Embed Size (px)
Citation preview

Network ProcessorsA generation of multi-core processors
INF5063:Programming Heterogeneous Multi-Core Processors
September 11, 2009
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
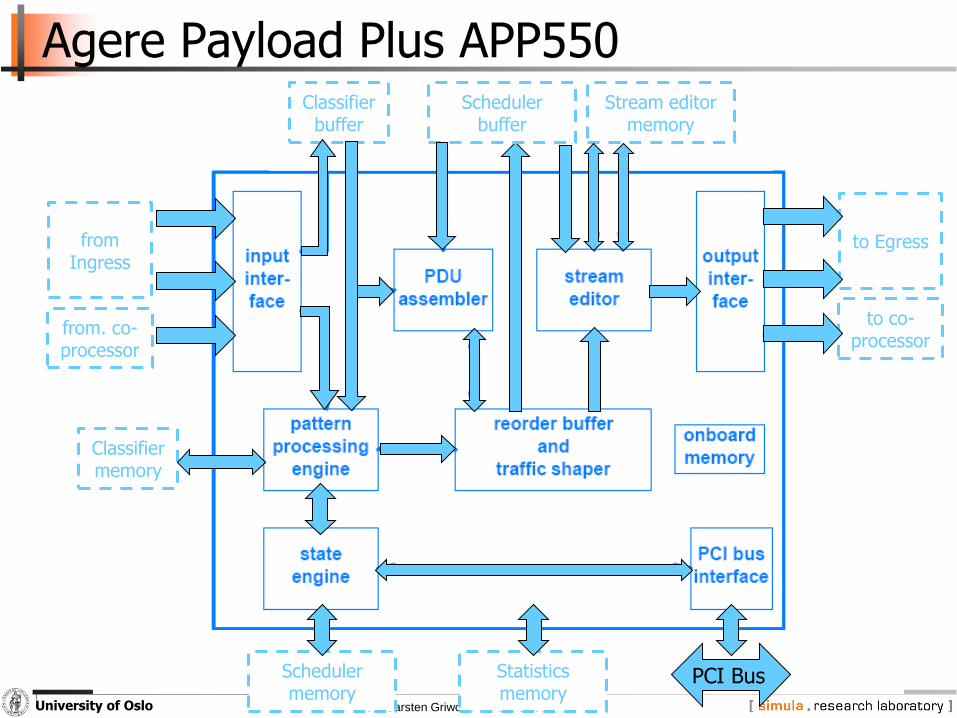
Agere Payload Plus APP550
Classifiermemory
Classifierbuffer
Schedulerbuffer
Stream editormemory
from Ingress
from. co-processor
to Egress
to co-processor
Schedulermemory
Statisticsmemory
PCI Bus
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
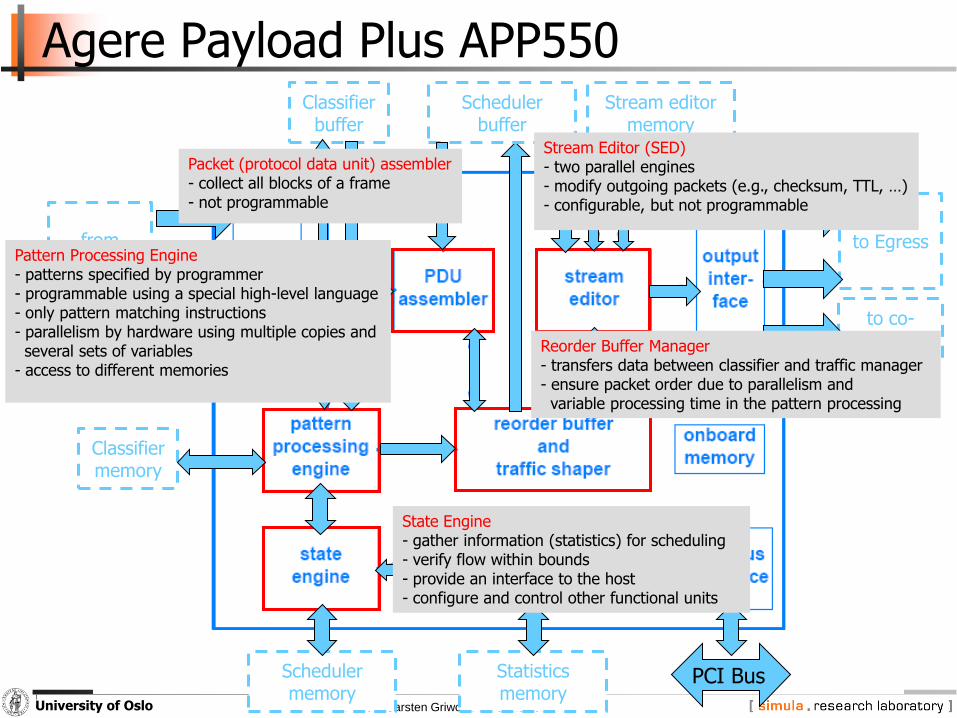
Agere Payload Plus APP550
Classifiermemory
Classifierbuffer
Schedulerbuffer
Stream editormemory
from Ingress
from. co-processor
to Egress
to co-processor
Schedulermemory
Statisticsmemory
PCI Bus
Pattern Processing Engine- patterns specified by programmer- programmable using a special high-level language- only pattern matching instructions- parallelism by hardware using multiple copies and several sets of variables
- access to different memories
State Engine- gather information (statistics) for scheduling - verify flow within bounds- provide an interface to the host- configure and control other functional units
Packet (protocol data unit) assembler- collect all blocks of a frame- not programmable
Stream Editor (SED)- two parallel engines- modify outgoing packets (e.g., checksum, TTL, …)- configurable, but not programmable
Reorder Buffer Manager - transfers data between classifier and traffic manager - ensure packet order due to parallelism andvariable processing time in the pattern processing
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Embedded processorsEmbedded processors
Embedded processorsEmbedded processors
Embedded processorsEmbedded processors
Embedded processorsEmbedded processors
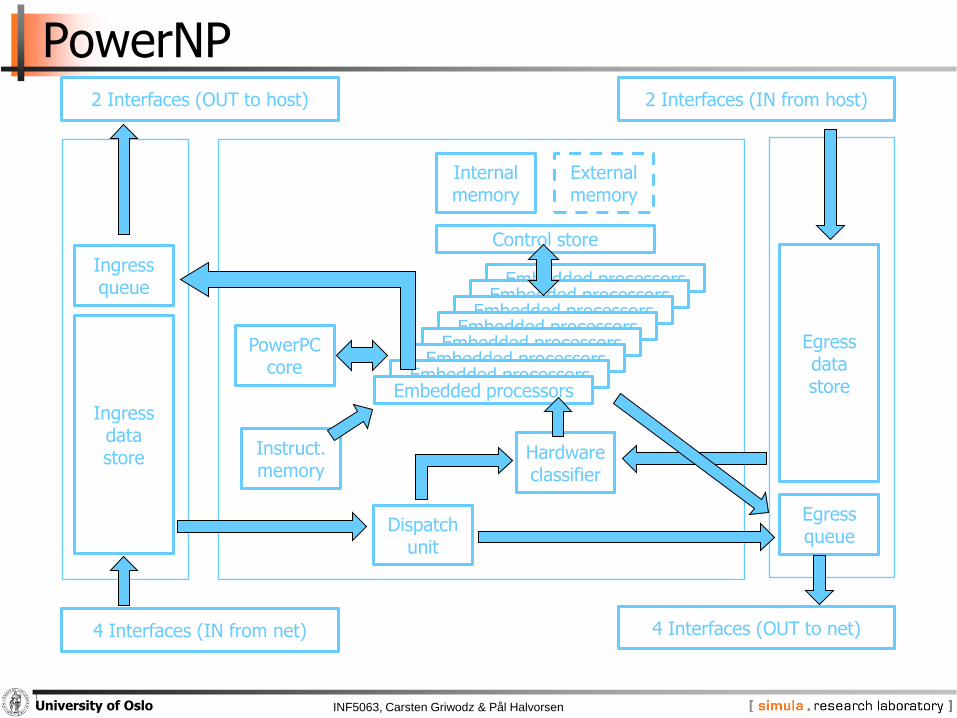
PowerNP
Ingress queue
Ingress data store
Egress queue
Egressdata store
4 Interfaces (IN from net) 4 Interfaces (OUT to net)
Internalmemory
Externalmemory
Control store
Instruct.memory
PowerPCcore
2 Interfaces (OUT to host) 2 Interfaces (IN from host)
Hardwareclassifier
Dispatchunit
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Embedded processorsEmbedded processors
Embedded processorsEmbedded processors
Embedded processorsEmbedded processors
Embedded processorsEmbedded processors
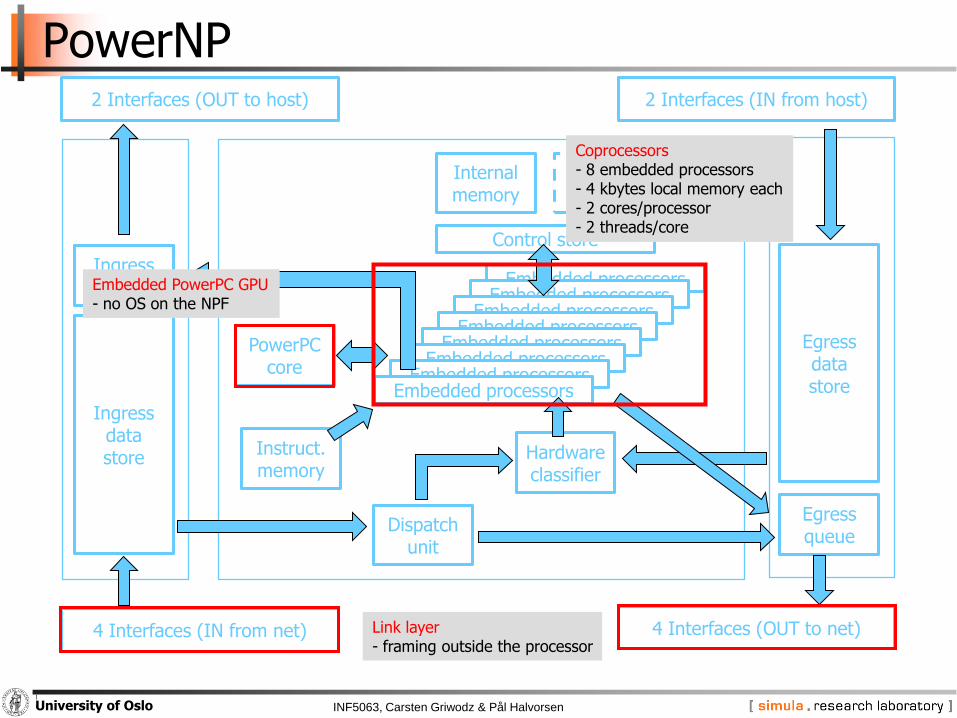
PowerNP
Ingress queue
Ingress data store
Egress queue
Egressdata store
4 Interfaces (IN from net) 4 Interfaces (OUT to net)
Internalmemory
Externalmemory
Control store
Instruct.memory
PowerPCcore
2 Interfaces (OUT to host) 2 Interfaces (IN from host)
Hardwareclassifier
Dispatchunit
Embedded PowerPC GPU- no OS on the NPF
Coprocessors- 8 embedded processors- 4 kbytes local memory each- 2 cores/processor- 2 threads/core
Link layer- framing outside the processor
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
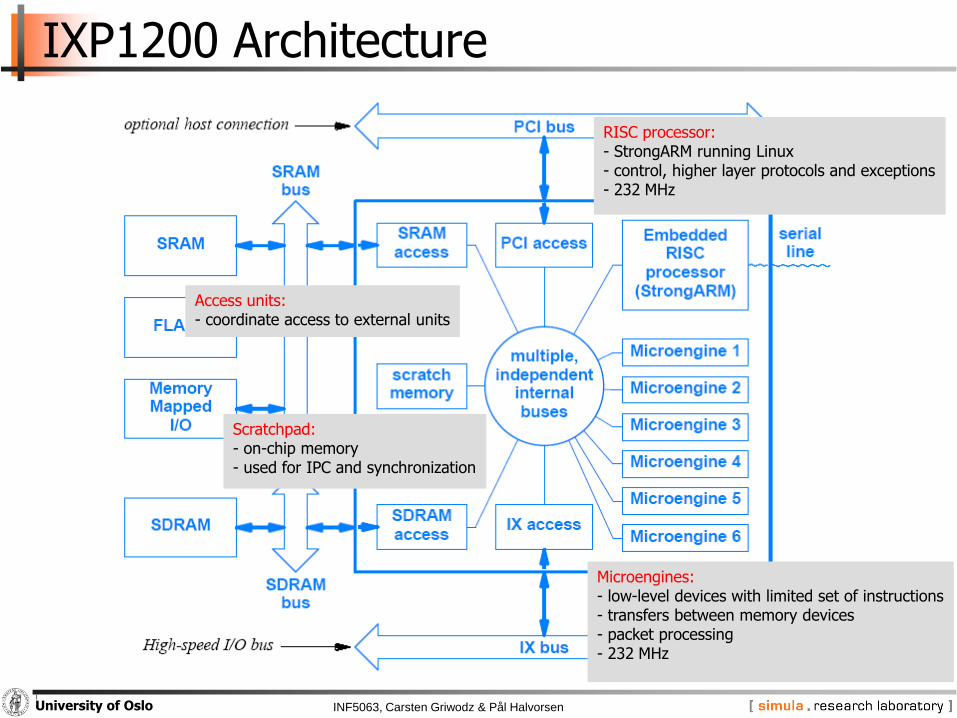
IXP1200 Architecture
RISC processor:- StrongARM running Linux- control, higher layer protocols and exceptions- 232 MHz
Microengines:- low-level devices with limited set of instructions- transfers between memory devices - packet processing- 232 MHz
Access units:- coordinate access to external units
Scratchpad:- on-chip memory- used for IPC and synchronization
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
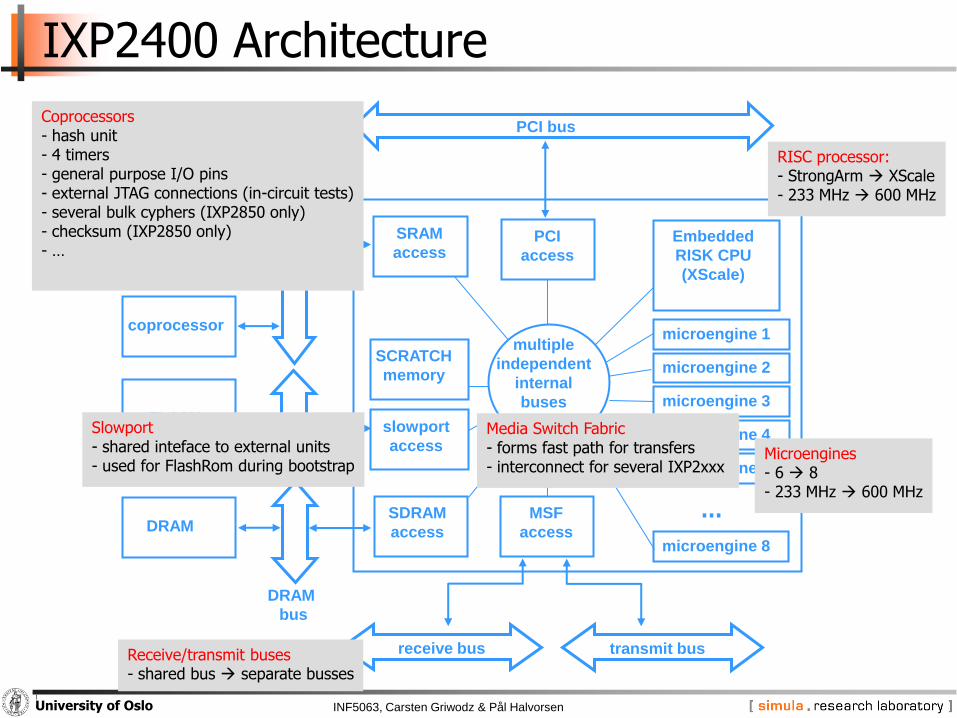
IXP2400 Architecture
microengine 8
SRAM
coprocessor
FLASH
DRAM
SRAM
access
SDRAM
access
SCRATCH
memory
PCI
access
MSF
access
Embedded
RISK CPU
(XScale)
PCI bus
receive bus
DRAM
bus
SRAM
bus
microengine 2
microengine 1
microengine 5
microengine 4
microengine 3
multiple
independent
internal
buses
slowport
access
…
transmit bus
RISC processor:- StrongArm XScale- 233 MHz 600 MHz
Microengines- 6 8- 233 MHz 600 MHz
Media Switch Fabric- forms fast path for transfers- interconnect for several IXP2xxx
Receive/transmit buses- shared bus separate busses
Slowport- shared inteface to external units- used for FlashRom during bootstrap
Coprocessors- hash unit- 4 timers- general purpose I/O pins- external JTAG connections (in-circuit tests)- several bulk cyphers (IXP2850 only)- checksum (IXP2850 only)- …

