Embed Size (px)
Citation preview

Multi-modal robotic perception
Stephen Gould, Paul Baumstarck,Morgan Quigley, Andrew Ng,
Daphne Koller
PAIL, January 2008

Gould, et al.
Multi-modal robotic perception
gratuitous request for comments, suggestions, or insights
(especially those that can be implemented in under 24 hours)

Gould, et al.
Motivation How can we design a robot
to “see” as well as a human?
desiderata: small household/office objects “no excuse” detection operate on timescale
commensurate with humans scaleable to large number of
objects
observation: 3-d information would greatly help with object detection and recognition
STanford AI Robot

Gould, et al.
Wouldn’t it be nice if we could extract 3-d features from monocular images?
Current state-of-the-art is not (yet?) good enough, especially when objects are small
3-d from images
[Hoiem et al., 2006] [Saxena et al., 2007]

Gould, et al.
Complementary sensors
Image sensors (cameras) provide high resolution color and intensity data
Range sensors (laser) provide depth and global contextual information
solution: augment visual information with 3-d features from a range scanner, e.g. laser
48
0
640
30

Gould, et al.
Overview Motivation Hardware architecture and dataflow Constructing a scene representation
Super-resolution sensor fusion Dominant planar surface extraction
Multi-sensor object detection 2-d sliding-window object detector 3-d features Multi-sensor object detector
Experimental results and analysis Future work
Gould, et al.
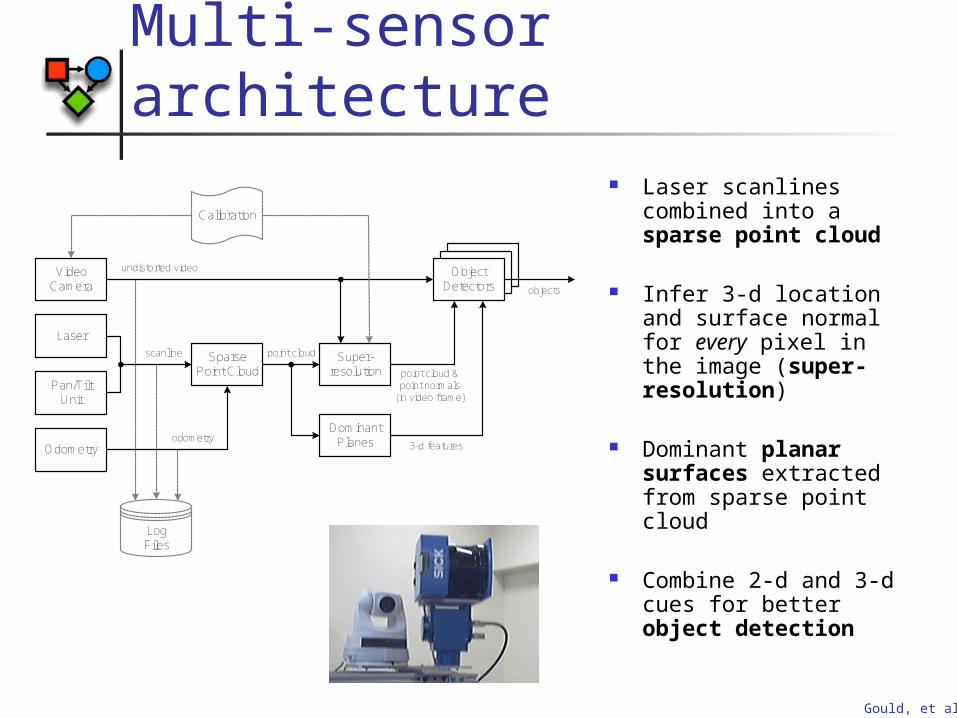
Multi-sensor architecture Laser scanlines
combined into a sparse point cloud
Infer 3-d location and surface normal for every pixel in the image (super-resolution)
Dominant planar surfaces extracted from sparse point cloud
Combine 2-d and 3-d cues for better object detection
VideoCamera
Laser
Pan/Tilt Unit
Odometry
Sparse Point Cloud
LogFiles
Calibration
ObjectDetectors
scanline
undistorted video
odometry
point cloud &point normals
(in video frame)
objects
Dominant Planes
Super-resolution
point cloud
3-d features

Gould, et al.
Super-resolution sensor fusion
Super-resolution MRF (similar to [Diebel and Thrun, 2006]) used to infer depth value for every image pixel from sparse point cloud:
singleton potential encodes our preference for matching laser measurements;
pairwise potential encodes our preference for planar surfaces.
Reconstruct dense point cloud and estimate surface normals (in camera coordinate system)
Algorithm can be stopped at anytime and later resumed from previous iteration enabling real-time implementation

