Embed Size (px)
Citation preview

Evaluating Continuous Top-k Queries over
Text Streams
Nelly Vouzoukidou
Thesis submitted in partial fulfilment of the requirements for the
Masters’ of Science degree in Computer Science
University of CreteSchool of Sciences and Engineering
Computer Science DepartmentKnossou Av., P.O. Box 2208, Heraklion, GR-71409, Greece
Thesis Advisor: Prof. Vassilis Christophides
The work is partially supported by the Institute of Computer Science (ICS) - Foundation of Researchand Technology (FORTH)


PANEPISTHMIO KRHTHSSQOLH JETIKWN KAI TEQNOLOGIKWN EPISTHMWN
TMHMA EPISTHMHS UPOLOGISTWN
ApotÐmhsh Suneq¸n k-KorufaÐwn Eperwt sewn ep�nw seRoèc Keimenik¸n Dedomènwn
ErgasÐa pou upobl jhke apì thnNèlh BouzoukÐdou
wc merik ekpl rwsh twn apait sewn gia thn apìkthshMETAPTUQIAKOU DIPLWMATOS EIDIKEUSHS
Suggrafèac:
Nèlh BouzoukÐdou, Tm ma Epist mhc Upologist¸n
Eishghtik Epitrop :
BasÐlhc QristofÐdhc, Kajhght c, Epìpthc
Dhm trhc Plexous�khc, Kajhght c
Bernd Amann, Kajhght c tou PanepisthmÐouPierre et Marie Curie, ParÐsi
'Aggeloc MpÐlac, Anapl. Kajhght cPrìedroc Epitrop c Metaptuqiak¸n Spoud¸n
Hr�kleio, Noèmbrioc 2011


Evaluating Continuous Top-k Queries over Text Streams
Nelly VouzoukidouMaster’s Thesis
Computer Science Department, University of Crete
Abstract
Web 2.0 technologies have transformed the Web from a publishing-only environment into avibrant information place where yesterday’s end users become content generators themselves.Besides traditional information sources, such as press websites, nowadays, social networks, blogsand forums are publishing on the web millions of items on daily basis. Given the immensevolume and vast diversity of the information generated in Web 2.0, there is a vital need forefficient real-time filtering methods across streams of information which allow millions of usersto effectively follow personally interesting information.
In this respect, users usually issue keyword-based queries, which can either be directly eval-uated by the underlying search engines or submitted to an alerting service and be continuouslynotified about newly published items matching their filtering criteria. In both settings, scoringfunctions are used both to measure the relevance of an item to the keywords employed by aquery as well as the importance of the item according to query- independent quality criteria.The latter considers parameters such as information novelty, diversity, authority, as well asthe significance of the thematic collection in which they belong (e.g. clustered to describe thesame real-word event). The effectiveness of the employed scoring function lies on how well arecombined a keyword- based similarity with item importance usually using a weighted sum overboth scores. Moreover, to guarantee freshness of information and deliver as recent informationas possible, combination of time decay and sliding windows techniques are considered over theemployed scoring functions.
In this thesis, we are interested in efficient algorithms and data-structures for online monitor-ing of web 2.0 content and more precisely for efficiently evaluating continuous top-k queries overtextual information streams. It should be stressed that existing commercial alerting essentiallytransform a continuous query to a series of periodically executed snapshot queries. This approachincurs serious limitations: for large numbers of users queries and high arrival information ratesit is practical impossible to repeatedly evaluate all queries at almost all new information items.For this reason, commercial systems usually decrease the frequency of snapshot query evaluationand thus important news may be missed.
Unlike existing research work on top-k continuous textual queries, in our work we considercomplex scoring functions that capture both the relevance of an information item with respectto the keywords of a user query as well as its importance and freshness with respect to whathas been already published. Then, we are proposing a representation of queries based on theirscores that enable us to resolve efficiently the problem of user query selection: given an incominginformation item determine which top-k query result lists need to be updated (i.e., have to insertthe item).
The novelty of our approach lies on the effectiveness of the induced boundary conditions todrastically prune this search space of queries during matching, and with a small update overheadwhen top-k lists are refreshed, for a fairly large class of scoring functions (weighed sum of querydependent scores and query independent scores modulated by decay functions).
Supervisor: Vassilis ChristophidesProfessor

PerÐlhyh
Oi teqnologÐec Web 2.0 èqoun metatrèyei ton Istì apì èna perib�llon apl c dhmosÐeushcse èna zwntanì q¸ro plhroforÐac, ìpou oi mèqri prìsfata telikoÐ qr stec èqoun metatrapeÐkai oi Ðdioi se paragwgoÔc plhroforÐac. Ektìc apì tic paradosiakèc phgèc plhrofìrhshc, ìpwcistoselÐdec TÔpou, s mera, koinwnik� dÐktua, istolìgia qrhst¸n (blogs) kai fìroum dhmosieÔounse kajhmerin b�sh ekatommÔria stoiqeÐa plhroforÐac (items). Dedomènou tou ter�stiou ìgkou kaithc meg�lhc poikilomorfÐac twn plhrofori¸n pou par�gontai sto Web 2.0, up�rqei mia epitaktik an�gkh gia apodotikèc kai pragmatikoÔ qrìnou mejìdouc filtrarÐsmatoc p�nw se roèc plhrofori¸npou ja epitrèpoun se ekatommÔria qr stec na parakolouj soun apotelesmatik� endiafèrousecplhroforÐec sÔmfwna me proswpik� krit ria.
Sto plaÐsio autì, oi qr stec sun jwc ekdÐdoun eperwt seic basismènec se lèxeic - kleidi�, oiopoÐec mporoÔn eÐte na apotimhjoÔn apeujeÐac apì mhqanèc anaz thshc, eÐte na upoblhjoÔn se u-phresÐec EidopoÐhshc (Alerts), pou analamb�noun na eidopoioÔn suneq¸c ton qr sth gia prìsfatadhmosieumèna stoiqeÐa plhroforÐac pou tairi�zoun sta dik� tou krit ria filtrarÐsmatoc. Kai sticdÔo peript¸seic, qrhsimopoioÔntai sunart seic apotÐmhshc prokeimènou na metrhjeÐ h susqètishtou stoiqeÐou plhroforÐac me touc ìrouc pou perièqei h eper¸thsh, kaj¸c epÐshc kai h spoudaiì-thta tou stoiqeÐou plhroforÐac sÔmfwn� me poiotik� krit ria anex�rthta thc eper¸thshc. Giathn apotÐmhsh thc spoudaiìthtac aut c qrhsimopoioÔntai par�metroi ìpwc hlikÐa thc plhroforÐ-ac, axiopistÐa kaj¸c epÐshc kai spoudaiìthta thc jematik c sullog c sthn opoÐa an koun lìgwp.q. tou ìti perigr�foun to Ðdio pragmatikì gegonìc. H apotelesmatikìthta thc sun�rthshc apo-tÐmhshc pou qrhsimopoieÐtai, sthrÐzetai sto pìso kal� sundu�zetai h susqètish basismènh stoucìrouc me thn spoudaiìthta tou stoiqeÐou plhroforÐac kai autì gÐnetai sun jwc qrhsimopoi¸ntacstajmismèno mèso ìro p�nw stic dÔo bajmologÐec. Epiplèon, gia na mporoÔme na egguhjoÔme ìtih plhroforÐa pou apostèlletai stouc qr stec eÐnai ìso to dunatìn pio prìsfath, qrhsimopoieÐtaisunduasmìc qronik c exasjènhshc thc bajmologÐac me teqnikèc kuliìmenwn parajÔrwn.
Se aut thn ergasÐa, epikentrwnìmaste sto prìblhma eÔreshc apodotik¸n algorÐjmwn kaidom¸n dedomènwn gia epigrammik parakoloÔjhsh tou perieqomènou tou Web 2.0 kai pio sugke-krimèna sthn apodotik apotÐmhsh suneq¸n k-korufaÐwn eperwt sewn ep�nw se k eimenikèc roècplhroforÐac. Prèpei na tonisteÐ, sto shmeÐo autì, ìti up�rqonta emporik� sust mata eidopoÐhshcmetatrèpoun mÐa suneq eper¸thsh se mÐa seir� periodik� ektelèsimwn stigmiaÐwn eperwt sewn.Aut h prosèggish emperièqei shmantikoÔc periorismoÔc: dedomènwn meg�lwn arijm¸n eperwt se-wn qrhst¸n kai meg�lwn rujm¸n dhmosÐeushc plhroforÐac eÐnai praktik� adÔnath h epanalamba-nìmenh apotÐmhsh ìlwn twn eperwt sewn aut¸n se sqedìn k�je nèa �fixh stoiqeÐou plhroforÐac.Gia autì to lìgo, ta emporik� sust mata sun jwc mei¸noun th suqnìthta apotÐmhshc twn eperw-t sewn kai wc ek toÔtou shmantikèc enhmer¸seic plhroforÐac mporeÐ na qajoÔn.
AntÐjeta me up�rqousa ereunhtik doulei� se suneqeÐc k-korufaÐec keimenikèc eperwt seic,sthn ergasÐa aut , jewroÔme polÔplokec sunart seic apotÐmhshc pou perilamb�noun tìso thn kei-menik susqètish tou stoiqeÐou plhroforÐac me thn eper¸thsh, ìso kai thn spoudaiìthta tou, all�thn nèa plhroforÐa pou prosfèrei wc proc to ti èqei dh dhmosieuteÐ. Sth sunèqeia, proteÐnoumethn anapar�stash twn eperwt sewn basismènoi sth bajmologÐa touc, k�ti pou mac epitrèpei naapotim soume apodotik� to prìblhma thc epilog c eperwt sewn qrhst¸n: h apotÐmhsh, dedomènouenìc stoiqeÐou plhroforÐac, twn qrhst¸n ekeÐnwn ìpou h lÐsta twn k-korufaÐwn apotelesm�twnprèpei na ananewjeÐ, dhlad , prèpei na eisaqjeÐ se autèc.
H kainotomÐa thc prosèggishc pou akoloujoÔme ègkeitai sthn apotelesmatikìthta oriak¸nsunjhk¸n pou èqoume ex�gei prokeimènou na periorÐsoume drastik� to sÔnolo eperwt sewn pouprèpei na elegqjoÔn kat� th di�rkeia thc apotÐmhshc kai me mikrì epiplèon kìstoc lìgw thcananèwshc twn k-korufaÐwn list¸n, gia èna arket� eurÔ f�sma sunart sewn apotÐmhshc (staj-

mismèno mèso ìro bajmologÐac basismènh sthn eper¸thsh kai bajmologÐac anex�rththc aut c,efarmìzontac p�nw thc sunart seic exasjènhshc bajmologÐac)
Epìpthc Kajhght c: BasÐlhc QristofÐdhcKajhght c

EuqaristÐec
Arqik�, ja jela na euqarist sw ton epìpth kajhght mou, BasÐlh QristofÐdh gia thn polÔti-mh kajod ghs tou, tic qr simec sumboulèc tou, all� kai gia touc epoikodomhtikoÔc mac kabg�deckat� th di�rkeia ekpìnhshc thc paroÔsac ergasÐac. Kaj' ìlh th di�rkeia twn metaptuqiak¸n mouspoud¸n, all� kai nwrÐtera me eis gage sthn ènnoia thc èreunac dÐnont�c mou tic b�seic gia ticmetèpeita spoudèc mou kai thn mellontik mou karièra.
Ja jela epiplèon na euqarist sw jerm� ton Bernd Amann, gia thn �yogh sunergasÐa mackat� th di�rkeia paramon c mou sth GallÐa, gia tic qr simec idèec tou pou tan kajoristikèc giathn olokl rwsh thc doulei�c aut c, all� kurÐwc gia th suneq tou di�jesh na bohj sei se k�jest�dio thc ergasÐac.
Ja jela epÐshc na euqarist sw touc fÐlouc mou, all� kai touc sumfoithtèc mou sto Hr�kleiokai sto ParÐsi gia thn st rix touc, all� kai gia tic upèroqec stigmèc pou per�same mazÐ ta dÔoteleutaÐa qrìnia. IdiaÐtera ja jela na euqarist sw touc SofÐa, MaÐrh, D mhtra, Dan�h, Pètrokai Stam�th pou tan p�nta ekeÐ gia mèna.
Tèloc, euqarist¸ thn oikogènei� mou, K¸sta, 'Anjh kai SÐssu, pou st�jhkan dÐpla mou mek�je dunatì trìpo kai se autì to st�dio twn spoud¸n kai thc zw c mou.


Contents
Table of Contents iii
List of Figures v
1 Introduction 1
1.1 Context and Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Problem Statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Organization of the Thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Related Work 7
2.1 Scoring Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Ranking Parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.2 Personalization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.3 Time decay . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 Continuous Top-k . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.1 Continuous Queries over Structured Data . . . . . . . . . . . . . . . . . . 10
2.2.2 Continuous Queries over Textual Data . . . . . . . . . . . . . . . . . . . . 10
3 Query Representation and Constraints Model 15
3.1 Query Representation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Constraints Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2.1 Optimal Local Upper Bound estimation (LUB) . . . . . . . . . . . . . . . 17
3.2.2 Reducing Global Redundancy . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2.3 Further analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4 Query Indexing 25
4.1 Grid Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.1.1 Grid Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.1.2 Score Decay over Time . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.1.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2 Constant Angle Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.2.1 Constant Angle Implementation . . . . . . . . . . . . . . . . . . . . . . . 30
4.2.2 Score Decay over Time . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5 Experiments 33
5.1 Impact of Number of Queries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.2 Impact of Query Length . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
i

5.3 Impact of Item Length . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 425.4 Impact of Tuning Parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.4.1 Number of buckets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 455.4.2 λ Parameter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.5 Impact of Ranking Function Parameters . . . . . . . . . . . . . . . . . . . . . . . 525.6 Impact of Decay Rate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 555.7 Query indexing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585.8 Experiments’ Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6 Conclusions & Future Work 63
ii

List of Tables
1.1 Main symbols used . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
5.1 Experiments’ parameters values . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
iii

iv

List of Figures
1.1 Google Alerts service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Continuous query evaluation system . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1 The naıve index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1 Query representation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.2 Choosing between the two secondary conditions: Condition . . . . . . . . . . . . 233.3 Query representation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.1 The Grid index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264.2 Linear time decay on Grid index . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.3 The Constant Angle index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.1 Precision over number of queries stored . . . . . . . . . . . . . . . . . . . . . . . 375.2 Time performance over number of queries stored . . . . . . . . . . . . . . . . . . 385.3 Precision over query length . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405.4 Time performance over query length . . . . . . . . . . . . . . . . . . . . . . . . . 415.5 Systems’ precision over item length . . . . . . . . . . . . . . . . . . . . . . . . . . 435.6 Systems’ time performance over item length . . . . . . . . . . . . . . . . . . . . . 445.7 Precision over number of buckets . . . . . . . . . . . . . . . . . . . . . . . . . . . 465.8 Time performance number of buckets . . . . . . . . . . . . . . . . . . . . . . . . . 475.9 Memory requirements over number of buckets . . . . . . . . . . . . . . . . . . . . 485.10 Precision over different values of λ . . . . . . . . . . . . . . . . . . . . . . . . . . 505.11 Time performance over different values of λ . . . . . . . . . . . . . . . . . . . . . 515.12 Precision over different values of α . . . . . . . . . . . . . . . . . . . . . . . . . . 535.13 Time performance over different values of α . . . . . . . . . . . . . . . . . . . . . 545.14 Precision over score decay . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565.15 Time performance over score decay . . . . . . . . . . . . . . . . . . . . . . . . . . 575.16 Time performance on query indexing . . . . . . . . . . . . . . . . . . . . . . . . . 595.17 Memory requirements on query indexing . . . . . . . . . . . . . . . . . . . . . . . 60
v

vi

Chapter 1
Introduction
1.1 Context and Motivation
Web 2.0 technologies have transformed the Web from a publishing-only environment into avibrant information place where yesterday’s end users become nowadays content generatorsthemselves. The vast amount of user generated content available in various social media (Face-book, Twitter, blogs, discussion forums) in conjunction with traditional information producers(newspapers, television, radio) poses new challenges in aggregating and processing continuousinformation streams. Given the immense volume and vast diversity of the information generatedon a daily basis in Web 2.0, there is a vital need for efficient real-time filtering methods acrossstreams of information which allow millions of users to effectively follow personally interestinginformation.
For example, online news aggregation systems like Google News1, Yahoo! News2 or MSNBCNews3 are harvesting on a daily basis information items from around 25K professional newssources4 while the number of sources could rise up to 16M for blog search engines such GoogleBlog Search5. According to a recent study [14] of the RSS/Atom feeds behavior usually accom-panying such sources, on average 31,23 items were published per minute by 8K of active feedsrelated to press sites, blogs, forums etc.
In order to filter the published information items, users usually issue keyword queries thatcan either be directly evaluated by the underlying search engines over the warehouse of locallystored items or submitted to an alerting service (e.g., Google ALert6, Yahoo Alert7) continuouslynotifying users about newly published items matching their filtering criteria. In both scenarios,the number of filtered items can rapidly become too high for being exploitable by the userin time. Therefore, filtering has to be extended by appropriate item clustering and rankingfunctions. Ranking consists in estimating of how important information items are according tosome quality criteria (e.g., freshness, authority, etc.), as well as, how relevant they are to filteringconditions stated in user subscriptions. For clustering, information items (news articles, userposts) are usually organized offline into meaningful collections sharing common characteristics(e.g., news articles referring to the same real-world event, called stories). Advanced solutions
1news.google.com2news.search.yahoo.com3search.msn.com/news4googlenewsblog.blogspot.com/2009/12/same-protocol-more-options-for- news.html5blogsearch.google.com6www.google.com/alerts7alerts.yahoo.com
1

