Embed Size (px)
Citation preview

Rapport de stage
Master « Maths en action » – Université Lyon 1
Modélisation de l’expression des gèneset inférence de réseaux de régulation
Ulysse Herbach
encadré par
Olivier Gandrillon Thibault EspinasseCGφMC, UMR 5534 ICJ, UMR 5208Inria, équipe Dracula
G1 G2
θ2,1
θ1,2
θ1,1 θ2,2
Stage effectué au CGφMC, Université Lyon 1 et à l’Inria— du 3 mars au 31 juillet 2015 —

Table des matières
Introduction 3Données expérimentales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3Objectifs et plan du rapport . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4Notations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1 Dynamique d’un gène isolé 71.1 Le modèle à deux états . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2 Distributions stationnaires : résultats actuels . . . . . . . . . . . . . . . . . . 111.3 Approximation déterministe par morceaux . . . . . . . . . . . . . . . . . . . . 171.4 Modèle déterministe associé . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2 Gènes en interaction 212.1 Extension du modèle à deux états . . . . . . . . . . . . . . . . . . . . . . . . 222.2 Exemples de réseaux concrets . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.3 Modèle déterministe associé . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3 Vers une inférence du réseau 293.1 Une première idée pour l’inférence . . . . . . . . . . . . . . . . . . . . . . . . 293.2 Un modèle linéaire sous-jacent . . . . . . . . . . . . . . . . . . . . . . . . . . 303.3 Premiers résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Conclusion 33
Références 35
A Détails mathématiques 37A.1 Rappels sur les processus markoviens de saut . . . . . . . . . . . . . . . . . . 37A.2 Preuves des lemmes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
B Détails sur les données 41
2

Introduction
Parmi les nombreux mystères de la vie, celui de la différenciation cellulaire occupe uneplace de choix : comment se fait-il qu’une simple cellule-œuf puisse, par divisions successives,donner naissance à un organisme complexe, constitué de nombreux types de cellules auxrôles bien distincts ? Comme l’explique Huang (2010), la quête de l’origine de la diversité enbiologie est aussi ancienne que la discipline elle-même. Tout comme la biologie de l’évolutiona cherché à expliquer la diversification des formes de vie à travers l’apparition des espèces,la biologie du développement tente aujourd’hui de comprendre la diversification des cellulesembryonnaires en une multitude de types capables de s’auto-renouveler.
Au cœur du processus de différenciation se trouve la relation complexe entre le génomed’une cellule et son comportement. S’il est bien établi que l’expression des gènes obéit à unestructure imposée par des réseaux de régulation, ces derniers ont longtemps été interprétés demanière déterministe, chaque cellule n’ayant alors qu’un seul destin possible. Or l’expressiondes gènes est le résultat de réactions biochimiques qui ont par nature un caractère aléatoireà l’échelle moléculaire. Il existe ainsi une variabilité intercellulaire observable expérimentale-ment : deux cellules génétiquement identiques et placées dans les mêmes conditions peuventexprimer une protéine donnée à des niveaux très différents.
Grâce à une amélioration spectaculaire des techniques d’observation, il est désormaispossible d’étudier cette variabilité de plus près. À présent, elle n’est plus considérée commeun simple bruit mais plutôt comme un élément fondamental dont les cellules sont capablesde tirer parti (Eldar et Elowitz, 2010). Au lieu de suivre un destin, la cellule est confrontéeà des choix probabilistes : on parle alors de décision cellulaire.
Données expérimentalesDans ce contexte, l’équipe BM2A (Bases Moléculaires de l’Auto-renouvellement et ses Al-
térations) s’intéresse à l’érythropoïèse, c’est-à-dire la formation des globules rouges. L’équipeutilise pour cela des progéniteurs érythrocytaires (Figure 1) qui sont des cellules situées àla fin du processus de différenciation, auxquelles il ne reste plus qu’un seul choix à faire :rester en état d’auto-renouvellement ou bien se différencier en globule rouge. Notre objectifest d’en savoir plus sur le réseau de régulation qui contrôle ce choix.
Figure 1 – Les cellules étudiées, icien état d’auto-renouvellement.
On dispose pour cela des niveaux d’expression, sousforme de quantités d’ARN messager transcrit, d’unecentaine de gènes à quatre instants de la différenciation(0, 8, 24 et 72 heures). Pour chaque instant, on observeenviron 80 cellules uniques. Contrairement aux donnéessur des populations de cellules qui n’apportent que desvaleurs moyennes donc déterministes, la stochasticitéde l’expression des gènes est ici directement observable.En particulier, les histogrammes associés confirment lagrande variabilité intercellulaire (Figure 2).
3

4 Introduction
Figure 2 – Histogrammes représentant, pour les quatre instants de mesure, le nombre de molé-cules d’ARN messager produites par le gène CD151 dans chaque cellule. On remarque une grandevariabilité entre les cellules à certains instants, de l’ordre de 10000 molécules.
Objectifs et plan du rapportOn observe donc simultanément les niveaux d’expression de nombreux gènes dans des
cellules individuelles. D’un point de vue statistique, ceci nous donne accès non seulement auxlois marginales, mais aussi à la loi jointe de tous ces gènes. Or cette loi jointe — en particulierles éventuelles corrélations — constitue elle-même la trace d’un certain réseau de régulation :c’est ce réseau que l’on va chercher à reconstruire (Figure 3).
Concrètement, il s’agit de proposer un modèle statistique, c’est-à-dire une famille de loisjointes pour les gènes, associée explicitement à une famille de réseaux de régulation. Lareconstruction d’un réseau à partir de données se ramènera alors à choisir le(s) réseau(x)dont la loi jointe correspond le mieux aux données selon un certain critère : c’est cette étapefinale que l’on appellera inférence de réseau de gènes.
Le tout doit être biologiquement cohérent : on veut que notre modèle statistique soit lereflet direct d’un modèle biochimique de réseau de gènes, et pas simplement une famille delois générique (modèle linéaire gaussien, etc.). On souhaite notamment que les coefficientsdu modèle correspondent à des quantités physiques éventuellement mesurables.
À notre connaissance, les approches actuelles sont appropriées dans le cas de donnéesissues de populations de cellules (les valeurs d’expression suivent alors des gaussiennes dontla variance correspond seulement à un bruit de fond), mais ne sont pas encore capablesd’extraire toute l’information contenue dans les observations de cellules uniques (voir parexemple Gallopin et al., 2013 ; Ocone et al., 2015).
On souhaite donc faire un pas vers des modèles de réseaux qui prennent en compteexplicitement certains aspects moléculaires, dont une stochasticité intrinsèque et des lienscausaux (influence d’un gène sur un autre). Pour cela, on présentera dans un premier tempsun modèle stochastique simple pour l’expression d’un gène isolé, puis on proposera une façonde mettre les gènes en réseau, et enfin on s’intéressera à l’inférence du réseau en pratique.
G2 G3
G1
Figure 3 – Un exemple de réseau de régulation que l’on aimerait pouvoir reconstruire à partirdes données (ici avec 3 gènes). Les flèches vertes (resp. rouges) correspondent à des rétroactionspositives (resp. négatives).

5
NotationsOn donne ici quelques notations, définitions et résultats classiques utilisés dans ce rap-
port. Les fonctions ne seront utilisées que sur les domaines précisés entre parenthèses et lesparamètres des lois considérées sont tous strictement positifs.
Fonctions spéciales• Fonction Gamma (x ∈ R∗
+) :
Γ(x) =
∫ +∞
0tx−1e−t dt
• Fonction Beta (a, b ∈ R∗+) :
B(a, b) =
∫ 1
0xa−1(1− x)b−1 dx =
Γ(a)Γ(b)
Γ(a+ b)
• Fonction hypergéométrique confluente (a, b ∈ R∗+, a < b, z ∈ C) :
M(a, b, z) = 1F1(a, b, z) = 1 ++∞∑k=1
a(a+ 1) · · · (a+ k − 1)
b(b+ 1) · · · (b+ k − 1)
zk
k!
=1
B(a, b− a)
∫ 1
0ezxxa−1(1− x)b−a−1 dx
• Fonction hypergéométrique 2F1 (a, b, c ∈ R∗+, b < c, |z| < 1) :
2F1(a, b, c, z) = 1 ++∞∑k=1
a(a+ 1) · · · (a+ k − 1)b(b+ 1) · · · (b+ k − 1)
c(c+ 1) · · · (c+ k − 1)
zk
k!
=1
B(b, c− b)
∫ 1
0xb−1(1− x)c−b−1(1− zx)−a dx
Lois et fonctions caractéristiques
Loi Notation Support Densité Fonction caractéristique
Poisson P(λ) N pn = e−λλn
n!ϕ(t) = exp(λ(eit − 1))
exponentielle E(λ) R+ f(x) = λe−λx ϕ(t) =(1− it
λ
)−1
gamma γ(a, θ) R+ f(x) =e−
xθ xa−1
Γ(a)θaϕ(t) = (1− θit)−a
Beta Beta(a, b) [0, 1] f(x) =xa−1(1− x)b−1
B(a, b)ϕ(t) =M(a, a+ b, it)

6 Introduction
NormesOn identifiera de manière classique Rn et Mn,1(R) et on notera pour tout A ∈ Mn,p(R) :
• ∥A∥1 =∑
i,j |Ai,j |
• ∥A∥2 =√∑
i,j(Ai,j)2
• ∥A∥op = sup∥x∥2=1
∥Ax∥2

Chapitre 1
Dynamique d’un gène isolé
Avant d’envisager la modélisation d’un système aussi complexe qu’un réseau de gènes, ilest nécessaire de s’intéresser à la dynamique individuelle de chaque gène. On a besoin d’unmodèle assez sophistiqué pour décrire l’évolution des quantités qui nous intéressent (ARN,protéines), mais également assez simple pour être accessible mathématiquement.
Les modélisateurs se penchent depuis longtemps sur la dynamique stochastique des gèneset il existe aujourd’hui de nombreux modèles (Boettiger, 2013). Leur complexité est trèsvariable mais ils ont en commun un formalisme mathématique hérité de la chimie, où ladynamique temporelle des molécules est décrite par des processus markoviens de type nais-sance/mort. Puisque l’expression d’un gène se résume à un ensemble (très grand) de réactionschimiques, l’idée est de choisir quelles réactions on souhaite décrire précisément.
1.1 Le modèle à deux étatsParmi les nombreux choix possibles, nous utiliserons le modèle dit à deux états, qui
semble être un bon compromis entre la précision de la description du gène et la simplicitémathématique. Dans ce modèle, souvent appelé Random Telegraph par les biologistes, le gène(en fait son promoteur) n’a que deux états possibles : un état ON où il produit de l’ARNmessager, et un état OFF où il n’en produit pas. Plus précisément, on considère au niveaumicroscopique les réactions suivantes, supposées élémentaires et de taux 1 constants :• Le gène passe de OFF à ON avec le taux kon et de ON à OFF avec le taux koff
• Dans l’état ON, le gène produit des molécules d’ARN avec le taux s0 (transcription)• Chaque molécule d’ARN produit des protéines avec le taux s1 (traduction)• Les molécules d’ARN se dégradent chacune au taux d0 et les protéines au taux d1
Remarque 1.1. Les états ON et OFF sont ici vus comme deux espèces chimiques : uneespèce “gène inactif” G et une espèce “gène actif” G∗. Les réactions chimiques précises sont
Gkon−−→ G∗, G∗ koff−−→ G, G∗ s0−→ G∗ +M, M
s1−→M + P, Md0−→ ∅, P
d1−→ ∅
où M désigne l’ARN, P les protéines et ∅ une espèce dégradée. Si le sens physique de s0,s1, d0 et d1 est relativement clair, celui des taux kon et koff l’est moins car ils résument enfait chacun un ensemble potentiellement très grand de réactions sous-jacentes. L’idée de lamise en réseau (cf. chapitre 2) sera de préciser ces réactions, ce qui nous permettra de définirexplicitement des liens de cause à effet entre les gènes.
1. Le taux est l’analogue microscopique de la vitesse de réaction en cinétique chimique : on peut le voircomme la “probabilité de réaction par seconde”. Les taux kon, koff, s0, s1, d0 et d1 correspondent donc pournotre système total (un seul gène et plusieurs ARN et protéines) à des coefficients de vitesse.
7

