Embed Size (px)
Citation preview

Minimizing Energy Costs for GeographicallyDistributed Heterogeneous Data CentersNinad Hogade , Student Member, IEEE, Sudeep Pasricha , Senior Member, IEEE,
Howard Jay Siegel, Fellow, IEEE, Anthony A. Maciejewski , Fellow, IEEE,
Mark A. Oxley,Member, IEEE, and Eric Jonardi,Member, IEEE
Abstract—The recent proliferation and associated high electricity costs of distributed data centers have motivated researchers to
study energy-cost minimization at the geo-distributed level. The development of time-of-use (TOU) electricity pricing models and
renewable energy source models has provided the means for researchers to reduce these high energy costs through intelligent
geographical workload distribution. However, neglecting important considerations such as data center cooling power, interference
effects from task co-location in servers, net-metering, and peak demand pricing of electricity has led to sub-optimal results in prior work
because these factors have a significant impact on energy costs and performance. We propose a set of workload management
techniques that take a holistic approach to the energy minimization problem for geo-distributed data centers. Our approach considers
detailed data center cooling power, co-location interference, TOU electricity pricing, renewable energy, net metering, and peak demand
pricing distribution models. We demonstrate the value of utilizing such information by comparing against geo-distributed workload
management techniques that possess varying amounts of system information. Our simulation results indicate that our best proposed
technique is able to achieve a 61 percent (on average) cost reduction compared to state-of-the-art prior work.
Index Terms—Geo-distributed data centers, workload management, memory interference, peak shaving, net metering
Ç
1 INTRODUCTION
THE success of cloud computing has resulted in data cen-ter operators expanding and geographically distributing
their data center locations, e.g., Google [1] and Amazon [2].Distributing data centers geographically offers severalbenefits to the clients such as low latency due to shorter com-munication distances and service resiliency. A strong moti-vating factor for data center operators to geographicallydistribute their data centers is to reduce operating expendi-tures by exploiting time-of-use (TOU) electricity pricing [3].Electricity prices are not constant, but rather follow a TOUpricing model where the cost of electricity varies based onthe time of day as demonstrated in Fig. 1. Electricity pricesare higher when total electrical grid demand is high, and fallduring periods when electrical grid demand is low [4], [5].Beyond the TOU electricity costs, most utility providers alsocharge a flat-rate (peak demand) fee based on the highest(peak) power consumed at any instant during a given billing
period, e.g., month [6], [7]. Reducing electricity costs hasbeen a major focus of data center management, and hascontinued to grow in importance as the annual electricityexpenditure for powering data centers has, in some cases,surpassed the costs of purchasing the equipment itself [8].
Relocating workloads among geo-distributed data cen-ters is one effective approach to curb electricity expendi-tures. Workloads can be migrated to data centers located indifferent times zones with the goal of concentrating theworkload in regions with the lowest TOU electricity andpeak demand pricing available at that time. The allocationof workloads within a data center can also reduce electricitycost by exploiting dynamic voltage and frequency scaling(DVFS) and any heterogeneity across compute nodes (e.g.,different power and performance characteristics).
Due to the ever-increasing electricity consumption ofdata centers, the use of on-site renewable energy sources,e.g., solar and wind, has grown rapidly in recent years. Sev-eral data center operators have already built or announcedplans to build “green” data centers, i.e., data centers, thatare completely (or at least partially) operated with the helpof renewable energy. For example, a portion of Apple’s datacenters in North Carolina are powered by a 60 MW solarplant [10]. McGraw-Hill operates a data center using a 14MW solar array [11]. Similar to these examples, major globaldata center providers, e.g., Microsoft [12], Google [13], andFacebook [14], have invested in green energy facilities.Some data center providers have begun to use locationswith large amounts of renewable energy available to reduceenergy costs, or even exploit net metering. Net metering is abilling mechanism that gives renewable energy customerscredit on their utility bills for the excess clean energy theysell back to the grid [15]. Adding on-site renewable power
� N. Hogade and A.A. Maciejewski are with the Department of Electricaland Computer Engineering, Colorado State University, Fort Collins, CO80523. E-mail: {ninad.hogade, aam}@colostate.edu.
� S. Pasricha and H.J. Siegel are with the Department of Electrical and Com-puter Engineering and the Department of Computer Science, Colorado StateUniversity, Fort Collins, CO 80523. E-mail: {sudeep, hj}@colostate.edu.
� M.A. Oxley is with Numerica Corporation, Fort Collins, CO 80528.E-mail: [email protected].
� E. Jonardi is with Rockwell Automation, Milwaukee, WI 53204.E-mail: [email protected].
Manuscript received 3 Dec. 2017; accepted 13 Mar. 2018. Date of publication3 Apr. 2018; date of current version 6 Dec. 2018.(Corresponding author: Ninad Sanjay Hogade.)Recommended for acceptance by P. Bouvry.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference the Digital Object Identifier below.Digital Object Identifier no. 10.1109/TSUSC.2018.2822674
318 IEEE TRANSACTIONS ON SUSTAINABLE COMPUTING, VOL. 3, NO. 4, OCTOBER-DECEMBER 2018
2377-3782� 2018 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See ht _tp://www.ieee.org/publications_standards/publications/rights/index.html for more information.

and exploiting net metering can reduce electricity costs [16],peak grid power costs [17], or both [18], [19]. This can pro-vide additional opportunities for geographical load distri-bution (GLD) techniques to reduce overall electricity costs.
The goal of our research is to design techniques for geo-graphical load distribution that will minimize the energycost for executing incoming workloads considering manyaspects of the overall system. We use detailed models fordata center cooling power, co-location interference, TOUelectricity pricing, renewable energy, net metering, andpeak demand pricing distribution to provide the most-accurate information possible to the geo-distributed work-load manager. Co-location interference is a phenomena thatoccurs when multiple cores within the same multicore pro-cessor are executing tasks simultaneously and compete forshared resources, e.g., last-level cache or DRAM. Our workis highly useful for environments where historical executioninformation about the types of tasks executed is readilyavailable. Examples of such environments exist in industry,e.g., commercial companies (DigitalGlobe, Google), militarycomputing installations (Department of Defense), and gov-ernment labs (National Center for Atmospheric Research).
By considering data center cooling power, co-locationinterference, TOU electricity pricing, renewable energy, netmetering, and peak demand pricing distribution models,we design three new workload management techniques.These techniques assume varying degrees of co-locationinterference characteristics to distribute or migrate theworkload to low-cost data centers at regular time intervals,while ensuring that all of the workload is completed. Wecompare these techniques to a state-of-the-art method [20],and our previous work [21], and show that our best pro-posed resource management heuristic can, on average,achieve a cost reduction of 61 percent. Key contributions inour work can be summarized as follows:
� a hierarchical framework for the GLD problem thatconsiders cost-minimization oriented workloadmanagement at both the geo-distributed and localheterogeneous data center level;
� a new detailed data center model that exploits netmetering and peak shaving, i.e., peak power reduc-tion, by considering information about heteroge-neous compute node-types, P-states, compute nodetemperatures, cooling power, TOU and peak demandpricing, renewable power sources, and performancedegradation caused by co-location interference;
� the design of three resource management heuristicsthat possess varying degrees of co-location interfer-ence prediction information to demonstrate andmotivate the use of detailed models in workloadmanagement decisions.
The rest of the paper is organized as follows. In Section 2,we review relevant prior work. Our system model is
characterized in Section 3. Sections 4 and 5 describe ourspecific problem in detail and the heuristics we propose tosolve it. The simulation environment is discussed in Sec-tion 6. Lastly, we analyze and evaluate the results of ourapproach in Sections 7 and 8, respectively.
2 RELATED WORK
There have been many recent efforts proposing methods tominimize electricity costs across geo-distributed data cen-ters, with the fundamental decisions of the optimizationproblem relying on a TOU electricity pricing model [22].These models either use data analytics for pricing models ormake predictions of electricity costs. Electricity costs areoften much higher during peak hours of the day (typically 8A.M. to 5 P.M.). The TOU electricity cost models, sometimesin combination with a model for revenue generated fromcomputation of a workload, motivates the use of optimiza-tion techniques to minimize energy cost or, if provided arevenue model, to maximize total profit.
Workload distribution for geo-distributed data centershas been studied in prior work such as [20], [21], [23], [24],[25], [26], [27], [28]. Information about TOU pricing is typi-cally used to either minimize electricity costs across all geo-distributed data centers, e.g., [20], [21], [23], [25], [26],[27], [28], or to maximize profits when a revenue model isincluded for computational work performed, e.g., [24]. Aquality of service (QoS) constraint of some form is recog-nized in most of the aforementioned works. Typically,this is incorporated into the model as a queuing delayconstraint [23], [25], [27]. Other works incorporate QoSviolations into a cost function, where a monetary penaltyis associated with violating service level agreements(SLAs) due to excessive queuing delay [24], latency [26],or migration penalties [20]. The detail of each modelvaries significantly among approaches in the prior work.Some works include DVFS in decision making [25], someinclude power consumption of the cooling system inaddition to the computing system [26], [27], and othersconsider real-world TOU pricing data [24], [25].
Our research considers all of the aforementioned modelingaspects to assist in workload management decisions: (a) DVFSto exploit the power/performance trade-offs of P-states; (b)cooling system power and thermal properties to reduce cool-ing cost; (c) TOU and peak demand pricing data to reducemonetary electricity cost. To the best of our knowledge, ourwork is the first to integrate all of these aspects within the GLDproblem. In addition, unlike any prior work in GLD, we con-sider performance degradation caused by co-location interfer-ence as part of our load distribution techniques.
