Embed Size (px)
Citation preview

ALPS Winter School 2021
Natural Language GenerationBetter Decoding
Claire Gardent
Advanced Language Processing Winter School, 1722 January 2021
1 / 30

ALPS Winter School 2021
Part 1: Basics of Neural NLG
The Encoder-Decoder FrameworkThe Recurrent EncoderDecoder
Better DecodingAttention, Copy and Coverage
EncodersImproved Recurrent Neural Network (RNN): LSTM, biLSTM, GRUConvolutional Neural Network (CNN)Transformer
EvaluationBLEU, PARENT, BLEURT, BERTScoreROUGEEvaluating faithfulness
2 / 30

ALPS Winter School 2021
SomeProblemswithNeuralGeneration
Accuracy/Faithfulness
The output text sometimes contains information not present inthe input.
Repetitions
The output text sometimes contains repetitions
Coverage
The output text sometimes does not cover all the input
Rare or Unknown Words
3 / 30

ALPS Winter School 2021
T2T Example: Summarisation
4 / 30
ALPS Winter School 2021
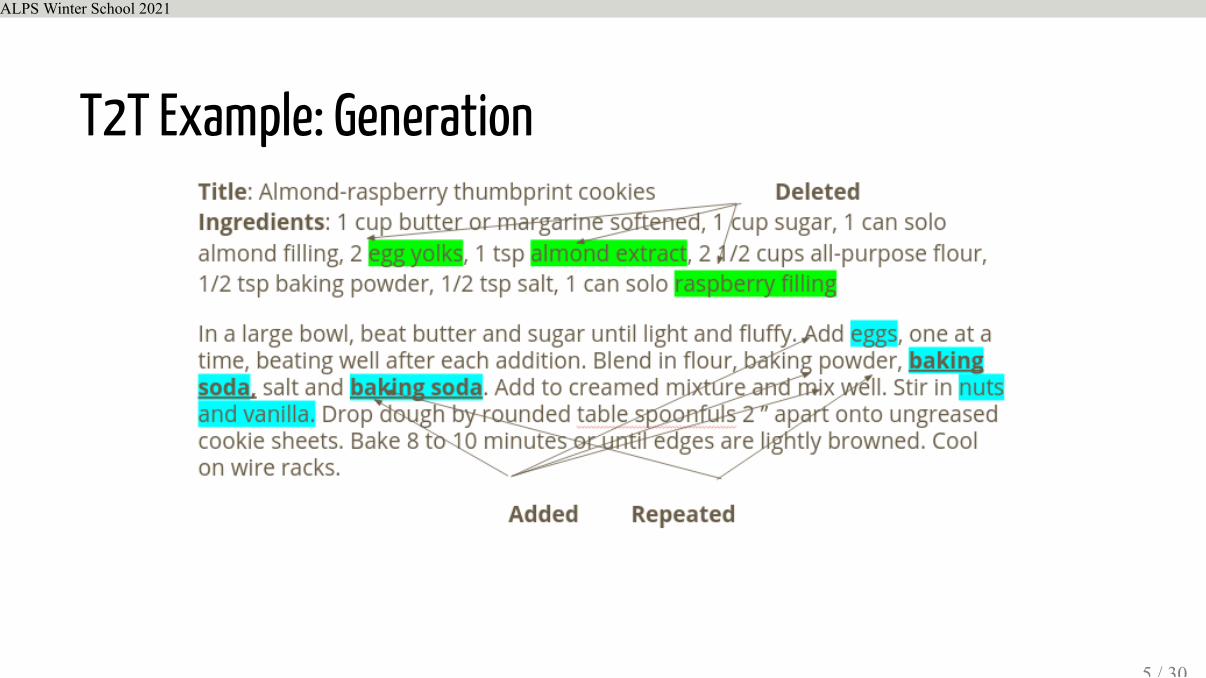
T2T Example: Generation
5 / 30

ALPS Winter School 2021
T2T Example: MR2T
6 / 30

ALPS Winter School 2021
Three Ways to Improve DecodingAttention
To improve accuracy
Copy
To copy from the inputTo handle rare or unknown words
Coverage
To help cover all and only the inputTo avoid repetitions
7 / 30

ALPS Winter School 2021
AttentionAttention
8 / 308 / 30

ALPS Winter School 2021
Standard RNN Decoding
The input is compressed into a fixedlength vector
Performance decreases with the length of the input
Sutskever et al. NIPS 2014
9 / 30

ALPS Winter School 2021
Decoding with AttentionInput
the previous state
the previously generated token and
a context vector
Context vector
depends on the previous state and therefore changes at each step
indicates which part of the input is most relevant to the decoding step
s =t f(s , y , c )t−1 t−1 ts t−1
y t−1
c t
10 / 30

ALPS Winter School 2021
can be viewed as a probability distribution over the sourcewords
A score is computed between each input token encoderstate and the current state
The context vector is the weighted sum of the encoderstates
The new state is computed taking into account thiscontext vector.
The next predicted token is sampled from the new targetvocabulary distribution
RNN with Attention
α =t softmax(a )t
α
a =t,j v⊤tanh(W h +h j W s +s t b)
c =t softmax( α .h )j
∑ t,j j
s =t f(s , y , c )t−1 t−1 t
P =vocab softmax(Ws )t
11 / 30

