Embed Size (px)
Citation preview
![Page 1: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/1.jpg)
Neural Networks II
Robert Jacobs
Department of Brain & Cognitive SciencesUniversity of Rochester
October 26, 2015
![Page 2: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/2.jpg)
Nonlinear Activation Functions
(1) Threshold activation function
y =
{1 if ~wT~x > 00 otherwise
0
1
Inspired by neural “all or none” principle
![Page 3: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/3.jpg)
Example: AND function
x1 x2 y∗
0 0 00 1 01 0 01 1 1
AND
O
O
O
X
![Page 4: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/4.jpg)
Example: OR function
x1 x2 y∗
0 0 00 1 11 0 11 1 1
OR
O
X
X
X
![Page 5: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/5.jpg)
Example: Exclusive-OR (XOR)
x1 x2 y∗
0 0 00 1 11 0 11 1 0
O X
X O
Let θ = bias weight
(0, 0)→ 0 means that θ < 0(0, 1)→ 1 means that w2 + θ > 0(1, 0)→ 1 means that w1 + θ > 0(1, 1)→ 0 means that w1 + w2 + θ < 0
⇒ Not possible to satisfy all of these constraints
![Page 6: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/6.jpg)
But, but, but...what about:
x1 x2 x1 × x2 y∗
0 0 0 00 1 0 11 0 0 11 1 1 0
XOR
⇒ New representation formed from original variables makes XORtask performable!!!
Q: In general, how do we find new representations that are usefulfor a given task?
![Page 7: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/7.jpg)
(2) Logistic activation function
y =1
1 + exp[−~wT~x]
“Soft” approximation to threshold activation function
![Page 8: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/8.jpg)
Relation to mixture model with two normal components
I Data: {xt}Tt=1
I Assume xt came from one of two normal distributions
I Assume distributions have equal variances (σ21 = σ2
2 = 1)
I Assume distributions have equal priors (π1 = π2 = 0.5)
Recall:
p(i|xt) =p(xt|i)πip(xt)
=p(xt|i)πi∑2j=1 p(xt|j)πj
![Page 9: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/9.jpg)
p(1|xt) =
1√2π
exp[−12(xt − µ1)
2]π11√2π
exp[−12(xt − µ1)2]π1 +
1√2π
exp[−12(xt − µ2)2]π2
=exp[−1
2(xt − µ1)
2]
exp[−12(xt − µ1)2] + exp[−1
2(xt − µ2)2]
=1
1 +exp[− 1
2(xt−µ2)2]
exp[− 12(xt−µ1)2]
=1
1 + exp[−12[(xt − µ2)2 − (xt − µ1)2]]
=1
1 + exp[−12[distance from µ2 - distance from µ1]]
![Page 10: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/10.jpg)
Let ~wT~x = −12[(xt − µ2)
2 − (xt − µ1)2]
Logistic function gives the posterior probability that the input xt isfrom one of the two components
I If ~wT~x = 0 (y = 0.5), xt is equally likely to belong to eithercomponent
I If ~wT~x > 0 (y > 0.5), xt is more likely to belong to one ofthe components
I If ~wT~x < 0 (y < 0.5), xt is more likely to belong to the othercomponent
⇒ Logistic units are binary feature detectors
I Relation to Bernoulli distribution (y = probability of somebinary event)
![Page 11: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/11.jpg)
(3) Softmax activation function
yi =exp[~wTi ~x]∑j exp[~w
Tj ~x]
Because yi ∈ (0, 1) and∑
i yi = 1, the {yi} form a multinomialprobability distribution
Relation to “soft” winner-take-all
![Page 12: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/12.jpg)
Relation to logistic:
exp[~wT1 ~x]
exp[~wT1 ~x] + exp[~wT2 ~x]=
1
1 + exp[~wT2 ~x− ~wT1 ~x]
Two classes → use logisticMore than two classes → use softmax
![Page 13: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/13.jpg)
Multilayer Neural Networks
Hidden units: use logistic activation functionOutput units: use linear, logistic, or softmax function dependingon the nature of the task
Q: Why are hidden units nonlinear?A: A linear function composed with another linear function resultsin a linear function
![Page 14: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/14.jpg)
h1 = a1x1 + b1x2 + c1
h2 = a2x1 + b2x2 + c2
y = dh1 + eh2 + f
![Page 15: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/15.jpg)
y = d(a1x1 + b1x2 + c1) + e(a2x1 + b2x2 + c2) + f
= da1x1 + db1x2 + dc1 + ea2x1 + eb2x2 + ec2 + f
Let g = da1 + ea2 , h = db1 + eb2, and k = dc1 + ec2 + f
Theny = gx1 + hx2 + k
![Page 16: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/16.jpg)
Exception: Neural Networks and PCA
Auto-associator: Instance when one might want linear hidden units
65,536
input
units
7 hidden
units
65,536
output
units
Relation between neural networks and PCA: After training, spacespanned by the 7 hidden units’ weight vectors is the same as thespace spanned by the 7 eigenvectors with the largest eigenvalues ofthe data covariance matrix
Q: Is this supervised or unsupervised training?
