Embed Size (px)
Citation preview

Why NoCs

The System Interconnect
Chips tend to have more than one “core” Control processors Accelerators Memories I/O
How do we get them to talk to each other? This is called “System Interconnect”
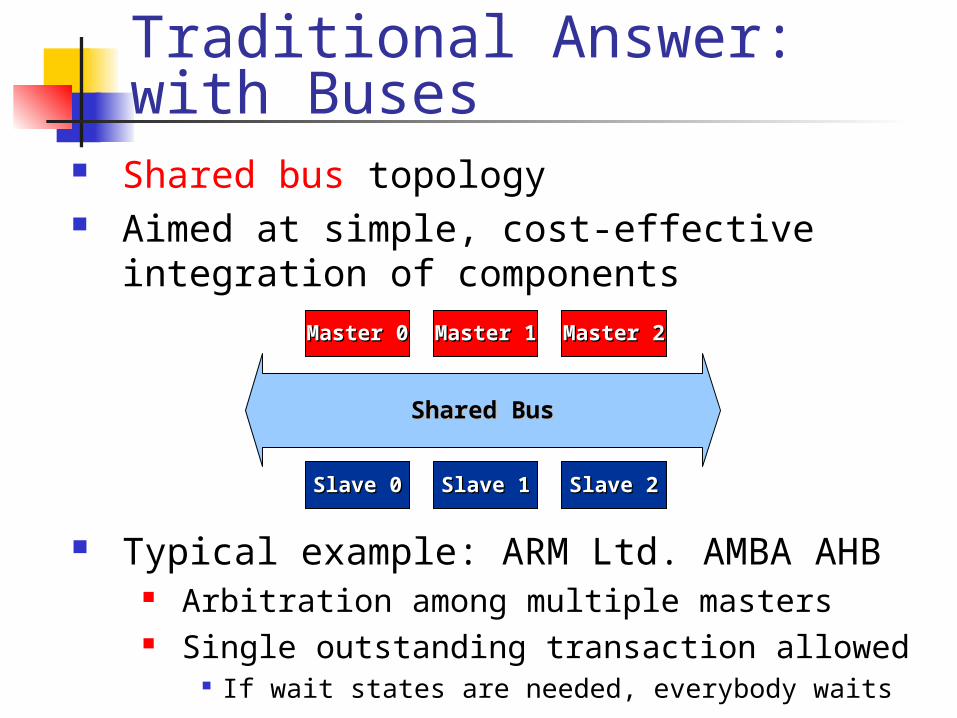
Shared bus topology Aimed at simple, cost-effective integration
of components
Shared BusShared Bus
Slave 2Slave 2Slave 1Slave 1Slave 0Slave 0
Master 2Master 2Master 1Master 1Master 0Master 0
Typical example: ARM Ltd. AMBA AHB Arbitration among multiple masters Single outstanding transaction allowed
If wait states are needed, everybody waits
Traditional Answer: with Buses

So, Are We All Set?
Well... not really. Let’s consider two trends
System/architectural: systems are becoming highly parallel
Physical: wires are becoming slower (especially in relative terms)

System/Architectural Level Parallel systems... OK, but how much?
CPUs: currently four cores (not so many...) Playstation/Cell: currently nine engines
(still OK) GPUs: currently 100+ shaders (hey!) Your next cellphone: 100+ cores (!!!)
And the trend is: double every 18 months

Multicore Testimonials 1
Intel IXP2800Intel IXP2800with 16 micro-engineswith 16 micro-engines
and one Intel XScale coreand one Intel XScale core
““We believe that Intel’s We believe that Intel’s Chip Level Chip Level
Multiprocessing (CMP) Multiprocessing (CMP) architectures represent architectures represent
the future of the future of microprocessors because microprocessors because
they deliver massive they deliver massive performance scaling performance scaling
while effectively while effectively managing power and managing power and
heat”.heat”.
White paper “Platform 2015: White paper “Platform 2015: Intel Processor and Platform Intel Processor and Platform
evolution for the next decade”evolution for the next decade”
““We believe that Intel’s We believe that Intel’s Chip Level Chip Level
Multiprocessing (CMP) Multiprocessing (CMP) architectures represent architectures represent
the future of the future of microprocessors because microprocessors because
they deliver massive they deliver massive performance scaling performance scaling
while effectively while effectively managing power and managing power and
heat”.heat”.
White paper “Platform 2015: White paper “Platform 2015: Intel Processor and Platform Intel Processor and Platform
evolution for the next decade”evolution for the next decade”

Multicore Testimonials 2
"The next 25 years of "The next 25 years of digital signal processing digital signal processing technology will literally technology will literally integrate hundreds of integrate hundreds of processors on a single processors on a single
chip to conceive chip to conceive applications beyond our applications beyond our
imagination.”imagination.”
Mike Hames, senior VP, Mike Hames, senior VP, Texas Instruments Texas Instruments
"The next 25 years of "The next 25 years of digital signal processing digital signal processing technology will literally technology will literally integrate hundreds of integrate hundreds of processors on a single processors on a single
chip to conceive chip to conceive applications beyond our applications beyond our
imagination.”imagination.”
Mike Hames, senior VP, Mike Hames, senior VP, Texas Instruments Texas Instruments
““Focus here is on Focus here is on parallelism and what's parallelism and what's
referred to as multi-core referred to as multi-core technology.”technology.”
Phil Hester, CTO, AMD Phil Hester, CTO, AMD
““Focus here is on Focus here is on parallelism and what's parallelism and what's
referred to as multi-core referred to as multi-core technology.”technology.”
Phil Hester, CTO, AMD Phil Hester, CTO, AMD
Intel: 80-core chip Intel: 80-core chip shown at ISSCC 2007shown at ISSCC 2007Intel: 80-core chip Intel: 80-core chip
shown at ISSCC 2007shown at ISSCC 2007
Rapport: Kilocore (1024 Rapport: Kilocore (1024 cores), for gaming & cores), for gaming &
mediamedia
Expected mid 2007Expected mid 2007
Rapport: Kilocore (1024 Rapport: Kilocore (1024 cores), for gaming & cores), for gaming &
mediamedia
Expected mid 2007Expected mid 2007
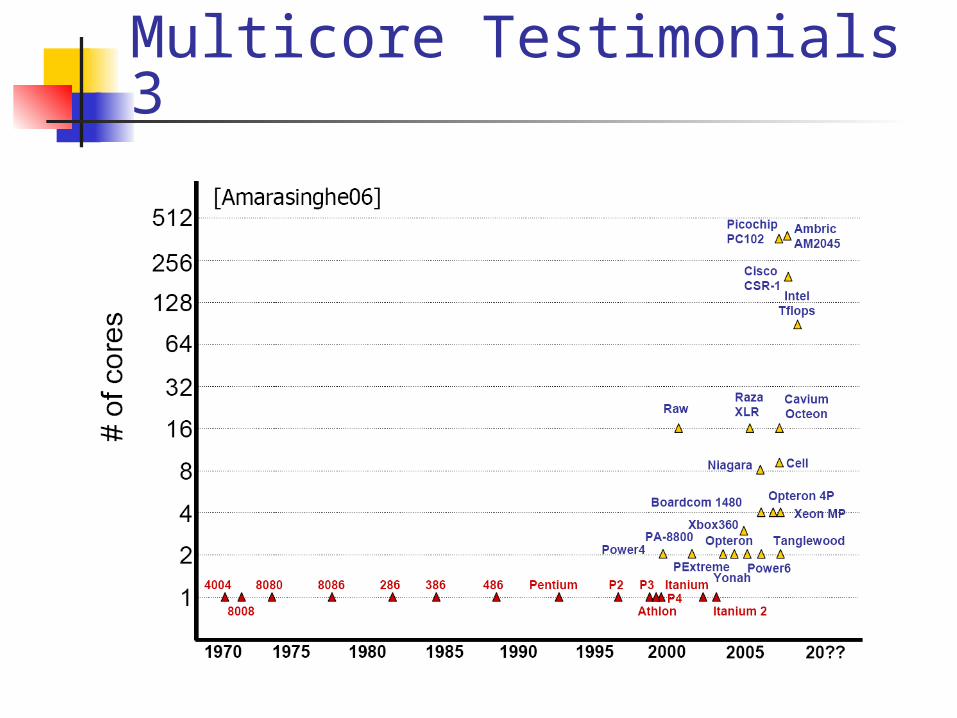
Multicore Testimonials 3

