Embed Size (px)
Citation preview

Mining Structured Data on the Web
Alon Halevy Google
KDD MLG
August 20, 2011

Structured Data on the Web
• The most fascinating database ever – Examples and some properties
• What can we (do we, should we) do with it?
• New challenges and opportunities

The Data
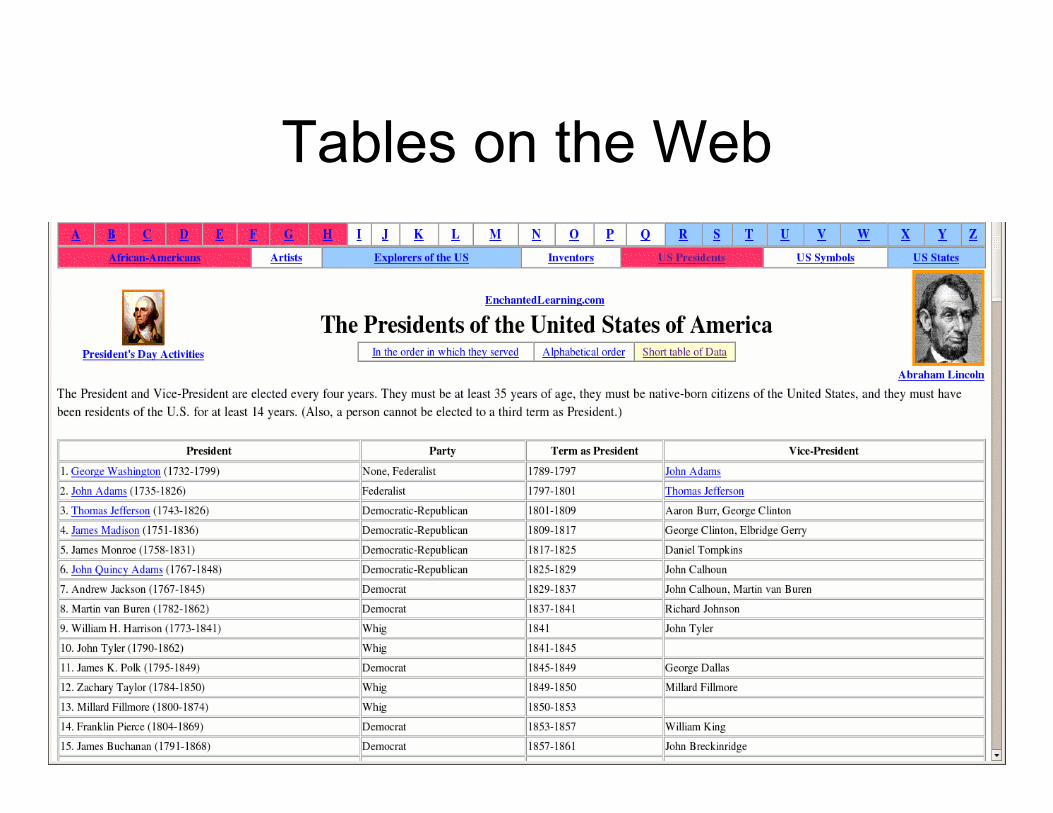
Tables on the Web
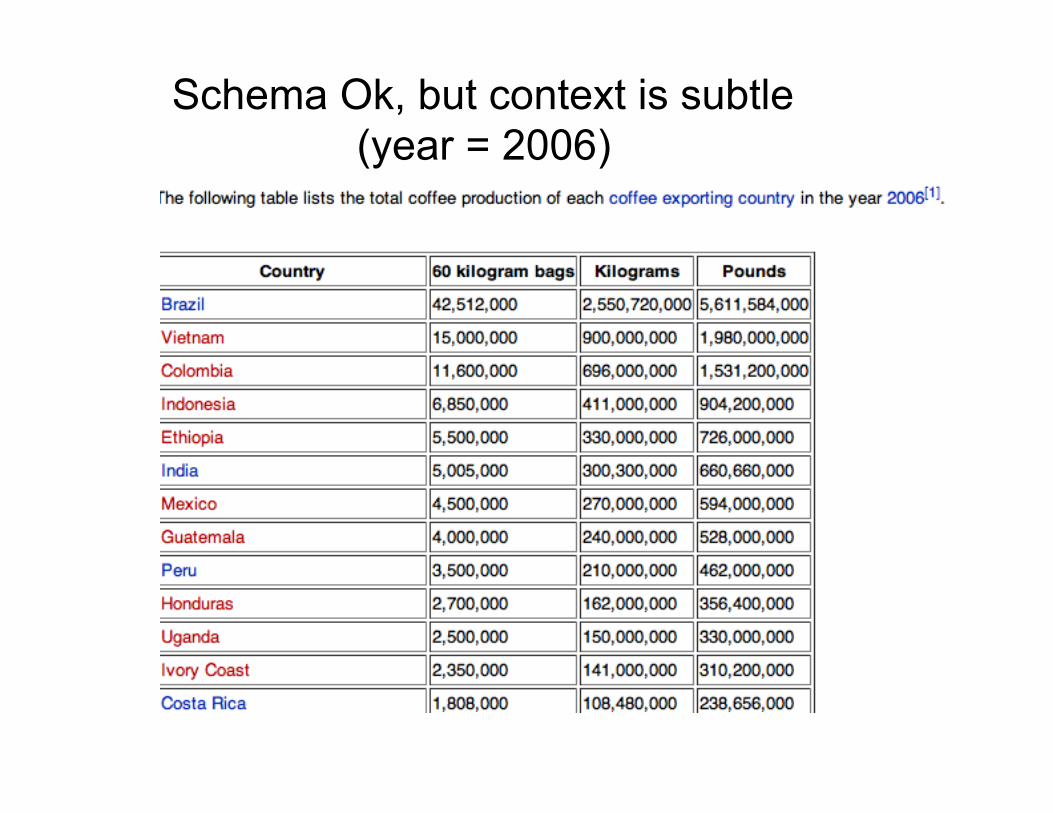
Schema Ok, but context is subtle (year = 2006)

