Embed Size (px)
Citation preview

NLTK chapter 2, 4(approximately)
NLTK programming coursePeter Ljunglöf
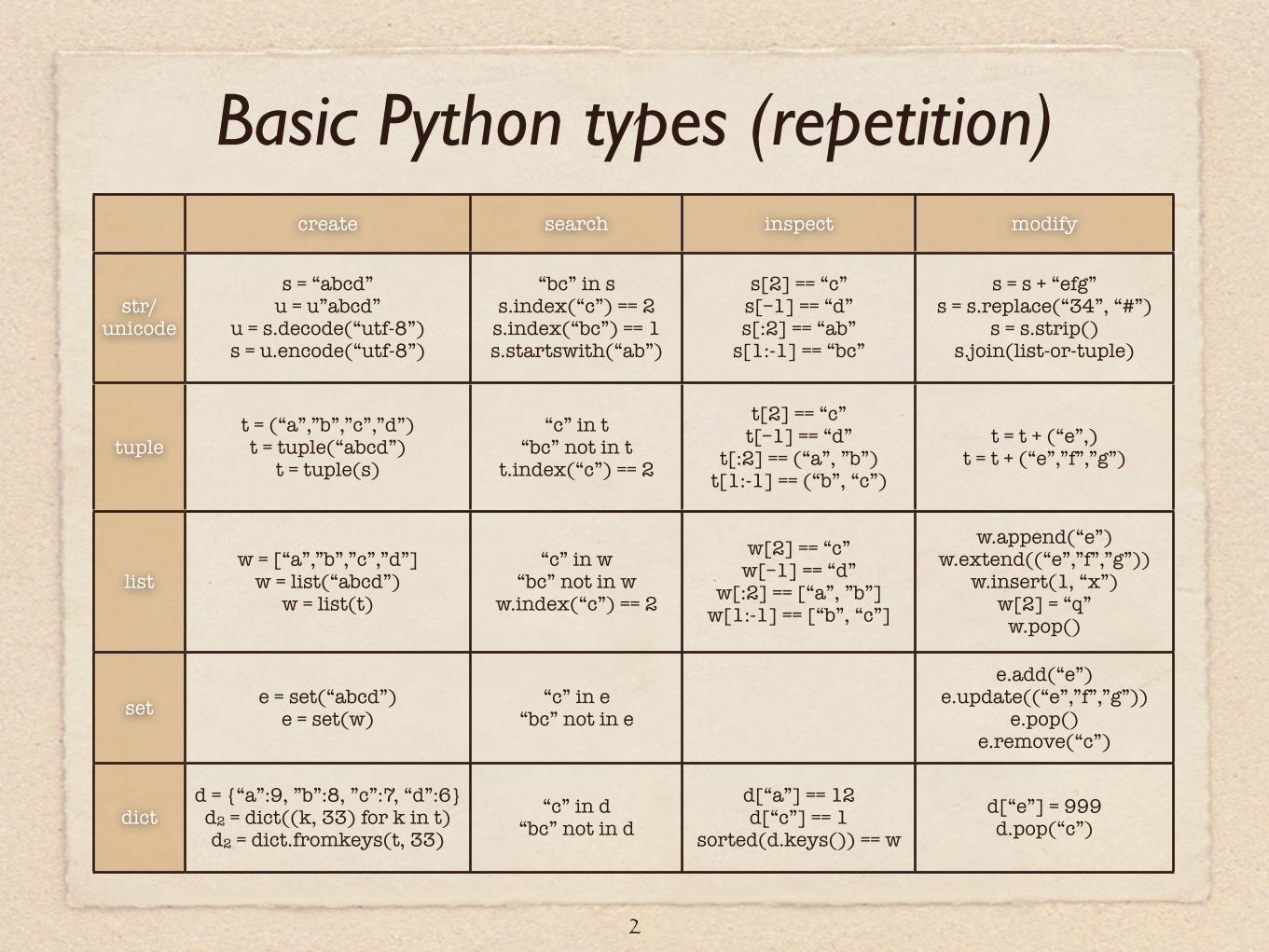
Basic Python types (repetition)
2
create search inspect modify
str/unicode
tuple
list
set
dict
s = “abcd”u = u”abcd”
u = s.decode(“utf-8”)s = u.encode(“utf-8”)
“bc” in ss.index(“c”) == 2
s.index(“bc”) == 1s.startswith(“ab”)
s[2] == “c”s[–1] == “d”s[:2] == “ab”
s[1:-1] == “bc”
s = s + “efg”s = s.replace(“34”, “#”)
s = s.strip()s.join(list-or-tuple)
t = (“a”,”b”,”c”,”d”)t = tuple(“abcd”)
t = tuple(s)
“c” in t“bc” not in t
t.index(“c”) == 2
t[2] == “c”t[–1] == “d”
t[:2] == (“a”, ”b”)t[1:-1] == (“b”, “c”)
t = t + (“e”,)t = t + (“e”,”f”,”g”)
w = [“a”,”b”,”c”,”d”]w = list(“abcd”)
w = list(t)
“c” in w“bc” not in w
w.index(“c”) == 2
w[2] == “c”w[–1] == “d”
w[:2] == [“a”, ”b”]w[1:-1] == [“b”, “c”]
w.append(“e”)w.extend((“e”,”f”,”g”))
w.insert(1, “x”)w[2] = “q”
w.pop()
e = set(“abcd”)e = set(w)
“c” in e“bc” not in e
e.add(“e”)e.update((“e”,”f”,”g”))
e.pop()e.remove(“c”)
d = {“a”:9, ”b”:8, ”c”:7, “d”:6}d2 = dict((k, 33) for k in t)d2 = dict.fromkeys(t, 33)
“c” in d“bc” not in d
d[“a”] == 12d[“c”] == 1
sorted(d.keys()) == wd[“e”] = 999d.pop(“c”)

