Embed Size (px)
Citation preview

CHAPTER 6
MORPHOLOGICAL CROSS
REFERENCE METHOD
FOR ENGLISH TO
TELUGU
TRANSLITERATION

192
6.1 INTRODUCTION
Transliteration is the technique of mapping text written in one language using
the orthography of another language by means of a pre-defined mapping. In general,
the mapping between the alphabet in one language and the other in a transliteration
scheme will be as close as possible to the pronunciation of the word. Depending on
various factors like mapping, pronunciation etc., a word in one language can have
more than one possible transliterations in the other language. This is more frequently
seen in the case of transliteration of named entities and vocabulary words. This kind
of transliterated text is often referred by the words formed by a combination of
English and the language in which transliteration is performed like Telugu, Hindi etc.
It is useful when a is familiar with knows a language but does not know how to write
its script and in case of unavailability of a direct method to input data in a given
language. However, English to Telugu transliterated text has found widespread use
with the growth of Internet usage in the form of mails, chats, blogs and other forms of
individual online writing.
A corpus is generally regarded as a bank of machine-readable authentic texts
that are sampled to be representative of a particular language or language variety. A
parallel corpus is a corpus which contains both source texts and their transliterations
in the target language. Parallel corpora can be built to serve diverse purposes, such as
bilingual dictionary compilation, machine transliteration, language teaching etc.
Morphological method deals with both Grapheme and phoneme based
transliteration. In Graphemic approach, the source language word is split into
individual sound elements. For example: bharath is split as bha-ra-th, b(బ్),h(హ్),a(అ)

193
are combined to form bha(భ),r(ర్),a(అ) are combined to form ra(ర),t(ట్),h(హ్) are
combined to form th(త్) by using an input mapping table. The table contains the
phonetically equivalent combination of target language alphabets in terms of the
source language and its relevant Unicode hexadecimal value of target language
alphabets. According to the source input , the exact hexadecimal Unicode equivalent
of the target language is retrieved and displayed as transliterated text.
Generally characters in English and Telugu languages do not adhere to a one-
to-one mapping because English has 26 alphabets and Telugu has 56 alphabets. So
our system combines Grapheme model with the Phoneme based transliteration model
in which a parallel corpus is maintained which contains source English words and
Telugu phonetically equivalent Romanized text in terms of the source language. For
example: ‘period’ English word has its relevant Romanized text as ‘piriyad’. If
‘period’ is transliterated using Grapheme based model the result is ‘పెరిఒడ్’ but by
combining Grapheme with Phoneme we can get exact transliteration which is
'పిరియడ్'.
This system provides a user friendly environment, which is platform and
browser independent, case insensitive with the vocabulary words which are placed in
parallel corpus, case sensitive to the general text, so our transliteration system will
work very quickly and provides accurate results when compared to the other
transliteration systems like Google, Baraha, Quillpad etc.

194
MOTIVATION
Telugu is one of the fifteen most spoken languages in the world, the third most
spoken language in India which is the official language of Andhra Pradesh. Telugu
has 56 alphabets, among them 18 are vowels and 38 are consonants and English has
26 alphabets among them 5 are vowels and 21 are consonants. By using Unicode
mapping for phonetic variants of each vowel and consonant, the English text can be
transliterated to Telugu. One problem here in Transliteration is a text input method
[104]. Most of the users of Indian language on the Internet are those who are familiar
with typing using an English keyboard. Hence, instead of introducing them to a new
Telugu keyboard designed for Indian languages, it is easier to let them type their
source language words using the Roman script. For Indian Languages, many tools and
applications have been designed for text input method [104]. However, Telugu still
does not have a user efficient text input method and a user friendly environment,
which is widely accepted and used, and an evaluation of the existing methods has not
been performed in a structured manner to standardize on an efficient and accurate
input method. Another problem with transliteration is, when we consider a word
without knowledge of pronunciation, the transliteration (Grapheme) will be different
from the transliteration (Phoneme) of the word with knowledge of pronunciation. This
thesis tries to solve the above problem by combining Grapheme and Phoneme based
Transliteration models to form a new Model called Morphological Cross Reference
Method, which produces correct transliteration for Dictionary words with the
knowledge of pronunciation and without knowledge of pronunciation produces same
transliteration for Out of Vocabulary words when compared with other transliteration
systems.