What Does This Mean for the Interconnect?
A new set of requirements! High performance
Many cores will want to communicate, fast High parallelism (bandwidth)
Many cores will want to communicate, simultaneously
High heterogeneity/flexibility Cores will operate at different frequencies, data
widths, maybe with different protocols
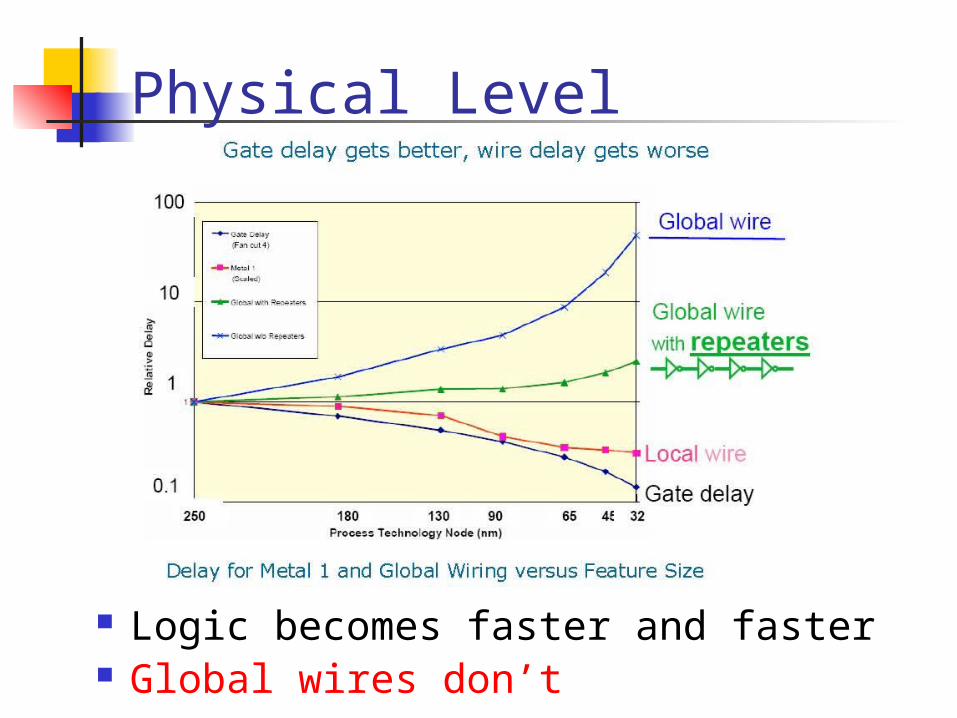
Physical Level
Logic becomes faster and faster Global wires don’t
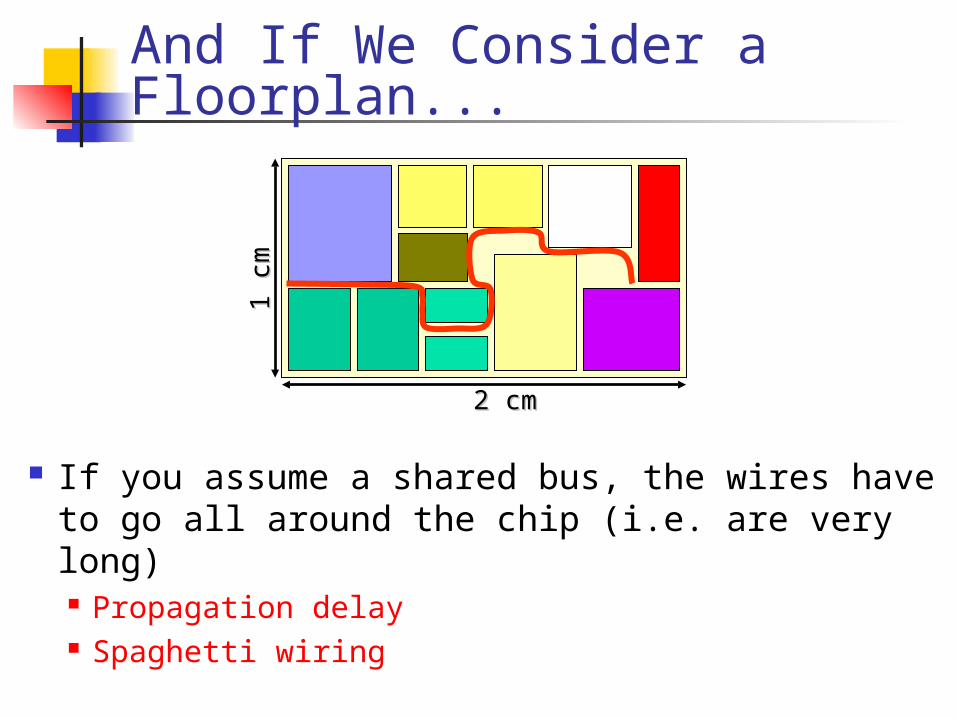
If you assume a shared bus, the wires have to go all around the chip (i.e. are very long) Propagation delay Spaghetti wiring
1 c
m1
cm
2 cm2 cm
And If We Consider a Floorplan...

