Embed Size (px)
Citation preview

Miron LivnyCenter for High Throughput Computing
Computer Sciences DepartmentUniversity of Wisconsin-Madison
Condor – a Projectand a System

www.cs.wisc.edu/~miron
How can I use Condor?
› As a job manager and resource scheduler for a dedicated collection of rack mounted computers
› As a job manager and resource scheduler for a collection of desk-top computers
› As a job manager and a resource scheduler for a collection of batch/grid/cloud systems
› As a job manager and resource scheduler for all of the above
Everything “looks” and is treated like a job
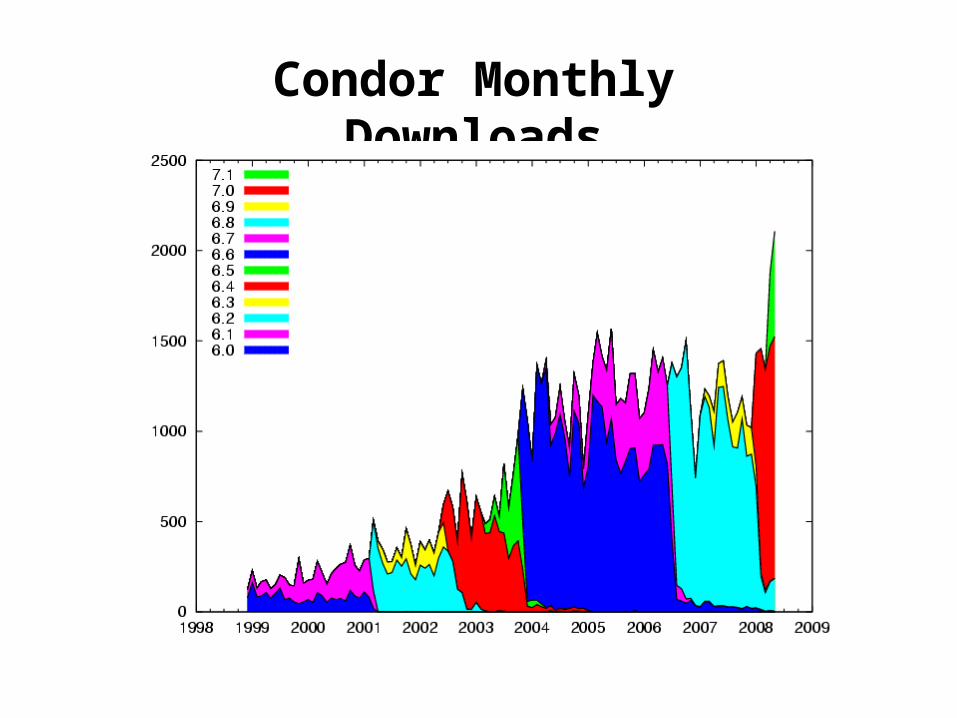
Condor Monthly Downloads
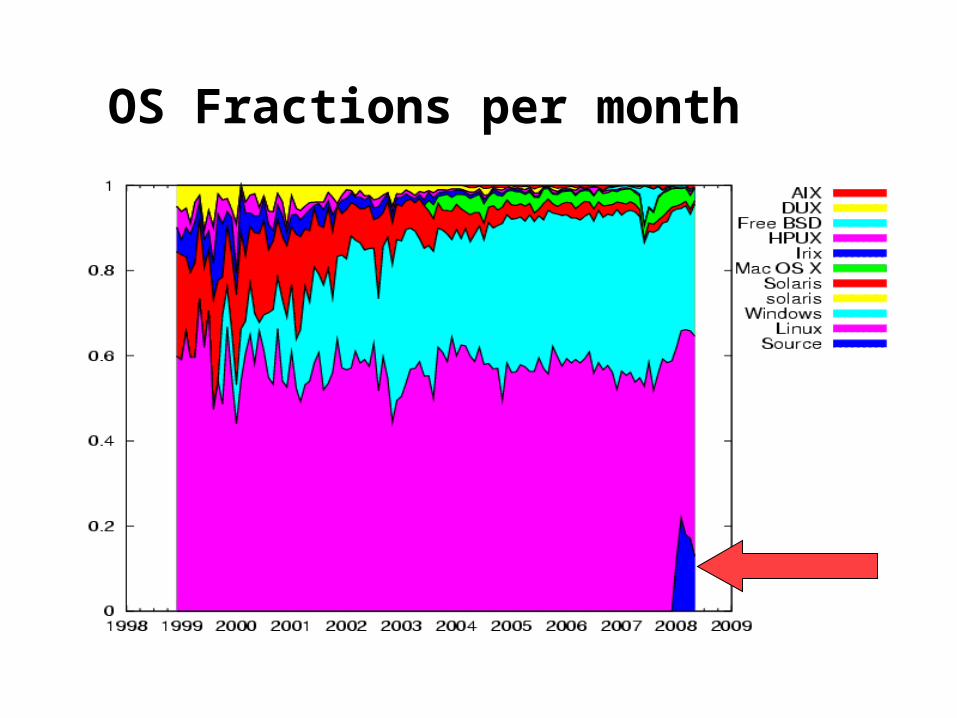
OS Fractions per month

