Embed Size (px)
Citation preview

Computers and the Humanities 30: 1-10, 1996. 1
© 1996 Kluwer Academic Publishers. Printed in the Netherlands.
Neural Network Applications in Stylometry: The Federalist Papers
E J. Tweedie,* S. Singh t & D. I. H o l m e s ~; Department of Mathematical Sciences, University of the West of England, Frenchay Campus, Coldharbour Lane, Bristol BS16 1QY, UK e-mail: [email protected]
Key words: neural networks, function words, authorship attribution, The Federalist Papers
Abstract
Neural Networks have recently been a matter of extensive research and popularity. Their application has increased considerably in areas in which we are presented with a large amount of data and we have to identify an underlying pattern. This paper will look at their application to stylometry. We believe that statistical methods of attributing authorship can be coupled effectively with neural networks to produce a very powerful classification tool. We illustrate this with an example of a famous case of disputed authorship, The Federalist Papers. Our method assigns the disputed papers to Madison, a result which is consistent with previous work on the subject.
1. Introduction
The origins of stylometry - the statistical analysis of literary style - date back to 1851 when the English logician Augustus de Morgan suggested in a letter to a friend that questions of authorship might be settled by determining if one text "does not deal in longer words" than another (de Morgan, 1882). His hypothesis was investigated in the 1880s by Thomas Mendenhall, an American physicist who subsequently published the results of an impressive display of academic labour on word length "spectra" (Mendenhall, 1887). Since then,
* Fiona J. Tweedie is a research student and tutor at the University of the West of England, Bristol, currently working on the provenance of "De Doctrina Christiana", attributed to John Milton. She has presented papers at the ACH/ALLC conference in 1995 and has forthcoming papers in Forensic Linguistics and Revue.
t Sameer Singh is a research student and tutor at the University, of the West of England, Bristol, working in the application of artificially intelligent methods and statistics for quantifying language disorders. His main research interests include neural networks, fuzzy logic, expert systems and linguistic computing.
David I. Holmes is a Principal Lecturer in Statistics at the University of the West of England, Bristol. He has published several papers on the statistical analy sis of literary style in journals including the Journal of the Royal Statistical Society and History and Comput- ing. He has presented papers at ACI-FALLC conferences in 1991, 1993 and 1995.
stylometrists have been searching for a unit of counting which enumerates the style of the text. We define style as a set of measurable patterns which may be unique to an author. In this quest almost every conceivable measure has been considered, ranging from sentence lengths to the number of nouns, articles or pronouns occurring in the text. The vocabulary of the author has also undergone scrutiny, with counts being taken of words that occur only once in the text, to the most common words that act as fillers. Between these two extremes are function words, certain non-contextual words occurring in the text. They can be used as "markers" for different authors. A useful review of recent developments can be found in Holmes (1994).
Stylometry primarily concerns itself with attribu- tion studies, although chronological studies on the dating of work within the corpus of an author have also been investigated (see Cox and Brandwood, 1959). Writing in a forensic context, Bailey (1979) proposed three rules to define the circumstances necessary for authorship attribution:
1. the number of putative authors should constitute a well-defined set;
2. the lengths of the writings should be sufficient to reflect the linguistic habits of the author of the dis- puted text and also those of each of the candidates;

3. the texts used for comparison should be commen- surate with the disputed writing.
A statistical study of disputed authorship should involve comparisons of the disputed text with works by each of the possible candidate authors using appro- priate statistical tests on quantifiable features of the texts - features which reflect the style of the writing as defined above.
Growing computer power and the availability of machine-readable versions of literary texts have now helped to overcome the drudgery of conducting stylo- metric analyses on textual samples. We intend to investigate the use of a technique developed in arti- ficial intelligence that is now being applied to many problems outside its initial field: the neural network. To do this, we consider the problem of the Federal- ist Papers, something of a proving ground for new techniques in authorship attribution.
2. Neural N e t w o r k s
One characteristic that stylometry shares with other applications is that it is essentially a case of pattern recognition. However, in most cases of disputed authorship we do not know what the pattern is and we probably would not be able recognize it even if we did.