195
OBJECTIVE
India is a multi-language, multi-script country where different languages have
different scripts. Nowadays, many people know how to speak in different languages
but they are not aware of the scripts of different languages. Transliteration is a method
where the user can write in one language and it will be converted into another
language automatically. Parallel Corpus based Morphological Cross Reference
Approach is one of the Machine transliteration models which combine both grapheme
and phoneme based transliteration models. Machine transliteration plays an important
role in many multilingual speech and language applications. Many models which
were designed for the transliteration purpose are given importance either to sound or
spelling of the word. The main objective of this project is to transliterate the words by
considering both the spelling and the pronunciation of a word where user can easily
write the text either using the spelling of the word or based on the pronunciation for
which Morphological Cross Reference Approach is applied for the transliteration
purpose. In addition to this another important objective of this project is to
transliterate English document where the complete text in a file will be transliterated
into Telugu language.
6.1.1 TELUGU CHARACTER SET
Telugu has 56 alphabets, among them 18 are vowels and 38 are consonants.
English has 26 alphabets among them 5 are vowels and 21 are consonants. By using
Unicode mapping for phonetic variants of each vowel and consonant, the English text
can be transliterated to Telugu. The Telugu character set and related English alphabet
are given below.

196
Figure.6.1.Telugu Character Set
6.1.2 DIVERSITY OF INDIAN LANGUAGES
India is a multi-lingual nation with 17 languages recognized as official
languages. These languages are: 1) Assamese 2) Tamil 3) Malayalam 4) Gujarati 5)
Telugu 6) Oriya 7) Urdu 8) Bengali 9) Sanskrit 10) Kashmiri 11) Sindhi 12) Punjabi
13) Konkani 14) Marathi 15) Manipuri 16) Kannada and17) Nepali. Except Urdu and
English, all of the remaining official languages have a common phonetic base, i.e.,
they share a common set of speech sounds across all of these languages. While all of
these languages share a common phonetic base, some of the languages such as Hindi,

197
Marathi and Nepali also share a common script known as Devanagari. But languages
such as Telugu, Kannada and Tamil have their own script. Each of these languages
has their own scripts. The property that makes these languages separate could be
attributed to Phonotactics that takes place in each of these languages rather than the
scripts and the speech sounds. Phonotactics deals with the permissible combinations
of phones that can co-occur in a language.
THE SHAPE OF AN AKSHARA
The shape of an Akshara depends on its composition of consonants and the
vowel. It is also dependant on the sequence of the consonants. Of defining the shape
of an Akshara , one of the consonant symbols acts as a pivotal symbol. Depending on
the context, an Akshara can have a complex shape with another consonant and vowel
symbols being placed on top, below, before, after or sometimes surrounding the
pivotal symbol. The following are reasonable representations of Telugu Aksharas:
Vowel
Consonant + vowel
Literature Review
English to Telugu Translator
Consonant + Vowel
Consonant + consonant + vowel
Ideally the basic rendering unit for Indian language scripts should be Aksharas
themselves. However, a language such as Telugu has around 15 vowels and 36
consonants. To render Aksharas as a whole unit, one would require 540 CV units,
19440 CCV units and 699840 CCCV units. It is reasonable to assume that all

198
combinations of consonant clusters are not allowed, but even then one might be
required.
6.1.3 PROBLEMS WITH TELUGU CHARACTERS
In Telugu many characters have the same sound with different representation.
There are many problems with the Telugu language character set. They are :
ENCODING
Encoding problems occur in Telugu language during the character
representation, because Telugu language has multiple spelling variants for the same
word. The following characters create encoding problem for ‘kalam’ (pen) without
dictionary base, it becomes as కలం, ఖలం, కళమ్
SEGMENTATION
The process of breaking words into meaningful words is called segmentation.
A good segmentation leads to improving the precision rate, it makes searching easy in
search engines and IR systems. Generally segmenting English words is very easy
because it maintains a limited list of suffixes, prefixes and compound words, whereas
in Telugu segmentation process is difficult.
SPELLING VARIATIONS
Telugu language is rich in character set, in which characters have same
phonetic sounds, some words have the same meaning with different characters.

199
6.1.4 UNICODE
Computers can only interpret the bits and bytes and hence the representation
of a script should also be defined in terms of bits and bytes. ASCII – American
Standard Code for Information Interchange is a 8-bit code representing the English
character set. Similarly there is an Indian Standard Code for Information Interchange
(ISCII) that defines a 8-bit character code for Indian language scripts. However, both
these codes overlap and hence the computers on which ASCII character set is enabled
would not able to interpret ISCII as a code for Indian language scripts. With an 8-bit
code, one can define only 256 unique characters. To allow computers to represent any
character in any language, the international standard ISO 10646 defines the Universal
Character Set (UCS). The UCS contains the characters practically to represent all
known languages in the world. ISO 10646 originally defined a 32-bit character set.
Each character is assigned a 32 bit code, however, these codes vary only in the least-
significant 16 bits.
Though started as two projects, finally merged their character set around 1991
and both are compatible with each other. In addition to the character set, Unicode
standard specifies the recommendation for the rendering of the scripts, handling of bi-
directional texts that mix for instance Latin (left to right writing system) and Hebrew
(right to left writing system), algorithms for storage and manipulation of Unicode
strings.
UTF-8 AND UTF-16
It has to be noted that Unicode is a table of codes that assign integer numbers
to characters. One still has to define its implementation or encoding in the computers.

