Embed Size (px)
Citation preview

Comput Sci Res DevDOI 10.1007/s00450-016-0334-3
SPECIAL ISSUE PAPER
NoSQL database systems: a survey and decision guidance
Felix Gessert1 · Wolfram Wingerath1 · Steffen Friedrich1 · Norbert Ritter1
© Springer-Verlag Berlin Heidelberg 2016
Abstract Today, data is generated and consumedat unprece-dented scale. This has lead to novel approaches for scalabledata management subsumed under the term “NoSQL” data-base systems to handle the ever-increasing data volume andrequest loads. However, the heterogeneity and diversity ofthe numerous existing systems impede the well-informedselection of a data store appropriate for a given applicationcontext. Therefore, this article gives a top-down overview ofthe field: instead of contrasting the implementation specificsof individual representatives, we propose a comparative clas-sification model that relates functional and non-functionalrequirements to techniques and algorithms employed inNoSQL databases. This NoSQL Toolbox allows us to derivea simple decision tree to help practitioners and researchersfilter potential systemcandidates based on central applicationrequirements.
Keywords NoSQL · Data management · Scalability · Datamodels · Sharding · Replication
B Felix [email protected]
Wolfram [email protected]
Steffen [email protected]
Norbert [email protected]
1 Universität Hamburg, Hamburg, Germany
1 Introduction
Traditional relational database management systems(RDBMSs) provide powerful mechanisms to store and querystructured data under strong consistency and transactionguarantees and have reached an unmatched level of reliabil-ity, stability and support through decades of development.In recent years, however, the amount of useful data insome application areas has become so vast that it cannotbe stored or processed by traditional database solutions.User-generated content in social networks or data retrievedfrom large sensor networks are only two examples of thisphenomenon commonly referred to as Big Data [35]. Aclass of novel data storage systems able to cope with BigData are subsumed under the term NoSQL databases, manyof which offer horizontal scalability and higher availabilitythan relational databases by sacrificing querying capabilitiesand consistency guarantees. These trade-offs are pivotal forservice-oriented computing and as-a-service models, sinceany stateful service can only be as scalable and fault-tolerantas its underlying data store.
There are dozens of NoSQL database systems and it ishard to keep track ofwhere they excel, where they fail or evenwhere they differ, as implementation details change quicklyand feature sets evolve over time. In this article, we thereforeaim to provide an overview of the NoSQL landscape by dis-cussing employed concepts rather than system specificitiesand explore the requirements typically posed toNoSQLdata-base systems, the techniques used to fulfil these requirementsand the trade-offs that have to be made in the process. Ourfocus lies on key-value, document and wide-column stores,since these NoSQL categories cover the most relevant tech-niques and design decisions in the space of scalable datamanagement.
123

F. Gessert et al.
In Sect. 2, we describe the most common high-levelapproaches towards categorizing NoSQL database systemseither by their data model into key-value stores, documentstores andwide-column stores or by the safety-liveness trade-offs in their design (CAP and PACELC). We then surveycommonly used techniques in more detail and discuss ourmodel of how requirements and techniques are related inSect. 3, before we give a broad overview of prominent data-base systems by applying our model to them in Sect. 4. Asimple and abstract decision model for restricting the choiceof appropriate NoSQL systems based on application require-ments concludes the paper in Sect. 5.
2 High-level system classification
In order to abstract from implementation details of individualNoSQL systems, high-level classification criteria can be usedto group similar data stores into categories. In this section, weintroduce the two most prominent approaches: data modelsand CAP theorem classes.
2.1 Different data models
The most commonly employed distinction between NoSQLdatabases is the way they store and allow access to data. Eachsystem covered in this paper can be categorised as either key-value store, document store or wide-column store.
2.1.1 Key-value stores
A key-value store consists of a set of key-value pairs withunique keys. Due to this simple structure, it only supportsget and put operations. As the nature of the stored value istransparent to the database, pure key-value stores do not sup-port operations beyond simple CRUD (Create, Read, Update,Delete). Key-value stores are therefore often referred to asschemaless [44]: any assumptions about the structure ofstored data are implicitly encoded in the application logic(schema-on-read [31]) and not explicitly defined through adata definition language (schema-on-write).
The obvious advantages of this data model lie in its sim-plicity. The very simple abstraction makes it easy to partitionand query the data, so that the database system can achievelow latency as well as high throughput. However, if an appli-cation demandsmore complex operations, e.g. range queries,this data model is not powerful enough. Figure 1 illustrateshow user account data and settings might be stored in a key-value store. Since queries more complex than simple lookupsare not supported, data has to be analyzed inefficiently inapplication code to extract information like whether cookiesare supported or not (cookies: false).
User:2:friends {23, 76, 233, 11}
[234, 3466, 86, 55]
User:2:se�ngs
User:3:friends
Theme: dark, cookies: false
Value (Opaque)Key
Fig. 1 Key-value stores offer efficient storage and retrieval of arbitraryvalues
12338
{_id: 12338,customer: { name: 'Ri�er ', age: 32, ... } ,items: [ { product: 'PC x', qty: 4, ... } , ... ]
}
JSON Document
Key
12339 { ... }
Fig. 2 Document stores are aware of the internal structure of the storedentity and thus can support queries
2.1.2 Document stores
A document store is a key-value store that restricts valuesto semi-structured formats such as JSON1 documents. Thisrestriction in comparison to key-value stores brings greatflexibility in accessing the data. It is not only possible tofetch an entire document by its ID, but also to retrieve onlyparts of a document, e.g. the age of a customer, and to executequeries like aggregation, query-by-example or even full-textsearch (Fig. 2).
2.1.3 Wide-column stores
Wide-column stores inherit their name from the image thatis often used to explain the underlying data model: a rela-tional tablewithmany sparse columns. Technically, however,a wide-column store is closer to a distributed multi-level2
sorted map: the first-level keys identify rows which them-selves consist of key-value pairs. The first-level keys arecalled row keys, the second-level keys are called columnkeys. This storage schememakes tableswith arbitrarilymanycolumns feasible, because there is no column key without acorresponding value. Hence, null values can be stored with-out any space overhead. The set of all columns is partitionedinto so-called column families to colocate columns on diskthat are usually accessed together. On disk, wide-columnstores do not colocate all data from each row, but insteadvalues of the same column family and from the same row.Hence, an entity (a row) cannot be retrieved by one singlelookup as in a document store, but has to be joined together
1 The JavaScript Object Notation is a standard format consisting ofnested attribute-value pairs and lists.2 In some systems (e.g. Bigtable andHBase),multi-versioning is imple-mented by adding a timestamp as third-level key.
