Embed Size (px)
Citation preview

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 20191
Lecture 4:Neural Networks and
Backpropagation

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
Administrative: Assignment 1
Assignment 1 due Wednesday April 17, 11:59pm
If using Google Cloud, you don’t need GPUs for this assignment!
We will distribute Google Cloud coupons by this weekend
2

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
Administrative: Alternate Midterm Time
If you need to request an alternate midterm time:
See Piazza for form, fill it out by 4/25 (two weeks from today)
3

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
Administrative: Project Proposal
Project proposal due 4/24
4

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
Administrative: Discussion Section
Discussion section tomorrow (1:20pm in Gates B03):
How to pick a project / How to read a paper
5

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 20196
How to find the best W?
Linear score function
SVM loss (or softmax)
data loss + regularization
Where we are...
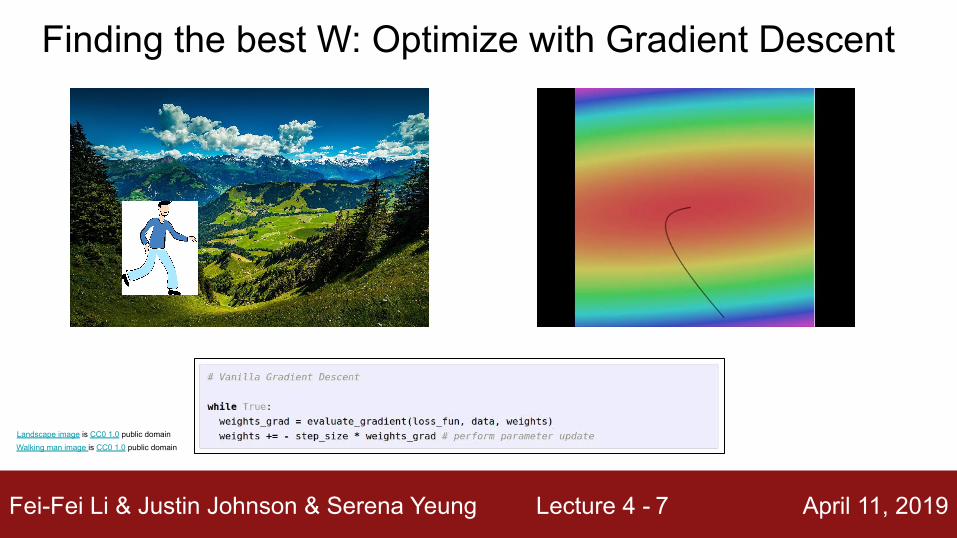
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 20197
Finding the best W: Optimize with Gradient Descent
Landscape image is CC0 1.0 public domainWalking man image is CC0 1.0 public domain

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 20198
Numerical gradient: slow :(, approximate :(, easy to write :)Analytic gradient: fast :), exact :), error-prone :(
In practice: Derive analytic gradient, check your implementation with numerical gradient
Gradient descent

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
Problem: Linear Classifiers are not very powerful
9
Visual Viewpoint
Linear classifiers learn one template per class
Geometric Viewpoint
Linear classifiers can only draw linear decision boundaries

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
One Solution: Feature Transformation
10
f(x, y) = (r(x, y), θ(x, y))
Transform data with a cleverly chosen feature transform f, then apply linear classifier
Color Histogram Histogram of Oriented Gradients (HoG)
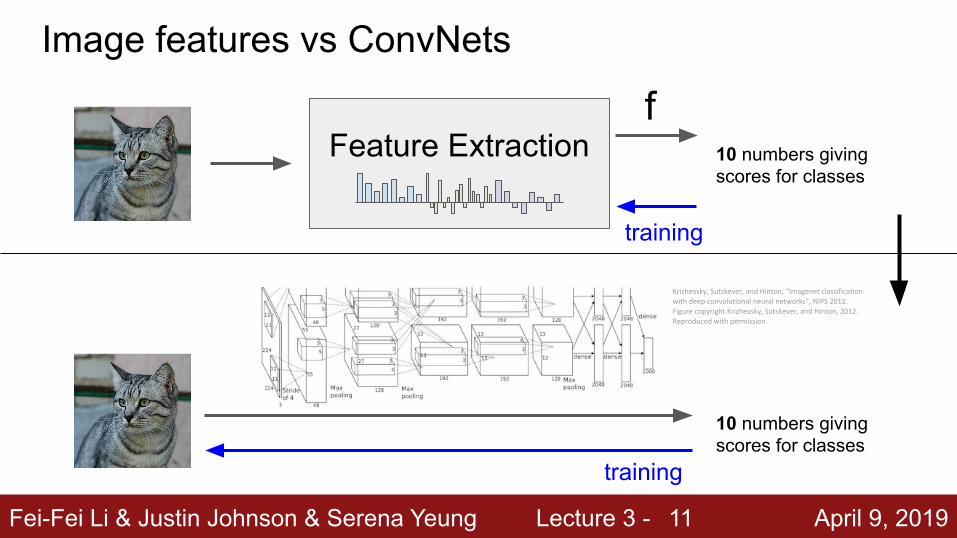
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 3 - April 9, 2019
Feature Extraction
Image features vs ConvNets
11
f10 numbers giving scores for classes
training
training
10 numbers giving scores for classes
Krizhevsky, Sutskever, and Hinton, “Imagenet classification with deep convolutional neural networks”, NIPS 2012.Figure copyright Krizhevsky, Sutskever, and Hinton, 2012. Reproduced with permission.

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201912
Today: Neural Networks

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201913
Neural networks: without the brain stuff
(Before) Linear score function:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201914
(Before) Linear score function:
(Now) 2-layer Neural Network
Neural networks: without the brain stuff
(In practice we will usually add a learnable bias at each layer as well)

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201915
(Before) Linear score function:
(Now) 2-layer Neural Network
Neural networks: without the brain stuff
(In practice we will usually add a learnable bias at each layer as well)
“Neural Network” is a very broad term; these are more accurately called “fully-connected networks” or sometimes “multi-layer perceptrons” (MLP)

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201916
Neural networks: without the brain stuff
(Before) Linear score function:
(Now) 2-layer Neural Network or 3-layer Neural Network
(In practice we will usually add a learnable bias at each layer as well)

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201917
(Before) Linear score function:
(Now) 2-layer Neural Network
Neural networks: without the brain stuff
x hW1 sW2
3072 100 10

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201918
(Before) Linear score function:
(Now) 2-layer Neural Network
Neural networks: without the brain stuff
x hW1 sW2
3072 100 10

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
The function is called the activation function.Q: What if we try to build a neural network without one?
19
(Before) Linear score function:
(Now) 2-layer Neural Network
Neural networks: without the brain stuff

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
The function is called the activation function.Q: What if we try to build a neural network without one?
20
(Before) Linear score function:
(Now) 2-layer Neural Network
Neural networks: without the brain stuff
A: We end up with a linear classifier again!

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201921
Sigmoid
tanh
ReLU
Leaky ReLU
Maxout
ELU
Activation functions

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201922
Sigmoid
tanh
ReLU
Leaky ReLU
Maxout
ELU
Activation functions ReLU is a good default choice for most problems
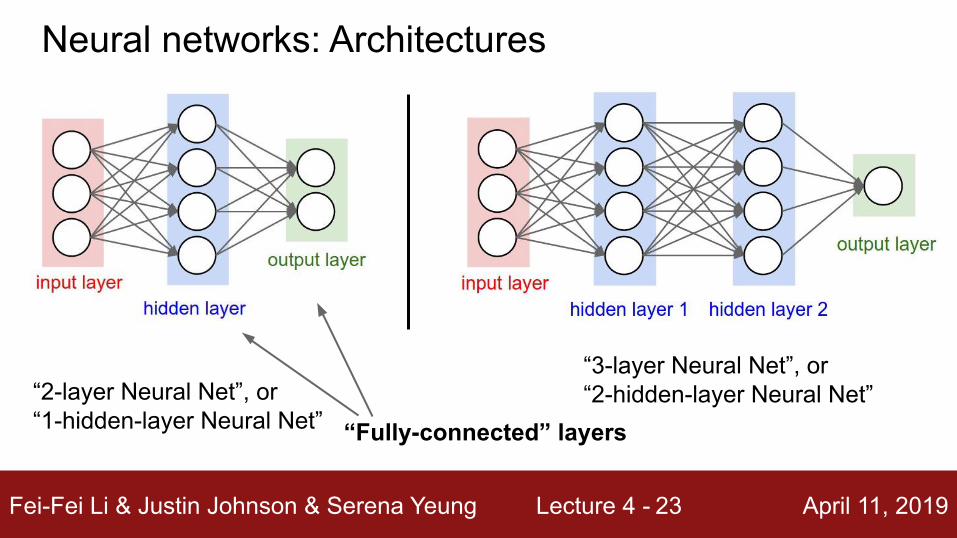
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201923
“Fully-connected” layers“2-layer Neural Net”, or“1-hidden-layer Neural Net”
“3-layer Neural Net”, or“2-hidden-layer Neural Net”
Neural networks: Architectures

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201924
Example feed-forward computation of a neural network

