Embed Size (px)
Citation preview

MINJAE HWANGTHAWAN KOOBURAT
CS758 CLASS PROJECT FALL 2009
Extending Task-based Programming Model beyond
Shared-memory Systems

Outline
IntroductionRelated WorksDesignImplementationEvaluation

Introduction
Parallel programming in shared-memory systems OpenMP Pthreads Cilk/TBB
What if we need multiple machines to solve a problem? Cluster of shared-memory systems

Examples
Jaguar – ORNLFastest supercomputer

Related Works
Message Passing Interface (MPI)
Distributed Shared Memory (DSM) Distributed Cilk Intel OpenMP Cluster
OpenMP/MPI

Task-based Programming
Task-based Programming Intel Thread Building Block (TBB) Cilk Java Fork/Join Framework (JSR166)
Characteristics Fork/Join parallelism Task is a small non-blocking portion of code Allows programmers to easily express fined-grain
parallelism

Programming Model Considerations
There are 2 characteristics inside the cluster In a single machine
Implicit communication via shared-memory In a cluster
Explicit communication via network Network latency and bandwidth limitation
The programming model should be able to capture the hierarchical nature of the system.

Programming Model
TaskGroup/Task Programming Model Programmer divide computation into TaskGroup
Use divide-and-conquer pattern to generate TaskGroup All input be included into TaskGroup itself
TaskGroup executes by spawning Tasks Tasks always run in the same machine as its parent
TaskGroup Tasks communicate via shared memory

public class FibTG extends TaskGroup<Long> { int size; protected Long compute() { if (size == 2 || size == 1)
return 1L;
FibTG first = new FibTG(size - 1); FibTG second = new FibTG(size - 2);
first.fork(); return second.invoke() + first.join(); }}
Fibonacci Example
public class FibTG extends TaskGroup<Long> { int size; protected Long compute() { if (size == 2 || size == 1)
return 1L;
FibTG first = new FibTG(size - 2); FibTG second = new FibTG(size - 1);
if (size >= 35) {first.remoteFork();return second.invoke() + first.remoteJoin();
} else {first.fork();return second.invoke() + first.join();
} }}
Use cutoff value to say that task can be run on another machineOtherwise, run locally
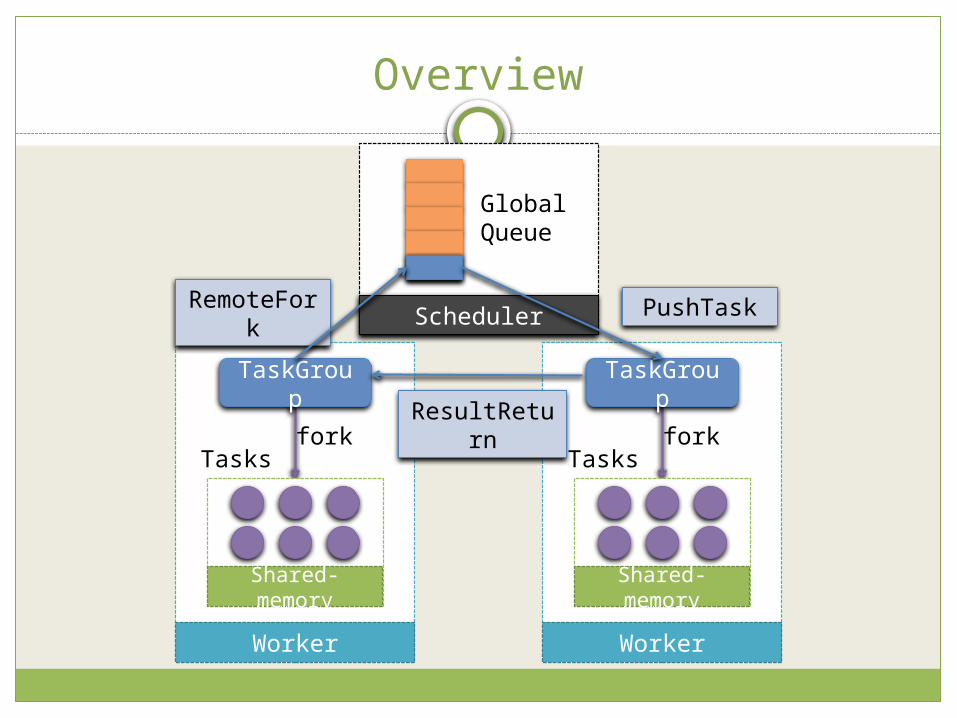
Overview
fork
TaskGroup
Tasks
Shared-memory
Worker
GlobalQueue
fork
TaskGroup
Tasks
Shared-memory
Worker
ResultReturn
SchedulerRemoteFor
kPushTask

