Embed Size (px)
Citation preview

Mul$threadingandVectoriza$ononIntel®Xeon™andIntel®XeonPhi™
architecturesusingOpenMP
SilvioStanzani,RaphaelCóbe,RogérioIopeUNESP-NúcleodeComputaçãoCienKfica

• NCC/UNESPPresenta$on• ParallelArchitectures• IntelXeonandIntelXeonPhi• OpenMP• ThreadAffinity• Vectoriza$on• Offloading• ThreadLeague• N-bodySimula$on
6/28/16 VECPAR2016 2
Agenda

• Source-code,slidesandbookchapter(inPortuguese):
h[ps://github.com/intel-unesp-mcp/talks-source-code/tree/master/OpenMP4
6/28/16 3
ReferenceMaterial

UNESPCenterforScien$ficCompu$ng
• Consolidatesscien$ficcompu$ngresourcesforSãoPauloStateUniversity(UNESP)researchers– ItmainlyusesGridcompu$ngparadigm
• Mainusers– UNESPresearchers,students,andsodwaredevelopers– SPRACE(SãoPauloResearchandAnalysisCenter)physicists
andstudentsq Caltech,Fermilab,CERNq SãoPauloCMSTier-2Facility
6/28/16 4

UNESPCenterforScien$ficCompu$ng
6/28/16 5

• 96workernodes– PhysicalCPUs:128– LogicalCPUs(cores):1152– HEPSpec06:17456– 128cores:3GB/core– 1024cores:4GB/core
• 02headnodes• 13storageservers
– 1PB(effec$ve)• Network
– LAN:1Gbps&10Gbps– WAN:2x10Gbps,2x40Gbps(1x100GinQ32016)
6/28/16 6
SPRACE-LHC/CMSTier2Facility

• CampusGrid– 1centralcluster+6secondaryclusters(deployedindifferent
UnespcampiatSãoPauloState)• Workernodes@NCC
– PhysicalCPUs:256(2009)– LogicalCPUs(cores):2048-2GB/core
• 1headnode• 1storageserver
– 132TB(effec$ve)• Network
– LAN:1Gbps– WAN:2x10Gbps
6/28/16 7
GridUnesp-HPCinfrastructure

Unesp/IntelCollabora$veEfforts
• IPCC(IntelParallelCompu$ngCenter)– Vectoriza$on&Paralleliza$onofGeant(GEometryANdTracking)
• IntelModernCode– WorkshopsandTutorials
q HighPerformanceCompu$ng(HPC)q DataScience/BigDataAnaly$cs
– HPCConsultancy6/28/16 8

• NCCPresenta$on• ParallelArchitectures• IntelXeonandIntelXeonPhi• OpenMP• ThreadAffinity• Vectoriza$on• Offloading• ThreadLeague• N-bodySimula$on
6/28/16 VECPAR2016 9
Agenda
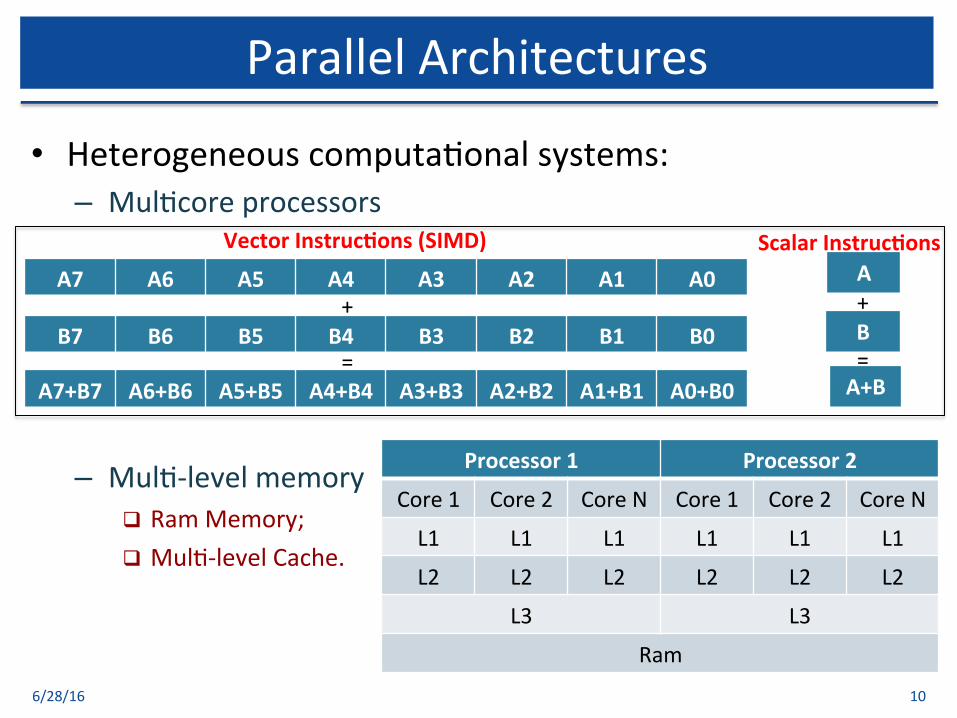
• Heterogeneouscomputa$onalsystems:– Mul$coreprocessors
– Mul$-levelmemoryq RamMemory;q Mul$-levelCache.
6/28/16 10
ParallelArchitectures
A7 A6 A5 A4 A3 A2 A1 A0
B7 B6 B5 B4 B3 B2 B1 B0
A7+B7 A6+B6 A5+B5 A4+B4 A3+B3 A2+B2 A1+B1 A0+B0
A
B
A+B
+
=
VectorInstrucKons(SIMD) ScalarInstrucKons
Processor1 Processor2
Core1 Core2 CoreN Core1 Core2 CoreN
L1 L1 L1 L1 L1 L1
L2 L2 L2 L2 L2 L2
L3 L3
Ram
+
=
6/28/16 11
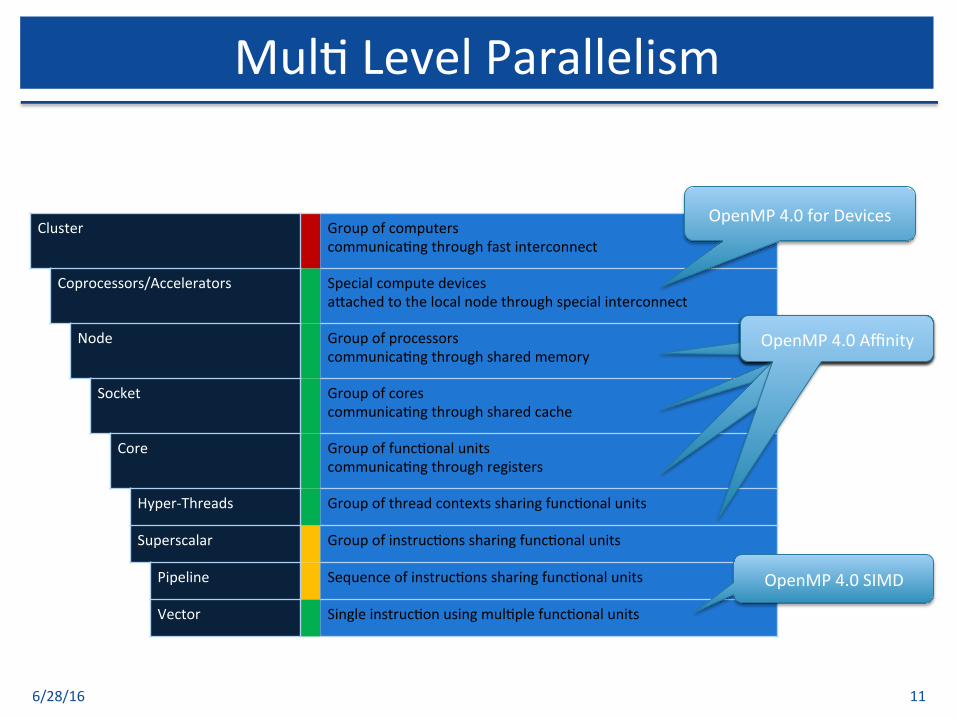
Mul$LevelParallelism
Cluster Groupofcomputerscommunica$ngthroughfastinterconnect
Coprocessors/Accelerators Specialcomputedevicesa[achedtothelocalnodethroughspecialinterconnect
Node Groupofprocessorscommunica$ngthroughsharedmemory
Socket Groupofcorescommunica$ngthroughsharedcache
Core Groupoffunc$onalunitscommunica$ngthroughregisters
Hyper-Threads Groupofthreadcontextssharingfunc$onalunits
Superscalar Groupofinstruc$onssharingfunc$onalunits
Pipeline Sequenceofinstruc$onssharingfunc$onalunits
Vector Singleinstruc$onusingmul$plefunc$onalunits
OpenMP4.0SIMD
OpenMP4.0forDevices
OpenMP4.0AffinityOpenMP4.0AffinityOpenMP4.0AffinityOpenMP4.0Affinity
6/28/16 12
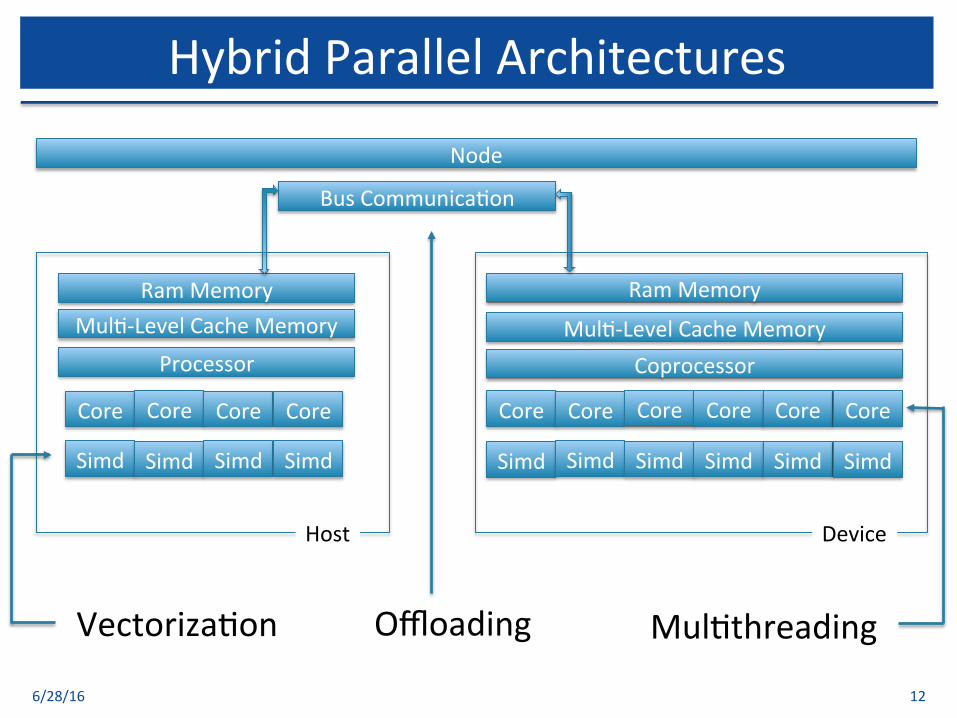
HybridParallelArchitectures
Processor Coprocessor
Core
Simd
Core
Simd
Core
Simd
Core
Simd
Core
Simd
Core
Simd
Core
Simd
Core
Simd
Core
Simd
Core
Simd
RamMemory RamMemory
BusCommunica$on
Mul$threadingVectoriza$on Offloading
Node
DeviceHost
Mul$-LevelCacheMemoryMul$-LevelCacheMemory

