Embed Size (px)
Citation preview

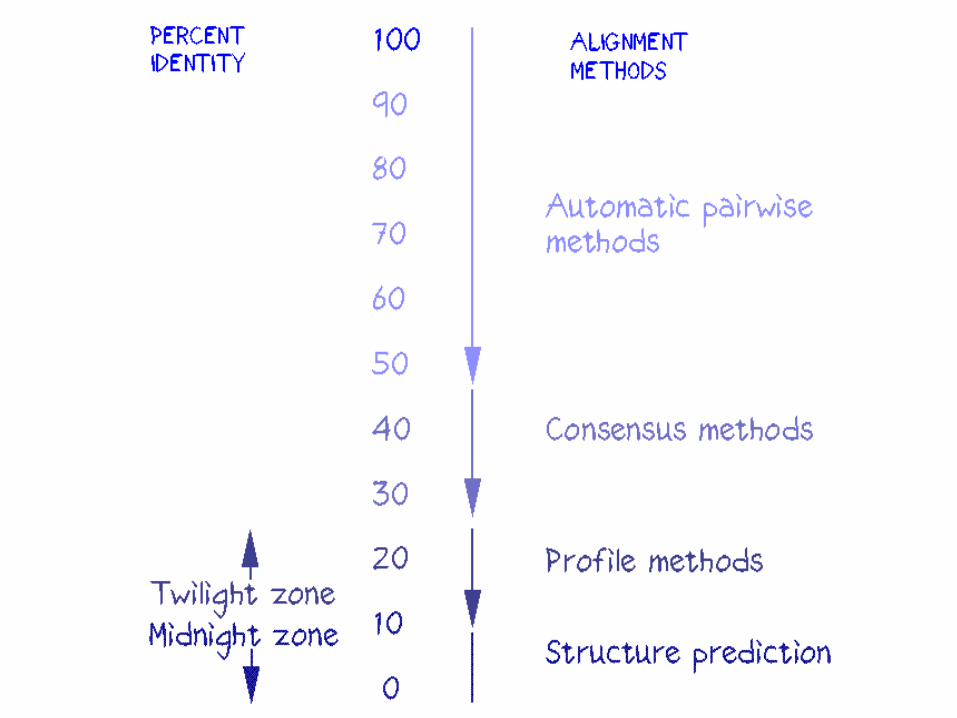
Multiple Sequence Alignment

Alignment can be easy or difficult
Easy
Difficult due to insertions or deletions
(indels)
GCGGCCCA TCAGGTAGTT GGTGG
GCGGCCCA TCAGGTAGTT GGTGG GCGTTCCA TCAGCTGGTT GGTGG
GCGTCCCA TCAGCTAGTT GGTGG
GCGGCGCA TTAGCTAGTT GGTGA
******** ********** *****
TTGACATG CCGGGG--- A AACCG
TTGACATG CCGGTG-- GT AAGCC TTGACATG - CTAGG--- A ACGCG
TTGACATG - CTAGGGAAC ACGCG
TTGACATC - CTCTG--- A ACGCG
******** ?? ???????? *****

Homology: Definition• Homology: similarity that is the result of inheritance from a common ancestor - identification and analysis of homologies is central to phylogenetic systematics.
• An Alignment is an hypothesis of positional homology between bases/Amino Acids.

Multiple Sequence Alignment- Goals
• To generate a concise, information-rich summary of sequence data.
• Sometimes used to illustrate the dissimilarity between a group of sequences.
• Alignments can be treated as models that can be used to test hypotheses.
• Used to identify homologous residues within sequences.

Multiple sequence alignments - problems
• All sequences show some similarity (even random sequences).
• Similarity levels might be high in some parts of the sequence and low in other parts.
• Sequences might show substantial length variation and presence/absence of various domains.

SSU rRNA
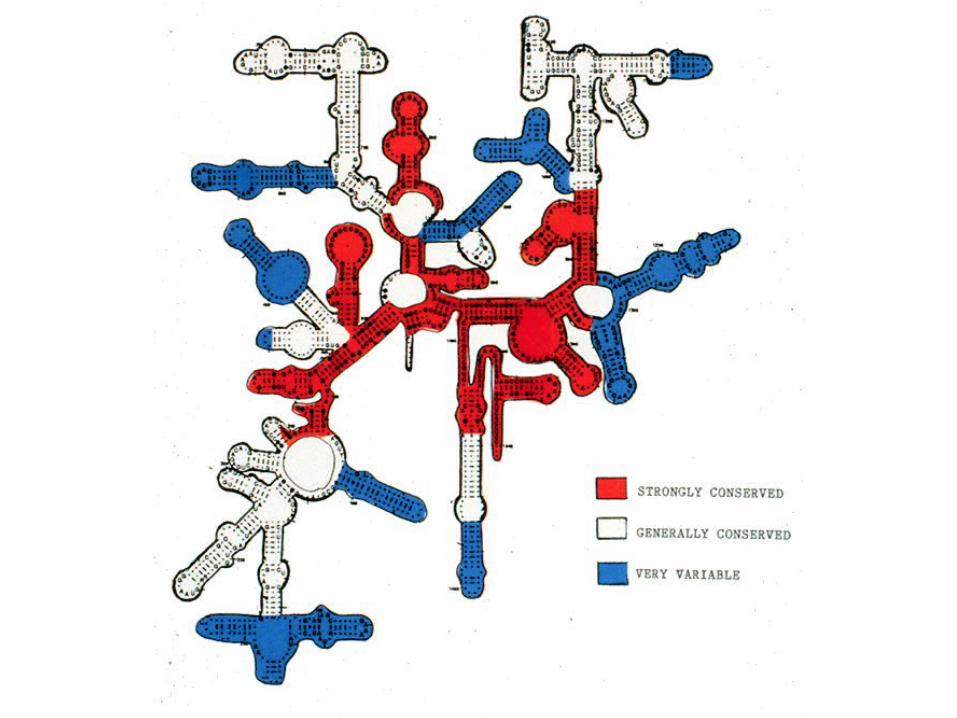
• Structural RNA (not translated)• Found in the small ribosomal subunit.
• Widely-used for phylogeny reconstruction (found in every species)
• Contains stem and loop structures.• Stem structures usually conform to watson-crick base pairing.

Alignment of 16S rRNA can be guided by secondary structure
<---------------(--------------------HELIX 19---------------------)<---------------(22222222-000000-111111-00000-111111-0000-22222222Thermus ruber UCCGAUGC-UAAAGA-CCGAAG=CUCAA=CUUCGG=GGGU=GCGUUGGATh. thermophilus UCCCAUGU-GAAAGA-CCACGG=CUCAA=CCGUGG=GGGA=GCGUGGGAE.coli UCAGAUGU-GAAAUC-CCCGGG=CUCAA=CCUGGG=AACU=GCAUCUGAAncyst.nidulans UCUGUUGU-CAAAGC-GUGGGG=CUCAA=CCUCAU=ACAG=GCAAUGGAB.subtilis UCUGAUGU-GAAAGC-CCCCGG=CUCAA=CCGGGG=AGGG=UCAUUGGAChl.aurantiacus UCGGCGCU-GAAAGC-GCCCCG=CUUAA=CGGGGC=GAGG=CGCGCCGAmatch ** *** * ** ** * **
Alignment of 16S rRNA sequences from different bacteria
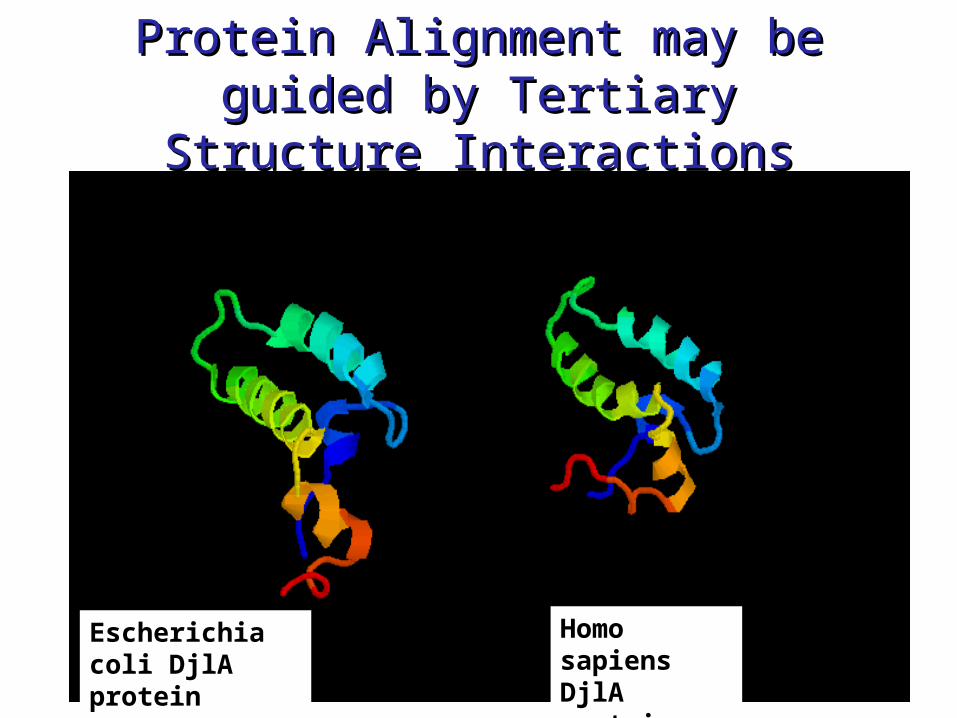
Protein Alignment may be Protein Alignment may be guided by Tertiary guided by Tertiary
Structure InteractionsStructure Interactions
Homo sapiens DjlA protein
Escherichia coli DjlA protein

Multiple Sequence Alignment- Methods
–3 main methods of alignment:
• Manual (using custom-built text editors).
• Automatic (using custom-built alignment software).
• Combined

Manual Alignment - reasons• Might be carried out because:
– Alignment is easy.– There is some extraneous information (structural).
– Automated alignment methods have encountered the local minimum problem.
– An automated alignment method can be “improved”.