What will Red Hat be doing?Red Hat will be investing into the Condor project locally in Madison WI, in
addition to driving work required in upstream and related projects. This work will include:
Engineering on Condor features & infrastructure Should result in tighter integration with related technologies Tighter kernel integration
Information transfer between the Condor team and Red Hat engineers working on things like Messaging, Virtualization, etc.
Creating and packaging Condor components for Linux distributions
Support for Condor packaged in RH distributions
All work goes back to upstream communities, so this partnership will benefit all.
Shameless plug: If you want to be involved, Red Hat is hiring...
5
CW 2007

www.cs.wisc.edu/~miron
CW 2008

www.cs.wisc.edu/~miron
The search for SUSY
Sanjay Padhi is a UW Chancellor Fellow who is working at the group of Prof. Sau Lan Wu at CERNUsing Condor Technologies he established a “grid access point” in his office at CERNThrough this access-point he managed to harness in 3 month (12/05-2/06) more than 500 CPU years from the LHC Computing Grid (LCG) the Open Science Grid (OSG) and UW Condor resources

www.cs.wisc.edu/~miron
“Seeking the massive computing power needed to hedge a portion of its book of annuity business, Hartford Life, a subsidiary of The Hartford Financial Services Group (Hartford; $18.7 billion in 2003 revenues), has implemented a grid computing solution based on the University of Wisconsin's (Madison, Wis.) Condor open source software. Hartford Life's SVP and CIO Vittorio Severino notes that the move was a matter of necessity. "It was the necessity to hedge the book," owing in turn to a tight
reinsurance market that is driving the need for an alternative risk management strategy, he says. The challenge was to support the risk generated by clients opting for income protection benefit riders on popular
annuity products” Mother of Invention - Anthony O'Donnell, Insurance & Technology December 20, 2004

www.cs.wisc.edu/~miron
“Resource: How did you complete this project—on your own or with a vendors help?
Severino (Hartford CIO): We completed this project very much on our own. As a matter of fact it is such a new technology in the insurance industry, that others were calling us for assistance on how to do it. So it was interesting because we were breaking new ground and vendors really couldn’t help us. We eventually chose grid computing software from the University of Wisconsin called Condor; it is open source software. We chose the Condor software because it is one of the oldest grid computing software tools around; so it is mature. We have a tremendous amount of confidence in the Condor software”
Grid Computing At Hartford Life -From Resource, February 2005 Copyright by LOMA

Use of Condor by the LIGO Scientific CollaborationGregory Mendell, LIGO Hanford Observatory
On behalf of the LIGO Scientific Collaboration
The Laser Interferometer Gravitational-Wave Observatory
Supported by the United States National Science Foundation