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201925
Full implementation of training a 2-layer Neural Network needs ~20 lines:
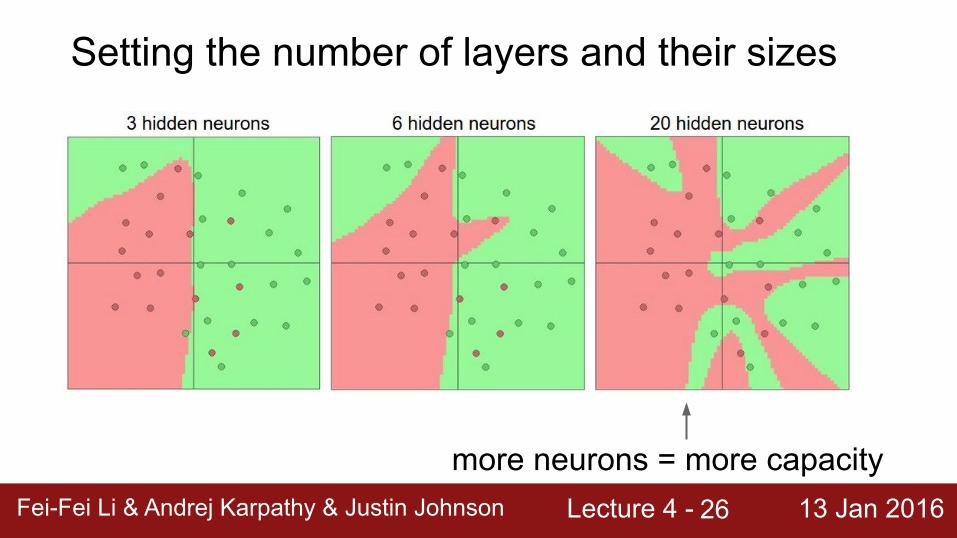
Lecture 4 - 13 Jan 2016Fei-Fei Li & Andrej Karpathy & Justin JohnsonFei-Fei Li & Andrej Karpathy & Justin Johnson Lecture 4 - 13 Jan 201626
Setting the number of layers and their sizes
more neurons = more capacity
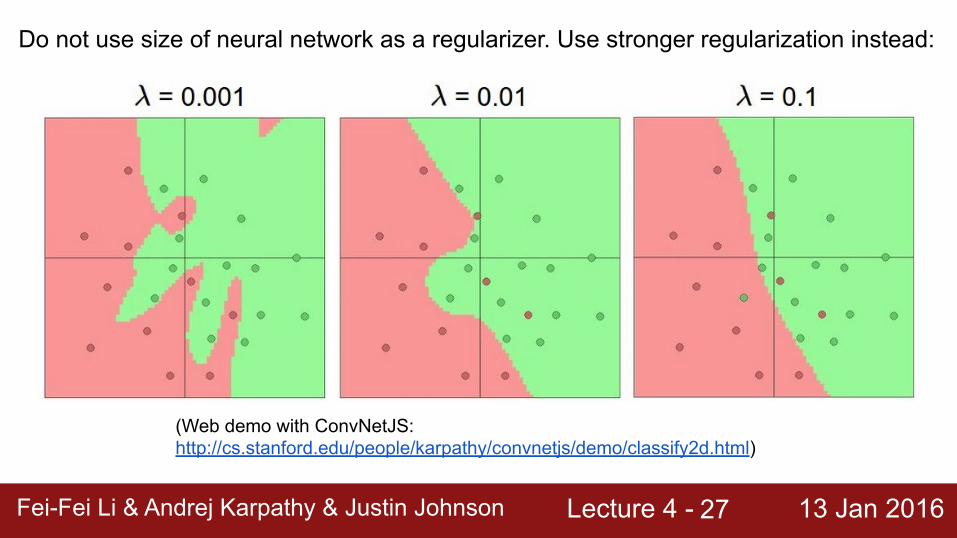
Lecture 4 - 13 Jan 2016Fei-Fei Li & Andrej Karpathy & Justin JohnsonFei-Fei Li & Andrej Karpathy & Justin Johnson Lecture 4 - 13 Jan 201627
(Web demo with ConvNetJS: http://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html)
Do not use size of neural network as a regularizer. Use stronger regularization instead:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201928
This image by Fotis Bobolas is licensed under CC-BY 2.0
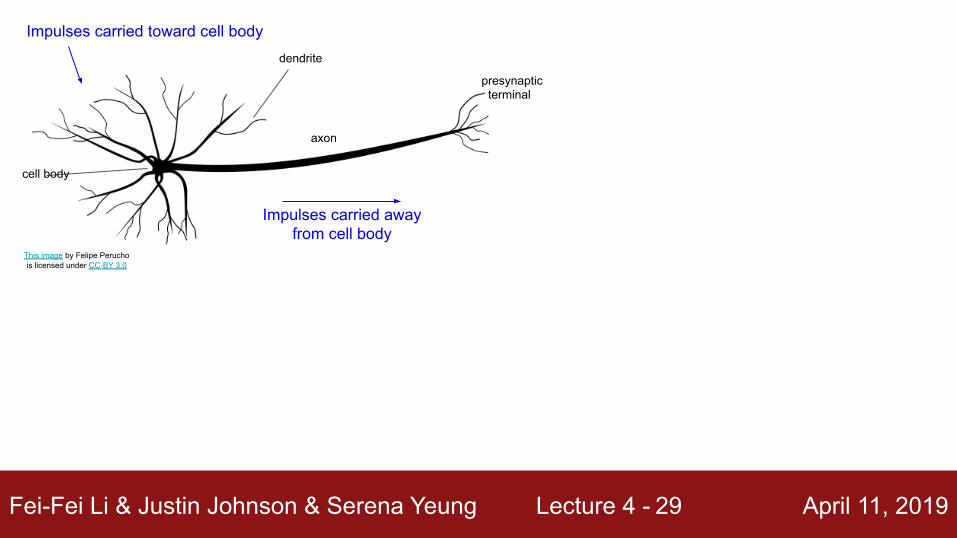
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201929
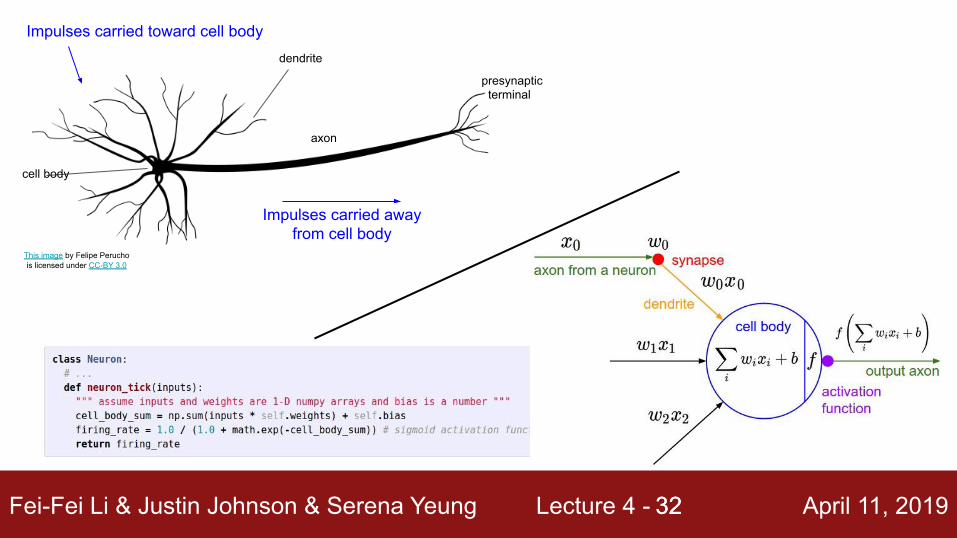
Impulses carried toward cell body
Impulses carried away from cell body
This image by Felipe Peruchois licensed under CC-BY 3.0
dendrite
cell body
axon
presynaptic terminal
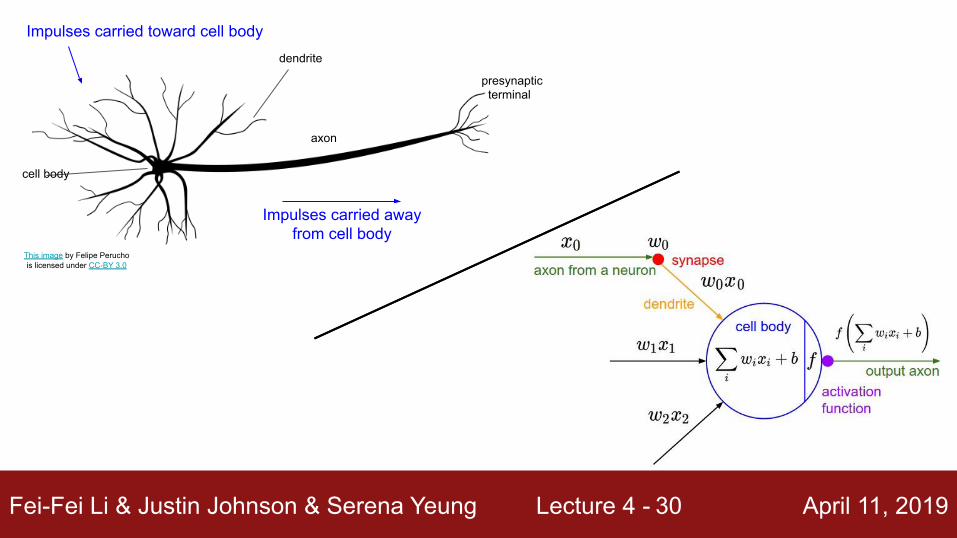
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201930
Impulses carried toward cell body
Impulses carried away from cell body
This image by Felipe Peruchois licensed under CC-BY 3.0
dendrite
cell body
axon
presynaptic terminal
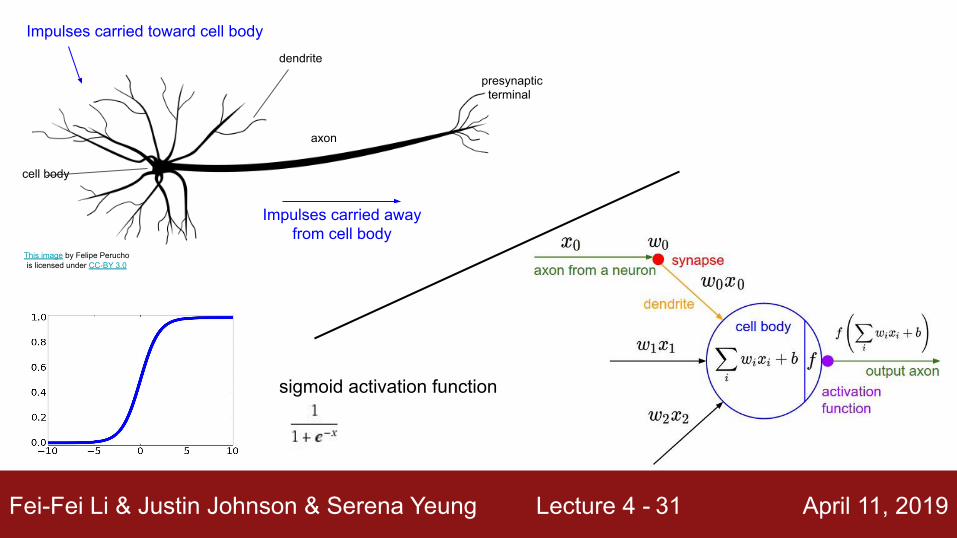
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201931
sigmoid activation function
Impulses carried toward cell body
Impulses carried away from cell body
This image by Felipe Peruchois licensed under CC-BY 3.0
dendrite
cell body
axon
presynaptic terminal
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 20193232
Impulses carried toward cell body
Impulses carried away from cell body
This image by Felipe Peruchois licensed under CC-BY 3.0
dendrite
cell body
axon
presynaptic terminal
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201933
This image is CC0 Public Domain
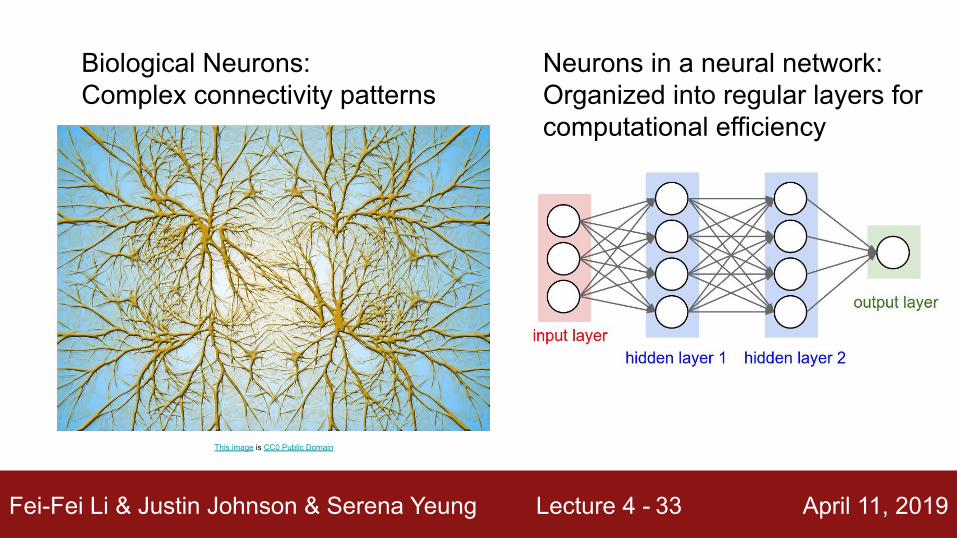
Biological Neurons: Complex connectivity patterns
Neurons in a neural network:Organized into regular layers for computational efficiency
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201934
This image is CC0 Public Domain
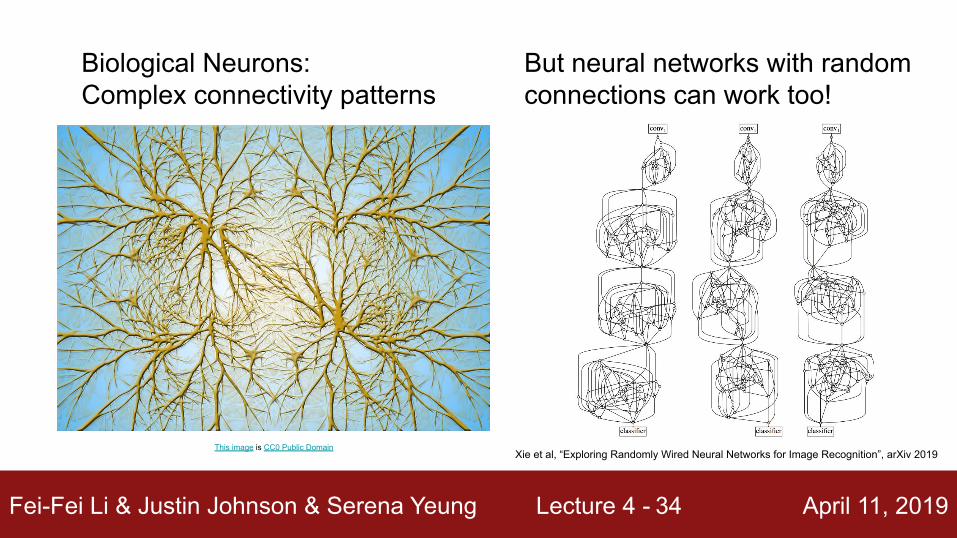
Biological Neurons: Complex connectivity patterns
But neural networks with random connections can work too!
Xie et al, “Exploring Randomly Wired Neural Networks for Image Recognition”, arXiv 2019

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201935
Biological Neurons:● Many different types● Dendrites can perform complex non-linear computations● Synapses are not a single weight but a complex non-linear dynamical
system● Rate code may not be adequate
[Dendritic Computation. London and Hausser]
Be very careful with your brain analogies!

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
If we can compute then we can learn W1 and W2
36
Problem: How to compute gradients?
Nonlinear score function
SVM Loss on predictions
Regularization
Total loss: data loss + regularization

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201937
(Bad) Idea: Derive on paper
Problem: What if we want to change loss? E.g. use softmax instead of SVM? Need to re-derive from scratch =(
Problem: Very tedious: Lots of matrix calculus, need lots of paper
Problem: Not feasible for very complex models!
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201938
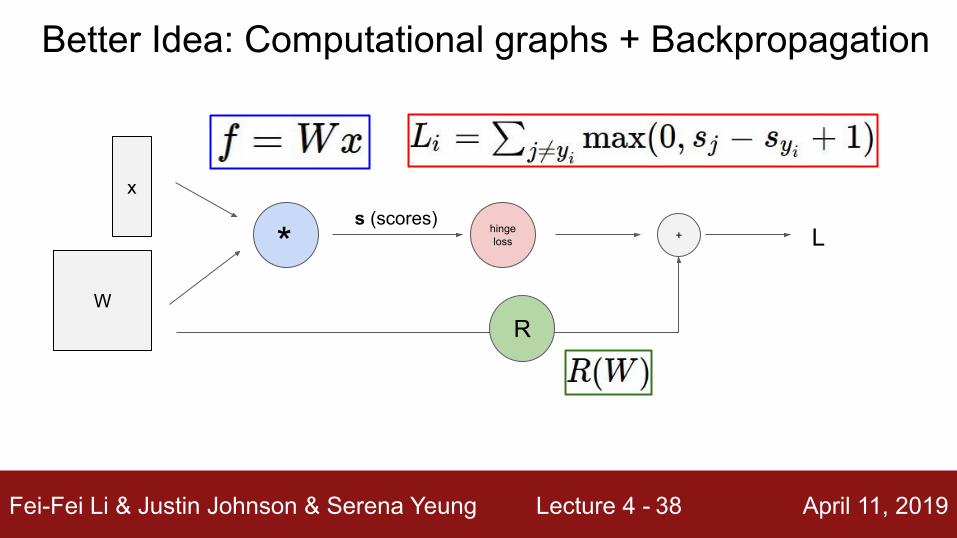
x
W
hinge loss
R
+ Ls (scores)
Better Idea: Computational graphs + Backpropagation
*
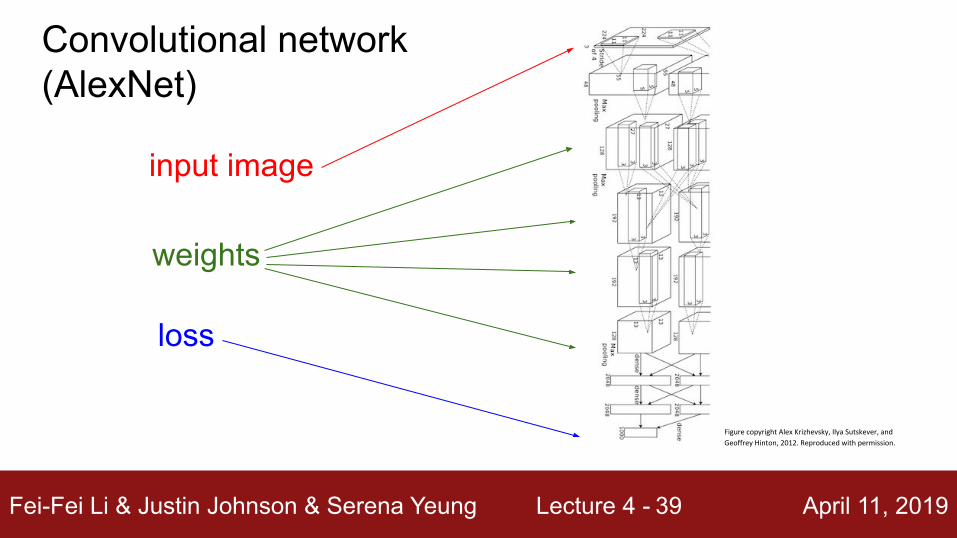
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201939
input image
loss
weights
Convolutional network(AlexNet)
Figure copyright Alex Krizhevsky, Ilya Sutskever, and
Geoffrey Hinton, 2012. Reproduced with permission.

