Embed Size (px)
Citation preview

Tao Lei, Regina Barzilay and Tommi Jaakkola MIT, CSAIL
Molding CNNs for text: non-linear, non-consecutive convolutions
{taolei, regina, tommi}@csail.mit.edu
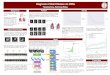
Motivation
The success of deep learning often derives from well-chosen operational building blocks.
Question: can we design neural network components better for text processing?
This work
Motivated by previous NLP methods like string kernels, we revise the feature mapping operation (i.e. convolution operation) of CNNs
➡ Use tensor algebra to capture n-gram interactions
➡ Directly handles non-consecutive n-gram patterns, e.g. “not nearly as good” etc.
Example
Consider generating the feature representation of the following sentence:
“the movie is not that good”
linear kernel
moviegoodnot…
bag-of-words indicators
“neuralize” …
avg. embedding
string kernel
movie ismovie _ not not that
…not _ goodmovie _ _ that
is not _ good
is _ that
bag-of-ngrams, non-consecutive
?Our code and data are available at
https://github.com/taolei87/text_convnet
Apply the “string kernel” idea to CNN feature mapping. 2gram case:
Model
The movie
was
fantastic
!
softmax(output
input(x feature maps
low.level(features high.level(features
…
… average and concatenate
(i) non-linear high-order filters
not that goodmovie isthenot that goodthe movie is
f [i] f [i]
(ii) averaging non-consecutive ngrams
f [i] P
j<i �i�j�1
T · (xj ⌦ xi)
f [i] P
k<j<i �i�k�2
T · (xk ⌦ xj ⌦ xi)
(2-gram)
(3-gram)
Results
(iii) linear time dynamic programming possible when T is low-rank factorized!
Architecture
➡ Directly plug into CNNs for feature extraction
➡ Can be stacked or feed into activation cells
Model evaluated on sentiment analysis task, newswire and POS classification tasks.
Model Fine Binary Time DCNN [1] 48.5 86.9 - DNN-MC [2] 47.4 88.1 156 RLSTM [3] 51.0 88.0 164 Ours (best) 52.7 88.6 28 (avg.) 51.4 88.4
Table 1: Results on Stanford Sentiment Treebank.
44.5%
46.1%
47.8%
49.4%
51.0%
45.0% 46.3% 47.5% 48.8% 50.0%
decay=0.0 decay=0.3 decay=0.5
44.5%
46.1%
47.8%
49.4%
51.0%
43.5% 45.1% 46.8% 48.4% 50.0%
1 layer 2 layers 3 layers
Figure 1: Analysis of our model. (a) better acc% when handles non-consecutive ngrams; (b) deeper model gives better acc%.
References
Figure 2: Results on document classification (left) and POS classification (right).
[1] Nal Kalchbrenner, Edward Grefenstette, and Phil Blunsom. A convolutional neural network for modelling sentences. ACL 2014
[2] Yoon Kim. Convolutional neural networks for sentence classification. EMNLP 2014
[3] Kai Sheng Tai, Richard Socher, and Christopher D Manning. Improved semantic representations from tree-structured long short-term memory networks. ACL 2015
SVM CNN Ours
80.0
79.2
78.5
80.0
79.5
78.2
Basic +EMB +Ours Best Reported
97.5
97.3
97.1
96.8
classifiers
CRF