Embed Size (px)
Citation preview

Machine Learning for 21st Century Biology and Medicine
Robert F. Murphy Lane Professor of
Computational Biology and
Professor of Biological Sciences,
Biomedical Engineering and
Machine Learning

Outline
• Digital Pathology and Location Biomarkers
• Active Learning for Drug Development
• Personal genome analysis: plans and challenges
• Challenges of automated systems for biomedicine
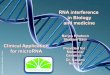
DIGITAL PATHOLOGY AND LOCATION BIOMARKERS

Motivation
• Protein function is modulated by changing its
subcellular abundance, activity or location
• Differential protein abundance is routinely
studied for biomarker discovery

Motivation
• Protein function is modulated by changing its
subcellular abundance, activity or location
• Differential protein abundance is routinely used
for biomarker discovery
• Less work has been done on using subcellular
location differences for biomarker discovery

Motivation
• Protein function is modulated by affecting its subcellular abundance or location
• Differential protein abundance is routinely used for biomarker discovery
• Less work has been done on using subcellular location differences for biomarker discovery
• Ultimately, both abundance and location biomarkers are important for the systematic study of disease processes as well as the development of clinical therapeutics
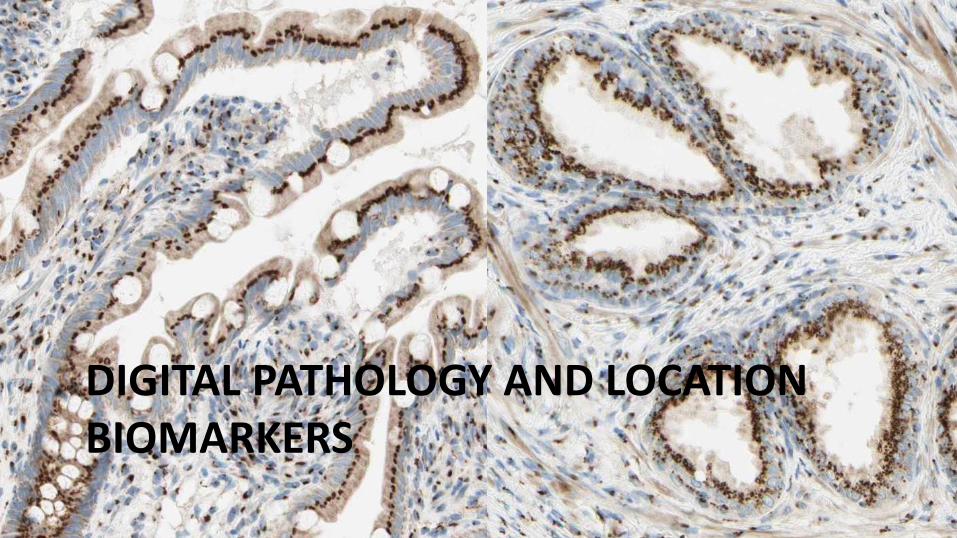
Example Location Biomarker
• Cytoplasmic phospho-β-catenin inversely correlated with tumor size and stage (breast, skin cancer) .
healthy cancer
nucleus
cytoplasm
nucleus
cytoplasm
phospho- β-catenin
nucleus
cytoplasm
Nakopoulou, Mod Path. 2006
Chung, Clinical Cancer Res., 2001
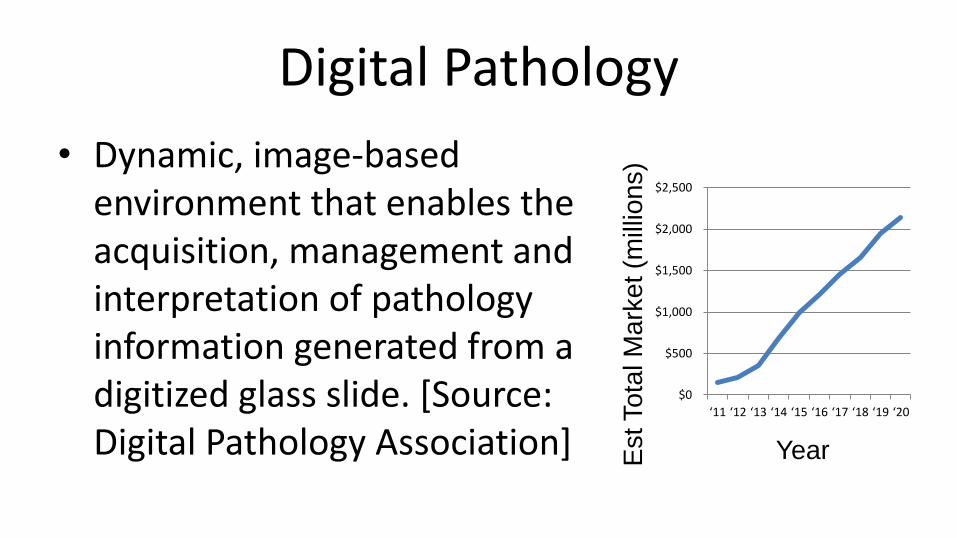
Digital Pathology
• Dynamic, image-based environment that enables the acquisition, management and interpretation of pathology information generated from a digitized glass slide. [Source: Digital Pathology Association]
$0
$500
$1,000
$1,500
$2,000
$2,500
‘11 ‘12 ‘13 ‘14 ‘15 ‘16 ‘17 ‘18 ‘19 ‘20
Year Est Tota
l M
ark
et (m
illio
ns)

Opportunity for Automated Analysis
• Increasing availability of tissue images in digital form opens opportunity for automating tasks performed by pathologists