The Deep Web
store locations used cars
radio stations patents recipes
See “Google’s Deep Web Crawl”, VLDB 2008
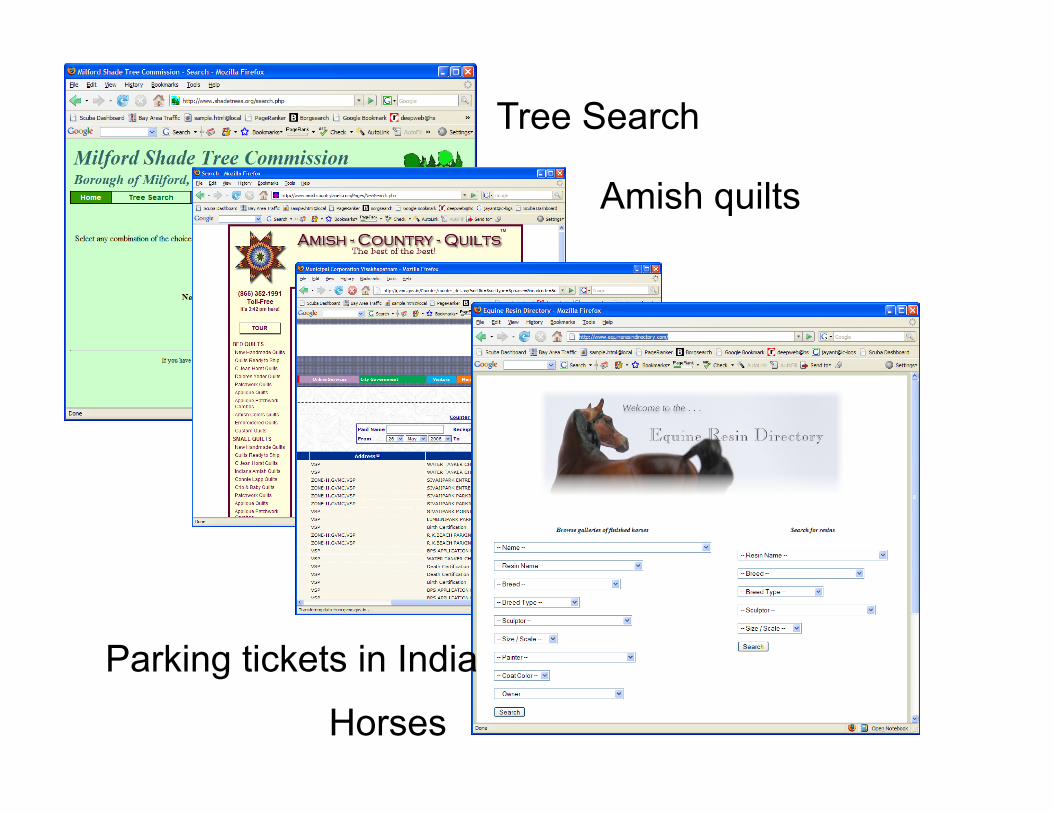
Tree Search
Amish quilts
Parking tickets in India
Horses
