Embed Size (px)
Citation preview

Nick Cercone
Faculty of Computer Science
From Simple Techniques to Impressive Results

2 Faculty of Computer Science
Abstract

3 Faculty of Computer Science
Less Abstract
We explore the simple technique of n-gram analysis as it is applied to three disparate and seemingly unrelated problems. We apply our technique to solve a problem of author attribution, to classify levels of dementia in patients with mild cognitive impairment by examining patient-care-giver transcripts, and then use n-gram analysis to detect new malicious code.

4 Faculty of Computer Science
A Motivational Story about Style
Generations ago a minister in a Scottish Highland parish was mystified by the behaviour in church of the three sons of the local doctor. Though the boys were at the difficult ages of 5, 7, and 10 years, they sat entranced through the longest sermon. Such concentration is not common among boys of that age, and the minister pressed the doctor to reveal how this miracle was repeatedly performed. The doctor was reluctant to disclose how it was done but finally gave way and told the minister what was happening.

5 Faculty of Computer Science
Story (cont.)
The doctor took to church each Sunday a bar of chocolate. When the sermon began he gave it to the eldest boy and whenever the minister came out with one of his favourite phrases, that is true or everyone will agree or all right thinking people, the boy would hand the bar to his brother. Up and down it would go until the benediction was pronounced, when the boy who was holding it was allowed to eat it.

6 Faculty of Computer Science
Story (cont.)
This simple story illustrates a fact which we all know, but do not much like admitting, that
we have habits of speech, and of writing too, of which we are so little aware that we sometimes seem to be their prisoner.

7 Faculty of Computer Science
Introduction
• Character-based n-gram methods assume that text can be considered as a concatenated sequence of characters instead of words.
• Character-based n-gram methods possess several advantages, including: (1) small vocabulary; (2) language independence; and (3) no word segmentation problems in many Asian languages such as Chinese and Thai

8 Faculty of Computer Science
How do character n-grams work?
Marley was dead: to begin with. There
is no doubt whatever about that. …
n = 3Mararlrleleyey_y_w_wawas
_th 0.015 ___ 0.013 the 0.013 he_ 0.011 and 0.007 _an 0.007 nd_ 0.007 ed_ 0.006
sort by frequency
L=5
(from Christmas Carol by Charles Dickens)
…
9 Faculty of Computer Science
How do we compare two profiles?
_th 0.015 ___ 0.013 the 0.013 he_ 0.011 and 0.007
Dickens: Christmas Carol _th 0.016 the 0.014 he_ 0.012 and 0.007 nd_ 0.007
Dickens: A Tale of Two Cities
_th 0.017 ___ 0.017 the 0.014 he_ 0.014 ing 0.007
Carroll: Alice’s adventures in wonderland
?
?

10 Faculty of Computer Science
N-gram distribution
0.00E+00
5.00E-04
1.00E-03
1.50E-03
2.00E-03
2.50E-03
3.00E-03
3.50E-03
4.00E-03
4.50E-03
5.00E-03
1 4 7 10 13 16 19 22 25 28 31 34
6-grams
(From Dickens: Christmas Carol)

11 Faculty of Computer Science
CNG Method for Authorship Attribution
• The Common N-Grams classification method for authorship attribution is based on extracting the most frequent byte n-grams of size n from the training data.
• The n-grams are sorted by their normalized frequency, and the first L most-frequent n-grams define an author profile.
• Given a test document, the test profile is produced in the same way, and the distances between the test profile and the author profiles are calculated.
• The test document is classified using k-nearest neighbours method with k = 1, i.e., the test document is attributed to the author whose profile is closest to the test profile.