Opportunity for New Analyses
• Potentially more important opportunity for performing analyses that are difficult for pathologists to perform visually
• Example: detecting location biomarkers
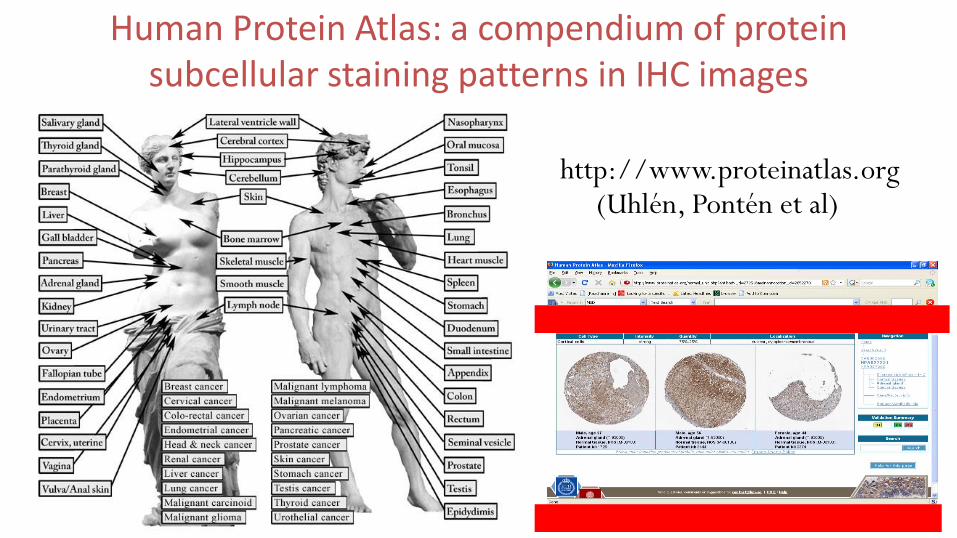
Human Protein Atlas: a compendium of protein subcellular staining patterns in IHC images
http://www.proteinatlas.org (Uhlén, Pontén et al)
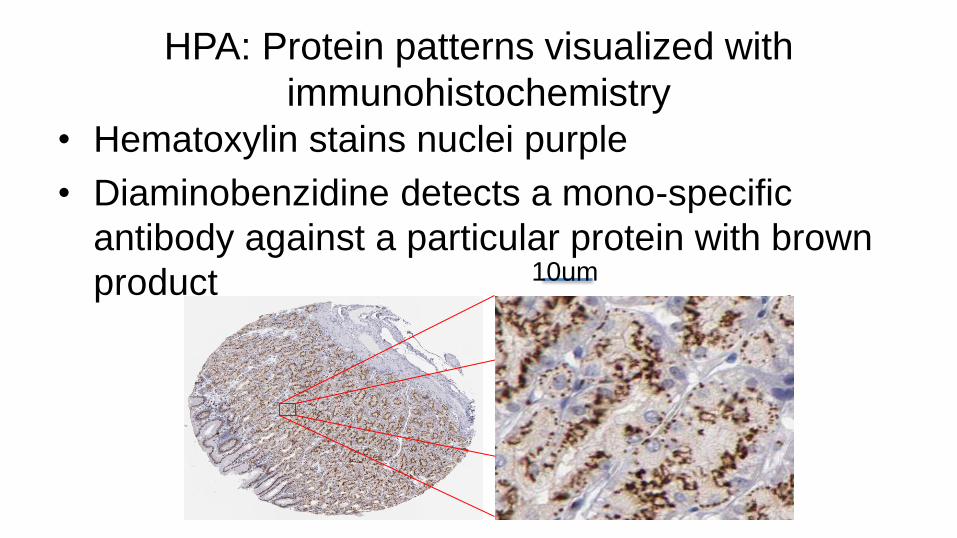
HPA: Protein patterns visualized with
immunohistochemistry
• Hematoxylin stains nuclei purple
• Diaminobenzidine detects a mono-specific
antibody against a particular protein with brown
product
Brightfield image, ~1 mm in width Brightfield image, ~0.1 mm in width
10um
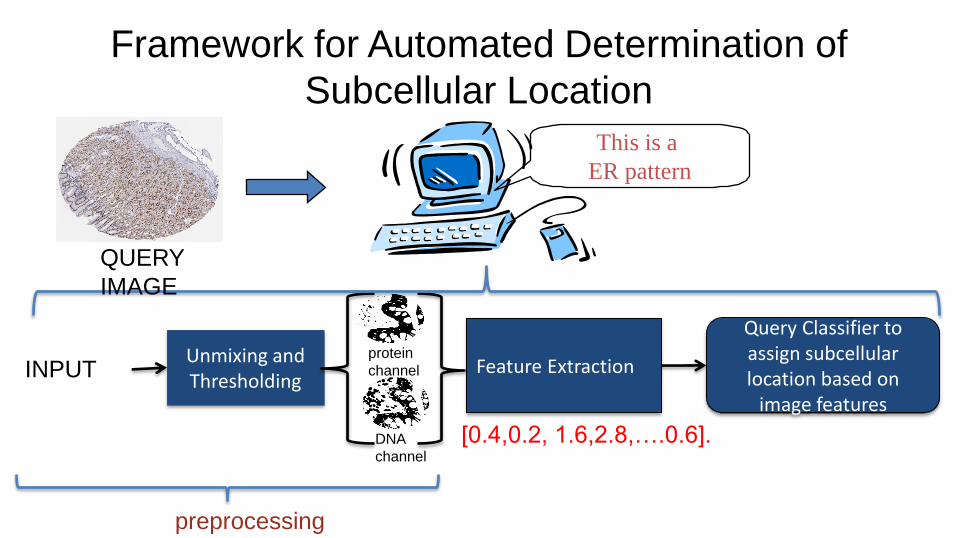
Framework for Automated Determination of
Subcellular Location
INPUT protein
channel
DNA
channel
Unmixing and Thresholding
Feature Extraction
preprocessing
Query Classifier to assign subcellular location based on
image features
QUERY
IMAGE
[0.4,0.2, 1.6,2.8,….0.6].
This is a
ER pattern
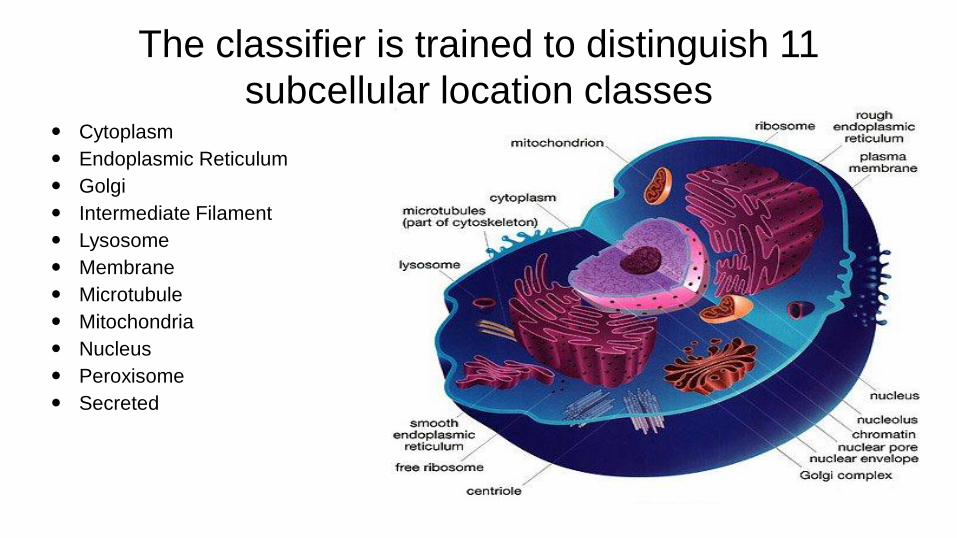
Cytoplasm
Endoplasmic Reticulum
Golgi
Intermediate Filament
Lysosome
Membrane
Microtubule
Mitochondria
Nucleus
Peroxisome
Secreted
The classifier is trained to distinguish 11
subcellular location classes
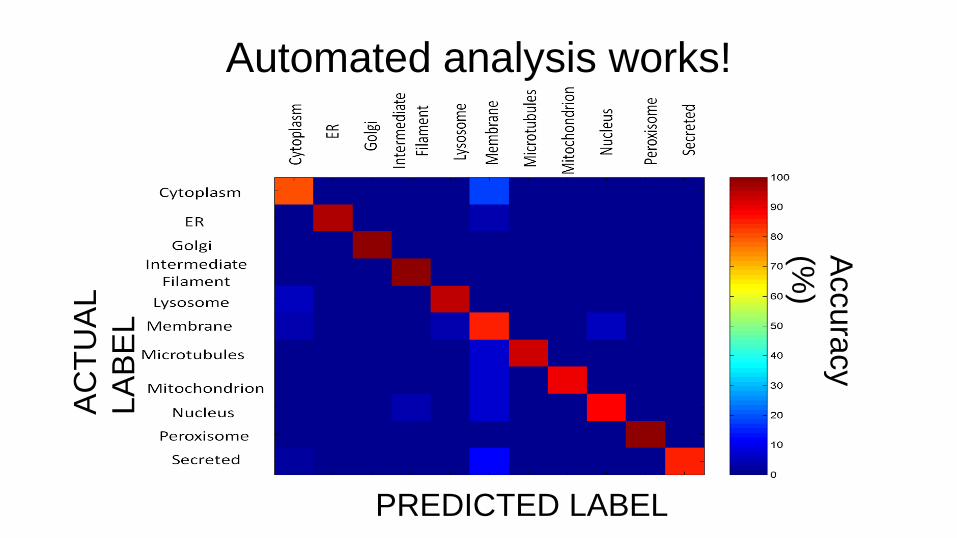
Automated analysis works! A
CT
UA
L
LA
BE
L
PREDICTED LABEL
Accura
cy
(%)
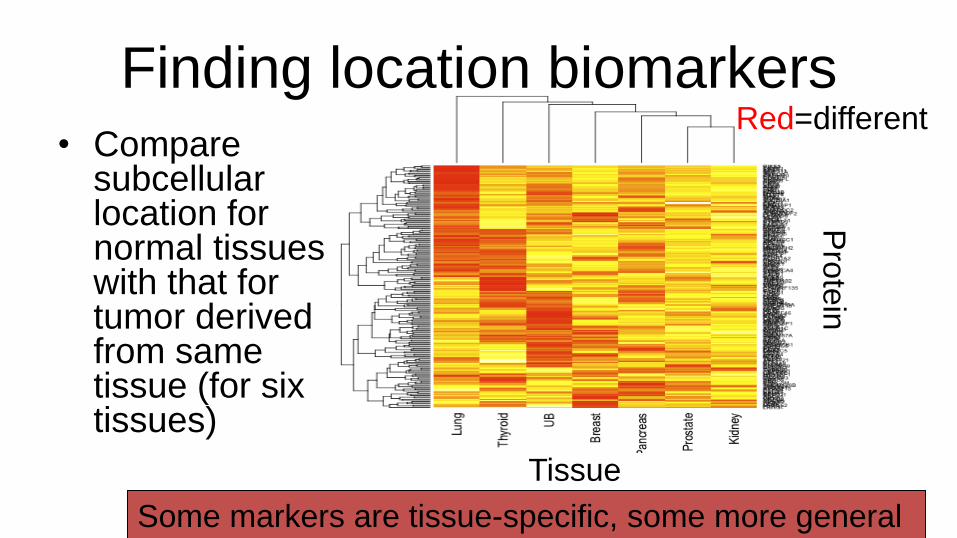
Finding location biomarkers • Compare
subcellular location for normal tissues with that for tumor derived from same tissue (for six tissues)
Pro
tein
Tissue
Red=different
Some markers are tissue-specific, some more general

