Embed Size (px)
Citation preview

Model-Based Resource Provisioning for a Web Service
UtilityRon Doyle*, Jeff Chase, Omer Asad, Wei Jin, Amin Vahdat
Internet Systems and Storage GroupDepartment of Computer Science
Duke University
*

Internet Service Utilities
Shared server cluster
• Web hosting centers
• Shared reserve capacity to handle surges and failures.
• Service/load multiplexing
• Dynamic provisioning
Service is contractual
• Performance isolation
• Differentiated service
• SLAs

Utility Resource Management
Goal: meet contractual service quality (SLA) targets under changing load; use resources efficiently.
Approach: assign each hosted service a dynamic “slice” of resources. •Combine “slivers” of shared servers, i.e., CPU time and memory.
Resource containers [Banga99], VMware ESX [Waldspurger02], PlanetLab
•Assign shares of storage server I/O throughput.
Given the mechanisms for performance isolation and proportional sharing, how do we set the knobs?
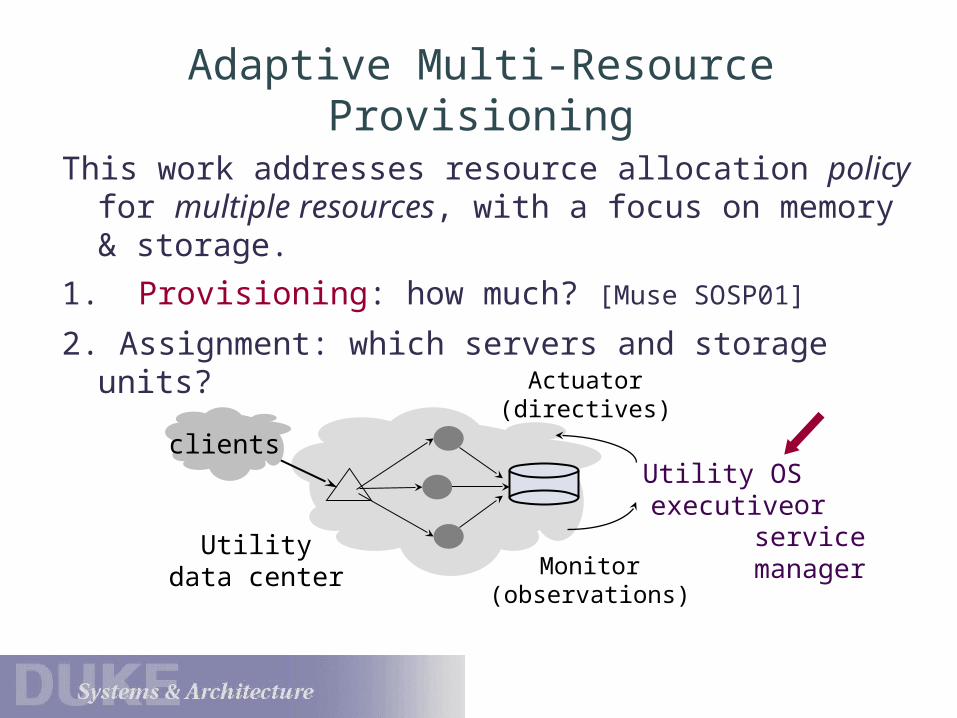
Adaptive Multi-Resource Provisioning
This work addresses resource allocation policy for multiple resources, with a focus on memory & storage.
1. Provisioning: how much? [Muse SOSP01]
2. Assignment: which servers and storage units?
clients
Utility data center
Utility OS executive
Actuator(directives)
Monitor(observations)
or service manage
r

Model-Based Provisioning
Resources interact in complex ways to determine overall service performance.
Resource manager
performance predictions
Applicationmodels
candidate allotments
• Incorporate a model of application behavior.
• Model predicts effects of candidate allotments.
• Plan allotments that are predicted to yield desired behavior.
• Monitor load and adapt as load intensity varies.
workload profiles (e.g., access
locality)storage models

Goals
Research question: how can a resource manager incorporate these models when they exist?
Manage multiple resources for diverse system goals.
Meet SLA targets for response time
Use surplus to optimize global average response time, yield, or value.
Adjust to constraints discovered during assignment.Storage-aware caching [Forney03]
Demonstrate that even simple models are a powerful basis for dynamic resource management.

Non-goals
We are NOT trying to:•build better models (you can plug in your favorite)
•parameterize or adapt models online from system observations
•manage network bandwidth
•schedule resources within each slice
•solve the assignment problem (bin-packing)
•allocate resources across the wide area
•make probabilistic performance guaranteesAssume stable average case behavior at
each load level, and provision for average response time.