Figure 1.1: Google Alerts service
also take account of both, the item story and the item contents during keyword-based matchingthrough adequate scoring functions [30].
To deliver as resent information as possible [5], commercial news aggregation systems relyon a combination of time decay [4] and sliding time window [17] techniques. For example,Google News maintains a window of articles in the last 30 days although the top-k resultspresented without queries are rarely published more than a day earlier. Such articles could bereturned only in cases when queries do not return many related recent results. Furthermore, thefunctionality of commercial web alerts systems is reminiscent of continuous top-k textual queryevaluation [25, 13]. For example, the Google Alerts service periodically evaluates separately everysubmitted query on the Google News engines according to a predefined refreshing policy, retrievesthe top-k results at that moment and notifies users for newly published items. Transforming acontinuous query to a series of periodically executed snapshot queries incurs serious limitations.For large numbers of user queries and high arrival rates it is practical impossible to repeatedlyevaluate all queries at almost all new information items. For this reason, commercial systemsusually decrease the frequency of snapshot query evaluation and thus important news may bemissed.
1.2 Problem Statement
In this thesis are interested in efficient algorithms and data-structures for processing a largenumber of continuous textual queries (i.e., user subscriptions) on information streams. In par-ticular, we are focusing on continuous top-k textual query evaluation when scoring functionscaptures besides the relevance of an information item with respect to a user query also its im-portance and freshness with respect to others. We are thus proposing representation of queriesbased on their scores that enable us to resolve efficiently two related problems: (a) user queryselection: given an incoming information item determine which top-k query result lists need tobe updated (i.e., have to insert the item) (b) top-k results maintenance: given an update in thescore of an item incrementally maintain the top-k query result lists (i.e. without re-computingthe score of all items in top-k lists).
Figure 1.2 shows the way query filtering is applied: As items are published they are aggre-gated and grouped in clusters. Using cluster metadata and some other parameters an item scoreis assigned to each item. Finally, considering stored user queries, a total score is computed foreach query-item pair. If this score is higher than the minimal score of the query, the item is
2

Figure 1.2: Continuous query evaluation system
inserted in the corresponding top-k list. A decay function is continuously applied on the scoresof the top-k lists to guarantee freshness of information.
More formally, let Q be a finite set of keyword-based queries submitted by the users underthe form of subscriptions and I(τ) be a stream of information items published at some timeinstant τ . Without loss of generality we consider that all queries are applied against a singleI(τ) aggregating different news streams. The Publish/Subscribe system maintains for eachsubscription/query q ∈ Q a list of the k most relevant items i ∈ I(τ) satisfying the followingcondition with respect to some decay function Sdecay(i, q,): The top-k result R(q, τ) of somequery q ∈ Q at some time instant τ is a subset of k items i ∈ I(τ) such that there exists no itemi′ ∈ I(τ)−R(q, τ) where Sdecay(i
′, q, τ) > Sdecay(i, q, τ). For each query, we denote by Sminq,τ thescore of the item ranked in the k-th position in R(q, τ) at time instant τ .
The complexity of maintaining for each query q ∈ Q its top-k result R(q, τ) depends on thetotal number of queries, the employed scoring function of items and the used decay function.Without decay, a trivial solution to this problem is to compute at the arrival of each new itemi its score Stotal(i, q) and update all queries for which this score is higher than the minimalscore Sminq,τti . However, this naıve solution raises serious scalability concerns when Q is big. Likeexisting algorithms for tackling this problem [25, 13], in this thesis we are interested in pruningthe search space of examined top-k results. The main difference with respect to these existingsolutions is that we want to solve the problem for a larger class of scoring functions combiningboth query dependent and query independent item scores [30] as follows:
Stotal(q, i) = α · Sitem(i) + β · Squery(q, i)
where α is a non-negative constant in interval [0, 1] and β = 1−α. We should observe here thatall existing solutions can only be applied for homogeneous scoring functions (α = 0) while oursolutions applies to both, homogeneous and inhomogeneous (α > 0) functions.
For the query related part of the scoring function Squery(q, i), representing the textual simi-larity between the query and the item, we base our proofs and solutions on the cosine similarityfunction:
Squery(q, i) =∑t∈V
ωq,t · ωi,t (1.1)
where ωq,t and ωi,t represent the weight assigned to the query q or the item i for term t. Anyscoring scheme, such as TF-IDF, can be used to assign weights to the terms. Without loss ofgenerality, we assume that term weights for both queries and items are always normalized, so
3

that their sum is always 1. Note that with or without normalization, the results in the top-klists are always the same (although they have different score values).
Our approach can also be used for Okapi-BM25 [27] similarity scoring function commonlyused in web search engines:
Squery(q, i) =∑t∈q
ωi,t ·(1 +m) · tf
m · ((1− b) + b · |i|avgl ) + tf(1.2)
where tf is the term frequency (i.e., the number of occurrences) in the item, |i| is the documentlength, avdl is the average length of all items in the collection, m (≥ 0) and b (∈ [0, 1]) are twoparameters.
Concerning ageing of items score, we consider in our work linear decay functions which donot change the order of items in the top-k lists. This simplifies list maintenance since the currentminimal score of a list can simply be obtained by applying the decay function.
Symbol Description
q a queryi an itemτ a time instant
Q the set of all queriesI(τ) the set containing all items until time instant τV the vocabulary (the set of terms)
ωq,t the weight assigned to term t in the query qωi,t the weight assigned to term t in the item iSminq the minimal score in the top-k list of query q
Sitem(i) the item score assigned to item iSquery(q, i) the query score assigned to query q and item iStotal(q, i) the total score assigned to query q and item i
Table 1.1: Main symbols used
1.3 Contributions
The main contributions of this thesis are the following:
• We propose an original spatial representation of queries based on the weight of employedterms and their minimal score per top-k list. Then, we identify necessary boundary con-ditions over this representation, while supporting a fairly large class of scoring functions(weighted sum of query dependent scores and query independent scores modulated bylinear decay)
• We introduce two new query indexing schemes, Grid and Constant Angle, which considerthe above boundary conditions to drastically prune the search space during item matchingwith a small update overhead.
• We provide a thorough experimental evaluation of our framework for critical workloadparameters (e.g., number and length of queries or items), scoring function parameters(e.g. α, decay rate, etc.) and memory requirements. The main conclusions drawn fromour experiments are:
– The matching time scales more smoothly w.r.t. the number of indexed queries inour Grid index than the state of the art COL-Filter [13] (which only applies to
4

homogeneous scoring functions). In particular for 1M of queries the former is 35%faster than the latter.
– The matching precision of our Grid index is significantly better (up to 110%) thanCOL-Filter for small length queries (representing the majority of user subscriptions)and does not get worse than COL-Filter for lengthy queries.
– Finally, Constant Angle index clearly behaves worse than the other two indexes.During matching the pruned search space is up to two orders of magnitude larger thanfor Grid which significantly increases the matching time requirements. On the otherhand, this performance loss is equilibrated by significantly less memory requirements.
1.4 Organization of the Thesis
The rest of this thesis is organized as follows: In Chapter 2 we present the related work. InSection 2.1 we give the state of the art for scoring functions proposed so far for steamingtextual information items and study their characteristics. In Section 2.2, we present systemsproposed so far in literature for continuous top-k query evaluation that are closely related to ourwork. We discuss their qualitative, in terms of offered functionalities, and their quantitative, interms of performance, features and limitations. Following, in Chapter 3 we propose our queryrepresentation in a two-dimensional space. After a theoretical analysis, we define a set of linearconstraints bounding the result search space in our setting. Then, in Chapter 4, we propose twoimplementations based on the constraints model including time decay. In Chapter 5 we givean experimental evaluation over the most important parameters affecting the performance ofour systems and compare them to systems proposed in related work. Finally, in Chapter 6 wepresent the main conclusions of this thesis and ideas for future work.
5

6

Chapter 2
Related Work
Building a Publish/Subscribe system for matching online long lasting user queries to informationitems as they are published, requires both a good estimation of how important information itemsare according to some criteria, such as novelty of information, source authority etc., as well ashow relevant they are according to the filtering criteria stated in user subscriptions. Apart fromthe problem of effectiveness, determined by the scoring function, another important issue isthat of efficiency. An online Publish/Subscribe system should efficiently retrieve all subscribersinterested in a newly published information item by pruning the search space of subscribers.Proposed solutions so far in related work [13, 25], support only a limited number of scoringfunctions corresponding to filtering criteria and fail to support others including metrics on theimportance of the item itself. In this thesis, we focus on the problem of efficiency, while alsosupporting more complex scoring function.
The measure of importance of information, which is an item in this context, for a given user’squery is calculated by a scoring function, assigning a value to a query-item pair. The scoringfunction is a very important parameter, as it determines the quality of results sent to users while,it also defines the efficiency of such a system: A high time complexity for the computation ofthe scoring function can make it infeasible to provide an online service. The need for efficiencygrows when considering the number of sources used in commercial systems, such as Google Newsor Yahoo! News, and the arrival rates reported in literature, as discussed in Section 1.1.
In this chapter we give an overview over the most important scoring functions proposed inliterature for streaming textual data and remark their characteristics and properties. Usingthese properties, we manage to define in the following chapters, data structures supportingefficient evaluation of users interested by a newly published item. Then, we examine GoogleAlerts, a commercial system providing a ranked streaming information service over publishednews articles, based on users’ stored queries. Finally, we present the two studies most closelyrelated to our work, Incremental Threashold [25] and COL-Filter [13], which propose solutionsto the problem of efficient top-k query evaluation limiting however, the problem definition tosimple scoring functions.
2.1 Scoring Functions
The problem of defining effective scoring functions has attracted both research and commercialattention and numerous definitions have been proposed in literature during the last few years.In most of these, complex computations are required in order to evaluate the scoring function, asthey use notions such as time decay and dynamic story importance. Time decay is an alternative
7

to time based or count based sliding windows commonly used for processing streaming data. Ina sliding window, a value representing the importance is assigned to every information publishedand this value remains constant over time. In order to guarantee freshness of information, aftersome given time the information is considered no longer valid and its importance is changed tozero. In time decay, on the other hand, an initial value of importance is assigned to a publishedinformation and decay is applied to it, i.e. the value decreases continuously as time goes by, thuscreating a more complex scoring scheme. The notion of story refers to a set of items concerningthe same real-world event. Scoring functions proposed in this context propose a computationof the items’ importance as a function over all previous items consisting the story. This wouldnormally require a linear time complexity computation over the number of items in the story,which could be a high overload for the initial computation of score by the system. However, weprove in the following that constant time complexity can be achieved by gradually evaluatingthe result as items are inserted in the story.
Scoring functions with such characteristics lead to a highly dynamic environment were scorescontinuously change over time. Thus, we can easily see that a straightforward evaluation of thescores at every time instant is infeasible. Due to this problem posed, solutions proposed so farfor online items matching to user queries [25, 13] use sliding windows rather than time decayand simple scoring functions without considering the items importance.
Most scoring functions proposed in literature over the past few years for streaming textualdata concern for news articles. The increasing research interest in this field can be explainedby the fact that news articles searching is one of the most important user activities online, asshown in a recent survey by Nielsen NetRatings. Here we will focus on these studies and thescoring functions they propose in order to define a general ranking function that we will use andbase our solutions. Although the proposed functions refer to news articles rather than itemsfrom feeds, in the context of news, items contain the title, as well as a brief summary of newsarticles (usually the first paragraph of the article). Consequently, ranking of news items doesnot require a different scoring setting. In the following we will use both item and article termsto refer the to textual information the system receives as input.
2.1.1 Ranking Parameters
The following parameters have been proposed in literature from ranking streaming textual data.Here, we make the distinction between the query independent parameters (media focus, novelty,user attention, source authority) that rank the items independently to any user and the querydependent parameters that are used for personalization.
Media Focus In order to decide on the importance of an article, it is crucial to determine theimportance of the real-world event it refers to. To do that, several studies propose clusteringof articles in stories. A story contains all published articles that refer to the same real-worldevent and the more articles are added the a story, the more important the story is considered.Studies considering this observation (such as [8, 21, 29]), referred to as media focus assign thescore of the story to the newly arriving articles, as soon as the story in which they belong to isdetermined.
Novelty Such a metric guarantees that articles published over an important story will beassigned a quite high score. However, even though it manages to capture the importance ofa real-world event when the story grows in terms of number of articles, it fails to evaluate asimportant the first articles referring to a potentially important event. In order to fulfil this need,
8

[12] proposes novelty as a ranking metric: articles referring to novel information, i.e. the firstarticles of a story or articles containing fresh information over an old information are assigneda higher score compared to those articles containing recaps of information already available.
User Attention At the same time, it is also important to evaluate whether web users areactually interested in some real-world event, as the measure of media focus might not capturethe actual interest of users. [29] refers to this measure as user attention and proposes assigninghigher scores to items and stories read by more users, while also considering the time decaydimension. [6] and [18] also propose using users clicking behavior as a measure of importancefor the article.
Source Authority Finally, many scoring functions have been proposed focusing on newssourceauthority [8, 15, 21, 22]. In the field of web search, the authority of web pages plays an im-portant role in the score calculation. The most commonly scoring function used for evaluatingsource authority is PageRank [3], which bases the calculation on the links between pages. Sim-ilar techniques have been proposed in the context of news, to measure the authority. Since it israther infrequent to have links towards newly published information, these works create a graphof virtual links, which are in fact similarity connections between items. The proposed solutionsalso adopt to the temporal dimension of news over their techniques. [21] bases its ranking onthe T-Rank algorithm [2], a variation of PageRank considering time.
2.1.2 Personalization
Even though the aforementioned ranking parameters capture the importance of an item, they donot personalize this measure of importance. On the contrary, they define a total order over thearticles for all users of the system. Some works however, focus on the need for personalizationof information according to the needs and interests of specific users [6, 12, 18, 19, 26]. Thesemainly focus on implicit data user gives to the system, such as his click behavior and readingpatterns similarity with other users in order to propose articles with high importance as well asdiversity, in comparison to what the user has already read.
In our work, we focus on ranking news based on both user independent ranking parameters,such as those presented previously, as well as explicitly given user queries a methodology alsoused web searching as shown in [30]. Similarly to this study, we base our scoring function in theweighted sum between the query dependent and query independent score.
2.1.3 Time decay
An important aspect when considering streaming information is the temporal dimension. Worksbased on sliding windows (such as [18]) chose either to include or exclude textual data in theranking according to whether they have been published before or after some time limit. However,generally in streaming information and especially in streams of news articles, it is important toassign higher scores to fresh information and decrease this score over time. The need for decay,compared to sliding windows, becomes even more obvious when considering the aforementionedranking parameters. For instance, when considering media focus, at some point of time twostories might have the same number of articles. Obviously, if one of them gathered this numberof articles within the last hour and the other one within the last two days, the first one shouldbe considered as more important.
9