12 Faculty of Computer Science
CNG profile similarity measure
• a profile = the set of L the most frequent n-grams• profile dissimilarity measure:
weight
2
profile 21
21
2
profile 21
21
)()(
))()((2
2)()()()(
nn nfnf
nfnfnfnfnfnf
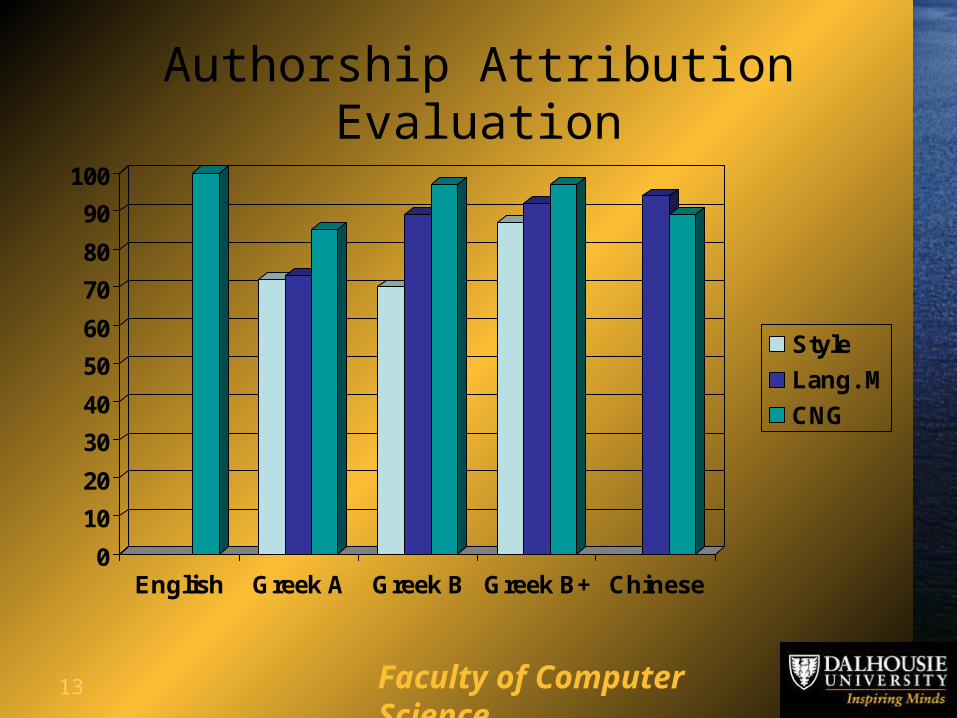
13 Faculty of Computer Science
Authorship Attribution Evaluation
0
10
20
30
40
50
60
70
80
90
100
English Greek A Greek B Greek B+ Chinese
Style
Lang. M
CNG

14 Faculty of Computer Science
Analysis of speech in dementia of Alzheimer type
• Bucks et al., 2000
• experiment with 24 participants:
• 8 patients and 16 healthy individuals
• measures: noun rate, pronoun rate, verb rate, etc.
• results:
• 100% on training data
• 87.5% with cross-validation

15 Faculty of Computer Science
ACADIE Data Set
• 189 GAS interviews (Goal Attainment Scaling)
• 95 patients (2 interviews per patient, except 1 patient)
• 6 sites; 17 MB of data (3.2 million words)
• interview participants:
• FR – field researcher
• Pt – patient
• Cg – caregiver
• other people

16 Faculty of Computer Science
Experiment set-up
• pre-processing
• patients divided into two groups
• 85 training group (169 interviews)
• 10 testing group (20 interviews)
• patient speech in training group is used to build Alzheimer profile
• non-patient speech in training group is used to build non-Alzheimer profile
• two experiments:
• classification
• improvement detection