• Exploringparallelisminhybridparallelarchitectures– Mul$threading– Vectoriza$on
q Autovectoriza$onq Semi-autovectoriza$onq Explicitvectoriza$on
– Offloadingq Offloadingcodetodevice
• OpenMP4.0– Supportsvectoriza$onandoffloadingonhybridparallelarchitectures
6/28/16 13
HybridParallelArchitectures

• NCCPresenta$on• ParallelArchitectures• IntelXeonandIntelXeonPhi• OpenMP• ThreadAffinity• Vectoriza$on• Offloading• ThreadLeague• N-bodySimula$on
6/28/16 VECPAR2016 14
Agenda
15
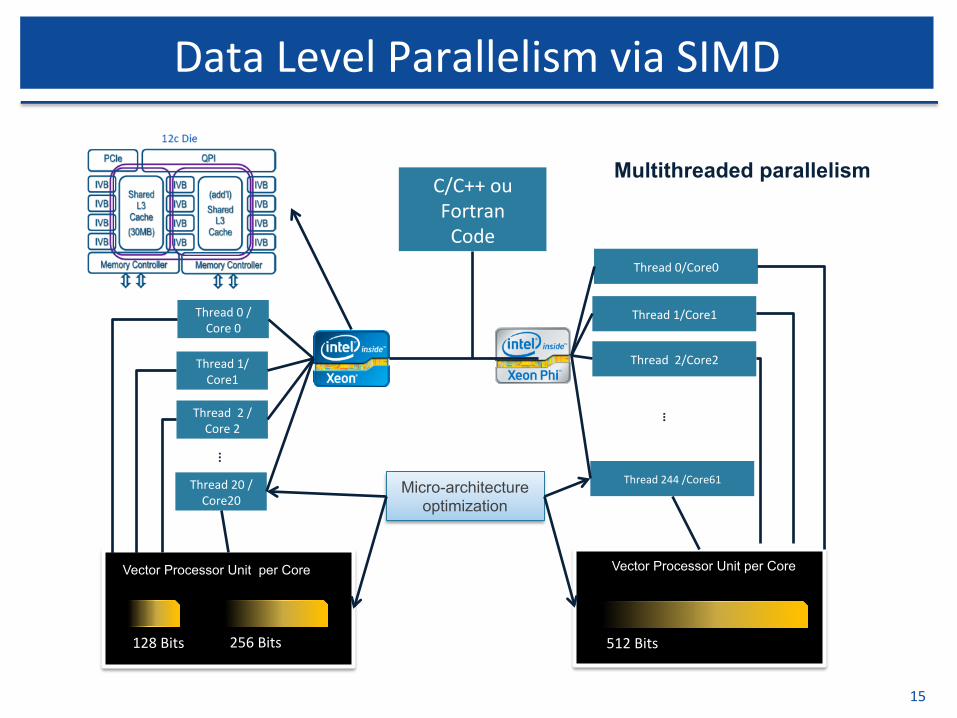
DataLevelParallelismviaSIMD
C/C++ouFortranCode
Thread0/Core0
Thread1/Core1
Thread2/Core2
Thread20/Core20
...
Thread0/Core0
Thread1/Core1
Thread2/Core2
Thread244/Core61
...
128Bits 256Bits
Vector Processor Unit per Core Vector Processor Unit per Core
Multithreaded parallelism
512Bits
Micro-architecture optimization
16
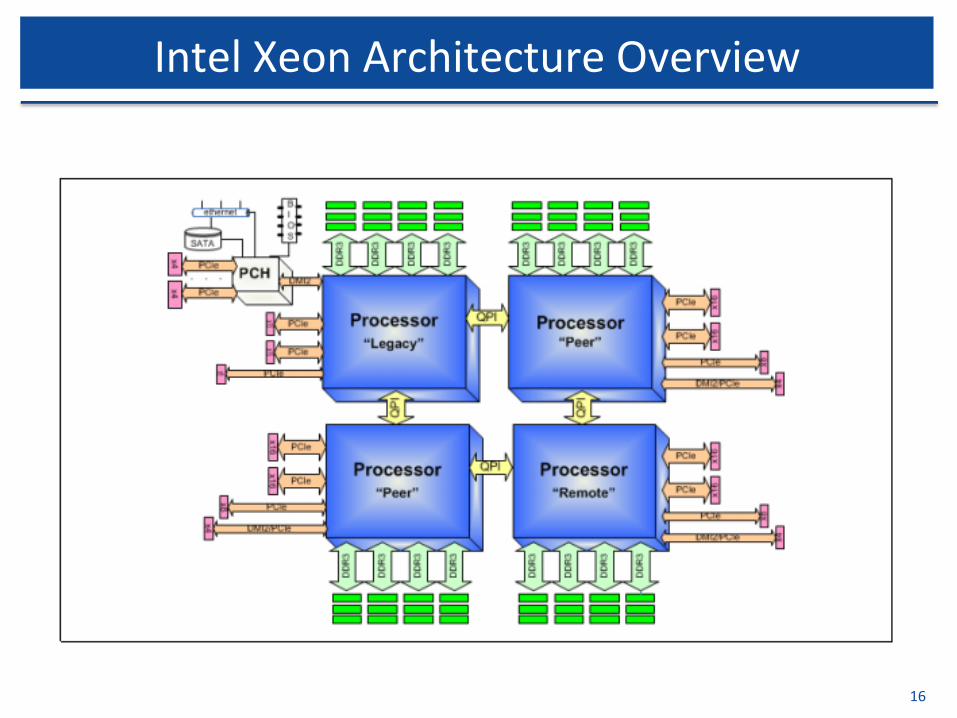
IntelXeonArchitectureOverview

• Socket:mechanicalcomponentthatprovidesmechanicalandelectricalconnec$onsbetweenamicroprocessorandaprintedcircuitboard(PCB).
• QPI(IntelQuickPathInterconnect):highspeed,packe$zed,point-to-pointinterconnec$on,thats$tchtogetherprocessorsindistributedsharedmemoryandintegratedI/Oplavormarchitecture.
17
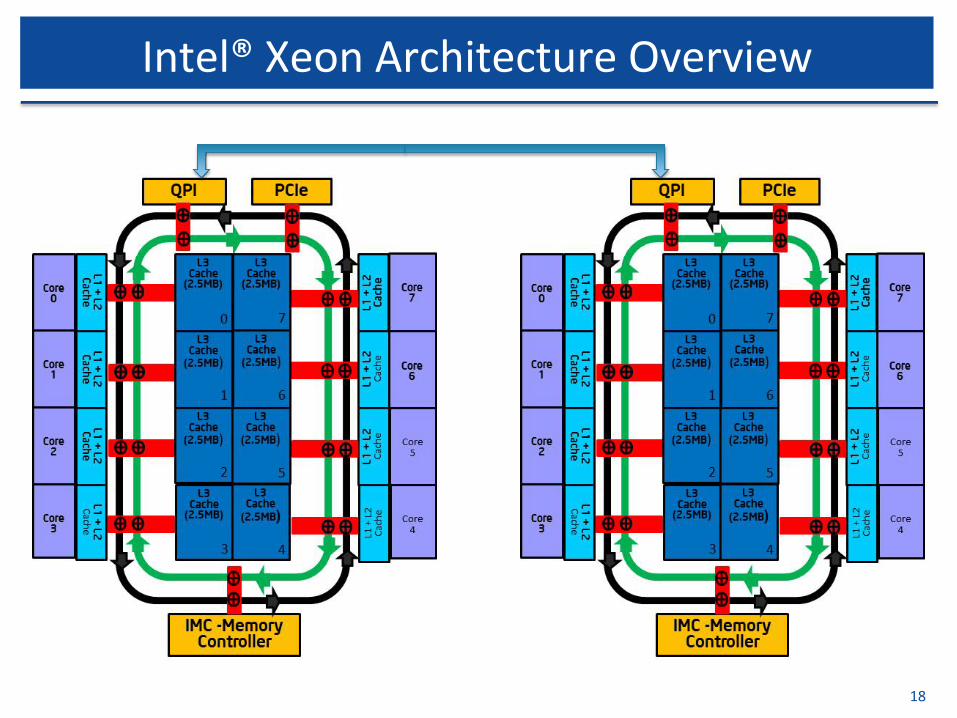
IntelXeonArchitectureOverview
18
Intel®XeonArchitectureOverview
19
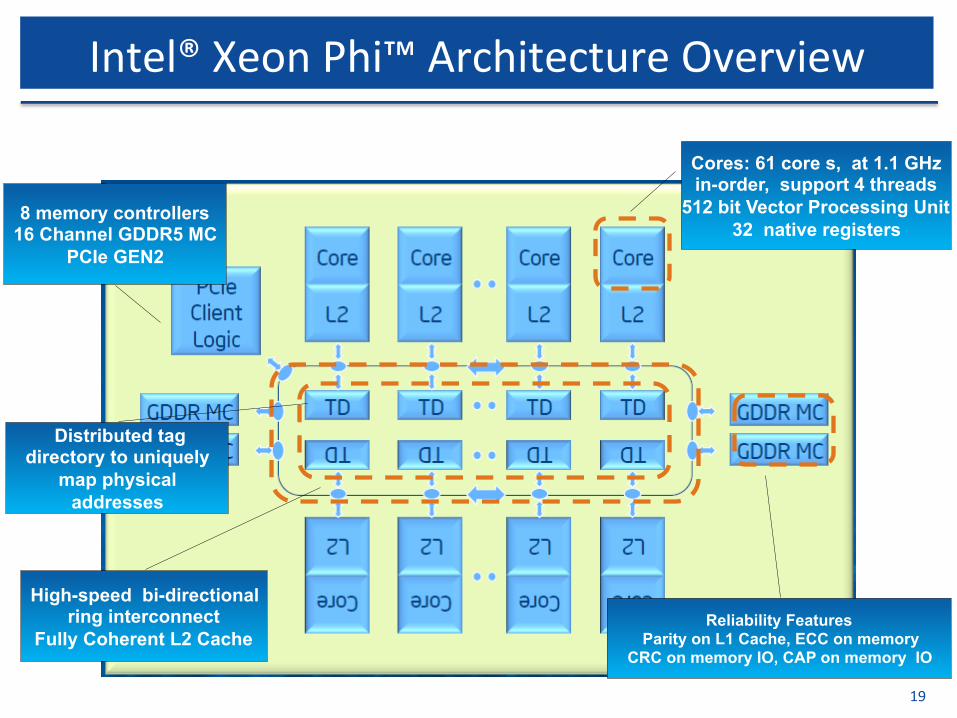
Intel®XeonPhi™ArchitectureOverview
Cores: 61 core s, at 1.1 GHz in-order, support 4 threads
512 bit Vector Processing Unit 32 native registers
Reliability Features Parity on L1 Cache, ECC on memory
CRC on memory IO, CAP on memory IO
High-speed bi-directional ring interconnect
Fully Coherent L2 Cache
8 memory controllers 16 Channel GDDR5 MC
PCIe GEN2
Distributed tag directory to uniquely
map physical addresses
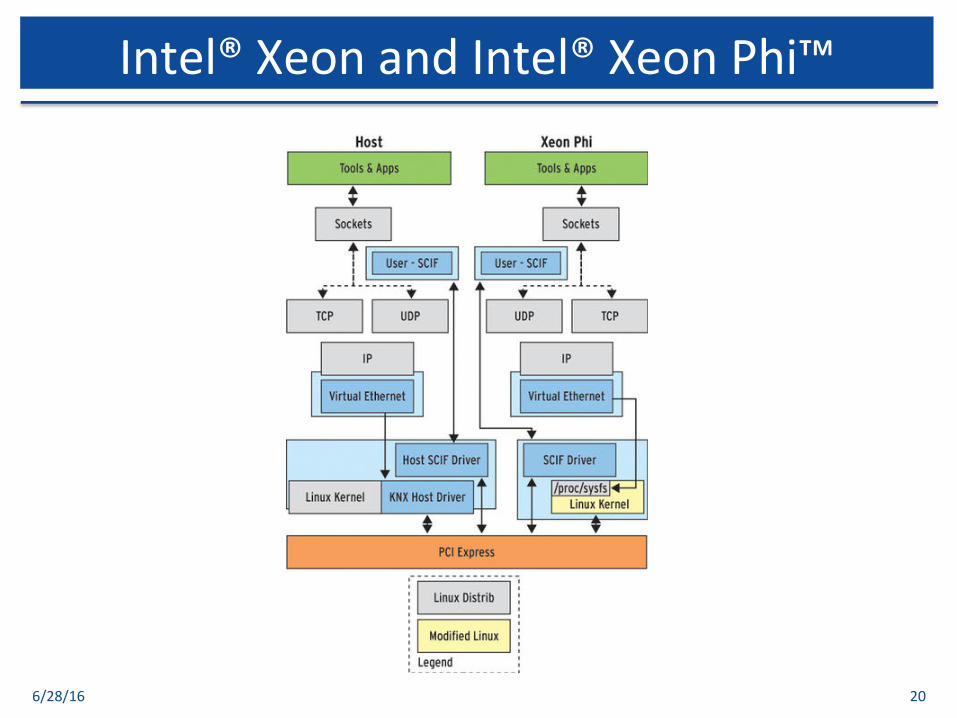
6/28/16 20
Intel®XeonandIntel®XeonPhi™
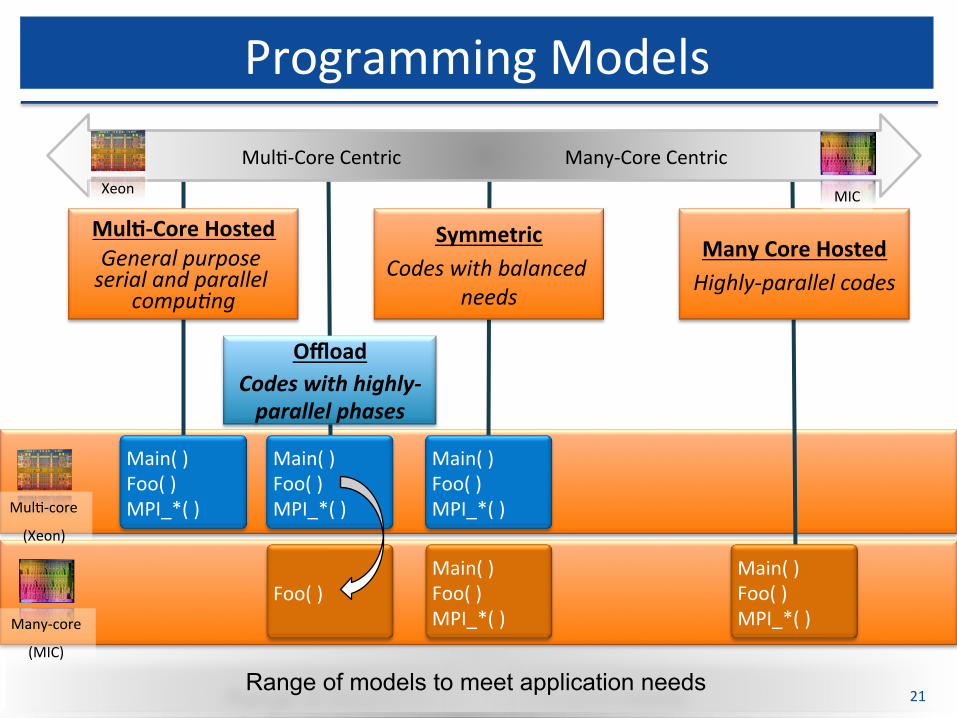
Range of models to meet application needs
Foo()Main()Foo()MPI_*()
Main()Foo()MPI_*()
21
ProgrammingModels
Main()Foo()MPI_*()
Main()Foo()MPI_*()
Main()Foo()MPI_*()Mul$-core
(Xeon)
Many-core
(MIC)
Mul$-CoreCentricMany-CoreCentric
MulK-CoreHostedGeneralpurposeserialandparallel
compu0ng
OffloadCodeswithhighly-parallelphases
ManyCoreHostedHighly-parallelcodes
SymmetricCodeswithbalanced
needs
Xeon MIC