Matrix Multiplication Example
TaskGroup divide and copy matrix into smaller one
a1 a2
a3 a4
b1 b2
b3 b4
c1 c2
c3 c4
a1 b1 a2 b3 c1
TaskGroup
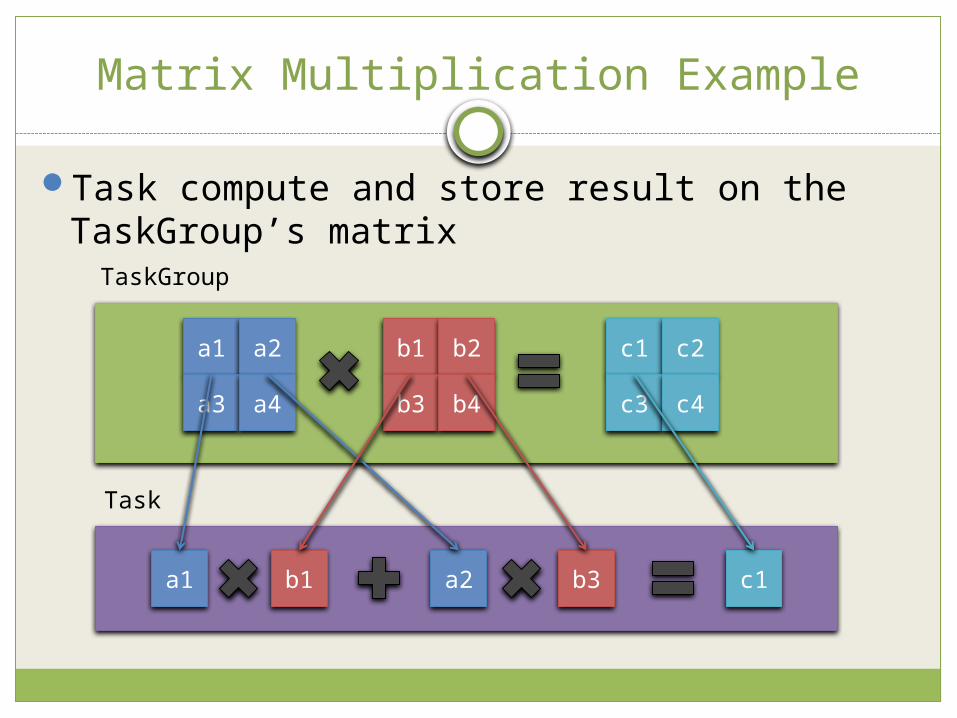
Task
Matrix Multiplication Example
Task compute and store result on the TaskGroup’s matrix
a1 a2
a3 a4
b1 b2
b3 b4
c1 c2
c3 c4
a1 b1 a2 b3 c1
TaskGroup

Scheduling Considerations
Work-stealing is common practice in task-based scheduler
What kind of modification required to existing local work-stealing scheduler? Work-stealing is not instant. Work-stealing requires serialization. Returning a result require extra works.
Bottom Line Steal-0n-demand is not efficient