123

NoSQL database systems: a survey and decision guidance
com.cnn.www
com.google.www
"CNN"
"Google"
"anchor:cnnsi.com"
"<html>…"
"contents:"
"Anchor"Column Family
"anchor:heise.de"
"Contents"Column Family
"anchor:my.look.ca"
"CNN.com"
"<html>…"
Row Keys
Versions
Column Keys
t6 t5 t3
t9 t8
t4 t7 t10
t14
Fig. 3 Data in a wide-column store
from the columns of all column families. However, this stor-age layout usually enables highly efficient data compressionandmakes retrieving only a portion of an entity very efficient.The data are stored in lexicographic order of their keys, sothat data that are accessed together are physically co-located,given a careful key design. As all rows are distributed intocontiguous ranges (so-called tablets) among different tabletservers, row scans only involve few servers and thus are veryefficient.
Bigtable [9], which pioneered the wide-column model,was specifically developed to store a large collection of web-pages as illustrated in Fig. 3. Every row in thewebpages tablecorresponds to a single webpage. The row key is a concate-nation of the URL components in reversed order and everycolumn key is composed of the column family name and acolumn qualifier, separated by a colon. There are two col-umn families: the “contents” column family with only onecolumn holding the actual webpage and the “anchor” columnfamily holding links to each webpage, each in a separate col-umn. Every cell in the table (i.e. every value accessible bythe combination of row and column key) can be versioned bytimestamps or version numbers. It is important to note thatmuch of the information of an entity lies in the keys and notonly in the values [9].
2.2 Consistency-availability trade-offs:CAP and PACELC
Another defining property of a database apart from how thedata are stored and how they can be accessed is the level ofconsistency that is provided. Somedatabases are built to guar-antee strong consistency and serializability (ACID3), whileothers favour availability (BASE4). This trade-off is inherentto every distributed database system and the huge number ofdifferent NoSQL systems shows that there is awide spectrumbetween the two paradigms. In the following, we explain thetwo theorems CAP and PACELC according to which data-base systems can be categorised by their respective positionsin this spectrum.
3 ACID [23]: Atomicity, Consistency, Isolation, Duration.4 BASE [42]: Basically Available, Soft-state, Eventually consistent.
CAP Like the famous FLP Theorem5 [19], the CAP Theo-rem, presented by Eric Brewer at PODC 2000 [7] and laterproven by Gilbert and Lynch [21], is one of the truly influen-tial impossibility results in the field of distributed computing,because it places an ultimate upper bound on what can pos-sibly be accomplished by a distributed system. It states thata sequentially consistent read/write register6 that eventuallyresponds to every request cannot be realised in an asynchro-nous system that is prone to network partitions. In otherwords, it can guarantee at most two of the following threeproperties at the same time:
– Consistency (C) Reads and writes are always executedatomically and are strictly consistent (linearizable [26]).Put differently, all clients have the same view on the dataat all times.
– Availability (A) Every non-failing node in the system canalways accept read and write requests by clients and willeventually return with a meaningful response, i.e. notwith an error message.
– Partition-tolerance (P) The system upholds the previ-ously displayed consistency guarantees and availabilityin the presence of message loss between the nodes orpartial system failure.
Brewer argues that a system can be both available and con-sistent in normal operation, but in the presence of a systempartition, this is not possible: If the system continues to workin spite of the partition, there is some non-failing node thathas lost contact to the other nodes and thus has to decide toeither continue processing client requests to preserve avail-ability (AP, eventual consistent systems) or to reject clientrequests in order to uphold consistency guarantees (CP). Thefirst option violates consistency, because it might lead tostale reads and conflicting writes, while the second optionobviously sacrifices availability. There are also systems thatusually are available and consistent, but fail completelywhenthere is a partition (CA), for example single-node systems. Ithas been shown that the CAP-theorem holds for any consis-tency property that is at least as strong as causal consistency,which also includes any recency bounds on the permissi-ble staleness of data (�-atomicity) [37]. Serializability asthe correctness criterion of transactional isolation does notrequire strong consistency. However, similar to consistency,serializability can also not be achieved under network parti-tions [15].
5 The FLP theorem states, that in a distributed system with asynchro-nous message delivery, no algorithm can guarantee to reach a consensusbetween participating nodes if one or more of them can fail by stopping.6 A read/write register is a data structure with only two operations:setting a specific value (set) and returning the latest value that was set(get).
123

F. Gessert et al.
The classification of NoSQL systems as either AP, CPor CA vaguely reflects the individual systems’ capabilitiesand hence is widely accepted as a means for high-levelcomparisons. However, it is important to note that the CAPTheorem actually does not state anything on normal opera-tion; it merely tells us whether a system favors availability orconsistency in the face of a network partition. In contrast tothe FLP-Theorem, the CAP theorem assumes a failure modelthat allows arbitrary messages to be dropped, reordered ordelayed indefinitely. Under the weaker assumption of reli-able communication channels (i.e. messages always arrivebut asynchronously and possibly reordered) a CAP-systemis in fact possible using the Attiya, Bar-Noy, Dolev algorithm[2], as long as a majority of nodes are up7.
PACELC This lack of the CAP Theorem is addressed in anarticle by Daniel Abadi [1] in which he points out that theCAP Theorem fails to capture the trade-off between latencyand consistency during normal operation, even though it hasproven to be much more influential on the design of dis-tributed systems than the availability-consistency trade-offin failure scenarios. He formulates PACELC which unifiesboth trade-offs and thus portrays the design space of distrib-uted systems more accurately. From PACELC, we learn thatin case of a Partition, there is an Availability-Consistencytrade-off; Else, i.e. in normal operation, there is a Latency-Consistency trade-off.
This classification basically offers two possible choicesfor the partition scenario (A/C) and also two for normal oper-ation (L/C) and thus appears more fine-grained than the CAPclassification. However, many systems cannot be assignedexclusively to one single PACELC class and one of the fourPACELC classes, namely PC/EL, can hardly be assigned toany system.
3 Techniques
Every significantly successful database is designed for aparticular class of applications, or to achieve a specific com-bination of desirable system properties. The simple reasonwhy there are so many different database systems is that it isnot possible for any system to achieve all desirable proper-ties at once. Traditional SQL databases such as PostgreSQLhave been built to provide the full functional package: avery flexible data model, sophisticated querying capabilitiesincluding joins, global integrity constraints and transactionalguarantees. On the other end of the design spectrum, thereare key-value stores like Dynamo that scale with data and
7 Therefore, consensus as used for coordination in many NoSQL sys-tems either natively [4] or through coordination services like Chubbyand Zookeeper [28] is even harder to achieve with high availability thanstrong consistency [19].
request volume and offer high read and write throughput aswell as low latency, but barely any functionality apart fromsimple lookups.