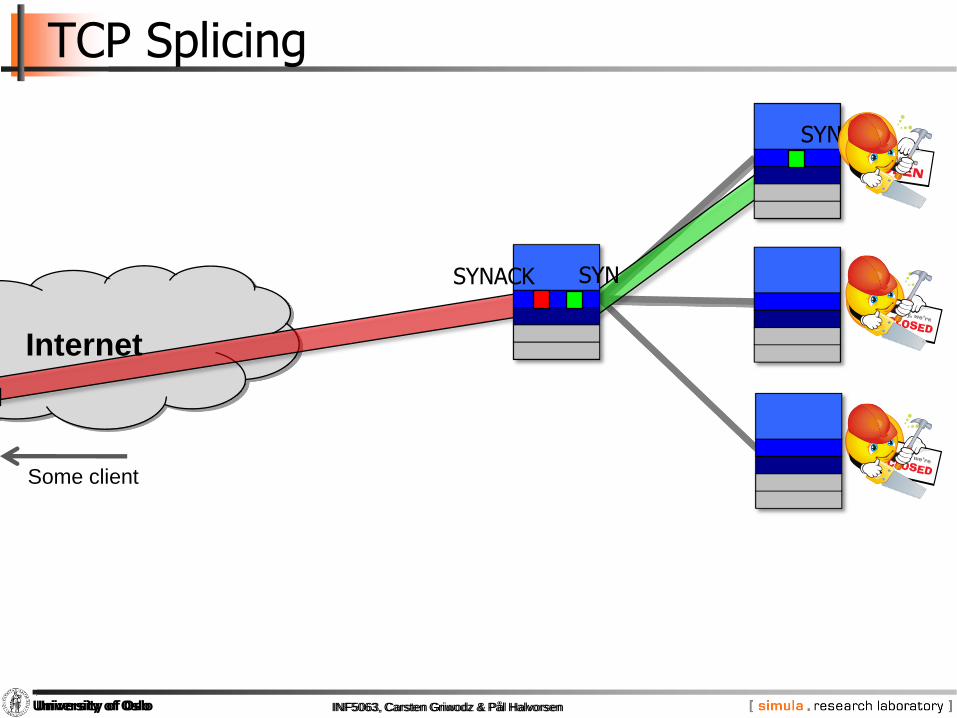
Example: SpliceTCP
INF5063:Programming Heterogeneous Multi-Core Processors
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Internet
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
TCP Splicing
SYN
SYNACK
SYNACK
Some client
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Internet
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
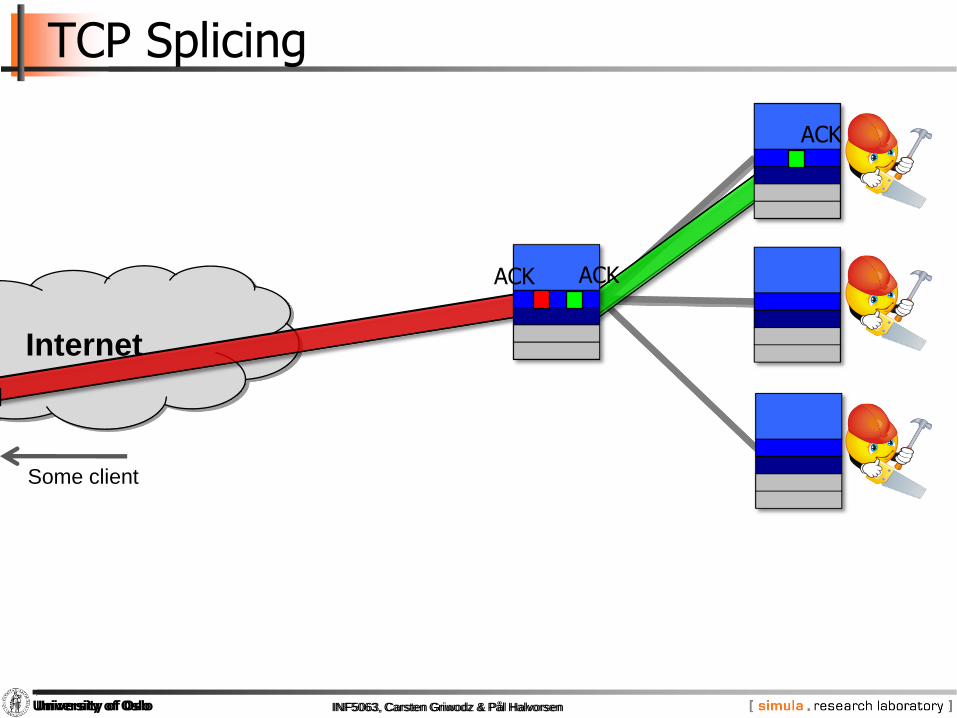
TCP Splicing
ACK
ACK
ACK
Some client
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Internet
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
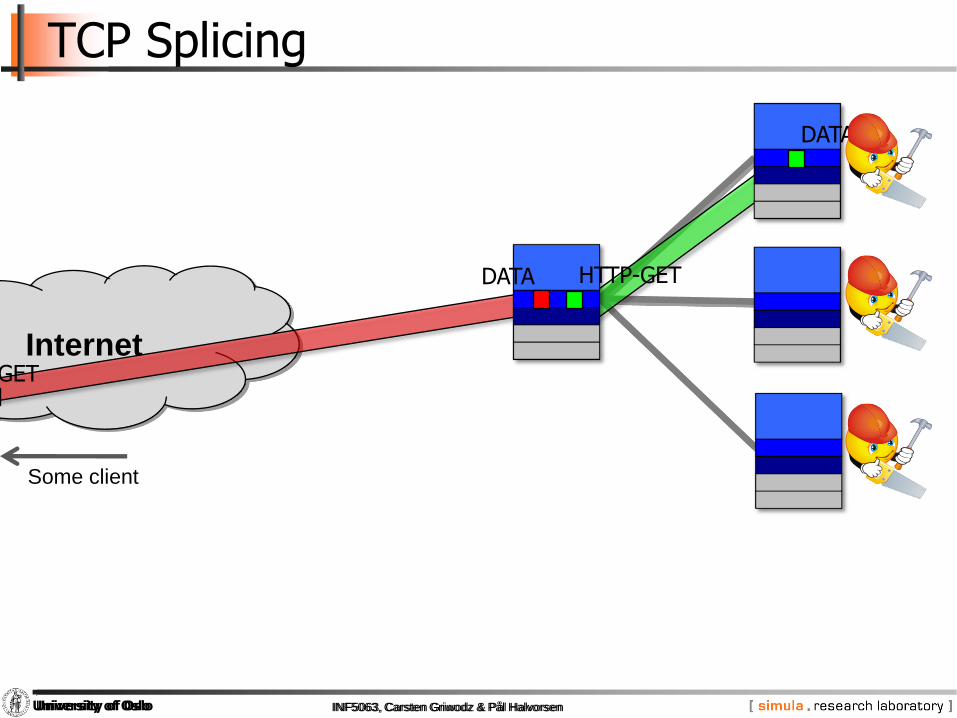
TCP Splicing
HTTP-GET
HTTP-GET
DATA
DATA
Some client
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Internet
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
TCP Splicing
Some client
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
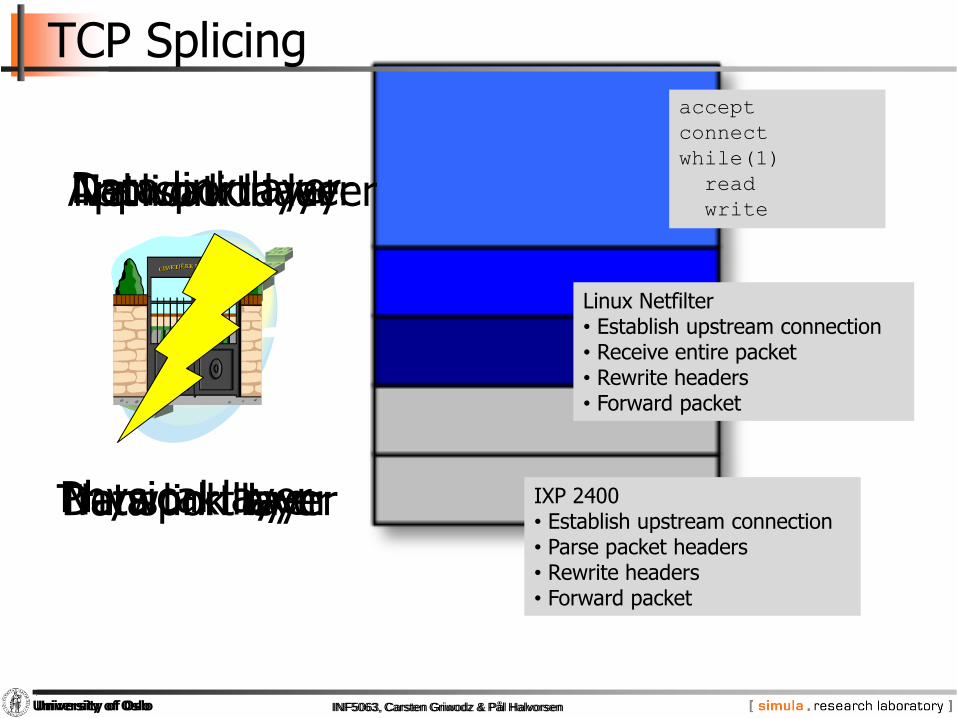
TCP Splicing
Data link layer
Physical layer
Network layer
Data link layer
Transport layer
Network layer
Application layer
Transport layer
accept
connect
while(1)
read
write
Linux Netfilter• Establish upstream connection• Receive entire packet• Rewrite headers• Forward packet
IXP 2400• Establish upstream connection• Parse packet headers• Rewrite headers• Forward packet
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
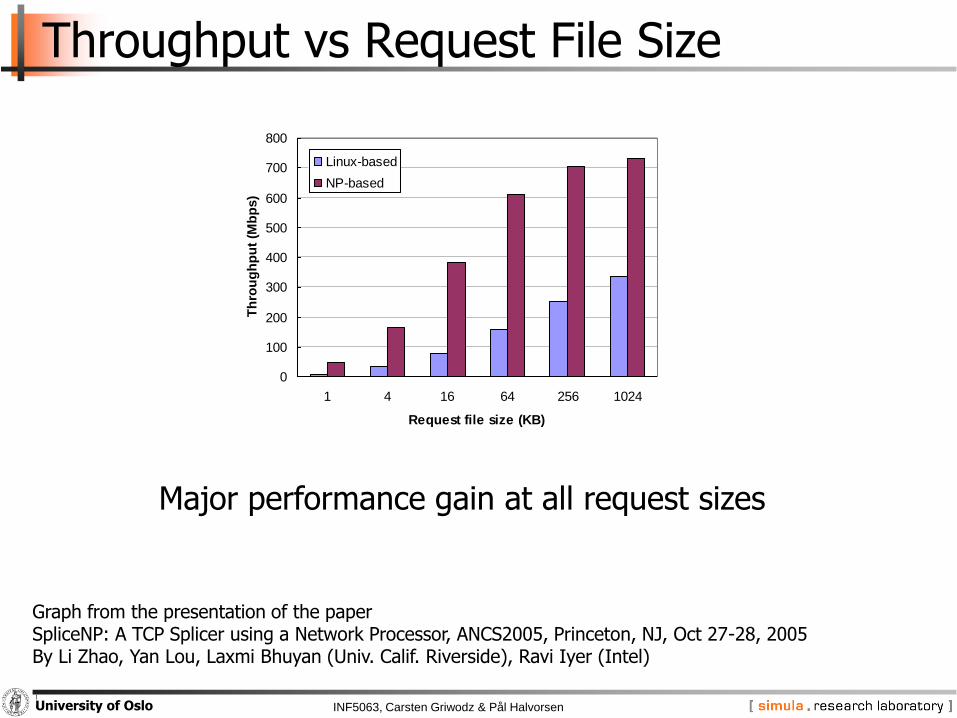
Throughput vs Request File Size
0
100
200
300
400
500
600
700
800
1 4 16 64 256 1024
Request file size (KB)
Th
rou
gh
pu
t (M
bp
s)
Linux-based
NP-based
Graph from the presentation of the paperSpliceNP: A TCP Splicer using a Network Processor, ANCS2005, Princeton, NJ, Oct 27-28, 2005By Li Zhao, Yan Lou, Laxmi Bhuyan (Univ. Calif. Riverside), Ravi Iyer (Intel)
Major performance gain at all request sizes

