Embed Size (px)
Citation preview

Nov 22nd, 2006
Multimodal Analysis of Expressive Human Communication:
Speech and gesture interplay
Ph.D. Dissertation Proposal
Carlos Busso
Adviser: Dr. Shrikanth S. Narayanan

Nov 22nd, 2006
Outline
Introduction Analysis Recognition Synthesis Conclusions

Nov 22nd, 2006
Introduction
• Gestures and speech are intricately coordinated to express messages
• Affective and articulatory goals jointly modulate these channels in a non-trivial manner
• A joint analysis of these modalities is needed to better understand expressive human communication
• Goals: • Understand how to model the spatial-temporal modulation of these
communicative goals in gestures and speech
• Use these models to improve human-machine interfaces• Computer could give specific and appropriate help to users • Realistic facial animation could be improved by learning human-like gestures
01/40 IntroductionIntroduction
Motivation
This proposal focuses on the analysis, recognition and synthesis of expressive human communication under a multimodal framework
This proposal focuses on the analysis, recognition and synthesis of expressive human communication under a multimodal framework

Nov 22nd, 2006
Introduction
• How to model the spatio-temporal emotional modulation• If audio-visual models do not consider how the coupling between gestures
and speech changes in presence of emotion, they will not accurately reflect the manner in which human communicate
• Which interdependencies between the various communicative channels appear in conveying verbal and non-verbal messages?• Interplay between communicative, affective and social goals
• How to infer meta-information from speakers (emotion, engagement)?• How gestures are used to respond to the feedback given by the
listener?• How the verbal and non-verbal messages conveyed by one speaker are
perceived by others?• How to use models to design and enhance applications that will help
and engage the users?
01/40 IntroductionIntroduction
Open challenges
Nov 22nd, 2006
Introduction
01/40 IntroductionIntroduction
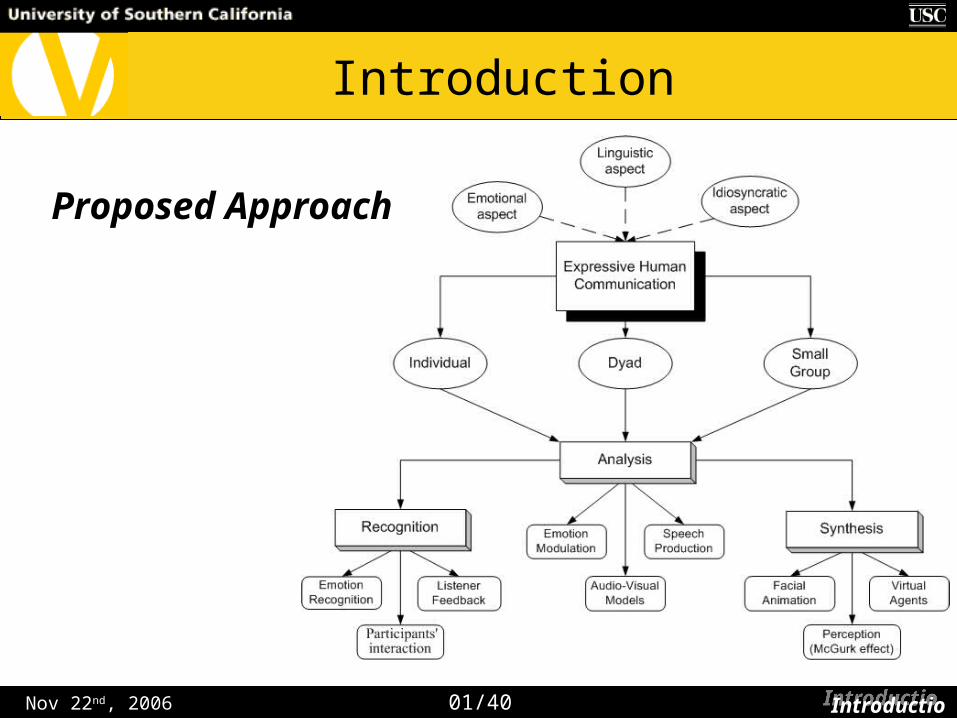
Proposed Approach
Nov 22nd, 2006
Analysis
Introduction
Analysis• Facial Gesture/speech Interrelation
• Affective/Linguistic Interplay
Recognition Synthesis Conclusions
01/40 AnalysisAnalysis
• Facial Gesture/speech Interrelation• Facial Gesture/speech Interrelation
C. Busso and S.S. Narayanan. Interrelation between Speech and Facial Gestures in Emotional Utterances. Under submission to IEEE Transactions on Audio, Speech and Language Processing.

Nov 22nd, 2006
Facial gestures/speech interrelation
• Gestures and speech interact and cooperate to convey a desired
message [McNeill,1992], [Vatikiotis,1996], [Cassell,1994]
• Notable among communicative components are the linguistic, emotional and idiosyncratic aspects of human communication
• Both gestures and speech are affected by these modulations
• It is important to understand the interrelation between facial gestures and speech in terms of all these aspects of human communication
01/40 AnalysisAnalysis
Motivation

Nov 22nd, 2006
Facial gestures/speech interrelation
• To focus on the linguistic and emotional aspects of human communication• To investigate the relation between certain gestures and acoustic features
• To propose recommendations for synthesis and recognition applications
• Relationship between gestures and speech as conversational functions [Ekman,1979], [Cassell,1999], [Valbonesi,2002], [Graf,2002], [Granstrom,2005]
• Relationship between gestures and speech as results of articulation [Vatikiotis,1996], [Yeshia,1998], [Jiang,2002], [Barker,1999]
• Relationship between gestures and speech influenced by emotions [Nordstrand,2003], [Caldognetto,2003], [Bevacqua,2004] [Lee, 2005]
01/40 AnalysisAnalysis
Goals
Related work[s]
Nov 22nd, 2006
Facial gestures/speech interrelation
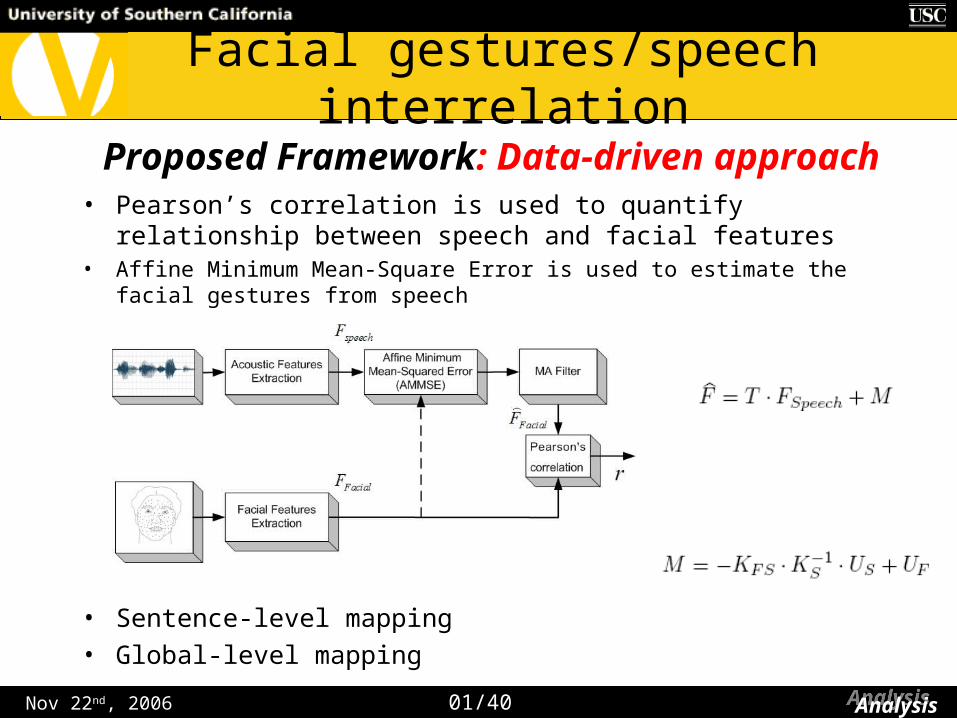
• Pearson’s correlation is used to quantify relationship between speech and facial features
• Affine Minimum Mean-Square Error is used to estimate the facial gestures from speech
• Sentence-level mapping
• Global-level mapping
01/40 AnalysisAnalysis
Proposed Framework: Data-driven approach
Nov 22nd, 2006
Facial gestures/speech interrelation
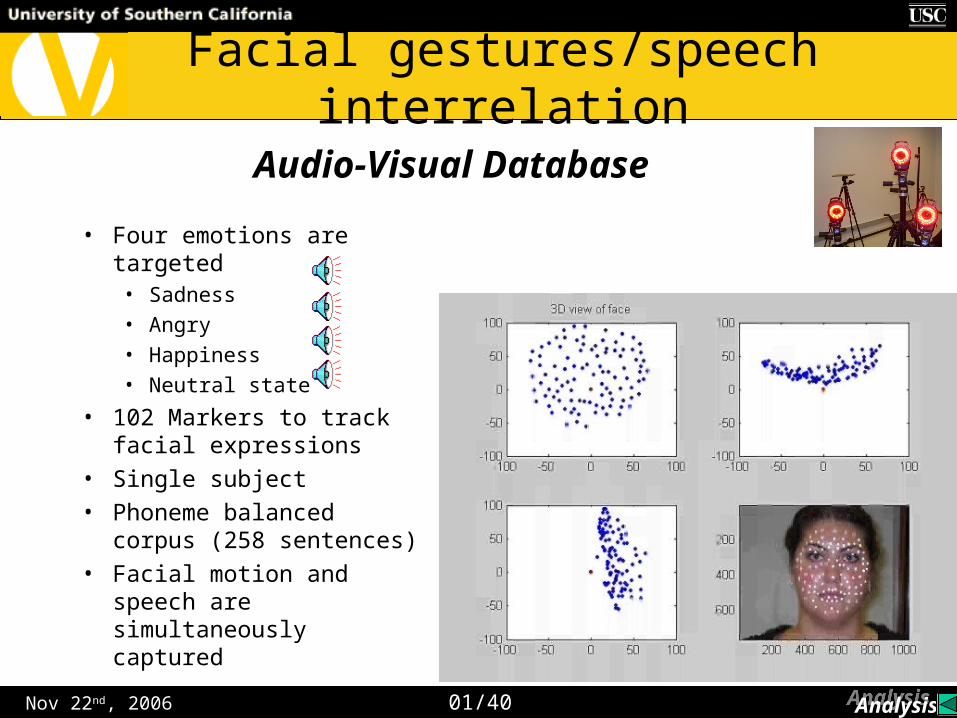
• Four emotions are targeted• Sadness
• Angry
• Happiness
• Neutral state
• 102 Markers to track facial expressions
• Single subject
• Phoneme balanced corpus (258 sentences)
• Facial motion and speech are simultaneously captured
01/40 AnalysisAnalysis
Audio-Visual Database