Most of the aforementioned works on news articles ranking propose decay on their functions.The proposed ways of decaying the ranking score is by linear decay [12], exponential or geo-metrical series decay [8, 21] or decay by a sigmoid function [15]. An interesting property of allthese functions is that even though they consider all previous values of articles in the same storyin their computation, they can be calculated in constant time. Moreover, it is easy to showthat using these decay functions, the order between different scores remains the same over time.More formally:
Suppose that q and q′ are queries, i and i′ are items, and Sτ (q, i) is the score assigned tothe query-item pair, at time instant τ . if at some time instant τ, Sτ (q, i) ≥ Sτ (q′, i′) then,Sτ ′(q, i) ≥ Sτ ′(q′, i′) for any other time instant τ ′.
Commercial news aggregation systems such as Google News use a combination of time decayand sliding time window to rank their results. Google News maintains a window of articles inthe last 30 days however, the top-k results presented on their website are rarely older than oneday. Articles published before are used and presented only in cases where users post querieswith not many related recent results.
2.2 Continuous Top-k
2.2.1 Continuous Queries over Structured Data
The problem of continuous top-k query evaluation has also been studied over structured data,where the streaming information is tuples, rather than text. A motivation example commonlyused for such a service is a house selling service, where several parameters of the house, such assurface, city name, apartment type, distance from the city center, are attributes of the tuples.Arriving adverbs on houses contain all this information and are matched with continuous top-kuser queries defining equality/inequality (e.g. city = ”Athens”), preferences over them (e.g. type: prefer ”2-rooms” to ”studio”), range queries (e.g. 30 ≥ size ≥ 50), minimization/maximizationqueries (e.g. minimum distance from city center).
[23, 20, 9, 7] are some of the works concerning continuous top-k queries over databases.[20] focuses on the problem of range queries, while [9] on the problem of preference evaluationand neither of these match or could be used to match our problem definition. On the otherhand, [23] using skylines and [7] using geometric arrangements provide solutions that couldbe adapted to a system over textual streams. However, both these solutions assume a smallnumber of dimensions: each attribute in the tuples is a dimension of the problem. Deducingthis solution to textual data, each term in the vocabulary would be a new dimension. The highsize of terms vocabularies and thus, the high number of dimensions, make such solution unableto be applied in our context.
2.2.2 Continuous Queries over Textual Data
Recently, two studies over the problem of continuous top-k query evaluation over text streamshave been published [25, 13]. In 2009, the authors in [24] and [25] proposed the IncrementalThreshold algorithm which is based on the Threshold Algorithm [10]. A year later, an alternativerepresentation of the problem was proposed in [13] and two algorithms were given: COL-Filterand POL-Filter. These two studies are the works most closely related to ours. The maindifferences in the problem solved compared to our problem definition is that they assume timewindow instead of time decay and that they limit the scoring functions to the query score only.
In Chapter 5 we evaluate and compare the performance of COL- Filter to our proposed
10

Figure 2.1: The naıve index
solutions. Incremental Threshold algorithm was not implemented as experimental evaluationin [13] shows that it performs even worse than the naıve solution. Before presenting the solutionsproposed in the two related studies we present this naıve solution which we will later use inChapter 5 as a baseline to compare the performance of the systems.
Naıve solution
In a naıve solution indexing queries and supporting the item matching algorithm, an unorderedset of queries per term would be stored (Figure 2.1). This set of queries is also called theposting list of the term. Using this index, in order to match an arriving item all queries in thecorresponding posting lists, i.e. the lists of all terms in the item, would be visited at each itemarrival (Algorithm 2). All solutions proposed so far in literature, as well as those proposed inthis thesis, also use an inverted file to store the queries. The difference from the naıve algorithmis that they store the posting lists in such a way as to further prune the search space and limitthe queries visited.
Algorithm 1: Naıve-Insertion
Input: The Query q to be insertedforeach Term t ∈ q do
list = map.get(t);list.add(q);
Algorithm 2: Naıve-ItemMatch
Input: The Item i to be matchedforeach Term t ∈ i do
list = map.get(t);foreach Query q ∈ list do
if Stotal(q, i) > Sminq,τ then
update(q);
11

Incremental Threshold
In the Incremental Threshold algorithm [25], two indices are maintained. The first one holds aninverted file mapping each term to the posting list of items containing this term and are includedin the current time window. Every time a new article is published it is inserted in this datastructure, while items that expire due to the sliding window are removed. At the posting list ofany term t, items are sorted by the term weight assigned to tfor the given item, in descendingorder, just like in the Threshold Algorithm [10] (TA). The second data structure is anotherinverted file mapping terms to the posting list of queries containing them. Each posting list ofqueries q for term t, is sorted by a value θq,t. This value indicates the minimum document termweight for term t that could influence the top-k result of the given query.
At query insertion, for the initial computation of the top-k list, the first data structure isused, by directly applying TA. At the same time, the values θq,t are computed and the queryin inserted in the corresponding posting lists of the second data structure. When a new item ispublished, at first it is inserted in the inverted file of items. Then, the inverted file of queries isused to retrieve the queries that should be updated: Knowing the term weight for each term inthe item, we retrieve from the posting list of queries, those where the value of θq,t is lower thanthe item’s term weight, as according to θq,t definition, these are the ones that could be updatedby the item.
As shown in the experimental evaluation of [13] the performance of this index is up to 60%worse than even the naıve solution. The main reasons for that are: i) the need for continuousupdates on the inverted file of items on item publications and expirations creates a high overloadfor the system, ii) on item publication, all queries having a value θq,t lower that its term weightfor each term t it can be proven that on average, half of the queries in the posting lists will bevisited. Although this seems as a big gain compared to the naıve solution, the more complexdata structures (trees, since queries need to be sorted) as well as the updates on the item’s indexcause this index to have high memory requirements.
COL and POL-Filter
COL-Filter is and algorithm proposed in [13] and the first one achieving a significant gaincompared to the naıve solution. Like Incremental Threshold algorithm, it also uses a variationof TA to retrieve the correct queries to be updated. POL-Filter, also proposed in this study is avariation of COL-Filter aiming at achieving better performance when items update on averagea high number of queries.
In COL-Filter one data structure is maintained: an inverted file mapping terms to queries.In the posing list of each term t, all queries q are sorted in descending order on a value υq,t,defined as υq,t = ωq,t/S
minq . Note that ωq,t remains constant, while Sminq can only change due
to query updates.
At query insertion, the query has an zero minimum score Sminq and thus, the value of υq,t isinfinity, so the query is always inserted in the beginning of the posting list. When queries areupdated, i.e. when their minimum score is changed, the new value of υq,t is calculated and theposition in the posting list changes.
On item matching, the posting lists of all terms of the arriving item are retrieved. Then, ina round-robin way the queries in the lists are visited and checked for potential updates. Theauthors in [13] have proven that when the weighted sum of the υq,t values from one pass reaches1, it is safe to stop the algorithm, any false negatives, i.e. without missing any queries thatshould have been updated.
12

Finally, POL-Filter changes the data structure in the following way: instead of having astrictly descending order over the value υq,t for queries, they group queries in buckets havingsome upper and lower υq,t bound. Here, on item matching all queries within each bucket arescanned and the upper bound of the bucket is used as the υq,t value used previously for thestopping condition. The gain in performance is achieved only for query updates: when theminimum score changes, it is probable that the υq,t value does not change enough for the queryto be moved to another bucket.
Limitations
The main limitation of both these solutions is that the assumed scoring function considers onlytextual similarity between the query and the item, and cannot include item score. More preciselythe Incremental Threshold algorithm proposed in [25] assumes cosine similarity, while COLand POL-Filters assume a more general form using a combination of monotonic, homogeneousfunctions. As defined in [25] a function f(x1, ..., xm) is monotonic iff f(x1, ..., xm) ≤ f(x′1, ..., x
′m)
whenever xi ≤ x′i for all i. A function is homogeneous if it preserves the scalar multiplicationoperation: f(αx1, ..., αxm) ≤ αrf(x1, ..., xm). As a result, functions such as cosine similarity orOkapi-BM25 (Equation 1.2 can be used for the total score, which correspond to only the queryrelated part of the scoring function we assumed. Scoring functions like the weighted sum of aquery score and an item score given in Section 1.2 are not homogeneous and are not supported.
Another limitation of these algorithms is that they do not support score decay over time.Instead they use a sliding window in order to guarantee freshness of information, a fact thatcauses both effectiveness and efficiency problems. Considering, for instance a time window of30 days, the threshold used by Google News, freshness of information cannot be guaranteed, asnews published a month ago cannot be considered “fresh”. On the other hand, smaller timewindows would lead queries with a low rate of arriving relevant publications to receive all itemsthese items thus, removing for them the top-k factor. Moreover, the way they apply slidingwindow can also cause efficiency problems. Generally, when applying sliding windows, itemsthat are in top-k lists can expire due to the window limit and have to be replaced by itemsvalid at that point of time. For both these works, in some occasions, after the expiration ofan item, the top-k result has to be re-evaluated from the beginning. Due to the high rate ofarrival, the number of items considered at each point of time can be quite high and if alsoassuming a high number of stored queries, this re-evaluation in normally expected to have hightime requirements.
13

14

Chapter 3
Query Representation andConstraints Model
In this chapter we will represent the problem of matching a new item with all queries that haveto be updated as a search problem in a multi-dimensional space. More precisely, queries arerepresented as points in |V | two-dimensional spaces as shown in Figure 3.1. Each such spacecorresponds to a term t in V and will be called the query index of t denoted by P(t). Theprecise definition of these indexes will be explained later. Based on the scoring function definedin Section 1.2 we define three linear bounding functions computing for each item a subdivisionof the space containing all candidate queries, i.e. queries whose top-k list is potentially updatedby the item. Using these constraints, item matching is performed in two phases: in the first step,the bounding constraints are applied on the two-dimensional query index of each item term toprune the search space. In the second phase, all candidate queries are visited, i.e. checked forpotential updates by calculating their total score for the given item and considering the updatingcondition (Equation 3.2). Our goal is to reduce the target search space in the first phase, inorder to visit as less as possible queries on the second one. In this chapter we only concentrateon the formal definition and validation of the constraints. Later, in Chapter 4, we present afamily of algorithms, Grid Algorithm and the Constant Angle Aglorithm, for processing largecollections of continuous top-k text filter queries, based on this constraints model.
For the sake of simplicity and without loss of generality, we first assume that there is noscore decay over time. How decay can be applied on the total score Stotal(q, i) will be thoroughlydiscussed in the following chapter (Chapter 4) concerning the implementation. Moreover, we willpresent our approach using the cosine similarity score (scalar product) for the query related partof the scoring function Squery(q, i). Again, this is not a restriction and the proposed constraintscan be adapted to more complex similarity scores such as Okapi-BM25 [27] frequently used inInformation Retrieval. We essentially exploit the fact that a monotonic weight combinationfunction (multiplication) can be distributed over the monotonic aggregation function (sum).Finally, we assume that the item score Sitem(i) of an item is constant over time which is astandard assumption in the literature as presented in Chapter 2.
3.1 Query Representation
As mentioned before, each query is represented as a set points in the two-dimensional space.More precisely, for each term t in the vocabulary of terms V , we define a two-dimensional spacein which the horizontal axis (x-axis) corresponds to the minimum scores in the query top-k lists
15

Figure 3.1: Query representation
and the vertical axis (y-axis) corresponds to the query term weights. In this representation, aquery q is represented as a set of points {(Sminq , ωq,t)|t ∈ V }. Let P(t) be the index storing thistwo-dimensional representation for term t:
P(t) = {(Sminq , ωq,t, q))|q ∈ Q}
Consequently, for a given set of queries Q having |V | distinct terms, |V | two-dimensionalspaces and indexes are defined. For simplicity, we assume that each query is only stored inthe indexes P(t) of the terms t it contains (ωq,t > 0). However, an alternative representation,storing queries in the rest of the indexes and having on these zero term weight, would still bevalid.
For example, let q be a query containing two terms, t and t′. As we can see in Figure 3.1, qis stored in the corresponding indexes P(t) and P(t’) and positioned in the coordinates definedby the term weights and minimum score at that time instant. The right part of the image zoomsinto P(t) index. All queries q′ in this index also contain term t.
3.2 Constraints Model
Using the aforementioned representation we define three linear bounding functions for identifyinga reduced set of query candidates for an incoming item i.
The following two equations define the global score and the set U(i) of all queries q that areupdated by the arrival of an item i at time instant τ :
Stotal(q, i) = α · Sitem(i) + β · Squery(q, i)(τ) (3.1)
As said before, equation 3.1 considers item score Sitem(i) to be constant. Weighting parametersα ∈ [0, 1] and β = 1 − α allow to fix the influence of the item score with respect to the queryscore Squery(q, i)(τ).
U(i) = {Stotal(q, i) ≥ Sminq (τ)} (3.2)
16

As said before, in the following we also will assume the query score and the minimum score tobe constant (no decay). We will use cosine similarity for estimating score Squery(q, i):
Squery(q, i) =∑t∈V
ωq,t · ωi,t (3.3)
The above definition of Squery(q, i) can be replaced by any scoring function composing twohomogeneous monotone functions g (sum) and f (product) as defined in [13]. Under this settinga naıve nested-loop algorithm for aggregating the weights over all queries q ∈ Q and all termst ∈ V is obviously too costly (cost O(|Q| · |V |)). This cost can easily be reduced by consideringonly terms tcontained in item i, denoted t ∈ i (ωi,t) and maintaining for each term a list ofqueries Qt where ωq,t > 0. The cost would then be
∑t∈i |Qt|, where t ∈ i are the terms in the
item and |Qt| is the number of queries containing term t. . This value could still be quite high,especially for items containing many terms with high frequency.
Starting from the proposed representation, our goal is to define efficient upper bound con-straints allowing us to reduce the search space in each query index P(t). These constraintsshould be verifiable locally in P(t) for each term t in the item and for each query q by usingknowledge only on the item term weights, the query minimal score Sminq and the local queryweight ωq,t, without taking account of the other query term weights ωq,t′ (t′ 6= t).
We define three constraints based on two general observations:
• knowledge on the value of ωq,t · ωi,t, representing the query-term similarity for the giventerm t bounds the maximum similarity score this pair can achieve.
• every query is indexed as many times as the number of terms it contains. However, it issufficient to only visit a query that is updated once, in any of the indexes P(t) in which itis stored.
In the following, we prove three bounding constraints, LUB, HTA and MQW. For LUBconstraint we additionally prove that is locally optimal: no further improvement can be achievedwithin the P(t) without missing any queries in the U(t) set. For conditions HTA and MQW we
3.2.1 Optimal Local Upper Bound estimation (LUB)
On item arrival, we can immediately determine the item score Sitem(i), as it is assigned to theitem i on its publication and does not change and thus, we focus on bounding the query scoreSquery(q, i). The main problem we want to solve is to estimate Squery(q, i) locally in P(t) foreach term t without any knowledge on the number of terms t′ shared by the query-item pairor on the query’s positions in the corresponding indexes. Evidently, it is impossible to computethe precise value of Squery(q, i) without this knowledge so, we can only estimate an upper boundby determining the maximum potential value of M(q, i, t):
Squery(q, i) =∑t′∈V
ωq,t′ · ωi,t′ = ωq,t · ωi,t +
M(q,i,t)︷ ︸︸ ︷∑t′∈V,t6=t′
ωq,t′ · ωi,t′
In order to obtain a safe estimation for M(q, i, t), we must consider the worst case queryscore distribution generating the maximum value for M(q, i, t). It is easy to see that M(q, i, t)becomes maximal if query q shares exactly one other term tmax 6= t with item i where tmax hasthe maximal query weight ωq,tmax = 1−ωq,t and the maximal item weight ωi,tmax = max{ωi,t′ |t′ ∈
17