With respect to energy usage, some studies have consid-ered renewable energy for energy optimization of geo-dis-tributed data centers [20], [21], [29], [30]. Similar to [19], ourwork uses information about TOU electricity pricing, peakdemand pricing and peak shaving, renewable energy usage,and net metering. However, reference [19] proposes a solu-tion for a single data center rather than for a group of geo-distributed data centers. Moreover, it does not considerheterogeneous compute node-types, different performancestates of cores, compute node temperatures, cooling power,or co-location interference. Our work considers all these fac-tors at a geo-distributed level. Similar to our work, reference[29] proposes a workload scheduling technique that usesboth peak shaving and renewable energy prediction
Fig. 1. TOU electricity pricing, PG&E Schedule E-19 [9].
HOGADE ET AL.: MINIMIZING ENERGY COSTS FOR GEOGRAPHICALLY DISTRIBUTED HETEROGENEOUS DATA CENTERS 319

models. However, it does not consider net metering anddetailed cooling power and co-location interference models.Similar to [20] and our prior work in [21], our study consid-ers a renewable energy source at each geo-distributed datacenter, a cooling system at each data center, and migrationpenalties associated with moving already-assigned work-loads to different data centers. We differ significantly from[20] by including TOU electricity pricing traces, consideringDVFS P-state decisions, and integrating interference causedby the co-location of multiple tasks to cores that shareresources in our management techniques. We extend ourprior work significantly from [21] by including a peakdemand price model and also exploiting peak shaving andnet metering.
3 SYSTEM MODEL
3.1 OverviewWe propose a hierarchical framework for a geo-distributedresource manager (GDRM) that consists of a high-level man-ager to distribute incoming workload requests and migratealready-allocated requests to geographically distributeddata centers. The goal of the GDRM is to minimize the totalenergy cost of the system while servicing all requests. Eachdata center has its own local workload management systemthat takes the workload assigned to it by the GDRM andmaps requests to compute cores within the data center. Wefirst describe the system model at the geo-distributed leveland then provide further details into the models of compo-nents at the data center level. We provide a list of abbrevia-tions and notations in the appendix, which can be foundon the Computer Society Digital Library at http://doi.ieeecomputersociety.org/10.1109/TSUSC.2018.2822674.
3.2 Geo-Distributed Level ModelWe consider a rate-based workload management scheme,where workload arrival rate can be predicted over the deci-sion interval called an epoch [31], [32]. In our work, an epochlength Te is one hour, and a 24-epoch period represents afull day. Over the course of an epoch, the workload arrivalrates can be reasonably approximated as constant, e.g., theArgonne National Lab Intrepid log shows mostly-constantarrival rates over large intervals of time [33].
We assume that the beginning of each epoch represents asteady-state scheduling problem where we assign executionrates, i.e., reciprocal of the execution time, of a set of I work-load task-types to D data centers. A task-type i 2 I is charac-terized by its arrival rateARi, and the estimated time requiredto complete a task of task-type i on each of the heterogeneouscompute nodes in each P-state. The assignment problem at thegeo-distributed level is to assign execution rates for each task-type i to each data center d 2 D such that total energy costacross all data centers is minimized, with the constraint thatthe execution rates of all task-typesmeet their arrival rates, i.e.,all tasks complete without being dropped or unexecuted. Tofulfill this constraint, for each epoch t, we assign a maximumdata center execution rate ERDC
d;i for each task-type i to eachdata center d such that the total execution rate for all task-typesexceed (or equal) the corresponding arrival rate, ARi, thusensuring theworkload can be completed. That is
XDd¼1
ERDCi;d ðtÞ � ARiðtÞ; 8i 2 I: (1)
3.3 Data Center Level
3.3.1 Organization of Each Data Center
Each data center d houses NNd number of nodes that arearranged in hot aisle/cold aisle fashion (Fig. 2), and a cool-ing system comprised of NCRd number of computer roomair conditioning (CRAC) units. Heterogeneity exists amongcompute nodes, where nodes vary in their execution speeds,power consumption characteristics, and number of cores.Cores within a compute node are homogeneous, and eachcore is DVFS-enabled to allow independent configuration ofits P-states. The number of cores in node n is NCNn, andNTk is the node type to which core k belongs.
3.3.2 Compute Core Execution Rates
Recall that our GDRM determines the distribution of tasksof each task-type among all data centers. At each data centerd, the sum of execution rates of all cores that are assigned toexecute task-type i must exceed or equal ERDC
d;i ðtÞ. Weassume that we know the estimated computational speedðECSÞ of any task of type i on a core of node-type n in P-state p, ECSði; n; pÞ, determined using historical, experi-mental, or analytical techniques [35], [36].
For epoch t, we assign a desired fraction DFi;kðtÞ of timeeach core k will spend executing tasks of type i and the P-state PSi;kðtÞ each core k is configured when executing tasksof type i. We assume tasks will run serially until completion.That is, a core sharing its time among multiple tasks impliesthat a scheduler will assign different tasks to execute on thecore in such a manner that, over a long period of time(i.e., steady-state), the amount of time a core k spends execut-ing a task of type i would equal its assigned DFi;kðtÞ value.The core execution rateERcore
i;k of tasks of type i on core k is
ERcorei;k ðtÞ ¼ DFi;kðtÞ � ECSði;NTk; PSi;kðtÞÞ: (2)
At the data center level, we assign DFi;kðtÞ and PSi;kðtÞsuch that power is minimized (see Section 3.3.3), and theexecution rates of all task-types on cores in all data centersequal the arrival rate ensuring that the arriving workload isfully executed. That is
XDd¼1
XNNd
n¼1
XNCNn
k¼1
ERcorei;k ðtÞ ¼ ARiðtÞ; 8i 2 I; 8d 2 D: (3)
3.3.3 Compute Node Power Model
The power consumption of a compute node consists of thestatic overhead power consumption (equal to the amount of
Fig. 2. Data center in hot aisle/cold aisle configuration [34].
320 IEEE TRANSACTIONS ON SUSTAINABLE COMPUTING, VOL. 3, NO. 4, OCTOBER-DECEMBER 2018

power consumed when the system is idle) and the addi-tional dynamic power consumed when cores are executingtasks. We define On as the overhead power consumption ofcompute node n (a constant value independent of the work-load resulting from system components such as storage,network interfaces). Let APC(i, NTk, PSi;kðtÞ) be the averagepower consumed by core k in a node of type NTk when exe-cuting tasks of type i in P-state PSi;kðtÞ during epoch t. Thepower consumption of node n during epoch t, PNnðtÞ, is
PNnðtÞ ¼ On þXNCNn
k¼1
XIi¼1
APCði; NTk; PSi;kðtÞÞ �DFi;kðtÞ: (4)
3.3.4 Cooling Power Model
The heat generated by compute nodes is removed by theCRAC units. The airflow within the data center causes heatgenerated from nodes to propagate to other nearby nodes,thereby increasing the inflow temperature of those nodes.Using the notion of thermal influence indices [37] that werederived using computational fluid dynamics simulations,we can calculate the steady-state temperatures at computenodes and CRAC units in each data center. Because weassume the same physical layout for each of the data centers(Fig. 2), we use thermal influence indices derived for onedata center layout based on an average workload thatwould be executed by the data center.
The outlet temperature of each compute node is a func-tion of the inlet temperature, the power consumed, and theair flow rate of the node. The inlet temperature of each com-pute node is a function of the outlet temperatures of eachCRAC unit and the outlet temperatures of all computenodes of the same data center [34]. The ASHRAE guidelineshave designated the inlets of IT equipment as the commonmeasurement point for temperature compliance [38], andtherefore we consider thermal constraints at the inlets ofcompute nodes. For all nodes, the inlet temperature of eachnode is constrained to be less than or equal to the red-linetemperature (maximum allowable node temperature).
The power consumed by a CRAC unit is a function of theheat removed at that CRAC unit and the Coefficient of Per-formance (CoP) of the CRAC unit [39]. Let rd be the densityof air and Cd be the specific heat capacity of air at data cen-ter d. Let TCin
d;cðtÞ, TCoutd;c ðtÞ, and AFCd;cðtÞ be the inlet tem-
perature, outlet temperature, and air flow rate, respectively,of CRAC unit c in data center d during epoch t. Then thepower consumed by this CRAC unit, PCRd;cðtÞ, can be cal-culated as [39]
PCRd;cðtÞ ¼rd � Cd �AFCd;cðtÞ � TCin
d;cðtÞ � TCoutd;c ðtÞ
� �CoPd TCout
d;c ðtÞ� � : (5)
3.3.5 Node Activation/Deactivation Power Overhead
At each data center, the number of nodes of each node-typethat are in-use frequently changes among epochs. Inactivenodes are placed in a sleep state, but entering and exitingthis sleep state takes some time due to the actions requiredin both hardware and software to transition the systembetween states. Each node that is active is considered to beactive for the entire epoch, which requires that any nodetransitioning to/from a sleep state do so during the epochfollowing/before the current epoch, respectively.
For each data center d, letNtransd;j ðtÞ be the number of nodes
of type j that activate or deactivate during epoch t. Let PSleepj
be the average sleep power for node-type j. Let PDj be the
average peak dynamic power for node-type j. It is calculatedby averaging over all task-types the peak power for eachtask-type i executing on node-type j. The average node utili-zation of node-type j defined as mj. Let CoP of the CRACunit at data center d be CoPd. Without loss of generality, weassume that each data center contains the same number ofnodes, however each data center is heterogeneous in thesense that the number of nodes belonging to each node-typeamong data centers varies. Let Jd be the set of node-types indata center d. Let TS be the time required for a node to transi-tion to/from a sleep state. Recall that Te is the duration of anepoch. The node activation/deactivation power ADPd fordata center d during epoch t is then calculated as
ADPdðtÞ ¼Xj2Jd
mjPDj � PSleep
j
� ��Ntrans
d;j ðtÞh i
� 1þ 1
CoPd
� �� T
S
Te:
(6)
3.3.6 Renewable Power Model
Each data center is equipped with and partially powered bya renewable energy source. Every location can have eithersolar power, wind power, or some combination of both.Solar power Psolar
d and wind power Pwindd (both have units
of kW ) are calculated as [40] for each data center d as anaverage per epoch t. The total renewable power, PRdðtÞ,available at data center d during epoch t is the sum of thewind and solar power available at that time. We use thesemodels with historical data [41] to predict the renewablepower available at each data center
PRdðtÞ ¼ Psolard ðtÞ þ Pwind
d ðtÞ: (7)
3.3.7 Overall Data Center Power Model
Let Effd be an approximation of the power overhead coeffi-cient in data center d due to the inefficiencies of power sup-ply units. Effd is always greater than or equal to 1. The totalnon-renewable power consumed throughout data center dduring epoch t, PDdðtÞ, is calculated as
PDdðtÞ ¼XNCRd
c¼1
PCRd;cðtÞ þXNNd
n¼1
PNnðtÞ þADPdðtÞ !