Neural networks have the ability to recognize the underlying organization of data which is of vital impor- tance for any pattern recognition problem. Their appli- cation in stylometry will be useful for a number of reasons:
1. Neural networks can learn from the data them- selves. Implementing a rule-based system in linguistic computing may become complex as the number of distinguishing variables increases and even the most complex rules may still not be good enough to completely characterize the training data. In essence, neural networks are more adaptive.
2. Neural networks can generalize. This ability is particularly required in the literary field, as only limited data may be available.
3. Neural networks can capture non-linear inter- actions between the input variables.
4. Neural networks are capable of fault tolerance. Hence a particular work which is not in line with the usual writing style of an author will not affect the network to a considerable extent.
Thus, neural networks appear to promise much for the field of stylometry. Their application would appear to be worthy of investigation.
2.1. Structure of a neural network
A neural network is made up of nodes which are struc- tured as shown in Figure 1. Each node has several input connections from other nodes or from data provided to it. These inputs are then multiplied by weights, result- ing in a value S where
S = ~ wixi, (1) i = 0
where n is the number of inputs to that node. The value Of Xo is usually set to 1 and Wo is a threshold or biasing weight. Before presenting the value of S to the output, it is passed through a transfer function. This is usually a sigmoid function, a monotonically increasing S-shaped curve, which accomplishes two tasks. It introduces elements of non-linearity to the network, allowing it to deal with more complex functions, and secondly, the raw sums are constrained within certain limits, here 0 and 1, in a smooth manner. This ensures that each hidden node contributes a similar value to the output layer. Different researchers use different functions but the one below is common. The final output from the node is thus
1 o -- 1 + e -8 (2)
This output is passed on as the input to the next layer of nodes in the network, or as a final output value.
The nodes are often connected in a structure similar to that shown in Figure 2. The nodes are in 3 layers, known as the input, hidden and output layers. Each node in the input layer is connected to every node in the hidden layer, which is in turn connected to every node in the output layer. Only some of these connections are shown in Figure 2 in aid of clarity. It has been shown that three layers are sufficient to cope with any classification problem. The number of hidden nodes used should be selected with care so that there are enough to ensure proper recognition of the patterns. Recognition of more patterns than required may result in over-generalization - in other words, the network may recognize patterns when they are not present.

2.2. Training a network
In order to correctly classify input, the neural network must be trained! that is, the weights need to be adjusted to provide the correct output.
Initially the weights are set to random values between - 1 and 1. The network is then presented with a set of input values and the correct output values. This is known as the training data set. There should be sufficient data to allow the neural network to learn correctly to differentiate the categories. Matthews and Merriam (1993) suggest using the following equation to determine the approximate number of data items required.
ArT = 10(NI + No) (3)
where ArT is the number of training patterns, Nx is the number of inputs and No is the number of outputs of the neural network. For each pattern, the sum of the squared errors from each output node can be calcu- lated. The training algorithm is designed to minimize this error by changing the values of the weights appro- priately.
The process can be thought of geometrically. The solution-space for the weights has the same dimen- sion as the number of weights in the neural network. The error for different combinations of weights can be found and an error surface can be visualized. In training, we are searching for the minimum of this error surface. The training algorithm may utilize tech- niques for looking for the steepest gradient towards the minimum in order to get there as quickly as possible. In reality, however, the error surface is not a simple bowl shape and it may contain local minima in which a training algorithm may become "stuck". If this occurs, training must be restarted with different initial weight values. Training should therefore be tried with differ- ent configurations of initial values to determine if a smaller minima can be found.
Several different neural network training algo- rithms have been developed to minimize the error between the desired output and the output actually produced by the neural network. One of the earliest, and most popular techniques is known as back- propagation. Here, the error between the desired and actual outputs is used in a function which modifies the weights in the network. The changes are propagated through the network, hence the name.
Other techniques make use of the geometric inter- pretation of the error surface. The Momentum Descent
method uses the "speed" of descent towards the mini- mum error as a parameter when adjusting the weights. The Conjugate Gradient technique (McMurty 1994, p. 254), avoids getting caught in a local minima by searching for the global minima of the error surface in directions that are conjugate to previous ones.