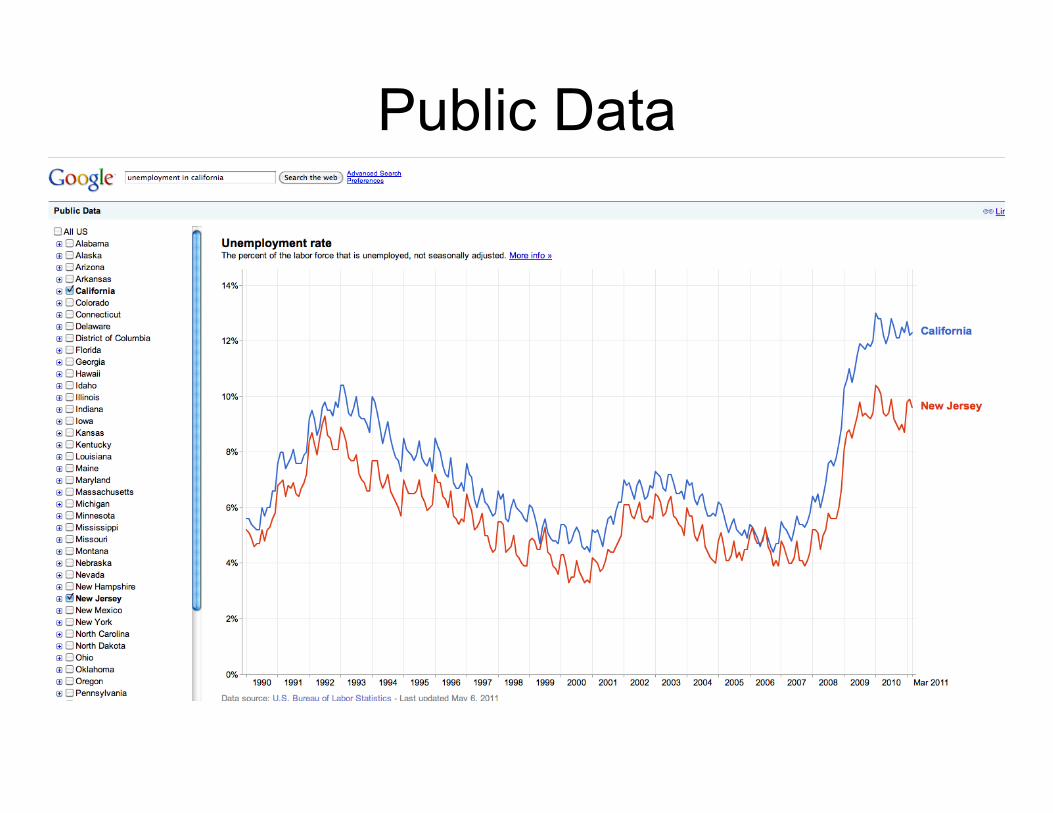
Public Data
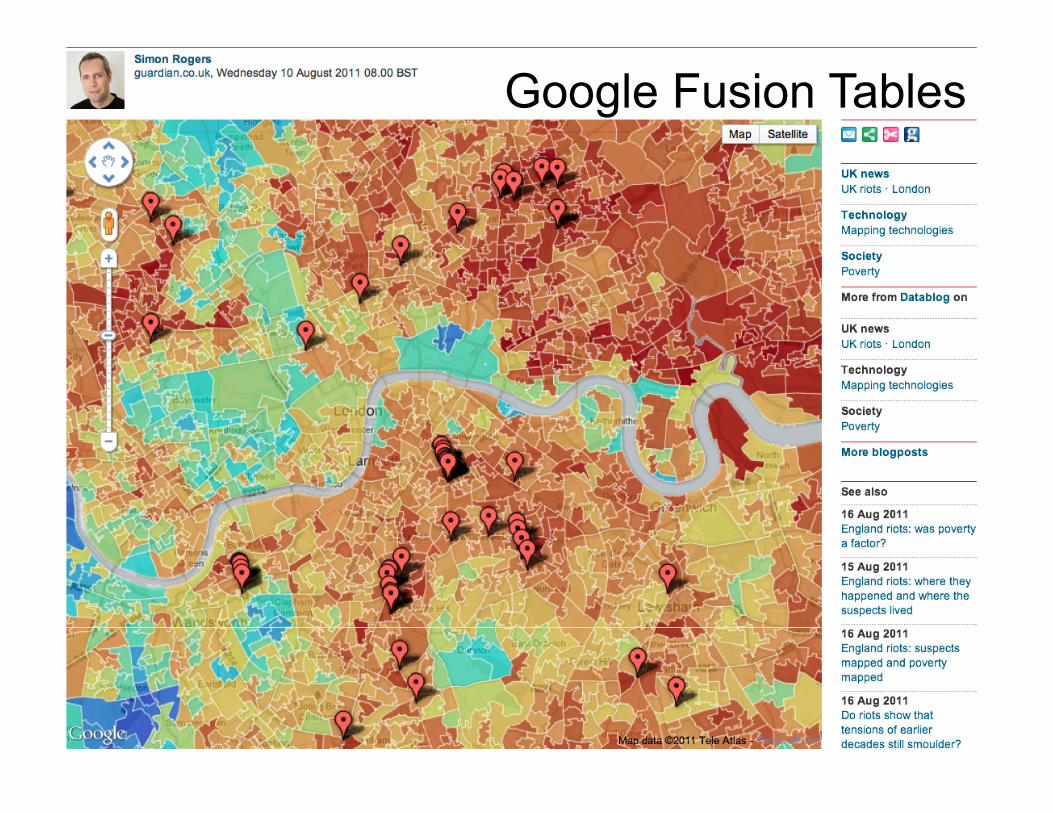
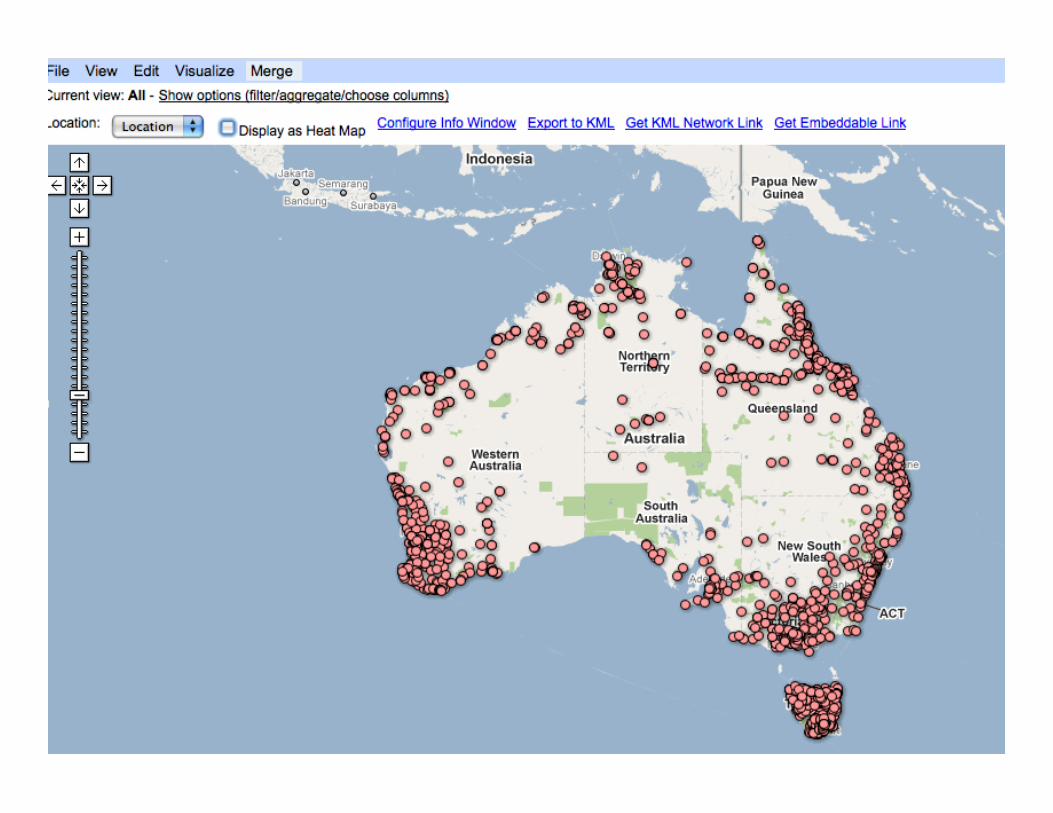
Google Fusion Tables
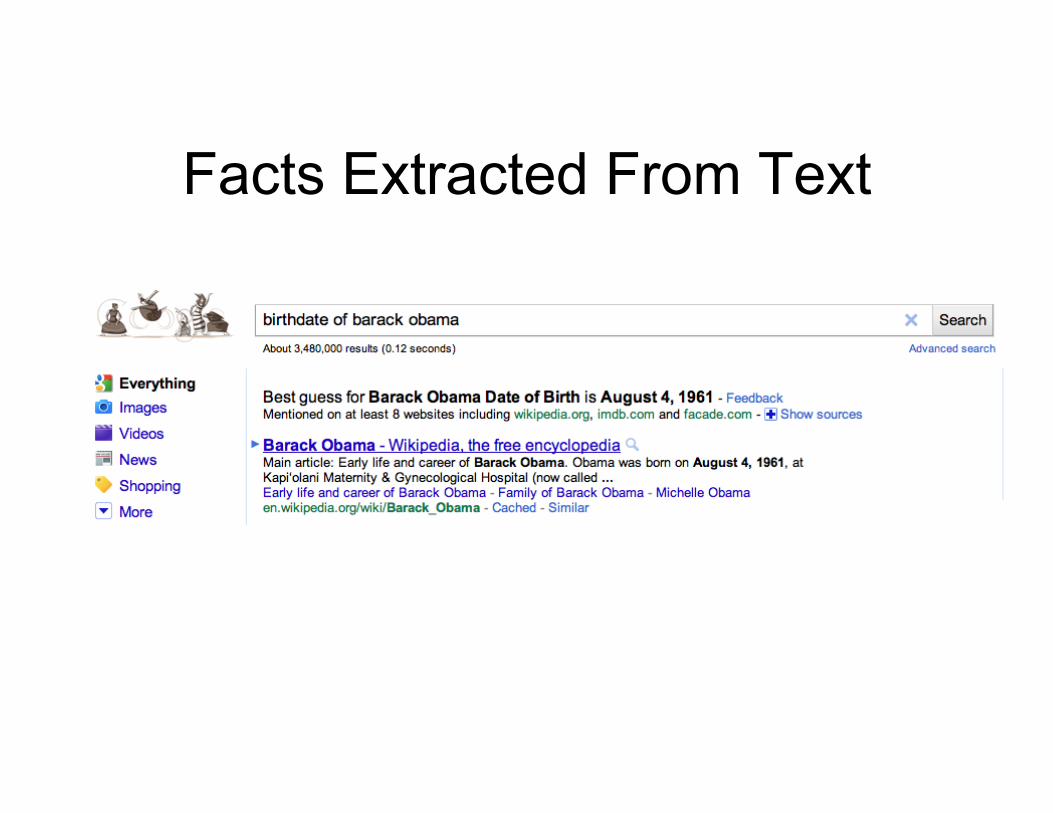
Facts Extracted From Text