In this section, we highlight the design space of distributeddatabase systems, concentrating on sharding, replication,storage management and query processing. We survey theavailable techniques and discuss how they are related to dif-ferent functional and non-functional properties (goals) ofdata management systems. In order to illustrate what tech-niques are suitable to achieve which system properties, weprovide the NoSQL Toolbox (Fig. 4) where each techniqueis connected to the functional and non-functional propertiesit enables (positive edges only).
3.1 Sharding
Several distributed relational database systems such as Ora-cle RAC or IBM DB2 pureScale rely on a shared-diskarchitecture where all database nodes access the same cen-tral data repository (e.g. a NAS or SAN). Thus, these systemsprovide consistent data at all times, but are also inherentlydifficult to scale. In contrast, the (NoSQL) database systemsfocused in this paper are built upon a shared-nothing archi-tecture, meaning each system consists of many servers withprivate memory and private disks that are connected througha network. Thus, high scalability in throughput and datavolume is achieved by sharding (partitioning) data acrossdifferent nodes (shards) in the system.
There are three basic distribution techniques: range-sharding, hash-sharding and entity-group sharding. To makeefficient scans possible, the data can be partitioned intoordered and contiguous value ranges by range-sharding.However, this approach requires some coordination througha master that manages assignments. To ensure elasticity, thesystem has to be able to detect and resolve hotspots automat-ically by further splitting an overburdened shard.
Range sharding is supported by wide-column stores likeBigTable, HBase or Hypertable [49] and document stores,e.g.MongoDB,RethinkDB,Espresso [43] andDocumentDB[46]. Another way to partition data over several machines ishash-sharding where every data item is assigned to a shardserver according to some hash value built from the primarykey. This approach does not require a coordinator and alsoguarantees the data to be evenly distributed across the shards,as long as the used hash function produces an even distribu-tion. The obvious disadvantage, though, is that it only allowslookups andmakes scans unfeasible. Hash sharding is used inkey-value stores and is also available in some wide-coloumnstores like Cassandra [34] or Azure Tables [8].
The shard server that is responsible for a record can bedetermined as serverid = hash(id)mod servers, for exam-ple. However, this hashing scheme requires all records to bereassigned every time a new server joins or leaves, because it
123

NoSQL database systems: a survey and decision guidance
lanoitcnuF-noNseuqinhceTlanoitcnuF
Scan Queries
ACID Transac�ons
Condi�onal or Atomic Writes
Joins
Sor�ng
Filter Queries
Full-text Search
Aggrega�on and Analy�cs
Sharding
Replica�on
LoggingUpdate-in-PlaceCachingIn-Memory StorageAppend-Only Storage
Storage Management
Query Processing
Elas�city
Consistency
Read Latency
Write Throughput
Read Availability
Write Availability
Durability
Write Latency
Write Scalability
Read Scalability
Data Scalability
Global Secondary IndexingLocal Secondary IndexingQuery PlanningAnaly�cs FrameworkMaterialized Views
Commit/Consensus ProtocolSynchronousAsynchronousPrimary CopyUpdate Anywhere
Range-ShardingHash-ShardingEn�ty-Group ShardingConsistent HashingShared-Disk
Fig. 4 The NoSQL Toolbox: It connects the techniques of NoSQL databases with the desired functional and non-functional system propertiesthey support
changes with the number of shard servers (servers). Conse-quently, it infeasible to use in elastic systems like Dynamo,Riak or Cassandra, which allow additional resources to beadded on-demand and again be removed when dispensable.For increased flexibility, elastic systems typically use con-sistent hashing [30] where records are not directly assignedto servers, but instead to logical partitions which are thendistributed across all shard servers. Thus, only a fraction ofthe data have to be reassigned upon changes in the systemtopology. For example, an elastic system can be downsizedby offloading all logical partitions residing on a particularserver to other servers and then shutting down the now idlemachine. For details on how consistent hashing is used inNoSQL systems, see [18].
Entity-group sharding is a data partitioning scheme with thegoal of enabling single-partition transactions on co-locateddata. The partitions are called entity-groups and either explic-itly declared by the application (e.g. in G-Store [14] andMegaStore [4]) or derived from transactions’ access patterns(e.g. in Relational Cloud [13] and Cloud SQL Server [5]). Ifa transaction accesses data that spans more than one group,data ownership can be transferred between entity-groups or
the transaction manager has to fallback to more expensivemulti-node transaction protocols.
3.2 Replication
In terms of CAP, conventional RDBMSs are often CA sys-tems run in single-server mode: The entire system becomesunavailable on machine failure. And so system operatorssecure data integrity and availability through expensive, butreliable high-end hardware. In contrast, NoSQL systems likeDynamo, BigTable or Cassandra are designed for data andrequest volumes that cannot possibly be handled by one sin-gle machine, and therefore they run on clusters consistingof thousands of servers8. Since failures are inevitable andwill occur frequently in any large-scale distributed system,the software has to cope with them on a daily basis [24].In 2009, Google fellow Jeff Dean stated [16] that a typicalnew cluster at Google encounters thousands of hard drivefailures, 1,000 single-machine failures, 20 rack failures andseveral network partitions due to expected and unexpected
8 Low-end hardware is used, because it is substantially more cost-efficient than high-end hardware [27, Sect. 3.1].
123

F. Gessert et al.
circumstances in its first year alone. Many more recent casesof network partitions and outages in large cloud data cen-ters have been reported [3]. Replication allows the systemto maintain availability and durability in the face of sucherrors. But storing the same records on different machines(replica servers) in the cluster introduces the problem ofsynchronization between them and thus a trade-off betweenconsistency on the one hand and latency and availability onthe other.
Gray et al. [22] propose a two-tier classification of dif-ferent replication strategies according to when updates arepropagated to replicas and where updates are accepted.There are two possible choices on tier one (“when”): Eager(synchronous) replication propagates incoming changes syn-chronously to all replicas before a commit can be returned tothe client, whereas lazy (asynchronous) replication applieschanges only at the receiving replica and passes them onasynchronously. The great advantage of eager replicationis consistency among replicas, but it comes at the cost ofhigher write latency due to the need to wait for other repli-cas and impaired availability [22]. Lazy replication is faster,because it allows replicas to diverge; as a consequence, staledata might be served. On the second tier (“where”), again,two different approaches are possible: Either amaster-slave(primary copy) scheme is pursued where changes can onlybe accepted by one replica (the master) or, in a updateanywhere (multi-master) approach, every replica can acceptwrites. In master-slave protocols, concurrency control is notmore complex than in a distributed system without repli-cas, but the entire replica set becomes unavailable, as soonas the master fails. Multi-master protocols require complexmechanisms for prevention or detection and reconciliationof conflicting changes. Techniques typically used for thesepurposes are versioning, vector clocks, gossiping and readrepair (e.g. in Dynamo [18]) and convergent or commutativedatatypes [45] (e.g. in Riak).