Example:Transparent protocol translation and load balancing in a media streaming scenario
slides from an ACM MM 2007 presentationby Espeland, Lunde, Stensland, Griwodz and Halvorsen
INF5063:Programming Heterogeneous Multi-Core Processors
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
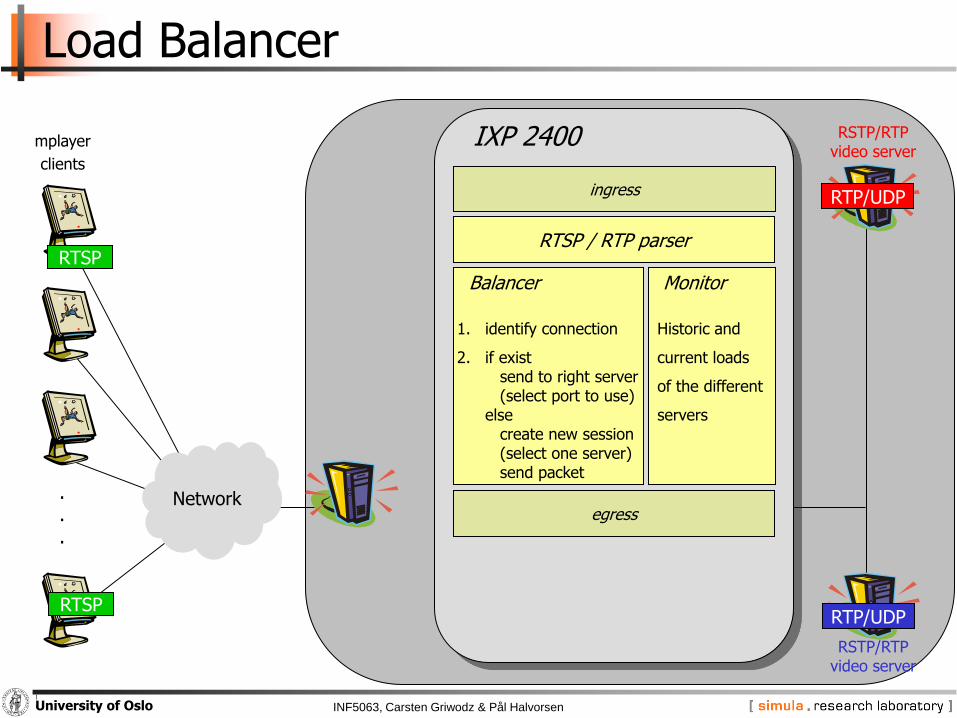
Load Balancer
Network...
IXP 2400
ingress
egress
Balancer
1. identify connection
2. if exist send to right server(select port to use)
elsecreate new session(select one server)send packet
Monitor
Historic and
current loads
of the different
servers
RSTP/RTPvideo server
RSTP/RTPvideo server
mplayer
clients
RTSP / RTP parserRTSP
RTP/UDPRTSP
RTP/UDP
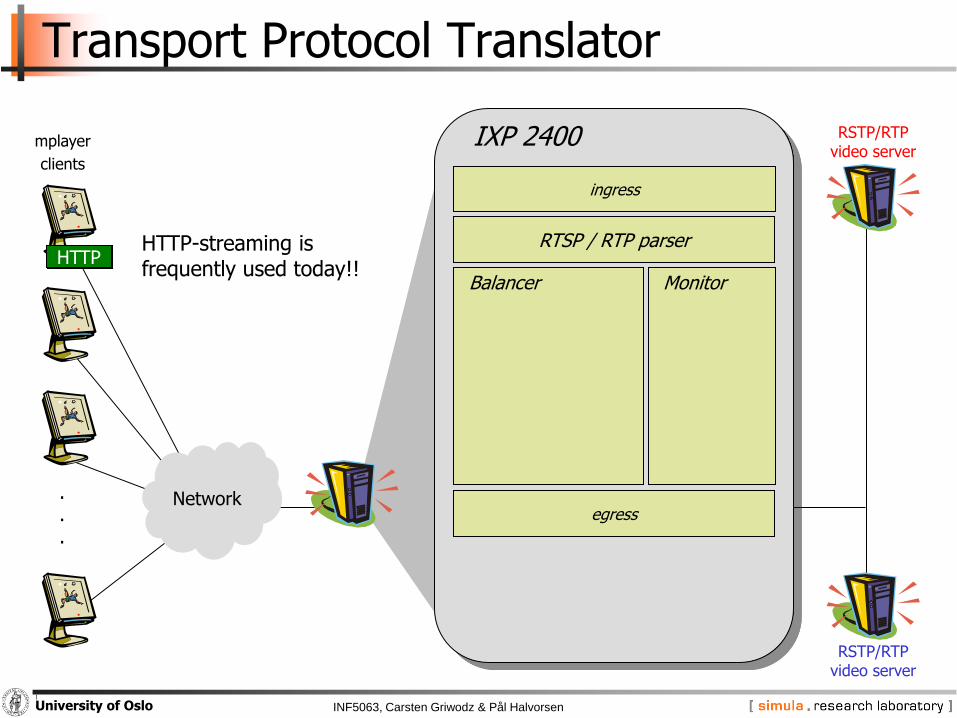
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Transport Protocol Translator
Network...
IXP 2400
ingress
RSTP/RTPvideo server
RSTP/RTPvideo server
mplayer
clients
egress
Balancer Monitor
RTSP / RTP parserRTSP
HTTP-streaming isfrequently used today!!
HTTP
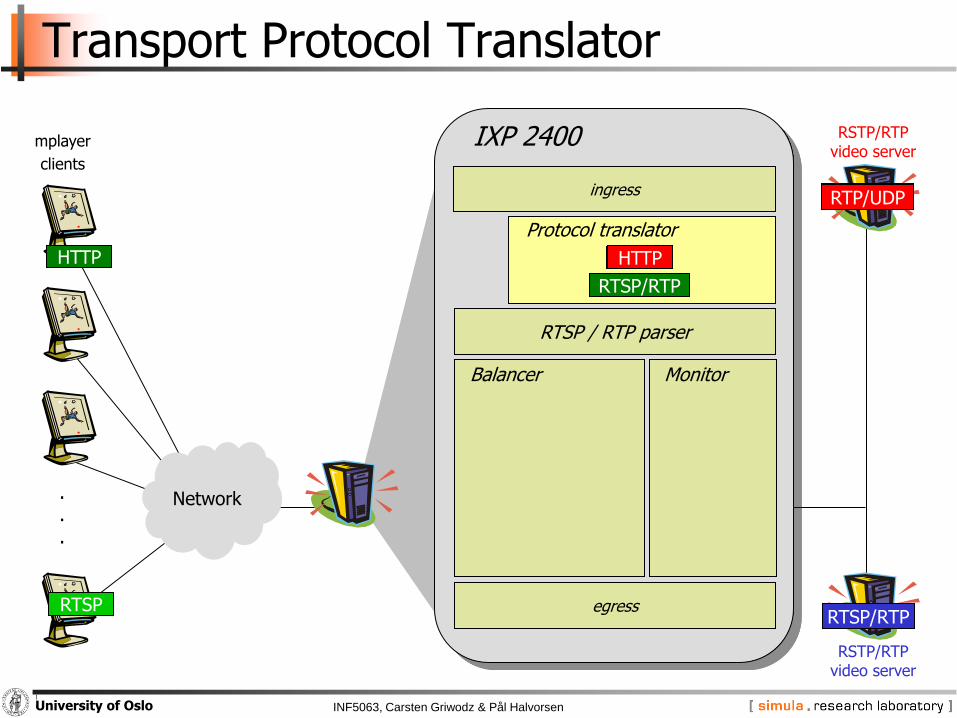
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Transport Protocol Translator
Network...
IXP 2400
ingress
RSTP/RTPvideo server
RSTP/RTPvideo server
mplayer
clients
egress
Balancer Monitor
RTSP / RTP parser
RTSP/RTP
Protocol translator
RTP/UDP
HTTP
RTSP/RTP
HTTP
RTP/UDP
HTTP
RTSP
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
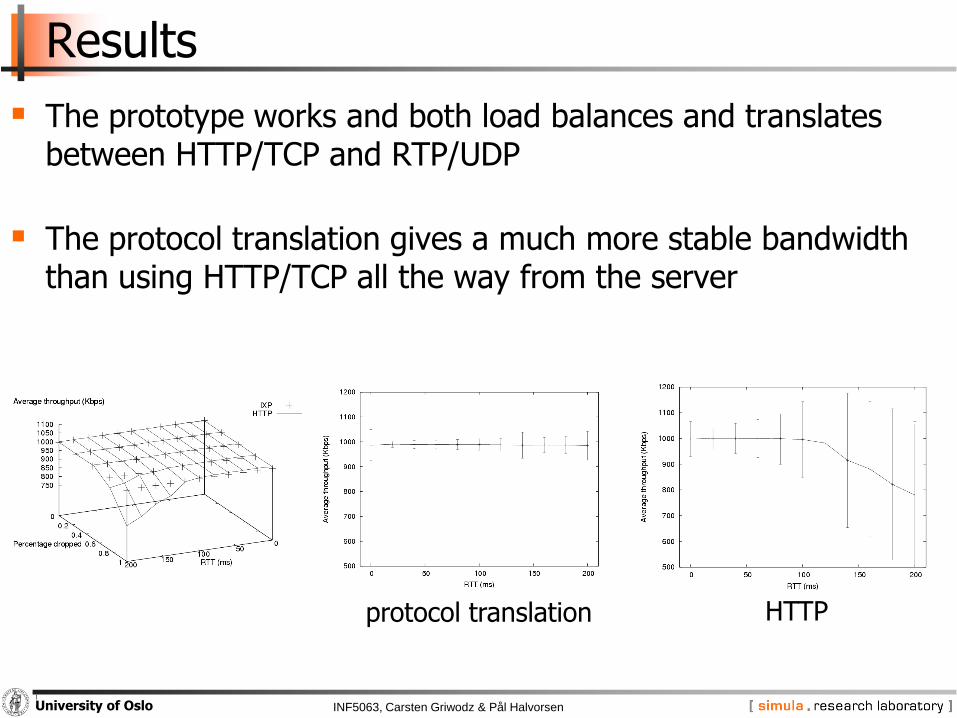
Results
The prototype works and both load balances and translates between HTTP/TCP and RTP/UDP
The protocol translation gives a much more stable bandwidth than using HTTP/TCP all the way from the server
protocol translation HTTP