Use of Condor by the LIGO Scientific Collaboration
• Condor handles 10’s of millions of jobs per year running on the LDG, and up to 500k jobs per DAG.
• Condor standard universe checking pointing widely used, saving us from having to manage this.
• At Caltech, 30 million jobs processed using 22.8 million CPU hrs. on 1324 CPUs in last 30 months.
• For example, to search 1 yr. of data for GWs from the inspiral of binary neutron star and black hole systems takes ~2 million jobs, and months to run on several thousand ~2.6 GHz nodes.
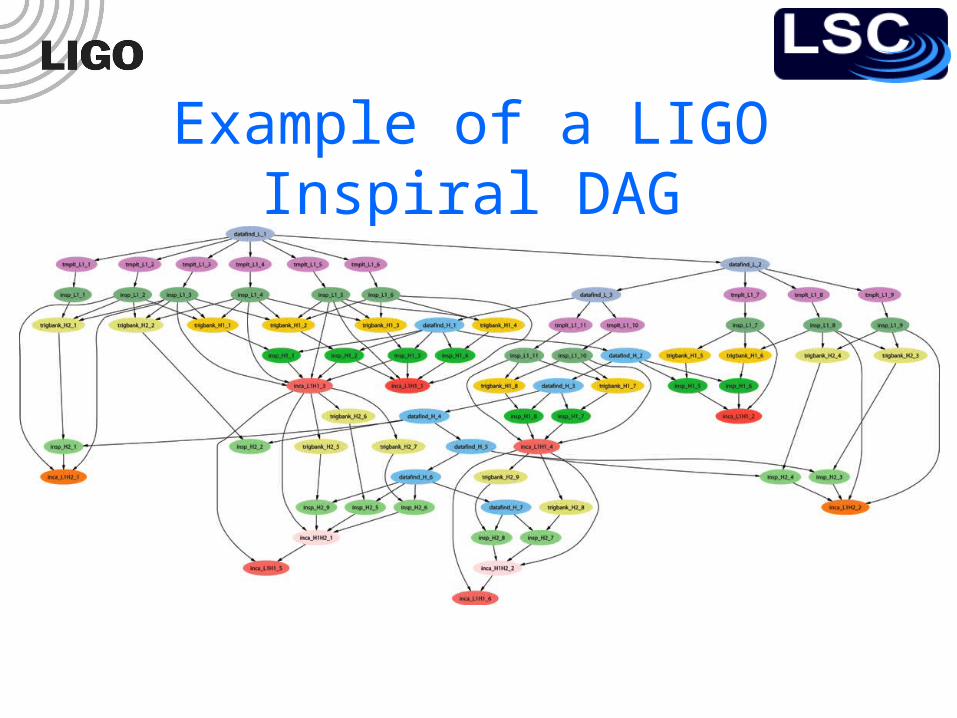
Example of a LIGO Inspiral DAG

Example Test DAG for Condor Regression Testing
• Makes fake data for each detector (same code is used in Monte Carlo simulations).
• Run the fully-coherent multi-detector continuous-wave search code, used to search for GWs from rotating neutron stars.
• Compares the output with reference data.