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201940
Neural Turing Machine
Figure reproduced with permission from a Twitter post by Andrej Karpathy.
input image
loss

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
Neural Turing Machine
Figure reproduced with permission from a Twitter post by Andrej Karpathy.

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201942
Backpropagation: a simple example
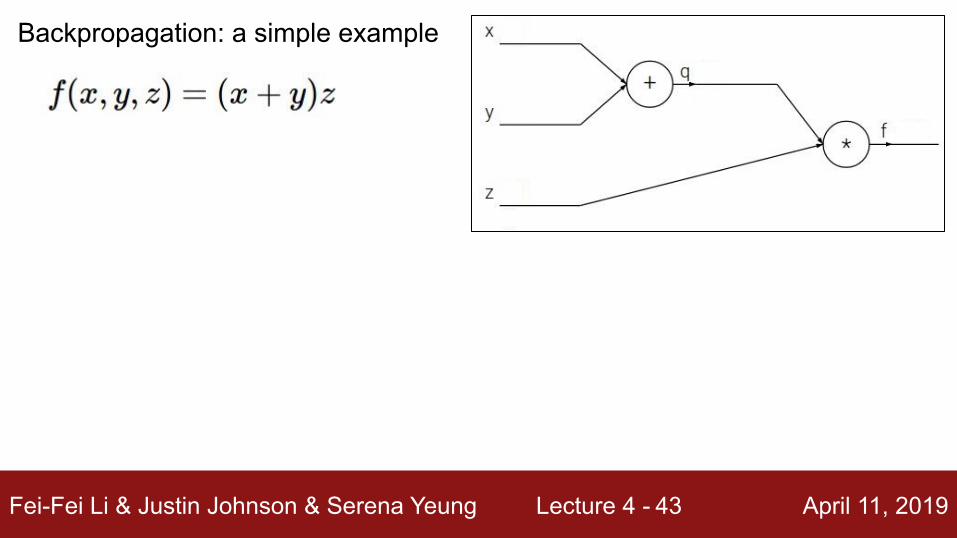
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201943
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201744
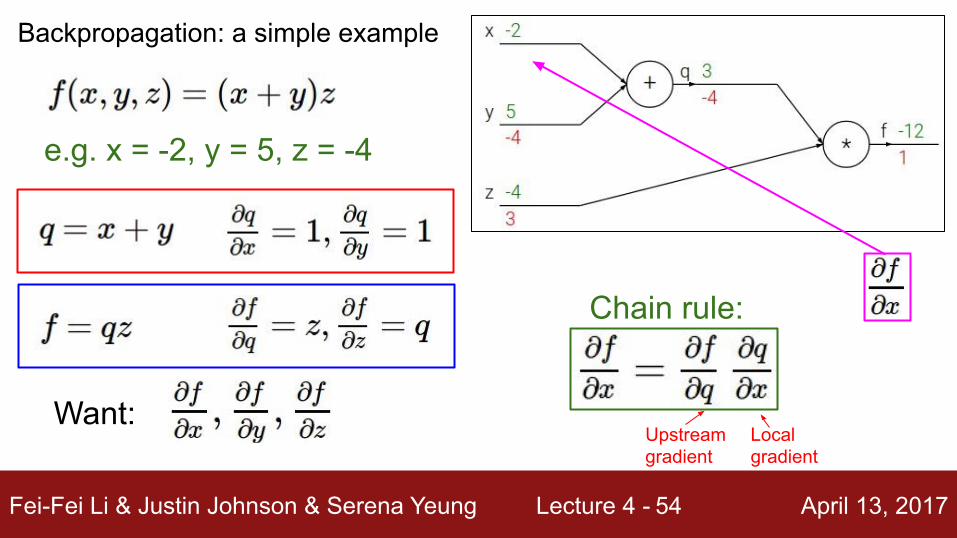
e.g. x = -2, y = 5, z = -4
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201745
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201746
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201747
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201748
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201749
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201750
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201751
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201752
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example
Chain rule:
Upstream gradient
Localgradient

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201753
Chain rule:
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example
Upstream gradient
Localgradient
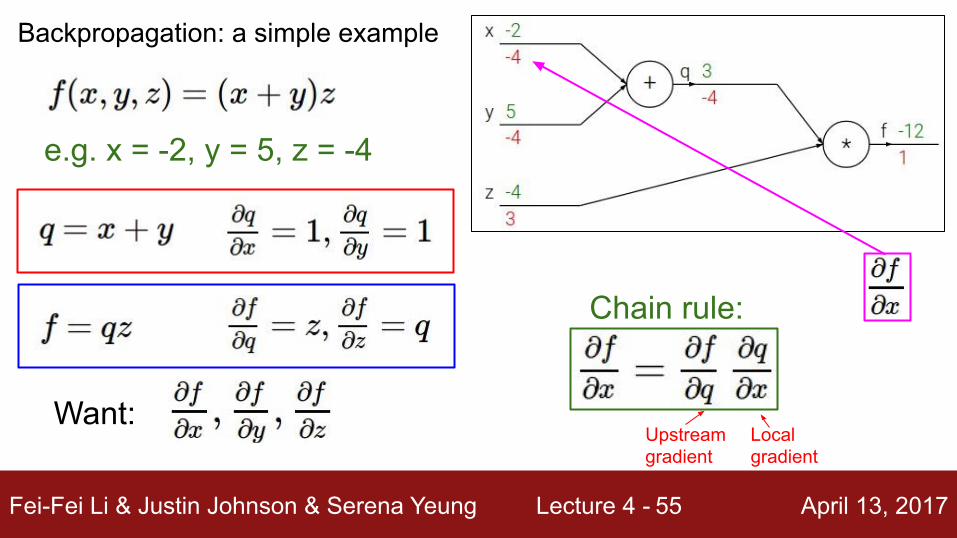
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201754
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example
Chain rule:
Upstream gradient
Localgradient
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201755
Chain rule:
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example
Upstream gradient
Localgradient
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201956
f

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201957
f
“local gradient”

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201958
f
“local gradient”
“Upstreamgradient”
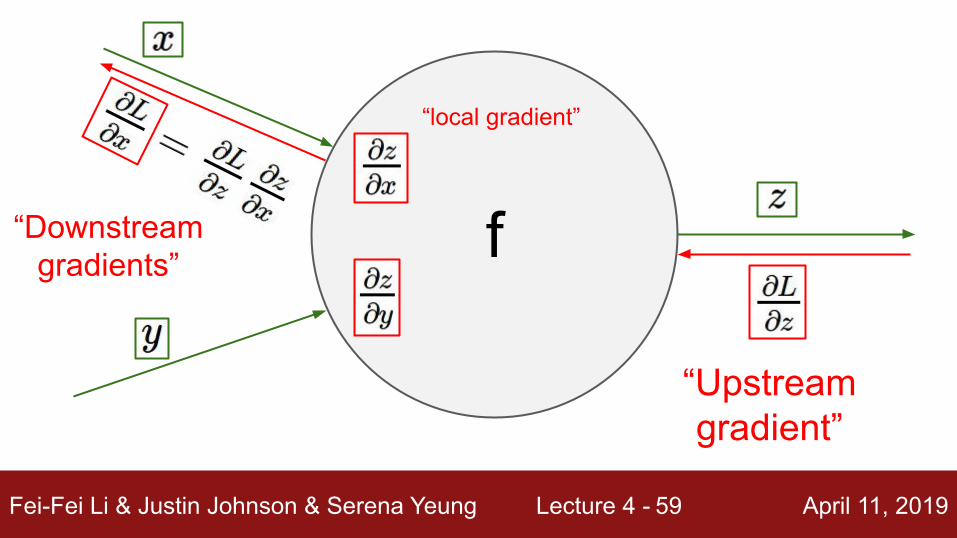
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201959
f
“local gradient”
“Upstreamgradient”
“Downstreamgradients”

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201960
f
“local gradient”
“Upstreamgradient”
“Downstreamgradients”