![Page 17: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/17.jpg)
(Nonlinear) Neural Networks areUniversal Approximators
input
units
hidden
units
output
unit
For any function, there exists a neural network with exactly onelayer of hidden units (hidden units use the logistic activationfunction; output unit is linear) that can approximate that functionarbitrarily close
Theorem does not say how many hidden unitsTheorem does not say how to find the weightsThis is a theorem about representation, not learning
![Page 18: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/18.jpg)
Method for Training Nonlinear Neural Networks
Backpropagation Algorithm (see next class)
![Page 19: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/19.jpg)
Alternative Method for TrainingNonlinear Neural Networks
Step 1: Run clustering algorithm with a large number ofcomponents
I Each mixture component is a hidden unit
I Posterior probability of a component (given an input) is thehidden unit’s activation
I Provides a (nonlinear) “covering” of the space of inputs
Step 2: Run LMS algorithm to learn weights from hidden units tooutput unit
⇒ Relation to “kernel based” methods
![Page 20: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/20.jpg)
Yet Another Alternative Method forTraining Nonlinear Neural Networks
Linear Basis Function Models:
y = ~wT ~φ(~x)
=∑i
wiφi(~x)
where φi(~x) are fixed functions known at basis functions.
When φi(~x) are nonlinear basis functions, then output y is anonlinear function of input ~x.
![Page 21: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/21.jpg)
Polynomial regression: φi(x) = xi (assuming single input x)
φ0(x) = 1φ1(x) = xφ2(x) = x2
φ3(x) = x3
y =∑
iwiφi(x)
![Page 22: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/22.jpg)
Gaussian basis functions:
φi(x) = exp
{−(x− µi)2
2s2
}
Sigmoidal basis functions:
φi(x) =1
1 + exp(x−µis
)
![Page 23: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/23.jpg)
Neural Network Applications(networks trained with the backpropagation algorithm)
![Page 24: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/24.jpg)
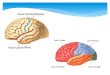
Rueckl, J. G., Cave, K. R., & Kosslyn, S. M. (1989). Why are“what” and “where” processed by separate cortical visual systems?A computational investigation. Journal of Cognitive Neuroscience,1, 171-186.
In the primate visual system:I object identificationI spatial localization
are performed by different cortical pathways.
Compared two systems:I One network for both tasksI Two networks—one for each task
Results: Two-network system betterI learns fasterI representation more interpretable
![Page 25: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/25.jpg)
![Page 26: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/26.jpg)
![Page 27: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/27.jpg)
![Page 28: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/28.jpg)
Sejnowski, T. J. & Rosenberg, C. R. (1987). Parallel networksthat learn to pronouce English text. Complex Systems, 1, 145-168.
![Page 29: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/29.jpg)
![Page 30: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/30.jpg)
Elman, J. L. (1990). Finding structure in time. Cognitive Science,14, 179-211.
S → NP VP “.”NP → PropN | N | N RCVP → V (NP)RC → who NP VP | who VP (NP)N → boy | girl | cat | boys | girls | catsPropN → John | MaryV → chase | feed | see | chases | feeds | sees
![Page 31: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/31.jpg)
Language has a componential structure
Learning language: Determine the componential structure fromthe sentences of the language
Rules coordinate dependencies among words:
I John chases cats.
I Boys chase cats.
⇒ Requires memory
![Page 32: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/32.jpg)
![Page 33: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/33.jpg)
![Page 34: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/34.jpg)
Zipser, D. & Andersen, R. A. (1988). A back-propagationprogrammed network that simulates response properties of asubset of posterior parietal neurons. Nature, 331, 679-684.
![Page 35: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/35.jpg)
![Page 36: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/36.jpg)
![Page 37: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/37.jpg)
![Page 38: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/38.jpg)
Hinton, G. E., Plaut, D. C. & Shallice, T. (1993). Simulatingbrain damage. Scientific American, 269, 76-82.
Deep dyslexia:I (1) Visual errors:
I stock → “shock”I crowd → “crown”
I (2) Semantic errors:I symphony → “orchestra”I uncle → “nephew”
I (3) Visual and semantic errors:I sympathy → “orchestra”I cat → “bed”
![Page 39: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/39.jpg)
![Page 40: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/40.jpg)
![Page 41: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/41.jpg)
![Page 42: Neural Networks II - bcs.rochester.edu · exp[1(x t 1)2] ˇ 1 + p1 2ˇ exp[1(x t 2) ... I sympathy !\orchestra" I cat !\bed" Title: Neural Networks II Author: Robert Jacobs Created](https://reader039.pdfslide.us/reader039/viewer/2022031505/5c887bff09d3f291748cdf3e/html5/page/42.jpg)