Scheduling Designs
Designs Hierarchical queue
Work-stealing policy

Hierarchical Work-stealing Queue
TaskGroup scheduling is entirely based on ‘queue management’
Hierarchical work-stealing queue 3 levels of queue
Global Queue Local Queue Thread Queue
Pre-fetch To hide network latency
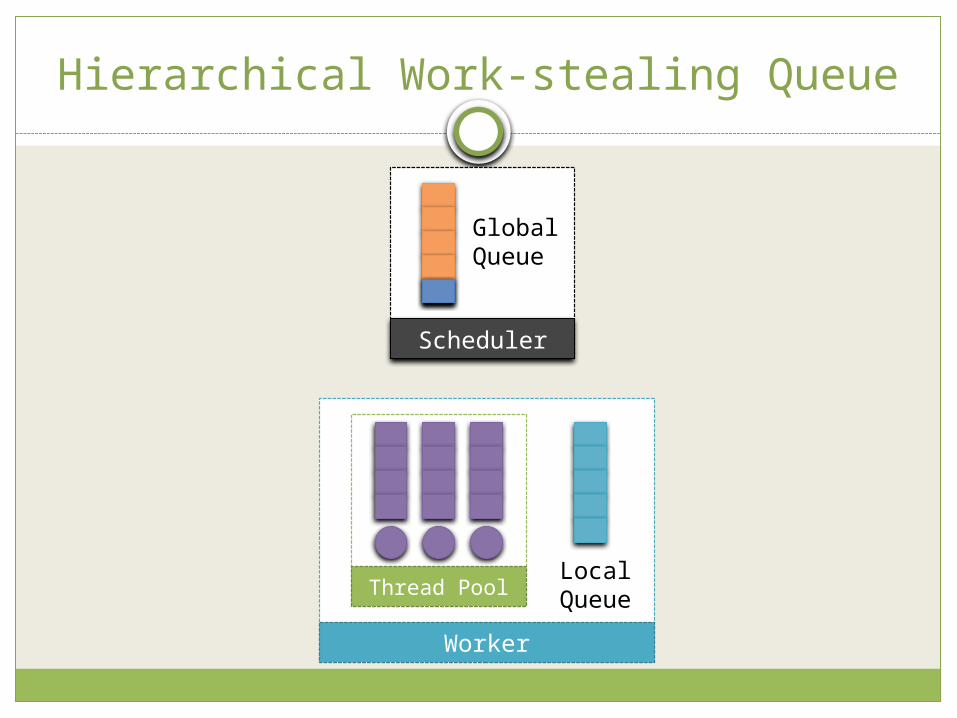
Hierarchical Work-stealing Queue
Scheduler
GlobalQueue
Thread Pool
Worker
LocalQueue

Work-stealing Policies
Static distribution Immediately distribute in round-robin fashion when
you have something in global queue Pro/Con
Best when the size of problem (TaskGroup) is equal Fail when there is load imbalance
Purely work-stealing Each machine tries to steal when its queue is empty Pro/Con
Best when the execution time of TaskGroup is a way bigger than round-trip time
You will see network latency.

