Embed Size (px)
Citation preview

Music retrieval
• Conventional music retrieval systems• Exact queries: ”Give me all songs from J.Lo’s latest album”• What about ”Give me the music that I like”?
New methods are needed:sophisticated similarity measures
• Increasing importance:• MP3 players (103 songs)• Personal music collections (104 songs)• Music on demand
• many songs, huge market value…

Proposal
• Try a classifier method– Similarity measure
enables matching of fuzzy data always returns results
• Implement relevance feedback– User feedback
Improves retrieval performance

Classifier systems
• Genetic programming
• Neural networks
• Curve fitting algorithms
• Vector quantizers

Tree structured Vector Quantization
• Audio parameterizationFeature space: MFCC coefficients
• Quantization treeA supervised learning algorithm, TreeQ:
• Attempts to partition feature space for maximum class separation

Features: MFCC coefficients
waveform
DFT Log Mel IDFT
MFCCs:
A 13-dimensional vector per window
5 minutes song 30103 windows
100 Hamming windows/second

Classifying feature space

Nearest neighbor
Discrimination line in feature space
• Problems:– Curse of
dimensionality– Distribution
assumptions– Complicated
distributions

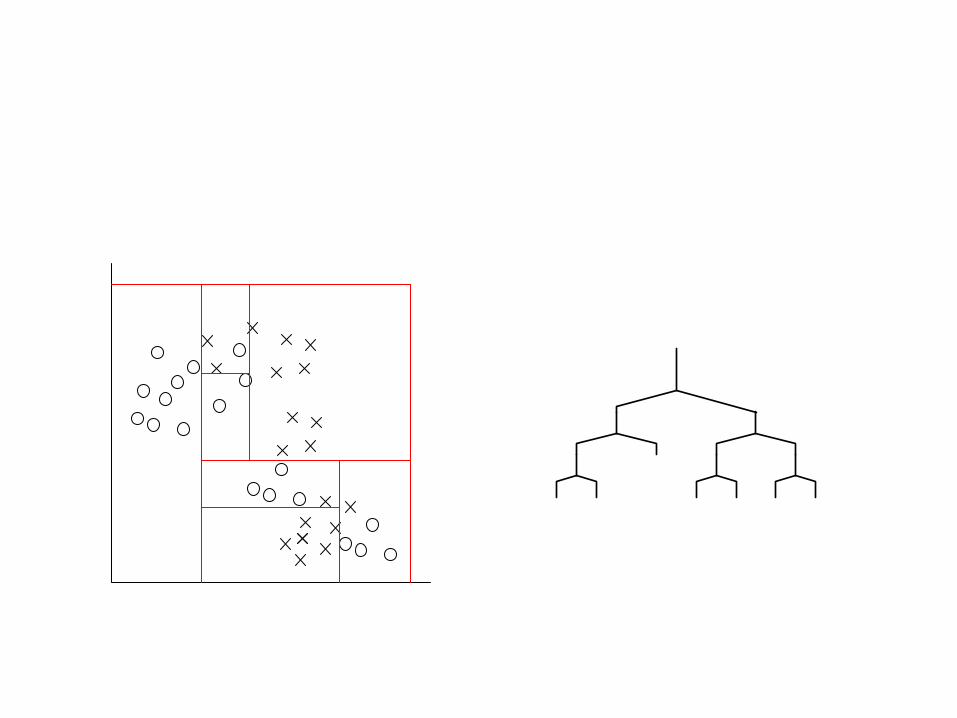
Vector Quantization:Adding decision surfaces
• Each surface is added such that
• It cuts only one dimension (speed)
• the mutual information is maximized:


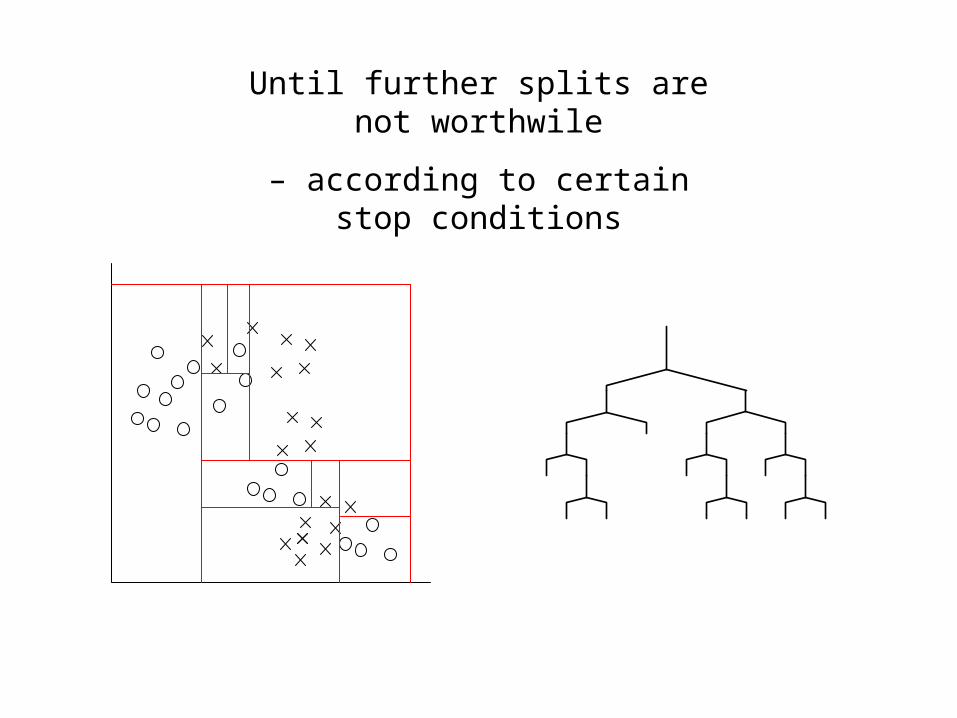
Until further splits are not worthwile
– according to certain stop conditions

