Embed Size (px)
Citation preview

Copyright © 2003 NISC Pty LtdSOUTHERN AFRICAN LINGUISTICSAND APPLIED LANGUAGE STUDIES
ISSN 1607–3614
Southern African Linguistics and Applied Language Studies 2003 21(4): 307–326Printed in South Africa — All rights reserved
Non-word error detection in current South African spellcheckers
DJ Prinsloo1* and Gilles-Maurice de Schryver1,2
1 Department of African Languages, University of Pretoria, Pretoria 0002, South Africa2 Department of African Languages and Cultures, Ghent University, Rozier 44, B-9000 Ghent,
Belgium* Corresponding author, e-mail: [email protected]
Abstract: The main objective of this article is to investigate the effectiveness of the current SouthAfrican spellcheckers built by the authors of this article.1 To this end translations of the same text,namely the Universal Declaration of Human Rights, will be spellchecked, and the performancescompared across various sample languages. The spellcheckers themselves will be engaged in lay-ers, so as to monitor the effect of the number of items in the spellchecker lexica. This innovativeresearch will be preceded by a discussion of HLT (Human Language Technologies) in South Africaand the authors’ philosophy in this regard, a brief theoretical conspectus of spellcheckers, a pre-sentation of the methodology employed to create the spellcheckers, an in-depth study on how todeal with diacritics in spellcheckers, and a walkthrough of standard spelling and grammar checkingfunctions — all with specific reference to the African languages.
IntroductionHuman Language Technologies inSouth AfricaAll efforts regarding state-of-the-art, high-techdevelopment of especially the African lan-guages in South Africa should be applauded.We believe, however, that such activities andstrategies for their advancement ought to besensitive to certain local realities, and shouldaddress Human Language Technology (HLT)requirements on a priority basis rather thanaccording to an ideal HLT-development sched-ule. This means that major projects must bedesigned in such a way as to render regularspin-offs, i.e. usable applications that areurgently needed. This might even entail takingshortcuts in the short term in order to provideproducts for immediate use for which the tech-nology is in real terms still under development.
This crucial philosophy underpins all ourwork, and is no different when it comes to thecurrent creation of South African spellcheckers,the topic of the present contribution. Africanlanguages in particular require what could becalled first-generation spellcheckers now tosatisfy the immediate needs that could bedescribed as software modules that can detectmost incorrectly typed words and can suggestalternatives. This should be followed by subse-
quent, more sophisticated and improved, sec-ond-generation spellcheckers with a better per-formance, and ultimately even superior third-generation spellcheckers which can also checkgrammatical structures. We are thus convincedthat if ways can be found to satisfy the immedi-ate requirements of the users of specific lan-guages, the process should not be delayedsimply for the sake of releasing a moreadvanced spellchecker as the first product.
Since this is a pioneering publication on theissue for the African languages, and asspellcheckers are a relatively new researchfield in South Africa, it was felt that it would beuseful to lay the groundwork and to devotesome time to the basics first, albeit in a non-complex manner. To this end, a brief theoreticalconspectus will be presented in whichspellcheckers will be defined and the mainstrategies for their construction described. Thiswill make it possible to place current SouthAfrican endeavours in context, and will thenlead to an elucidation of our own approach.This section will be followed by one in which theillusion is shattered that spellchecking is not yetfeasible for African languages that are writtenwith scores of so-called ‘special characters’, asis the case in, for instance, Tshivenda.

Prinsloo and De Schryver308
Subsequently, a walkthrough of the basic func-tions of spellcheckers will be presented for thebenefit of the reader who might not be familiarwith the use of such a tool. An exhaustive cov-erage of the functions of spelling and especial-ly grammar checkers will, however, not beattempted. Although the latter are often men-tioned in the same breath as spelling checkers,and although they are briefly illustrated below,grammar-checking technology lies beyond thescope of this article. The emphasis will ratherbe on typical functions pertinent to current andfuture developments in spellcheckers for theAfrican languages. In the final section thelaunching of our own spellcheckers for all offi-cial South African languages, viz. for the nineAfrican languages and Afrikaans (Englishalready being catered for in the group of world-English spellcheckers), will be discussed. Theperformance of these spellcheckers will beillustrated with an in-depth evaluation forSesotho sa Leboa, isiZulu and Afrikaans. Ineach case the (lexical) recall values for transla-tions of the same text, namely the UniversalDeclaration of Human Rights, will be calculat-ed. The obtained results will then be placed ina wider context, by way of a comparison withfour other languages spoken on the Africancontinent, viz. Hausa, Somali, Lingala andisiXhosa. The article will be concluded withsome suggestions for improving the next-gen-eration spellcheckers.
Brief theoretical conspectus ofspellcheckersFrom the early 1960s onwards, researchershave designed various methods for the compu-tational detection of erroneous words in runningelectronic text. Today, four decades later, thereisn’t any reputable word processor that doesn’tinclude spelling checkers, as well as spellingsuggestors and/or correctors, and even the-sauri and grammar checkers as integral parts.This is true for all languages with significantworldwide commercial importance, less so forthose languages with a limited commercialvalue. Sadly, commercially available spellcheck-ers are unfortunately the exception rather thanthe rule in the case of African languages.
The term ‘spellchecker’ is used here tocover what the average user understandsunder this term today, i.e. a software applica-tion, generally integrated into a word processor
like Microsoft Word or Corel WordPerfect,which: (i) checks for spelling (and grammatical)errors, (ii) automatically corrects some typo-graphical errors, (iii) suggests stylistic andpunctuation replacements, and (iv) oftenincludes a thesaurus (i.e. a list with synonymsand antonyms). Thus, in over-simplified terms,it can be said that the purpose of a spellcheck-er in word processing software is to alert theuser to possibly incorrectly typed words orstrings of text and to suggest options for cor-rection. This article will be concerned with the‘word’ level only, and not with ‘strings of text’;and will mainly focus on the ‘detection’ of errorsrather than on their ‘correction’. Reformulated,this means that ‘non-word error detection’ willbe treated, non-words being words that do notexist. Non-word error detection is a necessaryfirst step towards a truly professional spell-checker, i.e. one where ‘context’ (and by exten-sion ‘grammar’) also comes into play.
Basically there are two main approaches tothe creation of spellcheckers. Firstly, a programcan simply compare the spelling of typed (orscanned) words with a so-called ‘spellcheckerlexicon’, being a stored list of valid full ortho-graphic words. Secondly, one can programsoftware with a proper description of a lan-guage, including detailed morphophonologicaland syntactic rules, which computes over aseries of stored lists of word roots. Whereas thefirst approach only stores full orthographicwords, the second approach has very few ofthose. In the first approach all inflections andderivations of a lemma, as well as compounds,are thus physically listed — or ‘spelled out’ soto say; while they are analysed/generated onpurely linguistic grounds in the second. Formany languages either approach will giveacceptable results, for others only the secondapproach is feasible. Physically listing all validorthographic words in Finnish, for example,where word roots may easily have thousands ofinflectional forms each, is simply impossible.
Although it can hardly be disputed that boththe development and use of spellcheckers forthe African languages at large are still in theirinfancy, single implementations of the two typesof spellcheckers already exist for these lan-guages. Wordlist-based spellcheckers forSesotho sa Leboa, Setswana, isiZulu andisiXhosa were developed by DJ Prinsloo forCorel WordPerfect 9, and have been available

