Embed Size (px)
Citation preview

MPI & MPICH Presenter: Naznin Fauzia
CSE 788.08 Winter 2012

Outline
• MPI-1 standards
• MPICH-1
• MPI-2
• MPICH-2
• MPI-3

Overview
• MPI (Message Passing Interface) • Specification for a standard library for message
passing • Defined by MPI forum
• Designed for high performance • on both massively parallel machines and on
workstation clusters.
• Widely available • both free available and vendor-supplied
implementations

Goals • To develop a widely used standard for writing message-passing programs.
• Establish a practical, portable, efficient, and flexible standard for message passing.
• Design an application programming interface (not necessarily for compilers or a system implementation library).
• Allow efficient communication: Avoid memory-to-memory copying and allow overlap of computation and communication and offload to communication co-processor, where available.
• Allow for implementations that can be used in a heterogeneous environment.
• Allow convenient C and Fortran 77 bindings for the interface.
• Assume a reliable communication interface: the user need not cope with communication failures. Such failures are dealt with by the underlying communication subsystem.

Example #include <mpi.h> int main(int argc, char **argv){ /* Initialize MPI */ MPI_Init(&argc, &argv); /* Find out my identity in the default communicator */ int my_rank; MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); int number ; if (my_rank == 0) { number = -1; MPI_Send(&number, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); } else if (my_rank == 1) { MPI_Recv(&number, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf("Process 1 received number %d from process 0\n", number); } /* Shut down MPI */ MPI_Finalize(); return 0; }

MPI-1 • Point-to-point communication
• basic, pairwise communication (i.e., send and receive)
• Collective operations • process-group collective communication operations (i.e., barrier, broadcast,
scatter, gather, reduce )
• Process groups & communication contexts • how groups of processes are formed and manipulated, how unique
communication contexts are obtained, and how the two are bound together into a communicator (i.e., MPI_COMM_WORLD)
• Process topologies • explains a set of utility functions meant to assist in the mapping of process
groups (a linearly ordered set) to richer topological structures such as multi-dimensional grids.

MPI-1 contd.
• Bindings for Fortran 77 and C • gives specific syntax in Fortran 77 and C, for all MPI
functions, constants, and types.
• Environmental Management and inquiry • explains how the programmer can manage and make
inquiries of the current MPI environment
• Profiling interface • ability to put performance profiling calls into MPI
without the need for access to the MPI source code

MPICH
• Freely available implementation of MPI specification • Argonne National Laboratory, Mississippi State
University
• Portability and High-performance
• “CH” => “Chameleon” • Symbol of adaptability
• Other – LAM, CHIMP-MPI, Unify etc. • Focus on the work station environment

Portability of MPICH
• Distributed-memory Parallel Supercomputer • Intel Paragon, IBM SP2, Meiko CS-2, Thinking Machines
CM-5, Ncube-2, Cray T3D
• Shared-memory architectures • SGI Onyx, Challenge, Power Challenge, IBM SMP's the
Convex Exempler, the Sequent Symmetry
• Networks of Workstations • Ethernet-connected Unix workstations (may be of
multiple vendors) • Sun, DEC, HP, SGI, IBM, Intel

MPICH Architecture
• ADI (Abstract Device Interface) • Central mechanism for portability • Many implementations of ADI • MPI functions are implemented in terms of ADI
macros and function • Not MPI library specific – can be used for any high-
level message passing library