Next steps
• Patent pending on biomarker detection
• Clinical collaborations to verify that these proteins are location biomarkers and to determine whether they have diagnostic/prognostic/theranostic value
• Incorporation of analysis technology into digital pathology platforms
ACTIVE LEARNING FOR DRUG DEVELOPMENT
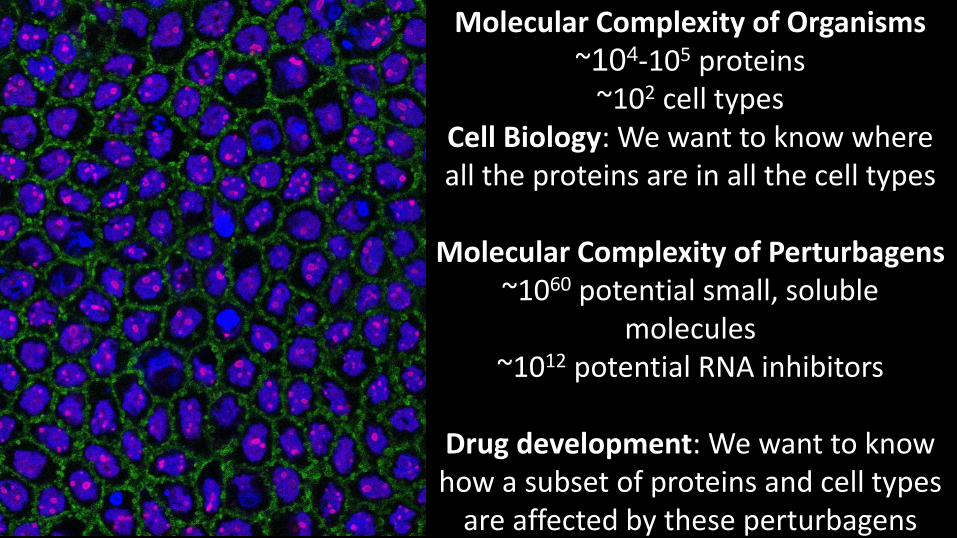
Molecular Complexity of Organisms ~104-105 proteins
~102 cell types Cell Biology: We want to know where all the proteins are in all the cell types
Molecular Complexity of Perturbagens
~1060 potential small, soluble molecules
~1012 potential RNA inhibitors
Drug development: We want to know how a subset of proteins and cell types
are affected by these perturbagens
Establish Assay for a Target
Traditional HCS/HTS
Identify Positive and Negative Controls
Negative Positive Measured Unmeasured
Screen 107 Compounds
Negative Positive