ALPS Winter School 2021
AttentionAttention is a way to obtain a fixedsize representation
of an arbitrary set of representations (the values),dependent on some other representation (the query)
EncoderDecoder
Query = current decoder stateValues = encoder hidden states
Transformer
Query = token embeddingValues = surrounding tokens embeddings
12 / 30

ALPS Winter School 2021
Encoder-Decoder AttentionValues = Encoder hidden states Query = Decoder state at time t Attention scores at time Attention distribution
Context vector (weighted sum of the encoder hidden states)
The new decoder state is computed taking into account this context vector.
h …h 1 n
s t
t e =t [s ⊤h … s ⊤h ]t 1 t n
α =t softmax(e )t
c =t α h
i=1
∑n
it
i
s =t f(s , y , c )t−1 t−1 t
13 / 30

ALPS Winter School 2021
Attention Score VariantsDot product
Multiplicative
Additive
e =i s⊤h i
e =i s⊤Wh i
e =i v⊤tanh(W h +1 i W s)2
Ruder 2017, Britz et al 2017
14 / 30

ALPS Winter School 2021
CopyCopy
15 / 3015 / 30

ALPS Winter School 2021
CopyMotivation
To copy from the input (E.g., in Text Summarisation applications)To handle rare or unknown words
Method
At each time step, the model decides whether to copy from the input or to generatefrom the target vocabulary.
See et al. ACL 2017
16 / 30

ALPS Winter School 2021
Learn a Copy/Generate Switch
Learned soft switch to choose between generating a word from the vocabulary bysampling from , or copying a word from the input sequence by sampling fromthe attention distribution .
Probability of generating a word from the vocabulary versus copying a word from thesource
P ∈gen [0, 1]
P vocab
α t
P =gen σ(w c +c t w s +s t w y )y t−1
17 / 30

ALPS Winter School 2021
Final Probability DistributionOver source and target vocabulary
, probability of generating word , decoder probability of generating
= 0 if is not in the target vocabulary (OOV), probability of copying word from the source
Cumulated attention score
if is not in the input
P (w) = p P (w) +gen target (1 − p ) P gen source
P (w) w
P target w
w
P source
= α ∑i:w=w i t,i
= 0 w
18 / 30

ALPS Winter School 2021
CoverageCoverage
19 / 3019 / 30

ALPS Winter School 2021
CoverageNeural models tend to omit or repeat information from the input
Solution
(Tu et al. 2017)
Coverage: cumulative attention, what has been attended to so farUse coverage as extra input to attention mechanismLoss: Penalises attending to input that has already been covered
Tu et al. ACL 2016
20 / 30

ALPS Winter School 2021
CoverageA coverage vector captures how much attention each input words has received
The attention mechanism takes coverage into account
The loss penalizes repeatedly attending to the same location
k t
k =t α
t=0
∑t−1
t
α =t,j v tanh(W h +Th j W s +s t W k +k t b)
loss =t −logP (w ) +t λ min(α , k )j
∑ t,j t,j
21 / 30

ALPS Winter School 2021
The proportion of duplicate ngramsis similar in the reference summariesand in the summaries produced bythe model with coverage.
Coverage successfully eliminatesrepetitions.
Impact of Coverage on Duplicate N-Grams
See et al. ACL 2017
22 / 30

ALPS Winter School 2021
Rare WordsCopying
Delexicalisation
CharacterBased Network
smaller vocabularyunknown words handled by copying characters
WordPieces, Byte Pair Encoding (BPE)
23 / 30

ALPS Winter School 2021
inform(restaurant name = Au Midi ,neighborhood= midtown , cuisine =french )
Au Midi is in Midtown and servesFrench food .
inform(restaurant name = restaurantname, neighborhood= neighborhood,cuisine = cuisine)
restaurant name is in neighborhoodand serves cuisine food.
DelexicalisationSlot values occurring in training utterances are replaced with a placeholder tokenrepresenting the slotAt generation time, these placeholders are then copied over from the inputspecification to form the final output
24 / 30

ALPS Winter School 2021
Character-Based GenerationMuch smaller vocabulary
Word embeddings are composed of character embeddings
Similar embeddings for words with similar spelling
Particularly interesting for languages with rich morphology
Competitive results on
E2E benchmark: Generating from dialog movesWebNLG benchmark: Generating from RDF graphs
Jagfeld et al. 2018
25 / 30

ALPS Winter School 2021
Word PiecesA finite set of word pieces allows for an infinite sets of words
Byte Pair Encoding (BPE)
Most frequent character pairs new word piece
Bottomup clustering of characters
Start with unigram vocabulary of (Unicode) characters in the dataAdd most frequent character pairs to vocabularyand repeat until target vocabulary size is reached
Segment input words into wordpieces and concatenated output wordpieces intowords
→
Sennrich et al. ACL 2016
26 / 30

ALPS Winter School 2021
BPE Vocabulary
Image credit: Sennrich et al. ACL 2016
27 / 30

ALPS Winter School 2021
BPE Vocabulary
28 / 30

ALPS Winter School 2021
BPE Vocabulary
29 / 30

ALPS Winter School 2021
BPE Vocabulary
30 / 30





























