Embed Size (px)
Citation preview

Memory Bandwidth Management for EfficientPerformance Isolation in Multi-core Platforms
Heechul Yun†, Gang Yao‡, Rodolfo Pellizzoni?, Marco Caccamo‡, Lui Sha‡† University of Kansas, USA. [email protected]
‡ University of Illinois at Urbana-Champaign, USA. {gangyao,mcaccamo,lrs}@illinois.edu? University of Waterloo, Canada. [email protected]
F
Abstract—Memory bandwidth in modern multi-core platforms is highlyvariable for many reasons and is a big challenge in designing real-time systems as applications are increasingly becoming more memoryintensive. In this work, we proposed, designed, and implemented an ef-ficient memory bandwidth reservation system, that we call MemGuard.MemGuard distinguishes memory bandwidth as two parts: guaranteedand best effort. It provides bandwidth reservation for the guaranteedbandwidth for temporal isolation, with efficient reclaiming to maximallyutilize the reserved bandwidth. It further improves performance byexploiting the best effort bandwidth after satisfying each core’s reservedbandwidth. MemGuard is evaluated with SPEC2006 benchmarks on areal hardware platform, and the results demonstrate that it is able toprovide memory performance isolation with minimal impact on overallthroughput.
1 INTRODUCTIONComputing systems are increasingly moving toward multi-coreplatforms and their memory subsystem represents a crucialshared resource. As applications become more memory inten-sive and processors include more cores that share the samememory system, the performance of main memory becomesmore critical for overall system performance.
In a multi-core system, the processing time of a memoryrequest is highly variable as it depends on the location of theaccess and the state of DRAM chips and the DRAM controller.There is inter-core dependency as the memory accesses fromone core could also be influenced by requests from othercores; the DRAM controller commonly employs schedulingalgorithms to re-order requests in order to maximize overallDRAM throughput [21]. All these factors affect the temporalpredictability of memory intensive real-time applications dueto the high variance of their memory access time. This imposesa big challenge for real-time systems because guarantee on anycore can be invalidated by workload changes in other cores.Therefore, there is an increasing need for memory bandwidthmanagement solutions that provide Quality of Service (QoS).
Resource reservation and reclaiming techniques [22], [1]have been widely studied by the real-time community tosolve the problem of assigning different fractions of a sharedresource in a guaranteed manner to contending applications.Many variation of these techniques have been successfullyapplied to CPU management [17], [8], [7] and more recently
to GPU management [15], [16]. In the case of main mem-ory resource, there has been several efforts to design morepredictable memory controllers [4], [3] providing latency andbandwidth guarantee at the hardware level.
Unfortunately, existing solutions cannot be easily used formanaging memory bandwidth on Commercial Off-The-Shelf(COTS) based real-time systems. First, hardware-based so-lutions are not generally possible in COTS based systems.Moreover, state-of-art resource reservation solutions [8], [9]cannot be directly applied to the memory system, mostlybecause the achievable memory service rate is highly dynamic,as opposed to the constant service rate in CPU scheduling.To address these limitations and challenges, we propose aefficient and fine-grained memory bandwidth managementsystem, which we call MemGuard.
MemGuard is a memory bandwidth reservation system im-plemented in the OS layer. Unlike CPU bandwidth reservation,under MemGuard the available memory bandwidth can be de-scribed as having two components: guaranteed and best effort.The guaranteed bandwidth represents the minimum servicerate the DRAM system can provide, while the additionallyavailable bandwidth is best effort and can not be guaranteedby the system. Memory bandwidth reservation is based onthe guaranteed part in order to achieve temporal isolation.However, to efficiently utilize all the guaranteed memorybandwidth, a reclaiming mechanism is proposed leveragingeach core’s usage prediction. We further improves the overallsystem throughput by exploiting the best effort bandwidth afterthe guaranteed bandwidth of each core is satisfied.
Since our reclaiming algorithm is prediction based, mispre-diction can lead to a situation where guaranteed bandwidth isnot delivered to the core. Therefore, MemGuard is intended tosupport mainly soft real-time systems. However, hard real-timetasks can be accommodated within this resource managementframework by selectively disabling the reclaiming feature.We evaluate the performance of MemGuard under differentconfigurations and we present detailed results in the evaluationsection.
In our previous work [26], we presented basic reservation,reclaiming, and sharing algorithms of MemGuard. As an ex-tension of our previous work, in this article, we present a new
0.8
1
1.2
1.4
1.6
1.8
2
2.2
470.lb
m
437.leslie3
d
462.lib
quan
tum
410.b
wav
es
471.o
mnetp
p
459.G
emsF
DT
D
482.sp
hin
x3
429.m
cf
450.so
plex
433.m
ilc
434.zeu
smp
483.x
alancb
mk
436.cactu
sAD
M
403.g
cc
456.h
mm
er
473.astar
401.b
zip2
400.p
erlben
ch
447.d
ealII
454.calcu
lix
464.h
264ref
445.g
obm
k
458.sjen
g
435.g
rom
acs
481.w
rf
444.n
amd
465.to
nto
416.g
amess
453.p
ovray
geo
mean
Slo
wdow
n R
atio
background(470.lbm)foreground(X-axis)
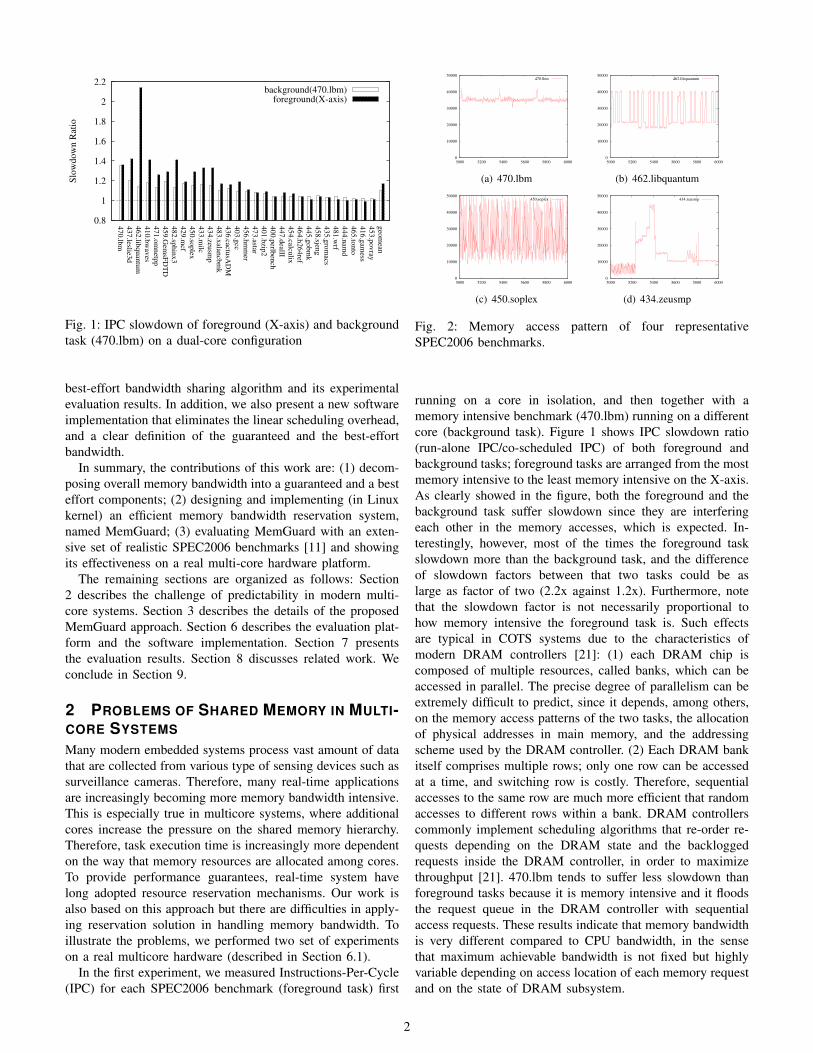
Fig. 1: IPC slowdown of foreground (X-axis) and backgroundtask (470.lbm) on a dual-core configuration
best-effort bandwidth sharing algorithm and its experimentalevaluation results. In addition, we also present a new softwareimplementation that eliminates the linear scheduling overhead,and a clear definition of the guaranteed and the best-effortbandwidth.
In summary, the contributions of this work are: (1) decom-posing overall memory bandwidth into a guaranteed and a besteffort components; (2) designing and implementing (in Linuxkernel) an efficient memory bandwidth reservation system,named MemGuard; (3) evaluating MemGuard with an exten-sive set of realistic SPEC2006 benchmarks [11] and showingits effectiveness on a real multi-core hardware platform.
The remaining sections are organized as follows: Section2 describes the challenge of predictability in modern multi-core systems. Section 3 describes the details of the proposedMemGuard approach. Section 6 describes the evaluation plat-form and the software implementation. Section 7 presentsthe evaluation results. Section 8 discusses related work. Weconclude in Section 9.
2 PROBLEMS OF SHARED MEMORY IN MULTI-CORE SYSTEMS
Many modern embedded systems process vast amount of datathat are collected from various type of sensing devices such assurveillance cameras. Therefore, many real-time applicationsare increasingly becoming more memory bandwidth intensive.This is especially true in multicore systems, where additionalcores increase the pressure on the shared memory hierarchy.Therefore, task execution time is increasingly more dependenton the way that memory resources are allocated among cores.To provide performance guarantees, real-time system havelong adopted resource reservation mechanisms. Our work isalso based on this approach but there are difficulties in apply-ing reservation solution in handling memory bandwidth. Toillustrate the problems, we performed two set of experimentson a real multicore hardware (described in Section 6.1).