� Effd � PRdðtÞ:(8)
For epoch t, PDdðtÞ can be negative if the renewablepower available at the data center, PRdðtÞ, is greater thanthe cooling and computing power.
3.3.8 Net Metering Model
Net metering allows data center operators to sell back theexcess renewable power generated on-site to the utilitycompany. When the excess power is added into the grid,utility companies pay a fraction of the retail price. This frac-tion is called the net metering factor, a.
3.3.9 Peak Demand Model
Most utility providers charge a flat-rate (peak demand) feebased on the highest (peak) power consumed at any instant
HOGADE ET AL.: MINIMIZING ENERGY COSTS FOR GEOGRAPHICALLY DISTRIBUTED HETEROGENEOUS DATA CENTERS 321

during a given billing period, e.g., month. The peak demand
price per kW at data center d is denoted as Ppriced . We define
Pcpeakd ðtÞ as the highest grid power consumed since thebeginning of the current month, including the current epocht. We define Pppeakd ðtÞ as the highest grid power consump-tion since the beginning of the current month until the startof the current epoch t. The peak power increase at data cen-ter d during epoch t, Dpeak
d ðtÞ, is then defined as
Dpeakd ðtÞ ¼ Pcpeakd ðtÞ � Pppeakd ðtÞ; (9)
if Pcpeakd ðtÞ � Pppeakd ðtÞ else it is equal to 0. The peak powerincrease Dpeak
d ðtÞ is calculated in each epoch t and summedover all epochs in a billing period to calculate total peakpower.
3.3.10 System Electricity Cost
The electricity price per kWh at data center d during epoch t
is defined as Epriced ðtÞ. Data center operators can use net
metering if total non-renewable power consumed through-out the data center, PDdðtÞ, is negative. For such conditions,the total power/electricity cost PCdðtÞ for data center d dur-ing epoch t can be defined as
PCdðtÞ ¼ Epriced ðtÞ � PDdðtÞ þ Pprice
d � Dpeakd ðtÞ; (10a)
if PDdðtÞ is positive. If PDdðtÞ is negative then
PCdðtÞ ¼ Epriced ðtÞ � a � PDdðtÞ þ Pprice
d � Dpeakd ðtÞ; (10b)
where a = 0 if net metering is not available. The first term inEquation (10) represents the TOU electricity cost and thesecond term represents the peak demand cost.
3.3.11 Co-Location Interference Model
Tasks competing for shared memory in multicore process-ors can cause severe performance degradation, especiallywhen competing tasks are memory-intensive [42]. Thememory-intensity of a task refers to the ratio of last-levelcache misses to the total number of instructions executed.We employ a linear regression model from [43] that com-bines a set of disparate features (i.e., inputs that are corre-lated with task execution time) based on the current tasksassigned to a multicore processor to predict the executiontime of a target task i on core k in the presence of perfor-mance degradation due to interference from task co-loca-tion. These features are, the number of applications co-located on that multicore processor, the base executiontime, the clock frequency, the average memory intensity ofall applications on that multicore processor, and the mem-ory intensity of application i on core k.
In our linear model, the output is a linear combination ofall features and their calculated coefficients. We classify thetask-types into memory-intensity classes on each of thenode-types, and calculate the coefficients for each memory-intensity class using the linear regression model to deter-mine a co-located execution rate for task-type i on core k,CERcore
i;k ðtÞ. The total execution rate for task-type i in epocht is therefore given by
CERiðtÞ ¼XDd¼1
XNCd
k¼1
CERcorei;k ðtÞ: (11)
Because co-location interference degrades the executionrate of task-types, some tasks may be unable to finish if task-types are allocated to cores based on Equation (2) that does notconsider degradation effects. To allocate tasks to cores whenconsidering co-location interference, some of our techniquesuse information about CERcore
i;k to judge actual execution ratesmore accurately than techniques that do not consider co-loca-tion interference.When considering co-location at a data centerd, the data center execution rate constraint becomes
XNCd
k¼1
CERcorei;k ðtÞ � ERDC
d;i ðtÞ; 8i 2 I; 8d 2 D: (12)
The linear regression model was trained using executiontime data that was collected by executing benchmarks fromthe PARSEC [44] and NAS parallel [45] benchmark suiteson a set of server class multicore processors that define thenodes used in our study (see Table 1 in Section 6 for detailsabout each node). This model for execution time predictionunder co-location interference is derived from real work-loads and machines, and results in a mean prediction errorof approximately 7 percent.
4 PROBLEM FORMULATION
We consider a scenario with multiple data centers sharing asingle workload. The system is assumed to be under-subscribed in the sense that the system is expected to haveenough computation resources to complete the workloadwithout requiring that any tasks be dropped. Though thesystem is under-subscribed, individual data centers may beexecuting at full capacity. The tasks originate off-site from thedata centers, and we make the simplifying assumptions thatthe transmission time and cost from a task origin to a datacenter is equivalent for all data centers. The objective of aGDRM is to minimize monetary electricity cost of the geo-distributed system (the sum of Equation (10) across all datacenters) while ensuring that the workload is completedaccording to the constraints defined byEquations (1) and (12).
The problem is especially challenging when consideringthe variable amount of renewable power available at eachdata center, the heterogeneity of compute nodes within a datacenter, and the additional constraint that the entire workloadmust complete without dropping any tasks. Having informa-tion about TOU electricity pricing, peak demand pricing, aprediction of the amount of renewable power, net meteringpolicy at each data center, the incoming workload, and theexecution speeds of task-types on the heterogeneous computenodes allows ourGDRM tomake intelligent decisions for allo-cating theworkload, as described next in Section 5.
5 HEURISTICS DESCRIPTIONS
5.1 OverviewThe GDRM allocates the incoming workload not only toindividual data centers, but also to specific nodes within
TABLE 1Node Processor Types Used in Experiments
Intel processor # cores L3 cache frequency range
Xeon E3-1225v3 4 8 MB 0.8-3.20 GHzXeon E5649 6 12 MB 1.60-2.53 GHzXeon E5-2697v2 12 30 MB 1.20-2.70 GHz
322 IEEE TRANSACTIONS ON SUSTAINABLE COMPUTING, VOL. 3, NO. 4, OCTOBER-DECEMBER 2018

each data center. The GLD problem is NP-hard [20], andtherefore we propose three resource management heuristicsfor GDRM, with each having different levels of detail of thesystem model available to it.
5.2 Force Directed Load Distribution HeuristicsForce-directed loaddistribution (FDLD) is a variation of force-directed scheduling [46], a technique often used for optimiz-ing semiconductor logic synthesis. FDLD is an iterative heu-ristic that selectively performs operations to minimize systemforces until all constraints are met. We adapt the FDLDapproach proposed in [20] to the rate-based allocation envi-ronment we have outlined in Section 3, and enhance it to pro-pose two new FDLD based heuristics to solve our problem.
Our baseline FDLD heuristic is the one proposed in [20],which we enhance with simple over-provisioning (FDLD-SO) to compensate for performance degradation due to co-location. This allows the FDLD heuristic to meet the execu-tion rate constraint at a given data center. This heuristicover-provisions all task-types equally by scaling estimatedtask execution rates by a factor fC . Our first new heuristicimproves upon FDLD-SO by using task aware over-provi-sioning (FDLD-TAO) to estimate co-location effects for eachtask-type by a factor specific to each task-type i, fC
i . Forboth FDLD-SO and FDLD-TAO, the degree of over-provi-sioning (fC and fC
i , respectively) is determined empiricallythrough simulation studies to provide values that give thesystem the best possible performance. Lastly, our secondnew heuristic uses the co-location (FDLD-CL) models givenin Section 3.3.11 to account for co-location effects whencalculating task execution rates.
The fundamental operation of all FDLD variants isdescribed in Algorithm 1. To generate the initial solution,every node in every data center in every epoch is assignedto execute all task-types (step 1). Each iteration of the FDLDremoves one instance of one task-type from a single node,selecting the task to remove, resulting in the lowest totalsystem force FS (steps 4-23). After getting the final alloca-tion solution from the heuristic, we calculate the final execu-tion rates and the system electricity cost by summing thepower costs across all data centers. The rest of this sectionpresents the derivation of the total system force FS , Equa-tion (15) (used in steps 10 and 12 in Algorithm 1), and Equa-tion (16) (used in step 15 in Algorithm 1).
As per Equation (2), the task execution rate is a functionof the P-state of the node the task is executing at, but FDLDis not designed to make DVFS decisions to set the executionrates of task-types, and therefore we assume that it is goingto make the decisions based on the node utilization. Anaverage execution rate must be determined for all task-typesusing the average node utilization factor mj for each node-type j. Let ERj;iðPMAXÞ and ERj;iðP0Þ be the execution ratesof task-type i running on a single core of a node of type j inthe highest numbered P-state and lowest numbered P-state,respectively. Therefore, the equivalent single core executionrate Rj;i of task-type i on node-type j is
Rj;i ¼ ERj;i PMAXð Þ þ ERj;i P0ð Þ �ERj;i PMAXð Þ� �mj: (13)
The single core execution rate of the application is equalto the minimum execution rate executing at the highestnumbered P-state (first term in Equation (13)) plus a perfor-mance factor (second term in Equation (13)). The node utili-zation will affect the single core execution rate such that
the execution rate will be proportional to the node utiliza-tion, e.g., Rj;i will be ERj;iðP0Þ for mj = 1 and ERj;iðPMAXÞfor mj = 0.