What Does This Mean for the Interconnect?
A new set of requirements! Short wiring
Point-to-point and local is best Simple, structured wiring
Bundles of many wires are impractical to route
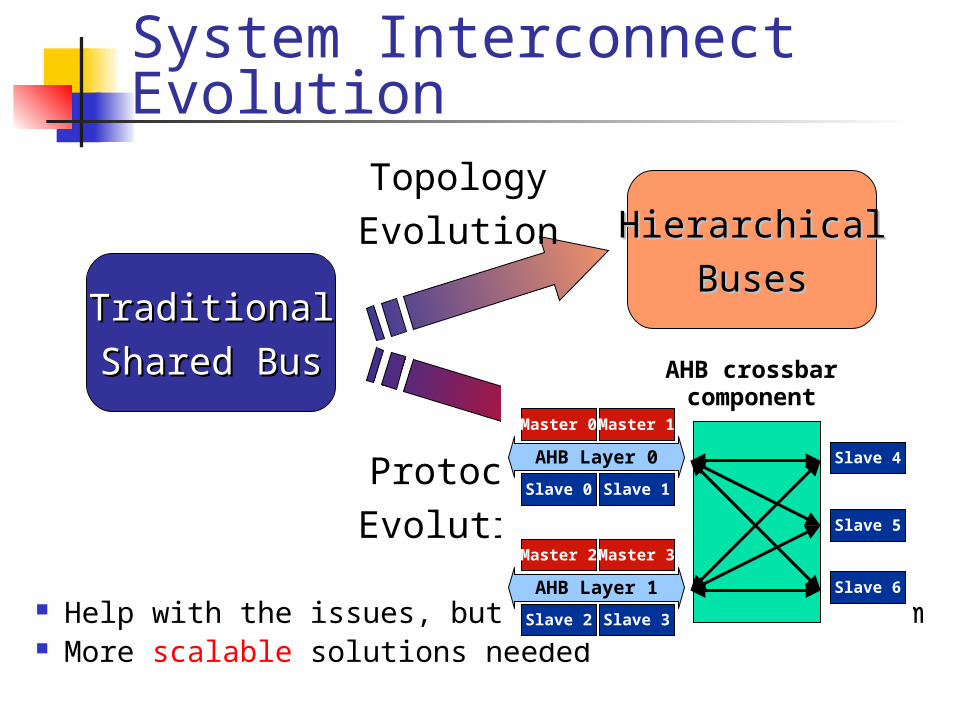
System Interconnect Evolution
TraditionalTraditional
Shared BusShared Bus
HierarchicalHierarchical
BusesBuses
AdvancedAdvanced
Bus ProtocolsBus Protocols
TopologyEvolution
ProtocolEvolution
Help with the issues, but do not fully solve them More scalable solutions needed
Master 0
AHB Layer 0
Slave 0 Slave 1
Master 1
Master 2
AHB Layer 1
Slave 2 Slave 3
Master 3
Slave 4
Slave 5
Slave 6
AHB crossbarcomponent
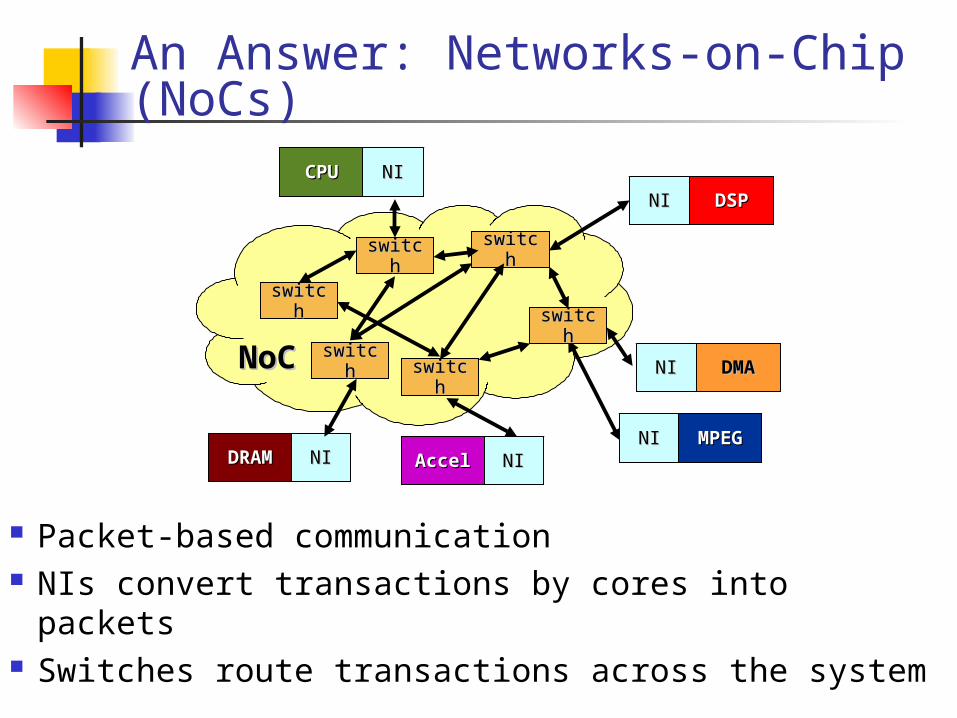
An Answer: Networks-on-Chip (NoCs)
DSPDSPNINI
NINIDRAMDRAM
switcswitchh
DMADMANINI
CPUCPU NINI
NINIAccelAccelNINI MPEGMPEG
switcswitchh
switcswitchh
switcswitchh
NoCNoC
switcswitchh
switcswitchh
Packet-based communication NIs convert transactions by cores into packets Switches route transactions across the system

First Assessment of NoCs
High performance High parallelism (bandwidth)
Yes: just add links and switches as you add cores High heterogeneity/flexibility
Yes: just design appropriate NIs, then plug in Short wiring
Yes: point-to-point, then just place switches as close as needed
Simple, structured wiring Yes: links are point-to-point, width can be tuned

Problem Solved?
Maybe, but... buses excel in simplicity, low power and low area
When designing a NoC, remember that tradeoffs will be required to keep those under control
Not all designs will require a NoC, only the “complex” ones

How to Design NoCs

How to Make NoCs Tick A NoC is a small network
Many of the same architectural degrees of freedom
Some problems are less stringent Static number of nodes (Roughly) known traffic patterns and
requirements Some problems are much tougher
MANY less resources to solve problems Latencies of nanoseconds, not
milliseconds But... what characterizes a network?

Key NoC Properties
Topology Routing policy (where) Switching policy (how) Flow control policy (when) Syn-, asyn- or meso-chronicity ...and many others!
Huge design space

NoC Topologies
Must comply with demands of… performance (bandwidth & latency) area power routability
Can be split in… direct: node connected to every switch indirect: nodes connected to specific subset
of switches
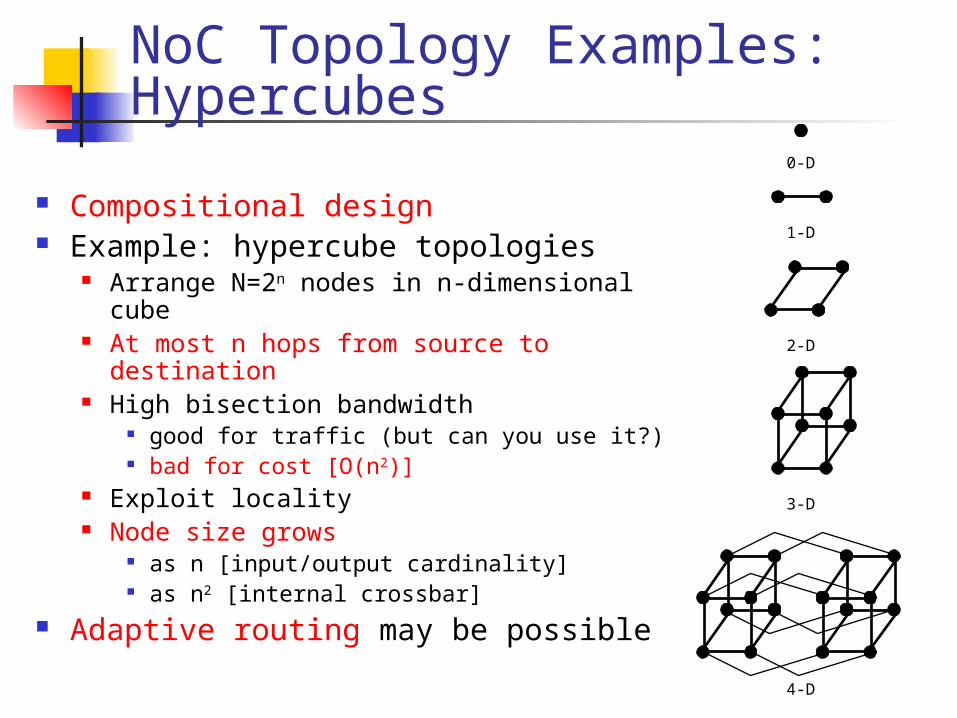
NoC Topology Examples: Hypercubes
Compositional design Example: hypercube topologies
Arrange N=2n nodes in n-dimensional cube
At most n hops from source to destination
High bisection bandwidth good for traffic (but can you use it?) bad for cost [O(n2)]
Exploit locality Node size grows
as n [input/output cardinality] as n2 [internal crossbar]
Adaptive routing may be possible
0-D
1-D
2-D
3-D
4-D