In the first experiment, we measured Instructions-Per-Cycle(IPC) for each SPEC2006 benchmark (foreground task) first
0
10000
20000
30000
40000
50000
5000 5200 5400 5600 5800 6000
470.lbm
(a) 470.lbm
0
10000
20000
30000
40000
50000
5000 5200 5400 5600 5800 6000
462.libquantum
(b) 462.libquantum
0
10000
20000
30000
40000
50000
5000 5200 5400 5600 5800 6000
450.soplex
(c) 450.soplex
0
10000
20000
30000
40000
50000
5000 5200 5400 5600 5800 6000
434.zeusmp
(d) 434.zeusmp
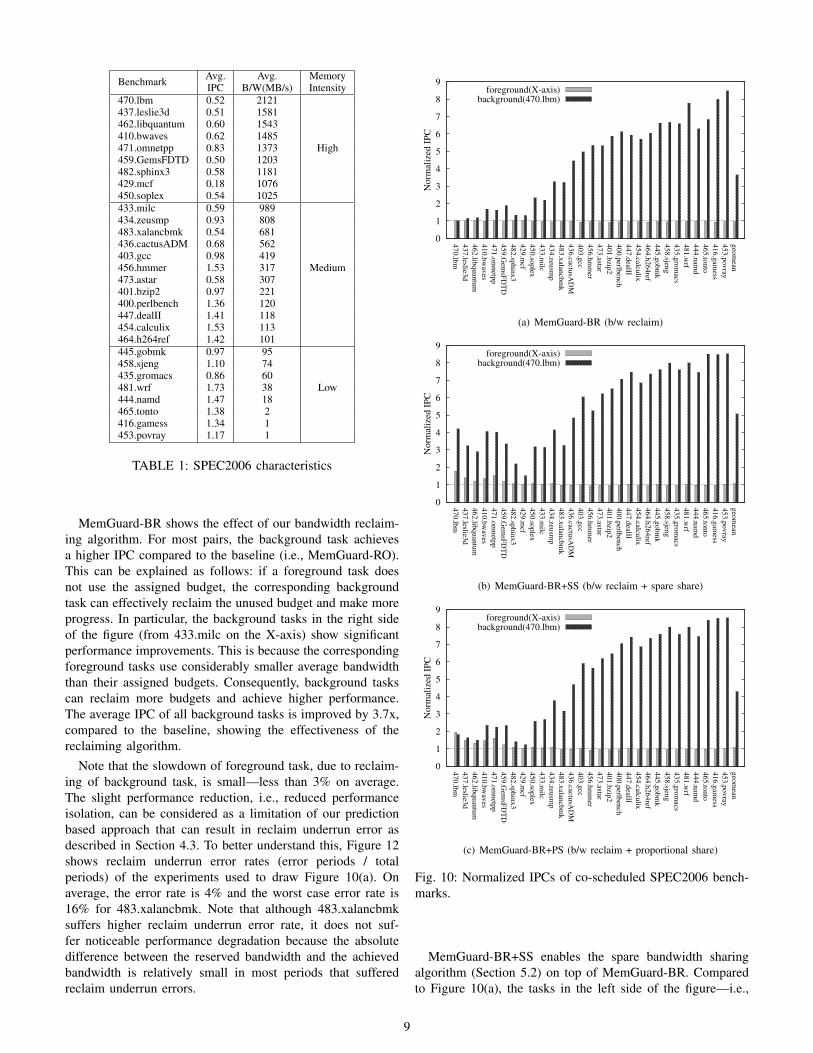
Fig. 2: Memory access pattern of four representativeSPEC2006 benchmarks.
running on a core in isolation, and then together with amemory intensive benchmark (470.lbm) running on a differentcore (background task). Figure 1 shows IPC slowdown ratio(run-alone IPC/co-scheduled IPC) of both foreground andbackground tasks; foreground tasks are arranged from the mostmemory intensive to the least memory intensive on the X-axis.As clearly showed in the figure, both the foreground and thebackground task suffer slowdown since they are interferingeach other in the memory accesses, which is expected. In-terestingly, however, most of the times the foreground taskslowdown more than the background task, and the differenceof slowdown factors between that two tasks could be aslarge as factor of two (2.2x against 1.2x). Furthermore, notethat the slowdown factor is not necessarily proportional tohow memory intensive the foreground task is. Such effectsare typical in COTS systems due to the characteristics ofmodern DRAM controllers [21]: (1) each DRAM chip iscomposed of multiple resources, called banks, which can beaccessed in parallel. The precise degree of parallelism can beextremely difficult to predict, since it depends, among others,on the memory access patterns of the two tasks, the allocationof physical addresses in main memory, and the addressingscheme used by the DRAM controller. (2) Each DRAM bankitself comprises multiple rows; only one row can be accessedat a time, and switching row is costly. Therefore, sequentialaccesses to the same row are much more efficient that randomaccesses to different rows within a bank. DRAM controllerscommonly implement scheduling algorithms that re-order re-quests depending on the DRAM state and the backloggedrequests inside the DRAM controller, in order to maximizethroughput [21]. 470.lbm tends to suffer less slowdown thanforeground tasks because it is memory intensive and it floodsthe request queue in the DRAM controller with sequentialaccess requests. These results indicate that memory bandwidthis very different compared to CPU bandwidth, in the sensethat maximum achievable bandwidth is not fixed but highlyvariable depending on access location of each memory requestand on the state of DRAM subsystem.
2

Furthermore, the memory access patterns of tasks can behighly unpredictable and significantly change over time. Fig-ure 2 shows the memory access patterns of four benchmarksfrom SPEC2006. Each benchmark runs alone and we collectedmemory bandwidth usage using hardware Performance Mea-suring Counters (PMC) between time 5 to 6 seconds, sampledover every 1ms time interval. 470.lbm shows highly uniformaccess pattern throughout the whole time. On the other hand,462.libquantum and 450.soplex show highly variable accesspattern, while 434.zeusmp show mixed behavior over time.
When resource usage changes significantly over time, astatic reservation approach results in poor resource utilizationand poor performance. If the resource is reserved with themaximum request, it would lead to significant waste as thetask usually does not consume that amount; while if it is withthe average value, the task would suffer slowdown wheneverit tries to access more than that average value during onesampling period. The problem is only compounded when theavailable resource amount also changes over time, as it isthe case for memory bandwidth. One ideal solution is todynamically adjust the resource provision based on its actualusage: when the task is highly demanding on the resource, itcan try to reclaim some possible spare resource from otherentities; on the other hand, when it consumes less than thereserved amount, it can share the extra resource with otherentities in case they need. Furthermore, if the amount ofavailable resource is higher than expected, we can allocate theremaining resource units among demanding tasks. There havebeen two types of dynamic adaptation schemes: feedback-control based adaptive reservation approaches [2] and resourcereclaiming based approaches [7], [17]. In our work, we choosea reclaiming based approach for simplicity.
The details of our bandwidth management system, Mem-Guard, are provided in the next section. In summary, basedon the discussed experiments, the system will need to: (1)reserve memory bandwidth resource to one specific core(a.k.a. resource reservation) to provide predictable and guar-anteed worst-case behavior; and (2) provide some dynamicresource adjustment on the resource provision (a.k.a. resourcereclaiming) to efficiently exploit varying system resources andimprove task responsiveness.
3 MEMGUARD OVERVIEW
The goal of MemGuard is to provide memory performanceisolation while still maximizing memory bandwidth utilization.By memory performance isolation, we mean that the averagememory access latency of a task is no larger than whenrunning on a dedicated memory system which processesmemory requests at a certain service rate (e.g., 1GB/s). Amulticore system can then be considered as a set of unicoresystems, each of which has a dedicated, albeit slower, memorysubsystem. This notion of isolation is commonly achievedthrough resource reservation approaches in real-time literature[1] mostly in the context of CPU bandwidth reservation.
In this paper, we focus on systems where the last level cacheis private or partitioned on a per-core basis, in order to focus onDRAM bandwidth instead of cache space contention effects.
CORE
DRAM Controller
PMC
DRAM
CORE CORE CORE
PMC PMC PMC
Multicore Processor
Operating System
B/WRegulator
B/WRegulator
B/WRegulator
B/WRegulator
Reclaim managerMemGuard
Fig. 3: MemGuard system architecture.
We assume system operators or an external user-level daemonwill configure MemGuard either statically or dynamically viathe provided kernel filesystem interface.
Figure 3 shows the overall system architecture of Mem-Guard and its two main components: the per-core regulatorand the reclaim manager. The per-core regulator is responsiblefor monitoring and enforcing its corresponding core memorybandwidth usage. It reads the hardware PMC to account thememory access usage. When the memory usage reaches a pre-defined threshold, it generates an overflow interrupt so thatthe specified memory bandwidth usage is maintained. Eachregulator has a history based memory usage predictor. Basedon the predicted usage, the regulator can donate its budgetso that cores can start reclaiming once they used up theirgiven budget. The reclaim manager maintains a global sharedreservation for receiving and re-distributing the budget for allregulators in the system.
