Embed Size (px)
Citation preview

James MaloneProduct Manager
More data. Zero headaches.Making the Spark and Hadoop ecosystem fast, easy, and cost-effective.

Google Cloud Platform 2
Cloud Dataproc features and benefits

Google Cloud Platform 3
Apache Spark and Apache Hadoop should be fast, easy, and cost-effective.

Easy, fast, cost-effective
FastThings take seconds to minutes, not hours or weeks
EasyBe an expert with your data, not your data infrastructure
Cost-effectivePay for exactly what you use
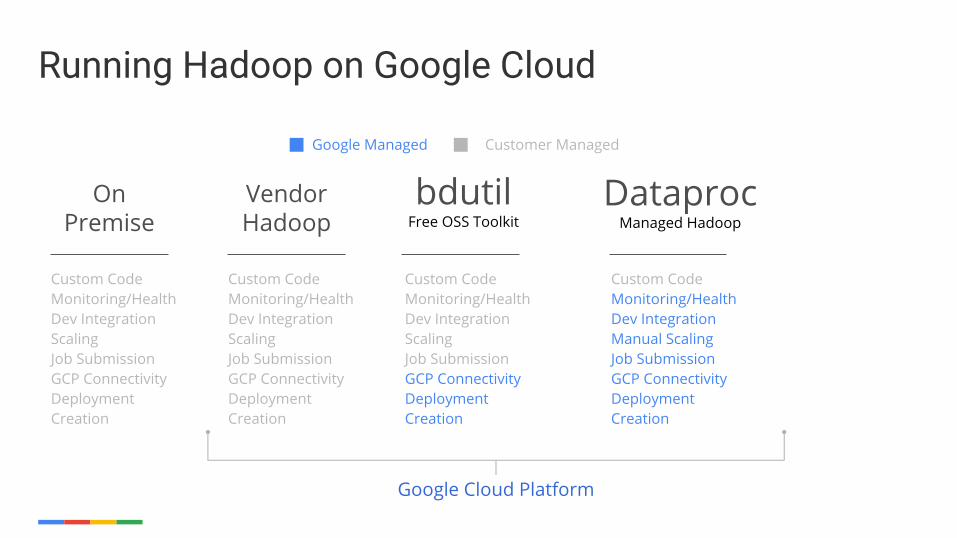
Running Hadoop on Google Cloud
bdutilFree OSS Toolkit
DataprocManaged Hadoop
Custom CodeMonitoring/HealthDev IntegrationScalingJob SubmissionGCP ConnectivityDeploymentCreation
Custom CodeMonitoring/HealthDev IntegrationManual ScalingJob SubmissionGCP ConnectivityDeploymentCreation
On Premise
Custom CodeMonitoring/HealthDev IntegrationScalingJob SubmissionGCP ConnectivityDeploymentCreation
Google Managed
Google Cloud Platform
Customer Managed
Vendor Hadoop
Custom CodeMonitoring/HealthDev IntegrationScalingJob SubmissionGCP ConnectivityDeploymentCreation