V −{t}} if ∃t′ 6= t, ωi,tmax = 0 otherwise (see proof below). This equation leads a safe and locallyoptimal upper bound for condition 3.2 which is satisfied by all updated queries q ∈ U(i):
Sminq ≤ α · Sitem(i) + β · (ωq,t · ωi,t + ωi,tmax · (1− ωq,t)) (3.4)
Based on the representation given previously (Section 3.1) we can replace Sminq with x andωq,t with y. After a few transformation we have the following linear inequality constraint:
x ≤ α · Sitem(i) + β · (y · ωi,t + ωi,tmax · (1− y))⇒y · β(ωi,t − ωi,ttmax
) ≥ x− α · Sitem(i) + β · ωi,tmax (3.5)
This inequality equation defines a semi-plane CLUB(i, t) of candidate queries in P(t) thatcould potentially be updated by i. In the following we prove the correctness of this condition,we prove that it is locally optimal and finally, we prove that it achieves optimal performance (interms of visited queries) in two extreme cases.
Proof Let tmax = argmaxt′
{ωi,t′ |t′ 6= t} ⇒
∀t′ ∈ V, t′ 6= t, ωi,t′ ≤ ωi,tmax (3.6)
From definition we know that term weights in queries are normalized:
∀q,∑t′∈V
ωq,t′ = 1⇒∑t′∈V−{t}
ωq,t′ + ωq,t = 1⇒
∑t′∈V−{t}
ωq,t′ = 1− ωq,t (3.7)
Using equations (3.6) and (3.7) we will find an upper bound for M(q, i, t):
M(q, i, t) =∑
t′∈V−{t}
ωq,t′ · ωi,t′ (from (3.6))
≤∑
t′∈V−{t}
ωq,t′ · ωi,tmax
= ωi,tmax ·∑
t′∈V−{t}
ωq,t′ (from (3.7))⇒
M(q, i, t) ≤ ωi,tmax · (1− ωq,t) (3.8)
Having found an upper bound for the M(q, i, t) we can replace it on the scoring function:
Stotal(q, i) = α · Sitem(i) + β · Squery(q, i)= α · Sitem(i) + β · (ωq,t · ωi,t +M(q, i, t)) (from (3.8))
≤ α · Sitem(i) + β · (ωq,t · ωi,t + (1− ωq,t) · ωi,tmax) (3.9)
A query q is updated by an item i if and only if Stotal(q, i) ≥ Sminq . Thus, we deduce thefollowing condition, which is Condition LUB:
Sminq ≤ α · Sitem(i) + β · (ωq,t · ωi,t + (1− ωq,t) · ωi,tmax)
18

Local Optimality We will prove that Condition LUB is locally optimal and cannot be furtherimproved using only knowledge on the current term t we are considering. To do that, we willshow that any query within the bounds of Condition LUB could potentially be updated. Moreformally, we will prove that ∀q ∈ CLUB(i, t), ∃q′, ωq′,t = ωq,t, S
minq′ = Sminq , s.t. q′ ∈ U(i). Note
that q′ is not necessarily in the set Q and of course qcould be equal to q′.
We have already defined tmax = argmaxt′
{ωi,t′ |t′ 6= t}. Let q’ be a query with two terms{t, tmax}. We will show that this query is updated.
By definition we know that ωq′,t = ωq,t and since query term weights are normalizedωq′,tmax = 1− ωq′,t = 1− ωq,t
The total score of query q′ is:
Stotal(q′, i) = α · Sitem(i) + β · Squery(q′, i)
= α · Sitem(i) + β ·∑t∈V
ωq′,t · ωi,t
= α · Sitem(i) + β · (ωq′,t · ωi,t + ωq′,tmax · ωi,tmax)
= α · Sitem(i) + β · (ωq,t · ωi,t + (1− ωq,t) · ωi,tmax)
≥ Sminq = Sminq′ ⇒ (since LUB holds)
q′ ∈ U(i)
Extreme Cases Here, we will prove that LUB visits exactly the set of queries to be visited,i.e. U(i) = CLUB(i, t), in the extreme cases where item length is 1 or all query lengths are 1.
When item length is 1: Let t be the only term of item i. According to the definition of LUB,ωi,tmax = 0. When also considering Equation 3.4 we can deduce that:
Sminq ≤ α · Sitem(i) + β · (ωq,t · ωi,t)
Since term t is the only term in the intersection of the item i and the query q(as t is the onlyterm of i), this last equation immediately means that q ∈ U(i)
Similarly, when query length is 1 ∀q ∈ Q, due to term weight normalization ωq,t = 1. Thusthe (1− ωq,t) term in Equation 3.4 becomes 0 and again:
Sminq ≤ α · Sitem(i) + β · (ωq,t · ωi,t)
As before, t is the only term in common between the query and the item and thus, q ∈ U(i).
3.2.2 Reducing Global Redundancy
So far, we have shown that LUB is a local optimal condition within any index P(t) and thus,no better bound can be achieved using the assumed knowledge and without missing any queriesthat are updated by the arriving item. Observe, however, that as each query can have multipleentries across different query indexes, it can also be visited multiple times. More precisely, usingonly condition LUB, each query q ∈ U(i) will be visited exactly as many times, as the numberof terms in the intersection of the query’s and the item’s terms set.
In an effort towards reducing redundancy, we try to define necessary conditions a queryshould fulfil in order to be updated, but also do not force retrieval of an updated query q inall indexes P(t) of terms both query q and the item icontain. In the following we proposetwo additional conditions, HTA and MQW, either of which can be used additionally to LUBcondition. The intuition in both these secondary conditions is that we try to retrieve the queries
19

(a) (b)
Figure 3.2: Choosing between the two secondary conditions: Condition
to be updated in the most “promising” term index. For condition HTA, we try to retrieve thequeries in the index where the product ωq,t · ωi,t is quite high (more precisely higher that theminimum possible average), while for condition MQW, we try to find the queries in the indexwhere their query score is maximum. In the following, we detail into these conditions. Observethat even though the secondary conditions try to reduce revisiting more than once the samequeries out of those that will be updated, they achieve at the same time reducing the numberto those queries q 6∈ U(i)
Higher Than Average - HTA In this condition, we focus on the value of the ωq,t · ωi,tcomponent used in the query score. On the first step towards defining this condition, we evaluatethe minimum possible query score Squery(q, i) a query q ∈ U(i) can have and then, estimate anaverage value of the minimum possible ωq,t · ωi,t product for any term t the query contains.Based on this, we can safely decide to avoid visiting all queries within an index P(t) for whichthe term weight product is lower that the evaluated average (see proof below). In the definitionof HTA condition we use an estimation of the maximum query length λ within our dataset. Thisestimation needs to be at least a safe upper bound if not exact: λ ≥ max{|q||∀q ∈ Q}. Theequation concluded for this condition is:
ωi,t ≥Sminq − α · Sitem(i)
λ · β · ωi,t(3.10)
Replacing Sminq with x and ωq,t with y, based on our query representation we have thefollowing linear inequality equation:
y ≥ x− α · Sitem(i)
λ · β · ωi,t(3.11)
20

Proof: For any query q ∈ U(i) we know that:
α · Sitem(i) + β ·∑t∈V
ωq,t · ωi,t ≥ Sminq ⇒
∑t∈V
ωq,t · ωi,t ≥Sminq − α · Sitem(i)
β⇒
λ ·∑
t∈V ωq,t · ωi,tλ
≥Sminq − α · Sitem(i)
β(3.12)
Where∑
t∈V ωq,t·ωi,t
λ is the average value ωq,t · ωi,t required, for terms t in the intersectionbetween the query and item, in order for query qto be updated. In this condition we only wantto visit queries only in those terms where the value of ωq,t ·ωi,t is higher than the average. Thus:
ωq,t · ωi,t ≥∑
t∈V ωq,t · ωi,tλ
⇒
λ · ωq,t · ωi,t ≥ λ ·∑
t∈V ωq,t · ωi,tλ
(from (3.12)⇒
λ · ωq,t · ωi,t ≥Sminq − α · Sitem(i)
β⇒
ωq,t ≥Sminq − α · Sitem(i)
λ · β · ωi,t
Which is condition HTA.
Maximum Query Weight - MQW Similarly to the previous condition, here too we tryto reduce the redundancy or revisiting the same queries. In this condition we try to retrievethe queries q to be updated from the index P(tmax) of the term tmax, where ωq,t is maximum:tmax = argmax
t{ωq,t|t ∈ q}. Based on the fact that term weights in the items are normalized to
sum to 1 we prove the following condition:
ωi,t ≥Sminq − α · Sitem(i)
β · ωi,t(3.13)
As we did in the previous conditions, we replacing Sminq with x and ωq,t with y and have thefollowing linear inequality equation:
y ≥ x− α · Sitem(i)
β · ωi,t(3.14)
Proof: From our definition we have that:
tmax = argmaxt{ωq,t|t ∈ q} ⇒
ωq,tmax ≥ ωq,t, ∀t ∈ q (3.15)
21
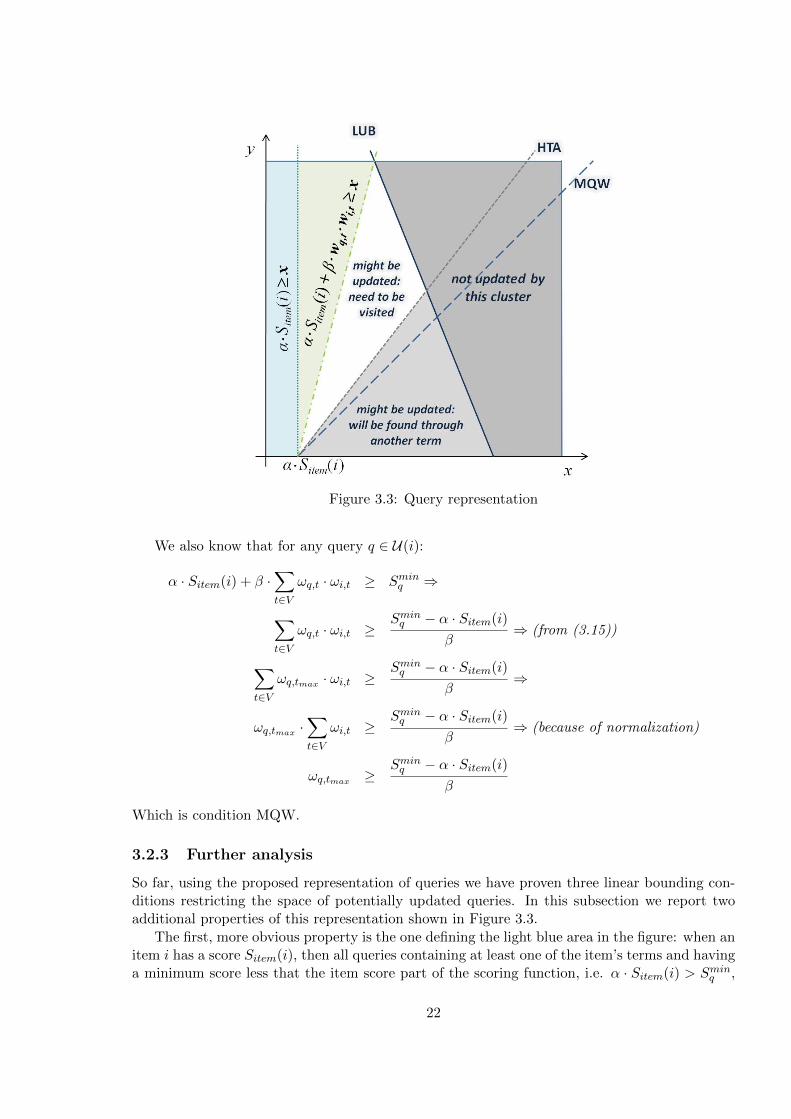
Figure 3.3: Query representation
We also know that for any query q ∈ U(i):
α · Sitem(i) + β ·∑t∈V
ωq,t · ωi,t ≥ Sminq ⇒
∑t∈V
ωq,t · ωi,t ≥Sminq − α · Sitem(i)
β⇒ (from (3.15))
∑t∈V
ωq,tmax · ωi,t ≥Sminq − α · Sitem(i)
β⇒
ωq,tmax ·∑t∈V
ωi,t ≥Sminq − α · Sitem(i)
β⇒ (because of normalization)
ωq,tmax ≥Sminq − α · Sitem(i)
β
Which is condition MQW.
3.2.3 Further analysis
So far, using the proposed representation of queries we have proven three linear bounding con-ditions restricting the space of potentially updated queries. In this subsection we report twoadditional properties of this representation shown in Figure 3.3.
The first, more obvious property is the one defining the light blue area in the figure: when anitem i has a score Sitem(i), then all queries containing at least one of the item’s terms and havinga minimum score less that the item score part of the scoring function, i.e. α · Sitem(i) > Sminq ,
22

they will be updated. This means that the item score and only that is sufficient to update thequery.
The second property, defining the light green area in Figure 3.3, also defines an area ofqueries that are always updated. These are the queries, where the sum of the item score andthe score assigned for text similarity only by this term, is sufficient to update the query: α ·Sitem(i) + ωq,t · ωi,t > Sminq .
Although these two properties are not used in the proposed implementations of the followingsection, they help us further understand the queries representation and could potentially be usedin some future implementation.
23

24

Chapter 4
Query Indexing
In this chapter, after a brief discussion, two solutions are proposed based on the representationand constraints presented in the previous chapter: Grid and Constant Angle.
Using the representation and constraints model proposed in the previous chapter we manageto prune the search space and visit only a subset of queries stored. The main difficulty and themost important decision here is on how to store queries in such a way as to both efficiently a)retrieve the subspace defined by the constraints in item matching and b) change the positionsof the queries, i.e. the points, after updates.
Similarly to the naıve solution and to the ones previously proposed in literature [25, 13],we also use a mapping from terms to queries and focus on the representation of queries perterm in order to efficiently retrieve the correct results, i.e. the queries to be updated. Thesolutions proposed are based on the representation in the two-dimensional space as describedpreviously in Section 3.1. In order to better understand the decisions made, we make thefollowing observations on the characteristics of queries concerning their spatial representation:
• queries can only move from left to right when updated (their minimum score can onlyincrease) and continuously move from right to left because of score decay. In the contrary,they do not change their position in the y-axis, since we assume that query term weightsdo not change.
• no assumption can be made on the distribution of queries’ minimum scores per term. Ingeneral, the top-k list of queries containing hot terms, i.e. terms frequently appearingin items, are updated more frequently and are less influenced by the decay function.Consequently, for such terms the average minimum query scores are expected to be high.However, items and especially those from feeds in news sources have a very bursty behaviorand the set of hot terms changes frequently over time. As a result, so does the distributionof queries in the x-axis.
On item matching, it is crucial to efficiently retrieve in the posting list of each term the queriessatisfying the constraints defined in the previous section. We make the following observationson the subspaces as defined by the constraints:
• we observe that each arriving item defines for each of the terms it contains a polygon whichis defined by the intersection of all half-planes defined by the constraints and the two axis
• None of the constraint lines is predictable without knowledge of the attributes of the itemto be matched (item score, item weight per term). The only exception to that is the lineof the third condition, which has constant angle for any item (independently of its term
25

Figure 4.1: The Grid index
weights). The angle of this line only depends on the α and β parameters used in theranking function as defined in Section 1.2, which is always predefined in the system.
Based on these observations we present in the following two Sections two solutions calledGrid and Constant Angle.
4.1 Grid Index
The general problem we want to solve here is to define a data structure for the two-dimensionalsearch space as defined above. This data structure plays the role of an index and should beefficient for searching and updating the posting lists of each term. A straightforward way topartition the search space is to define a grid dividing the space horizontally and vertically in rowsand columns of constant size as shown in Figure 4.1. Another solution would include using morecomplex spatial indexes (data partitioning data structures), such as Quadtrees [11], R-Trees [16]etc. In Subsection 4.1.3 we discuss the advantages of this methodology compared to that ofusing more complex data structures.
4.1.1 Grid Implementation
In the Grid Index solution, we define a two-dimensional data structure called term grid foreach term in the queries vocabulary. Each of these term grids is divided horizontally andvertically into a two-dimensional bucket of some predefined constant size. Each bucket containsan unordered set of all those queries whose coordinates (minimum score, term weight) are withinthe bucket’s bounds. Thus, a grid is a two-dimensional array of buckets containing a set of queries(Figure 4.1).
When a new query is inserted in the system it initially has a minimum score equal to zeroand thus, the x coordinate for all terms it contains is always zero. This means that every newquery is inserted into a bucket on the left side of the terms’ indexes of all terms it contains.Based on the term weights of the query’s terms, we can directly retrieve the correct y coordinateon each grid. The algorithm for inserting a new query into the index is given in Algorithm 3.
On item matching (Algorithm 4), the grids for each of the terms in the item are retrieved.For each of them, the required subspace (as defined by the two bounding lines) is found as
26