Gould, et al.
Super-resolution sensor fusion We define our super-resolution MRF over image pixels
xij, laser measurements zij and reconstructed depths yij as
where
and h(x;¸) is the Huber penalty, wvij and wh
ij are weighting factors indicating how unwilling we are to allow smoothing to occur across edges in the image as in [Diebel and Thrun, 2006].
p(y j x;z) =1
´(x;z)exp
8<
:¡ k
X
(i ;j )2L
©i j ¡X
(i ;j )2 I
ª i j
9=
;
©i j (y;z) = h(yi ;j ¡ zi ;j ;¸)
ª i j (x;y) = wvi j h(2yi ;j ¡ yi ;j ¡ 1 ¡ yi ;j +1;¸)
+whi j h(2yi ;j ¡ yi ¡ 1;j ¡ yi+1;j ;¸)

Gould, et al.
Dominant plane extraction
Plane clustering based on greedy, region-growing algorithm with smoothness constraint [Rabbani et al., 2006]
Extracted planes used for determined object “support”
(a) Compute normal vectors using neighborhood
(b) Grow region over neighbors with similar normal vectors
(c) Use neighbors with low residual to expand region

Gould, et al.
Multi-modal scene representation
We now have a scene represented by: intensity/color for every pixel, xij
3-d location for every pixel, Xij
surface orientation for every pixel, nij
set of dominant planar surfaces, {Pk}
All coordinates in “image”-space

Gould, et al.
Overview Motivation Hardware architecture and dataflow Constructing a scene representation
Super-resolution sensor fusion Dominant planar surface extraction
Multi-sensor object detection 2-d sliding-window object detector 3-d features Multi-sensor object detector
Experimental results and analysis Future work

Gould, et al.
Sliding-window object detectors
task: find the disposable coffee cups

Gould, et al.
Sliding-window object detectors
task: find the disposable coffee cups

Gould, et al.
2-d object detectors We use a sliding-window object detector to compute
object probabilities given image data only, Pimage(o |x,y,σ )
Features are based on localized patch responses from pre-trained dictionary and applied to image at multiple scales [Torralba et al., 2007]
Gentle-boost [Friedman et al., 1998] classifier applied to each window
examples from “mug” dictionary
Gould, et al.
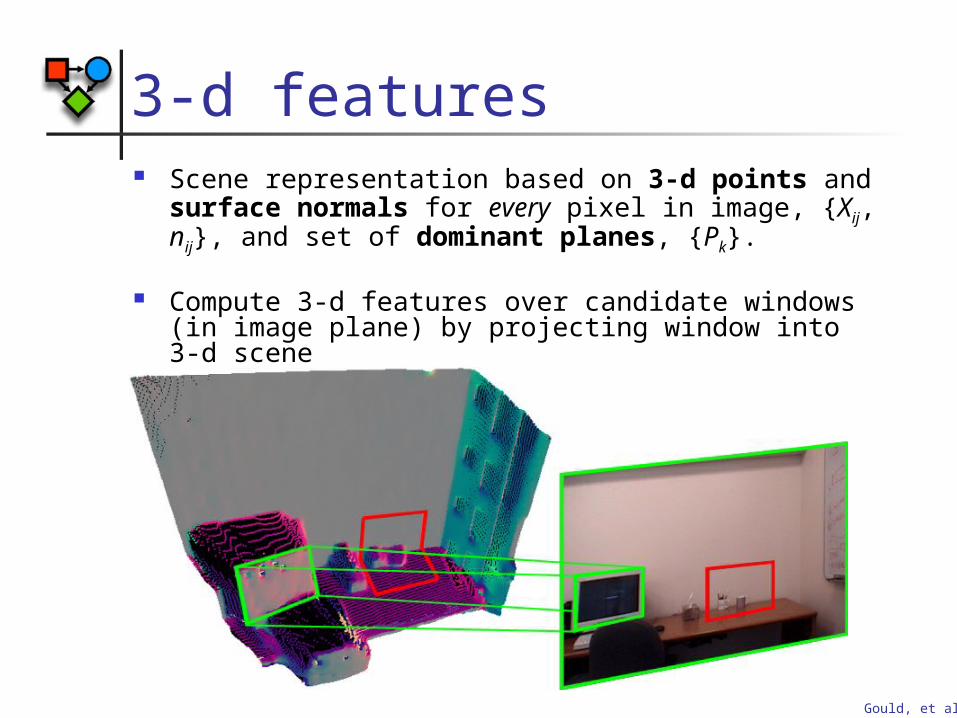
3-d features Scene representation based on 3-d points and
surface normals for every pixel in image, {Xij, nij}, and set of dominant planes, {Pk}.
Compute 3-d features over candidate windows (in image plane) by projecting window into 3-d scene

