Embed Size (px)
Citation preview

Managing Uncertainty within Value FunctionApproximation in Reinforcement LearningWorkshop on Active Learning and Experimental Design
Matthieu GEIST and Olivier [email protected]
May, 16 - 2010
Olivier PIETQUIN – AL&ED 2010 1/21

Some BackgroundParadigmFormalismSolving (Dynamic Programming)
Value function approximation & Managing uncertaintyGeneralized policy iterationWhy managing uncertainty in RL ?
A Kalman-based value function trackerCasting VFA as a filtering problemKalman Temporal Differences
Managing UncertaintyComputing values standard deviationsAn active learning SchemeExploration/exploitation dilemma
Conclusion and perspective
Olivier PIETQUIN – AL&ED 2010 2/21
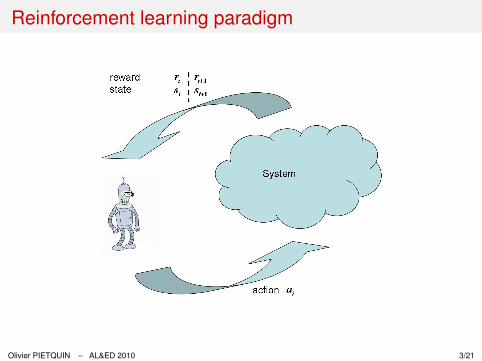
Reinforcement learning paradigm
Olivier PIETQUIN – AL&ED 2010 3/21
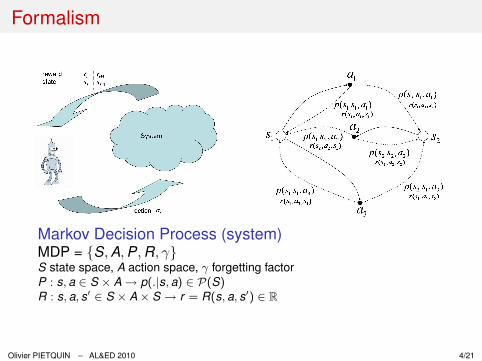
Formalism
Markov Decision Process (system)MDP = {S, A, P, R, γ}S state space, A action space, γ forgetting factorP : s, a ∈ S × A → p(.|s, a) ∈ P(S)R : s, a, s′ ∈ S × A× S → r = R(s, a, s′) ∈ R
Olivier PIETQUIN – AL&ED 2010 4/21

Formalism
Policy (control of the system by the agent)π : s ∈ S → π(.|s) ∈ P(A)
Olivier PIETQUIN – AL&ED 2010 4/21

Formalism
Value function (control quality)Qπ(s, a) = E [
∑∞i=0 γ i ri |s0 = s, a0 = a, π]
Olivier PIETQUIN – AL&ED 2010 4/21
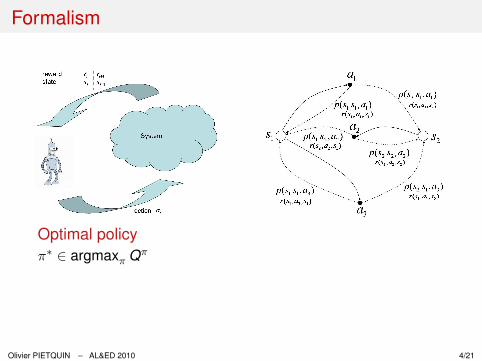
Formalism
Optimal policyπ∗ ∈ argmaxπ Qπ
Olivier PIETQUIN – AL&ED 2010 4/21

Policy iteration
Policy Iteration
I Bellman evaluation equation :Qπ(s, a) = Es′,a′|π,s,a[R(s, a, s′) + γQπ(s′, a′)],∀s, a
I greedy policy :πgreedy(s) = argmaxa∈A Qπ(s, a),∀s
Olivier PIETQUIN – AL&ED 2010 5/21

Value iteration
Value IterationI (nonlinear) Bellman optimality equation :
Q∗(s, a) = E [R(s, a, s′) + γ maxa′ Q∗(s′, a′)] = TQ∗(s, a)
I T is a contraction and Q∗ its unique fixed pointI Qi+1 = TQi , Qi → Q∗
I optimal policy : greedy resp. to Q∗
Olivier PIETQUIN – AL&ED 2010 6/21