Basically, all four combinations of the two-tier classifi-cation are possible. Distributed relational systems usuallyperform eager master-slave replication to maintain strongconsistency. Eager update anywhere replication as for exam-ple featured in Google’s Megastore suffers from a heavycommunication overhead generated by synchronisation andcan cause distributed deadlocks which are expensive todetect. NoSQL database systems typically rely on lazy repli-cation, either in combination with the master-slave (CPsystems, e.g. HBase and MongoDB) or the update anywhereapproach (AP systems, e.g. Dynamo and Cassandra). ManyNoSQL systems leave the choice between latency and con-sistency to the client, i.e. for every request, the client decideswhether to wait for a response from any replica to achieveminimal latency or for a certainly consistent response (bya majority of the replicas or the master) to prevent staledata.
An aspect of replication that is not covered by the two-tier scheme is the distance between replicas. The obviousadvantage of placing replicas near one another is low latency,but close proximity of replicas might also reduce the positiveeffects on availability; for example, if two replicas of the thesame data item are placed in the same rack, the data item isnot available on rack failure in spite of replication. But morethan the possibility of mere temporary unavailability, placingreplicas nearby also bears the peril of losing all copies at oncein a disaster scenario. An alternative technique for latencyreduction is used in Orestes [20], where data is cached closeto applications using web caching infrastructure and cachecoherence protocols.
Geo-replication can protect the system against completedata loss and improve read latency for distributed access fromclients. Eager geo-replication, as implemented in Google’sMegastore [4], Spanner [12], MDCC [32] and Mencius[38] achieve strong consistency at the cost of higher writelatencies (typically 100ms [12] to 600ms [4]).With lazy geo-replication as in Dynamo [18], PNUTS [11], Walter [47],COPS [36], Cassandra [34] and BigTable [9] recent changesmay be lost, but the systemperforms better and remains avail-able during partitions. Charron-Bost et al. [10, Chapter 12]and Öszu and Valduriez [41, Chapter 13] provide a compre-hensive discussion of database replication.
For best performance, database systems need to be opti-mized for the storage media they employ to serve and persistdata. These are typically main memory (RAM), solid-statedrives (SSDs) and spinning disk drives (HDDs) that canbe used in any combination. Unlike RDBMSs in enter-prise setups, distributed NoSQL databases avoid specializedshared-disk architectures in favor of shared-nothing clustersbased on commodity servers (employing commodity storagemedia). Storage devices are typically visualized as a “storagepyramid” (see Fig. 5) [25]. There is also a set of transparentcaches (e.g. L1-L3CPUcaches and disk buffers, not shown inthe Figure), that are only implicitly leveraged through well-engineered database algorithms that promote data locality.The very different cost and performance characteristics ofRAM, SSD and HDD storage and the different strategies toleverage their strengths (storagemanagement) are one reasonfor the diversity of NoSQL databases. Storage managementhas a spatial dimension (where to store data) and a tem-poral dimension (when to store data). Update-in-place andappend-only-IO are two complementary spatial techniquesof organizing data; in-memory prescribes RAM as the loca-tion of data, whereas logging is a temporal technique thatdecouples main memory and persistent storage and thus pro-vides control over when data is actually persisted.
In their seminal paper “the end of an architectural era”[48], Stonebraker et al. have found that in typical RDBMSs,only 6.8% of the execution time is spent on “useful work”,while the rest is spent on:
123

NoSQL database systems: a survey and decision guidance
Fig. 5 The storage pyramidand its role in NoSQL systems
Size
HDD
SSD
RAM
SRRR
SWRW
SRRR
SWRW
SRRR
SWRWCachingPrimary StorageData Structures
Dura
ble
Vola
�le
CachingLoggingPrimary Storage
LoggingPrimary Storage
High Performance
Typical Uses in DBMSs:
Low Performance RR: Random Reads RW: Random Writes
SR: Sequen�al Reads SW: Sequen�al Writes
Spee
d, C
ost
RAM
Persistent Storage
Logging
Append-OnlyI/O
Update-In-Place
Data In-Memory
Log
Data
– buffer management (34.6%), i.e. caching to mitigateslower disk access
– latching (14.2%), to protect shared data structures fromrace conditions caused by multi-threading
– locking (16.3%), to guarantee logical isolation of trans-actions
– logging (11.9%), to ensure durability in the face of fail-ures
– hand-coded optimizations (16.2 %)
This motivates that large performance improvements canbe expected if RAM is used as primary storage (in-memorydatabases [50]). The downside are high storage costs andlack of durability—a small power outage can destroy thedatabase state. This can be solved in two ways: The statecan be replicated over n in-memory server nodes protect-ing against n − 1 single-node failures (e.g. HStore, VoltDB[29]) or by logging to durable storage (e.g. Redis or SAPHana). Through logging, a random write access pattern canbe transformed to a sequential one comprised of receivedoperations and their associated properties (e.g. redo informa-tion). Inmost NoSQL systems, the commit rule for logging isrespected, which demands every write operation that is con-firmed as successful to be logged and the log to be flushedto persistent storage. In order to avoid the rotational latencyof HDDs incurred by logging each operation individually,log flushes can be batched together (group commit) whichslightly increases the latency of individual writes, but drasti-cally improves throughput.
SSDs and more generally all storage devices based onNAND flash memory differ substantially from HDDs invarious aspects: “(1) asymmetric speed of read and writeoperations, (2) no in-place overwrite – the whole block mustbe erased before overwriting any page in that block, and (3)limited program/erase cycles” [40]. Thus, a database sys-tem’s storage management must not treat SSDs and HDDsas slightly slower, persistent RAM, since random writes
to an SSD are roughly an order of magnitude slower thansequential writes. Random reads, on the other hand, canbe performed without any performance penalties. There aresome database systems (e.g. Oracle Exadata, Aerospike) thatare explicitly engineered for these performance characteris-tics of SSDs. In HDDs, both random reads and writes are10-100 times slower than sequential access. Logging hencesuits the strengths of SSDs and HDDs which both offer asignificantly higher throughput for sequential writes.