NoC Topology Examples: Multistage Topologies
Need to fix hypercube resource requirements Idea: unroll hypercube vertices
switch sizes are now bounded, but loss of locality more hops can be blocking; non-blocking with even more stages
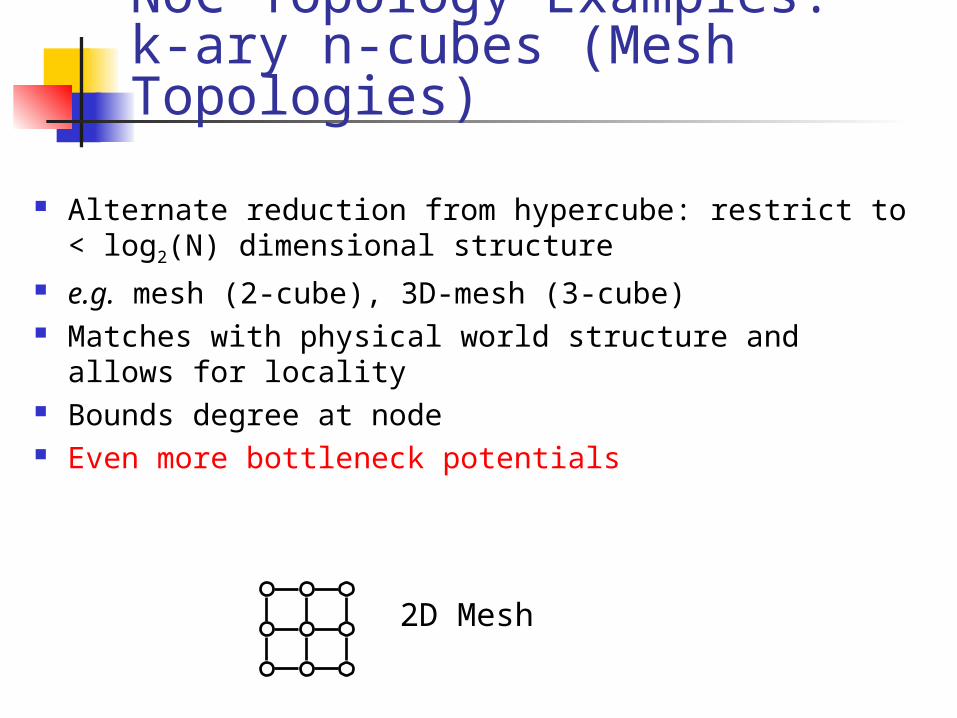
Alternate reduction from hypercube: restrict to < log2(N) dimensional structure
e.g. mesh (2-cube), 3D-mesh (3-cube) Matches with physical world structure and allows for
locality Bounds degree at node Even more bottleneck potentials
2D Mesh
NoC Topology Examples:k-ary n-cubes (Mesh Topologies)
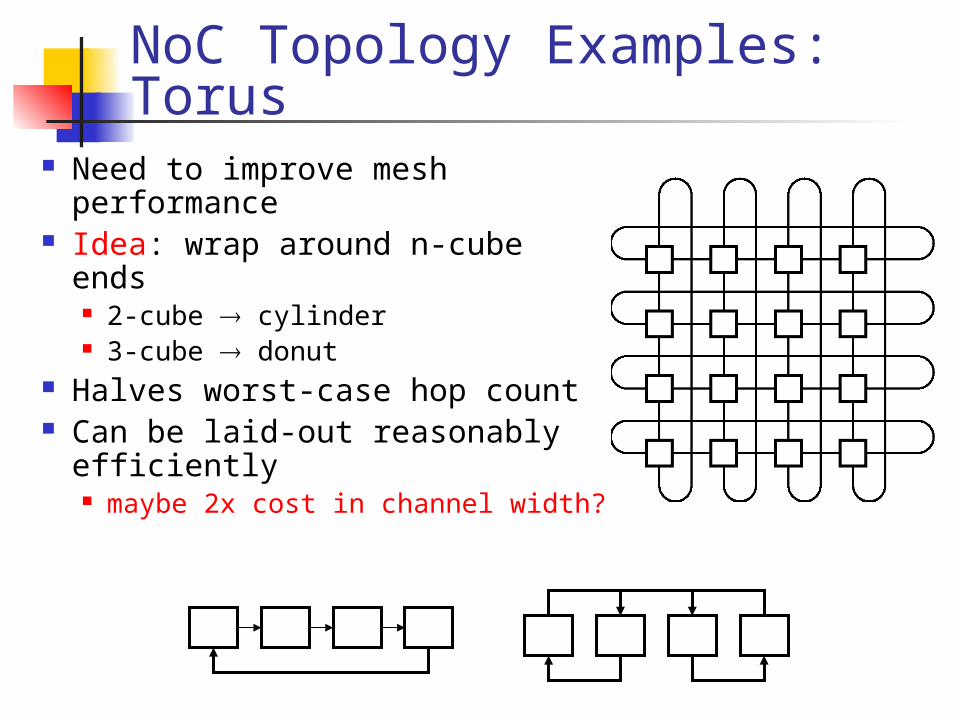
Need to improve mesh performance
Idea: wrap around n-cube ends 2-cube cylinder 3-cube donut
Halves worst-case hop count Can be laid-out reasonably
efficiently maybe 2x cost in channel width?
NoC Topology Examples:Torus
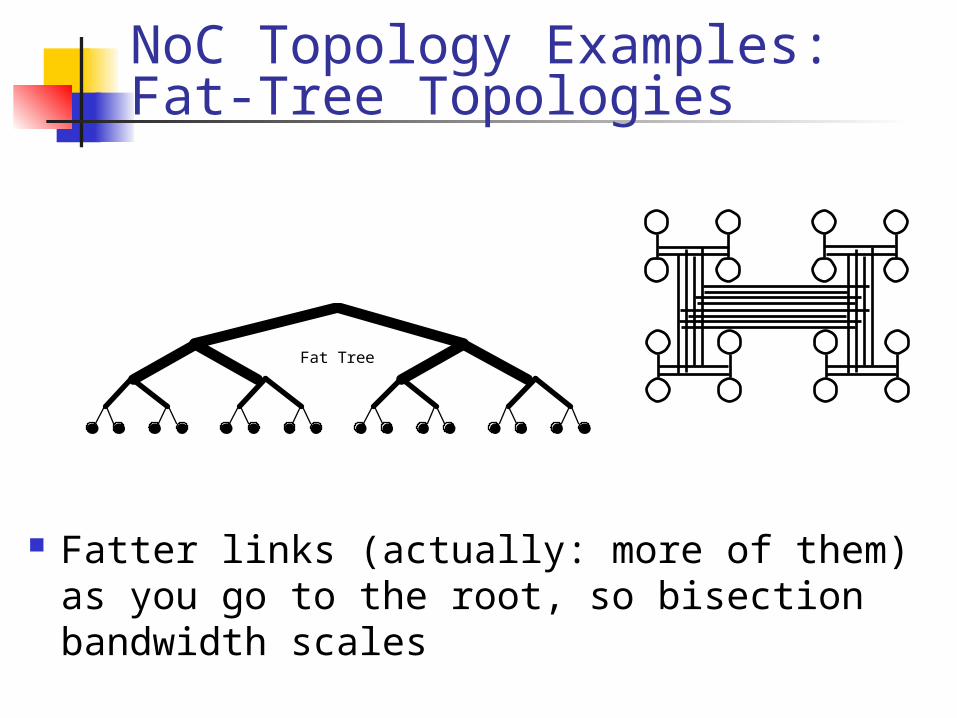
NoC Topology Examples:Fat-Tree Topologies
Fatter links (actually: more of them) as you go to the root, so bisection bandwidth scales
Fat Tree

NoC Routing Policies
Static e.g. source routing or coordinate-based simpler to implement and validate
Adaptive e.g. congestion-based potentially faster much more expensive allows for out-of-order packet delivery possibly a bad idea for NoCs
Huge issue: deadlocks
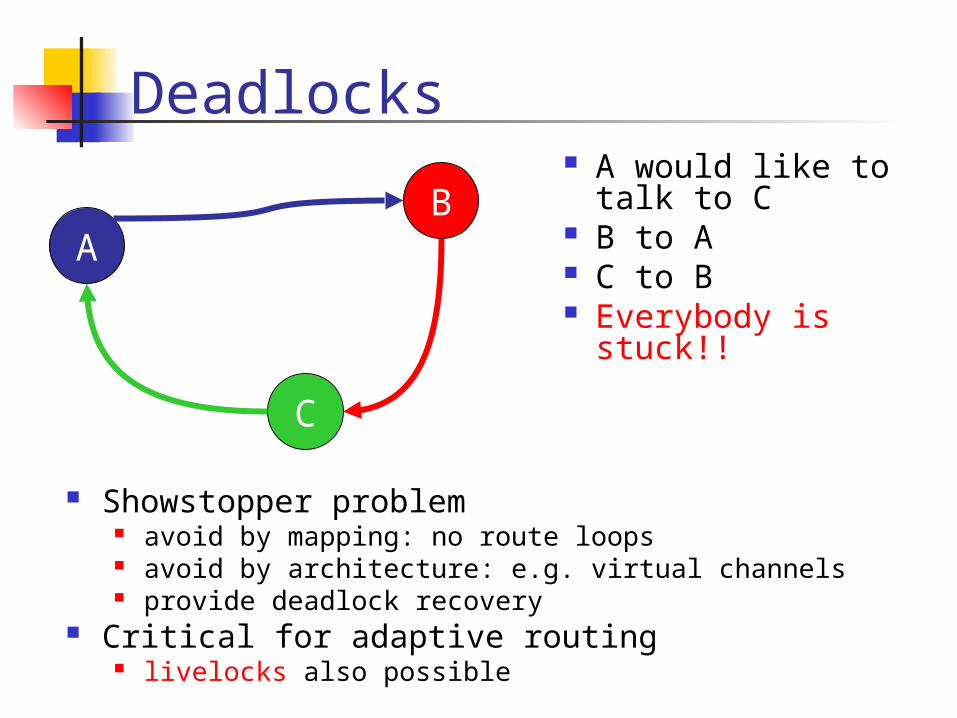
Deadlocks
Showstopper problem avoid by mapping: no route loops avoid by architecture: e.g. virtual channels provide deadlock recovery
Critical for adaptive routing livelocks also possible
A
C
B A would like to talk
to C B to A C to B Everybody is stuck!!

