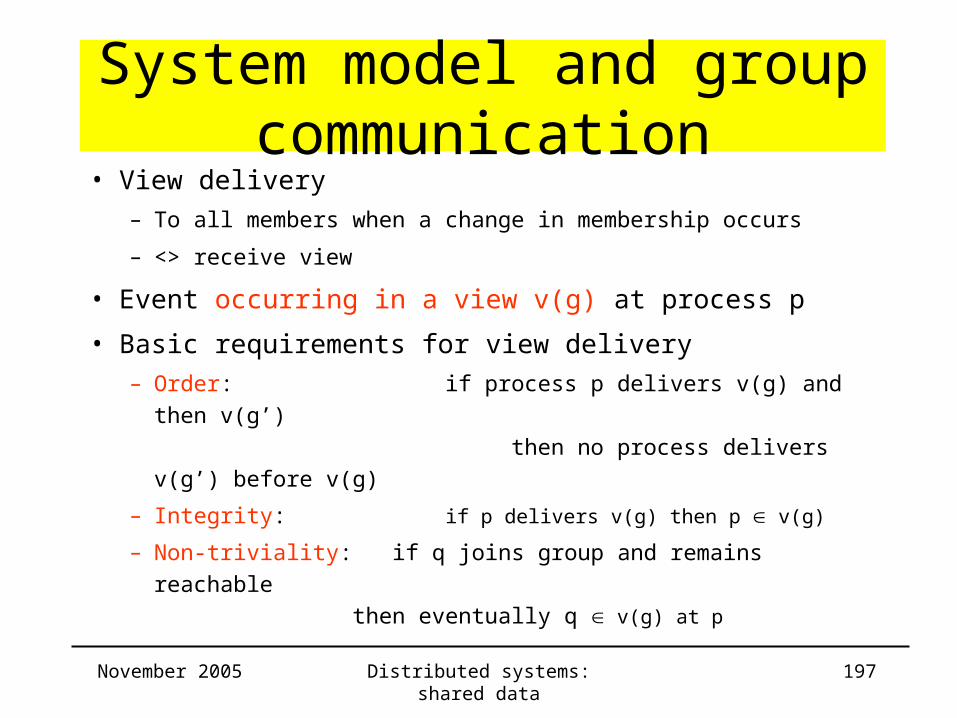
• View delivery
– To all members when a change in membership occurs
– <> receive view
• Event occurring in a view v(g) at process p
• Basic requirements for view delivery
– Order: if process p delivers v(g) and then v(g’)
then no process delivers v(g’) before v(g)
– Integrity: if p delivers v(g) then p v(g)
– Non-triviality: if q joins group and remains reachable
then eventually q v(g) at p

November 2005 Distributed systems: shared data 198
System model and group communication
• View-synchronous group communication
– Reliable multicast + handle changing group views
– Guarantees
• Agreement: correct processes deliver the same set of
messages in any given view
• Integrity: if a process delivers m, it will not deliver it again
• Validity: if the system fails to deliver m to q
then other processes will deliver v’(g) (=v(g) –
{q})
before delivering m
November 2005 Distributed systems: shared data 199
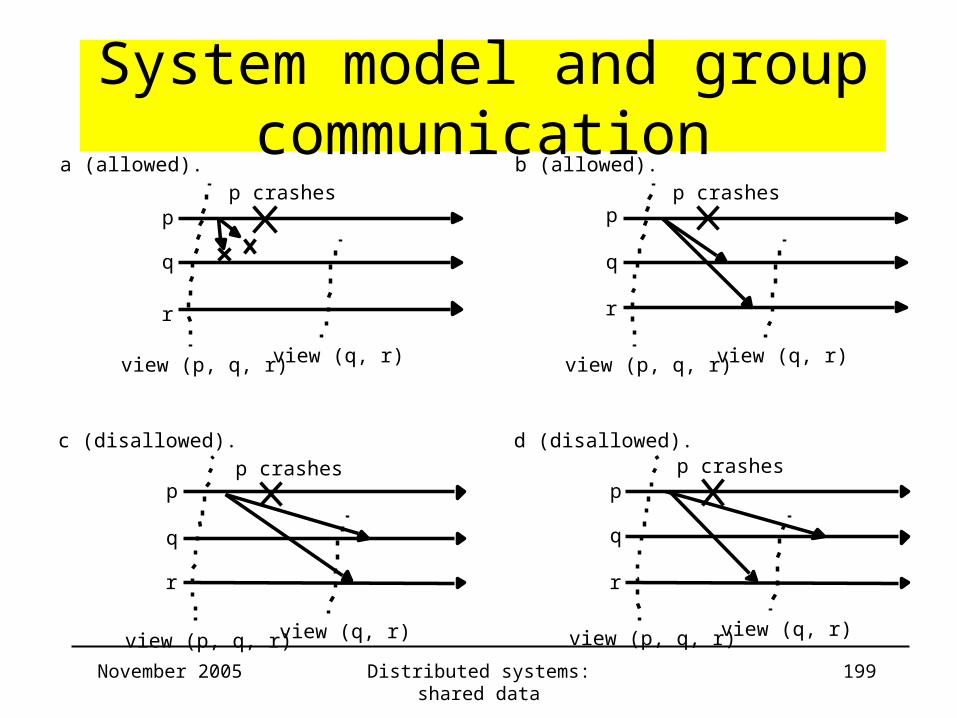
System model and group communication
p
q
r
p crashes
view (q, r)view (p, q, r)
p
q
r
p crashes
view (q, r)view (p, q, r)
a (allowed). b (allowed).
p
q
r
view (p, q, r)
p
q
r
p crashes
view (q, r)view (p, q, r)
c (disallowed). d (disallowed).
p crashes
view (q, r)

November 2005 Distributed systems: shared data 200
Overview• Transactions
• Distributed transactions
• Replication– System model and group communication– Fault-tolerant services– Highly available services– Transactions with replicated data

November 2005 Distributed systems: shared data 201
Fault-tolerant services• Goal: provide a service that is correct
despite up to f process failures
• Assumptions:– Communication reliable– No network partitions
• Meaning of correct in case of replication– Service keeps responding– Clients cannot discover difference with ...

November 2005 Distributed systems: shared data 202
Fault-tolerant services• Naive replication system:
– Clients read and update accounts at local replica manager
– Clients try another replica manager in case of failure
– Replica managers propagate updates in the background
• Example: 2 replica managers: A and B
2 bank accounts: x and y
2 clients: client 1 will use B by preference
client 2 will use A by preference
Client 1 Client 2
setBalanceB(x,1)
setBalanceA(y,2)
getBalanceA(y) 2
getBalanceA(x) 0
Strange behavior:
Client 2 sees 0 on account x and NOT 1
2 on account y
and update of x has been done earlier!!