Local minimum
GARFIELDTHEFAT---CATGARFIELDTHEFATFATCAT

• The dotplot provides a way of quickly visualizing the similarities between all parts of two sequences simultaneously.
• Lets consider a dotplot between sperm whale and human myoglobins
Dotplots
Sperm whale myoglobin
GLSDGEWQLV LNVWGKVEAD IPGHGQEVLI RLFKGHPETL EKFDKFKHLK SEDEMKASED LKKHGATVLT ALGGILKKKG HHEAEIKPLA QSHATKHKIP VKYLEFISEC IIQVLQSKHP GDFGADAQGA MNKALELFRK DMASNYKELG FQG
human myoglobin
VLSEGEWQLV LHVWAKVEAD VAGHGQDILI RLFKSHPETL EKFDRFKHLK TEAEMKASED LKKHGVTVLT ALGAILKKKG HHEAELKPLA QSHATKHKIP IKYLEFISEA IIHVLHSRHP GDFGADAQGA MNKALELFRK DIAAKYKELG YQG

• Put one sequence on top
• the other on the side
• where residues are identical put a dot
• Diagonal lines of dots show similarities
Dotplot example sperm whale vs human myg
Sperm whale myoglobin G L S D G E W Q L V ...V * L * *S *E * G * * E * W * Q *L * *V * *...
Human myoglobin
•just do the first 10 amino acids of each•make a table with
–whale sequence on top –human sequence on the side

• This is the result for the whole sequence
• It is easy to see that the diagonal is a line of dots.
• So sperm whale and human myoglobin are very similar
• But the picture is noisy can smooth using a sliding window which considers neighbouring residues as well
Dotplot example sperm whale vs human myg
16
Sperm whale myoglobin G L S D G E W Q L V ...V * L * *S *E * G * * E * W * Q *L * *V * *...
Human myoglobin

• can smooth noise using a sliding window which considers neighbouring residues as well
• Have done this here can see the diagonal is highly similar
• Also instead of using using a simple identity use a scoring matrix
Dotplot example sperm whale vs human myg

Dotplots in practice• The best tool is an applet* called dotlet
• www.isrec.isb-sib.ch/java/dotlet/Dotlet.html• www.bip.bham.ac.uk/dotlet/Dotlet.html
• *an applet is a program that runs in a web browser. This means that you can produce dotplots within a netscape/IE window.
• Dotplots are often useful to identify things like repeated domains or duplications in big proteins...

Example dotplot - repeated domains in Drosophila melanogaster SLIT protein.
• Protein has many repeats • SLIT_DROME (P24014):
MAAPSRTTLMPPPFRLQLRLLILPILLLLRHDAVHAEPYSGGFGSSAVSSGGLGSVGIHIPGGGVGVITEARCPRVCSCT GLNVDCSHRGLTSVPRKISADVERLELQGNNLTVIYETDFQRLTKLRMLQLTDNQIHTIERNSFQDLVSLERLDISNNVI TTVGRRVFKGAQSLRSLQLDNNQITCLDEHAFKGLVELEILTLNNNNLTSLPHNIFGGLGRLRALRLSDNPFACDCHLSW LSRFLRSATRLAPYTRCQSPSQLKGQNVADLHDQEFKCSGLTEHAPMECGAENSCPHPCRCADGIVDCREKSLTSVPVTL PDDTTDVRLEQNFITELPPKSFSSFRRLRRIDLSNNNISRIAHDALSGLKQLTTLVLYGNKIKDLPSGVFKGLGSLRLLL LNANEISCIRKDAFRDLHSLSLLSLYDNNIQSLANGTFDAMKSMKTVHLAKNPFICDCNLRWLADYLHKNPIETSGARCE SPKRMHRRRIESLREEKFKCSWGELRMKLSGECRMDSDCPAMCHCEGTTVDCTGRRLKEIPRDIPLHTTELLLNDNELGR ISSDGLFGRLPHLVKLELKRNQLTGIEPNAFEGASHIQELQLGENKIKEISNKMFLGLHQLKTLNLYDNQISCVMPGSFE HLNSLTSLNLASNPFNCNCHLAWFAECVRKKSLNGGAARCGAPSKVRDVQIKDLPHSEFKCSSENSEGCLGDGYCPPSCT CTGTVVACSRNQLKEIPRGIPAETSELYLESNEIEQIHYERIRHLRSLTRLDLSNNQITILSNYTFANLTKLSTLIISYN KLQCLQRHALSGLNNLRVVSLHGNRISMLPEGSFEDLKSLTHIALGSNPLYCDCGLKWFSDWIKLDYVEPGIARCAEPEQ MKDKLILSTPSSSFVCRGRVRNDILAKCNACFEQPCQNQAQCVALPQREYQCLCQPGYHGKHCEFMIDACYGNPCRNNAT CTVLEEGRFSCQCAPGYTGARCETNIDDCLGEIKCQNNATCIDGVESYKCECQPGFSGEFCDTKIQFCSPEFNPCANGAK CMDHFTHYSCDCQAGFHGTNCTDNIDDCQNHMCQNGGTCVDGINDYQCRCPDDYTGKYCEGHNMISMMYPQTSPCQNHEC KHGVCFQPNAQGSDYLCRCHPGYTGKWCEYLTSISFVHNNSFVELEPLRTRPEANVTIVFSSAEQNGILMYDGQDAHLAV ELFNGRIRVSYDVGNHPVSTMYSFEMVADGKYHAVELLAIKKNFTLRVDRGLARSIINEGSNDYLKLTTPMFLGGLPVDP AQQAYKNWQIRNLTSFKGCMKEVWINHKLVDFGNAQRQQKITPGCALLEGEQQEEEDDEQDFMDETPHIKEEPVDPCLEN KCRRGSRCVPNSNARDGYQCKCKHGQRGRYCDQGEGSTEPPTVTAASTCRKEQVREYYTENDCRSRQPLKYAKCVGGCGN QCCAAKIVRRRKVRMVCSNNRKYIKNLDIVRKCGCTKKCY
• Perform a dotplot of the SLIT protein against itself www.bio.bham.ac.uk/dotlet/Dotlet.html.
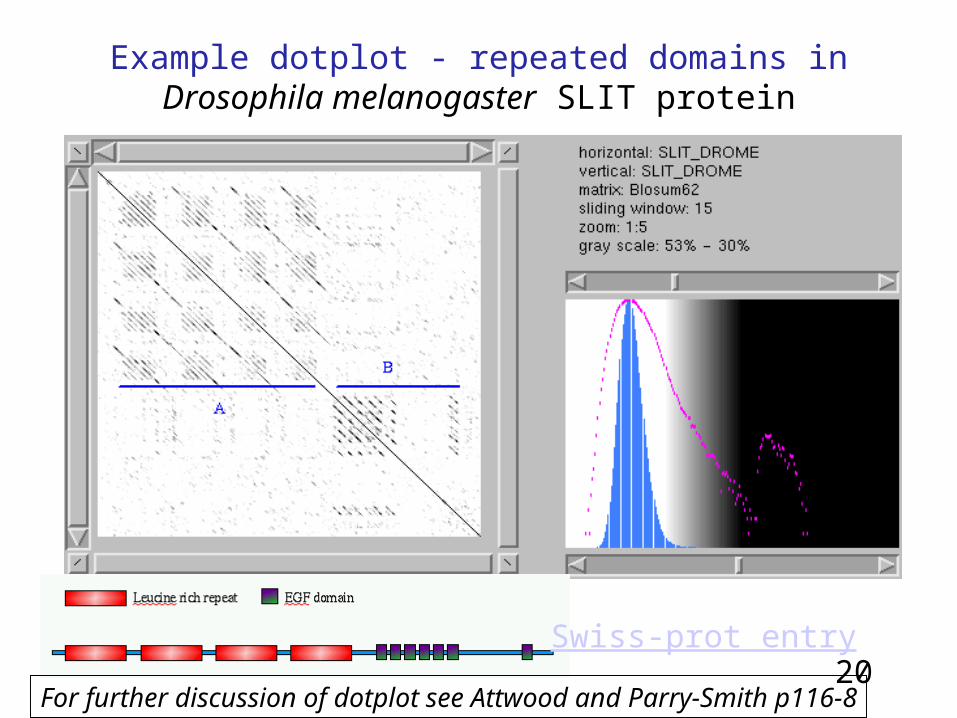
Example dotplot - repeated domains in Drosophila melanogaster SLIT protein
20Swiss-prot entry
For further discussion of dotplot see Attwood and Parry-Smith p116-8

Dynamic programming
2 methods:• Dynamic programming
– Consider 2 protein sequences of 100 amino acids in length.
– If it takes 1002 seconds to exhaustively align these sequences, then it will take 1003 seconds to align 3 sequences, 1004 to align 4 sequences...etc.
– More time than the universe has existed to align 20 sequences exhaustively.
• Progressive alignment