Some BackgroundParadigmFormalismSolving (Dynamic Programming)
Value function approximation & Managing uncertaintyGeneralized policy iterationWhy managing uncertainty in RL ?
A Kalman-based value function trackerCasting VFA as a filtering problemKalman Temporal Differences
Managing UncertaintyComputing values standard deviationsAn active learning SchemeExploration/exploitation dilemma
Conclusion and perspective
Olivier PIETQUIN – AL&ED 2010 7/21
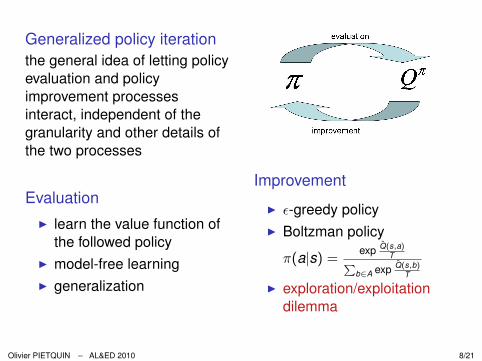
Generalized policy iterationthe general idea of letting policyevaluation and policyimprovement processesinteract, independent of thegranularity and other details ofthe two processes
EvaluationI learn the value function of
the followed policyI model-free learningI generalization
Improvement
I ε-greedy policyI Boltzman policy
π(a|s) =exp Q̂(s,a)
TPb∈A exp Q̂(s,b)
T
I exploration/exploitationdilemma
Olivier PIETQUIN – AL&ED 2010 8/21

Why should we manage uncertainty in RL ?
Exploration/exploitation dilemma
I having an uncertainty information about value’s estimateprovides useful for deciding between exploration and exploitation
I this kind of information is used in some schemes for theexploration/exploitation dilemma, however most of them are forthe tabular case
Active learning
I consider the Bellman optimality operator (Q-learning-likealgorithm)
I learn the optimal Q-function from any sufficient explorative policy
I if control of this policy is possible, how to choose actions in orderto speed up learning ?
Olivier PIETQUIN – AL&ED 2010 9/21

Some BackgroundParadigmFormalismSolving (Dynamic Programming)
Value function approximation & Managing uncertaintyGeneralized policy iterationWhy managing uncertainty in RL ?
A Kalman-based value function trackerCasting VFA as a filtering problemKalman Temporal Differences
Managing UncertaintyComputing values standard deviationsAn active learning SchemeExploration/exploitation dilemma
Conclusion and perspective
Olivier PIETQUIN – AL&ED 2010 10/21

VFA reformulation
Statistical filtering point of viewθi = θi−1 + vi
ri = Q̂θi (si , ai)− γ
{Q̂θi (si+1, ai+1)
maxa Q̂θi (si+1, a)+ ni
Minimized cost functionI conditional mean square error minimization :
θ̂i = argminθ E [‖θ − θi‖2|r1:i ]
I restriction to linear estimators :θ̂i = θ̂i−1 + Ki(ri − r̂i)
Olivier PIETQUIN – AL&ED 2010 11/21

Kalman equations
I Prediction step
θ̂i|i−1 = θ̂i−1|i−1
Pi|i−1 = Pi−1|i−1 + Pvi−1
r̂i = E [Q̂θi (si , ai)− γQ̂θi (si+1, ai+1)|r1:i−1]
I Correction step
Ki = Pθri P−1ri|i−1
Pθri P−1ri|i−1
θ̂i|i = θ̂i|i−1 + Ki(ri − r̂i)
Pi|i = Pi|i−1 − KiPri|i−1 Pri|i−1 K Ti
ProblemsI Choice of priors θ0|0 et P0|0 (classical)
I Compute statistics of interest r̂i , Pθri and Pri|i−1 ? Compute 1st and 2nd
moments of a nonlinearly mapped random variable ?
Olivier PIETQUIN – AL&ED 2010 12/21
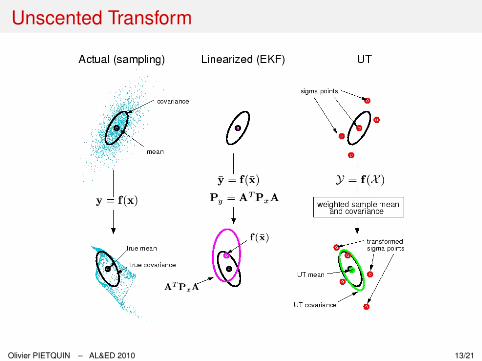
Unscented Transform
Olivier PIETQUIN – AL&ED 2010 13/21