November 2005 Distributed systems: shared data 203
Fault-tolerant services• Correct behaviour?
– Linearizability• Strong requirement
– Sequential consistency• Weaker requirement

November 2005 Distributed systems: shared data 204
Fault-tolerant services• Linearizability
– Terminology:• Oij: client i performs operation j• Sequence of operations by one client: O20, O21, O22,...• Virtual interleaving of operations performed by all clients
– Correctness requirements: interleaved sequence ...• Interleaved sequence of operations meets specification of a
(single) copy of the objects• Order of operations in the interleaving is consistent with the
real times at which the operations occurred
– Real time?• Yes, we prefer up-to-date information• Requires clock synchronization: difficult

November 2005 Distributed systems: shared data 205
Fault-tolerant services• Sequential consistency
– Correctness requirements: interleaved sequence ... (red = difference!)
• Interleaved sequence of operations meets specification of a (single) copy of the objects
• Order of operations in the interleaving is consistent with the program order in which each individual client executed them
– Example: sequential consistent not linearizable
Client 1 Client 2
setBalanceB(x,1)
getBalanceA(y) 0
getBalanceA(x) 0
setBalanceA(y,2)
November 2005 Distributed systems: shared data 206
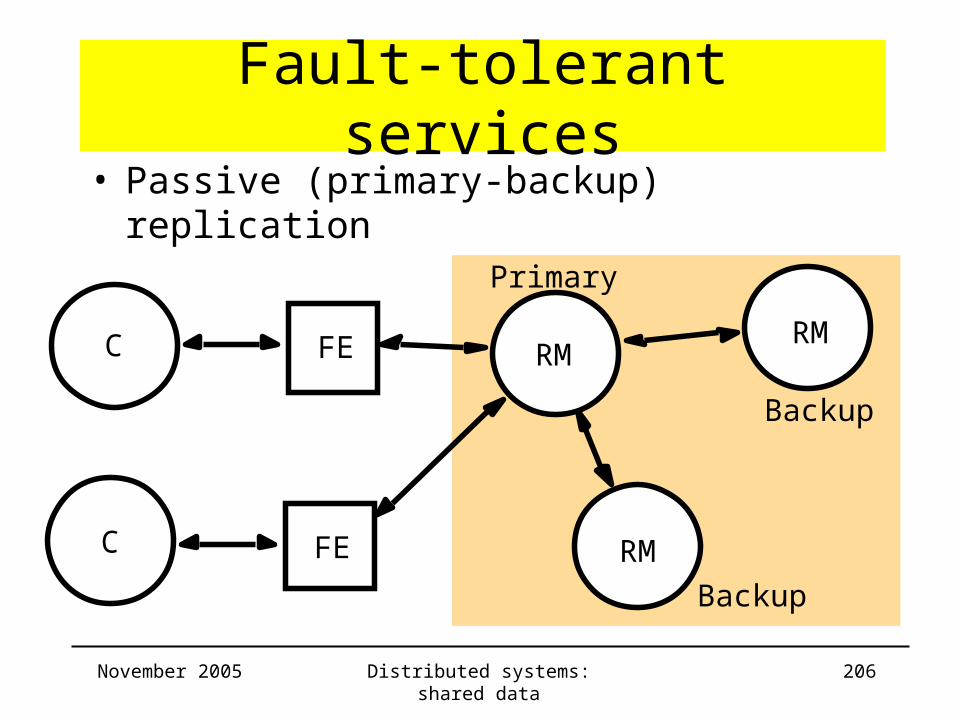
Fault-tolerant services• Passive (primary-backup) replication
FEC
FEC
RM
Primary
Backup
Backup
RM
RM

November 2005 Distributed systems: shared data 207
Fault-tolerant services• Passive (primary-backup) replication
– Sequence of events for handling a client request:• Request: FE issues request with unique id to primary• Coordination: request handled atomically in order; if
request already handled, re-send response
• Execution: execute request and store response• Agreement: primary sends updated state to backups and
waits for acks• Response: primary responds to FE; FE hands response
back to client
– Correctness: linearizability– Failures?

November 2005 Distributed systems: shared data 208
Fault-tolerant services• Passive (primary-backup) replication
– Failures?• Primary uses view-synchronous group communication• Linearizability preserved, if
– Primary replaced by a unique backup– Surviving replica managers agree on which operations had been
performed at the replacement point
– Evaluation:• Non-deterministic behaviour of primary supported• Large overhead: view-synchronous communication required• Variation of the model:
– Read requests handled by backups: linearizability sequential consistent
November 2005 Distributed systems: shared data 209
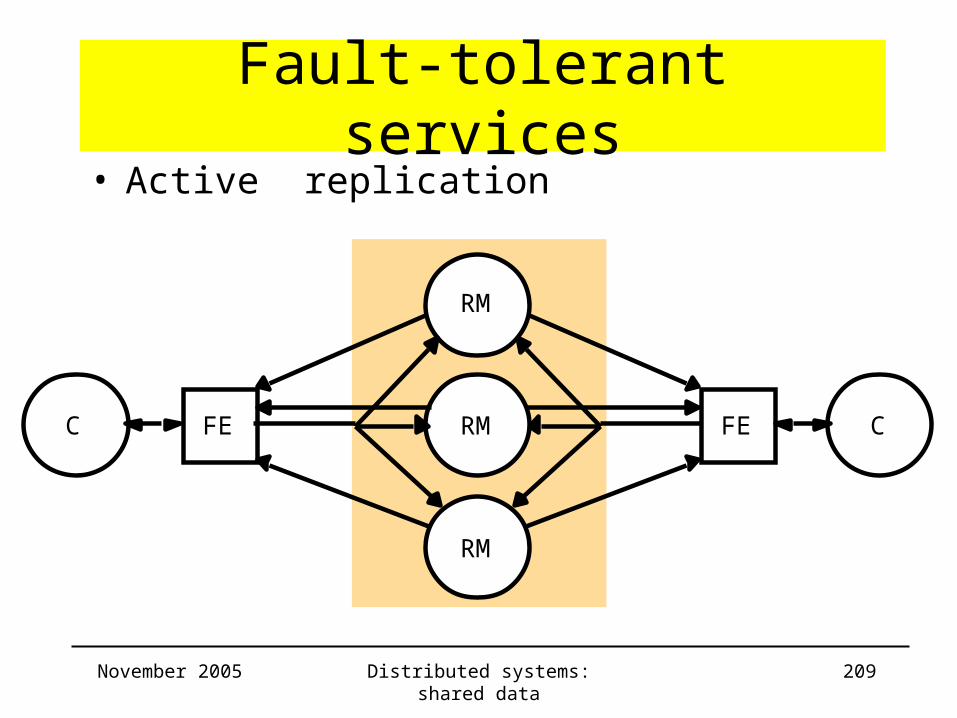
Fault-tolerant services• Active replication
FE CFEC RM
RM
RM