Another problem that can occur when training the neural network is that of over-training. If the neural network is presented with the training data often enough, it may learn to classify the training set per- fectly. However, it loses the ability to generalize from this data to new data that may be presented later. This can be dealt with by the use of a cross-validation set of data that can be used to check the progress of training. An indication of over-training is that, although classi- fication of the training set improves, classification of the cross-validation set will deteriorate. Thus 100% accuracy in classifying the training set is unlikely to be a desirable objective. A balance has to be struck where the neural network can classify a certain percentage of both the training and cross-validation sets correctly.
This paper is intended as an introduction to the field of neural networks and their application to stylometry. The interested reader may like to consult other books in the field, especially Hecht-Nielson (1989) and Ander- son and Rosenfield (1989).
3. The Federalist Papers
One of the classic problems in authorship attribution is that of the Federalist Papers. They were written in 1787-1788 by Hamilton, Madison and Jay in an effort to persuade the citizens of New York State to ratify the Constitution. Each essay is of 900-3500 words in length and was published under the name "Publius". In total, there are 85 essays; the first 77 appeared in several different newspapers and Hamilton wrote a final eight essays to complete the set. Of the first 77, numbers 2-5 and 64 were written by Jay, numbers 10, 14 and 37-48 by Madison, numbers 18-20 jointly by Hamilton and Madison, and the remainder by Hamilton. Contemporary lists of the papers' authors also assigned papers 49-58, 6-2 and 63 to Madison. However, the night before he was killed in a duel, Hamilton claimed authorship of them as well. These twelve papers are known as the "disputed papers".
The Federalist Papers fulfil the conditions set down by Bailey (1989), noted in Section 1. The author of each disputed paper is either Hamilton or Madison; no one else is considered. There are many papers of

4
undisputed authorship for comparison, offering suffi- cient data from each author. As the texts are taken from a series of papers that include the disputed works, they should be commensurate. These facts make the Federalist Papers an excellent proving ground for new techniques in authorship attribution. The defini- tive study was carried out by Mosteller and Wallace in 1964, a work which forms the methodological basis for many modern investigations. Since then, others have tested their techniques on the Feder- alist Papers, comparing their results with those of Mosteller and Wallace as a measure of success. They include McColly and Weier (1983); Merriam (1989); Farringdon and Morton (1989) and Hilton and Holmes (1993).
3.1. Function words
Of all the measures of style mentioned in Section 1, perhaps the one most associated with the Federalist Papers is that of function words. Rather than counting the number of words that appear once or twice, we count the number of times that predetermined words occur. These words should occur relatively frequently in the text. They should also be good discriminators, that is their rate of use should be relatively constant in each author's work, but each author should have a distinguishable rate. In order to ensure that the rate is constant for each author and that the words are context-free, the distribution of the positions of each chosen word should be examined. Damerau (1975) notes that the positions of words are independent, and thus context-free, if they follow a Poisson distribution, that is, they are as likely to appear in one place in the text as in any other. He suggests the use of Lewis' S statistic for determining if this holds for the chosen words. Oakman (1980) notes that
The lesson seems clear, not only for function words, but for authorship studies in general: partic- ular words may work for specific cases such as the Federalist Papers but cannot be counted on for other analyses.
In future work we would like to consider other measures of style, but for this initial experiment we decided to use function words since the work of estab- lishing which words are appropriate has already been performed by Mosteller and Wallace.
Table 1. The function words used in this study.
any his from do an there may on upon every £ a n
4. The Federalist Neural Network
Having decided to use function words as inputs to our neural network we had to choose a subset of those used by Mosteller and Wallace (1964). After some preliminary experiments we settled on eleven words. They are shown in Table 1. They were chosen for their ability to discriminate between Hamilton and Madison. However, words such as whilst, used exclusively by Madison, and enough and while, used exclusively by Hamilton were unable to be used. Should such words be used, the neural network may be unable to classify a work that uses, say, both enough and whilst. The initial nine words were investigated by Mosteller and Wallace (1964) and generally found to have a Poisson distribution, while the final two were chosen for their discriminatory ability in a weight-rate analysis.
We used the Oxford Concordance Program, a stan- dard piece of software in textual analysis, to find the number of occurrences of each word in each of the 85 papers. These figures were then converted into rates per 1000 words. The papers by Jay, numbers 2-5 and 64, were then removed from the set. In order to investi- gate whether there was evidence of non-linearity in the data, a principal components analysis was performed. The first prineipal component broadly separates the Hamilton and Madison papers, but there are several Hamilton papers amongst ones by Madison and vice versa. We would hope that the neural network will be able to discriminate between the authors successfully, and make correct inferences about the disputed papers.