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201961
f
“local gradient”
“Upstreamgradient”
“Downstreamgradients”
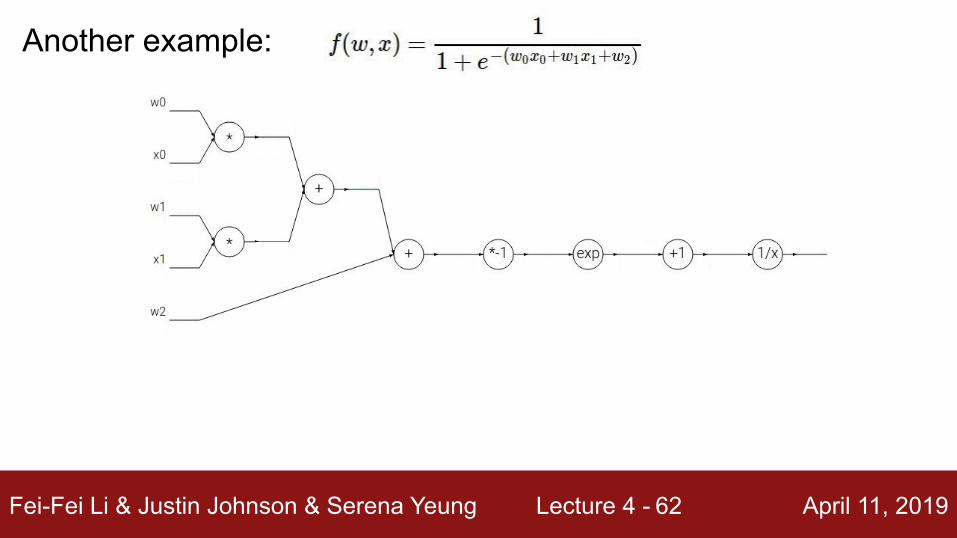
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201962
Another example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201963
Another example:
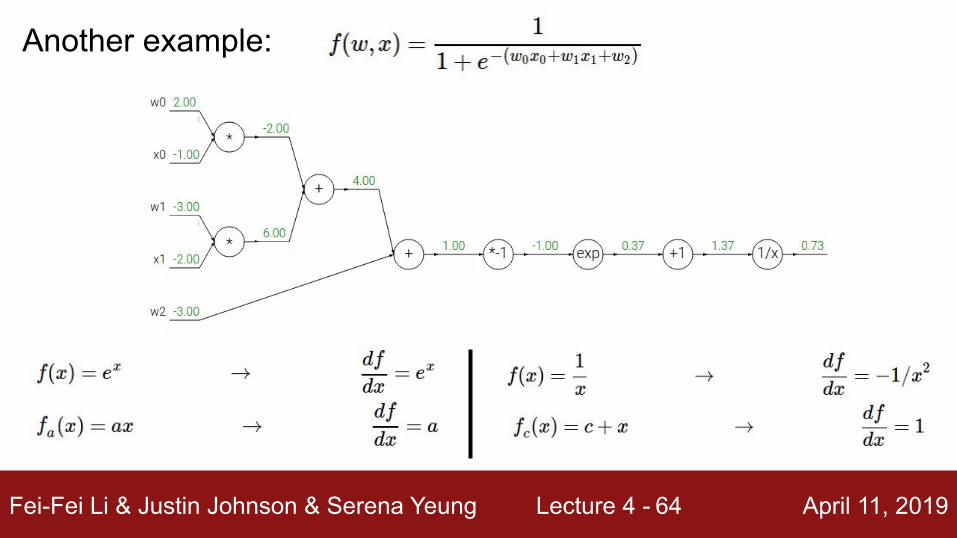
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201964
Another example:
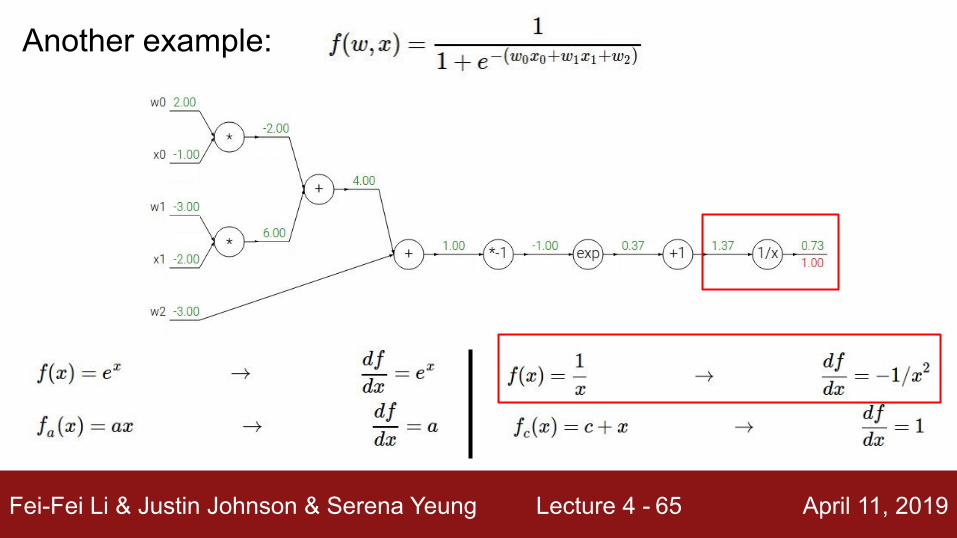
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201965
Another example:
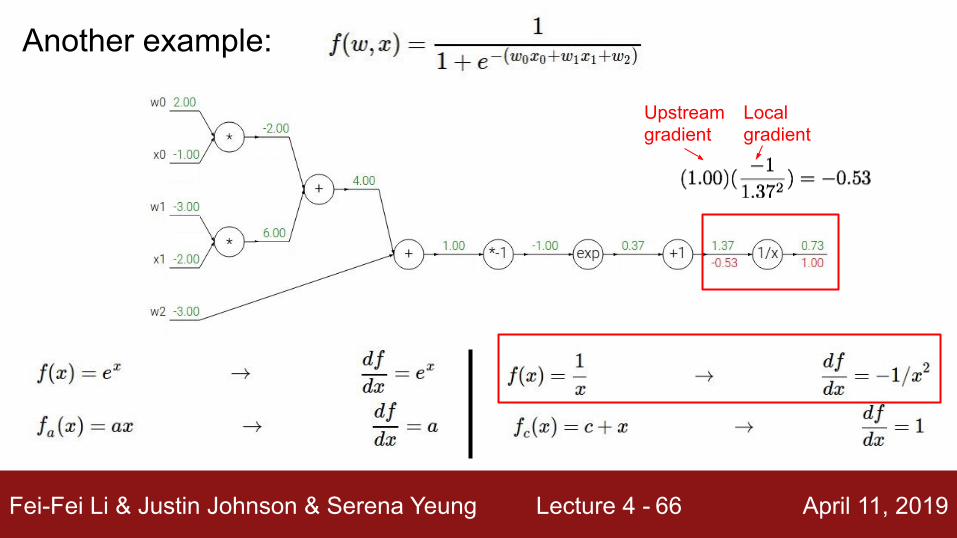
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201966
Another example:
Upstream gradient
Localgradient
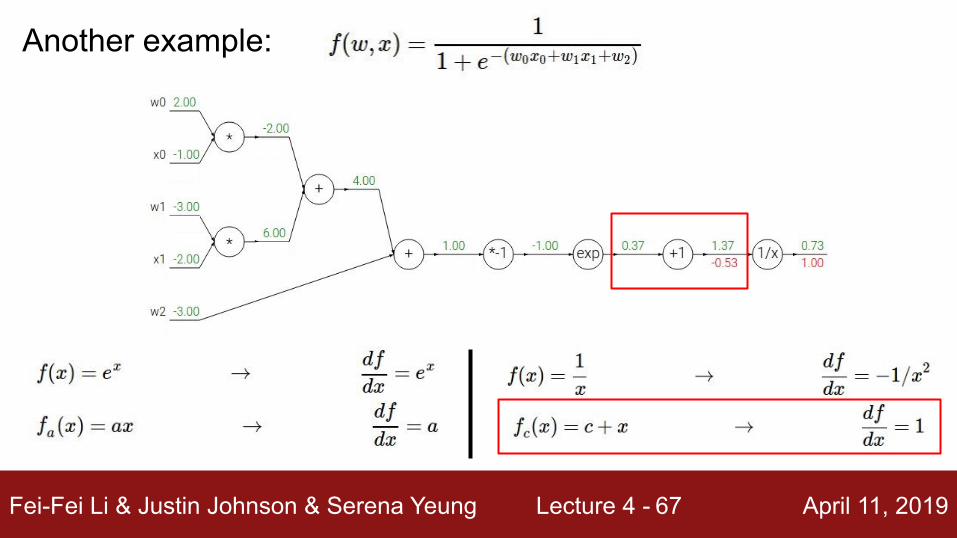
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201967
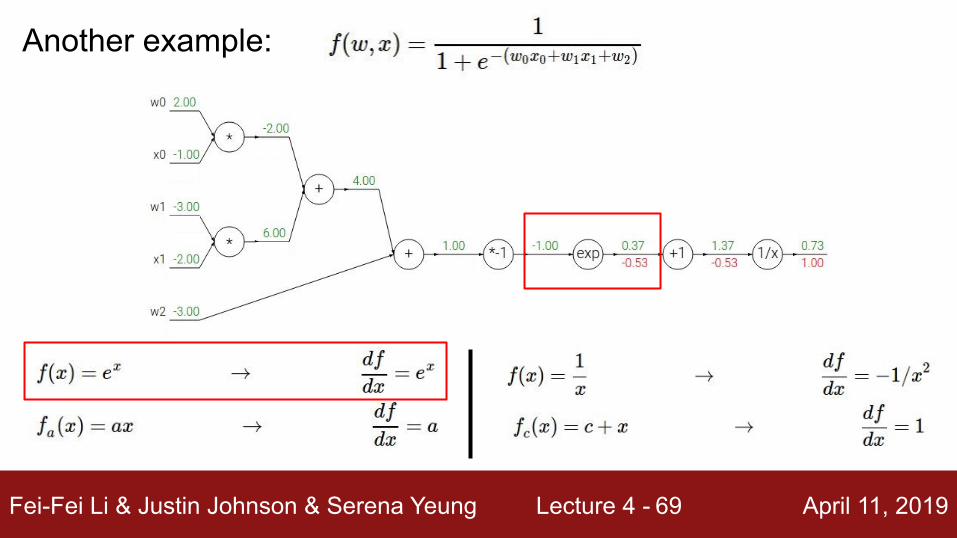
Another example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201968
Another example:
Upstream gradient
Localgradient
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201969
Another example:
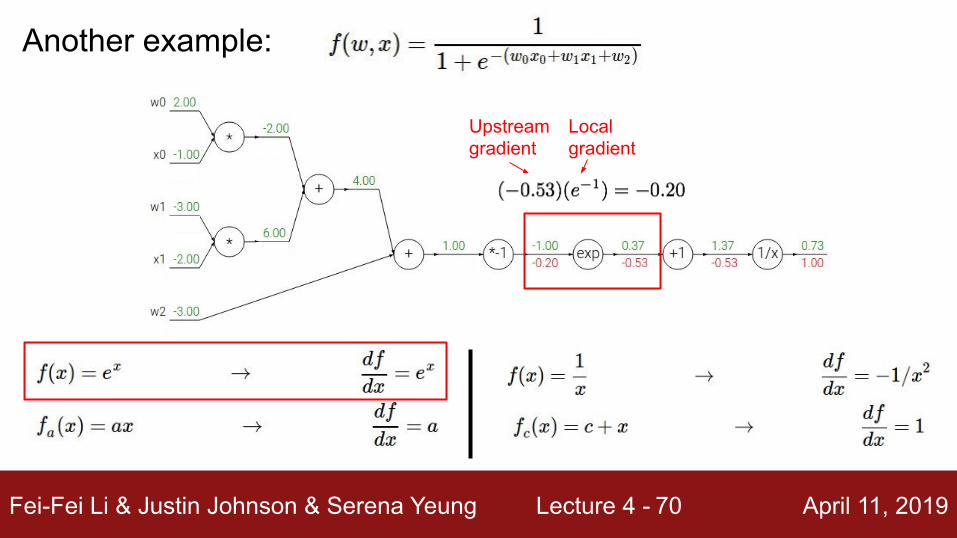
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201970
Another example:
Upstream gradient
Localgradient

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201971
Another example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201972
Another example:
Upstream gradient
Localgradient
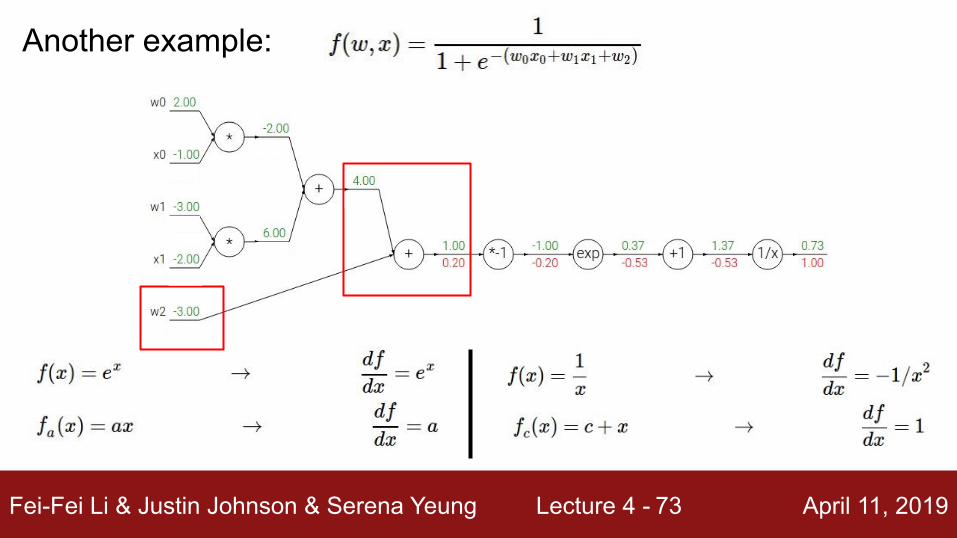
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201973
Another example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201974
Another example:
[upstream gradient] x [local gradient][0.2] x [1] = 0.2[0.2] x [1] = 0.2 (both inputs!)

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201975
Another example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201976
Another example:
[upstream gradient] x [local gradient]x0: [0.2] x [2] = 0.4w0: [0.2] x [-1] = -0.2
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201977
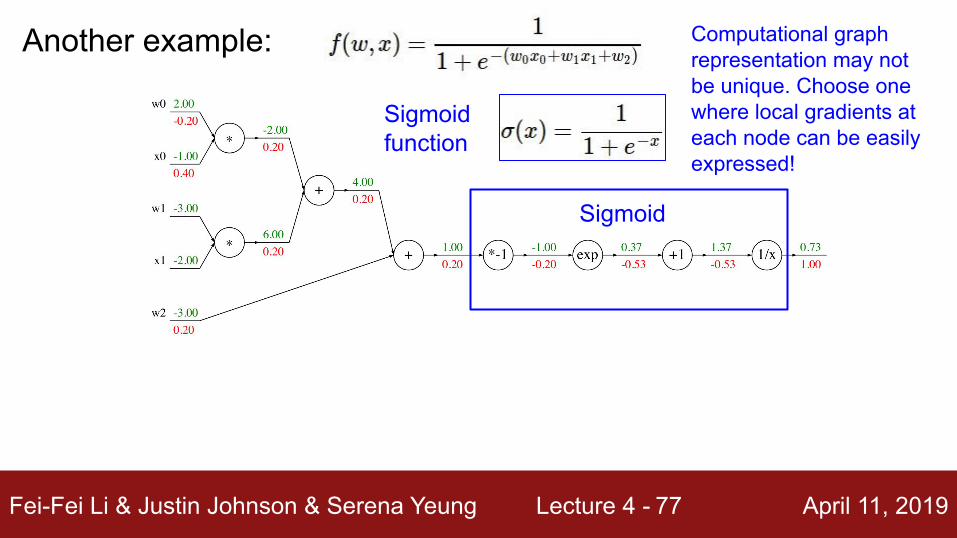
Another example:
Sigmoid
Sigmoid function
Computational graph representation may not be unique. Choose one where local gradients at each node can be easily expressed!

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201978
Another example:
Sigmoid
Sigmoid function
Sigmoid local gradient:
Computational graph representation may not be unique. Choose one where local gradients at each node can be easily expressed!