200
A straightforward encoding of these integers is to store the Unicode text as sequences
of 2 byte sequences. This encoding is referred to as UTF-16. An ASCII file can be
transformed into a UTF-16 file by simply inserting a 0x00 byte in front of every
ASCII byte. However, operating systems such as Unix/Linux have been written based
on ASCII (1 byte code) character set and they expect each byte as a character. For
these reasons, UTF-16 may not be an appropriate encoding of Unicode in the case of
filenames, text files, environment variables, etc. The UTF-8 encoding is a solution to
use Unicode in compatible with operating systems working with 1-byte characters.
UTF-8 has the following properties:
Unicode characters U+0000 to U+007F (ASCII) are encoded simply as Bytes
0x00 to 0x7F( ASCII compatibility). This means that files and strings which
contain only 7-bit ASCII characters have the same Encoding under both ASCII
and UTF-8.
All Unicode characters >U+007F are encoded as a sequence of several bytes, each
of which has the most significant bit set. Therefore, no ASCII byte (0x00-0x7F)
can appear as part of any other character.
The first byte of a multibyte sequence that represents a non-ASCII character is
always in the range 0xC0 to 0xFD and it indicates how many bytes follow for this
character.
All further bytes in a multibyte sequence are in the range 0x80 to 0xBF. This
allows easy resynchronization and makes the encoding stateless and robust against
missing bytes.
UTF-8 encoded characters may theoretically be up to six bytes long to Handle 32-
bit character set, however 16-bit characters are only up to three bytes long.
The bytes 0xFE and 0xFF are never used in the UTF-8 encoding. These Bytes are
used to denote the byte order for the UTF-16 codes.

201
REPRESENTATION OF INDIAN LANGUAGE SCRIPTS
Having known the syllabic nature of Indian language scripts, it is easy to
understand the notation followed by the Unicode to represent Indian language
characters. The following are the principles used by Unicode to represent the Indian
language characters.
A Unicode is assigned to each consonant symbol, i.e., a consonant sound
along with the inherent vowel.
Each independent vowel is represented by a Unicode
Each Maatra is also represented by a Unicode.
Viraam has a Unicode number too.
The following are Unicode Ranges for Indian Languages:
Tamil : 0B82 to 0BFA
Oriya : 0B01 to 0B71
Guajarati : 0A81 to 0AF1
Telugu : 0C01 to 0C7F
Kannada : 0C82 to 0CF2
UNICODE RENDERING RECOMMENDATIONS
It should be noted that half-forms of the consonants are not represented by the
Unicode. The half-forms are essential to render Aksharas involving consonant
clusters. The Unicode recommendation for rendering resolves the issue of half-forms.
These rules describe the mapping between Unicode characters and the glyphs in a
font. They also describe the combining and ordering of these glyphs. These

202
recommendations are used to build Unicode rendering engines in Windows and Linux
operating systems to display Unicode characters.
6.1.5 TELUGU UNICODE CHARACTERS
The Unicode helps in mapping English characters to Telugu by converting
English alphabets into Unicode characters.
Figure 6.2: Telugu Unicode Character Set
6.2 RELATED WORK

203
There has been a large amount of interesting work in the area of
Transliteration from the past few decades.
[103] proposed the problem of transliterating English to Kannada using SVM
kernel which is modelled using the sequence labelling method. This framework is
based on data driven method and one to one mapping approach which simplifies the
development procedure of the transliteration system.[104] proposed a simple and
efficient technique for text input in Telugu in which Levenshtein distance based
approach is used. This is because of the relation between the nature of typing Telugu
through English and Levenshtein distance.
[105] identified a critical issue namely the incomplete search-results problem
resulting from the lack of a translation standard on foreign names and the existence of
synonymous transliterations in searching the Web to address the issue of using only
one of the synonymous transliterations as search keyword will miss the web pages
which use other transliterations for the foreign name, they proposed a novel two-stage
framework for mining as many synonymous transliterations as possible from Web
snippets with respect to a given input transliteration.
[106] proposed a supervised transliteration person name identification process,
which helps to classify the types of the query Lexicon and concepts of transliteration
characters and transliteration probability of a character.
[107] introduced a transliteration approach to semantic languages, easy way
and fast process in Jawi to Malay transliteration in which Jawi stemming process was
developed to make a word as short as possible but only focus on root word and some

