Embed Size (px)
Citation preview

Thomas Clauwaert
administratorsManagement of polyglot persistent integrations with virtual
Academic year 2017-2018Faculty of Engineering and ArchitectureChair: Prof. dr. ir. Bart DhoedtDepartment of Information Technology
Master of Science in Information Engineering TechnologyMaster's dissertation submitted in order to obtain the academic degree of
Counsellors: ing. Merlijn Sebrechts, Dr. ir. Gregory Van SeghbroeckSupervisors: Prof. dr. ir. Filip De Turck, Dr. ir. Gregory Van Seghbroeck


Preface
It is crazy how fast the past few months went by. I have tried my best to research and learn as muchas possible while also implementing interesting things. It was not always easy and from time to timeI got stuck here and there. Looking back, I am glad about what I achieved but the big added value forme is the priceless experience I’ve gained throughout this journey.
It is impossible to list every single person that helped me throughout this period but a few peopledeserve to be in the spotlight. First and foremost, I want to thank prof. Filip De Turck, dr. ir. GregoryVan Seghbroeck and ing. Merlijn Sebrechts for writing out this thesis proposal and providing theopportunity for a student likeme to tackle this research. Merlijn especially deserves a round of applausefor all the guidance and patience he had when I was stuck or in need of some advice. Next, a big shoutout to all the people on the IRC channel of Juju. Even though the community is rather small, the peopleout there really want to help you. Finally, I’m grateful to all my friends and family for their supportand every single piece of advice. You guys were great!
Thomas Clauwaert
Ghent, June 2018


Toelating tot bruikleen
“De auteur(s) geeft (geven) de toelating deze masterproef voor consultatie beschikbaar te stellen en de-len van de masterproef te kopiëren voor persoonlijk gebruik. Elk ander gebruik valt onder de bepalin-gen van het auteursrecht, in het bijzonder met betrekking tot de verplichting de bron uitdrukkelijk tevermelden bij het aanhalen van resultaten uit deze masterproef.”
“The author(s) gives (give) permission to make this master dissertation available for consultation andto copy parts of this master dissertation for personal use. In the case of any other use, the copyrightterms have to be respected, in particular with regard to the obligation to state expressly the sourcewhen quoting results from this master dissertation.”
Thomas Clauwaert, June 2018


Abstract
Data management plays a crucial role in the area of information technology, as it impacts the efficiencyof the system in use. End users often expect these systems to be responsive and available at any time.Good infrastructure design choices, that provide flexibility and scalability, are therefore crucial build-ing blocks of modern applications. In the state of the art, a lot of different database systems have beenproposed which offer (dis-)advantages in a number of key areas. The traditional relational database isstill the predominant system, although NoSQL databases are finding their way into many applicationstacks. Modern systems often use a combination of several database systems andmake the developmenteffort a lot more complex. Industry therefore relies on modern data administrators or operations engi-neers who have the know-how to use, setup and manage these polyglot persistent applications. Sincethese people are hard to find, developers or data scientists are looking at other solutions to simplify theoperation of different technologies.
The goal of this thesis is to propose a service which transparently manages different database systems.The idea behind a script or tool lies often in performing specific tasks which would otherwise need to beperformed manually. They can be seen as virtual administrators who perform predefined tasks. In thisthesis several possibilities are investigated to create a virtual administrator that is responsible for themanagement of polyglot persistent applications and all its derivatives. The generic database serviceas presented in this research offers an easy-to-use platform where users request a specific databasetechnology and the service itself will take care of installing all required components and sharing allneeded information. The virtual administrator makes its own choices in deciding what services needto be deployed in order to provide the requested database technology. This way developers can askthe virtual administrator for a database technology and a database name and they end up with theconnection details to use it. The developer becomes self-reliant and the time needed to get the requestedoperational tasks done, reduces significantly.
A proof of concept was made in the application modelling tool Juju for the generic database service.With the help of a use case and the reactive framework, a requesting service can successfully requestmultiple databases of a different type. The generic database service would then correctly share thedetails to the requesting service. It only acts as a proxy that relays the database details. Furthermore,the service is resource-demanding and more database technologies should be supported. In iterativesteps, support for any database technology could be added so the end result becomes a full-fledgedapplication ready for use in Juju. The idea behind the generic database service is not bound to Juju andcan be (re-)used in other environments aiming to achieve the same goal.


Samenvatting
Data speelt een cruciale rol in de meeste informatie- en technologiesystemen. De manier waaropgegevens worden verwerkt bepaalt hoe efficiënt een systeem werkelijk is. Omdat eindgebruikers ver-wachten dat een systeem op elkmoment reageert en beschikbaar is, vormen de keuzes voor het ontwerpvan de infrastructuur de bouwstenen van moderne toepassingen. Op het gebied van databanktechnolo-gieën is er veel keuze. Traditionele relationele databanksystemen zijn nog steeds het populairst, maarNoSQL-technologieën vonden ook hunweg in applicatie infrastructuren. Inmoderne systemenwordenontwikkelaars uitgedaagd om verschillende databanktechnologieën te gebruiken in hun toepassingen,afhankelijk van het type gegevens. Deze heterogene dataopslagtechnieken resulteren in een complexereinfrastructuur naarmate er meer en verschillende technologieën worden gebruikt. Om die reden zijnmoderne databankbeheerders of operations engineers nodig die deze verschillende systemen weten tegebruiken, te configureren en te beheren.
Het doel van deze masterproef is om een dienst voor te stellen die helpt om dit probleem aan te pakken.Machines, computers en technologie in het algemeen, helpen mensen om veel processen te automa-tiseren. Het idee achter een script (of tool) ligt vaak in het uitvoeren van specifieke taken die andershandmatig uitgevoerd moeten worden. Op een bepaalde manier zijn het virtuele administratoren. Indezemasterproef is onderzocht of hetmogelijk is om een virtuele administrator te creëren die verantwo-ordelijk is voor het beheer van deze heterogene dataopslagtechnieken. De generieke databank service,zoals gepresenteerd in dit onderzoek, biedt een eenvoudig te gebruiken platform waar gebruikers eendatabanktechnologie vragen en de service zelf zorgt voor het installeren van alle benodigde compo-nenten en het delen van alle informatie. De virtuele administrator bepaalt zelf welke diensten opgezetmoeten worden wanneer er om een databank gevraagd wordt. De ontwikkelaar wordt op deze manieronafhankelijk van een fysieke administrator en de tijd die nodig is om de gevraagde operationele takente voltooien, vermindert aanzienlijk.
Een proof of concept is gemaakt in de applicatiemodelleringstool Juju voor de generieke databankservice. Met behulp van een use-case en het reactive framework kan een applicatie met succesmeerderedatabanken van verschillende types opvragen. De generieke databank service gaat de gegevens dancorrect delen met de oorspronkelijke applicatie. De implementatie van de service fungeert alleen alseen proxy die de gegevens van de databank doorgeeft. Bovendien vergt deze dienst (te) veel middelenen moeten meer databanktechnologieën worden ondersteund. In iteratieve stappen kan ondersteuningvoor elke databanktechnologie worden toegevoegd, zodat het eindresultaat een volwaardige toepassingwordt. Het idee achter de generieke databank service is bovendien niet gebonden aan Juju en kan(her)gebruikt worden in andere omgevingen om hetzelfde doel te bereiken.


Virtuele administratoren voor het beheer vanheterogene dataopslagtechnieken
Thomas Clauwaert
Begeleiders: prof. Filip De Turck, dr. ir. Gregory Van Seghbroeck, dr. ir. Tim Wauters,ing. Merlijn Sebrechts
Abstract— In een wereld waar alles 24/7 beschikbaar moet zijn, is hetonderhoud van services en applicaties van cruciaal belang. Het uitteke-nen, opzetten en uiteindelijk beheren van deze applicatie infrastructurenzijn vaak de grootste uitdagingen van moderne systeembeheerders. In dezemasterproef wordt onderzocht hoe databanken eenvoudiger gebruiksklaargemaakt kunnen worden aan de hand van virtuele systeemadministrato-ren. Deze virtuele entiteiten nemen de taak over van de systeembeheerderen configureren de nodige zaken op een automatische manier zonder dat degebruikscomplexiteit hierbij verloren gaat. Dit laat toe dat niet-experts inde databanktechnologieën op een vlotte, flexible en eenvoudige manier eendatabanktype naar keuze beschikbaar hebben voor gebruik. Aan de handvan een praktijkvoorbeeld wordt de generische databank service gedefini-eerd in een functionele analyse. Nadien wordt deze use case geïmplemen-teerd aan de hand van de applicatiemodelleer-tool Juju. Het resultaat vandit onderzoek toont dat de generische databank service de vooropgesteldeuse case succesvol kan uitvoeren. De implementatie van de generische da-tabank legt dan ook de basis voor verdere ondersteuning en ontwikkelingom tot een volwaardige service te komen. Doordat deze service nog in eenbeginfase zit, kent het nog een aantal beperkingen zoals gelimiteerde on-dersteuning voor verschillende databanktechnologieën of de noodzaak vanenkele vooropgestelde precondities. Mits ondersteuning staat de service na-genoeg elk gebruik van verschillende databankentypes toe in Juju. Het con-cept kan eveneens (her)gebruikt worden in andere omgevingen met oog opdezelfde einddoelen.
Kernwoorden— Service orchestration, polyglot persistence, Juju, auto-matisatie, configuration management, virtuele systeembeheerders, hetero-gene databanktechnologieën, systeembeheer
I. INLEIDING
NOG nooit werd er zoveel data gegenereerd als vandaag. Ditvormt dan ook vaak de kern van applicaties of diensten.
Deze informatie moet opgeslagen worden in databanken. Waarmen vroeger hoofdzakelijk relationele systemen gebruikte voordataopslag, kent men vandaag de dag ook niet-relationele vari-anten die gecategoriseerd worden onder de NoSQL term. Ditbetekent dat informatie, applicatie- en vormafhankelijk, op ver-schillende systemen wordt opgeslagen. Moderne databankbe-heerders worden vertrouwd geacht te zijn met deze verschil-lende technologieën. Deze, schaars te vinden personen, krijgenvaak de vraag om nieuwe systemen op te zetten of de verbin-dingsgegevens van de databank uit te delen. In een ideaal scena-rio zouden de data-analisten of ontwikkelaars, zelf in staat moe-ten zijn om dit te realiseren. Door een gebrek aan operationelekennis bij niet-experts, is dit vaak niet het geval. Virtuele sys-teembeheerders die deze taak op zich nemen, bieden een mooialternatief om het werk van beide partijen te verlichten en deoperationele kennis te abstraheren. Data analisten of ontwikke-laars kunnen op deze manier snel aan de slag met een databanknaar keuze en zijn zo in staat om zich te focussen op hun exper-tise.
II. ACHTERGROND
Het aantal machines, services en applicaties dat een modernesysteembeheerder moet beheren is de afgelopen jaren enormtoegenomen. Dankzij diensten als Amazon AWS, Google cloudcomputing of Microsoft Azure is het eenvoudiger gewordenom snel machines operationeel te maken. Vanuit een business-standpunt zijn deze services ook interessant omdat de gebruiks-prijs vaak bepaald wordt op basis van de gebruikte resources.Configuration management tools en Agile of DevOps filosofieënhelpen systeembeheerders en developers om snellere workflowste bereiken. Aan de hand van scripts kunnen ze machines opzet-ten en services configureren. Configuration management toolsschieten echter te kort wanneer gebruikers de gewenste configu-raties niet exact weten. Specifieke features, bepaalde parametersen de opmaaktaal van de tools moeten gekend zijn om deze toolsgoed te kunnen gebruiken. Deze operationele kennis, is niet bijiedereen gekend en vertraagt vaak het gehele proces.
Het eerste onderdeel van dit onderzoek, ligt bij de virtuele ad-ministratoren. In “A Taxonomy and Survey of Clooud ResourceOrchestration Techniques” [1] en Orchestrator Conversation:Distributed Management of Cloud Applications [2] worden re-cente uitdagingen en state-of-the-art oplossingen met betrekkingop cloud computing besproken. Het onderzoek toont aan datorchestration technieken ervoor zorgen dat virtuele administra-toren op een automatische en flexibile manier aan herschalenkunnen doen. Deze benadering, waarin applicaties dynamischop elkaar kunnen reageren, ligt dan ook aan de basis van auto-matisatie. Sebrechts et al. stellen het reactive pattern voor, omservices in Juju, optimaal op te zetten en te beheren [3] als oplos-sing voor de . Dit pattern zal samen met de applicatiemodelleer-tool Juju [4] gebruikt worden bij de implementaties. Juju en deTOSCA cloud modelleer standaard [5] kennen heel wat over-eenkomsten. Deze specificatie laat toe om (cloud) applicatiesvoor te stellen aan de hand van modellen. Zo wordt er beschre-ven hoe verschillende applicaties samenhangen, interageren metelkaar of welke workflow ze moeten hanteren. Typisch aan deTOSCA taal is het vastleggen van wat een service nodig heeftom goed te kunnen functioneren alsook wat de service aanbiedtnaar andere services toe. Dit is ook terug te vinden in Juju enlegt de basis voor de vooropgestelde service in dit onderzoek.
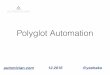
Het tweede luik waarop dit onderzoek steunt, is te vindenin de databanksector. Wanneer een applicatie gebruik maaktvan meerdere, verschillende databanktechnologieën dan spreektmen over de term “polyglot persistent” applicaties (zie ook fi-guur 1). Met een enorm aanbod aan databanktechnologieën ishet niet altijd evident om een keuze te maken, in dit onderzoek