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201979
Another example:
Sigmoid
Sigmoid function
Sigmoid local gradient:
Computational graph representation may not be unique. Choose one where local gradients at each node can be easily expressed!
[upstream gradient] x [local gradient][1.00] x [(1 - 0.73) (0.73)] = 0.2
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201980
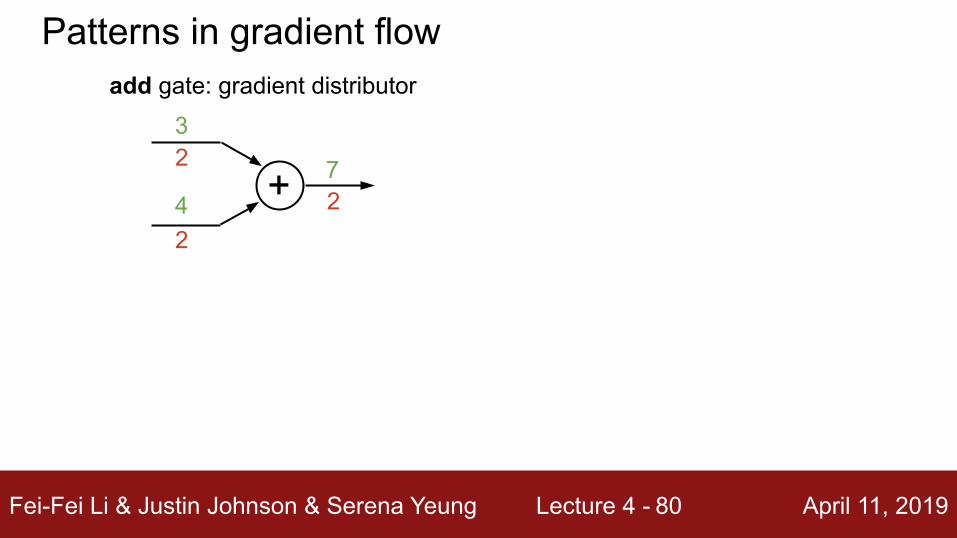
add gate: gradient distributor
Patterns in gradient flow
+3
472
2
2

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201981
add gate: gradient distributor
Patterns in gradient flow
+3
472
2
2
mul gate: “swap multiplier”
×2
365
5*3=15
2*5=10
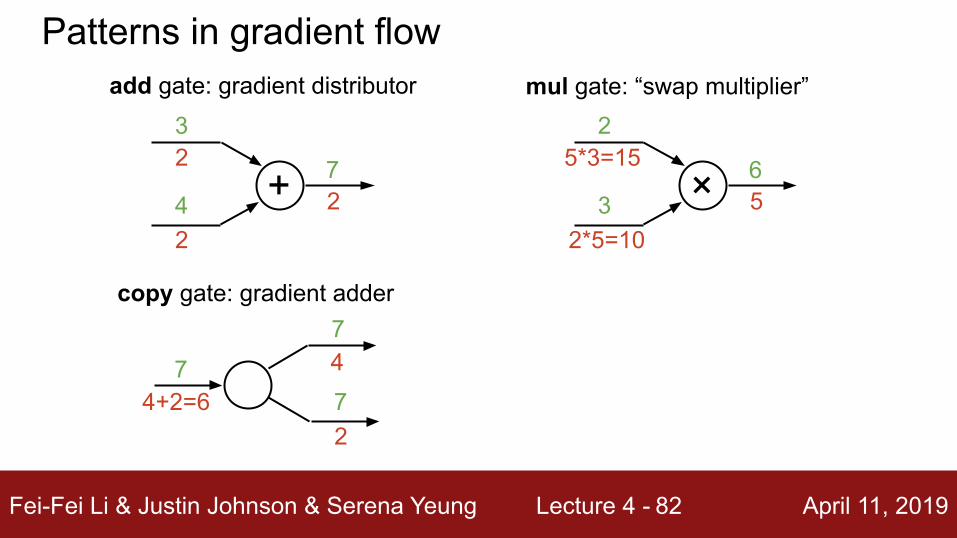
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201982
add gate: gradient distributor
Patterns in gradient flow
+3
472
2
2
mul gate: “swap multiplier”
copy gate: gradient adder
×2
365
5*3=15
2*5=10
7
77
4+2=6
4
2
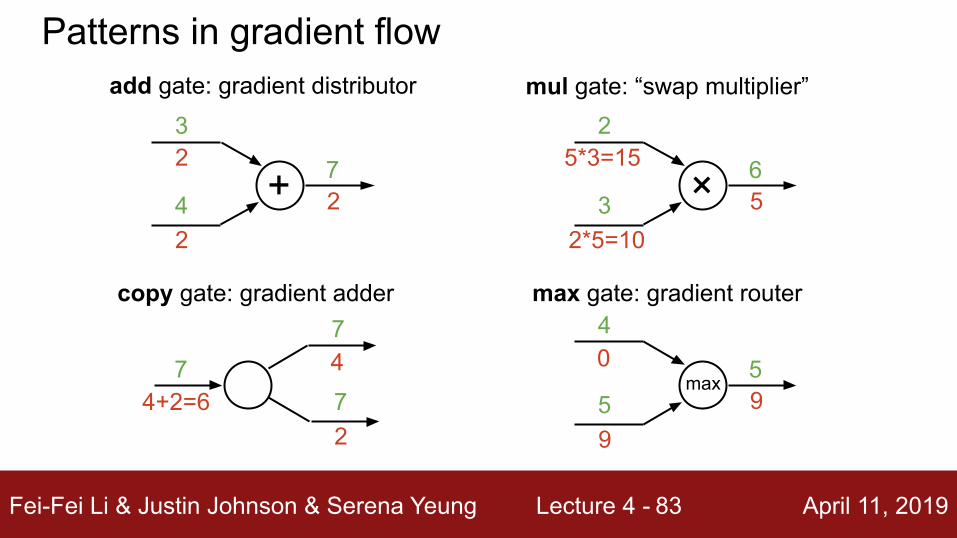
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201983
add gate: gradient distributor
Patterns in gradient flow
+3
472
2
2
mul gate: “swap multiplier”
max gate: gradient router
max
copy gate: gradient adder
×2
365
5*3=15
2*5=10
4
559
0
9
7
77
4+2=6
4
2
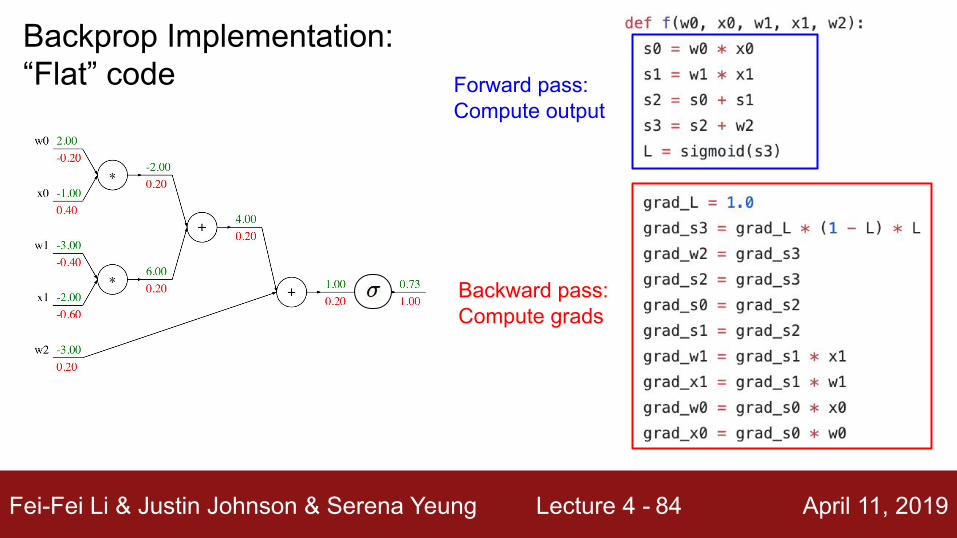
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201984
Backprop Implementation: “Flat” code Forward pass:
Compute output
Backward pass:Compute grads
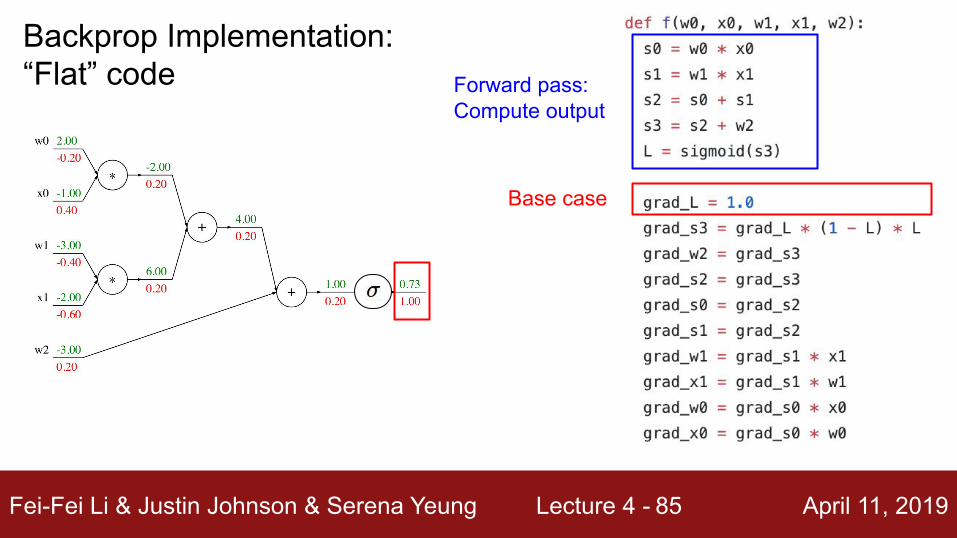
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201985
Backprop Implementation: “Flat” code Forward pass:
Compute output
Base case
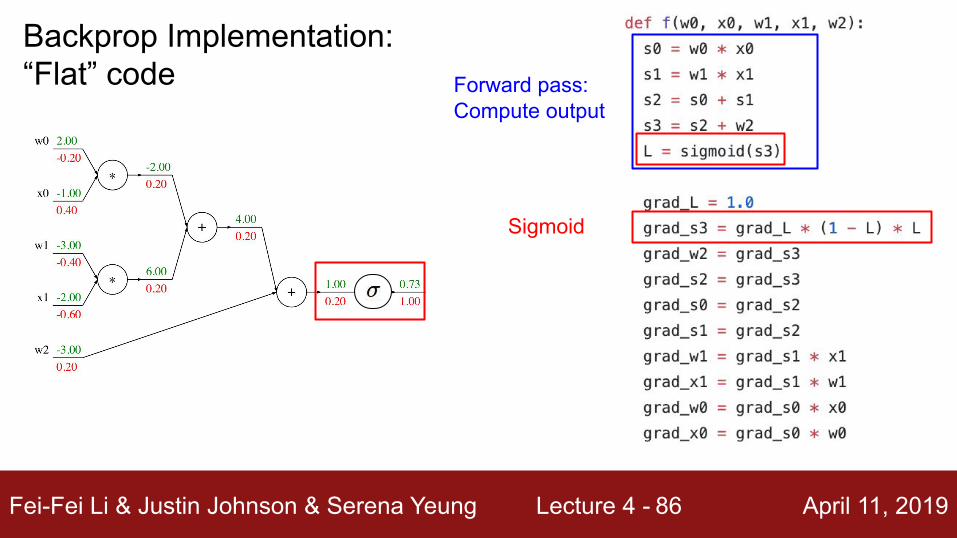
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201986
Backprop Implementation: “Flat” code Forward pass:
Compute output
Sigmoid
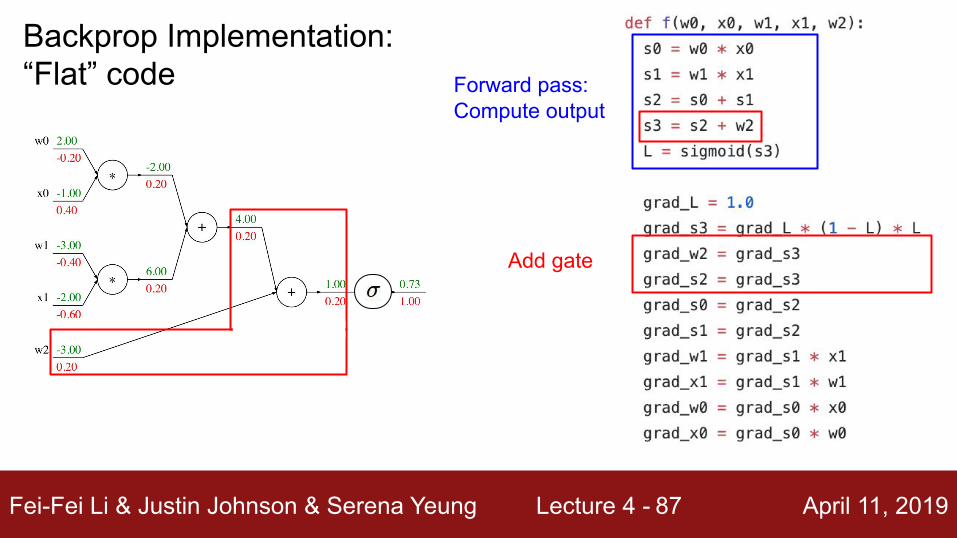
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201987
Backprop Implementation: “Flat” code Forward pass:
Compute output
Add gate
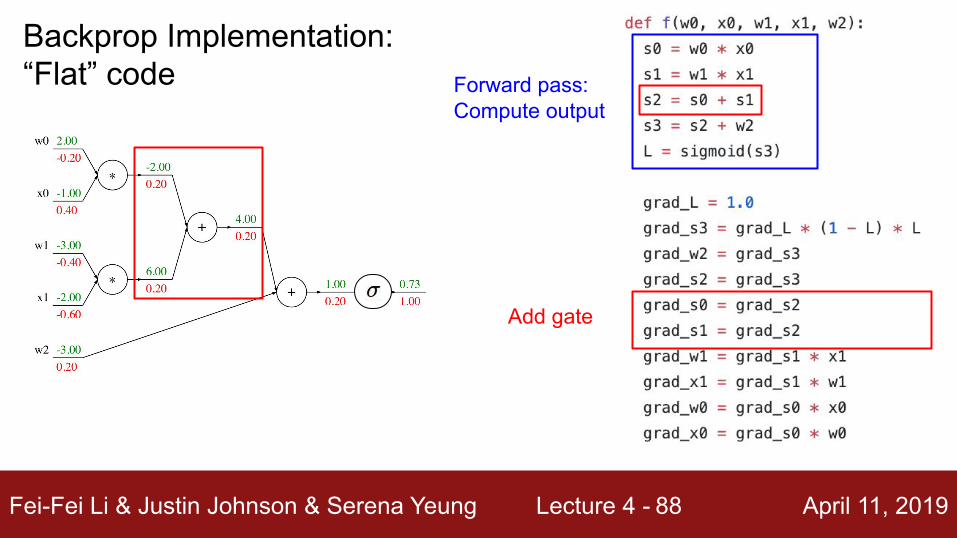
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201988
Backprop Implementation: “Flat” code Forward pass:
Compute output
Add gate
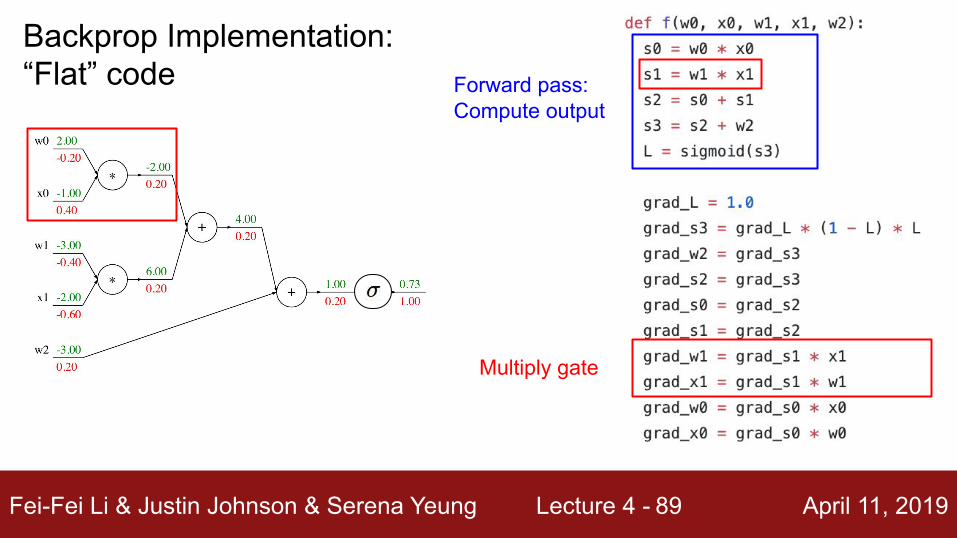
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201989
Backprop Implementation: “Flat” code Forward pass:
Compute output
Multiply gate