Work-stealing Policies
Pre-fetching work-stealing On-demand-steal mode
Worker - When the local queue is empty It hints to the global scheduler that it is idling.
Scheduler - When some worker is idling It tries to steal from other non-idle workers as much as
possible Pre-fetching mode
Worker - When the local queue is below than LOW threshold It requests TaskGroup to the global scheduler
Worker – When the local queue is higher than HIGH threshold It sends surplus TaskGroup
Best when The nature of problem is dynamic
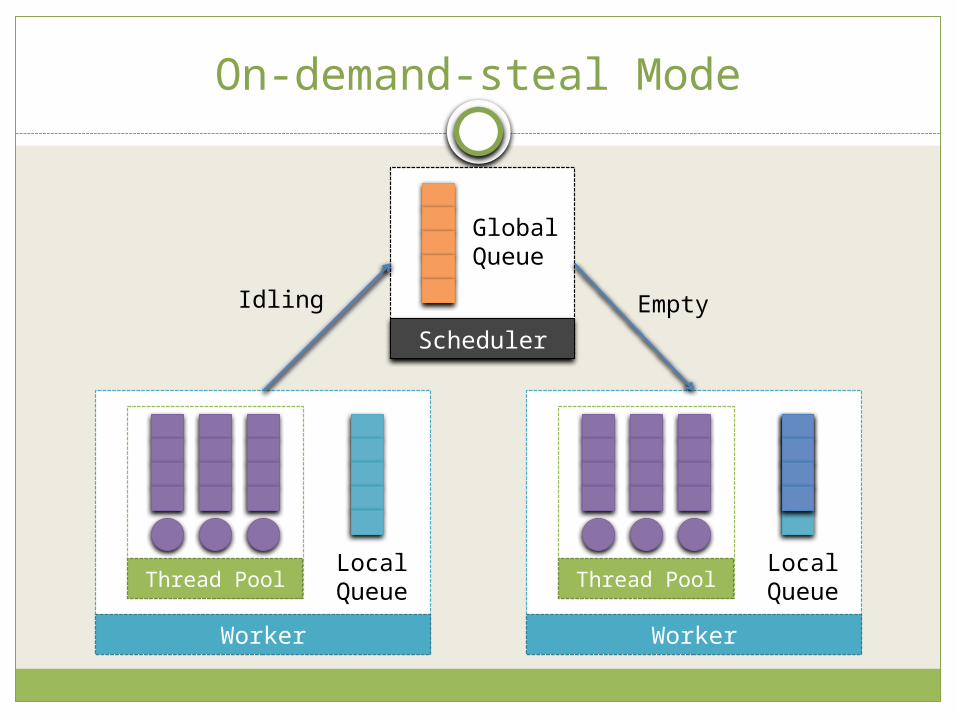
On-demand-steal Mode
Scheduler
GlobalQueue
Thread Pool
Worker
LocalQueue Thread Pool
Worker
LocalQueue
Idling Empty
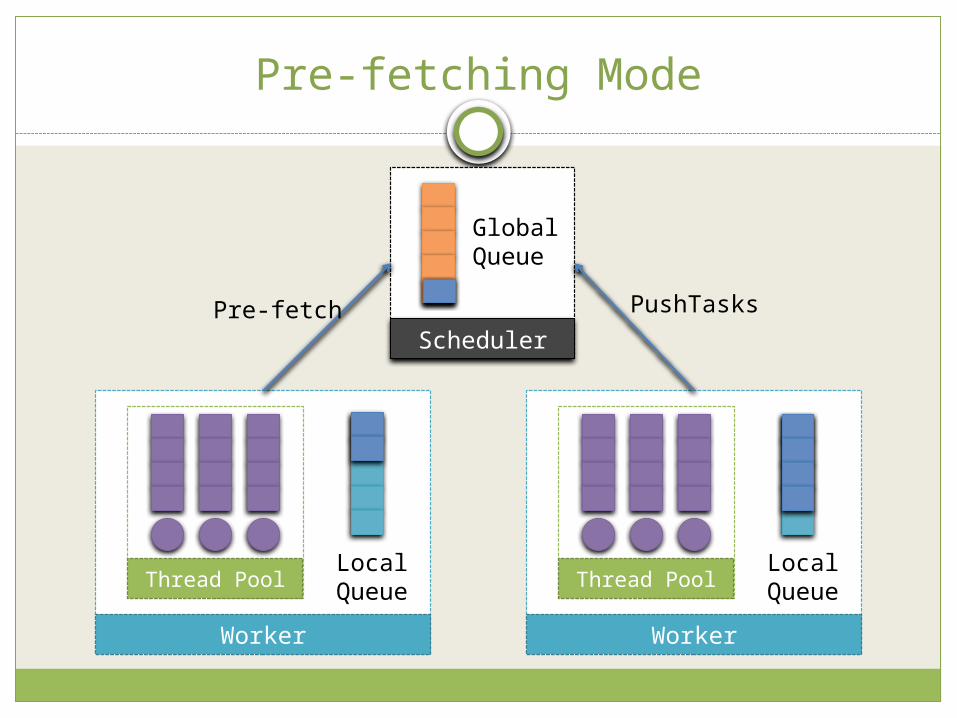
Pre-fetching Mode
Scheduler
GlobalQueue
Thread Pool
Worker
LocalQueue Thread Pool
Worker
LocalQueue
Pre-fetch PushTasks

Implementation Details
Components Java Fork/Join Framework
Similar to Thread Building Block. Manage Per-thread Queue
MPJ Express (MPI impl. for Java) Establishes point-to-point communication Launches Java App in N-node cluster
We implemented Global Scheduler/Local Queue Manager Various Optimization Techniques Work-stealing Policies

Evaluation
Test Environment Mumble cluster (mumble-01~mumble-40)
Intel Q9400, Quad-core 2.66GHz, Shared 6MB L2 Cache, 8GB RAM
Benchmark Program Matrix
Large Matrix Multiplication(4k x 4k) Word Count
Producer/Consumer style implementation N-Queens
Classic search problem – recursive task generation, load imbalance
Fibonacci Micro-benchmark for evaluating pure overhead