Nov 22nd, 2006
Facial gestures/speech interrelation
• Speech• Prosodic features (source of the speech): Pitch, energy and
they first and second derivatives
• MFCC coefficients (vocal tract)
• Facial features• Head motion
• Eyebrow
• Lips
• Each marker grouped in• Upper, middle and lower
face regions
01/40 AnalysisAnalysis
Facial and acoustic features
Nov 22nd, 2006
Facial gestures/speech interrelation
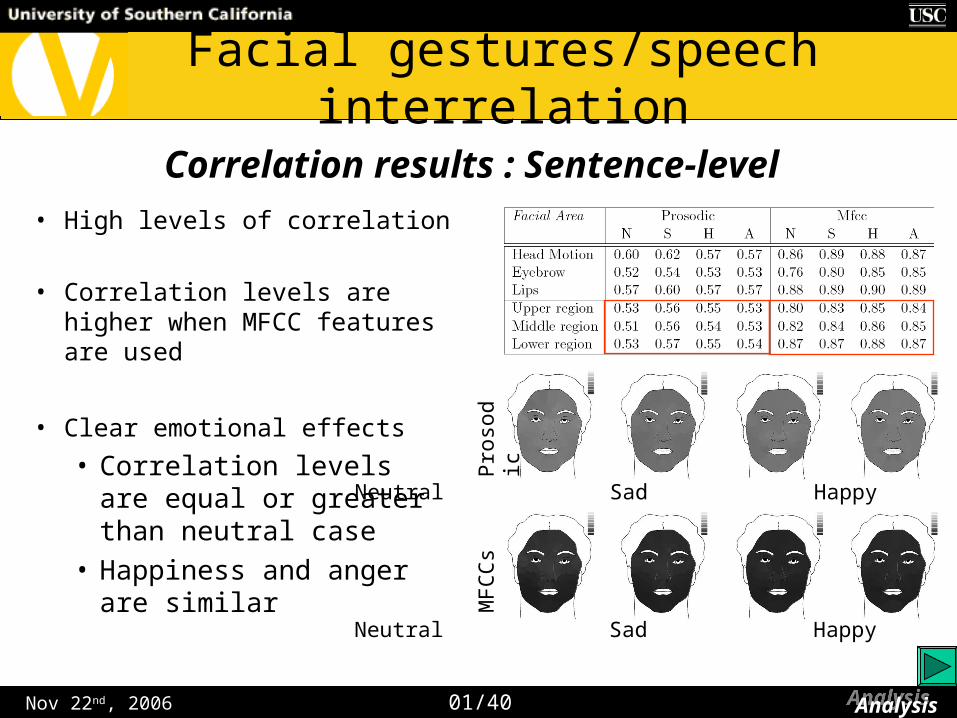
• High levels of correlation
• Correlation levels are higher when MFCC features are used
• Clear emotional effects
• Correlation levels are equal or greater than neutral case
• Happiness and anger are similar
01/40 AnalysisAnalysis
Correlation results : Sentence-level
Neutral Sad Happy Angry
Neutral Sad Happy Angry
Pro
sodi
cM
FC
Cs
Nov 22nd, 2006
Facial gestures/speech interrelation
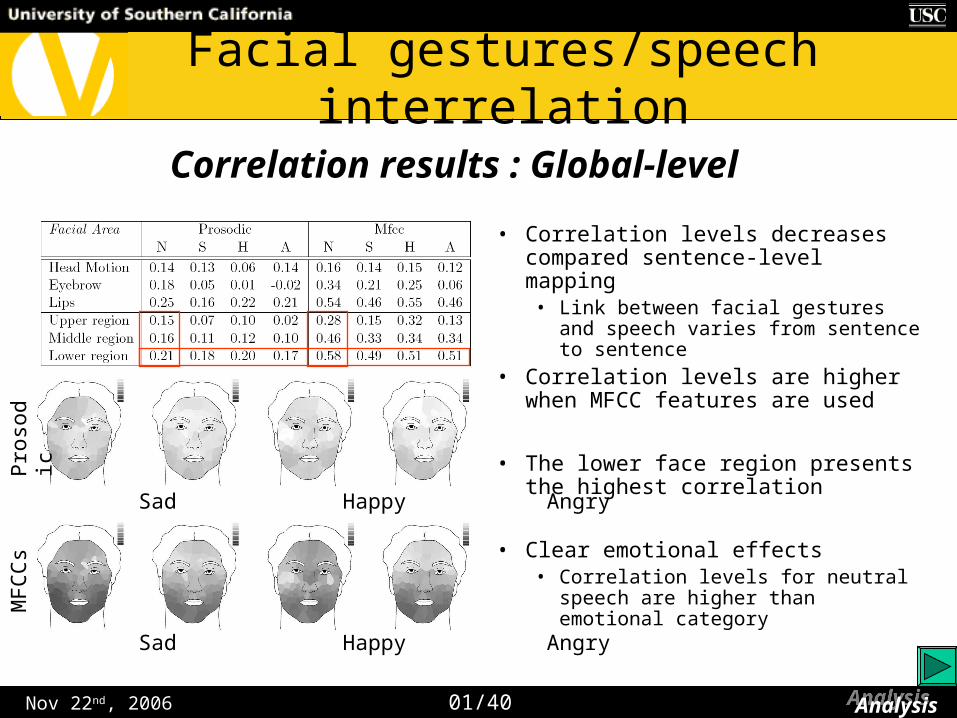
• Correlation levels decreases compared sentence-level mapping
• Link between facial gestures and speech varies from sentence to sentence
• Correlation levels are higher when MFCC features are used
• The lower face region presents the highest correlation
• Clear emotional effects• Correlation levels for neutral speech
are higher than emotional category
01/40 AnalysisAnalysis
Correlation results : Global-level
Neutral Sad Happy Angry
Neutral Sad Happy Angry
Pro
sodi
cM
FC
Cs

