Embed Size (px)
DESCRIPTION
MC 2 : Map Concurrency Characterization for MapReduce on the Cloud. Mohammad Hammoud and Majd Sakr. Hadoop MapReduce. MapReduce is now a pervasive data processing framework on the cloud Hadoop is an open source implementation of MapReduce - PowerPoint PPT Presentation
Citation preview

1
MC2: Map Concurrency Characterization for MapReduce on
the Cloud
Mohammad Hammoud and Majd Sakr

Hadoop MapReduce• MapReduce is now a pervasive data processing framework on the cloud
• Hadoop is an open source implementation of MapReduce
• Hadoop MapReduce incorporates two phases, Map and Reduce phases, which encompass multiple Map and Reduce tasks
Map Task
Map Task
Map Task
Map Task
Reduce Task
Reduce Task
Reduce Task
Partition
PartitionPartition
Partition
PartitionPartition PartitionPartition
Partition
To HDFSDataset
HDFS
HDFS BLK
HDFS BLK
HDFS BLK
HDFS BLK
Map PhaseShuffle Stage
Merge Stage Reduce Stage
Reduce Phase 2
Partition
Split 0
Split 1
Split 2
Split 3
PartitionPartition
Partition
PartitionPartition
Partition
Partition

How to Effectively Configure Hadoop?
• Hadoop has more than 190 configuration parameters 10-20 parameters can have significant impact on job performance
• A main challenge that faces Hadoop users on the cloud: Running MapReduce applications in the most economical way While still achieving good performance
• The burden falls on Hadoop users to effectively configure Hadoop
• Hadoop’s default configuration is not necessarily optimal Several X speedup/slowdown between tuned and default Hadoop
3

Map Tasks and Map Concurrency• Among the influential configuration parameters in Hadoop are:
Number of Map Tasks Determined by the number of HDFS blocks
Number of Map Slots Allocated to run Map Tasks
Core Switch
TaskTracker1
Request a Map TaskSchedule a Map Task at an Empty Map Slot on TaskTracker1
Rack Switch 1 Rack Switch 2
TaskTracker2 TaskTracker3 TaskTracker4 TaskTracker5 JobTrackerMT1 MT2 MT3MT2 MT3
Map Concurrency = Map Tasks/Map Slots
4

Impact of Map Concurrency
Observations: Map concurrency has a strong impact on Hadoop performance Hadoop’s default Map concurrency settings are not optimal For effective execution, Hadoop might require different Map
concurrencies for different applications
[2,65] [6,33] [2,448] [4,56] [2,84] [4,42] [2,448] [4,224] [2,224] [4,224]0
100200300400500600700800900
Series1
[Number of Map Slots Per Node, Total Number of Map Tasks]
Exec
ution
Tim
e (S
econ
ds) WordCount-CESobel K-Means Sort WordCount-CD
Default Hadoop Tuned Hadoop
5

Our Work• We propose MC2:
A simple, fast and static “utility” program
Which predicts the best Map Concurrency for any given MapReduce application
• MC2 is based on a mathematical model which exploits two main MapReduce internal characteristics:
Map Setup Time (or the total overhead for setting up all map tasks in a job)
Early Shuffle (or the process of shuffling intermediate data while the Map phase is still running) 6

Talk Roadmap
• Characterizing Map Concurrency Map Concurrency ≤ 1 Map Concurrency > 1
• A Mathematical Model for Predicting Runtimes of MR jobs
• The MC2 Predictor
• Quantitative Evaluation
• Concluding Remarks
7

Talk Roadmap
• Characterizing Map Concurrency Map Concurrency ≤ 1 Map Concurrency > 1
• A Mathematical Model for Predicting Runtimes of MR jobs
• The MC2 Predictor
• Quantitative Evaluation
• Concluding Remarks
8