204
prefix and suffix. Vocal filtering and diftong filtering methods are also introduced to
make a word simpler in the Unicode mapping process in which Jawi-Malay rules are
also applied to make the output more accurate. Other than the above stated method, a
dictionary database also provided for checking the words that cannot be found while
process occurs. This alternative method is used because format writing in Jawi is not
remained.
[108] proposed a new statistical modelling approach to the machine
transliteration problem for Chinese language by using the EM algorithm. The
parameters of this model are automatically learned from a bilingual proper name list.
Moreover, the model is applicable to the extraction of proper names.
[109] modeled the statistical transliteration problem as a language model for
post-adjustment plus a direct phonetic symbol transcription model, which is an
efficient algorithm for aligning phoneme chunks as a statistical transliteration method
for automatic translation according to pronunciation similarities, i.e. to map phonemes
comprising an English name to the phonetic representations of the corresponding
Chinese name
6.3 METHODOLOGY
This chapter deals with transliteration of a given word combining alphabet by
alphabet and transliteration of a given document completely
6.3.1 ALPHABET BY ALPHABET TRANSLITERATION
The whole model consists of two important phases:

205
Figure.6.3.Transliteration Procedure
6.3.1.1 PRE-PROCESSING PHASE
In pre-processing phase, English vocabulary words for which transliteration
will not produce correct results will be Romanized and Aligned in the parallel corpus
which is used in Transliteration phase to get the correct result.
ROMANIZATION
During this step, the transliteration system is trained in those words which
can’t be exactly transliterated using either Grapheme or Phoneme individually.

206
During the training step, first the words are converted into their phonetics and then
according to phonetic symbols, Telugu phonemic equivalent words in terms of
English alphabets are generated and maintained as a parallel corpus. Sample parallel
corpus is shown below.
<note>
<aback>abAk</aback>
<abacus>Abakas</abacus>
<abaft>abAft</abaft>
<abandon>abAndan</abandon>
<abandoned>abAndand</abandoned>
<abase>abeis</abase>
<abashed>abAShd</abashed>
<abate>abeit</abate>
<abattoir>AbatwA</abattoir>
<abbacy>Abasi</abbacy>
<abbess>Abes</abbess>
<abbey>Abi</abbey>
<abbot>Abat</abbot>
<abbreviate>abreevieit</abbreviate>
<abc>eibeesee</abc>
<abdicate>Abdikeit</abdicate>
<abdomen>Abdaman</abdomen>
<abduct>Abdakt</abduct>
<abeam>abeem</abeam>
<aberdonian>aberdnian</aberdonian>
<aberrant>Aberant</aberrant>

207
<aberration>AbareiShan</aberration>
<abet>abet</abet>
<abeyance>abeians</abeyance>
<abhor>abhO</abhor>
<abhorrence>abhorans</abhorrence>
<abhorrent>abhorant</abhorrent>
<abide>abaid</abide>
</note>
Table.6.1: Word Phonetic Transcription
English word
Phonetic
transcription
Romanized
word
Period pİriəd Piriad
Eagle i:gəl Eegal
Care Ker Ker
ALIGNMENT
XML is used for storage in parallel corpus in which English words and
Romanized words are aligned each other. Our Transliteration system is platform
independent because of using XML for storage purpose and Java script is used for
retrieval of the Parallel Corpus.
6.3.1.2 TRANSLITERATION PHASE
In transliteration phase the user entered English text or given file will be
transliterated into Telugu text.

208
SEARCHING PARALLEL CORPUS
For each word entered by the user it will search in Parallel Corpus. If a word is
found in Parallel corpus, the original source word will be replaced with its Romanized
equivalent word and it will be sent to Segmentation stage. Otherwise, original source
word will be sent for the Segmentation stage.
SEGMENTATION
Based on combination of vowels and consonants the source language text will
be segmented. Generally the segmentation unit will end with a vowel. Each
segmented unit is called Transliteration unit. There are four rules which are to be
followed while segmenting. They are described below with an example
For example: Consider the word ‘piriad’
i. Consonant followed by vowel pi
ii. Consonant followed by consonant ri
iii. Vowel followed by consonant ad
iv. Vowel followed by vowel ia
During Segmentation, two or more alphabets can be phonetically combined
only when it had consonant followed by a vowel or a consonant followed by
consonant and off remaining two, each alphabet is uniquely mapped.
Before Segmentation After Segmentation
p i r i y a d pi | ri | a |d
UNICODE MAPPING

