Embed Size (px)
Citation preview

MapReduce
Costin Raiciu
Advanced Topics in Distributed Systems, 2012

Motivating App
Web Search
12PB of Web data
Must be able to search it quickly
How can we do this?

Web Search Primer
Each document is a collection of wordsDifferent frequencies, counts, meaning
Users supply a few words – the query
Task: find all the documents which contain a specified word

Solution: an inverted web index
For each keyword, store a list of the documents that contain it:Student -> {a,b,c, …}UPB -> {x,y,z,…}…
When a query comes:Lookup all the keywordsIntersect document listsOrder the results according to their importance

How do we build an inverted web index? Read 12PB of web pages
For each page, find its keywordsSlowly build index: 2TB of data
We could run it on a single machine100MB/s hard disk read = 1GB read in 10s120.000.000s just to read on a single machine
~ 4 years!

We need parallelism!
Want to run this task in 1 dayWe would need 1400 machines at least
What functionality might we need?
Move data aroundRun processingCheck livenessDeal with failures (certainty!)Get results

Inspiration:
Functional Programming

Functional Programming Review
Functional operations do not modify data structures: They always create new ones
Original data still exists in unmodified form Data flows are implicit in program design Order of operations does not matter

Functional Programming Review
fun foo(l: int list) =
sum(l) + mul(l) + length(l)
Order of sum() and mul(), etc does not matter – they do not modify l

Map
map f list
Creates a new list by applying f to each element of the input list; returns output in order.
f f f f f f

Fold
fold f x0 list
Moves across a list, applying f to each element plus an accumulator. f returns the next accumulator value, which is combined with the next element of the list
f f f f f returned
initial

Implicit Parallelism In map
In a purely functional setting, elements of a list being computed by map cannot see the effects of the computations on other elements
If order of application of f to elements in list is commutative, we can reorder or parallelize execution
This is the “secret” that MapReduce exploits

MapReduce

Main Observation A large fraction of distributed systems code
has to do with: MonitoringFault toleranceMoving data around
ProblemsDifficult to get right even if you know what you are
doingEvery app implements its own mechanisms
Most of this code is app independent!

MapReduce
Automatic parallelization & distribution Fault-tolerant Provides status and monitoring tools Clean abstraction for programmers

Programming Model
Borrows from functional programming Users implement interface of two
functions:
map (in_key, in_value) ->
(out_key, intermediate_value) list
reduce (out_key, intermediate_value list) ->
out_value list

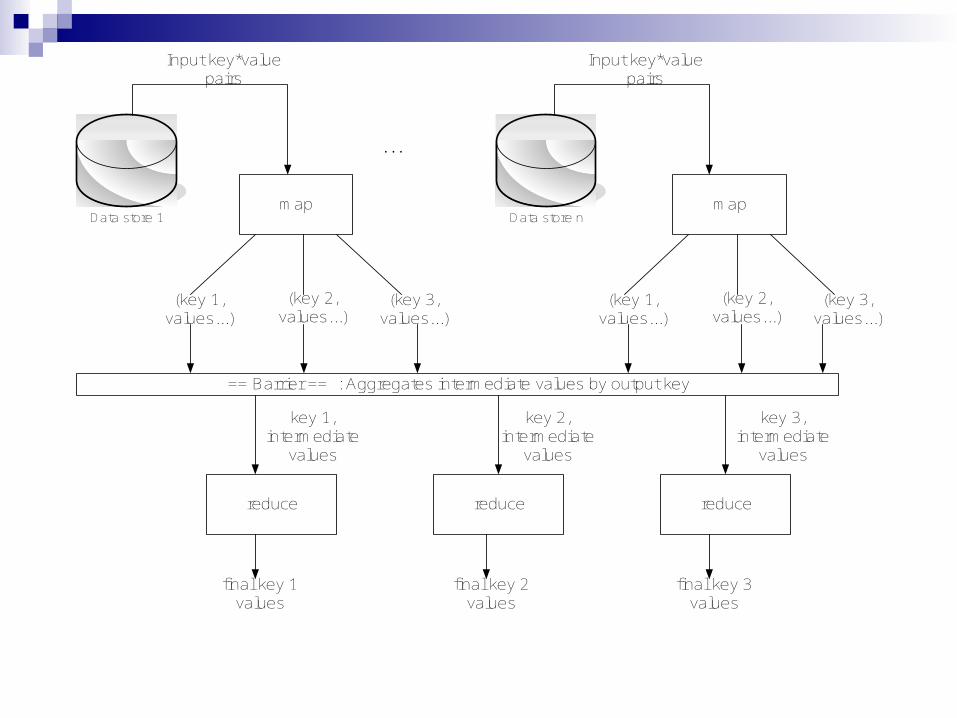
map
Records from the data source (lines out of files, rows of a database, etc) are fed into the map function as key*value pairs: e.g., (filename, line).
map() reads the input and produces one or more intermediate values along with an output key.