The LIGO/Condor Success Story
• Condor handles most of our searches and is vital to the success of LIGO.• Condor and LIGO have a biweekly telecon to discuss issues & enhancements.• In approximately the past year, Condor successfully
• enhanced scaling to support non-trivial O(1M) node DAGs,• implemented option to prioritize nodes, e.g., depth-first traversal of DAGs,• added categories to limit on number of resource intensive nodes in a DAG,• handling of priorities and staggered start of jobs.
• Condor is working on a list of enhancements to, e.g.,• speed up of starting DAGs by O(100x),• automate finding of rescue DAGs, e.g., when there are DAGs within DAGs,
and merging of sub-DAGs.• Add standard universe support on RHEL/CentOS and Debian.
• Condor is compatible with BOINC and can run backfill E@H jobs on the LDG clusters when there are idle cycles.
• For the future:• Our offline/online high throughput computing needs will continue to grow.• Online jobs moving towards low latency; need to think about computing
needs for realtime detection when Advanced LIGO comes on line.
Annotated candidate sRNA-encoding genesAnnotated candidate sRNA-encoding genes
PatserPatser
TFBSmatricesTFBS
matrices
TFBSsTFBSs sRNA AnnotatesRNA Annotate
Homologyto known
Homologyto known
BLASTBLAST
QRNAQRNA
BLASTBLAST
2o conservation2o conservation
FFN parseFFN parse
ORFs flankingknown sRNAsORFs flankingknown sRNAs
SyntenySynteny
ORFs flankingcandidates
ORFs flankingcandidates
BLASTBLAST
BLASTBLAST
ParaloguesParalogues
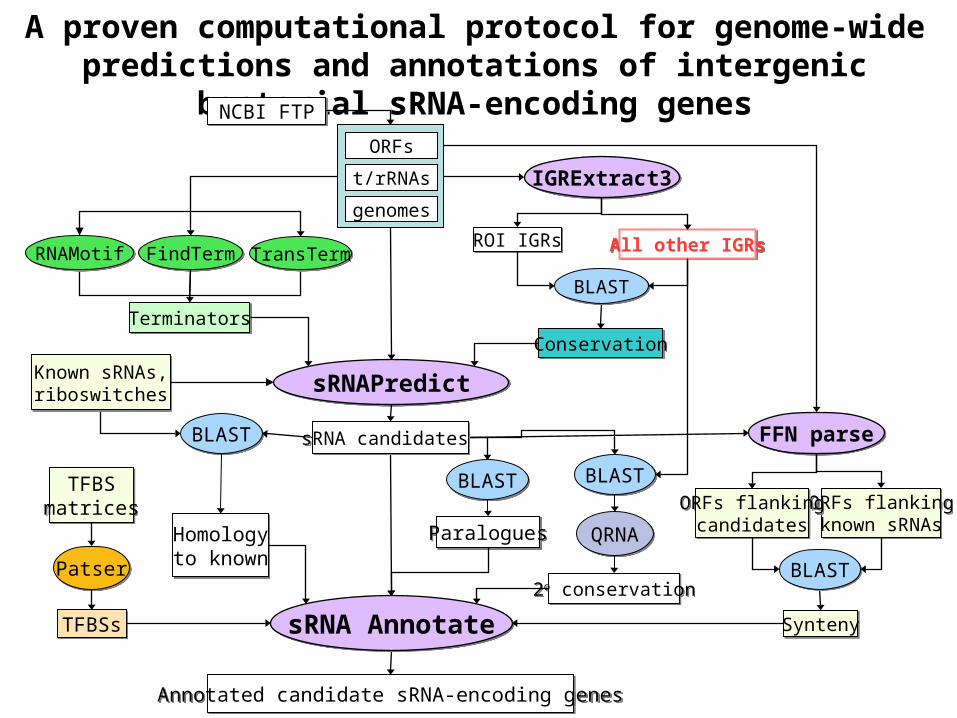
A proven computational protocol for genome-wide predictions and annotations of intergenic bacterial sRNA-encoding genes
IGRExtract3IGRExtract3
NCBI FTPNCBI FTP
Known sRNAs,riboswitches
Known sRNAs,riboswitches
All other IGRsAll other IGRs
sRNAPredictsRNAPredict
ConservationConservation
BLASTBLAST
sRNA candidates sRNA candidates
RNAMotifRNAMotif TransTermTransTermFindTermFindTerm
TerminatorsTerminators
t/rRNAs
ORFs
genomes
ROI IGRsROI IGRs