Progressive Alignment• Devised by Feng and Doolittle in 1987.
• Essentially a heuristic method and as such is not guaranteed to find the ‘optimal’ alignment.
• Requires n-1+n-2+n-3...n-n+1 pairwise alignments as a starting point
• Most successful implementation is Clustal (Des Higgins). This software is cited 3,000 times per year in the scientific literature.
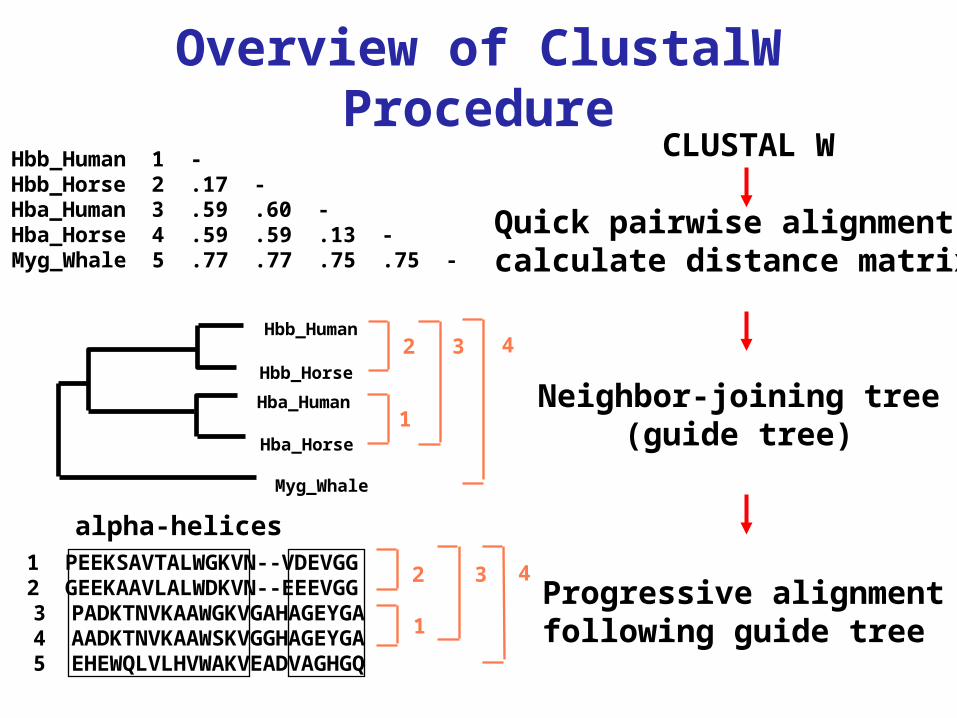
Overview of ClustalW Procedure
1 PEEKSAVTALWGKVN--VDEVGG2 GEEKAAVLALWDKVN--EEEVGG3 PADKTNVKAAWGKVGAHAGEYGA4 AADKTNVKAAWSKVGGHAGEYGA5 EHEWQLVLHVWAKVEADVAGHGQ
Hbb_Human 1 -Hbb_Horse 2 .17 -Hba_Human 3 .59 .60 -Hba_Horse 4 .59 .59 .13 -Myg_Whale 5 .77 .77 .75 .75 -
Hbb_Human
Hbb_Horse
Hba_Horse
Hba_Human
Myg_Whale
2
1
3 4
2
1
3 4
alpha-helices
Quick pairwise alignment: calculate distance matrix
Neighbor-joining tree(guide tree)
Progressive alignment following guide tree
CLUSTAL W

ClustalW- Pairwise Alignments
• First perform all possible pairwise alignments between each pair of sequences. There are (n-1)+(n-2)...(n-n+1) possibilities.
• Calculate the ‘distance’ between each pair of sequences based on these isolated pairwise alignments.
• Generate a distance matrix.
Path Graph for aligning two sequences.
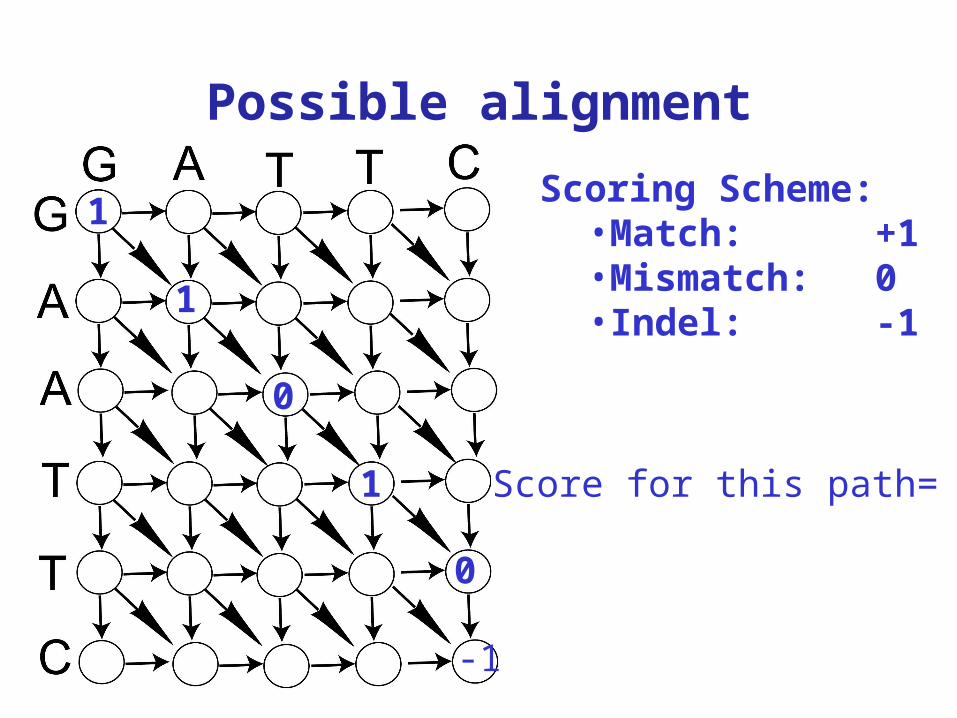
Possible alignment
1
1
0
1
0
-1
Scoring Scheme:•Match: +1•Mismatch: 0•Indel: -1
Score for this path= 2
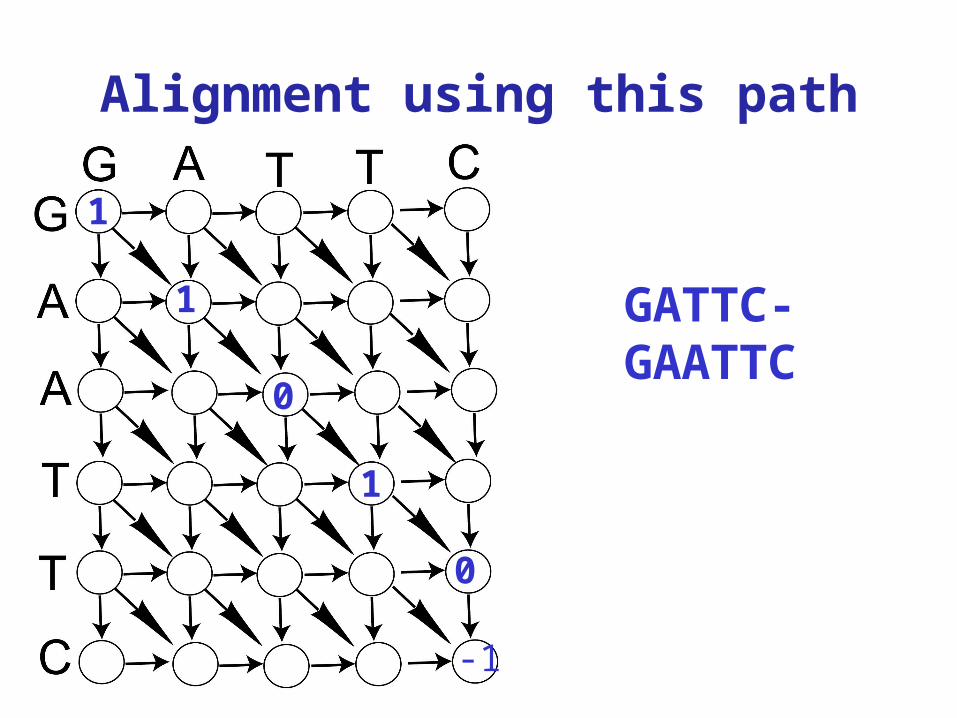
Alignment using this path
GATTC-GAATTC
1
1
0
1
0
-1
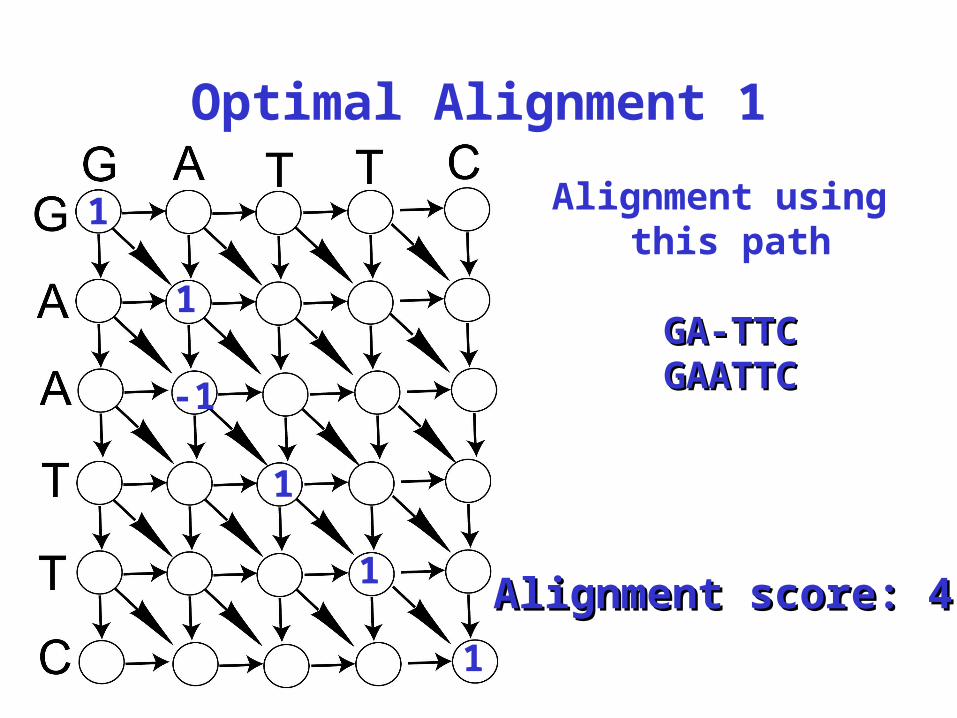
Optimal Alignment 1
1
1
-1
1
1
1
Alignment score: 4Alignment score: 4
Alignment using this path
GA-TTCGA-TTCGAATTCGAATTC
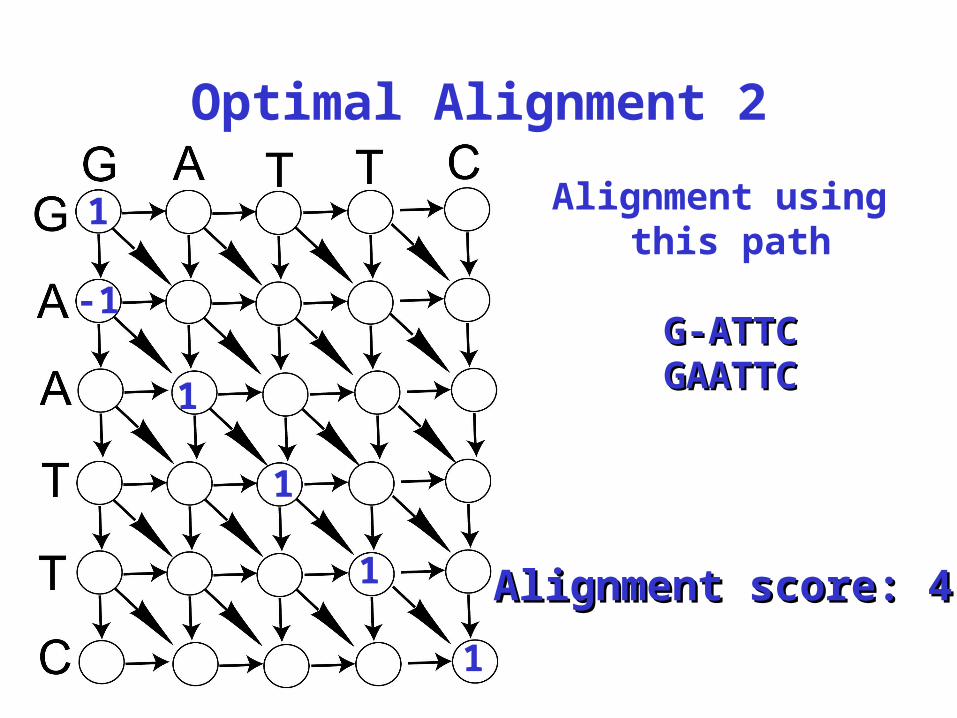
Optimal Alignment 2
1
-1
1
1
1
1
Alignment score: 4Alignment score: 4
Alignment using this path
G-ATTCG-ATTCGAATTCGAATTC
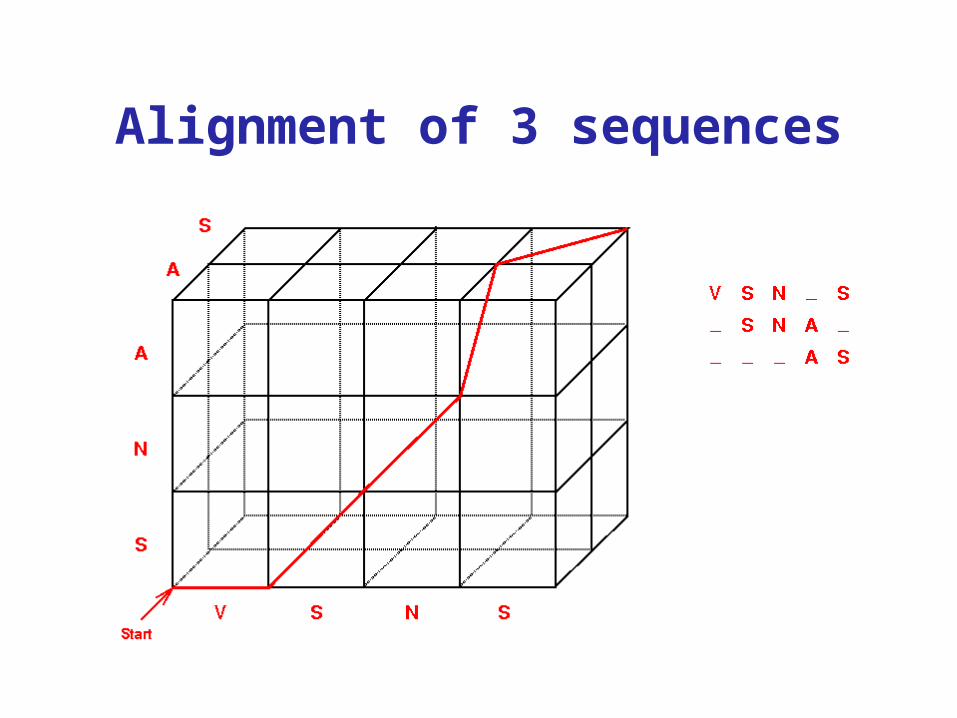
Alignment of 3 sequences