Southern African Linguistics and Applied Language Studies 2003. 21: 307–326 309
since 2000 (Prinsloo & De Schryver, 2001: 129).The sizes of these spellchecking lexica arerather modest, as they run into tens of thou-sands of items per language only. Conversely,Arvi Hurskainen began work on a rule-basedspellchecker for Kiswahili in 1987, a productthat saw the light as Orthografix 2 for Swahili adecade later, in 1999 (Hurskainen, 1999: 139).Starting from some 45 000 word roots, tens ofmillions of orthographic words may be recog-nised thanks to the incorporation of inflectionand derivation technology. This spellchecker(and hyphenator) can be used with MicrosoftWord and Adobe InDesign and is distributed byLingsoft (Lingsoft, 1999). Focusing on SouthAfrica, one can also observe that severalspellcheckers for Afrikaans, both wordlist-basedand rule-based, are already available commer-cially, some of which are currently beingredesigned, such as PUK/Microsoft Speltoetser,Pharos Speller or Ispell vir Afrikaans (VanHuyssteen & Van Zaanen, 2003).2
Our methodology for the developmentof spellcheckersGiven that the creation of rule-basedspellcheckers can easily take up to a decade,and in the light of our drive to be able to releaseapplications at this point in time, it should notcome as a surprise that our first-generationspellcheckers for the South African languagesare word-based. One may then firstly wonder:Which words? Ideally one would of course wishto list all orthographic words of a particular lan-guage, but this is never possible. In any lan-guage a relatively small number of words occurextremely often, while the largest section ofeach language’s lexicon occurs much less fre-quently or even rarely. A spellchecker lexiconwith only a limited number of valid orthograph-ic words will therefore obviously focus on themost frequent items. Reformulated, if softwarewould only allow the storage of 1 000 words,then choosing the top-frequent 1 000 words inthe language will result in the most efficientspellchecker with this 1 000-word restriction.Fortunately, tens of thousands, even hundredsof thousands, of orthographic words can bestored in current spellchecker lexica. So thenext question is: Where does one find thesehundreds of thousands of words? The answercould have been expected: Electronic corpora.For more than a decade corpora have been
compiled for all South African languages(Prinsloo, 1991; De Schryver & Prinsloo, 2000),and current spellchecker lexica are based onfrequency lists derived from them. Each andevery list proffered by corpus query software isof course manually checked before beingloaded into software — a non-trivial andextremely labour-intensive activity. As will beillustrated in the various tests below, the perfor-mance of the current spellcheckers is generallygood.
Thirdly, once spellchecker lexica have beenproduced as outlined above, one must write theappropriate software that enables the compari-son of word processor text with the items in thelexica. Here modern word processors provide apowerful feature that can be put to good use,namely the possibility of adding ‘custom dictio-naries’ to the main dictionaries. This basicallymeans that the spellchecker lexica must besaved in plain text with the required extension,for instance ‘.dic’ in Microsoft Word, and beengaged as custom dictionaries. One thuseffectively ‘borrows’ all the required spellcheck-ing functionality by running one’s own dictio-nary in parallel with a main dictionary. This hasthe huge advantage that no additional pro-gramming whatsoever is required, and that allavailable detection and suggestion/correctionfunctions can be drawn upon — even thoughthis functionality will of course be faster in trulyinternal dictionaries. Running, say, Xitsonga inparallel with a main dictionary like English hasthe additional benefit that both languages arespellchecked simultaneously. Especially in theSouth African context, where many documentsare of a multilingual nature, this is an addedvalue. Actually, on our own machines, alleleven South African languages are activated,one as default language, and ten as customdictionaries. This means that one can type textin any language — Setswana, isiNdebele,Sesotho — and swap to any other language —siSwati, Afrikaans, isiXhosa — at any time; alltext will be spellchecked. It must, however, beremembered that no grammar is checked inthis way, only specific word forms in isolation.From the moment that a word form is listed in aspellchecker lexicon, that word will be flaggedas correct. There is thus no over-generationwhatsoever in a word-based spellchecker,meaning that every accepted word also exists.It is of course still possible that a valid word was

Prinsloo and De Schryver310
used instead of an intended one, or that thesyntax is wrong. When using multiple customdictionaries, it is also possible that a non-wordin the language of, say, custom dictionary A isaccepted simply as a result of the fact that it isa valid word in the language of, say, customdictionary B. Lastly, observe that not all para-digms are always complete in a word-basedspellchecker lexicon. From a dictionary anglethis means that not all inflections and deriva-tions that belong to a particular lemma are nec-essarily listed, and thus necessarily recognisedby the spellchecker.
Spellchecking ‘all’ South Africanlanguages: Reality or chimera?So far it was claimed that by making use ofstandard word processing software in whichtop-frequency wordlists are loaded as customdictionaries, a level of non-word error detectioncan be achieved which may be considered highenough as to render functional spellcheckersfor the South African languages. One may,however, rightfully question this claim on pure-ly technical grounds, given that some of theSouth African languages employ characters notnormally included in commercial software. Thevelar and dental symbols for Tshivenda (cf.below) immediately come to mind.
As for most African languages, the charac-ter sets of the official South African languagesare based on the Latin alphabet. For some ofthese languages, a number of diacritics havebeen added to a few base symbols, in mostcases contrasting them with the base symbolsthemselves (e.g. e vs. ê or o vs. ô). If it goeswithout saying that a spellchecker for, say,French or Danish must be able to spellcheckwords with the symbol ç or ø respectively, it ofcourse also stands to reason that a spellcheck-er for Sesotho sa Leboa must recognise š anddifferentiate this symbol from s, or that aTshivenda spellchecker must be able to handleall so-called ‘special characters’ used in thislanguage. The Sesotho sa Leboa š and Š, forinstance, pose no problem for either compileror user of a spellchecker, since these symbolshave been assigned ASCII values, namely
0154 for š and 0138 for Š. The special charac-ters of Tshivenda, however, are more problem-atic.
Indeed, the great majority of the electronicdocuments available in Tshivenda are prone totypographic errors. On the Internet, for exam-ple, the diacritics for the single velar and fourdental symbols are rarely used, and these sym-bols are all simply collapsed with their respec-tive base symbols, viz. with n on the one hand,and d, l, n and t on the other. Where an effortis made to present the symbols correctly, web-masters either resort to a scanned image ofprinted text, or to a document saved in pdf(portable document format). An example of theformer is illustrated in Figure 1.
Whereas a scanned image is of course nota proper solution, pdf is not without problemseither, as can be seen from the screenshotsshown in Figures 2 and 3.
In Figure 2 the diacritics were added manu-ally, which is again not an acceptable solution,while Figure 3 indicates what happens whenthe fonts used in the creation of the pdf docu-ment have not been correctly embedded. Onlyin a few rare cases does one encounter pdfdocuments which are displayed satisfactorilyfor the end user. An example can be seen inFigure 4.
This situation for Tshivenda is in a way highlysurprising since, on the one hand, all modern
Figure 1: The Lord’s Prayer in Tshivenda, uploadedas a scanned image*, 3
* Due to the nature of ‘screenshots’ Figures 1–12 and Appendix 1 are not of the usual standard. They are includ-ed because of the value they add to the article. To view these figures in their original format consult the onlineversion of the journal available at: http://www.ingentaselect.com