In preparation for presentation to the neural net- work the papers were normalized so that each word had a rate that was normally distributed with a mean of 0 and a variance of 1. Matthews and Merriam (1993) note that this ensures that each word contributes equally to the training process. The original mean and variance of each word is given in Table 2. This set was then split into three: the joint papers, numbers 18-20; the disputed papers, numbers 49-58, 62 and 63; and the

•
Figure 1. Structure of a single node.
P
1,
input hidden output
layer layer layer
Figure 2. Structu;e of a multi-layer perceptron.
undisputed papers, numbers 1, 6-18, 21-49, 59-61 and 65-85. The joint and disputed papers will make up two testing sets while the undisputed papers will comprise the training set.
We have selected eleven function words as inputs to the neural network and have two possible outputs, "Hamilton" or "Madison". The most appropriate number of hidden nodes is usually identified experi- mentally. This involves trying various combinations, for example, one, two, and so on, nodes. After some initial experiments we decided to use three nodes in the hidden layer as this seemed to offer a good balance between being able to successfully classify the texts and avoiding over-generalization. We thus have a neural network with an 11-3-2 architecture as shown in Figure 3. Again some of the connections are omitted for clarity.
4.1. Training the neural network: undisputed papers
In order that the neural network can correctly identify texts from the Federalist Papers, it must first be
Table 2. Means and standard deviations of the function words.
Standard Word Mean Deviat ion
an 0.012661 0.008439 any 0.002872 0.001568 can 0.021207 0.019036 do 0.055090 0.028213
every 0.022992 0.021363 ~orn 0.008137 0.003603
his 0.022507 0.023313 m a y 0.016731 0.012848
on 0.033328 0.028338 there 0.028036 0.025758 upon 0.018847 0.016903
presented with data from the undisputed papers. The neural network should then be able to determine what makes a Madison paper a Madison paper and what makes a Hamilton paper a Hamilton paper.
The training takes the form of presenting rows of data to the neural network, where the data is the normalized rate per thousand words of each function word. The final two pieces of data are the desired out- put from the network. We have a "Madison" output and a "Hamilton" output, so for Madison papers the data would finish in 1 0, while data from a Hamilton paper would end in 0 1.
Since we have only fourteen papers by Madison and Equation 3 indicates that we need around 130 papers in total, we decided to duplicate the Madison data and mix it alternately with data from the Hamilton papers. This ordering of the data will ensure that the network is evenly trained and does not get too far from the optimum point. These techniques are used by neural network researchers (see for example Jain et al., 1987, and Evans, 1994.)
We decided to use the conjugate gradient method of training the neural network, rather than the back- propagation method used by Matthews and Merriam (1993). The conjugate gradient algorithm is more advanced, has a higher speed and will always find an optimum solution if one exists. Details about imple- menting this method can be found in Press et al. (1988).
As mentioned above, in order to ensure that the neural network is being trained correctly it is impor- tant to use some kind of cross-validation. Validation methods are described in detail in Fu (1994, Ch. 13). We use K-fold cross-validation (Stone, 1974).

n~itton ( ' ~ ( ' ~ M~aison
any from an may upon can every his do there on
F i g u r e 3. Structure of the Federalist neural network.
In this case K data items from the training data are kept aside and not used to train the neural network. These patterns are known as the cross-validation or training test set. The network is then presented with the reserved patterns. We have 102 training patterns and decided to use a value for K of 14. Hence on the first fold, the neural network is trained with the first 88 patterns, and the final 14, a cross-validation set, are tested against the network. In the second fold, the second 14 patterns are omitted, and so on. In the seventh fold 84 patterns were used to train the network and the final 16 as a cross-validation set. We found that only 3 patterns were misclassified in the cross-validation process, a recognition rate of 97.05 per cent. We were satisfied that the estimated error is the test error rather than the training error and that the neural network will train correctly.
The full data was then presented to the neural net- work. After under fifty iterations the neural network was correctly classifying all but one of the undisputed papers. The results are shown in Table 3. The correct assignations are shown in bold type. It can be seen that paper 25 has been incorrectly classified.
