Embed Size (px)
Citation preview

multimodal+emotion+recognition
a.k.a. ‘better than the sum of its parts’
Kostas Karpouzis
Assoc. researcher
ICCS/NTUA
http://www.image.ntua.gr

multimodal+emotion+recognition
• Three very different (and interesting!) problems– What is ‘multimodal’, why do we need
it, what do we earn from that?– What is ‘emotion’ in HCI applications?– What can we recognize and, better
yet, what should we recognize?

multimodal+emotion+recognition
• In terms of R&D, emotion/affect-aware human-computer interaction is a hot topic– Novel, interesting application for
existing algorithms– Demanding test bed for feature
extraction and recognition tasks– …and just wait until we bring humans
in the picture!

multimodal+emotion+recognition
• In terms of R&D, emotion/affect-aware human-computer interaction is a hot topic– Dedicated conferences (e.g. ACII, IVA, etc.)
and planned journals– Humaine Network of Excellence Humaine
Association • http://emotion-research.net
– Integrated Projects (CALLAS, Companions, LIREC, Feelix Growing, etc.)

yours truly
• Associate researcher at ICCS/NTUA, Athens
• Completed post-doc within Humaine– Signals to signs of emotion– Co-editor of Humaine Handbook
• Member of the EC of the Humaine Association
• Emotion modelling and development in Callas, Feelix Growing FP6 Projects

what next
• first we define ‘emotion’– terminology– semantics and representations– computational models– emotion in interaction– emotion in natural interaction

what next
• then ‘multimodal’– modalities related to emotion and
interaction– fusing modalities (how?, why?)– handling uncertainty, noise, etc.– which features from each modality?– semantics of fusion

what next
• and ‘recognition’– from individual modalities (uni-modal)– across modalities (multi-modal)– static vs. dynamic recognition– what can we recognize?
• can we extend/enrich that?
– context awareness

what next
• affect and emotion aware applications– can we benefit from knowing a user’s
emotional state?
• missing links– open research questions for the
following years

defining emotion

terminology
• Emotions, mood, personality• Can be distinguished by
– time (short-term vs. long-term)– influence (unnoticed vs. dominant)– cause (specific vs. diffuse)
• Affect classified by time– short-term: emotions (dominant, specific)– medium-term: moods (unnoticed, diffuse)– and long-term: personality (dominant)

terminology
• what we perceive is the expressed emotion at a given time– on top of a person’s current mood, which
may change over time, but not drastically– and on top of their personality
• usually considered a base line level
• which may differ from what a person feels– e.g. we despise someone, but are forced to
be polite

terminology
• Affect is an innately structured, non-cognitive evaluative sensation that may or may not register in consciousness
• Feeling is defined as affect made conscious, possessing an evaluative capacity that is not only physiologically based, but that is often also psychologically oriented.
• Emotion is psychosocially constructed, dramatized feeling

how it all started
• Charles Darwin, 1872• Ekman et al. since the 60s• Mayer and Salovey, papers on
emotional intelligence, 90s• Goleman’s book: Emotional
Intelligence: Why It Can Matter More Than IQ
• Picard’s book: Affective Computing, 1997

why emotions?
• “Shallow” improvement of subjective experience
• Reason about emotions of others– To improve usability– Get a handle on another aspect of the
"human world"– Affective user modeling– Basis for adaptation of software to
users

name that emotion
• so, we know what we’re after– but we have to assign it a name– in which we all agree upon– and means the same thing for all
(most?) of us
• different emotion representations– different context– different applications– different conditions/environments

emotion representations
• most obvious: labels– people use them in everyday life– ‘happy’, ‘sad’, ‘ironic’, etc.– may be extended to include user
states, e.g. ‘tired’, which are not emotions
– CS people like them• good match for classification algorithms

labels
• but…– we have to agree on a finite set
• if we don’t, we’ll have to change the structure of our neural nets with each new label
– labels don’t work well with measurements
• is ‘joy’ << ‘exhilaration’ and in what scale?• do scales mean the same to the
expresser and all perceivers?

labels
• Ekman’s set is the most popular– ‘anger’, ‘disgust’, ‘fear’, ‘joy’,
‘sadness’, and ‘surprise’– added ‘contempt’ in the process
• Main difference to other sets of labels:– universally recognizable across
cultures – when confronted with a smile, all
people will recognize ‘joy’

from labels to machine learning
• when reading the claim that ‘there are six facial expressions recognized universally across cultures’…
• …CS people misunderstood, causing a whole lot of issues that still dominate the field

strike #1
• ‘we can only recognize these six expressions’
• as a result, all video databases used to contain images of sad, angry, happy or fearful people
• a while later, the same authors discussed ‘contempt’ as a possible universal, but CS people weren’t listening

strike #2
• ‘only these six expressions exist in human expressivity’
• as a result, more sad, angry, happy or fearful people, even when data involved HCI– can you really be afraid when using
your computer?

strike #3
• ‘we can only recognize extreme emotions’
• now, happy people grin, sad people cry or are scared to death when afraid
• however, extreme emotions are scarce in everyday life– so, subtle emotions and additional
labels were out of the picture

labels are good, but…
• don’t cover subtle emotions and natural expressivity– more emotions are available in
everyday life and usually masked– hence the need for alternative emotion
representations
• can’t approach dynamics• can’t approach magnitude
– extreme joy is not defined

other sets of labels
• Plutchik– Acceptance, anger, anticipation, disgust, joy,
fear, sadness, surprise– Relation to adaptive biological processes
• Frijda– Desire, happiness, interest, surprise,
wonder, sorrow– Forms of action readiness
• Izard– Anger, contempt, disgust, distress, fear,
guilt, interest, joy, shame, surprise