8 Chapitre 1. Dynamique d’un gène isolé
La dynamique du modèle à deux états est résumée sur la Figure 4. Ce schéma n’a aucunsens mathématiquement, mais il est est souvent utilisé car il permet de décrire simplementles différentes réactions chimiques impliquées ainsi que leurs taux (par molécule de chaqueréactif) : chaque nœud correspond à une espèce et chaque flèche à une réaction.
OFF ON ARN Prot.
ARN Prot.
kon
koff
s0 s1
d0 d1
Figure 4 – Représentation classique utilisée en biologie pour le modèle à deux états.
On s’intéresse maintenant à la définition mathématique du modèle à deux états, qui esten fait lui-même une modélisation des réactions chimiques précédentes par un processusmarkovien de sauts. Avant de rentrer dans les détails, précisons le formalisme utilisé.
Notations et rappels sur les processus markoviens de sautsDans ce rapport, tous les processus considérés seront définis sur un même espace de
probabilité (Ω,A,P). On se permettra d’écrire P(A|B) pour tous A,B ∈ A, en prenant unevaleur arbitraire pour cette quantité lorsque P(B) = 0.
Définition 1. Soit S un espace métrique que l’on munit de sa tribu borélienne. Un processusde Markov X = (Xt)t⩾0 à valeurs dans S est appelé processus markovien de sauts si sestrajectoires sont constantes par morceaux et continues à droite.
Dans la suite, on se place dans le cas où l’espace d’états S est dénombrable et où X esthomogène en temps. Le générateur infinitésimal de X est alors une matrice L = (Lx,y)x,y∈S(éventuellement de taille infinie) qui vérifie :
∀x, y ∈ S, Lx,y ⩾ 0 si x = y et Lx,x = −∑y =x
Lx,y ⩽ 0.
La loi de X est donc entièrement caractérisée par les Lx,y pour x = y et la loi de X0. Enpratique, pour T > 0 fixé, on peut construire Xt, t ∈ [0, T ] de la manière suivante :
1. On part de X0 et on pose T0 = 0 ;2. Pour n ⩾ 0, sachant XTn = x ∈ S, on a Xt = x pour tout t ∈ [Tn, Tn + Sn[ où Sn suit
une loi exponentielle de paramètre λx défini par
λx =∑y =x
Lx,y
et au temps Tn+1 = Tn + Sn, le processus saute vers l’état y = x avec la probabilité
px,y =Lx,y
λx.
3. On répète l’étape 2 jusqu’au premier n ⩾ 0 tel que Tn > T et on a alors XT = XTn .

1.1. Le modèle à deux états 9
Cette méthode de construction du processus à partir de son générateur infinitésimalfournit directement un algorithme de simulation. Pour x, y ∈ S tels que x = y, on peut voirle coefficient Lx,y comme le taux de saut de l’état x vers l’état y et λx comme le taux desortie de l’état x, son inverse étant la durée moyenne de séjour en x.
Remarque 1.2. Pour que les trajectoires soient bien définies jusqu’à T pour tout T > 0,la suite (Tn)n⩾0 des temps de saut doit vérifier Tn → +∞ presque sûrement : on parle alorsde non explosion du processus. En pratique, une condition suffisante simple pour avoir nonexplosion est que les taux de sortie soient bornés, i.e. supx∈S λx < +∞.
Dans le cas particulier où S = Nd et où les sauts vérifient ∥XTn+1 −XTn∥1 = 1 pour toutn ⩾ 0, on parlera de processus de naissance/mort. Un exemple classique est le processus dePoisson d’intensité λ, dont l’espace d’états est S = N et qui peut seulement sauter de i ài+ 1 avec le taux λ, tous les autres taux de saut étant nuls.
Définition naturelle du modèle à deux étatsLe formalisme précédent permet de modéliser des réactions chimiques de manière très
intuitive (voir par exemple Ycart et al., 2011). On considère un processus de naissance/mortdont l’espace d’états est Nd, où d est le nombre d’espèces chimiques impliquées. Chaquecomposante représente alors le nombre de molécules d’une espèce donnée, et les taux de sautcorrespondent directement aux taux “chimiques” définis précédemment.
Dans notre cas, le modèle suppose que les nombres de molécules G et G∗ des espècesrespectives “gène inactif” et “gène actif” vérifient G+G∗ = 1 à tout instant 2, ce qui permetd’oublier une des deux espèces. On définit donc le modèle à deux états comme un processusde naissance/mort (Xt)t⩾0 = (Et,Mt, Pt)t⩾0 à valeurs dans S = 0, 1 × N× N où :• Et ∈ 0, 1 est l’état du gène, OFF (0) ou ON (1) ;• Mt ∈ N est le nombre de molécules d’ARN messager ;• Pt ∈ N est le nombre de protéines.
Décrivons maintenant les sauts possibles (en sous-entendant que tous les autres sauts ontun taux nul). Depuis l’état (0,m, n) avec m,n ∈ N, le processus peut sauter vers :• (1,m, n) avec le taux kon (le gène devient actif)• (0,m, n+ 1) avec le taux ms1 (synthèse d’une protéine)• (0,m− 1, n) avec le taux md0 (dégradation d’une molécule d’ARN)• (0,m, n− 1) avec le taux nd1 (dégradation d’une protéine)
et depuis l’état (1,m, n), le processus peut sauter vers :• (0,m, n) avec le taux koff (le gène devient inactif)• (1,m+ 1, n) avec le taux s0 (synthèse d’une molécule d’ARN)• (1,m, n+ 1) avec le taux ms1 (synthèse d’une protéine)• (1,m− 1, n) avec le taux md0 (dégradation d’une molécule d’ARN)• (1,m, n− 1) avec le taux nd1 (dégradation d’une protéine).
La Figure 5 montre quelques exemples de trajectoires possibles en fonction des para-mètres. On constate que ce modèle est capable de générer des comportements très différents,dont beaucoup sont réellement observables biologiquement. En particulier, les cas (a) et (b)peuvent être associés à une forme de mémoire du gène (Corre et al., 2014).
2. D’après les réactions chimiques considérées, si c’est vrai à t = 0 alors ça le reste pour tout t ⩾ 0. L’étatdu gène a donc le statut particulier d’une “espèce rare”, ce qui aura une importance dans la suite.

10 Chapitre 1. Dynamique d’un gène isolé
(a) (b)
(c) (d)
Figure 5 – Quelques exemples de trajectoires du Random Telegraph pour différentes valeursdes paramètres, sur une durée de 100/d0. (a) Dynamique lente du promoteur (kon < d0, koff <d0) avec d1 = d0 : le comportement des protéines est quasiment identique à celui de l’ARN.(b) Dynamique lente du promoteur avec d1 < d0 : les protéines ont alors plus d’inertie quel’ARN, ce qui induit une forme de mémoire. (c) Cas où s0 ≫ d0 : les variations de l’ARN etdes protéines en temps court (∆t ≪ 1/d0) deviennent négligeables par rapport aux variations àplus long terme (∆t > 1/d0). (d) Dynamique rapide du promoteur (kon ≫ d0, koff ≫ d0) avecd1 < d0 : l’ARN et les protéines ne dépendent plus que de l’état moyen de celui-ci.
Ce modèle a été introduit sous cette forme par Peccoud et Ycart (1995) dans le cass1 = 0, c’est-à-dire lorsqu’une seule espèce chimique est produite par le gène. Le cas générala été étudié par Shahrezaei et Swain (2008). On dispose donc déjà d’un certain nombre derésultats analytiques sur ce processus, ce qui en fait un bon candidat pour la mise en réseau.Dans la suite, on se placera dans le cas où tous les paramètres sont strictement positifs.
Remarque 1.3. Si l’on multiplie tous les paramètres par une constante, on ne change pasle comportement qualitatif du processus mais seulement l’échelle de temps. On peut prendrepar exemple 1/d0 (la durée de vie moyenne d’une molécule d’ARN) comme unité de temps,ce qui revient à diviser tous les paramètres par d0, i.e. à imposer d0 = 1.
Vocabulaire employéPour garder un vocabulaire simple en vue de la mise en réseau de plusieurs gènes, on
appellera désormais “gène” le système chimique promoteur, ARN, protéines. On fait doncl’hypothèse que chaque gène produit un type d’ARN messager et un type de protéine quilui sont spécifiques. Pour tout instant t ⩾ 0, on dira que (Et,Mt, Pt) est l’état du gène àl’instant t, et (Mt, Pt) son expression. En poursuivant l’analogie du Random Telegraph, ondira que le gène est allumé lorsque Et = 1 et éteint lorsque Et = 0.

1.2. Distributions stationnaires : résultats actuels 11
Écriture sous forme d’équations stochastiquesBien que la définition “constructive” du modèle à deux états soit intuitive et pratique
pour les simulations, nous allons aussi donner une définition “abstraite”, équivalente à laprécédente mais plus concise et mieux adaptée à une étude mathématique générale. SoientY1, . . . , Y6 des processus de Poisson indépendants et unitaires (d’intensité 1) et E0, M0, P0
des variables aléatoires indépendantes à valeurs dans 0, 1, R+ et R+ respectivement. Ondéfinit alors le modèle à deux états comme la solution (Et,Mt, Pt)t⩾0 ∈ 0, 1 × N × N dusystème de trois équations stochastiques suivant (en notant X(t) = Xt) :
E(t) = E0 − Y1
(koff
∫ t
0E(u) du
)+ Y2
(kon
∫ t
0(1− E(u)) du
)(1.1)
M(t) =M0 + Y3
(s0
∫ t
0E(u) du
)− Y4
(d0
∫ t
0M(u) du
)(1.2)
P (t) = P0 + Y5
(s1
∫ t
0M(u) du
)− Y6
(d1
∫ t
0P (u) du
)(1.3)
On remarque que ce système est triangulaire, au sens où chaque équation ne dépend quedes précédentes. Ainsi l’équation (1.1) dirige le système sans être influencée par les deuxautres, et la quantité E joue le rôle d’un environnement aléatoire markovien. Cette propriétése voyait aussi dans la définition par les taux de saut, mais on verra dans la suite qu’elle estplus facilement exploitable avec cette formulation.
Le modèle à deux états peut donc être vu comme un processus de naissance/mort (plussimple) en environnement aléatoire markovien, qui rentre en fait dans un cadre bien connupour lequel on dispose de résultats théoriques : on pourra consulter Peccoud et Ycart (1995)pour une revue de la bibliographie sur le sujet. On admettra dans la suite que pour kon, koff,s0, s1, d0 et d1 strictement positifs, le processus admet une unique distribution stationnaireet converge en loi vers celle-ci.
1.2 Distributions stationnaires : résultats actuelsOn s’intéresse maintenant à la distribution stationnaire du processus (Et,Mt, Pt)t⩾0.
Vu comme un opérateur sur RS où S = 0, 1 × N × N, le générateur L de ce processuspeut s’écrire, pour f : S → R et (e,m, n) ∈ S :
Lf(e,m, n) = (ekoff + (e− 1)kon) (f(1,m, n)− f(0,m, n))
+ es0 (f(e,m+ 1, n)− f(e,m, n))
+ ms1 (f(e,m, n+ 1)− f(e,m, n))
+ md0 (f(e,m− 1, n)− f(e,m, n))
+ nd1 (f(e,m, n− 1)− f(e,m, n)) .
(1.4)
Notons que cette formule a bien sens sur S puisque les états tels que m < 0 ou n < 0sont automatiquement éliminés de la somme. Pour (e,m, n) ∈ S et t ∈ R+, on note pe,m,n(t)la probabilité que le gène soit dans l’état (e,m, n) à l’instant t :
pe,m,n(t) = P((Et,Mt, Pt) = (e,m, n)
)= E
(fe,m,n(Et,Mt, Pt)
),
où fe,m,n = 1(e,m,n). On a alors d’après un résultat classique sur les processus de Markov 3 :
p′e,m,n(t) = E(Lfe,m,n(Et,Mt, Pt)).
3. Voir l’annexe A.1, p. 38 pour des détails supplémentaires.