ClustalW- Guide Tree
• Generate a Neighbor-Joining ‘guide tree’ from these pairwise distances.
• This guide tree gives the order in which the progressive alignment will be carried out.

Neighbor joining method
•The neighbor joining method is a greedy heuristic which joins at each step, the two closest sub-trees that are not already joined.•It is based on the minimum evolution principle.•One of the important concepts in the NJ method is neighbors, which are defined as two taxa that are connected by a single node in an unrooted tree
A B
Node 1
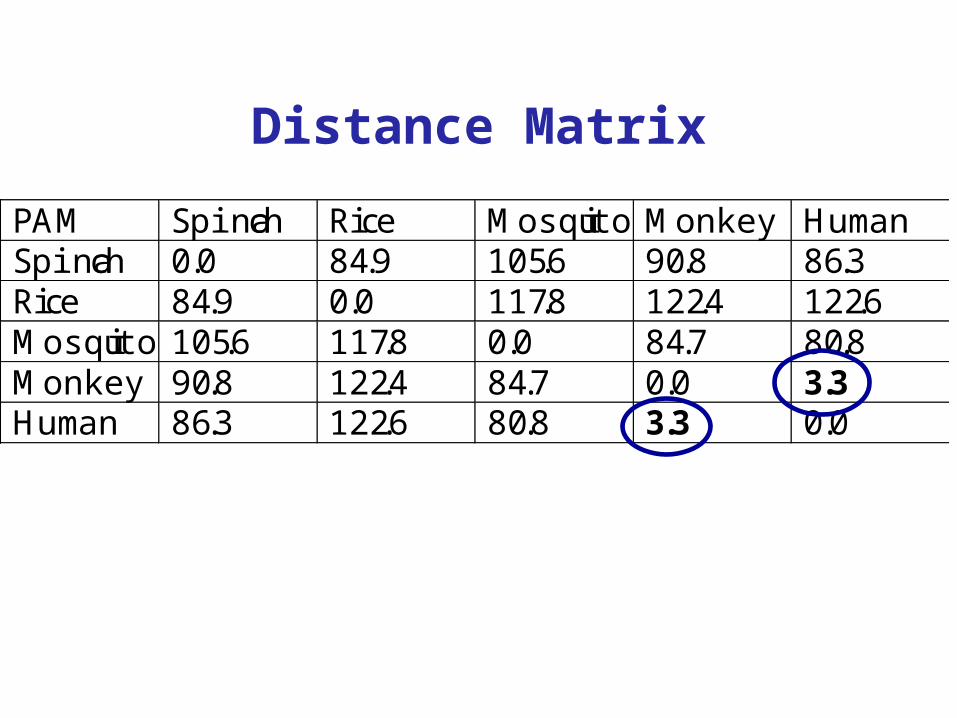
PAM Spinach Rice Mosquito Monkey HumanSpinach 0.0 84.9 105.6 90.8 86.3Rice 84.9 0.0 117.8 122.4 122.6Mosquito 105.6 117.8 0.0 84.7 80.8Monkey 90.8 122.4 84.7 0.0 3.3Human 86.3 122.6 80.8 3.3 0.0
What is required for the Neighbour joining method?Distance matrix
Distance Matrix
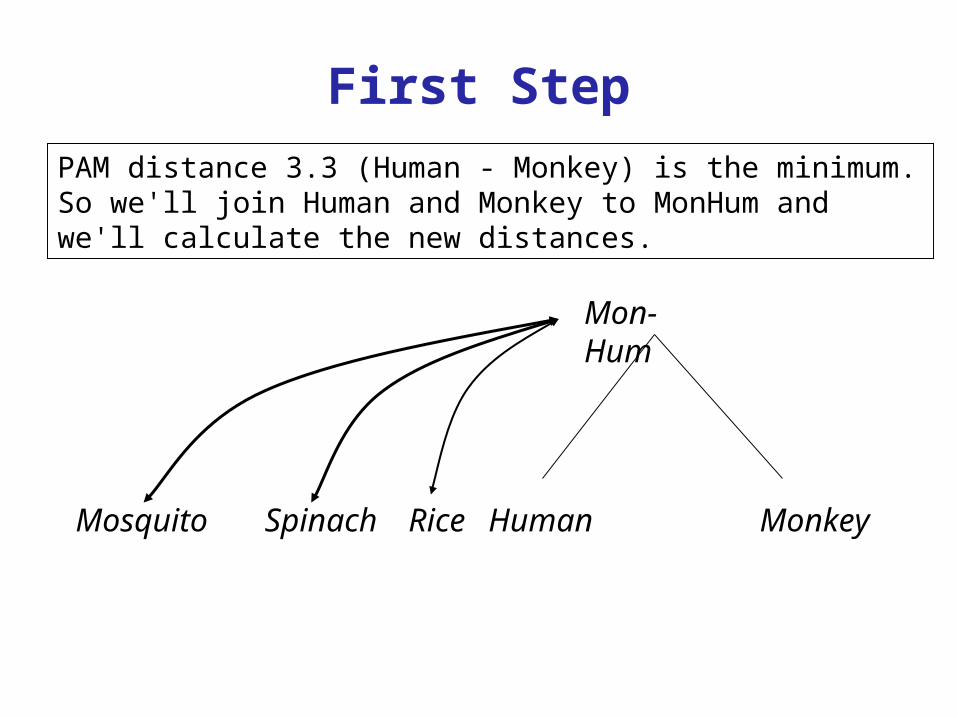
PAM distance 3.3 (Human - Monkey) is the minimum. So we'll join Human and Monkey to MonHum and we'll calculate the new distances.
Mon-Hum
MonkeyHumanSpinachMosquito Rice
First Step
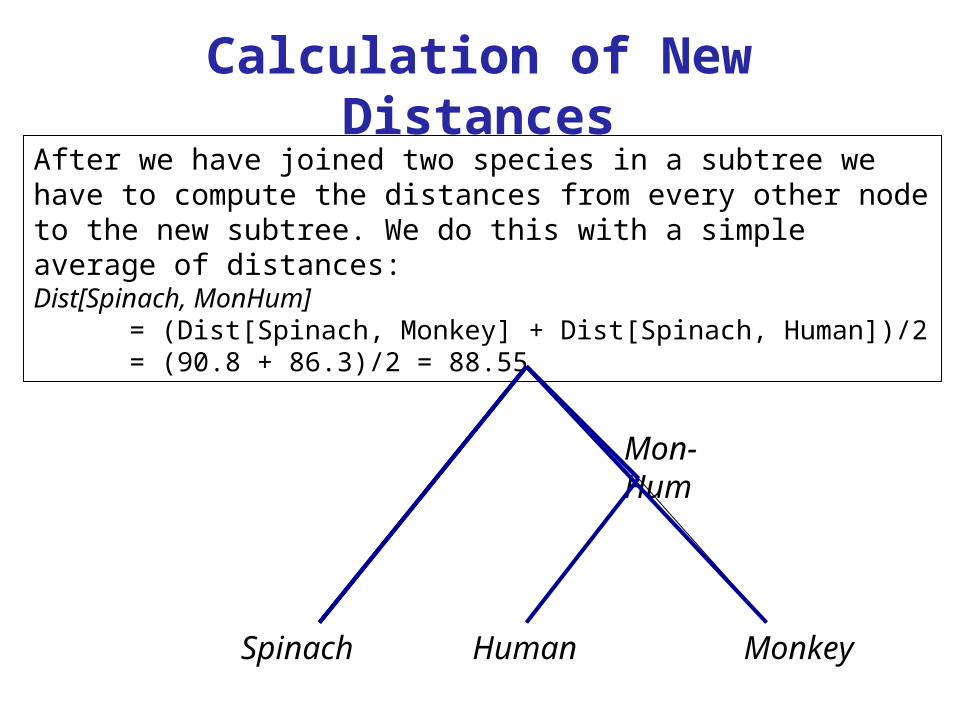
