Embed Size (px)
Citation preview

Measures to Detect Word Measures to Detect Word Substitution in Substitution in
Intercepted CommunicationIntercepted Communication
David Skillicorn, SzeWang FongDavid Skillicorn, SzeWang Fong
School of Computing, Queen’s UniversitySchool of Computing, Queen’s University
Dmitri RoussinovDmitri Roussinov
W.P. Carey School of Business, Arizona State W.P. Carey School of Business, Arizona State UniversityUniversity

What my lab does:
1. Detecting anomalies when their attributes have been chosen to try and make them undetectable;
2. Deception detection in text (currently Enron, Canadian parliament, Canadian election speeches, trial evidence);
3. Markers in text for anomalies and hidden connections.

Governments intercept communication as a defensive measure. Increasingly, this requires `domestic’ interception as well as more longstanding external interception – a consequence of asymmetric warfare. A volatile issue!
Organizations increasingly intercept communication (e.g. email) to search for intimidation, harassment, fraud, or other malfeasance. This may happen in an online way, e.g. as a response to due diligence requirements of post-Enron financial regulation; or may happen forensically after an incident.
There’s no hope of human processing of all of this communication. Indeed, there’s too much for most organizations to afford sophisticated data-mining of all of it.
Ways to automatically select the interesting messages are critical.
Early-stage filtering of communication traffic must:
* be cheap* have a low false negative rate (critical)* but a high false positive rate doesn’t matter (too much)
The goal is to be sure about innocence.
This is important to communicate to the public – all messages/calls/emails are not examined equally.
First technique for message selection: use a list of words whose presence (with the right frequency) in a message indicates an interesting message.
This seems like a very weak technique, because the obvious defense is not to use words that might be on the watchlist. However, …
* although the existence of the list might be public, it’s much harder to guess what’s on it and where it ends. E.g. `nuclear’ yes `bomb’ yes `ammonium nitrate’ ?? `Strasbourg cathedral’ ??
* the list’s primary role is to provoke a reaction in the guilty (but not in the innocent)
One possible reaction: encryption – but this is a poor idea since encryption draws attention to the message.
Another reaction: replace words that might be on the watchlist by other, innocuous, words.
Which words to choose as replacements?
If the filtering is done by humans, then substitutions should ‘make sense’,
e.g. Al Qaeda `attack’ `wedding’ works well, because weddings happen at particular places, and require a coordinated group of people to travel and meet.

Of course, large-scale interception cannot be handled by human processing.
If the filtering is done automatically, substitutions should be syntactically appropriate – e.g. of similar frequency.
Can substitutions like this be detected automatically?
YES, because they don’t fit as well into the original sentence;
The semantic differences can be detected using syntactic markers and oracles for the natural frequency of words, phrases, and bags of words.

We define a set of measures that can be applied to a sentence with respect to a particular target word (usually a noun).
1. Sentence oddity (SO), Enhanced sentence oddity (ESO)
SO = frequency of bag of words, target word removed frequency of entire bag of words
ESO = frequency of bag of words, target word excluded frequency of entire bag of words
Intuition: when a contextually appropriate word is removed, the frequency doesn’t change much; when a contextually inappropriate word is removed, the frequency may increase sharply.
increase possible substitution

Example original sentence:
“we expect that the attack will happen tonight”
Substitution: `attack’ `campaign’
“we expect that the campaign will happen tonight”
f(we expect that the attack will happen tonight) = 2.42Mf(we expect that the will happen tonight) = 5.78MSO = 2.4
f(we expect that the campaign will happen tonight) = 1.63Mf(we expect that the will happen tonight) = 5.78MSO = 3.5

2. Left, right and average k-gram frequencies
Many short exact (quoted) strings do not occur, even in large repositories!!
k-grams estimate frequencies of target words in context, but must keep the context small (or else the estimate is 0).
left k-gram = frequency of exact string from closest non-stopword to the left of the target word, up to and including the target word.
right k-gram = frequency of exact string from target word up to and including closest non-stopword to the right.
average k-gram = average of left and right k-grams.
small k-gram possible substitution

Examples of exact string frequencies
“the attack will happen tonight” f = 1 even though this seems like a plausible, common phrase
Left k-gram: “expect that the attack” f= 50Right k-gram: “attack will happen” f = 9260
Left k-gram: “expect that the campaign” f = 77 Right k-gram: “campaign will happen” f = 132
This should be smaller than 50, but may be affected by ‘election campaign’