Figure 4.2: Linear time decay on Grid index
follows: for each line of the Grid the rightmost bucket intersecting with each of the constraintlines is computed. Then, starting from this bucket and moving towards the left, each of thequeries in the buckets is visited to check if it should be updated by the given item. In case aquery is to be updated, it also needs to be repositioned in all grids in which it is contained.To do that, we retrieve all grids corresponding to its terms, we find the buckets where they arecontained, remove the query from these buckets and then add it in the buckets correspondingto their new position. Note that in some cases it is not necessary to reposition the query, asits new position might still lead to the same bucket, despite the update. The constant retrievaltime for the buckets within the Grid achieved due to the way the space is divided, guaranteesthat the update cost is essentially linear with respect to the size of the query .
Note that it is important to look into the buckets from right to left: as queries are updatedand as their minimum score decreases, they might move to a bucket on their right. Scanningthe buckets from right to left guarantees that the same query will not be checked twice in oneGrid.
4.1.2 Score Decay over Time
In the previous subsection we have presented the Grid solution in the static case, withoutapplying time decay. When also considering time decay in the scoring function, the minimumscore of all queries continuously decreases according to the given decay function. Since theminimum score of queries is the x-coordinate in the proposed representation, queries movecontinuously from right to left inside the query indexes P(t) of all terms they contain. A lazyapproach of applying time decay over the Grid solution consists in moving the queries betweenbuckets at every time instant, as their minimum score decays. However, we can easily see thatsuch a solution is completely inefficient.
In order to avoid this continuous re-evaluation of queries’ positions at each time instance wemake the following conversion: we fix a constant time instance τ0 for the system and calculatethe scores of the queries with respect to that. As shown in [4] and as we have seen in Section 2.1for all linear, exponential and geometrical series decay, the future or past score can be evaluatedin constant time.
Thus, for evaluating whether a query q is updated or not by a given item i at some timeinstant t, we compute the total score Stotal(q, i) and then apply on this value the decay functionin order to compute the score in the fixed future or past time instant τ0. Then, we only need
27

to compare the values of this score and of the previous minimum score of the query in orderto decide if the query should be updated. Observe that, since both scores are computed withrespect to τ0, this comparison is valid.
On item matching, the constraints lines are evaluated as originally proposed in Chapter 3,with one small differentiation: the decay is applied in the minimum score of the query, Sminq
which is now computed with respect to τ0. As a result, more buckets are visited.
To better understand the index evolution because of decay see the example in Figure 4.2showing the evolution over linear time decay. The figure represents one line of a Grid at threetime instances τ1, τ2 and τ3. The squares are the buckets of the line and the dots are the queries.The numbers below the lines represent the total scores as they actually are at the given timeinstance. At time τ1 we suppose we have a valid snapshot of the index. After some time, inτ2 no item that contains the term corresponding to this grid has been matched and thus, thereare no changes in the buckets. So, queries remain at their initial positions, even though theirscores have decayed and all of them should have been moved one bucket to the left. Then, attime instant τ3 an item arrives: the dashed line is the position the constraints line would havewithout any decay, while the solid one is the one actually used because of the decay, causing twoextra buckets to be visited. Finally, the decision on whether to update are made as previouslyexplained and the corresponding queries are updated. The last line of the figure shows the stateof the line of the grid after all updates have been performed.
Observe that at any time instant τ there is always the exactly same number of buckets used:if b buckets are out of date at some time instant τ then if a new item arrives all of these willbe updated due to the non-zero similarity score and these b buckets are removed (e.g. the threebuckets on the left at time instant τ3 in the example), while at the same time b new bucketsmust be created in order to be able to move queries that have just been updated to have themaximum possible minimum score. Also, note that this handling of decay would not be asefficient in linear decay if buckets did not have the same width.
4.1.3 Discussion
In the beginning of this section we have stated that the solution of dividing the space verticallyand horizontally in equal widths and heights is preferable to more complex spatial data struc-tures. The main reasons for that are the constant time constant time retrieval of the bucket aquery should be searched in for the update process and the fact that such a structure is easilytunable for decay: query points do not have to move continuously as they should due to scoredecay. That would not be possible in none of the aforementioned more complex dynamic spatialindex structures.
On the other hand, such a data structure is not tunable to the actual minimal score distri-bution of the queries, something which could lead to increased memory and time requirements(some buckets might be empty whereas other buckets might be overloaded). Moreover, noticethat buckets that intersect with the constraints lines contain queries both in and beyond theconstraints. In order for the algorithm to be accurate we have to visit all queries inside thesebuckets, too. This loss of accuracy compared to the constraints model is not negligible, as wewill later see in the experiments of Chapter 5. Defining a data structure that better approachesthe constraints and their performance in accuracy is subject of further study.
28

4.2 Constant Angle Index
In the beginning of this chapter we noted that it is impossible to predict the location of the linesof the three conditions, since they depend on the item score and on its terms’ weights. However,we also noted that the angle of the line in the MQW condition remains constant for any item.In this Section, we propose a solution based on this observation.
4.2.1 Constant Angle Implementation
In Chapter 3 we have seen that the cosine of the third constraint’s line is equal to the β parameterfrom the scoring function and that its distance from the origin is α ·Sitem(i) (Figure 3.3). Thus,for any new item we know in advance the angle, but not the location of the constraining line.In order to effectively retrieve the desired queries for items with any item score we organize thequeries in the following way: for each term, we hold a list of all relevant queries (an invertedlist) and we keep this list sorted by the queries’ distance from the line having the given angleand containing the point in the beginning of the axes (Figure 4.3). We define the distance tobe positive if the point is above the line and negative if it is below. Note that the exactly sameorder would be defined even if the line had the same angle but was positioned higher or lower.The list is sorted in descending order.
Using this index, we can scan the lists starting from the left top corner of the two-dimensionalspace and move towards the line of the third constraint as shown in Figure 4.3(b). On itemmatching we scan the lists and continue until the bounding line has been exceeded. This traversalguarantees that all and exactly those queries within the bounds will be checked for potentialupdates. The algorithms to insert a query in the data structure and to match an arrivingitem are given in Algorithm 5 and Algorithm 6 correspondingly. The function to calculate thedistance from the query to the line is given below and can be immediately found through thefunction to calculate the distance between a point and a line.
distance(q) = ωq,t/β − Sminq
The benefit of this index compared to the Grid solution is that it matches exactly the thirdconstraint. Grid on the other hand, has a loss of accuracy compared to the actual constraintsfor the buckets intersecting with the lines. However, as we will later see in the experiments ofChapter 5, the third condition does not achieve as a high performance as the combination ofthe first and second conditions do.
4.2.2 Score Decay over Time
Constant Angle index also supports linear decay. As time passes, queries’ minimum score dropsuniformly and thus queries are all repositioned at some dx distance towards the left. Observethat, although this movement changes the actual distance of each of the queries from the line(ε) it does not change their relevant position in the defined ordering and thus, no updates arerequired within the list.
In order to correctly index the queries, just like in the Grid solution, here too, we computethe query’s minimum score with respect to a fixed time instance τ0. This conversion is also usedin the matching algorithm where the minimum query scores are also computed with respect toτ0.
29

(a) (b)
Figure 4.3: The Constant Angle index
Algorithm 3: Grid-Insertion
Input: The Query q to be insertedforeach Term t ∈ q do
grid =map.get(t);y = ωq,t mod gridHeight;bucket = grid[0][y];bucket.add(q);
Algorithm 4: Grid-ItemMatch
Input: The Item i to be matchedforeach Term t ∈ i do
grid =map.get(t);for i = 0 to grid.height do
for j = rightmost-bucket to 0 dobucket = grid[i][j];foreach Query q ∈ bucket do
if Stotal(q, i) > Sminq,τ then
update(q);
Algorithm 5: ConstantAngle-Insert
Input: The Query q to be insertedforeach Term t ∈ i do
list =map.get(t);x = Sminq ;
y = ωq,t;dst = y/β − x;// adding the query in the position defined by dstlist.add(q, dst);
30

Algorithm 6: ConstantAngle-ItemMatch
Input: The Item i to be matchedforeach Term t ∈ i do
list =map.get(t);foreach Query q ∈ list do
if Stotal(q, i) > Sminq then
update(q);
if Sminq > α · Sitem(i) + β then
break;
31

32

Chapter 5
Experiments
In this Chapter we present an experimental evaluation of the Grid Index and Constant AngleIndex proposed in Chapter 4. Both index structures are compared to both a baseline (naıve)solution and COL-Filter [13]. In particular, we study the performance impact of different work-load parameters, such as query length, ranking weights and decay rate by measuring the timeand memory requirements, as well as their precision on item matching. Precision measure the“redundancy in query visiting” and is computed as the fraction of the number of updated queriesto the total number of visited queries by the system: higher values of precision, i.e. values closerto 1, indicate a better system performance. This metric offers an implementation-independentoverview of the indexes’ performance.
Datasets and Query Workload
The items used for the experiments are taken form the RoSeS testbed1 including over 1 millionitems. The items were collected from 8, 155 RSS feeds, including press, blog, forum feeds etc.,over an 8 month period. Before processing the items stemming, stop-word removal and htmltag removal was performed. This preprocessing times is excluded from all results in our tests.
Queries were generated by finding the most frequent, not necessarily sequential, term com-binations of size 2, 3 or 4 within the items, based on the intuition that these correspond to hottopics. For all tests, a query workload of 100, 000 queries was created by uniformly choosing themost frequent combinations of each size, thus leading to an average of 3 terms per query. Thechoice of query length range and average length was based on the assumption that queries ofsuch systems will have similar statistical characteristics to those of queries in web search engines.Several studies over web query logs have been performed and show that the average query lengthranges between 2.3 and 3.3 terms per query [1, 28, 31] and that less than 10% of queries havelength more than 4 [1, 28]. Finally, for both queries and items we used the standard TF-IDFweighting scheme.
Tested Solutions
The following systems were implemented and experimentally evaluated:
• naıve: a simple solution where queries are indexed in an inverted file mapping each termto the unsorted list of all corresponding queries. At each item arrival all queries in theposting lists have to be traversed and checked for potential updates.
1The testbed is available at http://deptmedia.cnam.fr/ traversn/roses/
33

• COL-Filter: the solution as presented in [13] including all optimizations proposed there.
• Grid Index: the solution presented in Algorithm 4. The horizontal and vertical divisionof grids in buckets was made as a trade-off between matching time and main memoryrequirements and is further explained in section 5.4
• Constant Angle Index: the solution presented in Algorithm 6.
• On Constraints: this refers to a theoretical solution, visiting only those queries in thespacial bounds defined by the three constraints discussed in Chapter 3. Although, this isnot an actually implemented system, the results in the experiments show the maximumpotential gains on the precision and accuracy a system could achieve using the constraintsmodel.
The first solution proposed in literature, Incremental Threshold [25] was not implementedor tested, since experimental evaluation on [13] shows that in most cases, this system performsworse than even the naıve solution.
In the following for all systems we will refer to the queries that contain a given term as theposting list of the term, independently to how it is implemented in each system.
Experimental setup
In order to compare the performance of the different systems, we made the following assumptions:a) The weight of item score in the ranking function (β) was set to zero for all experiments exceptfrom those in Section 5.5, since it is not supported by COL-Filter and b) no score decay wasapplied, except from the experiments in Section 5.6, since COL-Filter supports sliding windowfor updates instead of time decay. In order to prevent queries from reaching a saturation pointwhere the minimum query score reaches th maximal value 1 which drastically reduces the numberof further updates, we only match 10, 000 items at each experiment.
Before each experiment, all queries used were stored in the indexes and their minimum scoreSquery(q, i) was set to 0. A warm up of matching 3, 000 items was performed before each test, inorder for the queries to have some initial non-zero minimum score. As explained in Chapter 1, incontinuous top-k queries the results updating a query are only affected by the value of the lowestelement in the top-k list, independently to how small or large this is. Thus, for all experiments,without loss of generality we fix k to 1.
Table 5 depicts the values of all parameters used in the experiments. At each test, oneparameter varies within the given range and for the rest, the default value is used.
Parameter Default value Range
α 0.0 (β = 1.0) {0− 0.95}#items 10,000 or 100,000 (on decay) —
#queries 100,000 {10, 000− 100, 000}#buckets 200 {10− 200}item score 0 or random(0, 1) —
linear decay step 0 {0− 0.05} per secondwarm up 3,000 —
Squery(q, i) 0 —(before warm up)
Table 5.1: Experiments’ parameters values
All algorithms were implemented in Java 6. Experiments were carried out on an Intel Core2 Quad Q6600 @2.4 GHz, with 32-bit Windows 7 operating system, using 1GB of Java heapspace.
34

Reading the figures
A system behaves better when it has higher values for precision and lower values for time ormemory requirements. The images on the right are on log scale, while the ones on the left areon linear scale and zoom into the values observed for Grid and COL-Filter systems. Recall thatprecision is computed as:
precision =updated queries
visited queries
where visited queries is the sum of the number of queries visited in each posting list (we countall visits of a query in all posting lists). This means that a system A having N times worse(lower) precision than another system B, makes N times more visits than B (A and B mightvisit different queries and each query several times). At the same time, the value 1/precisionshows how many times more queries than the actually updated, the system visits.
35

5.1 Impact of Number of Queries
In this first set of experiments we capture the impact of the number of queries stored in theindexes on the systems’ performance. Figures 5.1 and 5.2 depict the precision and time require-ments for matching 10, 000 items after a warmup of 3, 000 items (as explained in the experimentalsetup).
A first observation on Figure 5.1 is that independently to the number of stored queries,Constant Angle has approximately 4 times better precision than the naıve solution, while thecorresponding benefit in precision for Grid and COL-Filter is two orders of magnitude. At thesame time, On Constraints has a 2.5 times better precision than both of these systems.
Focusing on the behavior of Grid and COL-Filter, we can see that the former has a slightlybetter performance than the latter as the number of queries increases. This behavior is explainedby the way each system chooses the subset of query candidates in the relevant posting lists. Onthe one hand, Grid chooses the query subset by taking only account of the item characteristics(item score and term weights) independently of the queries stored. This strategy leads Grid toalways visit a constant portion of the posting lists. On the other hand, the stopping conditionused by COL-Filter depends on the query term weights. This leads to a slightly increasingportion of the posting lists being visited, as more queries are considered.
Another interesting observation here, is that although both Grid and On Constraints arebased on the same constraints, the former visits approximately 2.5 more queries that the latterfor all values of number of queries stored. This difference indicates a high number of queriesgathered in buckets located on the separation line of the two constraints: queries in bucketsintersecting with the constraint lines are inevitably all visited by Grid, even those which wouldbe rejected by the optimal On Constraint solution (this loss of preciseness is proportional to thebicket size). At the same time, Constant Angle, the solution based on the third constraint doesnot seem to have an equally good performance as Grid or On Constraints.
Note that despite the large benefit compared to the naıve solution the values of precisionalso show that Grid visits 14 to 24 and COL-Filter 16 to 25 times more queries than an optimalsolution visiting all update queries exactly once. On Constraints only visits 6 to 8 times morequeries than required.
On Figure 5.2 depicting time requirements, we can see that despite the fact that both Gridand COL-Filter visit two orders of magnitude less queries than the naıve system, in time re-quirements they only have a benefit of about 50 to 60. This is due to the much faster retrievalof queries in the data structure used by the naıve solution (a simple unordered list). On Fig-ure 5.2(a) zooming in the values of Grid and COL-Filter we can better see the observation madepreviously on the performance of the stopping conditions of the two systems. While Grid scaleslinearly as more queries are stored, COL-Filter’s performance is a slightly worse than linear.This same behavior can be seen in the experiments of [13] where the authors use additionally asliding window strategy. Finally, we also note that all four systems have almost constant timerequirements per visited query.
36
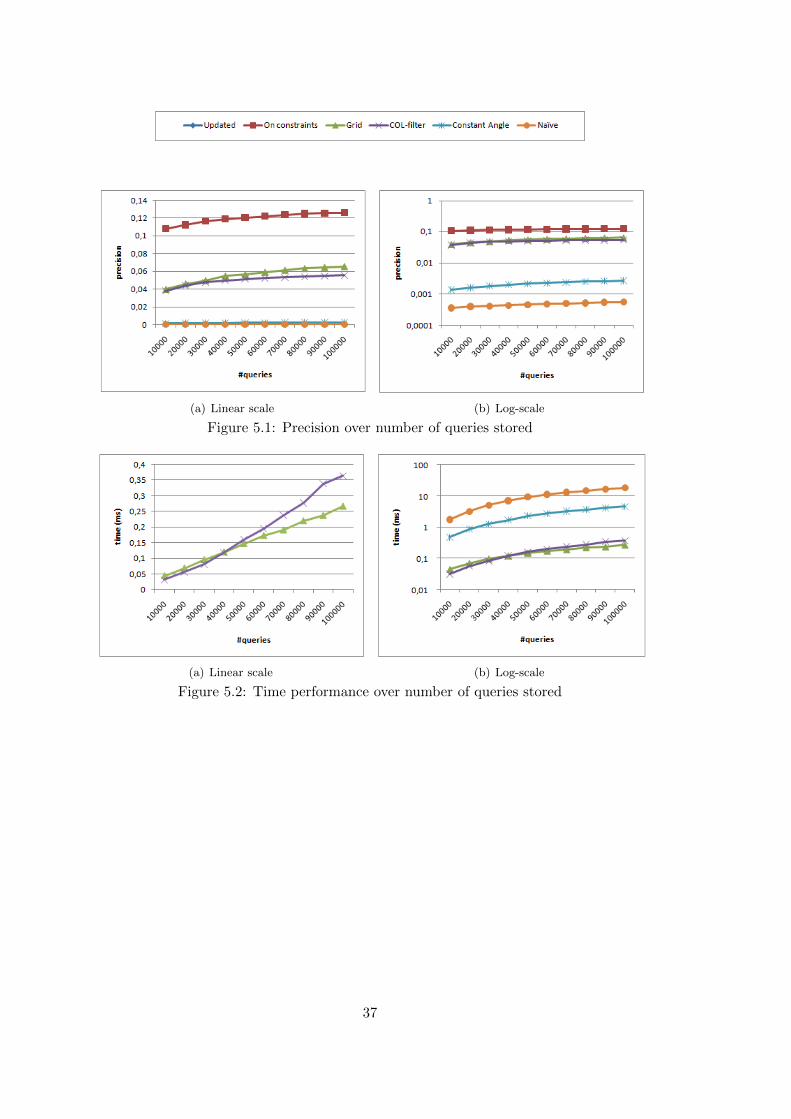
(a) Linear scale (b) Log-scale
Figure 5.1: Precision over number of queries stored
(a) Linear scale (b) Log-scale
Figure 5.2: Time performance over number of queries stored
37