12 Chapitre 1. Dynamique d’un gène isolé
En appliquant (1.4) aux fonctions fe,m,n pour (e,m, n) ∈ S, on en déduit 4 que les pe,m,n
vérifient le système d’équations différentielles suivant :
p′e,m,n = (1− 2e)(koffp1,m,n − konp0,m,n) + (m+ 1)d0pe,m+1,n + ms1pe,m,n−1
− (es0 +ms1 +md0 + nd1)pe,m,n + (n+ 1)d1pe,m,n+1 + es0p1,m−1,n
(1.5)
pour tout (e,m, n) ∈ S, où l’on a posé pe,−1,n = pe,m,−1 = 0 pour simplifier. Ce système,souvent appelé équation maîtresse, correspond à l’équation de Fokker-Planck du processusdans le cas particulier où S est dénombrable. La loi de (Et,Mt, Pt) pour tout t ⩾ 0 est doncentièrement caractérisée par des équations différentielles et par la loi de (E0,M0, P0).
Trouver la loi stationnaire p se ramène ainsi à résoudre le système (1.5) avec p′ = 0.Or ce système est très difficile à résoudre dans le cas général 5. Nous nous contenterons desmarginales, i.e. les lois stationnaires de (E)t⩾0, (M)t⩾0 et (P )t⩾0 : on dispose de résultatsexplicites pour les deux premiers et seulement d’une approximation pour le troisième.
Remarque 1.4. Si l’on se place dans RN où N = 2 est le nombre d’états possibles dupromoteur, cette équation maîtresse peut se réécrire sous la forme vectorielle
P′(m,n) = S0(P(m− 1, n)−P(m,n)) +D0((m+ 1)P(m+ 1, n)−mP(m,n))
+mS1(P(m,n− 1)−P(m,n)) +D1((n+ 1)P(m,n+ 1)− nP(m,n))
+KP(m,n)
avec
D0 =
(d0 00 d0
), D1 =
(d1 00 d1
), S0 =
(0 00 s0
), S1 =
(s1 00 s1
)et
K =
(−kon koffkon −koff
).
Dans le cas particulier où d0 = d1 = s0 = s1 = 0, on se ramène à étudier le promoteur seuldont l’équation maîtresse est P′ = KP. On constate que sur chaque colonne, la somme destermes vaut 0 : la matrice K est tout simplement la transposée – c’est-à-dire l’adjoint endimension finie – du générateur infinitésimal du promoteur.
Distribution stationnaire du promoteurIl s’agit de trouver une forme explicite pour p1 =
∑m,n p1,m,n = 1− p0. Ce cas est assez
simple et on peut en fait calculer directement p1(t) pour tout t ⩾ 0, en résolvant l’équationaux dérivées partielles vérifiée par la série génératrice
G1(x, y, t) =∑m,n
p1,m,n(t)xmyn.
Sans donner les détails des calculs qui se trouvent dans (Peccoud et Ycart, 1995), on obtient :
∀t ⩾ 0, p1(t) = G1(1, 1, t) =kon
kon + koff+
(p1(0)−
konkon + koff
)e−(kon+koff)t. (1.6)
4. Il faut faire attention car l’application de (1.4) qui n’est pas vraiment intuitive (on pourra par exemplepenser au fait que fe,m,n(e
′,m′ − 1, n′) = 1(e,m+1,n)(e′,m′, n′)). On calcule en fait L∗, l’adjoint de L.
5. Il n’a en fait à notre connaissance pas encore été résolu à ce jour.

1.2. Distributions stationnaires : résultats actuels 13
La convergence vers la loi stationnaire (une loi de Bernoulli de paramètre konkon+koff
) selit ici immédiatement, et elle se produit à la “vitesse” kon + koff. Ceci correspond bien àl’intuition : au bout d’un temps assez grand, le promoteur ne dépend plus de son état initialmais seulement des taux d’allumage et d’extinction. Plus précisément, on a
konkon + koff
=
1koff
1kon
+ 1koff
où l’on reconnaît les durées moyennes de séjour en ON et en OFF, respectivement 1koff
et 1kon
.
Distribution stationnaire de l’ARNOn cherche maintenant πM (m) :=
∑n p0,m,n +
∑n p1,m,n pour m ∈ N. On pose
κon =kond0, κoff =
koffd0, a0 =
s0d0, a1 =
s1d1, γ =
d0d1
et on introduit les deux séries génératrices “stationnaires” :
G0(x, y) =∑m,n
p0,m,nxmyn et G1(x, y) =
∑m,n
p1,m,nxmyn.
Elles définissent bien des fonctions, au moins continues sur 0, 1 × [0, 1] × [0, 1] et declasse C∞ sur 0, 1×]0, 1[×]0, 1[. D’après (1.5), elles sont solution du système d’équationsaux dérivées partielles couplées :
∂G0
∂y=
γ
y − 1(κoffG1 − κonG0) −
(γx− 1
y − 1+ a1
x
y
)∂G0
∂x(1.7)
∂G1
∂y=
γ
y − 1(−κoffG1 + κonG0) + γa0
x− 1
y − 1G1 −
(γx− 1
y − 1+ a1
x
y
)∂G1
∂x(1.8)
Ce système contient en fait toute l’information (hormis la condition initiale) puisque sasolution permet de décrire complètement la loi stationnaire de (Et,Mt, Pt)t⩾0, mais nous nesavons malheureusement pas le résoudre.
Pour obtenir la distribution stationnaire πM de l’ARN, on multiplie (1.7) et (1.8) pary − 1 puis on fait tendre y vers 1. Le système se simplifie alors en faisant apparaître deuxéquations différentielles ordinaires
(x− 1)f ′0(x) = κofff1(x)− κonf0(x) (1.9)(x− 1)f ′1(x) = −κofff1(x) + κonf0(x) + a0(x− 1)f1(x) (1.10)
avec f0(x) = G0(x, 1) et f1(x) = G1(x, 1). Par définition de G0 et G1, on a f0(1) + f1(1) = 1et on en déduit que
f0(1) =koff
kon + koffet f1(1) =
konkon + koff
,
ce qui permet de retrouver la distribution stationnaire du promoteur obtenue précédemment.
La difficulté pour résoudre les équations (1.9) et (1.10) vient de la singularité en x = 1.Néanmoins, en dérivant la première puis en l’utilisant dans la deuxième, on obtient une

14 Chapitre 1. Dynamique d’un gène isolé
équation différentielle d’ordre 2 assez classique, dont on peut exprimer les solutions grâce àla fonction hypergéométrique confluente 1F1 (cf. p. 5). On obtient finalement :
πM (m) =am0m!
κon(κon + 1) · · · (κon +m− 1)
(κon + κoff) · · · (κon + κoff +m− 1)1F1(κon +m,κon + κoff +m,−a0)
=am0m!
Γ(κon + κoff)
Γ(κon)Γ(κoff)
∫ 1
0xm+κon−1(1− x)κoff−1e−a0x dx
=Γ(κon + κoff)
Γ(κon)Γ(κoff)
∫ 1
0
(a0x)m
m!e−a0xxκon−1(1− x)κoff−1 dx.
(1.11)
La dernière ligne de (1.11) permet de prouver immédiatement la proposition suivante.
Proposition 1.5. Soit X une variable aléatoire de loi πM . Alors il existe une variablealéatoire Z telle que
Z ∼ Beta
(kond0,koffd0
)et L(X |Z) = P
(s0d0Z
).
Remarque 1.6. La loi πM peut donc être vue comme un “Beta-mélange” de lois de Poissons,appelé dans la suite loi Poisson-Beta. En plus de procurer une méthode de simulation trèsrapide de πM (bien plus rapide que l’utilisation de l’ergodicité du processus (Mt)t⩾0), ceciouvre la porte à différentes méthodes d’inférence statistique basées sur les modèles de mé-lange. Nous avons ainsi pu concevoir un algorithme de type EM pour estimer les paramètresd’un gène isolé 6. Cette propriété a aussi été remarquée et exploitée par Kim et Marioni (2013),qui ont pour leur part privilégié une approche bayésienne avec un algorithme MCMC.
Remarque 1.7. D’un point de vue biologique, la proposition 1.5 est aussi très intéressante.On vient de décomposer la stochasticité de l’ARN en deux sources bien distinctes :
— l’activité du promoteur relativement à la durée de vie moyenne d’un ARN ;— la dynamique générale “de croisière” de synthèse/dégradation de l’ARN.
La première semble être structurelle, tandis que la deuxième correspond aux fluctuations del’ARN autour de son niveau moyen 7.
Considérons d’abord la première source de stochasticité. L’espérance de la loi Beta im-pliquée vérifie
E(Z) =kond0
kond0
+ koffd0
=kon
kon + koff
et coïncide donc avec la proportion moyenne d’allumage du gène vue précédemment. En fait,la durée de vie moyenne 1
d0de l’ARN constitue une forme d’inertie (Figure 6) :
• si d0 ≫ kon, koff, l’ARN a très peu d’inertie par rapport au promoteur et a quasiment lemême comportement binaire que lui ;
• si d0 ≪ kon, koff, les fluctuations du promoteur sont trop rapides pour affecter l’ARN quiest donc quasiment constant, égal à la proportion moyenne d’allumage du gène.
6. Non détaillé ici par manque de temps, et aussi parce qu’il aurait plus de sens une fois adapté à unréseau de gènes. Dans le cas d’un gène isolé, Peccoud et Ycart (1995) ont donné un estimateur par la méthodedes moments qui est réellement imbattable, à la fois en termes de temps de calcul et de précision.
7. L’espérance de P(λ) est précisément λ : on parlera souvent de “fluctuations poissoniennes” pour désignercette source de stochasticité.

1.2. Distributions stationnaires : résultats actuels 15
(a) (b)
(c) (d)
Figure 6 – Graphes de la densité de la loi Beta pour différentes valeurs des paramètres. Lescas (a) et (b) correspondent à d0 ≫ kon, koff (faible inertie) : l’ARN est souvent dans un étatextrême et rarement entre les deux. Les cas (c) et (d) correspondent à d0 ≪ kon, koff (forteinertie) : l’ARN s’éloigne alors peu de sa valeur moyenne. On a pris la même moyenne pour(a)-(c) et pour (b)-(d). Le cas (b) décrit bien les données (cf. Figure 2).
Plus précisément, on a les lemmes suivants (cf. annexe A.2 pour les preuves). Le premierformalise le cas du promoteur rapide :
Lemme 1.8. Soient a, b > 0. Si (Xn) est une suite de v.a.r. telle que Xn ∼ Beta(na, nb),alors
XnL−−−−−→
n→+∞
a
a+ b.
Son interprétation est immédiate d’après ce que l’on a dit plus haut. Le deuxième lemmepermet d’analyser la source de stochasticité liée à la loi de Poisson :
Lemme 1.9. Soit Z une v.a.r. admettant une densité par rapport à la mesure de Lebesgue.Si (Xn) est une suite de v.a.r. telle que L(Xn |Z) = P(nZ), alors
Xn
n
L−−−−−→n→+∞
Z.
Une fois appliqué à Z de loi Beta, ce lemme montre que dans le cas où a0 = s0/d0 estgrand, la deuxième source de stochasticité disparaît et l’ARN est quasiment égal à a0Z. End’autres termes, les fluctuations de l’ARN autour de son niveau moyen sont d’autant plusnégligeables que ce niveau est élevé.
Ce constat fait le lien entre le point de vue stochastique (discret) et le point de vuedéterministe (continu) de la cinétique chimique. La proposition 1.5 nous apprend en effetque l’échelle de la quantité d’ARN produite est gouvernée indépendamment du promoteurpar a0. Or on rappelle que les écarts entre les quantités d’ARN observées par l’équipe BM2Asont souvent grands, de l’ordre de 103 à 106, ce qui donne un ordre de grandeur pour a0.À cette échelle là, il devient pertinent d’adopter le point de vue de la cinétique chimique,c’est-à-dire considérer la concentration d’ARN (continue) plutôt que le nombre exact demolécules. Les réactions se traduisent alors en équations différentielles plutôt qu’en processusde naissance/mort : on exploitera ce raisonnement dans la section 1.3.

