Embed Size (px)
Citation preview

Morphology & FSTsShallow Processing Techniques for NLP
Ling570October 17, 2011

RoadmapTwo-level morphology summary
Unsupervised morphology

Combining FST Lexicon & Rules
Two-level morphological system: ‘Cascade’Transducer from Lexicon to IntermediateRule transducers from Intermediate to Surface

Integrating the LexiconReplace classes with stems
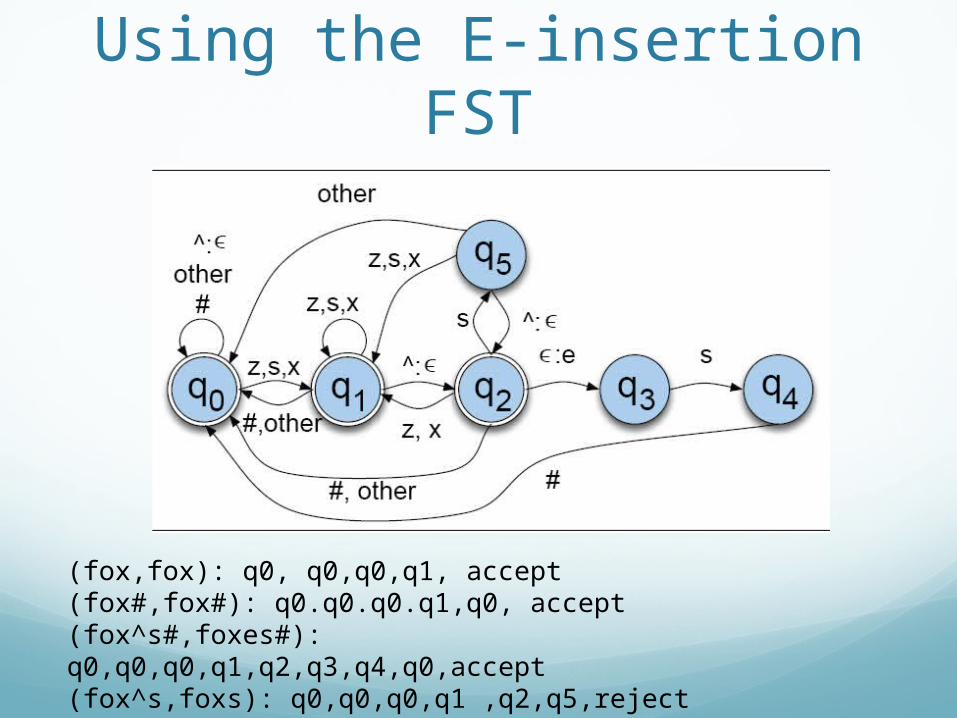
Using the E-insertion FST
(fox,fox): q0, q0,q0,q1, accept(fox#,fox#): q0.q0.q0.q1,q0, accept (fox^s#,foxes#): q0,q0,q0,q1,q2,q3,q4,q0,accept(fox^s,foxs): q0,q0,q0,q1 ,q2,q5,reject(fox^z#,foxz#) ?

IssuesWhat do you think of creating all the rules for a
languages – by hand?Time-consuming, complicated

IssuesWhat do you think of creating all the rules for a
languages – by hand?Time-consuming, complicated
Proposed approach: Unsupervised morphology induction

IssuesWhat do you think of creating all the rules for a
languages – by hand?Time-consuming, complicated
Proposed approach: Unsupervised morphology induction
Potentially useful for many applications IR, MT

Unsupervised MorphologyStart from tokenized text (or word frequencies)
talk 60talked 120walked 40walk 30

Unsupervised MorphologyStart from tokenized text (or word frequencies)
talk 60talked 120walked 40walk 30
Treat as coding/compression problemFind most compact representation of lexicon
Popular model MDL (Minimum Description Length) Smallest total encoding:
Weighted combination of lexicon size & ‘rules’

ApproachGenerate initial model:
Base set of words, compute MDL length

ApproachGenerate initial model:
Base set of words, compute MDL length
Iterate:Generate a new set of words + some model to
create a smaller description size

ApproachGenerate initial model:
Base set of words, compute MDL length
Iterate:Generate a new set of words + some model to
create a smaller description size
E.g. for talk, talked, walk, walked4 words