Using SIPHT, searches for sRNA-encoding genes were conducted in
556 bacterial genomes (936 replicons)
This kingdom-wide search:
• was launched with a single command line and required no further user intervention
• consumed >1600 computation hours and was completed in < 12 hours
• involved 12,710 separate program executions
• yielded 125,969 predicted loci, inlcluding ~75% of the 146 previously confirmed sRNAs and 124,925 previously unannotated candidate genes
•The speed and ease of running SIPHT allow kingdom-wide searches to be repeated often incorporating updated databases; the modular design of the SIPHT protocol allow it to be
easily modified to incorporate new programs and to execute improved algorithms

www.cs.wisc.edu/~miron
How CMS is using Condor
as a VO schedulerfor grid resources -
Just in time Scheduling with Condor GlideIns

Language Weaver Executive Summary
• Incorporated in 2002
– USC/ISI startup that commercializes statistical-based machine translation software
• Continuously improved language pair offering in terms of language pairs coverage and translation quality
– More than 50 language pairs
– Center of excellence in Statistical Machine Translation and Natural Language Processing

IT Needs
• The Language Weaver Machine Translation systems are trained automatically on large amounts of parallel data.
• Training/learning processes implement workflows with hundreds of steps, which use thousands of CPU hours and which generate hundreds of gigabytes of data
• Robust/fast workflows are essential for rapid experimentation cycles

Solution: Condor
• Condor-specific workflows adequately manage thousands of atomic computational steps/day.
• Advantages:– Robustness – good recovery from failures– Well-balanced utilization of existing IT
infrastructure

www.cs.wisc.edu/~miron
Basic Concepts
› Resource Allocation – binding a resource and a consumer (group/user/job/task/…)
› Work Delegation – assigning a unit of work (workflow/job/task/…) to a resource for execution
› Work fetching – a resource seeking a delegation of a unit of work for execution
› Scheduling – selecting the two end-points (consumer and resource) of a Resource Allocations
› Lease – action (allocation/delegation/… will expire unless renewed

www.cs.wisc.edu/~miron
Condor Building Blocks (1)
A “box” (Computer/blade/PC/laptop) manager (the StartD) Can manage a dynamic number of CPU-slots
• CPU-slots can be physical (a compute core) or logical (an interactive slot for monitoring and debugging)
Manages the allocation of the resources of a CPU-slot as defined by the resource provider
• Actively seeks customers• May preempt an allocation• Supports Computing On Demand (COD) allocations• Supports “backfill” via BOINC
Manages the job delegated to a CPU-slot• Delegation is not persistent• Delegation is rule driven• Monitors and reports resource consumption
Can fetch work from “other” job manager via user defined “hooks”

www.cs.wisc.edu/~miron
Condor Building Blocks (2)
A “community” (group/user) Job Manager (the SchedD) Accepts delegation of jobs through published interfaces
• Delegation is persistent and rule driven Can manage jobs for different groups or users
• Very large numbers of jobs• Job attributes can be defined and edited by user• Time dependent (e.g. cron) execution
Manages the allocation of the resources of a CPU-slot as the consumer
• Actively seeks resources• Assigns CPU-slots to jobs
Initiates and facilitates the delegation of jobs to Condor StartDs, Condor SchedDs and batch systems (LSF, PBS, Unicore) or remote systems like Globus and “clouds”
• Delegation is persistent and rule driven Manages the execution of “local” jobs

www.cs.wisc.edu/~miron
Job Submission Options
› leave_in_queue = < Boolean Expression> › on_exit_remove = < Boolean Expression> › on_exit_hold = < Boolean Expression> › periodic_remove = < Boolean Expression> › periodic_hold = < Boolean Expression> › periodic_release = < Boolean Expression> › noop_job = < Boolean Expression>

www.cs.wisc.edu/~miron
Condor Building Blocks (3)
A “community” resource manager (Collector and MatchMaker) Collects attributes, requirements and preferences
“pushed” by the SchedDs, StartDs (or anyone else) authorized to use its services.
Provides Match-making services based on the information provided by the community memebrs
• Based on the ClassAD language used to describe attributes, requirements and preferences
• Match maker is stateless except for accounting information
• Does not “understand” the semantics of (most) attributes or values in the ClassAd