At this point we decided to stop the ~training to avoid over-training the network.
4.2. Testing the neural network: disputed and joint papers
Once the neural network is trained the weights are frozen and new data can be applied to the network for classification. The twelve disputed papers were presented and were classified as being by Madison, the
outputs in each case being 0 on the Hamilton output and 1 on the Madison output.
We also examined the joint papers. Papers 18 and 20 are ascribed to Hamilton while paper 19 is assigned to Madison.
5. Analysis of the Results
Matthews and Merriam (1993) note that
there can be little doubt that the case in favour of attributing a particular work to a specific author is strengthened if a wide variety of independent stylometric tests point to a similar conclusion.
We will now review previous work on the Feder- alist Papers to determine how our results compare.
5.1. The disputed papers
As noted above, the definitive study on the Feder- alist Papers is by Mosteller and Wallace (1964). They use several different statistical methods, including Bayesian inference. Here numerical probabilities are used to express degrees of belief about statements such as "Madison wrote Paper 50" and then Bayes' theorem is used to alter the probabilities to take into account the different word rates in the papers. They also use weight-rate analysis and a three-category anal- ysis. Each study produces similar results, that all the disputed papers, with the possible exception of paper 55 are by Madison.
Merriam (1989) uses Michaelson et al.'s propor- tionate pairs technique to examine the ratio of occur-
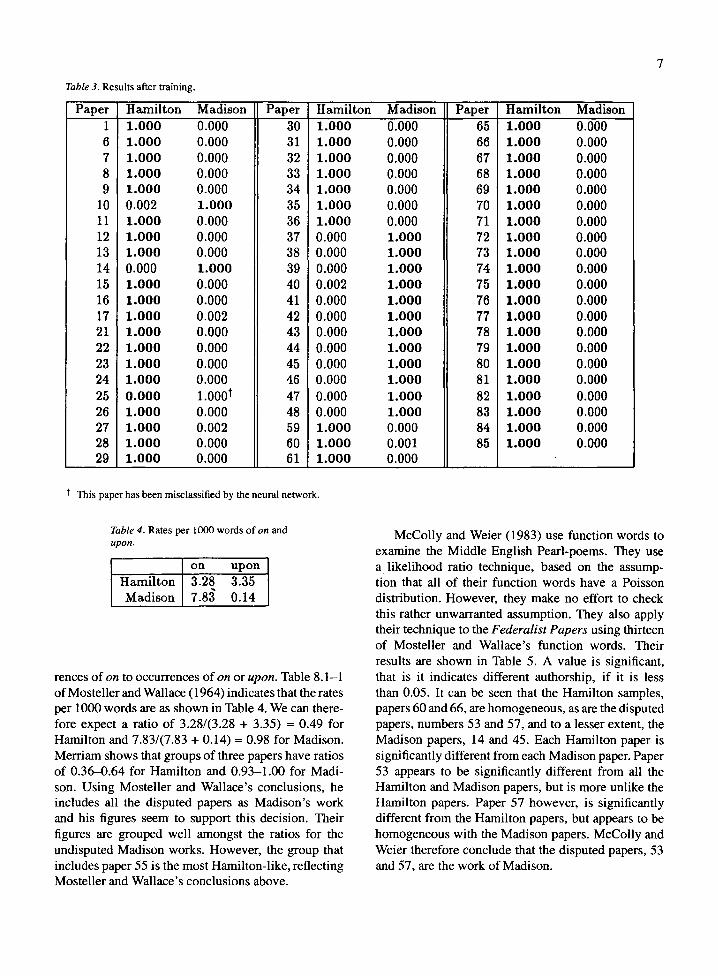
Table 3. Results after training.