Algorithm 1. Pseudo-Code for FDLD Heuristics
1. allocate an instance of each task-type to every node inevery data center in every epoch
2. operations-remaining = true3. while operations-remaining4. for each node with tasks still allocated to it5. for each task-type on the node6. temporarily remove task-type from node7. if FDLD-CL8. estimate execution rates using Equation (11) (CERi)9. else if FDLD-TAO10. estimate execution rates using Equation (15) and fC
i
11. else if FDLD-SO12. calculate execution rates using Equation (15) and fC
13. calculate estimated power costs PCEd ðtÞ
14. calculate FS from FER and FC
15. if execution rate constraints are not violated(Equation (12) for FDLD-CL, Equation (16) forFDLD-SO and FDLD-TAO)
16. add to set of possible task removal operations17. restore task-type to node18. end for19. end for20. if set of possible task removal operations is empty21. operations-remaining = false22. else23. choose and implement the task-type removal
operation that would result in the lowest FS
24. end while25. return final allocation solution
Let NNd;j be the number of nodes of type j in data centerd. Let Sd;j;nðtÞ be the set of instances of different task-typesplaced on a node n of node-type j in data center d duringepoch t. An instance of a task-type is a task that belongs tothe specific task-type. Let Qd;j;iðtÞ be the equivalent numberof nodes of type j running task-type i in data center d dur-ing epoch t. We assume that the compute time of each coreon a node is evenly divided among its assigned tasks.Therefore the equivalent number of nodes Qd;j;iðtÞ representthe compute time allocated to task-type i on node-type j fordata center d, given by
Qd;j;iðtÞ ¼XNNd;j
n¼1
1
Sd;j;nðtÞ�� �� if i 2 Sd;j;nðtÞ0 otherwise:
((14)
For example, for a data center with twelve nodes and threetask-types assigned, each task-type would get the equivalentof four nodes out of twelve, i.e., 1
3 of the available computeresources. This will be assigned such that each task-type gets13 of the execution time of each of the twelve nodes.
To compensate for performance degradation due to co-location effects, node over-provisioning is accomplished bythe factor f. Let Kj be the number of cores in a node of typej. The average estimated execution rate ERE
j;iðtÞ of task-typei on node-type j during epoch t, when using either theFDLD-SO or FDLD-TAO versions, is given by
HOGADE ET AL.: MINIMIZING ENERGY COSTS FOR GEOGRAPHICALLY DISTRIBUTED HETEROGENEOUS DATA CENTERS 323

EREj;iðtÞ ¼
XDd¼1
Xj2Jd
Kj �Rj;i � f �Qd;j;iðtÞ; (15)
subject to the constraint
EREj;iðtÞ � ARiðtÞ 8i 2 I: (16)
Where f is replaced by either fC or fCi in Equation (15)
when using either FDLD-SO or FDLD-TAO, respectively.Let Z be the term that is replaced by CERiðtÞ when con-
sidering the FDLD-CL heuristic and is replaced by EREj;iðtÞ
when using either FDLD-SO or FDLD-TAO. The executionrate force FER is calculated using
FERðtÞ ¼Xi2I
eZ
ARiðtÞ�1
� �� 1
" #: (17)
Observe that FERðtÞwill decrease to zero as the ratio of Z toARiðtÞ decreases to 1.
Let PEd;j;n be the estimated average power for node n of
node-type j in data center d, calculated as
PEd;j;n ¼ PSleep
j if Sd;j;nðtÞ�� �� ¼ 0
mjPDj þ PS
j otherwise:
((18)
For all FDLD variants, let PDEd ðtÞ be the estimated non-
renewable power consumed at data center d during epocht, calculated as
PDEd ðtÞ ¼
Xj2Jd
XNNd;j
n¼1
PEd;j;n � 1þ 1
CoPd
� �þADPdðtÞ
" #
� Effd � PRdðtÞ;(19)
For all FDLD variants, let PCEd ðtÞ be the estimated power
cost at data center d during epoch t. PCEd ðtÞ is calculated as
shown in Equation (10), where PDdðtÞ is replaced by its esti-mated version, i.e., PDE
d ðtÞ.Let PCmax
d ðtÞ be the maximum real power cost possible atdata center d, calculated using
PCmaxd ðtÞ ¼ Eprice
d ðtÞ �Xj2Jd
NNd;j � mjPDj þ PS
j
� �
þ Ppriced � Dpeak
d ðtÞ:(20)
The cost force FC can then be calculated with
FCðtÞ ¼XDd¼1
e
PCEdðtÞ
PCmaxd
ðtÞ
� �� 1
" #: (21)
Observe that the value of FC goes to zero as the ratio ofPCE
d ðtÞ to PCmaxd ðtÞ decreases to zero.
Let Nt be the total number of epochs being considered.The total system force across all epochs, FS , is calculated as
FS ¼XNt
t¼1
FERðtÞ þ FCðtÞ: (22)
5.3 Genetic Algorithm HeuristicWe designed a third heuristic: a genetic algorithm load dis-tribution with co-location awareness (GALD-CL). The Geni-tor style [47] GALD-CL heuristic has two parts: a genetic
algorithm based GDRM (Algorithm 2) and a local data cen-ter level greedy heuristic (Algorithm 3) that is used to calcu-late the fitness value of the genetic algorithm.
The initial population for GALD-CL (Algorithm 2) is gen-erated by randomly partitioning the global arrival rate ARi
for each task-type i in the epoch across all of the data centers(step 1). Each data center d gets a desired fraction of arrivalrateDARd;i for each task-type i such that
XDd¼1
DARd;iðtÞ ¼ ARiðtÞ; 8i 2 I: (23)
Each chromosome is a matrix of I x D genes, where eachgene is a DARd;i and d pair, representing the desired arrivalrate of each task-type i at each data center d. We performselection, crossover, and mutation that alter existing chromo-somes to generate new offspring chromosomes (step 3). Weuse a roulette wheel selector, a two-point crossover, and asimple real range mutator [48]. After the generation of twooffspring, for each new chromosome, a local greedy heuristicdiscussed in the next paragraph is used to perform allocationsat the data center level (steps 4-6). After the greedy heuristic,the fitness value (total energy cost including CRAC energy)for each chromosome is calculated (step 7). The population istrimmed to its original size by eliminating the least-fit (high-est cost) chromosomes (step 8). After reaching the time limit,the algorithm ends and the final allocation of arrival rates isobtained from the best (lowest cost) chromosome.
Algorithm 2. Pseudo-Code for GALD-CL Heuristic
1. create an initial population of chromosomes2. whilewithin time limit3. perform selection, crossover and mutation to create new
chromosomes4. for each new chromosome5. use greedy heuristic to perform allocations at data center
level6. end for7. find the fitness values (total energy costs) of the population8. trim population to its original size by eliminating the
least-fit chromosomes9. end while10. return best chromosome from population and use final
allocation from it
Local GreedyHeuristic.This greedy approach (Algorithm 3)is similar in concept to Min-min in [49], [50] and is used toassign the desired arrival rate DARd;i of each task-type i tocores in data center d. For this heuristic, cores are dedicatedto a single particular task-type, i.e., a core cannot executemore than one task-type at a time. Our greedy heuristic itera-tively assigns task-types to cores to find the most efficientmapping, where we define efficiency EFFi;k for a task map-ping of type i on a node of typeNTk in P-state PSi;kðtÞ as
EFFi;kðtÞ ¼ ECSði;NTk; PSi;kðtÞÞAPCði;NTk; PSi;kðtÞÞ : (24)
For each data center, we start this greedy heuristic by find-ing the task-type/node-type pair with the highest EFFi;kðtÞvalue (Equation (24)) among all possible pairs (step 2). Ourheuristic uses the most efficient P-state for a given task-type/node-type pair. All I x Jd task-type to node-type pairs
324 IEEE TRANSACTIONS ON SUSTAINABLE COMPUTING, VOL. 3, NO. 4, OCTOBER-DECEMBER 2018

are then sorted by their efficiency in descending order to cre-ate a list (step 3). At each iteration of the heuristic, the first(most efficient) pair is selected (step 5). Then the heuristicchecks if any unassigned cores within the selected node-typeexist (step 6). If so, we assign fraction of the DARd;i for theselected task-type to a core in the selected node-type (basedon ECSði; n; pÞ) (step 7) and that core is removed from con-sideration (step 8). The CRAC outlet temperatures are set tothe red-line temperature, and then the outlet temperatures ofall CRAC units are iteratively decreased by one degree untilthe thermal constraint (the inlet temperature of the node,with the selected core, should be less than the red-line tem-perature) is met (step 9). After the assignment, the executionrate ERDC
d;i is updated (step 10). If the ERDCd;i for the selected
task-type exceeds its DARd;i (step 11), all task-type/node-type pairs with that task-type are removed from the list(step 12). The heuristic uses Equation (11) to estimate coreexecution rates with constraint defined by Equation (12). Ifno unassigned cores within the selected node-type exist(step 13), that task-type/node-type pair is removed fromconsideration (list) (step 14). This iterative part (steps 4-15) ofthe heuristic stops when there are no more task-type/node-type pairs to consider.