webshop application
relational- based
e.g. MySQL
document-based
e.g. MongoDB
graph-based
e.g. Neo4J
user-relatedinformation
items for salerecommendation
information
Fig. 1. Voorbeeld van een polyglot persistence applicatie. De applicatie is pasvolledig operationeel, wanneer de verschillende databanken van de verschil-lende databanktypes bruikbaar zijn.
Operations
requestrequesting
service
requestgeneric database service
database technology
service
Application
direct connectionrequesting
service database technology
service
Fig. 2. Applicatiemodel van de generische databank service. Deze service ishet aanspreekpunt van services die nood hebben aan een databank. Merkop dat na het uitwisselen van de nodigege gevens, de oorspronkelijke ser-vice wel een rechtstreekse verbinding maakt met de databank. Binnenin deapplicatie-logica is er geen sprake van de generische databank service.
werd er vanuit gegaan dat de gewenste databanktypes van appli-caties gekend zijn.
III. GENERISCHE DATABANK
Stel dat een bedrijf ervoor kiest om een webshop-applicatie tebouwen. Zo wordt er bijvoorbeeld gekozen om alle gebruikers-data op te slaan in één soort databank. Alle informatie met be-trekking tot de items die te koop aangeboden worden blijken danweer efficiënter in een ander type. Bij het opzetten van zo eenwebshop-applicatie is er nood aan drie verschillende services.De twee verschillende databanktechnologieën moeten operatio-neel zijn. Vervolgens moet de databanken aangemaakt wordenen moeten de correcte connectiedetails ingevuld worden. Pas nadeze stappen kan de webshop-applicatie operationeel zijn. Hetdoel van de generische databank service is het automatisch uit-voeren van deze stappen.
Figuur 2 toont aan dat de generische databank werkt als proxy
layer "webapp"
interface layer "generic-database"
requires provides
layer "generic
database"
"wantsdatabase"
request "ensures database exists and is available"
"getsrequest"
"getsdatabase"
share_details "providesdetails"
charmcharm
Fig. 3. De communicatie tussen de twee charms gebeurt via de generische-databank interface layer. De verschillende endpointen gebruiken deze APIom informatie door te geven.
service tussen de applicatie die een databank aanvraagt en de ap-plicatie die voor één kan instaan. In de applicatiemodellen bete-kent dit dat de semantische waarde van de generische databankservice een atomaire databank is. Dit betekent dat de generischedatabank enkel en alleen een databank voorstelt. Applicatiesdie gebruik maken van deze service zijn in staat om een data-bank aan te vragen. In dit geval wordt de generische databankconcreet en zullen de details om verbinding te maken met dedatabank, gedeeld worden. Applicaties die nadien gebruik ma-ken van dezelfde generische databank service, die nu concreetis, maken op deze manier gebruik van dezelfde databank.
Een laatste grote opmerking (zoals eveneens te zien op fi-guur 2) bij deze applicatiemodellen is het verschil in perspec-tieven tussen de operations-kant en de applicatie-zijde. Een ap-plicatie die de generische databank service gebruikt, heeft geenweet van andere services bij het opzetten en configureren vandeze applicatie. Eens deze taken uitgevoerd zijn, zal de appli-catie werken met een rechtstreekse verbinding naar de databank(waar deze ook staat). Vanuit de applicatie is er dan ook geenweet meer van de generische databank. Dit betekent dat ontwik-kelaars of data analisten geen rekening moeten houden met degenerische databank service. Deze werkt louter op het niveauvan systeembeheer en wordt enkel gebruikt bij het opzetten vandatabanken en uitwisselen van de verbindingsgegevens.
IV. IMPLEMENTATIE
Aan de hand van een use case, wordt er naast de generischedatabank service ook een afzonderlijke webapplicatie gemaakt.Deze charm (Juju-term voor services) omkadert het beschikbaarstellen van een virtuele machine, het installeren van de apachesoftware en het opzetten van enkele webpagina’s. Deze webap-plicatie kan pas goed functioneren nadat een configuratiebestandcorrect ingevuld is met de verbindingsparameters van een data-bank.
Vervolgens is het hergebruiken van bestaande interface- encharms-layers op vlak van databanktechnologieën een belang-rijke leidraaid. Andere charm authors en Juju gebruikers heb-ben in het verleden deze services reeds gemaakt. Het is dan ookéén van de sterktes van Juju om elementen (vaak in de vorm vanlayers) te hergebruiken. Lego-blokjes zijn hiervoor een mooimetafoor.
De eigenlijke generische databank charm en interface layer

zijn dan uiteindelijk de kern van de use case. Via het reactiveframework en het endpoint pattern wordt er aan de hand vanflags gecommuniceerd. Figuur 3 toont aan hoe de communicatieprecies verloopt over de relatie (de interface layer). Het geheleproces kan als volgt samengevat worden:1. Een service vraagt het opzetten van een databank aan.2. Via de generische databank layer ontvangt de generische da-tabank service dit verzoek.3. De generische databank service gaat via de interface layervan dat overeenkomstige databanktype een formele aanvraaguitvoeren.4. De databanktechnologie service ontvangt de aanvraag, maaktde databank en deelt de details.5. De generische databank ontvangt de gegevens en deelt die opzijn beurt met de oorspronkelijke service uit stap 1.6. De service ontvangt de details en genereert het configuratie-bestand.
Aan de hand van de eerder vernoemde flags zorgt de gene-rische databank service er ook voor dat als een nieuwe serviceverbinding maakt met deze generische databank service, dat de-zelfde informatie gedeeld wordt. Dit was niet op een automati-sche manier mogelijk in Juju.
V. CONCLUSIE
Het doel van deze masterproef is nagaan in welke mate hetmogelijk is om een service te bouwen die ongeacht de data-banktechnologie, een databank kan voorzien en de verbindings-parameters kan delen. Aan de hand van een use case is dezeminimale proof of concept succesvol geïmplementeerd in deapplicatiemodelleer-tool Juju. Vooraleer er sprake kan zijn vaneen volwaardige service zijn er nog een aantal werkpunten voorde generische databank service. Zo is de performantie van deproof of concept niet optimaal en is er nog veel ruimte voor ver-dere ondersteuning voor meer databanktechnologieën. Wanneerdeze technologieën goed (via het reactive framework en inter-face layers) geïmplementeerd worden in Juju dan zal deze ge-nerische databank service de perfecte aanvulling zijn voor meerflexibiliteit en een gemakkelijkere, geautomatiseerde workflowbij het opzetten van applicaties. Een extra voordeel is dat hetgehele concept kan (her)gebruikt worden buiten Juju.
REFERENCES
[1] Denis Weerasiri, Moshe Chai Barukh, Boualem Benatallah, Quan Z. Sheng,and Rajiv Ranjan, “A taxonomy and survey of cloud resource orchestrationtechniques,” ACM Comput. Surv., vol. 50, no. 2, pp. 26:1–26:41, May 2017.
[2] M. Sebrechts, C. Johns, G. Van Seghbroeck, T. Wauters, B. Volckaert, andF. De Turck, “Orchestrator conversation: Distributed management of cloudapplications,” 2018.
[3] M. Sebrechts, C. Johns, G. Van Seghbroeck, T. Wauters, B. Volckaert, andF. De Turck, “Beyond generic lifecycles: Reusable modeling of custom-fitmanagement workflows for cloud applications,” 2018.
[4] Canonical, “Website of Juju,” https://jujucharms.com/, 2018,Accessed: 2018-05-01.
[5] OASIS Committee, “TOSCA Simple Profile in YAMLVersion 1.2,” https://docs.oasis-open.org/tosca/TOSCA-Simple-Profile-YAML/v1.2/TOSCA-Simple-Profile-YAML-v1.2.html, 2017, Accessed:2018-05-01.


Contents
List of Figures xix
List of Tables xxiii
List of Listings xxv
1 Introduction 1
1.1 IT experts as a scarce resource . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Virtual administrators & Operations knowledge . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Polyglot persistence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3.2 Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3.3 Concerns . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.4 Problem statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.5 Goal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.6 Research questions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.7 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Background 13
2.1 From infrastructure to infrastructure as code . . . . . . . . . . . . . . . . . . . . . . . . 14
xv

xvi CONTENTS
2.2 Service orchestration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3 OASIS TOSCA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.4 Juju . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.4.1 What is Juju . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.4.2 Juju internals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.4.3 Juju as a solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.4.4 Alternatives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.5 Database technologies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.5.1 History . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.5.2 Types . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.5.3 Relational database management systems . . . . . . . . . . . . . . . . . . . . . 32
2.5.4 Not-relational database systems . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3 Functional specification 37
3.1 Terms and visualisations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.1.1 Application modelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.1.2 OASIS TOSCA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.2 Example use case: company X . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.3 The generic database . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.3.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.3.2 Design choices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.4 Possible scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.5 Use case revisited . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.6 Caveats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44

CONTENTS xvii
4 Technical implementation 47
4.1 Juju specific terms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.2 Example use case: company X . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.3 The generic-database-charm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.3.1 Design Choices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.3.2 Other possibilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.3.3 The generic database under the hood . . . . . . . . . . . . . . . . . . . . . . . . 50
4.4 Use case revisited . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5 Discussion, Future work & Conclusion 55
5.1 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.2 Answers to research questions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.3 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
Bibliography 61
Appendices 65

xviii CONTENTS

List of Figures
1.1 Stackoverflow survery 2018 [1] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Traditional communications between operations and non-operations . . . . . . . . . . 5
1.3 The concept of a virtual administrator . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Example of a web shop application using multiple types of database technologies illus-trating the concept of polyglot persistence. . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1 The difference between service orchestration and service choreography . . . . . . . . . 16
2.2 Sequence diagram of an example use case where a buyer interacts with an agent. Af-terwards the agent formally performs all needed actions and communicates back withthe buyer [2]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.3 Resource entities and relationships of a Web application [3]. . . . . . . . . . . . . . . . 17
2.4 Example of an application topology illustrating the terms used by the TOSCA standard [4]. 18
2.5 TOSCA node types have requires and capabilities sections to fit together just like Legopieces. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.6 Juju GUI showing two applications (MySQL and Wordpress) connected to each other.The Wordpress application is in need of a database which is provided by the MySQLservice. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.7 Charm (bash template) structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.8 The architecture of the charms.reactive framework: when the orchestrator executes ahook, the reactive framework initiates and runs the handlers whose preconditions aretrue [5]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
xix

xx LIST OF FIGURES
2.9 The workflow of the automatic set flags in the endpoint . . . . . . . . . . . . . . . . . . 26
2.10 Disadvantages of relational database systems. An extra mapping step might be neededfrom data structure in the application to data structure on the database [6]. . . . . . . . 31
2.11 Most popular technologies in March 2018 . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.12 Data platformmap in 2016, illustrating the different types of database systems and tech-nologies [7]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.13 Example of a entity–relationship model illustrating how relational systems use tablesand relations to store and link data. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.1 Example application model of the Wordpress and MySQL services. . . . . . . . . . . . . 38
3.2 Logical diagram example of the TOSCA standard showing 3 nodes connected through“HostedOn”-relations. Nodes are defined by a name and a type and typically have a“properties” and a “capabilities” section. Some nodes also have a requirements sectionindicating how they need to function. Two nodes can have a relation if the requirementsof one are conform to the capabilities of another. [8] . . . . . . . . . . . . . . . . . . . . 40
3.3 Application model of use case: company X . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.4 Example hierarchy or categorisation of database technologies. The root of the tree isthe most generic database whereas the leafs represent technology specific databases. . 43
3.5 Application model of use case: company X with generic databases. . . . . . . . . . . . 45
3.6 The generic database service is only functional and present on the operations side ofthe application stack. The application itself directly connects to the database and is notaware of the generic database service. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.1 Application model with both the generic database charm and the generic database dbacharm. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.2 BPMN diagram of the generic database charm concept. . . . . . . . . . . . . . . . . . . 51
4.3 Sequence diagram of the implemented generic database service. It is assumed that thedatabase technology service is available. If the database is not concrete a request issend to set up the database. In the other scenario the generic database already knowsthe connection details. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52

LIST OF FIGURES xxi
4.4 Visualisation of the interface layer of the generic database. The black nodes can be seenas endpoints in charms. The interface layer is the API that tells how the charms shouldcommunicate. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.5 Application model of the use case as shown in the Juju GUI service. Two genericdatabase services represent two databases used by a webshop and a data analysis appli-cation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
1 Application model of the project. Two new charms layers will be created along withone interface layer. The “mysql” charm and “mysql-shared” interface will be reused. . . 69
2 Metadata and layer files of the two charm layers. They are the heart of the applications,allowing them to connect to each other. . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3 Visualisation of the interface layer of the generic database. The black nodes can be seenas endpoints in charms. The interface layer is the API that tells how the charms shouldcommunicate. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72

xxii LIST OF FIGURES

List of Tables
2.1 Summary of the most important terms in the TOSCA standard [8]. . . . . . . . . . . . 19
2.2 Juju terms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.3 Relational database and SQL terms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.4 Overview of non-relational (NoSQL) technologies . . . . . . . . . . . . . . . . . . . . . 35
3.1 Relation between the conceptual terms and how it is visualised. . . . . . . . . . . . . . 38
3.2 Different (possible) definitions for the generic database concept . . . . . . . . . . . . . 42
4.1 Summary of Juju terms and their meaning that are relevant in this chapter. . . . . . . . 48
xxiii

xxiv LIST OF TABLES

List of Listings
1 Example of a Puppet manifest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142 Example of a config.yaml file in JuJu. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243 Example of the Haproxy metadata.yaml file in Juju. . . . . . . . . . . . . . . . . . . . . 244 Example of an install hook in Juju. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245 Example of a handler in the reactive framework in Juju. . . . . . . . . . . . . . . . . . . 256 Pseudocode illustrating how flags and the endpoint-pattern are used in the reactive
framework of Juju. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 537 Interface.yaml file of the proxy interface layer . . . . . . . . . . . . . . . . . . . . . . . 708 Code of testwebapp/reactive/testwebapp.py that starts the workflow of the use case with
a request for a database. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 719 Code of interfaces/proxy/requires.py . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7210 Code of interfaces/proxy/requires.py . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7311 Code of gdb-charm/reactive/gdb-charm.py . . . . . . . . . . . . . . . . . . . . . . . . . . 7412 Code of testwebapp/reactive/testwebapp.py to render config file. . . . . . . . . . . . . . . 75
xxv


1Introduction
One of the most crucial and central subjects in information technology (IT) systems is data. In mostcases all that information needs to be stored in databases. The way data flows are treated often deter-mine how easily services can be managed. Different database technologies provide different strengthsand weaknesses. These days, it is not considered acceptable anymore to have significant downtime.Applications and all its stored data need to be accessible at any time. The lifecycle on how to store,process and analyse the bits and bytes is of great importance. Operation and system engineers havethe difficult task to create, deploy and maintain deployed services. In a lot of cases the central designconsiderations focus on application development, more than service operations which might reducethe quality of the cloud application. “The (5+1) Architectural View Model for Cloud Applications” bringsattention to all aspects of cloud applications [9]. Not only methodologies like Agile and DevOps butalso outsource-approaches have gained popularity over the last few years as they provide better de-velopment cycles, automation and scalability [10]. In this thesis, new state of the art approaches formanaging (cloud) applications are examined. With the gathered knowledge, the concept of a servicethat would help system and operations engineers in their day-to-day activities is constructed. Thanksto service orchestration and application modelling tools it becomes possible to define virtual (system)administrators. Operational tasks that were once the job of operations engineers or system administra-tors, are now performed in an automated way. These virtual entities aid data scientists or developersin obtaining configuration parameters of their wanted environments without the need of a physicaloperations engineer.
1

2 CHAPTER 1. INTRODUCTION
1.1 IT experts as a scarce resource
The digital and technical evolution resulted to ecosystems were different types of data became the cen-tral entity no matter what the actual business is. Guerra et al. [11] describes this phenomena wherethey emphasize that even computer science and engineering courses lack the “pedagogical practice inface of a reality that has required multidisciplinary, multidimensional, global, and contextualized prepa-ration”. This shows the lack of data analysis subjects and exercises in programs that focus on program-ming, computational insight and other IT-related skills. In a paper called “Integrating NoSQL, RelationalDatabase, and the Hadoop Ecosystem in an Interdisciplinary Project involving Big Data and Credit CardTransactions”, Rodrigues et al. [12] show how they tackled a real life use case concerning big data toolsand technologies for a group of 60 graduate students over the course of 17 academic weeks. The papershows the complexity of the Big data subject and the technical and mathematical requirements andtools before proper analysis can be performed (graduates need to understand the concepts of NoSQL,Hadoop, MapReduce and Hive before they are able to start performing analyses). This shows that anIT-minded person needs to know a lot of different things before his workflow becomes fluent.
The previous section briefly discussed that it is not always easy to find a lot of people with good hands-on experience. Education institutions need the time to re-educate themselves and transition theircourses to these subjects. In addition, the number of different topics to discuss in computer scienceand engineering studies keeps growing while there is only a fixed, limited amount of time. Therefore,it is difficult to find or become an IT expert that has themathematical and statistical foundations and theskill set to program properly and to have the knowledge to set up and maintain services. This group ofpeople would rise if the know-how of services and systems is not required as a part of their workflow. Arecent survey of Stack Overflow [1] shows that most people fall under the category “developer” (almost60% identify themselves as Back-end developer). Job titles such as “Database administrator” (not even15%), “System administrator (11,3%)”, “DevOps specialist (10,4%)” and “Data scientist or machine learn-ing specialist” (7,7%) are less present and it is safe to assume that there are less people employed in theseareas. Figure 1.1 illustrates the number differences on the X-axis. In other words IT experts, no matterthe expertise are scarce, especially maintainers of applications and services such as operations engi-neers or system administrators. The State of Developer Ecosystem Survey in 2018 is another recent studyperformed by JetBrains that confirms the imbalance between developers and other IT experts [13].