• NCCPresenta$on• ParallelArchitectures• IntelXeonandIntelXeonPhi• OpenMP• ThreadAffinity• Vectoriza$on• Offloading• ThreadLeague• N-bodySimula$on
6/28/16 VECPAR2016 22
Agenda

• OpenMPisanacronymforOpenMul$-Processing
• AnApplica$onProgrammingInterface(API)fordevelopingparallelprogramsinsharedmemoryarchitectures
• ThreeprimarycomponentsoftheAPIare:– CompilerDirec$ves– Run$meLibraryRou$nes– EnvironmentVariables
• Defactostandard-specifiedforC/C++andFORTRAN
• h[p://www.openmp.org/– Specifica$on,examples,tutorialsanddocumenta$on
6/28/16 23
OpenMP
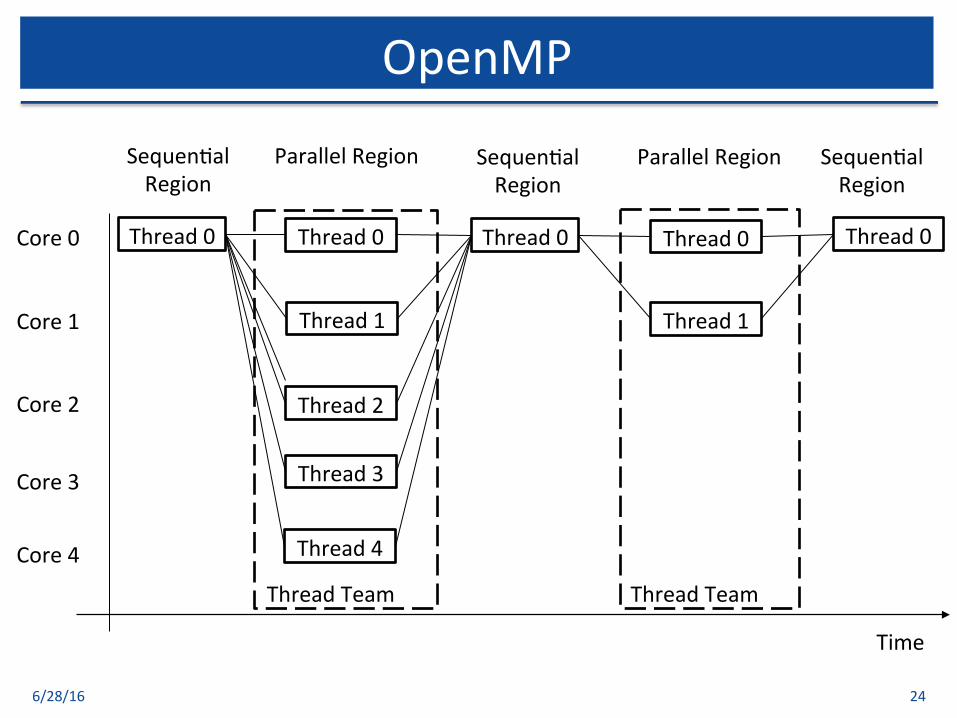
6/28/16 24
OpenMP
Time
Core0 Thread0 Thread0
Thread1
Thread2
ParallelRegion
Thread0 Thread0
Thread1
Thread0
ParallelRegionSequen$alRegion
Sequen$alRegion
Sequen$alRegion
ThreadTeam ThreadTeam
Core1
Core2
Core3
Core4
Thread3
Thread4
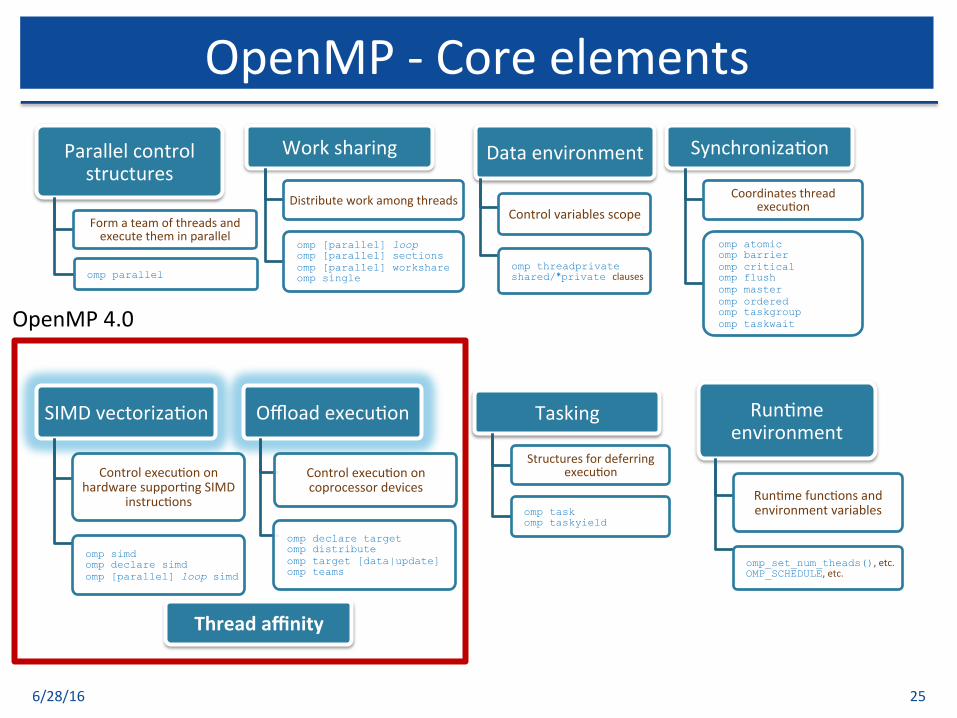
6/28/16 25
OpenMP-Coreelements
SIMDvectoriza$on
Controlexecu$ononhardwaresuppor$ngSIMD
instruc$ons
omp simd omp declare simd omp [parallel] loop simd
Offloadexecu$on
Controlexecu$ononcoprocessordevices
omp declare target omp distribute omp target [data|update] omp teams
Dataenvironment
Controlvariablesscope
omp threadprivate shared/*private clauses
Run$meenvironment
Run$mefunc$onsandenvironmentvariables
omp_set_num_theads(),etc. OMP_SCHEDULE,etc.
Parallelcontrolstructures
Formateamofthreadsandexecutetheminparallel
omp parallel
Worksharing
Distributeworkamongthreads
omp [parallel] loop omp [parallel] sections omp [parallel] workshare omp single
Tasking
Structuresfordeferringexecu$on
omp task omp taskyield
Synchroniza$on
Coordinatesthreadexecu$on
omp atomic omp barrier omp critical omp flush omp master omp ordered omp taskgroup omp taskwait OpenMP4.0
Threadaffinity

