Embed Size (px)
Citation preview

Magda – Manager for
grid-based data
Wensheng Deng
Physics Applications Software group
Brookhaven National Laboratory

What is Magda?
• A distributed data manager prototype for the ATLAS experiment.
• A project affiliated with the Particle Physics Data Grid (PPDG) .
• Uses Globus Toolkit wherever applicable.
• An end-to-end application layered over grid middleware.– gets thinner the more middleware we are able to use.

Why is it needed?• People are distributed. Hence data is distributed, computing power
distributed.
• People build networks, to extend their capability.
• Experiment needs to know what data they have, and where these data are.
• Experiment needs to send data to where computing power is available.
• Hence cataloging and data moving activities – that is the motivation of making Magda. Users need convenient data lookup
and retrieval!

How do we look at our data?
• Data is distributed, so storage facilities are distributed. We use the word site to abstract storage facility.
• Data is usually organized into directories at a storage facility. We use location to denote directory.
• Storage facility is accessed from computers. We use host to represent a group of computers. From a host, one can access a set of sites.
• That is how Magda organizes data: site, location, host
Architecture & Schema
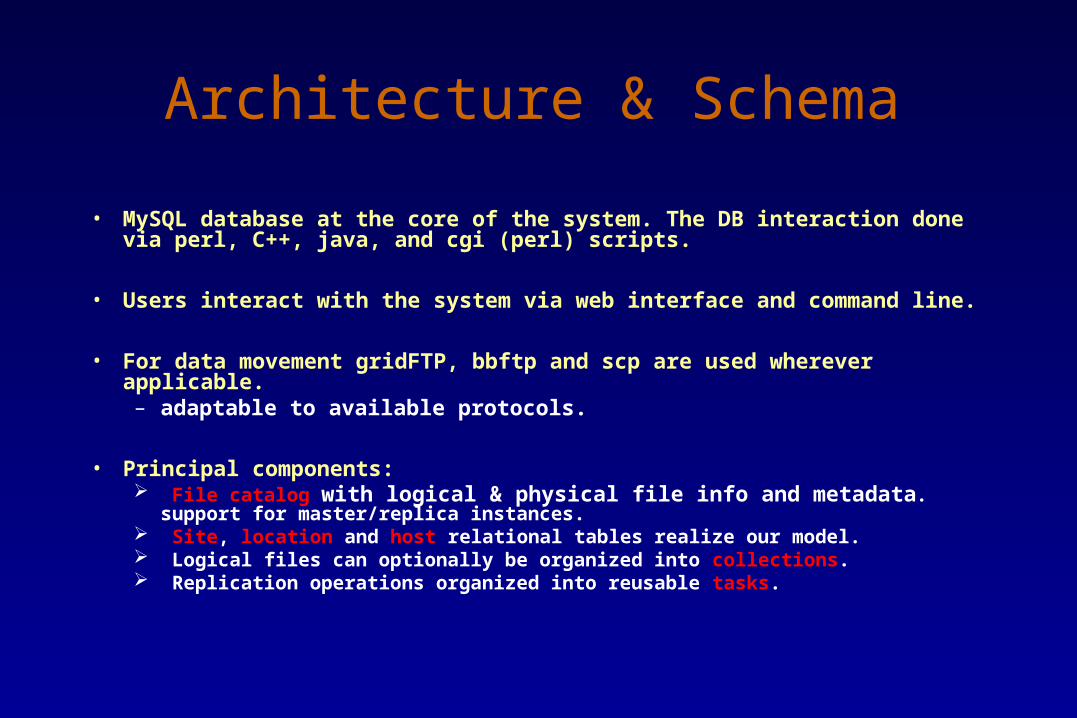
• MySQL database at the core of the system. The DB interaction done via perl, C++, java, and cgi (perl) scripts.
• Users interact with the system via web interface and command line.
• For data movement gridFTP, bbftp and scp are used wherever applicable.– adaptable to available protocols.
• Principal components: File catalog with logical & physical file info and metadata. support for
master/replica instances. Site, location and host relational tables realize our model. Logical files can optionally be organized into collections. Replication operations organized into reusable tasks.
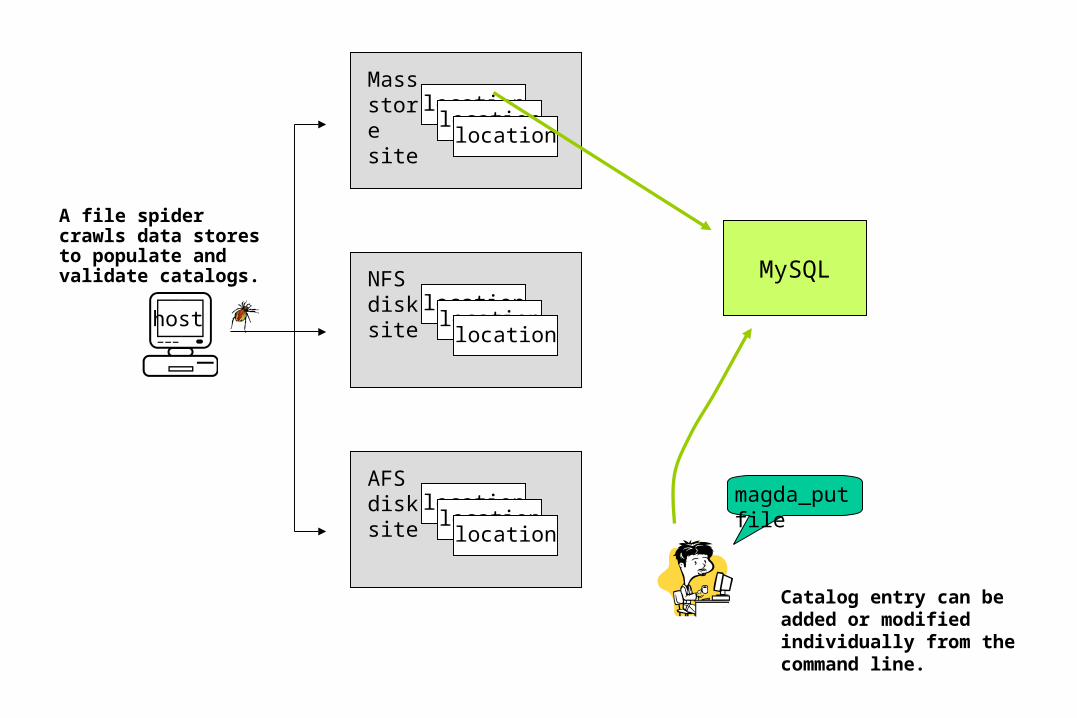
AFS disk site
locationlocation
location
Mass store site
locationlocation
location
NFS disk site
locationlocation
locationhost
MySQL
magda_putfile
A file spider crawls data stores to populate and validate catalogs.
Catalog entry can be added or modified individually from the command line.