www.cs.wisc.edu/~miron
One Simple Scenario1. StartD seeks a customer for the CPU-slot via the
matchmaker2. Job is delegated to SchedD by user3. StartD seeks a CPU-slot that meets job requirements via
matchmaker4. CPU-slot is allocated (matched) to SchedD 5. CPU-slot is allocated to Job6. Job is delegated to StartD for execution
Note that –› User may be a program like another SchedD› Allocation in #4 is decided by the Condor matchmaker› Allocation in #5 is decided by the SchedD› ScheD maintains delegations (#2 and #6) across crash/restarts› ScheD can decide at any time to allocate the CPU-slot to another job› StartD and ScheD can “break” the allocation at any time › All allocations and delegations are leases
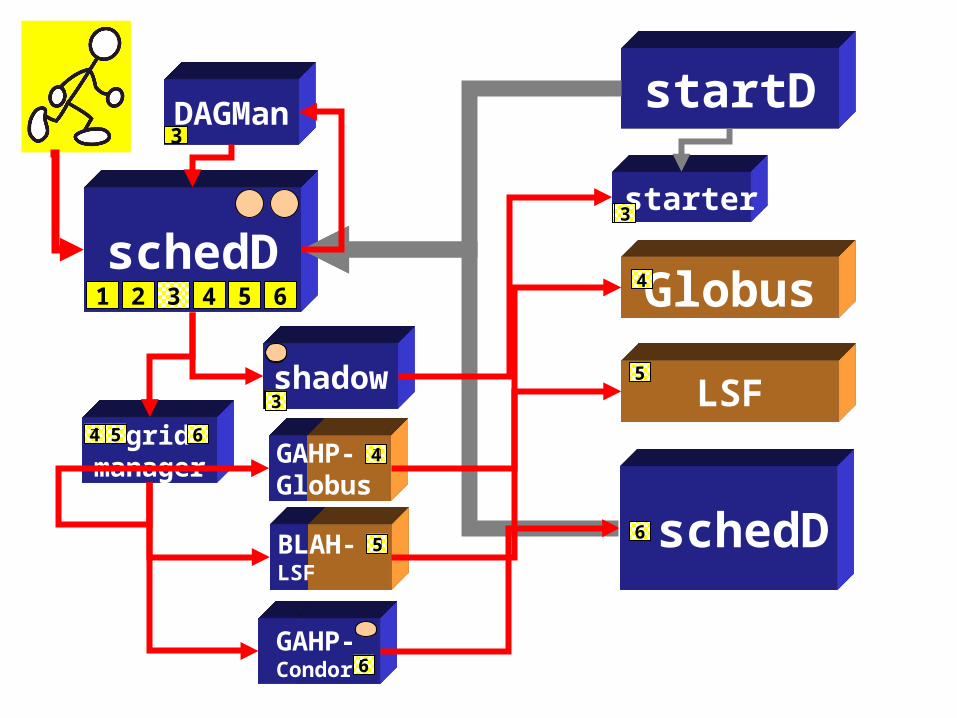
www.cs.wisc.edu/~miron
schedD
shadow
startD
starter
gridmanager
Globus
GAHP-Globus
BLAH-LSF
LSF
DAGMan
GAHP-Condor
1
1
1
2 3
3
3
3
4
44
45
5
5
5
6
6
6
schedD
shadow
startD
starter
gridmanager
Globus
GAHPGlobus
GAHPNorduGrid
NorduGrid
DAGMan
schedD
GAHPCondor
schedD66

www.cs.wisc.edu/~miron
Features
› All communication channels can be mutually authenticated and secured
› All components can be dynamically (hot) and remotely re-configured
› Checkpointing, remote I/O, sand-box placement, virtual machines,
› Operational information can be streamed to a RDBMS
› Detailed job logging› Documentation …