• OpenMP4.0– Supportforaccelerators– SIMDconstructstovectorizebothserialaswellasparallelized
loops– Threadaffinity
• OpenMP4.5– Improvedsupportfordevices– Threadaffinitysupport– SIMDextensions
6/28/16 26
OpenMP-ReleaseNotes
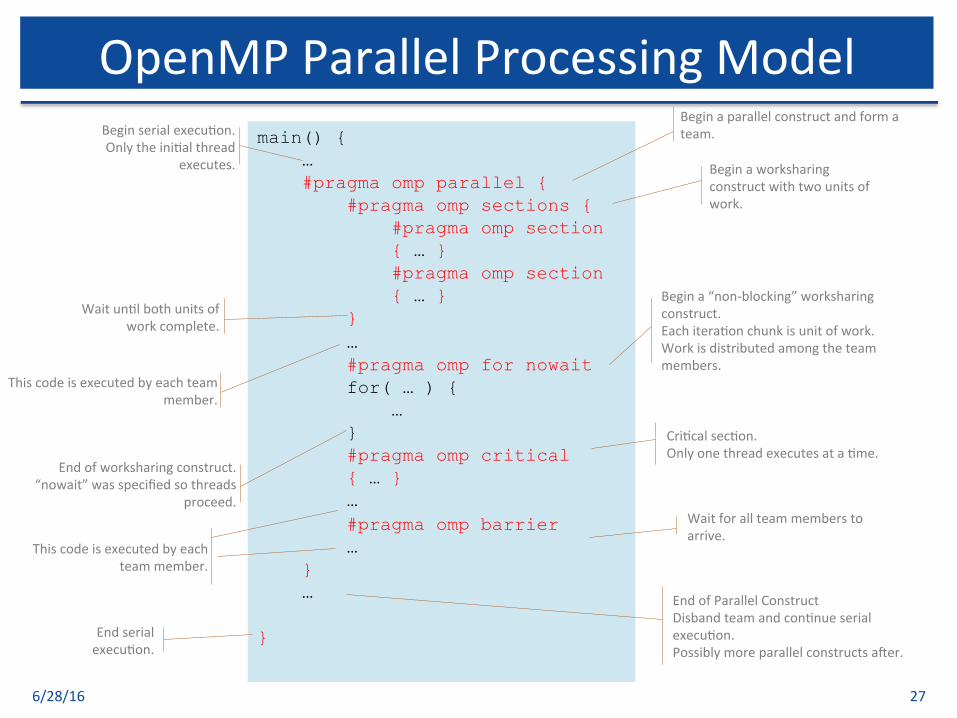
6/28/16 27
OpenMPParallelProcessingModelmain() { … #pragma omp parallel { #pragma omp sections { #pragma omp section { … } #pragma omp section { … } } … #pragma omp for nowait for( … ) { … } #pragma omp critical { … } … #pragma omp barrier … } … }
EndofParallelConstructDisbandteamandcon$nueserialexecu$on.Possiblymoreparallelconstructsader.
Beginserialexecu$on.Onlytheini$althread
executes.
Beginaparallelconstructandformateam.
Beginaworksharingconstructwithtwounitsofwork.
Waitun$lbothunitsofworkcomplete.
Thiscodeisexecutedbyeachteammember.
Begina“non-blocking”worksharingconstruct.Eachitera$onchunkisunitofwork.Workisdistributedamongtheteammembers.
Endofworksharingconstruct.“nowait”wasspecifiedsothreads
proceed.
Cri$calsec$on.Onlyonethreadexecutesata$me.
Thiscodeisexecutedbyeachteammember.
Waitforallteammemberstoarrive.
Endserialexecu$on.
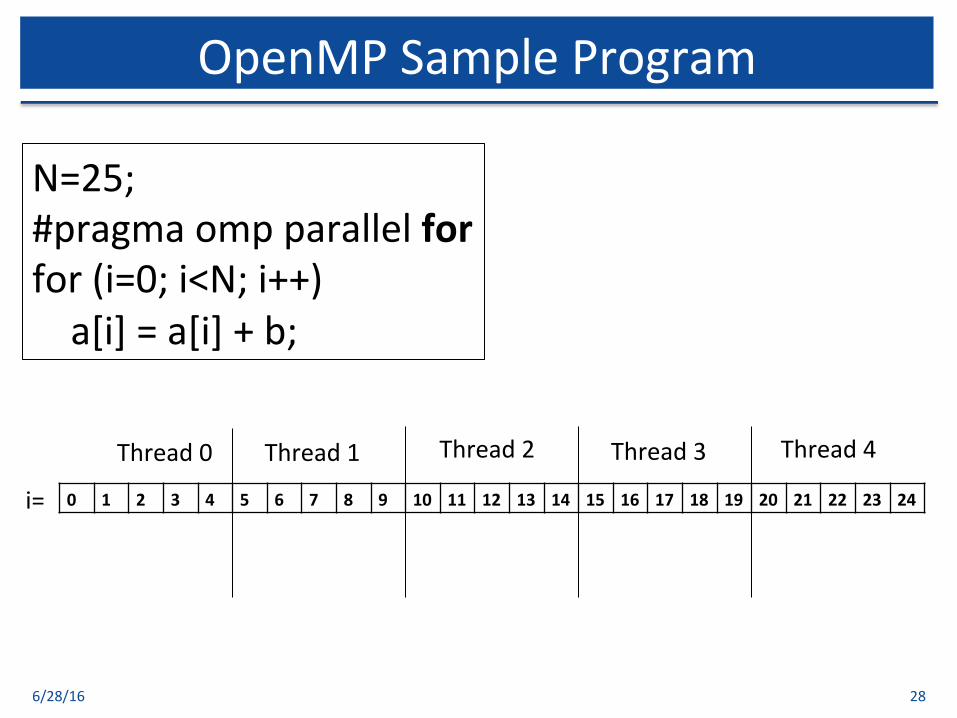
6/28/16 28
OpenMPSampleProgram
Thread0 Thread1 Thread2 Thread4Thread3
N=25;#pragmaompparallelforfor(i=0;i<N;i++)a[i]=a[i]+b;
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24i=

#include<stdio.h>#include<stdlib.h>#include<omp.h>#include<unistd.h>intmain(){intthid;charhn[600],i;doubleres,p[100];#pragmaompparallel{gethostname(hn,600);prinv("hostname%s\n",hn);}
res=0;#pragmaompforfor(i=0;i<100;i++){p[i]=i/0.855;}#pragmaompforfor(i=0;i<100;i++){res=res+p[i];}prinv("sum:%f",res);}
6/28/16 29
OpenMPSampleProgram

#Buildtheapplica$onforMul$coreArchitecture(Xeon)icc<source-code>-o<omp_binary>-fopenmp#Buildtheapplica$onfortheManyCoreArchitecture(XeonPhi)icc<source-code>-o<omp_binary>.mic-fopenmp-mmic
#Launchtheapplica$ononhost./omp_binary
#Launchtheapplica$ononthedevicefromhostmicna$veloadex./omp_binary.mic-e"LD_LIBRARY_PATH=/opt/intel/lib/mic/"
6/28/16 30
CompilingandrunninganOpenMPapplica$on

exportOMP_NUM_THREADS=10./OMP-hellohellofromhostnamephi02.ncc.unesp.brhellofromhostnamephi02.ncc.unesp.brhellofromhostnamephi02.ncc.unesp.brhellofromhostnamephi02.ncc.unesp.brhellofromhostnamephi02.ncc.unesp.brhellofromhostnamephi02.ncc.unesp.brhellofromhostnamephi02.ncc.unesp.brhellofromhostnamephi02.ncc.unesp.brhellofromhostnamephi02.ncc.unesp.brhellofromhostnamephi02.ncc.unesp.brLaunchtheapplica$onontheCoprocessorfromhost
micna$veloadex./OMP-hello.mic-e"OMP_NUM_THREADS=10LD_LIBRARY_PATH=/opt/intel/lib/mic/"hellofromhostnamephi02-mic0.ncc.unesp.brhellofromhostnamephi02-mic0.ncc.unesp.brhellofromhostnamephi02-mic0.ncc.unesp.brhellofromhostnamephi02-mic0.ncc.unesp.brhellofromhostnamephi02-mic0.ncc.unesp.brhellofromhostnamephi02-mic0.ncc.unesp.brhellofromhostnamephi02-mic0.ncc.unesp.brhellofromhostnamephi02-mic0.ncc.unesp.brhellofromhostnamephi02-mic0.ncc.unesp.brhellofromhostnamephi02-mic0.ncc.unesp.brsumofvectorelements:5789.473684
6/28/16 31
CompilingandrunninganOpenMPapplica$on

• NCCPresenta$on• ParallelArchitectures• IntelXeonandIntelXeonPhi• OpenMP• ThreadAffinity• Vectoriza$on• Offloading• ThreadLeague• N-bodySimula$on6/28/16 VECPAR2016 32
Agenda

• Threadaffinity:
– Restrictsexecu$onofcertainthreadstoasubsetofthephysicalprocessingunitsinamul$processorcomputer;
– OpenMPrun$melibraryhastheabilitytobindOpenMPthreadstophysicalprocessingunits.
6/28/16 33
ThreadAffinity

• KMP_AFFINITY:– Environmentvariablethatcontrolthephysicalprocessingunitsthat
willexecutethreadsofanapplica$on
• Syntax:
KMP_AFFINITY= [<modifier>,...] <type> [,<permute>] [,<offset>]Example:
exportKMP_AFFINITY=sca[er 6/28/16 34
ThreadAffinity-KMP_AFFINITY
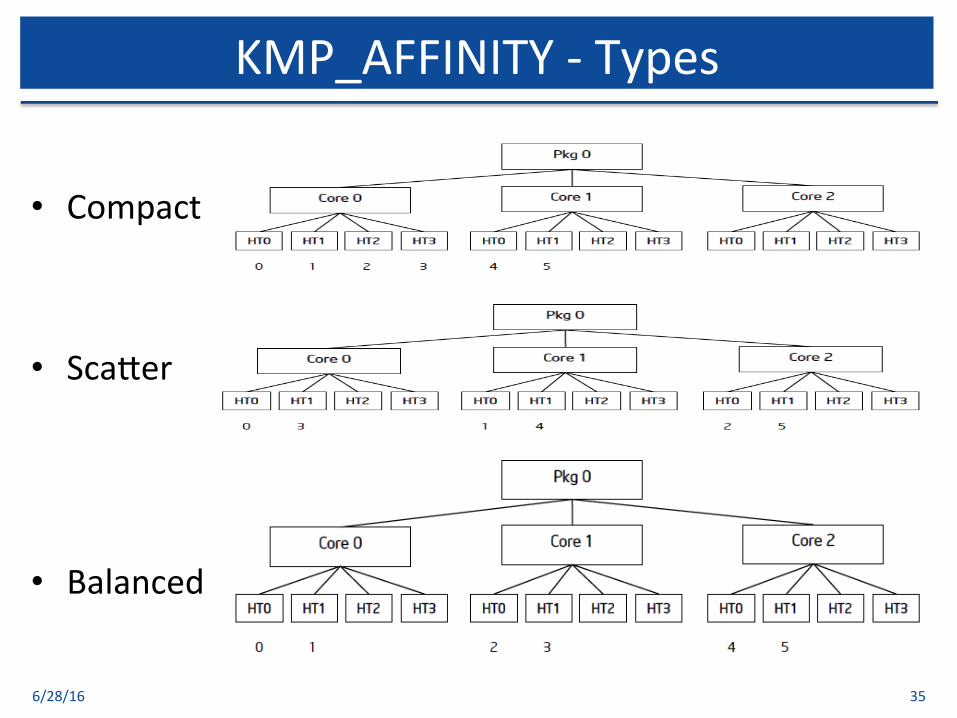
• Compact
• Sca[er
• Balanced
6/28/16 35
KMP_AFFINITY-Types