Two problems: (1) We don’t know effects on other targets
Negative Positive Intermediate
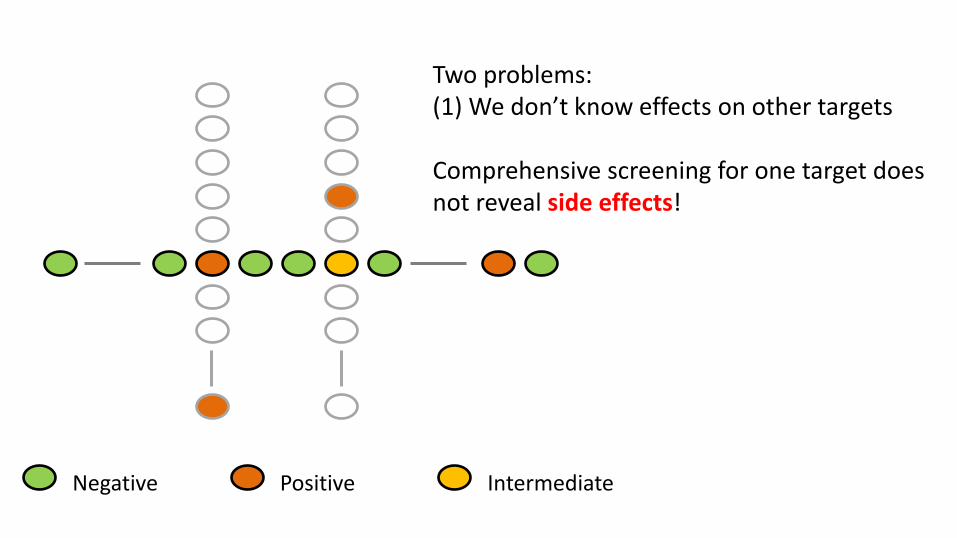
Two problems: (1) We don’t know effects on other targets Comprehensive screening for one target does not reveal side effects!
Negative Positive Intermediate
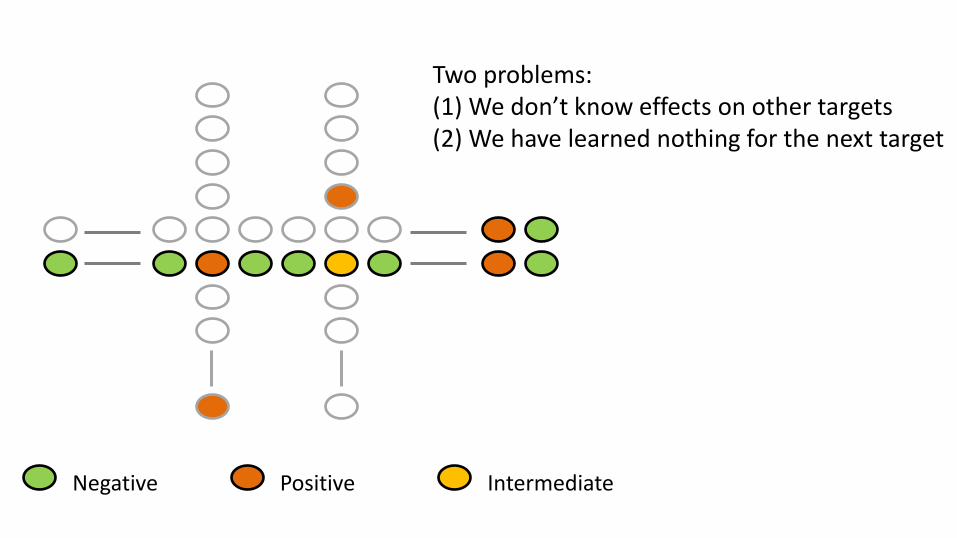
Two problems: (1) We don’t know effects on other targets (2) We have learned nothing for the next target
Negative Positive Intermediate
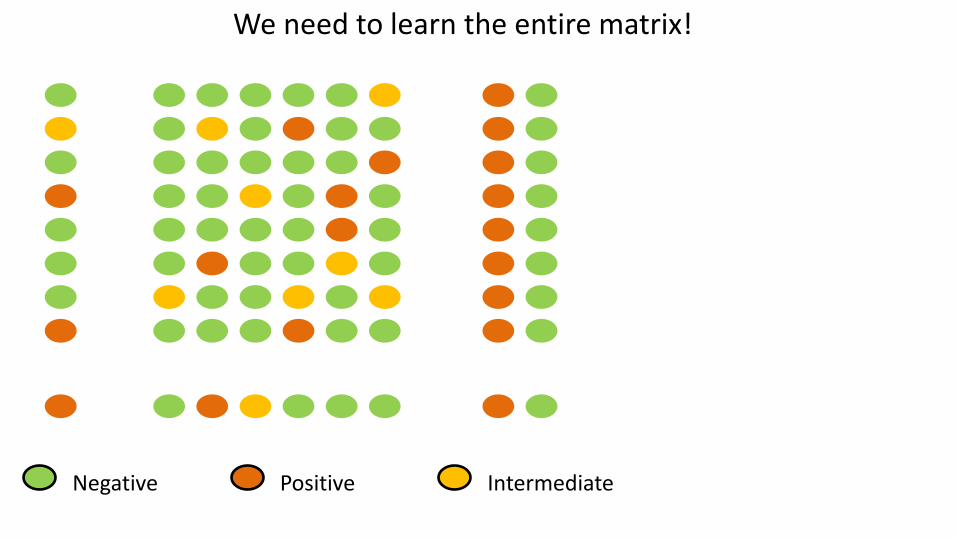
We need to learn the entire matrix!
Negative Positive Intermediate
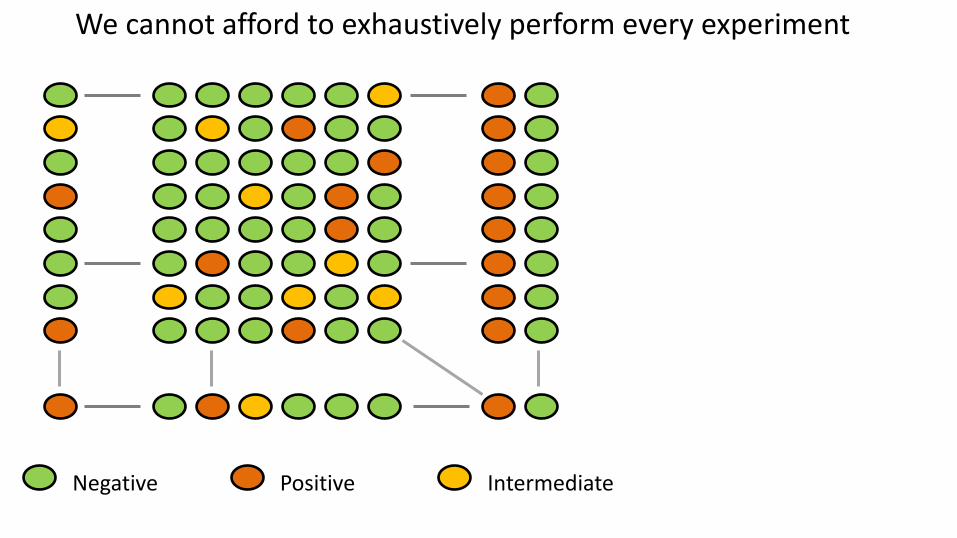
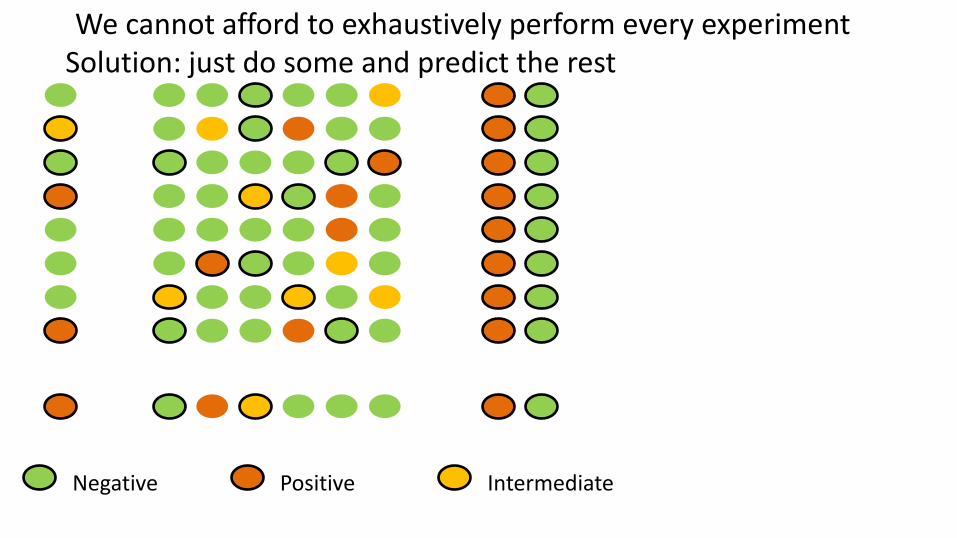
We cannot afford to exhaustively perform every experiment
Negative Positive Intermediate
X
X
X
X
X
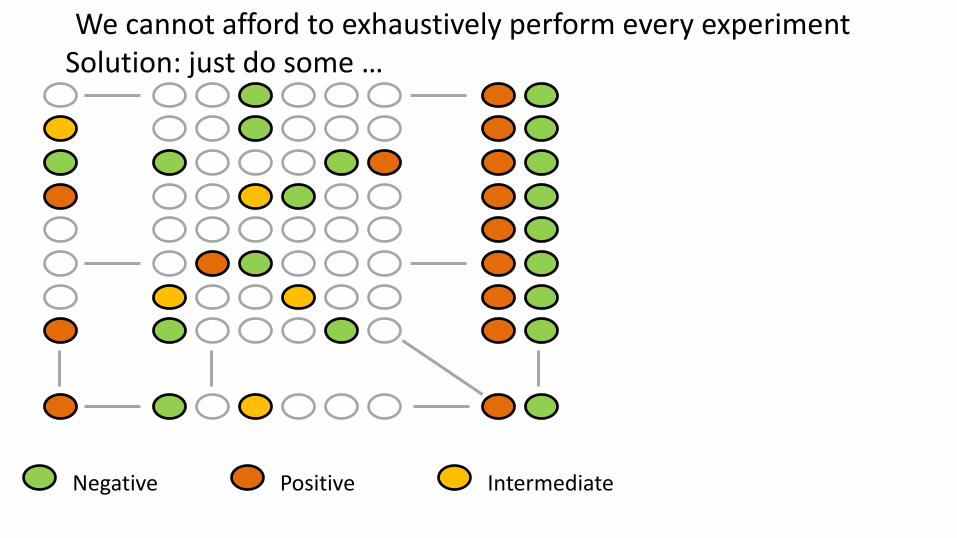
We cannot afford to exhaustively perform every experiment Solution: just do some …predict the rest
Negative Positive Intermediate
Negative Positive Intermediate
We cannot afford to exhaustively perform every experiment Solution: just do some and predict the rest