November 2005 Distributed systems: shared data 210
Fault-tolerant services• Active replication
– Sequence of events for handling a client request:• Request: FE does reliable TO-multicast(g, <m, i>) and
waits for reply• Coordination: every correct RM gets requests in same order• Execution: every correct RM executes the request;
all RMs execute all requests in the same order
• Agreement: not needed• Response: every RM returns result to FE;
when return result to client?– Crash failures: after first response from RM– Byzantine failures: after f+1 identical responses from RMs
– Correctness: sequential consistency, not linearizability

November 2005 Distributed systems: shared data 211
Fault-tolerant services• Active replication
– Evaluation• Reliable + totally ordered multicast solving consensus
Synchronous systemAsynchronous + failure detectors
– Overhead!
• More performance– Relax total order in case operations commute:
result of o1;o2 = result o2;o1
– Forward read-only request to a single RM

November 2005 Distributed systems: shared data 212
Overview• Transactions
• Distributed transactions
• Replication– System model and group communication– Fault-tolerant services– Highly available services– Transactions with replicated data

November 2005 Distributed systems: shared data 213
Highly available services• Goal
– Provide acceptable level of service– Use minimal number of RMs– Minimize delay for returning resultWeaker consistency
• Overview– Coda
– Gossip Architecture
– Bayou

November 2005 Distributed systems: shared data 214
Highly available services Coda
• Aims: constant data availability– better performance, e.g. for bulletin boards,
databases,…– more fault tolerance with increasing scale– support mobile and portable computers
(disconnected operation)
Approach: AFS + replication

November 2005 Distributed systems: shared data 215
Highly available services Coda
• Design AFS+– file volumes replicated on different servers– volume storage group (VSG) per file volume– Available Volume Storage group (AVSG) per
file volume at a particular instance of time– volume disconnected when AVSG is empty;
due to• network failure, partitioning• server failures• deliberate disconnection of portable workstation

November 2005 Distributed systems: shared data 216
Highly available services Coda
• Replication and consistency– file version
• integer number associated with file copy
• incremented when file is changed
– Coda version vector (CVV)• array of numbers stored with file copy on a
particular server (holding a volume)
• one value per volume in VSG

November 2005 Distributed systems: shared data 217
Highly available services Coda
• Replication and consistency: example 1
– File F stored at 3 servers: S1, S2, S3
– Initial values for all CVVs: CVVi = [1,1,1]
– update by C1 at S1 and S2; S3 inaccessibleCVV1 = [2,2,1], CVV2 = [2,2,1], CVV3 = [1,1,1]
– network repaired conflict detectedfile copy at S3 updated
CVV1 = [2,2,2], CVV2 = [2,2,2], CVV3 = [2,2,2]

November 2005 Distributed systems: shared data 218
Highly available services Coda
• Replication and consistency: example 2
– File F stored at 3 servers: S1, S2, S3
– Initial values for all CVVs: CVVi = [1,1,1]
– update by C1 at S1 and S2; S3 inaccessibleCVV1 = [2,2,1], CVV2 = [2,2,1], CVV3 = [1,1,1]
– update by C2 at S3 ; S1 and S2 inaccessibleCVV1 = [2,2,1], CVV2 = [2,2,1], CVV3 = [1,1,2]
– network repaired conflict detectedmanual intervention or ….

November 2005 Distributed systems: shared data 219
Highly available services Coda
• Implementation– On open
• Select one server from AVSG
• check CCV with all servers in AVSG
• files in replicated volume remain accessible to a client that can access at least one of the replica
• load sharing over replicated volumes
– On close• multicast file to AVSG
• update of CCV
– manual resolution of conflicts might be necessary

November 2005 Distributed systems: shared data 220
Highly available services Coda
• Caching: update semantics– successful open:
AVSG not empty and latest(F, AVSG, 0) or
AVSG not empty and latest(F, AVSG, T) and
lostcallback(AVSG, T) and incache (F) or
AVSG empty and incache (F)

November 2005 Distributed systems: shared data 221
Highly available services Coda
• Caching: update semantics– failed open:
AVSG not empty and conflict(F, AVSG) or
AVSG empty and not incache(F)
– successful close: AVSG not empty and updated(F, AVSG)
or
AVSG empty
– failed close: AVSG not empty and conflict(F, AVSG)

November 2005 Distributed systems: shared data 222
Highly available services Coda
• Caching: cache coherence– relevant events to detect by Venus within T seconds of
their occurrence:• enlargement of AVSG
• shrinking of AVSG
• lost callback event
– method: probe message to all servers in VSG of any cached file every T seconds

November 2005 Distributed systems: shared data 223
Highly available services Coda
• Caching: disconnected operation– Cache replacement policy: e.g. least-recently used
– how support long disconnection of portables:• Venus can monitor file referencing
• users can specify a prioritised list of files to retain on local disk
– reintegration after disconnection• priority for files on server
• client files in conflict are stored on covolumes; client is informed

November 2005 Distributed systems: shared data 224
Highly available services Coda
• Performance: Coda <> AFS– No replication: no significant difference– 3-fold replication & load for 5 users:
load +5%– 3-fold replication & load for 50 users
load + 70% for Coda <> +16% for AFS• Difference: replication + tuning?
• Discussion– Optimistic approach to achieve high availability– Use of semantics free conflict detection
(except file directories)

November 2005 Distributed systems: shared data 225
Highly available servicesGossip
• Goal of Gossip architecture– Framework for implementing highly ...
– Replicate data close to points where groups of clients need it
• Operations:– 2 types:
• Queries: read-only operations
• Updates: change state (do not read state)
– FE send operations to any RM selection criterium: available + reasonable response time
– Guarantees

November 2005 Distributed systems: shared data 226
Highly available servicesGossip
• Goal of Gossip architecture
• Operations:– 2 types: queries & updates– FE send operations to any RM – Guarantees:
• Each client obtains consistent service over time – even when communicating with different RMs
• Relaxed consistency between replicas– Weaker than sequential consistency