File replication task
• A task is defined by user specifying source collection and host, transfer tool, pull/push, destination host and location, and intermediate caches.
• The source collection can be a set of files with a particular user-defined key, or files from the same location.
• Besides pull/push, third party transfer is also supported.
• A task is reusable.
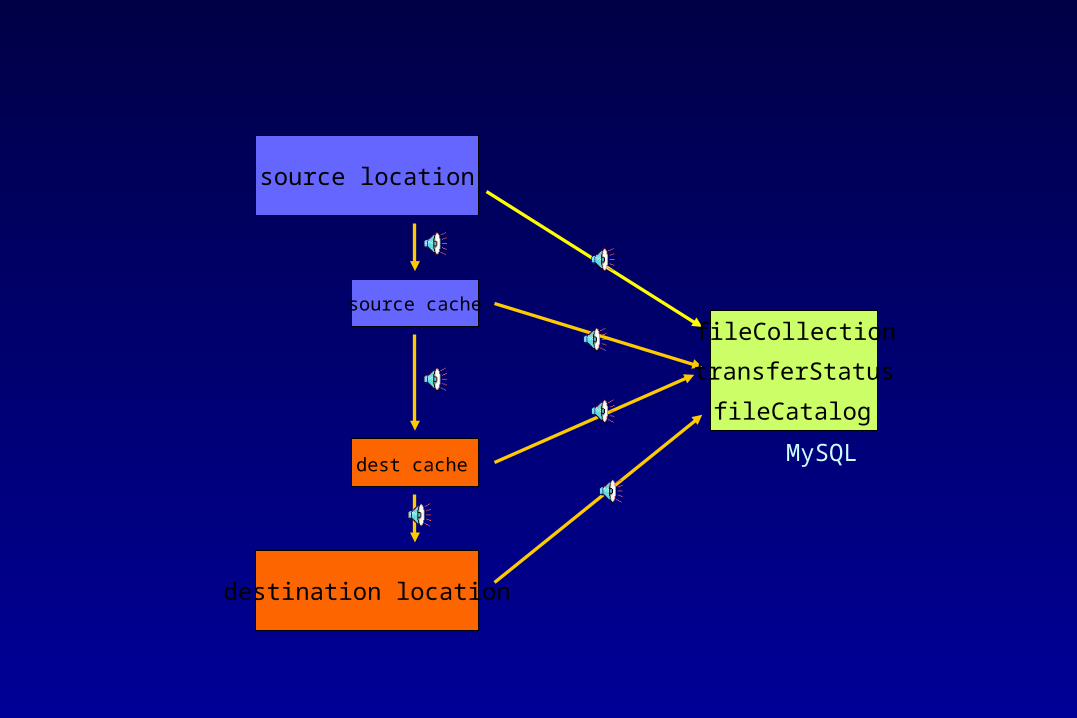
source location
source cache
destination location
dest cache MySQL
fileCollection
transferStatus
fileCatalog
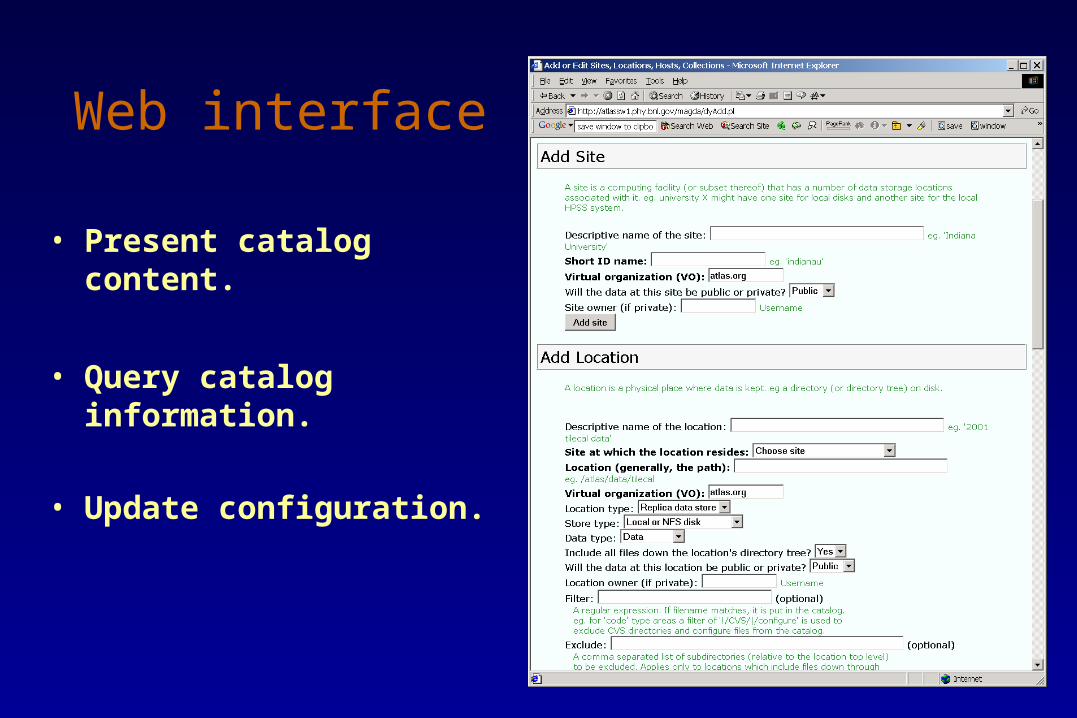
Web interface
• Present catalog content.
• Query catalog information.
• Update configuration.