17 Faculty of Computer Science
Classification
• from each test interview patient and non-patient speech is extracted
• this produces 40 speech extracts
• each speech extract is labelled by the classifier as Alzheimer or non-Alzheimer
• accuracy is reported
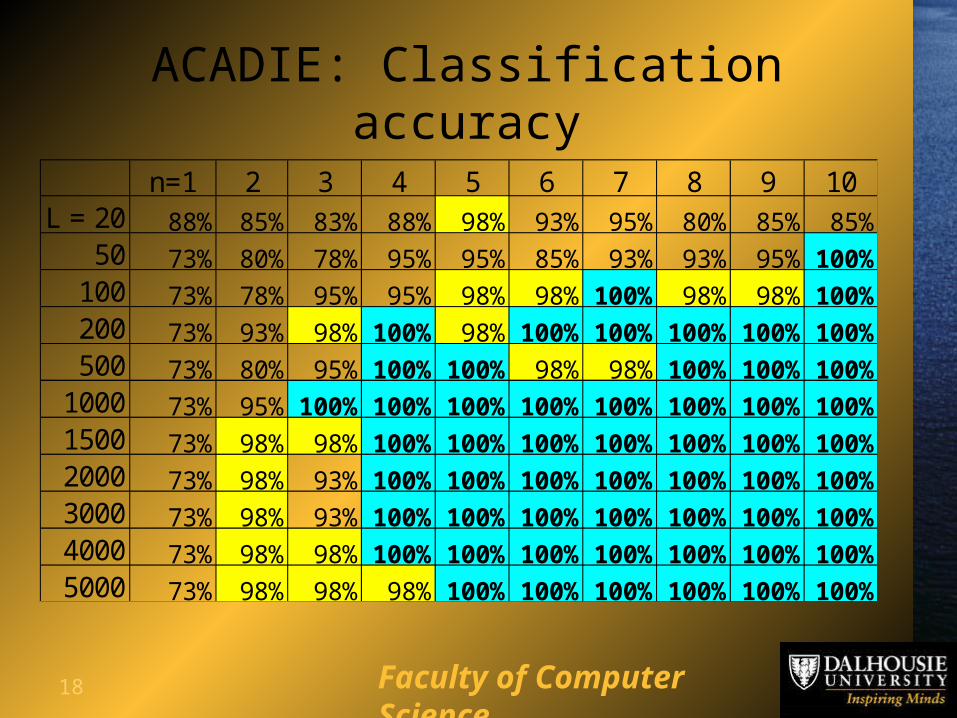
18 Faculty of Computer Science
ACADIE: Classification accuracy
n=1 2 3 4 5 6 7 8 9 10L = 20 88% 85% 83% 88% 98% 93% 95% 80% 85% 85%
50 73% 80% 78% 95% 95% 85% 93% 93% 95% 100%100 73% 78% 95% 95% 98% 98% 100% 98% 98% 100%200 73% 93% 98% 100% 98% 100% 100% 100% 100% 100%500 73% 80% 95% 100% 100% 98% 98% 100% 100% 100%
1000 73% 95% 100% 100% 100% 100% 100% 100% 100% 100%1500 73% 98% 98% 100% 100% 100% 100% 100% 100% 100%2000 73% 98% 93% 100% 100% 100% 100% 100% 100% 100%3000 73% 98% 93% 100% 100% 100% 100% 100% 100% 100%4000 73% 98% 98% 100% 100% 100% 100% 100% 100% 100%5000 73% 98% 98% 98% 100% 100% 100% 100% 100% 100%

19 Faculty of Computer Science
Improvement detection
) threshold(0.5 profileAlzheimer
withsimilarity normalized
profileAlzheimer -non with similarity
profileAlzheimer with similarity
ba
a
b
a
SS
SS
S
S
• improvement is detected by observing an increase in S value between the first and second interview

20 Faculty of Computer Science
ACADIE: Detected improvement
n=1 2 3 4 5 6 7 8 9 10L = 20 50% 60% 70% 80% 70% 50% 50% 40% 60% 50%
50 50% 70% 60% 30% 60% 30% 30% 60% 50% 70%100 40% 60% 40% 40% 40% 40% 80% 60% 70% 60%200 40% 30% 30% 40% 50% 70% 40% 70% 50% 60%500 40% 80% 60% 80% 60% 50% 40% 60% 80% 70%
1000 40% 50% 90% 60% 70% 70% 70% 90% 60% 60%1500 40% 70% 80% 70% 80% 60% 80% 80% 60% 50%2000 40% 60% 90% 70% 70% 70% 70% 70% 60% 60%3000 40% 60% 70% 70% 70% 60% 60% 70% 60% 70%4000 40% 60% 70% 90% 80% 80% 70% 60% 70% 70%5000 40% 60% 70% 80% 80% 70% 60% 70% 70% 70%