Ontologies on the Web
• Manually created (but large scale) – Freebase
• Crowd sourced: – Wikipedia, DBPedia, YAGO
• Dirty but very comprehensive: – Glance, Probase (created mostly using
Hearst patterns) – “southeast asian countries such as
vietnam, cambodia and laos”

WHAT TO DO WITH THIS DATA?
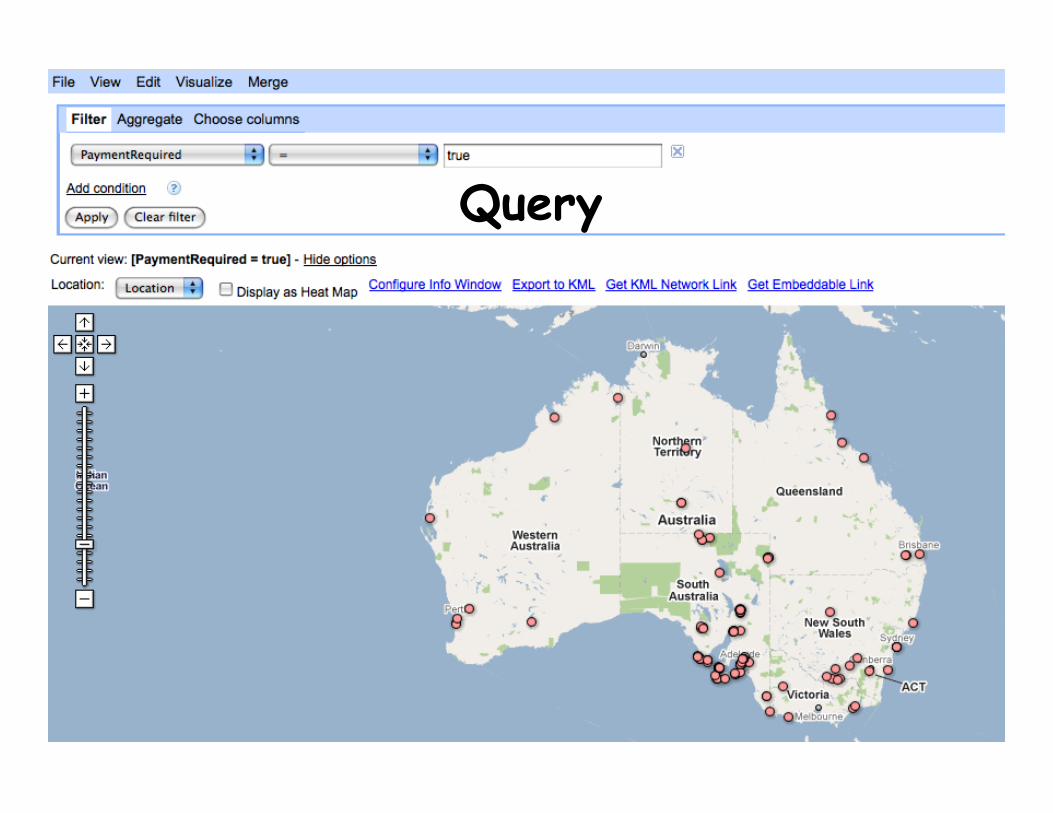
Query
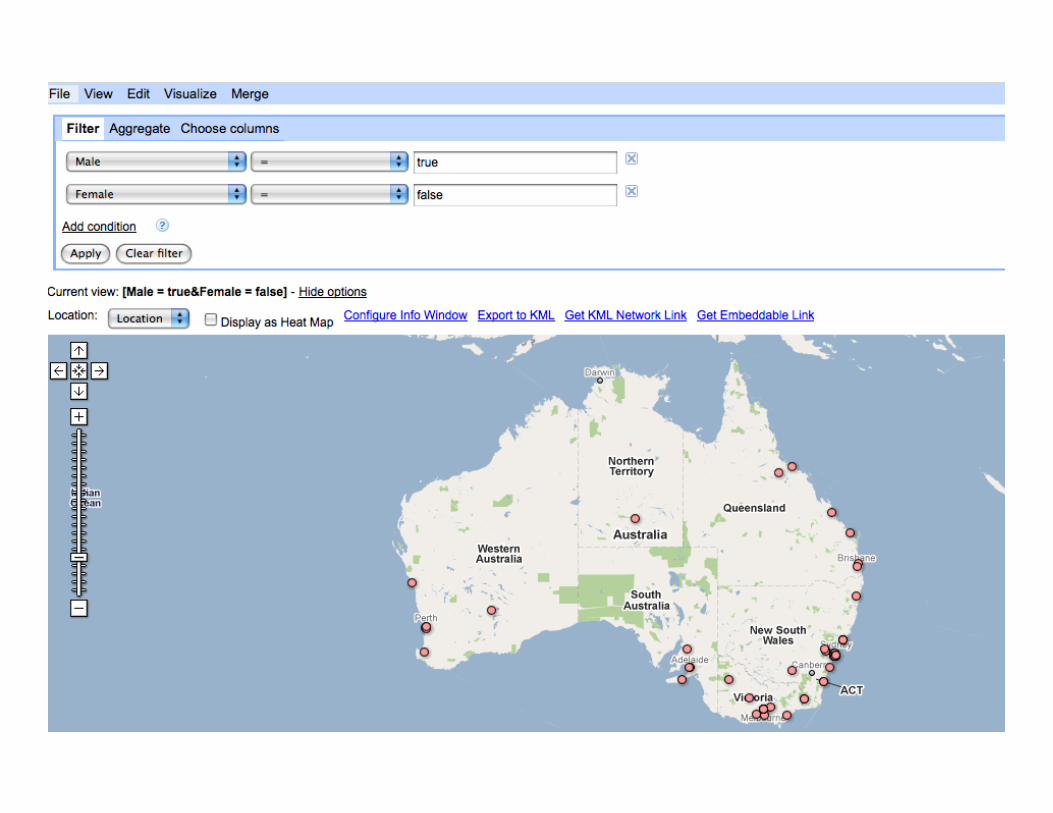
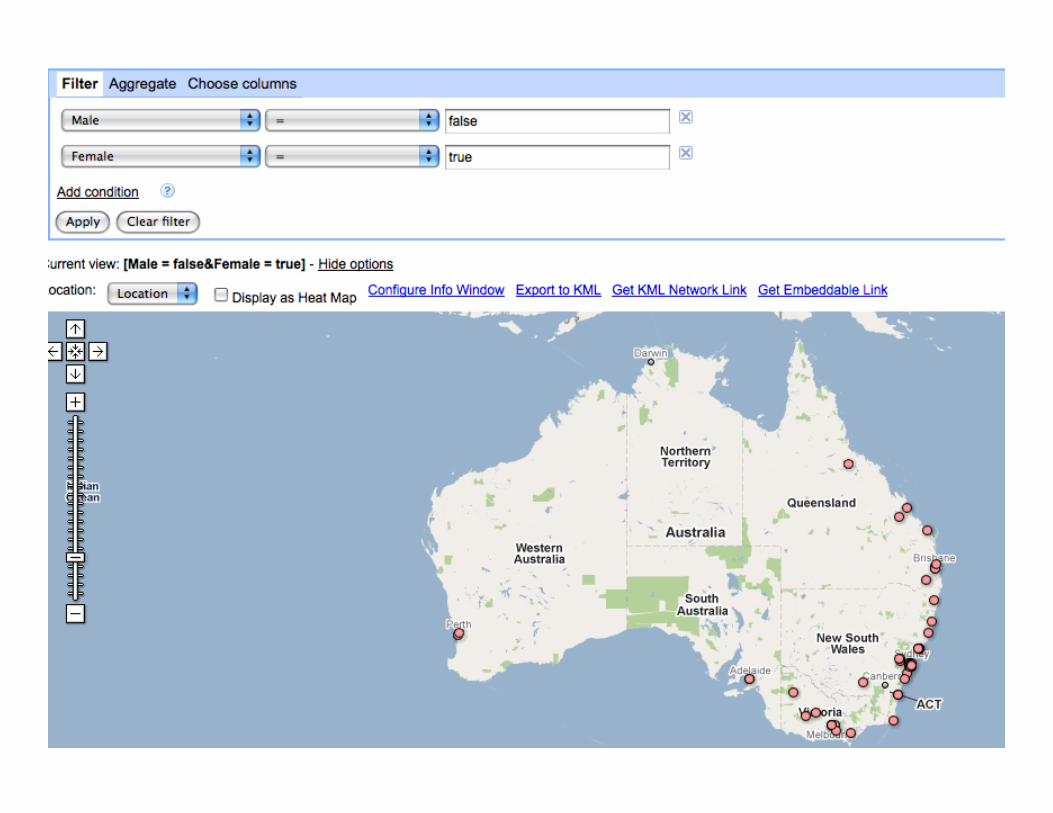
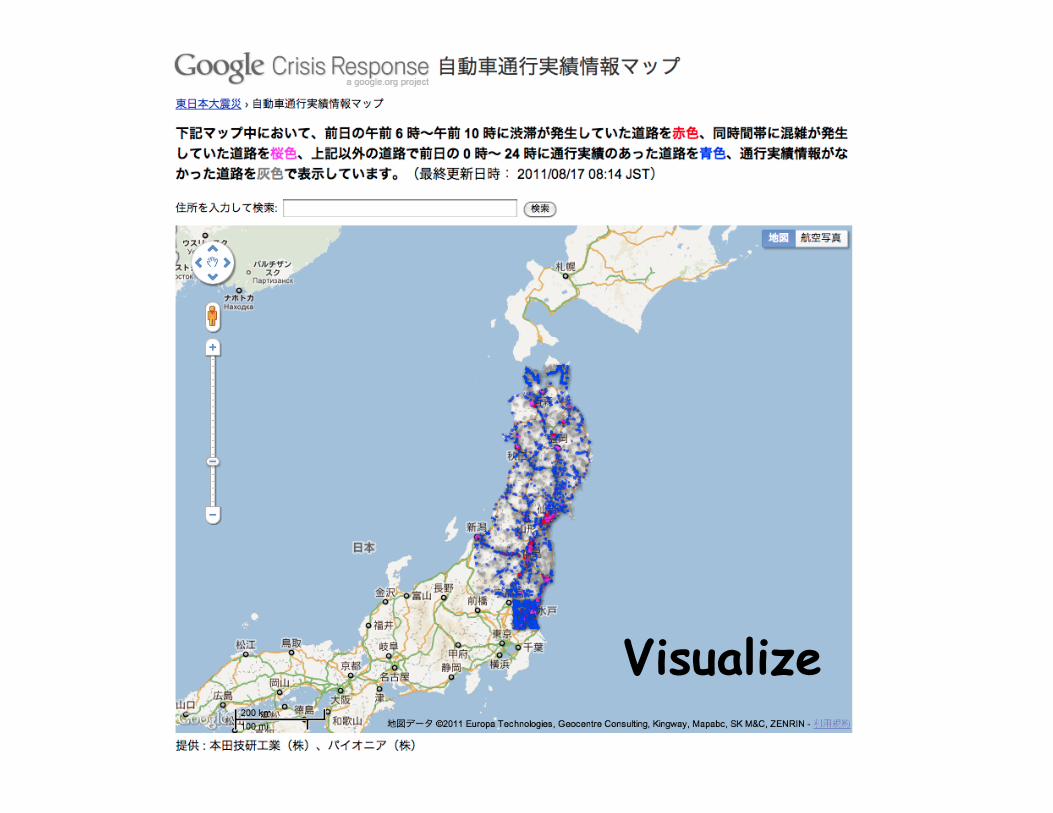
Visualize
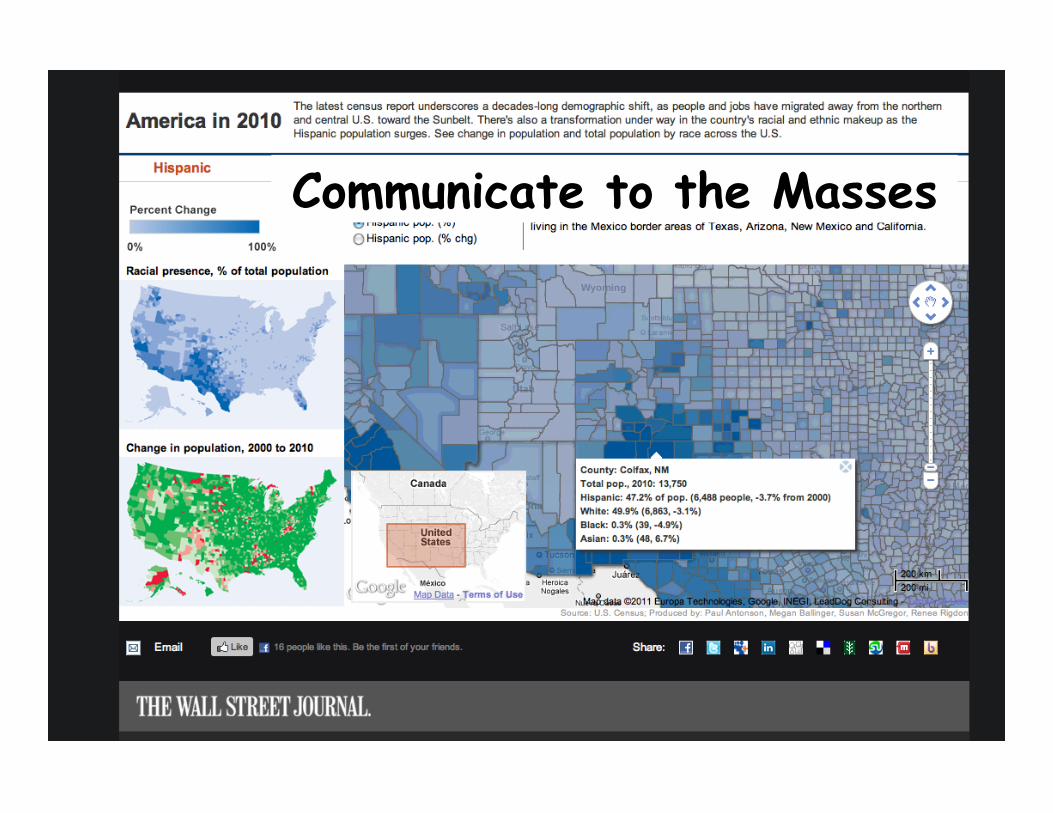