209
For each alphabet in English, a hexadecimal unique code is mapped and for
transliteration units which are obtained from the Segmentation stage these Unicode’s
are combined to get phonetically equivalent Telugu alphabets. This method can
convert English text into phonetically equivalent ones in Telugu. For Telugu, Unicode
range varies from 0C01 - 0C7F.
pi | ri | a | d
పి | రి | అ | డ
If a user enters text in the text - area of GUI, the output will be displayed on
another text-area which is on the same GUI. Otherwise, the transliterated text will be
saved in another file in the same directory as the source file that is given as input. The
mapping of letters is given below:
var vowels =
"(A(O)?)|(E)|(H)|(I)|(M)|(O)|(TR)|(U)|(a((a)|(e)|(i)|(u))?)|(e(e)?)|(i)|(o((a)|(o))?)|(tR)|(u)
|(an)"
var consonants =
"(B(h)?)|(Ch)|(D(h)?)|(G)|(J(h)?)|(K(h)?)|(L)|(N)|(R)|(Sh)|(T(h)?)|(b(h)?)|(ch)|(d(h)?)|(
g(h)?)|(h)|(j(h)?)|(k(h)?)|(l)|(m)|(n(Y)?)|(p(h)?)|(f)|(r)|(s(h)?)|(S)|(t(h)?)|(v)|(w)|(y)|(c)|(q
)|(z)|(Z)"
var numbers ="(1)|(2)|(3)|(4)|(5)|(6)|(7)|(8)|(9)|(0)"
var letter_codes = {
"0":"౦",

210
"1":"౧",
"2":"౨",
"3":"౩",
"4":"౪",
"5":"౫",
"6":"౬",
"7":"౭",
"8":"౮",
"":"౯",
"9":"౰",
"an" : "ం",
"~a" : "అ",
"~aa" : "ఆ",
"~A" : "ఆ",
"~i" : "ఇ",
"~ee" : "ఈ",
"~I" : "ఈ",
"~u" : "ఉ",
"~oo" : "ఊ",
"~U" : "ఊ",
"~oa" : "ఓ",
"~O" : "ఓ",
"i" : "ి",
"ee" : "ీ",
"I" : "ీ",
"u" : "ు",
"oo" : "ూ",
"U" : "ూ",
"e" : "ె",
"ae" : "ే",
"E" : "ే",
"ai" : "ై",
"o" : "ొ",
"oa" : "ో",
"O" : "ో",
"au" : "ౌ",
"tR" : "ృ",
"TR" : "ౄ",
"G" : "ఙ",
"z":"ఙ",
"ch" : "చ",
"Ch" : "ఛ",
"j" : "జ",
"jh" : "ఝ",
"J" : "ఝ",
"Jh" : "ఝ",
"nY" : "ఞ",
"t" : "ట",
"T" : "ఠ",
"d" : "డ",
"D" : "ఢ",
"N" : "ణ",
"th" : "త",
"Th" : "థ",
"B" : "భ",
"bh" : "భ",
"Bh" : "భ",
"m" : "మ",
"y" : "య",
"r" : "ర",
"R" : "ఱ",
"l" : "ల",
"L" : "ళ",
"v" : "వ",
"w":"వ",
"sh" : "శ",
"Sh" : "ష",
"s" : "స",
"S" : "స",
"h" : "హ",

211
"~au" : "ఔ",
"~tR" : "ఋ",
"~TR" :
"ౠ",
"a" : "",
"aa" : "ా",
"A" : "ా",
"k" : "క",
"q":"క",
"K" : "క",
"kh" : "ఖ",
"Kh" : "ఖ",
"g" : "గ",
"gh" : "ఘ",
"dh" : "ద",
"Dh" : "ధ",
"n" : "న",
"p" : "ప",
"ph" : "ఫ",
"f":"ఫ",
"b" : "బ",
"AO" : "ఁ",
"M" : "ం",
"H" : "ః",
"~AO" :
"ఁ",
"~M" : "ం",
"~H" : "ః",
"*" : "్"
}
6.3.2 TOTAL FILE TRANSLITERATION
In the total file transliteration first a screen will be appeared as shown in the
appendix A. From that we need to select the file that is to be used as input by clicking
the button browse. After selection of input file press the submit query button. The
output file will be saved in the same location as that of input file location with the
name “output” as an extension to input file. The procedure followed for file
transliteration is first file split into words. These spilt words are given as input to the
alphabet by alphabet transliteration.
6.4 EVALUATION AND RESULTS
The proposed model is trained for 50,000 words containing English
vocabulary words. The model is evaluated by taking articles and checking the