3. Maximum, minimum, average hypernym oddity (HO)
The hypernym of a word is the word or phrase above it in a taxonomy of meaning, e.g. `cat’ `feline’.
If a word is contextually appropriate, replacing it by its hypernym creates an awkward (pompous) sentence, with lower frequency.
If a word is contextually inappropriate, replacing it by its hypernym tends to make the sentence more appropriate, with greater frequency.
HO = frequency of bag of words with hypernym – frequency of original bag of words
increase possible substitution

Hypernym examples
Original sentence:
we expect that the attack will happen tonight f = 2.42Mwe expect that the operation will happen tonight fH = 1.31M
Sentence with a substitution:
we expect that the campaign will happen tonight f = 1.63Mwe expect that the race will happen tonight fH = 1.97M

Hypernyms are semantic relationships, but we can get them automatically using Wordnet (wordnet.princeton.edu).
Most words have more than one hypernym, because of their different senses.
We can compute the maximum, minimum and average hypernym oddity over the possible choices of hypernyms.

4. Pointwise mutual information (PMI)
PMI = f(target word) f(adjacent region) f(target word + adjacent region)
where the adjacent region can be on either side of the target. We use the maximum PMI calculated over all adjacent regions that have non-zero frequency. (Frequency drops to zero with length quickly.)
PMI looks for the occurrence of the target word as part of some stable phrase.
increase possible substitution

Frequency oracles:
We use Google and Yahoo as sources of natural frequencies for words, quoted strings, and bags of words.
Some issues:
* we use frequency of pages as a surrogate for frequency of words;* we don’t look at how close together words appear in each page, only whether they all occur;* search engines handle stop words in mysterious ways* order of words matters, even in bag of word searches* although Google and Yahoo claim to index about the same number of documents, their reported frequencies for the same word differ by a factor of at least 6 in some cases

Test data
We want text that is relatively informal, because most intercepted messages will not be polished text (email, phone calls).
We selected sentences of length 5-15 from the Enron email corpus.
Many of these sentences are informal (some are bizarre).
We constructed a set of sentences containing substitutions by replacing the first noun in each original sentence by a frequency-matched substitute.
We discarded sentences where the first noun wasn’t in the BNC corpus, or did not have a hypernym known to Wordnet.

We built a set of 1714 ‘normal’ sentences, and 1714 sentences with a substitution (but results were very stable for more than about 200 sentences)
We also constructed a similar, smaller, set from the Brown corpus (which contains much more formal, and older, texts).