After we have joined two species in a subtree we have to compute the distances from every other node to the new subtree. We do this with a simple average of distances:Dist[Spinach, MonHum]
= (Dist[Spinach, Monkey] + Dist[Spinach, Human])/2 = (90.8 + 86.3)/2 = 88.55
Mon-Hum
MonkeyHumanSpinach
Calculation of New Distances
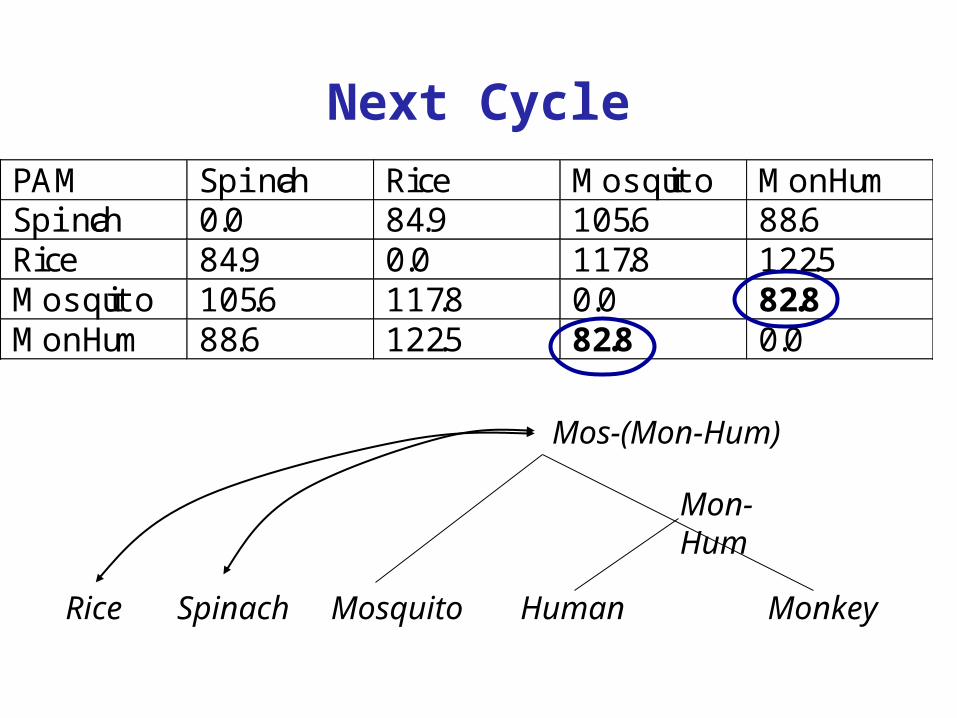
PAM Spinach Rice Mosquito MonHumSpinach 0.0 84.9 105.6 88.6Rice 84.9 0.0 117.8 122.5Mosquito 105.6 117.8 0.0 82.8MonHum 88.6 122.5 82.8 0.0
HumanMosquito
Mon-Hum
MonkeySpinachRice
Mos-(Mon-Hum)
Next Cycle
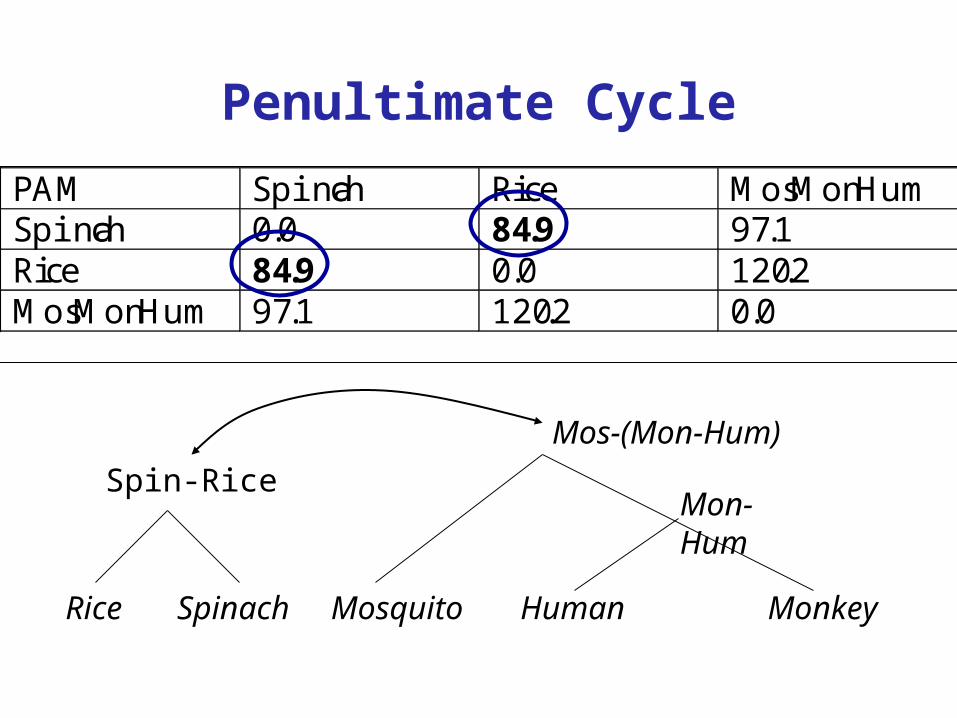
PAM Spinach Rice MosMonHumSpinach 0.0 84.9 97.1Rice 84.9 0.0 120.2MosMonHum 97.1 120.2 0.0
HumanMosquito
Mon-Hum
MonkeySpinachRice
Mos-(Mon-Hum)
Spin-Rice
Penultimate Cycle
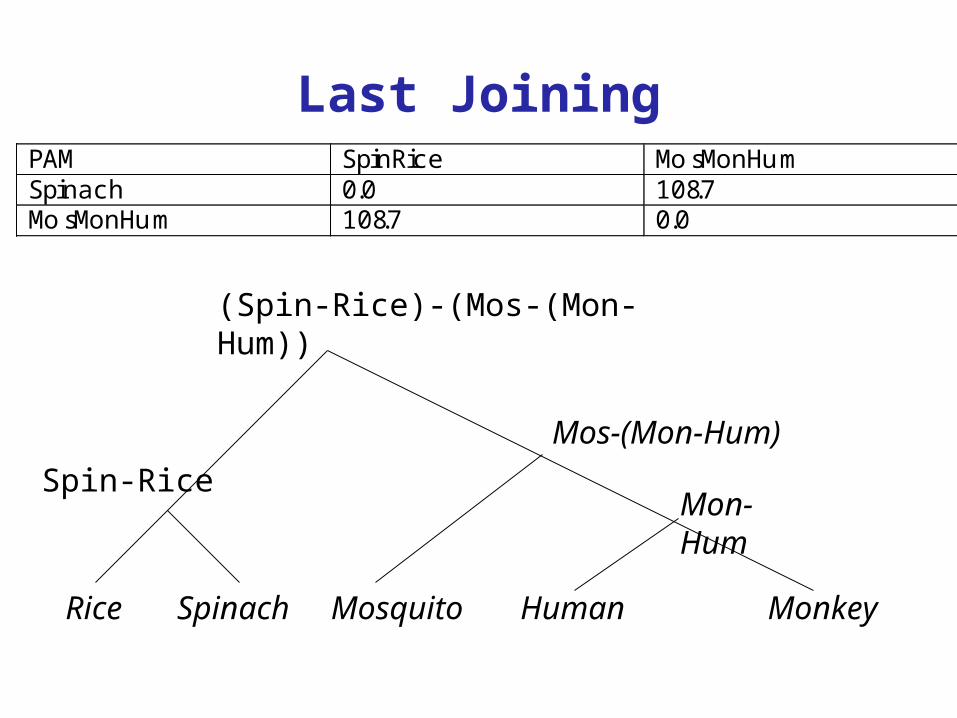
PAM SpinRice MosMonHumSpinach 0.0 108.7MosMonHum 108.7 0.0
HumanMosquito
Mon-Hum
MonkeySpinachRice
Mos-(Mon-Hum)
Spin-Rice
(Spin-Rice)-(Mos-(Mon-Hum))
Last Joining
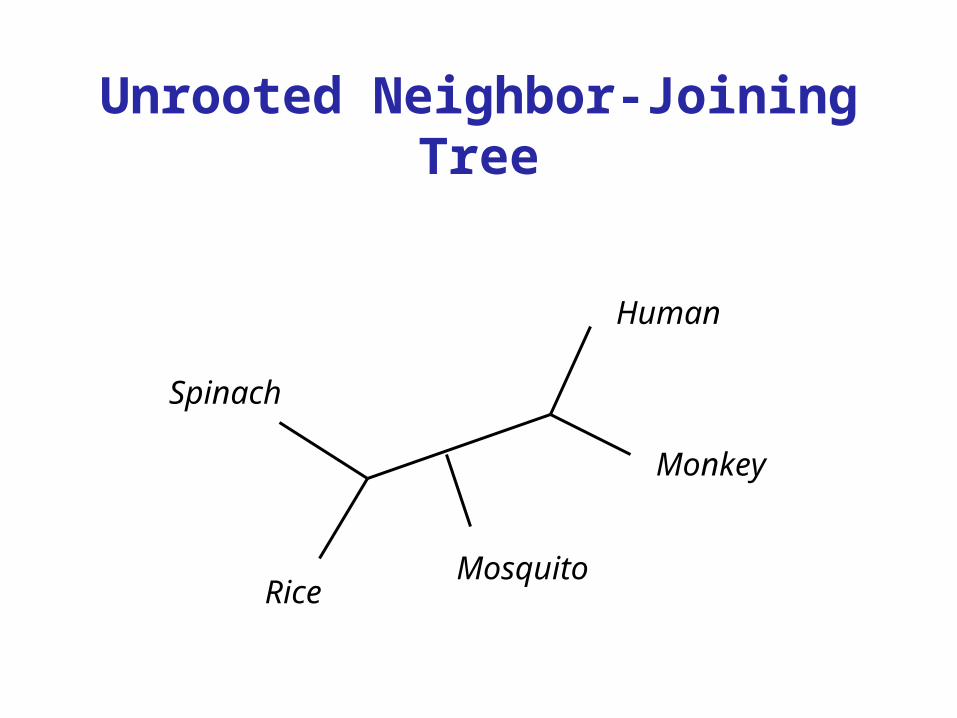
Human
Monkey
MosquitoRice
Spinach
Unrooted Neighbor-Joining Tree