Example: Booster Boxes
slide content and structure mainly from the NetGames 2002 presentation by Bauer, Rooney and Scotton
INF5063:Programming Heterogeneous Multi-Core Processors
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
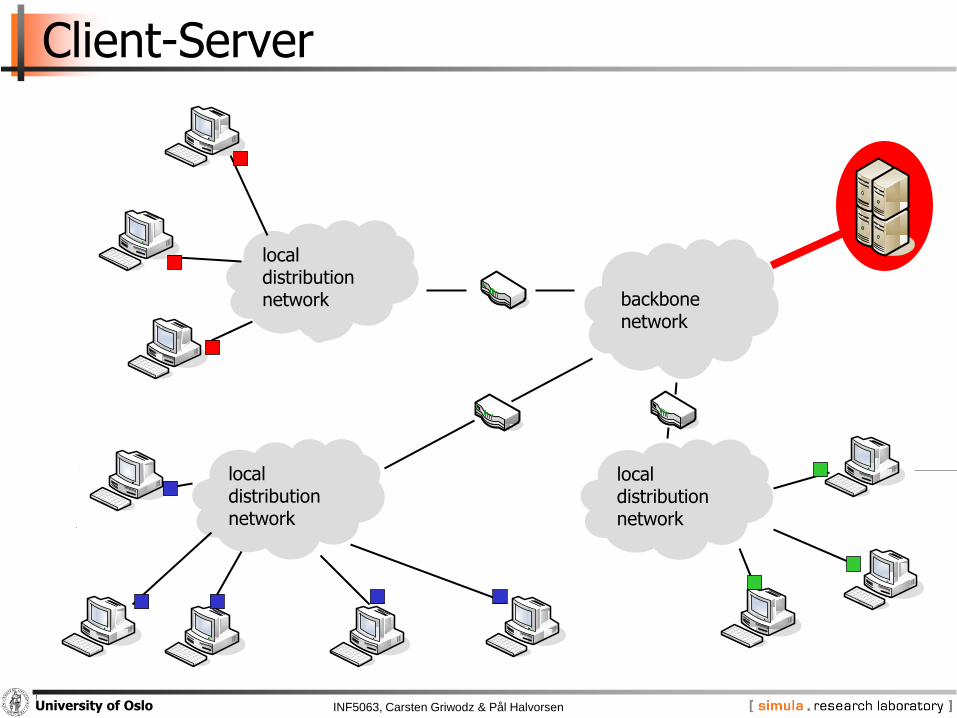
Client-Server
backbonenetwork
local distributionnetwork
local distributionnetwork
local distributionnetwork
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
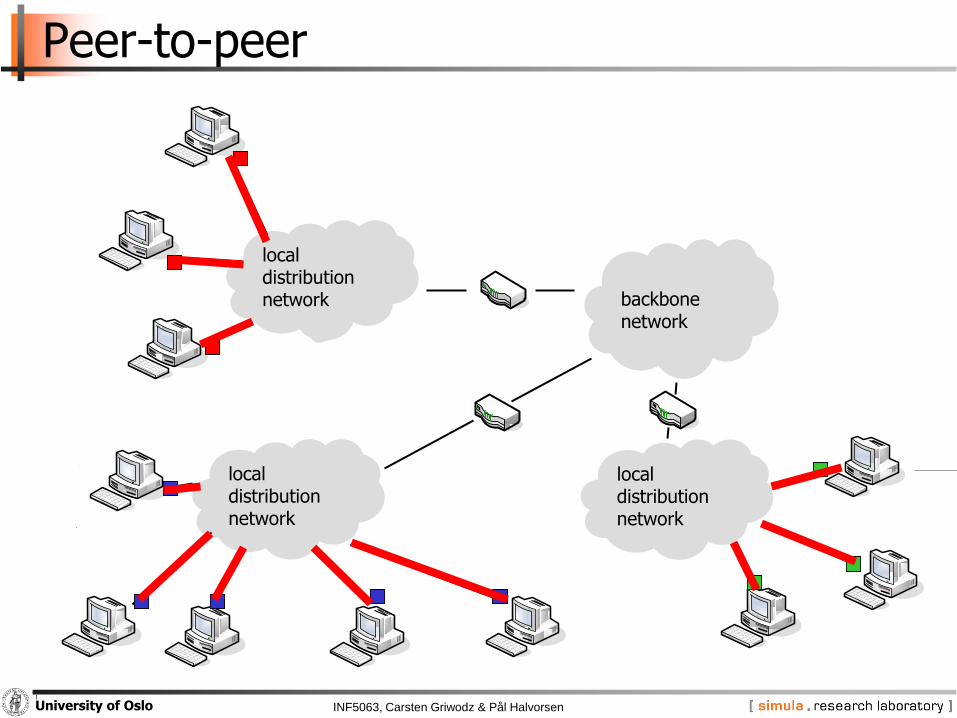
Peer-to-peer
backbonenetwork
local distributionnetwork
local distributionnetwork
local distributionnetwork