1.1. IT EXPERTS AS A SCARCE RESOURCE 3
Figure 1.1: Stackoverflow survery 2018 [1]

4 CHAPTER 1. INTRODUCTION
1.2 Virtual administrators & Operations knowledge
Before defining the problem statement and goal of this research some terms and concepts need to bedefined. Virtual administrators and operations knowledge are key points, crucial for understandingwhat the goal of this research is and why certain approaches are used.
Virtual administrators
To properly define the concept of a virtual administrator, it is interesting to look at some daily workcycles. These days, most teams have real life administrators to perform operations. These operationaltasks may vary from setting up and configuring new services and machines or monitoring existing ap-plications. Some companies also make use of the possibility to outsource these tasks as they often wantto focus on one specific thing without the cost and complexity of the tasks of a system administratoror network engineer. The same can be said about testing, quality assurance (QA), infosec or analytics.Figure 1.2 shows a common workflow of how non-operation minded people work together with systemadministrators. It is clear that there are at least two stakeholders, the person requesting something andthe system administrator providing it. Because multiple people are involved, time management andplanning becomes crucial. It does not occur frequently that people have the time and ability to performoperational tasks immediately, resulting in a slow process. The DevOps philosophy/approach intro-duced awareness and techniques to bundle forces between developers on the one side and operationsengineers on the other. This way both teams can deal with the big differences between developing apiece of software and deploying or managing it. Both work together with the product as ultimate goal.This mindset is already a huge step forward and reduces the time it takes from requesting an operationaltask to finishing it. The virtual administrator approach reduces this bottleneck completely. Figure 1.3shows that an operation engineer can create a virtual administrator and provide this entity with all thenecessary tools in order to perform the tasks he otherwise needed to do. In this case a non-operationsperson can make use of the virtual administrator at any time. This reduces the number of people whoare involved in the process to one. The developer or data scientist becomes self-reliant and the timeneeded to get the requested operational tasks done, reduces significantly. In other words, virtual ad-ministrators provide more flexibility to set up automated systems and users are not required to knowspecifications of the used systems.
Imagine the case where a group of developers or other non-operations engineers are in need of someservers and applications for a new project. One of the required services is a database. In a lot ofcases either the developer has access to the database or server himself or he must ask an operationsengineer or database administrator (DBA) to perform the steps that are necessary. In the first case thedeveloper is required to know how to deploy and configure these systems. These steps can for exampleinclude: setting up a server, installing software, creating users, creating a database and copying thedatabase details to the application the developer is working on. These are a lot of steps and they require

1.2. VIRTUAL ADMINISTRATORS & OPERATIONS KNOWLEDGE 5
Figure 1.2: Traditional communications between operations and non-operations
Figure 1.3: The concept of a virtual administrator

6 CHAPTER 1. INTRODUCTION
some specific knowledge and skills. It is a grey zone whether or not the developer should know thisknowledge as it is often not directly associated with his job. The idea of a virtual administrator is nottaking away the job of the DBA or operations engineer but is rather the concept of creating a system,a tool or a way that focuses on performing the tasks in such a way that the developer can get what hewants in a time and cost-friendly way. For the operations engineer the virtual administrator shouldalso be constructed with flexibility as a key element. Three concepts come forth from this idea:
• No physical other person is needed or must intervene when setting up these servers, applicationsor services.
• No real operations knowledge (see below) must be known by the developer.
• Flexibility and reusability are the main concerns for the operations engineer.
The virtual administrator handles all technical stuff and provides the requested services and details tothe developer in a way that he is ready to start carrying out his expertise without bothersome config-uration issues. When different virtual administrators have the flexibility to interact with each otherfull-fledged automated infrastructures become possible.
Operations knowledge
The abstract concept of operations knowledge can be defined as the overall sum of the knowledgeabout specific technologies, their relations, configurations and limitations. This includes version num-bers, technology-specific differences for the same physical or logical thing, configuration parametersand all other characteristics of a service or technology. Knowing that MySQL is a management systemfor databases is not necessarily considered to be operations knowledge, whereas knowledge about in-stalling MySQL or how a user can connect to a MySQL database is. The following example will clarifythis definition.
Imagine a team working on a web shop that sells items. The company chooses to performing dataanalysis on all sold units, they decide to put a team of data scientists to work. This team needs to set uptheir tools, configure the applications they want to use and they need to be able to get the data from theweb shop. This task and how it is achieved is what falls under the domain of operations knowledge. Thedata scientist does not care what database technology (MySQL, MongoDb, or Cassandra for example) orback- and front-end technology is used for the web shop. All they want, is the ability to retrieve the dataand work with it. In other areas, they might be a bit pickier as the data scientists might request somespecific version (of a tool or technology) because of some specific feature (for example Hadoop version3.0). Note that the same exercise can be made with developers instead of data scientists. Developersgenerally are not interested whether the web server runs Nginx or Apache, or if your database server

1.3. POLYGLOT PERSISTENCE 7
runs on a MySQL or a Mariadb instance. This flexibility to request things when having the operationsknowledge, and at the same time being able to work on a higher more abstract level that does notrequire operations knowledge, is not easily attained. With the help of virtual administrators a teamshould be able to have faster and easier deployments models without losing flexibility and power.
1.3 Polyglot persistence
1.3.1 Definition
Because this thesis looks at virtual administrators for the management of polyglot persistence applica-tions, this term is the final foundation of this research. The definition “polyglot persistence” originatedfrom the blog (2008) of Scott Leberknight [14] who applied the idea of polyglot programming (2006)from Neal Ford. The term polyglot programming was introduced as the idea of using multiple lan-guages making it possible to choose the right tool for the job [15]. Polyglot literally means “a mixtureof languages”1 . Persistence, in this case, refers to the process of storing data in storage whereas thedata itself will outlive the process that created it. In other words, polyglot persistence, is the term for anapplication, service or enterprise where multiple data store technologies coexist [16]. Picking the rightlanguage for the job may be more productive than trying to fit all aspects into a single language. Notethat the polyglot persistence idea resembles the concept of microservices where instead of a monolithapplication, an architecture of loosely coupled services is built. This architecture enables organisationsto focus on a separate business functionality within small services [17]. Microservices and polyglotpersistence fit perfectly together.
1.3.2 Example
Figure 1.4 shows an example of a polyglot persistent application. The web shop uses multiple databasesto store different types of information. The reason behind dividing the storage of these different typesof data is often two-sided. First, parts of the application might not be core-business. If the recommen-dation system for example does not function, the web shop itself is not necessarily offline as it shouldstill be possible to login and buy things. Secondly, and this is probably the biggest motivator for a lot ofteams, are the characteristics of the database technology. If an application uses a Key-Value model tostore its variables, an according database technology like Redis will be more efficient. Another examplewhy applications might choose not to use traditional relational database systems are the use of certainalgorithms. If an application uses graph data structures, a graph-based storage system might be moresuitable.
1https://www.merriam-webster.com/dictionary/polyglot

8 CHAPTER 1. INTRODUCTION
webshop application
relational- based
e.g. MySQL
document-based
e.g. MongoDB
graph-based
e.g. Neo4J
user-relatedinformation
items for salerecommendation
information
Figure 1.4: Example of a web shop application using multiple types of database technologies illustratingthe concept of polyglot persistence.

1.4. PROBLEM STATEMENT 9
1.3.3 Concerns
Choosing for microservice architectures and polyglot persistent models is not necessarily the best solu-tion. Adding more systems to an application, raises the complexity of the overall infrastructure. For theapplication it means more configuration parameters and maybe more libraries to use before everythingis properly connect. When it comes to system administration, more and different systems require moreattention. In NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence this challengeis described as follows “In this new world of polyglot persistence, the DBA groups will have to becomemore poly-skilled - to learn how some of these NoSQL technologies work, how to monitor these systems,back them up, and take data out of and put into these systems” [16]. In other words, not only the appli-cation specific configurations need attention but the deployment complexity also raises. As these newsystems are required by the applications, they will also need to exist in all environments (development,testing, quality assurance and production) as well. The advantages of polyglot persistence need to beweighed against the complexity that it entails. Choose the right tool for the job.
1.4 Problem statement
Right now developers or data scientists still need a lot of operational knowledge when they want toperform their job. Proper configurations often cause a lot of lost time and frustrations. These opera-tional tasks need to be performed by a group of scarce people, the operation engineers. If a user is inneed of a virtual machine, a web server or a database, he often needs help of another physical personeither explaining how things work or providing all the necessary instances and details.
Configuration management tools like Chef, Puppet or Ansible have grown in popularity over the lastfew years. More and more companies started to use them and the tools became more accessible2. Thisis already a huge step forward from the slow, manual steps one needed to take in a not so distant past.Tasks such as setting up a (virtual) machine, configuring and installing software should not be per-formed manually anymore. These tools help the operation engineers in performing their tasks but arehowever of no use for developers or data scientist who have no affinity with the operations knowledgethat is still required when using them. Even services offered by big companies such as Amazon, Googleor Microsoft still require some basic knowledge about configuring machines and services. Preconfig-ured machines or out-of-the-box solutions are therefore in a lot of cases definitely wanted.
2https://www.g2crowd.com/categories/configuration-management

10 CHAPTER 1. INTRODUCTION
1.5 Goal
In “The DevOps Handbook, How to create world-class agility, reliability, & security in technology organi-zations” finish their book with a call for action. They sell DevOps principles and patterns as a solutionthat “can help the creation of dynamic learning in organizations, achieving the amazing outcomes of afast flow and world-class reliability and security, as well as increased competitiveness and employee sat-isfaction” [18]. Even though this is written from a DevOps point of view it can be directly mapped onthe high-level goals and problems that are discussed in this research. When setting up tools, configu-rations and machines, people without operations knowledge should be able to receive their requestedoperational entities faster and more easily. Additionally, managing cloud applications should be donein the most flexible way as things may change rather quickly. In general, things should be easier!
The goal of this thesis can be found in its title. Management of polyglot persistent integrations withvirtual administrators refers towards the use of virtual administrators that allow services to requestany database type they want and end up with a working database, ready to connect to.
1.6 Research questions
The creation of this service is the main focus of this research. It is however possible to look at smallerresearch topics as well.
• Is it possible, and what is needed, to create a service for the management of polyglot persistentintegrations?
• What does this service formally represent in an application model?
• What problems does the service solve, and at what cost?
1.7 Overview
The next few chapters are organized as follows: chapter 2 focuses on existing tools and related work.It defines used concepts, languages and technologies such as the TOSCA standard and Canonical’sapplication modelling tool Juju. Some existing tools will be discussed illustrating why they fall short.The similarities and differences between database technologies are also defined as they provide crucialinformation in defining a generic database service. Chapter 3 focusses on the functional specification.This makes it possible to define the service without any tool-specific restraints. In this chapter thescope of the service is defined by a sample use case scenario. A technical implementation in Juju is

1.7. OVERVIEW 11
discussed in chapter 4. The presented use case acts as a proof of concept. Chapter 5 ends this thesiswith a discussion about the results, the limitations, some possible future work or research and finallya conclusion.

12 CHAPTER 1. INTRODUCTION

2Background
This chapter will give an overview of some key components and concepts about operational tasks. Asmall overview of old and new approaches will be given accompanied by concepts such as Infrastruc-ture as Code (IaC) and configuration management tools. Next, state of the art research concerningvirtual administrators and service orchestration will be thoroughly discussed. Afterwards, the TOSCAmodelling language and Canonical’s Juju will be examined for respectively the functional specifica-tion and the technological implementation. Finally, for the sake of completeness the different type ofdatabase technologies are discussed and compared.
13

14 CHAPTER 2. BACKGROUND
2.1 From infrastructure to infrastructure as code
When it comes to setting up machines and applications or deploying developed software a lot of oper-ational tasks used to be manual work. With virtualisation techniques and afterwards cloud computingpossibilities other approaches were needed. More and more principles of software development foundtheir way to infrastructure. “Infrastructure as Code” (IaC) is a term describing the act of setting up,managing and interacting with data centres or cloud computing models. The idea is that the configu-ration is written in files (typically YAML and JSON) to describe what the desired state should be for aspecific machine (see listing 1 for an example). The concept of idempotence, meaning “that a deploy-ment command always sets the target environment into the same configuration” 1 is very important.Configuration management tools such as CFEngine, Chef or Puppet can be seen as frameworks for IaC.
# execute 'apt-get update'exec { 'apt-update':
command => '/usr/bin/apt-get update'}
# install apache2 packagepackage { 'apache2':
require => Exec['apt-update'],ensure => installed,
}
# ensure apache2 service is runningservice { 'apache2':
ensure => running,}
Listing 1: Example of a Puppet manifest
IaC approaches and configurationmanagement tools becomemainstream and have improved the work-flow for both developers and operation engineers [13]. These tools however, only help when someoneuses them who has “operations knowledge” (see section 1.2 Operations knowledge). Users can definecertain parameters more easily and the deployment is faster but if the user does not know what to de-fine and setup these tools wont help. In an introductory video about Juju (see later) Jorge Castro talksabout “service orchestration” as the next step. He states: “We see the next step being service orchestra-tion, which is when you get to the level of scales when you are talking about thousands and hundreds ofthousands of instances, you have to manage at the service level instead of the individual machine. You careabout the individual machine but they become like CPU and RAM are today.”
1https://www.visualstudio.com/learn/what-is-infrastructure-as-code/

2.2. SERVICE ORCHESTRATION 15
2.2 Service orchestration
The idea behind service orchestration finds its roots in the Service Oriented Architecture (SOA) land-scape. In the early 2000s this approach focused on developing systems that are “loosely coupling inter-operable services” [19]. The reusability of components and the creation of multiple services interactingwith each other, lie at the core of SOA. Other extensions or inspirations of SOA include Web servicesbased onWeb Services Description Language (WSDL) and Simple Object Access Protocol (SOAP), Web 2.0and microservices. Service orchestration is a possible approach to help teams attain a system designcompatible with SOA. Mulesoft defines service orchestration as follows: “Similar to an organizationalworkflow, service orchestration is the coordination and arrangement of multiple services exposed as a singleaggregate service. Developers utilize service orchestration to support the automation of business processesby loosely coupling services across different applications and enterprises and creating “second-generation,”composite applications. In other words, service orchestration is the combination of service interactions tocreate higher-level business services” [19].
An orchestrator in its simplest form is “program” that interprets knowledge in the form of models orfiles and performs the necessary management actions in automated manner [20]. Orchestration shouldnot be confused by a similar but different approach namely the “Web Service Choreography”, a spec-ification to define business processes with XML. Not everyone agrees on terminology and concepts2
but the main difference lies in the management approach. Orchestration has a single entity orderingtasks and deciding things. With choreography there is no “conductor” (a central management node),the “performers” (webservices for example) need to act on their own. Figure 2.1 visualises the differencebetween the two. Note that because IT infrastructures can grow very complex, one central orchestratoroften lacks maintainability. Even meta-schedulers (decentralized scheduling) do not address the exten-sive needs in cloud modelling languages. To answer this issue Sebrechts et al. propose a distributedorchestrator in the paper “Distributed Service Orchestration: Eventually Consistent Cloud Operation andIntegration” [20].
2https://www.infoq.com/news/2008/09/Orchestration3https://stackoverflow.com/questions/4127241/orchestration-vs-choreography

16 CHAPTER 2. BACKGROUND
(a) Visual representation of service orchestration. (b) Visual representation of service choreography.
Figure 2.1: The difference between service orchestration and service choreography3.
The need for orchestration tools became apparent when knowledge reuse became a very requestedphenomenon. Code reuse in software development in the form of libraries has been around for years.With Infrastructure as Code, it became clear that concepts such as abstraction and encapsulation be-came crucial in operations as well. In the paper “Orchestrator Conversation: Distributed Management ofCloud Applications”, Sebrechts et al. [20] propose the orchestrator conversation. This approach shouldenable the reuse of knowledge.
In “Web services orchestration and choreography” [2] Peltz uses a sequence diagram (see figure 2.2) anda use case to illustrate how a user is communicating with an agent and how this agent performs all thehard work. The concept of a virtual administrator as introduced in 1.2 becomes clear. A user formulatesa high-level (with no operations knowledge) request and a virtual administrator (in this case the agent)performs all necessary tasks to fulfil the request.
In “A Taxonomy and Survey of Cloud Resource Orchestration Techniques” Weerasiri et al. provides anoverview of orchestration models, languages, platforms and tools related to cloud resources. In theirtaxonomy they visualise the different components of cloud resource orchestration. They also illustratethat cloud resource orchestration happens on different layers. For example a user layer exists at thehighest level, providing tools like command line interfaces (CLI), dashboards or other tools. This is anabstraction to the user and with the help of other layers such as the resource management or resourceprovisioning layer a whole hierarchy makes the orchestration of cloud resources possible.
Figure 2.3 shows an example of the resource entities and relationships of a Web application. It modelsthe infrastructure and shows how different entities are related. A standard that would use these di-agrams for a uniform understanding and a way for tools to interpret these models would help in theprocess of managing cloud based services. Such a standard is the TOSCA language.