Results
Scalability and SpeedupRelationship between number of TaskGroup
generated and execution time
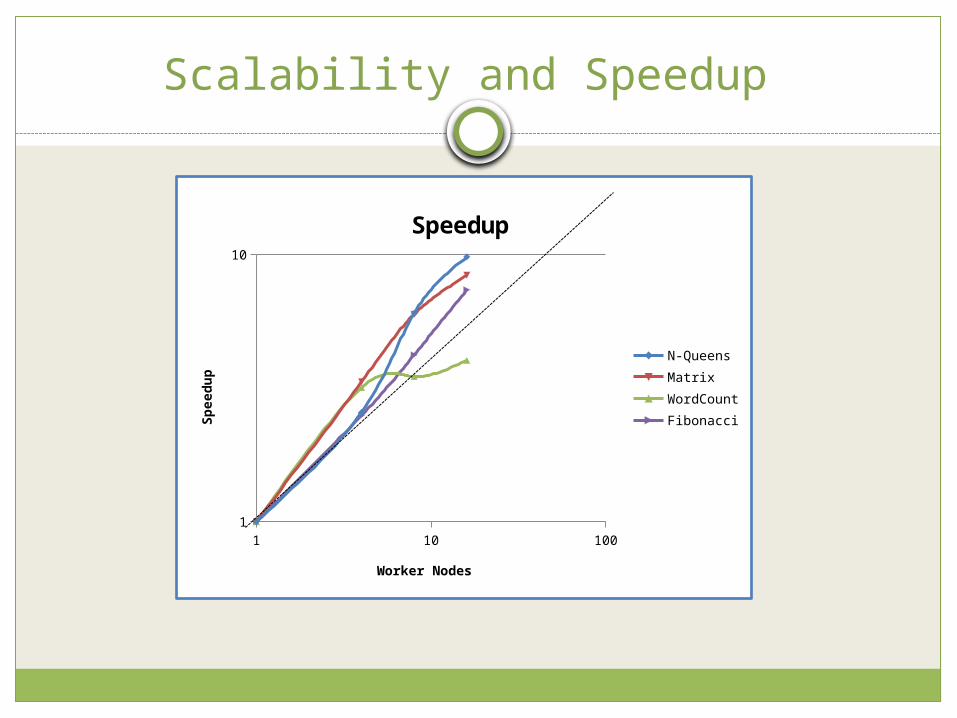
Scalability and Speedup
1 10 1001
10
Speedup
N-QueensMatrixWordCountFibonacci
Worker Nodes
Speedup
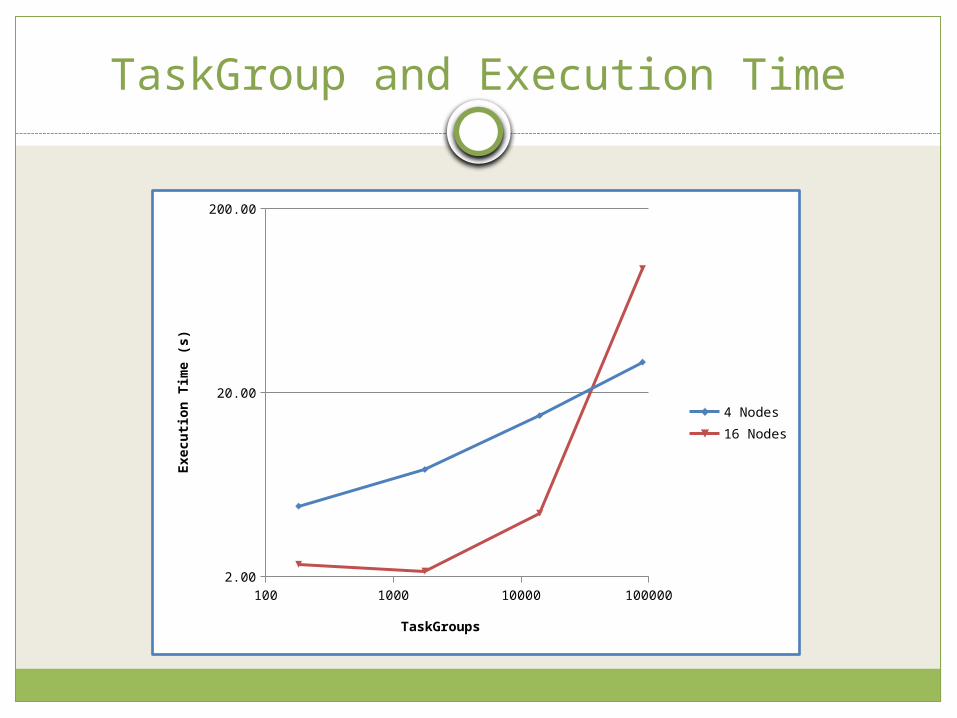
TaskGroup and Execution Time
100 1000 10000 1000002.00
20.00
200.00
4 Nodes16 Nodes
TaskGroups
Executi
on T
ime (
s)

Post-mortem
What went good Choosing Java, Fork/Join and MPJ express really made
our life easierWhat went wrong
Execution time and speed-up do not give any explanation.
How did we solve Gathered every possible statistics and trace program
execution However, it does not give direct understanding.
We tuned various aspects of the system and ran various benchmarks to understand the system.

Summary
We suggest TaskGroup-based Programming Model Ease of programming Allows dynamic task generation over cluster Scales up to 16 nodes and beyond
Questions
Q/A





