Algorithm 3. Pseudo-Code for Local Greedy Heuristic
1. for each data center2. find most efficient task-type/node-type pair among all
possible pairs3. sort all task-type/node-type pairs by efficiency in descend-
ing order4. while sorted list is not empty5. select first task-type/node-type pair6. if unassigned core within selected node-type exist7. assign fraction ofDARd;i for the selected
task-type to a core from the selected node-type8. remove that core from future consideration (assigned)9. set CRACoutlet temperatures to highest temperatures
such that node inlet temperature is less than red-linetemperature
10. update ERDCd;i
11. if ERDCd;i for the selected task-type exceeds itsDARd;i
12. remove all task-type/node-type pairswith that task-type
13. else //no more cores from node-type exist14. remove that task-type/node-type pair from the list15. end while16. end for17. for each data center18. for each task-type19. if DARd;i exceeds the data center assignment ERDC
d;i
//solution invalid20. adjustDARd;i value by reducing it by 10 percent
for data center where solution is invalid21. normalizeDARd;i values to modify chromosome
until valid solution reached, return to step 122. end for23. end for
After mapping the desired arrival rates DARd;i of eachtask-type i to cores in each data center d, if the DARd;i
exceeds the data center assignment ERDCd;i (checked for each
task-type in each data center), the solution is invalid(step 19). If so, we adjust DARd;i value by reducing it by
10 percent for the data center at which the solution is invalid(step 20). To calculate normalized arrival rate valueDARnorm
d;i , we then normalize the DARd;i values such thatthe sum of DARnorm
d;i values for each task-type matches theglobal arrival rate ARi
DARnormd;i ðtÞ ¼ DARd;iðtÞ � ARiðtÞPD
d¼1 DARd;iðtÞ: (25)
We then replace DARd;i with DARnormd;i for all data centers d
with the given task-type i to modify the chromosome until avalid solution can be reached (step 21), i.e., ERDC
d;i exceeds(or equals)DARd;i.
In summary, the GALD-CL heuristic addresses twopotential shortcomings of the FDLD variants. First, thenature of the decision making within the FDLD variants pre-vents them from making any kind of DVFS decisions, there-fore a single P-state is chosen for each node-type regardlessof the tasks executing on the node. The greedy heuristicwithin the GALD-CL approach chooses the most efficientP-state for each task-type on each node-type [34]. Second, theFDLD variants are susceptible to becoming trapped in localminima. The genetic algorithm portion of the GALD-CLapproach intrinsically enables escape from local minima,allowing amore complete search of the solution space.
6 SIMULATION ENVIRONMENT
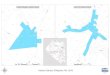
Experiments were conducted for three geo-distributed datacenter configurations containing four, eight, and sixteen datacenters. Locations of the data centers in the three configurationswere selected from major cities around the continental UnitedStates to provide a variety of wind and solar conditions amongsites and at different times of the day (see Fig. 3).
Experiments for the configuration with four data cen-ters used locations one through four from Fig. 3, whileexperiments using configuration with eight and sixteendata centers used locations one through eight and onethrough sixteen, respectively. The sites of each configura-tion were selected so that each configuration would havea fairly even east coast to west coast distribution to betterexploit TOU pricing, peak demand pricing, net metering,and renewable power. Each data center consists of 4,320nodes arranged in four aisles, and is heterogeneouswithin itself, having nodes from either two or three of thenode-types given in Table 1, with most locations havingthree node-types and per-node core counts that rangefrom 4-12 cores. For CRAC units, the red-line temperaturewas set to 30� C, which is on the high end of ASHRAE’stemperature guidelines [38].
Fig. 3. Location of simulated data centers overlaid on solar irradianceintensity map (average annual direct normal irradiance); wind datacollected but not shown [41].
HOGADE ET AL.: MINIMIZING ENERGY COSTS FOR GEOGRAPHICALLY DISTRIBUTED HETEROGENEOUS DATA CENTERS 325

Nodes placed in a sleep state by a heuristic are consid-ered to be in the Advanced Configuration and Power Inter-face (ACPI) node sleep state S3, where RAM remainspowered on. Sleep state S3, also commonly referred to assuspend or standby, allows greatly reduced power consump-tion while still possessing a small latency to return to anactive operating state. Sleep power for all nodes is calcu-lated as a fixed percentage of static power for each node-type, assumed to be 16 percent based on a study of nodepower states [51]. The average node utilization factor usedduring FDLD allocations, mj, is set as 0.75. The Coefficientof Performance of the CRAC unit was determined empiri-cally by simulating workloads with different memory inten-sity classes at each data center location, and its value rangesbetween 1.43 and 2.08 for different configurations. The timeof each epoch t was set to be one hour. The time required totransition a node to or from a sleep state, TS , was conserva-tively assumed to be five minutes.
The electricity prices used during experiments, as shownin Fig. 1, were taken directly from Pacific Gas and Electric(PG&E) Schedule E-19, which is for commercial locationsconsuming between 500 kW and 1 MW [9]. The peakdemand prices per kW are given in Table 2.
We assume that each data center has peak renewablepower generating capacity equivalent to its maximumpower consumption [10], [11], [52]. Renewable power ateach location was either wind power, solar power, or a com-bination of the two. For example, a location with high aver-age solar irradiance but low average wind speed would berestricted to having solar power only. Solar and wind datawas obtained from the National Solar Radiation Database[41]. An example of the renewable power available at differ-ent locations is given in Fig. 4.
In net metering, data centers send excess power back tothe grid and utility companies pay back the customer a frac-tion of retail price a. In most cases, the net metering factor ais 1; in very few cases, it is less than 1; and in some cases, it is0, i.e., net metering is not available at that location [15], [53].
Each task-type used in our experiment is representative ofa different benchmark from the PARSEC [44] andNAS paral-lel [45] benchmark suites. Task execution times and co-located performance data for the task of the different mem-ory intensity classes were obtained from running the bench-mark applications on the nodes listed in Table 1 [43].Synthetic task arrival patterns were constructed and thebaseline pattern is shown in Fig. 5. For reference, the figurealso shows TOUprices for an east coast and awest coast site.
7 EXPERIMENTS
7.1 Cost Comparison of HeuristicsOur first set of experiments analyzes the total system energycost for each heuristic described in Section 5 with and with-out peak shaving and net metering. For each heuristic, weevaluate four variants: (1) without both peak shaving andnet metering, (2) with net metering only, (3) with peak shav-ing only, and (4) with both peak shaving and net metering.Heuristic variants that are referred to as “without peakshaving” do not include the peak demand pricing factor intheir objective functions but consider it while calculating thetotal monthly electricity cost at the end of the billing period.These experiments use a data center configuration consistingof eight locations and a workload that was a hybrid mix ofmemory-intensive and CPU-intensive task-types (discussedin Section 7.2). The system energy costs are estimated over aduration of one day. The results are shown in Fig. 6a.
For each individual heuristic, considering both netmetering and peak shaving produced the best results, whileexperiments without these produced worse results. Thisvalidates our consideration of peak shaving and net meter-ing during geo-distributed data center workload manage-ment, to more effectively minimize energy costs. It can alsobe observed that the FDLD-CL heuristic, using the co-loca-tion models, performs the best among the FDLD variants.The FDLD-SO heuristic performed the worst, severely over-provisioning nodes and resulting in high operating costs.The GALD-CL heuristic with net metering and peak shav-ing outperformed all other approaches. This heuristic hascomplete information about the entire system model,including the co-location models and task-node power(DVFS) models, allowing it to make better placement deci-sions. With additional execution time and a larger popula-tion of chromosomes even better solutions can be found.
The decision option related to DVFS P-states gives theGALD-CL heuristic a strong advantage over the FDLD var-iants but it also takes longer to execute. The GALD-CL heu-ristic was limited to a run time of approximately one hourper epoch simulated. Alternatively, the FDLD heuristicscompleted in approximately six minutes per epoch
Fig. 4. Renewable power available at eight locations.
TABLE 2Peak Demand Prices Used in Experiments
data centerlocation
peak demandprice ($/kW)
data centerlocation
peak demandprice ($/kW)
New York 11.04 Detroit 14.54Chicago 3.82 Las Vegas 8.25Denver 6.75 San Francisco 13.01LA 8.91 Seattle 3.29Atlanta 8.11 Tampa 10.25Baltimore 3.84 Kansas City 6.39Dallas 11.88 Oklahoma City 6.20Indianapolis 10.57 Nashville 5.09
Fig. 5. Baseline task arrival rate and TOU prices at two sites (New York,Los Angeles) over 24 hours.
326 IEEE TRANSACTIONS ON SUSTAINABLE COMPUTING, VOL. 3, NO. 4, OCTOBER-DECEMBER 2018

simulated. While not performing as well as the GALD-CL,the FDLD variants have the advantage of reaching a solu-tion more quickly, which may be beneficial in some cases.
7.2 Workload Type AnalysisThe previous experiment used a workload that was a hybridmix of memory-intensive and CPU-intensive task-types.Fig. 6 shows experiments for all of the FDLD and GALD-CLheuristics for a group of eight data centers where two addi-tional workload types were evaluated: one where all of thetasks are highly memory-intensive (using data from canneal,cg, ua, sp, and lu benchmarks), and one where the tasks arehighly CPU-intensive (using data from fluidanimate, black-scholes, bodytrack, ep, and swaptions benchmarks) [44], [45].The composition of data center workloads can vary greatlyand can impact the resource requirements, and these experi-ments show that the techniques presented in our work willperform well for a variety of workload types. Observe thatthe CPU-intensive workload typically costs the least as itexperiences the least co-location degradation and thereforerequires fewer nodes. However, the memory-intensive taskscause performance degradation because they compete forshared memory in multicore processors.
7.3 Scalability Analysis
7.3.1 Data Center Scalability Analysis
In this experiment, we analyze heuristic performance foradditional problem sizes. Simulations running hybrid work-loads were conducted for four and sixteen data center con-figurations in addition to the previously discussed eightdata center configuration. For each configuration, the
average performance improvement of each heuristic overthe FDLD-SO heuristic with no peak shaving and no netmetering is given in Table 3. The GALD-CL heuristic waslimited to a run time of approximately one hour. FDLD heu-ristics for four, eight, and sixteen locations completed onaverage in two, six, and eighteen minutes per epoch simu-lated, respectively. These experiments confirm that allFDLD heuristics can perform well for smaller and largerproblem sizes but the GALD-CL heuristic consistently per-forms the best for all problem sizes.