Multiple Alignment- First pair
• Align the two most closely-related sequences first.
• This alignment is then ‘fixed’ and will never change. If a gap is to be introduced subsequently, then it will be introduced in the same place in both sequences, but their relative alignment remains unchanged.
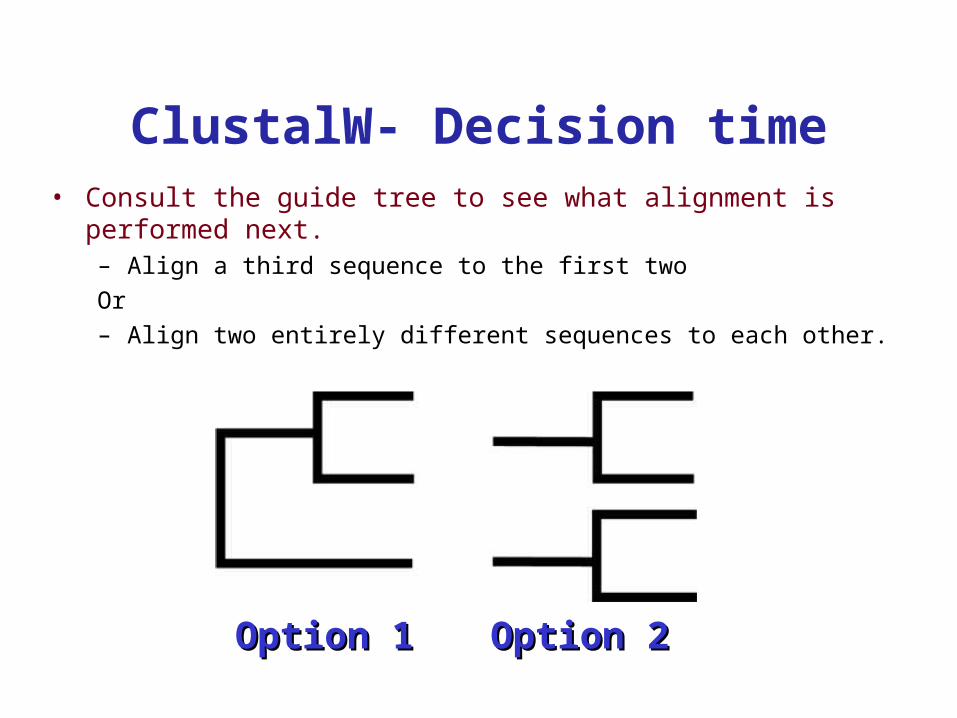
ClustalW- Decision time• Consult the guide tree to see what alignment is
performed next.– Align a third sequence to the first twoOr– Align two entirely different sequences to each other.
Option 1Option 1 Option 2Option 2

ClustalW- Alternative 1If the situation arises where a third sequence is aligned to the first two, then when a gap has to be introduced to improve the alignment, each of these two entities are treated as two single sequences.
+
ClustalW- Alternative 2
• If, on the other hand, two separate sequences have to be aligned together, then the first pairwise alignment is placed to one side and the pairwise alignment of the other two is carried out.
+