Google Cloud Dataproc
Managed Spark and Hadoop service on Google Cloud Platform which makes Spark and Hadoop fast, easy, and cost-effective.
7
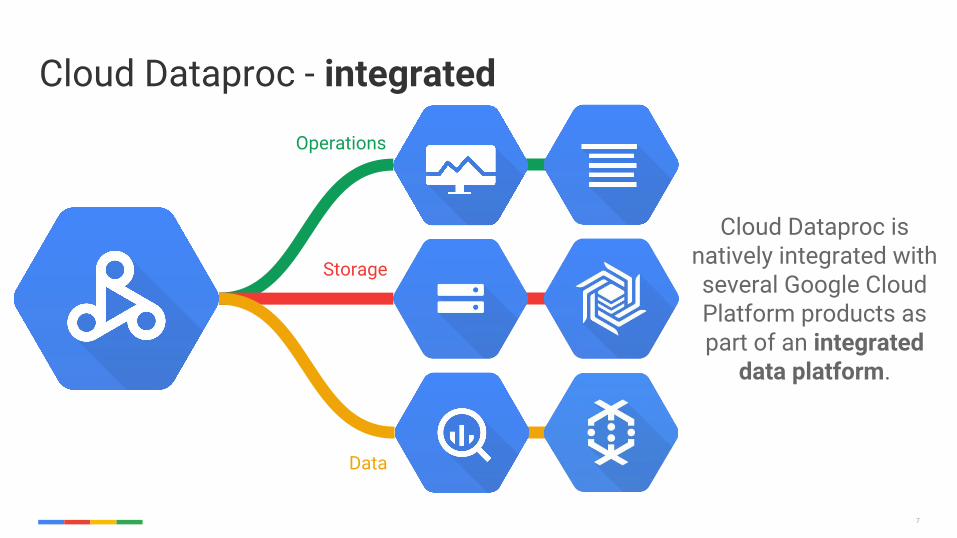
Cloud Dataproc - integrated
7
Cloud Dataproc is natively integrated with several Google Cloud Platform products as part of an integrated
data platform.
Storage
Operations
Data
8
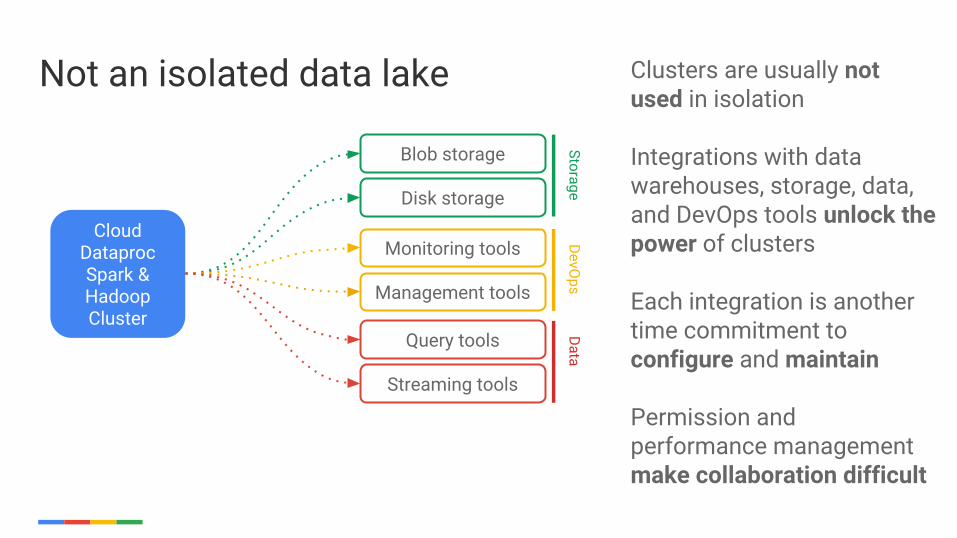
Not an isolated data lake
Cloud DataprocSpark & Hadoop Cluster
Disk storage
Monitoring tools
Management tools
DevOps
Blob storage
Query tools
Storage
Clusters are usually not used in isolation
Integrations with data warehouses, storage, data, and DevOps tools unlock the power of clusters
Each integration is another time commitment to configure and maintain
Permission and performance management make collaboration difficult
DataStreaming tools
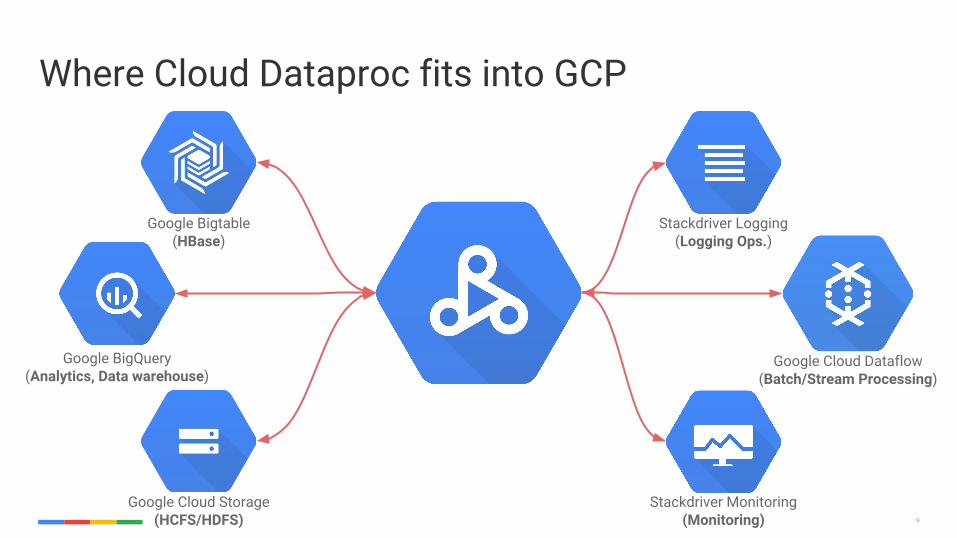
9
Where Cloud Dataproc fits into GCP
9
Google Bigtable(HBase)
Google BigQuery(Analytics, Data warehouse)
Stackdriver Logging(Logging Ops.)
Google Cloud Dataflow(Batch/Stream Processing)
Google Cloud Storage(HCFS/HDFS)
Stackdriver Monitoring(Monitoring)
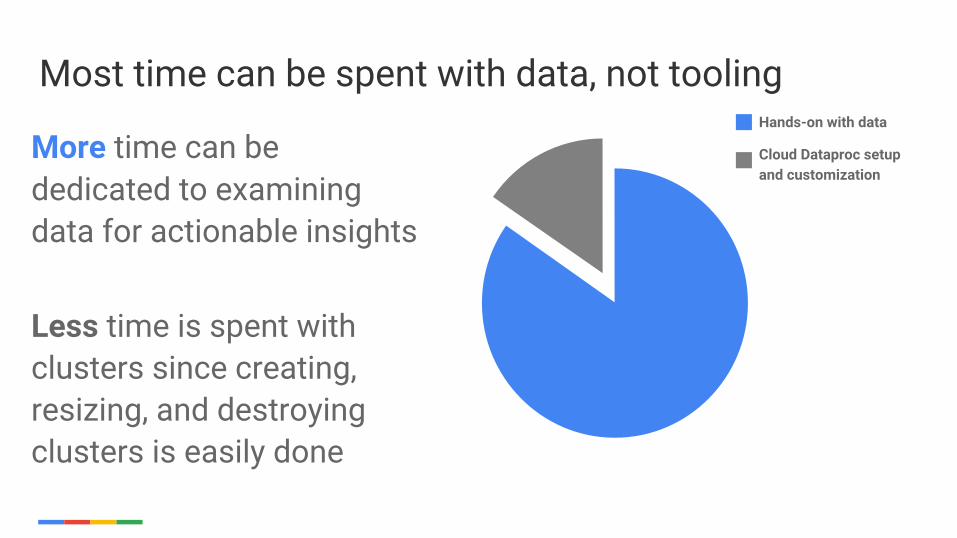
10
Most time can be spent with data, not tooling
More time can be dedicated to examining data for actionable insights
Less time is spent with clusters since creating, resizing, and destroying clusters is easily done
Hands-on with data
Cloud Dataproc setup and customization