ApproachGenerate initial model:
Base set of words, compute MDL length
Iterate:Generate a new set of words + some model to create
a smaller description size
E.g. for talk, talked, walk, walked4 words2 words (talk, walk) + 1 affix (-ed) + combination info2 words (t,w) + 2 affixes (alk,-ed) + combination info

Successful ApplicationsInducing word classes (e.g. N,V) by affix patterns
Unsupervised morphological analysis for MT
Word segmentation in CJK
Word text/sound segmentation in English

Unit #1 Summary

Formal Languages Formal Languages and Grammars
Chomsky hierarchy Languages and the grammars that
accept/generate

Formal Languages Formal Languages and Grammars
Chomsky hierarchy Languages and the grammars that
accept/generate
EquivalencesRegular languagesRegular grammarsRegular expressionsFinite State Automata

Finite-State Automata & Transducers
Finite-State Automata:Deterministic & non-deterministic automata
Equivalence and conversionProbabilistic & weighted FSAs

Finite-State Automata & Transducers
Finite-State Automata:Deterministic & non-deterministic automata
Equivalence and conversionProbabilistic & weighted FSAs
Packages and operations: Carmel

Finite-State Automata & Transducers
Finite-State Automata:Deterministic & non-deterministic automata
Equivalence and conversionProbabilistic & weighted FSAs
Packages and operations: Carmel
FSTs & regular relationsClosures and equivalencesComposition, inversion

FSA/FST ApplicationsRange of applications:
ParsingTranslationTokenization…

FSA/FST ApplicationsRange of applications:
ParsingTranslationTokenization…
Morphology:Lexicon: cat: N, +Sg; -s: PlMorphotactics: N+PLOrthographic rules: fox + s foxesParsing & Generation

ImplementationTokenizers
FSA acceptors
FST acceptors/translators
Orthographic rule as FST

Language Modeling

RoadmapMotivation:
LM applications
N-grams
Training and Testing
Evaluation: Perplexity

Predicting WordsGiven a sequence of words, the next word is
(somewhat) predictable: I’d like to place a collect …..

Predicting WordsGiven a sequence of words, the next word is
(somewhat) predictable: I’d like to place a collect …..
Ngram models: Predict next word given previous N
Language models (LMs):Statistical models of word sequences

Predicting WordsGiven a sequence of words, the next word is
(somewhat) predictable: I’d like to place a collect …..
Ngram models: Predict next word given previous N
Language models (LMs):Statistical models of word sequences
Approach: Build model of word sequences from corpusGiven alternative sequences, select the most
probable

N-gram LM ApplicationsUsed in
Speech recognition
Spelling correction
Augmentative communication
Part-of-speech tagging
Machine translation
Information retrieval

TerminologyCorpus (pl. corpora):
Online collection of text of speechE.g. Brown corpus: 1M word, balanced text collectionE.g. Switchboard: 240 hrs of speech; ~3M words

TerminologyCorpus (pl. corpora):
Online collection of text of speechE.g. Brown corpus: 1M word, balanced text collectionE.g. Switchboard: 240 hrs of speech; ~3M words
Wordform: Full inflected or derived form of word: cats,
glottalized

TerminologyCorpus (pl. corpora):
Online collection of text of speechE.g. Brown corpus: 1M word, balanced text collectionE.g. Switchboard: 240 hrs of speech; ~3M words
Wordform: Full inflected or derived form of word: cats,
glottalized
Word types: # of distinct words in corpus

TerminologyCorpus (pl. corpora):
Online collection of text of speechE.g. Brown corpus: 1M word, balanced text collectionE.g. Switchboard: 240 hrs of speech; ~3M words
Wordform: Full inflected or derived form of word: cats,
glottalized
Word types: # of distinct words in corpus
Word tokens: total # of words in corpus

Corpus CountsEstimate probabilities by counts in large
collections of text/speech
Should we count:Wordform vs lemma ?
Case? Punctuation? Disfluency?
Type vs Token ?

Words, Counts and Prediction
They picnicked by the pool, then lay back on the grass and looked at the stars.