16 Chapitre 1. Dynamique d’un gène isolé
Remarque 1.10. Comme le lemme 1.9 s’applique à toutes les lois à densité et pas seulementla loi Beta, une question intéressante serait de déterminer s’il existe une catégorie plus largede modèles pour lesquels on a le même type de décomposition “loi à densité+Poisson”.
Distribution stationnaire des protéinesOn s’intéresse finalement à la loi stationnaire πP des protéines. Il faut pour cela revenir
au système (1.7), (1.8). Nous nous contenterons ici d’expliciter le résultat de Shahrezaei etSwain (2008). C’est cette fois-ci le rapport γ = d0/d1 qui est fondamental : les auteurs seplacent dans le cas γ ≫ 1, qui semble pertinent biologiquement car il signifie que l’ARN àune durée de vie moyenne plus courte (et donc moins d’inertie) que les protéines. En utilisantla méthode des caractéristiques et en faisant une approximation liée à γ ≫ 1, ils obtiennentune expression approchée pour la distribution stationnaire des protéines :
∀n ⩾ 0, πP (n) =Γ(α+ n)Γ(β + n)Γ(γκon + γκoff)
Γ(n+ 1)Γ(α)Γ(β)Γ(γκon + γκoff + n)
(a1
γ + a1
)n(1− a1
γ + a1
)α
× 2F1
(α+ n, γκon + γκoff − β, γκon + γκoff + n,
a1γ + a1
),
(1.12)
avec
α =γ
2
(a0 + κon + κoff +
√(a0 + κon + κoff)2 − 4a0κon
),
β =γ
2
(a0 + κon + κoff −
√(a0 + κon + κoff)2 − 4a0κon
).
Cette expression est difficilement exploitable en pratique et les auteurs ne semblent pasavoir tenté de la simplifier. Cependant, on va voir que l’on peut encore décomposer πP enun mélange de lois. En utilisant la représentation intégrale 8 de 2F1 (cf. p. 5), on obtient :
πP (n)=an1Γ(α+ n)Γ(γκon + γκoff)
n!γnΓ(α)Γ(β)Γ(γκon + γκoff − β)
∫ 1
0xβ+n−1(1− x)γκon+γκoff−β−1
(1 +
a1γx
)−α−n
dx
=Γ(γκon + γκoff)
Γ(β)Γ(γκon + γκoff − β)
∫ 1
0
(a1x
γ + a1x
)n γαΓ(α+ n)
n!Γ(α)
xβ−1(1− x)γκon+γκoff−β−1
(γ + a1x)αdx
=
∫ 1
0
xβ−1(1− x)γκon+γκoff−β−1
B(β, γκon + γκoff − β)
∫ +∞
0
tα−1e−t
Γ(α)
e−a1
γxt
n!
(a1xt
γ
)n
dt dx.
On reconnaît alors un mélange de lois simples “Beta-gamma-Poisson”.
Proposition 1.11. Soit Z une variable aléatoire de loi πP . Alors il existe des variablesaléatoires X et Y telles que
X ∼ Beta (β, γκon + γκoff − β) , Y ∼ γ
(α,s1d0
)et L(Z |X,Y ) = P (XY ) .
Lorsque d0 ≫ d1, on retrouve donc les mêmes avantages avec cette approximation de πPque pour πM , à savoir une simulation rapide et une formulation plus agréable à manipuler.Remarquons que la loi de Poisson est encore présente de la même façon que pour l’ARN.
8. Euler, 1748.

1.3. Approximation déterministe par morceaux 17
Si l’on suppose de plus que s0 ≫ d1 et s0 ≫ kon+koff (ce qui est très vraisemblable d’aprèsles données disponibles), alors cette loi peut encore se simplifier. On a en effet d’après lesdéfinitions de α et β :
α ≈ s0d1
≫ 1 et β ≈ kond1
= γkon.
Les deux lemmes suivants (cf. annexe A.2) permettent alors de simplifier les choses.
Lemme 1.12. Soient a, θ > 0. Si (Xn) est une suite de v.a.r. telle que Xn ∼ γ(na, θ), alors
Xn
n
L−−−−−→n→+∞
aθ.
Lemme 1.13. Soient a, b > 0. Si (Xn) est une suite de v.a.r. telle que Xn ∼ Beta(a, nb−a),alors
nXnL−−−−−→
n→+∞γ
(a,
1
b
).
En utilisant le lemme 1.12 sur γ(α, 1) avec α ≫ 1, on obtient Y ≈ α et on a ainsi enpremière approximation :
P ∼ s0s1d0d1
Beta
(kond1,koffd1
). (1.13)
Enfin, si l’on fait l’hypothèse supplémentaire koff ≫ kon, c’est-à-dire que le gène est bienplus souvent éteint qu’allumé (ceci correspond à un comportement en bursts du gène), alorsd’après le lemme 1.13, la loi πP s’approche par une loi gamma :
P ∼ γ
(kond1,
s0s1d0(kon + koff)
). (1.14)
Bien que restant des approximations, ces lois semblent bien cohérentes. On remarque que laforme (1.13) de P est très proche de celle de l’ARN dans le cas s0 ≫ d0.
1.3 Approximation déterministe par morceauxL’inconvénient majeur du modèle “exact” défini par un processus de naissance/mort est
que les simulations nécessitent de calculer de très nombreux sauts (synthèses/dégradations),et ce d’autant plus que les vitesses de réactions sont élevées. Ceci rend souvent les simulationstrès longues, voire inaccessibles en pratique.
Par ailleurs, la remarque 1.7 et le lemme 1.9 nous ont permis de voir que dans le cas oùs0/d0 est grand, l’ARN et les protéines ont une échelle assez grande pour pouvoir négligerles fluctuations autour de leur moyenne et les supposer continues. Il est alors légitime des’intéresser à une approximation du modèle à deux états qui décrive ce cas : nous allons pourcela utiliser la formulation par les équations stochastiques (1.1), (1.2), (1.3). On considèredans ce qui suit N ∈ N “grand” et on pose s0 = Ns0, MN (t) =M(t)/N et PN (t) = P (t)/N .Les équations (1.2) et (1.3) peuvent se réécrire :
MN (t) =MN0 +
1
NY3
(Ns0
∫ t
0E(u) du
)− 1
NY4
(Nd0
∫ t
0MN (u) du
)(1.15)
PN (t) = PN0 +
1
NY5
(Ns1
∫ t
0MN (u) du
)− 1
NY6
(Nd1
∫ t
0PN (u) du
)(1.16)
où MN0 =M0/N et PN
0 = P0/N .

18 Chapitre 1. Dynamique d’un gène isolé
Soit t ∈ R+ fixé et soit E =∫ t0 E(u) du. Par définition, on a L(Y3(Ns0E) | E) = P(Ns0E).
On en déduit grâce au lemme 1.9 :
1
NY3
(Ns0
∫ t
0E(u) du
)L−−−−−→
N→+∞s0
∫ t
0E(u) du.
On peut procéder de la même manière pour Y4, Y5 et Y6. Ceci motive l’heuristique suivante :lorsque N → +∞, le processus (MN , PN ) converge 9 vers un processus (M, P ) qui vérifie
M(t) = M0 + s0
∫ t
0E(u) du− d0
∫ t
0M(u) du (1.17)
P (t) = P0 + s1
∫ t
0M(u) du− d1
∫ t
0P (u) du (1.18)
Ainsi, lorsque s0/d0 est grand, la solution de (1.1), (1.2), (1.3) ressemble à celle du système :
E(t) = E0 − Y1
(koff
∫ t
0E(u) du
)+ Y2
(kon
∫ t
0(1− E(u)) du
)(1.19)
M(t) =M0 + s0
∫ t
0E(u) du− d0
∫ t
0M(u) du (1.20)
P (t) = P0 + s1
∫ t
0M(u) du− d1
∫ t
0P (u) du (1.21)
Il s’agit d’un processus de Markov déterministe par morceaux ou PDMP, pour PiecewiseDeterministic Markov Process. On n’abordera pas ici la démonstration de cette convergencequi est relativement récente et demande l’introduction d’un certain formalisme. Pour plus dedétails, on pourra par exemple consulter Crudu et al. (2012) ou Kang et Kurtz (2013). Onpourra également consulter Malrieu (2014) pour une étude de quelques PDMP intéressantsqui apparaissent naturellement en modélisation.
Remarque 1.14. Sachant E, les équations (1.20) et (1.21) sont déterministes. La fonctionM est continue et dérivable par morceaux et la fonction P est dérivable et C1 par morceaux.Plus précisément, si on note (ti)i∈N∗ les instants de saut de E, on a pour tout t ∈]ti, ti+1[,
dM
dt(t) =
s0 − d0M(t) si E(ti) = 1
−d0M(t) si E(ti) = 0
Par continuité, on connaît toute la trajectoire de M , et P est alors solution de l’EDO :
dP
dt(t) = s1M(t)− d1P (t).
Partant de sa condition initiale, ce processus évolue donc selon les équations différentiellesordinaires, mais peut basculer à tout moment entre plusieurs équations différentielles (icideux seulement). Le processus (Et)t⩾0 garde sa particularité d’environnement aléatoire quidétermine cette fois le flot de (Mt, Pt). Cet environnement est toujours le même processusmarkovien de sauts que pour le modèle à deux états.
La Figure 7 montre un exemple de trajectoire du PDMP : puisque M et P sont continues,on peut normaliser leurs échelles sans perte de généralité. En pratique, on ne distinguequasiment plus le PDMP du vrai processus dès que s0 = 103.
9. C’est une convergence en loi assez intuitive mais il faut faire attention à la topologie utilisée...
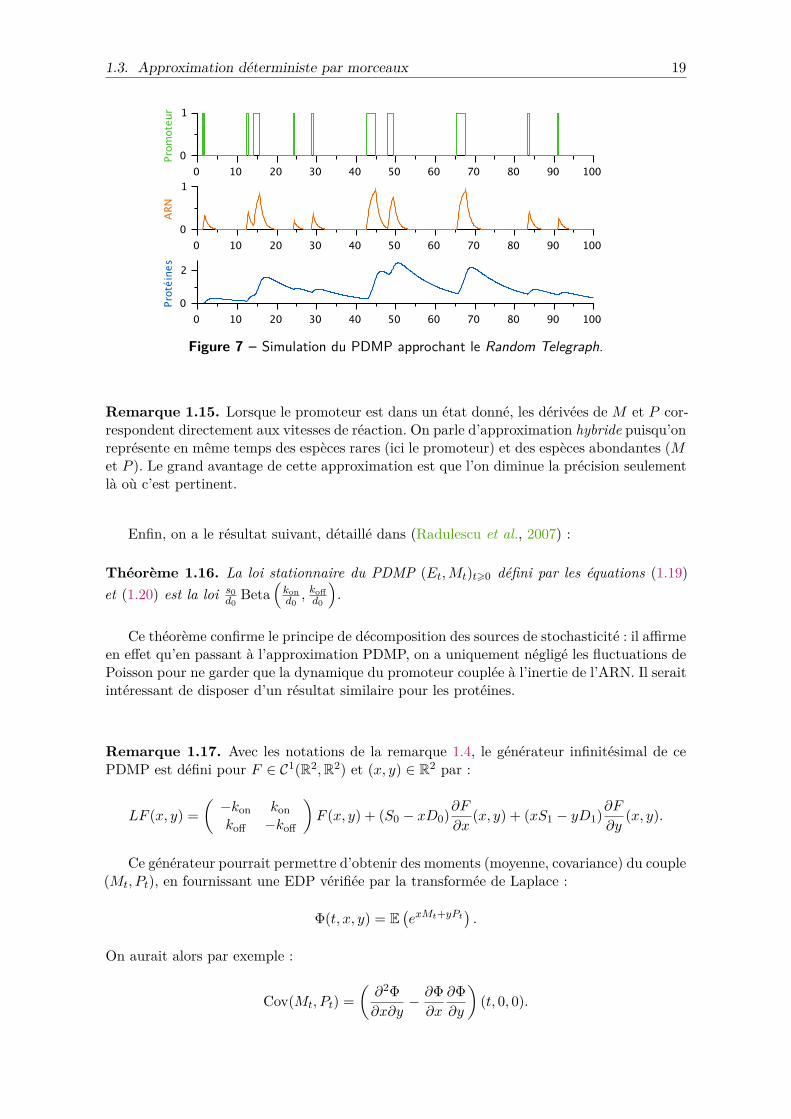
1.3. Approximation déterministe par morceaux 19
Figure 7 – Simulation du PDMP approchant le Random Telegraph.
Remarque 1.15. Lorsque le promoteur est dans un état donné, les dérivées de M et P cor-respondent directement aux vitesses de réaction. On parle d’approximation hybride puisqu’onreprésente en même temps des espèces rares (ici le promoteur) et des espèces abondantes (Met P ). Le grand avantage de cette approximation est que l’on diminue la précision seulementlà où c’est pertinent.
Enfin, on a le résultat suivant, détaillé dans (Radulescu et al., 2007) :
Théorème 1.16. La loi stationnaire du PDMP (Et,Mt)t⩾0 défini par les équations (1.19)et (1.20) est la loi s0
d0Beta
(kond0, koff
d0
).
Ce théorème confirme le principe de décomposition des sources de stochasticité : il affirmeen effet qu’en passant à l’approximation PDMP, on a uniquement négligé les fluctuations dePoisson pour ne garder que la dynamique du promoteur couplée à l’inertie de l’ARN. Il seraitintéressant de disposer d’un résultat similaire pour les protéines.
Remarque 1.17. Avec les notations de la remarque 1.4, le générateur infinitésimal de cePDMP est défini pour F ∈ C1(R2,R2) et (x, y) ∈ R2 par :
LF (x, y) =
(−kon konkoff −koff
)F (x, y) + (S0 − xD0)
∂F
∂x(x, y) + (xS1 − yD1)
∂F
∂y(x, y).
Ce générateur pourrait permettre d’obtenir des moments (moyenne, covariance) du couple(Mt, Pt), en fournissant une EDP vérifiée par la transformée de Laplace :
Φ(t, x, y) = E(exMt+yPt
).
On aurait alors par exemple :
Cov(Mt, Pt) =
(∂2Φ
∂x∂y− ∂Φ
∂x
∂Φ
∂y
)(t, 0, 0).