Using the regulators, MemGuard allows each core to re-serve a fraction of memory bandwidth, similar to CPU band-width reservation. Unlike CPU bandwidth, however, availablememory bandwidth varies depending on memory access pat-terns. In order to achieve performance isolation, MemGuardrestricts the total reservable bandwidth to the worst caseDRAM bandwidth—we call it guaranteed bandwidth, rmin;see Section 4—similar to the requirement of CPU bandwidthreservation in that the total sum of CPU bandwidth reservationmust be equal or less than 100% of CPU bandwidth. Ourobservation is that it greatly reduces contention in the DRAMcontroller, hence significantly improve performance isolation.While reservation provides performance isolation, reclaimingimproves overall resource utilization by re-distributing under-utilized memory bandwidth to demanding cores.
While the reservation and reclaiming achieve performanceisolation and efficient utilization of the guaranteed bandwidth,the guaranteed bandwidth is much smaller than the peakbandwidth of the given DRAM module. We call the difference(i.e., peak - guaranteed bandwidth) as best-effort bandwidth.MemGuard tries to utilize the best-effort bandwidth wheneverpossible.
Figure 4 shows the high level implementation of Mem-Guard. Using the figure as a guide, we now describe thememory bandwidth management mechanisms of MemGuard
3

in the following sections: Section 4 describes how MemGuardmanage the guaranteed bandwidth in more detail; Section 5describes two different methods to utilize the best-effort band-width.
function periodic timer handler ;1
begin2
Qpredicti ← output of usage predictor ;3
Qi ← user assigned static budget ;4
if Qpredicti > Qi then5
qi ← Qi;6
else7
qi ← Qpredicti ;8
G += max{0, Qi − qi};9
program PMC to cause overflow interrupt at qi;10
re-schedule all dequeued tasks;11
end12
function overflow interrupt handler ;13
begin14
ui ← used budget in the current period ;15
if G > 0 then16
if ui < Qi then17
qi ← min{Qi − ui, G} ;18
else19
qi ← min{Qmin, G} ;20
G -= qi;21
program PMC to cause overflow interrupt at qi ;22
Return ;23
if ui < Qi then24
Return ;25
if∑
ui = rmin then26
manage best-effort bandwidth (see Section 5) ;27
de-schedule tasks in the CPU run-queue ;28
end29Fig. 4: MemGuard Implementation
4 GUARANTEED BANDWIDTH MANAGEMENTIn this section, we first give necessary background informa-tion about DRAM based memory subsystems and define theguaranteed bandwidth which is the basis for our reservationand reclaiming. We then detail MemGuard’s reservation andreclaiming mechanisms that manage the guaranteed bandwidthto provide efficient performance isolation between cores thatshare the memory subsystem.
4.1 Guaranteed Memory BandwidthFigure 5 shows the organization of a typical DRAM basedmemory system. A DRAM module is composed of severalDRAM chips that are connected in parallel to form a wideinterface (64bits for DDR). Each DRAM chip has multiplebanks that can be operated concurrently. Each bank is thenorganized as a 2d array consisting of rows and columns. Alocation in DRAM can be addressed with the bank, row andcolumn number.
Ban
k 0
Row Buffer
Row 0
Row N-1
Bank 0
Bank 7
DRAM Chip 0
Ban
k 0
Row Buffer
Row 0
Row N-1
Bank 0
Bank 7
DRAM Chip 7
DRAM Controller
Fig. 5: DRAM based memory system organization—Adoptedfrom Fig. 2 in [20]
In each bank, there is a buffer, called row buffer, to store asingle row (typically 1˜2KB) in the bank. In order to accessdata, the DRAM controller must first copy the row containingthe data into the row buffer (i.e., opening a row). The requiredlatency for this operation is denoted as tRCD in DRAMspecifications. The DRAM controller then can read/write fromthe row buffer with only issuing column addresses, as long asthe requested data is in the same row. The associated latencyis denoted as tCL. If the requested data is in a different row,however, it must save the content of the row buffer back tothe originating row (i.e., closing a row). The associated latencyis denoted as tRP . In addition, in order to open a new rowin the same bank, at least tRC time should have been passedsince the opening of the current row. Typically tRC is slightlylarger than the sum of tRCD, tCL, and tRP . The accesslatency to a memory location, therefore, varies depending onwhether the data is already in the row buffer (i.e., row hit)or not (i.e., row miss) and the worst-case performance isdetermined by tRC parameter. Moreover, because banks canbe accessed in parallel, the achievable memory bandwidth alsoheavily depends on how many banks are accessed in parallel:For example, if two successive memory requests are targetingto bank0 and bank1 respectively, they can be requested inparallel, achieving higher bandwidth.
Considering these characteristics, we can distinguish themaximum (peak) bandwidth and the guaranteed (worst-case)bandwidth as follows:
• Maximum (peak) bandwidth: This is stated maximumperformance of a given memory module where the speedis only limited by I/O bus clock speed. For example,a PC6400 DDR2 memory module’s peak bandwidth is6400MB/s where it can transfer 64bit data at the risingand falling edge of bus cycle running at 400MHz.
• Guaranteed (worst-case) bandwidth: Achieved band-width is, however, limited by available parallelism andvarious timing requirements. The worst-case occurs whenall memory requests are targeting to a single memorybank (bank conflict), and each successive request isaccessing different row, causing a row switch (row miss).This can be calculated from the DRAM specification
4

using tRC parameter.Because the guaranteed bandwidth can be satisfied regard-
less of memory access locations, we use the guaranteed band-width as the basis for bandwidth reservation and reclaimingas we will detail in the subsequent subsections.
4.2 Memory Bandwidth Reservation
MemGuard provides two levels of memory bandwidth reser-vation: system-wide reservation and per-core reservation.
1) System-wide reservation regulates the total allowed mem-ory bandwidth such that it does not exceed the guaranteedbandwidth — denoted as rmin.
2) Per-core reservation assigns a fraction of rmin to eachcore, hence each core reserves bandwidth Bi and rmin =∑m
i=0 Bi.Each regulator reserves memory bandwidth represented by
memory access budget Qi for every period P : i.e. Bi =Qi
P .Regulation period P is a system-wide parameter and shouldbe small to effectively enforce specified memory bandwidth.Although small regulation period is better for predictability,there is a practical limit on reducing the period due to interruptand scheduling overhead; we currently configure the period as1ms. The reservation follows the common resource reservationrules [22], [24], [25]. Per-core instant budget qi is deductedas the core consumes memory bandwidth. For accuratelyaccounting memory usage, we use per-core PMC interrupt:specifically, we program the PMC at the beginning of eachregulation period so that it generates an interrupt when qi isdepleted for Core i. Once the interrupt is received, the regulatorcalls the OS scheduler to schedule a high-priority real-timetask to effectively idle the core until the next period begins.At the beginning of the next period the budget is replenishedin full and the real-time ”idle” task will be suspended so thatregular tasks can be scheduled.
4.3 Memory Bandwidth Reclaiming
Each core has statically assigned bandwidth Qi as the baseline.It also maintains an instant budget qi to actually program thePMC which can vary at each period based the output of thememory usage predictor. We currently use an ExponentiallyWeighted Moving Average (EWMA) filter as the memoryusage predictor which takes the memory bandwidth usage ofthe previous period as input. The reclaim manager maintainsa global shared budget G. It collects surplus bandwidth fromeach core and re-distributes it when in need. Note that G isinitialized at the beginning of each period and any unusedG is discarded at the end of this period. Each core onlycommunicates with the central reclaim manager for donatingand reclaiming its budget. This avoids possible circular re-claiming among all cores and greatly reduces implementationcomplexity and runtime overhead.
The details of the reclaiming rules are as follows:1) At the beginning of each regulation period, the current
per-core budget qi is updated as follows:
qi = min{Qpredicti , Qi}
1
3
3
stall CPU executionmemory access
global
1
time
2
4
Core0
Core1
0 5 10 15 2520
budget
G
Fig. 6: An illustrative example with two cores
If the core is predicted not to use the full amount of theassigned budget Qi, the current budget is set the predictedusage, Qpredict
i (See Line 5-8 in Figure 4).2) At the beginning of each regulation period, the global
budget G is updated as follows:
G =∑i
{Qi − qi}.
Each core donates its spare budget to G (See Line 9 inFigure 4).
3) During execution, the core can reclaim from the globalbudget if its corresponding budget is depleted. Theamount of reclaim depends on the requesting core’s con-dition: If the core’s used budget ui is less than the staticreserved bandwidth Qi (this happens when the predictionis smaller than Qi), then it tries to reclaim amount equalto the difference between Qi and the current usage ui; ifthe core used equal or greater than the assigned budgetQi, it only gets up to a small fixed amount of budget,Qmin (See Line 16-19 in Figure 4). If Qmin is toosmall, too many interrupts can be generated within aperiod, increasing overhead. As such, it is a configurationparameter and empirically determined for each particularsystem.
4) Since our reclaim algorithm is based on prediction, it ispossible a core may not be able to use the originallyassigned budget Qi. This can happen when the coredonates its budget too much (due to mis-prediction)and other cores already reclaimed the entire donatedbudget (i.e., G = 0) before the core tries to reclaim.When this happens, our current heuristic is to allow thecore continue execution, hoping that it may use its Qi,although it is not guaranteed (See Line 23-24 in Figure 4).At the beginning of the next period, we verify if itwas able to use the budget. If not, we call it a reclaimunderrun error and notify the predictor of the difference(Qi − ui). The predictor then tries to compensate it byusing Qi + (Qi − ui) as its input for the next period.