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201990
Backprop Implementation: “Flat” code Forward pass:
Compute output
Multiply gate

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201991
Stage your forward/backward computation!E.g. for the SVM:
margins
“Flat” Backprop: Do this for assignment 1!

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201992
“Flat” Backprop: Do this for assignment 1!E.g. for two-layer neural net:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201993
Backprop Implementation: Modularized API
Graph (or Net) object (rough pseudo code)

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201994
(x,y,z are scalars)
x
y
z*
Modularized implementation: forward / backward API
Need to stash some values for use in backward
Gate / Node / Function object: Actual PyTorch code
Upstream gradient
Multiply upstream and local gradients
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201995
Example: PyTorch operators

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201996
Source
Forward
PyTorch sigmoid layer

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201997
PyTorch sigmoid layer
Source
Forward
Forward actually defined elsewhere...

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201998
Source
Forward
Backward
PyTorch sigmoid layer
Forward actually defined elsewhere...

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 201999
So far: backprop with scalars
What about vector-valued functions?

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019100
Recap: Vector derivativesScalar to Scalar
Regular derivative:
If x changes by a small amount, how much will y change?

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019101
Recap: Vector derivativesScalar to Scalar
Regular derivative:
If x changes by a small amount, how much will y change?
Vector to Scalar
Derivative is Gradient:
For each element of x, if it changes by a small amount then how much will y change?

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019102
Recap: Vector derivativesScalar to Scalar
Regular derivative:
If x changes by a small amount, how much will y change?
Vector to Scalar
Derivative is Gradient:
For each element of x, if it changes by a small amount then how much will y change?
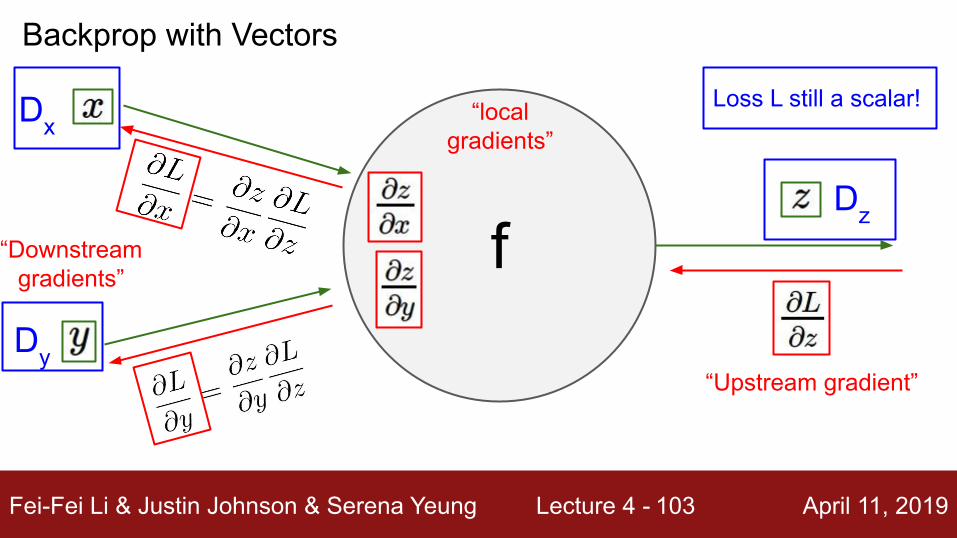
Vector to Vector
Derivative is Jacobian:
For each element of x, if it changes by a small amount then how much will each element of y change?
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019103
f
“local gradients”
“Upstream gradient”
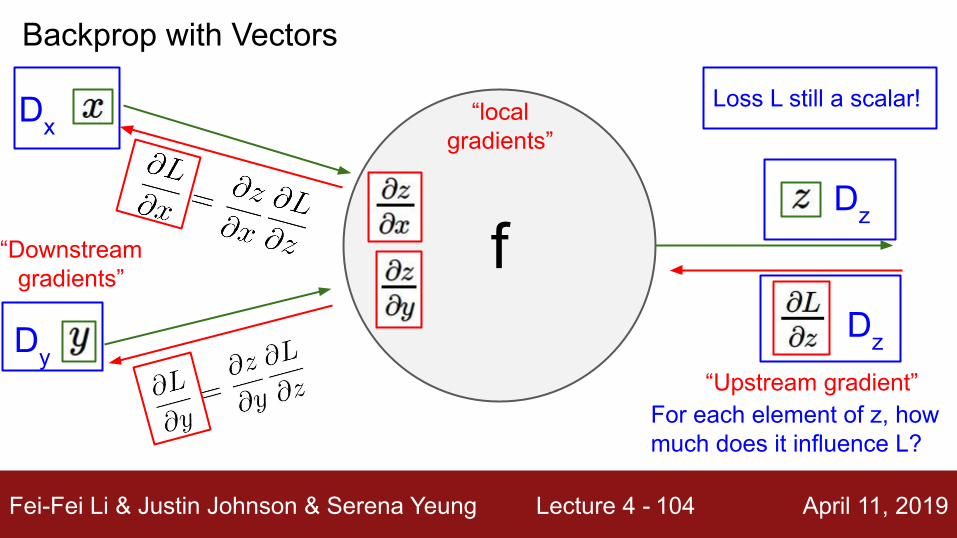
Backprop with Vectors
Dx
Dy
Dz
Loss L still a scalar!
“Downstream gradients”
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019104
f
“local gradients”
“Upstream gradient”
Dx
Dy
Dz
Dz
Loss L still a scalar!
For each element of z, how much does it influence L?
“Downstream gradients”
Backprop with Vectors
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019105
f
“local gradients”
“Upstream gradient”
Dx
Dy
Dz
Dz
Loss L still a scalar!
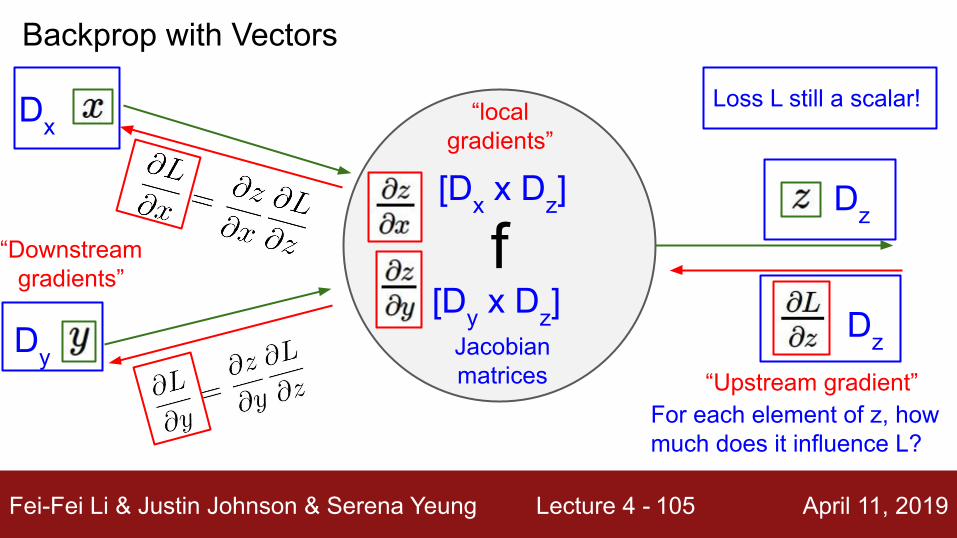
[Dy x Dz]
[Dx x Dz]
Jacobian matrices
For each element of z, how much does it influence L?
“Downstream gradients”
Backprop with Vectors

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019106
f
“local gradients”
“Upstream gradient”
“Downstream gradients”
Dx
Dy
Dz
Dz
Loss L still a scalar!
[Dy x Dz]
[Dx x Dz]
Jacobian matrices
For each element of z, how much does it influence L?
Dy
Dx
Matrix-vectormultiply
Backprop with Vectors

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019107
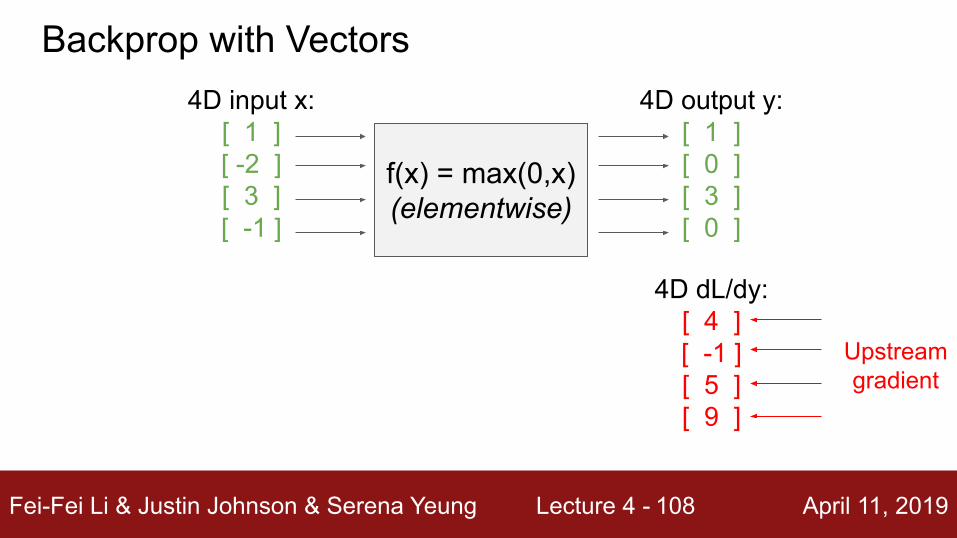
f(x) = max(0,x)(elementwise)
4D input x:[ 1 ][ -2 ][ 3 ][ -1 ]
Backprop with Vectors4D output y:
[ 1 ][ 0 ][ 3 ][ 0 ]
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019108
f(x) = max(0,x)(elementwise)
4D input x:[ 1 ][ -2 ][ 3 ][ -1 ]
Backprop with Vectors4D output y:
[ 1 ][ 0 ][ 3 ][ 0 ]
4D dL/dy: [ 4 ][ -1 ][ 5 ][ 9 ]
Upstreamgradient

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019109
f(x) = max(0,x)(elementwise)
4D input x:[ 1 ][ -2 ][ 3 ][ -1 ]
Backprop with Vectors4D output y:
[ 1 ][ 0 ][ 3 ][ 0 ]
4D dL/dy: [ 4 ][ -1 ][ 5 ][ 9 ]
Jacobian dy/dx[ 1 0 0 0 ] [ 0 0 0 0 ] [ 0 0 1 0 ] [ 0 0 0 0 ]
Upstreamgradient

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019110
f(x) = max(0,x)(elementwise)
4D input x:[ 1 ][ -2 ][ 3 ][ -1 ]
Backprop with Vectors4D output y:
[ 1 ][ 0 ][ 3 ][ 0 ]
4D dL/dy: [ 4 ][ -1 ][ 5 ][ 9 ]
[dy/dx] [dL/dy][ 1 0 0 0 ] [ 4 ][ 0 0 0 0 ] [ -1 ][ 0 0 1 0 ] [ 5 ][ 0 0 0 0 ] [ 9 ]
Upstreamgradient