Southern African Linguistics and Applied Language Studies 2003. 21: 307–326 311
web browsers can display Unicode, while, on theother, all recent operating systems have a largenumber of Unicode fonts installed by default. InUnicode, all the world’s scripts are supported:
The Unicode Standard is the universalcharacter encoding standard used for rep-resentation of text for computer processing.... Unicode provides a consistent way ofencoding multilingual plain text and bringsorder to a chaotic state of affairs that has
made it difficult to exchange text files inter-nationally. Computer users who deal withmultilingual text — business people, lin-guists, researchers, scientists, and others— will find that the Unicode Standard great-ly simplifies their work. ... The UnicodeStandard provides the capacity to encodeall of the characters used for the written lan-guages of the world. (Unicode, 2003)
At present, there should thus be no problem
Figure 2: The Media Development and Diversity Agency Position Paper in Tshivenda, uploaded as a pdf withmanually added diacritics4
Figure 3: PanSALB’s position on the promotion of multilingualism in South Africa in Tshivenda, uploaded as apdf without correct embedding of fonts5
Figure 4: The Revised National Curriculum Statement Grades R–9 (Schools) — First Additional Language inTshivenda, uploaded as a pdf with correct embedding of fonts6

Prinsloo and De Schryver312
whatsoever in treating the African languagescomputationally, neither on the Internet nor onone’s own PC. This is especially true for wordprocessing software and, as illustrated forHausa by Van der Veken and De Schryver(2003), for spellchecking. In other words, aslong as fonts are used that are encodedaccording to Unicode, these fonts will not onlybe supported in a recent word processor, butalso in the associated spellchecking modules.
Given that the ‘special characters’ requiredfor Tshivenda are not normally included withstandard PCs, the question arises: Can they beeasily found? Yes they can. Firstly, since March2002, Jako Olivier’s South African special char-acters font can be downloaded from his home-page (Olivier, 2002). With this set, all SouthAfrican special characters (for isiNdebele,isiZulu, Sesotho sa Leboa, Setswana andTshivenda) can be treated in a word processor.Unfortunately, as the font doesn’t comply withthe Unicode standard, nor with any other stan-dard known to us, documents created with thisfont are basically tied to this particular font.Documents cannot be interchanged, unlessthis font is installed on all computers where thedocuments are viewed, or unless the font itselfis included with the documents.
Secondly, since September 2002, VictorGaultney’s Gentium typeface, encoded accord-ing to Unicode, has been online (Gaultney,2002). As this font includes glyphs that corre-spond to all the Latin ranges of Unicode, thisfont may be used to handle Tshivenda (and the
other South African languages) in a wordprocessor, and also in a spellchecker.Document interchange is also greatly facilitatedas a result of this Unicode font character map-ping. One is thus not tied to this particular font,as any other Unicode font can be ‘dropped in’.
A Tshivenda spellchecker lexicon can besaved with the extension ‘.dic’ in Microsoft Word,but now as Encoded text/Unicode, in order tokeep all special characters embedded. This lex-icon is then loaded as a custom dictionary. As ademonstration of the spellchecking processitself, the text from Figure 4 was retyped, albeitwith three errors. These spelling errors are easi-ly picked up by the spellchecker (and are indi-cated with red underscores, cf. below), as canbe seen from the top half of Figure 5.
Spellchecking ‘all’ South African languagesis thus definitely not a chimera, but has becomea reality.
Since most Vhavenda and learners ofTshivenda who currently use word processingsoftware do not make use of the special char-acters, however, it is advisable to prepare twospellchecker lexica for Tshivenda. One lexiconincluding all diacritics on n, d, l, n and t, and theother lexicon without any diacritics. The latter isof course easy to generate from the former bymeans of a straightforward search-and-replaceprocedure. Users who wish to employ andspellcheck the correct orthography can firstlydecide to install a Unicode-based font forTshivenda, such as Gentium, and then engagethe Tshivenda spellchecker that includes the
Figure 5: Spellchecking a Tshivenda text (with additional information provided for the errors under the horizon-tal line)

Southern African Linguistics and Applied Language Studies 2003. 21: 307–326 313
diacritics; while users who prefer to employ theLatin characters only (e.g. in e-mail correspon-dence — where one, in any language, typicallycuts down on detail) may simply engage thesimplified Tshivenda spellchecker that doesn’tinclude any diacritics.
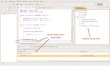
Standard spelling and grammarchecking functionsThe typical features of spelling and grammarcheckers that will be outlined in this section areillustrated with Microsoft Word, since this is theword processor most widely used in SouthAfrica. A first step for the user is to engage thespellchecker and to ensure that the correctmain dictionary, as well as the correct supple-mentary and/or custom dictionaries (if applica-ble), is loaded. Clicking on the ABC-button onthe navigation bar, see Figure 6, activates thespellchecking process.
If a main language was not preset, this canbe done following the navigation steps in theselection boxes shown in Figure 7. (Note thatno provision is made for an ‘empty’ default dic-tionary, which means that custom dictionarieshave to run concurrently with an existing maindictionary.)
If supplementary and/or custom dictionariesare required (which is definitely the case in ourapproach), or if certain spelling and grammarpreferences are to be set, these can beaccessed by clicking Tools, Options and manip-
ulating the set of selection boxes shown inFigure 8.
In the automatic spelling and grammarchecking mode (check spelling/grammar asyou type), spelling components typically usered underscores (sometimes referred to aswavy red underlines) to indicate possiblespelling errors, while grammar components usegreen underscores to indicate possible gram-matical errors. This is illustrated in Figure 9.
The spellchecker underlined the words‘lemmatization’, ‘macrostructural’ and ‘micro-structural’ in red as suggested misspellings,and ‘systems which’ in green as a potentialgrammatical error. Such suggestions can behandled in two ways, either by means of thestandard correction screen or a shortcut menu.The former, activated when clicking the ABC-button, is shown in Figure 10.
Figure 10 represents a typical example ofthe use of the standard correction screen offer-ing the main options ignore, ignore all, add,change, change all, and autocorrect. In this
Figure 7: Selection boxes for presetting the main language
Figure 6: Clicking the ABC-button on the navigationbar activates the spellchecker