NoC Switching Policies
Packet switching maximizes global network usage dynamically store-and-forward
minimum logic, but higher latency, needs more buffers wormhole
minimum buffering, but deadlock-prone, induces congestion
Circuit switching optimizes specific transactions
no contention, no jitter requires handshaking
may fail completely setup overhead
A
B
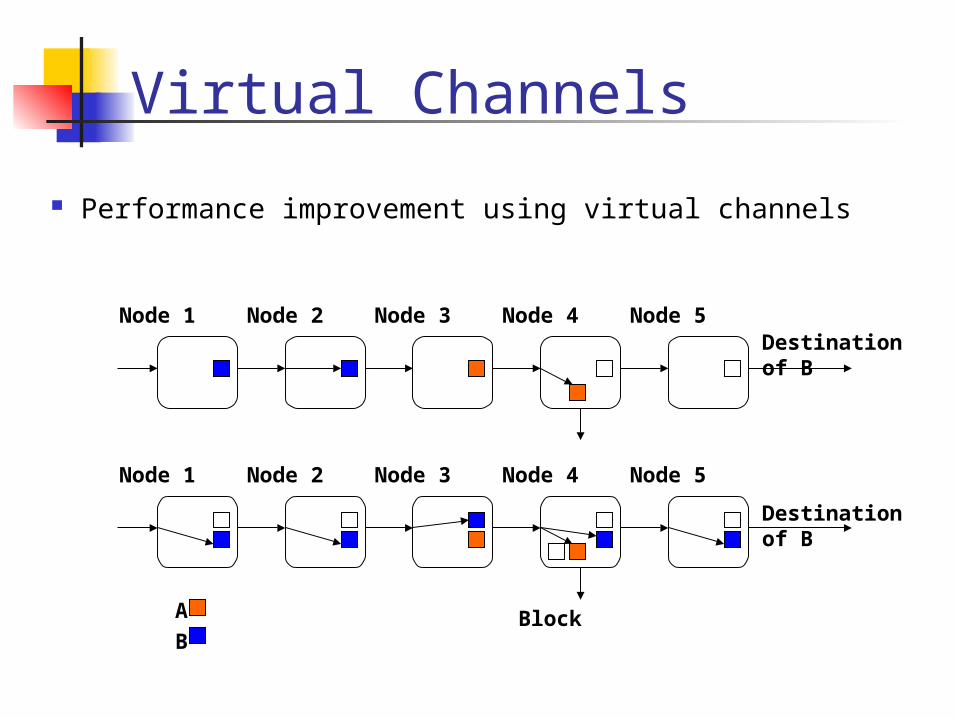
Virtual Channels
Performance improvement using virtual channels
Node 1 Node 2 Node 3 Node 4 Node 5Destination of B
Node 1 Node 2 Node 3 Node 4 Node 5
Block
Destination of B

NoC Flow Control Policies We need it because...
Sender may inject bursty traffic Receiver buffers may fill up Sender and receiver may operate at
different frequencies Arbitrations may be lost
How? TDMA: pre-defined time slots Speculative: send first, then wait for
confirmation (acknowledge - ACK) Conservative: wait for token, then send
(credit-based) Remember... links may be pipelined
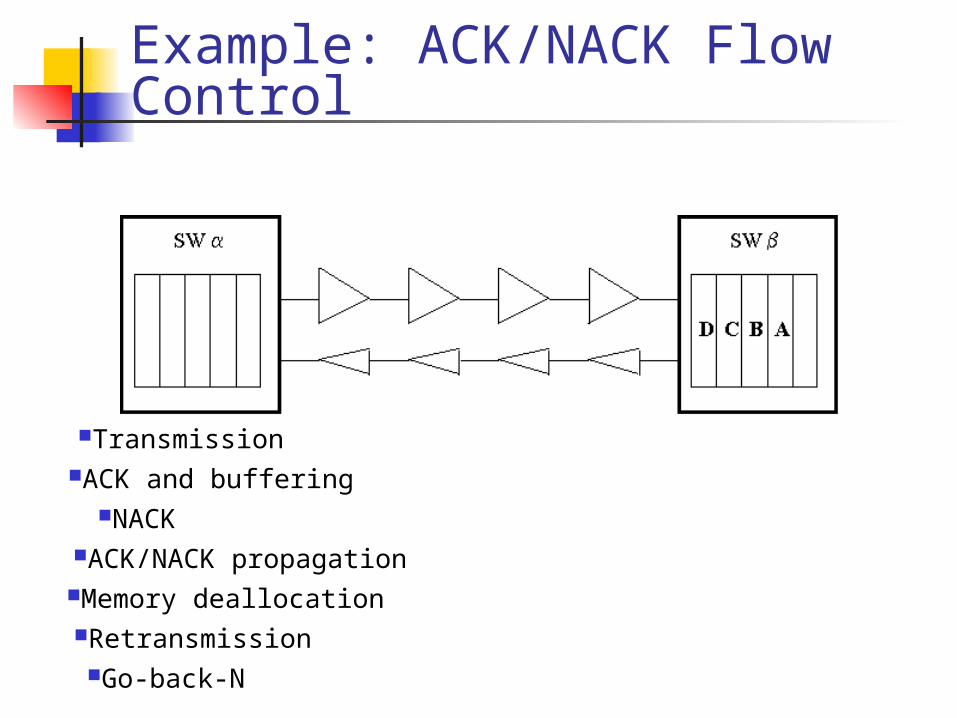
ACK/NACK propagationMemory deallocation
NACK
RetransmissionGo-back-N
Transmission
Example: ACK/NACK Flow Control
ACK and buffering

NoC Timing: Synchronous
Flip-flops everywhere, clock tree Much more streamlined design Clock tree burns 40% power
budget, plus flip flops themselves Not easy to integrate cores at
different speeds Increasingly difficult to constrain
skew and process variance Worst-case design