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019111
f(x) = max(0,x)(elementwise)
4D input x:[ 1 ][ -2 ][ 3 ][ -1 ]
Backprop with Vectors4D output y:
[ 1 ][ 0 ][ 3 ][ 0 ]
4D dL/dy: [ 4 ][ -1 ][ 5 ][ 9 ]
[dy/dx] [dL/dy][ 1 0 0 0 ] [ 4 ][ 0 0 0 0 ] [ -1 ][ 0 0 1 0 ] [ 5 ][ 0 0 0 0 ] [ 9 ]
Upstreamgradient
4D dL/dx: [ 4 ][ 0 ][ 5 ][ 0 ]

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019112
f(x) = max(0,x)(elementwise)
4D input x:[ 1 ][ -2 ][ 3 ][ -1 ]
Backprop with Vectors4D output y:
[ 1 ][ 0 ][ 3 ][ 0 ]
4D dL/dy: [ 4 ][ -1 ][ 5 ][ 9 ]
[dy/dx] [dL/dy][ 1 0 0 0 ] [ 4 ][ 0 0 0 0 ] [ -1 ][ 0 0 1 0 ] [ 5 ][ 0 0 0 0 ] [ 9 ]
Upstreamgradient
Jacobian is sparse: off-diagonal entries always zero! Never explicitly form Jacobian -- instead use implicit multiplication
4D dL/dx: [ 4 ][ 0 ][ 5 ][ 0 ]

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019113
f(x) = max(0,x)(elementwise)
4D input x:[ 1 ][ -2 ][ 3 ][ -1 ]
Backprop with Vectors4D output y:
[ 1 ][ 0 ][ 3 ][ 0 ]
4D dL/dy: [ 4 ][ -1 ][ 5 ][ 9 ]
[dy/dx] [dL/dy]4D dL/dx: [ 4 ][ 0 ][ 5 ][ 0 ]
Upstreamgradient
Jacobian is sparse: off-diagonal entries always zero! Never explicitly form Jacobian -- instead use implicit multiplication
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019114
“local gradients”
“Upstream gradient”
“Downstream gradients”
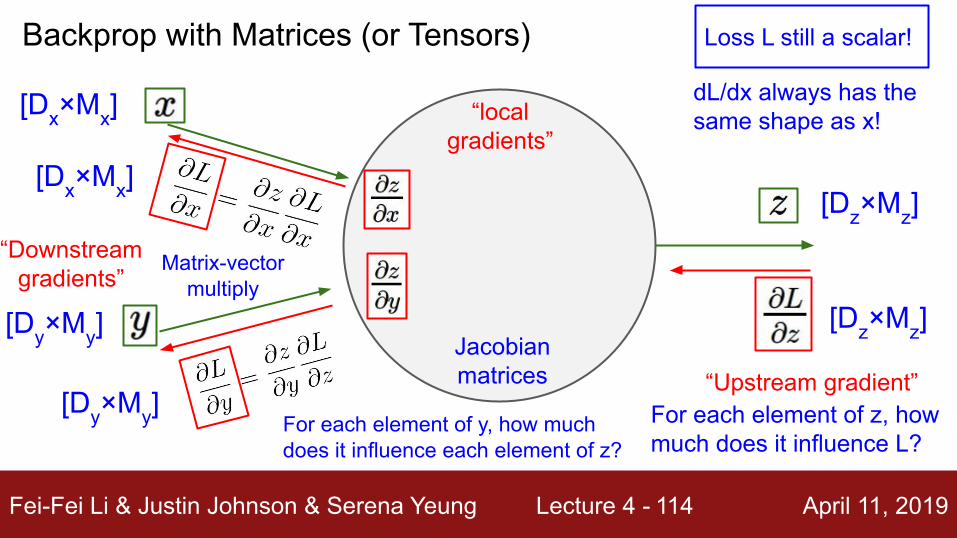
Backprop with Matrices (or Tensors)
[Dx×Mx]
Loss L still a scalar!
Jacobian matrices
For each element of z, how much does it influence L?
For each element of y, how much does it influence each element of z?
Matrix-vectormultiply
[Dy×My]
[Dz×Mz]
[Dz×Mz]
[Dx×Mx]
[Dy×My]
dL/dx always has the same shape as x!
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019115
“local gradients”
“Upstream gradient”
“Downstream gradients”
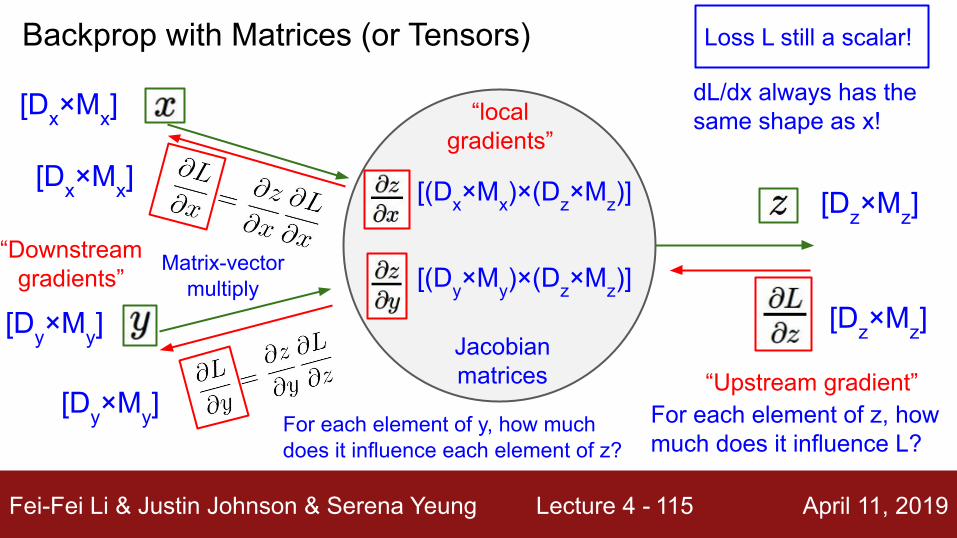
Backprop with Matrices (or Tensors)
[Dx×Mx]
Loss L still a scalar!
[(Dx×Mx)×(Dz×Mz)]
Jacobian matrices
For each element of z, how much does it influence L?
For each element of y, how much does it influence each element of z?
Matrix-vectormultiply
[Dy×My]
[Dz×Mz]
[Dz×Mz][(Dy×My)×(Dz×Mz)]
[Dx×Mx]
[Dy×My]
dL/dx always has the same shape as x!
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019116
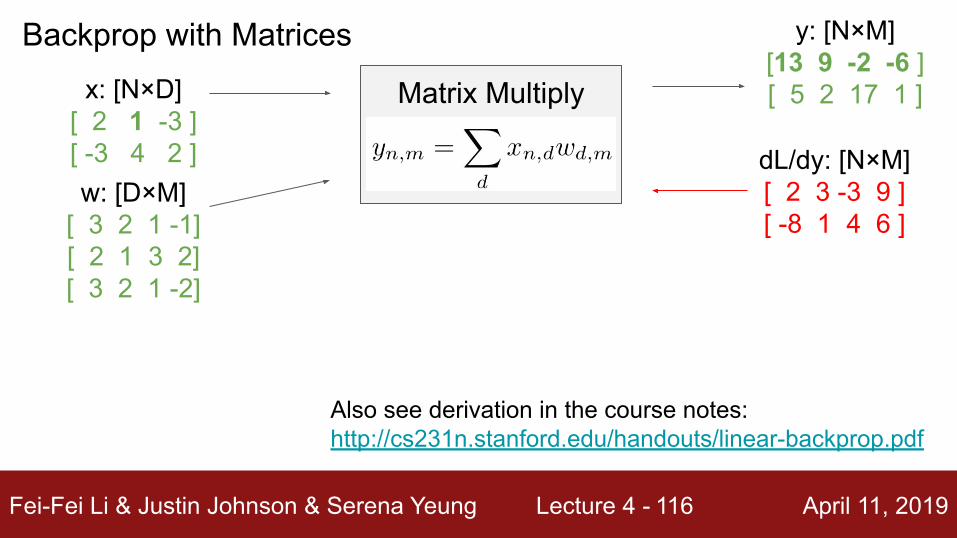
Backprop with Matricesx: [N×D]
[ 2 1 -3 ][ -3 4 2 ]w: [D×M]
[ 3 2 1 -1][ 2 1 3 2][ 3 2 1 -2]
Matrix Multiply
y: [N×M][13 9 -2 -6 ][ 5 2 17 1 ]
dL/dy: [N×M][ 2 3 -3 9 ][ -8 1 4 6 ]
Also see derivation in the course notes:http://cs231n.stanford.edu/handouts/linear-backprop.pdf
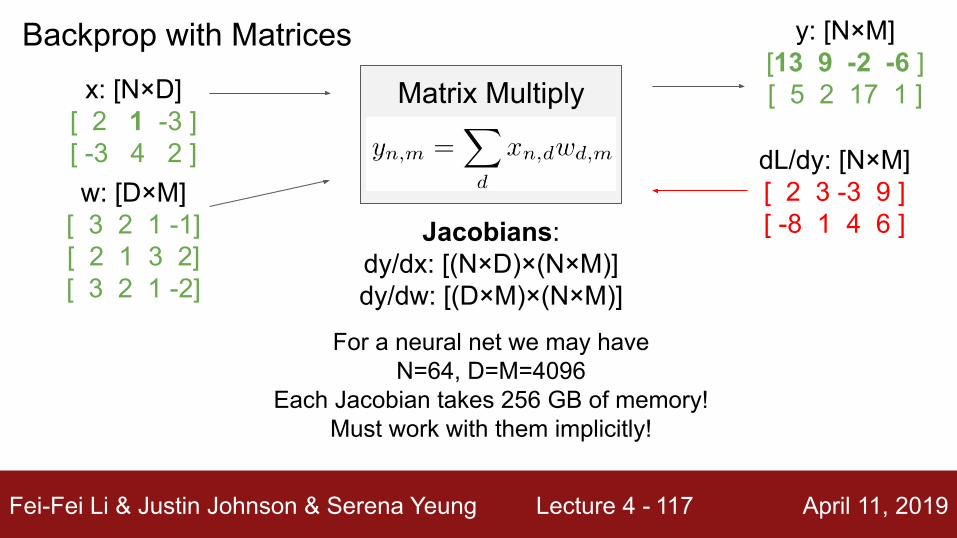
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019117
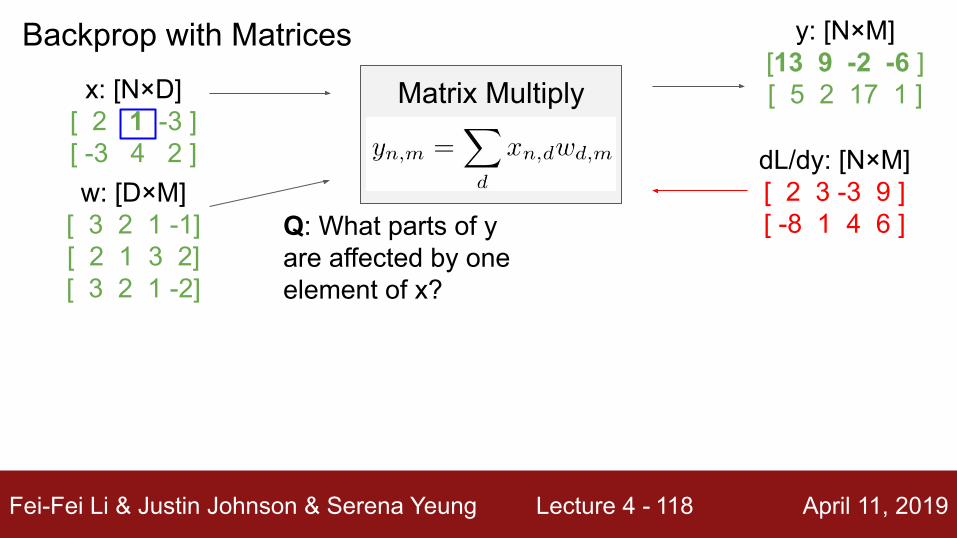
Backprop with Matricesx: [N×D]
[ 2 1 -3 ][ -3 4 2 ]w: [D×M]
[ 3 2 1 -1][ 2 1 3 2][ 3 2 1 -2]
Matrix Multiply
y: [N×M][13 9 -2 -6 ][ 5 2 17 1 ]
dL/dy: [N×M][ 2 3 -3 9 ][ -8 1 4 6 ]Jacobians:
dy/dx: [(N×D)×(N×M)]dy/dw: [(D×M)×(N×M)]
For a neural net we may have N=64, D=M=4096
Each Jacobian takes 256 GB of memory! Must work with them implicitly!
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019118
Backprop with Matricesx: [N×D]
[ 2 1 -3 ][ -3 4 2 ]w: [D×M]
[ 3 2 1 -1][ 2 1 3 2][ 3 2 1 -2]
Matrix Multiply
y: [N×M][13 9 -2 -6 ][ 5 2 17 1 ]
dL/dy: [N×M][ 2 3 -3 9 ][ -8 1 4 6 ]Q: What parts of y
are affected by one element of x?