21 Faculty of Computer Science
Experiment 1.2
• use only first interviews to create Alzheimer and Non-Alzheimer profiles

22 Faculty of Computer Science
Experiment 1.2: Classification accuracy
n=1 2 3 4 5 6 7 8 9 10L = 20 85% 85% 83% 88% 93% 90% 95% 80% 80% 83%
50 70% 90% 83% 98% 95% 85% 93% 95% 95% 90%100 73% 98% 98% 98% 90% 98% 98% 98% 95% 98%200 73% 88% 98% 100% 100% 98% 100% 95% 100% 100%500 73% 83% 98% 100% 95% 98% 95% 100% 98% 100%
1000 73% 95% 100% 100% 100% 100% 100% 100% 100% 100%1500 73% 95% 95% 100% 100% 100% 100% 100% 100% 100%2000 73% 95% 93% 100% 100% 100% 100% 100% 100% 100%3000 73% 95% 95% 100% 100% 100% 100% 100% 100% 100%4000 73% 95% 98% 100% 100% 100% 100% 100% 100% 100%5000 73% 95% 100% 100% 100% 100% 100% 100% 100% 100%
Improvement detection: 0.6-0.9

23 Faculty of Computer Science
Experiment 1.3
• use only first interviews• only speech produced by patients,
caregivers, and other (not field researchers)

24 Faculty of Computer Science
Experiment 1.3: Classification accuracy
n=1 2 3 4 5 6 7 8 9 10L = 20 75% 90% 85% 80% 65% 75% 80% 70% 75% 70%
50 73% 88% 68% 80% 90% 75% 75% 75% 80% 83%100 73% 85% 88% 85% 88% 80% 83% 88% 88% 88%200 73% 83% 90% 90% 95% 88% 93% 88% 98% 93%500 73% 65% 95% 95% 95% 95% 98% 90% 93% 95%
1000 73% 83% 93% 93% 98% 93% 98% 98% 98% 95%1500 73% 78% 80% 95% 95% 100% 98% 98% 98% 95%2000 73% 80% 75% 95% 100% 98% 98% 98% 98% 95%3000 73% 83% 83% 88% 95% 98% 95% 98% 95% 93%4000 73% 83% 90% 95% 95% 95% 98% 98% 95% 95%5000 73% 83% 93% 98% 95% 98% 98% 98% 98% 93%
Improvement detection: 0.6-0.8

25 Faculty of Computer Science
Some experiment observations
• Alzheimer n-gram profile captures many indefinite terms and negated (e.g., sometimes, don’t know, can not, …)
• the profiles captures reduced lexical richness
Alzheimer
non-Alzheimer
n-gram rank
n-gram
frequency

26 Faculty of Computer Science
Second set of experiments
• rating dementia levels
• implement method BSCW (by Bucks et al.),
• analysis and extension
• comparison with CNG
• application of a wider set of machine learning algorithms

27 Faculty of Computer Science
MMSE – Mini-Mental State Exam
• MMSE – a standard test for identifying cognitive impairment in a clinical setting
• 17 questions, 5-10 minutes• introduced in 1975 by Folstein et al.• score range from 0 to 30• a variety of cut points suggested over
years: 17.5, 21.5, 23.5, 25.5

28 Faculty of Computer Science
MMSE Score Gradation
• we use the following gradation
four classes: severe moderate mild normal
two classes: low high
0 14.5 20.5 24.5 30