Prinsloo and De Schryver314
case the spellchecker, which is set to SouthAfrican English, suggests that ‘lemmatization’should be spelled as ‘lemmatisation’. Selectingignore would leave the current occurrenceunchanged; while ignore all would leave alloccurrences in the document at handunchanged, with the spellchecker not stoppingat any subsequent occurrence(s) of this word.Selecting add would result in the word beingadded to the main custom dictionary (that is thetop dictionary ticked off in the list of custom dic-tionaries). From then onwards this word will be‘known’ to the spellchecker, and all future
occurrences of it, both in the current and infuture documents, will be accepted as correct.(This is true as long as one does not switch offor edit this word out of the main custom dictio-nary — cf. Figure 8, right-hand screenshot.)The outcome of selecting change is that thefirst occurrence only would be changed to ‘lem-matised’, while change all would change alloccurrences in the document to ‘lemmatised’.Lastly, autocorrect would not only change allexisting occurrences of ‘lemmatized’ to ‘lemma-tised’, but would automatically change, in thecurrent as well as all future documents, all
Figure 9: Red and green underscores indicating potential spelling (lemmatization, macrostructural, microstruc-tural) and grammatical (systems which) errors respectively
Figure 8: Selecting and engaging one or more custom dictionaries

Southern African Linguistics and Applied Language Studies 2003. 21: 307–326 315
newly typed occurrences of ‘lemmatized’ to‘lemmatised’ without any further notice.
The autocorrect feature can be used toautomatically detect and correct typographicalerrors, misspelled words, grammatical errors,and incorrect capitalisation. For example, if onetypes ‘teh’ plus a space it can be immediatelyreplaced with ‘the’. Firstly, this function uses alist of built-in, so-called autocorrect entries.Secondly, this is of course also a very usefulfunction to quickly insert text, graphics, or sym-bols in the text by simply typing the requiredminimum characters to trigger the desired out-put. For example, typing :) to obtain ☺, or i forI, or pslb instead of PanSALB, etc. (Here too,entries can be added or removed with relativeease.) Such behaviour can, unfortunately, alsobe counterproductive. It is believed that theautocorrect function that puts the first letter of asentence in upper case introduces on averagemore mistakes in text, and especially in tables,than correcting instances where the sentence-initial letter should have been typed with a cap-ital letter. Users do not normally know how todisengage this option.
Observe that the add option can of coursealso be used as an important tool in buildingand extending spellcheckers for the African lan-guages. In writing the 200-word Sesotho saLeboa abstract of a recent article (Nong et al.,
2002: 1–2), for example, the words bangwala-pukuntšu ‘dictionary writers’, pateroneng ‘in apattern’ and khophaseng ‘in a corpus’ were notrecognised by the spellchecker. These wordsare however all acceptable, correctly spelledSesotho sa Leboa words. Clicking the addoption in each case thus also instantly meantstrengthening/improving the spellchecker forfuture non-word error detection with three neworthographic words.
In the case of grammar checking, apartfrom suggested corrections and improvements,grammatical assistance may be offered bymeans of pop-up windows. Compare thedetailed guidance for the English phrase ‘sys-tems which’ in Figure 11 in this regard.
Users can even customise the grammarchecker by setting rules for grammar and writingstyles. For example, a built-in style such ascasual or technical may be selected, a new stylecan be created, or an existing style adapted.
A useful shorthand alternative to the stan-dard correction screen is simply to right-click anunderlined word, as illustrated in Figure 12.
When red underlining is right-clicked, a sim-plified version of the spelling correction screenappears with a number of suggested alterna-tives, as well as a selection of options such asto ignore all similar occurrences, to add theword to the main custom dictionary, to autocor-
Figure 10: Standard correction screen

Prinsloo and De Schryver316
rect, etc. (Note that when green underlining isright-clicked, a simplified version of the gram-mar correction screen appears.) In Figure 12the Sesotho sa Leboa word leswa ‘new’ wasmisspelled as *leeswa.8 In this case one mayalso consider the suitability of the suggestedalternatives. The options leswa, leswe,leswao and letswa are quite logical sugges-tions reflecting cases where a single charactercould have been typed twice, or one or twocharacters mistyped. All these are very com-
mon typing errors, and one thus finds that it ispossible to use built-in technology to go beyondthe mere ‘non-word error detection’ with customwordlists, in casu our African-language spell-checker lexica. As a result of the fact that thealgorithms for suggesting alternatives to non-words are to a large extent language-indepen-dent, it is already possible at this point in timeto perform some semi-automatic ‘isolated-worderror correction’ for the African languages.
Not all built-in technology is useful for theAfrican languages though. The disjunctivelywritten African languages, in particular, requireadjustments in the handling of occurrences ofsequences of identical orthographic words.One of the typical errors made in text produc-tion in any language is the erroneous repetitionof a word (‘the the’ is common in English, seefor an authentic example the text in the bottom-right corner of Appendix 1). Therefore, a stan-dard error-detecting function in spellcheckers isto highlight occurrences of supposedly erro-neous sequences of identical orthographicwords. For the disjunctively written African lan-guages this, unfortunately, results in the high-lighting of a large number of correctly typeddouble, triple, quadruple, etc. words. For theselanguages this feature is thus counterproduc-tive because it delays the process of verifica-tion rather than contributing to it. Compare the
Figure 12: Shorthand correction screen (right-click-ing underlined words)7
Figure 11: Grammatical pop-up window with additional information