5

4.4 Example
Figure 6 shows an example with two cores, each with anassigned static budget 3 (i.e., Q0 = Q1 = 3). The regulationperiod is 10 time units and the arrows at the top of the figurerepresent the period activation times. The figure demonstratesthe global budget together with these two cores.
When the system starts, each core starts with the assignedbudget 3. At time 10, the prediction for each core is 1 as itonly used budget 1 within the period [0,10], hence, the instantbudget becomes 1 and the global budget G becomes 4 (eachcore donates 2). At time 12, Core 1 depletes its instant budget.Since its assigned budget is 3, Core 1 tries to reclaim 2 from Gand G becomes 2. At time 15, Core 1 depletes its budget again.This time Core 1 already used its assigned budget, only a fixedamount of extra budget (Qmin) 1 is reclaimed from G and Gbecomes 1. At time 16, Core 0 depletes its budget. Since G is1 at this point, Core 0 only reclaims 1 and G drops to 0. Attime 17, Core 1 depletes its budget again then it dequeues allthe tasks as it cannot reclaim additional budget from G. Whenthe third period starts at time 20, the Qpredict
1 is larger thanQ1. Therefore, Core 1 gets the full amount of assigned budget3, according to Rule 1 in Section 4.3, while Core 0 only gets1, and donates 2 to G. At time 25, after Core 1 depletes itsbudget, Core 1 reclaims an additional budget Qmin from G.
5 BEST-EFFORT BANDWIDTH MANAGEMENT
In this section, we first define the best-effort memory band-width in MemGuard and describe two proposed managementschemes: spare sharing and propotional sharing.
5.1 Best-effort Memory Bandwidth
We define best-effort memory bandwidth as any additionalachieved bandwidth above the guaranteed bandwidth rmin.Because rmin is smaller than the peak bandwidth, efficientutilization of best-effort bandwidth is important, especially formemory intensive tasks.
As described in the previous section, memory reservationand reclaiming works w.r.t. rmin in MemGuard. If all coresexhaust their given bandwidths before the current period ends,all cores would wait for the next period doing nothing underthe rules described in Section 4. Since MemGuard alreadydelivered reserved bandwidth to each core, any additionalbandwidth is now considered as best-effort bandwidth. Wepropose two best-effort bandwidth management schemes inthe following subsections.
5.2 Spare Sharing
When all cores collectively use their assigned budgets (Line25 in Figure 4), the spare sharing scheme simply let all corescompete for the memory until the next period begins. Thisstrategy maximizes throughput as it effectively equivalent totemporarily disabling MemGuard. In another perspective, itgives an equal chance for each core to utilize the remainingbest-effort bandwidth, regardless of its reserved memory band-width.
Figure 7(a) shows an example operation of the scheme. Attime 5, Core 0 depletes its budget and it dequeues all tasksin the core, assuming the G is zero in the period. At time 7,Core 1 depletes its budget. At this point, there are no cores thathave remaining budgets. Therefore, Core 1 sends a broadcastmessage to wake-up the Core 0 and both cores compete thememory until the next period begins at time 10.
Note that this mechanism only starts after all the cores havedepleted their assigned budgets. The reason is that if a corehas not yet used qi, allowing other cores to execute may bringintensive memory contention, preventing the core from usingthe remaining qi.
5.3 Proportional SharingThe proportional sharing scheme also starts after all coresuse their budgets like the spare-sharing scheme, described inthe previous subsection but it differs in that it starts a newperiod immediately instead of waiting the remaining time inthe period. This effectively makes each core to utilize the best-effort bandwidth proportional to its reserved bandwidth—i.e.,the more the qi, the more best-effort bandwidth the core gets.
Figure 7(b) shows an example operation of the scheme. Attime 7, when all cores use their budgets, it starts a new periodand each core’s budget is recharged immediately. This meansthat the length of each period can be shorter depending onworkload. However, if the condition is not met, i.e., there isat least one core that does not use its budget, then the samefixed period length is enforced.
This scheme bears some similarities with the IRIS al-gorithm, a CPU bandwidth reclaiming algorithm [18], thatextends CBS [1] to solve the deadline aging problem of CBS;In the original CBS, when a server exhaust its budget, itimmediately recharges the budget and extend the deadline.This can cause a very long delay to CPU intensive servers thatextend deadlines very far ahead while other servers are inac-tive. The IRIS algorithm solves this problem by introducinga notion of recharging time in which a server that exhaustsits budget must wait until it reaches the recharging time. Ifthere is no active server and there is at least one server thatwait for recharging, IRIS updates server’s time to the earliestrecharging time. This is similar to the proportional sharingscheme presented in this subsection in that servers’ budgets arerecharged when all servers use their given budgets. They are,however, significantly different in the sense that proportionalsharing is designed for sharing memory bandwidth betweenmultiple concurrently accessing cores and is it is not based onCBS scheduling method.
6 EVALUATION SETUPIn this section, we introduce the platform used for the evalu-ation and the software system implementation.
6.1 Evaluation platformFigure 8 shows the architecture of our testbed, an IntelCore2Quad Q8400 processor. The processor is clocked at2.66GHz and has four physical cores. It contains two separate2MB L2 caches; each L2 cache is shared between two cores.
6

20stall CPU executionmemory access
0 5 10 15
3
3
1
time
core0
core1
(a) Spare Sharing
20stall CPU executionmemory access
0 5 10 15
3
3
1
time
core0
core1
(b) Proportional Sharing
Fig. 7: Comparison of two best-effort bandwidth management schemes
As our focus is not the shared cache, we use cores that donot share the same LLC for experiments (i.e., Core 0 and Core2 in Figure 8). We do, however, use four cores when tasks arenot sensitive to shared LLC by nature (e.g., working set sizeof each task is bigger than the LLC size).
We use two 2GB PC6400 DRAM modules, each of whichis having two ranks and 8 banks (8 x 14 x 10 x 64). Weemphirically estimated the guaranteed bandwidth rmin of thememory subsystem as 1.2GB, which is used to configure theMemGuard in the rest of our evaluation. Note that this numbermay vary depending on the number of memory banks andother timing parameters. The smaller the rmin is the betterit can be guaranteed at the cost of less reservable memorybandwidth and low overall memory bandwidth utilization. Asshown in Section 7.1, the estimated rmin provides strongisolation performance in our experiments.
In order to account per-core memory bandwidth usage, weused a LLC miss performance counter 1 per each core. Sincethe LLC miss counter does not account prefetched memorytraffic, we disabled all hardware prefetchers 2.
Note that LLC miss counts do not capture LLC write-back traffic which may underestimate actual memory traffic,particularly for write-heavy benchmarks. However, becauseSPEC2006 benchmarks, which we used in evaluation, are readheavy (only 20% of memory references are write [14]); andmemory controllers often implement write-buffers that can beflushed later in time (e.g., when DRAM is not in use by otheroutstanding read requests) and writes are considered to becompleted when they are written to the buffers [12], write-backtraffic do not necessarily cause additional latency in accessingDRAM. Analyzing the impact of accounting write-back trafficin terms of performance isolation and throughput is left asfuture work.
1. LAST LEVEL CACHE MISSES: event=2e, umaks=41. See [13]2. We used http://www.eece.maine.edu/∼vweaver/projects/prefetch-disable/
CORE 0CORE 0 CORE 1 CORE 2CORE 2 CORE 3
SYSTEM BUS
II DD I D II DD I D
MEMORY
L2 Cache L2 Cache
Intel Core2Quad Processor
Fig. 8: Hardware architecture of our evaluation platform.
6.2 Software ImplementationWe implemented MemGuard in Linux version 3.6 as a kernelmodule 3. We use the perf event infrastructure to install thecounter overflow handler at each period. The logic of bothhandlers is shown in Figure 4.
Compared to our previous implementation [26], we madeseveral changes. First, as explained in Section 4, we nowschedule a high-priority real-time task to “throttle” the coreinstead of de-scheduling all the tasks in the core. This solvesthe problem of linearly increasing overhead as the numberof tasks increase. Second, we now use a separate timer forpacing the regulation period, instead of using the OS tick, inorder to easily re-program the length of period. It is neededto support proportional sharing mode which may change theperiod length on-demand.
The PMC programming overhead is negligible as it onlyrequires a write to each core’s local register. The overheadof scheduling real-time idle task is equal to a single contextswitch overhead, which is typically less than 2us in thetested platform 4 , regardless of the number of tasks in thecore; this is a notable improvement compared to our previousimplementation that its overhead grows linearly as the numberof tasks increase.
3. MemGuard is available at https://github.com/heechul/memguard4. Measured using lat ctx of LMBench3[19].
7

MemGuard supports several memory bandwidth reservationmodes, namely per-core bandwidth assignment and per-taskassignment mode. In per-core mode, system designers canassign absolute bandwidth (e.g., 200MB/s) or relative weightexpressing relative importance. In the latter case, the actualbandwidth is calculated at every period by checking activecores (cores that have runnable tasks in their runqueues). Inper-task mode, the task priority is used as weight for the corethe task runs on. Notice that in this mode, a task can migrate toa different core with its own memory bandwidth reservation.In Section 7, we use per-core assignment mode using bothabsolute bandwidth and weight depending on experiments.
7 EVALUATION RESULTS AND ANALYSIS
In this section, we evaluate MemGuard in terms of per-formance isolation guarantee and throughput with a set ofsynthetic and SPEC2006 benchmarks.