29 Faculty of Computer Science
MMSE Score distribution in data set
severe moderate mild normal

30 Faculty of Computer Science

31 Faculty of Computer Science
Part-of-speech tagging, MA-A• following the BSCW method• applied Hepple from NL GATE and
Connexor• Hepple is based on Brill’s tagger• Connexor performed better• set of attributes MA-A: attributes similar to
BSCW:– excluded CSU-rate:1. manually annotated2. reported non-significant impact by BSCW

32 Faculty of Computer Science
Morphological Attribute Set: MA-B
• start with all POS attributes• regression-based attribute selection• 7 POS attributes selected (conjunctions
included)• add TTR and Honore statistics
– Brunet statistic shown to be non-significant
• use several machine learning algorithms with cross-validation, using software tool WEKA

33 Faculty of Computer Science

34 Faculty of Computer Science
Part-of-speech tagging, MA-A• following the BSCW method• applied Hepple from NL GATE and
Connexor• Hepple is based on Brill’s tagger• Connexor performed better• set of attributes MA-A: attributes similar
to BSCW:– excluded CSU-rate:1. manually annotated2. reported non-significant impact by
BSCW

35 Faculty of Computer Science
Morphological Attribute Set: MA-B
• start with all POS attributes• regression-based attribute selection• 7 POS attributes selected (conjunctions
included)• add TTR and Honore statistics
– Brunet statistic shown to be non-significant
• use several machine learning algorithms with cross-validation, using software tool WEKA
36 Faculty of Computer Science
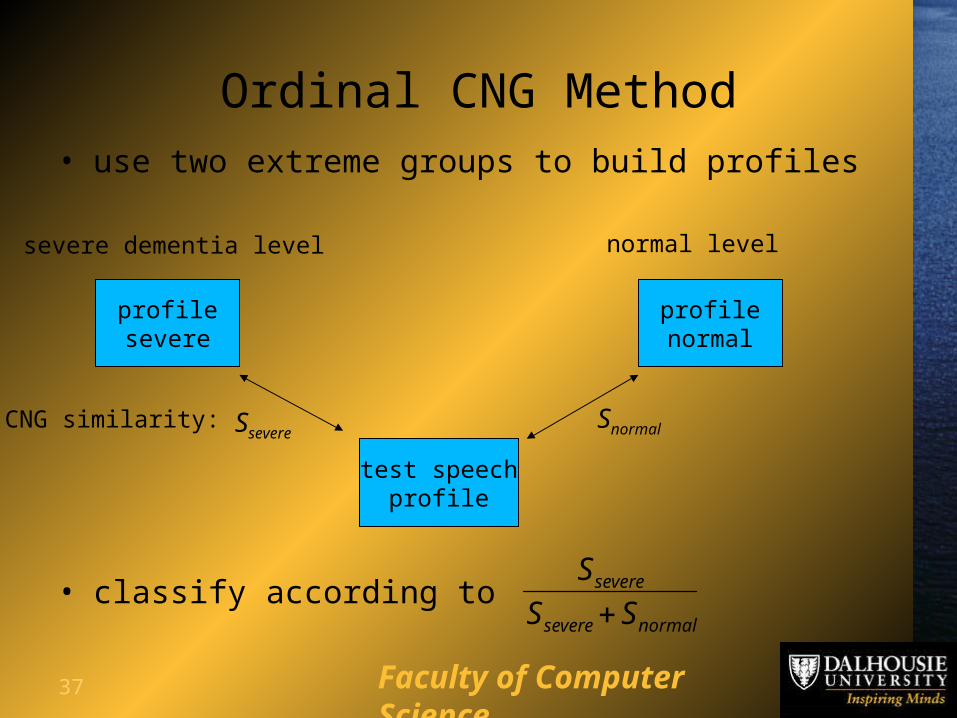
37 Faculty of Computer Science
Ordinal CNG Method• use two extreme groups to build profiles
severe dementia level normal level
profilesevere
profilenormal
test speechprofile
CNG similarity: SsevereSnormal
• classify according tonormalsevere
severe
SS
S