2.2. SERVICE ORCHESTRATION 17
Figure 2.2: Sequence diagram of an example use case where a buyer interacts with an agent. Afterwardsthe agent formally performs all needed actions and communicates back with the buyer [2].
Figure 2.3: Resource entities and relationships of a Web application [3].

18 CHAPTER 2. BACKGROUND
Figure 2.4: Example of an application topology illustrating the terms used by the TOSCA standard [4].
2.3 OASIS TOSCA
In “Declarative vs. Imperative: Two Modeling Patterns for the Automated Deployment of Applications”Endres et al. [21] discuss two modelling patterns for automated cloud deployments. Declarative work-flows focus on what needs to deployed. All logic is interpreted and the runtime performs the necessaryoperations. Imperative workflows on the other hand cover how deployments happen. All requiredsteps need to be explicitly described. The TOSCA standard supports both models as both modellingapplication topologies can be created as well as workflow models for deployments.
“Topology and Orchestration Specification for Cloud Applications” or TOSCA is an OASIS standard (firstdescribed in 2013) providing specifications to create self-contained cloudmodels that describe the topol-ogy of cloud applications alongside the management and orchestration in a workflow model [5, 8]. Thefundamental goal of TOSCA is the idea of enhancing portability and (re-)usability of cloud applicationsand services. As the lifecycles, relationships and operational behaviours of these services are oftenredundant, a general approach should aid in the process of deploying and maintaining cloud services.
The following use case will illustrate the key components of the TOSCA standard. The use case is basedon the notes of the OpenTOSCA Research Prototype4 [4]. A small group of developers want to deploy aJava WAR archive on a Tomcat instance, see figure 2.4. The Tomcat server runs on an operating system(Ubuntu) which is hosted on a virtual machine on a cloud provider (AWS for example). TOSCA modelsthese different entities and defines capabilities (what does the service provides) and requirements (whatdoes the service needs). This fundamental characteristic is visualised in figure 2.5 A formal definition ofthese concepts is summarised in table 2.1 taken from the official TOSCA Simple Profile document [8].
4http://www.opentosca.org/index.html

2.3. OASIS TOSCA 19
Figure 2.5: TOSCA node types have requires and capabilities sections to fit together just like Legopieces.
Table 2.1: Summary of the most important terms in the TOSCA standard [8].
Term Definition
Topology templateA topology template consists of a set of node template and relationshiptemplate definitions that together define the topology model of a serviceas a (not necessarily connected) directed graph.
Node template
A node template specifies the occurrence of a software component node aspart of a topology template. Each node template refers to a node type thatdefines the properties of the node (e.g. ). Node types are defined separatelyfor reuse purposes.
Relationship template
A relationship template specifies the occurrence of a relationship betweennodes in a topology template. Each relationship template refers to a relationshiptype that defines the properties of the relationship. Relation types are definedseparately for reuse purposes.
PropertiesThe semantics of a node or relationship e.g. attributes, requirements,capabilities, interfaces, etc.
ArtifactsCode or logic required by the node template to successfully meet certainrequirements. E.g. files to populate databases, archives to be deployed, imagefiles for setting up services or operating systems, etc.

20 CHAPTER 2. BACKGROUND
OpenTosca (Winery [22]), Cloudify and alien4cloud are tools based on the TOSCA standard. The toolused in this research is Juju. This application modelling tool, created by Canonical Ltd, is also charac-terised by the same concepts as TOSCA.
2.4 Juju
This section will give an extensive overview of the Juju platform. What Juju is, how it can be usedand what goals it tries to achieve. Next, a summary is given on how Juju works under the hood. Themain components such as charms, hooks and relations will be discussed and the new charms.reactiveframework will be examined closely as it enables reusability and provides more flexibility [5].
2.4.1 What is Juju
Concepts
Canonical describes Juju as follows: “Juju is a state-of-the-art, open source modelling tool for operatingsoftware in the cloud. Juju allows you to deploy, configure, manage, maintain, and scale cloud applicationsquickly and efficiently on public clouds, as well as on physical servers, OpenStack, and containers. You canuse Juju from the command line or through its beautiful GUI” [23]. Modern applications these days arenot monolithic or standalone applications anymore. Multiple services work together. Microservices,load balancers, worker and slave-nodes, caching tools are all examples of multi-application architec-tures. Even a website that uses a database consists of two different applications (the actual webserverwith the website and a database service). Application modelling is the art of modelling the differentapplications with the goal to easily manage and scale them.
When looking at the Juju GUI (see figure 2.6) it shows a visual representation of the different ap-plications and how they are connected. The model represents an undirected graph where each noderepresents an application and each vertex contains relation-specific details between the two applica-tions. This visual level is clearly an example of encapsulating complexity for users.

2.4. JUJU 21
Figure 2.6: Juju GUI showing two applications (MySQL and Wordpress) connected to each other. TheWordpress application is in need of a database which is provided by the MySQL service.
Charms & Bundles
Juju uses charms and bundles to set up infrastructures. Charms are the fundamental building blocksof Juju. They are a set of scripts for deploying and operating the application. Juju offers the possibilityto write charms in any language (including existing configuration management tools such as Chef andPuppet). These charms are event-driven and focus on reusing operational steps (or code) in differentcircumstances. If a team has multiple redundant setups for security or testing purposes ,the stepsto configure them are similar if not completely the same. Bundles are collections of charms that arelinked together. With the use of a bundle a team can deploy a whole stack of technologies at once. TheCanonical Distribution Of Kubernetes is a good example of such a bundle5.
The great thing about these charms is that once they are written they provide a way of setting up sys-tems without “application-specific” knowledge (hence operations knowledge). Things like dependen-cies, operational events like backups and updates can all be encapsulated in the charm. The strongerthe knowledge of the charm author, the more options will be available and the more flexibility one canhave when designing in the Juju GUI. Once done, a user ends up with a working infrastructure withoutcontinuously bothering an expert. In other words when the charms or bundles are written, Juju and itscharms act as virtual administrators for the user.
While charms and bundles are the central elements of Juju, a user gets confronted with some otherconcepts first. After installing Juju and optionally setting up the credentials for public cloud environ-ments such as Amazon Web Services, Windows Azure or Google Compute Engine one can “bootstrap”their environment. A Juju controller (which is also a machine) is the central communication andmanagement node for a cloud environment.
5https://jujucharms.com/canonical-kubernetes/

22 CHAPTER 2. BACKGROUND
Thanks to the controller it is possible to create Juju models. A model is always associated with onecontroller. Models can be easily added, destroyed or modified by users. It is at this level that operationsengineers also can invoke security by granting users access to specific models. In this model charmscan be added and linked together. This is the environment where “modelling an infrastructure” becomespossible through the use of the Juju commandline tool or the Juju GUI.
Juju Agents
The Juju agents are the building blocks of the entire tool. Juju agents are pieces of software that areinstalled on all Juju machines. There are two types of agents: themachine and unit agent. The machineagent takes care of all machine related communication whereas the unit agent specifically operatesat the application unit level. It is the machine agent that creates the unit agent and the unit agentthat takes care of all the charm related tasks. These agents make it possible to speak about serviceorchestration as discussed in 2.2.
Subordinates
Applications are composed of one or more application units. An application unit runs the application’ssoftware and is the smallest entity managed by Juju. Application units are typically run in an isolatedcontainer on a machine with no knowledge or access to other applications deployed onto the samemachine.
In Juju, applications have one or more application units running the application’s software. This unitis managed by the unit agent and typically runs in isolated containers. Thanks to these seperated con-tainers multiple applications can co-exist on the same machine without knowledge or interaction toeach other. There are two types of charms in Juju: the regular ones and the subordinates. “Subordinateapplications allow units of different applications to be deployed into the same container and to haveknowledge of each other.”6 They inherit the public/private address of their principal application anddo not function as standalone applications. Subordinates are perfectly suitable for logging or makingbackups.
6https://docs.jujucharms.com/stable/en/authors-subordinate-applications

2.4. JUJU 23
Figure 2.7: Charm (bash template) structure
2.4.2 Juju internals
Structure, hooks & relationships
As previously stated, Juju works with charms. Figure 2.7 shows the charm structure in its simplest form.The config.yaml (see listing 2 for an example that holds some options for a deployed http website) fileholds the different options that will be accessible by the end user. The icon.svg is the image used inthe Juju GUI to represent the service and the README should offer some explanation about the charmfor other uses. Revision is optional and rather deprecated. The metadata.yaml is another importantfile. A simplified version of the Haproxy service is given in listing 3. The first few lines give someinformation but the “provides” and “requires” tags are crucial. They define how charms can interactand communicate with each other. Finally there is a folder called hooks. A hook is an executable file(written in any language that can be interpreted by an Ubuntu machine). These files will be calledby the Juju unit agent depending on different events. The hooks inform Juju what events happenand what actions the charm should do. An example of a very basic install-hook is shown in listing 4.The language used is bash. It installs the apache software and deploys a basic website. Note that thereactive framework is built on top of this hook workflow. In fact the reactive framework inserts a hookthat will manage all other hooks. Because the reactive framework is the new and better [5] way towrite charms the lifecycle of the hooks become less relevant for charm authors and are therefore notcovered here. The “charm build” command creates all appropriate hooks based on the reactive files ofthe charm. Note that hooks are still the fundamental mechanisms of Juju. When debugging, the “jujudebug-hooks” command is needed and the according hook should be examined.

24 CHAPTER 2. BACKGROUND
options:website-name:
type: stringdefault: "My Website"description: "The title of your website"
port-number:type: intdefault: 80description: "Port to run website on"
Listing 2: Example of a config.yaml file in JuJu.
name: haproxysummary: "fast and reliable load balancing reverse proxy"maintainers: [Juan Negron <[email protected]>, Tom Haddon
<[email protected]>]↪→
description:HAProxy is a TCP/HTTP reverse proxy ...
tags: ["cache-proxy"]series:
- trusty- ...
requires:reverseproxy:
interface: httpprovides:
website:interface: http
...
Listing 3: Example of the Haproxy metadata.yaml file7
#!/bin/bash
set -eux
apt-get install apache2 -ya2ensite 000-defaultecho "<html><body>Hello World!</body></html>" > /var/www/html/index.htmlservice apache2 restart
Listing 4: Example of an install hook in Juju.7https://api.jujucharms.com/charmstore/v5/haproxy-43/archive/metadata.yaml

2.4. JUJU 25
Reactive framework
In the paper “Beyond Generic Lifecycles”, Sebrechts et al. discuss some limitations such as inflexibilityor good support to reuse certain steps with traditional charms. The reactive framework is an answer tothose shortcomings. They speak about “emergent workflows” using declarative flags and handlers [5].Through the use of @When annotations above functions, a charm author can define conditions when-ever the framework should “react” (hence the name charms.reactive8). These annotations, called deco-rators, allow the reactive framework to create hooks accordingly. Figure 2.8 shows the architecture ofthe reactive framework.
Because the reactive framework offers more flexibility and reusability in the form of layers it should bethe preferred method when writing charms. An example is given in listing 5.
@when('apache.available', 'mysql.availale')def setup_app(mysql):
render(source='configuration.php',target='/var/www/configuration.php',owner='www-data',perms='0o775',context={
'db': mysql,})
set_state('apache.start')status_set('maintenance', 'Starting apache')
Listing 5: Example of a handler in the reactive framework in Juju.
Figure 2.8: The architecture of the charms.reactive framework: when the orchestrator executes a hook,the reactive framework initiates and runs the handlers whose preconditions are true [5].
8https://charmsreactive.readthedocs.io/en/latest/

26 CHAPTER 2. BACKGROUND
SET 'joined'
No
Yes
any remote unit left?
SET 'changed'
SET 'departed'
add departed unit torelation.all_departed_units
First unit joins
CLEAR 'joined'
Note: all flags are prefixed with 'endpoint.{endpoint-name}.'
remote unit joins or published new
relation data
remote unit leaves relationship
Figure 2.9: The workflow of the automatic set flags in the endpoint
Endpoint pattern
A recent pattern in the reactive framework is the “Endpoint-pattern”9. The “Endpoint” class is the newbase class used in building interface layers. The class provides internal flags and makes the use of@when annotations possible instead of the @hook ones. These result in code that is more read- andwriteable.
As shown in figure 2.9, interface authors can use four flags that are automatically set by the endpoint-pattern:
• endpoint.{endpoint_name}.joined
• endpoint.{endpoint_name}.changed
• endpoint.{endpoint_name}.changed.{field}
• endpoint.{endpoint_name}.departed
2.4.3 Juju as a solution
When looking back at the problem, stated in section 1.4, it is interesting to look at the workflow of Jujuusers. Imagine the use case where a team has Juju installed and correctly configured. A data scientistwants to start performing some analysis. He needs two key aspects: his Big Data environment and thesource of the data he needs to analyse. The setup of his tools (for example a Hadoop and Spark cluster)
9https://charmsreactive.readthedocs.io/en/latest/charms.reactive.relations.html#charms.reactive.endpoints.Endpoint

2.4. JUJU 27
is something Juju can manage quite well in the user-friendly Juju GUI. Setting up the connection andrelation between these tools and (non-)existing datastore units show some issues. When tackling thisuse case practically there are a few scenarios possible (we assume the data scientist is given a Jujumodel to work with):
1. The operation engineer has already predefined all data store related charms in the model. Whatis left to do for the data scientist is setting up his tools and adding relationships.
2. The data scientist has access to charms from another model through cross model relations.
3. The user does not want to interact with Juju models at all (looking at tools that exist on top ofJuju: Conjure-up, Tengu or custom frameworks). All he wants to say is: “setup and configureeverything for me”.
4. (Proposed) The data scientist (and/or the layers on top of Juju) model everything but throughgeneric entities such as a charm representing a database instead of a concrete application.
It might be clear that approach 1 still requires some manual work from the operation engineer, some-thing fundamentally against the goal of this research. Approach 2 seems very promising but the JujuGUI offers no support whatsoever for cross model relations meaning the visual representation for non-technical users is of no help. In addition, there is still need for an entity in the model of the data scientistrepresenting the datastore in the form of a generic database or this approach becomes similar to ap-proach 1. Also note here that while Juju has its limitations, Juju focusses on modelling applications andapplications only. Approach 3 is the ultimate goal for both the data scientist and the operation engineerif it can all work in an automated way. Point 4 is the proposed idea of the virtual data administratorsfilling the gap and making approach 3 more and more possible.
Overview of things to keep in mind concerning Juju:
• Juju is more powerful than the Juju GUI alone, but using all its capabilities require some moreknowledge of the CLI on one hand and some experience with Juju on the other.
• Juju focusses on application modelling. Modelling more (or other) things that represent otherideas or concepts than applications is something out of the scope of Juju.
• Juju and its charms allows many languages but the reactive framework seems to be the preferredway.