11
Lift and shift workloads to Cloud Dataproc
Copy data to GCS
Copy your data to Google Cloud Storage (GCS) by
installing the connector or by copying manually.
Update file prefix
Update the file location prefix in your scripts from hdfs:// to gcs:// to
access your data in GCS.
Use Cloud Dataproc
Create a Cloud Dataproc cluster and run your job on the cluster against the data you copied to GCS. Done.
1 32

Google Cloud Platform 12
Cloud Dataproc features and benefits
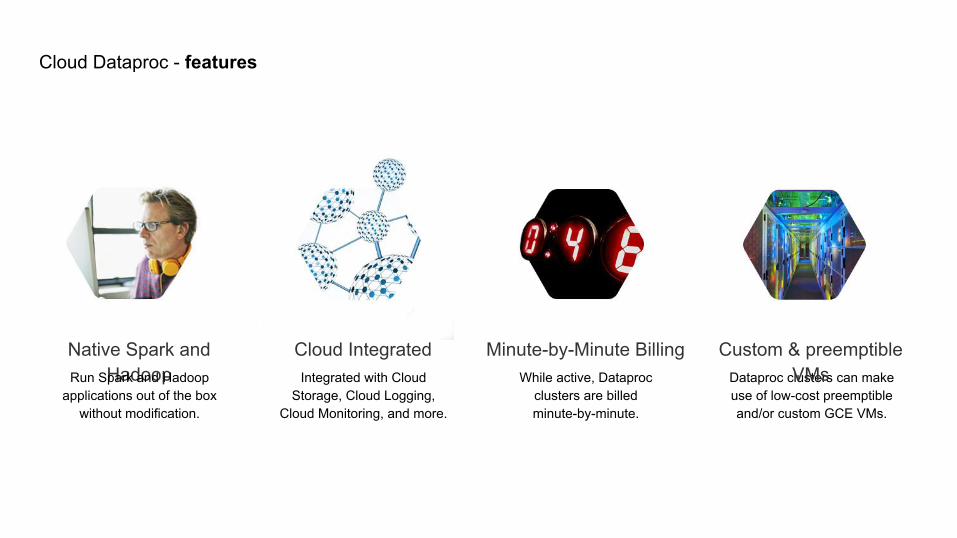
Cloud Dataproc - features
Integrated with Cloud Storage, Cloud Logging,
Cloud Monitoring, and more.
While active, Dataproc clusters are billed minute-by-minute.
Dataproc clusters can make use of low-cost preemptible and/or custom GCE VMs.
Minute-by-Minute Billing Custom & preemptible VMs
Native Spark and Hadoop
Cloud IntegratedRun Spark and Hadoop
applications out of the box without modification.

Cloud Dataproc - features
Manually scale clusters up or down based on need,
even when jobs are running.
REST API and Integration with Google Cloud SDK for
rapid development.
Available in every Google Cloud zone in the United States, Europe, and Asia
Developer Tools Global AvailabilityAnytime Scaling Initialization ActionsExecute scripts on cluster
creation to quickly customize and configure
clusters.

Cloud Dataproc - benefits
Enjoy lower total cost of ownership due to low prices
and minute-based billing.
Clusters start, stop, and scale in 90 seconds or less
on average, so you wait less.
Size and scale clusters anytime based on your
schedule and your needs.
Scalable EasyLow-cost SuperfastVanilla Spark and Hadoop supported by purpose-built
Cloud products.