reduce
After the map phase is over, all the intermediate values for a given output key are combined together into a list
reduce() combines those intermediate values into one or more final values for that same output key
(in practice, usually only one final value per key)
Data store 1 Data store nmap
(key 1, values...)
(key 2, values...)
(key 3, values...)
map
(key 1, values...)
(key 2, values...)
(key 3, values...)
Input key*value pairs
Input key*value pairs
== Barrier == : Aggregates intermediate values by output key
reduce reduce reduce
key 1, intermediate
values
key 2, intermediate
values
key 3, intermediate
values
final key 1 values
final key 2 values
final key 3 values
...

Parallelism
map() functions run in parallel, creating different intermediate values from different input data sets
reduce() functions also run in parallel, each working on a different output key
All values are processed independently Bottleneck: reduce phase can’t start until
map phase is completely finished.

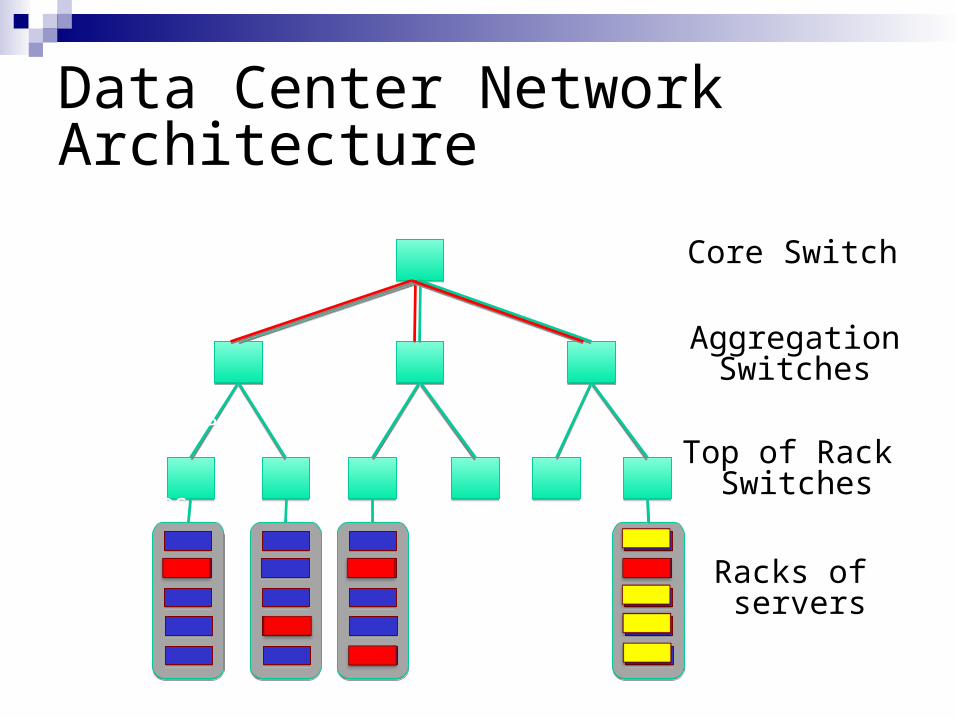
How do we place computation?
Master assigns map and reduce jobs to workersDoes this mapping matter?
Data Center Network Architecture
…Racks of servers
Top of Rack Switches
Aggregation Switches
Core Switch
1Gbps
10Gbps
10Gbps

Locality
Master program divides up tasks based on location of data: tries to have map() tasks on same machine as physical file data, or at least same rack
map() task inputs are divided into 64 MB blocks: same size as Google File System chunks

Communication
Map output stored to local disk
Shuffle phase:Reducers need to read data from all mappersTypically cross-rack and expensiveNeed full bisection bandwidth in theory

Fault Tolerance
Master detects worker failuresRe-executes completed & in-progress map()
tasks Why completed also?
Re-executes in-progress reduce() tasks

Fault Tolerance (2)
Master notices particular input key/values cause crashes in map(), and skips those values on re-execution.Effect: Can work around bugs in third-party
libraries!