For in-memory databases, an update-in-place access pat-tern is ideal: It simplifies the implementation and randomwrites to RAMare essentially equally fast as sequential ones,with small differences being hidden by pipelining and theCPU-cache hierarchy.However, RDBMSs andmanyNoSQLsystems (e.g. MongoDB) employ an update-in-place updatepattern for persistent storage, too. To mitigate the slow ran-dom access to persistent storage, main memory is usuallyused as a cache and complemented by logging to guaranteedurability. In RDBMSs, this is achieved through a complexbuffer poolwhich not only employs cache-replace algorithmsappropriate for typical SQL-based access patterns, but alsoensures ACID semantics. NoSQL databases have simplerbuffer pools that profit from simpler queries and the lack ofACID transactions. The alternative to the buffer pool modelis to leave caching to the OS through virtual memory (e.g.employed in MongoDB’s MMAP storage engine). This sim-plifies the database architecture, but has the downside ofgiving less control over which data items or pages reside inmemory and when they get evicted. Also read-ahead (specu-lative reads) and write-behind (write buffering) transparentlyperformed with OS buffering lack sophistication as they arebased on file system logics instead of database queries.
Append-only storage (also referred to as log-structuring)tries to maximize throughput by writing sequentially.Although log-structured file systems have a long researchhistory, append-only I/O has only recently been popularizedfor databases by BigTable’s use of Log-Structured Merge
123

F. Gessert et al.
(LSM) trees [9] consisting of an in-memory cache, a persis-tent log and immutable, periodically written storage files.LSM trees and variants like Sorted Array Merge Trees(SAMT) and Cache-Oblivious Look-ahead Arrays (COLA)have been applied in many NoSQL systems (Cassan-dra, CouchDB, LevelDB, Bitcask, RethinkDB, WiredTiger,RocksDB, InfluxDB, TokuDB) [31]. Designing a databaseto achieve maximum write performance by always writingto a log is rather simple, the difficulty lies in providingfast random and sequential reads. This requires an appro-priate index structure that is either permanently updated as acopy-on-write (COW) data structure (e.g. CouchDB’s COWB-trees) or only periodically persisted as an immutable datastructure (e.g. in BigTable-style systems). An issue of all log-structured storage approaches is costly garbage collection(compaction) to reclaim space of updated or deleted items.
In virtualized environments like Infrastructure-as-a-Service clouds many of the discussed characteristics of theunderlying storage layer are hidden.
3.3 Query processing
The querying capabilities of a NoSQL database mainly fol-low from its distribution model, consistency guarantees anddata model. Primary key lookup, i.e. retrieving data itemsby a unique ID, is supported by every NoSQL system, sinceit is compatible to range- as well as hash-partitioning. Fil-ter queries return all items (or projections) that meet apredicate specified over the properties of data items froma single table. In their simplest form, they can be per-formed as filtered full-table scans. For hash-partitioneddatabases this implies a scatter-gather pattern where eachpartition performs the predicated scan and results aremerged.For range-partitioned systems, any conditions on the rangeattribute can be exploited to select partitions.
To circumvent the inefficiencies of O(n) scans, secondaryindexes can be employed. These can either be local sec-ondary indexes that are managed in each partition or globalsecondary indexes that index data over all partitions [4]. Asthe global index itself has to be distributed over partitions,consistent secondary index maintenance would necessitateslow and potentially unavailable commit protocols. There-fore in practice,most systems only offer eventual consistencyfor these indexes (e.g. Megastore, Google AppEngine Data-store, DynamoDB) or do not support them at all (e.g. HBase,Azure Tables). When executing global queries over localsecondary indexes the query can only be targeted to a sub-set of partitions if the query predicate and the partitioningrules intersect. Otherwise, results have to be assembledthrough scatter-gather. For example, a user table with range-partitioning over an age field can service queries that have anequality condition on age from one partition whereas queriesover names need to be evaluated at each partition. A special
case of global secondary indexing is full-text search, whereselected fields or complete data items are fed into either adatabase-internal inverted index (e.g. MongoDB) or to anexternal search platform such as ElasticSearch or Solr (RiakSearch, DataStax Cassandra).
Queryplanning is the task of optimizing a query plan tomin-imize execution costs [25]. For aggregations and joins, queryplanning is essential as these queries are very inefficient andhard to implement in application code. The wealth of liter-ature and results on relational query processing is largelydisregarded in current NoSQL systems for two reasons.First, the key-value and wide-column model are centeredaround CRUD and scan operations on primary keys whichleave little room for query optimization. Second, most workon distributed query processing focuses on OLAP (onlineanalytical processing) workloads that favor throughput overlatency whereas single-node query optimization is not easilyapplicable for partitioned and replicated databases. However,it remains an open research challenge to generalize the largebody of applicable query optimization techniques especiallyin the context of document databases9.
In-database analytics can be performed either natively (e.g.in MongoDB, Riak, CouchDB) or through external analyticsplatforms such asHadoop, Spark and Flink (e.g. inCassandraand HBase). The prevalent native batch analytics abstrac-tion exposed by NoSQL systems is MapReduce10 [17] .Due to I/O, communication overhead and limited execu-tion plan optimization, these batch- andmicro-batch-orientedapproaches have high response times. Materialized viewsare an alternative with lower query response times. They aredeclared at design time and continuously updated on changeoperations (e.g. in CouchDB andCassandra). However, simi-lar to global secondary indexing, view consistency is usuallyrelaxed in favor of fast, highly-available writes, when thesystem is distributed. As only few database systems comewith built-in support for ingesting and querying unboundedstreams of data, near-real-time analytics pipelines com-monly implement either the Lambda Architecture [39] orthe Kappa Architecture [33]: the former complements abatch processing framework like HadoopMapReduce with astream processor such as Storm [6] and the latter exclusivelyrelies on stream processing and forgoes batch processingaltogether.
9 Currently only RethinkDB can perform general θ-joins. MongoDB’saggregation framework has support for left-outer equi-joins in itsaggregation framework and CouchDB allows joins for pre-declaredmap-reduce views.10 An alternative to MapReduce] are generalized data processingpipelines, where the database tries to optimize the flow of data andlocality of computation based on a more declarative query language(e.g. MongoDB’s aggregation framework).
123

NoSQL database systems: a survey and decision guidance
Table1
Adirect
comparisonof
functio
nalrequirem
ents,n
on-functionalrequirem
entsandtechniques
amongMongoDB,R
edis,H
Base,Riak,
Cassandra
andMyS
QLaccordingto
ourNoS
QL
Toolbox
Funct.req.
Non-funct.req.
Scan
queries
ACID
transactions
Conditio
nal
writes
Joins
Sorting
Filte
rqu
eries
Full-text
search
Analytic
sData
scalability
Write
scalability
Read
scalability
Elasticity
Con
sistency
MongoDB
XX
XX
XX
XX
XX
Redis
XX
XX
X
HBase
XX
XX
XX
XX
X
Riak
XX
XX
XX
Cassandra
XX
XX
XX
XX
X
MyS
QL
XX
XX
XX
XX
XX
Non-funct.req.
