Embed Size (px)
DESCRIPTION
Machine learning techniques for detecting topics in research papers. Amy Dai. The Goal. Build a web application that allows users to easily browse and search papers. Project Overview. Part I – Data Processing Convert PDF to text Extract information from documents - PowerPoint PPT Presentation
Citation preview

Amy Dai
Machine learning techniques for detecting topics in research
papers

The Goal
Build a web application that allows users to easily browse and search papers

Project Overview1. Part I – Data Processing
Convert PDF to text Extract information from documents
2. Part II – Discovering topics Index documents Group documents by similarity Learn underlying topics

Part I - Data Processing
How do we extract information from PDF documents?

Pdf to TextResearch papers are in PDFPDFs are imagesComputer sees colored lines and dotsConversion process loses some of the
formatting

Getting what we need Construct heuristic rules to extract info
• First line• Between title and abstract• Preceded by “Abstract”
• Preceded by “Keywords”

Finding Names
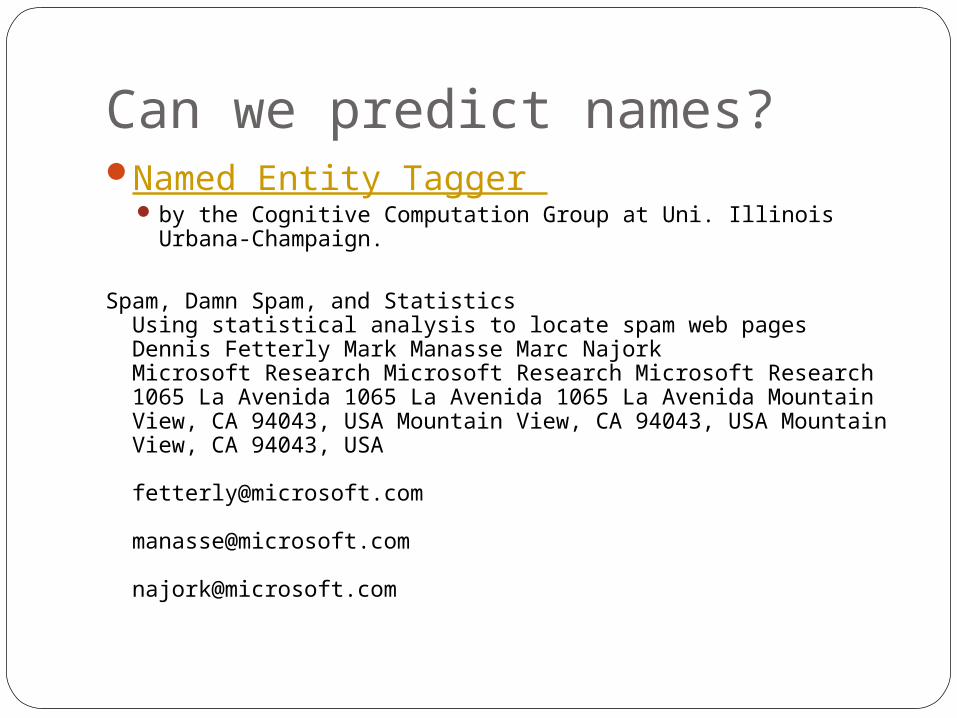
Can we predict names?Named Entity Tagger
by the Cognitive Computation Group at Uni. Illinois Urbana-Champaign.
Spam, Damn Spam, and StatisticsUsing statistical analysis to locate spam web pagesDennis Fetterly Mark Manasse Marc NajorkMicrosoft Research Microsoft Research Microsoft Research 1065 La Avenida 1065 La Avenida 1065 La Avenida Mountain View, CA 94043, USA Mountain View, CA 94043, USA Mountain View, CA 94043, USA

AccuracyTo determine how well my script to extract
info worked(# right + # needing minor changes)/ Total
# of documentsExample
30 were correctly extracted10 needed minor changes60 total documents(30+10)/60 = 66.7%

Accuracy and Error
Perfect Match
(%)
Partial Match
(%)
No Match
(%)
Title 78 5 17
Abstract
63 12 35
Keywords
68.75 12.5 18.75
Authors
38 31 31

Part II – Learning Topics
Can we use machine learning to discover underlying topics?

Indexing DocumentsIndex documents Remove common words leaving better
descriptors for clusteringCompare to corpus
Brown Corpus: A Standard Corpus of Present-Day Edited American English
From the Natural Language ToolkitReduce from 19,100 to 12,400 wordsDocuments contain between 100 – 1,700
words after common word removal

Effect on Index Size
Common Word Frequency Cutoff Index Size
20 35715 31810 2765 230
Changes in document index size for “Defining quality in web search results”

Keeping What’s Important
Common Word Frequency Cutoff5 10 15 20
querying web web webgoogle querying querying queryingyahoo google google google
metrics yahoo controversial controversialretrieval evaluating yahoo engines
metrics evaluating yahoo retrieval metrics evaluating retrieval metrics retrieval
Words in abstract of “Defining quality in web search results”

Documents as VectorsRepresent documents as numerical
vectors by transforming words to numbers using tf-idf
Length is normalizedVector length is the length of index
for corpusMostly sparse

Clustering using Machine LearningUse machine learning algorithms
to cluster by:K-means Group Average Agglomerative (GAA)
Unsupervised learningCosine similarity

Clustering Results
Documents K-Means A: SpamRank – Fully Automatic
Link Spam Detection B: An Approach to Confidence
Based Page Ranking for User Oriented Web Search
C: Spam, Damn Spam, and Statistics
D:Web Spam, Propaganda and Trust
E: Detecting Spam Web Pages through Content Analysis
F: A Survey of Trust and Reputation Systems for Online Service Provision
Group 1A
Group 2B,C,D,E
Group 3F
GAA
Group 1B
Group 2A,C,D,E
Group 3F

ChallengesK-Means
Finding KGroup Average Agglomerative
The depth to cut the dendogram

Labeling ClustersCompare term frequency in a
cluster with the collectionA frequent word within the cluster
and in the collection isn’t a good discriminative label
A good label is one that is infrequent in the collection

Summary1. Part I – Data Processing
• PDF to text conversion isn’t perfect and imperfections make it difficult to extract text
• Documents don’t follow one formatting standard, need heuristic rules to extract info
2. Part II – Discovering topics• Indexes are large, to keep the important we
need a good corpus to compare it to.• There are many clustering algorithms and
each has limitations• How do I choose the best label?

Ongoing workUse Bigrams
Keywords: Web search, adversarial information retrieval, web spam
Limit the number of topic labels by ranking
Use algorithm that clusters based on probabilistic distributionsLogistic normal distribution

Useful Tools1. Pdftotext – Unix command for
converting PDF to text2. Python libraries
Unicode Re –regular expressions
3. NLTK – Natural language processing tool Software and datasets for natural
language processing Used for clustering algorithms and
reference corpus