Command line tools• magda_findfile
– Search catalog for logical files and their instances, – Optionally shows only local instances.
• magda_getfile– Retrieve file via catalog lookup– Creates local soft link to disk instance, or a local copy– Usage count maintained in catalog to manage deletion
• magda_putfile– Archive files and register them in catalog
• magda_validate– Validate file instances by comparing size and md5sum.

acas001
acas002
acas003
acas055
/acas003.usatlas.bnl.gov/home/scratch
USATLAS linux farmMagda site: usatlasfarm
Local disks at linux farm nodes
They are seen as a special storage site ‘farm’
Usage so far
• Distributed catalog for ATLAS– Catalog of ATLAS data at Alberta, CERN, Lyon, INFN (CNAF,
Milan), FZK, IFIC, IHEP.su, itep.ru, NorduGrid, RAL, many US institutes.
– Supported data stores: CERN castor, BNL HPSS, Lyon HPSS, RAL tape system, NERSC HPSS, disk, code repositories.
– 264K files in catalog with total size 65.5 TB as of 2003-03-20.tested to 1.5M files.
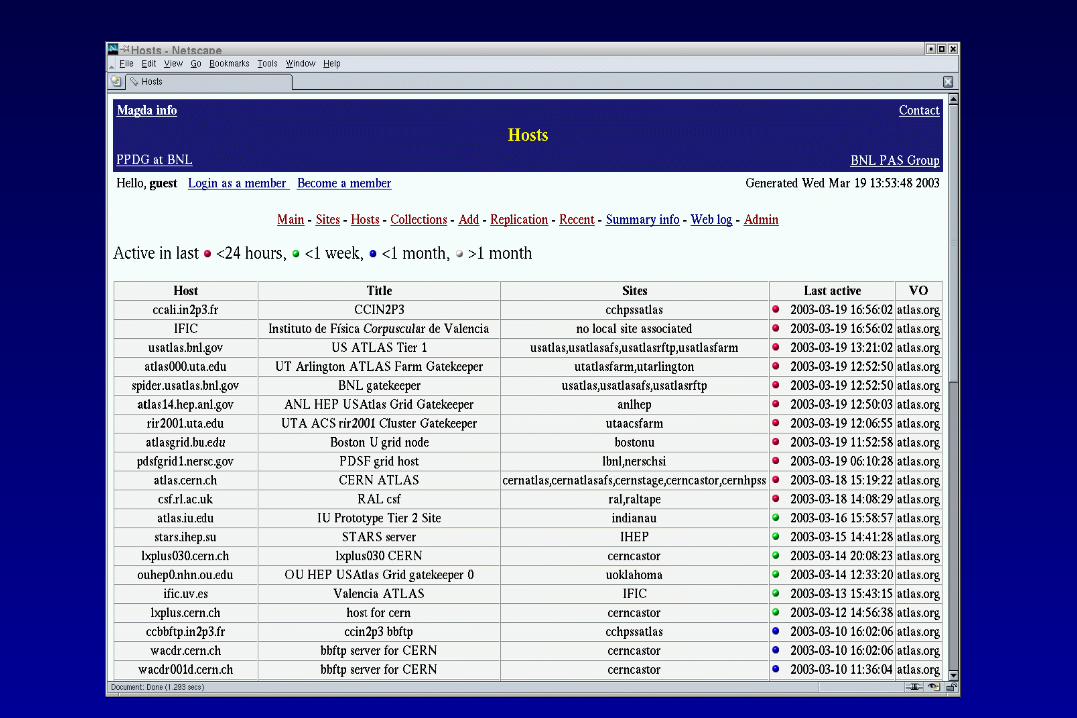
Usage so far (con’t)
• In stable operation since May 2001.
• Heavily used in Atlas DC0 and DC1. Catalog entries from 10 countries or region.
• Data replication tasks have transferred more than 6 TB data between BNL HPSS and CERN castor.
• Is a main component in US grid testbed production.
• Using Magda Phenix experiment replicates data from BNL to Stony Brook, and catalogs data at Stony Brook. It is being evaluated by others.

Current and near term work
• Implement Magda as an option of file catalog back end to the LCG POOL persistency framework.
• Data replication usage in non-BNL, non-CERN institutions. Application in Atlas DC.
• Under test in the EDG testbed.
• Continue evaluation/integration of middleware components (e.g. RLS).







![[Wensheng Peng, Chang Shu] Currency Internationali(BookFi.org)](https://img.pdfslide.us/doc/110x75/55cf8f89550346703b9d43e7/wensheng-peng-chang-shu-currency-internationalibookfiorg.jpg)





