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
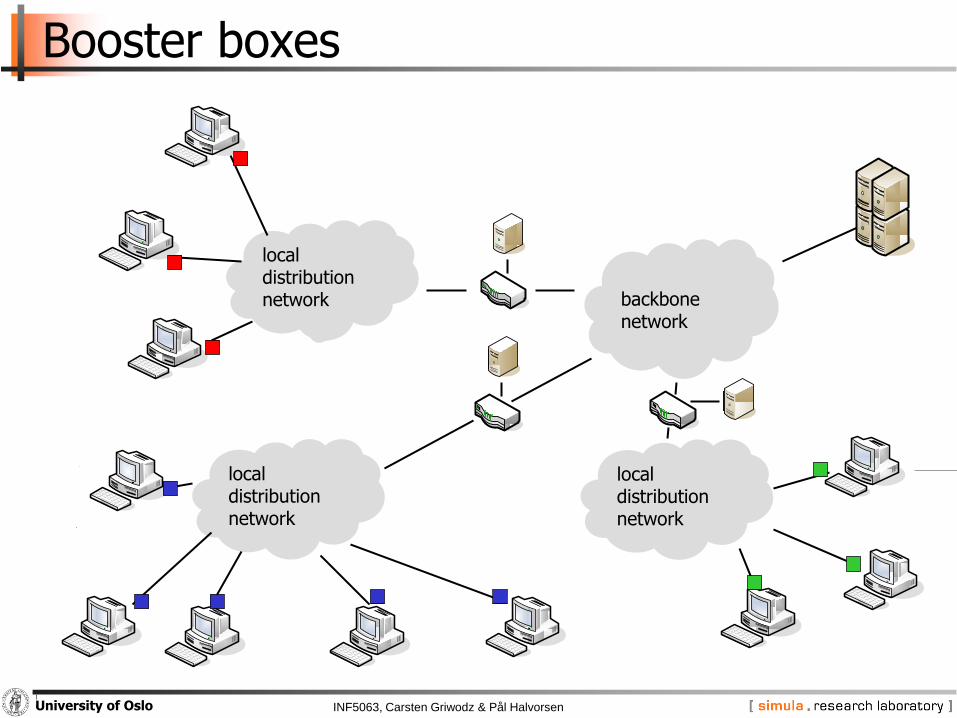
Booster boxes
Middleboxes
− Attached directly to ISPs’ access routers
− Less generic than, e.g. firewalls or NAT
Assist distributed event-driven applications
− Improve scalability of client-server and peer-to-peer applications
Application-specific code
− “Boosters”
− Caching on behalf of a server
− Aggregation of events
− Intelligent filtering
− Application-level routing
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Booster boxes
backbonenetwork
local distributionnetwork
local distributionnetwork
local distributionnetwork
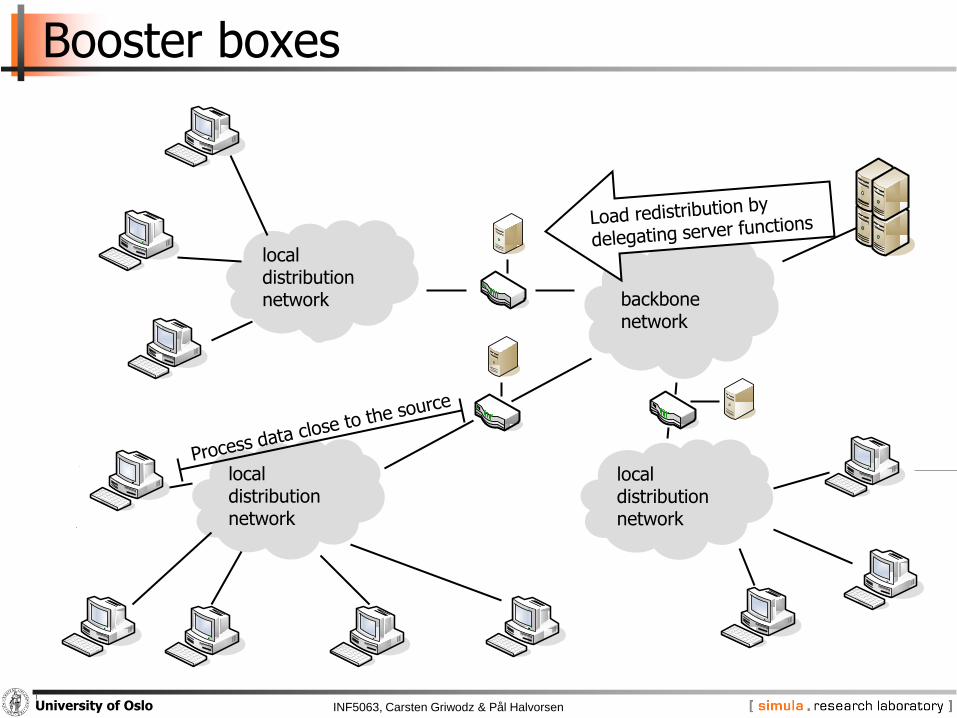
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Booster boxes
backbonenetwork
local distributionnetwork
local distributionnetwork
local distributionnetwork

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Booster boxes
Application-specific code
− Caching on behalf of a server• Non-real time information is cached
• Booster boxes answer on behalf of servers
− Aggregation of events• Information from two or more clients within a time window is aggregated
into one packet
− Intelligent filtering• Outdated or redundant information is dropped
−Application-level routing
• Packets are forward based on
Packet content
Application state
Destination address
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
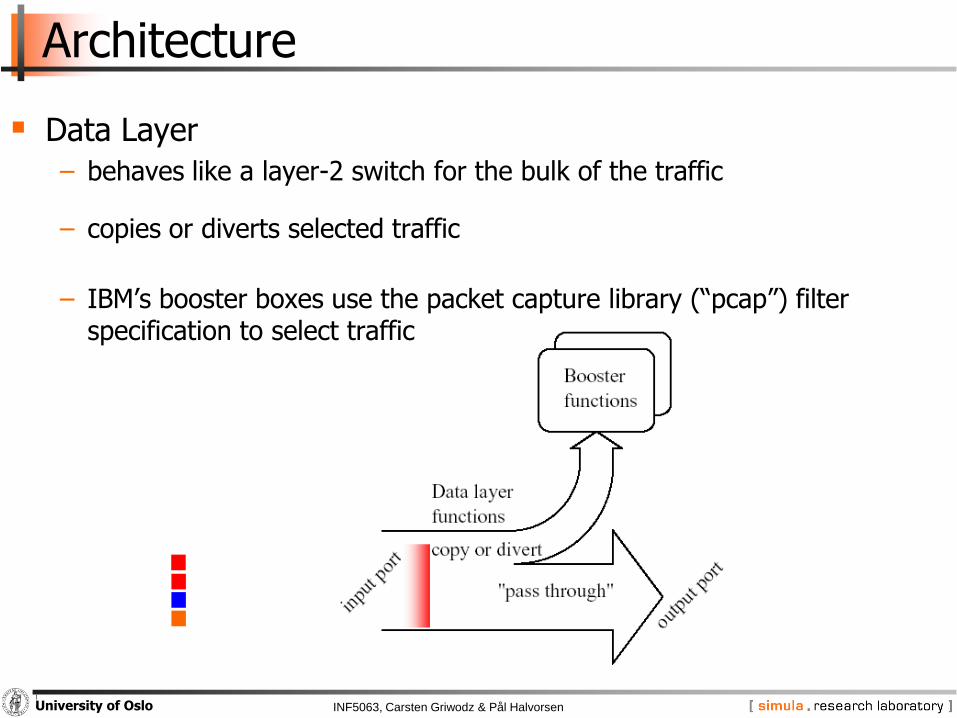
Architecture
Data Layer
− behaves like a layer-2 switch for the bulk of the traffic
− copies or diverts selected traffic
− IBM’s booster boxes use the packet capture library (“pcap”) filter specification to select traffic
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
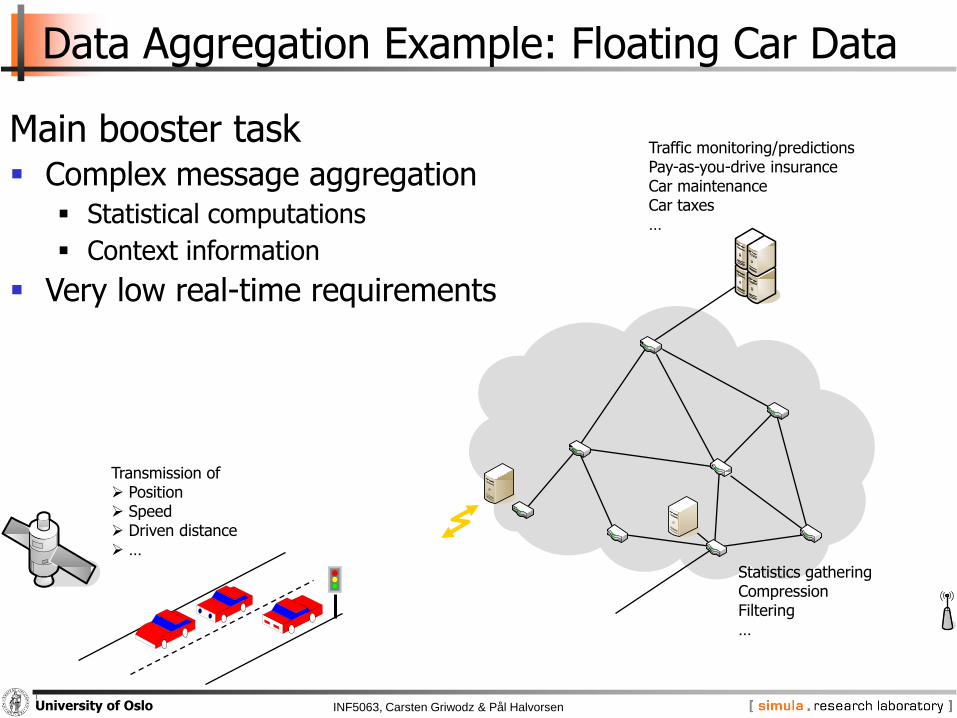
Data Aggregation Example: Floating Car Data
Main booster task Complex message aggregation
Statistical computations
Context information
Very low real-time requirements
Traffic monitoring/predictionsPay-as-you-drive insuranceCar maintenanceCar taxes…
Statistics gatheringCompressionFiltering…
Transmission of Position Speed Driven distance …
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
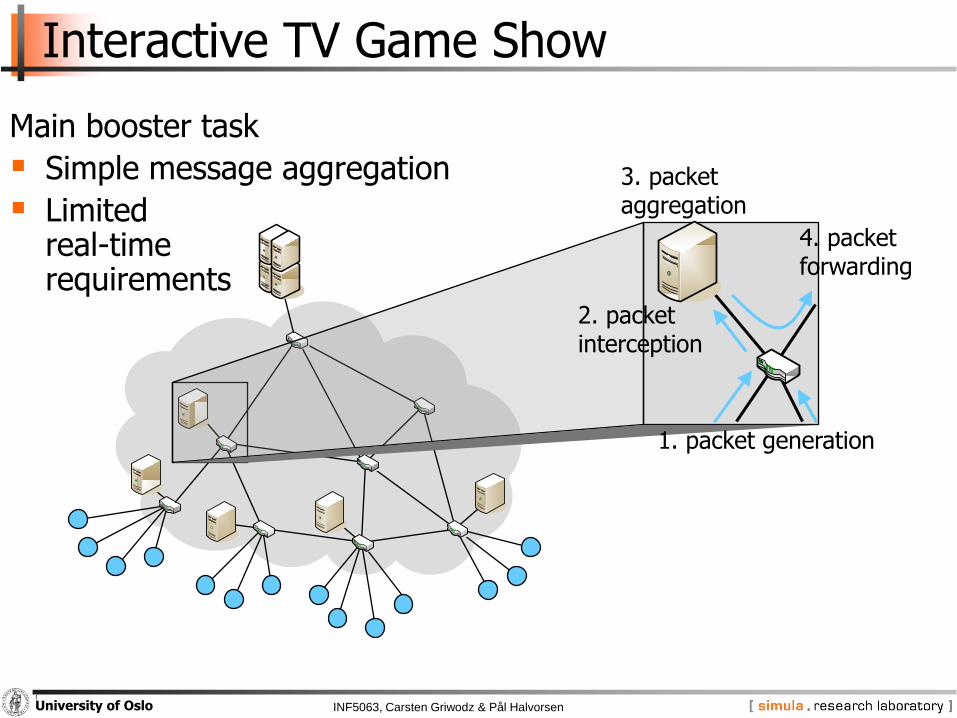
Interactive TV Game Show
Main booster task
Simple message aggregation
Limitedreal-timerequirements
1. packet generation
2. packetinterception
3. packetaggregation
4. packetforwarding
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
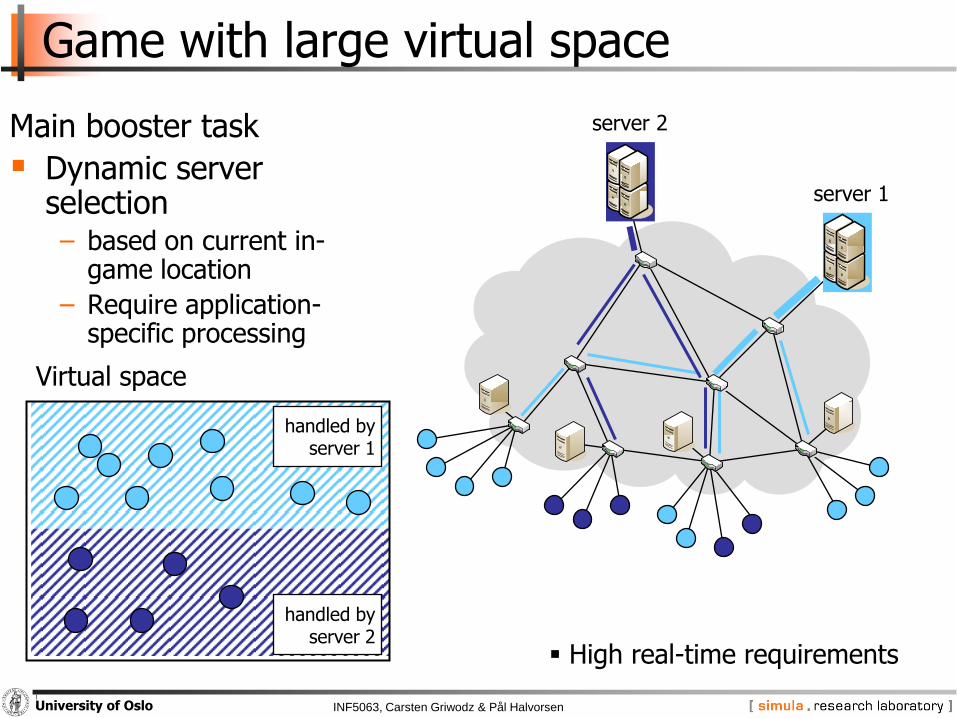
Game with large virtual space
Main booster task
Dynamic server selection− based on current in-
game location
− Require application-specific processing
handled byserver 1
handled byserver 2
server 2
server 1
Virtual space
High real-time requirements