other sets of labels
• James– Fear, grief, love, rage– Bodily involvement
• McDougall– Anger, disgust, elation, fear, subjection,
tender-emotion, wonder– Relation to instincts
• Oatley and Johnson-Laird– Anger, disgust, anxiety, happiness, sadness– Do not require propositional content
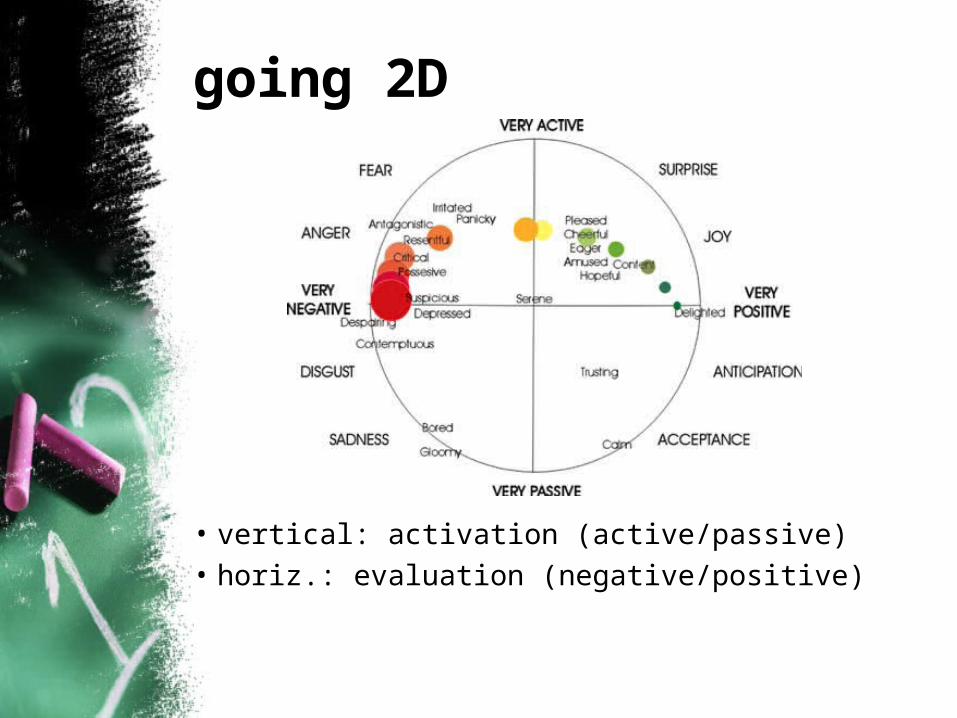
going 2D
• vertical: activation (active/passive)
• horiz.: evaluation (negative/positive)
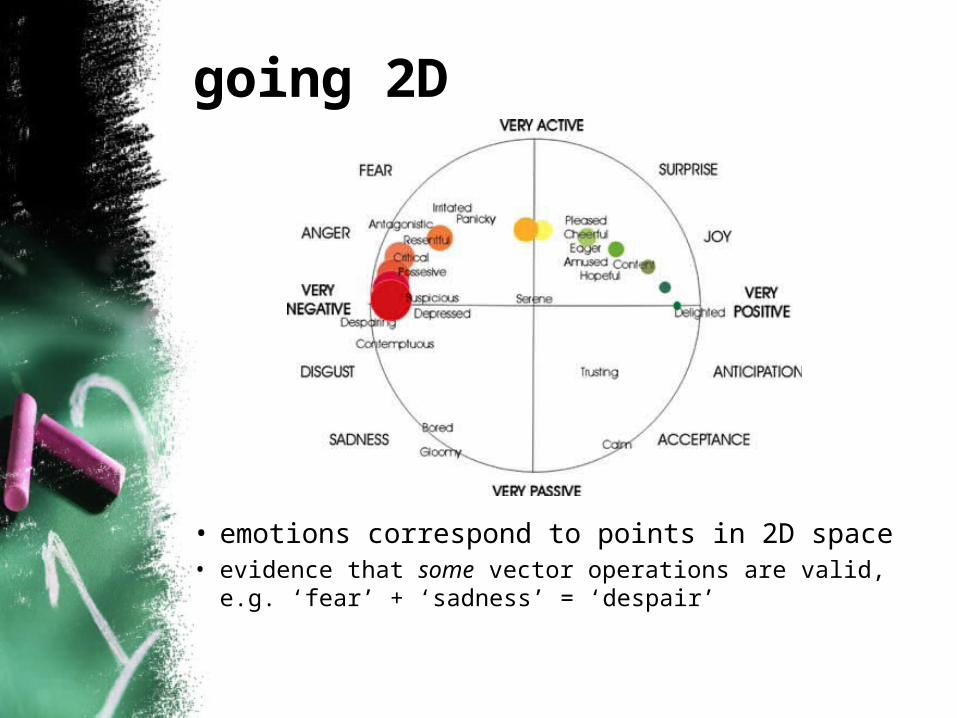
going 2D
• emotions correspond to points in 2D space• evidence that some vector operations are valid, e.g.
‘fear’ + ‘sadness’ = ‘despair’
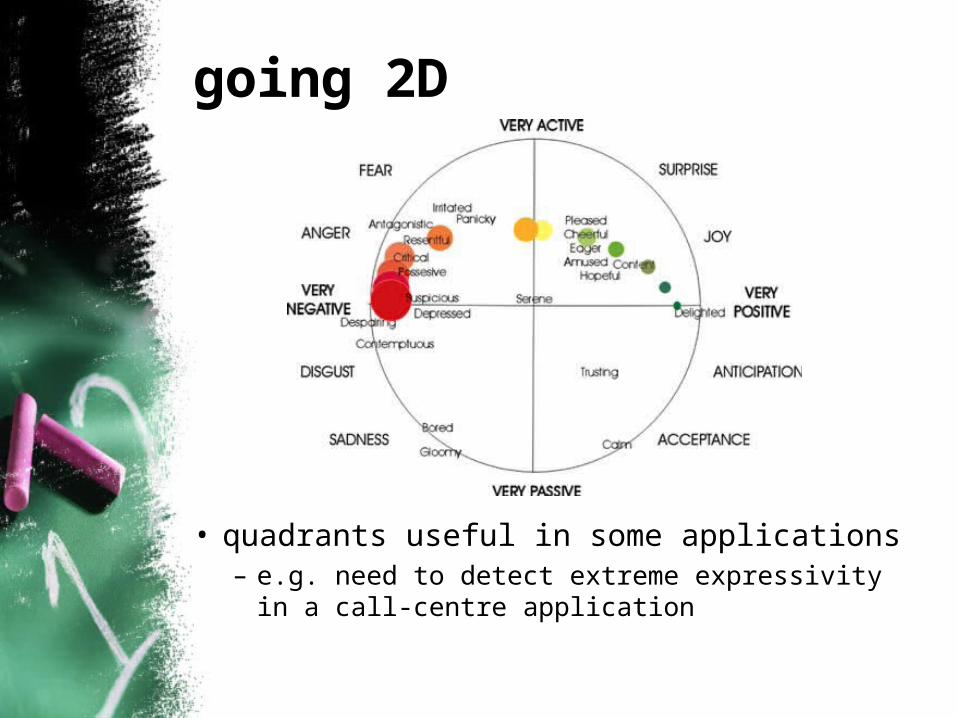
going 2D
• quadrants useful in some applications– e.g. need to detect extreme expressivity in a
call-centre application
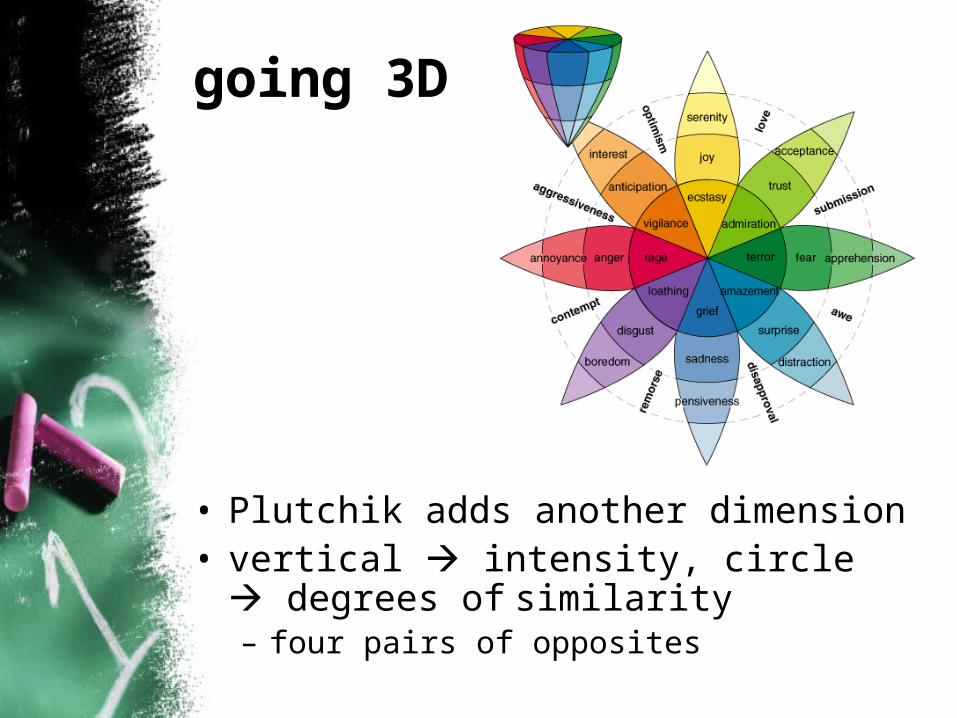
going 3D
• Plutchik adds another dimension• vertical intensity, circle degrees of
similarity – four pairs of opposites
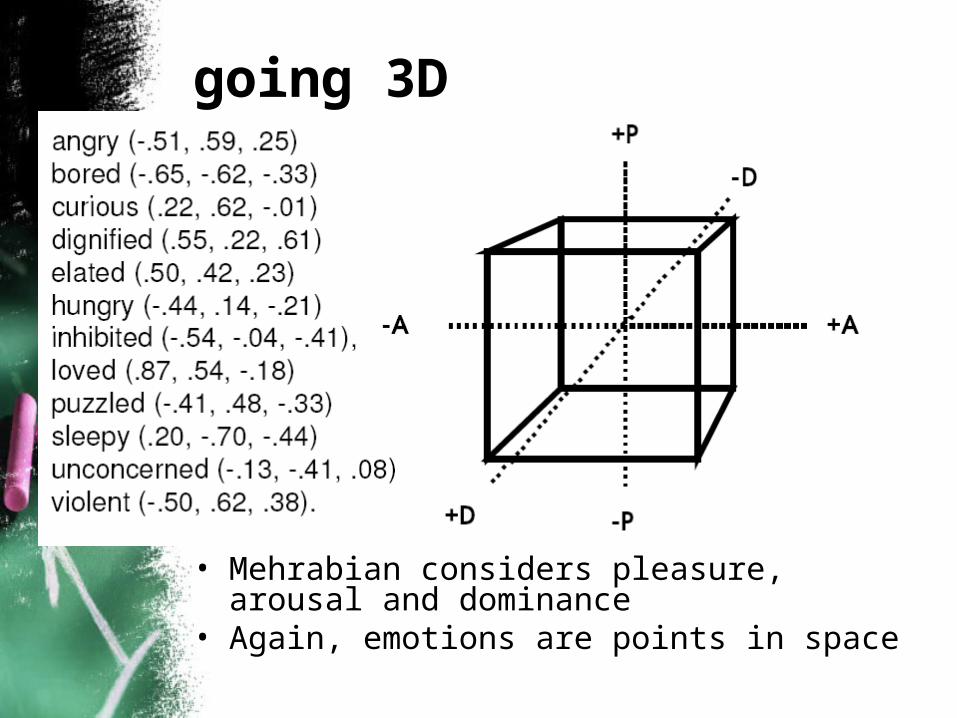
going 3D
• Mehrabian considers pleasure, arousal and dominance
• Again, emotions are points in space