Nov 22nd, 2006
Facial gestures/speech interrelation
• Goal: study structure of mapping parameters
• Approach: Principal Component analysis (PCA)
• For each facial feature, find P such that it cover 90% of the variance
• Emotional-dependent vs. emotional independent analysis
01/40 AnalysisAnalysis
Mapping parameter
Nov 22nd, 2006
Facial gestures/speech interrelation
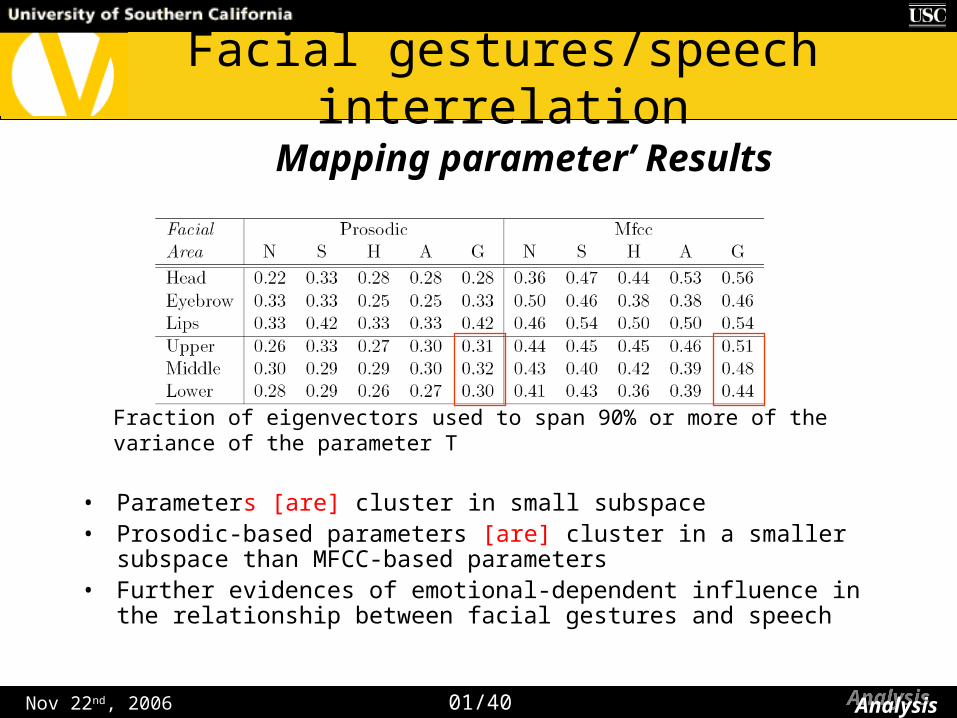
• Parameters [are] cluster in small subspace• Prosodic-based parameters [are] cluster in a smaller subspace than MFCC-
based parameters• Further evidences of emotional-dependent influence in the relationship
between facial gestures and speech
01/40 AnalysisAnalysis
Mapping parameter’ Results
Fraction of eigenvectors used to span 90% or more of the variance of the parameter T
Nov 22nd, 2006
Facial gestures/speech interrelation
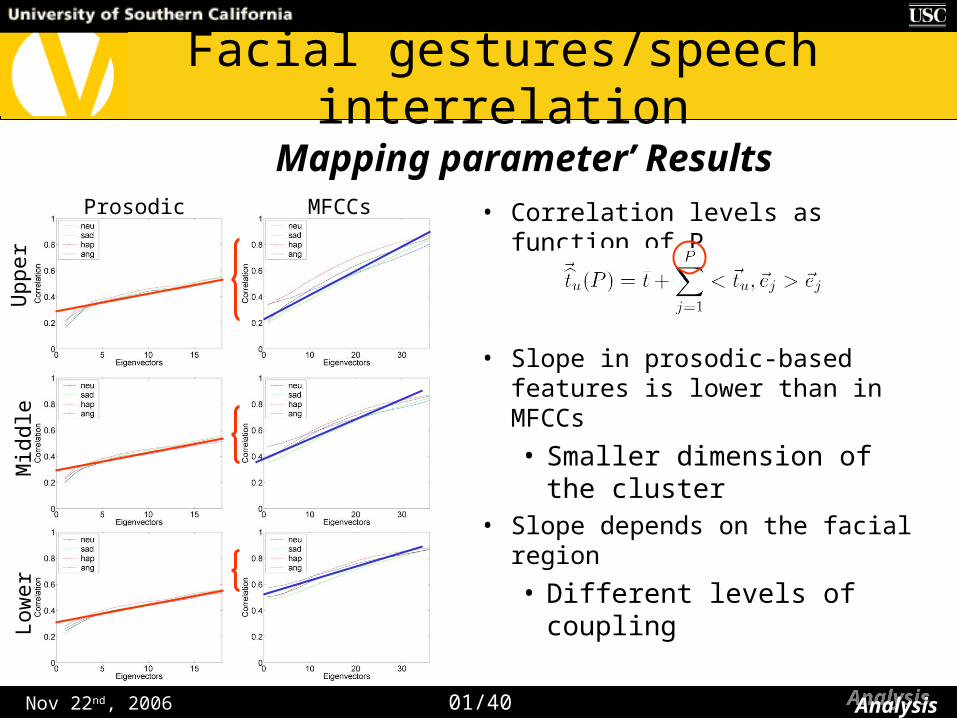
• Correlation levels as function of P
• Slope in prosodic-based features is lower than in MFCCs
• Smaller dimension of the cluster
• Slope depends on the facial region
• Different levels of coupling
01/40 AnalysisAnalysis
Mapping parameter’ Results
Mid
dle
Upp
erL
ower
Prosodic MFCCs

Nov 22nd, 2006
Affective/Linguistic Interplay
Introduction Analysis
• Facial Gesture/speech Interrelation
• Affective/Linguistic Interplay
Recognition Synthesis Conclusions
01/40 AnalysisAnalysis
• Affective/Linguistic Interplay• Affective/Linguistic Interplay
C. Busso and S.S. Narayanan. Interplay between linguistic and affective goals in facial expression during emotional utterances. To appear International seminar on Speech Production (ISSP 2006)

Nov 22nd, 2006
Linguistic/affective interplay
• Linguistic and emotional goals jointly modulate speech and gestures to convey the desired messages
• Articulatory and affective goals co-occur during normal human interaction, sharing the same channels
• Some control needs to buffer, prioritize and execute these communicative goals in coherent manner
• Linguistic and affective goals interplay interchangeably as primary and secondary controls
• During speech, affective goals are displayed under articulatory constraints• Some facial areas have more degree of freedom to display non-verbal clues
01/40 AnalysisAnalysis
Motivation
Hypotheses

Nov 22nd, 2006
Linguistic/affective interplay
• Low vowels (/a/) with less restrictive tongue position observed greater emotional coloring then high vowels (/i/) [Yildirim, 2004] [Lee,2005] [Lee, 2004]
• Focus of this analysis is on the interplay in facial expressions
• Compare facial expressions of neutral and emotional utterances with same semantic content• Correlation
• Euclidean Distance
• The database is a subset of the MOCAP data
01/40 AnalysisAnalysis
Previous results
Approach

Nov 22nd, 2006
Linguistic/affective interplay
01/40 AnalysisAnalysis
Facial activation analysis
Neutral Sad
Happy Angry
• Measure of facial motion
• Lower face area has the highest activeness levels• Articulatory processes play a
crucial role
• Emotional modulation• Happy and angry more active
• Sadness less active than neutral
• Activeness in upper face region increases more then other regions
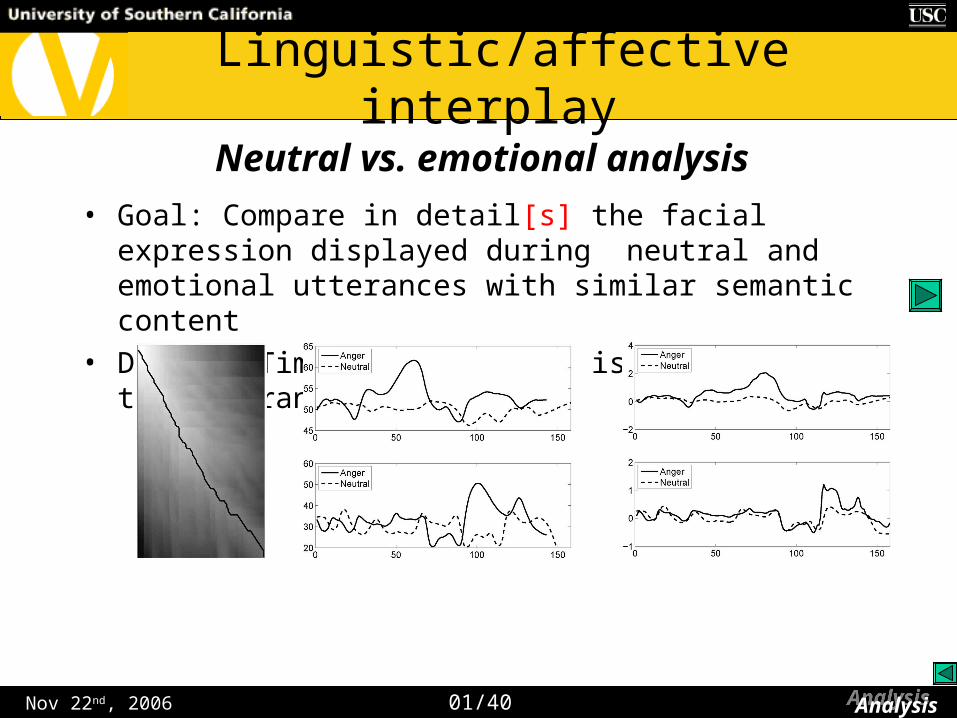
Nov 22nd, 2006
Linguistic/affective interplay
• Goal: Compare in detail[s] the facial expression displayed during neutral and emotional utterances with similar semantic content
• Dynamic Time Warping (DTW) is used to align the utterances
01/40 AnalysisAnalysis
Neutral vs. emotional analysis

Nov 22nd, 2006
Linguistic/affective interplay
• Higher correlation implies higher articulatory constraints
• Lower facial region has the highest correlation levels
• More constrained
• Upper facial region has the lower correlation levels
• Can communicate non-verbal information regardless of the linguistic content
01/40 AnalysisAnalysis
Correlation analysis : neutral vs. emotional
Neutral-Sad Neutral-Happy Neutral-Angry
(median results)

Nov 22nd, 2006
Linguistic/affective interplay
01/40 AnalysisAnalysis
Euclidean distance analysis : neutral vs. emotional
(median results)
Neutral-Sad Neutral-Happy Neutral-Angry
• After scaling the facial features, the Euclidean distance was estimated
• High values indicate that facial features are more independent of the articulation.
• Similar results than in correlation
• Upper face region less constrained by articulatory processes

Nov 22nd, 2006
Analysis
• Facial gestures and speech are strongly interrelated
• The correlation levels present inter-emotion differences
• There is an emotion-dependent structure in the mapping parameter that may be learned
• The prosodic-based mapping parameter set is grouped in a small cluster
• Facial areas and speech are coupled at different resolutions
01/40 AnalysisAnalysis
Remarks from analysis section

Nov 22nd, 2006
Analysis
• During speech, facial activeness is mainly driven by articulation
• However, linguistic and affective goals co-occur during active speech.
• There is an interplay between linguistic and affective goals in facial expression
• Forehead and cheeks have more degree of freedom to convey non-verbal messages
• The lower face region is more constrained by the articulatory process
01/40 AnalysisAnalysis
Remarks from analysis section
Nov 22nd, 2006
Recognition
Introduction Analysis Recognition
• Emotion recognition
• Engagement recognition
Synthesis Conclusions
01/40 RecognitionRecognition
• Emotion recognition• Emotion recognition
C. Busso, Z. Deng, S. Yildirim, M. Bulut, C.M. Lee, A. Kazemzadeh, S. Lee, U. Neumann, and S. Narayanan, “Analysis of emotion recognition using facial expressions, speech and multimodal information ,” in Sixth International Conference on Multimodal Interfaces ICMI 2004, State College, PA, 2004, pp. 205–211, ACM Press.