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Summary
Scalability
− by application-specific knowledge
− by network awareness
Main mechanisms
− Caching on behalf of a server
− Aggregation of events
− Attenuation
− Intelligent filtering
− Application-level routing
Application of mechanism depends on
− Workload
− Real-time requirements

Multimedia Examples
INF5063:Programming Heterogeneous Multi-Core Processors
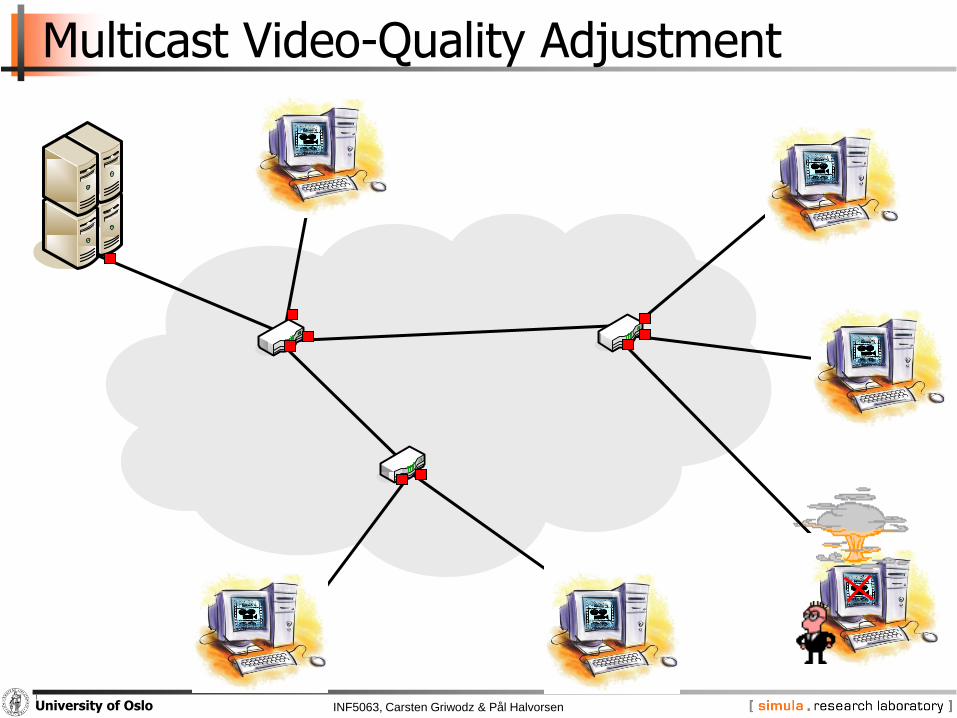
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
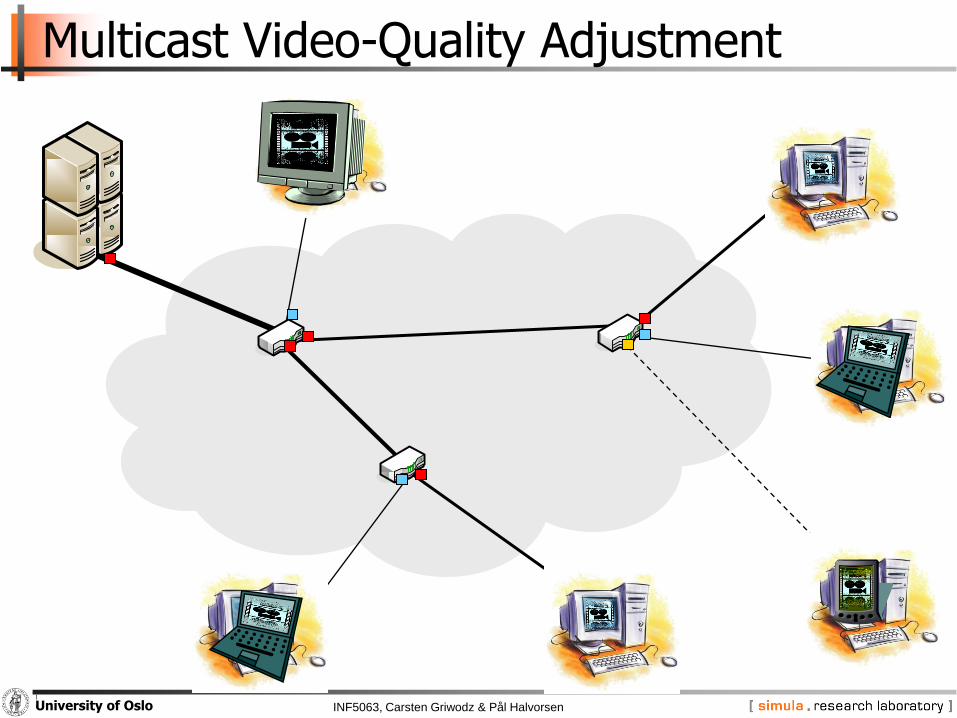
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
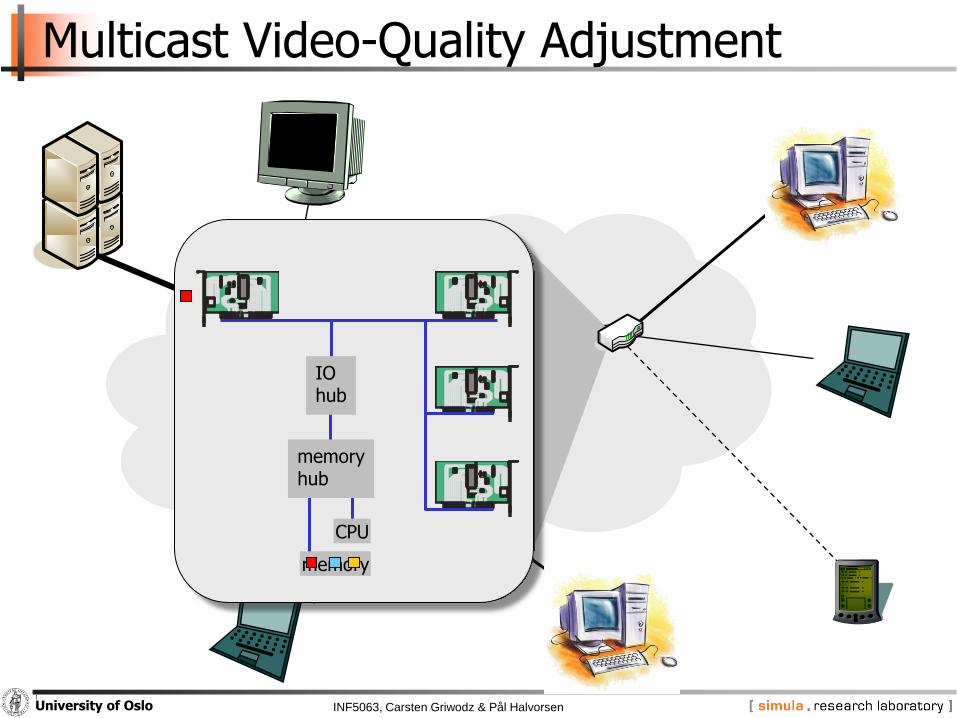
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
IOhub
memoryhub
CPU
memory

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
Several ways to do video-quality adjustments− frame dropping
− re-quantization
− scalable video codec
− …
Yamada et. al. 2002: use low-pass filter to eliminate high-frequency components of the MPEG-2 video signal and thus reduce data rate
− determine a low-pass parameter for each GOP
− use low-pass parameter to calculate how many DCT coefficients to remove from each macro block in a picture
− by eliminating the specified number of DCT coefficients the videodata rate is reduced
− implemented the low-pass filter on an IXP1200