For evaluation, we use four different modes of MemGuard:reserve only (MemGuard-RO), b/w reclaim (MemGuard-BR), b/w reclaim + spare share (MemGuard-BR+SS), andb/w reclaim + proportional sharing (MemGuard-BR+PS). InMemGuard-RO mode, each core only can use its reservedb/w as described in Section 4.2. The MemGuard-BR modeuses the predictive memory bandwidth reclaiming algorithmdescribed in Section 4.3. Both MemGuard-BR+SS mode andMemGuard-BR+PS use the bandwidth reclaiming but differin how to manage the best-effort bandwidth after all corescollectively consume the guaranteed bandwidth as describedin Section 5.2 and Section 5.3 respectively.
7.1 Isolation Effect of Reservation
In this experiment, we illustrate the effect of memory band-width reservation on performance isolation by configuringMemGuard with the reservation only mode (MemGuard-RO).We pair the most memory intensive benchmark, 470.lbm asthe background task, with a foreground task selected fromSPEC2006 benchmarks. Each foreground task runs on Core0 with 1.0GB/s memory bandwidth reservation while thebackground task runs on Core 2 with reservation varyingfrom 0.2GB/s to 2.0GB/s. Note that assigning more than0.2GB/s on Core 2 makes the total bandwidth exceeds theestimated minimum DRAM service rate of 1.2GB/s. Note thatMemGuard-RO mode only allows each core to use its assignedbandwidth only regardless of memory activities in other cores.
Figure 9 shows the IPC of each foreground task, normalizedto the IPC measured in isolation (i.e., no background task) withthe same 1.0GB/s reservation. First, notice that when we assign0.2GB/s to Core 2 (denoted “w/ lbm:0.2G”) the IPC of eachtask is very close to the ideal value 1.0—i.e., negligible perfor-mance impact from the co-running background task. However,as we increase the assigned memory bandwidth of Core 2, theIPC of the foreground task gradually decreases below 1.0—i.e., performance isolation is violated due to increased memorycontention. For example, 462.libquantum on Core0 shows 30%IPC reduction when the background task is running on Core2with 2.0GB/s reservation (denoted “w/ lbm:2.0G”).
0.5
0.6
0.7
0.8
0.9
1
1.1
470.lbm
437.leslie3d
462.libquantum
410.bwaves
471.omnetpp
459.GemsFDTD
482.sphinx3
429.mcf
450.soplex
433.milc
434.zeusmp
483.xalancbmk
436.cactusADM
403.gcc
456.hmmer
473.astar
401.bzip2
400.perlbench
447.dealII
454.calculix
464.h264ref
geomean
Norm
aliz
ed I
PC
w/ lbm:0.2G w/ lbm:0.8G w/ lbm:1.4G w/ lbm:2.0G
Fig. 9: Normalized IPC of a subset of SPEC2006 (Core 0),co-scheduled with 470.lbm (Core 2)
These results demonstrate that performance isolation canbe achieved by regulating the aggregated total request rate.Specifically, limiting the rate (to be smaller than rmin)achieves performance isolation for the SPEC benchmarksshown in this figure. The rest of SPEC benchmarks alsoshow consistent behavior but we omit them as they show lessinterference (less slowdown).
7.2 Results with SPEC2006 Benchmarks on TwoCoresWe now evaluate MemGuard using the entire SPEC 2006benchmarks. We first profile the benchmarks to better under-stand of their characteristics. We run each benchmark for 10seconds with the reference input and measure the instructioncounts and LLC miss counts, using perf tool included in theLinux kernel source tree, to calculate the average IPC and thememory bandwidth usage. We multiply the LLC miss countwith the cache-line size (64 bytes in our testbed) to get thetotal memory bandwidth usage.
Table 1 shows the characteristics of each SPEC2006 bench-mark, in decreasing order of average memory bandwidthusage, when each benchmark runs alone on our evaluationplatform. Notice that the benchmarks cover a wide range ofmemory bandwidth usage, ranging from 1MB/s (453.povray)up to 2.1GB/s (470.lbm).
We now evaluate the effect of the b/w reclaim algorithm(MemGuard-BR) and two best-effort bandwidth managementschemes (MemGuard-BR+SS and MemGuard-BR+PS) on adual-core system configuration.
Figure 10 shows the normalized IPCs (w.r.t. MemGuard-RO) of co-scheduled foreground and background task usingMemGuard-RO, MemGuard-BR+SS, and MemGuard-BR+PS.The foreground tasks in X-axis are sorted in decreasing orderof memory intensity. For all task pairs, the foreground taskruns on Core0 with 1.0GB/s reservation and the backgroundtask ( 470.lbm) run on Core2 with 0.2GB/s reservation. Noticethat the Core2 is severely under-reserved as 470.lbm’s averagebandwidth is above 2GB/s (see Table 1).
8
Benchmark Avg. Avg. MemoryIPC B/W(MB/s) Intensity
470.lbm 0.52 2121437.leslie3d 0.51 1581462.libquantum 0.60 1543410.bwaves 0.62 1485471.omnetpp 0.83 1373 High459.GemsFDTD 0.50 1203482.sphinx3 0.58 1181429.mcf 0.18 1076450.soplex 0.54 1025433.milc 0.59 989434.zeusmp 0.93 808483.xalancbmk 0.54 681436.cactusADM 0.68 562403.gcc 0.98 419456.hmmer 1.53 317 Medium473.astar 0.58 307401.bzip2 0.97 221400.perlbench 1.36 120447.dealII 1.41 118454.calculix 1.53 113464.h264ref 1.42 101445.gobmk 0.97 95458.sjeng 1.10 74435.gromacs 0.86 60481.wrf 1.73 38 Low444.namd 1.47 18465.tonto 1.38 2416.gamess 1.34 1453.povray 1.17 1
TABLE 1: SPEC2006 characteristics
MemGuard-BR shows the effect of our bandwidth reclaim-ing algorithm. For most pairs, the background task achievesa higher IPC compared to the baseline (i.e., MemGuard-RO).This can be explained as follows: if a foreground task doesnot use the assigned budget, the corresponding backgroundtask can effectively reclaim the unused budget and make moreprogress. In particular, the background tasks in the right sideof the figure (from 433.milc on the X-axis) show significantperformance improvements. This is because the correspondingforeground tasks use considerably smaller average bandwidththan their assigned budgets. Consequently, background taskscan reclaim more budgets and achieve higher performance.The average IPC of all background tasks is improved by 3.7x,compared to the baseline, showing the effectiveness of thereclaiming algorithm.
Note that the slowdown of foreground task, due to reclaim-ing of background task, is small—less than 3% on average.The slight performance reduction, i.e., reduced performanceisolation, can be considered as a limitation of our predictionbased approach that can result in reclaim underrun error asdescribed in Section 4.3. To better understand this, Figure 12shows reclaim underrun error rates (error periods / totalperiods) of the experiments used to draw Figure 10(a). Onaverage, the error rate is 4% and the worst case error rate is16% for 483.xalancbmk. Note that although 483.xalancbmksuffers higher reclaim underrun error rate, it does not suf-fer noticeable performance degradation because the absolutedifference between the reserved bandwidth and the achievedbandwidth is relatively small in most periods that sufferedreclaim underrun errors.