Southern African Linguistics and Applied Language Studies 2003. 21: 307–326 317
following random examples of concordancelines with multiple occurrences of ba and le(and se) culled from a 5.8-million-word Sesothosa Leboa corpus. The words that occur twice ormore in succession are highlighted as errors bythe spellchecker:9
1. ...ba topa tša fase, baeng bao bona ba ileba ba amogela ka tše pedi, ba ba ba babea fase ka a mabedi, ka gore lešago lamoeng le bewa ke...
2. ...batswadi ba ba ba ba bea fase, dipelo tšabona di sa ngongorega. Erile mo ba...
3. ...go tšwa ka sefero a ngaya sethokgwa sese bego se le mokgahlo ga lapa le le le lele latelago. O be a tseba gabotse gorebarwa ba Rre Hau o tlo ba hwetša ba...
4. ...ke yena monna yola wa mohumi le begole le ka gagwe maabane. Letsogo le le lebonago le golofetše le, e sa le le gobalamohlang woo.” Banna ba...From these lines it is clear that up to four
repetitions of the word ba and up to five repeti-tions of the word le do indeed form grammati-cal strings in Sesotho sa Leboa. Such stringsare frequent in this language, as is evident fromthe corpus counts shown in Table 1 for the pairsa a, ba ba, etc.
In order for such strings not to be highlighted,one shall have to wait until such time as sophis-ticated grammar components will have beendeveloped for African-language spellcheckers.The creation of such grammars will not be trivial.The four consecutive ba’s in the first exampleabove, for instance, are respectively the subjectconcord of class 2, the auxiliary verb stem, againthe subject concord of class 2, and then the
object concord of class 2; while the five consec-utive le’s in the third example are respectivelythe relative pronoun of class 5, the subject con-cord of class 5, the copulative verb stem, andthen again the relative pronoun of class 5, andthe subject concord of class 5.
Evaluation of the effectiveness of ourwordlist-based spellcheckersSo far we (i) expounded on our wordlist-basedapproach for the creation of South Africanspellcheckers, (ii) showed that no technicalconstraints preclude the compilation ofspellcheckers for all South African languages,and (iii) indicated which of the standard spellingand grammar checking functionalities arealready possible and useful for the SouthAfrican languages in current word processingsoftware. The proof of the pudding is in the eat-ing, however. Reformulated: Do our spellcheck-ers really work? Are lists of full orthographicwords really all that are needed for spellcheck-ing the South African languages? If not, doesthe approach work well for some, yet less wellfor other languages? Here, the orthographicdivide between the disjunctively written Africanlanguages on the one hand, and the conjunc-tively written ones on the other, suggests thatthere might indeed be a marked difference.Also: How does Afrikaans fit into the picture? Inorder to study these various aspects, a com-prehensive set of interlinked tests was devel-oped, enabling a direct comparison betweenthe different languages involved.
Translations of the same source text, name-ly the Universal Declaration of Human Rights(UDHR, cf. Appendix 1), were spellcheckedwith our spellcheckers. As the UDHR is of arather technical nature, spellchecking this textpresents a considerable challenge. (Note thatthe UDHR itself was obviously not used in thecompilation of the respective spellchecker lexi-ca.) Although spellcheckers were developedand tested for all South African languages, onlythree sets of results will be described in detailbelow, i.e. for Sesotho sa Leboa, for isiZulu andfor Afrikaans. The first represents the disjunc-tively written language group (which alsoincludes the other Sotho languages: Sesothoand Setswana; as well as Xitsonga andTshivenda); the second represents the conjunc-tively written language group (which alsoincludes the other Nguni languages: isiXhosa,
Double orthographic Frequency per words million wordsa a 862ba ba 1 147di di 17e e 46go go 232le le 703o o 54se se 644
Table 1: Typical legal occurrences of double ortho-graphic words in Sesotho sa Leboa, with their fre-quency counts derived from a 5.8-million-word cor-pus

Prinsloo and De Schryver318
isiNdebele and siSwati); while the third isknown to be a semi-agglutinative language withproductive compound formation (like Dutch,German, etc.). For each of these three lan-guages, the effectiveness of the cumulativebuild-up of spellchecker lexica will be studied indetail. It follows from the overview of themethodology above, that one expects thespellcheckers to be most effective when theyare loaded with the top-frequency words of thelanguage. Adding lower-frequency words willimprove the spellcheckers still, but the power ofthe latter to substantially improve the perfor-mance of the spellcheckers obviously becomessmaller and smaller as the frequency of theadded words decreases. In practical terms,subsequent — and cross-language comparable— ‘layers’ will be added to the spellcheckers.
For these tests we ensured that the transla-tions of the UDHR are error-free. Actually, therewere some spelling errors (which were uncov-ered with our spellcheckers, in combinationwith proofreading), and these were corrected. Aperfect spellchecker is one that flags all errors,whilst leaving everything that is correctunmarked. Given that the texts are error-free,everything should thus remain unmarked. Aperfect spellchecker would thus recognise or‘recall’ all words; the (lexical) recall value wouldbe 100%. Not all words are included in espe-cially the smaller lexica, which means that theabsent (but valid) UDHR words will be wronglyindicated as errors by the spellchecker, so therecall values will be smaller than 100%. Theidea now is to see how the recall valueschange, and how fast, with increasing sizes ofthe spellchecker lexica, i.e. with an increasingnumber of layers. These layers have all beenderived in the same way. Comparable-size cor-pora for Sesotho sa Leboa, isiZulu andAfrikaans of approximately five million runningwords (tokens) were queried and the frequencylists divided into five layers. Firstly all itemsoccurring 10 times or more, secondly all itemswith a frequency from 5 to 9, thirdly those itemswith frequencies of 3 and 4, fourthly those witha frequency of only 2, and lastly the hapaxlegomena (i.e. those items occurring only oncein the corpora).
The data for the first language, Sesotho saLeboa, are looked at first. From the left section ofTable 2 it can be seen that there are 5 762 549tokens in the corpus used, but only 148 697 dif-
ferent orthographic words (types). The firstlayer has 19 823 types, which corresponds to13.33% of all the types; the second has 12 220types, which corresponds to 8.22% of the total;etc. The hapax value is as high as 54.73%. Thismeans that more than half of all the types in aSesotho sa Leboa corpus occur just once.
The right section of Table 2 shows that theUDHR in Sesotho sa Leboa consists of 2 312tokens and 497 types. In a first test only the firstcorpus layer, i.e. all words with a frequency of 10or more, of which there are roughly 20 000, wasused as the spellchecker lexicon. Of the 2 312UDHR tokens, 77 were not recognised. The‘token recall’, with just 20 000 items in aSesotho sa Leboa spellchecker, is thus as highas 96.67%. This is an extremely good result.One can also consider the ‘type recall’, or thusfocus on the number of different words notrecognised by the first layer (56) versus thenumber of different words in the UDHR (497).With 88.73% the type recall is not as good asthe token recall. It is further possible to calcu-late a ‘recall value from the user’s point of view(p.v.)’, i.e. the number of types not recognisedcompared to the number of tokens in theUDHR. The reasoning is as follows: To a user,only the non-recognised types really count, nomatter how often they occur in the UDHR. Asseen in the description of standard spellcheck-er functions above, a user only needs to add anunrecognised type once to the main customdictionary, after which it will be recognised bythe spellchecker in all further instances. Therecall value from the user’s point of view is ashigh as 97.58%. When the second layer isadded to the first layer, the token recall gainsanother percent (from 96.67% to 97.53%).Again, this is a lot, even though one has actu-ally added 50% more words to the spellcheck-er lexicon (from roughly 20 000 to 30 000).Adding subsequent layers to the previous onespushes the token recall values up to 97.97%,98.31% and finally 99.18%. In each case, thetype recall values are lower, and those from theuser’s point of view slightly higher. Token andtype recall values for Sesotho sa Leboa areshown graphically in Figure 13.
From Figure 13 one can clearly see thattoken recall and type recall grow closer to oneanother with increasing lexicon size. This is pre-dictable, as the addition of each spellcheckerlayer means the gradual accumulation of