Techniques
Write
latency
Read
latency
Write
throughput
Read
availability
Write
availability
Durability
Range-sharding
Hash-sharding
Entity
-group
sharding
Consistent
hashing
Shared-disk
Transactio
nprotocol
Sync.
replication
MongoDB
XX
XX
XX
XX
Redis
XX
XX
X
HBase
XX
XX
Riak
XX
XX
XX
XX
Cassandra
XX
XX
XX
X
MyS
QL
XX
X
Techniques
Async.
replication
Prim
ary
copy
Update
anyw
here
Logging
Update-
in-place
Caching
In-m
emory
storage
Append-
only
storage
Global
indexing
Local
indexing
Query
planning
Analytic
sfram
ework
Materializ
edview
s
MongoDB
XX
XX
XX
X
Redis
XX
XX
HBase
XX
XX
Riak
XX
XX
XX
XX
Cassandra
XX
XX
XX
XX
MyS
QL
XX
XX
XX
X
123
F. Gessert et al.
Table2
Aqu
alita
tivecomparisonof
Mon
goDB,H
Base,Cassand
ra,R
iakandRedis
Dim
ension
MongoDB
HBase
Cassandra
Riak
Redis
Model
Docum
ent
Wide-column
Wide-column
Key-value
Key-value
CAP
CP
CP
AP
AP
CP
Scan
performance
High(w
ithappropriate
shardkey)
High(onlyon
rowkey)
High(using
compound
index)
N/A
High(depends
ondata
structure)
Disklatencypergetb
yrowkey
∼Severald
iskseeks
∼Severald
iskseeks
∼Severald
iskseeks
∼One
disk
seek
In-M
emory
Writeperformance
High(append-only
I/O)
High(append-only
I/O)
High(append-only
I/O)
High(append-only
I/O)
Veryhigh,in-mem
ory
Networklatency
Con
figurable:n
earestslave,
master(”readpreference”)
Designatedregion
server
Con
figurable:R
replicas
contacted
Config
urable:R
replicas
contacted
Designatedmaster
Durability
Config
urable:n
one,WAL,
replicated
(”write
concern”)
WAL,row
-levelversioning
WAL,W
replicas
writte
nCon
figurable:w
rites,
durablewrites,W
replicas
writte
n
Config
urable:n
one,
periodicloging,W
AL
Replic
ation
Master-slave,synchron
icity
confi
gurable
File-system-level(H
DFS
)Consistenth
ashing
Consistenth
ashing
Asynchronousmaster-slave
Sharding
Hash-
orrange-basedon
attribute(s)
Range-based
(row
key)
Consistenth
ashing
Consistenth
ashing
Onlyin
RedisCluster:
hashing
Con
sistency
Masterwrites,with
quorum
readslin
earizableandelse
eventual
Linearizable
Eventual,op
tional
linearizableup
dates
(”lig
htweight
transactions”)
Eventual,client-side
confl
ictresolution
Masterreads:lin
earizable,
slavereads:eventual
Atomicity
Sing
ledo
cument
Sing
lerow,o
rexplicit
locking
Singlecolumn
(multi-columnup
dates
may
causedirtywrites)
Sing
lekey/valuepair
Optim
istic
multi-key
transactions,atomicLua
scripts
Conditio
nalu
pdates
Yes
(mastered)
Yes
(mastered)
Yes
(Paxos-coordinated)
No
Yes
(mastered)
Interface
BinaryTCP
Thrift
Thrifto
rTCP/CQL
REST
orTCP/Protobuf
TCP/Plain-Text
Speciald
atatypes
Objects,arrays,sets,
coun
ters,fi
les
Counters
Counters
CRDTsforcounters,fl
ags,
registers,maps
Sets,hashes,coun
ters,
sorted
Sets,lists,
Hyper-LogLogs,
bitvectors
Queries
Query
byexam
ple(filter,
sort,p
roject),range
queries,Map
redu
ce,
aggregation
Getby
rowkey,scansover
rowkeyranges,p
roject
CFs/colum
ns
Getby
Partition
Key
and
filter/sortover
clusterkey,
FT-search
Getby
IDor
local
secondaryindex,
materializ
edview
s,MapReduce,FT
-search
DataStructureOperatio
ns
Secondaryindexing
Hash,
B-Tree,geo-spatial
indexes
None
Localsorted
index,
global
secondaryindex
(hash-based),searchindex
(Solr)
Localsecondaryindexes,
search
index(Solr)
Not
explicit
License
GPL
3.0
Apache2
Apache2
Apache2
BSD
123

NoSQL database systems: a survey and decision guidance
AccessFast Lookups
RAM
RedisMemcache
Unbounded
AP CP
CassandraRiak
VoldemortAerospike
HBaseMongoDBCouchBaseDynamoDB
Complex Queries
HDD-Size Unbounded
Analy�cs
MongoDBRethinkDB
HBase,AccumuloElas�cSeach, Solr
Hadoop, SparkParallel DWH
Cassandra, HBaseRiak, MongoDB
ACID Availability
RDBMSNeo4j
RavenDBMarkLogic
CouchDBMongoDBSimpleDB
Ad-hoc
Cache Shopping-basket
OrderHistory OLTP Website Social
Network Big Data
VolumeVolume
CAP Query Pa�ernConsistency
Example Applications
Fig. 6 A decision tree for mapping requirements to (NoSQL) database systems
4 System case studies
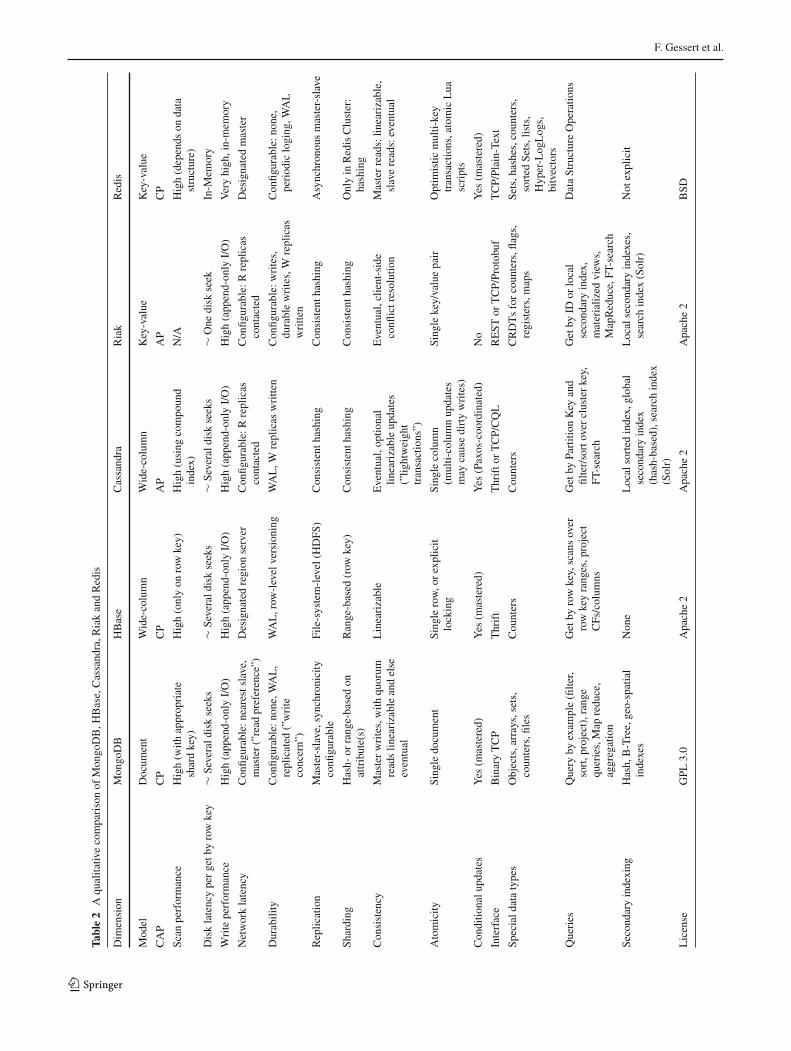
In this section, we provide a qualitative comparison of someof themost prominent key-value, document andwide-columnstores. We present the results in strongly condensed com-parisons and refer to the documentations of the individualsystems for in-detail information. The proposed NoSQLToolbox (see Fig. 4, p. 5) is a means of abstraction that canbe used to classify database systems along three dimensions:functional requirements, non-functional requirements andthe techniques used to implement them. We argue that thisclassification characterizes many database systems well andthus can be used to meaningfully contrast different databasesystems: Table 1 shows a direct comparison of MongoDB,Redis, HBase, Riak, Cassandra and MySQL in their respec-tive default configurations. A more verbose comparison ofcentral system properties is presented in Table 2 (see p. 11).
