Embed Size (px)
Citation preview

Nearest neighbours and kD-trees
Steve Renals
Informatics 2B— Learning and Data Lecture 6January 2007
Steve Renals Nearest neighbours and kD-trees

Overview
Today’s lecture
Instance-based learning: nearest neighbours
Data structures for multidimensional data
kD-trees
Steve Renals Nearest neighbours and kD-trees

Instance-based learning
Instance-based learning: store the training examples directly(ie no need to estimate the parameters of a model)
Nearest neighbour approach: Classify an unknown test pointaccording to the members of the training set to which it isclosest
Problems:
What is the distance between two points? (last lecture)How do we find the closest point (the nearest neighbour) to aninstance efficiently? (this lecture)How can we use the nearest neighbours for patternrecognition? Is this just a heuristic method, or does it have aprobabilistic underpinning?
Steve Renals Nearest neighbours and kD-trees

Finding nearest neighbours
Instance based learning is simple and effective...
But naively comparing a test example against the entiretraining set is linear in the dimension and the number ofexamples, Θ(nk)
Structuring the data set intelligently can avoid having tocompare against every point in the training set
Multidimensional structures which reduce the curse ofdimensionality
Steve Renals Nearest neighbours and kD-trees

Structuring multidimensional data: Grid
k-dimensional array of buckets
Uniformly partition each dimension
Different dimensions can be cut in adifferent number of pieces
Accessing a point involves checking eachdimension to determine in which bucketit falls
Ideal if the data is uniformly distributed(which is never the case in highdimensions)
Steve Renals Nearest neighbours and kD-trees

Structuring multidimensional data: Adaptive grid
k-dimensional array of buckets
Partition each dimension to produce afiner decomposition in parts of the spacewith more data points
Accessing a point involves processingeach dimension independently
Fast to access, easy to implement,doesn’t assume a uniform distribution
Can require many more buckets thannecessary: making a partition in 1dimension has a global effect
Steve Renals Nearest neighbours and kD-trees

Structuring multidimensional data: Multilevel grid
Space partitioned into a grid; each toplevel bucket with enough data is thenpartitioned into a grid, and the processcontinues recursively until each buckethas few enough point
Binary trie splits each dimension in half
In two dimensions this is called a quadtrie (or sometimes a quad tree)
Very memory intensive in higherdimensions
Steve Renals Nearest neighbours and kD-trees
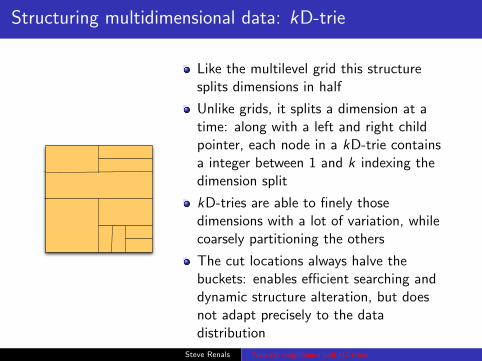
Structuring multidimensional data: kD-trie
Like the multilevel grid this structuresplits dimensions in half
Unlike grids, it splits a dimension at atime: along with a left and right childpointer, each node in a kD-trie containsa integer between 1 and k indexing thedimension split
kD-tries are able to finely thosedimensions with a lot of variation, whilecoarsely partitioning the others
The cut locations always halve thebuckets: enables efficient searching anddynamic structure alteration, but doesnot adapt precisely to the datadistribution
Steve Renals Nearest neighbours and kD-trees

Structuring multidimensional data: kD-tree
kD-tree is the most importantmultidimensional structure
Decomposes a multidimensional spaceinto hyperrectangles
A binary tree with both a dimensionnumber and splitting value at each node
Each node corresponds to ahyperrectangle
Fields of kD-tree node:
splitting dimension numbersplitting valueleft kD-treeright kD-tree
Steve Renals Nearest neighbours and kD-trees