Nov 22nd, 2006
Multimodal Emotion Recognition
• Emotions are an important element of human-human interaction• Design improved human-machine interfaces• Give specific and appropriate help to user
• Modalities give complementary information • Some emotions are better recognized in a particular domain• Multimodal approach provide better performance and robustness
• Decision-level fusion systems (rule-based system) [Chen,1998] [DeSilva,2000] [Yoshitomi,2000]
• Feature-level fusion systems [Chen,1998_2] [Huang,1998]
01/40 RecognitionRecognition
Motivation
Hypotheses
Related work

Nov 22nd, 2006
Multimodal Emotion Recognition
• Analyze the strength and limitation of unimodal systems to recognize emotion states
• Study the performance of multimodal system
• MOCAP database is used
• Sentence-level features (e.g. mean, variance, range, etc.)
• Speech : prosodic features
• Facial expression: upper and middle face area
• Sequential backward features selection
• Support vector machine classifier (SVC)
• Decision and feature level integration
01/40 RecognitionRecognition
Proposed work

Nov 22nd, 2006
Anger Sadness Happiness Neutral
Anger 0.95 0.00 0.03 0.03Sadness 0.00 0.79 0.03 0.18Happiness 0.02 0.00 0.91 0.08Neutral 0.01 0.05 0.02 0.92
Multimodal Emotion Recognition
• From speech• Average ~70%
• Confusion sadness-neutral ( )
• Confusion happiness-anger ( )
• From facial expression• Average ~85%
• Confusion anger-sadness ( )
• Confusion neutral-happiness ( )
• Confusion sadness-neutral ( )
• Multimodal system (feature-level)• Average ~90%
• Confusion neutral-sadness ( )
• Other pairs are correctly separated
01/40 RecognitionRecognition
Emotion recognition results
Anger Sadness Happiness Neutral
Anger 0.79 0.18 0.00 0.03Sadness 0.06 0.81 0.00 0.13Happiness 0.00 0.00 1.00 0.00Neutral 0.00 0.04 0.15 0.81
Anger Sadness Happiness NeutralAnger 0.68 0.05 0.21 0.05Sadness 0.07 0.64 0.06 0.22Happiness 0.19 0.04 0.70 0.08Neutral 0.04 0.14 0.01 0.81

Nov 22nd, 2006
Inferring participants’ engagement
Introduction Analysis Recognition
• Emotion recognition
• Engagement recognition
Synthesis Conclusions
01/40 RecognitionRecognition
• Engagement recognition• Engagement recognition
C. Busso, S. Hernanz, C.W. Chu, S. Kwon, S. Lee, P. G. Georgiou, I. Cohen, S. Narayanan. Smart Room: Participant and Speaker Localization and Identification. In Proc. ICASSP, Philadelphia, PA, March 2005. C. Busso, P.G. Georgiou and S.S. Narayanan. Real-time monitoring of participants’ interaction in a meeting using audio-visual sensors. Under submission to International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2007)

Nov 22nd, 2006
Inferring participants’ engagement
• At small group level, the strategies of one participant are affected by the strategies of other participants
• Automatic annotations of human interaction will provide better tools for analyzing teamwork and collaboration strategies
• Examples of application in which monitoring human interaction is very useful are summarization, retrieval and classification of meetings
• Infer meta-information from participants in a multiperson meeting
• To monitor and track the behaviors, strategies and engagements of the participants
• Infer interaction flow of the discussion
01/40 RecognitionRecognition
Motivation
Goals

Nov 22nd, 2006
Inferring participants’ engagement
• Extract high-level features from automatic annotations of speaker activity (e.g. number and average duration of each turn)
• Use an intelligent environment equipped with audio-visual sensors to get the annotations
• Intelligent environment [Checka,2004] [Gatica-Perez,2003] [Pingali,1999]
• Monitoring human interaction [McCowan,2005] [Banerjee,2004] [Zhang,2006] [Basu,2001]
01/40 RecognitionRecognition
Approach
Related work

Nov 22nd, 2006
Inferring participants’ engagement
• Visual• 4 firewire CCD cameras
• 360o Omnidirectional camera
• Audio• 16-channel microphone
array
• Directional microphone (SID)
01/40 RecognitionRecognition
Smart Room

Nov 22nd, 2006
Inferring participants’ engagement
• After fusing audio-visual stream of data, the system gives• Participants’ location• Sitting arrangement• Speaker identity • Speaker activity
• Testing (~85%)• Three 20-minute meeting
(4 participants)• Casual conversation with
interruptions and overlap
01/40 RecognitionRecognition
Localization and identification
Nov 22nd, 2006
Inferring participants’ engagement
• High level features per participant• Number of turns
• Average duration of turns
• Amount of time as active speaker
• Transition matrix depicting turn-taking between participants
• Evaluation• Hand-based annotation of speaker activity
• Results describe here correspond to one of the meetings
01/40 RecognitionRecognition
Participants interaction
Nov 22nd, 2006
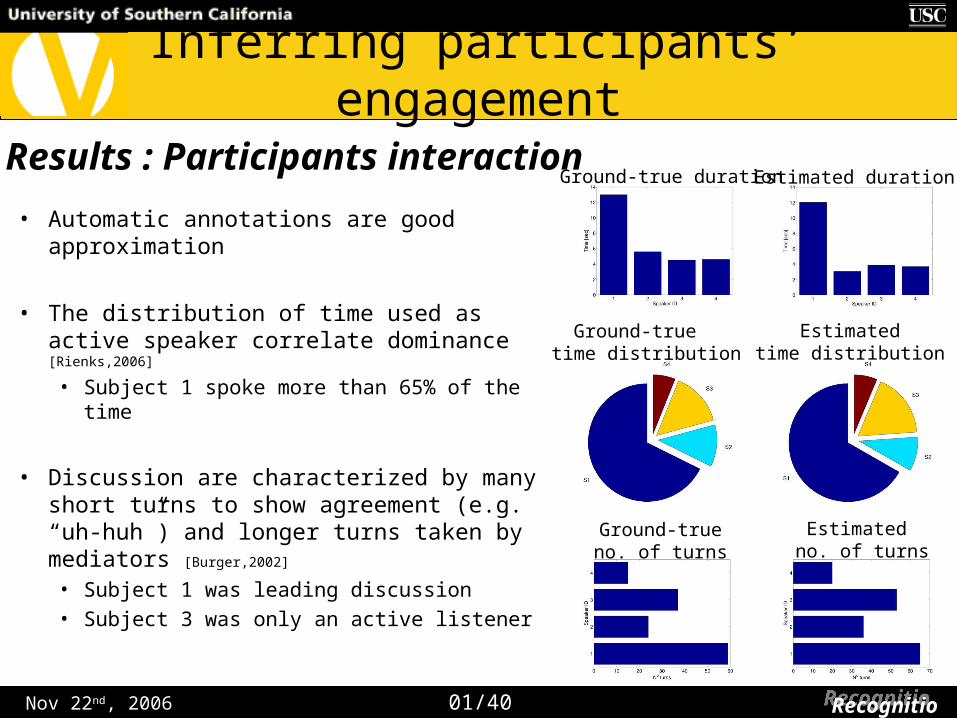
Inferring participants’ engagement
• Automatic annotations are good approximation
• The distribution of time used as active speaker correlate dominance [Rienks,2006]
• Subject 1 spoke more than 65% of the time
• Discussion are characterized by many short turns to show agreement (e.g. “uh-huh”) and longer turns taken by mediators [Burger,2002]
• Subject 1 was leading discussion
• Subject 3 was only an active listener
01/40 RecognitionRecognition
Results : Participants interactionEstimated durationGround-true duration
Ground-true time distribution
Estimatedtime distribution
Estimated no. of turns
Ground-trueno. of turns

Nov 22nd, 2006
Inferring participants’ engagement
• The transition matrix gives the interaction flow and turn taking patterns
• Claim: transition between speaker ~ who was being addressed• To evaluate this hypothesis, addressee
was manually annotated and compared with transition matrix
• Transition matrix provides a good first approximation to identifying the interlocutor dynamics.
• Discussion was mainly between subjects 1 and 3.
01/40 RecognitionRecognition
Results : Participants interaction
Ground-true transition
Estimatedtransition
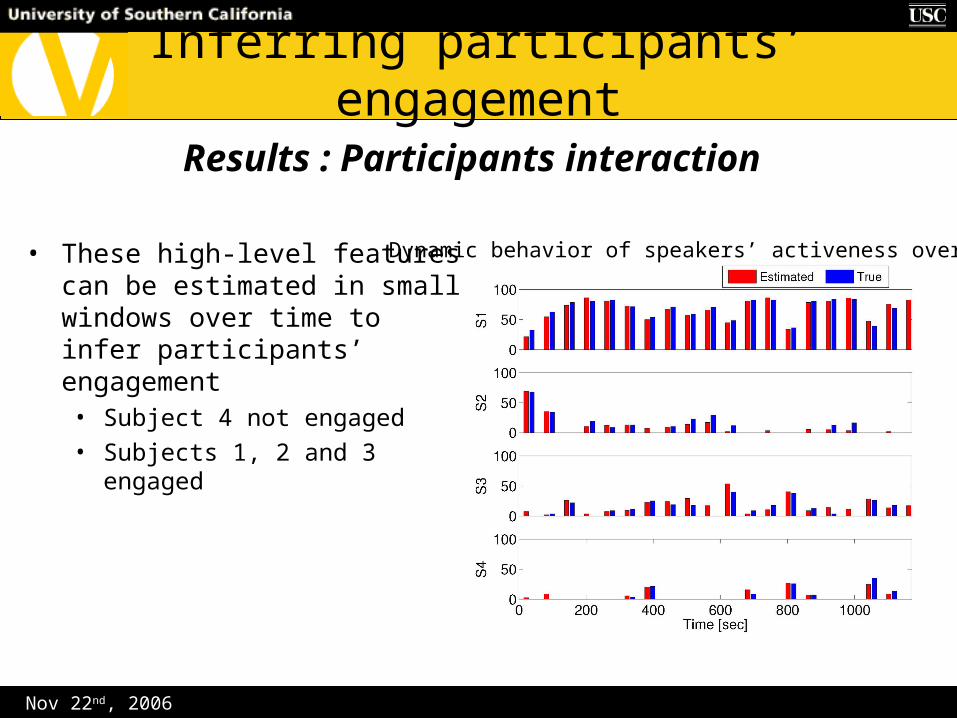
Nov 22nd, 2006
Inferring participants’ engagement
• These high-level features can be estimated in small windows over time to infer participants’ engagement• Subject 4 not engaged
• Subjects 1, 2 and 3 engaged
Results : Participants interaction
Dynamic behavior of speakers’ activeness over time