Communicate to the Masses
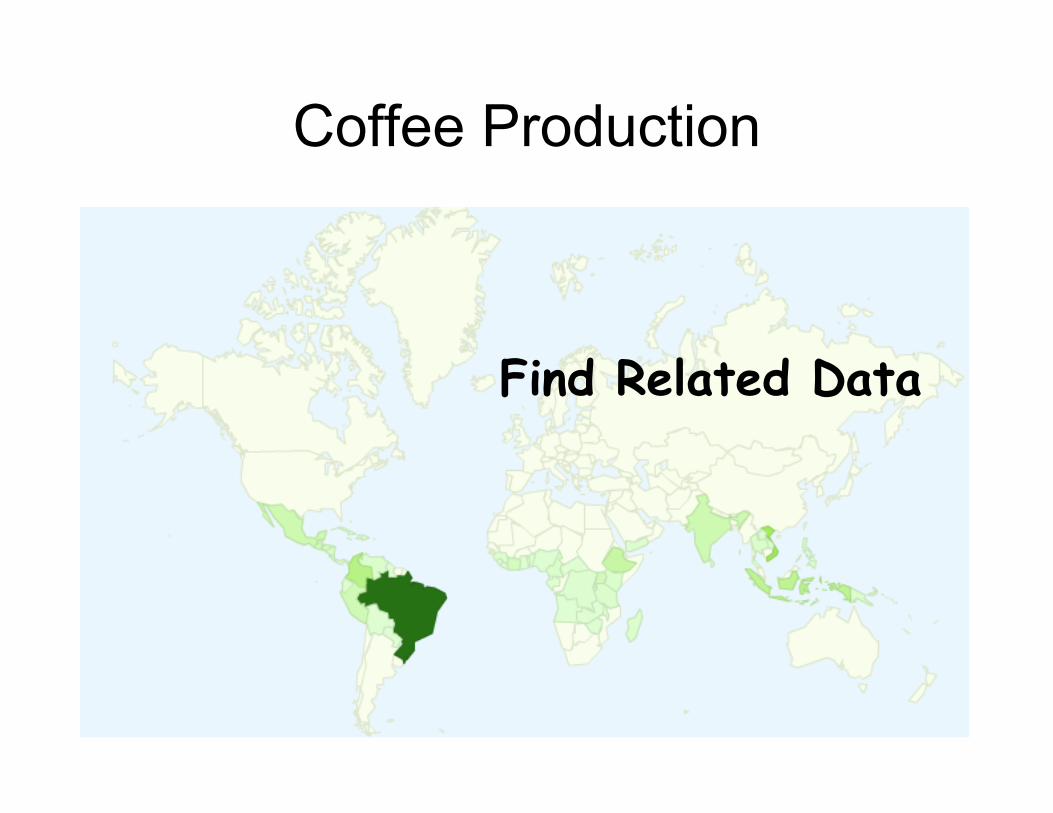
Coffee Production
Find Related Data
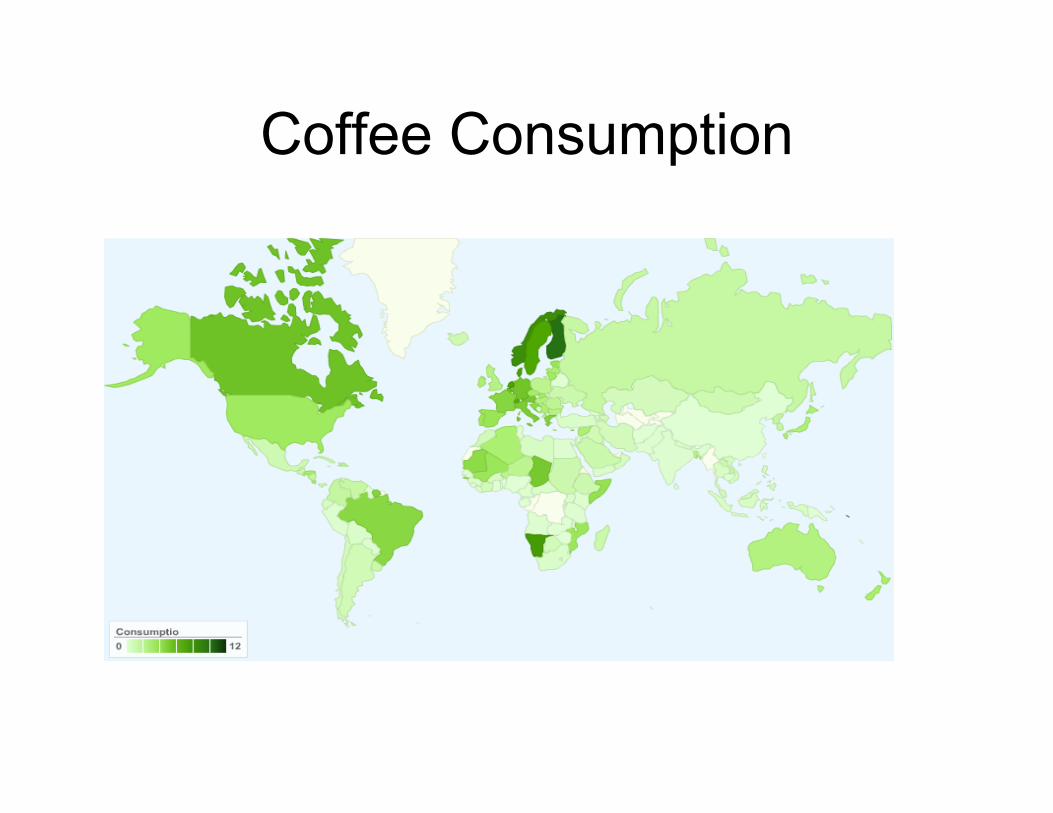
Coffee Consumption
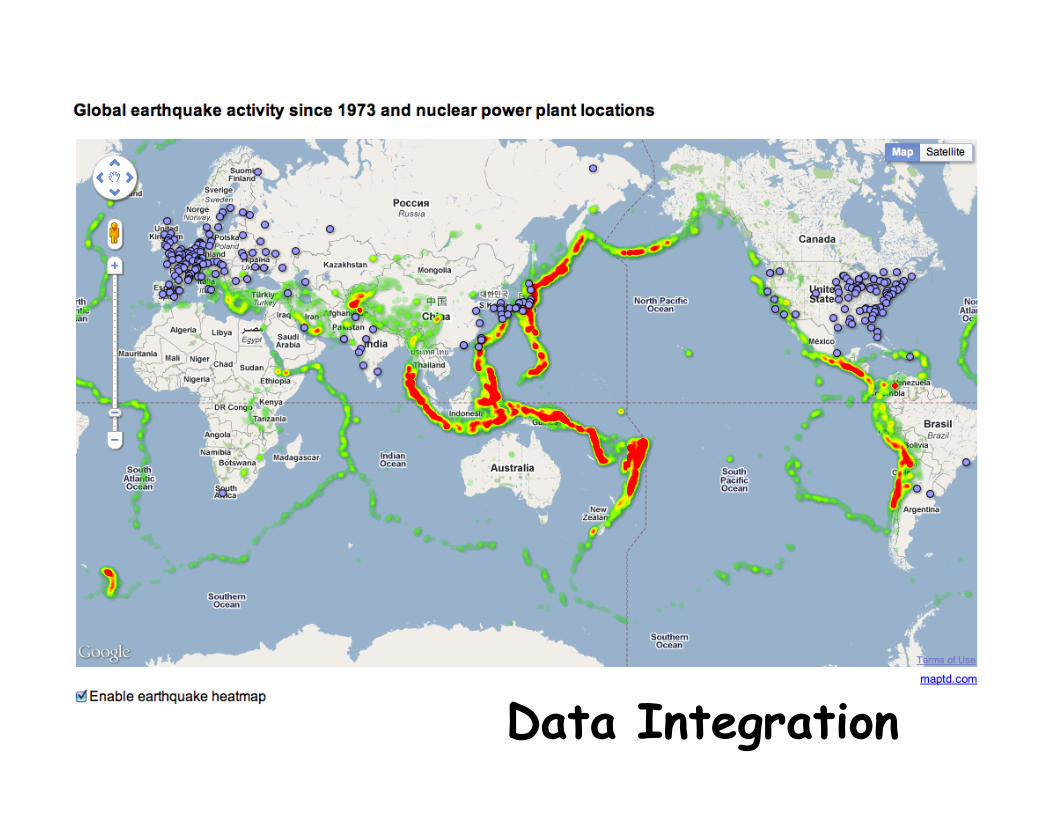
Data Integration
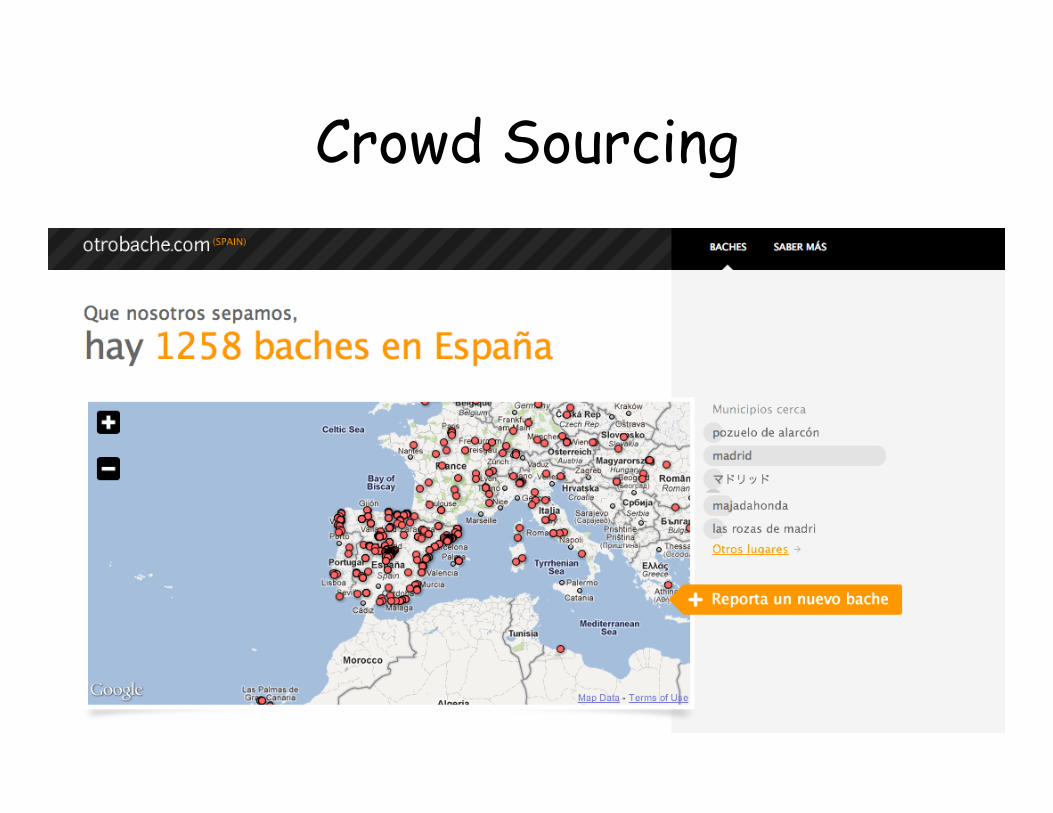
Crowd Sourcing