System Context
Load and performance measures
reconfigurable redirecting
switch
configurationcommands
offered load λ per
service server poolstateless
interchangeable
clients
Muse [SOSP01]
MBRP
storage tier

Enforcing Slices
Our prototype uses the Dash Web server [Asad02] to enforce resource control for slices at user level.•Based on Flash [Pai99] using DAFS network storage.
Asynchronous I/O from user space to user-level cache
Low overhead (zero-copy, etc.), and user-level control
•Fully asynchronous, event-driven server“SEDA meets Click.”
•Independently size caches for co-hosted services.
•Request Windows [Jin03]: control the number of outstanding I/Os on a per-service basis.
•Dash is part of the utility’s trusted computing base.

A Simple Web Service Model
CPU
arrival rate λ
Object cache (M)
StorageλS
M yields hit rate HλS= λ (1 – H)
•Streams of requests with stable average case behavior per request class
•Varying load intensity λ
•Provision each stage, and M
•Downstream demand grows and shrinks with M (inverse)
•Bottlenecks limit demand downstream
•Generalize to stages or tiers

5000 10000 15000 20000
0.2
0.4
0.6
0.8
1
1.1
.9
.7
Web Cache Model
Cache Size (M)
1 – M1 – α
1 – T1 – αH = --------------
H•Footprint T objects
•Average size S
•Size is independent of popularity
•Cache M objects
•Given Zipf popularity
•LFU approximation
•Integrate over the Zipf PDF

5000 10000 15000 20000
10
20
30
40
50
60
70
1.1.9.7
Storage Arrival Rate (IOPS)
Cache Size (M)
λs = λS(1 – H)
•Each miss requires S I/O operations.
•S determines intensity of bulk I/O in this service’s storage load.
•Model predicts storage response time RSfor load λS given an IOPS share per-service.
•Account for prefetching and sequential locality indirectly.
λS

0
20
40
60
80
100
120
140
0 10 20 30 40 50Time (Minutes)
Cac
he S
ize
(MB
)
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
Thou
sand
sλ S
(IO
PS
)
Allotted Memory
Consumed Memory
Predicted λ Storage (IOPS)
Storage IOPS Moving Average
An Example using Dash
•IBM 2001 segment
•Load λ grows during trace segment.
•Dynamic cache resizing
•Storage IOPS demand λS matches model prediction (squint)
•A few transient shifts in request locality

A Model-Based Allocator
MBRP is a package of three primitives that coordinate with an assignment planner.•Candidate
Plan an initial allotment vector with CPU share and [M, ]
•LocalAdjustAdjust a vector to adapt to a resource constraint or
surplus, while staying on target for response time.
•GroupAdjustModify a set of vectors to adapt to a fixed resource
constraint or surplus exposed during assignment.
Use any surplus to meet system-wide goals.

Candidate
There is a large space of possible allotment vectors to meet a given response time target.
Simplify the search space with a simple principle: Build a balanced system.•Set the CPU share and storage allotment to hit a
preconfigured target utilization level .
The determines response time at storage and CPU.
•Select the minimum M and H that can hit the SLA target for overall response time.
Refine based on M and H and resulting λS.
Converges quickly.