5.2 Impact of Query Length
In this set of experiments we capture the impact of the query length on the performance ofthe different systems. Figures 5.3 and 5.15 depict the precision and time requirements for itemmatching over four different query workloads: the first three sets contain the 100, 000 mostfrequent term combinations (queries) of size 2, 3 and 4 respectively. The last one, which is alsoused in all other experiments of this chapter, also contains 100, 000 queries and was created byuniformly choosing the most frequent combinations from the three previous query workloads.The value of λ, a tuning parameter of systems On Constraints, Grid and COL-Filter, was chosento have the least possible value, so as to guarantee a correct behavior. The importance of λ inthe performance is better explained in subsection 5.4.2.
In Figure 5.3 we observe that accuracy decreases for all systems as query length increases.The most important factor causing this rapid decrease of accuracy is that the query lengthdefines the number of posting lists a query appears in. As a result of this, the average size ofposting lists for queries of length 4 is two times greater than the average size for queries of size2. Thus, as query length grows the systems have a larger sample of queries from which theyhave to sort out the updated ones.
Another important factor affecting Grid and On Constraints, is that as queries contain moreterms, the minimum score Sminq is expected to be lower for each query. The reason is thatfor larger number of terms per query, it is less probable to have an exact or close to exactmatch between items and queries which leads to lower similarity scores. Since we assumed forthis experiment that only the similarity score is considered, we can immediately conclude thatminimum scores drop as query length increases. As we have seen in Chapter 4 the constraintsmodel and consequently Grid and Constant Angle are more efficient with a uniform distributionof queries over the search space than with a biased distribution. However, since for long querieswe have lower minimum scores, the distribution gets more biased and performance declines.
On the other hand, we observe that COL-Filter has a much slower decline of precision asquery length increases. However, it only reaches the performance of Grid for queries of length 4and still for that value, is has 2 times worse precision than On Constraints.
A general conclusion that can be drawn from this experiment is that Grid achieves betterprecision for lower query lengths, in values which are close to the ones observed in literature forquery lengths in web search engines. At the same time, our theoretical model On Constraintsalways achieves a much better precision than all other systems for all lengths up to 4.
On time performance, we observe that Grid performs better than COL-Filter for all querylengths and even for those where COL-Filter’s precision is better. This is due to the fasterscanning data structures used by Grid (static array for the grid and dynamic unsorted lists forthe buckets) compared to those of COL-Filter (sorted lists, i.e. binary trees, as proposed by theauthors of [13]).
38
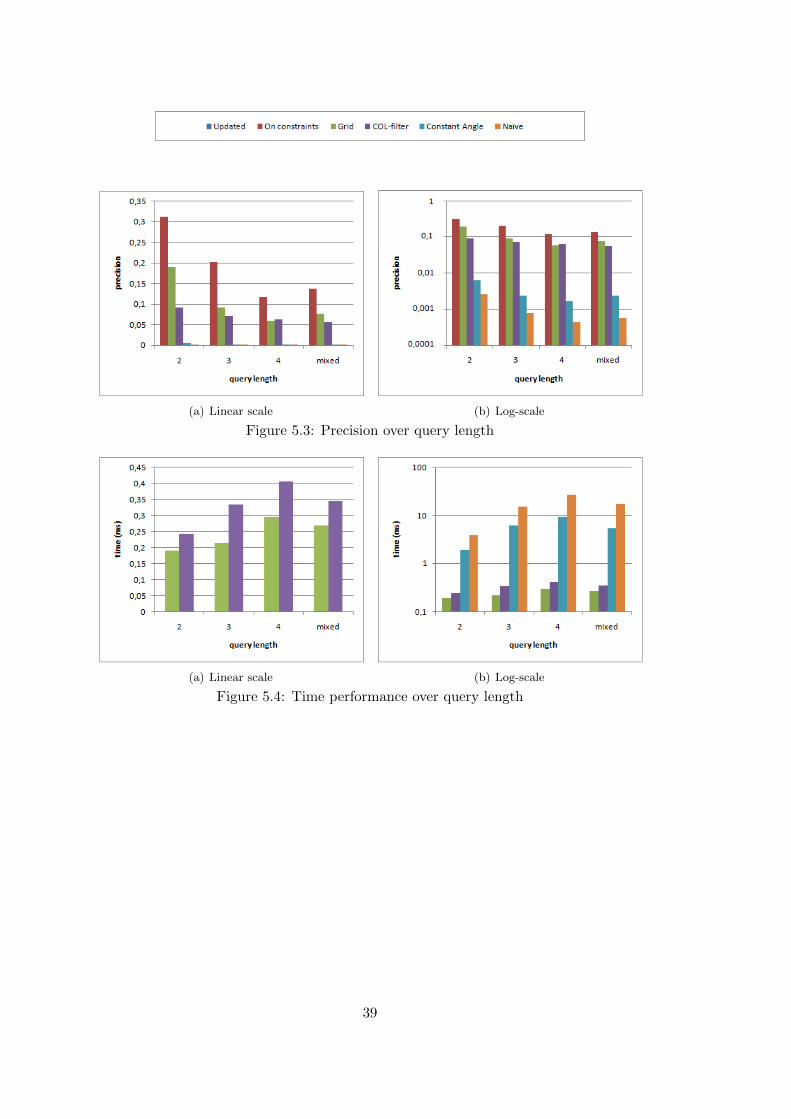
(a) Linear scale (b) Log-scale
Figure 5.3: Precision over query length
(a) Linear scale (b) Log-scale
Figure 5.4: Time performance over query length
39

5.3 Impact of Item Length
The number of terms in the item is an important parameter in the performance of item matching,as it defines the number of posting lists that need to be traversed in order to retrieve the updatedqueries. For this set of experiments we used 37 different datasets, each of which contains allitems with length l, where l ∈ [2, 38] within the 10, 000 items also used in the rest of experiments.For these performance tests, we also use the same set of 3, 000 items for warm up that are usedin all other sections.
Observing the relation between precision and item length in Figure 5.5, we notice thatprecision is inversely proportional to the length of the item for all systems: as the number ofterms in the item increases, precision gets worse. It is difficult to give a detailed explanation ofthis loss of precision, since it depends on the size and contents of the different datasets and theircorrelation with the generated query workload. A general explanation is the increase of visitedposting lists per item and the decrease of the average item term weight which might lead to anincrease of redundant query visits. The performance comparison between the different systemsgets more clear in logarithmic scale (Figure 5.5(b)) where we can see that Grid and COL- Filtervisit one order of magnitude less queries than Constant Angle and two orders of magnitude lessthan the naıve solution.
On the other hand On Constraints seems the have a close to constant behavior for lengthsmore than 20 and thus, the benefit from this theoretical model compared to all other, includingGrid, increases as length increases. Also, recall that for our theoretical model (as well as forCOL-Filter) we have proven that precision is always optimal and equal to 1 for items containingonly one term.
In Figure 5.6 we can see that despite the decrease in precision, time requirements for matchingfor both Grid and COL-Filter seem to be independent to the item size. The number of visitedqueries is almost remains constant for both systems, despite the fact that their precision drops.Recall that precision is a function over both the visited and the updated queries. In this set ofexperiments, precision drops mainly because of the decrease of number of updates rather thanon the increase of visited queries.
Comparing these two systems, we observe that COL-Filter achieves a better time perfor-mance than Grid for items of length higher than 30. However, the fact that more items in thisdataset have length between 12 and 30 explains why Grid has a better time performance in therest of the experiments.
Constant Angle has a drastic increase in time requirements as the items length increases.This behavior is expected since this system always visits a constant subspace of the postinglists of all terms the item contains. Consequently, the number of visited posting lists, which isdefined by the item length, is proportional to the number of visited queries.
40
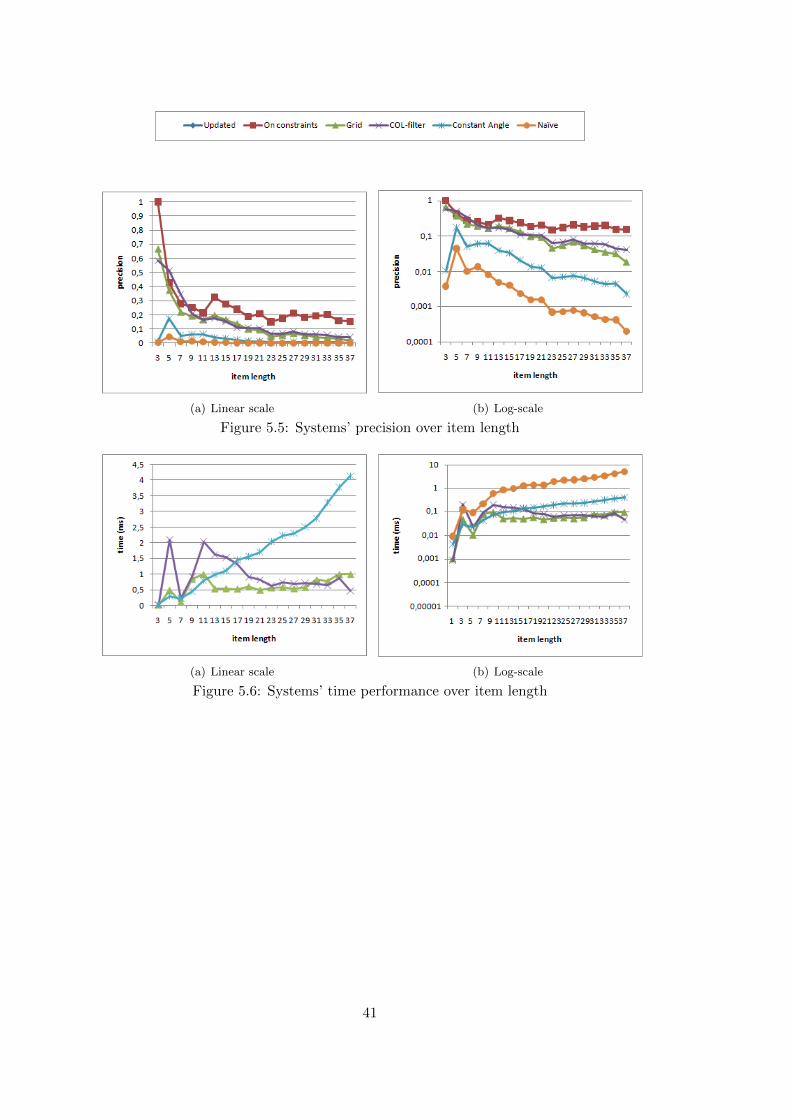
(a) Linear scale (b) Log-scale
Figure 5.5: Systems’ precision over item length
(a) Linear scale (b) Log-scale
Figure 5.6: Systems’ time performance over item length
41

5.4 Impact of Tuning Parameters
In this section, we evaluate the influence of different tuning parameters on the performance ofGrid and COL-Filter. In particular, we test the performance of Grid over the number of bucketsit contains (which is inversely proportional to the size of the buckets). We show that the bucketgranularity is a trade-off between used memory, time performance and precision. We also testthe performance of both Grid and COL-Filter on different values of the λ parameter, which isdefined as the maximum number of terms a query can contain. Both systems rely on λ havinga correct value, i.e. not lower that the actual one, in order to have correct results and at thesame time, a value as low as possible in order to achieve a better performance.
5.4.1 Number of buckets
As explained in Chapter 4, Grid divides the two dimensional query index P(t) into a grid ofequally sized buckets. The number of vertical and horizontal divisions has an immediate effecton both precision and time requirements of the matching algorithm. Recall that the (vertical) y-axes corresponds to the term weights, while the (horizontal) x-axis corresponds to the minimumquery scores. In Chapter 4 we have also seen that the distribution of query weights for TF-IDFweighting is predictable, since it relies on the query term distribution, which have been shownto follow a power law for various text corpora, including web query logs. On the other hand, theminimum score distribution cannot be predicted in advance, especially in the case of non-zeroitem scores. Thus, tuning the division of the horizontal axis (minimal scores) is more criticalthan the division of the query term weights. In the following tests, we fixed the number ofvertical divisions to 60 and varied the number of horizontal divisions from 200 to 5, 000 (whichcorresponds to score granularity between 0.005 and 0.0002).
On Figure 5.7 we can see that Grid approaches the precision of Constraints at a very highrate between 200 and 1, 200 score divisions and continues to improve at a lower rate until 5, 000.This behavior can be explained as follows. As we have already seen, the difference of precisionbetween the Grid solution and the On Constraints theoretical model is caused by the queriescontained in the buckets intersecting with the constraints lines. So, generally, a higher numberof divisions leads to smaller buckets and higher accuracy. For values until 1, 200 the gain fromincreasing the divisions is very high. However, further increasing this number also means thatsome buckets already containing very few, or even one single query are further divided withoutany gain in precision. This fact causes precision to continue to raise, but at a lower rate.
However, on time requirements (Figure 5.8) we observe that after 1, 200 buckets time remainsconstant, despite the increase in precision. This behavior can be explained as follows: while thenumber of buckets increases (a) there are more buckets that need to be traversed to cover thesame sub-space and (b) queries that are updated are more likely to have to be moved to bucketson the right after their minimum score update. Both these factors increase time requirements,an increase which is absorbed by the gain in precision and thus, leads to a saturation point.
On Figure 5.9 we can see that memory requirements have a normal behavior: they increaselinearly to the number of buckets used in the grids.
The saturation point for time performance, i.e. 1, 200 buckets, is the one chosen for all otherexperiments presented in this chapter, as having the minimum memory requirements whilehaving an optimal time performance.
42
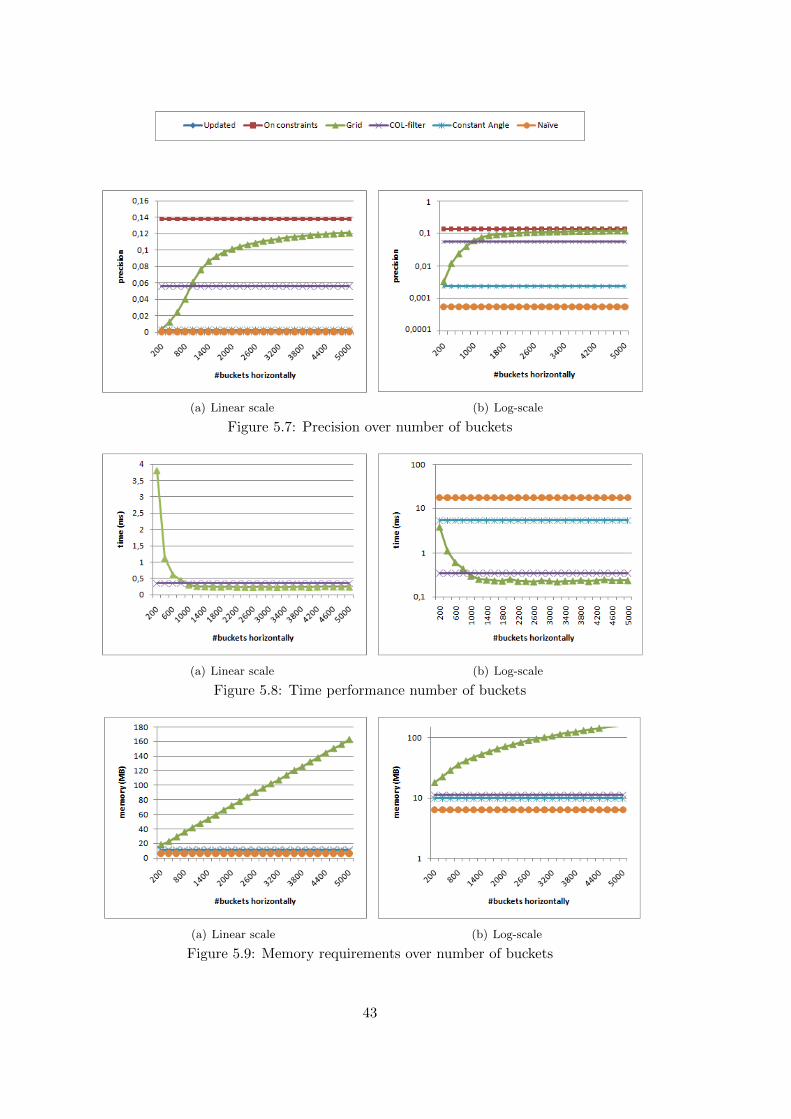
(a) Linear scale (b) Log-scale
Figure 5.7: Precision over number of buckets
(a) Linear scale (b) Log-scale
Figure 5.8: Time performance number of buckets
(a) Linear scale (b) Log-scale
Figure 5.9: Memory requirements over number of buckets
43