Ask Complex Queries
• Find data mining conferences that are close to a beach and I can get to with at most $300 in airfare.
• Find the coffee producing nation that had a World Barista Champion and is not the USA or Australia.

Some Challenges
• Data is semi-structured: – No schema – No integrity (columns do not have uniform
type) – Quality varies a lot – Finding tables in a haystack is hard
• Data is about everything. – You can’t build a schema!

Can (Web)-Scale Help?
And is there a Large Graph Here?
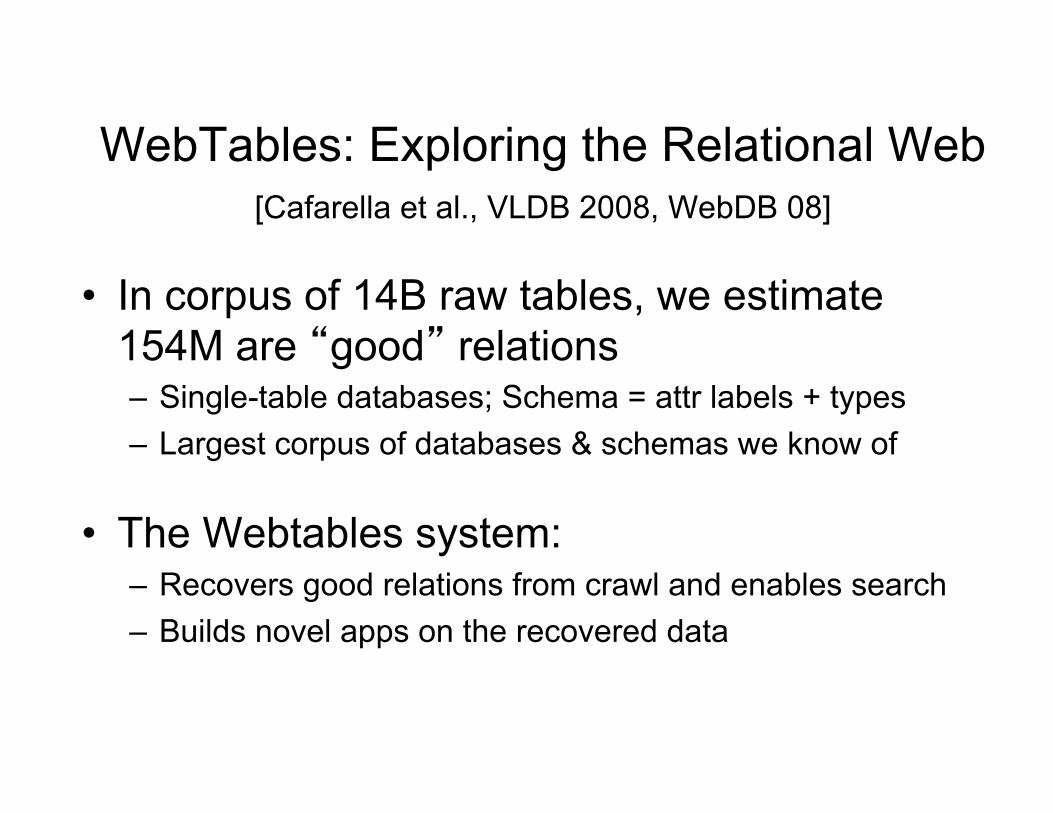
WebTables: Exploring the Relational Web [Cafarella et al., VLDB 2008, WebDB 08]
• In corpus of 14B raw tables, we estimate 154M are “good” relations – Single-table databases; Schema = attr labels + types – Largest corpus of databases & schemas we know of
• The Webtables system: – Recovers good relations from crawl and enables search – Builds novel apps on the recovered data
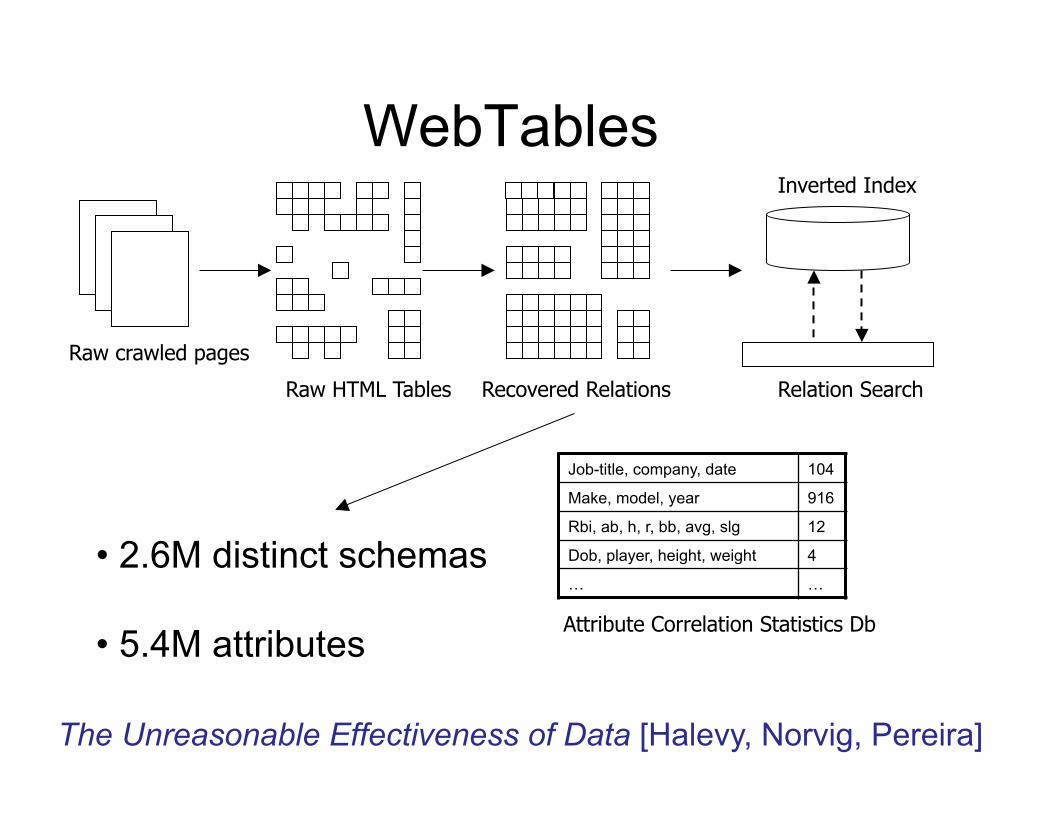
WebTables
Raw crawled pages
Raw HTML Tables Recovered Relations Relation Search
Inverted Index
Job-title, company, date 104
Make, model, year 916
Rbi, ab, h, r, bb, avg, slg 12
Dob, player, height, weight 4
… …
Attribute Correlation Statistics Db
• 2.6M distinct schemas
• 5.4M attributes
The Unreasonable Effectiveness of Data [Halevy, Norvig, Pereira]

