Embed Size (px)
Citation preview

4/1/2010 111
Map/Reduce• Topics
• MapReduce.• The MapReduce Database Debate.
• Learning objectives• Identify data management problems for which map/reduce is a
good approach.• Design map and reduce functions to solve data management
problems.• Have an opinion in the map/reduce debate:
• Is the debate relevant?• Should map/reduce and databases be in the same discussion?• What is similar about them?• What are the key differences?

4/1/2010 2
Overview• Map/Reduce is not a fundamentally new idea.
• These are primitives from functional programming that have beenaround “forever.”
• The “new” thing here is the implementation.• Highly parallelizable• Can be implemented by mortal programmers, not just parallelizing gurus.• Hides system failures, restart, reliability, etc.
• Google uses Map/Reduce to process vast amounts of data:• Data analysis• Index creation• Etc.
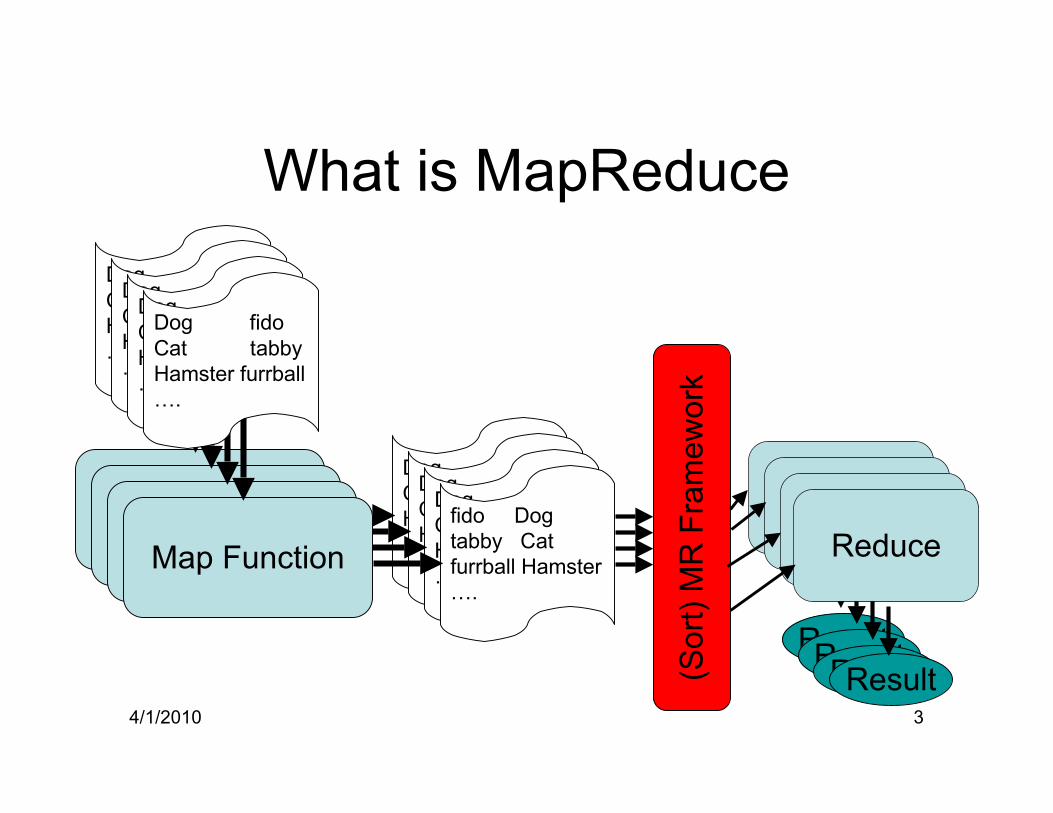
4/1/2010 3
ResultResultResultResult
What is MapReduce
Dog fidoCat tabbyHamster furrball….
Dog fidoCat tabbyHamster furrball….
Dog fidoCat tabbyHamster furrball….
fido Dogtabby Catfurrball Hamster….
Map FunctionMap FunctionMap FunctionMap Function
Dog fidoCat tabbyHamster furrball….
Dog fidoCat tabbyHamster furrball….
Dog fidoCat tabbyHamster furrball….
Dog fidoCat tabbyHamster furrball….
(Sor
t) M
R F
ram
ewor
k
ReduceReduceReduceReduce

4/1/2010 4
Sample Applications
• Distributed Grep• URL Access Frequency• Reverse Web-Link Graph• Term-Vector per Host• Inverted Index• Distributed Sort

4/1/2010 5
Target Environment
• Cluster of PCs (dual processor x86, Linux, 2-4 GB)• Commodity ethernet (100 Mbit, 1 Gbit)• Thousands of machines• Cheap IDE drives on GFS• Batch scheduling• Characteristics:
• Stuff fails (all the time)• Demands are huge -- must have parallelism.

4/1/2010 6
Implementation• Input split into M units (splits), one per machine.• Each split is 16-64 MB.• User specifies R, the parallelism of Reduce.• Hash function maps intermediate key space onto R nodes (by
key).• Map writes intermediate into buffer; buffers are written into R
files.• Master notifies Reduce of the locations of the partitioned files.• Reduce remotely reads file, sorts by key, and then performs
reduction. (Sort may be in-memory or external.)• Reduce appends output to partition results file.• User program must read all R results files.

4/1/2010 7
Data Structures
• Master keeps track of each task's status:• Idle, in-progress, completed, on-what-machine
• Master keeps track of each worker machine.• Master knows the location and size of each
intermediate file.