For each measure, we built a decision tree predicting normal vs substitution, using the measure value as the single attribute.
This gives us insight about the boundary between normal and substitution sentences for each kind of measure.
Measure Boundary: odd if
Semantic oddity > 4.6
Enhanced semantic oddity > 0.98
Left k-gram < 155
Right k-gram < 612
Average k-gram < 6173
Min hypernym oddity > -89129
Max hypernym oddity > -6
Average hypernym oddity > -6
Pointwise mutual information
> 1.34
These are newer results than those in the paper
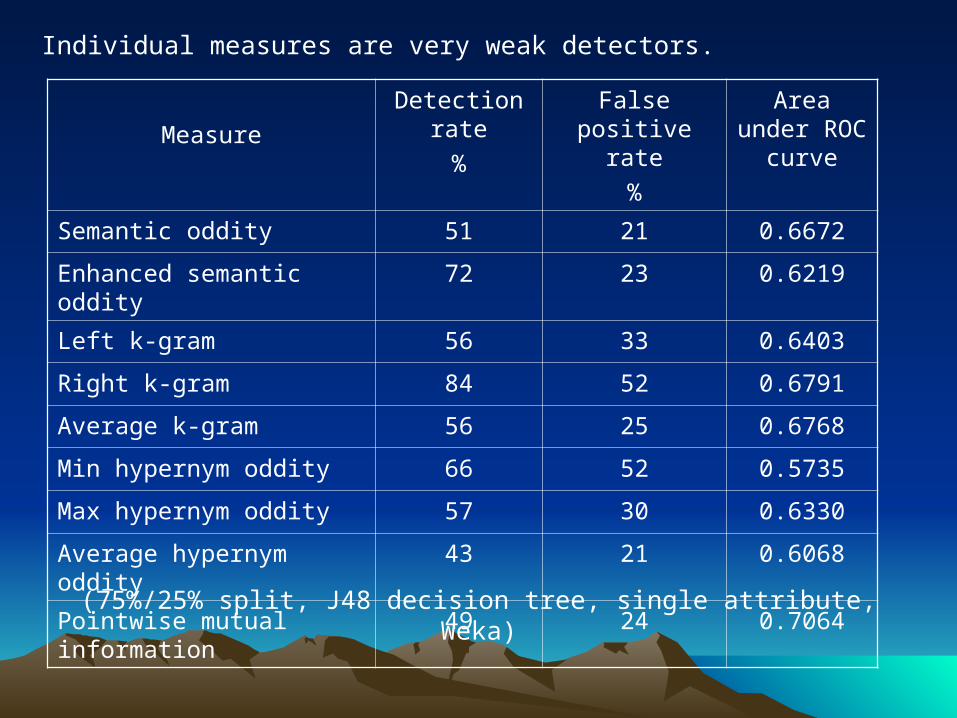
Individual measures are very weak detectors.
(75%/25% split, J48 decision tree, single attribute, Weka)
MeasureDetection
rate%
False positive rate%
Area under ROC
curve
Semantic oddity 51 21 0.6672
Enhanced semantic oddity
72 23 0.6219
Left k-gram 56 33 0.6403
Right k-gram 84 52 0.6791
Average k-gram 56 25 0.6768
Min hypernym oddity 66 52 0.5735
Max hypernym oddity 57 30 0.6330
Average hypernym oddity
43 21 0.6068
Pointwise mutual information
49 24 0.7064
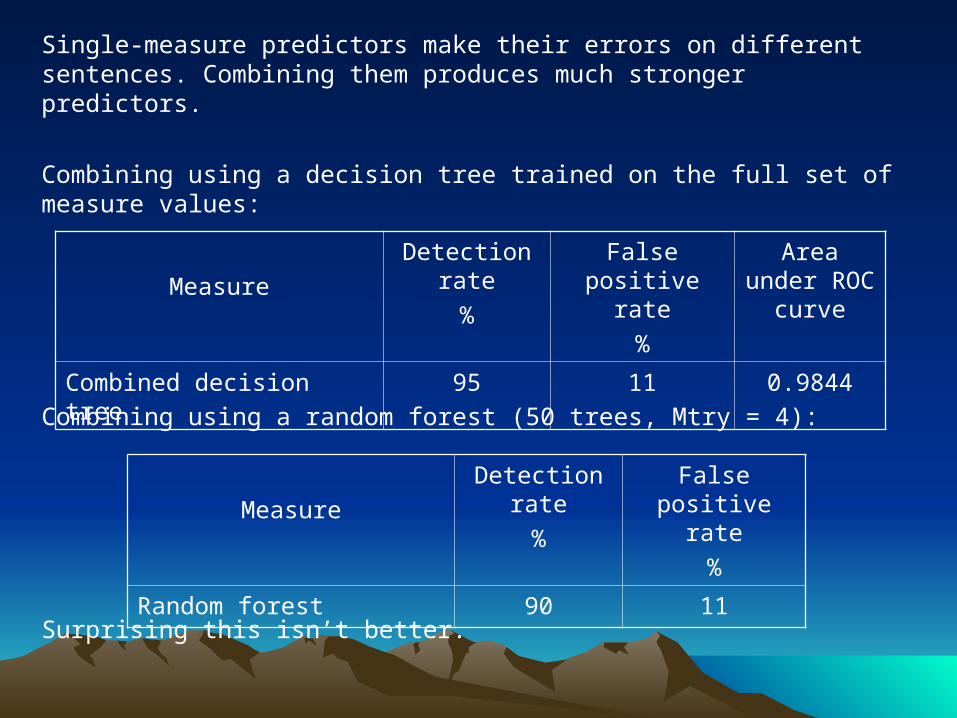
Single-measure predictors make their errors on different sentences. Combining them produces much stronger predictors.