compactxeonexportKMP_AFFINITY=compact,verbose./OMP_hellocompactxeonphimicna$veloadex./OMP-hello.mic-e"KMP_AFFINITY=compact,verboseOMP_NUM_THREADS=10LD_LIBRARY_PATH=/opt/intel/lib/mic/"sca[erxeonexportKMP_AFFINITY=sca[er,verbose./OMP_hellosca[erxeonphimicna$veloadex./OMP-hello.mic-e"KMP_AFFINITY=sca[er,verboseOMP_NUM_THREADS=10LD_LIBRARY_PATH=/opt/intel/lib/mic/"balancedxeonphimicna$veloadex./OMP-hello.mic-e"KMP_AFFINITY=balanced,verboseOMP_NUM_THREADS=10LD_LIBRARY_PATH=/opt/intel/lib/mic/"
36
ThreadAffinityExamples
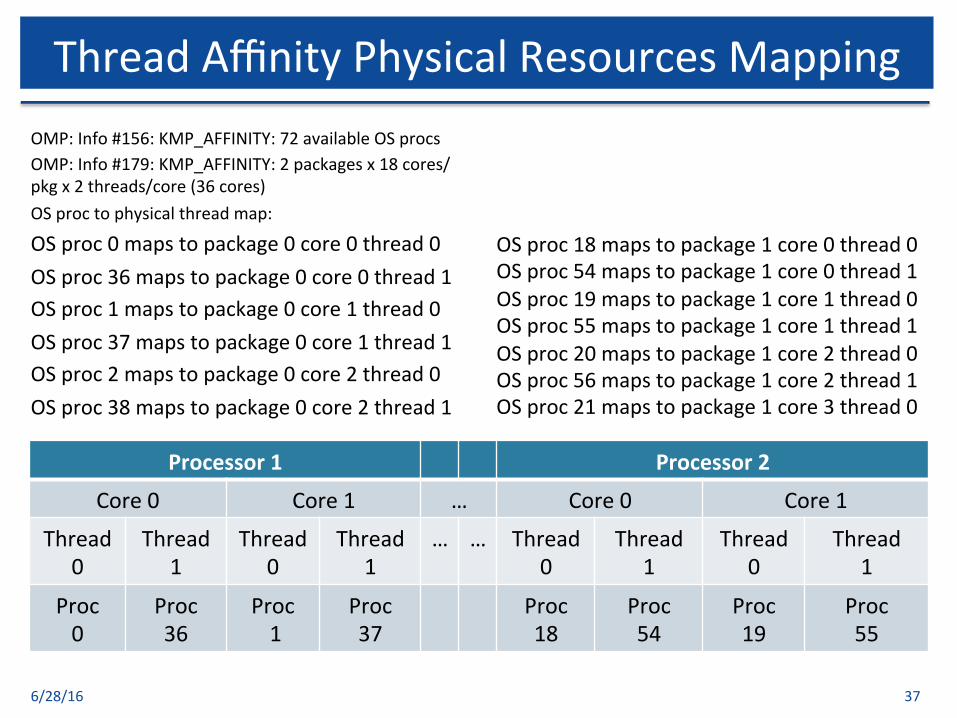
OMP:Info#156:KMP_AFFINITY:72availableOSprocsOMP:Info#179:KMP_AFFINITY:2packagesx18cores/pkgx2threads/core(36cores)OSproctophysicalthreadmap:
OSproc0mapstopackage0core0thread0OSproc36mapstopackage0core0thread1OSproc1mapstopackage0core1thread0OSproc37mapstopackage0core1thread1OSproc2mapstopackage0core2thread0OSproc38mapstopackage0core2thread1
OSproc18mapstopackage1core0thread0OSproc54mapstopackage1core0thread1OSproc19mapstopackage1core1thread0OSproc55mapstopackage1core1thread1OSproc20mapstopackage1core2thread0OSproc56mapstopackage1core2thread1OSproc21mapstopackage1core3thread0
6/28/16 37
ThreadAffinityPhysicalResourcesMapping
Processor1 Processor2
Core0 Core1 … Core0 Core1
Thread0
Thread1
Thread0
Thread1
… … Thread0
Thread1
Thread0
Thread1
Proc0
Proc36
Proc1
Proc37
Proc18
Proc54
Proc19
Proc55

OMP:Info#242:KMP_AFFINITY:pid68487thread0boundtoOSprocset{0,36}OMP:Info#242:KMP_AFFINITY:pid68487thread1boundtoOSprocset{0,36}OMP:Info#242:KMP_AFFINITY:pid68487thread2boundtoOSprocset{1,37}OMP:Info#242:KMP_AFFINITY:pid68487thread3boundtoOSprocset{1,37}OMP:Info#242:KMP_AFFINITY:pid68487thread4boundtoOSprocset{2,38}OMP:Info#242:KMP_AFFINITY:pid68487thread5boundtoOSprocset{2,38}OMP:Info#242:KMP_AFFINITY:pid68487thread6boundtoOSprocset{3,39}OMP:Info#242:KMP_AFFINITY:pid68487thread7boundtoOSprocset{3,39}OMP:Info#242:KMP_AFFINITY:pid68487thread8boundtoOSprocset{4,40}OMP:Info#242:KMP_AFFINITY:pid68487thread9boundtoOSprocset{4,40}
6/28/16 38
ThreadAffinitycompact

OMP:Info#242:KMP_AFFINITY:pid69401thread0boundtoOSprocset{0,36}OMP:Info#242:KMP_AFFINITY:pid69401thread1boundtoOSprocset{18,54}OMP:Info#242:KMP_AFFINITY:pid69401thread2boundtoOSprocset{1,37}OMP:Info#242:KMP_AFFINITY:pid69401thread3boundtoOSprocset{19,55}OMP:Info#242:KMP_AFFINITY:pid69401thread4boundtoOSprocset{2,38}OMP:Info#242:KMP_AFFINITY:pid69401thread5boundtoOSprocset{20,56}OMP:Info#242:KMP_AFFINITY:pid69401thread6boundtoOSprocset{3,39}OMP:Info#242:KMP_AFFINITY:pid69401thread7boundtoOSprocset{21,57}OMP:Info#242:KMP_AFFINITY:pid69401thread8boundtoOSprocset{4,40}OMP:Info#242:KMP_AFFINITY:pid69401thread9boundtoOSprocset{22,58}
6/28/16 39
ThreadAffinitysca[er

OMP:Info#242:KMP_AFFINITY:pid17662thread9boundtoOSprocset{0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,190,191,192,193,194,195,196,197,198,199,200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236,237,238,239}OMP:Info#242:KMP_AFFINITY:pid17662thread0boundtoOSprocset{1}OMP:Info#242:KMP_AFFINITY:pid17662thread8boundtoOSprocset{33}OMP:Info#242:KMP_AFFINITY:pid17662thread3boundtoOSprocset{13}OMP:Info#242:KMP_AFFINITY:pid17662thread4boundtoOSprocset{17}OMP:Info#242:KMP_AFFINITY:pid17662thread5boundtoOSprocset{21}OMP:Info#242:KMP_AFFINITY:pid17662thread9boundtoOSprocset{37}OMP:Info#242:KMP_AFFINITY:pid17662thread1boundtoOSprocset{5}OMP:Info#242:KMP_AFFINITY:pid17662thread6boundtoOSprocset{25}OMP:Info#242:KMP_AFFINITY:pid17662thread7boundtoOSprocset{29}OMP:Info#242:KMP_AFFINITY:pid17662thread2boundtoOSprocset{9}
6/28/16 40
ThreadAffinitybalanced

• NCCPresenta$on• ParallelArchitectures• IntelXeonandIntelXeonPhi• OpenMP• ThreadAffinity• Vectoriza$on• Offloading• ThreadLeague• N-bodySimula$on6/28/16 VECPAR2016 41
Agenda

• Instructsthecompilertoenforcevectoriza$onofloops(Semi-autovectorizaKon)
• ompsimd– marksalooptobevectorizedbythecompiler
• ompdeclaresimd– marksafunc$onthatcanbecalledfromaSIMDlooptobe
vectorizedbythecompiler
• ompparallelforsimd– marksaloopforthreadwork-sharingaswellasSIMDing
6/28/16 42
Vectoriza$on

• Evaluatemul$-threadingparalleliza$on
• Intel®AdvisorXEq Performancemodelingusingseveralframeworksformul$-threadinginprocessorsandco-processors:
o OpenMP,Intel®Cilk™Plus,Intel®ThreadingBuldingBlockso C,C++,Fortran(OpenMPonly)andC#(MicrosodTPL)
q Iden$fyparallelopportuni$eso Detailedinforma$onaboutvectoriza$on;o Checkloopdependencies;
q Scalabilitypredic$on:amountofthreads/performancegainsq Correctness(deadlocks,racecondi$on)
6/28/16 43
IntelAdvisor
6/28/16 44
IntelAdvisor
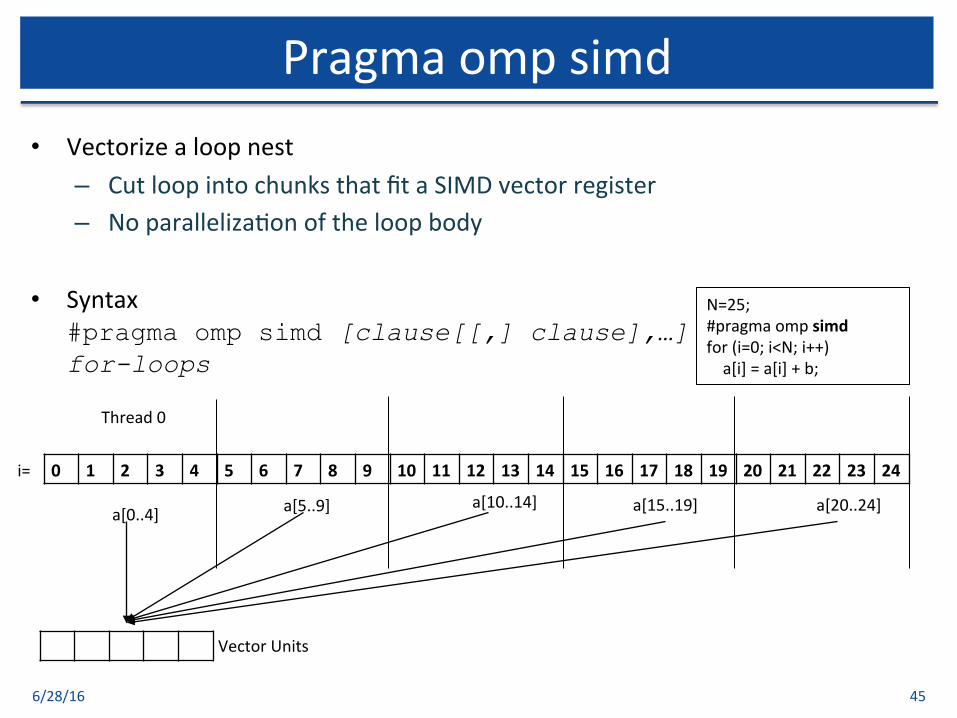
• Vectorizealoopnest– CutloopintochunksthatfitaSIMDvectorregister– Noparalleliza$onoftheloopbody
• Syntax#pragma omp simd [clause[[,] clause],…] for-loops
6/28/16 45
Pragmaompsimd
Thread0
N=25;#pragmaompsimdfor(i=0;i<N;i++)a[i]=a[i]+b;
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24i=
VectorUnits
a[0..4] a[5..9] a[10..14] a[15..19] a[20..24]