November 2005 Distributed systems: shared data 227
Highly available servicesGossip
• Update ordering:– Causal least costly
– Forced (= total + causal)
– Immediate• Applied in a consistent order relative to any other update at all
RMs, independent of order requested for other updates
• Choice– Left to application designer
– Reflects trade-off between consistency and operation cost
– Implications for users

November 2005 Distributed systems: shared data 228
Highly available servicesGossip
• Update ordering:– Causal least costly
– Forced (= total + causal)
– Immediate• Applied in a consistent order relative to any other update at all
RMs, independent of order requested for other updates
• Example electronic bulletin board:– Causal: for posting items
– Forced: for adding new subscriber
– Immediate: for removing a user

November 2005 Distributed systems: shared data 229
Highly available servicesGossip
• Architecture– Clients + FE/client– Timestamps added to operations: in next figure
• Prev: reflects version of latest data values seen by client
• New: reflects state of responding RM
– Gossip messages: • exchange of operations between RMs
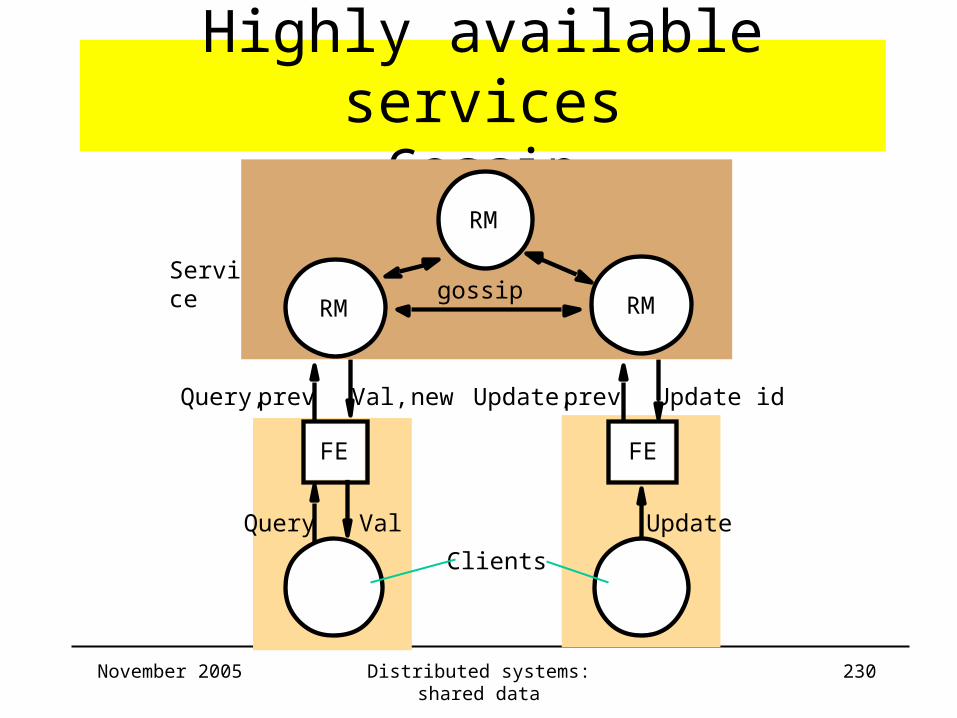
November 2005 Distributed systems: shared data 230
Highly available servicesGossip
Query Val
FE
RM RM
RM
Query, prev Val, new
Update
FE
Update, prev Update id
Clients
gossipService

November 2005 Distributed systems: shared data 231
Highly available servicesGossip
• Sequence of events for handling a client request:– Request:
• FE sends request to a single RM
• For query operation: Client blocked
• For update operation: FE returns to client asap; then forwards operation to one RM or f+1 RMs for increased reliability
– Update response: • if update operation, RM replies to FE after receiving the request
– Coordination:• Request stored in log queue till it can be executed
• Gossip messages can be exchanged to update state in RM
– Execution:

November 2005 Distributed systems: shared data 232
Highly available servicesGossip
• Sequence of events for handling a client request:– Request
– Update response
– Coordination
– Execution: • RM executes request
– Query response• If operation is query then RM replies at this point
– Agreement:• Lazy update by RMs

November 2005 Distributed systems: shared data 233
Highly available servicesGossip
• Gossip internals– Timestamps at FEs– State of RMs– Handling of Query operations– Processing of update operations in causal order– Forced and immediate update operations– Gossip messages– Update propagation

November 2005 Distributed systems: shared data 234
Highly available servicesGossip
• Timestamps at FEs– Vector timestamps with entry for every RM
– Local component updated at every operation
– Returned timestamp merged with local one
– Client-to client operations• Via FEs• Include timestamps (to preserve causal order)
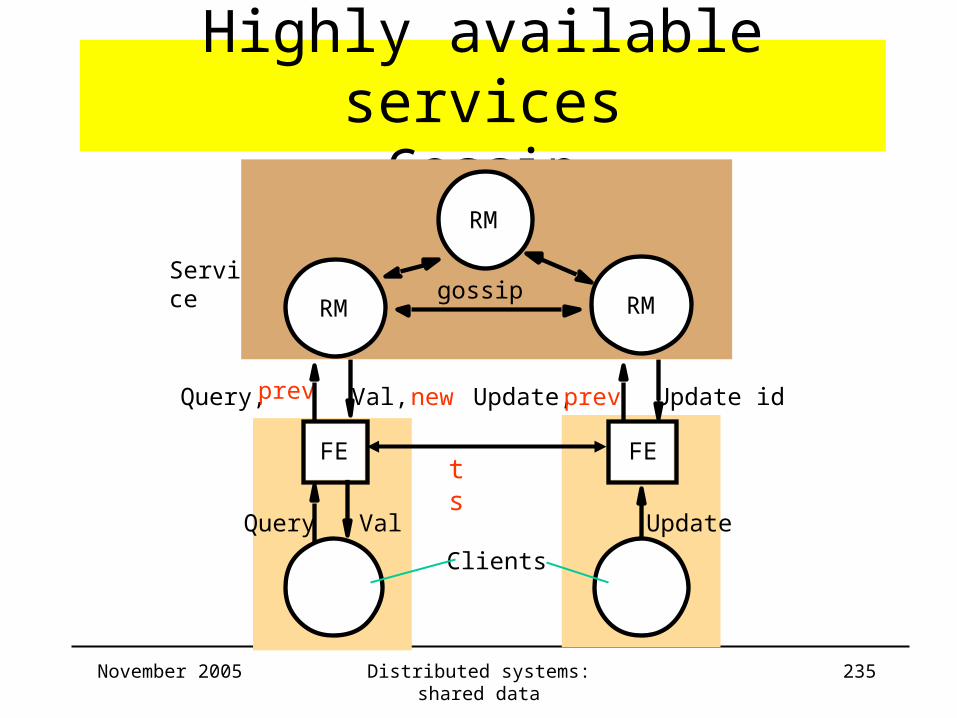
November 2005 Distributed systems: shared data 235
Highly available servicesGossip
Query Val
FE
RM RM
RM
Query, prev Val, new
Update
FE
Update, prev Update id
Clients
gossipService
ts