www.cs.wisc.edu/~miron
Condor-admin 18064“These are the problems I encountered until now by testing Condor or the ideas I had to improve this software. I will keep reporting them to you if I think that it is relevant or that it can be useful.
Furthermore, the Manual is so clear and well-written that it is a pleasure to read such a documentation and to familiarize with Condor.
Hoping this mail will contribute to improve the Condor Project, lookforward to receive your answer.
Sincerely,
A commercial user”

www.cs.wisc.edu/~miron
Condor Team 2007

www.cs.wisc.edu/~miron
The Condor Project (Established ‘85)
Distributed Computing research performed by a team of ~35 faculty, full time staff and students who
face software/middleware engineering challenges in a UNIX/Linux/Windows/OS X environment,
involved in national and international collaborations,
interact with users in academia and industry, maintain and support a distributed production
environment (more than 5000 CPUs at UW), and educate and train students.

www.cs.wisc.edu/~miron
Main Threads of Activities
› Distributed Computing Research – develop and evaluate new concepts, frameworks and technologies
› Keep Condor “flight worthy” and support our users
› The Open Science Grid (OSG) – build and operate a national distributed computing and storage infrastructure
› The Grid Laboratory Of Wisconsin (GLOW) – build, maintain and operate a distributed computing and storage infrastructure on the UW campus
› The NSF Middleware Initiative (NMI) – develop, build and operate a national Build and Test facility

www.cs.wisc.edu/~miron
Key Elements
› Distributed Computing
› High Throughput Computing
› Resource Allocation via Match -Matchmaking
› The master-Worker computing model
› Open Source Software

www.cs.wisc.edu/~miron
Claims for “benefits” provided by Distributed Processing Systems
High Availability and Reliability High System Performance Ease of Modular and Incremental Growth Automatic Load and Resource Sharing Good Response to Temporary Overloads Easy Expansion in Capacity and/or Function
P.H. Enslow, “What is a Distributed Data Processing System?” Computer, January 1978

www.cs.wisc.edu/~miron
Definitional Criteria for a Distributed Processing System
Multiplicity of resources Component interconnection Unity of control System transparency Component autonomy
P.H. Enslow and T. G. Saponas “”Distributed and Decentralized Control in Fully Distributed Processing Systems” Technical Report, 1981

www.cs.wisc.edu/~miron
I first introduced the distinction between High Performance Computing (HPC) and High Throughput Computing (HTC) in a seminar at the NASA Goddard Flight Center in July of 1996 and a month later at the European Laboratory for Particle Physics (CERN). In June of 1997 HPCWire published an interview on High Throughput Computing.
High Throughput Computing

www.cs.wisc.edu/~miron
Why HTC? For many experimental scientists, scientific progress and quality of research are strongly linked to computing throughput. In other words, they are less concerned about instantaneous computing power. Instead, what matters to them is the amount of computing they can harness over a month or a year --- they measure computing power in units of scenarios per day, wind patterns per week, instructions sets per month, or crystal configurations per year.