NoC Timing: Asynchronous
Potentially allows for data to arrive at any time, solves process variance etc.
Average-case behaviour Lower power consumption Maximum flexibility in IP integration More secure for encryption logic Less EMI Much larger area Can be much slower (if really robust)
Two-way handshake removes the “bet” of synchronous logic
Intermediate implementations exist Much tougher to design
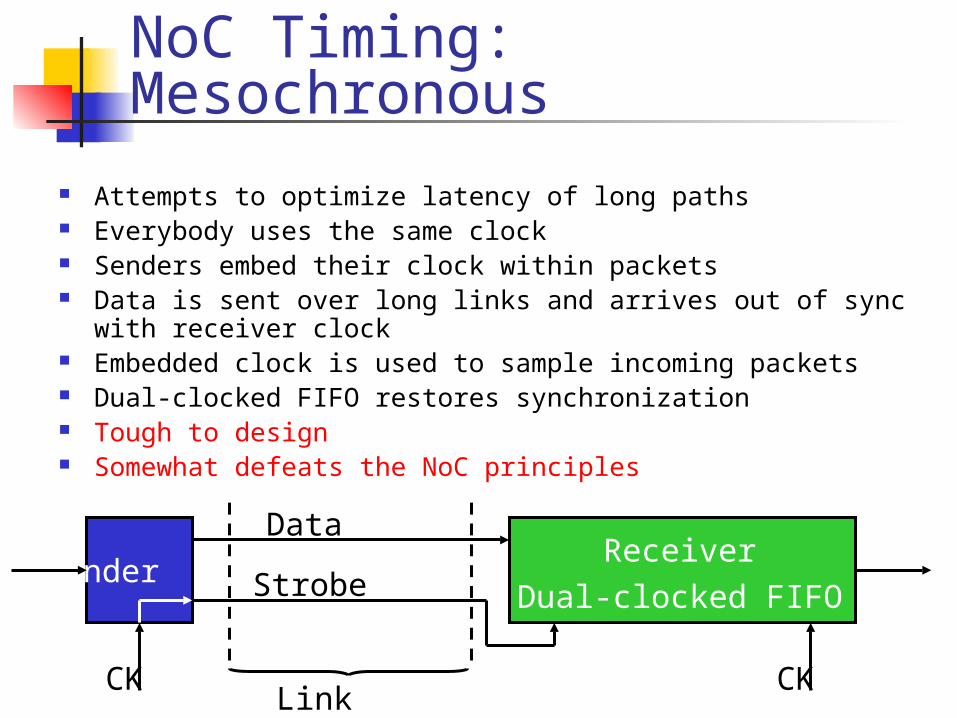
NoC Timing: Mesochronous
Attempts to optimize latency of long paths Everybody uses the same clock Senders embed their clock within packets Data is sent over long links and arrives out of sync with
receiver clock Embedded clock is used to sample incoming packets Dual-clocked FIFO restores synchronization Tough to design Somewhat defeats the NoC principles
ReceiverDual-clocked FIFO
Sender
Data
Strobe
CK CKLink

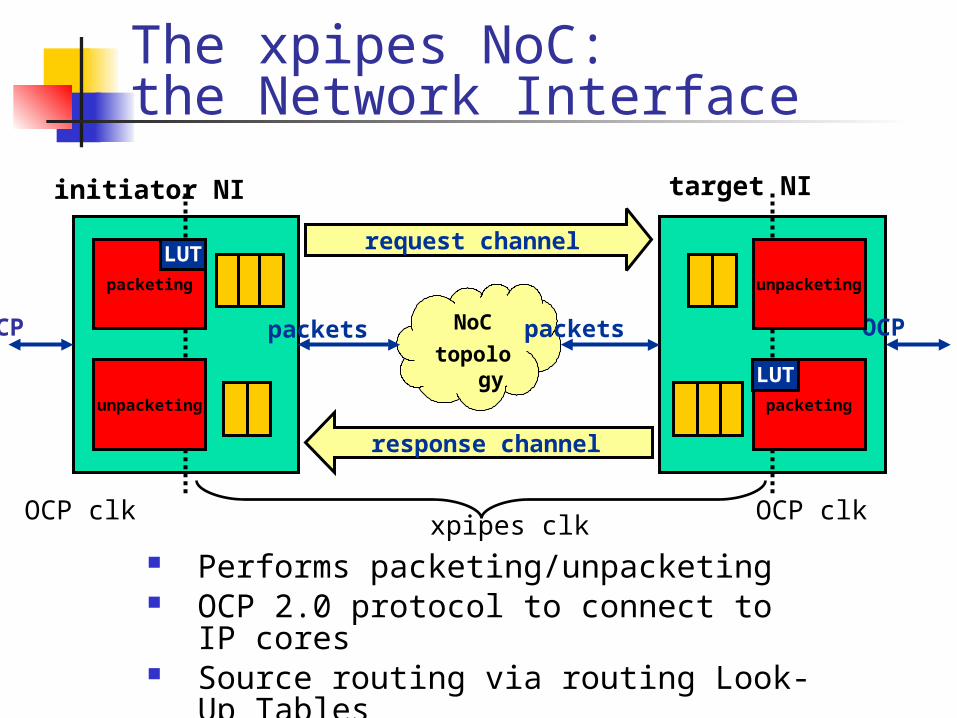
The xpipes NoC

xpipes is a library of NoC components Network Interface (NI), Switch, Link Configurability of parameters such as flit width,
amount of buffering, flow control and arbitration policies…
xpipes is designed to be scalable to future technology nodes, architecturally and physically
Leverages a cell synthesis flow, no hard macros Pipelined links to tackle wire propagation delay
A complete CAD flow is provided to move from the application task graph level to the chip floorplan
The xpipes NoC
NoC
topology
OCP OCP
OCP clk xpipes clk OCP clk
packets packets
packeting unpacketing
packetingunpacketing
initiator NI target NI
Performs packeting/unpacketing OCP 2.0 protocol to connect to IP
cores Source routing via routing Look-Up
Tables Dual Clock operation
LUT
LUT
request channel
response channel
The xpipes NoC:the Network Interface

Basic OCP Concepts Point-to-point, unidirectional, synchronous
Easy physical implementation Master/slave, request/response
Well-defined, simple roles Extensions
Added functionality to support cores with more complex interface requirements
Configurability Match a core’s requirements exactly Tailor design to required features only
Reference: [SonicsInc]Reference: [SonicsInc]
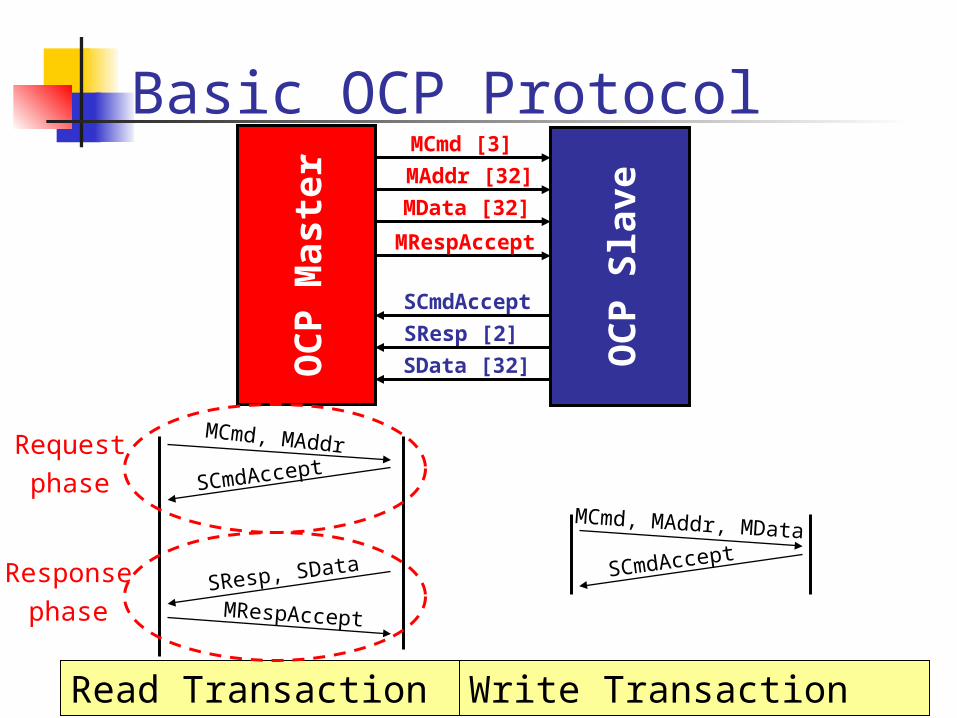
Basic OCP Protocol
OC
P M
aste
r
OC
P S
lave
MCmd [3]
MAddr [32]
MData [32]
SCmdAccept
SResp [2]
SData [32]
MCmd, MAddr
SCmdAccept
SResp, SData
MCmd, MAddr, MData
SCmdAccept
MRespAccept
Read Transaction Write Transaction
MRespAccept
Requestphase
Responsephase