212
correctness of transliteration by comparing with the Google transliteration system.
Accuracy of the system is calculated using the following equation:
(
)
where C indicates the number of test words with correct transliteration when
compared with Google transliteration systems and N indicates the total number of test
words.
6.4.1 COMPARISON WITH GOOGLE TRANSLITERATION SYSTEM
By comparing our Morphological Cross Reference System with publicly
available Google Indic Transliteration System ,the accuracy of the two systems is
observed .The system is evaluated by considering a random set of articles and
accuracy is experimentally calculated using equation 1.
6.4.1.1 ACCURACY BY TAKING DOCUMENTS AS INPUT
Accuracy of transliteration for 10 different articles which are taken from
Hindu News Paper for Google and MCR systems is presented in Table 6.2.
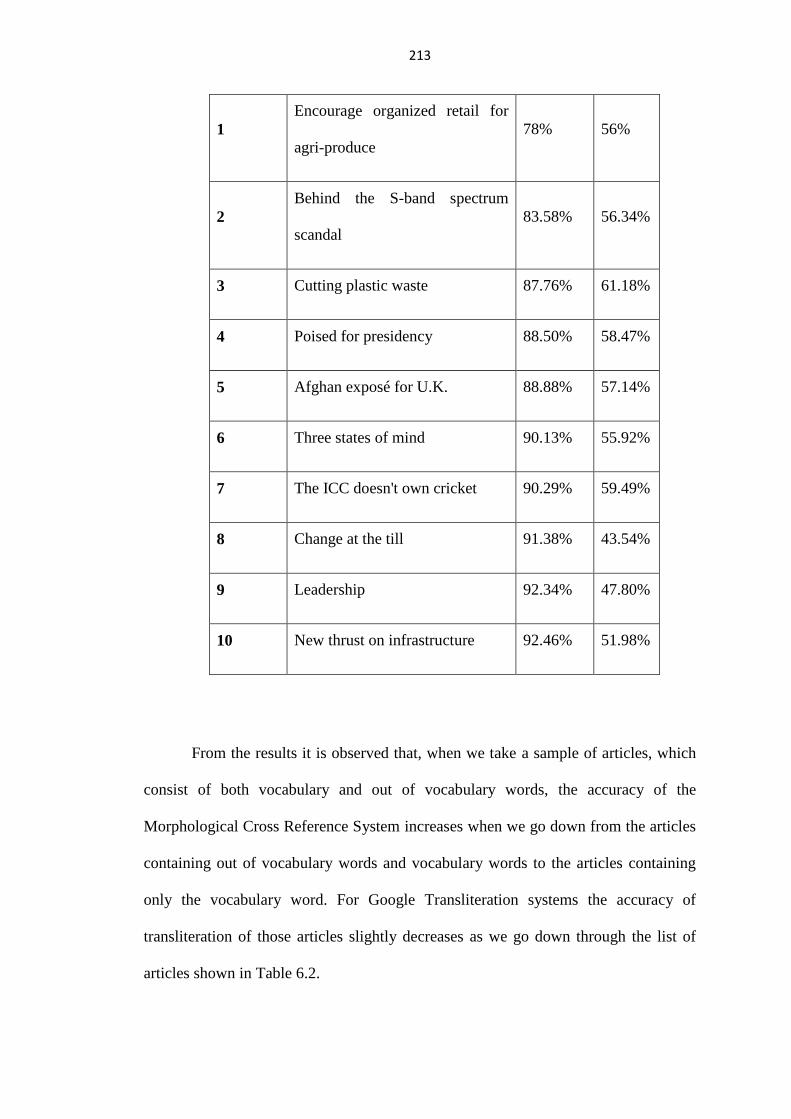
Table.6.2: Transliteration Accuracy
No. Article MCR Google
213
From the results it is observed that, when we take a sample of articles, which
consist of both vocabulary and out of vocabulary words, the accuracy of the
Morphological Cross Reference System increases when we go down from the articles
containing out of vocabulary words and vocabulary words to the articles containing
only the vocabulary word. For Google Transliteration systems the accuracy of
transliteration of those articles slightly decreases as we go down through the list of
articles shown in Table 6.2.
1
Encourage organized retail for
agri-produce
78% 56%
2
Behind the S-band spectrum
scandal
83.58% 56.34%
3 Cutting plastic waste 87.76% 61.18%
4 Poised for presidency 88.50% 58.47%
5 Afghan exposé for U.K. 88.88% 57.14%
6 Three states of mind 90.13% 55.92%
7 The ICC doesn't own cricket 90.29% 59.49%
8 Change at the till 91.38% 43.54%
9 Leadership 92.34% 47.80%
10 New thrust on infrastructure 92.46% 51.98%
214
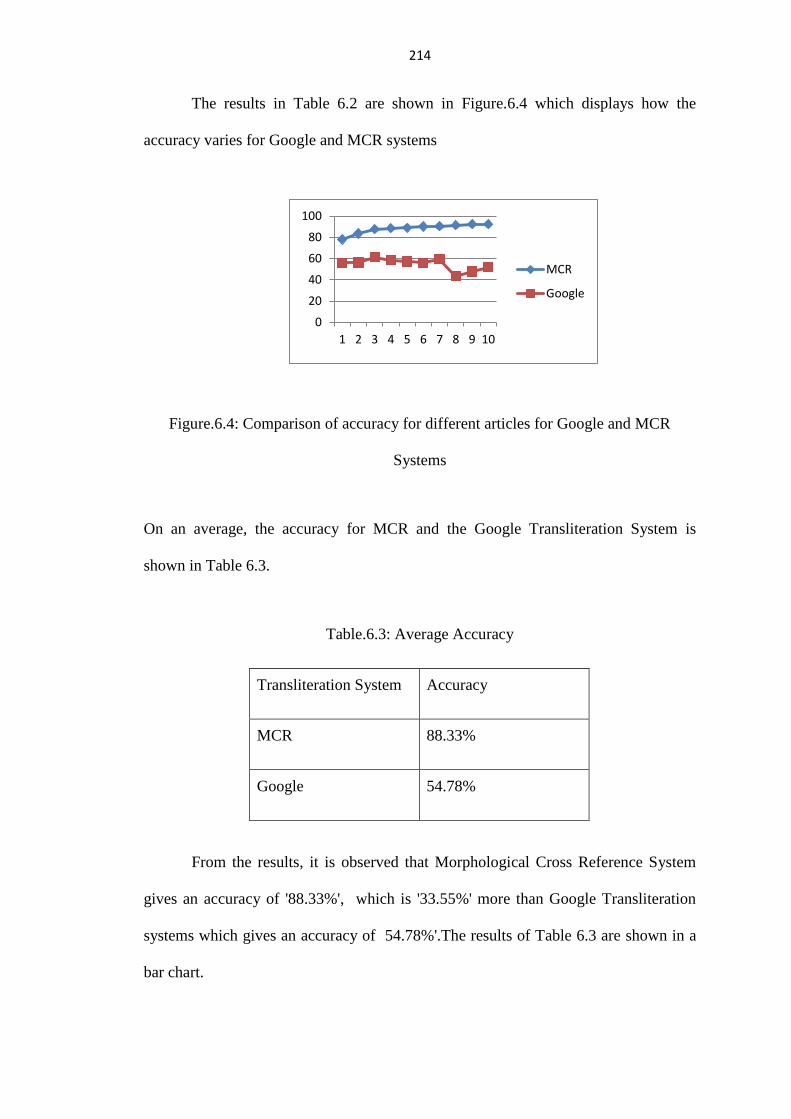
The results in Table 6.2 are shown in Figure.6.4 which displays how the
accuracy varies for Google and MCR systems
Figure.6.4: Comparison of accuracy for different articles for Google and MCR
Systems
On an average, the accuracy for MCR and the Google Transliteration System is
shown in Table 6.3.
Table.6.3: Average Accuracy
Transliteration System Accuracy
MCR 88.33%
Google 54.78%
From the results, it is observed that Morphological Cross Reference System
gives an accuracy of '88.33%', which is '33.55%' more than Google Transliteration
systems which gives an accuracy of 54.78%'.The results of Table 6.3 are shown in a
bar chart.
0
20
40
60
80
100
1 2 3 4 5 6 7 8 9 10
MCR