Southern African Linguistics and Applied Language Studies 2003. 21: 307–326 319
increasingly uncommon words, and thus by def-inition also words that are less frequent in thetexts to be spellchecked. The differencebetween word form and the number of times thatform occurs, or thus between type and token fre-quency, decreases. For very large spellcheckerlexica the three types of recall (token, type anduser’s p.v.) thus come together.
The major finding of this first series of testsis that a Sesotho sa Leboa spellchecker with150 000 items recognises, from the user’s pointof view, a stunning 99% of all words. Clearly,this is an excellent result for a first-generationspellchecker. A very different picture appearswhen an analogous series of tests is carried outfor isiZulu, as can be seen from the data inTable 3.
Although the isiZulu corpus is somewhatsmaller than the Sesotho sa Leboa one, thenumber of types is more than four times higher.This, of course, is a direct result of isiZulu’shigh degree of conjunctivism.10 This degree canbe calculated, and it turns out that each isiZuluword corresponds on average with 1.60Sesotho sa Leboa words (Prinsloo & DeSchryver, 2002: 261). IsiZulu words are thusalso longer, much longer, as they concatenatemany formatives that are simply words inSesotho sa Leboa. From the Sesotho sa Leboaperspective, all the possible permutations ofthe formatives result in a considerable increasein the number of orthographic words in isiZulu.It should thus not come as a surprise thatspellchecking in isiZulu is much more complex.
Table 2: Building and checking the performance of a Sesotho sa Leboa spellchecker
Spellchecker for Sesotho sa Leboa Universal Declaration of Human Rights in Sesotho sa Leboa(derived from 5 762 549 tokens) (2 312 tokens; 497 types)
words in each layer not recognised recall (in %)frequency # % tokens types tokens types user’s p.v.10 or more 19 823 13.33 77 56 96.67 88.73 97.585 to 9 12 220 8.22 57 40 97.53 91.95 98.273 and 4 14 985 10.08 47 32 97.97 93.56 98.622 20 288 13.64 39 25 98.31 94.97 98.921 (hapaxes) 81 381 54.73 19 17 99.18 96.58 99.26Total 148 697 100.00
��
��
��
��
��
���� ���������� ��� ������� �����������
����������� !
"����� ������ ������ #������ #"����� #������
����
�$��
Figure 13: Token and type recall values for a Sesotho sa Leboa spellchecker

Prinsloo and De Schryver320
Even from a user’s point of view, the data inTable 3 indicate that the first layer with as manyas 45 348 types recognises ‘only’ 72.63%. Withanother 42 515 types this recall climbs to78.28%, with another 60 185 types to 81.91%,with yet another 88 911 types to 83.92%, andwith all layers engaged, or thus after addinganother 434 777 types, to 88.23%. Token andtype recall values for isiZulu are shown inFigure 14.
A recall of 88% means that, on average,something like 40 valid isiZulu words per pagewill still not be recognised by our currentspellchecker. Even though many users mightbe satisfied that around 300 isiZulu words perpage are already recognised, it is clear that
developing techniques to increase the recall ofthe next-generation isiZulu spellcheckers is ahigh priority.
When it comes to Afrikaans one couldassume, given the semi-agglutinative and pro-ductive compounding features, that the recallvalues would lie somewhere in-between thosefor Sesotho sa Leboa and isiZulu. Surprisingly,spellchecking the Afrikaans version of the UDHRshows that the Afrikaans data approach theSesotho sa Leboa data, as is clear from Table 4.
Recall values for Afrikaans are trailing onlyslightly behind those for Sesotho sa Leboa, andwith all spellchecker layers engaged, or thuswith 284 398 types in all, the recall from theuser’s point of view again attains 99%. Token
� #������ %������ &������ �������
���� ��������� �'(�(� �����������
��
��
��
��
��
����������� !
����
�$��
Figure 14: Token and type recall values for an isiZulu spellchecker
Table 3: Building and checking the performance of an isiZulu spellchecker
Spellchecker for isiZulu Universal Declaration of Human Rights in isiZulu(derived from 5 000 411 tokens) (1 045 tokens; 681 types)
words in each layer not recognised recall (in %)frequency # % tokens types tokens types user’s p.v.10 or more 45 348 6.75 308 286 70.53 58.00 72.635 to 9 42 515 6.33 242 227 76.84 66.67 78.283 and 4 60 185 8.96 202 189 80.67 72.25 81.912 88 911 13.24 178 168 82.97 75.33 83.921 (hapaxes) 434 777 64.72 129 123 87.66 81.94 88.23Total 671 736 100.00

Southern African Linguistics and Applied Language Studies 2003. 21: 307–326 321
and type recall values for Afrikaans are shownin Figure 15.
Summarising the findings thus far, it is clearthat: (i) a Sesotho sa Leboa corpus of 5 800 000tokens, contains 150 000 types, with which aspellchecker is 99% effective; (ii) an isiZulu cor-pus of 5 000 000 tokens, contains 700 000 types,with which a spellchecker is 88% effective; and(iii) an Afrikaans corpus of 4 800 000 tokens, con-tains 300 000 types, with which a spellchecker is99% effective.11 Space-constraints unfortunatelydo not allow for a presentation and analysis of thetests that were done for all the other SouthAfrican languages. It is nonetheless highlyrevealing to briefly compare the data for the threelanguages discussed in this article, with the data
for the four languages of the Internet study of Vander Veken and De Schryver (2003).
These scholars sampled their languages insuch a way that the various regions of theAfrican continent were covered, viz. Hausa forWest Africa, Somali for East Africa, Lingala forCentral Africa, and isiXhosa for southern Africa.For each of these languages they searched theInternet for four days, compiled corpora with thedownloaded material, made spellcheckers, andalso tested these spellcheckers on the UDHR.12
Their results can be summarised as follows: (i)a Hausa corpus of 850 000 tokens, contains30 000 types, with which a spellchecker is 99%effective; (ii) a Somali corpus of 300 000 tokens,contains 40 000 types, with which a spellchecker
Table 4: Building and checking the performance of an Afrikaans spellchecker
Spellchecker for Afrikaans Universal Declaration of Human Rights in Afrikaans(derived from 4 815 579 tokens) (1 660 tokens; 468 types)
words in each layer not recognised recall (in %)frequency # % tokens types tokens types user’s p.v.10 or more 22 654 7.97 53 43 96.81 90.81 97.415 to 9 16 075 5.65 32 25 98.07 94.66 98.493 and 4 21 269 7.48 28 22 98.31 95.30 98.672 30 851 10.85 25 20 98.49 95.73 98.801 (hapaxes) 193 549 68.06 16 13 99.04 97.22 99.22Total 284 398 100.00
� ������ #������ #������ "������ "������ %������
���� ���������)������ � �����������
��
��
��
��
��
����������� !
����
�$��
Figure 15: Token and type recall values for an Afrikaans spellchecker