0
50
100
150
200
250
0 100 200 300 400Arrival Rate (λ)
Stor
age
Allo
tmen
t (φ)
0
10
20
30
40
50
60
70
Mem
ory
(MB
)
Storage Allotment (φ)
Memory Allotment
Candidate LocalAdjust
LocalAdjust
•LocalAdjust adapts to constraint in one resource by adding more of another.
•Take as much as you can of the constrained resource, then rebalance to meet SLA target.
•E.g., in this graph it grows memory to respond to an IOPS constraint.
Note: it’s not linear.
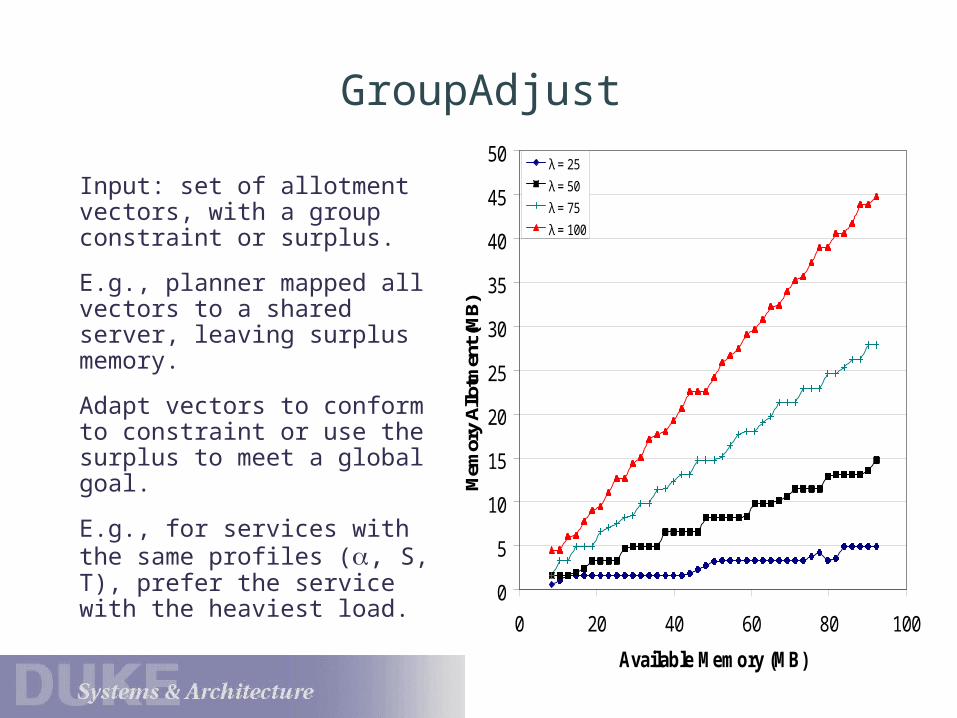
GroupAdjust
Input: set of allotment vectors, with a group constraint or surplus.
E.g., planner mapped all vectors to a shared server, leaving surplus memory.
Adapt vectors to conform to constraint or use the surplus to meet a global goal.
E.g., for services with the same profiles (, S, T), prefer the service with the heaviest load.
0
5
10
15
20
25
30
35
40
45
50
0 20 40 60 80 100
Available Memory (MB)
Mem
ory
Allo
tmen
t (M
B)
λ = 25
λ = 50
λ = 75
λ = 100

0
5
10
15
20
25
30
45 55 65 75 85Increase Total Memory (MB) ->
Mem
ory
All
otm
ent
(MB
)Highest SLA Response Time2nd Highest SLA Response3rd Highest SLA ReponseLowest SLA Response Time
Example: Differentiated Service
Four identical services:- same load λ- same profiles (, S, T) - same storage units
Different SLA targets.
Provision memory to meet targets first, then optimize global response time.
(Give next unit of surplus memory to the most constrained service.)

Some Other Results in the Paper
1. GroupAdjust for services with different profiles and equivalent loads: prefer higher-locality services.
2. Simple dynamic example to optimize for global response time in a storage-aware fashion.
3. “Putting it all together” experiment: adjust to changes in locality, SLA targets, and available resources as well as changes in load.
4. Handle overload by shifting a co-hosted service to another server (bin-packing assignment).
5. Preliminary evaluation of storage model.

Conclusion
Models are important for self-managing systems.
MBRP shows how to use models to adapt proactively. Respond proactively to changing load signal,
rather than reacting to off-target performance measures.
It’s easy to plug better models into the framework.
It seems clear that we can generalize this. Broader class of systems (e.g., multi-tier) and
system goals (e.g., availability).
But: models may be brittle or just plain wrong (HAL).
Self-managing systems will combine proactive and reactive mechanisms.

Assignment Planning
Map services to servers and storage units
Allocator primitives work in concert with assignment planning
Bin-packing services, balancing affinity, migration costs, local constraints/ surplus
Utility Center with Distributed Servers and Storage
Assignment

Related WorkProportional-share schedulers: mechanism to enforce provisioning
policies.
• Resource Containers[Banga99], Cluster Reserves[Aron00]
Response-time schedulers: meet SLA targets without explicit partitioning/provisioning.
• Neptune[Shen02], Facade [Lumb03]
Adaptive Resource Management for Servers: reactive, feedback-based adjustment of server resources.
• Web Server Performance Guarantees[Abdelzaher02], Predictable Web Server QoS[Aron-PhD], SEDA[Welsh01]
Memory/storage management: goal-directed allotment of resources to services.
• Storage Aware Caching[Forney02], Value Sensitive Caching [Kelly99], Hippodrome[Anderson02]

Multiple Shared Resources
Bottleneck BehaviorNon-bottleneck resource adjustments have
little effect.
Global ConstraintsServices compete for resources in zero-
sum game
Local ConstraintsService assignment to nodes exposes local
resource constraints.
CachingMemory allotment affects storage load for
single service, impacting available resources for other services


Adaptive Resource Provisioning
Utility OS Services•Predictable average-case response time
•Resource intensive
Workload Models predict•Resource Demand
•Resource Interaction
•Effect of allotment decisions
Framework is reactive to changes in workload characteristics for dynamic adaptation

Outline
Overview
Resource control mechanisms
Web Service Models
Model-Based Allocator
Conclusions






