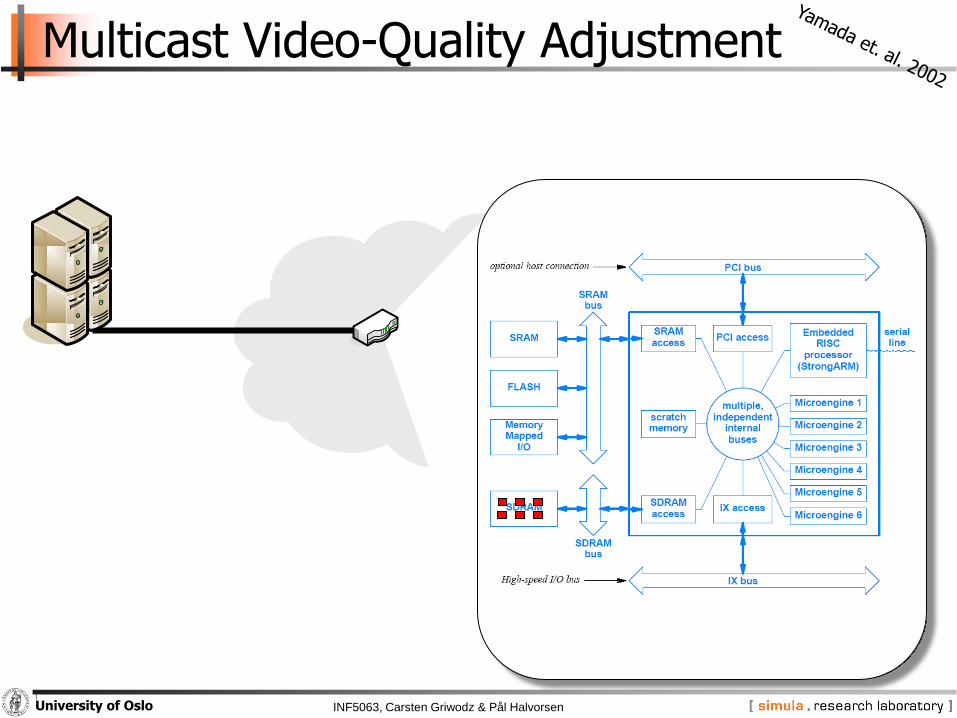
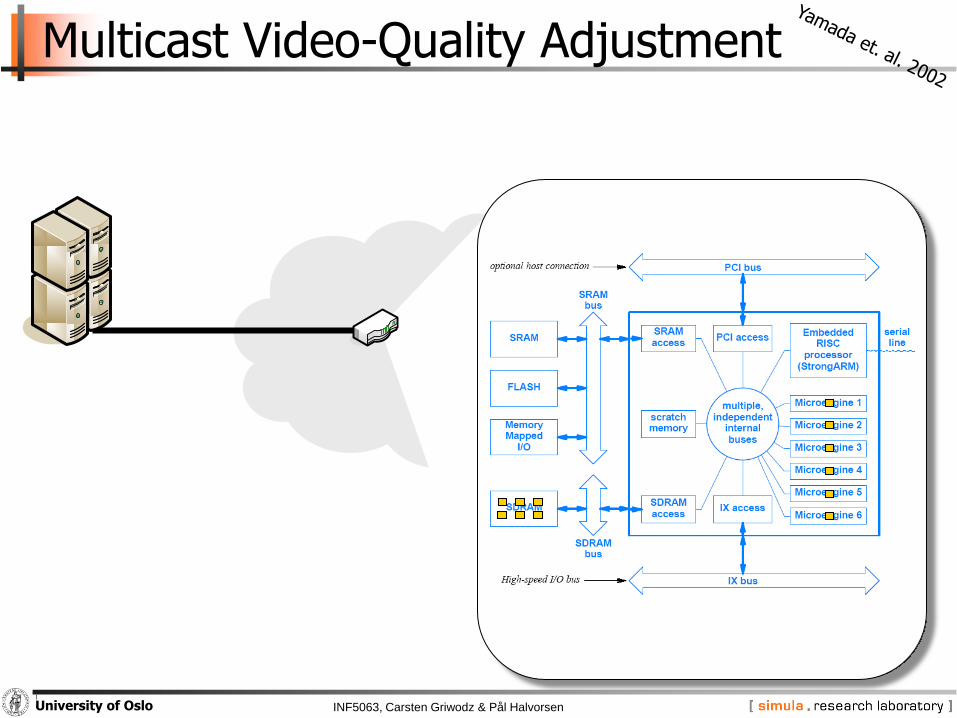
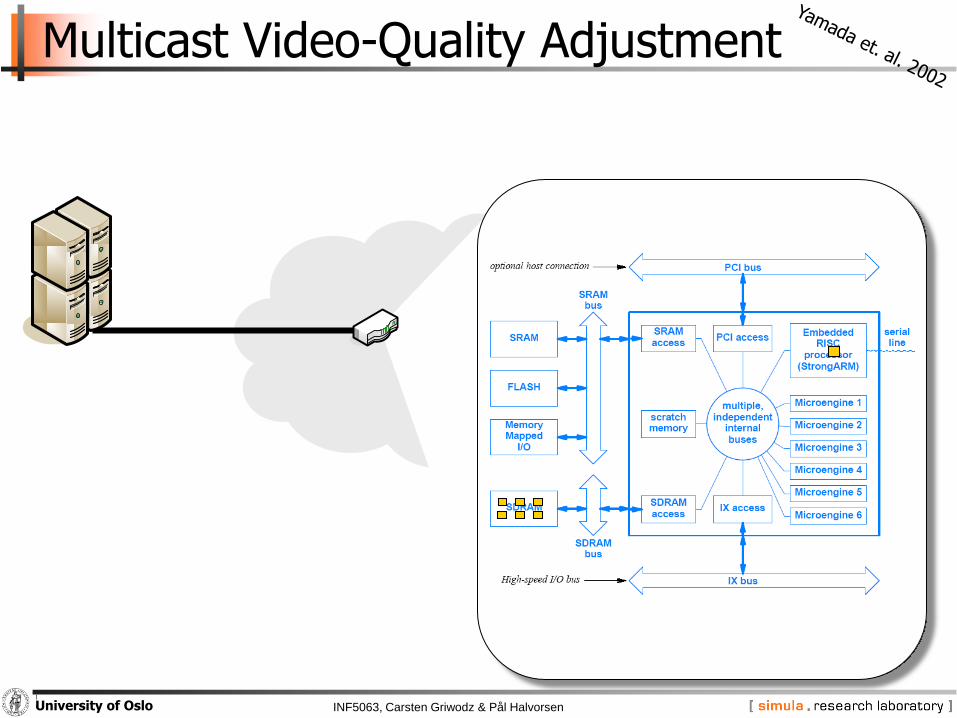
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
Low-pass filter on IXP1200
− parallel execution on 200MHz StrongARM and microengines
− 24 MB DRAM devoted to StrongARM only
− 8 MB DRAM and 8 MB SRAM shared
− test-filtering program on a regular PC determined work-distribution
• 75% of data from the block layer
• 56% of the processing overhead is due to DCT
five step algorithm:
1. StrongArm receives packet copy to shared memory area
2. StrongARM process headers and generate macroblocks (in shared memory)
3. microengines read data and information from shared memory and perform quality adjustments on each block
4. StrongARM checks if the last macroblock is processed (if not, go to 2)
5. StrongARM rebuilds packet

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
Segmentation of MPEG-2 data
− slice = 16 bit high stripes
− macroblock = 16 x 16 bit square
• four 8 x 8 luminance
• two 8 x 8 chrominance
DCT transformed with coefficients sorted in ascending order
Data packetization for video filtering
− 720 x 576 pixels frames and 30 fps
36 “slices” with 45 macroblocks per frame
− Each slice = one packet
− 8 Mbps stream ~7Kb per packet
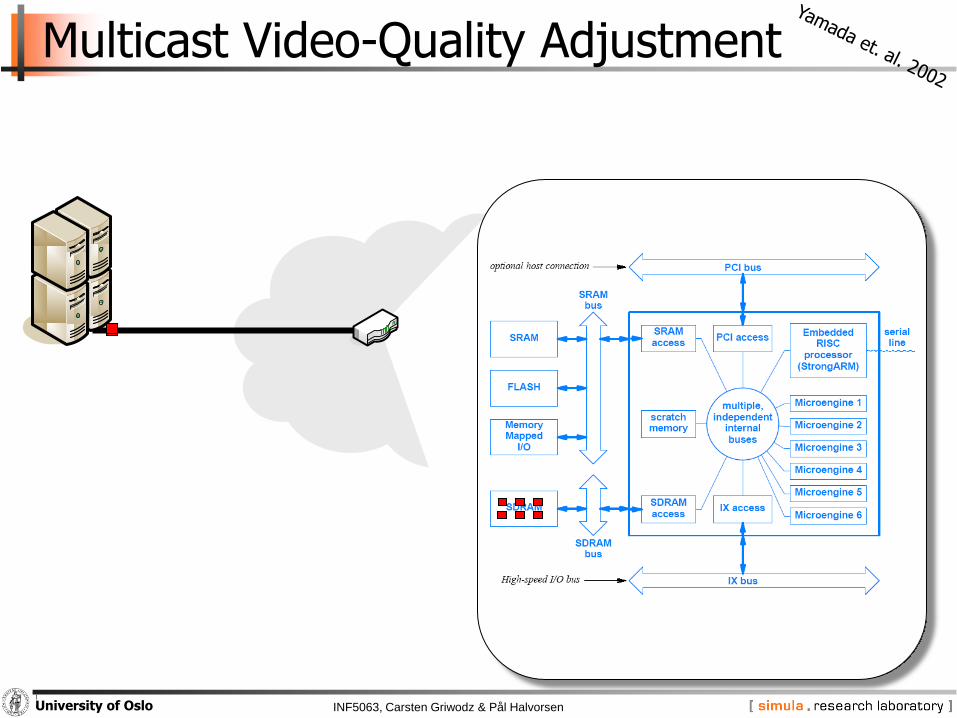
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Multicast Video-Quality Adjustment
Evaluation – three scenarios tested
− StrongARM only 550 kbps
− StrongARM + 1 microengine 350 kbps
− StrongARM + all microengines 1350 kbps
− achieved real-time transcoding not enough for practical
purposes, but distribution of workload is nice