7.3.2 GA Run Time Scalability Analysis
Table 3 shows similar energy cost reduction results for allFDLD variants in the cases of the data center configurationscontaining four, eight, and sixteen data centers runninghybrid workloads. But for GALD-CL, we notice that theenergy cost reduction decreases with the increasing numberof data centers. Here, as the number of data centers in thegroup grows larger, the problem size increases and thenumber of GALD-CL generations that can take place withinthe time limit (one hour by default) decreases, whichdecreases the performance of GALD-CL.
To better understand how the GALD-CL solution qualityis impacted by the heuristic’s run time, we increase theGALD-CL run time in proportion to the increase in numberof data centers. We execute GALD-CL for about one hourfor four data centers, about two hours for eight data centers,and about four hours for sixteen data centers. The resultsfrom Table 4 show that GALD-CL is capable of performingwell for larger problem size, when given more time. Forcomparison, the Table 4 also includes results for GALD-CLexecuted for about one hour for a group of four, eight, andsixteen data centers. It should be noted that, even whenallowing the GALD-CL to execute for one hour, it still pro-vides the system a significant energy cost reduction in com-parison to the all FDLD heuristics as shown in Table 3.
Fig. 6. Systemenergy costs for each heuristic over a day for (a) hybrid, (b) CPU-intensive, and (c)memory-intensiveworkloads, for eight data center locations.
TABLE 3Energy Cost Reduction Comparison
heuristic no PS andno NM
NMonly
PSonly
PS andNM
FDLD-SO 0.0% 0.2% 23.4% 23.6%4 data FDLD-TAO 12.3% 14.5% 33.4% 34.0%centers FDLD-CL 15.0% 15.7% 36.7% 37.9%
GALD-CL 49.5% 58.2% 67.3% 75.8%
FDLD-SO 0.0% 0.3% 20.8% 21.1%8 data FDLD-TAO 16.9% 16.8% 31.5% 32.5%centers FDLD-CL 19.6% 20.8% 36.9% 38.3%
GALD-CL 40.9% 45.7% 54.5% 60.8%
FDLD-SO 0.0% 0.4% 21.7% 24.5%16 data FDLD-TAO 11.1% 12.2% 30.9% 32.9%centers FDLD-CL 14.2% 16.1% 33.4% 36.6%
GALD-CL 33.1% 36.4% 44.0% 46.6%
PS = peak shaving, NM = net metering.
TABLE 4Impact of GALD-CL Run Time
GALD-CLepoch
no PS andno NM
NMonly
PSonly
PS andNM
4 data 1 hour 49.5% 58.2% 67.3% 75.8%centers
8 data 1 hour 40.9% 45.7% 54.5% 60.8%centers 2 hours 46.7% 55.2% 62.5% 72.2%
16 data 1 hour 33.1% 36.4% 44.0% 46.6%centers 4 hours 40.1% 49.4% 61.6% 69.9%
PS = peak shaving, NM = net metering.
HOGADE ET AL.: MINIMIZING ENERGY COSTS FOR GEOGRAPHICALLY DISTRIBUTED HETEROGENEOUS DATA CENTERS 327

7.3.3 Epoch-Based Analysis
For most of our experiments, we analyzed the total systemcost for each heuristic over one day. Fig. 7 shows a moredetailed view of the system operating cost at one-hour inter-vals over the course of a day for four, eight, and sixteen datacenters executing a hybrid workload. The four resourcemanagement heuristics in this study consider both peakshaving and net metering.
Net metering causes the plots to go into the negativeregion in certain epochs, which represents the case whenthe system earns money by selling excess renewable powerback to the utility companies. The operating cost for eachheuristic is very high during the first epoch because theperiod for which the results are shown represents the firstday of the month where the initial peak demand cost isadded. This effect would not be present for other days ofthe month. After a few epochs, the performance of theFDLD-CL came close to the GALD-CL, but was not able tosurpass its performance.
7.4 Sensitivity Analysis
7.4.1 Net Metering Factor
Renewable power generation changes throughout the year.The amount of renewable power generated at a data centeralso depends on its location. As discussed in Section 6, datacenters generate different amounts of renewable power ateach location. Different states have different net meteringlaws and utility companies from those states have differentenergy buy-back rates for net metering. In this section, weanalyze the impact of net metering (with no peak shaving)and study how the net metering factor impacts energy costsand the behavior of the heuristics. For these experiments,we consider a configuration with eight data centers execut-ing a hybrid workload. The experiments analyze the totalsystem cost for each heuristic utilizing only net metering.Peak shaving is ignored because this study focuses only onthe sensitivity analysis of the net metering factor.
Net metering factor values for data centers were ran-domly sampled (with uniform distribution) from three valueranges, where buy-back costs for renewable energy are low(0 � a1 < 0.4), medium (0.4 � a2 < 0.7), and high (0.7 � a3� 1). Furthermore, we consider five simulation runs for eachset of values and plot standard deviations as shown in Fig. 8.In the figure, the system energy costs decrease, but not dra-matically as the net metering factor values increase. How-ever, we can observe that GALD-CL is able to exploit netmetering better than the other heuristics as a values increase.
7.4.2 Peak Demand Price
As discussed in Section 6, the set of data centers we are con-sidering for these experiments are heterogeneous and there-fore consume different amounts of peak power. Utilities atdifferent locations have different peak prices as shown inTable 2. In this section, we analyze the impact of peak shaving(with no net metering) and study the impact of peak demandprice. For these experiments, we consider eight data centersexecuting a hybrid workload. The experiments analyze thetotal system cost for each heuristic utilizing only peak shav-ing.Netmetering is not considered because this study focusesonly on the sensitivity analysis of the peak demand price.
Peak demand pricing values for data centers were ran-domly sampled (with uniform distribution) from threevalue ranges, where these values are low (3 � p1 < 7),medium (7 � p2 < 11), and high (11 � p3 � 15). Further-more, we consider five simulation runs for each set of val-ues and plot standard deviations as shown in Fig. 9. Asexpected, the system energy costs increase as the peakdemand pricing values increase. We observe a significantcost change across p1, p2, and p3 because peak demand costis one of the two major components of the total system cost(see Equation (10)) and peak demand pricing has a majorimpact on the peak demand cost component.
The wide standard deviation for peak shaving shows thatthe system is highly sensitive to the peak demand price. By
Fig. 7. System energy costs for each heuristic over a day for epoch-based analysis, for a configuration with (a) four, (b) eight, and (c) 16 data centerlocations running the hybrid workloads.
Fig. 8. System energy costs for each heuristic over a day for net meter-ing factor sensitivity analysis, for eight data center locations running ahybrid workload.
Fig. 9. System energy costs for each heuristic over a day for peakdemand price sensitivity analysis, for eight data center locations runninga hybrid workload.
328 IEEE TRANSACTIONS ON SUSTAINABLE COMPUTING, VOL. 3, NO. 4, OCTOBER-DECEMBER 2018

comparing both net metering factor and peak demand pricesensitivity analyses, we can observe that peak shaving has abigger impact on system cost than net metering. The majorreason behind this is realistic assumptions of renewablepower generation capabilities at each data center. If we con-sider self-sustainable green data centers [10], [11], [52] andthe trend of increasing on-site renewable (solar/wind) powerfarms, more renewable power will be available for net meter-ingwhichwill have amore significant impact on the system.
7.5 Task Arrival Rate Pattern AnalysisAll of our experiments so far have assumed a sinusoidal taskarrival rate pattern as shown in Fig. 5. This kind of patternexists in environments where workload traffic depends onuser/consumer interaction and follows their demand duringthe day, e.g., Netflix [54], Facebook [55]. However, for theenvironments where continuous computation is needed andthe workload pattern is non user/consumer interactionspecific, the task arrival rate pattern is usually flat (nearly-constant). Examples of such environments exist in militarycomputing installations (Department of Defense), govern-ment research labs (National Center for AtmosphericResearch), etc. We conducted a set of simulations to analyzethe impact of varying the task arrival pattern. We consider aconfiguration with eight data centers executing a hybridworkloadwith both sinusoidal and flat arrival patterns.
Recall that each task-type is characterized by its arrivalrate and the estimated time required to complete the task oneach of the heterogeneous compute nodes in all P-states.The four GDRM heuristics map execution rates to minimizetotal energy cost across all data centers with the constraintthat the execution rates of all task-types meet their arrivalrates (see Equation (1)). Therefore the assignment of execu-tion rates alters with the change in arrival rates, which fur-ther affects the system cost. The results shown in Figs. 10cand 10d indicate that the geo-distributed system respondsdifferently for sinusoidal and flat arrival rate patterns.
Overall system energy cost is higher for the sinusoidalworkload arrival pattern because it produces higherpeak data center power, which further increases the peakdemand cost, than the flat workload arrival pattern. Peakshaving significantly reduces the energy costs for bothworkload patterns. The sinusoidal workload arrival patternroughly aligns with the pattern of the renewable power gen-eration (see Fig. 4), allowing data centers to utilize all of theavailable renewable power.
The flat (nearly-constant) workload arrival rate patterndoes not align with the pattern of the renewable power gen-eration. This leaves data centers with excess renewableenergy in the second half of the day, which allows heuristicsto exploit net metering heavily and produce more cost sav-ings. Thus, heuristics that consider net metering perform
better for the flat arrival rate pattern as compared to thesinusoidal arrival rate pattern.
8 CONCLUSIONS
We studied the problem of minimizing the energy costs forgeographically distributed heterogeneous data centers withthe constraint that all tasks complete without beingdropped. Renewable energy, peak demand, and co-locationinterference at data centers have a significant impact onenergy consumption. We capture these effects by includingnet metering, peak shaving, and co-location models in ourworkload distribution techniques. We analyzed severaltechniques that possess varying degrees of co-location inter-ference prediction information: (1) a force-directed schedul-ing technique, FDLD-TAO, that uses task aware over-provisioning to estimate co-location effects for each task-type, (2) a force-directed scheduling technique, FDLD-CL,that uses co-location models when calculating task execu-tion rates, and (3) a genetic algorithm combined with a localsearch technique, GALD-CL, that has information about theco-location models and DVFS P-states.