Nov 22nd, 2006
Recognition
• Multimodal approaches to infer meta-information from speaker gives better performance than unimodal system
• When acoustic and facial features are fused, the performance and the robustness of the emotion recognition system improve measurably
• In small group meetings, it is possible to accurately estimate in real-time not only the flow of the interaction, but also how dominant and engaged each participant was during the discussion
Remarks from recognition section
Nov 22nd, 2006
Synthesis
Introduction Analysis Recognition Synthesis
• Head motion synthesis
Conclusions Future Work
01/40 SynthesisSynthesis
• Head motion synthesis• Head motion synthesis
C. Busso, Z. Deng, U. Neumann, and S.S. Narayanan, “Natural head motion synthesis driven by acoustic prosodic features,” Computer Animation and Virtual Worlds, vol. 16, no. 3-4, pp. 283–290, July 2005. C. Busso, Z. Deng, M. Grimm, U. Neumann and S. Narayanan. Rigid Head Motion in Expressive Speech Animation: Analysis and Synthesis. IEEE Transactions on Audio, Speech and Language Processing, March 2007

Nov 22nd, 2006
Natural Head Motion Synthesis
• Mapping between facial gestures and speech can be learned using more sophisticated framework
• A useful and practical application is avatars driven by speech
• Engaging human-computer interfaces and application such as animated features films have motivated realistic avatars
• Focus of this section: head motion
01/40 SynthesisSynthesis
Motivation

Nov 22nd, 2006
Natural Head Motion Synthesis
• It has received little attention compared to other gestures
• Important for acknowledging active listening• Improves acoustic perception [Munhall,2004]
• Distinguish interrogative and declarative statements [Munhall,2004]
• Recognize speaker identity [Hill,2001]
• Segment spoken content [Graf,2002
01/40 SynthesisSynthesis
Why head motion?

Nov 22nd, 2006
Natural Head Motion Synthesis
• Head motion is important for human-like facial animation
• Head motion change the perception of the emotion
• Head motion can be synthesize from acoustic features
• Rule-based systems [Pelachaud,1994]
• Gaussian Mixtures Model [Costa,2001]
• Specific head motion (e.g. ‘nod’) [Cassell, 1994] [Graf, 2002]
• Example-based system [Deng, 2004], [Chuang, 2004]
01/40 SynthesisSynthesis
Hypotheses
Related Work

Nov 22nd, 2006
Natural Head Motion Synthesis
01/40 SynthesisSynthesis
• Hidden Markov Models are trained to capture the temporal relation between the prosodic features and the head motion sequence
• Vector quantization is used to produce a discrete representation of head poses
• Two-step smoothing techniques are used based on first order Markov model and spherical cubic interpolation
• Emotion perception is studied by rendering deliberate mismatches between the emotional speech and the emotional head motion sequences
Proposed Framework

Nov 22nd, 2006
Natural Head Motion Synthesis
• Same audio-visual database
• Acoustic Features ~ Prosody (6D)• Pitch
• RMS energy
• First and second derivative
• Head motion ~ head rotation (3DOF) • Reduce the number of HMMs
• For closed-view of the face, translation effect less important
01/40 SynthesisSynthesis
Database and features
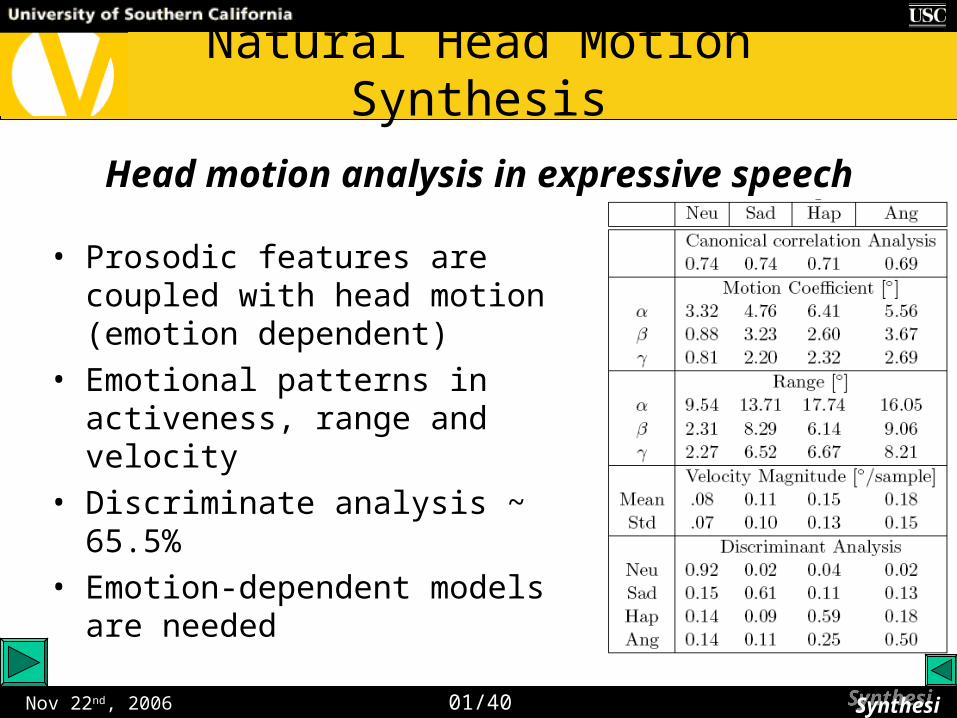
Nov 22nd, 2006
Natural Head Motion Synthesis
01/40 SynthesisSynthesis
Head motion analysis in expressive speech
• Prosodic features are coupled with head motion (emotion dependent)
• Emotional patterns in activeness, range and velocity
• Discriminate analysis ~ 65.5%
• Emotion-dependent models are needed

Nov 22nd, 2006
Natural Head Motion Synthesis
• Head motions are modeled with HMMs• HMMs provide a suitable and natural framework to model the
temporal relation between prosodic features and head motions• HMMs will be used as sequence generator (head motion sequence)
• Discrete head pose representation• The 3D head motion data is quantized using K-dimensional vector quantization
• Each cluster is characterized by its mean, and covariance,
01/40 SynthesisSynthesis
Head motion analysis in expressive speech
( ) iVHeadPose ≈= γβα ,, { }Ki ..1∈
iU iΣ

Nov 22nd, 2006
Natural Head Motion Synthesis
• The observation, O, are the acoustic prosodic features
• One HMM will be trained for each head pose cluster,
• Likelihood distribution: P(O/Vi )
• It is modeled as a Markov process
• A mixture of M Gaussian densities is used to model the pdf of the observations
• Standard algorithm are used to train the parameters (Forward-backward, Baum-Welch re-estimation)
01/40 SynthesisSynthesis
)()|()|( iii VPVOPcOVP ⋅=
iV
Learning natural head motion