• Specifiesthateachthreadhasitsowninstanceofavariable:– private(var-list):unini$alizedvectorsforvariablesinvar-list
– firstprivate(var-list):Ini$alizedvectorsforvariablesinvar-list
– lastprivate(var-list):q similartoprivateclauseq Privatecopyoflastitera$oniscopiedtotheoriginalvariable
– reduc$on(op:var-list):createprivatevariablesforvar-listandapplyreduc$onoperatoropattheendoftheconstruct
6/28/16 46
DataSharingClauses

• simdlen(length)– generatefunc$ontosupportagivenvectorlength
• safelen(length)– Maximumnumberofitera$onsthatcanrunconcurrentlywithout
breakingadependence• linear(list[:linear-step])
– Thevariable’svalueisinrela$onshipwiththeitera$onnumberxi=xorig+i*linear-step
• aligned(list[:alignment])– Specifiesthatthelistitemshaveagivenalignment– Defaultisalignmentforthearchitecture
• collapse(n)– Groupstwoormoreloopsintoasingleloop
6/28/16 47
SIMDLoopClauses

#pragmaompparallelforcolapse(2)for(i=0;i<msize;i++){for(k=0;k<msize;k++){#pragmaompsimdfor(j=0;j<msize;j++){c[i][j]=c[i][j]+a[i][k]*b[k][j];}}}
6/28/16 48
Pragmaompsimd-Example1

6/28/16 49
OMPSIMD-Vectoriza$onReport
Compilercouldnotautoma$callyvectorizelooponline228,becauseof“assumeddependency”

6/28/16 50
OMPSIMD-Vectoriza$onReport
Checkdependencyanalysisshowsthatitissafetoenforcethevectoriza$onofthisloop

6/28/16 51
OMPSIMD-Vectoriza$onReport
#pragmaompsimdguidedthecompilertovectorizeloopusingAVX2

voidvec3(float*a,float*b,intoff,intlen){inti;#pragmaompsimdaligned(a:64,b:64)simdlen(64)for(i=0;i<len;i++){a[i]=(sin(cos(a[i]))>2.34)?a[i]*atan(b[i]):a[i]+cos(sin(b[i]));}}6/28/16 52
Pragmaompsimd-Example2

6/28/16 53
OMPSIMDExample2-Vectoriza$onReport
Assumeddependencypreventsautoma$cvectoriza$on;

6/28/16 54
OMPSIMDExample2-Vectoriza$onReport
aligned64andsimdlen64guidedthecompilertovectorizeloopusingAVX2;

• Declareoneormorefunc$onstobecompiledforcallsfromaSIMD-parallelloop
• Syntax(C/C++):#pragma omp declare simd [clause[[,] clause],…]
[#pragma omp declare simd [clause[[,] clause],…]]
[…]
function-definition-or-declaration
6/28/16 55
SIMDFunc$onVectoriza$on

• uniform(argument-list)– argumenthasaconstantvaluebetweentheitera$onsofa
givenloop• inbranch
– func$onalwayscalledfrominsideanifstatement• no$nbranch
– func$onnevercalledfrominsideanifstatement
• simdlen(argument-list[:linear-step])• linear(argument-list[:linear-step])• aligned(argument-list[:alignment])• reduc$on(operator:list)
6/28/16 56
SIMDFunc$onVectoriza$on

#pragmaompdeclaresimdlen(SIMD_LEN)intFindPosi$on(doublex){return(int)(log(exp(x*steps)));}#pragmaompdeclaresimduniform(vals)doubleInterpolate(doublex,constpoint*vals){intind=FindPosi$on(x);...returnres;}
intmain(intargc,charargv[]){...for(i=0;i<ARRAY_SIZE;++i){dst[i]=Interpolate(src[i],vals);}...}
6/28/16 57
Pragmaompdeclaresimd
GeorgeM.Raskulinec,EvgenyFiksman“Chapter22-SIMDfuncKonsviaOpenMP”,InHighPerformanceParallelismPearls,editedbyJamesReindersandJimJeffers,MorganKaufmann,Boston,2015,Pages171-190,ISBN9780128038192

LOOPBEGINatmain.c(126,5)remark#15382:vectoriza$onsupport:calltofunc$onInterpolate(double,constpoint*)cannotbevectorized[main.c(127,18)]remark#15344:loopwasnotvectorized:vectordependencepreventsvectoriza$onLOOPEND
6/28/16 58
Vectoriza$onreportwithoutOpenMP-Mainloop

LOOPBEGINatmain.c(126,5)remark#15388:vectoriza$onsupport:referencesrchasalignedaccess[main.c(127,18)]remark#15388:vectoriza$onsupport:referencedsthasalignedaccess[main.c(127,9)]remark#15305:vectoriza$onsupport:vectorlength8remark#15399:vectoriza$onsupport:unrollfactorsetto2remark#15309:vectoriza$onsupport:normalizedvectoriza$onoverhead0.013remark#15300:LOOPWASVECTORIZEDremark#15448:unmaskedalignedunitstrideloads:1remark#15449:unmaskedalignedunitstridestores:1remark#15475:---beginvectorloopcostsummary---remark#15476:scalarloopcost:107remark#15477:vectorloopcost:14.500remark#15478:es$matedpoten$alspeedup:7.370remark#15484:vectorfunc$oncalls:1remark#15488:---endvectorloopcostsummary---remark#15489:---beginvectorfunc$onmatchingreport---remark#15490:Func$oncall:Interpolate(double,constpoint*)withsimdlen=8,actualparametertypes:(vector,uniform)[main.c(127,18)]remark#15492:Asuitablevectorvariantwasfound(outof4)withymm2,simdlen=4,unmasked,formalparametertypes:(vector,uniform)remark#15493:---endvectorfunc$onmatchingreport---LOOPEND
6/28/16 59
Vectoriza$onreportwithOpenMP-Mainloop

Beginop$miza$onreportfor:Interpolate.._simdsimd3__H2n_v1_s1.P(double,constpoint*)Reportfrom:Vectorop$miza$ons[vec]remark#15301:FUNCTIONWASVECTORIZED[main.c(74,48)]===========================================================================Beginop$miza$onreportfor:Interpolate.._simdsimd3__H2m_v1_s1.P(double,constpoint*)Reportfrom:Vectorop$miza$ons[vec]remark#15301:FUNCTIONWASVECTORIZED[main.c(74,48)]===========================================================================Beginop$miza$onreportfor:Interpolate.._simdsimd3__L4n_v1_s1.V(double,constpoint*)Reportfrom:Vectorop$miza$ons[vec]remark#15301:FUNCTIONWASVECTORIZED[main.c(74,48)]remark#15415:vectoriza$onsupport:gatherwasgeneratedforthevariablepnt:indirectaccess,64bitindexed[main.c(78,26)]remark#15415:vectoriza$onsupport:gatherwasgeneratedforthevariablepnt:indirectaccess,64bitindexed[main.c(78,36)]===========================================================================Beginop$miza$onreportfor:Interpolate.._simdsimd3__L4m_v1_s1.V(double,constpoint*)Reportfrom:Vectorop$miza$ons[vec]remark#15301:FUNCTIONWASVECTORIZED[main.c(74,48)]remark#15415:vectoriza$onsupport:gatherwasgeneratedforthevariablepnt:masked,indirectaccess,64bitindexed[main.c(78,26)]remark#15415:vectoriza$onsupport:gatherwasgeneratedforthevariablepnt:masked,indirectaccess,64bitindexed[main.c(78,36)]
6/28/16 60
Vectoriza$onreportwithOpenMP-Interpolate

eginop$miza$onreportfor:FindPosi$on.._simdsimd3__H2n_v1.P(double)Reportfrom:Vectorop$miza$ons[vec]remark#15301:FUNCTIONWASVECTORIZED[main.c(70,28)]===========================================================================Beginop$miza$onreportfor:FindPosi$on.._simdsimd3__H2m_v1.P(double)Reportfrom:Vectorop$miza$ons[vec]remark#15301:FUNCTIONWASVECTORIZED[main.c(70,28)]===========================================================================Beginop$miza$onreportfor:FindPosi$on.._simdsimd3__L4n_v1.V(double)Reportfrom:Vectorop$miza$ons[vec]remark#15301:FUNCTIONWASVECTORIZED[main.c(70,28)]===========================================================================Beginop$miza$onreportfor:FindPosi$on.._simdsimd3__L4m_v1.V(double)Reportfrom:Vectorop$miza$ons[vec]remark#15301:FUNCTIONWASVECTORIZED[main.c(70,28)]===========================================================================
6/28/16 61
Vectoriza$onreportwithOpenMP-FindPosi$on

• Withoutuniformclause./main0m36.828s• Usinguniformclause./main0m16.926s• OpenMPparameteruniformenabledthecompilertousethe“fusedmul$plyandadd”instruc$on
6/28/16 62
Analysisoffunc$onInterpolate
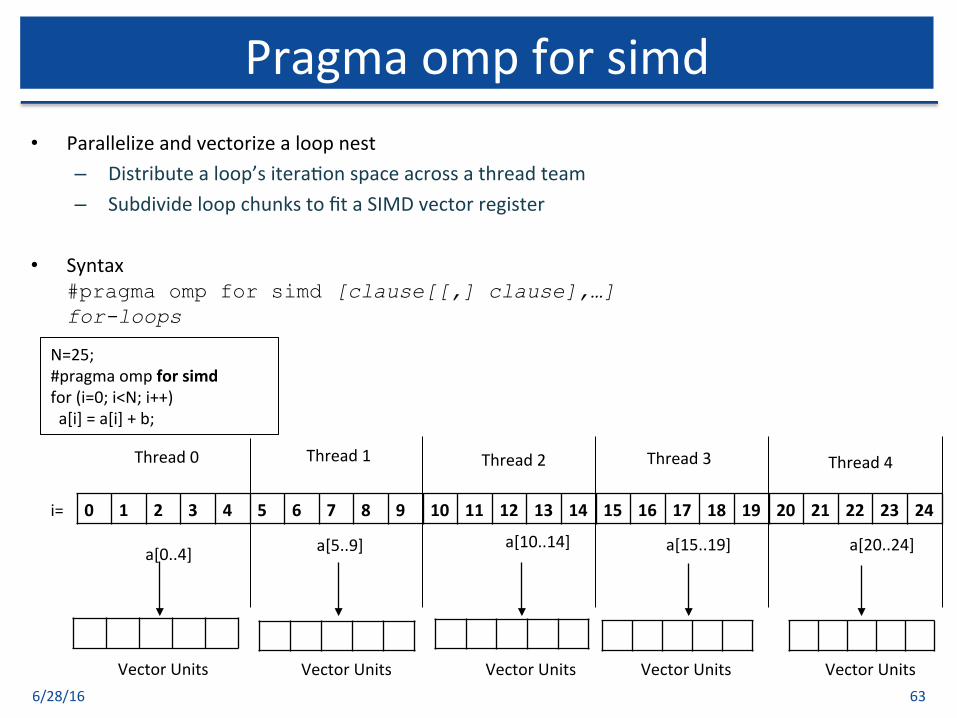
• Parallelizeandvectorizealoopnest– Distributealoop’sitera$onspaceacrossathreadteam– SubdivideloopchunkstofitaSIMDvectorregister
• Syntax#pragma omp for simd [clause[[,] clause],…] for-loops
6/28/16 63
Pragmaompforsimd
Thread0
N=25;#pragmaompforsimdfor(i=0;i<N;i++)a[i]=a[i]+b;
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24i=
VectorUnits
a[0..4] a[5..9] a[10..14] a[15..19] a[20..24]
Thread1 Thread2 Thread3 Thread4
VectorUnits VectorUnits VectorUnits VectorUnits