Words, Counts and Prediction
They picnicked by the pool, then lay back on the grass and looked at the stars.Word types (excluding punct):

Words, Counts and Prediction
They picnicked by the pool, then lay back on the grass and looked at the stars.Word types (excluding punct): 14Word tokens (“ ):

Words, Counts and Prediction
They picnicked by the pool, then lay back on the grass and looked at the stars.Word types (excluding punct): 14Word tokens (“ ): 16.
I do uh main- mainly business data processingUtterance (spoken “sentence” equivalent)

Words, Counts and Prediction
They picnicked by the pool, then lay back on the grass and looked at the stars.Word types (excluding punct): 14Word tokens (“ ): 16.
I do uh main- mainly business data processingUtterance (spoken “sentence” equivalent)What about:
Disfluenciesmain-: fragmentuh: filler (aka filled pause)

Words, Counts and Prediction
They picnicked by the pool, then lay back on the grass and looked at the stars.Word types (excluding punct): 14Word tokens (“ ): 16.
I do uh main- mainly business data processingUtterance (spoken “sentence” equivalent)What about:
Disfluenciesmain-: fragmentuh: filler (aka filled pause)
Keep, depending on app.: can help prediction; uh vs um

LM TaskTraining:
Given a corpus of text, learn probabilities of word sequences

LM TaskTraining:
Given a corpus of text, learn probabilities of word sequences
Testing:Given trained LM and new text, determine
sequence probabilities, orSelect most probable sequence among
alternatives

LM TaskTraining:
Given a corpus of text, learn probabilities of word sequences
Testing:Given trained LM and new text, determine
sequence probabilities, orSelect most probable sequence among
alternatives
LM types:Basic, Class-based, Structured

Word PredictionGoal:
Given some history, what is probability of some next word?
Formally, P(w|h)e.g. P(call|I’d like to place a collect)

Word PredictionGoal:
Given some history, what is probability of some next word?
Formally, P(w|h)e.g. P(call|I’d like to place a collect)
How can we compute?

Word PredictionGoal:
Given some history, what is probability of some next word?
Formally, P(w|h)e.g. P(call|I’d like to place a collect)
How can we compute?Relative frequency in a corpus
C(I’d like to place a collect call)/C(I’d like to place a collect)
Issues?

Word PredictionGoal:
Given some history, what is probability of some next word? Formally, P(w|h)
e.g. P(call|I’d like to place a collect)
How can we compute? Relative frequency in a corpus
C(I’d like to place a collect call)/C(I’d like to place a collect)
Issues? Zero counts: language is productive! Joint word sequence probability of length N:
Count of all sequences of length N & count of that sequence

Word Sequence ProbabilityNotation:
P(Xi=the) written as P(the)
P(w1w2w3…wn) =

Word Sequence ProbabilityNotation:
P(Xi=the) written as P(the)
P(w1w2w3…wn) =
Compute probability of word sequence by chain rule Links to word prediction by history

Word Sequence ProbabilityNotation:
P(Xi=the) written as P(the)
P(w1w2w3…wn) =
Compute probability of word sequence by chain rule Links to word prediction by history
Issues?

Word Sequence ProbabilityNotation:
P(Xi=the) written as P(the)
P(w1w2w3…wn) =
Compute probability of word sequence by chain rule Links to word prediction by history
Issues? Potentially infinite history

Word Sequence Probability Notation:
P(Xi=the) written as P(the)
P(w1w2w3…wn) =
Compute probability of word sequence by chain rule Links to word prediction by history
Issues? Potentially infinite history Language infinitely productive

Markov AssumptionsExact computation requires too much data

Markov AssumptionsExact computation requires too much data
Approximate probability given all prior wordsAssume finite history

Markov AssumptionsExact computation requires too much data
Approximate probability given all prior wordsAssume finite historyUnigram: Probability of word in isolation (0th order)Bigram: Probability of word given 1 previous
First-order Markov
Trigram: Probability of word given 2 previous

Markov AssumptionsExact computation requires too much data
Approximate probability given all prior words Assume finite history Unigram: Probability of word in isolation (0th order) Bigram: Probability of word given 1 previous
First-order Markov
Trigram: Probability of word given 2 previous
N-gram approximation
)|()|( 11
11
nNnn
nn wwPwwP
)|()( 11
1 k
n
kk
n wwPwPBigram sequence