Gould, et al.
3-d features Features include statistics on height above
ground, distance from robot, surface variation, surface orientation, support (distance and orientation), and size of object
These are combined probabilistically with log-odds ratio from 2-d detector
scene height support size
Gould, et al.
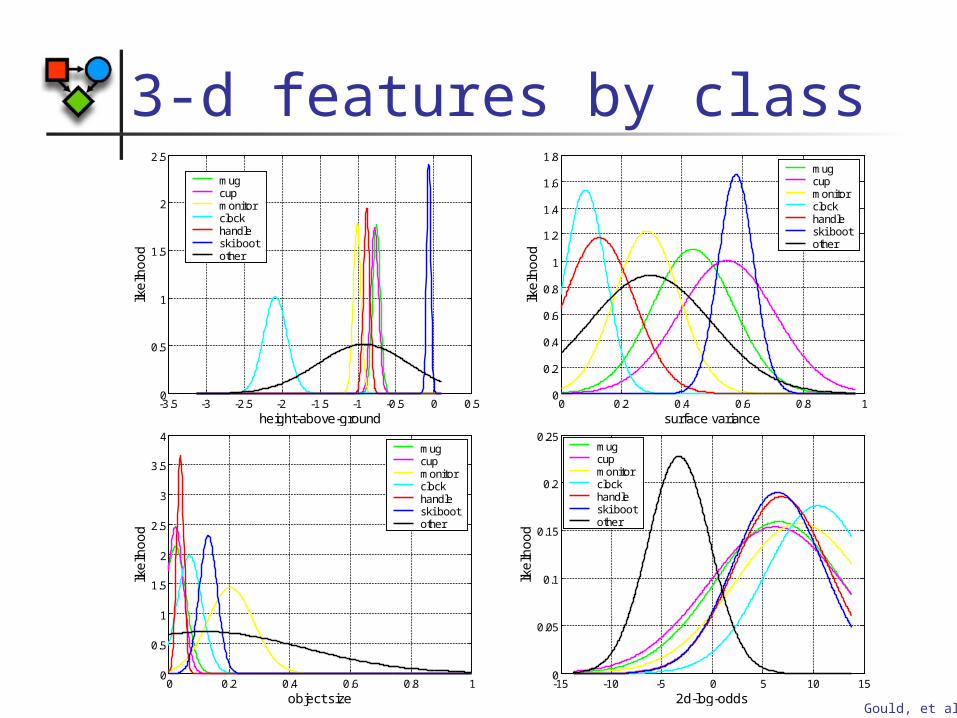
3-d features by class
-15 -10 -5 0 5 10 150
0.05
0.1
0.15
0.2
0.25
like
liho
od
2d-log-odds
mugcupmonitorclockhandleski bootother
-3.5 -3 -2.5 -2 -1.5 -1 -0.5 0 0.50
0.5
1
1.5
2
2.5
like
liho
od
height-above-ground
mugcupmonitorclockhandleski bootother
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
like
liho
od
surface variance
mugcupmonitorclockhandleski bootother
0 0.2 0.4 0.6 0.8 10
0.5
1
1.5
2
2.5
3
3.5
4
like
liho
od
object size
mugcupmonitorclockhandleski bootother

Gould, et al.
Combining 3-d and visual cues Simple logistic classifier probabilistically combines
features at location (x,y) and image scale σ
where q() is the logistic function and
advantages: simple and quick to train and evaluate can train 2-d object detectors separately
disadvantages: assumes 2-d and 3-d features are independent assumes objects are independent
f 2d(x;y;¾) = logµ
P image(o j x;y;¾)1¡ P image(o j x;y;¾)
¶
P (o j x;y;¾) = q¡µT
3df 3d(x;y;¾) +µ2df 2d(x;y;¾) +µbias
¢