November 2005 Distributed systems: shared data 236
Highly available servicesGossip
• State of RMs– Value: state as maintained by RM
– Value timestamp: associated with value
– Update log: why log?• Operation cannot be executed yet• Operation has to be forwarded to other RMs
– Replica timestamp: reflects updates received by RM
– Executed operation table: to prevent re-execution
– Timestamp table: • timestamps from other RMs• Received with Gossip messages• Used to check for consistency between RMs
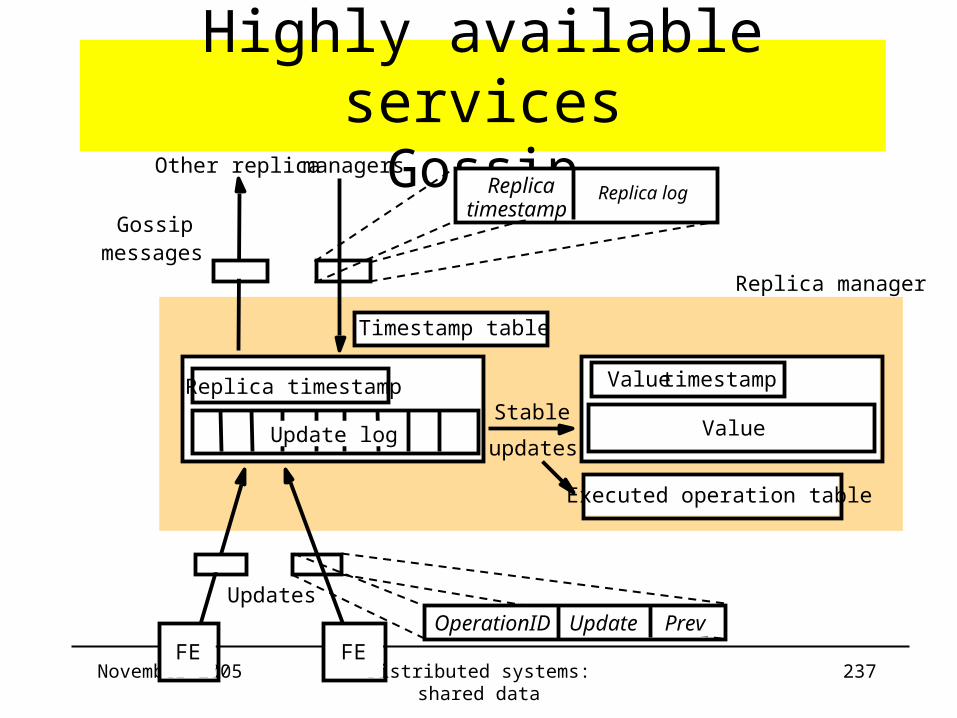
November 2005 Distributed systems: shared data 237
Highly available servicesGossip
Replica timestamp
Update log
Value timestamp
Value
Executed operation table
Stable
updates
Updates
Gossipmessages
FE
Replicatimestamp
Replica log
OperationID Update PrevFE
Replica manager
Other replica managers
Timestamp table

November 2005 Distributed systems: shared data 238
Highly available servicesGossip
• Handling of Query operations– Query request contains:
• q= operation
• q.prev = timestamp at FE
– If q.prev <= valueTSthen
operation can be executedelse operation put in hold-back queue
– Result contains new timestampmerged with timestamp at FE

November 2005 Distributed systems: shared data 239
Highly available servicesGossip
• Processing of update operations in causal order– Update request u
• u.op specification of operation (type & parameters)
• u.prev: timestamp generated at FE
• u.id: unique identifier
– Handling of u at RMi

November 2005 Distributed systems: shared data 240
Highly available servicesGossip
• Processing of update operations in causal order– Update request u = <u.op, u.prev, u.id>
– Handling of u at RMi
• u already processed?
• Increment i-the element in replicaTS
• Assign ts to uts[i] = replicaTS[i]ts[k] = u.prev[k], k<>i
• Log record r = <i, ts, u.op, u.prev, u.id> added to log
• ts returned to FE
• If stability condition u.prev <= valueTS is satisfiedthen value := apply(value, r.u.op)
valueTS := merge( valueTS, r.ts)executed := executed {r.u.id}

November 2005 Distributed systems: shared data 241
Highly available servicesGossip
• Forced and immediate update operations– Special treatment
– Forced = total + causal order• Unique global sequence numbers
by primary RM (reelection if necessary)
– Immediate• Placed in sequence by primary RM (forced order)
• Additional communication between RMs

November 2005 Distributed systems: shared data 242
Highly available servicesGossip
• Gossip messages– Gossip message m
• m.log = log
• m.ts = replicaTS
– Tasks done by RM when receiving m• Merge m with its own log
– Drop r when r.ts <= replicaTS
– replicaTS := merge(replicaTS, m.ts)
• Apply updates that have become stable
• Eliminate records from log and executed operations table

November 2005 Distributed systems: shared data 243
Highly available servicesGossip
• Update propagation– Gossip exchange frequency
• To be tuned by application
– Partner selection policy• Random• Deterministic• Topological
– How much time will it take for all RMs to receive an update
• Frequency and duration of network partitions• Frequency for exchanging gossip-messages• Policy for choosing partners

November 2005 Distributed systems: shared data 244
Highly available servicesGossip
• Discussion of architecture+ Clients can continue to obtain a service even with
network partition
- Relaxed consistency guarantees
- Inappropriate for updating replicas in near-real time
? Scalability? Depends upon• Number of updates in a gossip message
• Use read-only replicas

November 2005 Distributed systems: shared data 245
Highly available servicesBayou
• Goal– Data replication for high availability– Weaker guarantees than sequential consistency– Cope with variable connectivity
• Guarantees: Every RM eventually – receives the same set of updates– applies those updates