OCP Extensions
Simple Extensions Byte Enables Bursts Flow Control/Data Handshake
Complex Extensions Threads and Connections
Sideband Signals Interrupts, etc.
Testing Signals
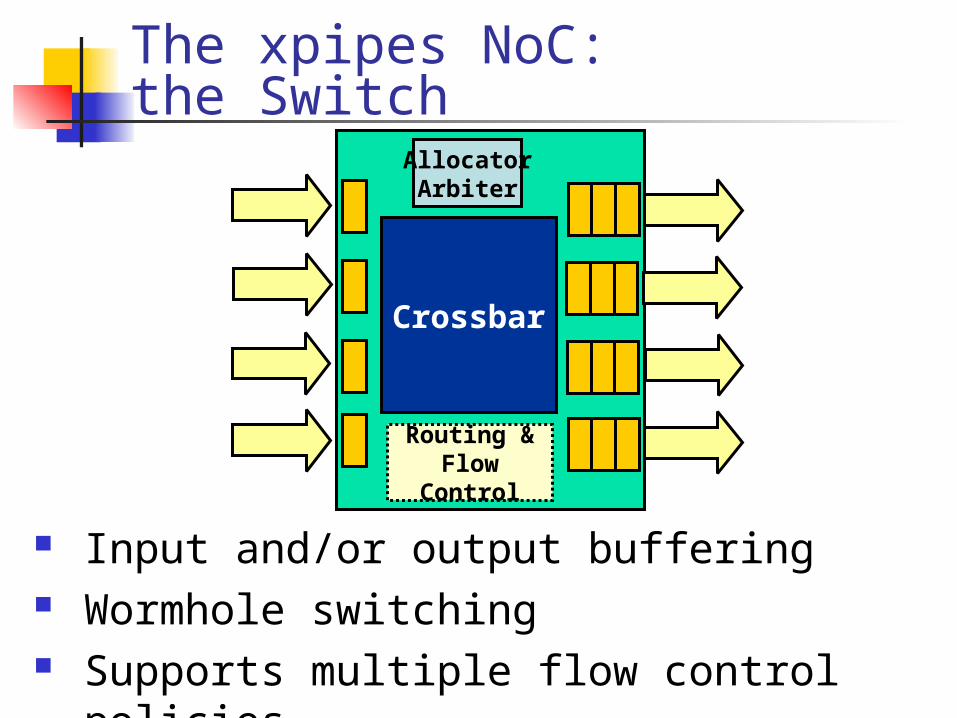
Crossbar
AllocatorArbiter
Routing & Flow
Control
Input and/or output buffering Wormhole switching Supports multiple flow control policies
The xpipes NoC:the Switch
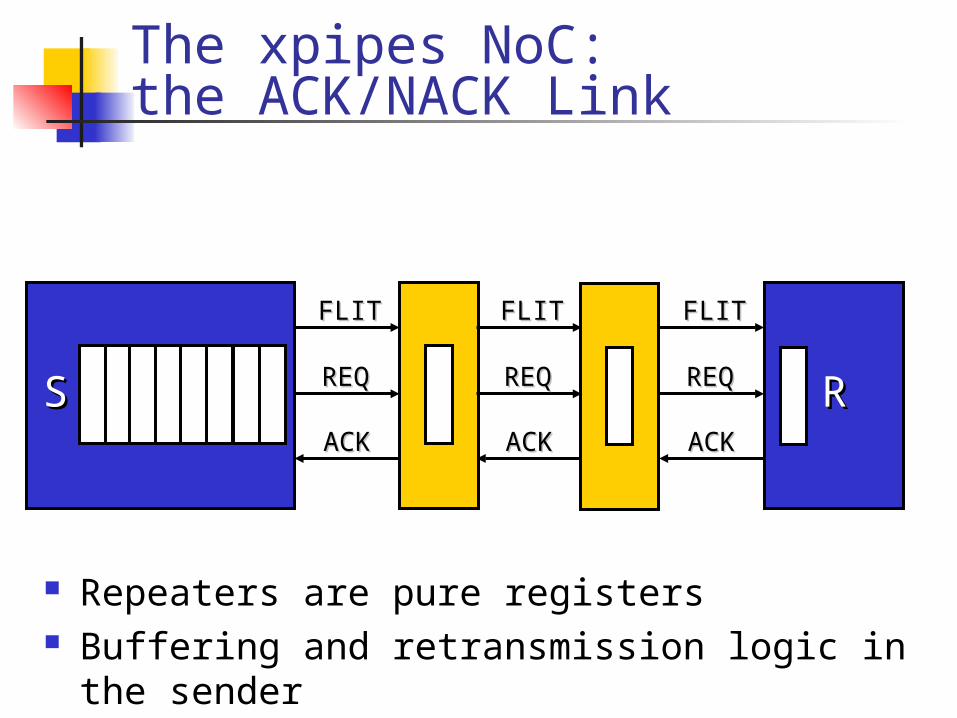
Repeaters are pure registers Buffering and retransmission logic in the
sender
SS RR
FLITFLIT
REQREQ
ACKACK
FLITFLIT
REQREQ
ACKACK
FLITFLIT
REQREQ
ACKACK
The xpipes NoC:the ACK/NACK Link
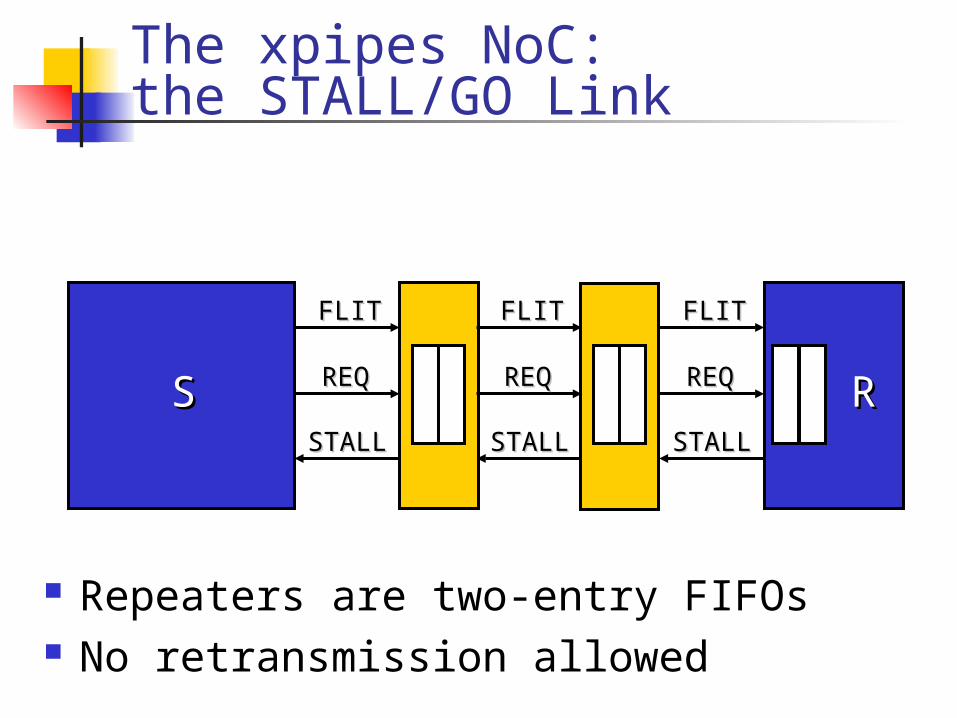
Repeaters are two-entry FIFOs No retransmission allowed
SS RR
FLITFLIT
REQREQ
STALLSTALL
FLITFLIT
REQREQ
STALLSTALL
FLITFLIT
REQREQ
STALLSTALL
The xpipes NoC:the STALL/GO Link