20 Chapitre 1. Dynamique d’un gène isolé
1.4 Modèle déterministe associéOn considère le modèle PDMP (1.19), (1.20), (1.21) et on note
a =s0d0
et b =s0s1d0d1
.
Si l’état initial vérifie M0 ∈]0, a[ et P0 ∈]0, b[, alors pour tout t ⩾ 0, le système (M(t), P (t))reste dans l’ouvert ]0, a[ × ]0, b[. Dans le cas extrême où d0 ≪ kon + koff, les fluctuationsdu promoteur sont assez rapides pour être complètement absorbées par l’inertie de l’ARN :l’environnement aléatoire E n’influence plus M et P que par sa moyenne, ce qui motive unmodèle complètement déterministe, i.e. un système d’EDO.
Un argument heuristique pour obtenir ce modèle déterministe consiste à exploiter ladifférence d’échelle de temps entre E et M pour appliquer l’ergodicité du processus E. On aainsi pour t ⩾ 1/d0 ≫ 1/(kon + koff) :
1
t
∫ t
0E(u) du ≈ E(E(t)).
La quantité∫ t0 E(u) dt est donc déterministe en première approximation, et par conséquent
quasiment égale à sa moyenne. On a alors directement par Fubini :∫ t
0E(u) du ≈ E
(∫ t
0E(u) du
)=
∫ t
0E(E(u)) du.
On remplace donc (1.20) par l’équation différentielle
M(t) =M0 + s0
∫ t
0E(u) du− d0
∫ t
0M(u) du,
où E(u) = E(E(u)). Or la fonction t 7→ E(t) vérifie d’après l’équation (1.6) :
E′(t) = kon(1− E(t))− koffE(t).
On obtient finalement le système d’EDO linéaires suivant :
E′(t) = kon − (kon + koff)E(t) (1.22)M ′(t) = s0E(t)− d0M(t) (1.23)P ′(t) = s1M(t)− d1P (u) (1.24)
Ce système admet un unique état d’équilibre, globalement asymptotiquement stable :
E =kon
kon + koff, M = a
konkon + koff
et P = bkon
kon + koff.
Remarque 1.18. La solution de ce système d’EDO correspond en fait à celui vérifié par lamoyenne du processus de naissance/mort associé. Au final, on n’a fait qu’appliquer deux foisla loi des grands nombres, mais sous des formes bien distinctes :• sous forme spatiale pour obtenir le modèle PDMP ;• sous forme temporelle pour obtenir le modèle EDO.
Il pourrait être intéressant de disposer d’un théorème limite central associé à ces deux pas-sages à la limite réalisés simultanément.

Chapitre 2
Gènes en interaction
On s’intéresse maintenant à un ensemble de gènes qui peuvent potentiellement interagirles uns avec les autres grâce à des interactions de type “activation/inhibition”, définissantun réseau de gènes. Plutôt que de simplement décrire la covariance entre deux gènes, notreobjectif est de définir physiquement ce que l’on entend par “activation” ou “inhibition”. Ceréseau pourra donc être défini par un graphe orienté dont les arcs représenteront un véritablelien de cause à effet. On souhaite de plus attribuer un poids à chaque arc qui correspond àl’importance de l’interaction.
Dans toute la suite, on considèrera un ensemble de gènes fixé dont le nombre sera noté G.On supposera que le système est fermé en négligeant les effets extérieurs au réseau (autresgènes, interactions entre cellules, etc.). Lorsque les gènes n’ont aucune interaction entre eux,il est clair que leur comportement peut être décrit par G processus indépendants dont ladynamique suit celle du modèle à deux états étudié au chapitre 1. L’idée de base est de relierces G modèles avec au plus une interaction pour chaque couple de gènes. La Figure 8 décritl’exemple d’un réseau de 2 gènes où il y a alors 4 interactions possibles.
OFF ON ARN Prot.
ARN Prot.
kon,1
koff,1
s0,1 s1,1
d0,1 d1,1
OFFONARNProt.
ARNProt.
kon,2
koff,2
s0,2s1,2
d0,2d1,2
θ2,1
θ1,2
θ1,1
θ2,2
Figure 8 – Illustration des quatre interactions possibles dans le cas d’un réseau de deux gènes.On associe à chaque interaction j → i un paramètre θi,j , avec l’idée que |θi,j | est le poids del’interaction (pouvant éventuellement être nul), que θi,j > 0 représente une activation et θi,j < 0une inhibition.
21

22 Chapitre 2. Gènes en interaction
2.1 Extension du modèle à deux états
On continue d’identifier un gène avec son triplet promoteur, ARN, protéines en faisantl’hypothèse que chaque gène produit un type d’ARN et un type de protéine qui lui sontpropres. Pour tout i ∈ 1 . . . , G, on note (Ei(t),Mi(t), Pi(t)) l’état du gène Gi à l’instant tet on considère les réactions :
Givon,i−−−→ G∗
i , G∗i
s0,i−−→ G∗i +Mi, Mi
d0,i−−→ ∅
G∗i
voff,i−−−→ Gi, Mis1,i−−→Mi + Pi, Pi
d1,i−−→ ∅(2.1)
On fait l’hypothèse biologique que la seule source d’interaction entre les gènes se situe auniveau des réactions entre promoteurs et protéines. Les réactions de production/dégradationd’ARN et de protéines sont supposées élémentaires comme dans le cas d’un gène isolé, maisplus les réactions d’allumage/extinction du gène.
En d’autres termes, les paramètres s0,i, s1,i, d0,i et d1,i sont encore supposés constantsmais les taux d’allumage et d’extinction s’écrivent maintenant sous la forme :
von,i = von,i(P1, . . . , PG) et voff,i = voff,i(P1, . . . , PG). (2.2)
Dans la suite, on notera P = (P1, . . . , PG) et on supposera que les fonctions P 7→ von,i(P )et P 7→ voff,i(P ) sont positives et continues pour tout i ∈ 1, . . . , G.
Remarque 2.1. On se place donc dans un cadre où l’expression des gènes est dynamiquemais où la structure du réseau est fixe et entièrement caractérisée par les von,i et voff,i.
Modèle « exact » discret
On peut à présent étendre de manière naturelle le modèle à deux états en un “modèleà 2G états”. L’écriture sous forme d’équations stochastiques est ici la mieux adaptée : on sedonne une famille (Y1,i, . . . , Y6,i)1⩽i⩽G de processus de Poisson unitaires et indépendants, desvariables aléatoires (E0,i,M0,i, P0,i)1⩽i⩽G indépendantes à valeurs dans 0, 1, R+ et R+, eton définit notre modèle comme la solution (Ei,Mi, Pi)1⩽i⩽G du système
Ei(t) = E0,i − Y1,i
(∫ t
0voff,i(P (u))Ei(u) du
)+ Y2,i
(∫ t
0von,i(P (u))(1− Ei(u)) du
)(2.3)
Mi(t) =M0,i + Y3,i
(s0,i
∫ t
0Ei(u) du
)− Y4,i
(d0,i
∫ t
0Mi(u) du
)(2.4)
Pi(t) = P0,i + Y5,i
(s1,i
∫ t
0Mi(u) du
)− Y6,i
(d1,i
∫ t
0Pi(u) du
)(2.5)
pour tout i ∈ 1, . . . , G.
Remarque 2.2. L’algorithme de simulation d’un tel processus est tout aussi simple quepour le modèle à deux états, mais le temps de calcul sur une machine classique devientrédhibitoire dès que G > 3. Ceci motive fortement l’approximation hybride correspondante.

2.1. Extension du modèle à deux états 23
Modèle hybride
L’approximation faite au chapitre 1 fonctionne ici de la même façon. Le modèle hybridecorrespondant est donc le PDMP (Ei,Mi, Pi)1⩽i⩽G défini par :
Ei(t) = E0,i − Y1,i
(∫ t
0voff,i(P (u))Ei(u) du
)+ Y2,i
(∫ t
0von,i(P (u))(1− Ei(u)) du
)(2.6)
Mi(t) =M0,i + s0,i
∫ t
0Ei(u) du− d0,i
∫ t
0Mi(u) du (2.7)
Pi(t) = P0,i + s1,i
∫ t
0Mi(u) du− d1,i
∫ t
0Pi(u) du (2.8)
Il n’est en revanche plus possible de simuler la partie stochastique (2.6) de manièreexacte puisque les taux de saut dépendent des protéines et donc du temps. De plus, ungrand nombre de gènes va nécessairement entraîner de nombreux sauts dans l’espace d’états0, 1G du promoteur, et a fortiori un temps de calcul trop important.
Nous proposons une méthode d’approximation valable dans le cas qui nous intéresse, àsavoir d1,i ≪ d0,i (forte inertie des protéines par rapport à l’ARN) pour tout i ∈ 1, . . . , G.Intuitivement, comme par définition les niveaux d’ARN ne peuvent pas varier plus vite quele promoteur et que les protéines fluctuent bien plus lentement que l’ARN, les coefficientsvon,i(P ) et voff,i(P ) vont eux aussi varier lentement par rapport au promoteur.
Méthode de simulation. On considère un pas de temps δt > 0 tel que
∀i ∈ 1, . . . , G, δt≪ 1
d0,i≪ 1
d1,i.
On a alors von,i(P ) et voff,i(P ) quasiment constants entre t et t + δt : tout se passe surcet intervalle comme si les Ei suivaient G modèles à deux états indépendants. D’après lechapitre 1, on connaît donc de manière exacte la loi de Ei(t+δt) à partir des valeurs de Ei(t)et P (t) : l’équation (1.6) établit que Ei(t+ δt) ∼ B(pi(t+ δt)) où
pi(t+ δt) = Ei(t)e−(von,i(t)+voff,i(t))δt +
von,i(t)(1− e−(von,i(t)+voff,i(t))δt
)von,i(t) + voff,i(t)
,
avec von,i(t) = von,i(P (t)) et voff,i(t) = voff,i(P (t)). Ceci nous conduit directement au schémanumérique “hybride” :
Mi(t+ δt) = (1− d0,iδt)Mi(t) + s0,iδtEi(t)Pi(t+ δt) = (1− d1,iδt)Pi(t) + s1,iδtMi(t)Ei(t+ δt) ∼ B(pi(t+ δt))
(2.9)
Remarque 2.3. La partie stochastique du schéma est bien cohérente puisque quand δt→ 0,on a
pi(t+ δt) → Ei(t) ∈ 0, 1
et ainsi Ei(t+ δt) converge en loi vers Ei(t).