Two versions of problem
• When information is available not only about the readout from experiments but about the similarity of compounds to each other and targets to each other (“internal and external data”)
• When information is only available about readout of experiments (“internal only”)

Two versions of readout
• Scalar (e.g., percentage of maximum hit)
• Vector (e.g., percentage of probe in different compartments)

Negative Positive Intermediate
Learning with internal and external data
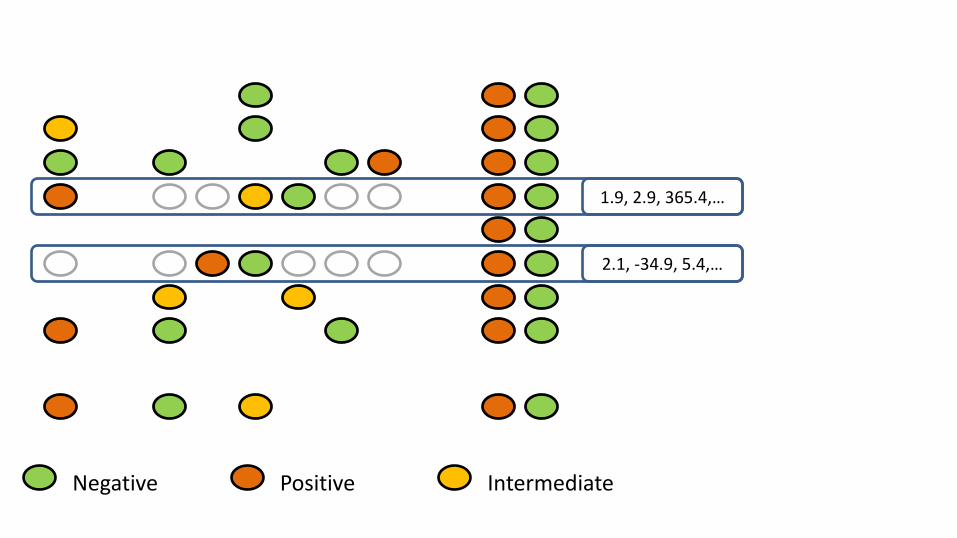
X
X
X
Negative Positive Intermediate
1.9, 2.9, 365.4,…
2.1, -34.9, 5.4,…
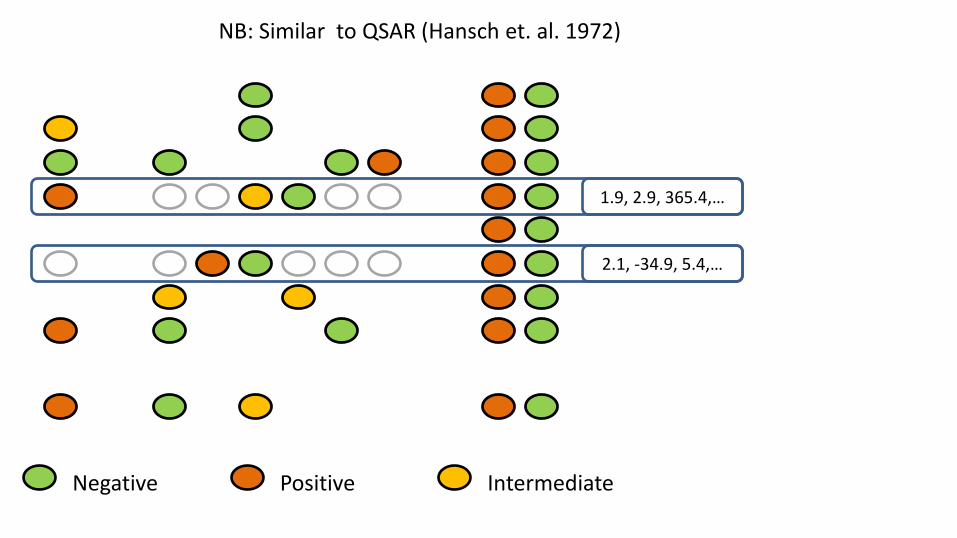
X
X
X
Negative Positive Intermediate
1.9, 2.9, 365.4,…
2.1, -34.9, 5.4,…
NB: Similar to QSAR (Hansch et. al. 1972)
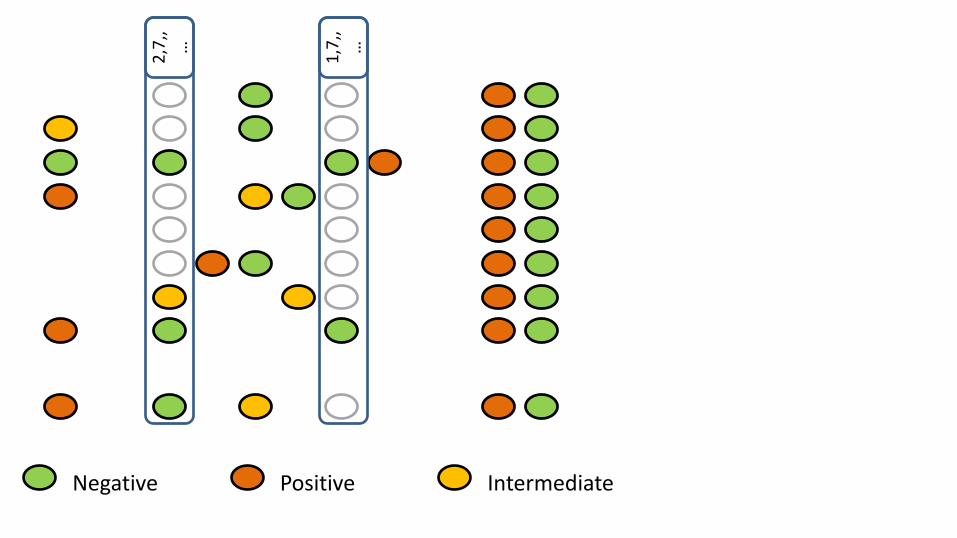
X
X
X
Negative Positive Intermediate
2,7
,,…
1,7
,,…
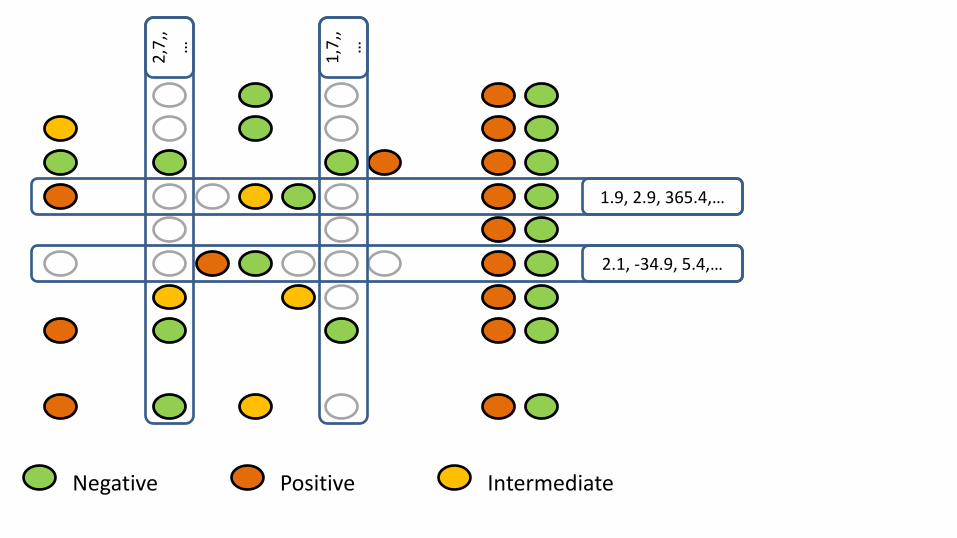
X
X
X
Negative Positive Intermediate
2,7
,,…
1,7
,,…
1.9, 2.9, 365.4,…
2.1, -34.9, 5.4,…
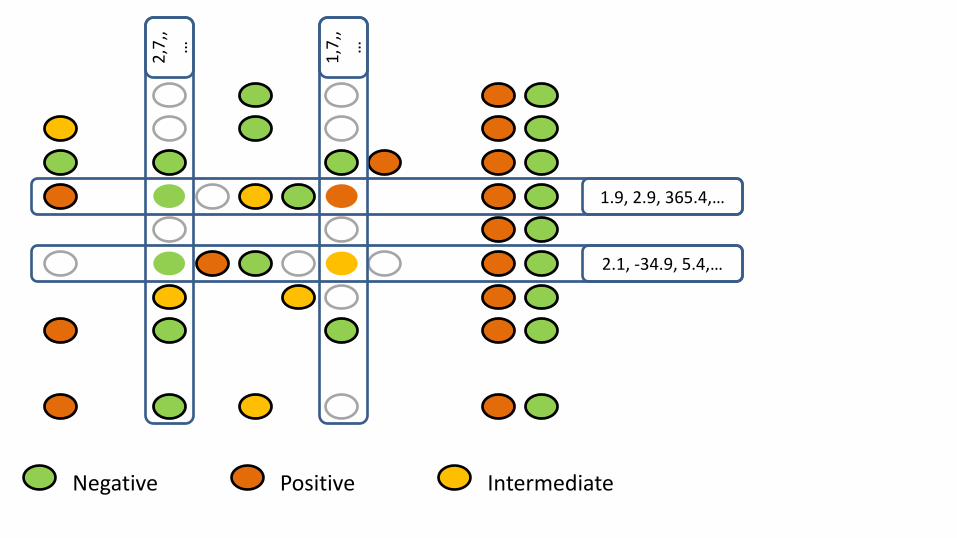
X
X
Negative Positive Intermediate
2,7
,,…
1,7
,,…
1.9, 2.9, 365.4,…
2.1, -34.9, 5.4,…