Gould, et al.
Overview Motivation Hardware architecture and dataflow Constructing a scene representation
Super-resolution sensor fusion Dominant planar surface extraction
Multi-sensor object detection 2-d sliding-window object detector 3-d features Multi-sensor object detector
Experimental results and analysis Future work
Gould, et al.
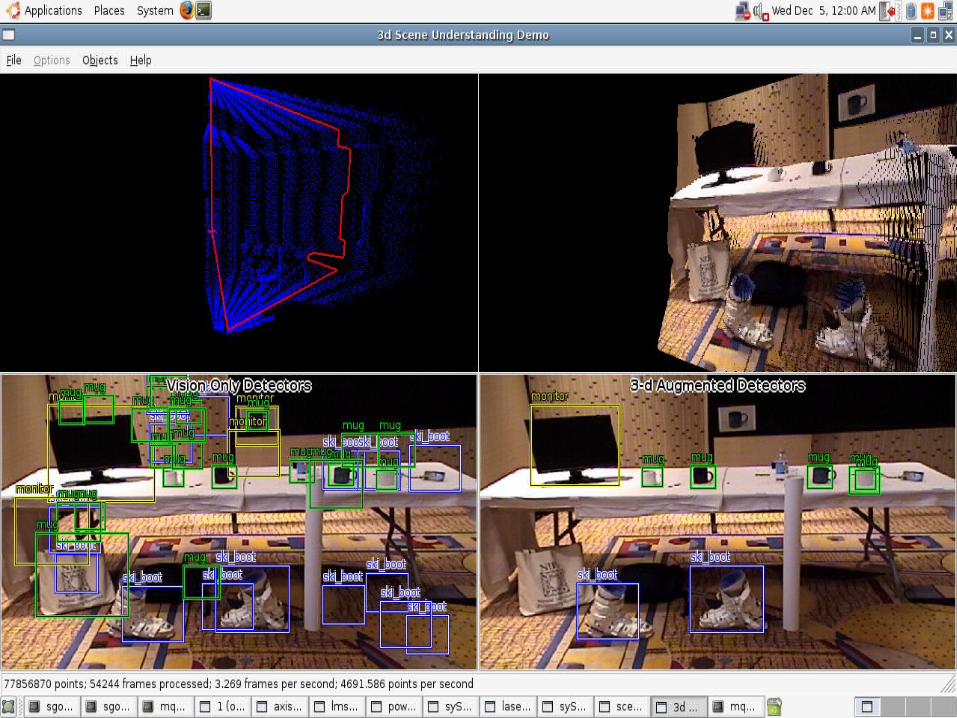
NIPS demonstration

Gould, et al.
NIPS demonstration hardware:
2 quad-core servers SICK laser on pan unit Axis PTZ camera
statistics: 4 hours, 30 minutes 54244 video frames (704x480 pixels; 3.269 fps)
took about 10 seconds to find new objects 77.8 million laser points (4.69 kpps)
correctly labeled approx. 150k coffee mugs, 70k ski boots, 50k computer monitors
very few false detections

Gould, et al.
Optimizations for real-time Bottleneck #1: super-resolution MRF
initialize using quadratic interpolation of points run on half-scale version of image and then up-sample update neighborhood gradient information
Bottleneck #2: 2-d feature extraction prune candidate windows based on color or depth
constancy integer operations for patch cross-correlation share patch normalization calculation between patch
features multi-thread patch response calculation
General principle: software framework: use Switchyard (ROS) robotic
framework to run modules in parallel on multiple machines; keep data close to processor that uses it