The primary contributions of our research are to provideanalyses of the aspects of the problems and solutions associ-ated with renewable energy, peak demand, and co-locationaware resource management in heterogeneous computingsystems. We used new peak demand and net metering mod-els that directly consider real-world peak demand prices andnet metering policies in calculation of the system electricitycost, and a new co-location interference model created froma linear regression technique using data from real servers.We demonstrated that including this additional informationin the decision process of the resource management heu-ristics resulted in a lower energy cost. This is achieved byreducing or eliminating node over-provisioning while stillmeeting all required workload execution rates. Ignoringinterference effects altogether can be especially detrimen-tal to overall performance and energy overheads whentask execution times deviate far from those expected dueto interference. We also demonstrated the importance ofnet metering and peak shaving by illustrating the impactof the awareness of these factors on reducing operatingcosts for geographically distributed data centers.
We compared our techniques across various workloadprofiles, performing a scalability assessment, examining sen-sitivity to renewable power availability and peak demandpricing parameters, and testing system behavior for differenttask arrival patterns. Our proposed FDLD-CL and GALD-CL heuristics resulted in 37 and 61 percent lower operationalcosts on average than an approach from prior work (repre-sented by the FDLD-SO heuristic) [20]. However, to
Fig. 10. Comparison of (a) sinusoidal and (b) flat workload arrival rate patterns. Comparison of system energy costs among heuristics over a day for(c) sinusoidal and (d) flat workload arrival rate patterns for eight data center locations running a hybrid workload.
HOGADE ET AL.: MINIMIZING ENERGY COSTS FOR GEOGRAPHICALLY DISTRIBUTED HETEROGENEOUS DATA CENTERS 329

implement our approach in a real system, it needs to be usedwith some form of a workload prediction technique, e.g.,[56], [57]. Additionally, due to scalability issues of GALD-CL, we recommend using FDLD-CLwith a workload predic-tion technique in systems where the workload profilechanges rapidly and therefore requires short epochs, e.g., afewminutes.When theworkload profile is not changing rap-idly and the workload distribution decisions are providedmore time, e.g., an hour, using GALD-CL with a workloadprediction technique is amore suitable heuristic.
ACKNOWLEDGMENTS
The authors thank Dr. Greg Pfister and Daniel Dauwe fortheir valuable comments on this work. This work is sup-ported by the US National Science Foundation (NSF) undergrant CCF-1302693. A preliminary version of portions ofthis work appeared in [21]. They expanded and significantlyimproved upon their prior work by considering peak shav-ing, net metering, and co-location interference models inour load distribution techniques. They also performed sev-eral new experiments and provided more in-depth analysesof the proposed resource management heuristics. The resultis notable improvements in reducing operational costs forgeo-distributed data centers.
REFERENCES
[1] Data center locations. [Online]. Available: http://www.google.com/about/datacenters/inside/locations/index.html, Accessedon: Aug. 1, 2017.
[2] Global infrastructure. [Online]. Available: http://aws.amazon.com/about-aws/global-infrastructure/, Accessed on:Aug. 1, 2017.
[3] Y. Li, H. Wang, J. Dong, J. Li, and S. Cheng, “Operating cost reduc-tion for distributed internet data centers,” in Proc. 13th IEEE/ACMInt. Symp. Cluster Cloud Grid Comput., May 2013, pp. 589–596.
[4] What is time-of-use pricing andwhy is it important? [Online].Avail-able: http://www.energy-exchange.net/time-of-use-pricing/,Accessed on: Aug. 1, 2017.
[5] Dynamic pricing. [Online]. Available: http://whatis.techtarget.com/definition/dynamic-pricing. Accessed on: Aug. 1, 2017.
[6] Demand charges. [Online]. Available: http://www.stem.com/resources/learning/, Accessed on: Aug. 1, 2017.
[7] Understanding peak demand charges. [Online]. Available:https://energysmart.enernoc.com/understanding-peak-demand-charges, Accessed on: Aug. 1, 2017.
[8] C. Hsu, “Rack PDU for green data centers,” in Data Center Hand-book, H. Geng, Ed. Hoboken, NJ, USA: Wiley, Nov. 2014, ch. 29.
[9] Pacific Gas and Electric Company, “Electric schedule e-19.”[Online]. Available: http://www.pge.com/tariffs/tm2/pdf/ELEC_SCHEDS_E-19.pdf, Accessed on: Apr. 15, 2015.
[10] Apple to build a 3rd massive solar panel farm in North Carolina.[Online]. Available: https://gigaom.com/2014/07/08/apple-to-build-a-3rd-massive-solar-panel-farm-in-north-carolina/,Accessed on: Aug. 1, 2017.
[11] Solar energy project at McGraw-Hill site recently completed.[Online]. Available: http://www.nj.com/mercer/index.ssf/2012/01/solar_energy_project_at_mcgraw.html/, Accessed on:Aug. 1, 2017.
[12] Green power: Accelerating the transition to a clean energy future.[Online]. Available: https://www.microsoft.com/about/csr/environment/renewable_energy/, Accessed on: Aug. 1, 2017.
[13] Achieving our 100% renewable energy purchasing goal and goingbeyond. [Online]. Available: https://static.googleusercontent.com/media/www.google.com/en//green/pdf/achieving-100-renewable-energy-purchasing-goal.pdf, Accessed on: Aug. 1, 2017.
[14] Facebook’s Altoona, Iowa data center to be completely wind-powered. [Online]. Available: https://www.slashgear.com/facebooks-altoona-iowa-data-center-to-be-completely-wind-powered-13305335/, Accessed on: Aug. 1, 2017.
[15] Net metering. [Online]. Available: http://freeingthegrid.org/,Accessed on: Aug. 1, 2017.
[16] I. Goiri, R. Beauchea, K. Le, T. D. Nguyen, M. E. Haque, J. Guitart,J. Torres, and R. Bianchini, “GreenSlot: Scheduling energy con-sumption in green datacenters,” in Proc. Int. Conf. High Perform.Comput. Netw. Storage Anal., Nov. 2011, pp. 1–11.
[17] C. Ren, D. Wang, B. Urgaonkar, and A. Sivasubramaniam,“Carbon-aware energy capacity planning for datacenters,” inProc. IEEE 20th Int. Symp. Model. Anal. Simul. Comput. Telecommun.Syst., Aug. 2012, pp. 391–400.
[18] I. Goiri, K. Le, T. D. Nguyen, J. Guitart, J. Torres, and R. Bianchini,“GreenHadoop: Leveraging green energy in data-processingframeworks,” in Proc. 7th ACM Eur. Conf. Comput. Syst., Apr.2012, pp. 57–70.
[19] I. Goiri, W. Katsak, K. Le, T. D. Nguyen, and R. Bianchini,“Parasol and GreenSwitch: Managing datacenters powered byrenewable energy,” in Proc. 18th Int. Conf. Archit. Support Program.Languages Operating Syst., Mar. 2013, pp. 51–64.
[20] H. Goudarzi and M. Pedram, “Geographical load balancing foronline service applications in distributed datacenters,” in Proc.IEEE 6th Int. Conf. Cloud Comput., Jun. 2013, pp. 351–358.
[21] E. Jonardi, M. A. Oxley, S. Pasricha, A. A. Maciejewski, and H. J.Siegel, “Energy cost optimization for geographically distributedheterogeneous data centers,” in Proc. 6th Int. Green SustainableComput. Conf., Dec. 2015, pp. 1–6.
[22] A. Wierman, Z. Liu, I. Liu, and H. Mohsenian-Rad,“Opportunities and challenges for data center demand response,”in Proc. Int. Green Comput. Conf., Nov. 2014, pp. 1–10.
[23] L. Gu, D. Zeng, S. Guo, and B. Ye, “Joint optimization of VMplacement and request distribution for electricity cost cut in geo-distributed data centers,” in Proc. Int. Conf. Comput. Netw. Com-mun., Feb. 2015, pp. 717–721.
[24] J. Zhao, H. Li, C. Wu, Z. Li, Z. Zhang, and F. C. M. Lau, “Dynamicpricing and profit maximization for the cloud with geo-distrib-uted data centers,” in Proc. IEEE Conf. Comput. Commun., Apr.2014, pp. 118–126.
[25] L. Gu, D. Zeng, A. Barnawi, S. Guo, and I. Stojmenovic, “Optimaltask placement with QoS constraints in geo-distributed data cen-ters using DVFS,” IEEE Trans. Comput., vol. 64, no. 7, pp. 2049–2059, Jul. 2015.
[26] H. Xu, C. Feng, and B. Li, “Temperature aware workload manage-mentin geo-distributed data centers,” IEEE Trans. Parallel Distrib.Syst., vol. 26, no. 6, pp. 1743–1753, Jun. 2015.
[27] M. Polverini, A. Cianfrani, S. Ren, and A. V. Vasilakos, “Thermal-aware scheduling of batch jobs in geographically distributed datacenters,” IEEETrans. Cloud Comput., vol. 2, no. 1, pp. 71–84, Jan. 2014.
[28] D. Mehta, B. O’Sullivan, and H. Simonis, “Energy cost manage-ment for geographically distributed data centres under time-vari-able demands and energy prices,” in Proc. IEEE/ACM 6th Int.Conf. Utility Cloud Comput., Dec. 2013, pp. 26–33.
[29] Z. Abbasi, M. Pore, and S. K. Gupta, “Impact of workload andrenewable prediction on the value of geographical workload man-agement,” in Proc. 2nd Int. Workshop Energy Efficient Data Centers,May 2013, pp. 1–15.
[30] C. Chen, B. He, and X. Tang, “Green-aware workload schedulingin geographically distributed data centers,” in Proc. 4th IEEE Int.Conf. Cloud Comput. Technol. Sci. Proc., Dec. 2012, pp. 82–89.