Concurrency with a Single Map Wave• The maximum number of concurrent Map tasks is bound by the total
number of Map slots in a Hadoop cluster We refer to the maximum concurrent Map tasks as Map Wave
MS1
MS2
MS3
MS4
MT1
MT2
MS5
MS6
MS1
MS2
MS3
MS4 MT3
MT4
MS5
MS6
MT1
MT2
Ends at time t + MST Ends at time t/2 + MST
MS1
MS2
MS3
MS4
MS5
MS6
Ends at time t/2 + 2MST
MST = Map Setup Time
• Fill as much Map slots as possible within a Map wave More Parallelism & Better Utilization
9
tMST
t/22MST
t/4 + t/4 = t/2
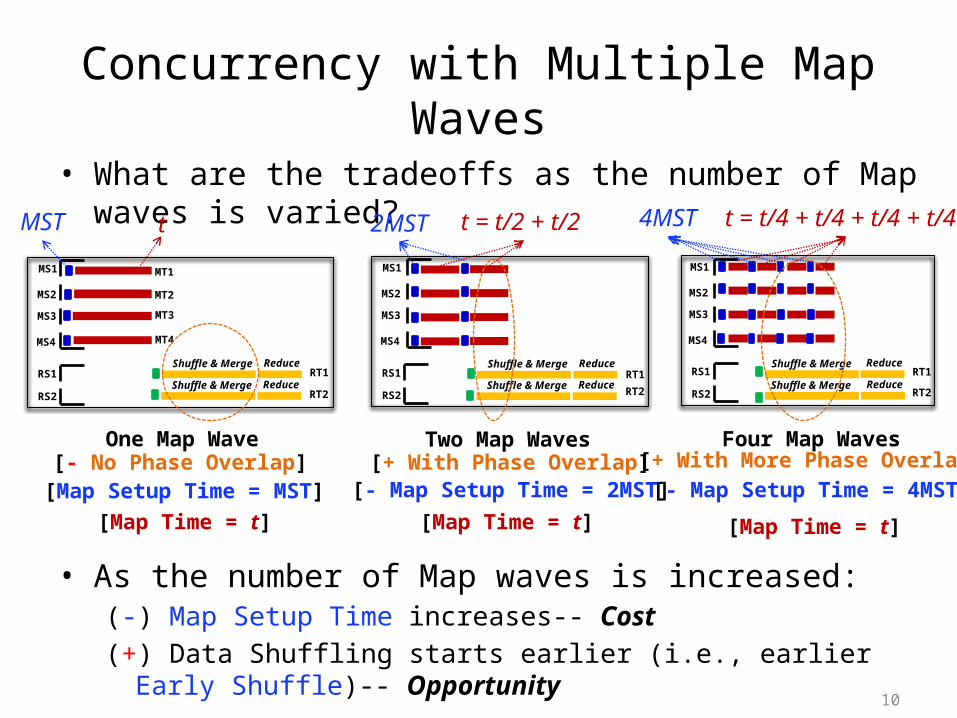
Concurrency with Multiple Map Waves• What are the tradeoffs as the number of Map waves is varied?
MS1
MS2
MS3
MS4
MT3
MT4
RS1
RS2
RT1
RT2
MT2
MT1
Shuffle & Merge Reduce
Shuffle & Merge Reduce
One Map Wave
MS1
MS2
MS3
MS4
RS1
RS2Shuffle & Merge Reduce
Shuffle & Merge ReduceRT1
RT2
RS1
RS2Shuffle & Merge Reduce
Shuffle & Merge Reduce
MS1
MS2
MS3
MS4
RT1
RT2
Two Map Waves Four Map Waves
• As the number of Map waves is increased:(-) Map Setup Time increases-- Cost(+) Data Shuffling starts earlier (i.e., earlier Early Shuffle)-- Opportunity
[- No Phase Overlap][Map Setup Time = MST]
[+ With Phase Overlap][- Map Setup Time = 2MST]
[+ With More Phase Overlap][- Map Setup Time = 4MST]
[Map Time = t]
t 2MST t = t/2 + t/2 4MST t = t/4 + t/4 + t/4 + t/4
[Map Time = t] [Map Time = t]
MST
10

When to Trigger Early Shuffle?
• Early Shuffle can be activated earlier by increasing the number of Map Waves
• The preference of when exactly the early shuffle process must be activated varies across applications
• The more the amount of data an application shuffles, the earlier the early shuffle process must be triggered With a larger shuffle data, a larger number of map waves is preferred
• We devise a mathematical model that allows locating the best number of map waves for any given MR application
11

Talk Roadmap
• Characterizing Map Concurrency Map Concurrency ≤ 1 Map Concurrency > 1
• A Mathematical Model for Predicting Runtimes of MR jobs
• The MC2 Predictor
• Quantitative Evaluation
• Concluding Remarks
12

13
A Mathematical Model (1)
• Assumptions: Map tasks start and finish at similar times Time impact of speculative execution is masked
Ignore slow Mappers and Reducers Map time is typically longer than Map Setup Time
Shuffle & Merge ReduceRS1
RS2
Total Map Setup Time (MST)
MS1
MS2MS3
MS4
Exposed Shuffle Time (EST)
Hidden Shuffle Time (HST)
Runtime
Reduce Time

A Mathematical Model (2)
14
Shuffle & Merge ReduceRS1
RS2
Total Map Setup Time (MST)
MS1
MS2MS3
MS4
Exposed Shuffle Time (EST)
Hidden Shuffle Time (HST)
Runtime
Reduce Time
(1)
(2)
(3)
(4)

Talk Roadmap
• Characterizing Map Concurrency Map Concurrency ≤ 1 Map Concurrency > 1
• A Mathematical Model for Predicting Runtimes of MR jobs
• The MC2 Predictor
• Quantitative Evaluation
• Concluding Remarks
15