0
1
2
3
4
5
6
7
8
9
470.lb
m
437.leslie3
d
462.lib
quan
tum
410.b
wav
es
471.o
mnetp
p
459.G
emsF
DT
D
482.sp
hin
x3
429.m
cf
450.so
plex
433.m
ilc
434.zeu
smp
483.x
alancb
mk
436.cactu
sAD
M
403.g
cc
456.h
mm
er
473.astar
401.b
zip2
400.p
erlben
ch
447.d
ealII
454.calcu
lix
464.h
26
4ref
445.g
ob
mk
458.sjen
g
435.g
rom
acs
481.w
rf
444.n
amd
465.to
nto
416.g
amess
453.p
ov
ray
geo
mean
Norm
aliz
ed I
PC
foreground(X-axis)background(470.lbm)
(a) MemGuard-BR (b/w reclaim)
0
1
2
3
4
5
6
7
8
9
470.lb
m
437.leslie3
d
462.lib
quan
tum
410.b
wav
es
471.o
mnetp
p
459.G
emsF
DT
D
482.sp
hin
x3
429.m
cf
450.so
plex
433.m
ilc
434.zeu
smp
483.x
alancb
mk
436.cactu
sAD
M
403.g
cc
456.h
mm
er
473.astar
401.b
zip2
400.p
erlben
ch
447.d
ealII
454.calcu
lix
464.h
264ref
445.g
obm
k
458.sjen
g
435.g
rom
acs
481.w
rf
444.n
amd
465.to
nto
416.g
amess
453.p
ovray
geo
mean
Norm
aliz
ed I
PC
foreground(X-axis)background(470.lbm)
(b) MemGuard-BR+SS (b/w reclaim + spare share)
0
1
2
3
4
5
6
7
8
9
470.lb
m
437.leslie3
d
462.lib
quan
tum
410.b
wav
es
471.o
mn
etpp
459.G
emsF
DT
D
482.sp
hin
x3
429.m
cf
450.so
plex
433.m
ilc
434.zeu
smp
483.x
alancb
mk
436.cactu
sAD
M
403.g
cc
456.h
mm
er
473.astar
401.b
zip2
400.p
erlben
ch
447.d
ealII
454.calcu
lix
464.h
264ref
445.g
obm
k
458.sjen
g
435.g
rom
acs
481.w
rf
444.n
amd
465.to
nto
416.g
amess
453.p
ovray
geo
mean
Norm
aliz
ed I
PC
foreground(X-axis)background(470.lbm)
(c) MemGuard-BR+PS (b/w reclaim + proportional share)
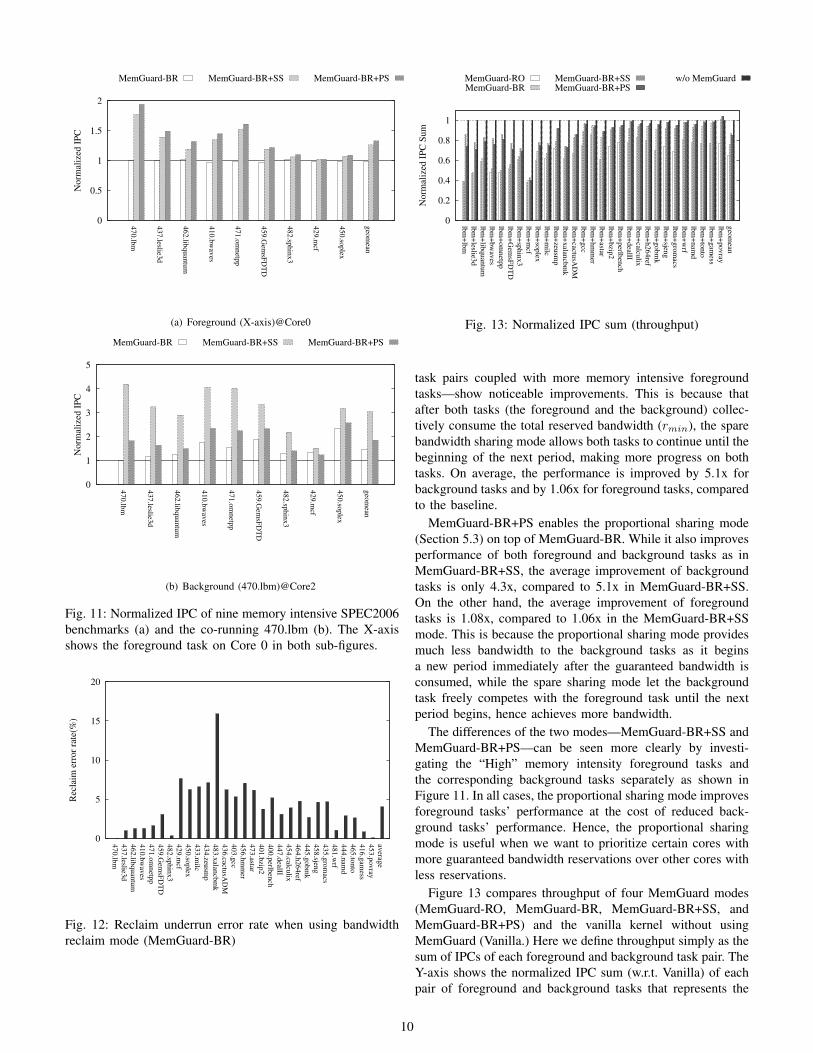
Fig. 10: Normalized IPCs of co-scheduled SPEC2006 bench-marks.
MemGuard-BR+SS enables the spare bandwidth sharingalgorithm (Section 5.2) on top of MemGuard-BR. Comparedto Figure 10(a), the tasks in the left side of the figure—i.e.,
9
0
0.5
1
1.5
2
470.lb
m
437.leslie3
d
462.lib
quan
tum
410.b
wav
es
471.o
mnetp
p
459.G
emsF
DT
D
482.sp
hin
x3
429.m
cf
450.so
plex
geo
mean
Norm
aliz
ed I
PC
MemGuard-BR MemGuard-BR+SS MemGuard-BR+PS
(a) Foreground (X-axis)@Core0
0
1
2
3
4
5
470.lb
m
437.leslie3
d
462.lib
quan
tum
410.b
wav
es
471.o
mnetp
p
459.G
emsF
DT
D
482.sp
hin
x3
429.m
cf
450.so
plex
geo
mean
Norm
aliz
ed I
PC
MemGuard-BR MemGuard-BR+SS MemGuard-BR+PS
(b) Background (470.lbm)@Core2
Fig. 11: Normalized IPC of nine memory intensive SPEC2006benchmarks (a) and the co-running 470.lbm (b). The X-axisshows the foreground task on Core 0 in both sub-figures.
0
5
10
15
20
470.lb
m
437.leslie3
d
462.lib
quan
tum
410.b
wav
es
471.o
mnetp
p
459.G
emsF
DT
D
482.sp
hin
x3
429.m
cf
450.so
plex
433.m
ilc
434.zeu
smp
483.x
alancb
mk
436.cactu
sAD
M
403.g
cc
456.h
mm
er
473.astar
401.b
zip2
400.p
erlben
ch
447.d
ealII
454.calcu
lix
464.h
264ref
445.g
obm
k
458.sjen
g
435.g
rom
acs
481.w
rf
444.n
amd
465.to
nto
416.g
amess
453.p
ovray
averag
e
Rec
laim
err
or
rate
(%)
Fig. 12: Reclaim underrun error rate when using bandwidthreclaim mode (MemGuard-BR)
0
0.2
0.4
0.6
0.8
1
lbm
+lb
m
lbm
+leslie3
d
lbm
+lib
quan
tum
lbm
+bw
aves
lbm
+om
netp
p
lbm
+G
emsF
DT
D
lbm
+sp
hin
x3
lbm
+m
cf
lbm
+so
plex
lbm
+m
ilc
lbm
+zeu
smp
lbm
+xalan
cbm
k
lbm
+cactu
sAD
M
lbm
+gcc
lbm
+hm
mer
lbm
+astar
lbm
+bzip
2
lbm
+perlb
ench
lbm
+dealII
lbm
+calcu
lix
lbm
+h264ref
lbm
+gobm
k
lbm
+sjen
g
lbm
+gro
macs
lbm
+w
rf
lbm
+nam
d
lbm
+to
nto
lbm
+gam
ess
lbm
+povray
geo
mean
Norm
aliz
ed I
PC
Sum
MemGuard-ROMemGuard-BR
MemGuard-BR+SSMemGuard-BR+PS
w/o MemGuard
Fig. 13: Normalized IPC sum (throughput)
task pairs coupled with more memory intensive foregroundtasks—show noticeable improvements. This is because thatafter both tasks (the foreground and the background) collec-tively consume the total reserved bandwidth (rmin), the sparebandwidth sharing mode allows both tasks to continue until thebeginning of the next period, making more progress on bothtasks. On average, the performance is improved by 5.1x forbackground tasks and by 1.06x for foreground tasks, comparedto the baseline.
MemGuard-BR+PS enables the proportional sharing mode(Section 5.3) on top of MemGuard-BR. While it also improvesperformance of both foreground and background tasks as inMemGuard-BR+SS, the average improvement of backgroundtasks is only 4.3x, compared to 5.1x in MemGuard-BR+SS.On the other hand, the average improvement of foregroundtasks is 1.08x, compared to 1.06x in the MemGuard-BR+SSmode. This is because the proportional sharing mode providesmuch less bandwidth to the background tasks as it beginsa new period immediately after the guaranteed bandwidth isconsumed, while the spare sharing mode let the backgroundtask freely competes with the foreground task until the nextperiod begins, hence achieves more bandwidth.
The differences of the two modes—MemGuard-BR+SS andMemGuard-BR+PS—can be seen more clearly by investi-gating the “High” memory intensity foreground tasks andthe corresponding background tasks separately as shown inFigure 11. In all cases, the proportional sharing mode improvesforeground tasks’ performance at the cost of reduced back-ground tasks’ performance. Hence, the proportional sharingmode is useful when we want to prioritize certain cores withmore guaranteed bandwidth reservations over other cores withless reservations.