Gould, et al.
Scoring results Non-maximal neighborhood suppression
discard multiple overlapping detections
Area-of-overlap measure positive detection if more than 50% overlap with
a groundtruth object of the correct class
AO(Di ;Gj ) =area(D i \ G j )area(D i [ G j )
Gould, et al.
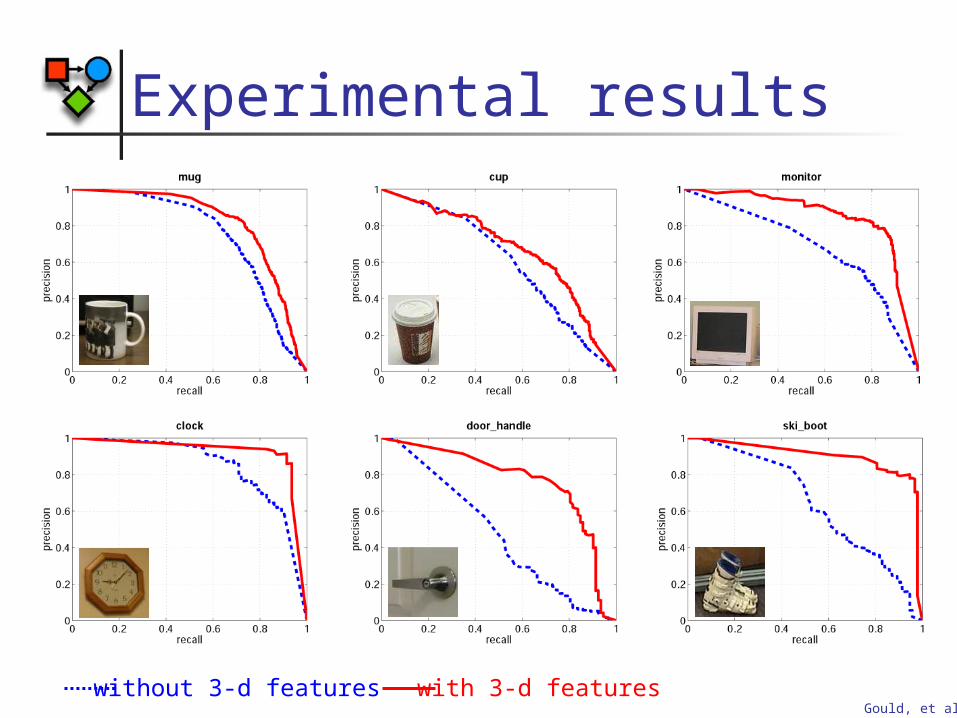
Experimental results
without 3-d features with 3-d features
Gould, et al.
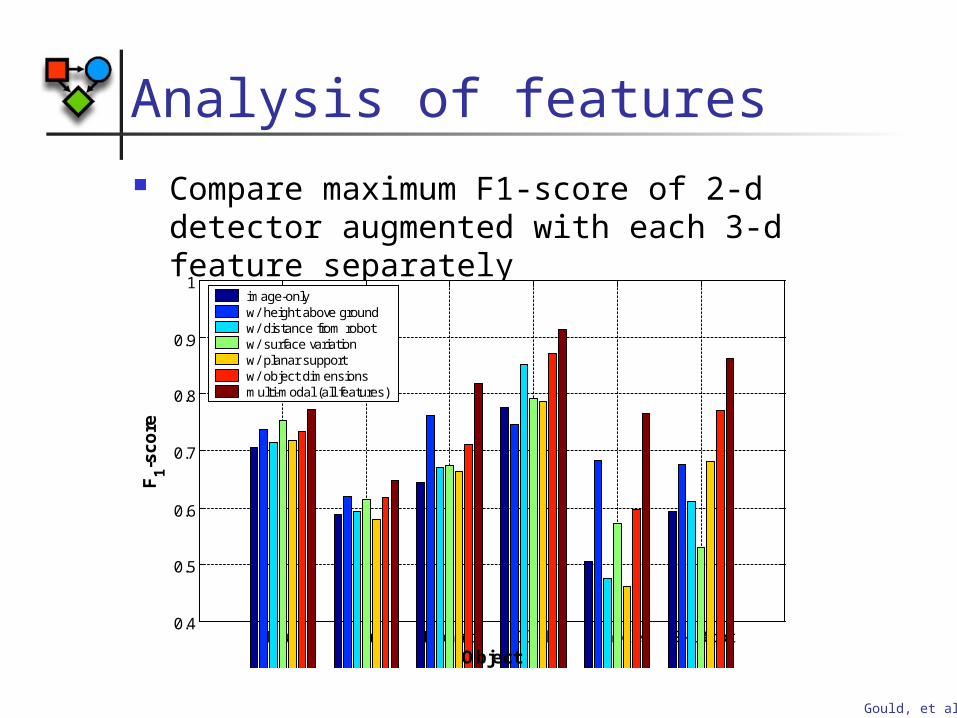
Analysis of features Compare maximum F1-score of 2-d
detector augmented with each 3-d feature separately
Mug Cup Monitor Clock Handle Ski Boot0.4
0.5
0.6
0.7
0.8
0.9
1
Object
F1-score
image-onlyw/ height above groundw/ distance from robotw/ surface variationw/ planar supportw/ object dimensionsmulti-modal (all features)

Gould, et al.
Example scenes
mug cup monitor clock handle ski boot
2-d only with 3-d 2-d only with 3-d

Gould, et al.
Future work Optimization: can 3-d features help reduce the
amount of computation needed? e.g. use surface variance or object size to reduce
candidate rectangles examined by sliding-window detector
Accuracy: can more detailed 3-d features or more sophisticated 3-d scene model help with recognition?
e.g. location of other objects in the scene
Whole-robot-integration: what other sensor modalities can be used to help detection and/or what active control strategies can be used for improving accuracy?
e.g. zooming in for a better view of an object Can robot actively help in data collection/learning?

Gould, et al.
Questions Motivation Hardware architecture and dataflow Constructing a scene representation
Super-resolution sensor fusion Dominant planar surface extraction
Multi-sensor object detection 2-d sliding-window object detector 3-d features Multi-sensor object detector
Experimental results and analysis Future work


















![EMPA Koller[1]](https://img.pdfslide.us/doc/110x75/577ccf8e1a28ab9e789008fa/empa-koller1.jpg)