Combining using a decision tree trained on the full set of measure values:
Combining using a random forest (50 trees, Mtry = 4):
Surprising this isn’t better.
MeasureDetection
rate%
False positive rate%
Area under ROC
curve
Combined decision tree 95 11 0.9844
MeasureDetection
rate%
False positive rate%
Random forest 90 11
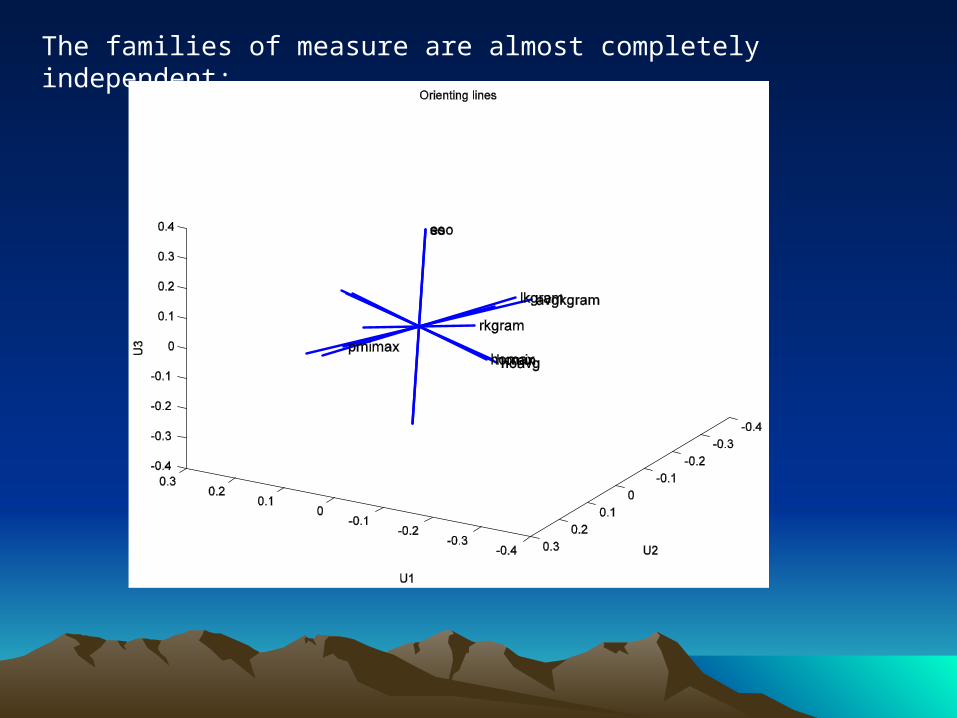
The families of measure are almost completely independent:
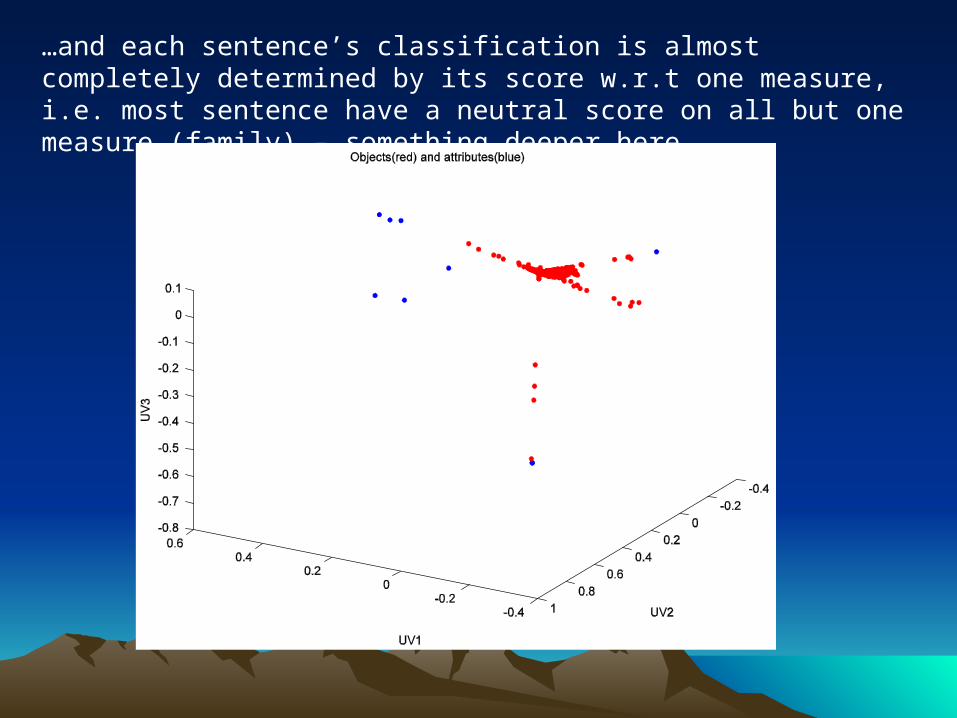
…and each sentence’s classification is almost completely determined by its score w.r.t one measure, i.e. most sentence have a neutral score on all but one measure (family) – something deeper here.
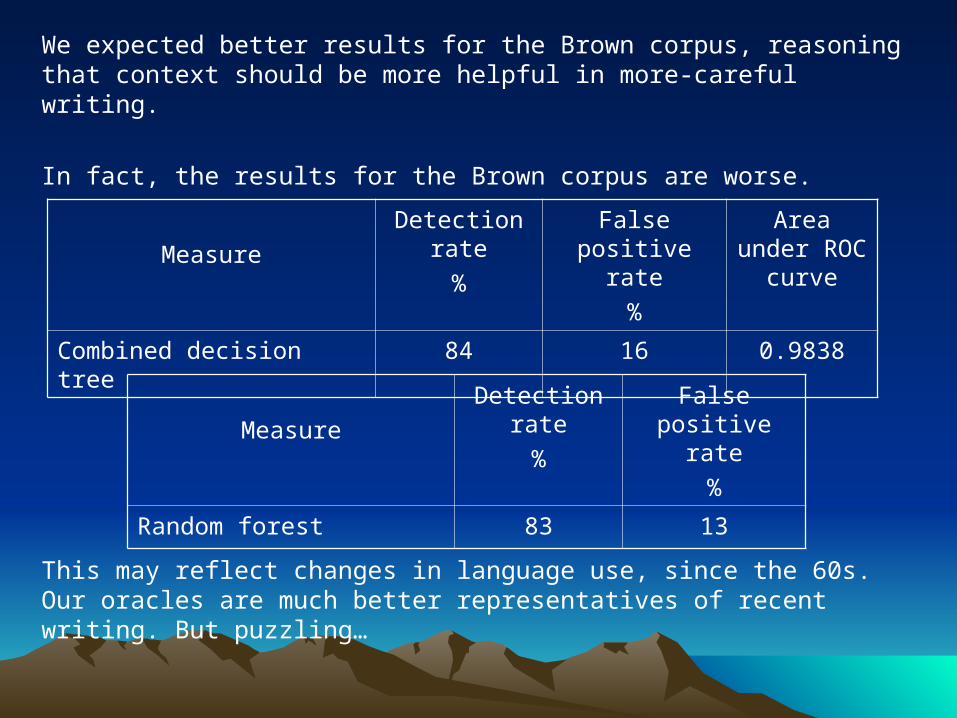
We expected better results for the Brown corpus, reasoning that context should be more helpful in more-careful writing.
In fact, the results for the Brown corpus are worse.
This may reflect changes in language use, since the 60s. Our oracles are much better representatives of recent writing. But puzzling…
MeasureDetection
rate%
False positive rate%
Area under ROC
curve
Combined decision tree 84 16 0.9838
MeasureDetection
rate%
False positive rate%
Random forest 83 13