November 2005 Distributed systems: shared data 246
Highly available servicesBayou
• Approach– Use a domain specific policy for detecting and
resolving conflicts– Every Bayou update contains
• Dependency check procedure– Check for conflict if update would be applied
• Merge procedure– Adapt update operation
» Achieves something similar
» Passes dependency check

November 2005 Distributed systems: shared data 247
Highly available servicesBayou
• Committed and tentative updates– New updates are applied and marked as tentative
– Tentative updates can be undone and reapplied later
– final order decided by primary replica manager committed order
– Tentative update ti becomes next committed update• Undo of all tentative updates after last committed update
• Apply ti
• Other tentative updates are reapplied
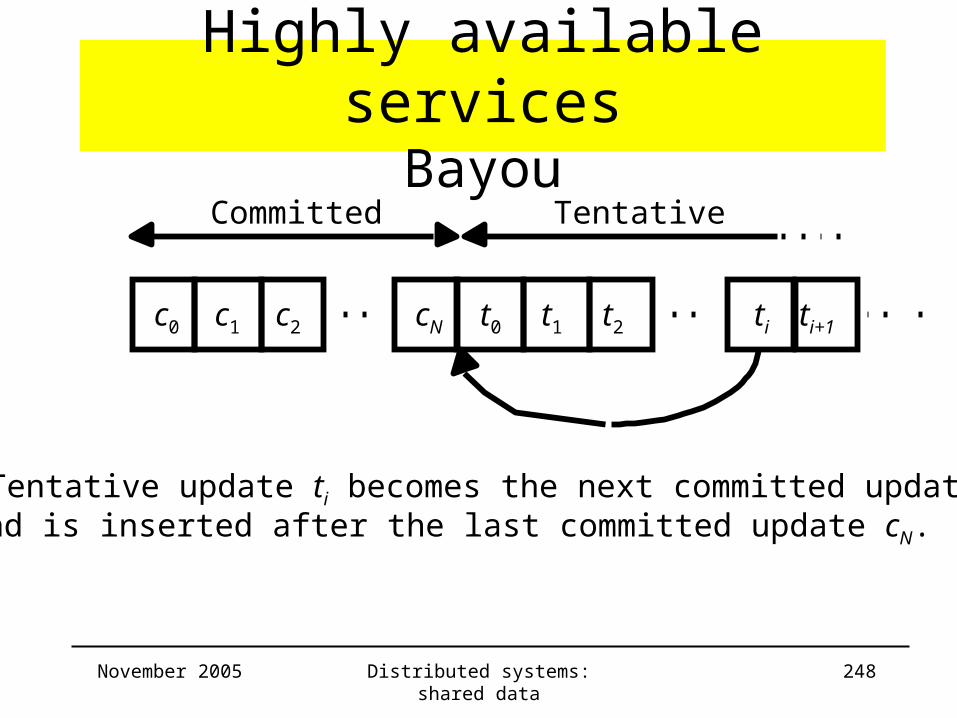
November 2005 Distributed systems: shared data 248
Highly available servicesBayou
c0 c1 c2 cN t0 t1 ti
Committed Tentative
t2
Tentative update ti becomes the next committed update and is inserted after the last committed update cN.
ti+1

November 2005 Distributed systems: shared data 249
Highly available servicesBayou
• Discussion– Makes replication non-transparant to the application
• Exploits application’s semantics to increase availability• Maintains replicated state as eventually sequentially consistent
– Disadvantages:• Increased complexity for application programmer• Increased complexity for user: returned results can be changed
– Suitable for applications ....• conflicts rare• Underlying data semantics simple• Users can cope with tentative information
e.g. diary

November 2005 Distributed systems: shared data 250
Overview• Transactions
• Distributed transactions
• Replication– System model and group communication– Fault-tolerant services– Highly available services– Transactions with replicated data

November 2005 Distributed systems: shared data 251
Transactions with replicated data• Introduction
– Replicated transactional service• each data item replicated at a group of servers
replica managers
• transparency one-copy serializability
– Why?• increase availability
• increase performance
– Advantages/disadvantages• higher performance for read-only requests
• degraded performance op update requests

November 2005 Distributed systems: shared data 252
Transactions with replicated data• Architectures for replicated transactions
– questions:
• Can a client send requests to any replica manager?
• How many replica managers are needed for a
successful completion of an operation?
• If one replica manager is addressed, can this one
delay forwarding till commit of transaction?
• How to carry out two-phase commit?

November 2005 Distributed systems: shared data 253
Transactions with replicated data• Architectures for replicated transactions
– Replication Schemes:• Read-one/Write-all
– a read request can be performed by a single replica manager
– a write request must be performed by all replica managers
• Quorum Consensus
• Primary Copy

November 2005 Distributed systems: shared data 254
Transactions with replicated data• Architectures for replicated transactions
– Replication Schemes:• Read-one/Write-all
• Quorum Consensus– nr replica managers required to read data item
– nw replica managers requited to update data item
– nr + nw > number of replica managers
– advantage: less managers needed for update
• Primary Copy– all requests directed to a single server
– slaves can take over when primary fails

November 2005 Distributed systems: shared data 255
Transactions with replicated data• Architectures for replicated transactions
– Forwarding update requests?• Read-one/Write-all
– as soon as operation is received (only write requests)
• Quorum Consensus– as soon as operation is received (read + write requests)
• Primary Copy– when transaction commits

November 2005 Distributed systems: shared data 256
Transactions with replicated data
• Architectures for replicated transactions
– Two-phase commit
• locking (read one/write all)
– read operation: lock on single replica
– write operation: locks on all replica
– one copy serializability: assured as read and write have
conflicting lock on at least one replica
• protocol:

November 2005 Distributed systems: shared data 257
Transactions with replicated data• Architectures for replicated transactions
– Two-phase commit• locking (read one/write all)
• protocol:– becomes two-level nested two-phase protocol
– first phase:
» worker receives CanCommit request
request passed to all replica managers
replies collected; one reply to coordinator
– second phase:
» same approach for DoCommit and Abort request

November 2005 Distributed systems: shared data 258
Transactions with replicated data• Architectures for replicated transactions
– Failure implications?• Read-one/Write-all
– updates impossible available copies replication
• Quorum Consensus– quorum satisfaction still possible
• Primary Copy– failure of primary election new primary?
– Failure of slave update delayed