The methodology used to identify the specific systemproperties consists of an in-depth analysis of publicly avail-able documentation and literature on the systems. Further-more, some properties had to be evaluated by researching theopen-source code bases, personal communication with thedevelopers as well as a meta-analysis of reports and bench-marks by practitioners.
The comparison elucidates how SQL and NoSQL data-bases are designed to fulfill very different needs: RDBMSsprovide an unmatched level of functionality whereas NoSQLdatabases excel on the non-functional side through scal-
ability, availability, low latency and/or high throughput.However, there are also large differences among the NoSQLdatabases. Riak and Cassandra, for example, can be con-figured to fulfill many non-functional requirements, but areonly eventually consistent and do not feature many func-tional capabilities apart from data analytics and, in case ofCassandra, conditional updates. MongoDB and HBase, onthe other hand, offer stronger consistency and more sophisti-cated functional capabilities such as scan queries and—onlyMongoDB:— filter queries, but do not maintain read andwrite availability during partitions and tend to display higherread latencies. Redis, as the only non-partitioned system inthis comparison apart from MySQL, shows a special set oftrade-offs centered around the ability to maintain extremelyhigh throughput at low-latency using in-memory data struc-tures and asynchronous master-slave replication.
5 Conclusions
Choosing a database system always means to choose oneset of desirable properties over another. To break down thecomplexity of this choice, we present a binary decision tree inFig. 6 that maps trade-off decisions to example applicationsand potentially suitable database systems. The leaf nodescover applications ranging from simple caching (left) to BigData analytics (right). Naturally, this view on the problem
123

F. Gessert et al.
space is not complete, but it vaguely points towards a solutionfor a particular data management problem.
The first split in the tree is along the access pattern ofapplications: they either rely on fast lookups only (left half)or require more complex querying capabilities (right half).The fast lookup applications can be distinguished further bythe data volume they process: if the main memory of one sin-gle machine can hold all the data, a single-node system likeRedis or Memcache probably is the best choice, dependingon whether functionality (Redis) or simplicity (Memcache)is favored. If the data volume is or might grow beyond RAMcapacity or is even unbounded, a multi-node system thatscales horizontally might be more appropriate. The mostimportant decision in this case is whether to favor avail-ability (AP) or consistency (CP) as described by the CAPtheorem. Systems like Cassandra and Riak can deliver analways-on experience, while systems like HBase, MongoDBand DynamoDB deliver strong consistency.
The right half of the tree covers applications requiringmore complex queries than simple lookups. Here, too, wefirst distinguish the systems by the data volume they have tohandle according towhether single-node systems are feasible(HDD-size) or distribution is required (unbounded volume).For common OLTP (online transaction processing) work-loads onmoderately large data volumes, traditionalRDBMSsor graph databases like Neo4J are optimal, because theyoffer ACID semantics. If, however, availability is of theessence, distributed systems like MongoDB, CouchDB orDocumentDB are preferrable.
If the data volume exceeds the limits of a single machine,the choice of the right system depends on the prevalent querypattern: When complex queries have to be optimised forlatency, as for example in social networking applications,MongoDB is very attractive, because it facilitates expressivead-hoc queries. HBase and Cassandra are also useful in sucha scenario, but excel at throughput-optimised Big Data ana-lytics, when combined with Hadoop.
In summary, we are convinced that the proposed top-down model is an effective decision support to filter thevast amount of NoSQL database systems based on centralrequirements. The NoSQL Toolbox furthermore provides amapping from functional and non-functional requirements tocommon implementation techniques to categorize the con-stantly evolving NoSQL space.
