Embed Size (px)
DESCRIPTION
Mining Quantitative Association Rules in Large Relational Tables. ACM SIGMOD Conference 1996 Authors: R. Srikant, and R. Agrawal Presented by: Biyu Liang March 29, 2006. Outline. Review of Association Analysis Introducing Quantitative AR Problem Partitioning Quantitative Attributes - PowerPoint PPT Presentation
Citation preview

Mining Quantitative Association Rules in Large Relational Tables
ACM SIGMOD Conference 1996Authors: R. Srikant, and R. AgrawalPresented by: Biyu LiangMarch 29, 2006

2
Outline
Review of Association Analysis Introducing Quantitative AR Problem Partitioning Quantitative Attributes Identifying the Interesting Rules Extending the Apriori Algorithm Conclusions

3
Association Rule Item sets X and Y Rule X => Y Support = Pr(XUY) Confidence
= Pr(Y|X)= Pr(XUY)/Pr(X)
Find rules that have MinSup and MinConf

4
Boolean Association Rules
TID Item1 Item2 Item3 Item4
100 1 1 0 1
200 0 1 1 1
300 1 1 1 0
400 0 0 1 0
Attribute has a value of “1” if the transaction contains the corresponding item; “0” otherwise.

5
Outline
Review of Association Analysis Introducing Quantitative AR Problem Partitioning Quantitative Attributes Identifying the Interesting Rules Extending the Apriori Algorithm Conclusions

6
Quantitative Association Rules
<Age: 30..39> and <Married: Yes> => <NumCars: 2>
Support = 40%, Conf = 100%
RecordID Age Married NumCars
100 23 No 1
200 25 Yes 1
300 29 No 0
400 34 Yes 2
500 38 Yes 2

7
Mapping to Boolean Association Rules Problem
Using <attribute: value> as new attribute, which has only boolean values
RecordID
Age: 20..29
Age: 30..39
Married: Yes
Married: No
NumCars: 0
NumCars: 1
100 1 0 0 1 0 1
200 1 0 1 0 0 1
300 1 0 0 1 1 0
400 0 1 1 0 0 0
500 0 1 1 0 0 0

8
Problems with Direct Mapping
MinSup: If number of intervals is large, the support of a single interval can be lower
MinConf: Information lost during partition values into intervals. Confidence can be lower as number of intervals is smaller

9
The Tradeoff Increase the number of intervals (to
reduce information lost) while combining adjacent ones (to increase support)
ExecTime blows up as items per record increases
ManyRules: Number of rules also blows up. Many of them will not be interesting

10
The Proposed Approach
Partition quantitative attribute values and combining adjacent partitions as necessary
Partial Completeness Measure for deciding the partitions
Interest Measure (pruning) to address the “ManyRules” problem
Extend the Apriori Algorithm

11
5 Steps of the Proposed Approach
1. Determine the number of partitions for each quantitative attribute
2. Map values/ranges to consecutive integer values such that the order is preserved
3. Find the support of each value of the attributes, and combine when support is less than MaxSup. Find frequent itemsets, whose support is larger than MinSup
4. Use frequent set to generate association rules5. Pruning out uninteresting rules

12
5 Steps of the Proposed Approach
1. Determine the number of partitions for each quantitative attribute
2. Map values/ranges to consecutive integer values such that the order is preserved
3. Find the support of each value of the attributes, and combine when support is less than MaxSup. Find frequent itemsets, whose support is larger than MinSup
4. Use frequent set to generate association rules5. Pruning out uninteresting rules

13
Outline
Review of Association Analysis Introducing Quantitative AR Problem Partitioning Quantitative Attributes Identifying the Interesting Rules Extending the Apriori Algorithm Conclusions

14
Partial Completeness R : rules obtained before partition R’: rules obtained after partition Partial Completeness measures the
maximum distance between a rule in R and its closest generalization in R’
is a generalization of itemset X: if
The distance is defined by the ratio of support
X
]ˆ,,,,)[( uullXulxXulxXattributesx

15
K-Complete C : the set of frequent itemsets For any K ≥ 1, P is K-complete w.r.t C if:
P C For any itemset X (or its subset) in C, there exists
a generalization whose support is no more than K times that of X (or its subset)
The smaller K is, the less the information lost

16
Theoretical Results Lemma 1: If P is K-complete set w.r.t C,
then any rule R obtained from C has a generalization R’ from P, such that conf(R’) is bounded by [conf(R)/K, K*conf(R)]
For given partial completeness level K, equi-depth partitioning satisfies the completeness level with minimum number of intervals: 2n/[m(K-1)], and MaxSup for each interval is m(K-1)/(2n)

17
Outline
Review of Association Analysis Introducing Quantitative AR Problem Partitioning Quantitative Attributes Identifying the Interesting Rules Extending the Apriori Algorithm Conclusions

18
Example of Uninteresting Rule Suppose a quarter of people in age
group 20..30 are in the age group 20..25 <Age: 20..30> => <Cars: 1..2>, with 8%
sup, 70% conf <Age: 20..25> => <Cars: 1..2>, with 2%
sup, 70% conf The second rule doesn’t give any
additional information, and is less general than the first rule

19
Expected Values Based on Generalization
Itemset Z = {<z1, l1, u1>, …, <z1, l1, u1>} The expected support of Z based on the
support of its generalization is defined asZ