Division in Python (repetition)
Dividing two integers returns an int:>>> 3 / 21
Coerce to float first:>>> float(3) / 21.5
or use Python 3 division:>>> from __future__ import division>>> 3 / 21.5
3

Mutable / immutable (rep.)
list, set, dict, nltk.FreqDist, … are mutable:(they have methods that modify themselves)
>>> m = w = [“a”, “b”, “c”, “d”]>>> w[2] = “#”>>> m[“a”, “b”, “#”, “d”]
tuple, str, unicode, int, float, … are immutable:(you have to create a copy)
>>> m = w = (“a”, “b”, “c”, “d”)>>> w[2]="#"TypeError: 'tuple' object does not support item assignment>>> w = w[:2] + (“#”,) + w[3:]>>> m(“a”, “b”, “c”, “d”)
4

Reading and writing (rep.)
Use Unicode strings:decode(“utf-8”) when reading from fileencode(“utf-8”) when writing to fileor use the codecs module
Use the with statement……for reading:with codecs.open(“inputfile”, “r”, encoding=”utf-8”) as F: content = F.read()…or writing:with codecs.open(“outputfile”, “w”, encoding=”utf-8”) as F: F.write(content)
5

Python files and modules
Standard file structure
Importing modules
Standard modules
6

Python file structure# -*- coding: utf-8 -*-”””module docstring — try to use docstrings instead of comments”””import sysimport nltkmodule_constant = 42another_constant = u”non-ascii letters: åäö ÅÄÖ”def main_function(input_file, another_arg): ”””description of main function, and its arguments””” with open(input_file, “r”) as F: …another_function(x, y)…def another_function(arg_1, arg_2): ”””another function, its arguments and the return value””” return some_resultif __name__ == ”__main__”: main_function(*sys.argv[1:])
7
constant declarations:don’t change
them later
the main function(s) before the helper(s)
import before everything
if you use non-ASCII strings/comments
if the file is run as a script,
call main function

Importing modules
Never use this:from os.path import *from nltk.tag.tnt import *
But it’s okay to assign short names:import os.path as Pimport nltk.tag.tnt as tnt
And sometimes this is okay:from glob import globfrom os.path import basename, dirnamefrom nltk.tag.tnt import TnT
8

Useful Python modulesstrings, unicode:re, codecs, unicodedata
objects, data types:copy, pprintcollections, heapq, bisectnumbers:math, randomiterators, higher-order functions:itertools, operator
9