215
0
20
40
60
80
100
Accuracy
MCR
Figure.6.5. Comparison of overall accuracy for Google and MCR Systems
As per the graph, the variation among the best Transliteration System and our
system are proven high.
6.4.1.2. ACCURACY BY TAKING SILENT WORDS AS INPUT
A sample Test Data used to compare the results of our model with that of a
Google Transliteration System for Vocabulary words excluding silent words which
are taken from a Leader ship article from the Hindu News Paper are shown in
Table.6.4.
Table.6.4.Transliterated Text for MCR and Google System
Sample English Text

216
This kind of sing or swim approach wherein the leaders are allowed to learn
tough lessons by going through their own trials by fire can prove to be
extremely costly both to the organisation and the leaders . The testing process
can turn out to be too tumultuous at times causing severe blows to the bottom
line and the leader’s morale as well. It is here that executive coaching comes
to play an important role.
Transliterated Text
MCR System Google Transliteration System
థిస్ క ైన్్డ అవ్ సింగ్ ఓర్ సిిమ్ అప్రొ ఉచ్
వెరిన్డ ది లీడర్్ ఆర్ అలౌడ్ టూ లార్న్ టఫ్
లెసన్డ్ బ ై గొఉఇంగ్ త్రొ దెర్ ఒఉన్డ ట్ైఅైల్స్
బ ై ఫెైఅర్ కయాన్డ ప్రూ వ్ టూ బీ ఇకట్రొమి్ల కయసిలి
బొ ఉత్ టూ ది ఓరగనెైఙెఇషన్డ ఆన్్డ ది లీడర్్
. ది ట్సిటంగ్ ప్రొ క స్్ కయాన్డ టార్న్ ఔట్ టూ
బీ టూ టూమలచూఅస్ ఆట్ ట్ైమ్్
కయఙ ంగ్ సివిఅర్ బొి ఉస్ టూ ది బాటమ్
లెైన్డ ఆన్్డ ది లీడర్్ మొరయాల్స ఆఙ్ వెల్స .
థిస్ క ంద అఫ్ సింగ్ ఓర సిిమ్ అప్్ రోఅచ్
వహేరేయిన్డ ది లేఅదేర్్ అర అలలి వహడ్ తో
లేఅర్్ తౌఘ్ లేసర ్ంస్ బ ై గోయింగ్ త్రొ
థేఇర్ ఒవ్్ త్రొఅల్స్ బ ై ఫెైర్ కయన్డ ప్్ొ వహ తో బ
ఎక్ష్త ర ూమెల్సా కయస్లి బొ త్ తో ది ఓరయగ నిసత్రఒన్డ
అండ్ది లెఅదేర్్. ది ట్సిటంగ్ ప్యొసెస్ కయన్డ
త్రర్్ అవుట్ తో బ టూ త్ఉములతర ఔస్
అట ట్ైమ్్ కయఉసింగ్ సేవహరే బలి వ్్ తో ది
బొ త్ర ం లెైన్డ అండ్ ది లేఅదేర్్ మొరయలే