Paper Hamilton Madison Paper 1 1.000 0.000 30 6 1.000 0.000 31 7 1.000 0.000 32 8 1.000 0.000 33 9 1.000 0.000 34
10 0.002 1.000 35 11 1.000 0.000 36 12 1.000 0.000 37 13 1.000 0.000 38 14 0.000 1.000 39 15 1.000 0.000 40 16 1.000 0.000 41 17 1.000 0.002 42 21 1.000 0.000 43 22 1.000 0.000 44 23 1.000 0.000 45 24 1.000 0.000 46 25 0 .000 1.000 t 47 26 1.000 0.000 48 27 1.000 0.002 59 28 1.000 0.000 60 29 1.000 0.000 61
Hamilton Madison Paper Hamilton Madison 1.000 0.000 65 1.000 0.000 1.000 0.000 66 1.000 0.000 1.000 0.000 67 1.000 0.000 1.000 0.000 68 1.000 0.000 1.000 0.000 69 1.000 0.000 1.000 0.000 70 1.000 0.000 1.000 0.000 71 1.000 0.000 0.000 1.000 72 1.000 0.000 0.000 1.000 73 1.000 0.000 0.000 1.000 74 1.000 0.000 0.002 1.000 75 1.000 0.000 0.000 1.000 76 1.000 0.000 0.000 1.000 77 1.000 0.000 0.000 1,000 78 1.000 0.000 0.000 1.000 79 1.000 0.000 0.000 1.000 80 1.000 0.000 0.000 1.000 81 1.000 0.000 0.000 1.000 82 1.000 0.000 0.000 1.000 83 1.000 0.000 1.000 0.000 84 1.000 0.000 1 .000 0.001 85 1 .000 0.000 1.000 0.000
t This paper has been misclassified by the neural network.
Table 4. Rates per 1000 words of on and upon.
on upon Hamilton 3.28 3.35 Madison 7.83 0.14
rences o f on to occurrences o f on or upon. Table 8.1-1 of Mosteller and Wallace (1964) indicates that the rates per 1000 words are as shown in Table 4. We can there- fore expect a ratio of 3.28/(3.28 + 3.35) -- 0.49 for Hamilton and 7.83/(7.83 + 0.14) -- 0.98 for Madison. Merriam shows that groups of three papers have ratios of 0.36-0.64 for Hamilton and 0.93-1.00 for Madi- son. Using Mosteller and Wallace's conclusions, he includes all the disputed papers as Madison's work and his figures seem to support this decision. Their figures are grouped well amongst the ratios for the undisputed Madison works. However, the group that includes paper 55 is the most Hamilton-like, reflecting Mosteller and Wallace's conclusions above.
McColly and Weier (1983) use function words to examine the Middle English Pearl-poems. They use a likelihood ratio technique, based on the assump- tion that all of their function words have a Poisson distribution. However, they make no effort to check this rather unwarranted assumption. They also apply their technique to the F e d e r a l i s t P a p e r s using thirteen of Mosteller and Wallace's function words. Their results are shown in Table 5. A value is significant, that is it indicates different authorship, if it is less than 0.05. It can be seen that the Hamilton samples, papers 60 and 66, are homogeneous, as are the disputed papers, numbers 53 and 57, and to a lesser extent, the Madison papers, 14 and 45. Each Hamilton paper is significantly different from each Madison paper. Paper 53 appears to be significantly different from all the Hamilton and Madison papers, but is more unlike the Hamilton papers. Paper 57 however, is significantly different from the Hamilton papers, but appears to be homogeneous with the Madison papers. McColly and Weier therefore conclude that the disputed papers, 53 and 57, are the work of Madison.

Table 5. Results from McColly and Weier (1983).
Paper Number
Madison 14 45
Disputed 53 57
Hamilton 60 66
Madison 14 45
Disputed 53 57 60
0.0040 0.0002 0.7729
0.0801 0.0315 0.0499 0.1327 0.2011 0.0001 0.0006 0.0000 0.0001
0.5499 0.0022 0.0001
Hamilton 66
Thus, in other studies on the Federalist Papers,
people have concluded that the disputed papers are the work of Madison, with the possible exception of paper 55. Our results are consistent with these conclusions, assigning all of the disputed papers to Madison. Per- haps the subset of function words that we used omitted words that in other studies were less convincing in ascribing authorship of paper 55 to Madison.
5.2. The jo int papers
The joint papers, probably due to their nature, have not been investigated as much as the disputed papers. It is difficult to draw conclusions about a paper that is acknowledged to have been written by two people. Mosteller and Wallace conclude that papers 18 and 19 are largely written by Madison while paper 20 remains inconclusive.
Paper 18 is assigned to Hamilton by our neural network. Only seven of our eleven words occur at all in the text, and marker words for Madison may be missing from our subset of words. The sections written by Hamilton may include enough of his marker words to allow the neural network to conclude that it is his work.