what about interaction?
• these models describe the emotional state of the user
• no insight as to what happened, why the user reacted and how the user will react– action selection
• OCC (Ortony, Clore, Collins)
• Scherer’s appraisal checks
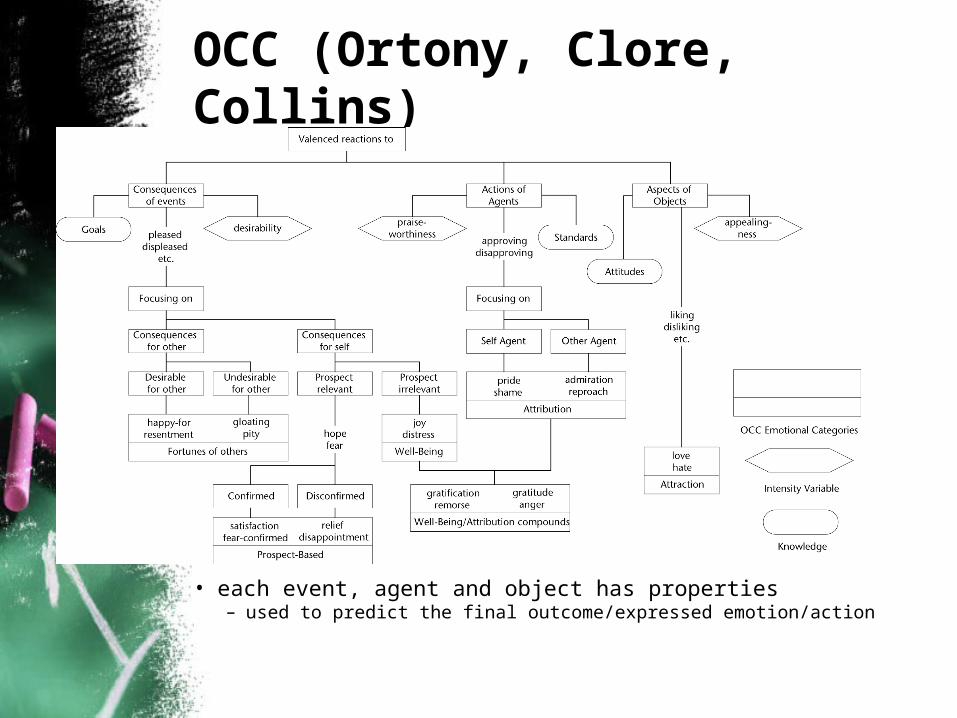
OCC (Ortony, Clore, Collins)
• each event, agent and object has properties– used to predict the final outcome/expressed emotion/action