28 CHAPTER 2. BACKGROUND
Table 2.2: Juju terms
Concept Meaning ExampleCloud Resource that provides machines. AWS, LXD
ControllerInitial cloud instance that functionsas central management node.
-
ModelA model has one controller and is theplayfield for deploying applications.
-
CharmThe sum of operations needed to install andconfigure applications on machines.
Wordpress
Bundle A collection of charms and their relations.Wiki-simple
MachineAn instance of the cloud(a virtual machine or container).
-
UnitThe deployed software on a machine,one machine can have multiple units.
-
RelationThe concept of connecting multiplecharms to share information.
-
AgentSoftware on a Juju machine to keeptrack of changes.
Machine agent,Unit agent

2.4. JUJU 29
2.4.4 Alternatives
There are a lot of tools, each with their own strengths and weaknesses. Most ease the operationalactivities for an operations engineer or focus on automating these tasks (see section 2.1). This is notthe area where Juju shines. Juju provides the flexibility of its virtual administrator and the availabilityof reusable charms and bundles. When looking at other tools to replace Juju and that operate at thesame application modelling level some characteristics need to be defined as metrics:
• What happens (what is the lifecycle) when two applications need to be connected?
• Are users able to work, deploy with the tool without knowing operations knowledge?
• Does an application request one specific other application or does it allow generic types?
• Is it possible to reuse parts of existing models or setups?
• Is it possible to connect to one and the same database with multiple applications?
When looking at these questions it already becomes clear that most configuration management tools orPaaS (Platform-as-a-Service) like solutions do not provide enough flexibility or possibilities. The needfor tools that work on the level of service orchestration (see section 2.2 Service orchestration) is crucial.
Conjure-up10 is a tool build on top of Juju. Its goal is to provide even less know-how and faster settingup times. With a mindset as “Start using your big software instead of learning how to deploy it.” theirfocus aligns with the goals of this research. Because Conjure-up is nothing more than a layer on top ofJuju (and therefore uses Juju), this tool wont be further examined.
Other tools such as Cloudify11, Mcollective in Puppet12, Heat13, Apache Brooklyn14 or alien4cloud +terraform15 were briefly examined. The tools were not further explored because either they did notoperate at the required level of operation management or the requested flexibility and reusability seemsnot present. Further research on possible Juju alternatives is needed. What is clear, however is thatJuju functions on a lot of levels including installing software, writing configurations, managing statesand orchestrating where all other tools fall short in at least one area.
10https://conjure-up.io11https://www.cloudify.co/12https://puppet.com/docs/mcollective/current/index.html13https://wiki.openstack.org/wiki/Heat14https://brooklyn.apache.org/15https://alien4cloud-blog.com/tag/terraform/

30 CHAPTER 2. BACKGROUND
2.5 Database technologies
2.5.1 History
In 1970 Edgar F. Codd [24] introduced the concept of relational databases. From that moment forwardthey have been in use ever since, proving their use and capabilities. The last few decades technologydid not stop evolving, as did customer satisfaction. Nowadays it is unacceptable if systems are notresponsive or fast enough. In addition, customers demand a 27/7 availability making downtime ormaintenance a weak spot for a service. In 1.3 introduction, the term polyglot persistence was brieflydiscussed and illustrated with an example as a way of solving the availability requirement. The idea ofusingmultiple databases to power one ormore applications (e.g. microservices) becamemore importantas soon as availability became a concern. In addition, sometimes certain data structures are moresuited in a non-relational model. In these cases, NoSQL solutions are the way to go. In a blogpost [6],Nikola Živković, speaks about “impedance mismatch”, a term that describes the difference betweenthe relational model and the in-memory data structure. The traditional relational database systemsare however still needed and should not be replaced as they are perfectly suitable in certain cases.The polyglot persistence concept however makes system designers aware that more possibilities exist.There are multiple types of NoSQL database technologies each with their strengths and weaknesses.These characteristics define how the data is stored. Figure 2.10 illustrates a crucial mapping step in theprocess of storing application data to a relational database. This, often complex mapping step, wouldbe unnecessary if one would use a graph store NoSQL technology such as Neo4J. This illustrates thatthe choice of database technologies is often related to the use case. Figure 2.11 gives an overview ofthe most popular technologies as of March 2018.
2.5.2 Types
When It comes to database types there are generally two big categorisations. The relational databasesand the NoSQL systems. A new, third concept saw the daylight in 2011. The term “NewSQL” wasintroduced by Matthew Aslett making a new class of database systems that combine the best of thetwo worlds. NewSQL systems maintain the ACID (Atomic, Consistency, Isolation, Durability) of tradi-tional database systems while also providing the scale features of NoSQL technologies [25]. Relationaldatabase systems also know multiple categories such as object database systems or object-relationaldatabase systems. These, together with NewSQL technologies will not be further examined in this re-search. 451research.com created a map as shown on figure 2.12 with a lot of data platform providers [7].Discussing the architecture of database systems are full-fledged researches and books on themselves.The components of a DBMS, the used algorithms and data structures in terms of storing and optimisa-tions when querying, are crucial elements of every database system. In this research these details wont
16https://db-engines.com/en/ranking

2.5. DATABASE TECHNOLOGIES 31
Figure 2.10: Disadvantages of relational database systems. An extra mapping step might be neededfrom data structure in the application to data structure on the database [6].

32 CHAPTER 2. BACKGROUND
Figure 2.11: Most popular technologies in March 201816
be examined. For more information refer to the Architecture of a Database System article of Hellersteinet al. who performed a comprehensive research [26].
2.5.3 Relational database management systems
Relational database systems use tables, consisting of rows and columns, to store data. Typically, SQL(=Structured Query Language) is used to insert or withdraw information. Table 2.3 gives an overviewof some frequently used terms and their meaning. Examples of big enterprise relational database man-agement systems (RDBMS) are Oracle or Microsoft SQL Server. Free to use, sometimes open source,examples are MySQL, PostgreSQL, MariaDB or SQLite. Figure 2.13 illustrates the relational aspect inan example entity relationship diagram.
2.5.4 Not-relational database systems
The no-relational databases (NoSQL) have multiple data models. An overview is given in table 2.4 withsome example technologies listed aswell. These datamodels are themain reasonwhy onewould choosethat specific technology. A Key-Value store might be interesting for session data, recommendation

2.5. DATABASE TECHNOLOGIES 33
114
Rela%onal zone
Non-‐rela%onal
zone
IBM Lotus N
otes
Objec2vity
MarkLogic
InterSystems
Caché
McO
bject
Starcounter
ArangoDB
Neo4J
InfiniteGraph
Apache CouchDB Oracle
NoSQ
L
Redis
Handlersocket
RavenDB
RethinkDB LevelDB Apache Accum
ulo
Apache Cassandra
Apache HBase
Riak
Couchbase
Splice Machine
Ac2an Ingres SAP Sybase ASE
EnterpriseDB
SQL
Server
MySQ
L
IBM
Informix
MariaDB
SAP HAN
A
IBM
DB2
Database.com
ClearDB
Google Cloud SQL
Rackspace Cloud Databases
AWS RDS
Azure SQL
Database
HP Cloud Rela2onal Database
Teradata Aster
HPCC
Cloudera
Azure Data Lake
MapR IBM
BigInsights
Metascale
Rackspace
Qubole
Voldemort
Teradata Database
IBM PureData
for Analy2cs/dashDB
Pivotal Greenplum/
Greenplum Database
HP Ver2ca SAP Sybase IQ
IBM InfoSphere
Ac2an Vector
XtremeData
Kx Systems
Exasol
Ac2an Matrix
Citrix ParStream
Percona TokuDB
ScaleDB
ScaleArc
VMware Con2nuent
NuoDB
JustOneDB
Galera
Clustrix
Tesora DVE
Mem
SQL
Datomic
Urika-‐GD
Allegrograph HypergraphDB
Mem
Cachier
Redis Labs Mem
cached Cloud
FairCom
IronCache
Grid/cache zone
Mem
cached
Ehcache
ScaleOut
So\ware
IBM
eXtreme Scale
Oracle
Coherence
GigaSpaces XAP Apache Ignite
Pivotal Gem
Fire
InfiniCache
InfiniSpan
Hazelcast
Oracle
Exaly2cs
Oracle
Database
MySQ
L Cluster
Oracle
Endeca Server A]vio
LucidWorks
Big Data
Apache Solr
IBM InfoSphere
Data Explorer
Towards
E-‐discovery
Towards
enterprise search
Documentum
xDB
Tamino
XML Server
Ipedo XML
Database
ObjectStore
LucidDB
MonetDB
Druid
Apache Spark
AWS
Elas2Cache
Firebird SQ
Lite
Oracle Tim
esTen
solidDB
Adabas
IBM IM
S
UniData
UniVerse
WakandaDB
Al2scale
Oracle Big Data Appliance
OrientDB
Sparksee
Doopex
Treasure Data
PostgreSQL
Percona Server
© 2016 by 451 Research LLC.
All rights reserved
HyperDex
TIBCO
Ac2veSpaces
SAP Sybase SQL Anyw
here
JethroData Ac2an Vortex
Pivotal HD/ Apache HAW
Q
BigMem
ory
Ac2an Versant
DataStax Enterprise
Deep Engine
Infobright
Google Cloud Datastore
Heroku Postgres
GrapheneDB Instaclustr
Hypertable
BerkeleyDB
Sqrrl Enterprise
Azure HDInsight
HP IDOL
Oracle
Exadata IBM
PureData
IBM
Big SQL
Apache Im
pala
Apache Drill
Presto
Microso\
SQL Server PDW
Apache Tajo
Apache Hive
Mam
mothDB
Al2base HDB
SRCH2
TIBCO
LogLogic Splunk
Towards
SIEM
Loggly Sum
o Logic
Logentries
InfiniSQL
Ac2an PSQL
Progress OpenEdge
Kogni2o
Al2base XDB
xPlenty
Stardog
MariaDB
Enterprise
Apache Storm
Apache S4 IBM
InfoSphere Streams
TIBCO Stream
Base
DataTorrent/Apache Apex
AWS
Kinesis
SQLStream
So\w
are AG
Key: General purpose Specialist analy2c
BigTables Graph Docum
ent Key value stores
-‐as-‐a-‐Service
Key value direct access Hadoop
MySQ
L ecosystem
Advanced clustering/sharding New
SQL databases
Data caching
Data grid
Search
Appliances
In-‐mem
ory
Stream processing
OpenStack Trove
1010data Google BigQ
uery
AWS
Redshi\ Tem
poIQ
InfluxDB WebScaleSQ
L
MySQ
L Fabric
Spider
2
E D ABC
E D ABC
2 4
3 5
SQream
SpaceCurve
Postgres-‐XL
Google Cloud Dataflow
EsgnDB/ Apache Trafodion
Azure Search
Red Hat JBoss Data Grid
6 5
4
MongoDB
IBM Cloudant
MongoLab
IBM
Compose
ObjectRocket
Azure DocumentDB
1 3
1 6
Data Platform
sM
apJanuary 2016
https://451research.com
/state-‐of-‐the-‐
database-‐landscape
CockroachDB
AWS Dynam
oDB AW
S Sim
pleDB
Redis Labs Redis Cloud
RedisGreen
AWS Elas2Cache
with Redis
MagnetoDB
ObjectRocket with Redis
Percona Server for MongoDB
VoltDB
CortexDB
Oracle Big Data Cloud
AWS
EMR
Stra2o
Teradata Cloud for Hadoop
MapR-‐DB
Snowflake
IBM Cloudant Local
GridGain In-‐Mem
ory Data Fabric
Databricks
Apache Hadoop
MongoDirector
Redis-‐to-‐go
Redis Labs Enterprise Cluster
Azure Redis Cache
SciDB AsterixDB
Apache Flink Data Ar2sans
Brytlyt MapD
Modulus
Elas2csearch Elas2c Found
Orchestrate
By CenturyLink HP N
onStop SQL
Titan
Tesora DBaaS
AWS Aurora
MariaDB M
axScale
Azure SQL
Data Warehouse
Hortonworks
Google Cloud BigTable
Maana
jSonar
Aerospike
Azure Stream Analy2cs
Ontotext GraphDB
Microso\
Graph Engine
CitusDB
Apache Geode
ObjectRocket for Elas2csearch
Flingual
Google Cloud Dataproc
Varnish Cache NCache
TazyGrid
LeanXcale
ScyllaDB
ToroDB
Tibero
IBM Analy2cs for Apache Spark
Oracle Stream
Explorer Apache Sam
za Apache Lucene
Cloudera Search
Confluent/Apache Kaea
Teradata Listener MapR Stream
s
PipelineDB
Cloudera Distribu2on of Apache Kae
a
Ry\
GroveStreams
X15 So\ware
Inmem
ory.net
QuasarDB
Apache Kudu
Cazena
Crate
AgilData
Gaffer
Figure2.12:D
ataplatform
map
in2016,illustrating
thedifferenttypesofdatabase
systemsand
technologies[7].

34 CHAPTER 2. BACKGROUND
Table 2.3: Relational database and SQL terms
Relational database term SQL term MeaningRelation Table Structured collection consisting of columns and rowsRecord Row Collection of fields, representing a single itemField Column One specific, labeled attribute of a recordUnique key Primary key Unique defined attribute
UsersPK userIdFK postalCode
firstName lastName
ItemsPK itemId
itemNamepriceavailableUnits
ProvincesPK provinceId
provinceName
PostalCodesPK postalCode
cityNameFK provinceId
OrdersPK orderIdFK userIdFK itemId
Figure 2.13: Example of a entity–relationship model illustrating how relational systems use tables andrelations to store and link data.

2.5. DATABASE TECHNOLOGIES 35
Table 2.4: Overview of non-relational (NoSQL) technologies
Data model Examples
Key-Value DatabasesRedisMemcached
Document DatabasesMongoDBCouchDB
Column-Family StoreCassandraBHase
Graph DatabasesNeo4JFlockDB
systems built on top of social graphs might benefit from a graph store while for inventories traditionalrelational database systems might still be best.

36 CHAPTER 2. BACKGROUND

3Functional specification
In this chapter a conceptual approach and outline is given of the generic database concept. First, someterms are clarified for a proper understanding with the help of the TOSCA standard. Next, the genericdatabase concept is discussed using an example use case. Afterwards, a clear definition illustrates thatthe generic database only works on the operational side of services, leading to an explanation aboutcertain design choices. Finally, some caveats wrap up this chapter.
37

38 CHAPTER 3. FUNCTIONAL SPECIFICATION
Table 3.1: Relation between the conceptual terms and how it is visualised.
Conceptual Visualised Meaning RemarksApplicationmodel
GraphThe full software stack with all itscomponents and underlying relations
A full ecosystemof software components.
Service/Application
NodeA software componentproviding functionality
Acts as a self-providingvirtual administrator.
Relation VertexThe relation betweenone or more services
This often indicates shareddata between the services.
3.1 Terms and visualisations
3.1.1 Application modelling
The idea of application modelling will be used to visualise software stacks or infrastructure ecosystems.Graphs are used in computer science and mathematics to represent data types that are related to eachother in one way or another. Applications or services are represented by nodes, while the verticesrepresent data types. Table 3.1 summarises the different terms used interchangeably in the followingsections. Unless otherwise stated, each graph, represents an application model that omits entities suchas machines or operating systems. An example of such an application model is given in figure 3.1where a Wordpress application needs a database to work with. The graph therefore represents twoservices: the Wordpress application itself and a database technology service (e.g. MySQL) that canprovide a database. The relationship between the two applications denotes a shared entity, in this casea database which has several attributes such as the databasename, the username, the password and theport number. In other words the necessary details to establish a proper connection to the database.
databasewordpress mysql
- databasename - hostname - username - password - port
Figure 3.1: Example application model of the Wordpress and MySQL services.