More Python modulesfile system, operating system:os.path, globtime, os, sys, subprocessreading/writing special files:pickle, cPicklezlib, gzip, bz2, zipfile, tarfile
html, cgi:urllib, HTMLParser, htmlentitydefscgi, cgitbtesting efficiency and correctness:timeit, doctest
10

Modules for stringsre — last lecture
codecs:codecs.open(filename, mode, encoding)
unicodedata:>>> unicodedata.name(u'\u00e4')'LATIN SMALL LETTER A WITH DIAERESIS'>>> unicodedata.lookup('LATIN SMALL LETTER A WITH DIAER…u'\xe4'>>> unicodedata.category(u'\xe4')'Lu' # Letter Uppercase>>> unicodedata.category(u'2')'Nd' # Number Decimal
11

Objects, data typesdeep copying of nested objects:copy.deepcopy(obj)
pretty-printing of nested objects:pprint.pprint(object, [stream], [indent], [width], [depth])
default dictionaries:ctr = collections.defaultdict(int)ctr[‘a’] # returns 0ctr[‘b’] += 3 # ctr[‘b’] is now 3
priority queues; fast searching in sorted lists:heapq.heappush, heapq.heappop, heapq.heapifybisect.bisect_left, bisect.bisect_right
12

Numbersmath functions:math.exp(x) == ex math.log(x) == ln xmath.pow(x, y) == xy math.sqrt(x) == √xmath.sin(x) == sin x math.cos(x) == cos xmath.pi == π math.e == e
random numbers and sequences:random.random() ==> 0.70117748128509816random.randrange(10) ==> 7random.randrange(100, 110) ==> 103random.choice(“abcdef”) ==> “c”random.sample(“abcdef”, 3) ==> [“d”, “a”, “c”]
xs = [1,2,3,4,5]random.shuffle(xs)# result: xs == [5, 1, 4, 2, 3]
13

File system, OS utilitiespathname manipulation & expansionos.path.basename(“/test/a/path.xml”) ==> “path.xml”os.path.dirname(”/test/a/path.xml”) ==> “/test/a”glob.glob(“test/∗/∗.xml”) ==> [“test/a/path.xml”, “test/b/zip.xml”]
timetime.time() ==> nr seconds since the epoch (1970 on unix)time.strftime(format, [time]) ==> pretty-formatted time string
os, sys, subprocessos.getcwd(), os.chdir(path), os.listdir(path), os.mkdir(path)os.environ, sys.argv, sys.platformsys.stdin, sys.stdout, sys.stderrsubprocess.Popen(…), subprocess.call(…)
14

And the rest…pickle, cPickle:for reading/writing Python objects from/to fileszlib, gzip, bz2, zipfile, tarfile: for reading/writing compressed dataurllib, HTMLParser, htmlentitydefs: for reading/parsing htmlcgi, cgitb: for writing cgi scriptstimeit, doctest: for testing efficiency and correctness of your code
15

NLTK
Frequency distributions
Conditional frequency distributions
16

NLTK frequency distribution
FreqDist is a dictionary with counters
initialize by giving a sequence of elementse.g., a string, a list of words, a list of bigrams
a lot of useful methodscompare (<, <=, ==, >=, >), add (+)statistics (B, N, Nr, freq, d[x])get elements (hapaxes, max, samples, items)change (inc, update, d[x]=n)display (tabulate, plot)
17

ConditionalFreqDist
a dictionary of FreqDist’sinitialize by a sequence of (cond, sample) pairs
useful methods:==, <, >, N, conditions, plot, tabulatehowever: keys, values, in, for…in are missing
examples:figure 2.1: words “america” vs “citizen”figure 2.2: word length in different languagesfigure 2.10: last letter of male/female namesexample 2.5: random text generation
18

Example cond. freq. dist
modals in different text types (2.1 Brown)cfd = nltk.ConditionalFreqDist( (genre, word) for genre in brown.categories() for word in brown.words(categories=genre))genres = ['hobbies', 'lore', 'news', 'romance']modals = ['can', 'could', 'may', 'might', 'must', 'will']cfd.tabulate(conditions=genres, samples=modals)
can could may might must willhobbies 268 58 131 22 83 264lore 170 141 165 49 96 175news 93 86 66 38 50 389romance 74 193 11 51 45 43
19

Python coding tips
Coding style
Procedural vs declarative
Looping
Named function arguments
Defensive programming
20