Prinsloo and De Schryver322
is 95% effective; (iii) a Lingala corpus of 200 000tokens, contains 10 000 types, with which aspellchecker is 96% effective; and (iv) anisiXhosa corpus of 950 000 tokens, contains150 000 types, with which a spellchecker is86% effective. Hausa and Somali are both Afro-Asiatic languages, belonging to the Chadic andthe Cushitic families respectively. These lan-guages are not related to the languages dis-cussed in this article, but it is interesting to notethat, with relatively small corpora and a verylimited number of words, excellent spellcheck-ers can be made for these Afro-Asiatic lan-guages. Lingala, and of course isiXhosa, dobelong to the same language family as all offi-cial African languages spoken in South Africa.Lingala is written disjunctively, isiXhosa con-junctively. This orthographic difference againhas direct implications for wordlist-basedspellcheckers, as just 10 000 orthographicwords in the Lingala lexicon pushes the recallup to 96%, while as many as 150 000 ortho-graphic words in the isiXhosa lexicon onlyresults in a recall of 86% — a difference of10%. These various studies thus clearly indi-cate that the effectiveness of word-based
spellchecker lexica for the African languages isinversely related to the degree of conjunctivismof the orthographies of these languages.
In all tests it is also evident that the mostpowerful sections of the wordlists are the firstfew layers, or thus the top-frequent words.Especially the addition of the last layer, thehapaxes, doesn’t substantially increase therecall any further. Hapaxes, by definition, just‘happen’ to occur in corpora. In order to be ableto single out those hapaxes that have a rela-tively higher occurrence likelihood, the corpussizes must be increased even more — say,from five to ten million tokens — at which pointthe more ‘important’ hapaxes will have a higherfrequency, while the accidental ones will still begenuine hapaxes. Ideally, one should reach astage where only top-frequency wordlists areloaded as spellchecker lexica.
ConclusionIn this article spellcheckers for the SouthAfrican languages were presented. We indicat-ed what spellcheckers are, what they typicallydo, how they can be built, and pointed out thatthe technology is available to produce such
��
��
��
��
��
��
� #������ %������ &������ ����������� �������� �����������
����������� !
*�( �
�� ��� ������
�)������
���+���
�,���
� �-� �
� �'(�(
Figure 16: Comparing the effectiveness of various spellcheckers

Southern African Linguistics and Applied Language Studies 2003. 21: 307–326 323
proofing tools for all South African languages,including those that have diacritics in theirorthography. We characterised our top-fre-quency wordlist-based approach, and defend-ed this decision. This approach was then eval-uated with a series of tests applied to thespellcheckers.
The outcome of these tests can now besummarised in a graph to which the resultsreported by Van der Veken and De Schryver(2003) have also been added. The same text,namely the Universal Declaration of HumanRights, was spellchecked for all languagesinvolved, and the effectiveness (here the ‘recallvalues from the user’s point of view’) for allspellcheckers is compared in Figure 16.
The impact on spellchecker effectiveness ofthe orthographic dichotomy that exists betweenthe disjunctively and the conjunctively writtenAfrican languages is clearly visible in Figure 16.Spellchecking a disjunctively written Africanlanguage such as Sesotho sa Leboa (andLingala) is definitely feasible with a word-basedapproach. The recall values are located in thetop-left corner. This means that few words areneeded to reach a good performance, and thatmany words will push that performance close to100%. Spellchecking a conjunctively writtenAfrican language such as isiZulu (and isiXhosa)is much more difficult with a word-basedapproach, since a large number of words isrequired to reach a good recall. Somewhat sur-prisingly, a word-based approach worksremarkably well for Afrikaans.
From these data one may conclude that themain focus during the creation of second-gen-eration spellcheckers for the South African lan-guages will have to be on the conjunctively writ-ten languages, or thus the Nguni group (isiZulu,isiXhosa, siSwati and isiNdebele). Furtherimproving the power of the other spellcheckers(for Sesotho sa Leboa, Sesotho, Setswana,Xitsonga, Tshivenda and Afrikaans) willnonetheless still be a worthwhile venture inorder to move closer to a performance of100%, or thus spellcheckers in which all thevalid words remain unflagged and in which onlythe non-words are detected as errors. In orderto achieve this it is clear that an increase in thesizes of the corpora and, by extension, thesizes of the spellchecker lexica, would berequired. More promising, especially for theNguni group, will be to experiment with soft-
ware modules that can handle the basics ofmorphological decomposition.
Notes1 An earlier version of this article was present-
ed by the authors at the 6th InternationalTerminology in Advanced ManagementApplications Conference (Prinsloo & DeSchryver, 2003). Since this article has beensubmitted for publication in South Africa, nec-essary sensitivity with regard to the term‘Bantu’ languages is exercised in the authors’choice rather to use the term African lan-guages. Keep in mind, however, that the lat-ter includes more than just the ‘BantuLanguage Family’.
2 Except for the Pharos Speller (NBPublishers, 2003), all these spellcheckers aswell as others are freely available on theInternet: • PUK/Microsoft Speltoetser (PU for CHE,2000), • Ispell vir Afrikaans (CompuFocus, s.d.), • Spell Checker for Edit Boxes (Conradie,2002), • Afrikaanse woordelyste (Naudé, 2000), etc.
3 Translated from: “Pray then, in this way: OurFather, who art in heaven, hallowed be Thyname. Thy kingdom come. Thy will be doneon earth as it is in heaven. Give us this dayour daily bread and forgive us our trespassesas we forgive those who trespass against us.And lead us not into temptation, but deliverus from evil.” (Olivier, s.d.)
4 Translated from: “It will seek collaborationwith bodies dealing with telecommunications,licensing, film and video, to achieve coordi-nation and avoid duplication. Apart from itsprimary role of media support, it will commis-sion research and make recommendations togovernment, the media industry and otherrelevant bodies. The MDDA will relate to allbodies with a direct or indirect interest inmedia development and diversity, amongstthem the Independent CommunicationsAuthority of SA (ICASA). The MDDA will holdan Annual Review Forum where such bodieswill consider the MDDA’s annual report.”(South Africa Government Online, 2000)
5 Translated from: “The PANSALB legislationis the most significant indicator that there is acommitment to articulate and monitor a lan-guage policy and plan broad enough to