PubChem Data Preparation • Assays: 177
– 108 in vitro – 69 in vivo – Sign of score reflects type of assay (inhibition or activation)
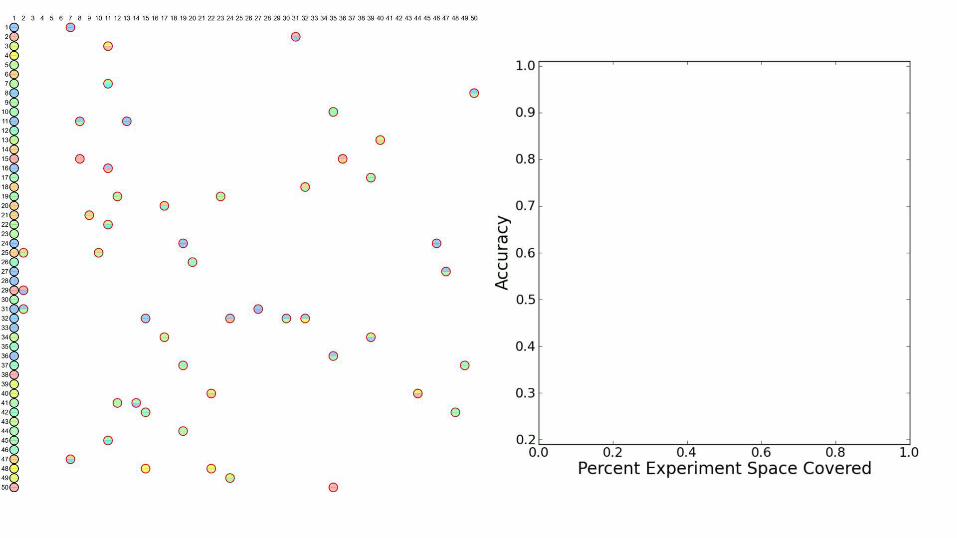
• Unique Protein Targets: 133 • Compounds: 20,000 • Experiments: ~1,000,000 (30% coverage) • Goal: discover hits - drug-target pairs whose |rank score| > 80 • Very few hits (0.096%)
38
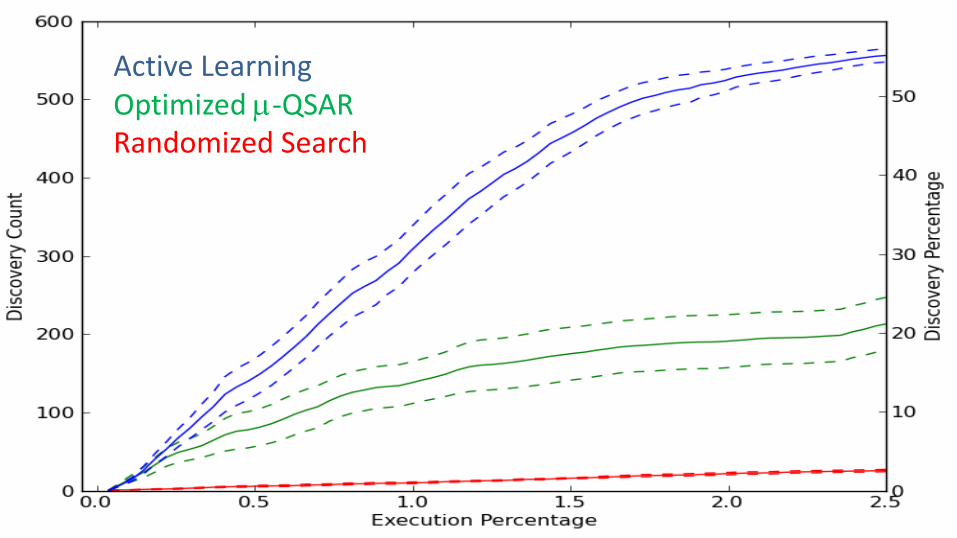
Active Learning Optimized -QSAR Randomized Search
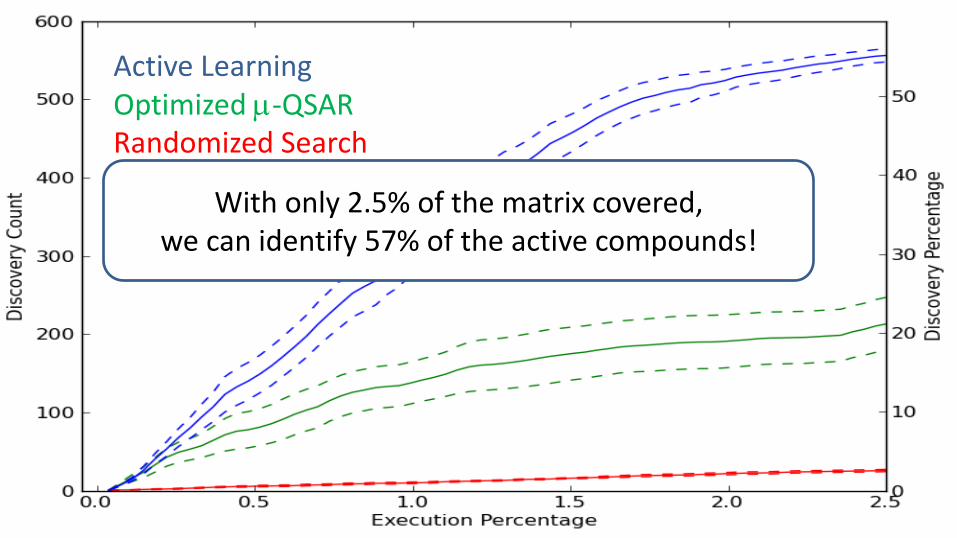
Active Learning Optimized -QSAR Randomized Search
With only 2.5% of the matrix covered, we can identify 57% of the active compounds!