3.2. EXAMPLE USE CASE: COMPANY X 39
3.1.2 OASIS TOSCA
Section 2.3 gave a brief introduction to the TOSCA standard language [8], explaining concepts such asnode templates, relationship templates and topology templates to describe topologies of cloud basedweb services. Note the similarities (nodes and relations) between the application model shown beforeand the TOSCA definitions. The standard however goes a little further in describing the micro servicesarchitecture. Things like operating systems, scripts to populate databases, hosts being containers ornot are also described in the standard. The simplified graphs in the following sections use the sameconcepts and visual guidelines of TOSCA but for the sake of simplicity, characteristics that are free tochoose such as for instance the operating system are left out of the graphs. In addition, the YAML codeas presented in TOSCA is also omitted as it gives no additional benefits in this case.
Figure 3.2, directly taken from the TOSCA Simple Profile document [8], shows an example of a logicaldiagram meeting the requirements of the TOSCA standard. Note the three different nodes, each with a“Capabilities” and optional “Requirements” section. These characteristics work like Lego pieces, offeringand requiring structures to fit together. This means that one node requiring “X” can hook into a nodeoffering (capabilities) “X”.This is illustrated in figure 3.2 for theMySQL host: the Database.MySQL nodehas this information in the requirements section whereas for the DBMS.MySQL node this is providedthrough the capabilities section.
Figure 3.1 is based on the same concept. The Wordpress node has a “requires” which is identical to the“capabilities” of the MySQL node. Nodes that indicate the host or DBMS system are omitted for clarityand the attributes of the database connection are put on top of the relation. This leads to smaller andclearer graphs but with the same conceptual idea as described in the TOSCA standard.
3.2 Example use case: company X
Before properly defining the generic database concept, an example use case will be examined. CompanyX decides to invest in the creation of a web shop. The developers creating the online application decidedto use two different database technologies. All user-related information of the customers will be storedon a PostgreSQL database and all the available items of the shop will be saved in a MySQL one. Becausecompany X wants to analyse the web shop extensively, they also decide to create an application thatwill perform a statistical analysis. The database containing all user-related information needs to beaccessible for this application as well. From now on the web shop webservice will be referred to as“webshop” and the statistical application as “data-app”. The two databases are named “users” and “items”respectively. Figure 3.3 shows a simplified OASIS TOSCA application model of this use case. The graphshows that the (topology) model consists of four nodes and three relationships in this case.

40 CHAPTER 3. FUNCTIONAL SPECIFICATION
Figure 3.2: Logical diagram example of the TOSCA standard showing 3 nodes connected through“HostedOn”-relations. Nodes are defined by a name and a type and typically have a “properties” anda “capabilities” section. Some nodes also have a requirements section indicating how they need tofunction. Two nodes can have a relation if the requirements of one are conform to the capabilities ofanother. [8]

3.3. THE GENERIC DATABASE 41
db:items
db:users
webapp
db:usersdata-app
postgresql
mysql
databasename username password port
databasename username password port
db:users
db:items
Figure 3.3: Application model of use case: company X
The different steps for setting up this use case could be summarised as follows:
1. Creation of the webshop and data-app applications.
2. Deployment and configuration of a PostgreSQL and MongoDB server.
3. Creation of both the users and items databases.
4. Deployment and configuration (including database connection details) of the webshop and data-app applications.
3.3 The generic database
3.3.1 Definition
Section 1.2 introduced the concept of virtual administrators. The idea of a tool that would automatemost manual processes concerning system administration, is the fundamental starting point of thegeneric database concept. A rather abstract definition of the generic database could therefore be:
“ A generic database is a virtual administrator that handles the operational tasks, suchas setting up a database server, creating databases and sharing connection details, of adatabase administrator regardless of the database technology. ”
In other words, the generic database automates all operational steps from the moment a request ismade. When these operational steps are finished the generic database is no longer generic but becomesconcrete and holds certain properties such as databasename, username, password and the port number.The name “generic” refers to the database’s ability to offer support for polyglot heterogeneous database

42 CHAPTER 3. FUNCTIONAL SPECIFICATION
Table 3.2: Different (possible) definitions for the generic database concept
Name What Remarks
Def. 1The atomicgeneric database
One service equals one database This is the chosen definition
Def. 2Multiple types of genericdatabases in a hierarchy
One service equals one databasebut there is a distinctionbetween services
There is no benefit or reasonto use a sql-generic-databaseover a generic-database
Def. 3 Generic database managerThe idea that a requestingservice needs n databases.One service equals n databases
Possible, create a new servicethat uses Def. 1
Def. 4Global genericdatabase manager
The idea that every databaseis represented by the service.One service equals all databases
Also possible with Def. 1
technologies. Note the similarities with the “tosca.nodes.Database” definition from the TOSCA stan-dard in the OASIS TOSCA Simple Profile. There are however some key differences between the TOSCAconceptual defined database and the generic database presented here. The TOSCA database assumes itis “hosted on” a node of the type “RDBMS” illustrating that the database knows at any time what typeof database technology is used. This is not the case with the generic database. In addition, the genericdatabase is first considered to be a service with the ability to provide a database. Only after a request,the generic database is considered a similar concrete database just like the TOSCA database.
3.3.2 Design choices
When designing infrastructures, services or applications, certain choices need to be made such as whatdoes the service do and what does it not? These choices are crucial and often determine the usage,capabilities and limitations of a certain service. The generic database service, as defined in the previoussection, is considered to represent either no database, still generic and available to fulfil a request, ora single concrete database. This choice, for an atomic-like structure, came from the idea that all otherdefinitions were either meaningless or still possible with the generic database as is. Four approacheswere examined and are summarised in table 3.2.
The second definition needs a bit of explanation. It sounds more complex than initially intended. One ofthe first ideas when approaching the generic database concept was to look at the idea of encapsulationand inheritance from object-oriented programming principles. Database technologies could be puttogether in a hierarchy as shown on figure 3.4 in the form of a small example. A possible thinking pathwas the idea to start at the bottom and add more and more support creating new services, or start atthe top and make sure all necessary features were present. This approach was not further researched

3.3. THE GENERIC DATABASE 43
Generic database
SQL Generic
Database
NoSQL Generic
Database
MongoDB Database
Cassandra Database
SQL Enterprise Generic
Database
PostgreSQL Database
MySQL Database
Oracle Database
SQL Server Database
Figure 3.4: Example hierarchy or categorisation of database technologies. The root of the tree is themost generic database whereas the leafs represent technology specific databases.
as there is no reason why anyone would want to use the NoSQL generic database service over thegeneric database service. Additionally, it would not be interesting to have a list of slightly similar butstill different generic database services.
The generic database manager definitions are not useless as they tackle the generic database servicefrom another perspective. In these definitions the service itself represents a database administratorthat will make sure a database is arranged and potentially allows more functionality. This is anotherapproach towards the generic database with another semantic meaning. The choice was made to notimplement the generic database service as such because in this definition it would not be possible tomodel the database as is. In addition, a new second service could be created that would use the atomicgeneric database (from now on generic database) service.
The generic database is therefore an intermediate/proxy service between a requesting service and aproviding database technology service. When designing an application model, any requesting serviceor application in need of a database can connect to the generic database without any constraints. Thegeneric database takes care of all necessary actions such as creating the database and sharing the con-nection details. The generic database is therefore by definition a virtual administrator but the semanticmeaning of the service is only the representation of database and not a database administrator.

44 CHAPTER 3. FUNCTIONAL SPECIFICATION
3.4 Possible scenarios
The generic database represents a single database. This means that if an application needs ten differ-ent databases, ten different generic databases will exist in the application model. This results in thefollowing scenarios:
• Scenario A: A one-on-one relation between requester node and generic database node. This is themost trivial graph. In this case one service needs one database.
• Scenario B: A n-on-one relation between requester node and generic database node. In this casemultiple requester nodes want a connection to one and the same generic database. This meansthat one requesting service did a request for a database and n other requesting services want toconnect to this very database. The connection details are therefore the same.
• Scenario C:A one-on-n relation between requester node and generic database node. This scenariois reached when one requesting service needs multiple databases.
• Scenario D: A n-on-n relation between requester node and generic database node. This is a com-bination of the previous two scenarios. A requesting service needs multiple databases and thesedatabases are also used by various other services.
3.5 Use case revisited
The use case of company X can be remodelled with generic databases. This use case is an exampleof situation D. The “users” database needs to be accessible for two services (the webshop and data-appapplications) and thewebshop requires two databases (users and items). Creating the application modelwith generic databases results in a graph as shown in figure 3.5.
3.6 Caveats
This chapter introduced the idea of a generic database virtual administrator in a descriptive manner.The idea of a virtual administrator taking care of all operational tasks for a service (or another virtualadministrator) offers workflows that are easy to use. There are however some important remarks andcaveats concerning the generic database concept.
It is important to realise that the generic database concept only works on the operational level of theinfrastructure. This chapter used application models and graphs to illustrate workflows and commu-nication models. They only represent the “operations” side of applications, meaning that the generic

3.6. CAVEATS 45
db:items
db:users
webapp
db:usersdata-app
db:usersgeneric database (users)
db:itemsgeneric database (items)
databasename username password port
databasename username password port
db:users
db:items
postgresql
mysql
Figure 3.5: Application model of use case: company X with generic databases.
database is not relevant in the application topology. Once a requesting node such as the webshop appli-cation in the use case receives the connection details of a database, all interactions are directly with thedatabase and not through the generic database in contrast of what might seem intuitive when lookingat the graphs. As shown in figure 3.6 there is a distinct difference between the operations perspectiveand the application workflow perspective. A developer or an application does not need knowledgeabout the generic developer whatsoever. No special actions or setups should be required as the genericdatabase service is not present in the workflow of the applications using it. This is an interesting char-acteristic but it might be counterintuitive and weird at first. Once again there is a distinction betweenthe operations side and the inner workings of the applications.
The formal definition of the generic database service does not describe how the setup and underlyingrelation between database technologies is done. If a generic database represents a MySQL databaseafter a request, the generic database needs access to or communication with a MySQL service. The wayin which this is achieved is free to choose. Maybe the generic database service and MySQL are bothhosted on the samemachines, maybe in different containers or maybe they are two completely differentand independent machines. A fully-fledged generic database service would allow all these possibilities.
A requesting service still requests a database for a specific technology. This means that the virtualadministrator of this requesting application needs the knowledge of that specific technology. An in-teresting feature would therefore be a service that would help teams choose in deciding what type ofdatabase technology would fit their application best. Such a feature would look at certain requirementsor needs and determine what database technology should be used. This could be implemented on topof the generic database service or as a service that would communicate with the generic database. Withsuch a service the database specific knowledge or requirements of an application would be completelygone and all would be automated by virtual administrators. This lies however beyond the scope of this

46 CHAPTER 3. FUNCTIONAL SPECIFICATION
Operations
requestrequesting
service
requestgeneric database service
database technology
service
Application
direct connectionrequesting
service database technology
service
Figure 3.6: The generic database service is only functional and present on the operations side of theapplication stack. The application itself directly connects to the database and is not aware of the genericdatabase service.
research.
The generic database as proposed here, deliberately does not limit features of the generic database. Inthe section about design choices it is stated that the generic database at least needs a way of request-ing databases and its properties such as hostname, databasename, password and port. But backups,schemes, views, triggers or other database defined elements might also be requirements of a user. Inaddition, it might be interesting for a user to have SQL-query support directly from the generic databaseservice. All previous features reside in a grey zone as they operate on the management of databasesand not on the request level. The atomic generic database service was defined as the representationof a single database to keep things as clear and simple as possible. Because the previous mentionedfeatures are useful it would be interesting to have an additional service, an extra node in the graph,with a different relation that would offer these features. This way the generic database is used for thedeployment part of the database and the other service, for example the generic database dba service, isresponsible for the operational tasks on the database. Depending on the use case, teams could opt forimplementing them together.
Finally, the ease of use towards the user is another key element for this service. Even though the serviceadds new components to the application model, the end model might end up being more clear. As everydatabase is modelled in the application model, it becomes clear how applications are related to differentdatabases.

4Technical implementation
The technical implementation of a tangible product is the focus of this chapter. The concept of thegeneric database as described in chapter 3 will be implemented in the application modelling tool Juju.This chapter follows a similar structure of the previous one. First the different terms and visualisationsof the conceptual specifications will be translated to their Juju counterparts. Next, the use case ofcompany X will be shortly described as if an implementation would be done without the use of thegeneric database concept. Afterwards, an example implementation will explain how the theoreticalideas can be constructed in Juju along with certain design choices. The same use case will be revisitedonce again.
47

48 CHAPTER 4. TECHNICAL IMPLEMENTATION
4.1 Juju specific terms
This chapter will use the terms as defined by Juju. Refer to chapter 2 for an in-depth explanation. Termsused in chapter 3 are mapped to their Juju names and summarised in table 4.1.
Table 4.1: Summary of Juju terms and their meaning that are relevant in this chapter.
Conceptual Visualised Juju MeaningApplicationmodel
Graph ModelThe workspace Juju usesto deploy charms.
Service orApplication
Node CharmAll information to deploy andconfigure a service or application.
Relation VertexRelation(interface-layer)
This often indicates shareddata between the services using endpoints.
- - BundleA collection of charms. Makes itpossible to deploy a model at once.
4.2 Example use case: company X
The use case of a web shop in need of two databases, one of which is also used by another data analysisapplication can be implemented in Juju but not in a fully automated way. If a Juju user wanted toimplement this use case in Juju, he could tackle this problem as follows:
1. Determining what database technologies are needed.
2. Creating the webshop and data analysis app.
3. Creating 2 charms: one for the webshop and one for the data analysis applications.
4. Deploying the (existing) PostgreSQL and MongoDB charms from the charm store.
5. Deploying the (self-written) charms for the webshop and data analysis applications.
6. Adding relations accordingly.
7. Copying the connection details through manual intervention, to make sure multiple charms canaccess one and the same database.

4.3. THE GENERIC-DATABASE-CHARM 49
Note the final step. It is, at design level in Juju, impossible for multiple charms to access the samedatabase. This is a result of the implementation of the existing interface layers and database technologycharm layers. They are configured in a way that new incoming relations create new databases. Thewhole goal of an easy-to-use application modelling tool becomes unpleasant as manual steps are stillrequired when multiple charms need access to the same database. The generic database charm (generic-database-charm from now on) should resolve this issue.
4.3 The generic-database-charm
4.3.1 Design Choices
When creating a charm, a clear concept of the service is needed for optimal choices. One of the firstquestions that arises is what type of charm the generic-database-charm needs to be. Juju offers supportfor regular charms or subordinates. Since the generic database represents a database, a subordinate(see section 2.4.1) seems the suitable choice. There are however reasons why a regular charm is moreinteresting and therefore chosen in this implementation:
• Subordinates only exist for the lifetime of their principal service, this is a regular charm in whosecontainer the subordinate service would run. This means that it is impossible to model thedatabase without a requesting charm. In the use case of company X this would mean that nogeneric-database-charm can be created without the web application and/or data analysis app. Inaddition, the generic-database-charm would be gone if the principal service would be destroyed.
• The use of subordinates would also result in another interesting feature being lost. Regularcharms can be on “stand-by”. This means that they can be deployed and be ready for use assoon as a requesting service is in need of a database.
4.3.2 Other possibilities
This section will cover other perspectives of the generic-database-charm. In the functional specificationsome different definitions were summarised in table 3.2. This already showed that different perspectivesor use cases can result in different semantic meanings of the generic database service. The atomicgeneric database is defined as a service that represents one database either generic or concrete. Insome cases it might be interesting that the generic database service would also provide features ascreating users, running SQL-queries or performing backups. In this scenario the service would act moreas a generic database administrator. A possible approach is the creation of a new charm and interfacelayer.