ADI
• A set of function definitions
• Four set of functions • Specifying a message to be sent or received • Moving data between the API and the message
passing h/w • Managing list of pending messages (both sent or
received) • Providing basic information about the execution
environment (i.e., how many tasks are there)
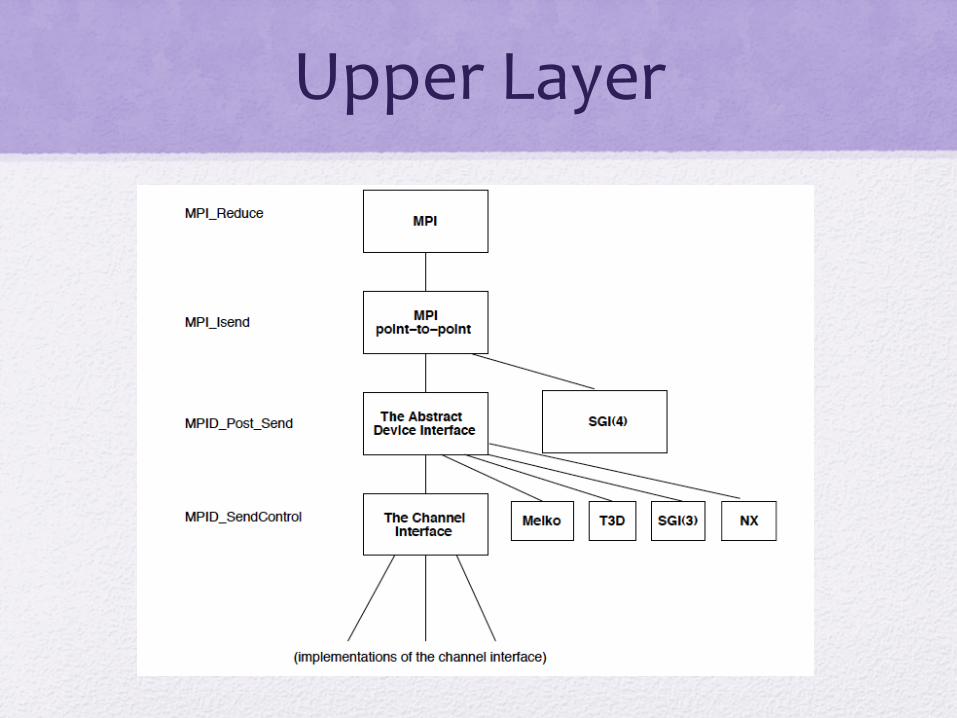
Upper Layer
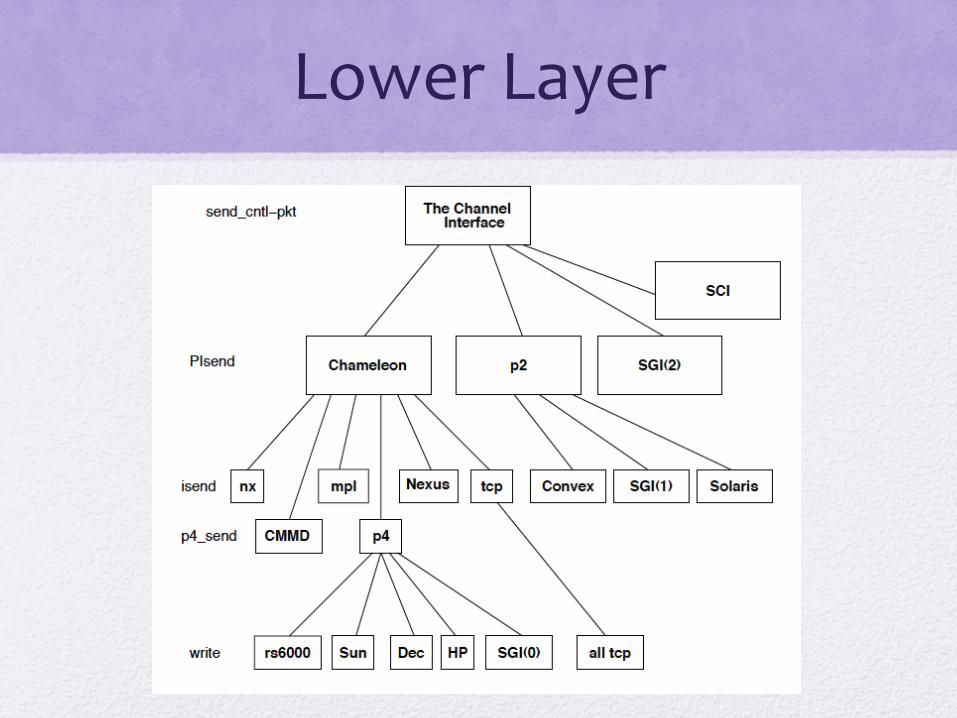
Lower Layer

Features of MPICH • Groups • An ordered list of process identifiers • Stored as an integer array • Process's rank in a group is its index in the list
• Communicators • MPICH intracommunicators and intercommunicators uses
same structure • Both has a local group and a remote group – identical
(intra) or disjoint (inter) • Send and receive context – equal (intra) or different (inter) • Contexts are integers