Nov 22nd, 2006
Natural Head Motion Synthesis
• Prior distribution: P(Vi)
• It is built as bi-gram models learned from the data (1st smoothing step)
• Transitions between clusters that do not appear in the training data are penalized
• This smoothing constraint is imposed in the decoding step
01/40 SynthesisSynthesis
)()|()|( iii VPVOPcOVP ⋅=
Learning natural head motion
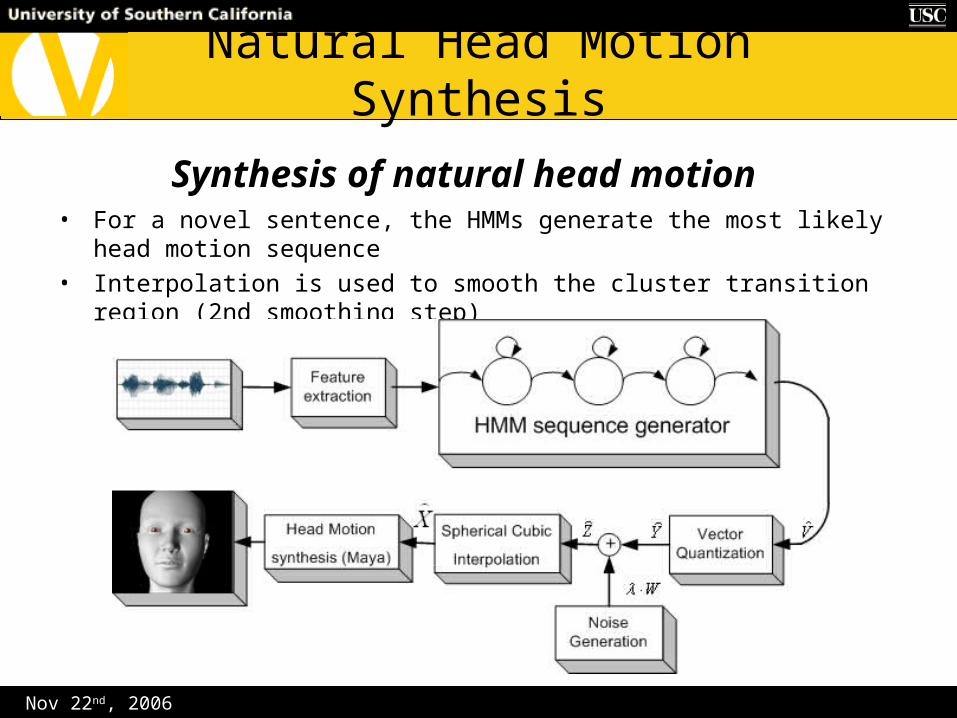
Nov 22nd, 2006
Natural Head Motion Synthesis
Synthesis of natural head motion• For a novel sentence, the HMMs generate the most likely head motion sequence
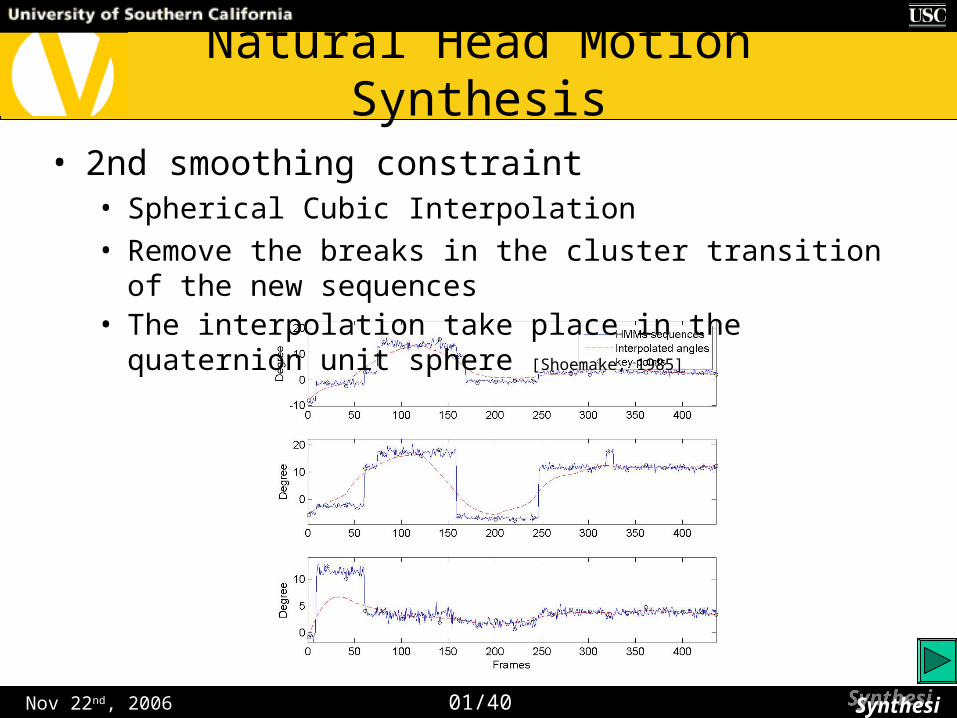
• Interpolation is used to smooth the cluster transition region (2nd smoothing step)
Nov 22nd, 2006
Natural Head Motion Synthesis
• 2nd smoothing constraint• Spherical Cubic Interpolation
• Remove the breaks in the cluster transition of the new sequences• The interpolation take place in the quaternion unit sphere [Shoemake, 1985]
01/40 SynthesisSynthesis

Nov 22nd, 2006
Natural Head Motion Synthesis
• Configuration• Left-to-Right topology• K=16 (number of cluster)• S=2 (number of states)• M=2 (number of mixtures)• 80% training set, 20% test set
• A set of HMMs was built for each emotion• From Euler angles to talking avatars
• The Euler angles are directed applied to the control parameters of the face model
• Face is synthesized with techniques given in [Deng,2004], [Deng,2005], [Deng,2005_2], [Deng,2006]
01/40 SynthesisSynthesis
Nov 22nd, 2006
Natural Head Motion Synthesis
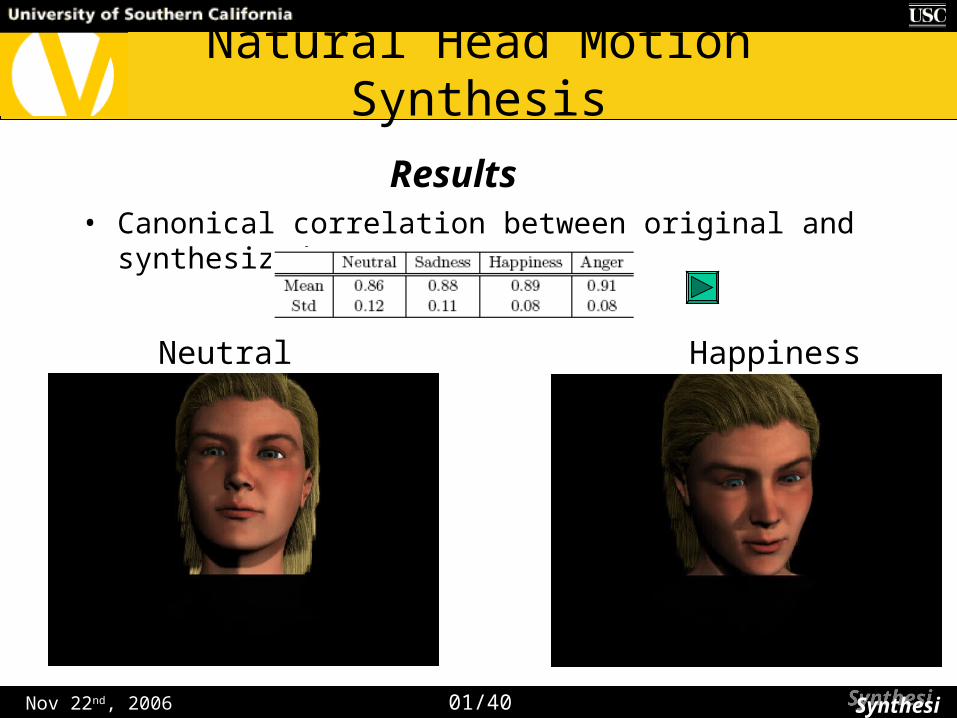
• Canonical correlation between original and synthesized sequence
01/40 SynthesisSynthesis
Results
Neutral Happiness

Nov 22nd, 2006
Natural Head Motion Synthesis
01/40 SynthesisSynthesis
ResultsSadness Anger
Subjective naturalness assessment

Nov 22nd, 2006
Natural Head Motion Synthesis
• Approach: Render animations with deliberate mismatches between the emotional content of the speech and the emotional pattern of head motion
• Dynamic Time Warping for alignment
• 17 human subjects assessed the videos
• Evaluation is performed in primitives attributes domain (valence, activation and dominance)
Emotional Perception
01/40 SynthesisSynthesis

Nov 22nd, 2006
Natural Head Motion Synthesis
01/40 SynthesisSynthesis
• Happy head motion make the attitude of the animation more positive (s.s.)
• Angry head motion make the attitude of the animation more negative (n.s.s.)
Results: Valence (Positive-Negative)
1 2 3 4 5

Nov 22nd, 2006
Natural Head Motion Synthesis
01/40 SynthesisSynthesis
Results: Activation (Excited-Calm)
• Anger head motion makes the attitude of the animation more excited than happy head motion (s.s)
• Happy speech with sad head motion is perceived more excited (s.s.)• Artifact of the approach
• True effect generated by combination of modalities (McGurk effect)
1 2 3 4 5

Nov 22nd, 2006
Natural Head Motion Synthesis
01/40 SynthesisSynthesis
• Head motion does not modify this attribute
• Neutral speech with happy head motion is perceived more strong (n.s.s.)
• Happy speech synthesized with angry head motion is perceived more strong (n.s.s.)
Results: Dominance (Weak-strong)
1 2 3 4 5

Nov 22nd, 2006
Synthesis
Remarks from synthesis section• Re-visiting the hypotheses
Head motion is important for human-like facial animation• Animation is perceived more natural with head motion
Head motion change the perception of the emotion• Specially in valence and activation domain
• Head motion need to be designed to convey the desire emotion
Head motion can be synthesize from acoustic features• The synthesized sequences were perceives as natural as the original
sequences
• HMMs capture the relation between prosodic and head motion features

Nov 22nd, 2006
Conclusions
Introduction Analysis Recognition Synthesis Conclusions
Proposed work Timeline
01/40 ConclusionsConclusions

Nov 22nd, 2006
Proposed work
• To jointly model different modalities within an integrated framework• gestures and speech are not synchronous and they are coupled at different
resolutions
• Explore human emotional perception• Different combination of modalities may create different emotion percept
• The idiosyncratic influence in expressive human communication• How speaker-dependent are the results presented here
• At dyad level, how gestures and speech of the speakers are affected by the feedbacks provided by other interlocutors
• At small group level, to infer meta-information from participants’ gestures
Research goals
01/40 ConclusionsConclusions