24 Chapitre 2. Gènes en interaction
2.2 Exemples de réseaux concretsPour le moment, nous avons seulement défini un cadre théorique général pour mettre en
réseau le modèle à deux états, sans expliciter von et voff. La puissance de ce cadre est qu’àtravers la formulation (2.1), on suppose simplement que von et voff sont des taux de réaction(ou des vitesses de réaction du point de vue macroscopique). Or les réactions
Givon,i−−−→ G∗
i , et G∗i
voff,i−−−→ Gi
ne sont plus des réactions élémentaires comme dans le modèle à deux états, mais plutôtdes réactions composées, c’est-à-dire les bilans d’un système de réactions élémentaires sous-jacentes. Définir notre réseau revient à définir ces réactions élémentaires : c’est l’endroitidéal pour traduire explicitement toutes sortes d’hypothèses biologiques sur la nature desinteractions gène-protéines.
Le réseau « élémentaire additif »Un premier modèle de réseau simple vient naturellement à l’esprit. Il correspond au
système suivant de 2(G+ 1)G réactions élémentaires se produisant en parallèle :
∀i ∈ 1, . . . , G,
Gikon,i−−−→ G∗
i
G∗i
koff,i−−−→ Gi
∀i, j ∈ 1, . . . , G,
Gi + Pj
νi,j−−→ G∗i + Pj
G∗i + Pj
µi,j−−→ Gi + Pj
(2.10)
Remarque 2.4. Le système de réactions (2.10) traduit l’hypothèse biologique selon laquelleles protéines agissent sur le gène indépendamment les unes des autres : au niveau microsco-pique, deux protéines qui arrivent en même temps sur le lieu 1 d’interaction avec le promoteuront la même influence que si elles arrivaient à des instants différents.
On a alors par définition des réactions élémentaires en parallèle :
von,i(P1, . . . , PG) = kon,i +G∑
j=1
νi,jPj et voff,i(P1, . . . , PG) = koff,i +G∑
j=1
µi,jPj . (2.11)
Nous appellerons ce modèle « élémentaire additif ». Les coefficients (kon,i)1⩽i⩽G, (koff,i)1⩽i⩽G,(νi,j)1⩽i,j⩽G et (µi,j)1⩽i,j⩽G sont donc constants et positifs, et (νi,j , µi,j) représente l’influencedu gène Gj sur le gène Gi. En particulier :
— si νi,j = µi,j = 0, le gène Gj n’a pas d’influence sur le gène Gi ;— si (νi,j)1⩽i,j⩽G et (µi,j)1⩽i,j⩽G sont tous nuls, ce modèle correspond à G modèles à
deux états évoluant de manière indépendante.
On peut déjà faire deux remarques sur le modèle :• Si kon,i, koff,i > 0 pour tout i ∈ 1, . . . , G, il existe une unique distribution stationnaire.• Chimiquement, rien ne nous empêche d’avoir simultanément νi,j > 0 et µi,j > 0 : il se
peut qu’une protéine soit impliquée dans les deux types de réactions. Cependant, celacomplique la définition du fait qu’un gène active ou réprime un autre gène.
1. On risque de devoir ouvrir un livre de génétique pour exprimer ceci de manière moins naïve...

2.2. Exemples de réseaux concrets 25
Une piste pour la simplification. Pour simplifier, on peut faire l’hypothèse que lasomme des vitesses de réaction est bornée de manière indépendante du réseau, i.e. qu’ilexiste (ki)1⩽i⩽G et (λi,j)1⩽i⩽G fixés tels que
∀(P1, . . . , PG) ∈ (R+)G, von,i(P1, . . . , PG) + voff,i(P1, . . . , PG) ⩽ ki +
G∑j=1
λi,jPj .
Comme von,i et voff,i sont en fait dans R1[X1, . . . , XG]G, ceci est équivalent à imposer
∀i, j ∈ 1, . . . , G, kon,i + koff,i ⩽ ki et νi,j + µi,j ⩽ λi,j .
Pour simplifier encore, on peut supposer que νi,j , µi,j ∈ 0, 1 et que λi,j = 1. On n’aplus que 3 cas possibles pour une interaction (νi,j , µi,j) :• Si (νi,j , µi,j) = (0, 0), le gène Gj n’a pas d’influence sur le gène Gi,• Si (νi,j , µi,j) = (1, 0), on dit que le gène Gj active le gène Gi,• Si (νi,j , µi,j) = (0, 1), on dit que le gène Gj inhibe (ou réprime) le gène Gi.
On pose alors :∀i, j ∈ 1, . . . , G, θi,j = νi,j − µi,j ∈ −1, 0, 1.
Ceci nous permet de définir un graphe orienté et labellisé par des signes ± de manièrenaturelle : un arc i → j n’est tracé que lorsque (νi,j , µi,j) = (0, 0), et dans ce cas on luiaffecte le signe + (resp. −) si (νi,j , µi,j) = (1, 0) (resp. (0, 1)). On considère enfin kon,i et koff,ifixés, et le réseau est alors entièrement défini par la matrice (θi,j)1⩽i,j⩽G.
Le réseau « élémentaire multiplicatif »Le modèle de réseau précédent est séduisant, mais on vient de voir qu’il pose des pro-
blèmes pour définir explicitement l’activation et l’inhibition. Dans toute la suite de ce rapport,on s’intéresse à un second modèle dont la forme est plus simple à exploiter (cf. chapitre 3).Ce modèle correspond à l’hypothèse que les réactions suivantes sont élémentaires :
Gi + νi,1P1 + · · ·+ νi,nPnvon,i−−−→ G∗
i + νi,1P1 + · · ·+ νi,nPn
G∗i + µi,1P1 + · · ·+ µi,nPn
voff,i−−−→ Gi + µi,1P1 + · · ·+ µi,nPn
La forme des vitesses est donc :
von,i(P1, . . . , PG) = kon,i
G∏j=1
Pνi,jj et voff,i(P1, . . . , PG) = koff,i
G∏j=1
Pjµi,j , (2.12)
d’où le nom de réseau « élémentaire multiplicatif ». Or, si l’on suppose que les protéinessuivent approximativement une loi Beta (ce qui est motivé par l’étude d’un gène isolé avecl’équation (1.13)), on a
Pi ≈ E(Pi | von,i(P ), voff,i(P )) ≈ s0,is1,id0,id1,i
von,i(P )
von,i(P ) + voff,i(P )=s0,is1,id0,id1,i
∏nj=1 Pj
νi,j−µi,j
ci +∏n
j=1 Pjνi,j−µi,j
où ci = koff,i/kon,i. Ceci nous incite à définir notre réseau par θi,j = νi,j−µi,j : c’est l’approcheque nous utiliserons au chapitre suivant. On peut déjà faire des simulations qui montrentque ce modèle de réseau présente un comportement cohérent. Par exemple, pour 2 gènes, onpeut considérer la forme de réseau définie par le graphe de la Figure 9. On obtient les typesde trajectoires de la Figure 10.

26 Chapitre 2. Gènes en interaction
G1 G2
−1
−1
Figure 9 – Réseau simple de 2 gènes avec rétroactions négatives, utilisé pour les graphes de lafigure 10. Ce réseau correspond à θ1,2 = θ2,1 = −1 et θ1,1 = θ2,2 = 0.
(a) (b)
(c) (d)
Figure 10 – Simulations de la version PDMP du réseau via l’algorithme proposé, pour 2 gènes(graphes (a),(b),(c)) et 3 gènes (graphe (d)). (a) Cas du réseau trivial (pas interaction) : les tauxd’allumage et d’extinction restent constants. (b) Cas où θ1,2 = θ2,1 = −1 : un comportementbistable apparaît. (c)-(d) si l’on augmente la valeur absolue des θ, la bistabilité s’amplifie et onfinit par se rapprocher d’un comportement déterministe.

2.3. Modèle déterministe associé 27
2.3 Modèle déterministe associéLes graphes précédents ont fait apparaître des états d’équilibre “quasi déterministes” : les
gènes semblent stables au voisinage de ces points, mais il y a toujours des petites oscillationsautour et une éventuelle oscillation un peu plus forte peut faire basculer le système d’unéquilibre à un autre. On va chercher à en savoir plus sur ces équilibres.
On considère le modèle PDMP (2.6), (2.7), (2.8) et on note pour tout i ∈ 1, . . . , n :
ai =s0,id0,i
et bi =s0,is1,id0,id1,i
.
Si l’état initial vérifieM0,i ∈]0, ai[ et P0,i ∈]0, bi[, alors pour tout t ⩾ 0, le système (M(t), P (t))reste dans l’ouvert
Ω =G∏i=1
]0, ai[ ×G∏i=1
]0, bi[ .
Un raisonnement analogue à celui de la section 1.4 est valable dans le cas d1,i ≪ d0,i pourtout i ∈ 1, . . . , G. On obtient le système de 3G équations diférentielles :
E′i(t) = von,i(P (t))(1− Ei(t))− voff,i(P (t))Ei(t) (2.13)
M ′i(t) = s0,iEi(t)− d0,iMi(t) (2.14)
P ′i (t) = s1,iMi(t)− d1,iPi(u) (2.15)
Les éventuels points d’équilibre de ce système vérifient : ∀i ∈ 1, . . . , G,
Ei =von,i(P )
von,i(P ) + voff,i(P ), (2.16)
Mi = aivon,i(P )
von,i(P ) + voff,i(P ), (2.17)
Pi = bivon,i(P )
von,i(P ) + voff,i(P ). (2.18)
L’ensemble des équilibres est donc l’intersection de G variétés de dimensions inférieuresou égales à G – plus précisément des quadriques en dimension G – déterminées par leséquations (2.18). La Figure 11 montre un exemple de tels points dans le cas de 2 gènes pourle réseau élémentaire additif 2 et la Figure 12 pour le réseau élémentaire multiplicatif. Onconstate qu’il est possible de générer des points d’équilibres intéressants et qui sont cohérentsavec le comportement attendu des gènes.
Remarque 2.5. Même dans le cas très particulier avec θi,j ∈ −1, 0, 1 que l’on a définiplus haut, les équilibres ne semblent en général pas calculables explicitement.
2. kon = 0.7, koff = 10, ν1,1 = ν2,2 = 0.5, µ1,2 = µ2,1 = 1, b = 80.

28 Chapitre 2. Gènes en interaction
-25 0 25 50 75 100 125 150 175 200
-25
25
50
75
100
125
150
Figure 11 – Exemple de points d’équilibres possibles dans le cas de deux gènes, correspondant àl’intersection des deux variétés (ici des hyperboles). Il s’agit ici d’une double rétroaction négativecomme précédemment : les deux points respectivement proches de l’abscisse et de l’ordonnéesont stables (un gène très exprimé tandis que l’autre ne l’est pas), et le troisième au milieu estinstable.
-0.4 0 0.4 0.8 1.2 1.6 2 2.4 2.8 3.2
-0.4
0.4
0.8
1.2
1.6
2
2.4
Figure 12 – Même idée, cette fois avec le modèle élémentaire multiplicatif.