Optimizations
No reduce can start until map is complete:A single slow disk controller can rate-limit the
whole process Master redundantly executes stragglers:
“slow-moving” map tasksUses results of first copy to finish
Why is it safe to redundantly execute map tasks? Wouldn’t this mess up the total computation?

Optimizations
“Combiner” functions can run on same machine as a mapper
Causes a mini-reduce phase to occur before the real reduce phase, to save bandwidth
Under what conditions is it sound to use a combiner?
More and more mapreduce

Apache
An Implementation of MapReduce

http://hadoop.apache.org/ Open source Java Scale
Thousands of nodes and petabytes of data
Used by many

Hadoop
MapReduce and Distributed File System framework for large commodity clusters
Master/Slave relationshipJobTracker handles all scheduling & data flow
between TaskTrackersTaskTracker handles all worker tasks on a nodeIndividual worker task runs map or reduce
operation Integrates with HDFS

Hadoop Supported File Systems
HDFS: Hadoop's own file system. Amazon S3 file system.
Targeted at clusters hosted on the Amazon Elastic Compute Cloud server-on-demand infrastructure
Not rack-aware CloudStore
previously Kosmos Distributed File System like HDFS, this is rack-aware.
FTP Filesystem stored on remote FTP servers.
Read-only HTTP and HTTPS file systems.

Hadoop scheduler
Runs a few map and reduce tasks in parallel on the same machineTo overlap IO and computation
Whenever there is an empty slot the scheduler chooses:A failed task, if it existsAn unassigned task, if it existsA speculative task (also running on another node)

"Rack awareness"
optimization which takes into account the geographic clustering of servers
network traffic between servers in different geographic clusters is minimized.

wordCount
A Simple Hadoop Examplehttp://wiki.apache.org/hadoop/WordCount

Word Count Example
Read text files and count how often words occur. The input is text filesThe output is a text file
each line: word, tab, count Map: Produce pairs of (word, count) Reduce: For each word, sum up the
counts.

WordCount Overview 3 import ...
12 public class WordCount {
13
14 public static class Map extends MapReduceBase implements Mapper ... {
17
18 public void map ...
26 }
27
28 public static class Reduce extends MapReduceBase implements Reducer ... {
29
30 public void reduce ...
37 }
38
39 public static void main(String[] args) throws Exception {
40 JobConf conf = new JobConf(WordCount.class);
41 ...
53 FileInputFormat.setInputPaths(conf, new Path(args[0]));
54 FileOutputFormat.setOutputPath(conf, new Path(args[1]));
55
56 JobClient.runJob(conf);
57 }
58
59 }

wordCount Mapper 14 public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text,
IntWritable> {
15 private final static IntWritable one = new IntWritable(1);
16 private Text word = new Text();
17
18 public void map(
LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
19 String line = value.toString();
20 StringTokenizer tokenizer = new StringTokenizer(line);
21 while (tokenizer.hasMoreTokens()) {
22 word.set(tokenizer.nextToken());
23 output.collect(word, one);
24 }
25 }
26 }

wordCount Reducer
28 public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
29 30 public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException {
31 int sum = 0; 32 while (values.hasNext()) { 33 sum += values.next().get(); 34 } 35 output.collect(key, new IntWritable(sum)); 36 } 37 }

wordCount JobConf
40 JobConf conf = new JobConf(WordCount.class); 41 conf.setJobName("wordcount"); 42 43 conf.setOutputKeyClass(Text.class); 44 conf.setOutputValueClass(IntWritable.class); 45 46 conf.setMapperClass(Map.class); 47 conf.setCombinerClass(Reduce.class); 48 conf.setReducerClass(Reduce.class); 49 50 conf.setInputFormat(TextInputFormat.class); 51 conf.setOutputFormat(TextOutputFormat.class);

Invocation of wordcount
1. /usr/local/bin/hadoop dfs -mkdir <hdfs-dir>2. /usr/local/bin/hadoop dfs -copyFromLocal
<local-dir> <hdfs-dir> 3. /usr/local/bin/hadoop
jar hadoop-*-examples.jar wordcount <in-dir> <out-dir>