Traversing a kD-tree
Each node splits the space into two subspaces according to thesplitting dimension of the node, and the node’s splitting value
Geometrically this represents a hyperplane perpendicular tothe direction specified by the splitting dimension
Searching for a point in the dataset represented in a kD-treeis accomplished in a traversal of the tree from root to leaf(O(lg(n)) if there are n data points).
Steve Renals Nearest neighbours and kD-trees
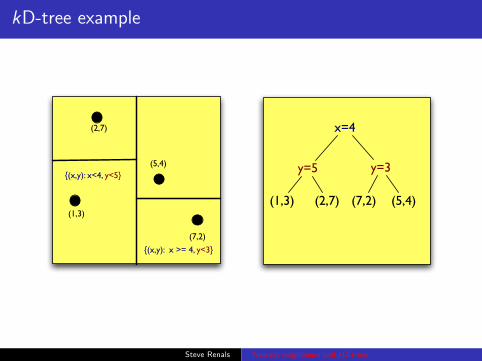
kD-tree example
(2,7)
(1,3)
(5,4)
(7,2)
y=5
x=4
{(x,y): x<4, y<5}
{(x,y): x >= 4, y<3}
y=3
(1,3) (2,7) (5,4)(7,2)
Steve Renals Nearest neighbours and kD-trees
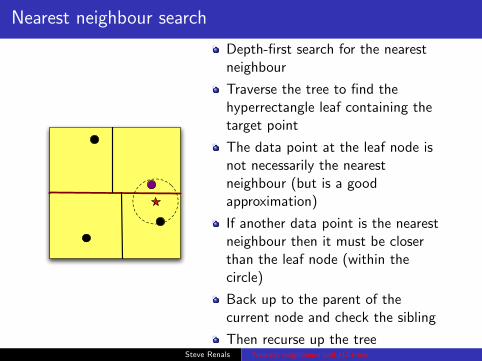
Nearest neighbour search
Depth-first search for the nearestneighbour
Traverse the tree to find thehyperrectangle leaf containing thetarget point
The data point at the leaf node isnot necessarily the nearestneighbour (but is a goodapproximation)
If another data point is the nearestneighbour then it must be closerthan the leaf node (within thecircle)
Back up to the parent of thecurrent node and check the sibling
Then recurse up the treeSteve Renals Nearest neighbours and kD-trees

Hyperrectangles
Each node defines a hyperrectangle
A hyperrectangle is represented by an array of minimumcoordinates and an array of maximum coordinates (eg in 2dimensions (k = 2), (xmin, ymin) and (xmax , ymax))
When searching for the nearest neighbour we need to know ifa hyperrectangle intersects with a hypersphere
Steve Renals Nearest neighbours and kD-trees

Intersection of a hyperrectangle and a hypersphere
Consider hypersphere Y (t, r) centred at the target t, withradius r defined by the distance to the current closest point
If Y (t, r) intersects with a hyperrectangle H in a kD-tree,then a nearer neighbour to t might exist in H
To test if hypersphere Y (t, r) intersects with hyperrectangleH = ((Hmin
1 ,Hmin2 , . . . ,Hmin
k ), (Hmax1 ,Hmax
2 , . . . ,Hmaxk )), we
need to find the point p in H that is closest to t
To find p = (p1, p2, . . . , pk) we build it up dimension bydimension. For dimension i :
pi =
Hmin
i if ti ≤ Hmini
ti if Hmini < ti < Hmax
i
Hmaxi if ti ≥ Hmax
i
Then Y (t, r) and H intersect if the euclidean distancebetween them r2(p, t) ≤ r
Steve Renals Nearest neighbours and kD-trees
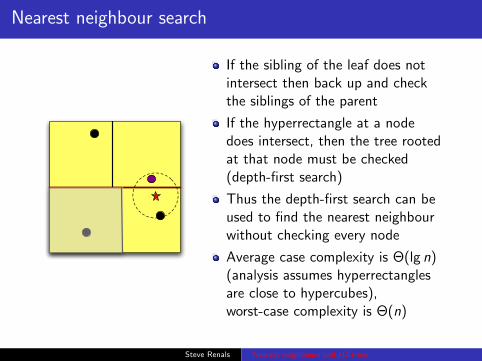
Nearest neighbour search
If the sibling of the leaf does notintersect then back up and checkthe siblings of the parent
If the hyperrectangle at a nodedoes intersect, then the tree rootedat that node must be checked(depth-first search)
Thus the depth-first search can beused to find the nearest neighbourwithout checking every node
Average case complexity is Θ(lg n)(analysis assumes hyperrectanglesare close to hypercubes),worst-case complexity is Θ(n)
Steve Renals Nearest neighbours and kD-trees
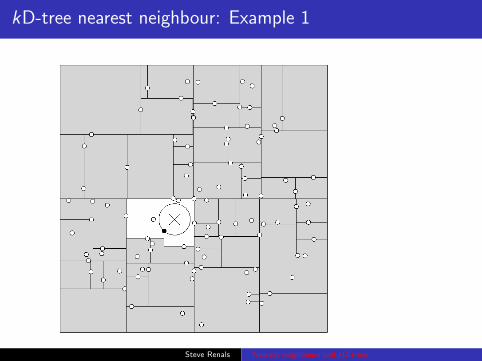
kD-tree nearest neighbour: Example 1
(From Andrew Moore’s Introductory tutorial on kd-trees)Steve Renals Nearest neighbours and kD-trees
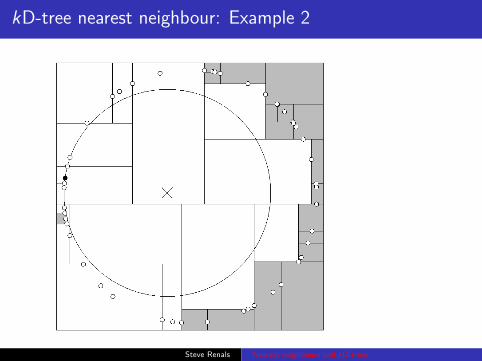
kD-tree nearest neighbour: Example 2
(From Andrew Moore’s Introductory tutorial on kd-trees)Steve Renals Nearest neighbours and kD-trees