20
Expected Values Based on Generalization
The expected confidence of the rule X => Y based on the confidence of its generalization is defined as
YX ˆˆ

21
Interest Measure Itemset X is R-interesting w.r.t its
generalization if The support of X is no less than R times the
expected supports based on , and For any specialization X' of , X – X' is R-
interesting w.r.t Rule X => Y is R-interesting w.r.t its
generalization if the support or confidence is R times that of , and the itemset is R-interesting w.r.t
X
X
XX
YX ˆˆ YX ˆˆ
YX YX ˆˆ

22
Outline
Review of Association Analysis Introducing Quantitative AR Problem Partitioning Quantitative Attributes Identifying the Interesting Rules Extending the Apriori Algorithm Conclusions

23
Candidate Generation
Given the set Lk-1 of all frequent (k-1)-itemset, generate the set of Lk
The process has three parts: Join Phase Subset Prune Phase Interest Prune Phase

24
Join Phase Lk-1 joined with itself Join condition: k-2 items are the same, the
remaining ones have different attribute Example, L2:
{<Married:Yes> <Age:20..24>} {<Married:Yes> <Age:20..29>} {<Married:Yes> <Cars:0..1>} {<Age:20..29> <Cars:0..1> }
Result of self-join, C3: {<Married:Yes> <Age:20..24><Cars:0..1>} {<Married:Yes> <Age:20..29><Cars:0..1>}
25
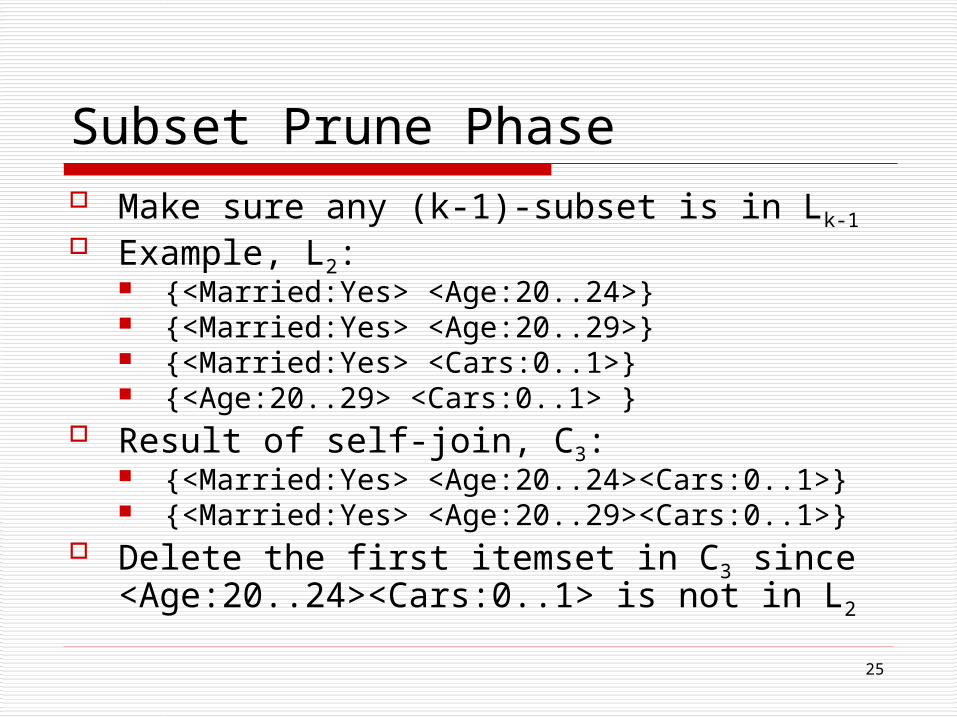
Subset Prune Phase Make sure any (k-1)-subset is in Lk-1 Example, L2:
{<Married:Yes> <Age:20..24>} {<Married:Yes> <Age:20..29>} {<Married:Yes> <Cars:0..1>} {<Age:20..29> <Cars:0..1> }
Result of self-join, C3: {<Married:Yes> <Age:20..24><Cars:0..1>} {<Married:Yes> <Age:20..29><Cars:0..1>}
Delete the first itemset in C3 since <Age:20..24><Cars:0..1> is not in L2

26
Interest Prune Phase
Given user-specified interest level R Delete any itemset that contains a
item with support greater than 1/R Lemma 5 guarantees that such
itemsets cannot be R-interesting w.r.t to their generalizations

27
Outline
Review of Association Analysis Introducing Quantitative AR Problem Partitioning Quantitative Attributes Identifying the Interesting Rules Extending the Apriori Algorithm Conclusions

28
Conclusions This paper introduced the problem of
mining quantitative association rules in large relational tables
It dealt with quantitative attributes by fine-partitioning the values and combining adjacent partitions as necessary
Partial completeness quantifies the info lost, and help decide the partitions
Interest measure to identify interesting rules

Thanks! Question?

30
Final Exam Questions What is Partial Completeness? (p.14-15) Determine a number of intervals, where
there 3 quantitaive attributes, .70 min support and a 1.5 partial completeness level? (p.16)
If Intervals are too large, rules may not have MinConf, and if they are too samll, rules may not have MinSupp, how Do you go about solving this catch 22 problem? (p.8-9)





