[31] P. Bodik, R. Griffith, C. Sutton, A. Fox, M. I. Jordan, andD. A. Patterson, “Automatic exploration of datacenter perfor-mance regimes,” in Proc. 1st Workshop Automated Control Datacen-ters Clouds, Jun. 2009, pp. 1–6.
[32] G. Chen, W. He, J. Liu, S. Nath, L. Rigas, L. Xiao, and F. Zhao,“Energy-aware server provisioning and load dispatching for con-nection-intensive internet services,” in Proc. 5th USENIX Symp.Netw. Syst. Des. Implementation, Apr. 2008, pp. 337–350.
[33] D. G. Feitelson, D. Tsafrir, and D. Krakov, “Experience with usingthe parallel workloads archive,” J. Parallel Distrib. Comput., vol. 74,no. 10, pp. 2967–2982, Oct. 2014.
[34] M.A.Oxley, E. Jonardi, S. Pasricha, A.A.Maciejewski, H. J. Siegel, P.J. Burns, andG.A.Koenig, “Rate-based thermal, power, and co-loca-tion aware resourcemanagement for heterogeneous data centers,” J.Parallel Distrib. Comput., vol. 112, no. 2, pp. 126–139, Feb. 2018.
[35] V. Shestak, J. Smith, A. A.Maciejewski, andH. J. Siegel, “Stochasticrobustness metric and its use for static resource allocations,” J. Par-allel Distrib. Comput., vol. 68, no. 8, pp. 1157–1173, Aug. 2008.
[36] M. A. Iverson, F. Ozguner, and L. Potter, “Statistical prediction oftask execution times through analytic benchmarking for schedul-ing in a heterogeneous environment,” IEEE Trans. Comput.,vol. 48, no. 12, pp. 1374–1379, Dec. 1999.
330 IEEE TRANSACTIONS ON SUSTAINABLE COMPUTING, VOL. 3, NO. 4, OCTOBER-DECEMBER 2018

[37] H. Bhagwat, U. Singh, A. Deodhar, A. Singh, and A. Sivasubrama-niam, “Fast and accurate evaluation of cooling in data centers,” J.Electron. Packag., vol. 137, no. 1, pp. 1–9, Mar. 2015.
[38] ASHRAE Technical Committee 9.9, “Thermal guidelines for dataprocessing environments-expanded data center classes and usageguidance,”American Society of Heating, Refrigerating, and Air-Conditioning Engineers, Inc Tech. Rep., 2011, [Online]. Available:http://ecoinfo.cnrs.fr/IMG/pdf/ashrae_2011_thermal_guideli-nes_data_center.pdf
[39] J. D. Moore, J. S. Chase, P. Ranganathan, and R. K. Sharma,“Making scheduling “Cool”: Temperature-aware workload place-ment in data centers,” in Proc. USENIX Annu. Tech. Conf., Apr.2005, pp. 61–75.
[40] X. Deng, D. Wu, J. Shen, and J. He, “Eco-aware online power man-agement and load scheduling for green cloud datacenters,” IEEESyst. J., vol. 10, no. 1, pp. 78–87, Mar. 2016.
[41] NREL, “National solar radiation database.” [Online]. Available:https://mapsbeta.nrel.gov/nsrdb-viewer/, Accessed on: Apr. 15,2015.
[42] S. Govindan, J. Liu, A. Kansal, and A. Sivasubramaniam, “Cuanta:Quantifying effects of shared on-chip resource interference forconsolidated virtual machines,” in Proc. 2nd ACM Symp. CloudComput., Oct. 2011, Art. no. 22.
[43] D. Dauwe, E. Jonardi, R. D. Friese, S. Pasricha, A. A. Maciejewski,D. A. Bader, and H. J. Siegel, “HPC node performance and energymodeling with the co-location of applications,” J. Supercomput.,vol. 72, no. 12, pp. 4771–4809, Dec. 2016.
[44] PARSEC benchmark suite. [Online]. Available: http://parsec.cs.princeton.edu/index.htm/, Accessed on: Aug. 1, 2017.
[45] NAS parallel benchmarks. [Online]. Available: https://www.nas.nasa.gov/publications/npb.html, Accessed on: Aug. 1, 2017.
[46] P. G. Paulin and J. P. Knight, “Force-directed scheduling for thebehavioral synthesis of ASICs,” IEEE Trans. Comput.-Aided Des.Integr. Circuits Syst., vol. 8, no. 6, pp. 661–679, Jun. 1989.
[47] D. Whitley, “The GENITOR algorithm and selective pressure:Why rank-based allocation of reproductive trials is best,” in Proc.3rd lnt. Conf. Genetic Algorithms, Jun. 1989, pp. 116–121.
[48] Pyevolve: A complete genetic algorithm framework. [Online].Available: http://pyevolve.sourceforge.net/0_6rc1/index.html,Accessed on: Aug. 1, 2017.
[49] T.D. Braun,H. J. Siegel,N. Beck, L. B€ol€oni, R. F. Freund,D.Hensgen,M. Maheswaran, A. I. Reuther, J. P. Robertson, M. D. Theys, andB. Yao, “A comparison of eleven static heuristics formapping a classof independent tasks onto heterogeneous distributed computingsystems,” J. Parallel Distrib. Comput., vol. 61, no. 6, pp. 810–837,Jun. 2001.
[50] M. Maheswaran, S. Ali, H. J. Siegel, D. Hensgen, and R. F. Freund,“Dynamic mapping of a class of independent tasks onto heteroge-neous computing systems,” J. Parallel Distrib. Comput., vol. 59,no. 2, pp. 107–131, Nov. 1999.
[51] C. Isci, S. McIntosh, J. Kephart, R. Das, J. Hanson, S. Piper,R. Wolford, T. Brey, R. Kantner, A. Ng, J. Norris, A. Traore, andM. Frissora, “Agile, efficient virtualization power managementwith low-latency server power states,” in Proc. 40th Annu. Int.Symp. Comput. Archit., Jun. 2013, pp. 96–107.
[52] G. Cook, T. Dowdall, D. Pomerantz, and Y. Wang, “Clicking clean:How companies are creating the green internet,” Greenpeace Inc.,Washington, DC, Apr. 2014, [Online]. Available: https://www.greenpeace.org/usa/wp-content/uploads/legacy/Global/usa/planet3/PDFs/clickingclean.pdf
[53] Net metering policies. [Online]. Available: http://www.dsireusa.org/, Accessed on: Aug. 1, 2017.
[54] Scryer: Netflix’s predictive auto scaling engine. [Online]. Available:https://medium.com/netflix-techblog/scryer-netflixs-predictive-auto-scaling-engine-a3f8fc922270, Accessed on: Aug. 1, 2017.
[55] Making Facebook’s software infrastructure more energy efficientwith Autoscale. [Online]. Available: https://code.facebook.com/posts/816473015039157/making-facebook-s-software-infrastructure-more-energy-efficient-with-autoscale/, Accessedon: Aug. 1, 2017.
[56] R. N. Calheiros, E. Masoumi, R. Ranjan, and R. Buyya, “Workloadprediction using ARIMA model and its impact on cloudapplications’ QoS,” IEEE Trans. Cloud Comput., vol. 3, no. 4,pp. 449–458, Oct. 2015.
[57] J. Xue, F. Yan, R. Birke, L. Y. Chen, T. Scherer, and E. Smirni,“PRACTISE: Robust prediction of data center time series,” in Proc.11th Int. Conf. Netw. Service Manage., Nov. 2015, pp. 126–134.
Ninad Hogade received the BE degree in elec-tronics engineering from the Vishwakarma Insti-tute of Technology, Pune, India. He is currentlyworking toward the graduate degree in electricalengineering at Colorado State University, FortCollins, Colorado. His research interests includeenergy aware scheduling of high performancecomputing systems and data centers. He is a stu-dent member of the IEEE.
Sudeep Pasricha received the BE degree inelectronics and communications from the DelhiInstitute of Technology, in 2000, and the MS andPhD degrees in computer science from the Uni-versity of California, Irvine, in 2005 and 2008,respectively. He is currently a Monfort and Rock-well-Anderson professor in the Department ofElectrical and Computer Engineering and alsothe Department of Computer Science, ColoradoState University. He is a senior member of theIEEE and ACM. More information about himcan be found at: http://www.engr.colostate.edu/~sudeep.
Howard Jay Siegel received the BS degree fromMIT, and the MSE and PhD degrees from Prince-ton University. He is a professor Emeritus withColorado State University. From 2001 to 2017,he was the Abell Endowed chair distinguishedprofessor of electrical and computer engineeringthere, where he was also a professor of computerscience. From 1976 to 2001, he was a professorwith Purdue University. He is a fellow of the IEEEand ACM. More information about him can befound at: http://www.engr.colostate.edu/~hj.
Anthony A. Maciejewski received the BSEE,MS, and PhD degrees from theOhio State Univer-sity, in 1982, 1984, and 1987, respectively. From1988 to 2001, he was a professor of electrical andcomputer engineering with Purdue University,West Lafayette. He is currently a professor anddepartment head of electrical and computer engi-neering at Colorado State University. He is a fel-low of the IEEE. A complete vita is available at:http://www.engr.colostate.edu/�aam.
Mark A. Oxley received the BS degree in com-puter engineering from the University of Wyom-ing, and the PhD degree in electrical engineeringfrom Colorado State University, in 2016. Hisresearch interests include energy-aware, ther-mal-aware, and robust resource managementtechniques. He is currently a research scientistfor Numerica Corporation in Fort Collins, Colo-rado. He is a member of the IEEE.
Eric Jonardi received the BS degree in electricalengineering from Marquette University, in 2013and the MS degree in electrical engineering fromColorado State University, in 2015. He is cur-rently working as a hardware development engi-neer for Rockwell Automation. He is a member ofthe IEEE.
" For more information on this or any other computing topic,please visit our Digital Library at www.computer.org/publications/dlib.
HOGADE ET AL.: MINIMIZING ENERGY COSTS FOR GEOGRAPHICALLY DISTRIBUTED HETEROGENEOUS DATA CENTERS 331