OCC (Ortony, Clore, Collins)
Group Specification Name & typeWellBeing
Appraisal of situation as event
Joy - pleased about eventDistress - displeased about event
FortunesofOthers
Appraisal of situation as event affecting another
Happy-for: pleased about an event desirable for anotherResentment: displeased about an event desirable for another
Prospect-based
Appraisal of situation as a prospective event
Hope: pleased about a prospective desirable eventFear: displeased about a prospective undesirable event

OCC (Ortony, Clore, Collins)
• Appraisals– Assessments of events, actions, objects
• Valence– Whether emotion is positive or negative
• Arousal– Degree of physiological response
• Generating appraisals– Domain-specific rules– Probability of impact on agent’s goals
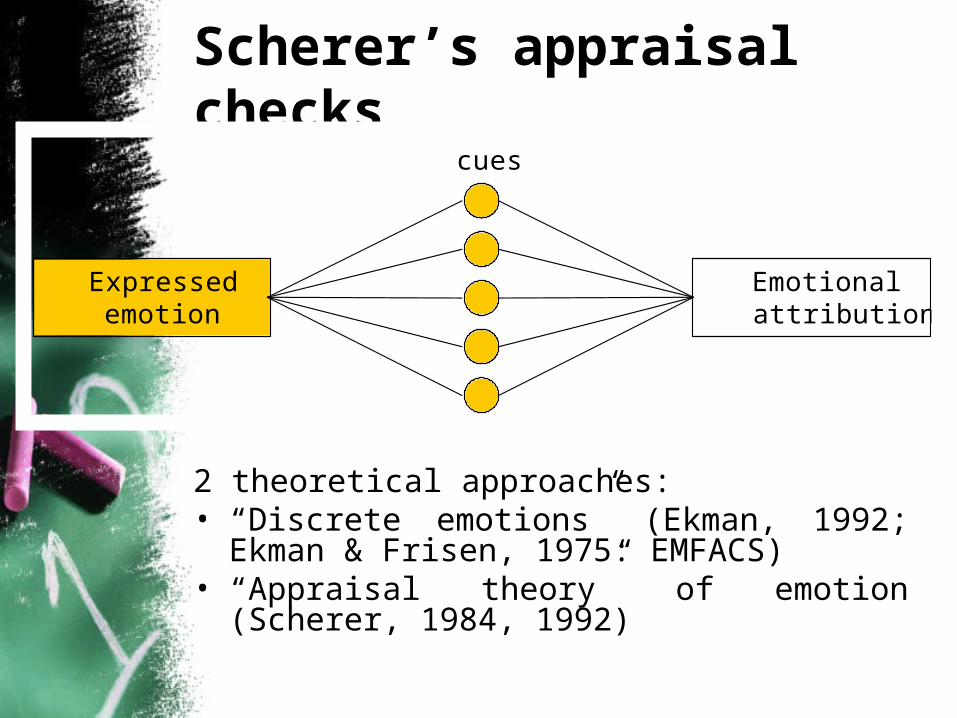
Scherer’s appraisal checks
2 theoretical approaches:• “Discrete emotions” (Ekman, 1992; Ekman &
Frisen, 1975: EMFACS)• “Appraisal theory” of emotion (Scherer, 1984,
1992)
Expressedemotion
Emotionalattribution
cues

Scherer’s appraisal checks
• Componential Approach– Emotions are elicited by a cognitive
evaluation of antecedent events.– Patterning of reactions are shaped by this
appraisal process. Appraisal dimensions are used to evaluate stimulus, in an adaptive way to the changes.
• Appraisal Dimensions: Evaluation of significance of event, coping potential, and compatibility with the social norms
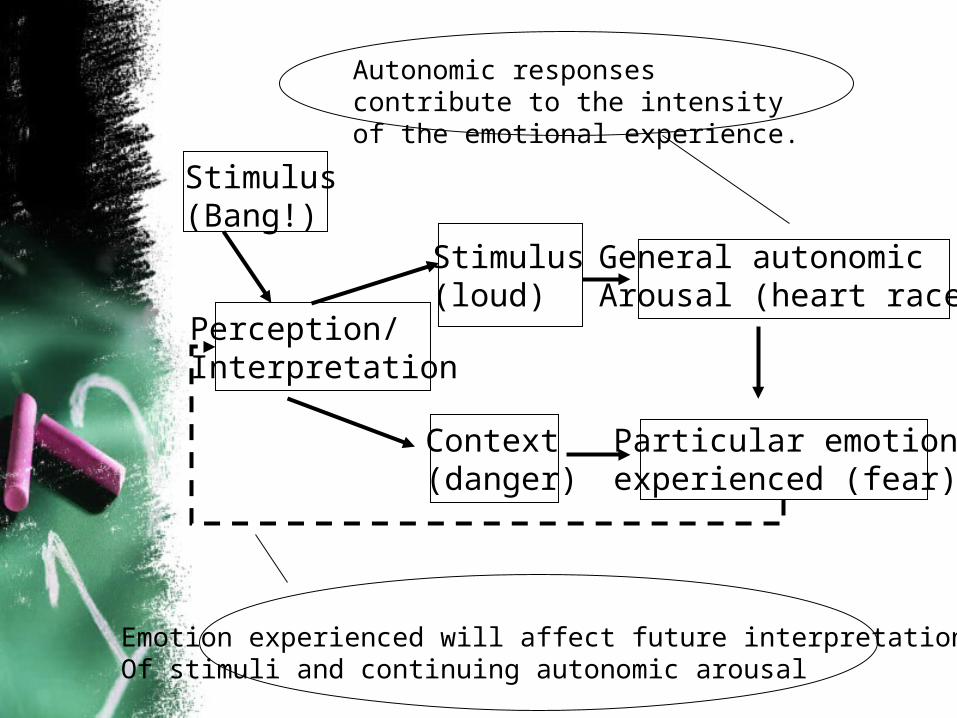
Stimulus(Bang!)
Perception/Interpretation
Stimulus(loud)
Context(danger)
General autonomicArousal (heart races)
Particular emotionexperienced (fear)
Emotion experienced will affect future interpretationsOf stimuli and continuing autonomic arousal
Autonomic responses contribute to the intensity of the emotional experience.