Chapitre 3
Vers une inférence du réseau
On s’intéresse maintenant à quelques idées pour tenter d’inférer le réseau à partir desdonnées. Une particularité importante de celles-ci est qu’elles ne correspondent pas à 100réalisations d’une trajectoire (X(1),X(2),X(3),X(4)) (les 4 instants de mesure) : en effet,on tue les cellules en mesurant leur niveau X d’ARN donc on observe à chaque fois unéchantillon issu d’une nouvelle trajectoire.
Par contre, dès le premier instant t > 0, le vecteur X(t) contient des corrélations : eneffet, même si les composantes X(t) sont indépendantes, les couplages induits par le réseaufont que les composantes de X(t+1) ne sont plus indépendantes. Ceci motive un passage à lalimite en temps long : le but est de décrire la loi stationnaire des gènes, qui contient toutesces corrélations et dont chaque donnée est une réalisation.
3.1 Une première idée pour l’inférenceOn va se contenter dans ce rapport de construire un modèle bayésien hiérarchique de type
“champ de Markov caché”, à partir d’une discrétisation du temps dans le modèle proposé auchapitre 2 : intuitivement, comme ce sont les protéines qui gouvernent le réseau, ce sont ellesqui possèdent une grande corrélation. Si les protéines sont assez corrélées, comme ce sontelles qui dirigent les paramètres du Random Telegraph suivi par l’ARN, on a espoir que cedernier contienne encore une information sur la structure du réseau. On peut résumer cecipar un diagramme en plaque comme sur la Figure 13.
θ z xN
Figure 13 – Diagramme en “plaque” du modèle bayésien considéré. θ représente les paramètresdu réseau, z les protéines et x l’ARN. Les cercles correspondent aux variables et le rectanglecorrespond à N répétitions indépendantes de son contenu. Les observations sont représentéespar un cercle grisé.
29

30 Chapitre 3. Vers une inférence du réseau
3.2 Un modèle linéaire sous-jacentOn note dans la suite n = G le nombre de gènes. En considérant un analogue discret
du modèle élémentaire multiplicatif du chapitre précédent et en supposant que le réseau est“parcimonieux”, i.e. tel que ∥θ∥1 ⩽ λ fixé, on a pour ci assez grand :
Pi(t+1) =
∏nj=1 (P
(t)j )
θi,j
ci +∏n
j=1 (P(t)j )
θi,j≈ 1
ci
n∏j=1
(P(t)j )
θi,j.
Notre approximation finale consiste à supposer que l’erreur d’approximation suit un bruitgaussien centré. Le changement de variable Z = ln(P ) transforme alors le produit en unecombinaison linéaire beaucoup plus agréable à manipuler. Plus précisément, on s’intéresse àprésent au modèle suivant :
Z(t+1)i ∼ − ln(ci) +
n∑j=1
θi,jZ(t)j + ε
(t+1)i
où ε(t)i ∼ N (0, σ2). En posant bi = ln(ci), on a alors :
Z(t+1) = AZ(t) −B + ε(t+1)
où A = (θi,j) est la matrice définissant le réseau.
Ce type de processus est appelé modèle auto-régressif vectoriel. Si Z(0) est un vecteurgaussien, alors Z(t) ∼ N (µ(t),Γ(t)) aussi et pour tout t :
µ(t+1) = Aµ(t) −B
Γ(t+1) = AΓ(t)A⊤ + σ2In
d’où, si µ(0) = −B et Γ(0) = σ2In :
µ(t) = −
(t∑
k=0
Ak
)B
Γ(t) = σ2t∑
k=0
Ak(A⊤)k
On note à présent ∥A∥ la norme d’opérateur de A induite par la norme euclidienne sur Rn.
Proposition 3.1. On suppose que ∥A∥ < 1. Alors les suites (µ(t)) et (Γ(t)) convergent dansMn(R). Si de plus AA⊤ = A⊤A, alors les matrices A− In et AA⊤ − In sont inversibles eton a
µ = limt→+∞
µ(t) = (A− In)−1B
Γ = limt→+∞
Γ(t) = σ2((In −AA⊤)−1 − In)
Remarque 3.2. En utilisant la formule ∥A∥ =√ρ(A⊤A), ceci revient à supposer qu’on a
ρ(A⊤A) < 1. On remarque que σ2 ne joue pas de rôle particulier : on prend dans la suiteσ2 = 1.
Remarque 3.3. Si AA⊤ = A⊤A, on a donc AA⊤ = In − (Γ + In)−1 ∈ S+
n (R).

3.3. Premiers résultats 31
3.3 Premiers résultatsOn s’intéresse dans un premier temps à l’identifiabilité de la matrice A : celle-ci est assurée
lorsque A est symétrique et a toutes ses valeurs propres de même signe. Le cas général sembleen revanche bien plus complexe. Intuitivement, des résultats devraient pouvoir s’obtenir enimposant une hypothèse de parcimonie, c’est-à-dire en supposant que A contient beaucoupde coefficients nuls. On s’intéresse ensuite à la définitition finale de notre modèle statistiqueen prenant en compte l’ARN.
Cas où A est symétrique, semi-définie positive ou négative : identifiabilitéC’est-à-dire : A ∈ S+
n (R)∪S−n (R). On a alors AA⊤ = A2 = In− (Γ+In)
−1. Si on connaîtΓ, alors on connaît A de manière unique : en effet, on sait qu’il existe un unique H ∈ S+
n (R)tel que H2 = In − (Γ + In)
−1, et comme A ∈ S+n (R) on a nécessairement A = H.
Dans le cas général, on voit immédiatement que la connaissance de Γ seule ne permet pasde distinguer A de −A. Le résultat suivant montre que µ résout ce problème dans la plupartdes cas.
Définition 2. Pour A ∈ Mn(R) telle que ∥A∥ < 1, on pose
µ+ = (A− In)−1B et µ− = (−A− In)
−1B.
On dit que le signe de A est identifiable lorsque µ+ = µ−.
Proposition 3.4. Le signe de A est identifiable si et seulement si AB = 0.
Démonstration. Soit A ∈ Mn(R) telle que ∥A∥ < 1. On a µ+ = µ− si et seulement si
((A− In)−1 + (A+ In)
−1)B = 0.
Or en écrivant les formes en série de (A− In)−1 et (A+ In)
−1, on obtient
(A− In)−1 + (A+ In)
−1 = −+∞∑k=0
(1− (−1)k)Ak = −2+∞∑k=0
A2k+1 = 2(A2 − In)−1A,
d’oùµ+ = µ− ⇔ 2(A2 − In)
−1AB = 0 ⇔ AB = 0.
Remarque 3.5. Dans le cas particulier où toutes les composantes de B sont égales à α = 0,cette condition se réécrit :
∃ i ∈ 1, . . . , n tel quen∑
j=1
ai,j = 0.
Ainsi, Z(t) converge dans en loi vers Z ∼ Nn(µ,Γ). On peut voir cette variable commeun champ de Markov dont le graphe se lit sur la matrice Γ−1 = (In − AA⊤)/σ2 : lescoefficients non nuls (autres que diagonaux) de la matrice In−AA⊤ représentent les arrêtes,et un zéro correspond à une absence d’arrête.

32 Chapitre 3. Vers une inférence du réseau
Vers une inférence en pratiqueAu final, on considère le champ de Markov caché A→ Z → X tel que
L(Z |A) = Nn(µ,Σ)
etL(X |Z) =
n⊗i=1
L(Xi |Zi),
avecL(Xi |Zi) = γ (exp(2Zi), exp(−Zi)) .
On a donc plus précisément :
π(Z |A) =(
1√2π
)n 1√det(Σ)
exp
(−1
2(Z − µ)⊤Σ−1(Z − µ)
)
π(X |Z) =n∏
i=1
exp(Zi exp(2Zi))
Γ(exp(2Zi))e−Xi exp(Zi)Xi
exp(2Zi)−1.
Nous avons pu obtenir quelques résultats prometteurs sur des données simulées dans le casd’un petit nombre de gènes (n < 10), en appliquant les résultats ci-dessus dans un algorithmeMCMC et en mettant un prior Bernoulli sur les coefficients de A. Mais il reste beaucoup dechemin à parcourir pour parvenir à une inférence effective du vrai réseau (n ≈ 100)...

Conclusion
Durant ce stage, nous avons pu entrevoir une partie de l’extrême complexité des réseauxd’interactions entre les gènes. Après une étude approfondie d’un modèle de gène isolé, nousavons proposé une façon de construire des “réseaux de modèles” à partir de concepts issus dela cinétique chimique. Une structure naturelle et très générale s’est dégagée, permettant lamodélisation de nombreux types d’interactions à travers des réactions chimiques élémentairesou composées.
Nous avons également développé des algorithmes de simulation afin de vérifier la co-hérence de ces modèles et mieux les comprendre. L’analyse mathématique de ces modèlessemble très difficile sans faire des hypothèses supplémentaires assez fortes. Cependant, l’ap-proximation la plus grossière a déjà permis de faire apparaître un processus vectoriel autoré-gressif assez intéressant en soi et de faire un pas vers une inférence “grandeur nature”. Noussouhaitons continuer dans cette direction afin de trouver un compromis entre faisabilité etpertinence biologique.
Il s’est avéré que ce sujet attire de plus en plus de personnes d’origines variées autres quela biologie (physique (Zhang et Wolynes, 2014), informatique (Teles et al., 2013), mathéma-tiques (Kang et Kurtz, 2013)...). Ceci est une grande chance et devrait à l’avenir apporterde nombreuses découvertes dans le domaine.
RemerciementsUn grand merci à tous les membres de l’équipe BM2A pour leur accueil très chaleureux,
et leur patience lorsque je posais (et reposerai) plusieurs fois les mêmes questions... Merci àAngélique Richard pour la photo de la Figure 1, mais aussi pour m’avoir montré les cellulesau microscope dès le début et pour les échanges intéressants qui m’ont ouvert une fenêtre surle monde de la biologie cellulaire, dont la richesse est à la fois déroutante et fascinante. Mercienfin à mes maîtres de stage Olivier Gandrillon et Thibault Espinasse pour leur encadrementextraordinaire, à la fois exigeant et me laissant une grande liberté dans mes recherches : jen’aurais su trouver de meilleures conditions pour une thèse.
ALAS1
CTSA
HRAS1
BCL11A
RPL22L1
STX12
SMPD1
PAPD5
STARD4
UCK1
SULF2
AMDHD2
betaglobin
CREG1
CRIP2 CYP51A1
DCP1A
DHCR24
DHCR7
FHL3 FNIP1GLRX5 GPT2HMGCS1 LDHAMKNK2
MTFR1
NCOA4
PIK3CG
PLS1
PLS3
PPP1R15B
RBM38 REXO2
RFFLSLC25A37
SLC6A9
SLC9A3R2
SNX27
SQLE
SQSTM1
SULT1E1
TADA2L
TBC1D7
TPP1
VDAC3 WDR91
Figure 14 – Un exemple de réseau obtenu avec la méthode du chapitre 3 : la méthode est encoreextrêmement peu robuste et on aimerait pouvoir inférer des réseaux avec moins d’arrêtes... Il restedu travail !
33


Références
Boettiger, A. N. Analytic Approaches to Stochastic Gene Expression in MulticellularSystems. Biophysical Journal, 105(12) :2629 – 2640, 2013.
Corre, G., Stockholm, D., Arnaud, O., Kaneko, G., Viñuelas, J., Yamagata, Y.,Neildez-Nguyen, T. M. A., Kupiec, J.-J., Beslon, G., Gandrillon, O., et Paldi,A. Stochastic Fluctuations and Distributed Control of Gene Expression Impact CellularMemory. PLoS ONE, 9(12) :e115574, 2014.
Crudu, A., Debussche, A., Muller, A., et Radulescu, O. Convergence of stochasticgene networks to hybrid piecewise deterministic processes. The Annals of Applied Proba-bility, 22(5) :1822–1859, 2012.
Eldar, A. et Elowitz, M. B. Functional roles for noise in genetic circuits. Nature,467(7312) :167–173, 2010.
Gallopin, M., Rau, A., et Jaffrézic, F. A hierarchical poisson log-normal model fornetwork inference from rna sequencing data. PLoS ONE, 8(10) :e77503, 2013.
Huang, S. Cell Lineage Determination in State Space : A Systems View Brings Flexibilityto Dogmatic Canonical Rules. PLoS Biology, 8(5), 2010.
Kang, H.-W. et Kurtz, T. G. Separation of time-scales and model reduction for stochasticreaction networks. The Annals of Applied Probability, 23(2) :529–583, 2013.
Kim, J. K. et Marioni, J. C. Inferring the kinetics of stochastic gene expression fromsingle-cell RNA-sequencing data. Genome Biology, 14 :R7, 2013.
Malrieu, F. Some simple but challenging Markov processes, 2014. Prépublication (hal-01097576).
Ocone, A., Haghverdi, L., Mueller, N., et Theis, F. Reconstructing gene regulatorydynamics from high-dimensional single-cell snapshot data. Bioinformatics, 31(12) :i89–i86,2015.
Peccoud, J. et Ycart, B. Markovian Modelling of Gene Product Synthesis. TheoreticalPopulation Biology, 48 :222–234, 1995.
Radulescu, O., Muller, A., et Crudu, A. Théorèmes limites pour les processus deMarkov à sauts Théorèmes limites pour les processus de Markov à sauts. Revue Techniqueet Science Informatiques, 26(3-4) :443–469, 2007.
Shahrezaei, V. et Swain, P. S. Analytical distributions for stochastic gene expression.PNAS, 105(45) :17256–17261, 2008.
35

36 Références
Teles, J., Pina, C., Edén, P., Ohlsson, M., Enver, T., et Peterson, C. Transcriptio-nal Regulation of Lineage Commitment - A Stochastic Model of Cell Fate Decisions. PLoSComputational Biology, 9(8), 2013.
Ycart, B., Pont, F., et Fournié, J.-J. Simulation of Gene Regulatory Networks.<hal-00869111>, 2011.
Zhang, B. et Wolynes, P. G. Stem cell differentiation as a many-body problem. PNAS,111(28) :10185–10190, 2014.