Features of MPICH • Collective operations • Implemented on top of point-to-point operations • Some vendor-specific collective operations (Meiko,
Intel and Convex)
• Job Startup • MPI forum did not standardize the mechanism for
starting jobs • mpirun
mpirun -np 12 myprog

• Command-Line Arguments and Standard I/O
mpirun –np 64 myprog –myarg 13 < data.in > results.out
mpirun –np 64 –stdin data.in myprog –myarg 13 > results.out
• Useful commands
mpicc –c myprog.c
Features of MPICH

MPE (Multi-Processing Environment) Extension Library
• Parallel X graphics – routines to provide all processes with access to a shared X display
• Logging – time stamped event trace file
• Sequential sections – one process at a time, in rank order
• Error handling – MPI_Errhandler_set

• MPICH has succeeded in popularizing the MPI standard
• Encouraging vendors to provide MPI to their customers • By helping to create demand • By offering them a convenient starting point
Contributions of MPICH

MPI-2
• Parallel I/O
• Dynamic process management
• One-sided communication
• New language bindings – C++ & F90
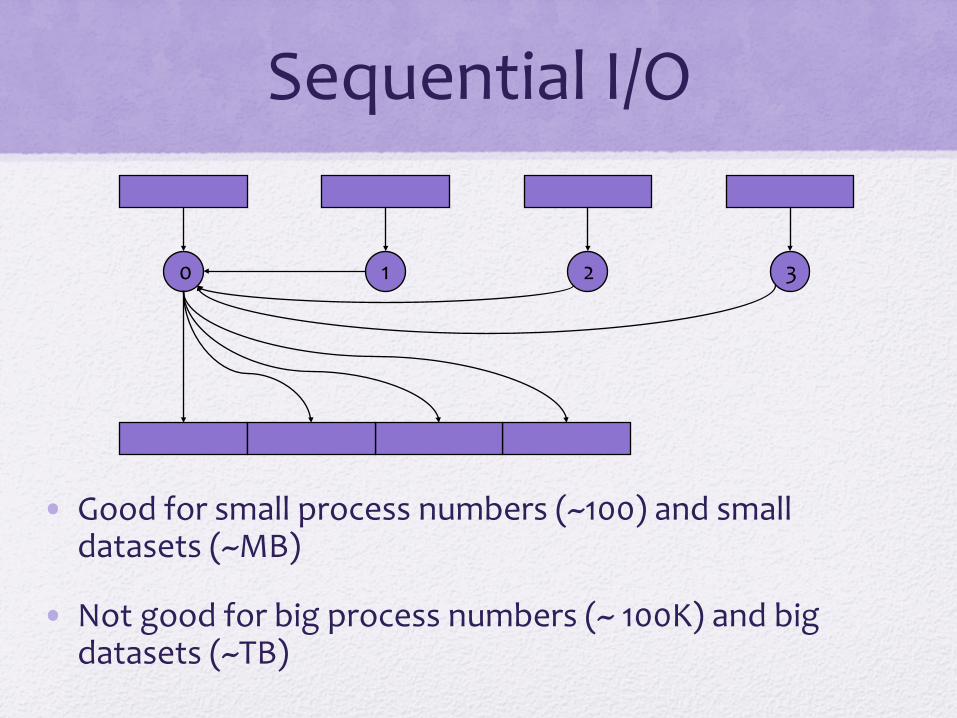
Sequential I/O
• Good for small process numbers (~100) and small datasets (~MB)
• Not good for big process numbers (~ 100K) and big datasets (~TB)
0 1 2 3

Parallel I/O
• Multiple processes of a parallel program accessing data from a common file
• Each process access a chunk of data using individual file pointers
• MPI_File_open, MPI_File_seek, MPI_File_read, MPI_File_close
FILE
P0 P1 P2 P(n-1)