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019119
Backprop with Matricesx: [N×D]
[ 2 1 -3 ][ -3 4 2 ]w: [D×M]
[ 3 2 1 -1][ 2 1 3 2][ 3 2 1 -2]
Matrix Multiply
y: [N×M][13 9 -2 -6 ][ 5 2 17 1 ]
dL/dy: [N×M][ 2 3 -3 9 ][ -8 1 4 6 ]Q: What parts of y
are affected by one element of x?A: affects the whole row

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019120
Backprop with Matricesx: [N×D]
[ 2 1 -3 ][ -3 4 2 ]w: [D×M]
[ 3 2 1 -1][ 2 1 3 2][ 3 2 1 -2]
Matrix Multiply
y: [N×M][13 9 -2 -6 ][ 5 2 17 1 ]
dL/dy: [N×M][ 2 3 -3 9 ][ -8 1 4 6 ]Q: What parts of y
are affected by one element of x?A: affects the whole row
Q: How much does affect ?
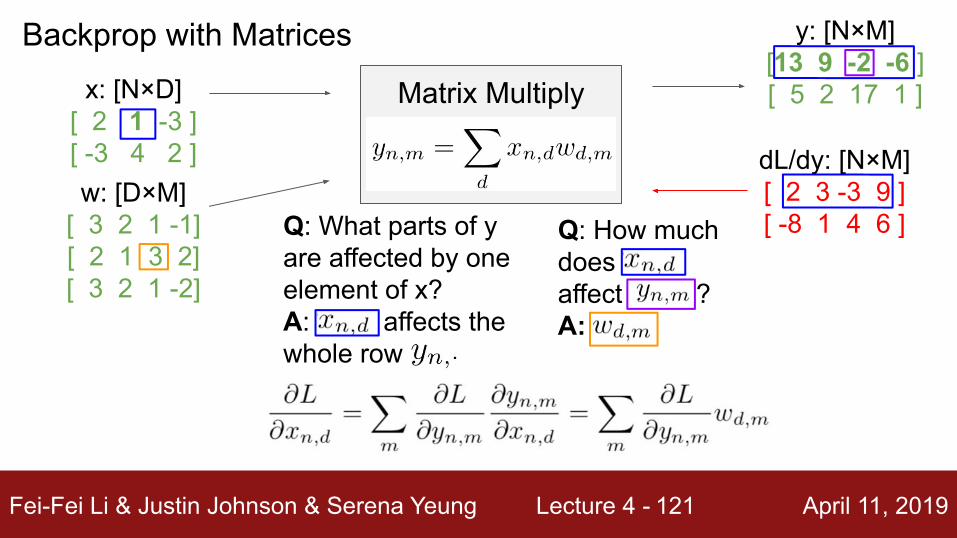
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019121
Backprop with Matricesx: [N×D]
[ 2 1 -3 ][ -3 4 2 ]w: [D×M]
[ 3 2 1 -1][ 2 1 3 2][ 3 2 1 -2]
Matrix Multiply
y: [N×M][13 9 -2 -6 ][ 5 2 17 1 ]
dL/dy: [N×M][ 2 3 -3 9 ][ -8 1 4 6 ]Q: What parts of y
are affected by one element of x?A: affects the whole row
Q: How much does affect ?A:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019122
Backprop with Matricesx: [N×D]
[ 2 1 -3 ][ -3 4 2 ]w: [D×M]
[ 3 2 1 -1][ 2 1 3 2][ 3 2 1 -2]
Matrix Multiply
y: [N×M][13 9 -2 -6 ][ 5 2 17 1 ]
dL/dy: [N×M][ 2 3 -3 9 ][ -8 1 4 6 ]Q: What parts of y
are affected by one element of x?A: affects the whole row
Q: How much does affect ?A:
[N×D] [N×M] [M×D]

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019123
Backprop with Matricesx: [N×D]
[ 2 1 -3 ][ -3 4 2 ]w: [D×M]
[ 3 2 1 -1][ 2 1 3 2][ 3 2 1 -2]
Matrix Multiply
y: [N×M][13 9 -2 -6 ][ 5 2 17 1 ]
dL/dy: [N×M][ 2 3 -3 9 ][ -8 1 4 6 ]
[N×D] [N×M] [M×D] [D×M] [D×N] [N×M]
By similar logic:
These formulas are easy to remember: they are the only way to make shapes match up!

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019124
● (Fully-connected) Neural Networks are stacks of linear functions and nonlinear activation functions; they have much more representational power than linear classifiers
● backpropagation = recursive application of the chain rule along a computational graph to compute the gradients of all inputs/parameters/intermediates
● implementations maintain a graph structure, where the nodes implement the forward() / backward() API
● forward: compute result of an operation and save any intermediates needed for gradient computation in memory
● backward: apply the chain rule to compute the gradient of the loss function with respect to the inputs
Summary for today:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019
Next Time: Convolutional Networks!
125

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019126
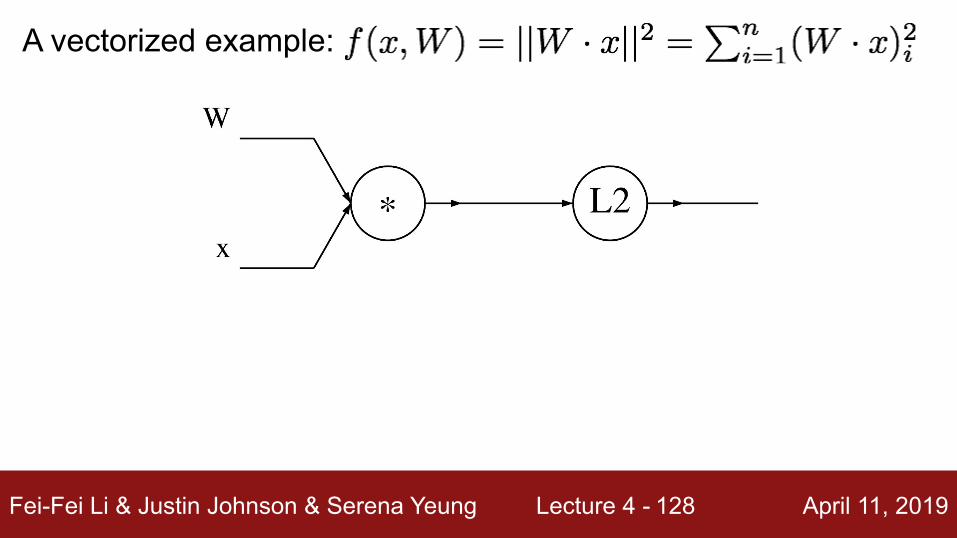
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019127
A vectorized example:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019128
A vectorized example:
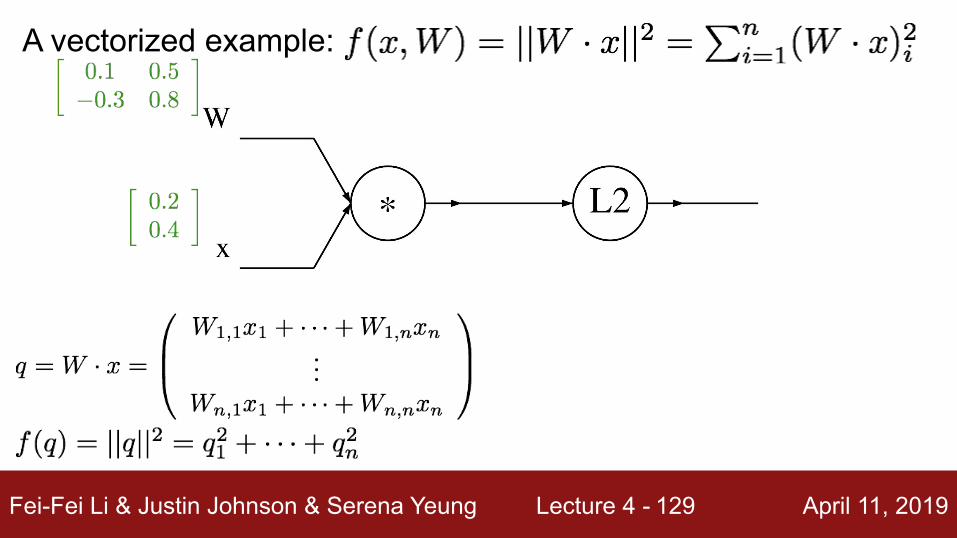
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019129
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019130
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019131
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019132
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019133
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019134
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019135
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019136
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019137
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019138
A vectorized example:
Always check: The gradient with respect to a variable should have the same shape as the variable
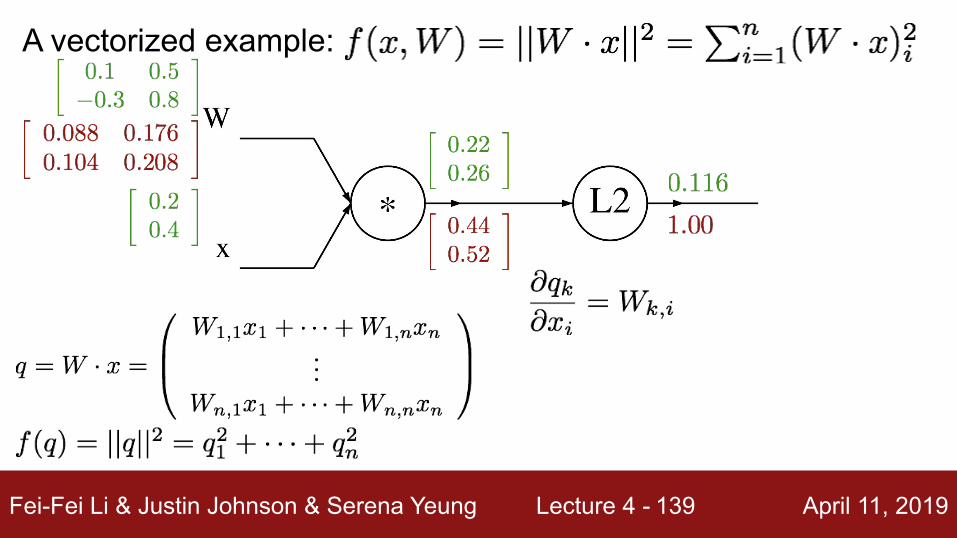
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019139
A vectorized example:
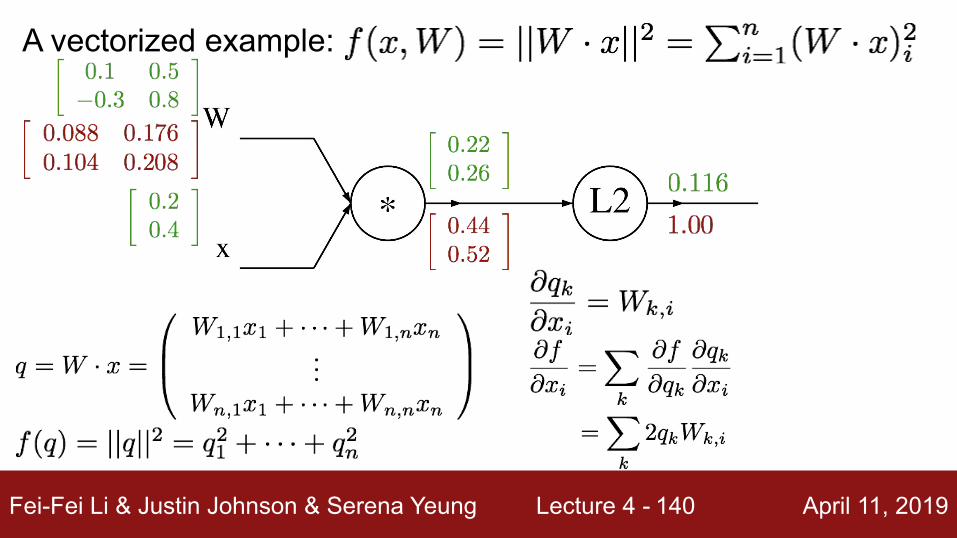
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019140
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 11, 2019141
A vectorized example:
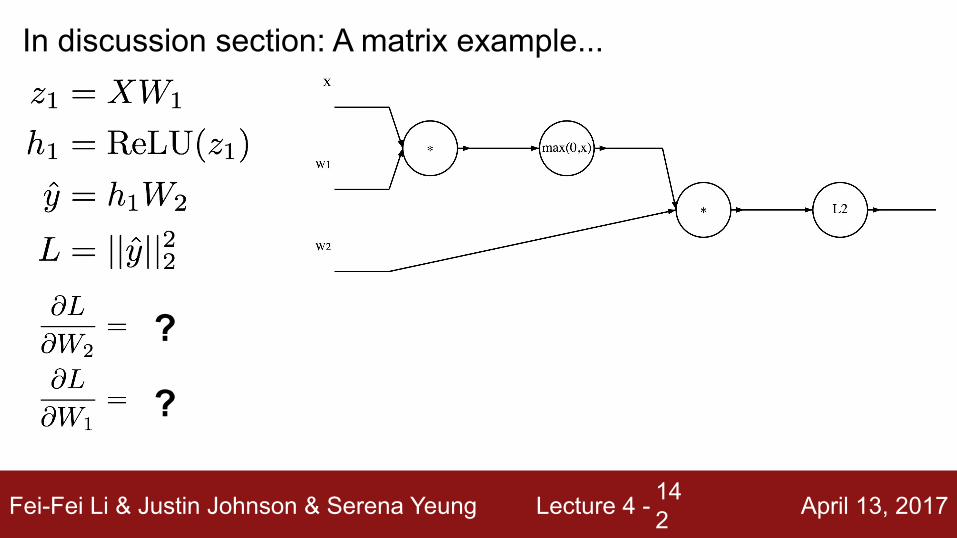
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 2017142
In discussion section: A matrix example...
?
?





