Scherer’s appraisal checks
• 2 theories, 2 sets of predictions:the example of Anger

summary on emotion
• perceived emotions are usually short-lasting events across modalities
• labels and dimensions are used to annotate perceived emotions– pros and cons for each
• additional requirements for interactive applications

multimodal interaction

a definition
• Raisamo, 1999
• “Multimodal interfaces combine many simultaneous input modalities and may present the information using synergistic representation of many different output modalities”

Twofold view
• A Human-Centered View– common in psychology– often considers human input channels, i.e.,
computer output modalities, and most often vision and hearing
– applications: a talking head, audio-visual speech recognition, ...
• A System-Centered View– common in computer science– a way to make computer systems more
adaptable
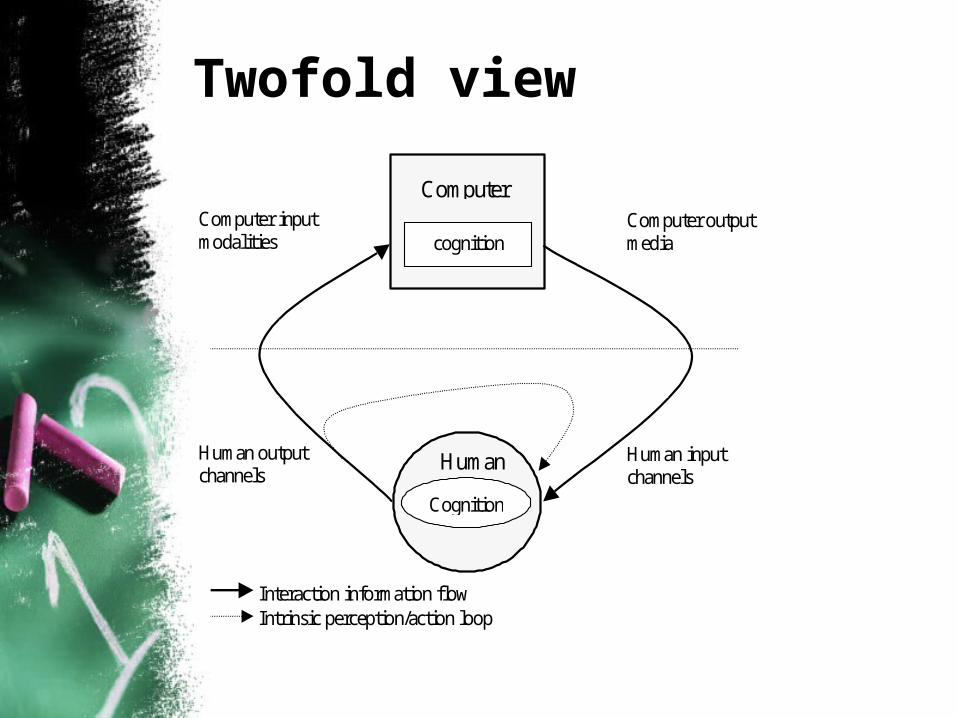
Twofold view
Cognition
”cognition”
Computer
Human
Computer inputmodalities
Human outputchannels
Computer outputmedia
Human inputchannels
Interaction information flowIntrinsic perception/action loop

going multimodal
• ‘multimodal’ is this decade’s ‘affective’!
• plethora of modalities available to capture and process– visual, aural, haptic…– ‘visual’ can be broken down to ‘facial
expressivity’, ‘hand gesturing’, ‘body language’, etc.
– ‘aural’ to ‘prosody’, ‘linguistic content’, etc.
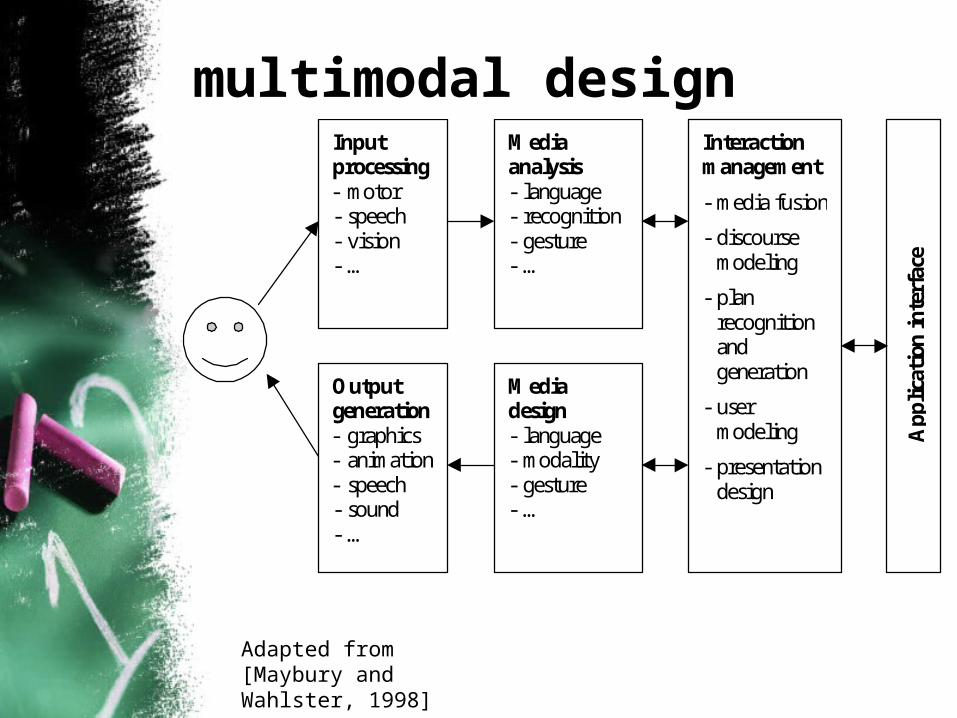
multimodal designInputprocessing- motor- speech- vision- …
Outputgeneration- graphics- animation- speech- sound- …
Mediaanalysis- language- recognition- gesture- …
Mediadesign- language- modality- gesture- …
Interactionmanagement
- media fusion
- discoursemodeling
- planrecognitionandgeneration
- usermodeling
- presentationdesign
Ap
plic
atio
n in
terf
ace
Adapted from [Maybury and Wahlster, 1998]