Figure 13 compares throughput of four MemGuard modes(MemGuard-RO, MemGuard-BR, MemGuard-BR+SS, andMemGuard-BR+PS) and the vanilla kernel without usingMemGuard (Vanilla.) Here we define throughput simply as thesum of IPCs of each foreground and background task pair. TheY-axis shows the normalized IPC sum (w.r.t. Vanilla) of eachpair of foreground and background tasks that represents the
10
0
2
4
6
8
10
Vanilla
MemGuard-RO
MemGuard-BR+SS
MemGuard-BR+PS
No
rmal
ized
IP
C
462.libquantum(Core0@900MB/s)433.milc(Core1@100MB/s)
410.bwaves(Core2@100MB/s)470.lbm(Core3@100MB/s)
(a) rmin=1.2GB/s
0
2
4
6
8
10
Vanilla
MemGuard-RO
MemGuard-BR+SS
MemGuard-BR+PS
No
rmal
ized
IP
C
462.libquantum(Core0@1800MB/s)433.milc(Core1@200MB/s)
410.bwaves(Core2@200MB/s)470.lbm(Core3@200MB/s)
(b) rmin=2.4GB/s
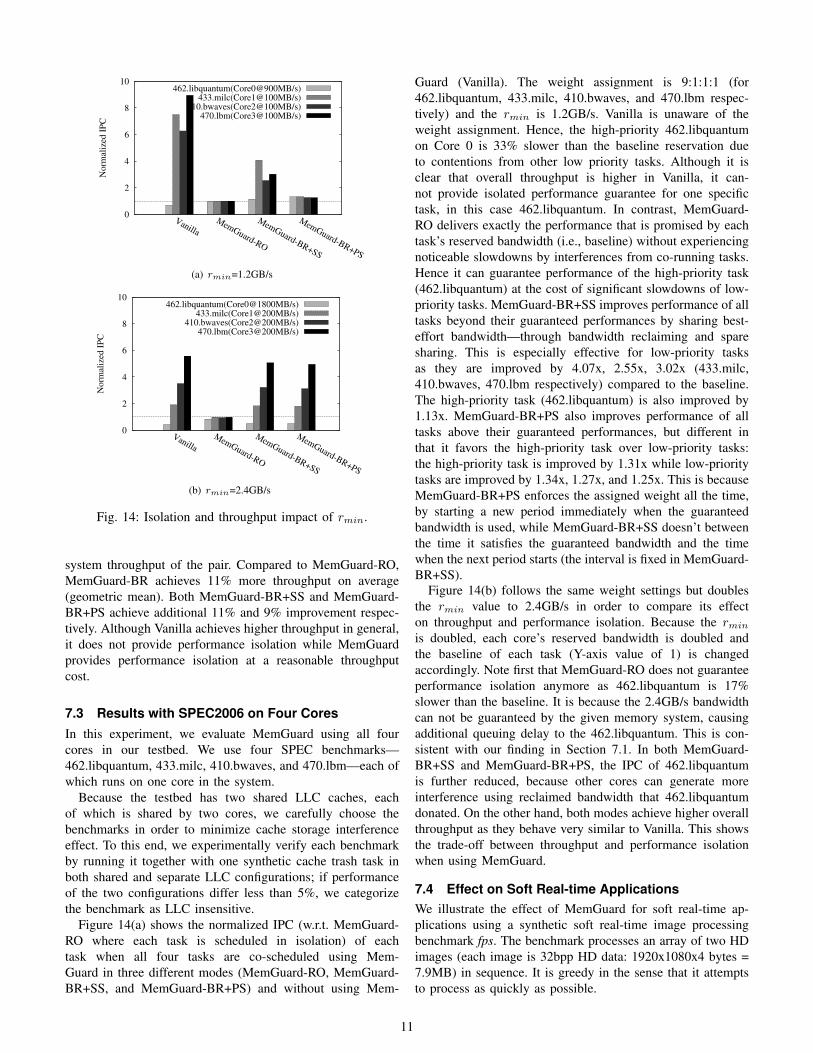
Fig. 14: Isolation and throughput impact of rmin.
system throughput of the pair. Compared to MemGuard-RO,MemGuard-BR achieves 11% more throughput on average(geometric mean). Both MemGuard-BR+SS and MemGuard-BR+PS achieve additional 11% and 9% improvement respec-tively. Although Vanilla achieves higher throughput in general,it does not provide performance isolation while MemGuardprovides performance isolation at a reasonable throughputcost.
7.3 Results with SPEC2006 on Four CoresIn this experiment, we evaluate MemGuard using all fourcores in our testbed. We use four SPEC benchmarks—462.libquantum, 433.milc, 410.bwaves, and 470.lbm—each ofwhich runs on one core in the system.
Because the testbed has two shared LLC caches, eachof which is shared by two cores, we carefully choose thebenchmarks in order to minimize cache storage interferenceeffect. To this end, we experimentally verify each benchmarkby running it together with one synthetic cache trash task inboth shared and separate LLC configurations; if performanceof the two configurations differ less than 5%, we categorizethe benchmark as LLC insensitive.
Figure 14(a) shows the normalized IPC (w.r.t. MemGuard-RO where each task is scheduled in isolation) of eachtask when all four tasks are co-scheduled using Mem-Guard in three different modes (MemGuard-RO, MemGuard-BR+SS, and MemGuard-BR+PS) and without using Mem-
Guard (Vanilla). The weight assignment is 9:1:1:1 (for462.libquantum, 433.milc, 410.bwaves, and 470.lbm respec-tively) and the rmin is 1.2GB/s. Vanilla is unaware of theweight assignment. Hence, the high-priority 462.libquantumon Core 0 is 33% slower than the baseline reservation dueto contentions from other low priority tasks. Although it isclear that overall throughput is higher in Vanilla, it can-not provide isolated performance guarantee for one specifictask, in this case 462.libquantum. In contrast, MemGuard-RO delivers exactly the performance that is promised by eachtask’s reserved bandwidth (i.e., baseline) without experiencingnoticeable slowdowns by interferences from co-running tasks.Hence it can guarantee performance of the high-priority task(462.libquantum) at the cost of significant slowdowns of low-priority tasks. MemGuard-BR+SS improves performance of alltasks beyond their guaranteed performances by sharing best-effort bandwidth—through bandwidth reclaiming and sparesharing. This is especially effective for low-priority tasksas they are improved by 4.07x, 2.55x, 3.02x (433.milc,410.bwaves, 470.lbm respectively) compared to the baseline.The high-priority task (462.libquantum) is also improved by1.13x. MemGuard-BR+PS also improves performance of alltasks above their guaranteed performances, but different inthat it favors the high-priority task over low-priority tasks:the high-priority task is improved by 1.31x while low-prioritytasks are improved by 1.34x, 1.27x, and 1.25x. This is becauseMemGuard-BR+PS enforces the assigned weight all the time,by starting a new period immediately when the guaranteedbandwidth is used, while MemGuard-BR+SS doesn’t betweenthe time it satisfies the guaranteed bandwidth and the timewhen the next period starts (the interval is fixed in MemGuard-BR+SS).
Figure 14(b) follows the same weight settings but doublesthe rmin value to 2.4GB/s in order to compare its effecton throughput and performance isolation. Because the rmin
is doubled, each core’s reserved bandwidth is doubled andthe baseline of each task (Y-axis value of 1) is changedaccordingly. Note first that MemGuard-RO does not guaranteeperformance isolation anymore as 462.libquantum is 17%slower than the baseline. It is because the 2.4GB/s bandwidthcan not be guaranteed by the given memory system, causingadditional queuing delay to the 462.libquantum. This is con-sistent with our finding in Section 7.1. In both MemGuard-BR+SS and MemGuard-BR+PS, the IPC of 462.libquantumis further reduced, because other cores can generate moreinterference using reclaimed bandwidth that 462.libquantumdonated. On the other hand, both modes achieve higher overallthroughput as they behave very similar to Vanilla. This showsthe trade-off between throughput and performance isolationwhen using MemGuard.
7.4 Effect on Soft Real-time ApplicationsWe illustrate the effect of MemGuard for soft real-time ap-plications using a synthetic soft real-time image processingbenchmark fps. The benchmark processes an array of two HDimages (each image is 32bpp HD data: 1920x1080x4 bytes =7.9MB) in sequence. It is greedy in the sense that it attemptsto process as quickly as possible.
11

0 100 200 300 400 500 600 700 800
2 4 6 8 10 12 14 16 18 20
Fra
mes/
sec.
Time(sec)
Core0Core1Core2Core3
(a) Vanilla
0 100 200 300 400 500 600 700 800
2 4 6 8 10 12 14 16 18 20
Fra
mes/
sec.
Time(sec)
Core0Core1Core2Core3
(b) MemGuard-BR+SS
0 100 200 300 400 500 600 700 800
2 4 6 8 10 12 14 16 18 20
Fra
mes/
sec.
Time(sec)
Core0Core1Core2Core3
(c) MemGuard-BR+PS
Fig. 15: Frame-rate comparison. The weight assignment is 1:2:4:8 (Core0,1,2,3) and rmin = 1.2GB/s for MemGuard-BR+SSand MemGuard-BR+TR.
Figure 14(a) shows frame-rates of fps instances on our4-core system using MemGuard in two different modes(MemGuard-BR+SS, MemGuard-BR+PS) and without usingMemGuard (Vanilla). The weight assignment is 1:2:4:8 (forCore0,1,2,3 respectively) and the rmin is 1.2GB/s. Vanillais unaware of the weight assignment. Hence, all instancesshow almost identical frame-rates. MemGuard-BR+SS re-serves memory bandwidth for each core, as long as thetotal sum of the reservations is smaller than the guaranteedbandwidth. Therefore the frame-rates are different dependingon the amount of reservations. However, the ratio of frame-rates is different from the ratio of weight assignments becausethe total reserved bandwidth is small compared to the peakmemory bandwidth; after all cores are served their reservedbandwidths, they equally compete for the remaining band-width. On the other hand, the frame-rate ratios in MemGuard-BR+PS are in line with the ratios of assigned weights. Thisis because MemGuard-BR+PS enforces the given bandwidthassignment all the time (by starting a new period immediatelyafter cores use the rmin), resulting in better prioritization overMemGuard-BR+SS.
8 RELATED WORKResource reservation has been well studied especially in thecontext of CPU scheduling [22], [1] and has been appliedto other resources such as GPU [15], [16]. The basic ideais that each task or a group of tasks reserves a fractionof the processor’s available bandwidth in order to providetemporal isolation. Abeni and Buttazzo proposed ConstantBandwidth Server (CBS) [1] that implements reservation byscheduling deadlines under EDF scheduler. Based on CBS,many researchers proposed reclaiming policies in order toimprove average case performance of reservation schedulers[17], [8], [7], [18]. These reclaiming approaches are basedon the knowledge of task information (such as period) andthe exact amount of extra budget. While our work is inspiredby these works, we apply reclaiming on memory bandwidthwhich is very different from CPU bandwidth in many ways.