Annexe A
Détails mathématiques
A.1 Rappels sur les processus markoviens de saut
Notations et résultats classiques
Dans ce rapport, tous les processus considérés seront définis sur un même espace deprobabilité (Ω,A,P). On se permettra d’écrire P(A|B) pour tous A,B ∈ A, en prenant unevaleur arbitraire pour cette quantité lorsque P(B) = 0.
Définition 3. Soit S un espace métrique que l’on munit de sa tribu borélienne. Un processusde Markov X = (Xt)t⩾0 à valeurs dans S est appelé processus markovien de sauts si sestrajectoires sont constantes par morceaux et continues à droite.
Dans la suite, on se place dans le cas où l’espace d’états S est dénombrable et où X esthomogène en temps. On s’intéresse alors à la quantité P(Xt = y|Xs = x) pour 0 < s < t etx, y ∈ S : la propriété de Markov et l’homogénéité font que celle-ci ne dépend de (s, t) quepar la différence t− s, ce qui permet de noter
Px,y(t− s) = P(Xt = y|Xs = x)
puis de définir, pour tout t > 0, la matrice P (t) = (Px,y(t))x,y∈S , appelée matrice de transitionde X au temps t. Chaque composante Px,y(t) représente ainsi la probabilité d’aller en y enune durée t en partant de x.
Pour A ∈ A et x ∈ S on note Px(A) = P(A |X0 = x) et Ex l’espérance sous Px. On peutmontrer qu’il existe une matrice L = (Lx,y)x,y∈S telle que pour tous x, y ∈ S,
Lx,y ⩾ 0 si x = y et Lx,x = −∑y =x
Lx,y ⩽ 0
et telle que lorsque h → 0, Px(Xh = y) = Px,y(h) = Lx,yh+ o(h) si x = y et Px(Xh = x) =Px,x(h) = 1 + Lx,xh + o(h). La matrice L = (Lx,y)x,y∈S vue comme opérateur sur RS estappelée le générateur infinitésimal du processus 1.
On peut également montrer que le temps d’attente du processus dans l’état x (avant quele processus ne saute vers un autre état) suit une loi exponentielle E(λ(x)) où
λ(x) =∑y =x
Lx,y
1. On vérifie que cette définition coïncide avec la définition générale pour un processus de Markov.
37

38 Annexe A. Détails mathématiques
et que le processus saute alors vers l’état y = x avec la probabilité
px,y =Lx,y∑y =x Lx,y
.
Par conséquent la donnée des Lx,y pour x = y suffit à décrire entièrement la loi duprocessus et Lx,y peut être vu comme comme le taux de saut de x vers y, i.e. l’inverse de ladurée moyenne qui s’écoule avant que le processus ne saute de x à y.
Générateur infinitésimal et équation maîtresseOn considère un processus de Markov (Xt)t⩾0 relativement à sa filtration naturelle, à
valeurs dans S et de générateur infinitésimal L. On note (Qt)t⩾0 son semi-groupe de transitionqui vérifie par définition :
∀t ⩾ 0, ∀f ∈ C0(S), Qtf(X0) = E (f(Xt) |X0) ,
où C0(S) est l’espace des fonctions de S dans R continues et tendant vers 0 en ±∞. Lethéorème phare des processus de Markov nous dit alors que pour tout f ∈ D(L) ⊂ C0(S),
d
dtQtf = LQtf = QtLf.
Soit f ∈ C0(S). On considère la fonction g : t 7→ E(f(Xt)), et on veut trouver l’équationdifférentielle vérifiée par g. On a d’abord
g(t) = E(E(f(Xt) |X0)) = E(Qtf(X0)),
puis
dg
dt(t) =
d
dtE(Qtf(X0)) = E
(d
dtQtf(X0)
)= E (QtLf(X0)) (A.1)
= E (E (Lf(Xt) |X0)) = E(Lf(Xt)) (A.2)
=
∫SLf(x)PXt(dx) =
∫Sf(x)L∗PXt(dx) (A.3)
où L∗ est l’adjoint de L, défini par le fait que pour tout ϕ, ψ ∈ C∞c (S),∫
Sϕ(x)(L∗ψ)(x) dx =
∫S(Lϕ)(x)ψ(x) dx.
En pratique, on peut soit calculer L∗, soit s’arrêter à l’étape (A.2) et essayer d’exprimerdirectement E(Lf(Xt)) en fonction de g. On peut notamment le faire dans le cas des processusde naissance/mort pour fx = 1x où x ∈ S : l’équation différentielle obtenue, en fait unsystème d’équations sur les probabilités de chaque état (cas particulier de l’équation deFokker-Planck dans le cas où S est dénombrable) est appelée équation maîtresse.

A.2. Preuves des lemmes 39
A.2 Preuves des lemmesLemme 1.8. Soient a, b > 0. Si (Xn) est une suite de v.a.r. telle que Xn ∼ Beta(na, nb),alors
XnL−−−−−→
n→+∞
a
a+ b.
Démonstration. Pour tout t ∈ R, on a ϕXn(t) =M(na, n(a+ b), it), donc
ϕXn(t) = 1 +
+∞∑k=1
na(na+ 1) · · · (na+ k − 1)
n(a+ b)(n(a+ b) + 1) · · · (n(a+ b) + k − 1)
(it)k
k!= 1 +
+∞∑k=1
fk(n)
oùfk(x) =
a(a+ 1
x
)· · ·(a+ k−1
x
)(a+ b)
(a+ b+ 1
x
)· · ·(a+ b+ k−1
x
) (it)kk!
.
Or la série∑
k⩾1 fk converge normalement sur ]0,+∞[, et on obtient par interversion deslimites :
ϕnXn(t) −−−−−→n→+∞1 +
+∞∑k=1
1
k!
(a
a+ bit
)k
= ea
a+bit
pour tout t ∈ R, d’où le résultat.
Lemme 1.9. Soit Z une v.a.r. admettant une densité par rapport à la mesure de Lebesgue.Si (Xn) est une suite de v.a.r. telle que L(Xn |Z) = P(nZ), alors
Xn
n
L−−−−−→n→+∞
Z.
Démonstration. Pour tout t ∈ R,
ϕXnn(t) = E(ei
tnXn) = E
(E(ei
tnXn |Z)
)= E
(exp(nZ(ei
tn − 1))
),
et ainsi, en notant f la densité de Z,
ϕXnn(t) =
∫Renz(e
i tn−1)f(z) dz.
Or ei tn − 1 = i tn + o( 1n) quand n→ +∞ donc pour tout z ∈ R,
enz(ei tn−1) −−−−−→
n→+∞eitz
et on conclut par convergence dominée.
Lemme 1.12. Soient a, θ > 0. Si (Xn) est une suite de v.a.r. telle que Xn ∼ γ(na, θ), alorsXn
n
L−−−−−→n→+∞
aθ.
Démonstration. Pour tout t ∈ R, on a
ϕXnn(t) = ϕXn
(t
n
)=
(1− iθt
n
)−na
= exp
(−na ln
(1− iθt
n
)).
Pour n assez grand, on peut considérer la détermination principale du logarithme complexe :on a alors ln
(1− iθt
n
)= − iθt
n + o( 1n) quand n→ +∞, d’où
ϕXnn(t) = exp (iaθt+ o(1))
pour tout t ∈ R, et finalement ϕXnn(t) → exp (iaθt) = ϕaθ(t) quand n→ +∞.

40 Annexe A. Détails mathématiques
Lemme 1.13. Soient a, b > 0. Si (Xn) est une suite de v.a.r. telle que Xn ∼ Beta(a, nb−a),alors
nXnL−−−−−→
n→+∞γ
(a,
1
b
).
Démonstration. Pour tout t ∈ R, on a ϕnXn(t) = ϕXn(nt) =M(a, nb, int), donc
ϕnXn(t) = 1 ++∞∑k=1
a(a+ 1) · · · (a+ k − 1)
nb(nb+ 1) · · · (nb+ k − 1)
(int)k
k!= 1 +
+∞∑k=1
fk(n)
oùfk(x) =
a(a+ 1) · · · (a+ k − 1)
b(b+ 1
x
)· · ·(b+ k−1
x
) (it)k
k!.
Or la série∑
k⩾1 fk converge normalement sur ]0,+∞[, et on obtient par interversion deslimites :
ϕnXn(t) −−−−−→n→+∞1 +
+∞∑k=1
a(a+ 1) · · · (a+ k − 1)
k!
(it
b
)k
=
(1− it
b
)−a
pour tout t ∈ R, d’où le résultat.
Remarque A.1. Ainsi, si b ≫ a (mais sans autre contrainte sur a !), alors la loi Beta(a, b)ressemble à la loi γ(a, 1
a+b).

Annexe B
Détails sur les données
Indice Nom du gène1 AACS2 ACSL63 ALAS14 AMDHD25 ANGPTL46 ARHGEF27 BCL11A8 betaglobin9 BPI
10 CD15111 CREG112 CRIP213 CTSA14 CYP51A115 DCP1A16 DCTD17 DHCR2418 DHCR719 EMB20 FAM208B21 FDFT122 FHL323 FNIP124 GAB125 GLRX526 GPT2
Indice Nom du gène27 HMGCR28 HMGCS129 HRAS130 LCP131 LDHA32 MAPK1233 MFSD2B34 MID235 MKNK236 MTFMT37 MTFR138 MVD39 NCOA440 NSDHL41 PAPD542 PIK3CG43 PLS144 PLS345 PPP1R15B46 PTPRC47 RBM3848 REXO249 RFFL50 RHPN251 RPL22L152 RSFR
Indice Nom du gène53 SERPINI154 SLC25A3755 SLC6A956 SLC9A3R257 SMPD158 SNX2759 spike160 spike461 spike762 SQLE63 SQSTM164 STARD465 STX1266 SULF267 SULT1E168 TADA2L69 TBC1D770 TPP171 TTYH272 UCK173 UNKNOWN874 VDAC375 VRK376 WDR9177 XPNPEP1
Table B.1 – Liste des gènes considérés dans l’étude, ainsi que trois spikes : ces spikes sontdes fragments d’ADN synthétiques dont “l’expression” est constante (indépendante du réseau degènes) et qui servent d’étalon. Le fait de les rajouter dans les expériences permet d’éliminer unepartie du biais dû à la variabilité d’une étape expérimentale, la reverse transcription (RT).
41





