Google Cloud Platform 16
How does Google Cloud Dataproc help me?
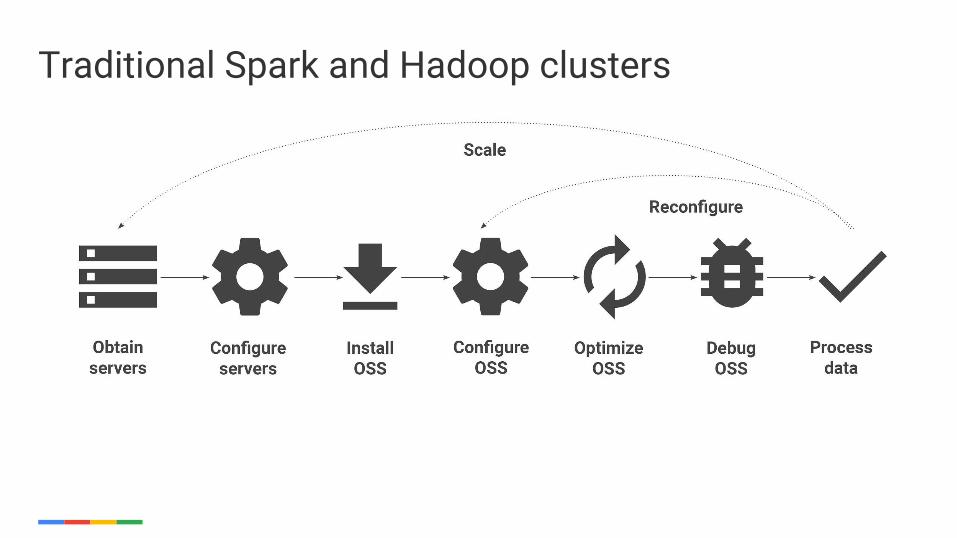
Traditional Spark and Hadoop clusters
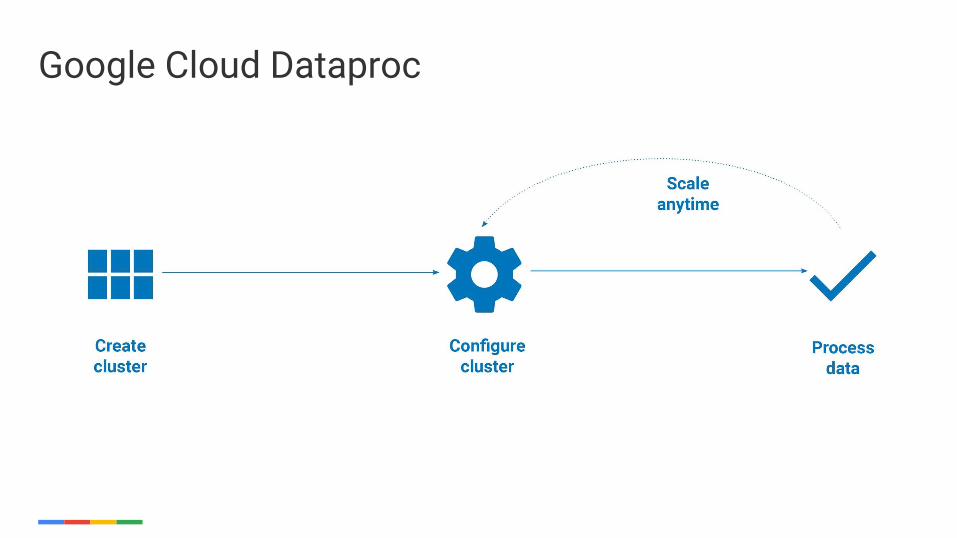
Google Cloud Dataproc

Cloud example - slow vs. fast
Things take seconds to minutes, not hours or weeks
capa
city
nee
ded
t
Time needed to obtain new capacity ca
paci
ty u
sed
t
Scaling can take hours, days, or
weeks to perform
Traditional clusters Cloud Dataproc

Cloud example - hard vs. easy
Be an expert with your data, not your data infrastructure
Need experts to optimize utilization
and deployment
Traditional clusters Cloud Dataproc
clus
ter
utili
zatio
n
Cluster Inactive
t
clus
ter
utili
zatio
n
t
cluster 1 cluster 2
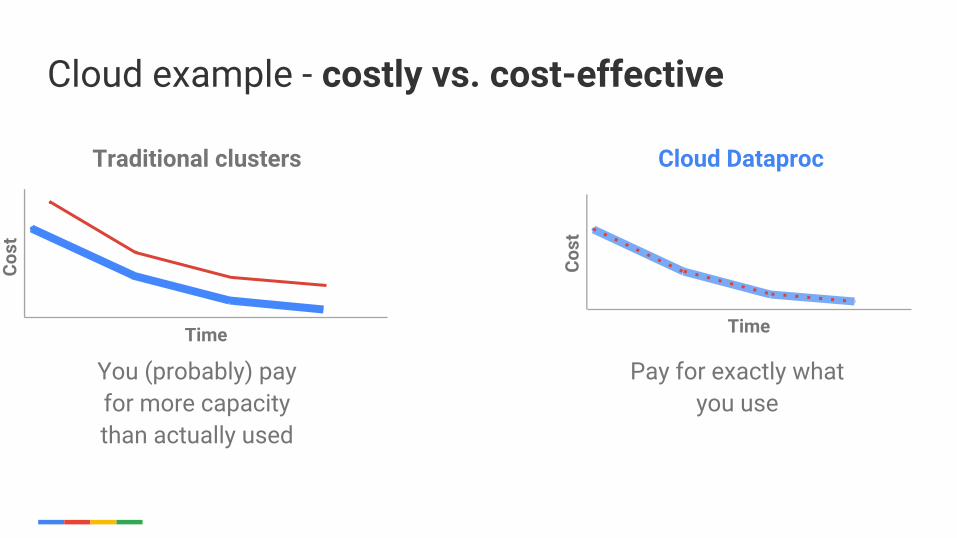
Cloud example - costly vs. cost-effective
Pay for exactly what you use
You (probably) pay for more capacity than actually used
Traditional clusters Cloud Dataproc
Time
Cost
Time
Cost