DRAM bandwidth is different from CPU bandwidth inthe sense that achieved bandwidth depends on the DRAMstate and access history which makes it difficult to guaranteeperformance. To solve this problem, several DRAM controllerswere proposed. Akesson et al. proposed Predator DRAM
controller that uses combination of regulators and credit basedscheduler to provide performance guarantee among multiplehardware components that access the DRAM [4], [3]. Reinekeet al. proposed PRET DRAM controller that partitions thephysical address space based on the internal structure of theDRAM chip in order to eliminate contention caused by sharingsuch internal resource [23]. Also in more general purposecomputing systems, DRAM controller is studied in order toimprove fairness and throughput. Nesbit et al. applied thenetwork fair queuing theory in designing DRAM controller[21]; Ebrahimi et al. proposed a cache controller level throt-tling mechanism [10], which is similar to our method in thesense that it effectively changes request rates. While theseDRAM controllers provide solutions to improve predictabilityand isolation in hardware level, we focus on a software levelsolution that can be applied to commodity hardware platforms.
OS level memory access control was first discussed inliterature by Bellosa [5], [6]. Similar to our work, this workalso proposed a software mechanism—increasing/decreasingthe number of idle loops in the TLB miss handler—in orderto control memory contention. There are, however, three majorlimitations, which are addressed in our work: First, it definesthe maximum reservable bandwidth in an ad-hoc manner—i.e., 0.9 × StreamB/W—that can be violated depending onmemory access patterns as shown in Section 2. Second, itdoes not address the problem of wasted memory bandwidthin case cores do not use their reserved bandwidth. Finally, itis designed for soft real-time guarantees as it allows cores tooveruse their reserved bandwidth until a control mechanismstabilizes the cores’ bandwidth usages by increasing/decreas-ing the idle loops in the TLB handler. It is, therefore, not ap-propriate to apply the technique for hard real-time applications.In contrast, our work clearly defines the maximum reservablebandwidth based on understanding of DRAM and the DRAMcontroller, provides stronger fine-grained bandwidth guaranteefor hard real-time applications, and provides reclaiming andsharing mechanisms to better utilize the memory bandwidthwhile still providing a minimum bandwidth guarantee to eachcore.
9 CONCLUSIONWe have presented MemGuard, a memory bandwidth reser-vation system, for supporting efficient memory performance
12

isolation on multicore platforms. It decomposes memory band-width as two parts, guaranteed bandwidth and best effortbandwidth. Memory bandwidth reservation is provided forthe guaranteed part for achieving performance isolation. Anefficient reclaiming mechanism is proposed for effectivelyutilizing the guaranteed bandwidth. It further improves systemthroughput by exploiting best effort bandwidth after each coresatisfies its guaranteed bandwidth. It has been implementedin Linux kernel and evaluated on a real multicore hardwareplatform.
Our evaluation with SPEC2006 benchmarks showed thatMemGuard is able to provide memory performance isolationunder heavy memory intensive workloads. It also showedthat the proposed reclaiming and sharing algorithms improveoverall throughput compared to a reservation only systemunder time-varying memory workloads.
ACKNOWLEDGEMENTS
This research is supported in part by ONR N00014-12-1-0046, Lockheed Martin 2009-00524, Rockwell Collins RPS#645038, NSERC, and NSF A17321.
REFERENCES[1] L. Abeni and G. Buttazzo. Integrating multimedia applications in hard
real-time systems. In Real-Time Systems Symposium (RTSS), pages 4–13. IEEE, 1998.
[2] L. Abeni, L. Palopoli, G. Lipari, and J. Walpole. Analysis of areservation-based feedback scheduler. In Real-Time Systems Symposium(RTSS), pages 71–80. IEEE, 2002.
[3] B. Akesson, K. Goossens, and M. Ringhofer. Predator: a predictablesdram memory controller. In Hardware/software codesign and systemsynthesis (CODES+ISSS), pages 251–256. ACM, 2007.
[4] B. Akesson, L. Steffens, E. Strooisma, and K. Goossens. Real-timescheduling using credit-controlled static-priority arbitration. In Embed-ded and Real-Time Computing Systems and Applications (RTCSA), pages3–14. IEEE, 2008.
[5] F. Bellosa. Process cruise control: Throttling memory access in a softreal-time environment. Technical Report TR-I4-97-02, University ofErlangen, Germany, July 1997.
[6] F. Bellosa. Process cruise control: Throttling memory access in a softreal-time environment. In Symposium on Operating Systems Principles(SOSP, Poster Session), 1997.
[7] M. Caccamo, G. Buttazzo, and L. Sha. Capacity sharing for overruncontrol. In Real-Time Systems Symposium (RTSS), pages 295–304. IEEE,2000.
[8] M. Caccamo, G. Buttazzo, and D. Thomas. Efficient reclaiming inreservation-based real-time systems. In Real-Time Systems Symposium(RTSS), pages 198–213. IEEE, 2005.
[9] T. Cucinotta, L. Abeni, L. Palopoli, and G. Lipari. A robust mechanismfor adaptive scheduling of multimedia applications. ACM Trans. Embed.Comput. Syst. (TECS), 10(4):46:1–46:24, November 2011.
[10] E. Ebrahimi, C.J. Lee, O. Mutlu, and Y.N. Patt. Fairness via sourcethrottling: a configurable and high-performance fairness substrate formulti-core memory systems. ACM Sigplan Notices, 45(3):335, 2010.
[11] J.L. Henning. Spec cpu2006 benchmark descriptions. ACM SIGARCHComputer Architecture News, 34(4):1–17, 2006.
[12] Intel. Intel R©64 and IA-32 Architectures Optimization ReferenceManual, April 2012.
[13] Intel. Intel R©64 and IA-32 Architectures Software Developer Manuals,2012.
[14] A. Jaleel. Memory Characterization of Workloads UsingInstrumentation-Driven Simulation, 2010.
[15] S. Kato, K. Lakshmanan, Y. Ishikawa, and R. Rajkumar. Resource shar-ing in gpu-accelerated windowing systems. In Real-Time and EmbeddedTechnology and Applications Symposium (RTAS). IEEE, 2011.
[16] S. Kato, K. Lakshmanan, R. Rajkumar, and Y. Ishikawa. Timegraph:Gpu scheduling for real-time multi-tasking environments. In USENIXAnnual Technical Conference (ATC). USENIX, 2011.
[17] G. Lipari and S.K. Baruah. Greedy reclaimation of unused bandwidthin constant bandwidth servers. In Euromicro Conference on Real-TimeSystems (ECRTS). IEEE, 2000.
[18] L. Marzario, G. Lipari, P. Balbastre, and A. Crespo. Iris: A newreclaiming algorithm for server-based real-time systems. In Real-Timeand Embedded Technology and Applications Symposium (RTAS), 2004.
[19] L. McVoy, C. Staelin, et al. Lmbench: Portable tools for performanceanalysis. In USENIX Annual Technical Conference. USENIX, 1996.
[20] O. Mutlu and T. Moscibroda. Stall-time fair memory access schedulingfor chip multiprocessors. In International Symposium on Microarchitec-ture (MICRO), pages 146–160. IEEE, 2007.
[21] K.J. Nesbit, N. Aggarwal, J. Laudon, and J.E. Smith. Fair queuingmemory systems. In International Symposium on Microarchitecture(MICRO), pages 208–222. IEEE, 2006.
[22] R. Rajkumar, K. Juvva, A. Molano, and S. Oikawa. Resource kernels:A resource-centric approach to real-time and multimedia systems. InMultimedia Computing and Networking (MNCN), January 1998.
[23] J. Reineke, I. Liu, H.D. Patel, S. Kim, and E.A. Lee. Pret dramcontroller: Bank privatization for predictability and temporal isolation.In Hardware/software codesign and system synthesis (CODES+ISSS),pages 99–108. ACM, 2011.
[24] I. Shin and I. Lee. Periodic resource model for compositional real-timeguarantees. In Real-Time Systems Symposium (RTSS), pages 2–13. IEEE,2003.
[25] B. Sprunt, L. Sha, and J. Lehoczky. Aperiodic task scheduling for hard-real-time systems. Real-Time Systems, 1(1):27–60, 1989.
[26] H. Yun, G. Yao, R. Pellizzoni, M. Caccamo, and L. Sha. Memguard:Memory bandwidth reservation system for efficient performance isola-tion in multi-core platforms. In Real-Time and Embedded Technologyand Applications Symposium (RTAS), 2013.
13













![Banshee: Bandwidth-Efficient DRAM Caching Via Software ...Tagless DRAM Cache (TDC [10]) also uses address remap-ping, but enables frequent cache replacement via hardware-managed TLB](https://img.pdfslide.us/doc/110x75/5f5b2ff9c3e89664d66f964e/banshee-bandwidth-eficient-dram-caching-via-software-tagless-dram-cache-tdc.jpg)






![Energy-Efficient BaseBand Processing via vBBU Migration in ...To alleviate the bandwidth requirements of the fronthaul, in a previous work [6], we proposed an architecture called](https://img.pdfslide.us/doc/110x75/600311f523630f405b4a5bf4/energy-eficient-baseband-processing-via-vbbu-migration-in-to-alleviate-the.jpg)