Some BackgroundParadigmFormalismSolving (Dynamic Programming)
Value function approximation & Managing uncertaintyGeneralized policy iterationWhy managing uncertainty in RL ?
A Kalman-based value function trackerCasting VFA as a filtering problemKalman Temporal Differences
Managing UncertaintyComputing values standard deviationsAn active learning SchemeExploration/exploitation dilemma
Conclusion and perspective
Olivier PIETQUIN – AL&ED 2010 14/21
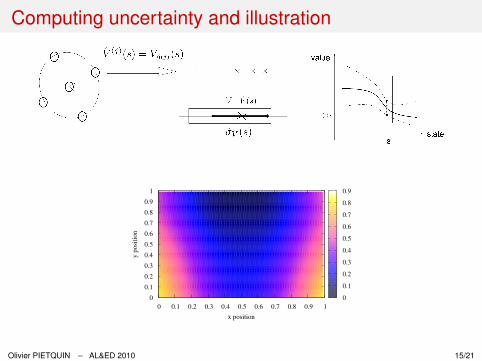
Computing uncertainty and illustration
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
x position
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
y p
osi
tio
n
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Olivier PIETQUIN – AL&ED 2010 15/21
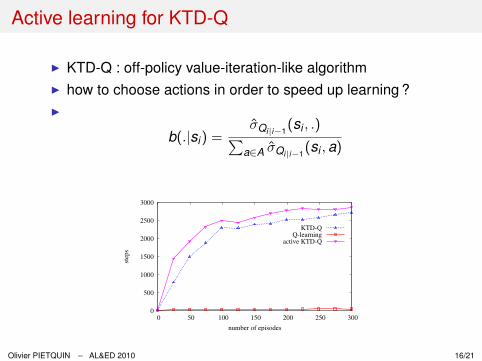
Active learning for KTD-Q
I KTD-Q : off-policy value-iteration-like algorithmI how to choose actions in order to speed up learning ?I
b(.|si) =σ̂Qi|i−1
(si , .)∑a∈A σ̂Qi|i−1
(si , a)
0
500
1000
1500
2000
2500
3000
0 50 100 150 200 250 300
step
s
number of episodes
KTD-QQ-learning
active KTD-Q
Olivier PIETQUIN – AL&ED 2010 16/21