One-Sided Communication • Remote Memory Access (RMA)
• Window – specific region of process memory made available for RMA by other processes
• MPI_Win_create – called by all processes within a communicator
• Origin: the process that performs the call • Target: the process in which memory is accessed
• Communication calls • MPI_Get: Remote read • MPI_Put: Remote write • MPI_accumulate
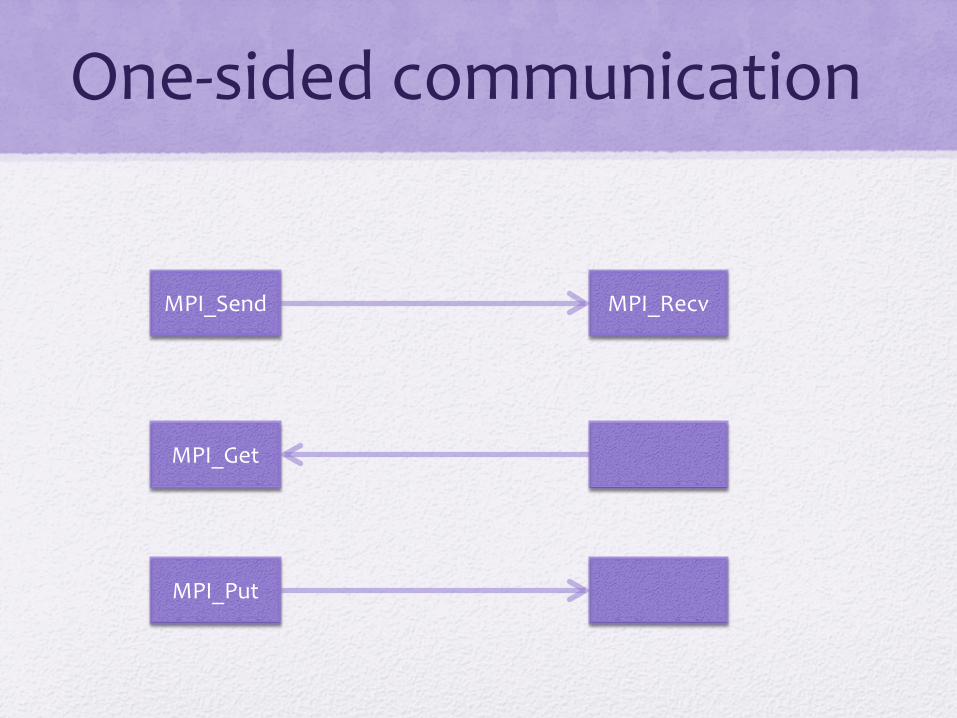
One-sided communication
MPI_Send MPI_Recv
MPI_Get
MPI_Put

Dynamic process mgt.
• MPI-1 • Does not specify how processes will be created • Does not allow processes to enter or leave a
running parallel application
• MPI-2 • Start new process, send them signals, find out when
they die, establish communication between two processes

MPICH-2
• ADI 3 – provides routines to support MPI-1 & 2
• Two types of RMA operations • Active target – target process must call an Mpi
routine • Origin calls MPI_Win_start/MPI_Win_complete • Target calls MPI_Win_post/MPI_Win_wait
• Passive target - target process not required to call any MPI routine • Origin calls MPI_Win_lock/MPI_Win_unlock

MPICH-2
• Dynamic process • There are no absolute and global process ids • No data structure that map a process rank into a
“global rank” (i.e., rank in MPI_COMM_WORLD) • All communications are considered locally in terms of
possible virtual connections to processes • Arrays of virtual connections indexed by rank

MPI-3
• Improved scalability
• Better support for multi-core, cluster & application
• Proposed => MPI_Count (larger than integer)
• Extension of collective operations • Include non-blocking • Sparse collective operations • MPI_Sparse_gather

MPI-3
• Extension of one-sided communication • To support RMA to arbitrary locations, no constraints (symmetric
allocation or collective window creation) on memory • RMA operations that are imprecise (such access to overlapping
storage) must be permitted, even if the behavior is undefined • The required level of consistency, atomicity, and completeness
should be flexible • Read-modify-write operations and compare and swap are
needed for efficient algorithms • MPI_Get_accumulate, MPI_Compare_and_swap
• Backward compatibility

References • http://www.mcs.anl.gov/research/projects/mpi/
• http://www.mpi-forum.org
• A High-Performance, Portable Implementation of the MPI Message Passing Interface Standard - W. Gropp et al
• MPI-2: Extending the Message Passing Interface - Al Geist et al
• MPICH Abstract Device Interface, version 3.3 Reference Manual
• http://meetings.mpi-forum.org/presentations/MPI_Forum_SC10.ppt.pdf
• http://wissrech.ins.uni-bonn.de/teaching/seminare/technum/pdfs/iseringhausen_mpi2.pdf
• www.sdsc.edu/us/training/workshops/docs





