Google Cloud Dataproc - under the hood
Google Cloud Services
Dataproc Cluster
Cloud Dataproc uses GCP - Compute Engine,
Cloud Storage, and Stackdriver tools

Google Cloud Dataproc - under the hood
Cloud Dataproc Agent
Google Cloud Services
Dataproc Cluster
Cloud Dataproc clusters have an agent
to manage the Cloud Dataproc cluster
Dataproc uses Compute Engine, Cloud
Storage, and Cloud Ops tools

Google Cloud Dataproc - under the hood
Spark & Hadoop OSS Spark, Hadoop, Hive, Pig, and other OSS
components execute on the cluster
Cloud Dataproc Agent
Google Cloud Services
Dataproc Cluster
Cloud Dataproc clusters have an agent
to manage the Cloud Dataproc cluster
Dataproc uses Compute Engine, Cloud
Storage, and Cloud Ops tools
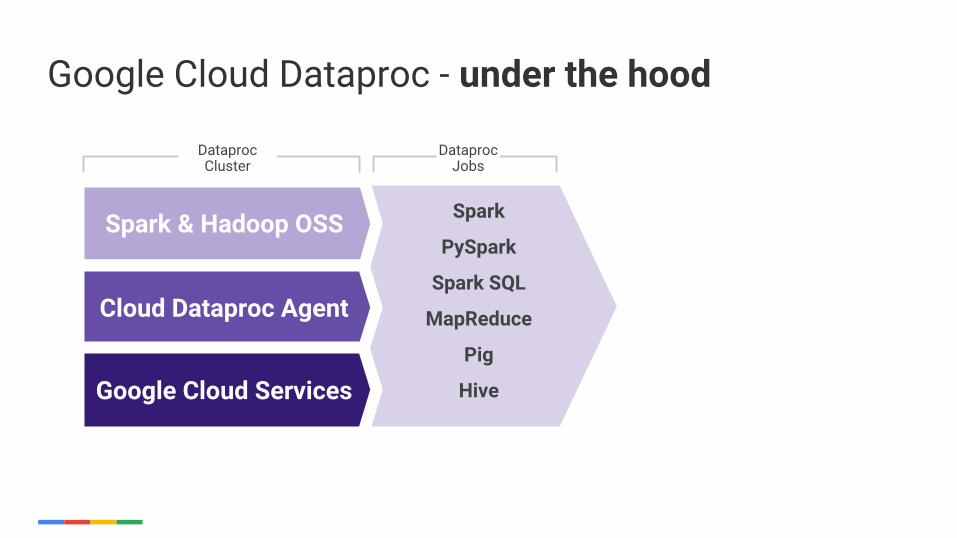
Google Cloud Dataproc - under the hood
Spark
PySpark
Spark SQL
MapReduce
Pig
Hive
Spark & Hadoop OSS
Cloud Dataproc Agent
Google Cloud Services
Dataproc Cluster
Dataproc Jobs

Google Cloud Dataproc - under the hood
Applications on the cluster
Dataproc Jobs
GCP Products
Spark
PySpark
Spark SQL
MapReduce
Pig
Hive
Dataproc Cluster
Spark & Hadoop OSS
Cloud Dataproc Agent
Google Cloud Services
Dataproc Jobs FeaturesData
Outputs
27
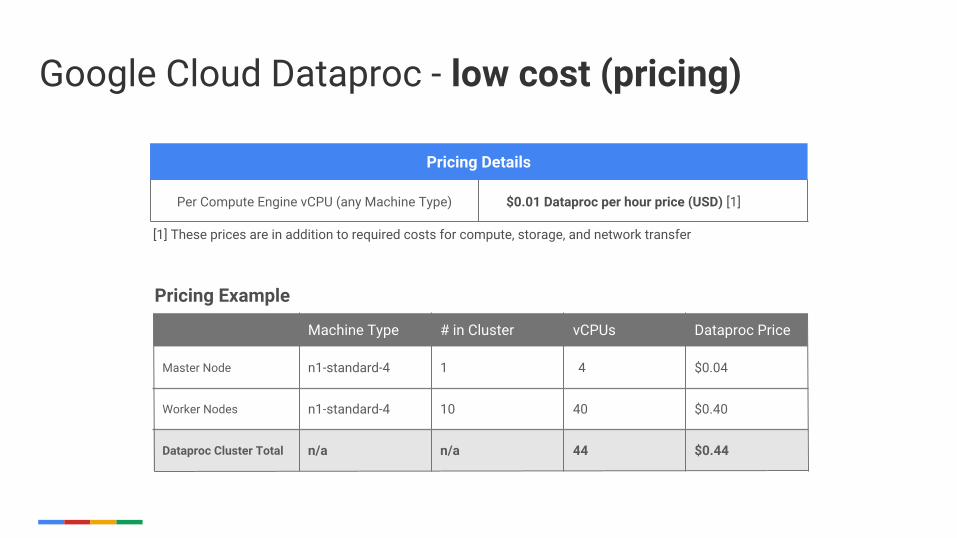
Google Cloud Dataproc - low cost (pricing)
Pricing Example
Machine Type # in Cluster vCPUs Dataproc Price
Master Node n1-standard-4 1 4 $0.04
Worker Nodes n1-standard-4 10 40 $0.40
Dataproc Cluster Total n/a n/a 44 $0.44
Pricing Details
Per Compute Engine vCPU (any Machine Type) $0.01 Dataproc per hour price (USD) [1]
[1] These prices are in addition to required costs for compute, storage, and network transfer