Paper 19 is investigated by Farringdon and Morton (1990). Using the cusum technique, they divide the text into sections by Madison and Hamilton. Paragraphs 1-3, 7 and 14-20 are assigned to Hamilton and the remainder to Madison. Farringdon and Morton (1990) conclude that
Hamilton would then be the source of 35 sentences out of the 66, supporting the claim of Mosteller and Wallace that his was the larger part of the paper.
However, Mosteller and Wallace (1964) actually conclude that Madison wrote most of paper 19 and Farringdon and Morton's technique has been discred- ited by many researchers including Holmes and
Tweedie (1995). Hilton and Holmes (1993) follow up on this work using their t-statistic. They discredit the cusum method, and their results do not support Farringdon and Morton (1990)'s conclusions. Don- nelly and Tweedie (1995) use a multivariate extension to Hilton and Holmes (1993)'s t-statistic and conclude that, although a significant difference between the sections is found with the division proposed by Farring- don and Morton (1990), their permutation test, which examines every possible division of text, finds that the most significantly different section is made up of sentences 31 to 64 which would straddle the Farringdon and Morton (1990) division.
Paper 20 has only 1512 words, making it one of the shorter papers in the series. Bourne (1901) says of it:
Fully nine-tenths of it is drawn from Madison's own abstract of Sir William Temple's Observations upon the United Provinces and of Fetice's Code de l 'Humanit~ . . . Sir William Temple's claim to be recognized as joint author of No. 20 is far stronger than Hamilton's. There are two paragraphs out of twenty-four in No. 20 which appear to have come from Hamilton.
Thus there is the possibility of Madison being influenced by Temple's words. Mosteller and Wallace (1964) spend some time investigating this paper. They find that some words normally used by Hamilton could be traced to Temple's work. Other such words led them to attribute three paragraphs to Hamilton. Since our work assigned paper 20 to Hamilton, we investigated the distribution of the function words that we used. The paragraphs that were attributed to Hamilton con- tain two occurrences of on and one each of upon and from. The rest of the text contains sixteen occurrences of from, six of on, three of an, two of may and one of every. It would appear that the influence of Temple is strong enough to lead the neural network to attribute the whole paper to Hamilton. It may be worth investi-

gating how the neural network attributes the separate sections of the paper, but the sample sizes appear too small for a meaningful comparison.
6. Conclusions
In this paper we have illustrated the principles of apply- ing neural network methods to stylometry. We have shown that neural computation offers several impor- tant advantages over current stylometric techniques. A neural network learns from data that is presented to it, and is able to generalize from that to classify previ- ously unseen works. They have a high level of fault tolerance and can deal with noise in the data while capturing the nuances of high level interactions between the input measures that even the researcher may not fully understand. Traditional techniques are unable to deal with many of these points.
We have shown the effectiveness of neural net- works by taking a famous example of disputed authorship, that of the Federalist Papers. Using the undisputed papers as training data we have shown that the network is able to classify the disputed papers as being by Madison, a conclusion that is consistent with previous work on the subject.
This initial experiment was performed using a subset of function words identified by Mosteller and Wallace. Other measures, such as the vocabulary rich- ness measures used by Holmes (1992), Brunet's W statistic or the proportional pairs method used by Merriam (1989), could also be used as input measures to a neural network. As learning techniques and archi- tectures change, neural networks should become more powerful classifiers. All of these aspects are worthy of further work and we hope to undertake a number of them. The results will be reported in due course.
7. Acknowledgements
We would like to thank Shane Dickson and Colin Campbell at the University of Bristol for their help and advice while working on this paper.
The neural network simulation software that we used was Xerion, developed by van Camp at the University of Toronto, April 1993.
References
Anderson, J. A. and E. Rosenfeld, eds. Neurocomputing: Founda- tions of Research. MIT Press, 1989.
Bailey, R. W. "Authorship Attribution in a Forensic Setting". In Advances in Computer-Aided Literary and Linguistic Research. Proceedings of the Fifth International Symposium on Computers in Literary and Linguistic Research. Eds. D. E. Ager, E E. Knowles and J. Smith. Birmingham, 1979, pp. 1-15.