38 Faculty of Computer Science
Ordinal CNG: Thresholds
• range of values: [0,1]– 0 corresponds to severe, 1 to
normal• what are good threshold• interesting observation:
– the optimal threshold is very close to the “natural threshold” – 0.5 (varies from 0.5 to 0.512)

39 Faculty of Computer Science

40 Faculty of Computer Science
Conclusions• extensive experiments on morphological and
lexical analysis of spontaneous speech for detecting dementia of Alzheimer type
• methods:– CNG and Ordinal CNG– extension of method proposed by use of POS
tags as suggested by BSCW• positive results in classification and detecting
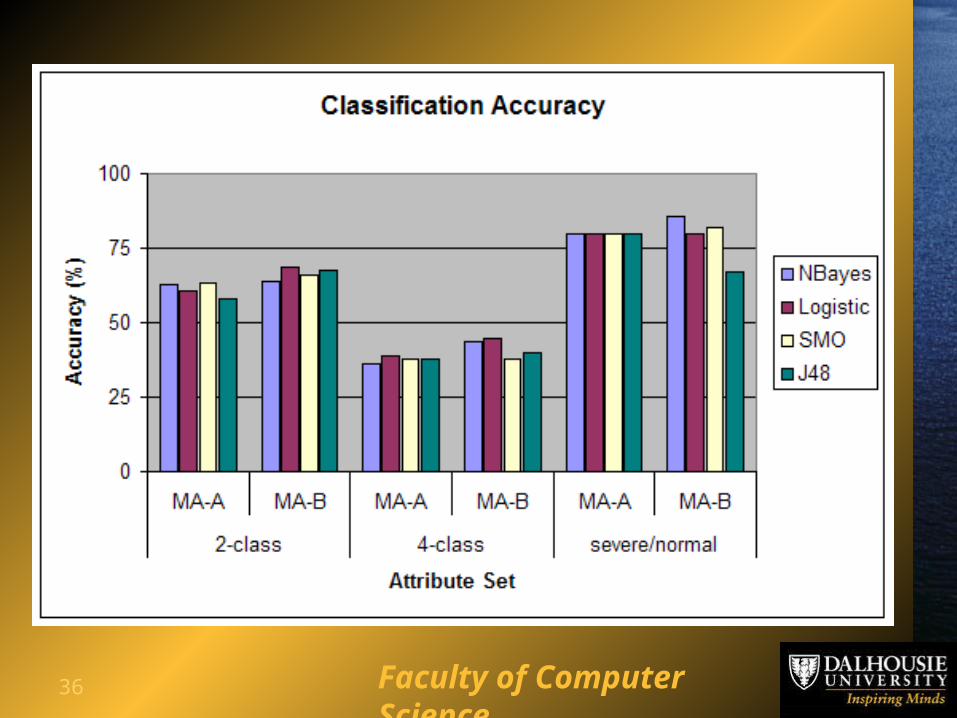
dementia level:– 100% discrimination accuracy (Pt and other)– 93% - severe/normal– 70% - two-class accuracy– 46% - four-class accuracy

41 Faculty of Computer Science
Future work
• improvement detection• use of word CNG method• stop-word frequency-based classifier• syntactic analysis• semantic analysis

42 Faculty of Computer Science
Concluding Remark - Dementia
• promising application of an authorship attribution method to patient interviews analysis
• achieved classification accuracy 100%, positive results in improvement detection
Future work - Dementia• refining experiment design• mining linguistic clues from profiles

43 Faculty of Computer Science
Detection of New Malicious Code Using N-grams Signatures
• Malicious Code (MC)• Viruses, worms, Trojan horses, spyware• Binary executables, scripts, source code
• Benign Code (BC)

44 Faculty of Computer Science
Traditional Virus Detection
• Signature based– A substring
• Usually, a signature is required for each variation
• Ineffective against new viruses

45 Faculty of Computer Science
Related Work
• Virus Signatures:– Kephart and Arnold, 1994
• Automatic extraction of signatures using n-grams
– Kephart, 1994• Computer immune systems
using n-grams