5.4.2 λ Parameter
All systems, Grid, On Constraints and COL-Filter use a λ parameter estimating an upper boundfor query length in their stopping conditions: λ ≥ max{|q||∀q ∈ Q}. On Constraints and Griduse λ in the computation of HTA constraint (see Subsection 3.2.2), while COL-Filter uses it inorder to perform an optimization crucial to the systems good performance (see Subsection 2.2.2).In this experiment, we explored the influence of λ using values between 4 and 20. Note thatthe value of 4 is the minimum acceptable for the used query workload which contains queries ofmaximal length 4.
In Figure 5.10 we can see that the performance of both On Constraints and Grid drops quitefast as the value of λ increases. COL-Filter, on the other hand, has much lower sensitivity tothis parameter. The curves of Grid and COL-Filter intersect at value 9, i.e. more than twicethe actual value of maximum query length. The corresponding value for On Constraints andCOL-Filter is λ = 15.
Figure 5.11 depicts the time requirements and we can see again the gain from the datastructures used by Grid: even though precision becomes worse than the one of COL-Filter aftervalue of 9, it is still better in time requirements until the value of 12, i.e. 3 times more than theactual value of λ. Also note that despite the increase in time requirements for both systems,their performance is still at least one order of magnitude better than the one of Constant Angleand naıve even for high values of λ.
44
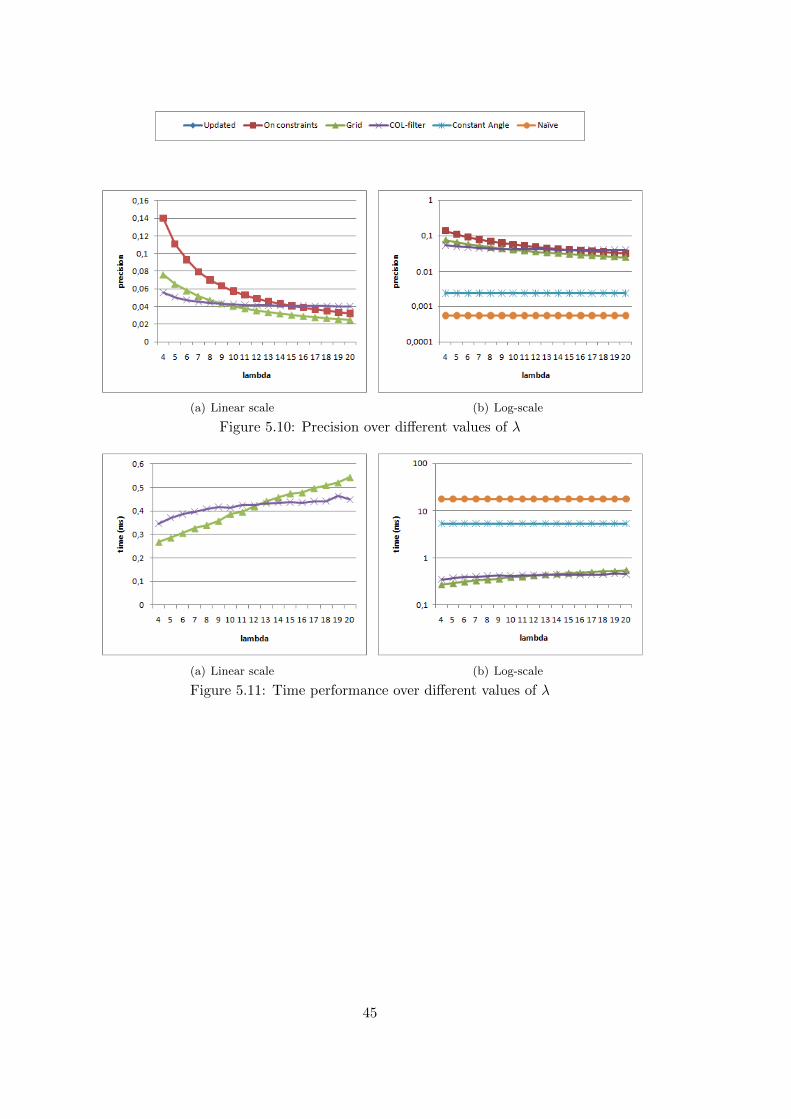
(a) Linear scale (b) Log-scale
Figure 5.10: Precision over different values of λ
(a) Linear scale (b) Log-scale
Figure 5.11: Time performance over different values of λ
45

5.5 Impact of Ranking Function Parameters
In the motivation of this work, we discussed the importance of considering item score additionallyto the textual similarity between the query-item pair in the scoring function. Using a weightedsum function to combine these two, the importance of each is defined by the α parameter. Recallthat the ranking function used is:
Stotal(q, i) = α · Sitem(i) + β · Squery(q, i)
and that β = 1 − α. In this set of experiments we evaluate the performance of the systemsproposed over different values of the item score weight in the ranking function (α).
In Figure 5.12 we can see the precision of the three systems for values of α between theminimum and maximum possible, i.e. in [0, 1] range. We observe that On Constraints hasan increasingly good precision as α increases: higher values of α give a better distribution ofthe minimum scores of queries and On Constraints has a better precision as queries are betterdistributed. The same behavior is observed for Grid, although it still has 2 to 2.5 times worseprecision than On Constraints. Their difference is more visible on log-scale (Figure 5.12(b). Fi-nally, Constant Angle has a much slower increase of precision as alpha value increases. However,even for the best value achieves, it is 5 times worse than the Grid solution and 9 times worsethan the theoretical model. The increase of precision for three solutions lies in the change ofdistribution as the value of α increases. As already explained, a good performance of each ofthese relies on a distribution of queries in the space close to uniform. Higher values of α guar-antees this distribution, as scores closer to random are assigned to the item and consequentlyto the queries minimum scores.
Figure 5.13 depicts the time performance of Grid, Constant Angle and the naıve solution.Here we can see the these three systems have a completely different behavior for different valuesof α. Starting with Grid, it has a close to linear behavior, which can be explained by the factthat as α increases, higher values are expected for the total score, which also means that highervalues are assigned to queries (as their minimum values) and thus, Grid needs to visit morebuckets on item matching.
On the other hand, Constant angle has a better performance as α increases. The good timeperformance can be explained by the fact that as queries are better distributed in space, morecross the border of the constraint used by this solution (Constraint MQW). So, although itvisits more queries than Grid, even for high values of α their retrieval is faster than that of Grid.However, it outperforms Grid only on very high values of alpha (over 0.75), while typical valuesof alpha range between 0 and 0.4 according to [30].
Finally, the naıve solution has a constant behavior in time performance over different valuesof α: independently to the scores assigned to queries it always visits the exactly set of queries:those contained in the posting lists of the item’s terms. Moreover, the time to update queriesin this system is negligible, as it only stores the new score to the query (there are no updatesrequired within the posting lists).
46
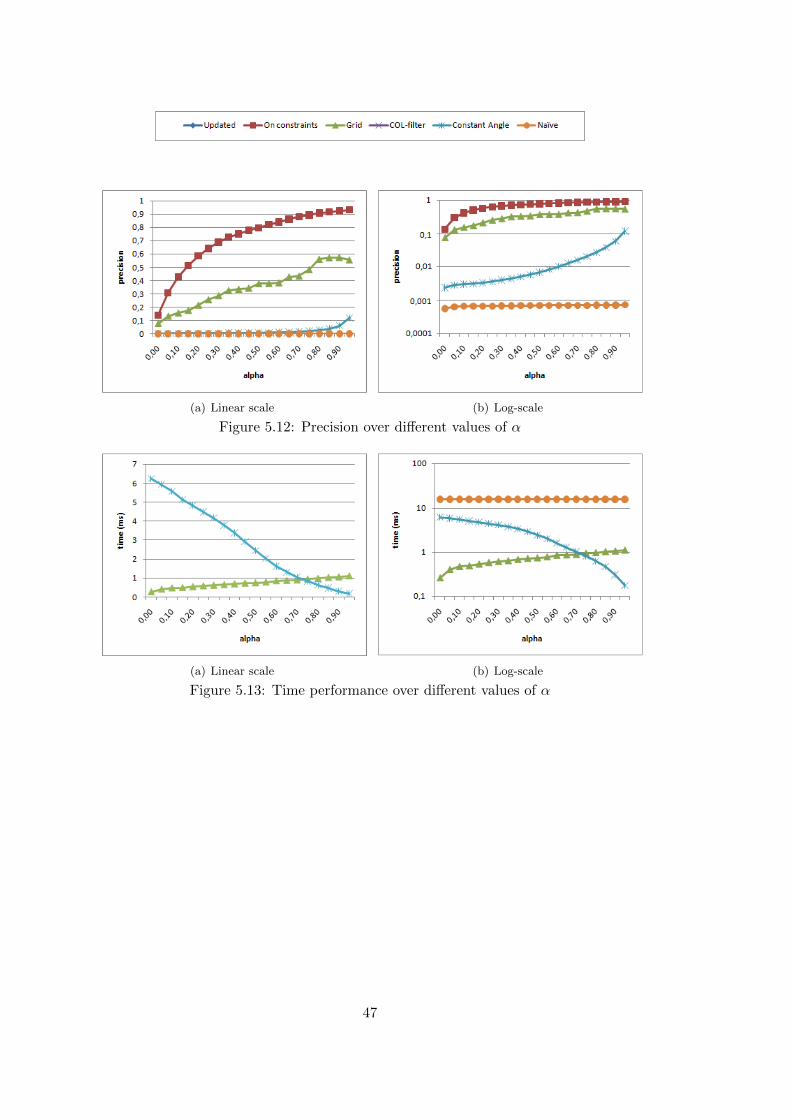
(a) Linear scale (b) Log-scale
Figure 5.12: Precision over different values of α
(a) Linear scale (b) Log-scale
Figure 5.13: Time performance over different values of α
47

5.6 Impact of Decay Rate
A novelty of our work compared to previous ones on continuous queries over text streams is thatwe consider time decay functions as a method to guarantee freshness of information. In thisset of experiments, we test the performance of our two proposed systems over linear decay. Forthe experiments, we used different values of how fast scores decrease over time. When scoresdecay faster, an immediate effect is that each query gets updated more easily. The values ofdecay chosen, range between 0.001 and 0.01 as score decay per day and were selected so as tocorrespond to an average of 2 to 20 updates per day per query.
In figure 5.14 we can see the precision of On Constraints, Grid and Constant Angle. Weobserve that all three have a higher precision over higher values of decay. This is due to thebetter distribution of queries on the minimum score axis (x-axis) because of decay, leading to abetter accuracy of the constraints lines. Moreover, the higher precision can be explained by thefact that for higher values of decay we have a higher number of query updates.
In figure ?? we can see the time requirements for Grid and Constant Angle. While thetime requirements increase on higher values of decay for Grid, we observe a slight decrease forConstant Angle. This indicates that the MQWcondition, in which Constant Angle is based,has a better performance when decay is applied, and especially for higher values of decay. Still,despite the increase of performance, Grid has a 10 to 20 times less time requirements thanConstant Angle.
48
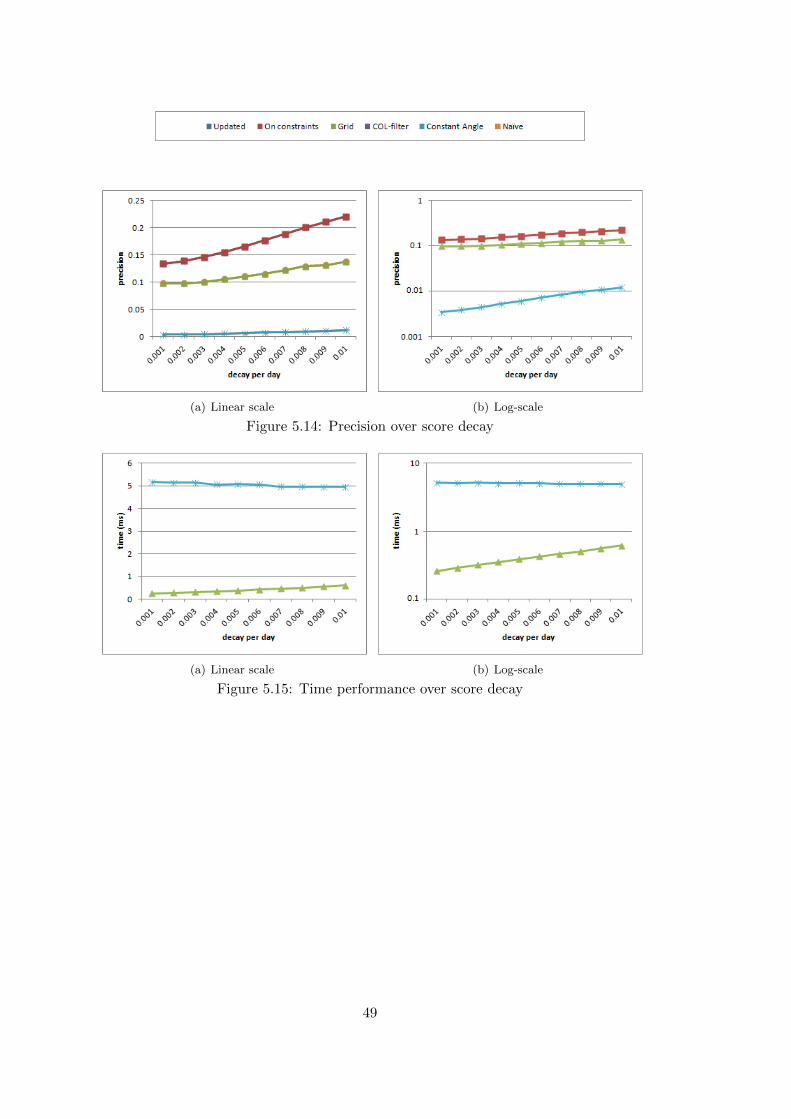
(a) Linear scale (b) Log-scale
Figure 5.14: Precision over score decay
(a) Linear scale (b) Log-scale
Figure 5.15: Time performance over score decay
49