Results are similar (within a few percentage points) across different oracles: Google, Yahoo, MSN despite their apparent differences.
Results are also similar if the substituted word is much less frequent than the word it replaces.
No extra performance from rarity of the replacement word. (cf Skillicorn ISI 2005 where this was critical)
But some loss of performance if the substituted word is much more frequent than the word it replaces.
This is expected since common words fit into more contexts.
Why do the measures make errors?
Looking at the first 100 sentences manually…
* some of the original sentences are very strange already, email written in a hurry or with strange abbreviations or style
* there’s only one non-stopword in the entire sentence, so no real context
* the substitution happens to be appropriate in the context
There’s some fundamental limit to how well substitutions can be detected because of these phenomena. Both detection rate and false positive rate may be close to their limits.

Mapping sentence predictions to message predictions:
There’s considerable scope to get nicer properties on a per-message basis by deciding how many sentences should be flagged as suspicious before a message is flagged as suspicious.
It’s likely that an interesting message contains more than 1 sentence with a substitution.
So a rule like: “select messages with more than 4 suspicious sentences, or more than 10% suspicious sentences” reduces the false positive rate, without decreasing the detection rate much.

Summary:
A good way to separate ‘bad’ from ‘good’ messages is to deploy a big, visible detection system (whose details, however, remain hidden), and then watch for reaction to the visible system
Often this reaction is easier to detect than the innate differences between ‘bad’ and ‘good’.
Even knowing this 2-pronged approach, senders of ‘bad’ messages have to react, or else risk being detected by the visible system.

For messages, the visible system is a watchlist of suspicious words.
The existence of the watchlist can be known, without knowing which words are on it.
Senders of ‘bad’ messages are forced to replace any words that might be on the watchlist – so they probably over-react.
These substitutions create some kind of discontinuity around the places where they occur.
This makes them detectable, although a variety of (very) different measures must be used – and, even then, decent performance requires combining them.
So far, detection performance is ~95% with a ~10% false positive rate.