50 CHAPTER 4. TECHNICAL IMPLEMENTATION
generic-database-dba
generic-database
webapp
generic-database
generic- dba
mysql-sharedgeneric- database mysql
Figure 4.1: Application model with both the generic database charm and the generic database dbacharm.
The generic database administrator charm could use the generic database charm shown on figure 4.1or both could be merged into one. Note that a new interface layer focusses on the operational tasks ofan administrator while the generic database interface layer simply provides a database to work with. Apossible use case would be populating a database as soon as the webapp is deployed. This way multiplegeneric databases can exist in the model whereas only one administrator offers functionality to thesedatabases. This service was not further implemented as the scope of this research is limited to a servicethat represents only a database.
4.3.3 The generic database under the hood
The following diagrams illustrate how the generic-database-charm works. Figure 4.2 is a BPMN (=Business Process Model and Notation) model that shows the workflow when setting up the charms.The whole process starts when thewebappwants a database, and ends when he receives the connectiondetails. The webapp charm renders a configuration file ready to be used by the application. Note that alot of events happen asynchronous as shown by the End objects, meaning that the activities are non-blocking.
The BPMN model shows the initial thought process of the wanted implementation of the use casethat was presented previously. There is however one part that did not end up in the implementedversion of the generic-database-charm. In the lane of the generic database, a gateway asks whetherthe database technology service is available or not. In the implementation it is a requirement for thedatabase technology charms to be deployed and connected to the generic-database-charm. With the

4.3. THE GENERIC-DATABASE-CHARM 51
help of the Libjuju-library1 this precondition could become obsolete but it was chosen to prioritizeother things such as the implementation of more technologies and as complete as possible.
Web
app
Has dbNeeds db
Requestdb
Connection details
Setup config files
Gen
eric
Dat
abas
e
Formally define request
Share connectiondetails
Yes
No
Has db
Is request correct db?
Yes
NoIs db service available?
No
Yes
Setup db service
Dat
abas
e Te
chno
logy
Setup db
BPM
N W
orkfl
ow o
f the
Gen
eric
Dat
abas
e Se
rvic
e
Does generic database already represent a database?
Request received
Error
Request received
Share connection details
Request received
Figure 4.2: BPMN diagram of the generic database charm concept.
1https://github.com/juju/python-libjuju

52 CHAPTER 4. TECHNICAL IMPLEMENTATION
SystemAdministrator
creates
Requesting Service
GenericDatabase
DatabaseTechnology
setups db
formally requests db
share connection details for db
alt
[concrete = false]requests db
share connection details for db
is operational
Figure 4.3: Sequence diagram of the implemented generic database service. It is assumed that thedatabase technology service is available. If the database is not concrete a request is send to set up thedatabase. In the other scenario the generic database already knows the connection details.
Figure 4.3 shows a similar workflow in the form of a sequence diagram. In this diagram it is very clearwhat the actual workflow looks like once the database request is made. A service requests a database,the generic database service provides it in case he already represents a database. In the other scenariothe generic database service proxies the request to the database technology service.
The reactive framework and the endpoint-pattern in Juju use flags as fundamental communicationmethod.The flags signal information to which handlers can react to. This mechanism functions as a trigger thatreacts when certain conditions are met or in other words when certain flags are set. Thanks to theseflags endpoints can be used granting objects to work with. These endpoints represent objects that aredefined in the interface layer. Listing 6 illustrates in pseudocode how this mechanism works. Finally,figure 4.4 illustrates how the interface layer of the generic database functions as API for both the we-bapp charm and the generic database charm. Interface layers typically have a requires and a providesside.
1 WHEN FLAG = "generic-database.ready" {2 endpoint = endpoint_from_flag("generic-database.ready")3 endpoint.request("technology", "mydatabasename")4 }5

4.4. USE CASE REVISITED 53
layer "webapp"
interface layer "generic-database"
requires provides
layer "generic
database"
"wantsdatabase"
request "ensures database exists and is available"
"getsrequest"
"getsdatabase"
share_details "providesdetails"
charmcharm
Figure 4.4: Visualisation of the interface layer of the generic database. The black nodes can be seen asendpoints in charms. The interface layer is the API that tells how the charms should communicate.
6 WHEN FLAG = "generic-database.mysql.ready" {7 endpoint = endpoint_from_flag("generic-database.mysql.ready")8 connection_details = endpoint.share_details()9 render(configfile, connection_details)
10 }
Listing 6: Pseudocode illustrating how flags and the endpoint-pattern are used in the reactive frame-work of Juju.
4.4 Use case revisited
With the help of the generic database charm the new (manual) approach is as follows:
1. Determining what database technologies are needed.
2. Creation of the webshop and data analysis applications.
3. Creating 2 charms: one for the webshop and one for the data analysis application.
4. Deployment of the (self-written) charms for the webshop and data analysis application.
5. Deployment of (existing) PostgreSQL and MongoDB charms from the charm store (can be madeobsolete with the help of the Libjuju library).
6. Adding relations accordingly.

54 CHAPTER 4. TECHNICAL IMPLEMENTATION
Figure 4.5: Application model of the use case as shown in the Juju GUI service. Two generic databaseservices represent two databases used by a webshop and a data analysis application.
Using a preconfigured bundle reduces this to:
1. Determining what database technologies are needed.
2. Creation of the webshop and data analysis applications.
3. Creating 2 charms: one for the webshop and one for the data analysis application.
4. Deploying the generic database bundle.
5. Adding relations accordingly.
This reduces the complexity by a lot. The key elements become application specific and the actualdeployment steps are fully automated. Figure 4.5 shows the final model in the Juju GUI webservice ofthe used use case. The implementations are available at the following repositories:
• https://github.com/Ciberth/gdb-use-case
• https://github.com/Ciberth/layer-generic-database
• https://github.com/Ciberth/interface-generic-database

5Discussion, Future work & Conclusion
In this chapter the results, limitations and possible future work are discussed. First, a comprehensiveand critical look is given at the generic database service. Afterwards, the research questions and theiranswers are summarised. Next, the many possible optimisations and further research are mentioned.Finally, a conclusion marks the end of this thesis.
55

56 CHAPTER 5. DISCUSSION, FUTURE WORK & CONCLUSION
5.1 Discussion
Chapter 4 focused on a use case and tried to implement the generic database service in the serviceorchestration tool Juju. The Lego-like structure to hook services into each other (as shown in theTOSCA standard) is the key for a good and flexible communication model. Configuration managementtools did not offer support to work on the service-orchestration base and they lack in encapsulatingoperations knowledge. In other words, people using configuration management tools are still requiredto know how the services are related to each other and how they work. Note that in Juju modellingthings (in this case databases), that are not really services, is not possible either. Creating a service thatdoes not represent a database but rather a database administrator would arguably solve this issue. Itwould however add more complexity and maintenance to the service as different libraries are requiredto connect to all the different database technologies.
The presented generic database service was tested, with the use case in mind, with success. This meansthat the generic database service was deployed successfully and both the requesting webshop and thestatistical analysis services correctly got the connection details for one and the same database. Thiswas previously not possible in Juju in an automated way. The development of the service did not goflawlessly as reactive programming requires a specific programming style. The new, state of the art,programming principles in the application modelling tool Juju also took some time getting used to.The documentation is not always newcomer friendly and clear examples are hard to find. Furthermore,there are some caveats. Because the existing interface layers of the database technology charms donot always offer all necessary capabilities, some workarounds are sometimes needed to ensure that theuse case can work as intended. Without these steps the connection details would be shared properlybut the requesting service (e.g. webshop) would not be allowed to access the database. This is becausethe requesting charm is not directly connected to the providing charm and thus does not receive theright privileges. The PostgreSQL charm for example uses the pgsql interface. With the help of thisinterface layer it is possible to request a database. The PostgreSQL charm will create a database andedit the pg_hba.conf file to allow the generic-database-charm to access PostgreSQL. As intended thegeneric-database-charm can connect to the database but the webapp cannot as that host is rejected. Anintermediate charm called pgbouncer makes it possible to receive connection details that can be usedfrom any host. This shows that a good security measure counteracts the generic database service andthe implemented solution loses this security feature. Another example are the MySQL interfaces. Rightnow there are multiple interfaces that a charm author can use when working with MySQL.The “mysql”interface makes it possible to request a database but the databasename cannot be set. The “mysql-shared” interface offers the ability to request multiple databases and to provide database names, but thesame problem of PostgreSQL happens. The created user by the MySQL charm only provides privilegesfrom the directly connected charms (hosts). Finally, the “mysql-root” interface creates a user with rootprivileges but the creation of databases with a database name is not directly supported. These crucialremarks illustrate that the generic database service is more complex and less robust than it should be.

5.2. ANSWERS TO RESEARCH QUESTIONS 57
A possible solution would require the interface layers of the providing database technology charms tooffer the necessary features that provide more flexibility.
The use of charms means that right now, the proof of concept generic database is only available anduseful for Juju users. Modifications to the charm require Python-code and knowledge of the reactiveframework. This greatly reduces the number of possible users of the generic database service. On theother hand, it might be an entry point to get started with Juju.
5.2 Answers to research questions
Is it possible, andwhat is needed, to create a service for themanagement of polyglot persistentintegrations?
With the help of Juju it was possible to create a generic database service that would allow polyglotpersistent applications to easily request different types of databases. Adding proper support for everypossible database technology is a big challenge but the proof of concept seemed hopeful.
In terms of application modelling, what does this service formally represent?
In the proof of concept implementation, it was chosen to create a generic database that represented adatabase only. This choice results in clear models. If an application is connected to 4 different genericdatabases, it becomes clear that the application uses 4 databases.
What problems does the service solve, and at what cost?
The generic database service offers an easy-to-use interface. This API requires a database technologyand a databasename. Once the request is done, the service will ensure that the database is available andit will share the connection details automatically. Users are not bothered anymore by operations tasksand can fully focus on their expertise. In addition, from a Juju perspective it becomes now possible formultiple charms to connect to one and the same database, which is a feature that is impossible withoutthe use of the generic database charm.
5.3 Future work
The presented generic database service is far from complete and requires more work. More databasetechnologies need to be supported. Additionally, new interface layers and providing charms need to becreated to realise the support for a specific database technology. In a perfect scenario, with all necessaryfunctions on interface layers, the need of third-party libraries (connecting and interacting with thedatabases) becomes unnecessary. Finally, the Libjuju library should be used, allowing the service to

58 CHAPTER 5. DISCUSSION, FUTURE WORK & CONCLUSION
deploy services by itself. This ability, to create standalone machines, eliminates the precondition ofhaving a database technology service ready for use. Another interesting research topic is the flexibilityof cross model relations. In Juju it is possible for relations to work across different models, even acrossmultiple controllers. Interesting research would be to look at the possibility of the current genericdatabase service to exist in one model and provide all necessary things to another model. This lowersthe complexity even further for the model of a user application. All the above paragraphs illustrate thatthe generic database service is not easily implemented, especially not as a full-fledged service.
Other possible future work would include research on comparing database technologies. When is itinteresting to choose MySQL over PostgreSQL? In what cases is a NoSQL-technology better? Thiswould be the basis for a service that could work on top of the generic database. This service wouldreduce every bit of operational knowledge concerning databases allowing teams to automatically makechoices for them.
Finally, not all charms are implemented with the reactive framework and the use of better, more com-plete, interface layers would also be a welcoming gift. A competitive tool that learns from Juju and thereactive framework, but also allows more and easier modelling might rise in the future. As previouslystated, the generic database service is only compatible with Juju. The idea behind the generic databasehowever, is not. A new other service using different tools would be interesting as well. Configura-tion management tools are slowly becoming the standard but service orchestration tools, whether ornot they use configuration management tools, are certainly a good next step in system administration.In the future new tools might rise, and once they do, the concept of the generic database service isdefinitely worth looking into.
5.4 Conclusion
This thesis looked at service orchestration principles with as goal the creation of a service that wouldhelp operations engineers, data scientists and developers when requesting databases. The service iscalled generic database and offers an easy-to-use interface with a lot of flexibility to support polyglotpersistent application stacks. Requesting services can easily use the generic database service withoutthe need of any operations knowledge. When formally defining this service, it soon became clearthat the service could be looked at from multiple perspectives. The choice presented here used thegeneric database service as a database. Therefore, the presented generic database service’s tasks areonly ensuring that a required database is present and that the requesting service is able to connect toit.
The implementation of the chosen generic database service was done in an application modelling toolcalled Juju. With the help of a specific use case, a proof of concept generic database service was createdas a starting point for future implementations. Thanks to the use case, the inner workings of the generic

5.4. CONCLUSION 59
database service could be determined and implemented accordingly. The proof of concept successfullyfunctions as a virtual administrator, creating databases and sharing its details. The generic databaseservice has a couple of weak points. This shows that a full-fledged, usable, service is not easily imple-mented. A crucial limitation in the proof of concept is the disability of the generic database to deployservices and machines where needed. This means that database technology services are required asa precondition of the generic database service. Furthermore, more support for other database tech-nologies would make the proof of concept generic database more complete and ready for professionaluse.
The goal of this researchwas primarily focused on researching the possibilities of one service requestinga database and another one providing it no matter the database type or technology. This automaticsupport for polyglot persistent application stacks seemed possible but there is still some work beforethe proof of concept can be called a full-fledged service. With iterative steps, slowly adding new featuresand new database technologies, the service looks promising for any Juju user.