Google Cloud Platform 28
What is unique about Google Cloud Dataproc?
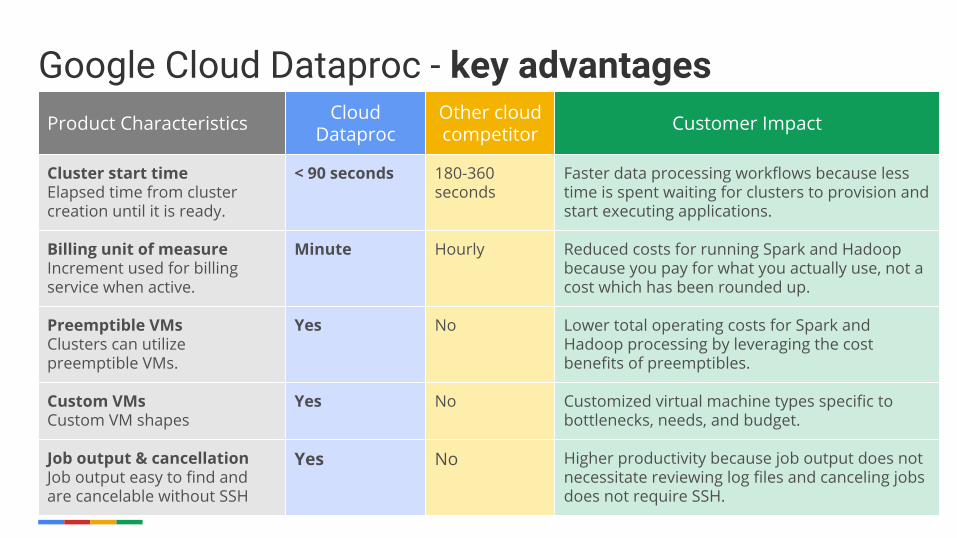
Product Characteristics Cloud Dataproc
Other cloud competitor Customer Impact
Cluster start timeElapsed time from cluster creation until it is ready.
< 90 seconds 180-360 seconds
Faster data processing workflows because less time is spent waiting for clusters to provision and start executing applications.
Billing unit of measureIncrement used for billing service when active.
Minute Hourly Reduced costs for running Spark and Hadoop because you pay for what you actually use, not a cost which has been rounded up.
Preemptible VMsClusters can utilize preemptible VMs.
Yes No Lower total operating costs for Spark and Hadoop processing by leveraging the cost benefits of preemptibles.
Custom VMsCustom VM shapes
Yes No Customized virtual machine types specific to bottlenecks, needs, and budget.
Job output & cancellationJob output easy to find and are cancelable without SSH
Yes No Higher productivity because job output does not necessitate reviewing log files and canceling jobs does not require SSH.
Google Cloud Dataproc - key advantages

Confidential & ProprietaryGoogle Cloud Platform 30
Google Cloud Dataproc - up to date
We believe you should have access to new developments in the Apache ecosystem in days or weeks, not months or quarters from now.
Cloud Dataproc takes advantage of the build speed of Apache Bigtop and the enterprise robustness of Google Cloud Platform.
You can always select which versions you wish you use by setting the “Dataproc version” when you create new clusters.

Google Cloud Platform 31
How can I use Cloud Dataproc?

Google Cloud Platform 32
Google Developers Consolehttps://console.developers.google.com/

Google Cloud Platform 33
Google Cloud SDKhttps://cloud.google.com/sdk/

Google Cloud Platform 34
Cloud Dataproc REST APIhttps://cloud.google.com/dataproc/reference/rest/

Google Cloud Platform 35
Example use cases

NeedA customer processes 50 gigabytes of (text) web log data per day to produce aggregated metrics. They have used a persistent on-premise cluster to store and process the logs with MapReduce.
How Dataproc addresses this needGoogle Cloud Storage can act as a landing zone for the log data for low-cost and high-durability storage. A Dataproc cluster can be created in less than 2 minutes to process this data with their existing MapReduce. Once finished, the Dataproc cluster can then be removed immediately.
Dataproc valueInstead of running all the time and incurring costs even when not used, Dataproc only runs to process the logs which saves money and reduces complexity.
Use case #1 - log processing

NeedA customer uses Spark standalone on one computer to perform data mining and analysis. The data is stored locally and they are using the Spark shell to examine the data along with Spark SQL.
How Dataproc addresses this needDataproc can create clusters that scale for speed and mitigate any single point of failure. Since Dataproc supports Spark, Spark SQL, and PySpark, they could use the web interface, Cloud SDK, or the native spark shell via SSH to perform their analysis safe from a single machine failure.
Dataproc valueDataproc quickly unlocks the power of the cloud for anyone without added technical complexity. Running complex computations now take seconds instead of minutes or hours.
Use case #2 - ad-hoc data mining & analysis

Use case #3 - machine learning
NeedA customer uses the Spark Machine Learning Libraries (MLlib) to run classification algorithms on very large datasets. They rely on cloud-based machines where they install, and customize Spark.
How Dataproc addresses this needSince Spark and the MLlib installed on any Dataproc cluster, the customer can save time by quickly creating Dataproc clusters. Any additional customizations can be applied easily to the entire cluster via initialization actions. To keep an eye on workflows, they can use the built-in Cloud Logging and Monitoring.
Dataproc valueWith Dataproc, resources spent on cluster creation and management can now be focused on the data. Integrations with new Google Cloud products unlock new features for Spark clusters.