References
1. Abadi D (2012) Consistency tradeoffs in modern distributed data-base system design: cap is only part of the story. Computer45(2):37–42
2. Attiya H, Bar-Noy A et al (1995) Sharing memory robustly inmessage-passing systems. JACM 42(1)
3. Bailis P, Kingsbury K (2014) The network is reliable. CommunACM 57(9):48–55
4. Baker J, Bond C, Corbett JC et al (2011) Megastore: providingscalable, highly available storage for interactive services. In: CIDR,pp 223–234
5. Bernstein PA, Cseri I, Dani N et al (2011) Adapting microsoft sqlserver for cloud computing. In: 27th ICDE, pp 1255–1263 IEEE
6. Boykin O, Ritchie S, O’Connell I, Lin J (2014) Summingbird: aframework for integrating batch and online mapreduce computa-tions. VLDB 7(13)
7. Brewer EA (2000) Towards robust distributed systems8. Calder B, Wang J, Ogus A et al (2011) Windows azure storage: a
highly available cloud storage service with strong consistency. In:23th SOSP. ACM
9. Chang F, Dean J, Ghemawat S et al (2006) Bigtable: a distributedstorage system for structured data. In: 7th OSDI, USENIX Asso-ciation, pp 15–15
10. Charron-Bost B, Pedone F, Schiper A (2010) Replication: theoryand practice, lecture notes in computer science, vol. 5959. Springer
11. Cooper BF, Ramakrishnan R, Srivastava U et al (2008) Pnuts:Yahoo!’s hosted data serving platform. Proc VLDB Endow1(2):1277–1288
12. Corbett JC, Dean J, Epstein M, et al (2012) Spanner: Google’sglobally-distributed database. In: Proceedings of OSDI, USENIXAssociation, pp 251–264
13. Curino C, Jones E, Popa RA et al. (2011) Relational cloud: a data-base service for the cloud. In: 5th CIDR
14. Das S, Agrawal D, El Abbadi A et al (2010) G-store: a scalabledata store for transactional multi key access in the cloud. In: 1stSoCC, ACM, pp 163–174
15. Davidson SB, Garcia-Molina H, Skeen D et al (1985) Consistencyin a partitioned network: a survey. SUR 17(3):341–370
16. Dean J (2009) Designs, lessons and advice from building largedistributed systems. Keynote talk at LADIS 2009
17. Dean J, Ghemawat S (2008)Mapreduce: simplified data processingon large clusters. COMMUN ACM 51(1)
18. DeC andia G, Hastorun D et al (2007) Dynamo: amazon’s highlyavailable key-value store. In: 21th SOSP, ACM, pp 205–220
19. Fischer MJ, Lynch NA, Paterson MS (1985) Impossibility of dis-tributed consensus with one faulty process. J ACM 32(2):374–382
20. Gessert F, Schaarschmidt M, Wingerath W, Friedrich S, Ritter N(2015) The cache sketch: Revisiting expiration-based caching inthe age of cloud data management. In: BTW, pp 53–72
21. Gilbert S, Lynch N (2002) Brewer’s conjecture and the feasibilityof consistent, available, partition-tolerant web services. SIGACTNews 33(2):51–59
22. Gray J, Helland P (1996) The dangers of replication and a solution.SIGMOD Rec 25(2):173–182
23. Haerder T, Reuter A (1983) Principles of transaction-oriented data-base recovery. ACM Comput Surv 15(4):287–317
24. Hamilton J (2007) On designing and deploying internet-scale ser-vices. In: 21st LISA. USENIX Association
25. Hellerstein JM, Stonebraker M, Hamilton J (2007) Architecture ofa database system. Now Publishers Inc
26. Herlihy MP, Wing JM (1990) Linearizability: a correctness condi-tion for concurrent objects. TOPLAS 12
27. Hoelzle U, Barroso LA (2009) The Datacenter As a Computer: anintroduction to the design of warehouse-scale machines. Morganand Claypool Publishers
28. Hunt P, Konar M, Junqueira FP, Reed B (2010) Zookeeper: wait-free coordination for internet-scale systems. In: USENIXATC.USENIX Association
29. Kallman R, Kimura H, Natkins J et al (2008) H-store: a high-performance, distributed main memory transaction processingsystem. VLDB Endowment
123

NoSQL database systems: a survey and decision guidance
30. Karger D, Lehman E, Leighton T et al (1997) Consistent hashingand random trees: distributed caching protocols for relieving hotspots on the world wide web. In: 29th STOC, ACM
31. Kleppmann M (2016) Designing data-intensive applications. OReilly, to appear
32. KraskaT, PangG, FranklinMJ et al (2013)Mdcc:Multi-data centerconsistency. In: 8th EuroSys, ACM
33. Kreps J (2014) Questioning the lambda architecture. Accessed: 17Dec 2015
34. LakshmanA,Malik P (2010) Cassandra: a decentralized structuredstorage system. SIGOPS Oper Syst Rev 44(2):35–40
35. Laney D (2001) 3d data management: Controlling data volume,velocity, and variety. Tech. rep, META Group
36. Lloyd W, Freedman MJ, Kaminsky, M et al (2011) Don’t settle foreventual: scalable causal consistency for wide-area storage withcops. In: 23th SOSP. ACM
37. Mahajan P, Alvisi L, Dahlin M et al (2011) Consistency, availabil-ity, and convergence. University of Texas at Austin Tech Report11
38. Mao Y, Junqueira FP, Marzullo K (2008) Mencius: building effi-cient replicated state machines for wans. OSDI 8:369–384
39. Marz N, Warren J (2015) Big data: principles and best practices ofscalable realtime data systems. Manning Publications Co
40. Min C, Kim K, Cho H et al (2012) Sfs: random write consideredharmful in solid state drives. In: FAST
41. Özsu MT, Valduriez P (2011) Principles of distributed databasesystems. Springer Science & Business Media
42. Pritchett D (2008) Base: an acid alternative. Queue 6(3):48–5543. Qiao L, Surlaker K, Das S et al (2013) On brewing fresh espresso:
Linkedin’s distributed data serving platform. In: SIGMOD, ACM,pp 1135–1146
44. Sadalage PJ, Fowler M (2013) NoSQL distilled : a brief guideto the emerging world of polyglot persistence. Addison-Wesley,Upper Saddle River
45. Shapiro M, Preguica N, Baquero C et al (2011) A comprehensivestudy of convergent and commutative replicated data types. Ph.D.thesis, INRIA
46. ShuklaD,ThotaS,RamanKet al (2015)Schema-agnostic indexingwith azure documentdb. PVLDB 8(12)
47. SovranY, PowerR,AguileraMK,Li J (2011) Transactional storagefor geo-replicated systems. In: 23th SOSP, ACM, pp 385–400
48. Stonebraker M, Madden S, Abadi DJ et al (2007) The end of anarchitectural era: (it’s time for a complete rewrite). In: 33rd VLDB,pp 1150–1160
49. Wiese L et al (2015) AdvancedDataManagement: For SQL. Cloudand Distributed Databases. Walter de Gruyter GmbH & Co KG,NoSQL
50. Zhang H, Chen G et al (2015) In-memory big data managementand processing: a survey. TKDE
123




























![Fundamentals of Database Systems - [NoSQL]](https://img.pdfslide.us/doc/110x75/621c7a5739274824355fa21e/fundamentals-of-database-systems-nosql.jpg)