www.cs.wisc.edu/~miron
High Throughput Computing
is a24-7-365activity
FLOPY (60*60*24*7*52)*FLOPS
© 2008 IBM Corporation
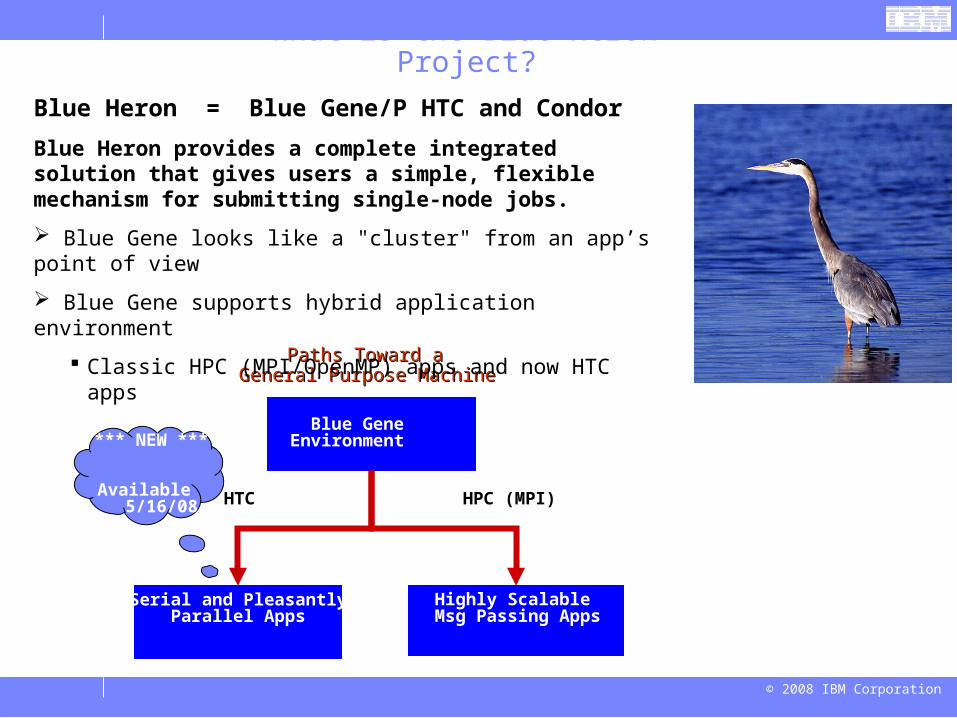
What is the Blue Heron Project?
Blue GeneEnvironment
Serial and Pleasantly Parallel Apps
Highly Scalable Msg Passing Apps
Paths Toward aPaths Toward aGeneral Purpose MachineGeneral Purpose Machine
*** NEW *** Available 5/16/08 HTC HPC (MPI)
Blue Heron = Blue Gene/P HTC and Condor
Blue Heron provides a complete integrated solution that gives users a simple, flexible mechanism for submitting single-node jobs.
Blue Gene looks like a "cluster" from an app’s point of view
Blue Gene supports hybrid application environment
Classic HPC (MPI/OpenMP) apps and now HTC apps

www.cs.wisc.edu/~miron
Every Communitycan benefit from the
services of
Matchmakers!
eBay is a matchmaker

www.cs.wisc.edu/~miron
Why? Because ...
.. someone has to bring together community members who have requests for goods and services with members who offer them. Both sides are looking for each other Both sides have
constraints/requirements Both sides have preferences

www.cs.wisc.edu/~miron
Being a Matchmaker
› Symmetric treatment of all parties› Schema “neutral” › Matching policies defined by parties› “Just in time” decisions › Acts as an “advisor” not “enforcer”› Can be used for “resource
allocation” and “job delegation”

www.cs.wisc.edu/~miron
“ … We claim that these mechanisms, although originally developed in the context of a cluster of workstations, are also applicable to computational grids. In addition to the required flexibility of services in these grids, a very important concern is that the system be robust enough to run in “production mode” continuously even in the face of component failures. … “
Miron Livny & Rajesh Raman, "High Throughput Resource Management", in “The Grid: Blueprint for a New Computing Infrastructure”.

www.cs.wisc.edu/~miron
In the words of the CIO of Hartford Life
“Resource: What do you expect to gain from grid computing? What are your main goals?
Severino: Well number one was scalability. …
Second, we obviously wanted scalability with stability. As we brought more servers and desktops onto the grid we didn’t make it any less stable by having a bigger environment. The third goal was cost savings. One of the most …”
Grid Computing At Hartford Life -From Resource, February 2005 Copyright by LOMA

www.cs.wisc.edu/~miron
Short and Long Term R&D
› Understanding and managing the footprint (memory and disk) of tasks/jobs/workflows
› Dynamic re-configuration and capacity planning
› Low latency “work units”› Manageability and scale – many users,
many jobs, many resources› Virtual Machines and Clouds› Software Quality

www.cs.wisc.edu/~miron
How can we accommodate
an unbounded need for computing
with an unbounded
amount of resources?





