4/1/2010 8
Fault Tolerance• Master uses heartbeat to check on status of workers.• Master declares a worker dead after a timeout.• Completed map tasks (with intermediate results on local disks)
are re-run at the master's direction.• Completed reduce tasks are not rerun, because their output is
on GFS.• In-progress tasks on a failed worker are restarted• Reduce tasks find out from the master where to read their data
after a failure.• Master is a single point of failure, but new master can pick up
from a checkpoint. (In practice, if the master fails, the entire jobis aborted and restarted.)

4/1/2010 9
Optimization• Locality
• GFS is highly replicated.• When possible, use the machine hosting a copy of a GFS file to
process that file.• If no such machine is available, pick one on the same network as
one containing the file.• Refinements
• User-specified partitioning of data prior to reduce.• Intermediate keys are sorted within a partition.• Can run combiners (a local reduce) after a map before parceling
out to reduce functions.• Library keeps track of bad records and skips them.• Status information generated and made available to users.

4/1/2010 10
Scale• Want M and R larger than number of workers.• “Typical numbers”
• 200,000 map jobs• 5000 reduce jobs• 2000 worker nodes
• A few slow machines can slow entire job (a lot).• Towards end of job, master schedules backup job to compensate
for slow jobs.• Performance evaluation:
• 1 TB data• •1800 dual processor machines• 2 * 160 GB * 1800 disks

4/1/2010 11
The Great Debate
• January 2008, two famous database experts(Stonebraker and DeWitt) write an article title,“MapReduce: A Giant Step Backwards?”
• The “community” goes wild!• A debate ensues.• The debate continues today
• Panel at 2009 HPTS• 2010 CACM paper• Ongoing research combining MapReduce and conventional
database technology.

4/1/2010 12
The Original Argument
• Giant step backwards in terms of a paradigm forlarge-scale data intensive applications.
• Sub-optimal implementation, using brute forceinstead of indexing.
• Not at all novel (been in functional langauges foryears).
• Missing most of the features traditionally in a DBMS.• Incompatible with tools that DBMS users depend on.

4/1/2010 13
Why a Step Backwards?
• No schema• Application *is* the schema• No higher level language

4/1/2010 14
Implementation Criticism
• No indexes• There have been parallel DBMS systems since the
80's• There are cluster-wide parallel SQL implementations• Skew in key space is a problem for MapReduce; well-
studied in the DB literature.• There are *a lot* of intermediate files and the
competition for network and disk bandwidth to movethose around is a problem.

4/1/2010 15
Not Novel
• Extensible systems permit user-defined functions.• Lots of systems had parallel aggregation support.• Commercial systems (Teradata) has offered
everything MapReduce does.

4/1/2010 16
Missing Features
• No bulk load into desired format.• No indexing• No updates• No transactions• No integrity constraints• No referential integrity• No views

4/1/2010 17
Incompatible with DBMS
• Doesn't work with report writers (Crystal reports)• Doesn't work with Business intelligence tools
(Business objects)• No data mining• No replication• No database design tools.

4/1/2010 18
Responses varied fromInsightful to Abusive
• “MapReduce isn’t meant to replace a RDB.”• MayReduce is not a database framework, instead, it’s a
computational framework.• This is the basic problem with database people. They view
everything as a database, and that everything must be donein/with a database.
• I think you could write an equivalent article: “Airplanes: A majorstep backward.” You could say something like, “road are good,everyone knows that, why would you throw them away?”
• It’s an apples and oranges comparison, and the author’s nevereaten an orange.
• It is also terrible for painting.• Databases are hammers; MapReduce is a screwdriver.

4/1/2010 19
A Few more EnlightenedComments (relevant to us)
• “For engineers, the underlying issue is picking the right tool forthe job. RDB versus Flat Files versus MQL versus MR smacksof the same "religious" debates between Java versus C++versus Ruby versus assembly and is generally a waste of effort.A good engineer understands the specific problem space,examines the potential solutions, and picks the right tool for thejob.” Ronn Brashear
• “I feel as if this post has misrepresented the MapReduce modeland the problems it was designed to solve. No one at Google orworking on Hadoop would tell you that MapReduce is areplacement for a generic RDBMS but is rather designed for aspecific set of issues and constraints. This is a valid method ofdoing work and does not deserve to be criticized out of context.”Toby DiPasquale

4/1/2010 20
Stonebraker and DeWitt Reply• 2009: Pavlo, Paulson, Rasin, Abadi, DeWitt, Madden,
Stonebraker publish: “A Comparison of Approaches to Large-Scale Data Analysis.”
• Their fundamental statement seems to be, “Even thoughMapReduce isn’t a general-purpose DBMS, it seems that youcan use a DBMS to solve MR problems, and it’s important tounderstand the trade-offs you make when you choose onetechnology over the other.”
• Conclusions:• DBMSs tend to require more complex installation and configuration• Load times are big for DBMSs and not for MR (just a file copy)• DBMS query optimizer automatically calculates a lot that is left to
figure out manuall with MR.

4/1/2010 21
Abadi and others buildHadoopDB - a hybrid approach• Built on Hadoop (open source Map Reduce
framework)• Adds a database on each node.• Provides a schema and potential to create and
maintain indices.• Query planner goes from SQL to MapReduce back to
SQL!• Achieve close to the best of both worlds.• Paper in VLDB 2009• Presentation at HPTS 2009

4/1/2010 22
Stonebraker, Abadi, DeWittand others
• Communications of the ACM, January 2010:MapReduce and parallel DBMSs: friends or foes?
• Don’t use MR for database tasks.• MR most suitable for extract-transform-load (ETL)
operations.• ETL used to prepare data for ingest into some other
system (that would be a DBMS).• The two systems are complementary and can work
well together, but each has its sweet spot.

4/1/2010 23




