Constructing a kD-tree
Constructing a kD-tree requires:
Selecting the splitting value to split atThe dimension to split on
Do this recursively to each child of the split and henceconstruct the entire tree
Steve Renals Nearest neighbours and kD-trees

kD-tree construction algorithm
1: procedure kdConstruct(trainingSet)2: . Returns a kdTree3: if trainingSet.isEmpty() then4: return emptyKdtree5: end if6: (s, val)← chooseSplit(trainingSet) . s is splitting
dimension7: trainLeft ← {x ∈ trainingSet : xs < val}8: trainRight ← {x ∈ trainingSet : xs ≥ val}9: kdLeft ← kdConstruct(trainLeft)
10: kdRight ← kdConstruct(trainRight)11: return kdtree(s, val , kdLeft, kdRight)12: end procedure
Steve Renals Nearest neighbours and kD-trees

Choosing the splitting dimension
We want to split along a dimension along which the trainingexamples are well spread.
Two possibilities:1 Choose the dimension with the greatest variance:
For each dimension i compute the sample variance Sii from thetraining instances, and choose to split along the dimension ifor which Sii is largest.
2 Choose the dimension with the greatest range:For each dimension i compute its range in the traininginstances:
∆i = (maxn
xni )− (min
nxn
i )
and choose dimension i with the largest ∆i
Steve Renals Nearest neighbours and kD-trees

Location of the split
We want to split ’in the middle’ of the points along thesplitting dimension
Two possibilities:1 Order the training instances along the splitting dimension s
and choose the median value for that dimension2 Choose the splitting value to be the mean of the training
instances along the splitting dimension µs
Splitting at the median ensures a balanced tree, but if thedata is unevenly distributed can result in long and skinnyhyperrectangles
Splitting at the mean may mean the tree is far from balanced,but results in squarer hyperrectangles
Steve Renals Nearest neighbours and kD-trees

Summary
Instance-based learning: no model, use the data directly
k-nearest neighbour approaches
kD-tree: an efficient data structure for finding (approximate)nearest neighbours in multidimensional data
References:
Wikipedia on kd-treeAndrew Moore, Introductory tutorial on kd-treesAndrew Moore, kD-tree animations
Steve Renals Nearest neighbours and kD-trees











![KD-R975BTS / KD-R970BTS / KD-R97MBS / KD … Size: B6L (182 mm x 128 mm) Book Size: B6L (182 mm x 128 mm) ENGLISH FRANÇAIS ESPAÑOL B5A-0813-10 [K] KD-R975BTS / KD-R970BTS / KD-R97MBS](https://img.pdfslide.us/doc/110x75/5aaf5da87f8b9a25088d67a8/kd-r975bts-kd-r970bts-kd-r97mbs-kd-size-b6l-182-mm-x-128-mm-book-size.jpg)

