Google Cloud Platform 39
Let’s see an example - Cloud Dataproc demo

Confidential & ProprietaryGoogle Cloud Platform 40
Google Cloud Dataproc - demo overview
In this demo we are going to do a few things:
● Create a cluster● Query a large set of data stored in Google Cloud Storage● Review the output of the queries● Delete the cluster

41
The New York City Taxi & Limousine Commission and Uber released a dataset of trips from 2009-2015
Original dataset is in CSV format and contains over 20 columns of data and about 1.2 billion trips
The dataset is about ~270 gigabytes
NYC taxi data
41
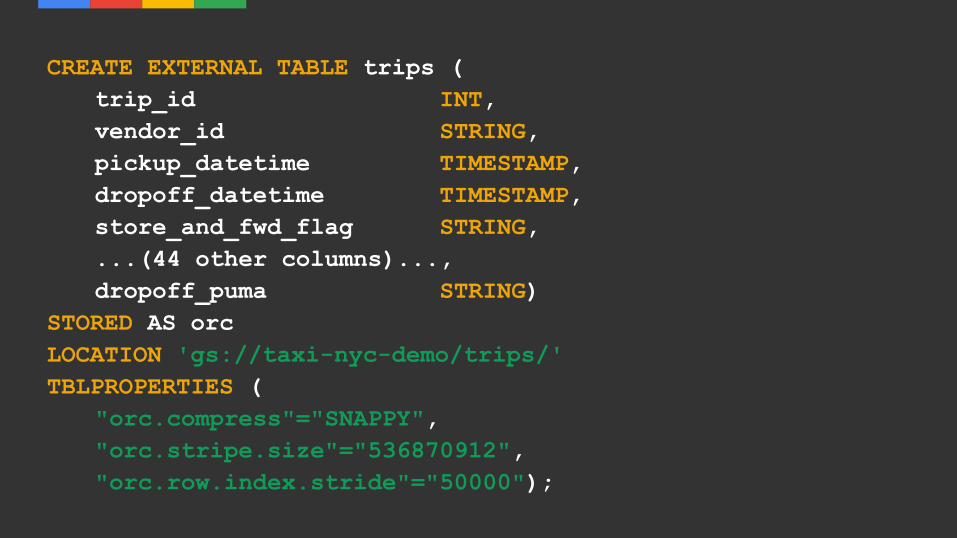
CREATE EXTERNAL TABLE trips (trip_id INT,vendor_id STRING,pickup_datetime TIMESTAMP,dropoff_datetime TIMESTAMP,store_and_fwd_flag STRING,...(44 other columns)...,dropoff_puma STRING)
STORED AS orcLOCATION 'gs://taxi-nyc-demo/trips/'TBLPROPERTIES (
"orc.compress"="SNAPPY","orc.stripe.size"="536870912","orc.row.index.stride"="50000");
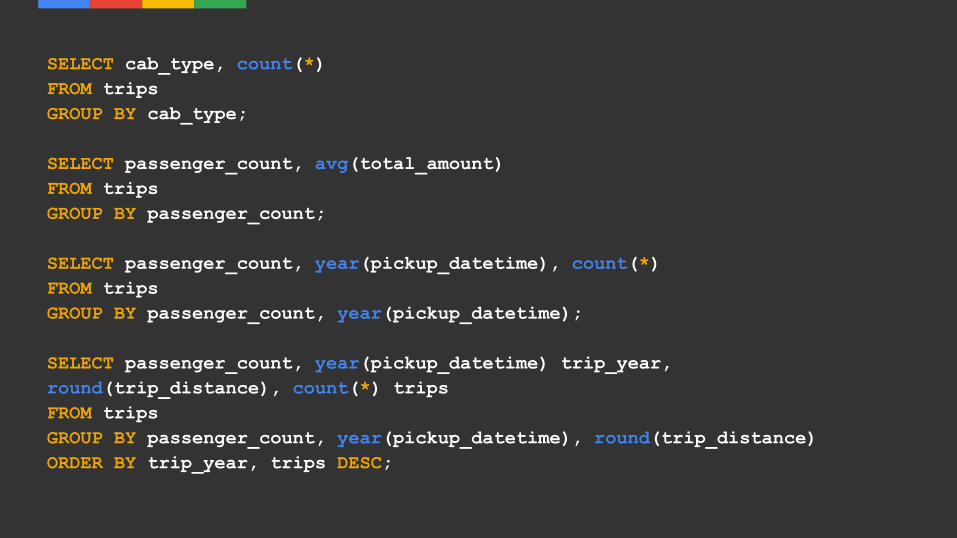
SELECT cab_type, count(*)FROM tripsGROUP BY cab_type;
SELECT passenger_count, avg(total_amount)FROM tripsGROUP BY passenger_count;
SELECT passenger_count, year(pickup_datetime), count(*)FROM tripsGROUP BY passenger_count, year(pickup_datetime);
SELECT passenger_count, year(pickup_datetime) trip_year, round(trip_distance), count(*) tripsFROM tripsGROUP BY passenger_count, year(pickup_datetime), round(trip_distance)ORDER BY trip_year, trips DESC;