217
6.4.1.3. ERROR RATE
The error rate is defined as the ratio of wrongly transliterated words to a total
number of Test words. The error rate of the MCR System can be calculated using the
following equation
(
)
where W indicates the number of wrongly Transliterated words when
compared with the Google Transliteration System and N is the total number of test
words.
The error rate for the MCR system is more when we consider the out of
ఇట్ ఇస్ హిఅర్ దయాట్ ఇగ ెకతాట వ్ కొఉచంగ్
కమ్్ టూ పెిఇ యాన్డ ఇమ్పోరటన్డట రొఉల్స
అస్ వెల్స. ఇట ఇస్ హియర్ తయత్
ఎక్ష్త కతత్రవె కోచంగ్ కయమేస్ తో పేి అన్డ
ఇమ్పోరరంట్ రోల్స.

218
vocabulary words like Ghulam Nabi Azad (ఙే్హలమ్ ణబి ఆఙడ్), Manmohan Singh
(ంంఅనమొహన్డ సిన్్డ), and for the abbreviations like GSM (ఙ్ం), ICC(ఈసిసి) but, is less
for vocabulary words lecture(లెకూర్), inflation(ఇనెలిఇషన్డ).
The error rate for the Google system is more when we consider vocabulary
words like lecture (లెచ్తర ర ), inflation (ఇంఫి్త్రఒన్డ) and also for abbreviations like
GSM(గ్్ం), ICC (ఇచ్్) but error rate is less for out of vocabulary words like Ghulam
Nabi Azad( ఘులం నబి అజాద్), Manmohan Singh (మనమొహన్డ సింగ్).
The system is evaluated by considering set of articles and the error rates which
are obtained by using equation 2 are shown in Table 6.5.
For MCR system, Error Rate is calculated using the above formula and found
as '0.22' and that of Google is '0.40' for Vocabulary words excluding Silent words. In
the vocabulary , a word including the Silent word error rate of the MCR system is
found as 0.19 and that on Google is found as 0.51.The error rates for our System and
already existing system are tabulated below.

219
Table.6.5.Comparision of Error Rates
Article MCR Google
1 0.22 0.444
2 0.1642 0.4366
3 0.1224 0.3882
4 0.1150 0.4153
5 0.1112 0.4286
6 0.0987 0.4408
7 0.0971 0.4051
8 0.0862 0.5646
9 0.0766 0.522
10 0.0754 0.4802
The results of error rates in Table 6.5 are shown in Figure 6.6. which displays how the
error rate varies for MCR and Google systems.

220
Figure.6.6. Graphical Representation of Comparison of Error rates for a set of
articles
On an average, the error rates for MCR and the Google Transliteration System are
shown in Table 6.6
Table.6.6. Comparison of Average Error Rates
The Average error rate for MCR and the Google Transliteration system is
graphically represented in Figure 6.7
Transliteration System Error Rate
MCR 0.1168
Google 0.4514
0
0.1
0.2
0.3
0.4
0.5
0.6
1 2 3 4 5 6 7 8 9 10
MCR

221
Figure 6.7.Graphical Representation of Comparison of Average Error rate
Hence by observing the above graph, we can say that our MCR system will
produce less error rates than that of Google Transliteration System.
6.5 SUMMARY
The work presented in this chapter addressed the problem of transliterating
English to Telugu language using Morphological Cross Reference System. This
framework is based on data driven method and one to one mapping approach and it
simplifies the development procedure of the transliteration system and facilitates
better improvement in transliteration accuracy when compared with the Google
Transliteration System. The model is trained in English Vocabulary words that don't
have exact transliteration by considering Phonemic or Grapheme Transliteration
models individually. The system is evaluated by considering set of English articles
and comparing the Telugu transliterated text with Google Transliteration system. The
model will work efficiently for English vocabulary words and in future , it will be
extended to work accurately for named entities and proper nouns also. We hope this
will be very useful in natural language applications like creating blogs, chatting,
sending emails and in many areas.
0
0.1
0.2
0.3
0.4
0.5
Error rate
MCR





