Bourne, E. G. "The Authorship of The Federalist". In Essays in Historical Criticism. New York: Charles Scribner's Sons, 1901, pp. 113-45.
Brunet, E. Vocabulaire de Jean Giraudoux: Structure et Evolution. Gen~ve: Slatkine, 1978.
Cox, D. R. and L. Brandwood. "On a Discriminatory Problem Con- nected with the Works of Plato". Journal of the Royal Statistical Society, Series B, 21, 1 (1959), 195-200.
Damerau, E J. "The Use of Function Word Frequencies as Indicators of Style". Computers and the Humanities, 9 (1975), 271-80.
de Morgan, S. E. Memoir of Augustus de Morgan by his Wife Sophia Elizabeth de Morgan with Selections from his Letters. London: Longmans, Green, and Co., 1882.
Donnelly, C. A. and E J. Tweedie. "A Multivariate Test for the Attribution of Authorship". Forthcoming in Forensic Linguistics, 3, 1 (1996).
Evans, W., P. B. Musgrove, J. Davies and J. D. Phillips. "Use of a Neural Network to Differentiate Iron Deficiency Anaemia from Beta Thalassaemia Minor". In Proceedings of the International Conference on Neural Networks and Expert Systems in Medicine andHealthcare. 1994, pp. 61-62.
Farringdon, M. G. and A. Q. Morton. "Fielding and the Federalist". TechnicalReport. CSC 90/R6. University of Glasgow, 1990.
Fu, L. M. Neural Networks in Computer Intelligence. Singapore: McGraw-Hill, 1994.
Hecht-Nielson, R. Neurocomputing. Addison Wesley, 1989. Hilton, M. L. and D. I. Holmes. "An Assessment of Cumulative
Sum Charts for Authorship Attribution". Literary and Linguistic Computing, 8, 2 (1993), 73-80.
Holmes, D. I. "A Stylometric Analysis of Mormon Scripture and Related Texts". Journal of the Royal Statistical Society, Series A, 155, 1 (1992),91-120.
Holmes, D. I. "Authorship Attribution". Computers and the Human- ities, 28, 2 (1994), 87-106.
Holmes, D. I. and E J. Tweedie. "The Cusum Controversy". Forth- coming in Forensic Linguistics, 3, 1 (1996).
Jain, A. K., R. C. Dubes and C. C. Chen. "Bootstrap Techniques for Error Estimation". IEEE Transactions on Pattern Analysis and Machine Intelligence, 9 (1987), 628-33.
Lewis, P. A. "Some Results in Tests for Poisson Processes". Biometrika, 52 (1965), 67-77.
Matthews, R. and T. Merriam. "Neural Computation in Stylometry I: An Application to the Works of Shakespeare and Fletcher". Literary and Linguistic Computing, 8, 4 (1993), 203-209.
McColly, W. B. and D. Weier. "Literary Attribution and Likelihood Ratio Tests: The Case of the Middle English Pearl-poems". Com- puters and the Humanities, 17 (1983), 65-75.
McMurty, G. J. "Adaptive Optimization Procedures". In A Prelude to Neural Networks: Adaptive and Learning Systems. Ed. J. M. Mendel. Prentice Hall, 1994.
Mendenhall, T. C. "'The Characteristic Curves of Composition". Science, 11 (1887), 237-49.
Merriam, T. V. N. "An Experiment with the Federalist Papers". Computers and the Humanities, 23 (1989), 251-54.

10
Michaelson, S., A. Q. Morton and N. Hamilton-Smith, "To Couple is the Custom". Technical Report CSR-22-79. University of Edinburgh Department of Computer Science, 1979.
Mosteller, E and D. L. Wallace. Applied Bayesian and Classical Inference: The Case of the Federalist Papers. Addison-Wesley, 1964.
Oakman, R. L. Computer Methods for Literary Research. Columbia: University of South Carolina Press, 1980.
Press, W., S. T. Flannery and W. Vetterling. NumericalRecipes in C. Cambridge University Press, 1988.
Stone, M. "Cross-validatory Choice and Assessment of Statistical Predictions". Journal of the Royal Statistical Society, Series B, 36 (1974), I 11-47.
van Camp, D. A Users Guide to the Xerion Neural Network Simu- lator: Version 3.1. Department of Computer Science, University of Toronto, 1993.