Adapting existing (tabular) approaches
I there exists some scheme for exploration/exploitationdilemma which uses an uncertainty information
I most of them are designed for the tabular case (in thiscase, uncertainty information linked to the number of visitsto the state)
I we propose to adapt some of them (very directly)
Olivier PIETQUIN – AL&ED 2010 17/21
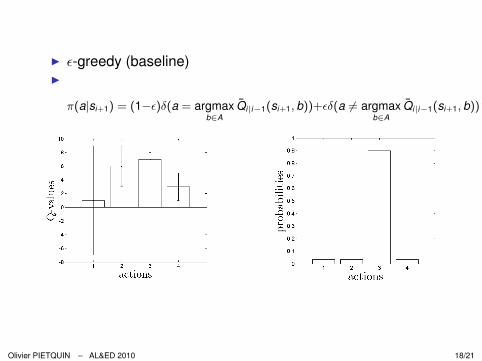
I ε-greedy (baseline)I
π(a|si+1) = (1−ε)δ(a = argmaxb∈A
Q̄i|i−1(si+1, b))+εδ(a 6= argmaxb∈A
Q̄i|i−1(si+1, b))
Olivier PIETQUIN – AL&ED 2010 18/21
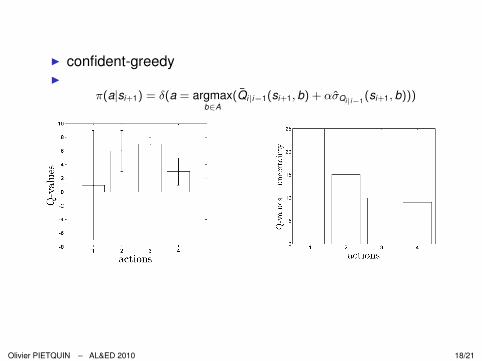
I confident-greedyI
π(a|si+1) = δ(a = argmaxb∈A
(Q̄i|i−1(si+1, b) + ασ̂Qi|i−1(si+1, b)))
Olivier PIETQUIN – AL&ED 2010 18/21
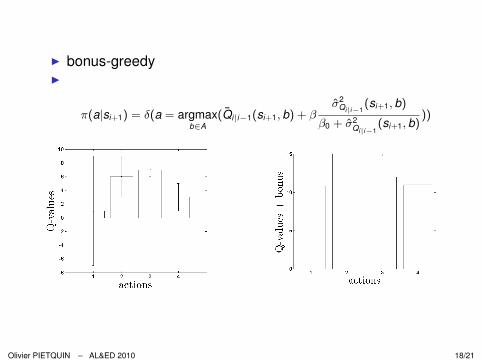
I bonus-greedyI
π(a|si+1) = δ(a = argmaxb∈A
(Q̄i|i−1(si+1, b) + βσ̂2
Qi|i−1(si+1, b)
β0 + σ̂2Qi|i−1
(si+1, b)))
Olivier PIETQUIN – AL&ED 2010 18/21
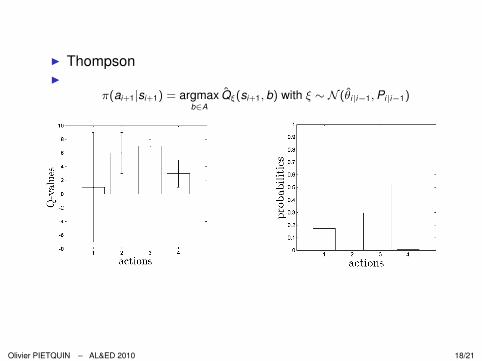
I ThompsonI
π(ai+1|si+1) = argmaxb∈A
Q̂ξ(si+1, b) with ξ ∼ N (θ̂i|i−1, Pi|i−1)
Olivier PIETQUIN – AL&ED 2010 18/21
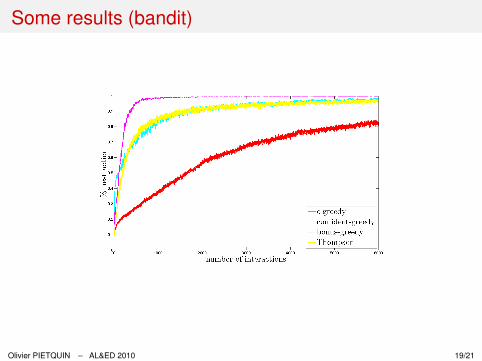
Some results (bandit)
Olivier PIETQUIN – AL&ED 2010 19/21

Some BackgroundParadigmFormalismSolving (Dynamic Programming)
Value function approximation & Managing uncertaintyGeneralized policy iterationWhy managing uncertainty in RL ?
A Kalman-based value function trackerCasting VFA as a filtering problemKalman Temporal Differences
Managing UncertaintyComputing values standard deviationsAn active learning SchemeExploration/exploitation dilemma
Conclusion and perspective
Olivier PIETQUIN – AL&ED 2010 20/21

I KTD : provides an uncertainty information (among otherthings : nonlinearities and nonstationarities handling)
I straightforwardly adapted tabular approaches work fine onsimple problems
I however :I there is a need to assess if the approach is theoretically
foundedI it should be experimented on more complex tasksI choice of parameters (prior variance and noises especially)
can be difficult, adaptive KTD ?
Olivier PIETQUIN – AL&ED 2010 21/21





