Hadoop At Work

Experimental setup 12 servers connected to a gigabit switch
Same hardwareSingle hard disk per server
Filesystem: HDFS with replication 2128MB block size
3 Map and 2 Reduce tasks per machine
DataCrawl of the .uk domain (2009)50GB (unreplicated)

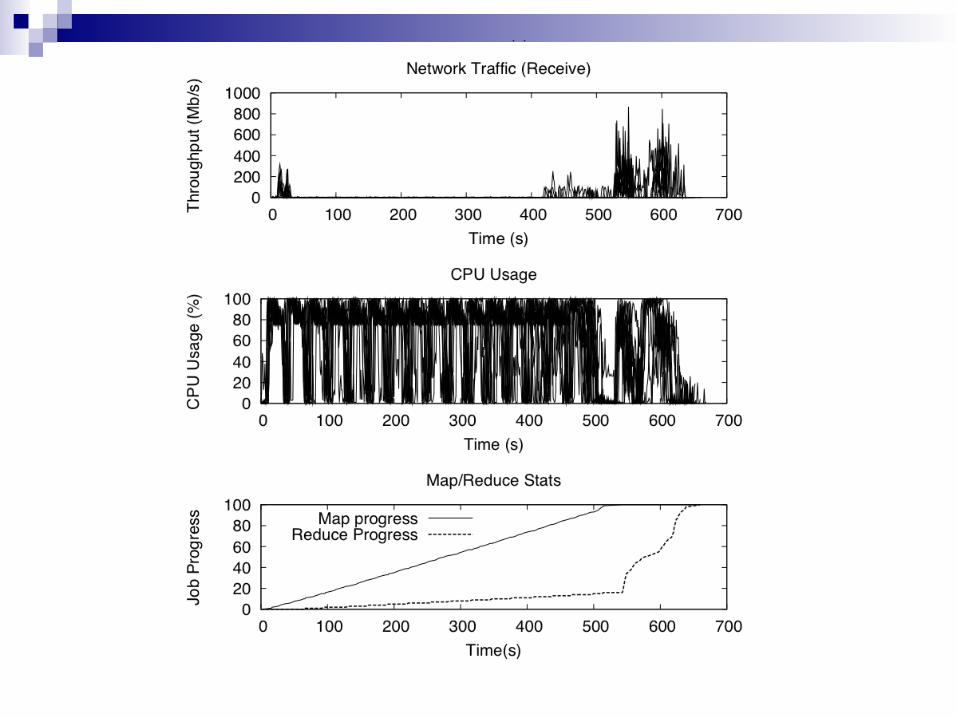
Monitoring Task Progress