App #1: Schema Auto-complete
• Useful for traditional schema design for non-
expert users
• Input I: attr0 • Output schema S: attr1, attr2, attr3, … • While p(S - I | I) > t
– Find attra that maximizes p(attra, S | I) – S = S U attra

Schema Auto-complete Examples
name! name, size, last-modified, type!
instructor! instructor, time, title, days, room, course!
elected! Elected, party, district, incumbent, status, …!
ab! ab, h, r, bb, so, rbi, avg, lob, hr, pos, batters!
sqft! sqft, price, baths, beds, year, type, lot-sqft, …!

Synonym Discovery
• Use schema statistics to automatically compute attribute synonyms – More complete than thesaurus
• Given input “context” attribute set C: 1. A = all attrs that appear with C 2. P = all (a,b) where a∈A, b∈A, a≠b 3. rm all (a,b) from P where p(a,b)>0 4. For each remaining pair (a,b) compute:

Synonym Discovery Examples name! e-mail|email, phone|telephone,
e-mail_address|email_address, date|last_modified!
instructor! course-title|title, day|days, course|course-#, course-name|course-title!
elected! candidate|name, presiding-officer|speaker!
ab! k|so, h|hits, avg|ba, name|player!
sqft! bath|baths, list|list-price, bed|beds, price|rent!

Turning Lists into Tables [Elmeleegy et al., VLDB 09]
A period (“.”) is used both as a delimiter and to
terminate abbreviations
A slash (“/”) is used both as a delimiter and as part of the text
The slash (“/”) delimiter is
missing (along with the prod.
year)

Table Search: Version 1 [Tweak Document Search, Cafarella 08]
• Consider new cues in ranking: – Hits on left column – Hits on schema (where there is one) – Number of rows, columns – Hits on table body – Size of table relative to page
• ~25% increase in good results in top-10 results (compared to filtering google results for tables)

Table Search: Version 2 [Recover Semantics]
[Wu, Madhavan, Miao, Pasca, Shen] • Ideally, we could associate a description
of every table: – Class of objects – Properties being modeled – Context, quality, …
• In practice, we approximate the above – isa-hierarchy extracted from the Web
using patterns: “ C such as | including I”

Recovering Table Semantics

Recovering Binary Relationships

Reference Reconciliation
• Can we infer synonyms and/or hierarchies from occurrences of strings in tables? E.g,. – South Korea = Korea, S., – IBM = International Business Machines

The Web is Uneven
• Detecting binary relationships – Paris, France – Berlin, Germany
– Lilongwe, Malawi
• We may not find evidence for all these assertions in text.

Evaluating Web Extractions
• The web is not an even characterization of the world
• Our extractors are inherently imperfect – E.g., we definitely won’t be able to extract
“acronyms such as ABC” or “graduate students such as Muthu Muthukrishnan”
• Version 1: maximum likelihood model (see Venetis et al., VLDB 2011).
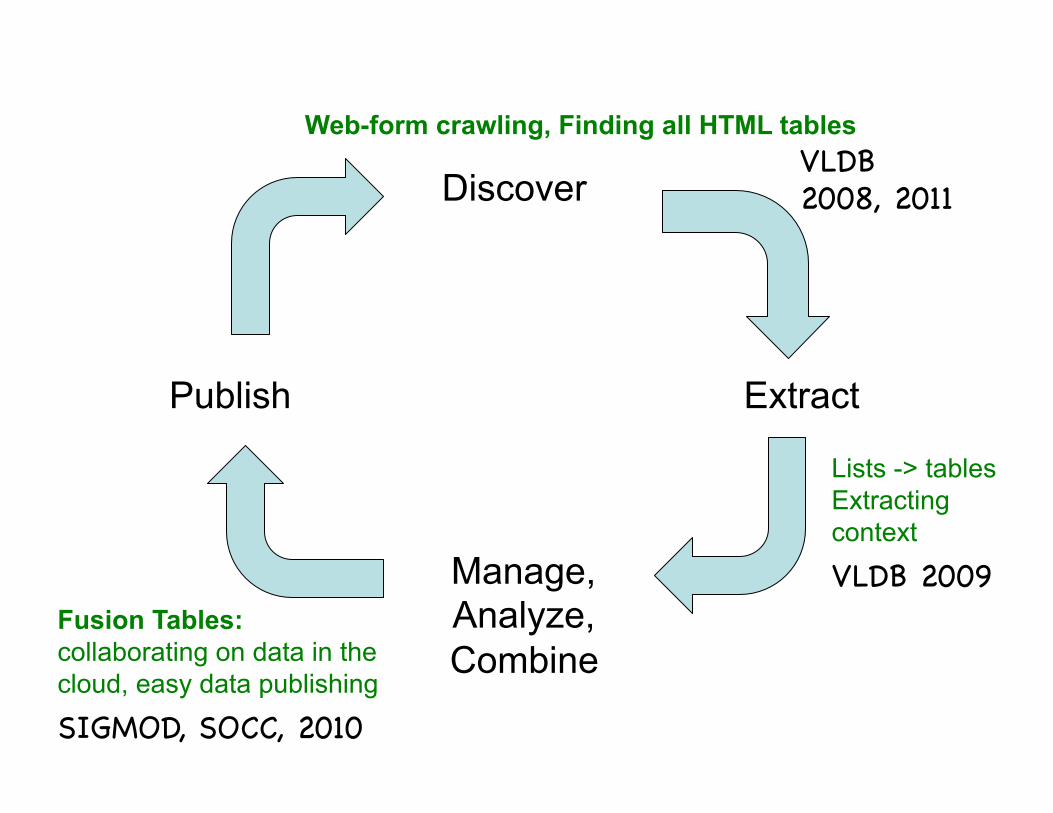
Discover
Manage, Analyze, Combine
Extract Publish
Fusion Tables: collaborating on data in the cloud, easy data publishing
Web-form crawling, Finding all HTML tables
Lists -> tables Extracting context
VLDB 2008, 2011 �
VLDB 2009 �
SIGMOD, SOCC, 2010 �

References • Structured data on the web:
– CACM, February 2011. • Fusion Tables:
– google.com/fusiontables, SIGMOD 2010 • Deep-web crawling:
– [Madhavan et al., VLDB 08] • WebTables:
– [Cafarella et al., VLDB 08, VLDB 09] – [Elmeleegy et al, VLDB 09] – [Venetis et al., VLDB 2011]





