#pragmaompparallelforsimdfor(i=0;i<msize;i++){a[i][j]=distsq(a[i][j],b[i][j])-auxrand;b[i][j]+=min(a[i][j],b[i][j])+auxrand;c[i][j]=(min(distsq(a[i][j],b[i][j]),a[i][j]))/auxrand;}
6/28/16 64
Pragmaompforsimd

• NCCPresenta$on• ParallelArchitectures• IntelXeonandIntelXeonPhi• OpenMP• ThreadAffinity• Vectoriza$on• Offloading• ThreadLeague• N-bodySimula$on
6/28/16 VECPAR2016 65
Agenda

• target:transfersthecontrolflowtothetargetdevice– Transferissequen$alandsynchronous– Transferclausescontroldataflow
• targetdata:createsascopeddevicedataenvironment– Doesnotincludeatransferofcontrol– Transferclausescontroldataflow– Thedevicedataenvironmentisvalidthroughthelife$meof
thetargetdataregion• targetupdate:requestdatatransfersfromwithinatargetdataregion
• ompdeclaretarget:createsastructured-blockoffunc$onsthatcanbeoffloaded.
6/28/16 66
OpenMP4.0Offload

• OFFLOADREPORT:– Measurestheamountof$meittakestoexecuteanoffloadregionofcode;– Measurestheamountofdatatransferredduringtheexecu$onoftheoffload
region;– Turnonthereport:exportOFFLOAD_REPORT=2
• [Var]Thenameofavariabletransferredandthedirec$on(s)oftransfer.• [CPUTime]Thetotal$memeasuredforthatoffloaddirec$veonthe
host.• [MICTime]Thetotal$memeasuredforexecu$ngtheoffloadonthe
target.• [CPU->MICData]Thenumberofbytesofdatatransferredfromthehost
tothetarget.• [MIC->CPUData]Thenumberofbytesofdatatransferredfromthe
targettothehost.
6/28/16 67
OpenMP4.0OffloadReport

• Createsastructured-blockoffunc$onsthatcanbeoffloaded.
• Syntax– #pragma omp declare target [clause[[,] clause],…]
declaration of functions
– #pragma omp end declare target
6/28/16 68
Pragmaompdeclaretarget

• Transfercontrol[anddata]fromhosttodevice
• Syntax– #pragma omp target [data] [clause[[,] clause],…]
structured-block
• Clauses– device(scalar-integer-expression):
q device to offload code;
– map(alloc | to | from | tofrom: list) : q map variables to device;
– if(scalar-expr) : q test an expression before offload:
o True executes on device; o False executes on host;
– Nowait q Execute the data transfer defined in map asynchronously;
6/28/16 69
Pragmaomptarget

• Mapclauses:– alloc:allocatememoryondevice;
– to:transferavariablefromhosttodevice;
– from:transferavariablefromdevicetohost;
– tofrom:q transferavariablefromhosttodevicebeforestartexecu$on;q transferavariablefromdevicetohostaderfinishexecu$on;
6/28/16 70
Pragmaomptarget
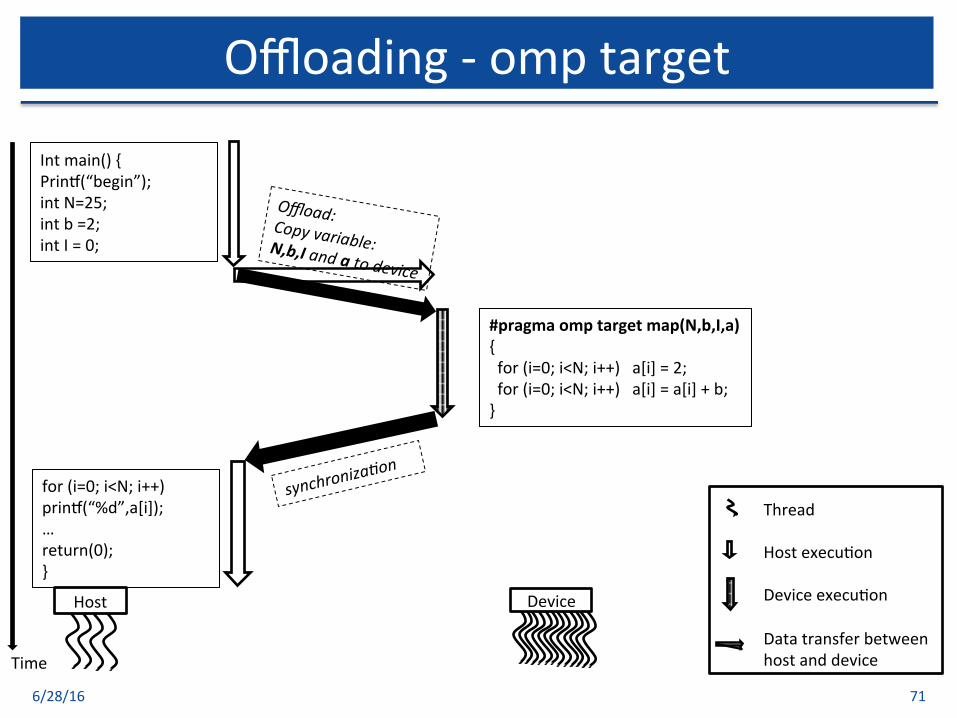
6/28/16 71
Offloading-omptarget
Time
Device
Intmain(){Prinv(“begin”);intN=25;intb=2;intI=0;
#pragmaomptargetmap(N,b,I,a){for(i=0;i<N;i++)a[i]=2;for(i=0;i<N;i++)a[i]=a[i]+b;}
Offload:Copyvariable:N,b,Iandatodevice
synchroniza0on
for(i=0;i<N;i++)prinv(“%d”,a[i]);…return(0);}
ThreadHostexecu$onDeviceexecu$onDatatransferbetweenhostanddevice
Host

#pragmaomptargetdevice(0)map(a[0:NUM][0:NUM])map(b[0:NUM][0:NUM])map(c[0:NUM][0:NUM]){#pragmaompparallelforcollapse(2)for(i=0;i<msize;i++){for(k=0;k<msize;k++){#pragmaompsimdfor(j=0;j<msize;j++){c[i][j]=c[i][j]+a[i][k]*b[k][j];}}}}
6/28/16 72
Pragmaomptargetexample

[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]256[Offload][MIC0][Tag]Tag0[Offload][HOST][Tag0][CPUTime]3.705509(seconds)[Offload][MIC0][Tag0][CPU->MICData]402653212(bytes)[Offload][MIC0][Tag0][MICTime]3.246152(seconds)[Offload][MIC0][Tag0][MIC->CPUData]402653188(bytes)• Ellapsed$me:
– Execu$on$me:16s;– Datatransfer(400MB):3s.
6/28/16 73
Pragmaomptargetexample
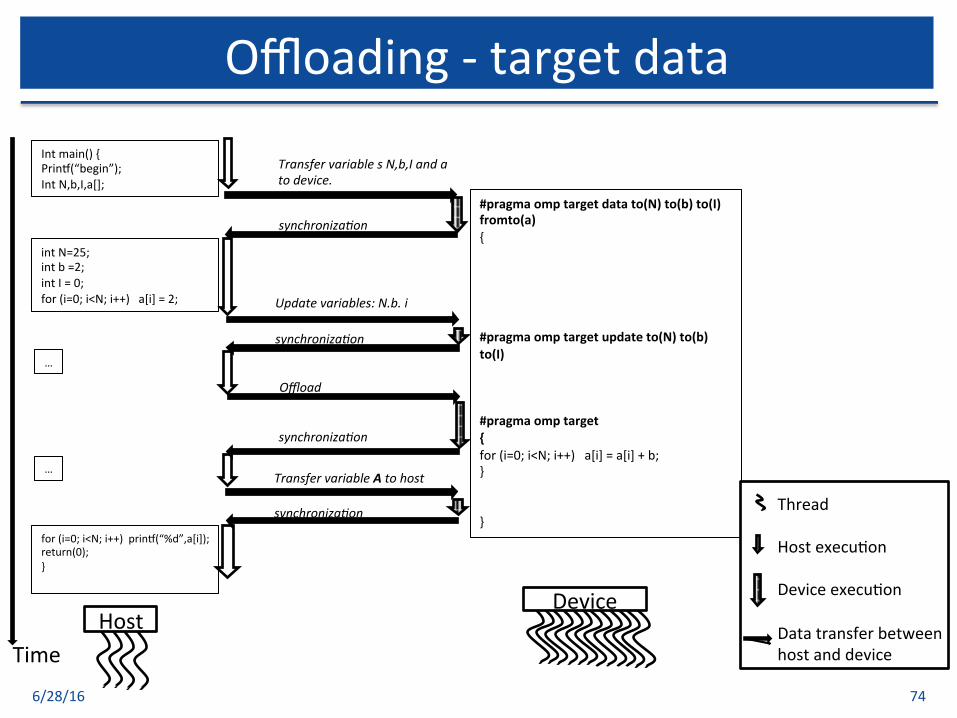
6/28/16 74
Offloading-targetdata
#pragmaomptargetdatato(N)to(b)to(I)fromto(a){#pragmaomptargetupdateto(N)to(b)to(I)#pragmaomptarget{for(i=0;i<N;i++)a[i]=a[i]+b;}}
HostTime
Device
TransfervariablesN,b,Iandatodevice.
TransfervariableAtohost
for(i=0;i<N;i++)prinv(“%d”,a[i]);return(0);}
intN=25;intb=2;intI=0;for(i=0;i<N;i++)a[i]=2;
…
Updatevariables:N.b.i
synchroniza0on
Intmain(){Prinv(“begin”);IntN,b,I,a[];
…
Offload
synchroniza0on
synchroniza0on
synchroniza0on ThreadHostexecu$onDeviceexecu$onDatatransferbetweenhostanddevice

#pragmaomptargetdatamap(to:a[0:NUM][0:NUM])map(i,j,k)map(to:b[0:NUM][0:NUM])map(tofrom:c[0:NUM][0:NUM]){#pragmaomptarget{#pragmaompparallelforcollapse(2)for(i=0;i<msize;i++){for(k=0;k<msize;k++){#pragmaompsimdfor(j=0;j<msize;j++){c[i][j]=c[i][j]+a[i][k]*b[k][j];}}}}6/28/16 75
Pragmaomptargetdataexample

[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]297[Offload][MIC0][Tag]Tag0[Offload][HOST][Tag0][CPUTime]1.594387(seconds)[Offload][MIC0][Tag0][CPU->MICData]402653220(bytes)[Offload][MIC0][Tag0][MICTime]0.000158(seconds)[Offload][MIC0][Tag0][MIC->CPUData]0(bytes)[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]299[Offload][MIC0][Tag]Tag1[Offload][HOST][Tag1][CPUTime]2.166915(seconds)[Offload][MIC0][Tag1][CPU->MICData]36(bytes)[Offload][MIC0][Tag1][MICTime]3.374661(seconds)[Offload][MIC0][Tag1][MIC->CPUData]4(bytes)[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]312[Offload][MIC0][Tag]Tag2[Offload][HOST][Tag2][CPUTime]0.014292(seconds)[Offload][MIC0][Tag2][CPU->MICData]56(bytes)[Offload][MIC0][Tag2][MICTime]0.000068(seconds)[Offload][MIC0][Tag2][MIC->CPUData]134217740(bytes)
6/28/16 76
Pragmaomptargetdataexample