Hadoop estimates task statusMap: % of input data read from HDFSReduce
33% - progress in copy (shuffle) phase 33% - sorting keys 33% - writing output in HDFS
Hadoop computes average progress score for each category
5 Sep, 2011: release 0.20.204.0 available
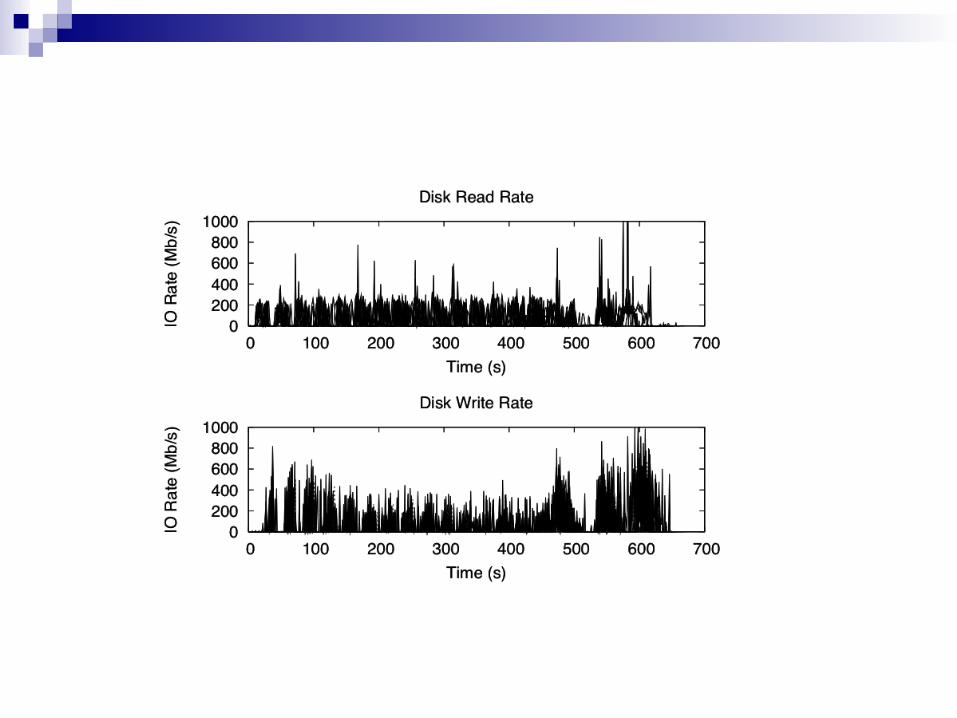
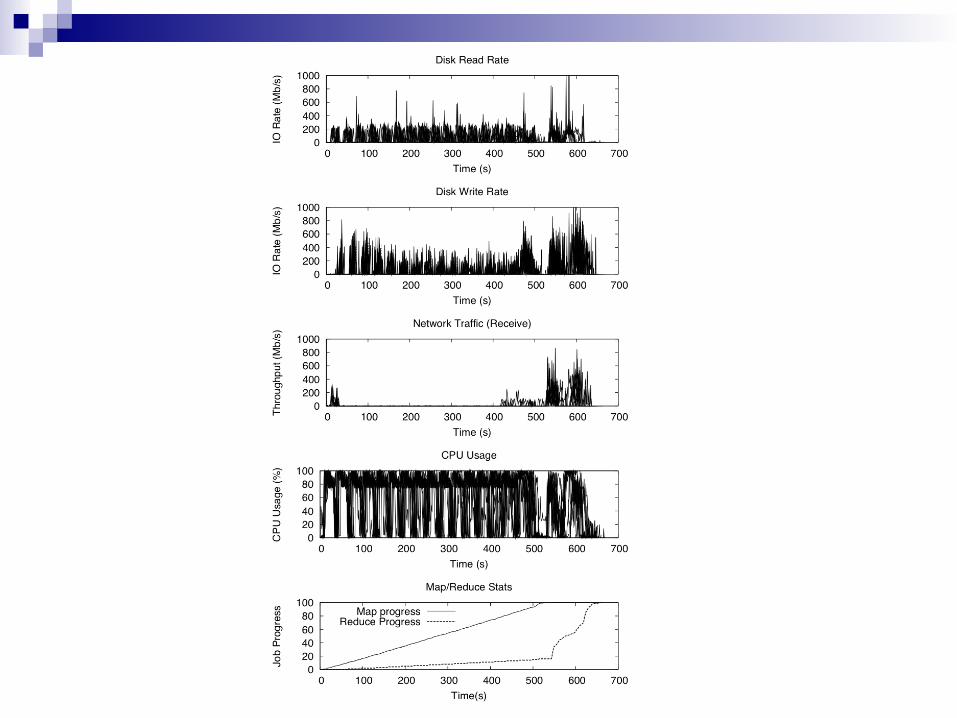