60 CHAPTER 5. DISCUSSION, FUTURE WORK & CONCLUSION

Bibliography
[1] S. Overflow, “Stack Overflow Developer Survey 2018,” 2018, accessed: 2018-03-20. [Online].Available: https://insights.stackoverflow.com/survey/2018/
[2] C. Peltz, “Web services orchestration and choreography,” Computer, vol. 36, no. 10, pp. 46–52, Oct2003.
[3] D. Weerasiri, M. Barukh, B. Benatallah, Q. Sheng, and R. Ranjan, “A taxonomy and survey of cloudresource orchestration techniques,” vol. 50, pp. 1–41, 05 2017.
[4] OpenTOSCA. (2013) TOSCA and OpenTOSCA: TOSCA Introduction and OpenTOSCA EcosystemOverview. Accessed: 2018-03-21. [Online]. Available: https://www.slideshare.net/OpenTOSCA/tosca-and-opentosca-tosca-introduction-and-opentosca-ecosystem-overview
[5] M. Sebrechts, C. Johns, G. V. Seghbroeck, T. Wauters, B. Volckaert, and F. D. Turck, “Reusablemodeling of custom-fit management workflows for cloud applications,” 2018.
[6] N. Živković. (2017) Introduction to NoSQL and Polyglot Persistence. Accessed: 2018-05-22. [Online]. Available: https://rubikscode.net/2017/07/19/introduction-to-nosql-and-polyglot-persistence/
[7] 451research. (2016) Data Platforms 2016 Map. Accessed: 2018-05-20. [Online]. Available:https://451research.com/state-of-the-database-landscape
[8] O. Committee. (2017) TOSCA Simple Profile in YAML Version 1.2. Accessed: 2018-03-21. [Online].Available: https://docs.oasis-open.org/tosca/TOSCA-Simple-Profile-YAML/v1.2/TOSCA-Simple-Profile-YAML-v1.2.html
[9] M. Hamdaqa and L. Tahvildari, “The (5+1) architectural view model for cloud applications,” inProceedings of 24th Annual International Conference on Computer Science and Software Engineering,ser. CASCON ’14. Riverton, NJ, USA: IBM Corp., 2014, pp. 46–60. [Online]. Available:http://dl.acm.org/citation.cfm?id=2735522.2735530
[10] M. Abramow, “How DevOps and Agile Development Can Drive Digital Transformation,”2017, accessed: 2018-03-21. [Online]. Available: http://www.oracle.com/us/corporate/profit/big-ideas/072417-mabramow-3839318.html
61

62 BIBLIOGRAPHY
[11] V. d. C. Guerra, E. Segeti, F. Hino, F. Kfouri, L. F. S. Mialaret, L. A. V. Dias, and A. M. d. Cunha,“Interdisciplinarity and agile development: A case study on graduate courses,” in Proceedingsof the 2014 11th International Conference on Information Technology: New Generations, ser. ITNG’14. Washington, DC, USA: IEEE Computer Society, 2014, pp. 622–623. [Online]. Available:http://dx.doi.org/10.1109/ITNG.2014.49
[12] R. A. Rodrigues, L. A. L. Filho, G. S. Gonçalves, L. F. S. Mialaret, A. M. da Cunha, and L. A. V. Dias,“Integrating nosql, relational database, and the hadoop ecosystem in an interdisciplinary projectinvolving big data and credit card transactions,” in Information Technology - New Generations,S. Latifi, Ed. Cham: Springer International Publishing, 2018, pp. 443–451.
[13] JetBrains. (2018) The State of Developer Ecosystem in 2018. Accessed: 2018-06-07. [Online].Available: https://www.jetbrains.com/research/devecosystem-2018
[14] S. Leberknight. (2008) Polyglot Persistence. Accessed: 2018-05-20. [Online]. Available:http://www.sleberknight.com/blog/sleberkn/entry/polyglot_persistence
[15] N. Ford. (2006) Polyglot Programming. Accessed: 2018-05-20. [Online]. Available: https://memeagora.blogspot.be/2006/12/polyglot-programming.html
[16] P. J. Sadalage and M. Fowler, NoSQL Distilled: A Brief Guide to the Emerging World of PolyglotPersistence. Pearson Education, Inc, 2013.
[17] P. Simoens, “System Design Course,” 2017, university Ghent.
[18] G. Kim, J. Humble, P. Debois, and J. Willis,The DevOps Handbook, How to create world-class agility,reliability, & security in technology organizations, 1st ed. IT Revolution Press, 2016.
[19] Mulesoft.com. (2017) Service Orchestration and SOA. Accessed: 2018-05-28. [Online]. Available:https://www.mulesoft.com/resources/esb/service-orchestration-and-soa
[20] M. Sebrechts, G. V. Seghbroeck, T. Wauters, B. Volckaert, and F. D. Turck, “Orchestrator conver-sation: Distributed management of cloud applications,” 2018.
[21] C. Endres, U. Breitenbücher, M. Falkenthal, O. Kopp, F. Leymann, and J. Wettinger, “Declarative vs.Imperative: Two Modeling Patterns for the Automated Deployment of Applications,” in Proceed-ings of the 9th International Conference on Pervasive Patterns and Applications. Xpert PublishingServices (XPS), 2017, pp. 22–27.
[22] O. Kopp, T. Binz, U. Breitenbücher, and F. Leymann, “Winery – modeling tool for TOSCA-basedcloud applications,” in 11th International Conference on Service-Oriented Computing, ser. LNCS.Springer, 2013.
[23] C. Ltd. (2017) What is Juju? Accessed: 2018-03-21. [Online]. Available: https://jujucharms.com/docs/stable/about-juju

BIBLIOGRAPHY 63
[24] E. F. Codd, “A relational model of data for large shared data banks,” Commun. ACM, vol. 13, no. 6,pp. 377–387, Jun. 1970. [Online]. Available: http://doi.acm.org/10.1145/362384.362685
[25] A. Pavlo and M. Aslett, “What’s really new with newsql?” SIGMOD Rec., vol. 45, no. 2, pp. 45–55,Sep. 2016. [Online]. Available: http://doi.acm.org/10.1145/3003665.3003674
[26] J. M. Hellerstein, M. Stonebraker, and J. Hamilton, “Architecture of a database system,”Foundations and Trends® in Databases, vol. 1, no. 2, pp. 141–259, 2007. [Online]. Available:http://dx.doi.org/10.1561/1900000002

64 BIBLIOGRAPHY

Appendices
65


67
Appendix A - Juju Tutorial Getting started
Overview
1. Introduction
2. Requirements
3. Goal
4. Design
5. implementation
6. Conclusion
Introduction
This guide is meant for people who want to start writing charms in the application modelling tool Juju.The reactive framework, the Endpoint pattern and interface layers provide an excellent frameworkto work with. It is not easy however for newcomers to find good examples or find the things youneed in the documentation. Code gets outdated very fast and some docs provide different insights.In addition, there is the Jujucharms website with information, the reactive framework documentation,the charmhelpers documentation and the charm store to explore. I’ve realised though that the bestexamples are found in github repositories of experienced users. Hang out in the irc #juju channel onfreenode to find out more! All code is accessible on https://github.com/Ciberth/MP-appendix-a.
Tl;dr: This is a guide for charm authors to create charm and interface layers in the reactive frameworkwith the use of the endpoint pattern.
Requirements
Knowledge about the basic terms1 used in juju and a basic understanding of hooks and their lifecycles2
are interesting lecture before continuing. Getting started with charm development3 is another goodplace to start. The basics of charm development will come back in this tutorial as well.
1https://docs.jujucharms.com/2.3/en/juju-concepts2https://docs.jujucharms.com/2.3/en/developer-event-cycle3https://docs.jujucharms.com/2.3/en/developer-getting-started

68
Furthermore I assume you:
• have a working Juju environment (bootstrapped and client so that you can create models anddeploy charms)
• have a JUJU_REPOSITORY directory; refer to creating a new layer (https://docs.jujucharms.com/2.3/en/developer-getting-started#creating-a-new-layer)
• installed charm tools (https://docs.jujucharms.com/2.3/en/tools-charm-tools)
Goal
Time to tell what we are creating. Because I want to show an example of an interface layer I will beusing multiple (layer) charms. In other words we will create two charms and one interface layer thatmakes it possible for them to have a relation. To demonstrate, we will create a charm that will act asproxy of another charm, passing some information. This shows the working of the interface layers andillustrates how one can use existing charms as well.
The use case we will implement can be summarised as follows:
1. A requesting charm, this will be awebpagewith the generated data running on top of awebserver,called “webapp”.
2. A proxy charm, called “gdb-charm” (generic database charm).
3. The interface layer that connects the previous 2 charms, called “proxy”.
4. An existing charm and existing interface layer. The name of the interface layer is “mysql-shared”and the charm we are going to use is the “mysql” charm from the Juju charm store.
To make this a bit more concrete we will make sure the following thing works. This is in other wordsthe lifecycle/workflow from an operations perspective when setting up the charms/services.
1. The webapp performs a request to the gdb-charm.
2. The gdb-charm recieves the request and proxies this to the mysql charm using the (existing)mysql-shared interface.
3. The (existing) mysql charm configures a database and shares the details with the gdb-charm.

69
4. The gdb-charm receives the connection details from the mysql charm and proxies it to the we-bapp.
5. The webapp receives the details and renders a page with this information.
Design
The application model looks like figure 1. There are a total of three charms and two interface layers.From right to left the “mysql” charm and the “mysql-shared” interface are already available from thecharmstore4. The other two charm layers webapp and gdb-charm will be created together with theproxy interface layer.
proxywebapp
mysql-sharedgdb-charm mysql
Figure 1: Application model of the project. Two new charms layers will be created along with oneinterface layer. The “mysql” charm and “mysql-shared” interface will be reused.
Implementation
A good way to start the creation for a charm is with the help of the “charm create <foldername>” com-mand. It will create all necessary files and folders to properly create a charm. Once you are done withediting all the files accordingly the “charm build <foldername>” will create the charm layers in yourJUJU_REPOSITORY folder under the proper releases. It is also in this folder under “interfaces” wherethe proxy interface layer must come.
Take a look at figure 2. This image shows the different files of both the webapp and the gdb-charm. Theyboth use the apache-layer to provide a website. Both charms will install a small website (adminer.php5
from a remote repository as can be seen in the apache.yaml file. More importantly the metadata fileillustrates how both charms can form a relation. The gdb-charm provides a database through the proxyinterface, whereas the webapp requires a database through the proxy interface. The layer file shouldlist all used layers, starting with basic and all used interfaces should be listed as well.
The structure of an interface layer is slightly different. In the interface layer there is a requires.py anda provides.py. In these files, objects are created that can be used by the corresponding charms. The
4https://jujucharms.com/mysql/5https://adminer.org

70
Figure 2: Metadata and layer files of the two charm layers. They are the heart of the applications,allowing them to connect to each other.
requires.py file is of great importance for charms that have the interface-layer as a requires in theirmetadata while the provides.py offers objects and methods for charm layers that provide the interfacelayer. Do note that the interface layer also has an interface.yaml which looks like listing 7. It is thisname that determines the name of the interface layer.
1 name: proxy2 summary: Example interface that proxies mysql data3 maintainer: user
Listing 7: Interface.yaml file of the proxy interface layer
Now it is time to look at the fundamental core of a charm layer. When using the reactive framework afolder called reactive is created with a python file in it. In this file we create handlers with decoratorsto react to certain conditions or events. Take a look at listing 8.
1 @when('endpoint.database.joined')2 @when_not('endpoint.database.connected')3 def request_mysql_db():4 endpoint = endpoint_from_flag('endpoint.database.joined')5 endpoint.request('mysql', 'mydbname')6 status_set('maintenance', 'Requesting mysql gdb')

71
Listing 8: Code of testwebapp/reactive/testwebapp.py that starts the workflow of the use case with arequest for a database.

72
As you can see we request the endpoint from a flag and receive an object. Afterwards we call methodson that object. This principle is realised by the interface layer. Figure 3 visualises how an interfacelayer connects two charms. Listing 9 illustrates how this is implemented. The {endpoint_name} will beautomatically replaced by the name it was given in the metadata files of the charms that use this.
layer "webapp"
interface layer "generic-database"
requires provides
layer "generic
database"
"wantsdatabase"
request "ensures database exists and is available"
"getsrequest"
"getsdatabase"
share_details "providesdetails"
charmcharm
Figure 3: Visualisation of the interface layer of the generic database. The black nodes can be seen asendpoints in charms. The interface layer is the API that tells how the charms should communicate.
1 class GenericDatabaseClient(Endpoint):2
3 @when('endpoint.{endpoint_name}.changed')4 def _handle_technology_available(self):5 if self.technology():6 set_flag(self.expand_name('endpoint.{endpoint_name}.available'))7
8 def request(self, technology, databasename, username):9 for relation in self.relations:
10 relation.to_publish['technology'] = technology11 relation.to_publish['databasename'] = databasename12 relation.to_publish['username'] = username13
14 def databasename(self):15 return self.all_joined_units.received['dbname']16
17 # same thing for host, port, user, password
Listing 9: Code of interfaces/proxy/requires.py
The provides side of the interface would look something like listing 10. Here the right flags are set tosignal change and the connection details are shared over the interface in share_details.
1 class GenericDatabase(Endpoint):

73
2
3 @when('endpoint.{endpoint_name}.joined')4 def _handle_joined(self):5 technology = self.all_joined_units.received['technology']6 dbname = self.all_joined_units.received['dbname']7 if technology:8 flag_t = 'endpoint.{endpoint_name}.' + technology + '.requested'9 set_flag(self.expand_name(flag_t))
10 if dbname:11 flag_d = 'endpoint.{endpoint_name}.' + dbname + '.requested'12 set_flag(self.expand_name(flag_d))13
14 def technology(self):15 return self.all_joined_units.received['technology']16
17 def databasename(self):18 return self.all_joined_units.received['databasename']19
20 def share_details(self, technology, host, dbname, user, password, port):21 for relation in self.relations:22 relation.to_publish['technology'] = technology23 relation.to_publish['host'] = host24 relation.to_publish['dbname'] = dbname25 relation.to_publish['user'] = user26 relation.to_publish['password'] = password27 relation.to_publish['port'] = port
Listing 10: Code of interfaces/proxy/requires.py
Next, listing 11 shows how the gdb-charm can request a database to the existing “mysql” charm overthe existing ‘‘mysql-shared” and share the details over the proxy interface back to the webapp charm.
1 @when('mysql.connected', 'endpoint.database.mysql.requested')2 def request_mysql_db():3 db_request_endpoint =
endpoint_from_flag('endpoint.database.mysql.requested')↪→
4
5 databasename = db_request_endpoint.databasename()6 username = db_request_endpoint.username()7
8 mysql_endpoint = endpoint_from_flag('mysql.connected')9 mysql_endpoint.configure(databasename, username, prefix="gdb")
10
11 status_set('maintenance', 'Requesting mysql db')12
13 @when('mysql.available', 'endpoint.database.mysql.requested')14 def render_mysql_config_and_share_details():

74
15
16 mysql_endpoint = endpoint_from_flag('mysql.available')17
18 # On own apache19 render('gdb-config.j2', '/var/www/generic-database/gdb-config.html', {20 'db_master': "no-master",21 'db_pass': mysql_endpoint.password("gdb"),22 'db_dbname': mysql_endpoint.database("gdb"),23 'db_host': mysql_endpoint.db_host(),24 'db_user': mysql_endpoint.username("gdb"),25 'db_port': "3306",26 })27
28 # share details to consumer-app29 gdb_endpoint = endpoint_from_flag('endpoint.database.mysql.requested')30
31 gdb_endpoint.share_details(32 "mysql",33 mysql_endpoint.db_host(),34 mysql_endpoint.database("gdb"),35 mysql_endpoint.username("gdb"),36 mysql_endpoint.password("gdb"),37 "3306",38 )39
40 clear_flag('endpoint.database.mysql.requested')41 set_flag('endpoint.database.mysql.available')42 set_flag('endpoint.database.concrete')43 set_flag('restart-app')
Listing 11: Code of gdb-charm/reactive/gdb-charm.py
Finally, the webapp charm can render its own config file the same way as the gdb-charm. Listing 12shows the final step in the workflow of a database request.
1 @when('endpoint.database.available')2 def mysql_render_config():3
4 mysql = endpoint_from_flag('endpoint.database.available')5
6 render('database-config.j2', '/var/www/testwebapp/database-config.html', {7 'gdb_host' : mysql.host(),8 'gdb_port' : mysql.port(),9 'gdb_dbname' : mysql.databasename(),
10 'gdb_user' : mysql.user(),11 'gdb_password' : mysql.password(),12 })

75
13 status_set('maintenance', 'Rendering config file')14 set_flag('endpoint.database.connected')15 set_flag('restart-app')
Listing 12: Code of testwebapp/reactive/testwebapp.py to render config file.
To properly watch all config files refer to the repository available at https://github.com/Ciberth/MP-appendix-a.
Conclusion
This guide showed a basic example on how to create reactive charms (with an interface layer) and usethe endpoint pattern. Note that the service created here is not really useful as the webapp did notreceive the privileges to properly access the database. To fix this issue another interface-layer needs tobe used or the feature to pass privileges should be added to the mysq-shared interface. The goal washowever to show how to share data over the relations and illustrate how interface layers function asproper APIs for the communication between charms. I hope you liked this short introduction, best ofluck in building your charms!