MC2: Map Concurrency Characterization
• Our mathematical model can be utilized to predict the best number of map waves for any given MR application– Fix all the model’s factors except the “Number of Map Waves”– Measure Runtime for a range of map wave numbers– Select the minimum Runtime
16
Single Map Wave Time
MST
1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
50
100
150
200
250
300
EST HST Total MST Runtime
# of Map Waves
Seco
nds
Sweet Spot
Total MST HST EST Runtime
Shuffle Data
Shuffle Rate
Reduce Time
Initial Map Slots Number
Compute:

Talk Roadmap
• Characterizing Map Concurrency Map Concurrency ≤ 1 Map Concurrency > 1
• A Mathematical Model for Predicting Runtimes of MR jobs
• The MC2 Predictor
• Quantitative Evaluation
• Concluding Remarks
17
18
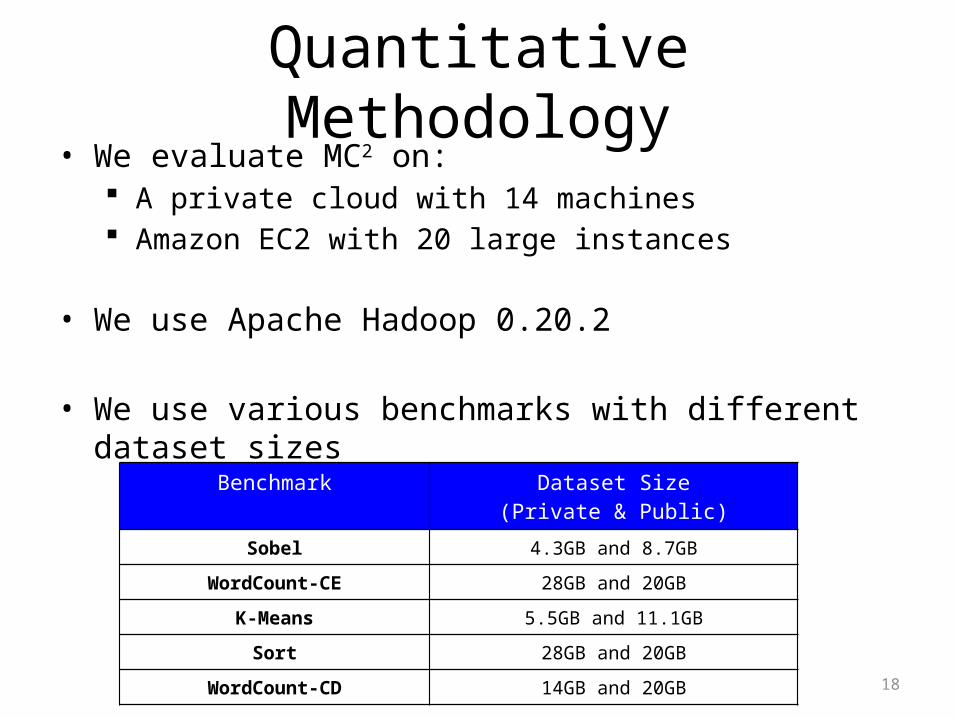
Quantitative Methodology• We evaluate MC2 on:
A private cloud with 14 machines Amazon EC2 with 20 large instances
• We use Apache Hadoop 0.20.2
• We use various benchmarks with different dataset sizes
Benchmark Dataset Size(Private & Public)
Sobel 4.3GB and 8.7GB
WordCount-CE 28GB and 20GB
K-Means 5.5GB and 11.1GB
Sort 28GB and 20GB
WordCount-CD 14GB and 20GB
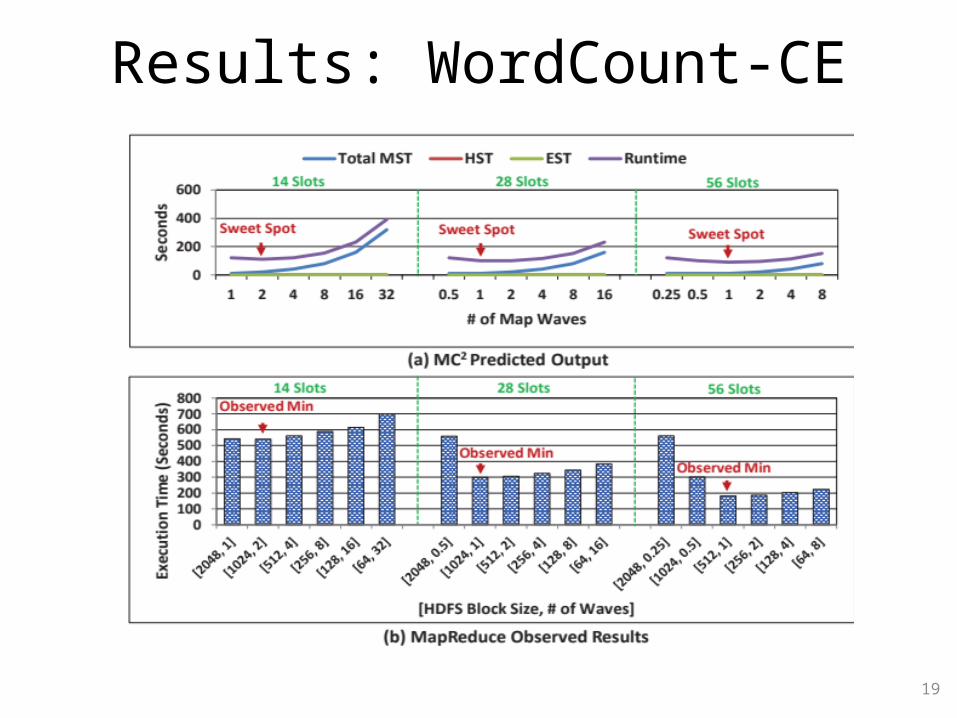
Results: WordCount-CE
19