ClustalW- Progression
• The alignment is progressively built up in this way, with each step being treated as a pairwise alignment, sometimes with each member of a ‘pair’ having more than one sequence.
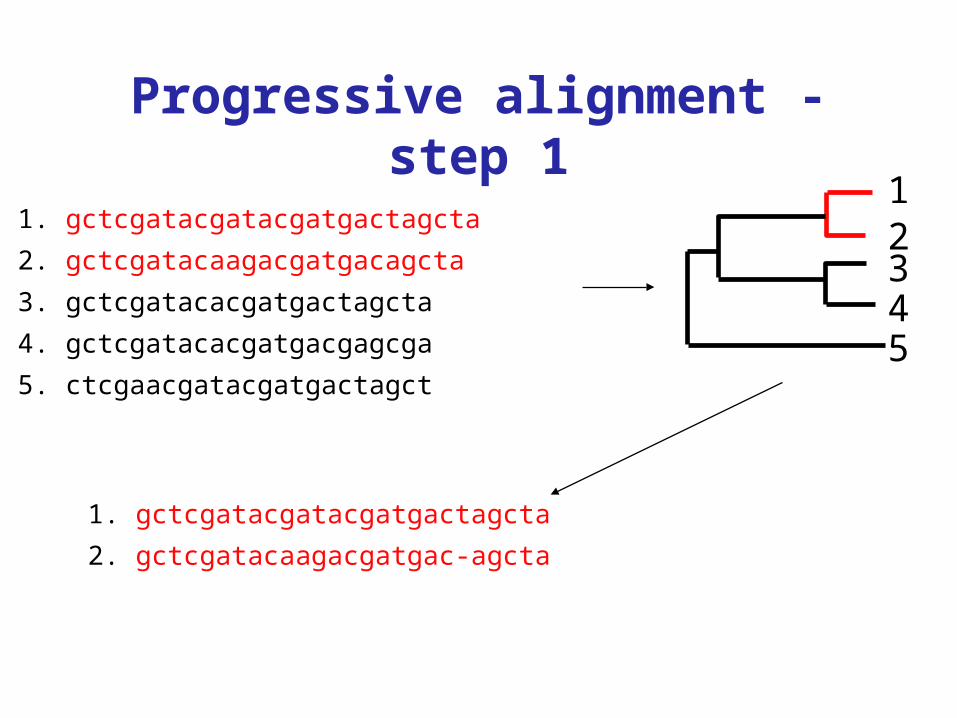
Progressive alignment - step 1
1. gctcgatacgatacgatgactagcta
2. gctcgatacaagacgatgacagcta
3. gctcgatacacgatgactagcta
4. gctcgatacacgatgacgagcga
5. ctcgaacgatacgatgactagct
1. gctcgatacgatacgatgactagcta
2. gctcgatacaagacgatgac-agcta
12345
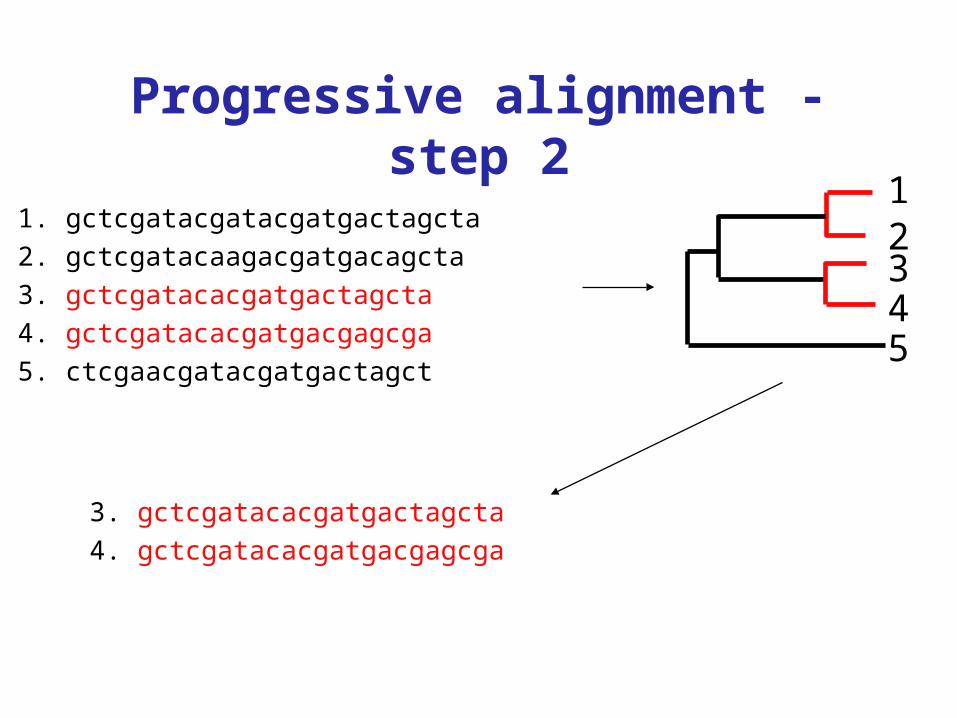
Progressive alignment - step 2
1. gctcgatacgatacgatgactagcta2. gctcgatacaagacgatgacagcta3. gctcgatacacgatgactagcta4. gctcgatacacgatgacgagcga5. ctcgaacgatacgatgactagct
3. gctcgatacacgatgactagcta4. gctcgatacacgatgacgagcga
12345
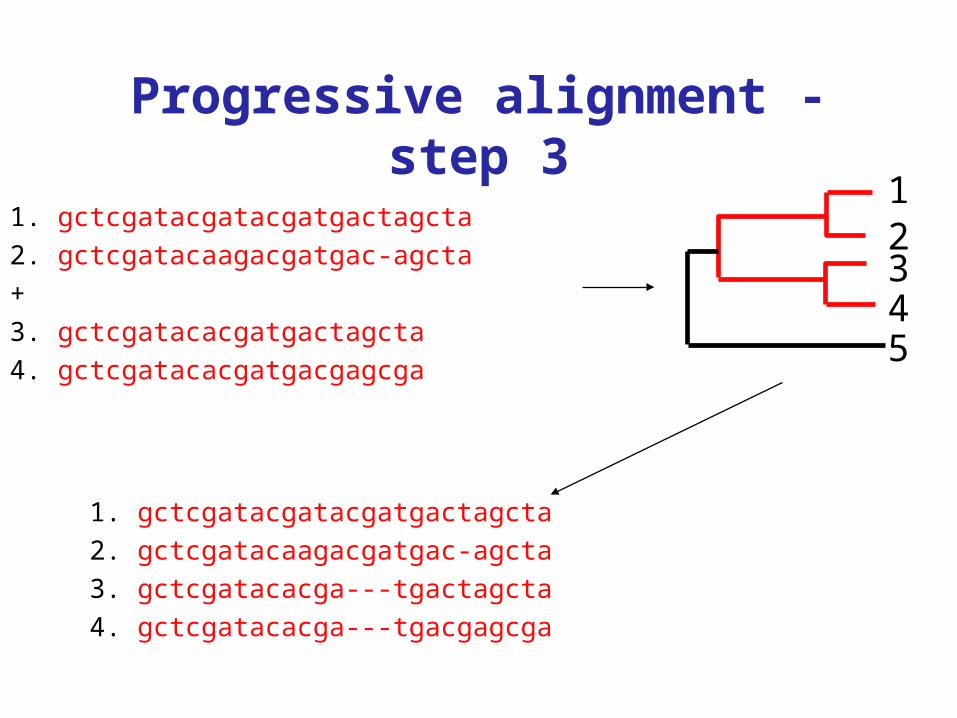
Progressive alignment - step 3
1. gctcgatacgatacgatgactagcta2. gctcgatacaagacgatgac-agcta+3. gctcgatacacgatgactagcta4. gctcgatacacgatgacgagcga
1. gctcgatacgatacgatgactagcta2. gctcgatacaagacgatgac-agcta3. gctcgatacacga---tgactagcta4. gctcgatacacga---tgacgagcga
12345
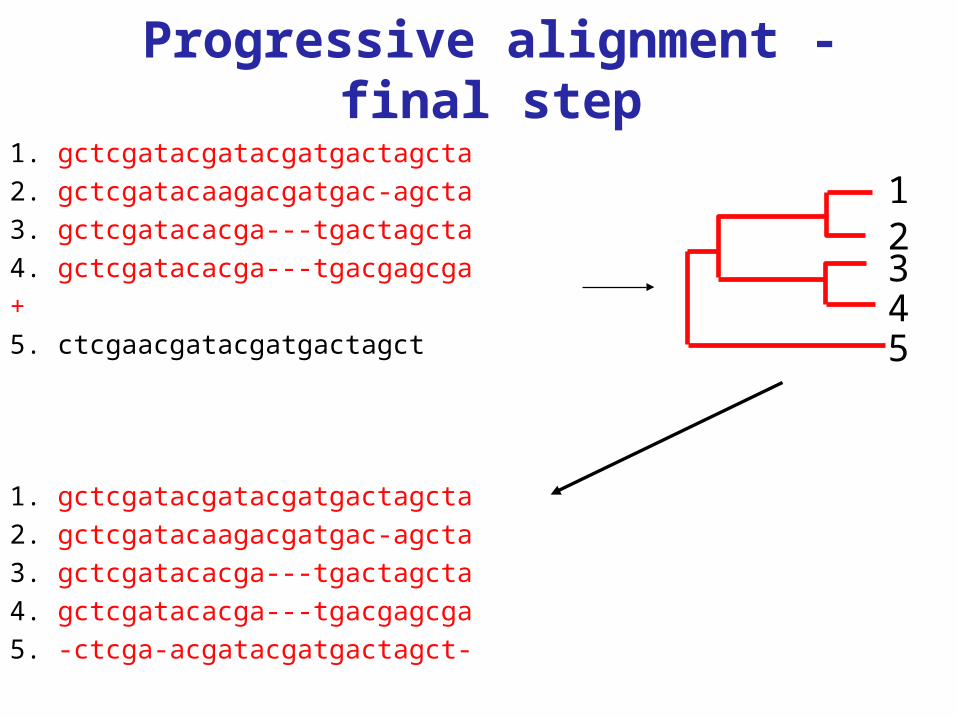
Progressive alignment - final step
1. gctcgatacgatacgatgactagcta2. gctcgatacaagacgatgac-agcta3. gctcgatacacga---tgactagcta4. gctcgatacacga---tgacgagcga+5. ctcgaacgatacgatgactagct
1. gctcgatacgatacgatgactagcta2. gctcgatacaagacgatgac-agcta3. gctcgatacacga---tgactagcta4. gctcgatacacga---tgacgagcga5. -ctcga-acgatacgatgactagct-
12345

ClustalW-Good points/Bad points
• Advantages:– Speed.
• Disadvantages:– No objective function.– No way of quantifying whether or not the alignment is good
– No way of knowing if the alignment is ‘correct’.

ClustalW-Local Minimum
• Potential problems:–Local minimum problem. If an error is introduced early in the alignment process, it is impossible to correct this later in the procedure.
–Arbitrary alignment.

Increasing the sophistication of the alignment process.
• Should we treat all the sequences in the same way? - even though some sequences are closely-related and some sequences are distant relatives.
• Should we treat all positions in the sequences as though they were the same? - even though they might have different functions and different locations in the 3-dimensional structure.