Google Cloud Platform 44
Cloud Dataproc tips and recommendations

45
Split up clusters and jobs
Move from running all jobs on very large clusters to running on many smaller clusters.
Large multi-tenant prod/dev cluster
Many small clusters
==
46
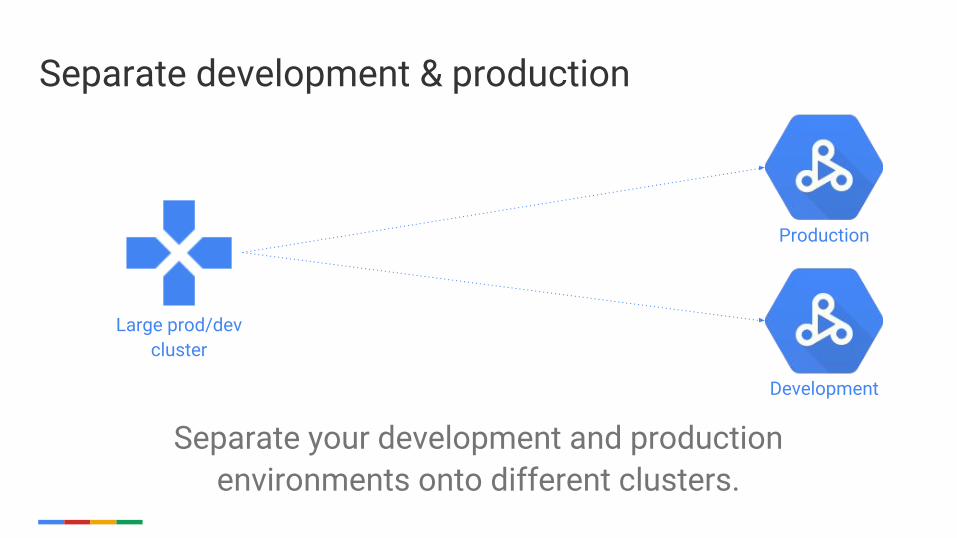
Separate development & production
Separate your development and production environments onto different clusters.
Large prod/dev cluster
Production
Development
47
Use Google Cloud Storage
Use Google Cloud Storage as a faster and more durable replacement for HDFS.
HDFS Google Cloud Storage

48
Create and delete clusters often
Use clusters only when you have work to do and then delete them.
Create Delete Repeat

49
Use the Apache ecosystem
Use the full power of the Apache data ecosystem on Cloud Dataproc

Google Cloud Platform 50
If you’re processing data, you may also want to consider...

Google Cloud Dataflow & Apache Beam
The Cloud Dataflow SDK, based on Apache Beam, is a collection of SDKs for building streaming
data processing pipelines.
Cloud Dataflow is a fully managed (no-ops) and integrated service for executing optimized parallelized
data processing pipelines.
Google BigQuery
Virtually unlimited resources, but you only pay for what you use
Fully-managed
Analytics Data Warehouse
Highly Available, Encrypted, Durable

Google Cloud Bigtable
Google Cloud Bigtable offers companies a fast, fully managed, infinitely scalable NoSQL database service with a HBase-compliant API included. Unlike comparable market offerings, Bigtable is the only fully-managed database where organizations don’t have to sacrifice speed, scale or cost-efficiency when they build applications.
Google Cloud Bigtable has been battle-tested at Google for 10 years as the database driving all major applications including Google Analytics, Gmail and YouTube.

Google Cloud Platform 54
Wrapping things up

Cloud Dataproc - get started today
Create a Google Cloud project
Visit Dataproc section
1
2
3
4
Open Developers Console
Create cluster in 1 click, 90 sec.

Cloud Dataproc - recap
Cloud Dataproc is a fully managed service that makes leveraging, tooling, libraries, and documentation from the
rich Spark/Hadoop ecosystem easy.
• With a low price and minute-by-minute billing, customers no longer need to worry about the economics of running a persistent Spark or Hadoop cluster to unlock the benefits of fast, efficient, and reliable data processing.
• Seamless integration into other Google Cloud products means data is more accessible, operations are easy to monitor, and scaling is a non-issue.
• The ability to manually scale, utilize initialization actions, and leverage preemptive and/or custom virtual machines means Cloud Dataproc clusters can be tailored based on individual needs.
• Cloud Dataproc is available in beta to all customers in all Google Cloud regions and zones.

If you only remember 3 things...
Cloud Dataproc is easy
Cloud Dataproc offers a number of tools to easily interact with clusters and
jobs so you can be hands-on with your data.
Cloud Dataproc is fast
Cloud Dataproc clusters start in under 90 seconds on average so you spend
less time and money waiting for your clusters.
Cloud Dataproc is cost effective
Cloud Dataproc is easy on the pocketbook with a low pricing of just 1c per vCPU
per hour and minute by minute billing

Thank You