paradigms for multimodal user interfaces
1. Computer as a tool– multiple input modalities are used to
enhance direct manipulation behavior of the system
– the machine is a passive tool and tries to understand the user through all different input modalities that the system recognizes
– the user is always responsible for initiating the operations
– follows the principles of direct manipulation [Shneiderman, 1982; 1983]

paradigms for multimodal user interfaces
2. Computer as a dialogue partner– the multiple modalities are used to
increase the anthropomorphism in the user interface
– multimodal output is important: talking heads and other human-like modalities
– speech recognition is a common input modality in these systems
– can often be described as an agent-based conversational user interface

why multimodal?
• well, why not?– recognition from traditional unimodal
databases had reached its ceiling– new kinds of data available
• what’s in it for me?– have recognition rates improved?– or just introduced more uncertain
features

essential reading
• Communications of the ACM,Nov. 1999, Vol. 42, No. 11, pp. 74-81

putting it all together
• myth #1: If you build a multimodal system, users will interact multimodally– Users have a strong preference to interact
multimodally rather than unimodally– no guarantee that they will issue every
command to a system multimodally– users express commands multimodally when
describing spatial information, but not when e.g. they print something

putting it all together
• myth #2: Speech and pointing is the dominant multimodal integration pattern
• myth #3: Multimodal input involves simultaneous signals– consider the McGurk effect:– when, the spoken sound /ga/ is
superimposed on the video of a person uttering /ba/, most people perceive the speaker as uttering the sound /da/.
– opening the mouth does not coincide temporally with uttering a word

putting it all together
• myth #4: Speech is the primary input mode in any multimodal system that includes it– Mehrabian indicates that most of the
conveyed message is contained in facial expressions
• wording 7%, paralinguistic 38%– Do you talk to your computer?– People look at the face and body more than
any other channel when they judge nonverbal behavior [Ambady and Rosenthal, 1992].

putting it all together
• myth #6: multimodal integration involves redundancy of content between modes
• you have features from a person’s– facial expressions and body language– speech prosody and linguistic content,– even their heartbeat rate
• so, what do you do when their face tells you different than their …heart?

putting it all together
• myth #7: Individual error-prone recognition technologies combine multimodally to produce even greater unreliability
• wait for multimodal results later• hint:
– facial expressions + speech >> facial expressions!
– facial expressions + speech > speech!

first, look at this video

and now, listen!

but it can be good
• what happens when one of the available modalities is not robust?– better yet, when the ‘weak’ modality
changes over time?
• consider the ‘bartender problem’– very little linguistic content reaches its
target– mouth shape available (viseme)– limited vocabulary

but it can be good

fusing modalities
• so you have features and/or labels from a number of modalities
• if they all agree…– no problem, shut down your PC and
go for a beer!
• but life is not always so sweet – so how do you decide?

fusing modalities
• two main fusion strategies– feature-level (early, direct)– decision level (late, separate)
• and some complicated alternatives– dominant modality (a dominant
modality drives the perception of others) – example?
– hybrid, majority vote, product, sum, weighted (all statistical!)

fusing modalities
• feature-level– one expert for all features– may lead to high dimensional feature
spaces and very complex datasets– what happens within each modality is
collapsed to a 1-D feature vector – features from robust modalities are
considered in the same manner as those from uncertain

fusing modalities
• feature-level– as a general rule, sets of correlated
features and sets of most relevant features determine the decision
– features may need clean-up!– e.g. a neural net will depend on
relevant features (and indicate them!) after successful training
– inconsistent features assigned lower weights

fusing modalities
• decision-level– one expert for each modality– fails to model interplay between features
across modalities• e.g. a particular phoneme is related with a specific
lip formation• perhaps some are correlated, so selecting just
one would save time and complexity
– assigning weights is always a risk– what happens if your robust (dominant?)
modality changes over time?– what happens if unimodal decisions differ?

fusing modalities
• decision-level– if you have a robust modality (and you
know which), you can get good, consistent results
– sometimes, a particular modality is dominant
• e.g. determined by the application
– however, in practice, feature-based fusion outperforms decision-level
• even by that much…

fusing modalities
• for a specific user– dominant modality can be identified almost
immediately– remains highly consistent over a session– remains stable across their lifespan– highly resistant to change, even when they
are given strong selective reinforcement or explicit instructions to switch patterns
• S. Oviatt, “Toward Adaptive Information Fusion in Multimodal Systems”

fusing modalities
• humans are able to recognize an emotional expression in face images with about 70-98% accuracy– 80-98% automatic recognition on 5-7 classes
of emotional expression from face images– computer speech recognition: 90% accuracy
on neutrally-spoken speech 50-60% accuracy on emotional speech
– 81% automatic recognition on 8 categories of emotion from physiological signals

again, why multimodal?
• holy grail: assigning labels to different parts of human-human or human-computer interaction
• yes, labels can be nice!– humans do it all the time– and so do computers (it’s called
classification!)– OK, but what kind of label?
• GOTO STEP 1

recognition

it’s all about the data!
• Sad, but true – very few multimodal (audiovisual)
databases exist– lots of unimodal, though– lots of acted emotion
• comprehensive list at http://emotion-research.net/wiki/Databases

acted, natural, or…?
• Acted is easy!– just put together a group of
students/volunteers and hand them a script
• Studies show that acted facial expressions are different than real ones– both feature- and activation-wise– can’t train on acted and test on real

acted, natural, or…?
• Natural is hard…– people don’t usually talk to microphones or
look into cameras– emotions can be masked, blended, subtle…
• What about induced?– The SAL technique (a la Wizard of Oz or
Eliza)– Computer provides meaningless cues to
facilitate discussion– Should you induce sadness or anger?

recognition from speech prosody
• Historically, one of the earliest attempts at emotion recognition
• Temporal unit: tune– a segment between two pauses– emotion does not change within a
tune!– but also some suprasegmental efforts
(extends over more than one sound segment)

recognition from speech prosody
• Most approaches based on pitch and its F0– and statistical measures on it– e.g. distance between peaks/between
pauses, etc. [Batliner et al.]