Negative Positive Intermediate
Learning with internal data only
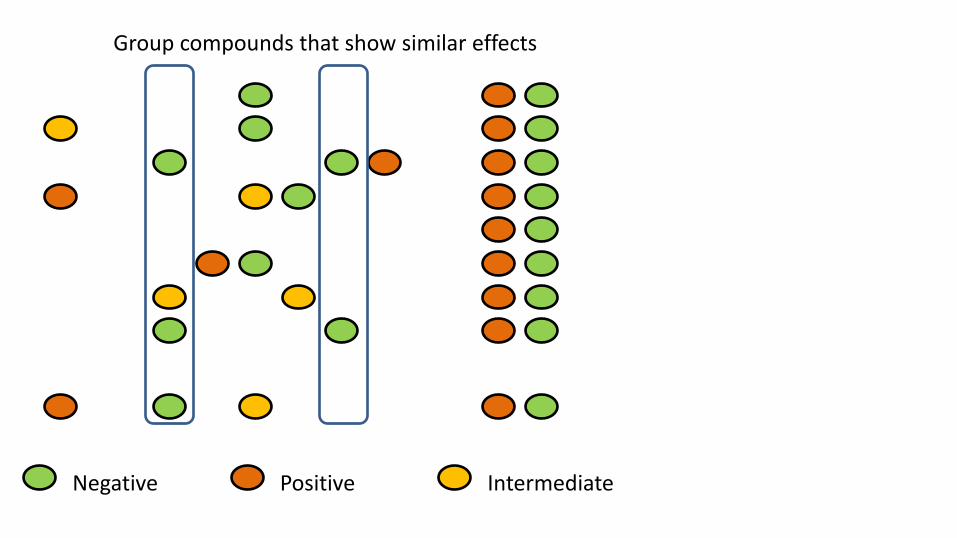
Negative Positive Intermediate
Group compounds that show similar effects
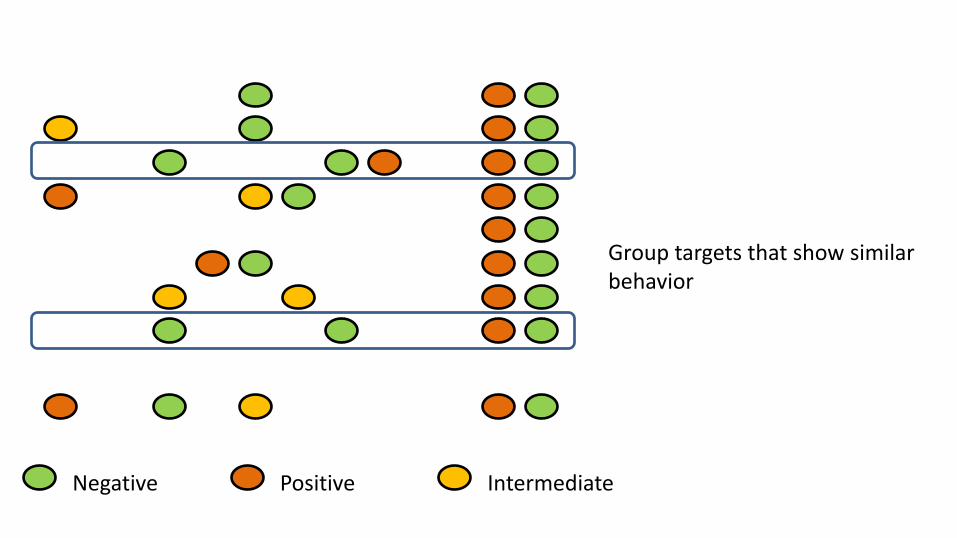
Negative Positive Intermediate
Group targets that show similar behavior
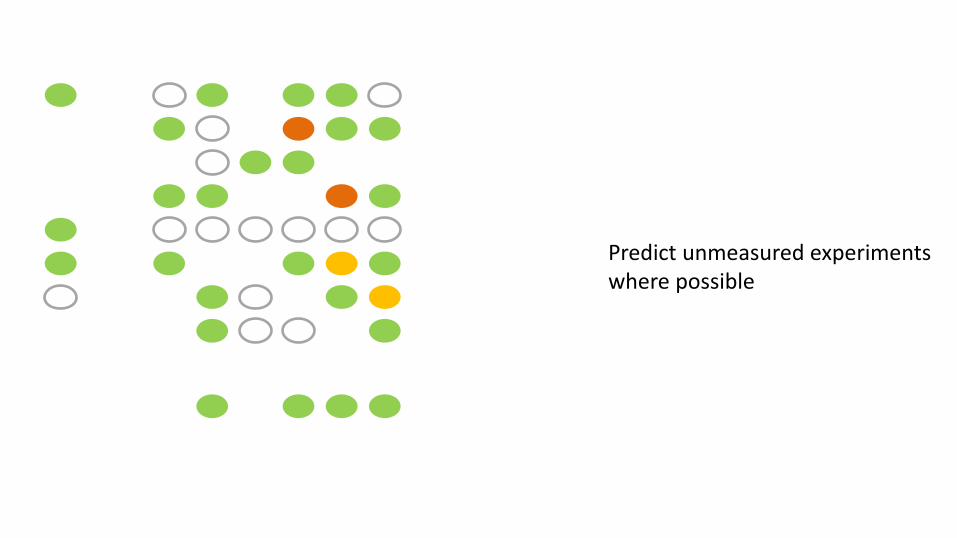
X
Predict unmeasured experiments where possible
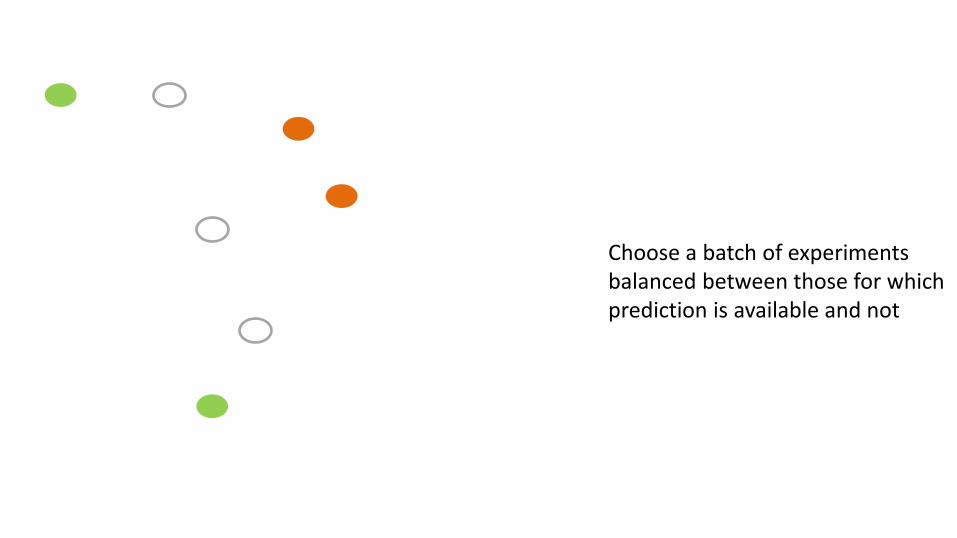
Choose a batch of experiments balanced between those for which prediction is available and not
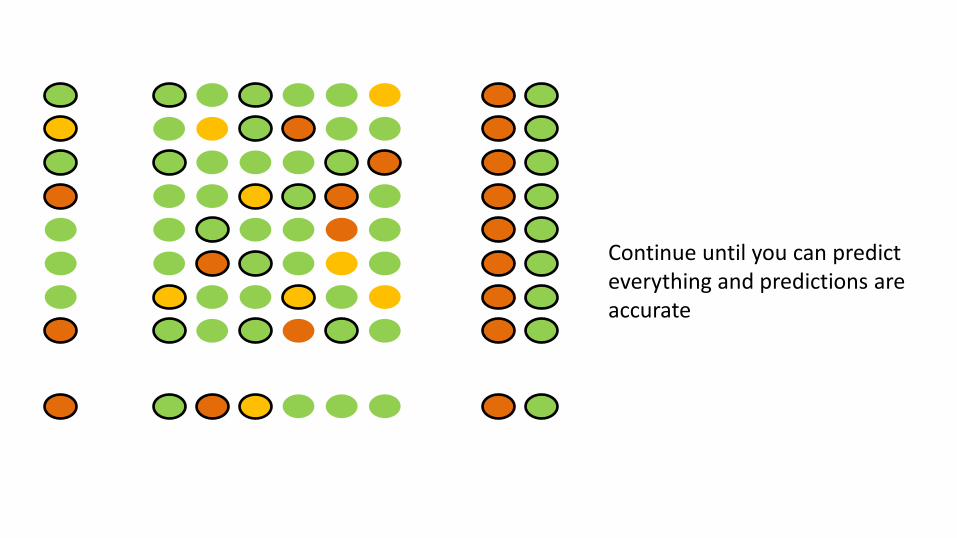
Continue until you can predict everything and predictions are accurate