ClustalW- Caveats• Sequence weighting• Varying substitution matrices• Residue-specific gap penalties and reduced penalties in hydrophilic regions (external regions of protein sequences), encourage gaps in loops rather than in core regions.
• Positions in early alignments where gaps have been opened receive locally reduced gap penalties to encourage openings in subsequent alignments

ClustalW- User-supplied values
• Two penalties are set by the user (there are default values, but you should know that it is possible to change these).
• GOP- Gap Opening Penalty is the cost of opening a gap in an alignment.
• GEP- Gap Extension Penalty is the cost of extending this gap.

Position-Specific gap penalties
• Before any pair of (groups of) sequences are aligned, a table of GOPs are generated for each position in the two (sets of) sequences.
• The GOP is manipulated in a position-specific manner, so that it can vary over the sequences.
• If there is a gap at a position, the GOP and GEP penalties are lowered, the other rules do not apply.
• This makes gaps more likely at positions where gaps already exist.

Discouraging too many gaps
• If there is no gap opened, then the GOP is increased if the position is within 8 residues of an existing gap.
• This discourages gaps that are too close together.• At any position within a run of hydrophilic
residues, the GOP is decreased.• These runs usually indicate loop regions in
protein structures.• A run of 5 hydrophilic residues is considered to
be a hydrophilic stretch.• The default hydrophilic residues are:
– D, E, G, K, N, Q, P, R, S– But this can be changed by the user.

Divergent Sequences• The most divergent sequences (most different,
on average from all of the other sequences) are usually the most difficult to align.
• It is sometimes better to delay their aligment until later (when the easier sequences have already been aligned).
• The user has the choice of setting a cutoff (default is 40% identity).
• This will delay the alignment until the others have been aligned.

T-COFFEETree-based consistency objective function for alignment
evaluation)
• Generate a library of all the pairwise alignments between the sequences.
• This gives positional information concerning which residues are homologous to which other residues.
• This can then be used to guide progressive alignments.
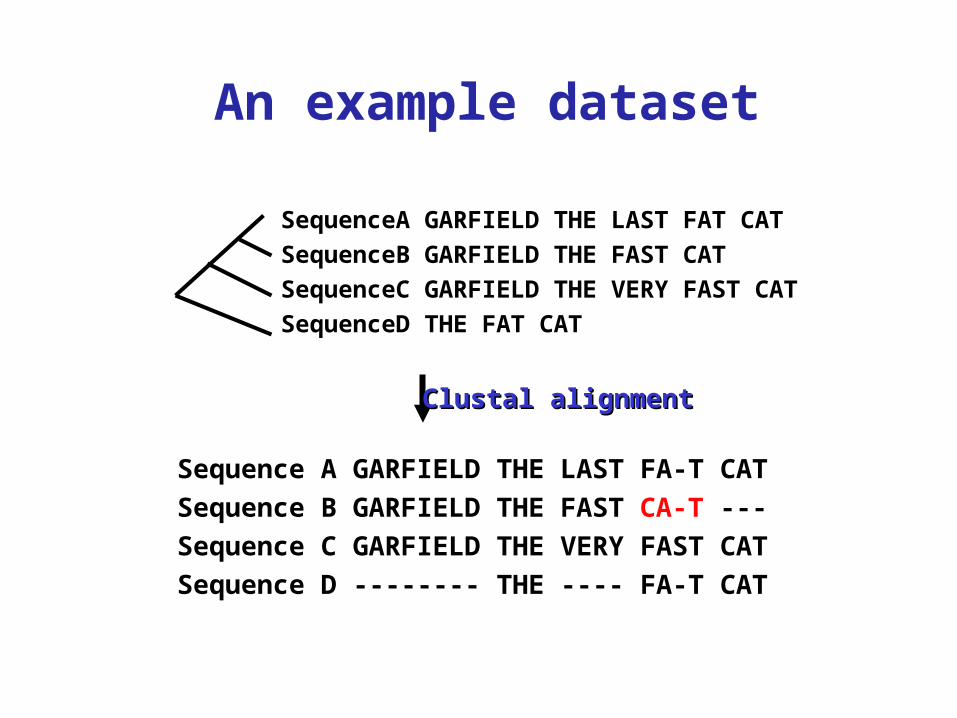
An example dataset
SequenceA GARFIELD THE LAST FAT CATSequenceB GARFIELD THE FAST CATSequenceC GARFIELD THE VERY FAST CATSequenceD THE FAT CAT
Sequence A GARFIELD THE LAST FA-T CATSequence B GARFIELD THE FAST CA-T ---Sequence C GARFIELD THE VERY FAST CATSequence D -------- THE ---- FA-T CAT
Clustal alignmentClustal alignment

Primary library
SeqA GARFIELD THE LAST FAT CAT SeqB GARFIELD THE ---- FAST CATSeqB GARFIELD THE FAST CAT --- 88 SeqC GARFIELD THE VERY FAST CAT 100
SeqA GARFIELD THE LAST FA-T CAT SeqB GARFIELD THE FAST CATSeqC GARFIELD THE VERY FAST CAT 77 SeqD -------- THE FA-T CAT 100
SeqA GARFIELD THE LAST FAT CAT SeqC GARFIELD THE VERY FAST CAT SeqD -------- THE ---- FAT CAT 100 SeqD -------- THE ---- FA-T CAT 100

Secondary library
SeqA GARFIELD THE LAST FAT CAT SeqB GARFIELD THE FAST CAT Weight = 88
SeqA GARFIELD THE LAST FAT CATSeqC GARFIELD THE VERY FAST CATSeqB GARFIELD THE FAST CAT Weight = 77
SeqA GARFIELD THE LAST FAT CATSeqD THE FAT CATSeqB GARFIELD THE FAST CAT Weight = 100
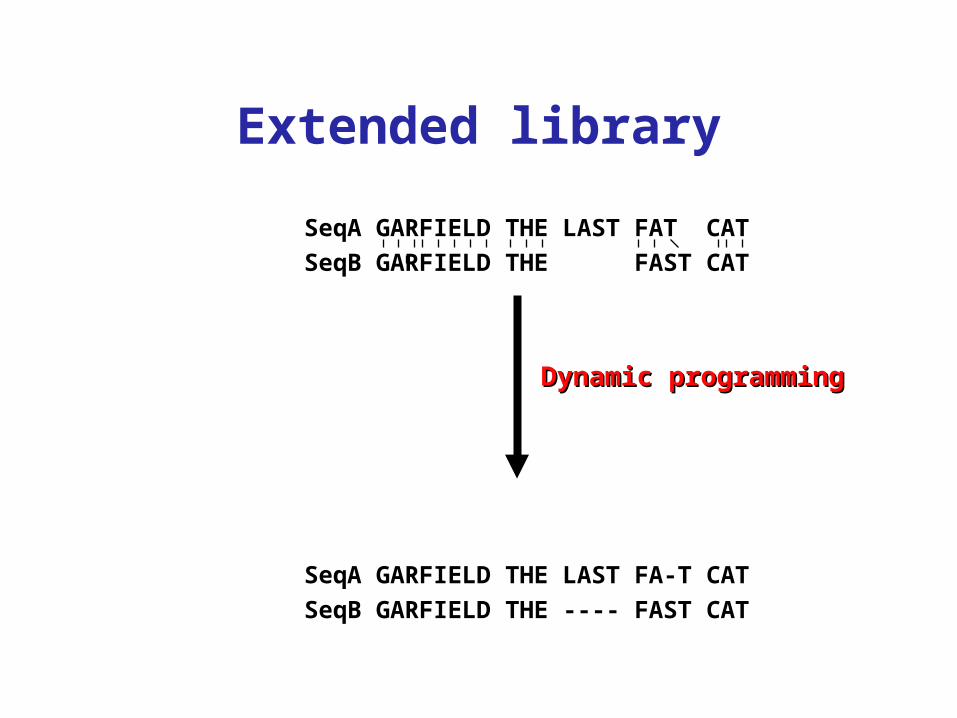
Extended library
SeqA GARFIELD THE LAST FAT CATSeqB GARFIELD THE FAST CAT
SeqA GARFIELD THE LAST FA-T CATSeqB GARFIELD THE ---- FAST CAT
Dynamic programmingDynamic programming

Advice on progressive alignment
• Progressive alignment is a mathematical process that is completely independent of biological reality.
• Can be a very good estimate• Can be an impossibly poor estimate.• Requires user input and skill.• Treat cautiously• Can be improved by eye (usually)• Often helps to have colour-coding.• Depending on the use, the user should be able to make
a judgement on those regions that are reliable or not.
• For phylogeny reconstruction, only use those positions whose hypothesis of positional homology is unimpeachable

Alignment of protein-coding DNA sequences
• It is not very sensible to align the DNA sequences of protein-coding genes.
ATGCTGTTAGGGATGACTCTGTTAGGG
ATG-CT--GTTAGGGATGACTCTGTTAGGG
The result might be highly-implausible and might not reflect what is known about biological processes.It is much more sensible to translate the sequences to their corresponding amino acid sequences, align these protein sequences and then put the gaps in the DNA sequences according to where they are found in the amino acid alignment.

Manual Alignment- softwareGDE- The Genetic Data Environment (UNIX)CINEMA- Java applet available from:
– http://www.biochem.ucl.ac.uk
Seqapp/Seqpup- Mac/PC/UNIX available from:– http://iubio.bio.indiana.edu
SeAl for Macintosh, available from:– http://evolve.zoo.ox.ac.uk/Se-Al/Se-Al.html
BioEdit for PC, available from:– http://www.mbio.ncsu.edu/RNaseP/info/programs/BIOEDIT/bioedit.html





