46 Faculty of Computer Science
Experiments
• Datasets:– I-Worm Collection: Windows
Internet worms• 292 files, 15.7 MB
– Win32 Collection: Windows binary viruses• 493 files, 21.2 MB
• N = 1 to 10• L = 20 to 5,000• Limit = 100,000

47 Faculty of Computer Science
Environment
• CGM1:– 32 nodes dual processor– 1.8 GHz Intel Xeon (x86) processors– 1 GB per node– RedHat based Linux
• Perl Package: Text::Ngrams

48 Faculty of Computer Science
Training Accuracy
n=1 2 3 4 5 6 7 8 9 10L = 20 54% 50% 65% 74% 68% 64% 52% 50% 52% 43%
50 62% 62% 83% 80% 85% 83% 72% 65% 60% 57%100 80% 65% 76% 68% 84% 86% 85% 83% 83% 85%200 75% 69% 63% 62% 79% 86% 89% 87% 89% 88%500 57% 87% 88% 70% 83% 89% 88% 87% 88% 89%
1000 57% 85% 89% 90% 90% 89% 88% 88% 89% 87%1500 57% 86% 89% 91% 88% 90% 86% 85% 83% 84%2000 57% 83% 90% 90% 88% 87% 84% 79% 73% 74%3000 57% 81% 88% 89% 86% 83% 71% 71% 64% 65%4000 57% 78% 88% 87% 84% 82% 68% 64% 61% 62%5000 57% 76% 88% 85% 80% 80% 64% 62% 58% 61%
I-Worm Collection

49 Faculty of Computer Science
Training Accuracy
n=1 2 3 4 5 6 7 8 9 10L = 20 45% 59% 51% 63% 67% 59% 54% 52% 51% 47%
50 60% 63% 88% 88% 87% 85% 74% 68% 81% 64%100 76% 73% 90% 88% 87% 90% 87% 85% 84% 85%200 85% 74% 87% 89% 92% 90% 93% 89% 89% 90%500 85% 87% 89% 91% 90% 90% 91% 91% 90% 89%
1000 85% 90% 93% 93% 91% 90% 89% 88% 87% 87%1500 85% 89% 94% 94% 91% 89% 88% 87% 87% 86%2000 85% 87% 94% 92% 91% 89% 87% 86% 85% 82%3000 85% 84% 93% 91% 90% 86% 83% 81% 80% 80%4000 85% 79% 93% 92% 87% 86% 81% 80% 80% 79%5000 85% 75% 93% 91% 87% 86% 81% 80% 78% 78%
Win32 Collection

50 Faculty of Computer Science
5-fold Cross-validation
n=1 2 3 4 5 6 7 8 9 10L = 20 59% 49% 61% 64% 72% 64% 57% 49% 50% 45%
50 67% 55% 80% 76% 83% 83% 63% 58% 60% 55%100 81% 73% 72% 73% 70% 84% 81% 79% 81% 82%200 77% 69% 69% 66% 79% 85% 86% 85% 87% 86%500 56% 85% 85% 78% 82% 86% 87% 85% 86% 86%
1000 56% 84% 89% 89% 90% 88% 85% 87% 88% 87%1500 56% 82% 89% 91% 88% 89% 87% 85% 84% 85%2000 56% 83% 89% 89% 87% 87% 85% 83% 82% 84%3000 56% 82% 88% 88% 87% 84% 80% 82% 80% 81%4000 56% 80% 87% 86% 83% 81% 79% 81% 78% 80%5000 56% 79% 86% 83% 81% 81% 79% 79% 77% 78%
I-Worm Collection