5.7 Query indexing
In this set of experiments we capture the time and memory behavior for query insertion. In theservice we want to provide, items arrive and are matched with queries, but at the same time,new user queries can also arrive. Of course, the arrival rate of queries is much lower that the oneof items. However, indexing performance of queries is still an important performance indicatorfor the system.
Figure 5.16 shows the time requirements of each solution for indexing a given number ofqueries. The performance shown depicts the indexing complexity of the data structures usedin each solution. Both Constant Angle and COL- Filter use binary trees (Red-Black Trees) forindexing the queries in the posting lists which has a time complexity of O(N log(N)) to storeN queries. On the other hand, in query indexing, Grid needs to retrieve the correct bucketsand insert the query there. As explained in Section 4.1 constant time is required to retrievethe correct buckets, while buckets are implemented as hash tables which also have a constantinsertion time. Thus, O(N) time is required to store N queries. The simplest solution (naıve)uses a dynamic array (an array list) to store queries in the posting lists. This also guaranteesconstant insertion time for each query (O(N) for N queries) but also is a simple data structure,very fast in insertion. From the observed values we can see that insertion in naıve is almost oneorder of magnitude faster than Grid and much faster than the other two systems. For 100,000queries naıveis 30 times faster than both Constant Angle and COL-Filter.
On memory requirements, on the other hand, all systems have a linear increase (O(N) spacecomplexity). The simple data structures used by naıve lead to it having the lowest memoryrequirements: 1.5 times less than Constant Angle and COL-Filter and 10 times less than Grid.
50
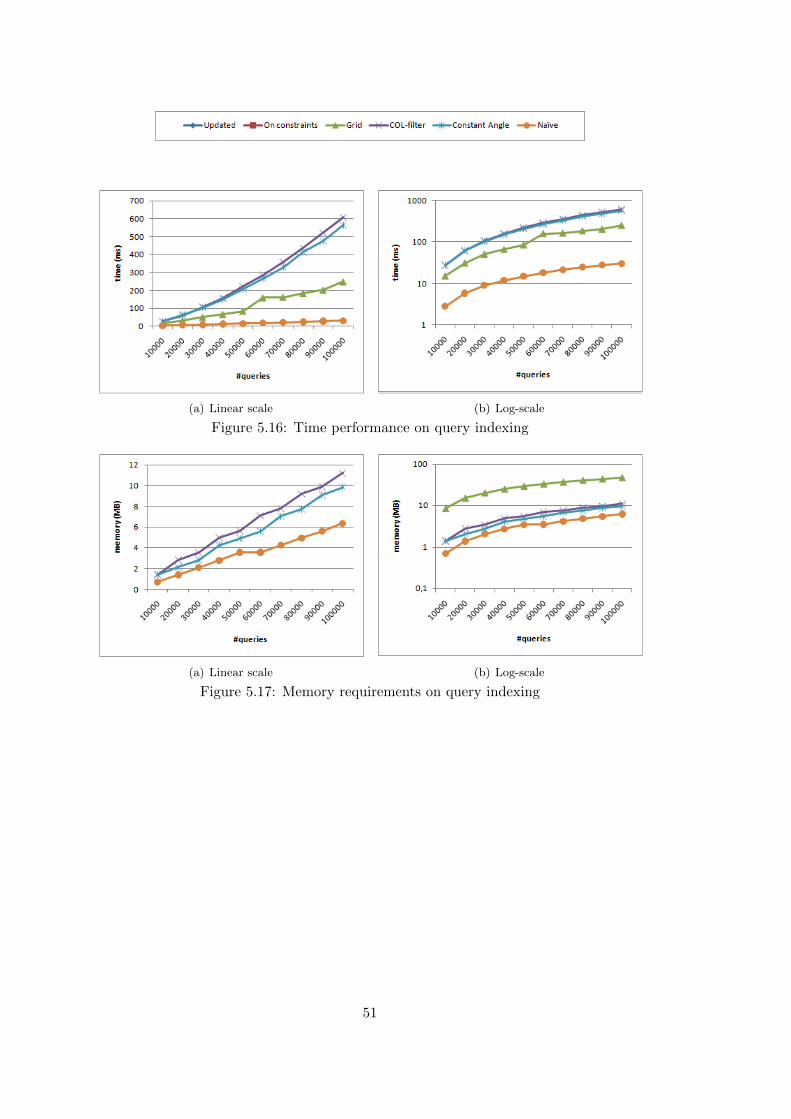
(a) Linear scale (b) Log-scale
Figure 5.16: Time performance on query indexing
(a) Linear scale (b) Log-scale
Figure 5.17: Memory requirements on query indexing
51

5.8 Experiments’ Conclusions
Through the experimental evaluation of the four implemented systems (Grid, Constant Angle,COL-Filter and naıve) and of our theoretical model (On Constraints) over the most importantof the parameters affecting their performance, the main conclusions drawn are the following:
• Despite generalising the problem of efficient continuous top-k query evaluation for morecomplex scoring functions, and despite the deduction of data structures in the two di-mensions, Grid solution achieves an up to 30% better performance than COL-Filter, boththeoretically, in terms of queries visited and practically, on time measurements. However,Grid’s main memory requirements are quite high and can go up to 4 times more than thoseof COL-Filter.
• As shown in the experiments, the parameters that better show the benefits of Grid overCOL-Filter and vice versa are the number of queries stored and query length. For thetime performance over the number of queries, we have observed that COL-Filter performsslightly better for very low values of number of queries stored (less than 4,000), but thentime requirements increase much faster than Grid, leading to the latter being 35% fasterthan the former for 100,000 queries stored. On query length and especially for precision,we have seen that Grid has a much better performance than that of COL-Filter for smallvalues of query lengths but as length increases its performance drops fast and reaches theprecision of COL-Filter for query length 4.
• Even though Grid applies the constraints model and uses the same bounding conditionsas On Constraints, it still has a precision 40 to 90% worse than it. Although the precisionfor Grid can approach that of On Constraints when having more divisions, as shown inexperiments of Subsection 5.4.1, this increase of precision does not lead to time require-ments optimization. This indicates that the simple way of partitioning the search spacecan be further improved in order to benefit from the good performance of our theoreticalmodel and achieve a better approximation.
• Constant Angle, the solution based on the third constraint, does not have an equally goodbehavior as the other two implemented systems. The behavior shown in all experiments ofthis chapter indicate that such a system needs to visit up to two orders of magnitude morequeries than Grid and has correspondingly high time requirements. On the other hand, inrequires one third or even less main memory than Grid, while also offering a rather elegantsolution, supporting both linear time decay and ranking functions with an item score part.
52

Chapter 6
Conclusions & Future Work
In this thesis, we have tackled the problem of efficient continuous top-k query evaluation overtext streams. Counter to previous works on similar problems, we have considered more complexscoring function, including both query dependent (similarity) and query independent (item)score, and to the best of our knowledge we are the first to consider time decay over these scores.
More precisely, in this work we have proposed an original spatial representation of queriesbased on term weights and queries minimal score per top-k list. Over this representation, wehave identified and proven necessary and/or sufficient boundary conditions, pruning the searchspace during item match. Then, we introduced two indexing schemes of queries by applying ourprevious observations. Finally, we provided a thorough experimental evaluation of our frameworkfor critical workload parameters (e.g., number and length of queries or items), scoring functionparameters (e.g. α, decay rate, etc.) and memory requirements, and presented the quantitativegains of our solutions compared to the state of art COL-Filter.
Future Work
An important parameter considered in item score estimation is the number of page views. Theintuition of this parameter is that as more users read a given article the more important itshould be considered. Such a factor, however dynamically changes over time and thus, Sitem(i)is no longer static. Additionally to this, many commercial systems, such as Google News, rankcollections of items (stories), rather than single items, i.e. present a ranking of top stories ateach point of time. Considering the text of the collection to be the concatenation of texts inall items it contains, the similarity score between each query and the story also dynamicallychanges over time. Considering these, it would be interesting to investigate in future work, ifand how our proposed model could be applied to this, even more dynamic environment and tomore complex scoring functions than the ones we have considered.
Furthermore, for the current scoring functions we are considering, future work could includestudying the effects of exponential decay or sigmoid decay over the Grid solution. Finally, apartfrom Grid, we could also try to define a different partitioning of the two- dimensional spacesthat could guarantee a better approximation to our theoretical model.
53

54

Bibliography
[1] Michael Bendersky and W. Bruce Croft. Analysis of long queries in a large scale search log.In Proceedings of the 2009 workshop on Web Search Click Data, WSCD ’09, pages 8–14,New York, NY, USA, 2009. ACM.
[2] Klaus Berberich, Michalis Vazirgiannis, and Gerhard Weikum.
[3] Sergey Brin and Lawrence Page. The anatomy of a large-scale hypertextual web searchengine. Computer Networks and ISDN Systems, 30(1-7):107 – 117, 1998. Proceedings ofthe Seventh International World Wide Web Conference.
[4] Graham Cormode, Vladislav Shkapenyuk, Divesh Srivastava, and Bojian Xu. Forwarddecay: A practical time decay model for streaming systems. Data Engineering, InternationalConference on, 0:138–149, 2009.
[5] Na Dai and Brian D. Davison. Freshness matters: in flowers, food, and web authority. InProceeding of the 33rd international ACM SIGIR conference on Research and developmentin information retrieval, SIGIR ’10, pages 114–121, New York, NY, USA, 2010. ACM.
[6] Abhinandan S. Das, Mayur Datar, Ashutosh Garg, and Shyam Rajaram. Google news per-sonalization: scalable online collaborative filtering. In Proceedings of the 16th internationalconference on World Wide Web, WWW ’07, pages 271–280, New York, NY, USA, 2007.ACM.
[7] Gautam Das, Dimitrios Gunopulos, Nick Koudas, and Nikos Sarkas. Ad-hoc top-k queryanswering for data streams. In Proceedings of the 33rd international conference on Verylarge data bases, VLDB ’07, pages 183–194. VLDB Endowment, 2007.
[8] Gianna M. Del Corso, Antonio Gullı, and Francesco Romani. Ranking a stream of news.In Proceedings of the 14th international conference on World Wide Web, WWW ’05, pages97–106, New York, NY, USA, 2005. ACM.
[9] Marina Drosou, Kostas Stefanidis, and Evaggelia Pitoura. Preference-aware pub-lish/subscribe delivery with diversity. In Proceedings of the Third ACM International Con-ference on Distributed Event-Based Systems, DEBS ’09, pages 6:1–6:12, New York, NY,USA, 2009. ACM.
[10] Ronald Fagin. Combining fuzzy information: an overview. SIGMOD Rec., 31:109–118,June 2002.
[11] R. A. Finkel and J. L. Bentley. Quad trees a data structure for retrieval on composite keys.Acta Informatica, 4:1–9, 1974. 10.1007/BF00288933.
55

[12] Evgeniy Gabrilovich, Susan Dumais, and Eric Horvitz. Newsjunkie: providing personalizednewsfeeds via analysis of information novelty. In Proceedings of the 13th internationalconference on World Wide Web, WWW ’04, pages 482–490, New York, NY, USA, 2004.ACM.
[13] Parisa Haghani, Sebastian Michel, and Karl Aberer. The gist of everything new: personal-ized top-k processing over web 2.0 streams. In Proceedings of the 19th ACM internationalconference on Information and knowledge management, CIKM ’10, pages 489–498, NewYork, NY, USA, 2010. ACM.
[14] Zeinab Hmedeh, Nelly Vouzoukidou, Nicolas Travers, Vassilis Christophides, Cedricdu Mouza, and Michel Scholl. Characterizing web syndication behavior and content. InAthman Bouguettaya, Manfred Hauswirth, and Ling Liu, editors, Web Information SystemEngineering WISE 2011, Lecture Notes in Computer Science, pages 29–42. Springer Berlin/ Heidelberg, 2011.
[15] Yang Hu, Mingjing Li, Zhiwei Li, and Wei-ying Ma. Discovering authoritative news sourcesand top news stories. In Hwee Ng, Mun-Kew Leong, Min-Yen Kan, and Donghong Ji, edi-tors, Information Retrieval Technology, volume 4182 of Lecture Notes in Computer Science,pages 230–243. Springer Berlin / Heidelberg, 2006.
[16] Sangyong Hwang, Keunjoo Kwon, Sang Cha, and Byung Lee. Performance evaluation ofmain-memory r-tree variants. In Thanasis Hadzilacos, Yannis Manolopoulos, John Roddick,and Yannis Theodoridis, editors, Advances in Spatial and Temporal Databases, volume 2750of Lecture Notes in Computer Science, pages 10–27. Springer Berlin / Heidelberg, 2003.
[17] Jurgen Kramer and Bernhard Seeger. Semantics and implementation of continuous slidingwindow queries over data streams. ACM Trans. Database Syst., 34:4:1–4:49, April 2009.
[18] Jiahui Liu, Peter Dolan, and Elin Rønby Pedersen. Personalized news recommendationbased on click behavior. In Proceeding of the 14th international conference on Intelligentuser interfaces, IUI ’10, pages 31–40, New York, NY, USA, 2010. ACM.
[19] Xiaofeng Liu, Chuanbo Chen, and YunSheng Liu. Algorithm for ranking news. In Pro-ceedings of the Third International Conference on Semantics, Knowledge and Grid, pages314–317, Washington, DC, USA, 2007. IEEE Computer Society.
[20] Ashwin Machanavajjhala, Erik Vee, Minos Garofalakis, and Jayavel Shanmugasundaram.Scalable ranked publish/subscribe. Proc. VLDB Endow., 1:451–462, August 2008.
[21] Xi Mao and Wei Chen. A method for ranking news sources, topics and articles. In ComputerEngineering and Technology (ICCET), 2010 2nd International Conference on, volume 4,pages V4–170 –V4–174, April 2010.
[22] Yajie Miao, Chunping Li, Liu Yang, Lili Zhao, and Ming Gu. Evaluating importance ofwebsites on news topics. In Byoung-Tak Zhang and Mehmet Orgun, editors, PRICAI 2010:Trends in Artificial Intelligence, volume 6230 of Lecture Notes in Computer Science, pages182–193. Springer Berlin / Heidelberg, 2010.
[23] Kyriakos Mouratidis, Spiridon Bakiras, and Dimitris Papadias. Continuous monitoring oftop-k queries over sliding windows. In Proceedings of the 2006 ACM SIGMOD internationalconference on Management of data, SIGMOD ’06, pages 635–646, New York, NY, USA,2006. ACM.
56

[24] Kyriakos Mouratidis and HweeHwa Pang. An incremental threshold method for continuoustext search queries. volume 0, pages 1187–1190, Los Alamitos, CA, USA, 2009. IEEEComputer Society.
[25] Kyriakos Mouratidis and HweeHwa Pang. Efficient evaluation of continuous text searchqueries. IEEE Transactions on Knowledge and Data Engineering, 23:1469–1482, 2011.
[26] Georgios Paliouras, Mouzakidis Alexandros, Christos Ntoutsis, Angelos Alexopoulos, andChristos Skourlas. Pns: Personalized multi-source news delivery. In Bogdan Gabrys, RobertHowlett, and Lakhmi Jain, editors, Knowledge-Based Intelligent Information and Engineer-ing Systems, volume 4252 of Lecture Notes in Computer Science, pages 1152–1161. SpringerBerlin / Heidelberg, 2006.
[27] S.E. Robertson, S. Walker, S. Jones, M.M. Hancock-Beaulieu, and M. Gatford. Okapi attrec-3.
[28] Craig Silverstein, Hannes Marais, Monika Henzinger, and Michael Moricz. Analysis of avery large web search engine query log. SIGIR Forum, 33:6–12, September 1999.
[29] Canhui Wang, Min Zhang, Liyun Ru, and Shaoping Ma. Automatic online news topicranking using media focus and user attention based on aging theory. In Proceeding ofthe 17th ACM conference on Information and knowledge management, CIKM ’08, pages1033–1042, New York, NY, USA, 2008. ACM.
[30] Fan Zhang, Shuming Shi, Hao Yan, and Ji-Rong Wen. Revisiting globally sorted indexesfor efficient document retrieval. In Proceedings of the third ACM international conferenceon Web search and data mining, WSDM ’10, pages 371–380, New York, NY, USA, 2010.ACM.
[31] Jason Y. Zien, Jorg Meyer, John A. Tomlin, and Joy Liu. Web query characteristics andtheir implications on search engines. In WWW Posters’01, pages –1–1, 2001.
57





