November 2005 Distributed systems: shared data 259
Transactions with replicated data• Available copies replication
– updates only performed by all available replica managers (cfr. Coda)
– no failures:• local concurrency control one copy
serializability
– failures:• additional concurrency control is needed• example (next slides)
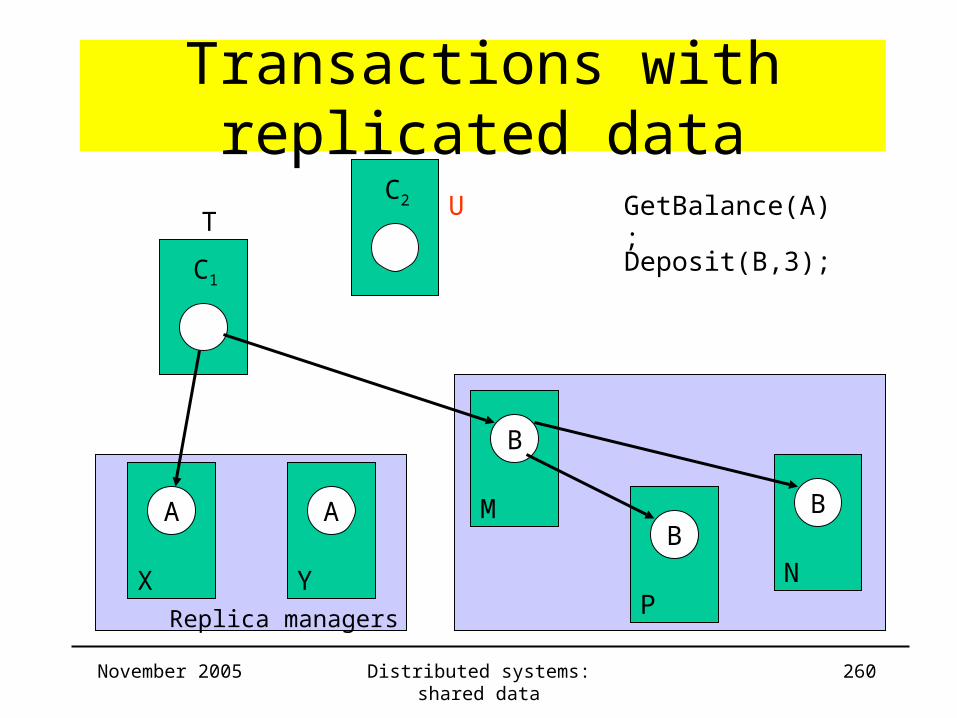
November 2005 Distributed systems: shared data 260
Transactions with replicated data
A
X
A
Y
Replica managers
B
MB
P
B
N
C1
C2 GetBalance(A);
Deposit(B,3);
UT
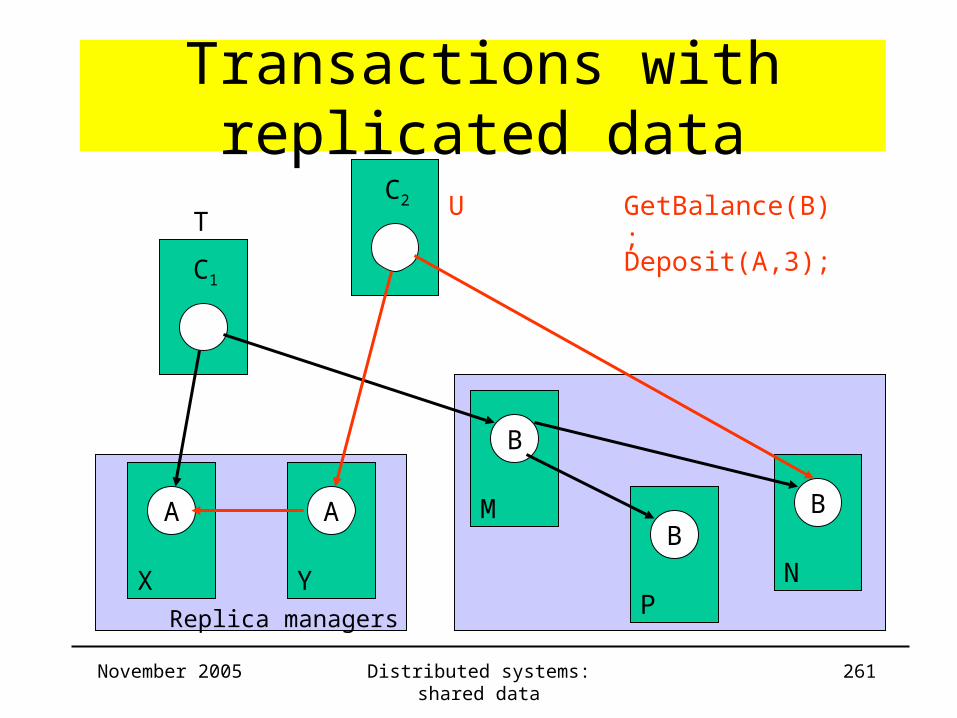
November 2005 Distributed systems: shared data 261
Transactions with replicated data
A
X
A
Y
Replica managers
B
MB
P
B
N
C1
C2 GetBalance(B);
Deposit(A,3);
TU
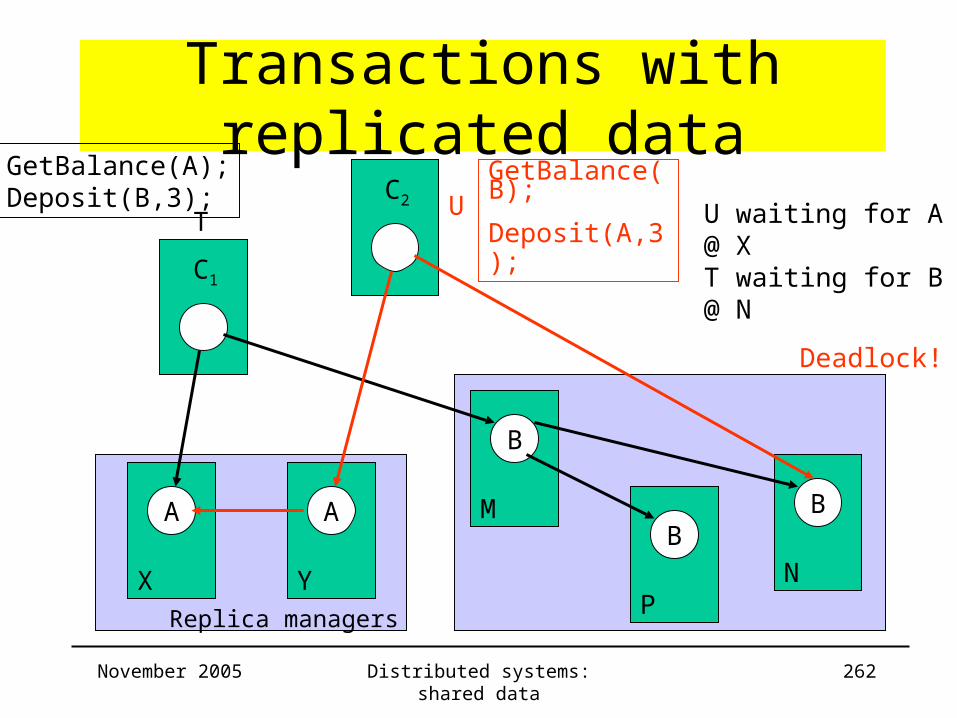
November 2005 Distributed systems: shared data 262
Transactions with replicated data
A
X
A
Y
Replica managers
B
MB
P
B
N
C1
C2
TU U waiting for A @ X
T waiting for B @ N
Deadlock!
GetBalance(A);Deposit(B,3);
GetBalance(B);
Deposit(A,3);
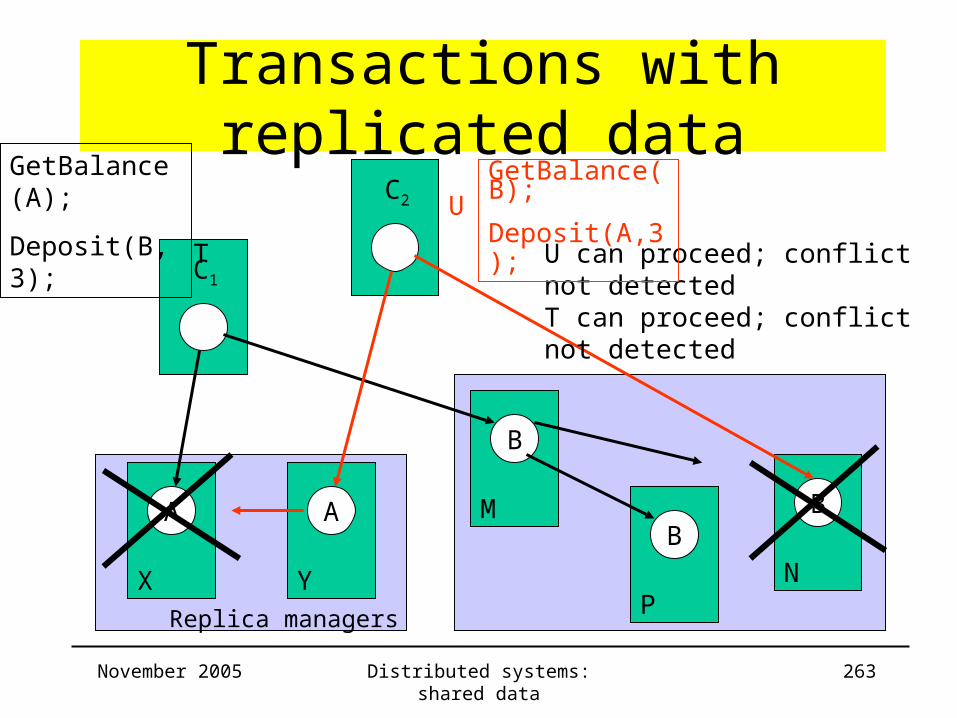
November 2005 Distributed systems: shared data 263
Transactions with replicated data
A
X
A
Y
Replica managers
B
MB
P
B
N
C1
C2
TU
U can proceed; conflict not detected
T can proceed; conflict not detected
GetBalance(A);
Deposit(B,3);
GetBalance(B);
Deposit(A,3);