Results: K-Means
20

Results: Sort
21

Results: WordCount-CD
22
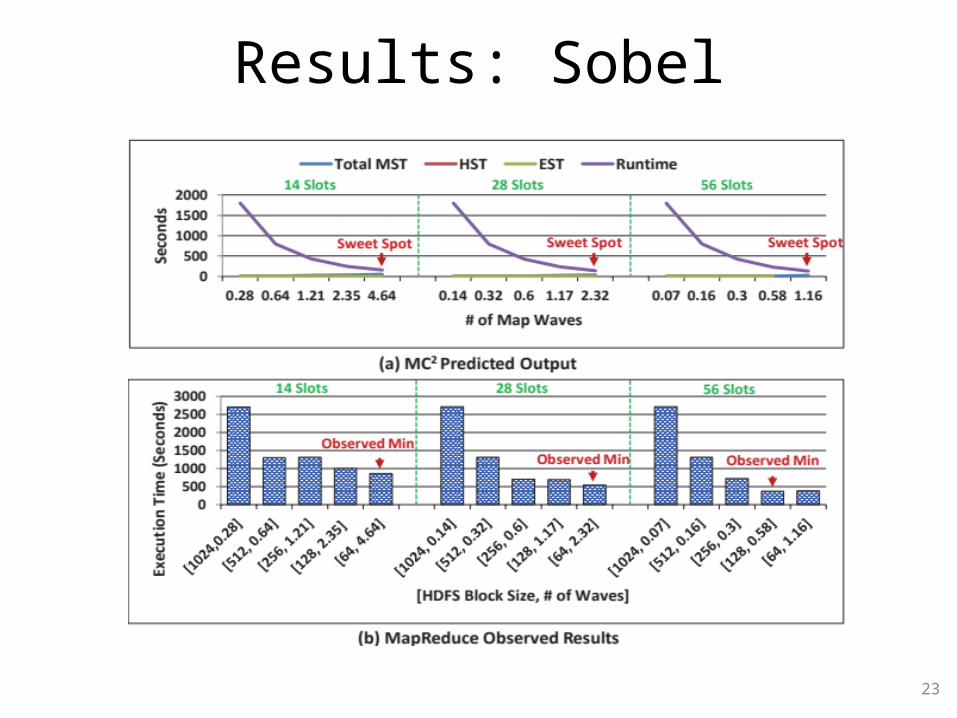
Results: Sobel
23

MC2 Results: Summary
Benchmark Private Cloud Amazon EC2WordCount-CE 2.1X 1.2X
K-Means 1.34X 1.13XSort 1.07X 1.1X
WordCount-CD 1.1X 2.2XSobel 1.43X 1.04X
Runtime speedups provided by MC2 versus default Hadoop
24
• MC2 correctly predicts the best numbers of map waves for WordCount-CE, K-Means, Sort, WordCount-CD and Sobel on our private cloud and on Amazon EC2
• Even if a miss-prediction occurs, it is typically the case that the sweet spot is very close to the observed minimum

Talk Roadmap
• Characterizing Map Concurrency Map Concurrency ≤ 1 Map Concurrency > 1
• A Mathematical Model for Predicting Runtimes of MR jobs
• The MC2 Predictor
• Quantitative Evaluation
• Concluding Remarks
25

26
Concluding Remarks• We observed a strong dependency between map concurrency and
MapReduce performance
• We realized that a good map concurrency configuration can be determined by simply leveraging two main MapReduce characteristics, data shuffling and map setup time (MST)
• We developed a mathematical model that exploits data shuffling and MST, and built MC2 which uses the model to predict the best map concurrency for any given MR application
• MC2 works successfully on a private cloud and on Amazon EC2

27
Thank You!
Questions?





