Python coding style (sect. 4.3)
Indent with 4 spaces; not tabs
Don’t write long lines; line break insteadeither use parentheses:if ( len(syllables) > 4 and len(syllables[2]) == 3 and syllables[2][2] in “aeiou” and syllables[2][3] == syllables[1][3] ):or add a backslash at the end of the line:if len(syllables) > 4 and len(syllables[2]) == 3 and \ syllables[2][2] in “aeiou” and \ syllables[2][3] == syllables[1][3]:
With the risk of being repetitive:write docstrings!
21

Procedural vs declarative (4.3)
Procedural:count = 0; total = 0for token in tokens: count += 1 total += len(token)print float(total) / count
Declarative:count = len(tokens)total = sum(len(t) for t in tokens)print float(total) / count
The declarative style needs more infrastructurehigher-order functions, generic classes
22

Sorted word list (1st attempt)
A very procedural version:word_list = []len_word_list = 0i = 0while i < len(tokens): j = 0 while j < len_word_list and word_list[j] < tokens[i]: j += 1 if j == 0 or tokens[i] != word_list[j]: word_list.insert(j, tokens[i]) len_word_list += 1 i += 1
Note: we only use len, insert and lookup
23

Sorted word list (2nd)
Using a for loop instead:word_list = []for token in tokens: j = 0 while j < len(word_list) and word_list[j] < token: j += 1 if j == 0 or token != word_list[j]: word_list.insert(j, token)
Note: we didn’t need the i, just the tokenthe for loop takes care of i and increasing itbut, we do need jwe rely on the fact that len() is efficient for lists
24

Sorted word list (3rd attempt)
A very declarative version:word_list = sorted(set(tokens))
Note: we’re not only using sorted and setsince they rely on a lot of underlying methods
25

Looping in Python
Other languages often use a counter : C: for (i = 0; i < mylist_length; i++) { token = mylist[i] // do something with token… }
Pascal: for i := 0 to mylist_length do begin token := mylist[i] {do something with token…} end
In Python we just loop over the elements:for token in tokens: # do something with token…
26

Getting the index
Sometimes we really want the list index toothen we use the function enumerate:for i, token in enumerate(tokens): # now this holds: token == tokens[i]
And sometimes we don’t have list to loop overthen we use the range function:for i in range(10): # i will be 0, 1, 2, …, 9range can take a start value:for i in range(1, 11): # i will be 1, 2, 3, …, 10
27

Looping over two lists
Sometimes we want to loop in parallele.g., part-of-speech taggingdef postag(word): if word in (“a”, “the”, “all”): return “det” else: return “noun”getting a list of postags:postaglist = [postag(w) for w in corpus_words]loop over each word and postag:for word, postag in zip(corpus_words, postaglist): # do something with the word and its postag…
28

Loops vs comprehensions
Getting all words that starts with a string:def prefix_search(prefix, words): result = set() for word in words: if word.startswith(prefix): result.add(word) return result
The same thing using a set comprehension:def prefix_search(prefix, words): return set(word for word in words if word.startswith(prefix))
More declarative = shorter = more readable
29

Named arguments
You can always call a function with named args:prefix_search(“engl”, brown.words())…vs…prefix_search(prefix=“engl”, words=brown.words())
Often it is more readable:codecs.open(“inputfile”, “wb”, “gbk”)…vs…codecs.open(“inputfile”, mode=“wb”, encoding=“gbk”)
But sometimes it doesn’t give us anything:nltk.bigrams(brown.words())…vs…nltk.bigrams(sequence=brown.words())
30

Named arguments
Since you can always use named args, it is especially important with good names:
def prefix_search(prefix, words):…vs…def prefix_search(x, y):
31

Defensive programminguse assert to check input arguments:def prefix_search(prefix, words): assert isinstance(prefix, (str, unicode)), “prefix must be a string” assert isinstance(words, (list, tuple, set)), “words must be a sequ… # the rest…
…to check return values:def prefix_search(prefix, words): # the rest… assert isinstance(result, set), “result should be a set” return result
…to check return values:search_result = prefix_search(“engl”, brown.words())assert isinstance(search_result, set), “search result should be a set”assert search_result, “search result should be non-empty”
32





