Decision tree
• Tree partitions features space – L regions (cells/leaves)
– Based on class belonging of training data

Template generation
• Generate templates for – Training data
– Test data
• Each MFCC vector is routed through the tree

Template generation
• With a series of feature vectors,
each vector will end up in one of the leaves.
• This results in a histogram, or template, for each series of feature vectors.

Template comparisonCorpus templates – one per training class
A B n
X
Query template
Compute similarity
sim(X,A), sim(X,B), sim(X,C), …sim(X,n)
Augmented similarity measure, e.g.
DiffSim(X) = sim(X,A) – sim(X,C)

Template comparisonCorpus templates – one per training class
A B n
Query templates
Compute similarity
DiffSim(X)
Sort
Result list

Preliminary experiments• Test subjects listened to 107 songs
Rated them:good, fair, poor (class belonging Cg, Cf, Cp)
• Training process:– For each user
• Select randomly a subset (N songs) from each class
• Construct a tree based on class belonging
• Generate histogram templates for Cg, Cf, Cp
• For each song X– Generate histogram template
– Compute DiffSim(X) = sim(X,Cg) – sim(X,Cp)
• Sort the list of songs according to DiffSim

Results
N 1 3 5 7 9
random ,236 ,234 ,246 ,240 ,234
cos ,305 ,364 ,370 ,388 ,389
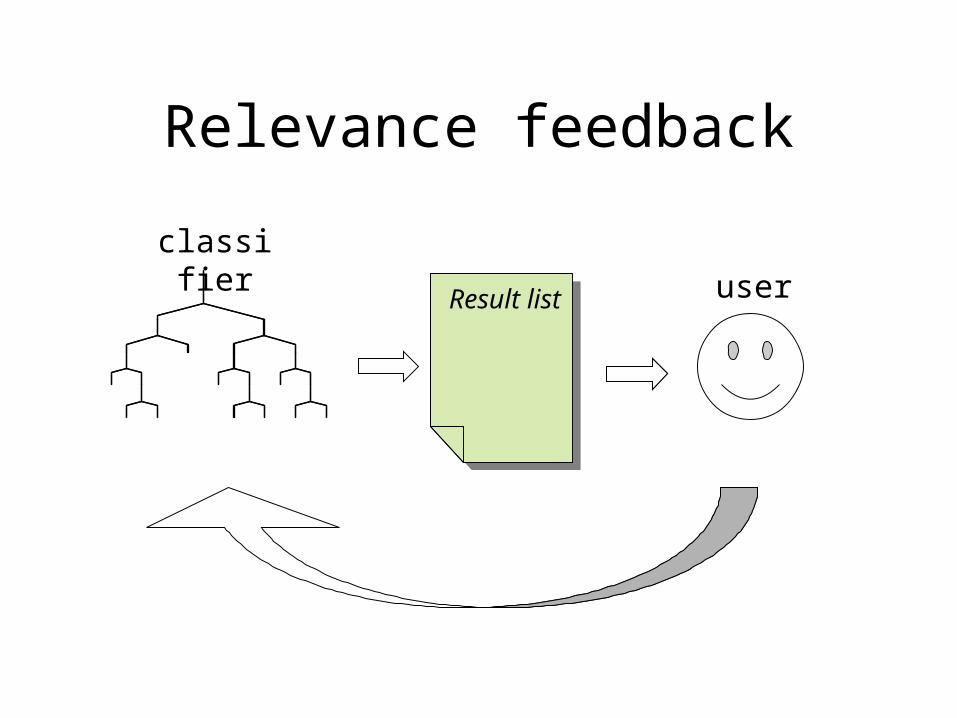
Relevance feedback
Result list user
classifier

Implementation
Adjust histogram profiles based on user feedback
• For each user– Select the top M songs from the
result list
– Add the contents of the songs to the histogram profile based on the user rating (class belonging Cg, Cf, Cp)
– For each song X• Generate histogram template
• Compute DiffSim(X) = sim(X,Cg) – sim(X,Cp)
– Sort the list of songs according to DiffSim

Improvement
Amount of training data N
M 1 3 5 7 9
1 27,68 5,88 10,22 2,52 4,74
3 40,94 19,70 23,80 17,20 27,50
5 52,15 32,14 34,08 27,99 40,59
7 62,89 43,45 43,76 36,45 52,89