Parallelism, Pipelining &Workload Partitioning
INF5063:Programming Heterogeneous Multi-Core Processors
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
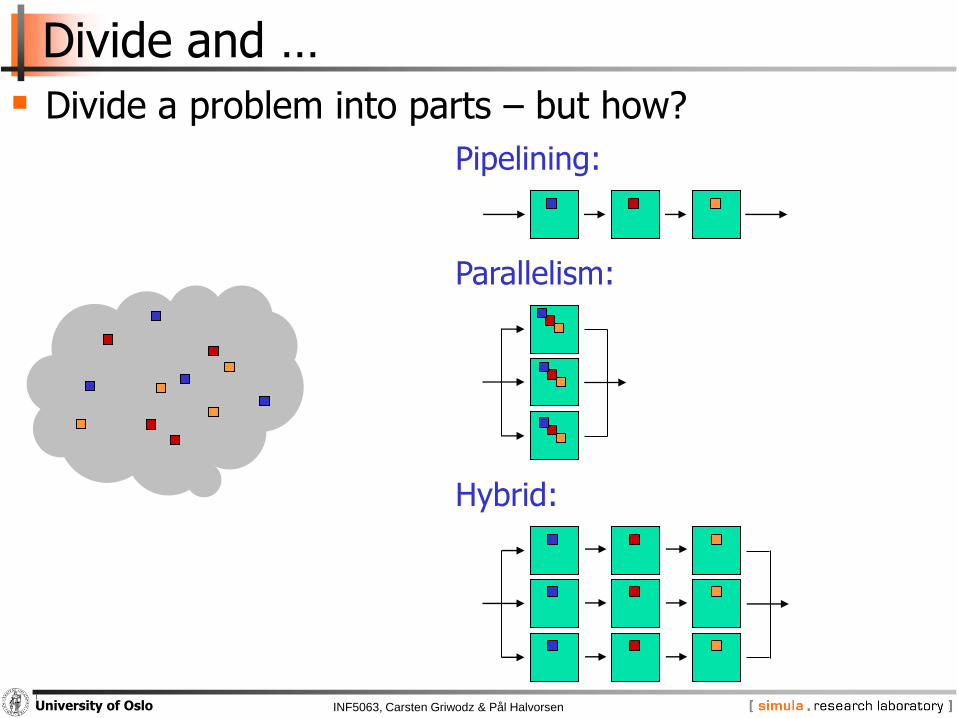
Divide and …
Divide a problem into parts – but how?
Pipelining:
Parallelism:
Hybrid:

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Key Considerations
System topology− processor capacities:
different processors have different capabilities
− memory attachments:• different memory types have different rates and access times• different memory banks have different access times
− interconnections: different interconnects/busses have different capabilities
Requirements of the workload?− dependencies
Parameters?− width of pipeline (level of parallelism)− depth of pipeline (number of stages)− number of jobs sharing busses
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
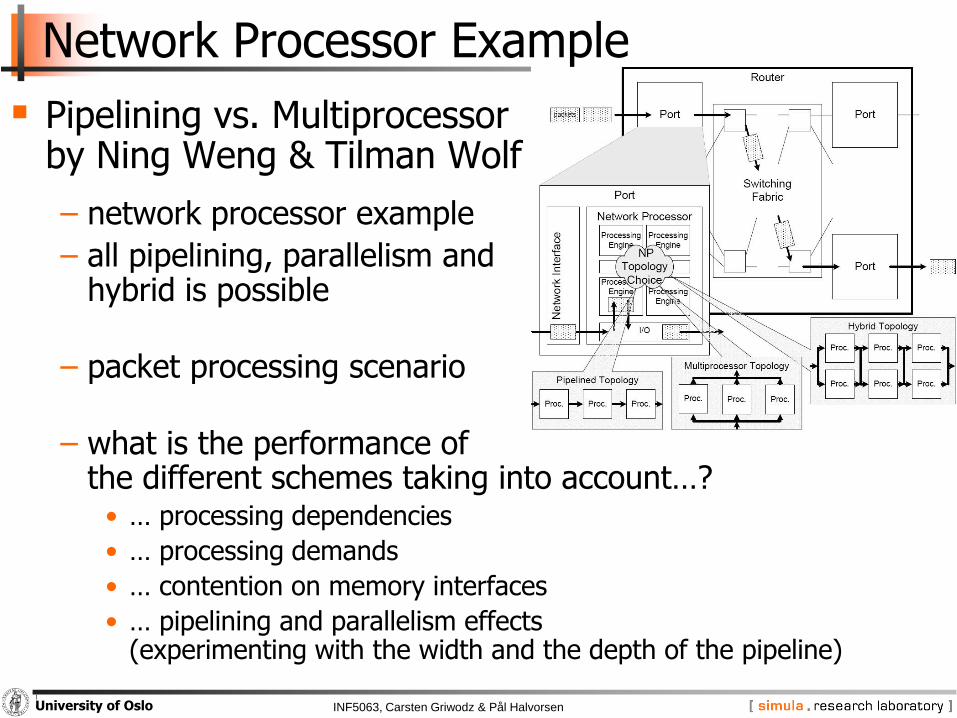
Network Processor Example
Pipelining vs. Multiprocessor by Ning Weng & Tilman Wolf
− network processor example
− all pipelining, parallelism and hybrid is possible
− packet processing scenario
− what is the performance of the different schemes taking into account…?
• … processing dependencies
• … processing demands
• … contention on memory interfaces
• … pipelining and parallelism effects (experimenting with the width and the depth of the pipeline)
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
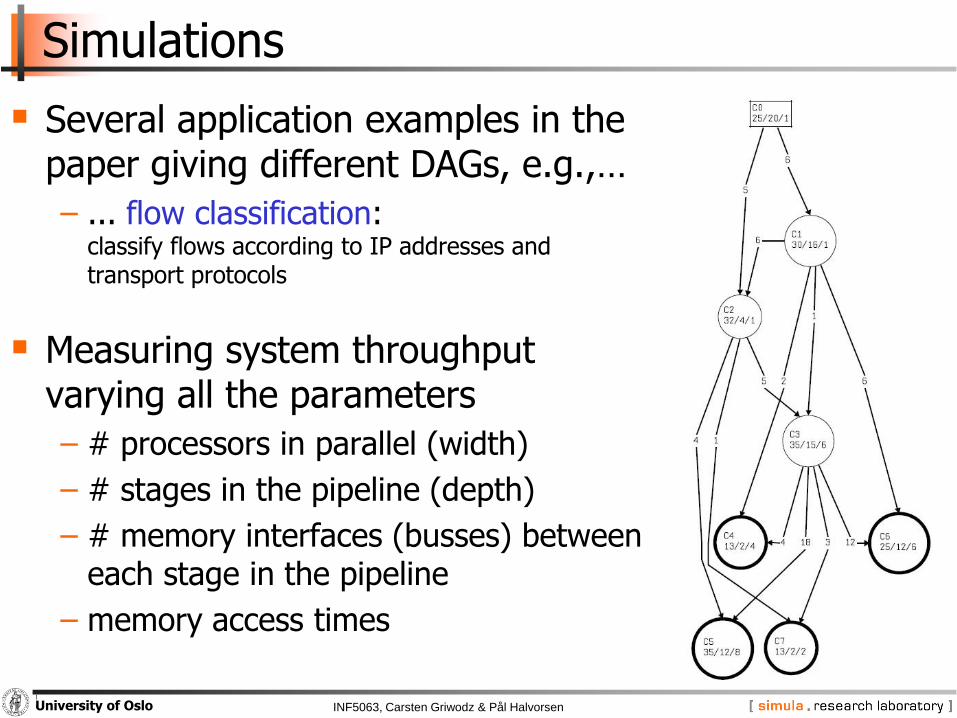
Simulations
Several application examples in the paper giving different DAGs, e.g.,…
− ... flow classification:classify flows according to IP addresses and transport protocols
Measuring system throughput varying all the parameters
− # processors in parallel (width)
− # stages in the pipeline (depth)
− # memory interfaces (busses) between each stage in the pipeline
− memory access times
INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
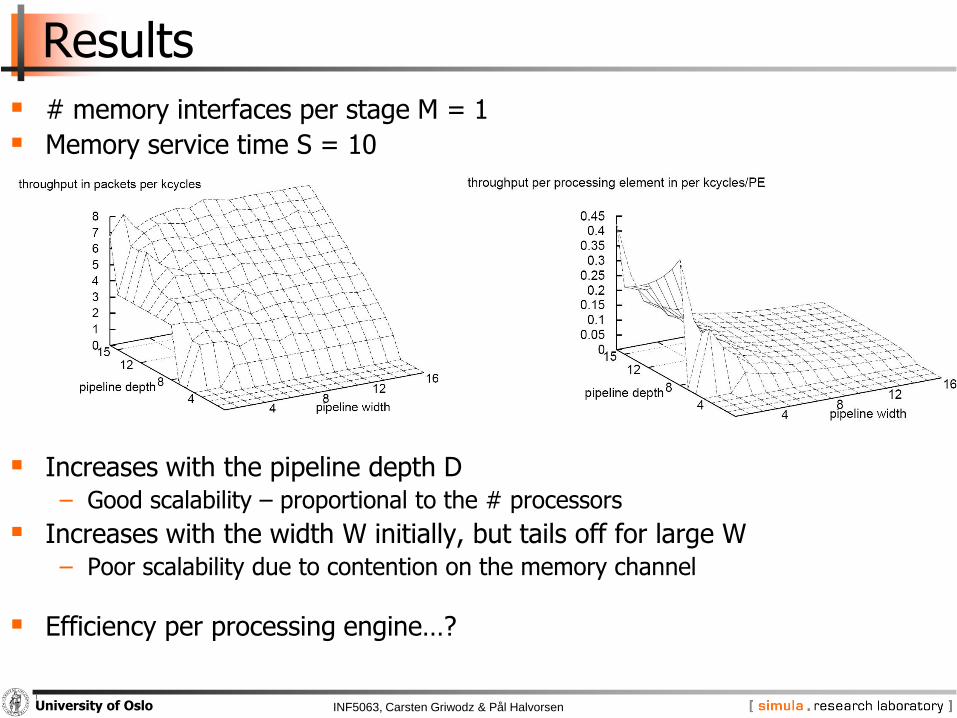
Results
# memory interfaces per stage M = 1
Memory service time S = 10
Increases with the pipeline depth D− Good scalability – proportional to the # processors
Increases with the width W initially, but tails off for large W− Poor scalability due to contention on the memory channel
Efficiency per processing engine…?

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Lessons learned…
Memory contention can become a severe system bottleneck
− the memory interface saturates with about two processing elements per interface
− off-chip memory access cause significant reduction in throughput and drastic increase in queuing delay
− performance increase with more
• memory channels
• lower access times
Most NP applications are of sequential nature which leads to highly pipelined NP topologies
Balancing processing tasks to avoid slow pipeline stages
Communication and synchronization are the main contributors to the pipeline stage time, next to the memory access delay
“Topology” has significant impact on performance

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Some References1. Tatsuya Yamada, Naoki Wakamiya, Masayuki Murata, and Hideo Miyahara: "Implementation
and Evaluation of Video-Quality Adjustment for heterogeneous Video Multicast“, 8th Asia-Pacific Conference on Communications, Bandung, September 2002, pp. 454-457
2. Daniel Bauer, Sean Rooney, Paolo Scotton, “Network Infrastructure for Massively Distributed Games”, NetGames, Braunschweig, Germany, April 2002
3. J.R. Allen, Jr., et al., “IBM PowerNP network processor: hardware, software, and applications”, IBM Journal of Research and Development, 47(2/3), pp. 177-193, March/May 2003
4. Ning Weng, Tilman Wolf, “Profiling and mapping of parallel workloads on network processors”, ACM Symposium of Applied Computing (SAC 2005), pp. 890-896
5. Ning Weng, Tilman Wolf, “Analytic modeling of network processors for parallel workload mapping”, ACM Trans. on Embedded Computing Systems, 8(3), 2009
6. Li Zhao, Yan Lou, Laxmi Bhuyan, Ravi Iyer, “SpliceNP: A TCP Splicer using a Network Processor”, ANCS2005, 2005
7. Håvard Espeland, Carl Henrik Lunde, Håkon Stensland, Carsten Griwodz, Pål Halvorsen, ”Transparent Protocol Translation for Streaming”, ACM Multimedia 2007

INF5063, Carsten Griwodz & Pål HalvorsenUniversity of Oslo
Summary
TODO





