• UpdateDatabetweenhostanddevice
• Syntax#pragma omp target update [clause[[,] clause],…] structured-block
• Clausesdevice(scalar-integer-expression) map(alloc | to | from | tofrom: list) if(scalar-expr)
6/28/16 77
Pragmaomptargetupdate

#pragmaomptargetdatamap(to:a[0:NUM][0:NUM])map(i,j,k)map(to:b[0:NUM][0:NUM])map(to:c[0:NUM][0:NUM]){#pragmaomptarget{#pragmaompparallelforcollapse(2)for(i=0;i<msize;i++){for(k=0;k<msize;k++){#pragmaompsimdfor(j=0;j<msize;j++){c[i][j]=c[i][j]+a[i][k]*b[k][j];}}}}#pragmaomptargetupdatefrom(c[0:NUM][0:NUM])}
6/28/16 78
Pragmaomptargetupdateexample

[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]300[Offload][MIC0][Tag]Tag0[Offload][HOST][Tag0][CPUTime]1.621304(seconds)[Offload][MIC0][Tag0][CPU->MICData]402653220(bytes)[Offload][MIC0][Tag0][MICTime]0.000151(seconds)[Offload][MIC0][Tag0][MIC->CPUData]0(bytes)[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]302[Offload][MIC0][Tag]Tag1[Offload][HOST][Tag1][CPUTime]18.781722(seconds)[Offload][MIC0][Tag1][CPU->MICData]36(bytes)[Offload][MIC0][Tag1][MICTime]29.251363(seconds)[Offload][MIC0][Tag1][MIC->CPUData]4(bytes)[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]314[Offload][MIC0][Tag]Tag2[Offload][HOST][Tag2][CPUTime]0.013202(seconds)[Offload][MIC0][Tag2][CPU->MICData]0(bytes)[Offload][MIC0][Tag2][MICTime]0.000000(seconds)[Offload][MIC0][Tag2][MIC->CPUData]134217728(bytes)[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]315[Offload][MIC0][Tag]Tag3[Offload][HOST][Tag3][CPUTime]0.002192(seconds)[Offload][MIC0][Tag3][CPU->MICData]56(bytes)[Offload][MIC0][Tag3][MICTime]0.000078(seconds)[Offload][MIC0][Tag3][MIC->CPUData]12(bytes)
6/28/16 79
Pragmaomptargetupdateexample

• NCCPresenta$on• ParallelArchitectures• IntelXeonandIntelXeonPhi• OpenMP• ThreadAffinity• Vectoriza$on• Offloading• ThreadLeague• N-bodySimula$on
6/28/16 VECPAR2016 80
Agenda

• ompteams:createsaleagueofthreadteams
– #pragmaompteams[clause[[,]clause]...]q num_teams(amount):definetheamountofthreadteamsq thread_limit(limit):definethehighestamountofthreadsthatcanbe
createdineachteam;
• ompdistribute:distributesaloopovertheteamsintheleague
– #pragmaompdistribute[clause[[,]clause]...]q dist_schedule(sta$c[blocksize]):
6/28/16 81
ThreadLeague
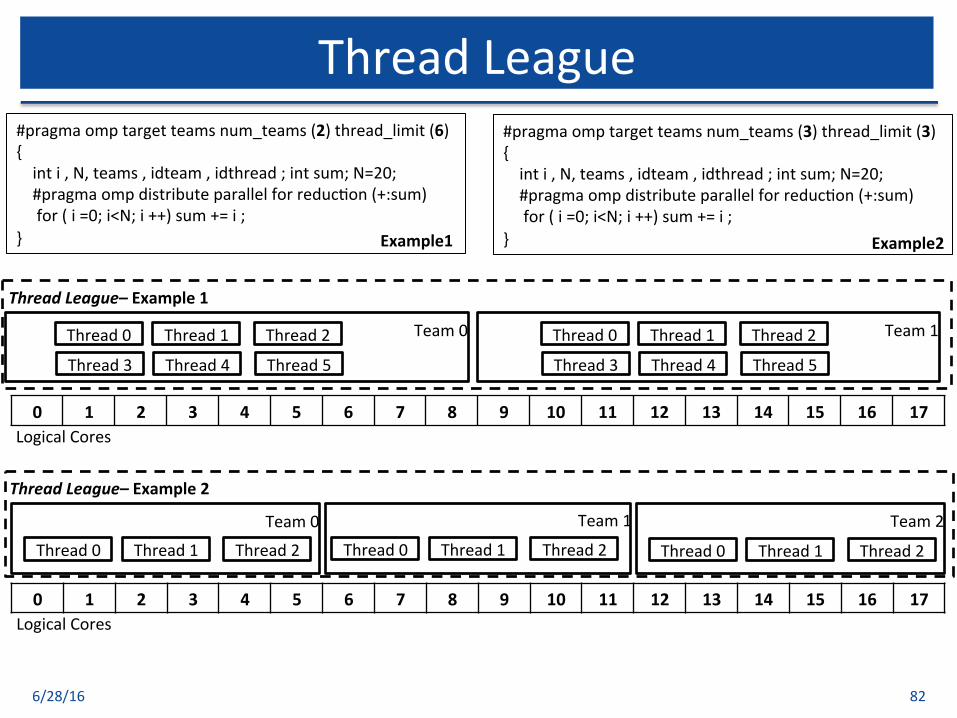
6/28/16 82
ThreadLeague
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17LogicalCores
Thread0
ThreadLeague–Example2
Team0 Team1 Team2
Thread1 Thread2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17LogicalCores
ThreadLeague–Example1
Team0 Team1
Thread0 Thread1 Thread2 Thread0 Thread1 Thread2
Thread0 Thread1 Thread2
Thread3 Thread4 Thread5
Thread0 Thread1 Thread2
Thread3 Thread4 Thread5
#pragmaomptargetteamsnum_teams(2)thread_limit(6){inti,N,teams,idteam,idthread;intsum;N=20;#pragmaompdistributeparallelforreduc$on(+:sum)for(i=0;i<N;i++)sum+=i;}
#pragmaomptargetteamsnum_teams(3)thread_limit(3){inti,N,teams,idteam,idthread;intsum;N=20;#pragmaompdistributeparallelforreduc$on(+:sum)for(i=0;i<N;i++)sum+=i;}Example1 Example2

#pragmaomptargetteamsnum_teams(2)thread_limit(3){inti,N,teams,idteam,idthread;intsum;N=20;#pragmaompdistributeparallelforreduc$on(+:sum)for(i=0;i<N;i++){sum+=i;idthread=omp_get_thread_num();idteam=omp_get_team_num();teams=omp_get_num_teams();prinv("i%dn%didteam%didthread%dteams%d\n",i,N,idteam,idthread,teams);}}
6/28/16 83
ThreadLeague-Example1

#pragmaomptargetdatadevice(0)map(i,j,k)map(to:a[0:NUM][0:NUM])map(to:b[0:NUM][0:NUM])map(tofrom:c[0:NUM][0:NUM]){#pragmaomptargetteamsdistributeparallelforcollapse(2)num_teams(2)thread_limit(30)for(i=0;i<NUM;i++){for(k=0;k<NUM;k++){#pragmaompsimdfor(j=0;j<NUM;j++){c[i][j]=c[i][j]+a[i][k]b[k][j];}}}}
6/28/16 84
ThreadLeague-Example2

[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]277[Offload][MIC0][Tag]Tag0[Offload][HOST][Tag0][CPUTime]1.593593(seconds)[Offload][MIC0][Tag0][CPU->MICData]402653220(bytes)[Offload][MIC0][Tag0][MICTime]0.000147(seconds)[Offload][MIC0][Tag0][MIC->CPUData]0(bytes)[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]279[Offload][MIC0][Tag]Tag1[Offload][HOST][Tag1][CPUTime]3.759050(seconds)[Offload][MIC0][Tag1][CPU->MICData]44(bytes)[Offload][MIC0][Tag1][MICTime]5.854270(seconds)[Offload][MIC0][Tag1][MIC->CPUData]12(bytes)[Offload][MIC0][File]../src/mul$ply.c[Offload][MIC0][Line]288[Offload][MIC0][Tag]Tag2[Offload][HOST][Tag2][CPUTime]0.039104(seconds)[Offload][MIC0][Tag2][CPU->MICData]56(bytes)[Offload][MIC0][Tag2][MICTime]0.000073(seconds)[Offload][MIC0][Tag2][MIC->CPUData]402653196(bytes)
6/28/16 85
ThreadLeague-Example2

• NCCPresenta$on• ParallelArchitectures• IntelXeonandIntelXeonPhi• OpenMP• ThreadAffinity• Vectoriza$on• Offloading• ThreadLeague• N-bodySimula$on
6/28/16 VECPAR2016 86
Agenda

• AnN-bodysimula$on[1]aimstoapproximatethemo$onofpar$clesthatinteractwitheachotheraccordingtosomephysicalforce;
• Usedtostudythemovementofbodiessuchassatellites,planets,stars,galaxies,etc.,whichinteractwitheachotheraccordingtothegravita$onalforce;
• Newton´ssecondlawofmo$oncanbeusedinaN-bodysimula$ontodefinethebodies’movement.
6/28/16 87
N-BodySimula$on
[1]AARSETH,S.J.GravitaKonaln-bodysimulaKons.[S.l.]:CambridgeUniversityPress,2003.CambridgeBooksOnline.

• Bodiesstruct:– 3matrixrepresentsvelocity(x,yandz)– 3matrixrepresentsposi$on(x,yandz)– 1matrixrepresentmass
• Aloopcalculatetemporalsteps:– Ateachtemporalstepnewvelocityandposi$onarecalculated
toallbodiesaccordingtoafunc$onthatimplementsNewton´ssecondlawofmo$on
6/28/16 88
N-BodyAlgorithm

func$onNewton(step){#pragmaompforforeachbody[x]{#pragmaompsimdforeachbody[y]calcforceexertedfrombody[y]tobody[x];calcnewvelocityofbody[x] }#pragmaompsimdforeachbody[x]calcnewposi$onofbody[x] }Main(){foreachtemporalstepNewton(step)}
6/28/16 89
N-Body-Parallelversion(hostonly)

• Thetemporalsteploopremainssequen$al
• TheN-bodiesaredividedamonghostanddevicestobeexecutedusingNewton
• OpenMPoffloadpragmasareusedto– Newtonfunc$onoffloadingtodevices– Transferdata(bodies)betweenhostanddevices
6/28/16 90
N-Body-Parallelversion(Loadbalancing)

func$onNewton(step,begin_body,end_body,deviceId){#pragmaomptargetdevice(deviceId){#pragmaompforforeachbody[x]fromsubset(begin_body,end_body){#pragmaompsimdforeachbody[y]fromsubset(begin_body,end_body)calcforceexertedfrombody[y]tobody[x];calcnewvelocityofbody[x] }#pragmaompsimdforeachbody[x]calcnewposi$onofbody[x] }}6/28/16 91
N-Body-Parallelversion(Loadbalancing)

foreachtemporalstepDividetheamountofbodiesamonghostanddevices;#pragmaompparallel{#pragmaomptargetdatadevice(Kd)to(bodies[begin_body:end_body]){Newton(step,begin_body,end_body,deviceId) #pragmaomptargetupdatedevice(Kd)(from:bodies) #pragmaompbarrier#pragmaomptargetdatadevice(Kd)to(bodies[begin_body:end_body])}}
6/28/16 92
N-Body-Parallelversion(Loadbalancing)

Thankyouforyoura[en$on(Obrigado!)
93
SilvioStanzani,RaphaelCóbe,RogérioIopeUNESP-NúcleodeComputaçãoCienKfica





