recognition from speech prosody
• Huge number of available features– all of them relevant?– imminent need to clean up– correlation, ANOVA, sensitivity analysis– irrelevant features hamper training– good results even with 32 features

recent findings
• Batliner et al, from Humaine NoE
• The impact of erroneous F0 extraction– recent studies question the role of
pitch as the most important prosodic feature
– manually corrected pitch outperforms automatically extracted pitch
– extraction errors?

recent findings
• Voice quality and emotion – claims that voice quality serves the marking
of emotions are not verified in natural speech, mostly for acted or synthesized data
– at first sight, some emotions might display higher frequencies of laryngealizations
– rather, a combination of speaker-specific traits and lexical/segmental characteristics which causes the specific distribution

recent findings
• Impact of feature type and functionals on classification performance
• Emotion recognition with reverberated and noisy speech – good microphone quality (close-talk
microphone), artificially reverberated speech, and low microphone quality (room microphone) flavours
– speech recognition deteriorates with low quality speech
– emotion recognition seems to be less prone to noise!

recognition from facial expressions
• Holistic approaches– image comparison
with known patterns, e.g. eigenfaces
• suffer from lighting, pose, rotation, expressivity, etc.

recognition from facial expressions
• Facial expressions in natural environments are hard to recognize– Lighting conditions (edge artifacts)– Colour compression, e.g. VHS video
(colour artifacts)– Not looking at camera– Methods operating on a single feature
are likely to fail– Why not try them all?!

feature extraction
• Train a neural net with Y,Cr,Cb, 10 DCT coefficients
• Eye position corrects face rotation

feature extraction
• Canny operator for edge detection
• Locates eyebrows, based on (known) eye position

feature extraction
• Texture information is richer within the eye– especially around the
borders between eyebrows, eye white and iris
• Complexity estimator: variance around a window size n
n=3
n=6
final

feature extraction
• same process for the mouth– neural network

feature extraction
• same process for the mouth– luminosity

mask fusion
• comparison with anthropometric criteria
• better performing masks rewarded
• for a video with good colour conditions colour-based masks
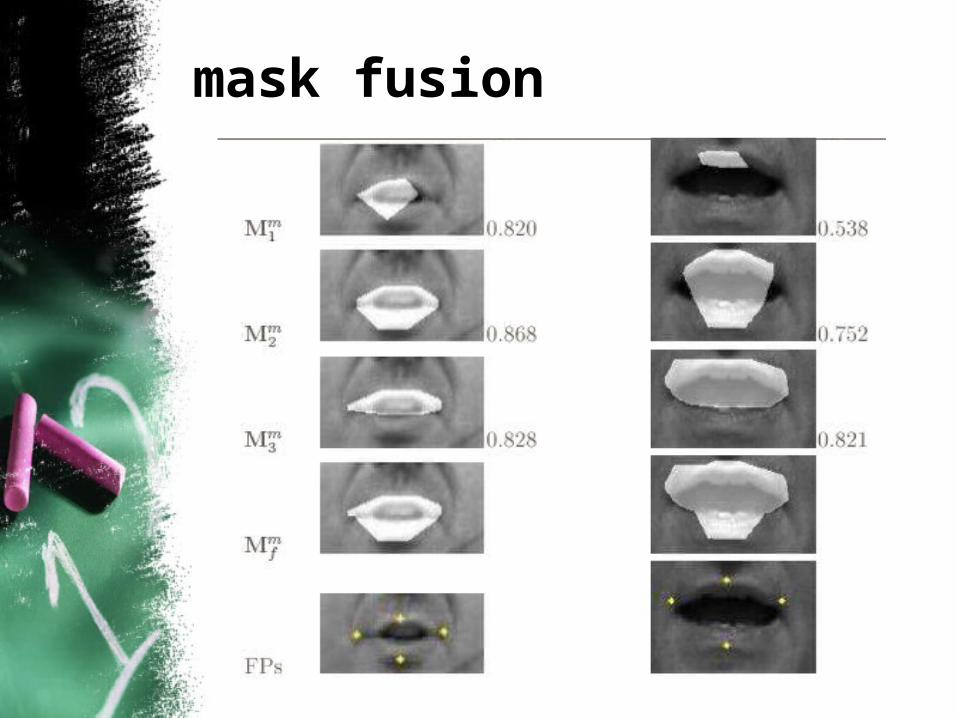
mask fusion

from areas to points
• Areas bounding boxes Points
• Compatible with MPEG-4 Facial Animation Parameters (FAPs)

from areas to points
• Sets of FAP values facial expressions

from areas to points
• Sets of FAP values facial expressions
• Example in the positive/active quadrant (+,+)
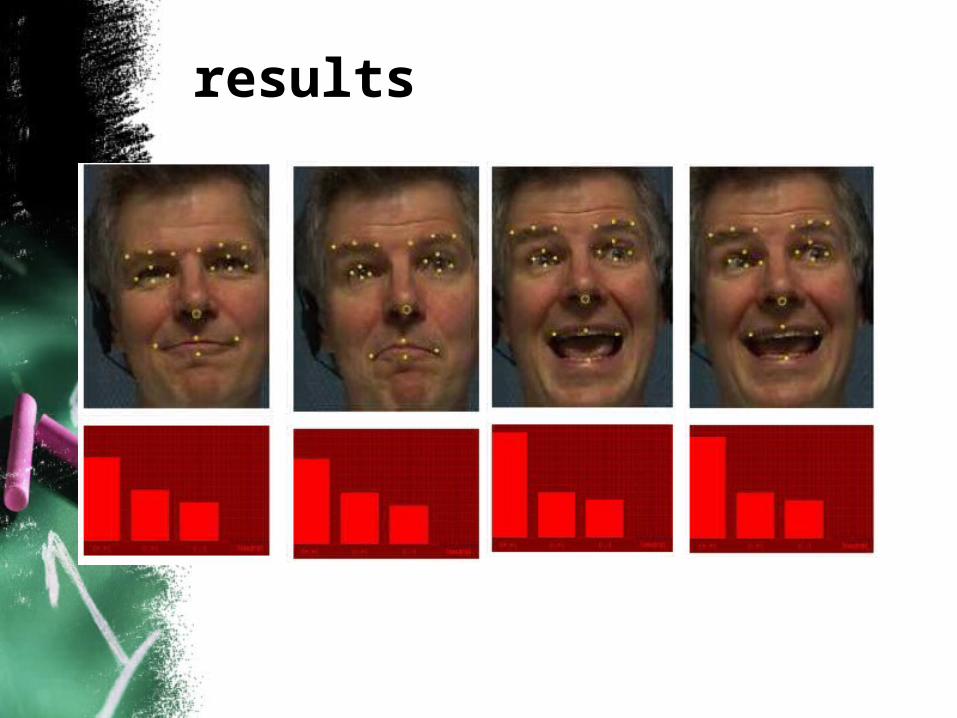
results