Unigram ModelsP(w1w2…w3)~

Unigram ModelsP(w1w2…w3) ~ P(w1)*P(w2)*…*P(wn)
Training: Estimate P(w) given corpus

Unigram ModelsP(w1w2…w3) ~ P(w1)*P(w2)*…*P(wn)
Training: Estimate P(w) given corpusRelative frequency:

Unigram ModelsP(w1w2…w3) ~ P(w1)*P(w2)*…*P(wn)
Training: Estimate P(w) given corpusRelative frequency: P(w) = C(w)/N, N=# tokens in
corpusHow many parameters?

Unigram ModelsP(w1w2…w3) ~ P(w1)*P(w2)*…*P(wn)
Training: Estimate P(w) given corpusRelative frequency: P(w) = C(w)/N, N=# tokens in
corpusHow many parameters?
Testing: For sentence s, compute P(s)
Model with PFA: Input symbols? Probabilities on arcs? States?

Bigram ModelsP(w1w2…w3) = P(BOS w1w2….wnEOS)

Bigram ModelsP(w1w2…w3) = P(BOS w1w2….wnEOS)
~ P(BOS)*P(w1|BOS)*P(w2|w1)*…*P(wn|wn-1)*P(EOS|wn)
Training: Relative frequency:

Bigram ModelsP(w1w2…w3) = P(BOS w1w2….wnEOS)
~ P(BOS)*P(w1|BOS)*P(w2|w1)*…*P(wn|wn-1)*P(EOS|wn)
Training: Relative frequency: P(wi|wi-1) = C(wi-1wi)/C(wi-1)
How many parameters?

Bigram ModelsP(w1w2…w3) = P(BOS w1w2….wnEOS)
~ P(BOS)*P(w1|BOS)*P(w2|w1)*…*P(wn|wn-1)*P(EOS|wn)
Training: Relative frequency: P(wi|wi-1) = C(wi-1wi)/C(wi-1)
How many parameters?
Testing: For sentence s, compute P(s)
Model with PFA: Input symbols? Probabilities on arcs? States?

Trigram ModelsP(w1w2…w3) = P(BOS w1w2….wnEOS)

Trigram ModelsP(w1w2…w3) = P(BOS w1w2….wnEOS)
~ P(BOS)*P(w1|BOS)*P(w2|BOS,w1)*… *P(wn|wn-2,wn-
1)*P(EOS|wn-1,wn)
Training: P(wi|wi-2,wi-1)

Trigram ModelsP(w1w2…w3) = P(BOS w1w2….wnEOS)
~ P(BOS)*P(w1|BOS)*P(w2|BOS,w1)*… *P(wn|wn-2,wn-
1)*P(EOS|wn-1,wn)
Training: P(wi|wi-2,wi-1) = C(wi-2 wi-1wi)/C(wi-2wi-1)
How many parameters?

Trigram ModelsP(w1w2…w3) = P(BOS w1w2….wnEOS)
~ P(BOS)*P(w1|BOS)*P(w2|BOS,w1)*… *P(wn|wn-2,wn-
1)*P(EOS|wn-1,wn)
Training: P(wi|wi-2,wi-1) = C(wi-2 wi-1wi)/C(wi-2wi-1)
How many parameters?
How many states?

Speech and Language Processing - Jurafsky and Martin
An Example<s> I am Sam </s>
<s> Sam I am </s>
<s> I do not like green eggs and ham </s>

RecapNgrams:
# FSA states:

RecapNgrams:
# FSA states: |V|n-1
# Model parameters:

RecapNgrams:
# FSA states: |V|n-1
# Model parameters: |V|n
Issues:

RecapNgrams:
# FSA states: |V|n-1
# Model parameters: |V|n
Issues:Data sparseness, Out-of-vocabulary elements
(OOV) Smoothing
Mismatches between training & test dataOther Language Models


























![[Nlp ebook] anne linden - mindworks - nlp tools](https://img.pdfslide.us/doc/110x75/55b3712cbb61eb73368b45f7/nlp-ebook-anne-linden-mindworks-nlp-tools.jpg)