Prinsloo and De Schryver324
ANC. s.d. What is the African NationalCongress? Available at: http://www.anc.org.za/about/anc.html [Accessed 24 August2002].
CompuFocus. s.d. Ispell vir Afrikaans.Available at: http://www.compufocus.co.za/afrik/ispell/ [Accessed 26 April 2003].
Conradie P. 2002. Spell checker for editboxes. Available at: http://www.afrikaner.co.za/pietwerf/speltest.htm [Accessed 26 April2003].
Department of Education. 2002. RevisedNational Curriculum Statement Grades R–9(Schools) — First Additional Language.Available at: http://education.pwv.gov.za/DoE_Sites/Curriculum/Final%20curriculum/policy/policy.htm [Accessed 24 August2002].
De Schryver G-M & Prinsloo DJ. 2000. The
compilation of electronic corpora, with spe-cial reference to the African languages.Southern African Linguistics and AppliedLanguage Studies 18(1–4): 89–106.
Gaultney V. 2002. Gentium typeface. Availableat: http://www.sil.org/~gaultney/gentium/download.html [Accessed 26 April 2003].
Hurskainen A. 1999. SALAMA: Swahili lan-guage manager. Nordic Journal of AfricanStudies 8(2): 139–157.
Lingsoft. 1999. Orthografix 2 for Swahili.Available at: http://www.lingsoft.fi/news/1999/o2-swahili.html [Accessed 26 April2003].
Louwrens LJ. 1991. Aspects of Northern SothoGrammar. Pretoria: Via Afrika Limited.
Naudé FJ. 2000. Afrikaanse woordelyste.Available at: http://www.naude.co.za/frank/afr/index.htm#woorde [Accessed 26 April
encompass every sector of society and it isthis, which places us ahead of other coun-tries. We have the added advantage of beingable to learn from the paths chosen else-where on this continent. There are somebasic steps, which need to be followed inarticulating and implementing a feasible lan-guage policy and plan.” (Pan South AfricanLanguage Board, 1998)
6 Translated from: “Understands concepts andsome vocabulary relating to:• identity (e.g. ‘My name is...’);• number (e.g. one, two);• size (e.g. big, small);• colour (e.g. red, yellow).” (Department ofEducation, 2002)
7 Translated from: “In 1994 the ANC adoptedthe Reconstruction and DevelopmentProgramme (RDP) as the basic policy frame-work guiding the ANC in the transformation ofSouth Africa. The key programmes of theRDP are:• meeting basic needs • developing our human resources • building the economy • democratising the state and society.” (ANC,s.d.)
8 This word was spelled correctly in the originaltext and the error only serves as an illustra-tion here.
9 Translations (thanks are due to MJ Mojalefa):1. ... they are very poor, those guests; they
then welcomed them with open arms andhosted them well because they have theresponsibility of welcoming (them) ...2. ... the parents welcomed them, and they(their hearts) did not complain (at all) whenthey ...3. ... coming out of the gate he took a short-cut route which was between the woods andthe courtyard. He knew very well that hewould find father Hau’s sons ...4. ... it is that rich man at whose place youwere yesterday. This arm that you can see isinjured, was injured on that occasion.” Thesemen ...
10 See for the term ‘conjunctivism’, as opposedto ‘disjunctivism’, for instance Louwrens(1991: 1–12) or Van Wyk (1995: 83–84).
11 Note that less formal tests on a few other par-allel texts (of various types) indicate onlymarginal variation in these recall percent-ages.
12 The fact that one of the authors was co-researcher in both the Van der Veken and DeSchryver (2003) study and the current oneexplains why the methodology of the twostudies is analogous. Choosing to spellchecktranslations of the same document, theUDHR, was also a deliberate move, as thisallows a direct comparison of the results, andenables one to place the South African datain a wider African context.
References

Southern African Linguistics and Applied Language Studies 2003. 21: 307–326 325
2003].NB Publishers. 2003. Pharos Speller:
Speltoetser en Woordafbreker vir Afrikaans.Available at: http://www.nb.co.za/Pharos/phArticleDisplay.asp?iCategory_id=31[Accessed 26 April 2003].
Nong S, De Schryver G-M & Prinsloo DJ.2002. Loan Words versus IndigenousWords in Northern Sotho — A lexicographicperspective. Lexikos 12 (AFRILEX-reeks/series 12: 2002): 1–20.
Office of the High Commissioner for HumanRights. 1948–. Universal Declaration ofHuman Rights. Available at: http://193.194.138.190/udhr/index.htm [Accessed 26 April2003].
Olivier J. s.d. Lord’s Prayer in Tshivenda.Available at: http://www.cyberserv.co.za/users/~jako/lang/ventexts.htm [Accessed26 April 2003].
Olivier J. 2002. South African special charac-ters font. Available at: http://www.cyberserv.co.za/users/~jako/lang/fonts.htm[Accessed 26 April 2003].
Pan South African Language Board. 1998.PanSALB’s position on the promotion ofmultilingualism in South Africa. Available at:h t tp : / /www.pansa lb .o rg .za /pub .h tm[Accessed 24 August 2002].
Prinsloo DJ. 1991. Towards computer-assist-ed word frequency studies in NorthernSotho. South African Journal of AfricanLanguages 11(2): 54–60.
Prinsloo DJ & De Schryver G-M. 2001.Corpus applications for the African lan-guages, with special reference to research,teaching, learning and software. SouthernAfrican Linguistics and Applied LanguageStudies 19(1–2): 111–131.
Prinsloo DJ & De Schryver G-M. 2002.Towards an 11 x 11 array for the degree ofconjunctivism/disjunctivism of the SouthAfrican languages. Nordic Journal ofAfrican Studies 11(2): 249–265.
Prinsloo DJ & De Schryver G-M. 2003.Towards second-generation spellcheckersfor the South African languages. In: DeSchryver G-M (ed) TAMA 2003 SouthAfrica: Conference Proceedings. Pretoria:(SF)2 Press. pp. 135–141.
PU for CHE (Potchefstroom University forChristian Higher Education). 2000.PUK/Microsoft Speltoetser. Available at:http://www.puk.ac.za/spel/en/index.html[Accessed 26 April 2003].
South Africa Government Online. 2000.Media Development and Diversity AgencyPosition Paper. Available at: http://www.gov.za/documents/2000/mdda/ [Accessed 24August 2002].
Unicode. 2003. The Unicode® Standard: Atechnical introduction. Available at:http://www.unicode.org/standard/principles.html [Accessed 26 April 2003].
Van der Veken A & De Schryver G-M. 2003.Les langues africaines sur la Toile. Étudedes cas haoussa, somali, lingala et isi-xhosa. Cahiers du Rifal 23 (Thème: Letraitement informatique des languesafricaines): 33–45.
Van Huyssteen GB & Van Zaanen MM. 2003.A Spellchecker for Afrikaans, Based onMorphological Analysis. In: De Schryver G-M (ed) TAMA 2003 South Africa:Conference Proceedings. Pretoria: (SF)2
Press. pp. 189–194.Van Wyk EB. 1995. Linguistic assumptions
and lexicographical traditions in the Africanlanguages. Lexikos 5 (AFRILEX-reeks/series 5B: 1995): 82–96.

Prinsloo and De Schryver326
Appendix 1: Homepage of the Universal Declaration of Human Rights (note the 'more' link on the left to trans-lations into many of the world's languages)
(Source: Office of the High Commissioner for Human Rights 1948–)