recognition from hand gestures
• Very few gestures have emotion-related meaning
• Emotions change the way we perform a particular gesture– consider how you wave at a friend or
someone you don’t really like
• We can check motion-based features for correlation with an emotion representation– activation half plane

recognition from hand gestures
•Skin probability
•Thresholding & Morphological Operations
•Distance Transform
•Frame difference

expressivity features
• A set of parameters that modifies the quality of movement
• Based on studies by Wallbott-Scherer and Gallaher:– Spatial: amplitude of movement (arm extension: wrist
location)– Temporal: duration of movement (velocity of wrist
movement)– Power: dynamic property of movement (acceleration)– Fluidity: smoothness and continuity of movement– Repetitiveness: tendency to rhythmic repeats
(repetition of the stroke)– Overall Activation: quantity of movement across
modalities

multimodal recognition
• Neural networks and Bayesian networks most promising results– usually on acted data– what about the dynamics of an
expression– in natural HCI, when you smile you
don’t go neutral grin neutral
• Need to learn/adapt to sequences of samples

recognizing dynamics
• Modified Elman RNN deployed to capture dynamics of facial expressions and speech prosody– Used in tunes lasting >10 frames (i.e.
half a second)
x1w
1b2b
2w 1a
1ar
Input Layer
Hidden Layer Output Layer Integrating Module
ox 1a 2a o
c1 o
c 2a

multimodal excellence!
• Results from the SALAS dataset– As expected, multimodal recognition
outperforms visual (by far) and speech recognition
– Confusion matrix
Neutral Q1 Q2 Q3 Q4 Totals Neutral 100,00% 0,00% 0,00% 0,00% 0,00% 100,00%
Q1 0,00% 98,29% 1,71% 0,00% 0,00% 100,00% Q2 1,79% 1,79% 96,43% 0,00% 0,00% 100,00% Q3 0,00% 0,00% 0,00% 100,00% 0,00% 100,00% Q4 0,00% 0,00% 0,00% 0,00% 100,00% 100,00%
Totals 8,67% 50,00% 16,47% 8,67% 16,18% 100,00%

multimodal excellence!
• Comparison with other techniques
Methodology Rule based Possibilistic rule based Dynamic and multimodal Classification
rate 78,4% 65,1% 98,55%
Methodology Classification
rate Data set TAN 83,31% Cohen2003
Multi-level HMM 82,46% Cohen2003 TAN 73,22% Cohn–Kanade
PanticPatras2006 86,6% MMI Multistream HMM 72,42% Chen2000
Modified RNN 81,55% SALAS Database Modified RNN 98,55% SALAS tunes > 10 frames
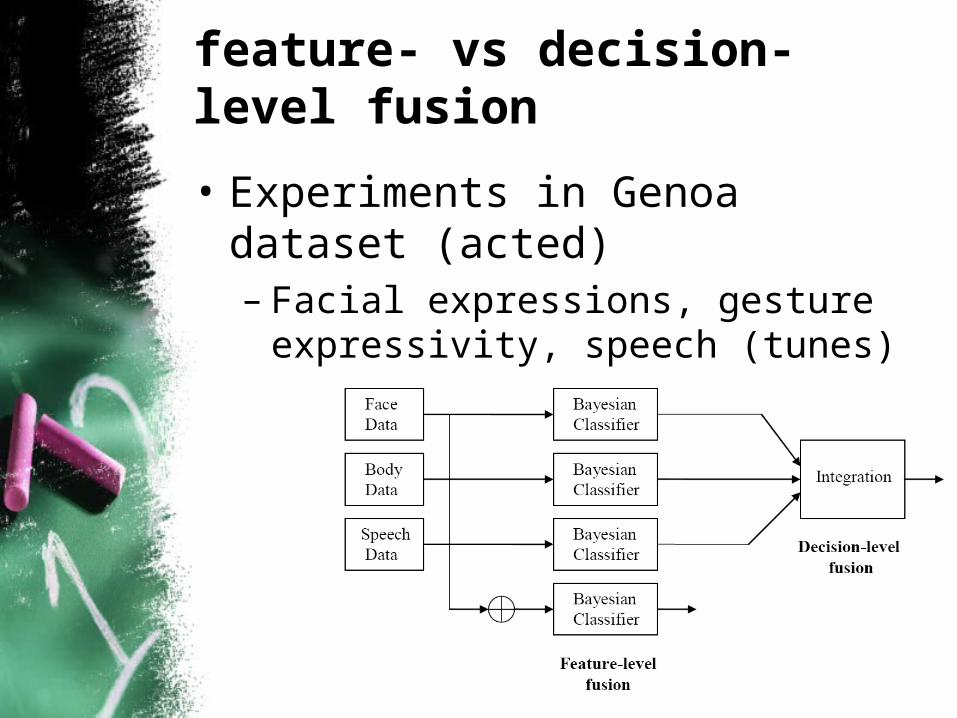
feature- vs decision-level fusion
• Experiments in Genoa dataset (acted)– Facial expressions, gesture
expressivity, speech (tunes)

feature- vs decision-level fusion
• Decision-level fusion obtained lower recognition rates than feature-level fusion– best probability and majority (2 out of
3 modalities) voting

multimodal+emotion+recognition 2010
two years from now in a galaxy (not) far, far
away…

a fundamental question

a fundamental question
• OK, people may be angry or sad, or express positive/active emotions
• face recognition provides response to the ‘who?’ question
• ‘when?’ and ‘where?’ are usually known or irrelevant
• but, does anyone know ‘why?’– context information is crucial

a fundamental question (2)

is it me or?...

is it me or?...
• some modalities may display no cues or, worse, contradicting cues
• the same expression may mean different things coming from different people
• can we ‘bridge’ what we know about someone with what we sense?– and can we adapt what we know based on
that?– or can we align what we sense with other
sources?

another kind of language

another kind of language
• sign language analysis poses a number of interesting problems– image processing and understanding
tasks– syntactic analysis– context (e.g. when referring to a third
person)– natural language processing– vocabulary limitations

want answers?
see you in 2010!