Quality of Service andthe Æthereal NoC

Very challenging!
Signal processing
hard real timevery regular load
high quality
worst casetypically on DSPs
Media processing
hard real timeirregular load
high quality
average caseSoC/media processors
Multi-media
soft real timeirregular load
limited quality
average casePC/desktop
Speaking of Quality of Service...
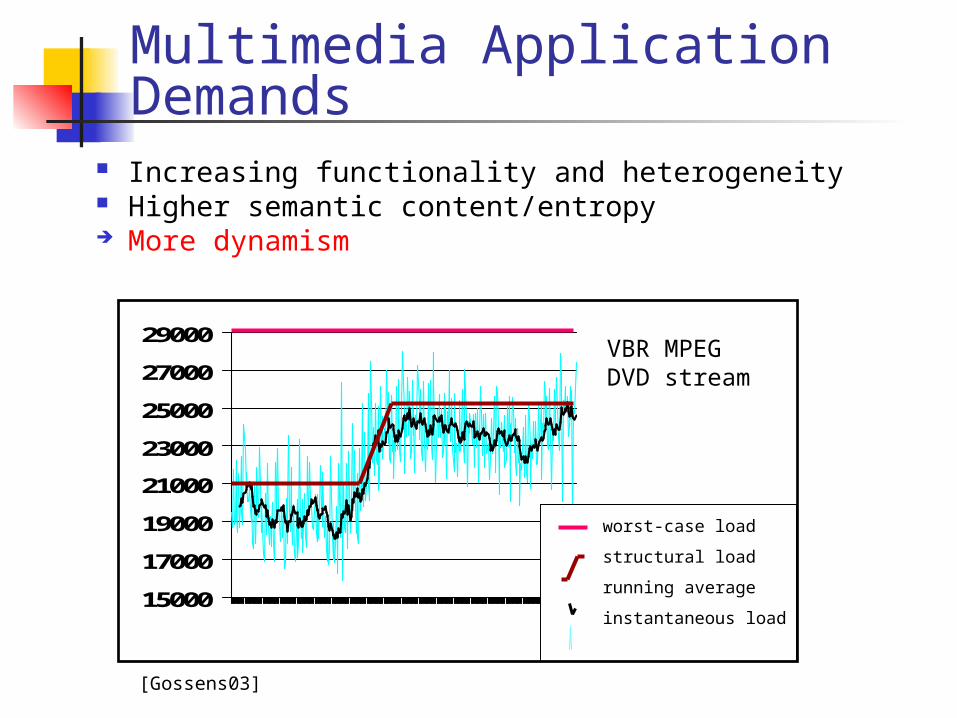
Multimedia Application Demands
Increasing functionality and heterogeneity Higher semantic content/entropy More dynamism
15000
17000
19000
21000
23000
25000
27000
29000
worst-case load
structural load
running average
instantaneous load
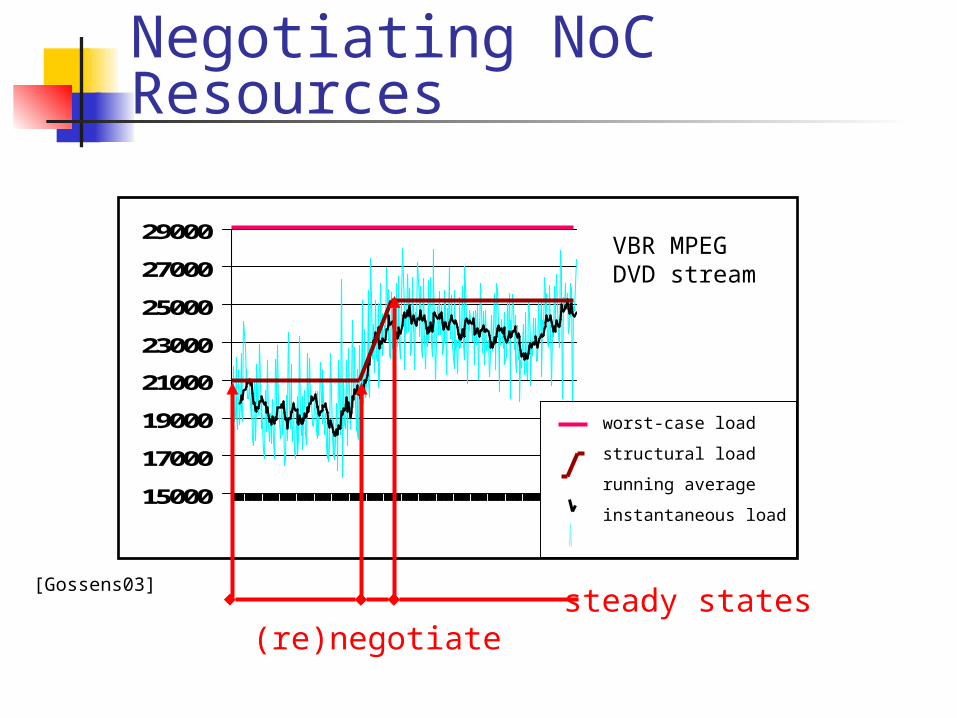
VBR MPEGDVD stream
[Gossens03]
Negotiating NoC Resources
15000
17000
19000
21000
23000
25000
27000
29000
worst-case load
structural load
running average
instantaneous load
VBR MPEGDVD stream
[Gossens03]
(re)negotiatesteady states

A QoS Approach Essential to recover global predictability and
improve performance Applications require it! It fits well with protocol stack concept
What is QoS? Requester poses the service request (negotiation) Provider either commits to or rejects the request Renegotiate when requirements change
After negotiation, steady states that are predictable Guaranteed versus best-effort service Types of commitment
correctness e.g. uncorrupted data completion e.g. no packet loss bounds e.g. maximum latency
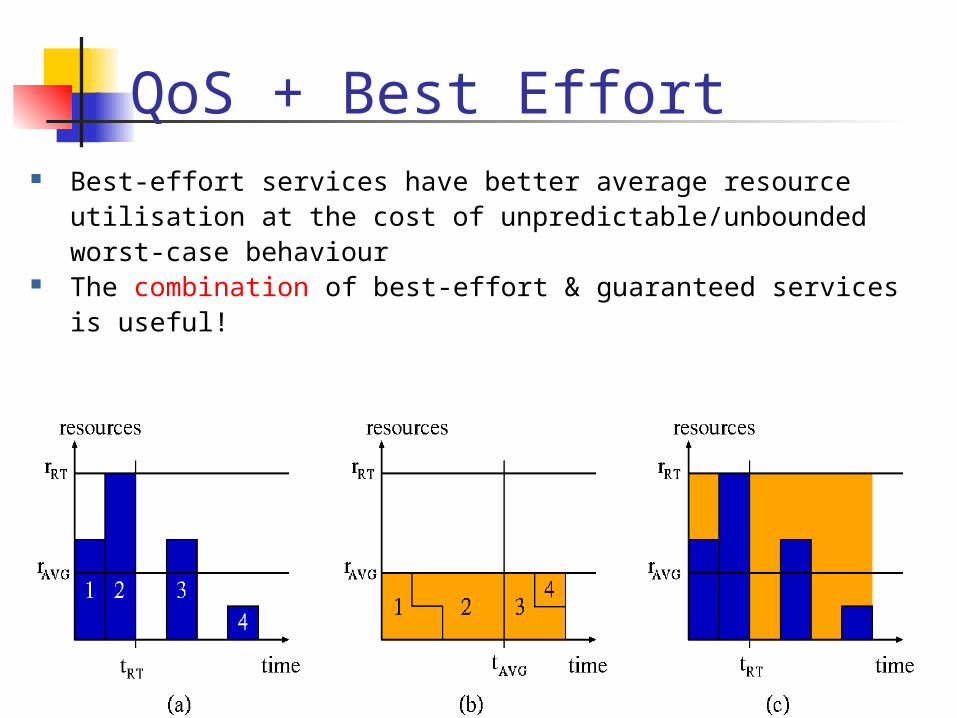
Best-effort services have better average resource utilisation at the cost of unpredictable/unbounded worst-case behaviour The combination of best-effort & guaranteed services is useful!
QoS + Best Effort

QoS in the Æthereal NoC Conceptually, two disjoint networks
a network with throughput+latency guarantees (GT) a network without those guarantees (best-effort, BE)
Several types of commitment in the network combine guaranteed worst-case behaviour
with good average resource usage
priority/arbitration
best-effortrouter
guaranteedrouter
programming

Æthereal Router Architecture
Best-effort router Wormhole routing Input queueing Source routing
Guaranteed throughput router Contention-free routing
synchronous, using slot tables time-division multiplexed circuits
Store-and-forward routing Headerless packets
information is present in slot table A lot of hardware overhead!!!

Æthereal: Contention-Free Routing
Latency guarantees are easy in circuit switching
With packet switching, need to “emulate” Schedule packet injection in network such
that they never contend for same link at same time in space: disjoint paths in time: time-division multiplexing
Use best-effort packets to set up connections Distributed, concurrent, pipelined, consistent Compute slot assignment at build time, run
time, or combination Connection opening may be rejected






