51 Faculty of Computer Science
5-fold Cross-validation
n=1 2 3 4 5 6 7 8 9 10L = 20 64% 63% 63% 61% 58% 58% 55% 52% 50% 47%
50 58% 70% 81% 87% 85% 86% 80% 63% 68% 64%100 75% 74% 90% 87% 87% 89% 88% 85% 86% 85%200 85% 70% 87% 88% 90% 90% 91% 88% 87% 89%500 85% 81% 88% 91% 90% 90% 90% 89% 89% 88%
1000 85% 88% 90% 91% 89% 89% 86% 86% 87% 86%1500 85% 86% 91% 91% 90% 88% 87% 87% 87% 85%2000 85% 86% 91% 91% 89% 88% 87% 85% 84% 84%3000 85% 84% 91% 90% 88% 87% 85% 84% 83% 83%4000 85% 84% 91% 91% 89% 86% 86% 84% 82% 82%5000 85% 79% 91% 90% 88% 86% 86% 83% 81% 87%
Win32 Collection

52 Faculty of Computer Science
Concluding Remarks
• Promising results!– Training accuracy
• I-Worm Collection: 91%• Win32 Collection: 94%
– 5-fold cross-validation• I-Worm Collection: 91%• Win32 Collection: 91%
• Compact representation of MC and BC• Easy to compute• Easy to test

53 Faculty of Computer Science
Pitfalls
• How does the limit affect accuracy?• Computational resources for training• Imbalanced datasets• Automatic selection of N and L

54 Faculty of Computer Science
Future Work
• Larger datasets (100MB+)• Alternatives to using limit• Parallel CNG• Mining the n-grams signatures• Reverse engineering source code• Application to other types of MC

55 Faculty of Computer Science
Conclusions
• All those who believe in telekinesis, raise my hand.
• OK, so what's the speed of dark?• I intend to live forever - so far, so good.• 24 hours in a day ... 24 beers in a case;
coincidence?• What happens if you get scared half to
death twice?• Plan to be spontaneous tomorrow.• 42.7 percent of all statistics are made up
on the spot.

56 Faculty of Computer Science
Postscript
In 1939 Andrew Q. Morton published a book entitled Who Was Socrates? Which was followed in 1940 by The Genesis of Plato’s Thought. Morton argued that both Socrates and Plato were much more closely involved in the politics of their time than scholars had imagined, and that the work of both men was, in substance, an apologia for Greek conservatism. In working out the evidence, Morton relied on the Seventh Letter which he took to be Plato’s political apology, just as the Apology of Plato was that of Socrates.

57 Faculty of Computer Science
At that time, these books seemed heretical to Classical scholars.
In relying heavily on the Seventh Letter of Plato, Morton was in line with the best scholarly opinion of the time. Later the Seventh Letter came under heavy attack and its authenticity was sharply challenged! If the Letter proved to be spurious or forged, then the thesis of Morton’s book would have been undermined.

58 Faculty of Computer Science
Morton decided to put the Seventh Letter on the computer to examine the skeletal structure of the language. A statistical analysis revealed that if the Apology of Socrates was Platonic, the Seventh Letter must be rejected and that, in fact, the Seventh Letter was not homogeneous. – Very bad news indeed!
Thinking adroitly, Morton suggested computer analysis of a letter to Philip of Macedon attributed to Speusippus, Plato’s nephew and successor. The results were sensational. Computer analysis revealed that the letter to Philip of Macedon agreed exactly with part of the Seventh Letter attributed to Plato. This result strongly suggested that the Letter had been revised by Plato’s nephew within four year’s of Plato’s death.

59 Faculty of Computer Science
The strong implication of these results is that the Letter was intended as Plato’s political apoligia, written by his successor, just as the Apology of Socrates was Socrates’ political apologia, written a few years after the master’s death. Subsequent analysis of additional of Speusippus’ work strengthened Morton’s argument.

60 Faculty of Computer Science
Real Concluding Remarks
The Road to WisdomThe road to wisdom? – Well, it's plain and simple to express:
Err and err and err again but less and less and less.
On ProblemsOur choicest plans have fallen through,our airiest castles tumbled over,because of lines we neatly drewand later neatly stumbled over.





