Nov 22nd, 2006
Proposed work
• Features• Dyad interaction
• 5 session 2 actor each
• Emotions were elicited in context
• ~14 hour of data
• Markers on the face and on the hands
• Happiness, sadness anger, frustration neutral state
• Still under preparation
01/40 ConclusionsConclusions
Interactive and emotional motion capture database

Nov 22nd, 2006
Proposed work
Gesture and speech framework• To model different modalities with a single framework that considers
asynchrony and interrelation between modalities• Coupled HMMs and graphical models
• Multiresolution analysis of gestures and speech during expressive utterances• Facial gestures and speech are systematically synchronized in different
scales (phonemes-wordsphrases-sentences) [Cassell,1994]• The lower face area is strongly constrained by articulation• The upper face area has more degrees of freedom to communicate non-
linguistic messages• A multiresolution decomposition approach may provide a better
framework to analyze the interrelation between facial and acoustic features• We will study the correlation levels of coarse-to-fine representations of
acoustic and facial features
01/40 ConclusionsConclusions
Individual level

Nov 22nd, 2006
Proposed work
Emotion perception• Evaluate the hypothesis that different combination of
modalities create different emotion percept (McGurk effect)• Approach: design controlled experiments using facial animations• Create deliberate mismatches between the emotional speech and
specific facial gestures (e.g. eyebrow)• Human raters will assess the emotions conveyed in these animations• For facial animation the open source software Xface will be used
• Emotion perception in different modalities• We will compare acoustic versus visual emotion perception• We will evaluate the importance of content in emotion perception• Approach: assess the IEMOCAP database
01/40 ConclusionsConclusions
Individual level

Nov 22nd, 2006
Proposed work
Gestures and speech driven by discourses functions• Study influence of high-level linguistic functions in the relationship between
gestures and speech• We propose to analyze gestures that are generated as discourse functions (e.g.
head nod for “yes”)
• Application: Improve facial animations• e.g. Head motion sequences driven by prosody and discourse functions
Analysis of personal styles
• We propose to study the idiosyncrasy aspect of expressive human communication
• Since IEMOCAP database has 10 subjects, results can generalized• To learn inter-personal similarities (speaker-independent emotion
recognition systems)• To learn inter-personal differences, (better human-like facial animation)
01/40 ConclusionsConclusions
Individual level

Nov 22nd, 2006
Proposed work
Extension of interplay theory
• Analyze facial expressions during acoustic silence
• The lower face area may be modulated as much as the upper/middle face areas
Gestures of active listeners
• Active listeners respond with non-verbal gestures• These gestures appear in specific structure of the speaker’s word [Ekman,1979]
• Application: design active listener virtual agents
• We propose to analyze the gestures and speech of the subjects when they are trying to positively affect the mood of the other interlocutor• Hypothesis: particular gestures are used which can be learned and
synthesize
01/40 ConclusionsConclusions
Dyad level

Nov 22nd, 2006
Proposed work
Gestures of the participants
• Rough estimations of the participant gestures will be extracted
• We propose to include this information as additional clue to measure speaker engagement
• Use gestures to improve fusion algorithm• A measure of hand activeness can be used for speaker localization
• Head postures of the participant can improve the change of turns detection
Smart room as training tool
• Evaluate whether the report provided by the smart room can be used as training tool for improving participant skills during discussions
01/40 ConclusionsConclusions
Small group level

Nov 22nd, 2006
Timeline
January-March
• Multiresolution analysis of gestures and speech during expressive utterances
• Analysis of McGurk effects in emotional perception of expressive facial animations
• Relation between visual and acoustic boundaries
April-June
• Gesture and Speech framework (e.g. CHMM, graphical models)
• Emotion perception in different modalities (context vs. insolated emotional assessments)
• Extension of the interplay theory during acoustic silence

Nov 22nd, 2006
Timeline
July-September
• Facial Animation driven by discourse function and acoustic features
• Study of idiosyncrasy aspect of human communication
• Engagement analysis in multiparty discussion
October-November
• Active listeners analysis
• Hand gestures analysis and its relationship with speech

Nov 22nd, 2006
Publications
Journal Articles[1] C. Busso and S.S. Narayanan. “Interrelation between Speech and Facial Gestures in Emotional
Utterances”. Submitted to IEEE Transactions on Audio, Speech and Language Processing.[2] C. Busso, Z. Deng, M. Grimm, U. Neumann and S. Narayanan. “Rigid Head Motion in Expressive
Speech Animation: Analysis and Synthesis”. IEEE Transactions on Audio, Speech and Language Processing, March 2007
[3] C. Busso, Z. Deng, U. Neumann, and S.S. Narayanan, “Natural head motion synthesis driven by acoustic prosodic features,” Computer Animation and Virtual Worlds, vol. 16, no. 3-4, pp. 283-290, July 2005.
Conferences Proceedings[1] C. Busso, P.G. Georgiou and S.S. Narayanan. “Real-time monitoring of participants’ interaction in a
meeting using audio-visual sensors”. Submitted to International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2007)
[2] C. Busso and S.S. Narayanan. “Interplay between linguistic and affective goals in facial expression during emotional utterances”. To appear International seminar on Speech Production (ISSP 2006)
[3] M. Bulut, C. Busso, S. Yildirim, A. Kazemzadeh, C.M. Lee, S. Lee, and S. Narayanan, “Investigating the role of phoneme-level modifications in emotional speech resynthesis,” in 9th European Conference on Speech Communication and Technology (Interspeech 2005 - Eurospeech), Lisbon, Portugal, September 2005, pp. 801804.

Nov 22nd, 2006
Publications
Conferences Proceedings (cont)[4] C. Busso, S. Hernanz, C.W. Chu, S. Kwon, S. Lee, P. G. Georgiou, I. Cohen, S.
Narayanan. “Smart Room: Participant and Speaker Localization and Identification”. In Proc. ICASSP, Philadelphia, PA, March 2005.
[5] C. Busso, Z. Deng, S. Yildirim, M. Bulut, C.M. Lee, A. Kazemzadeh, S. Lee, U. Neumann, and S. Narayanan, “Analysis of emotion recognition using facial expressions, speech and multimodal information,” in Sixth International Conference on Multimodal Interfaces ICMI 2004, State College, PA, 2004, pp. 205211, ACM Press.
[6] Z. Deng, C. Busso, S. Narayanan, and U. Neumann, “Audio-based head motion synthesis for avatar-based telepresence systems,” in ACM SIGMM2004Workshop on Effective Telepresence (ETP 2004), New York, NY, 2004, pp. 2430, ACM Press.
[7] C.M. Lee, S. Yildirim, M. Bulut, A. Kazemzadeh, C. Busso, Z. Deng, S. Lee, and S.S. Narayanan, “Emotion recognition based on phoneme classes,” in 8th International Conference on Spoken Language Processing (ICSLP 04), Jeju Island, Korea, 2004.
[8] S. Yildirim, M. Bulut, C.M. Lee, A. Kazemzadeh, C. Busso, Z. Deng, S. Lee, and S.S. Narayanan, “An acoustic study of emotions expressed in speech,” in 8th International Conference on Spoken Language Processing (ICSLP 04), Jeju Island, Korea, 2004.
Nov 22nd, 2006
Publications
Abstracts[1] S. Yildirim, M. Bulut, C. Busso, C.M. Lee, A. Kazamzadeh, S. Lee, and S. Narayanan. “Study of
acoustic correlates associate with emotional speech”. J. Acoust. Soc. Am., 116:2481, 2004.
[2] C. M. Lee, S. Yildirim, M. Bulut, C. Busso, A. Kazamzadeh, S. Lee, and S. Narayanan. “Effects of emotion on different phoneme classes”. J. Acoust. Soc. Am., 116:2481, 2004.
[3] M. Bulut, S. Yildirim, S. Lee, C.M. Lee, C. Busso, A. Kazamzadeh, and S. Narayanan. “Emotion to emotion speech conversion in phoneme level”. J. Acoust. Soc. Am., 116:2481, 2004.
Thanks!Thanks!