November 2005 Distributed systems: shared data 264
Transactions with replicated data• Available copies replication
– failures & additional concurrency control• at commit time it is checked
– servers unavailable during transaction: still unavailable?– Servers available during transaction: still available?
– If no abort transaction
• implications for two-phase commit protocol?

November 2005 Distributed systems: shared data 265
Transactions with replicated data
• Replication and network partitions– optimistic approach: available copies
• operations can go on in each partition
• conflicting transactions should be detectedand compensated for
• conflict detection:– for file systems: version vector (see Coda)
– for read/write conflicts: ….

November 2005 Distributed systems: shared data 266
Transactions with replicated data
• Replication and network partitions (cont.)
– pessimistic approach: quorum consensus
• operations can go on in a single partition only
• R read quorum & W write quorum– W > half of the votes
– R + W > total number of votes
• out of date copies should be detected– version vectors
– timestamps

November 2005 Distributed systems: shared data 267
Transactions with replicated data• Replication and network partitions (cont.)
– quorum consensus + available copies• virtual partitions advantages of both approaches
• virtual partition = abstraction of real partition
• transaction can operate in a virtual partition– sufficient replica managers to have read & write quorum
– available copies is used in transaction
• virtual partition changes during transactionabort of transaction
• member of virtual partition cannot access other membercreate new partition

November 2005 Distributed systems: shared data 268
Overview• Transactions
• Distributed transactions
• Replication– System model and group communication– Fault-tolerant services– Highly available services– Transactions with replicated data

November 2005 Distributed systems: shared data 269
Distributed Systems:
Shared Data






![BEST 3 - podbbang.comcdn.podbbang.com/data1/cbsjin/5PDFAppCenter.pdf팟캐스트 MC가 즐겨쓰는 에버노트 연 동앱 9가지 작성자: 진대연 최근 [나는 에버노터다]](https://img.pdfslide.us/doc/110x75/5f2d94c35037f80a3c12d0ac/best-3-oe-mce-ee-ee-e-9e-.jpg)

![[모바일용]cdn.podbbang.com/data1/donghwa/salomeM.pdf · 2016-08-20 · 살로메Salome:원서로읽는세계명작019 화수분출판사/무료 예스24,알라딘,반디앤루니스,리디북스,](https://img.pdfslide.us/doc/110x75/5fa53b5581b03a162a065306/eecdn-2016-08-20-eoeesalomeoeeoeeee019-eoeoeeeoe.jpg)
![[모바일용] - podbbang.comcdn.podbbang.com › data1 › donghwa › dorianM.pdf · DorianGray:원서로읽는세계명작018 화수분출판사/500원 예스24,알라딘,반디앤루니스,리디북스,](https://img.pdfslide.us/doc/110x75/5f0f4fde7e708231d4438938/ee-a-data1-a-donghwa-a-dorianmpdf-doriangrayoeeoeeee018.jpg)



