Back to Hadoop Overview

Speculative Execution
Rerun a task if it is slow:Threshold for speculative execution: 20% less
than its category’s average
AssumptionsAll machines are homogeneousTask progress at constant rateThere is no cost in launching speculative
tasks

Thought Experiment
What happens if one machine is slow?
What happens if there is network congestion on one link in the reduce phase?

LATE scheduler[Zaharia, OSDI 2008] Calculate progress rate:
ProgressRate = ProgressScore / TTime to finish:
(1-ProgressScore)/ProgressRate Only rerun on fast nodes
Put a cap on the number of speculative tasks
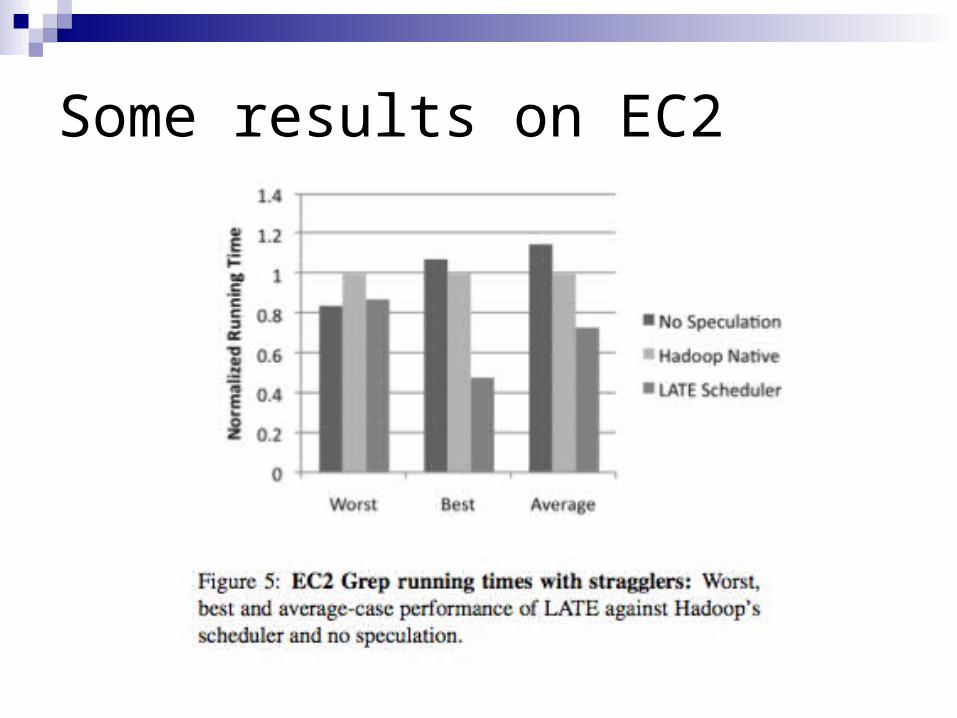
Some results on EC2
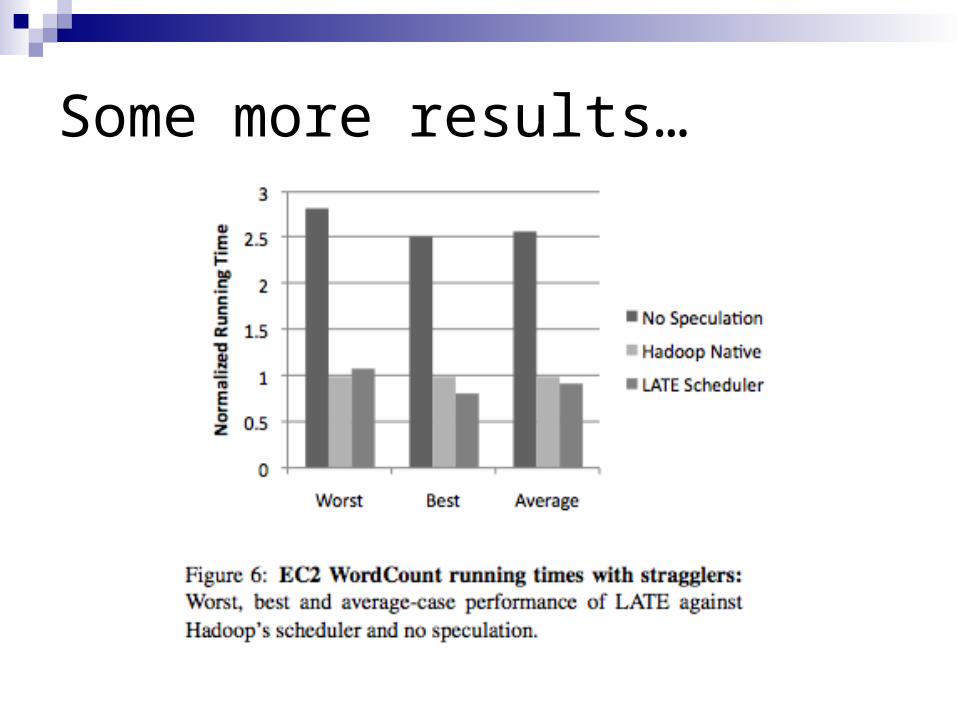
Some more results…

MapReduce Related Work Shared memory architectures: do not scale up MPI: general purpose, difficult to scale up to
more than a few tens of hosts Driad/DriadLINQ: computation is Directed
Acyclic GraphMore general computation modelStill not Turing Complete
Active area of researchHotCloud 2010, NSDI 2011: Spark / Ciel

Conclusions
MapReduce is a very useful abstraction: it greatly simplifies large-scale computations Does it replace traditional databases? What is missing?
Fun to use: focus on problem, let library deal w/ messy details





