Nov 22nd, 2006
Spherical Cubic Interpolation
• Interpolation procedure• Euler angles are transformed to quaternion• Key-points are selected by down-sampling the quaternion• Spherical cubic interpolation (squad) is used to interpolate key-
points• The interpolated results are transformed to Euler angles
• Motivation for spherical cubit interpolation• Interpolation in Euler space introduce jerky movement• Introduce undesired effects such as Gimbal lock
))1(2),,,(),,,((),,,,( 32414321 uuuqqslerpuqqslerpslerpuqqqqsquad −=
2121 sin
sin
sin
)1sin(),,( q
uq
uuqqslerp
θθ
θθ
+−
=
SynthesisSynthesis

Nov 22nd, 2006
Techniques
SynthesisSynthesis
• Scale-invariant optimum linear framework to measure the correlation between two streams of data with different dimensions [Dehon, 2000]
• Basic idea: project the features into a common space in which Pearson’s correlation can be computed
• Def: The standard deviation of the sentence-level mean-removed signal
Canonical correlation analysis (CCA)
Motion Coefficient
Nov 22nd, 2006
HMM Configuration
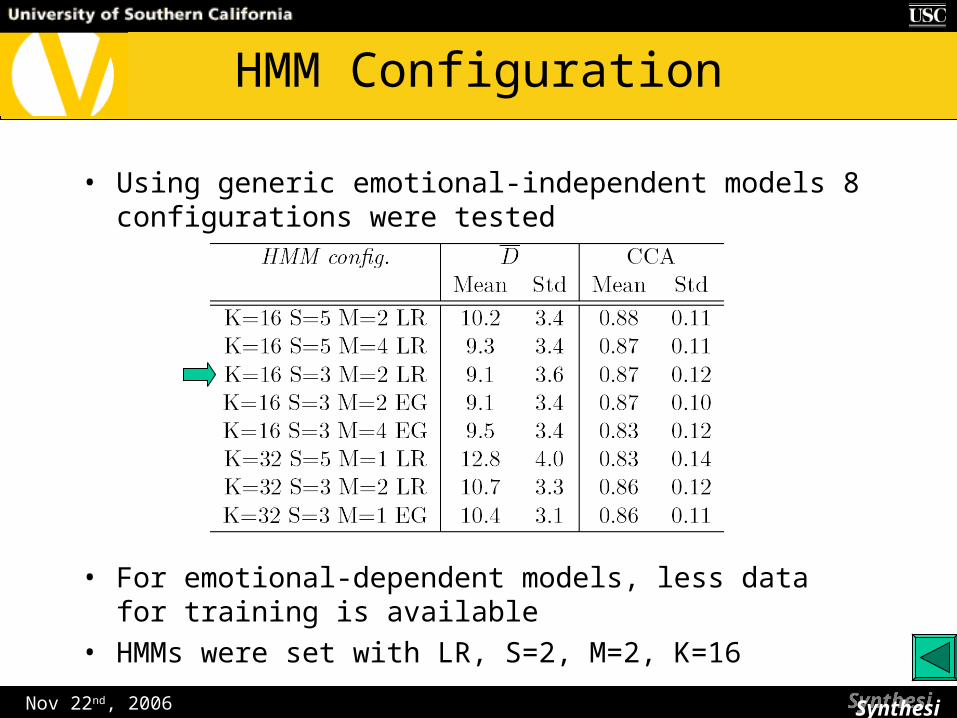
• Using generic emotional-independent models 8 configurations were tested
• For emotional-dependent models, less data for training is available
• HMMs were set with LR, S=2, M=2, K=16
SynthesisSynthesis

Nov 22nd, 2006
From Euler Angles to Talking Avatars
• Improve
• Avatar is synthesized using Maya
• A model with 46 blend shapes is used• Lip and eye motions are also included [Deng,2004], [Deng,2005],
[Deng,2005_2], [Deng,2006]
SynthesisSynthesis
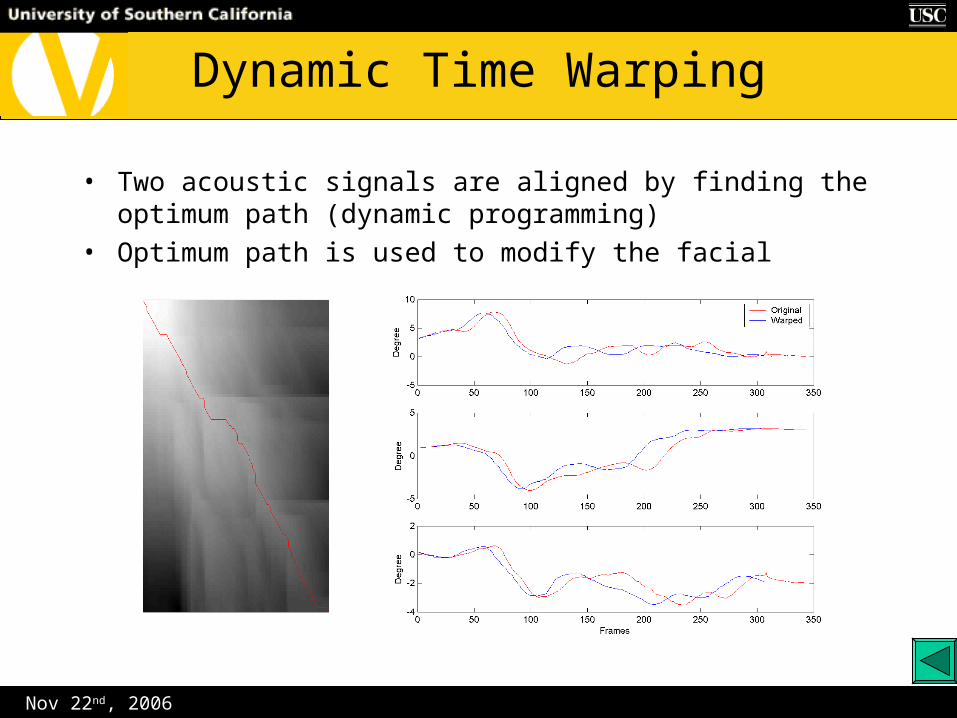
Nov 22nd, 2006
Dynamic Time Warping
• Two acoustic signals are aligned by finding the optimum path (dynamic programming)
• Optimum path is used to modify the facial gestures

Nov 22nd, 2006
MFCC features
• The first coefficient of the MFCCs was removed (Energy)
• The velocity and acceleration coefficients were also included
• Feature vector was reduced from 36 to 12 using Principal Component Analysis (95% of the variance)
• This post-processed feature vector is what will be referred here on as MFCCs.
AnalysisAnalysis

Nov 22nd, 2006
Markers post processing
• Translate the markers (nose marker is the reference)
• Frames are multiplied by a rotational matrix• Choose a neutral pose as reference (102×3 Mref)
• For the frame t, construct a similar matrix Mt
• Compute Singular Value Decomposition, UDVT , of matrix (Mref) T ·Mt
• The product VUT gives the rotational matrix, Rt, [Stegmann,2002]
AnalysisAnalysis
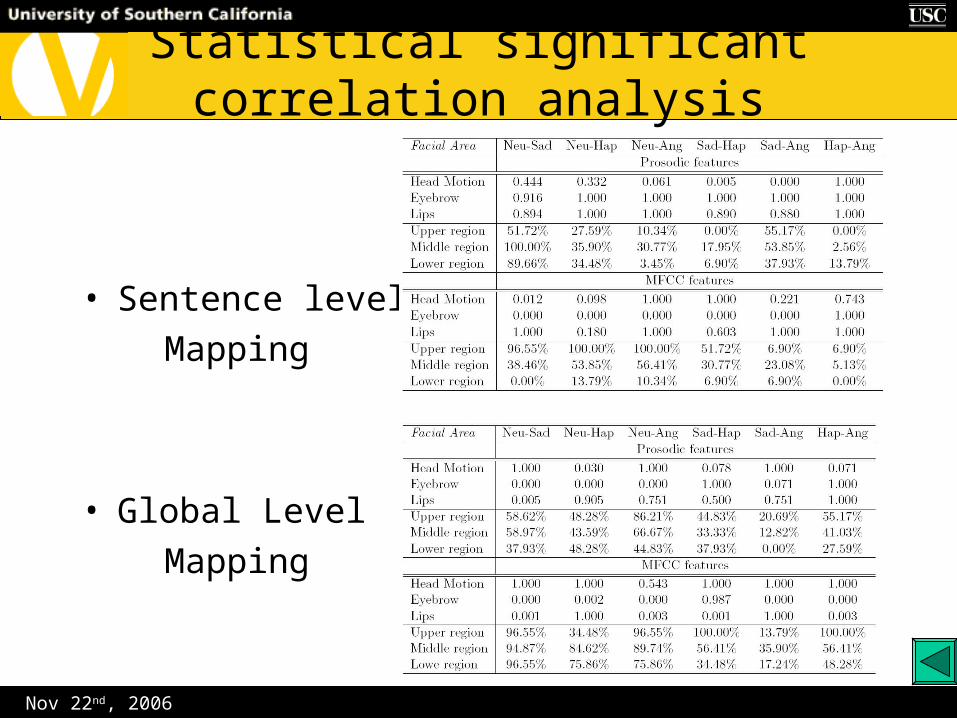
Nov 22nd, 2006
Statistical significant correlation analysis
• Sentence level
Mapping
• Global Level
Mapping

Nov 22nd, 2006
Phoneme level analysis of correlation

Nov 22nd, 2006
Features from Facial Expression
• 4-D feature vector
• Data is normalized to remove head motion
• Five facial areas are defined
• 3-D coordinates are concatenated
• PCA is used to reduce to 10-D vector
• Frame level classification (K-nearest neighbor)
• The statistic of the frame at utterance level are aggregated forming a 4D feature vector

Nov 22nd, 2006
More details on emotion recognition
• Feature-level integration (89%)• High performance of anger, happiness and
neutral state
• Bad performance of sadness 79%
• The performance of happiness decreased
• Decision-level integration (89%)• Product of the posterior probabilities was the best
criterion
• Product criterion: Same results, big differences
Multimodal Systems
Anger Sadness Happiness Neutral
Anger 0.95 0.00 0.03 0.03Sadness 0.00 0.79 0.03 0.18Happiness 0.02 0.00 0.91 0.08Neutral 0.01 0.05 0.02 0.92
Overall Anger Sadness Hapiness Neutral
Maximum combining 0.84 0.82 0.81 0.92 0.81Averaging combining 0.88 0.84 0.84 1.00 0.84Product combining 0.89 0.84 0.90 0.98 0.84Weight combining 0.86 0.89 0.75 1.00 0.81
In detail
Anger Sadness Happiness Neutral
Anger 0.84 0.08 0.00 0.08Sadness 0.00 0.90 0.00 0.10Happiness 0.00 0.00 0.98 0.02Neutral 0.00 0.02 0.14 0.84

Nov 22nd, 2006
Smart room fusion





