Next steps
• Patent pending for active learning methodology
• Collaborate with pharmaceutical companies to demonstrate that methodology would have worked using complete datasets
• Use with robotics to tackle new problems
• Extend to combinations of perturbagens
• Many problems in biology of similar complexity

PERSONAL GENOME ANALYSIS: PLANS AND CHALLENGES

Personal genome sequencing arrives
• The advent of machines capable of determining personal genome sequences for $1,000 will user in a new era of personalized medicine
• Danger in possible proliferation of fragmented, proprietary genome analysis software
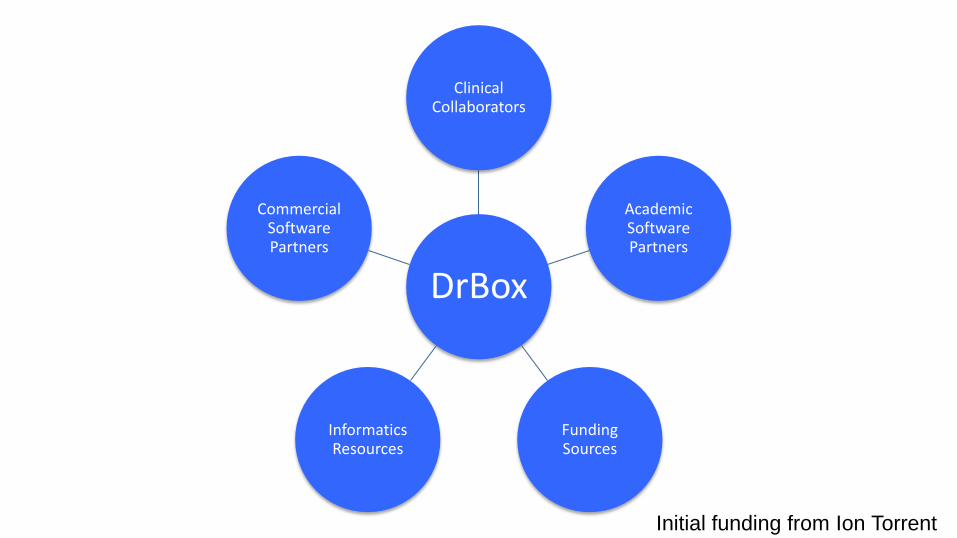
DrBox
Clinical Collaborators
Academic Software Partners
Funding Sources
Informatics Resources
Commercial Software Partners
Initial funding from Ion Torrent

Operating Principles
• Open source, free licensing (GPLv2)
• Encourage collaborations/contributions under that licensing
• Frequent releases
• Enable compression, assuming resequencing easy
• Never-ending learning (online learning)

1. Clinical Collaborations • Clinical collaborators provide personal genome
sequence, other omics data (optional) and clinical phenotype information (disease, onset, severity, survival time, treatment responsiveness)
• Primary goals: Development and testing of methods AND learning of new associations
• Data typically confidential/proprietary at least until publication
• Typically requires research agreement

2. Software Collaborations
• Open source, no license fee software
model
• New releases frequently
• Collaborators and contributors welcome
• No agreements necessary

3. Dissemination Collaborations
• Commercial organizations who provide data storage and computing resources (e.g., cloud)
• Entire analysis pipeline is open source (including DrBox)
• Personnel may make contributions to software development and testing
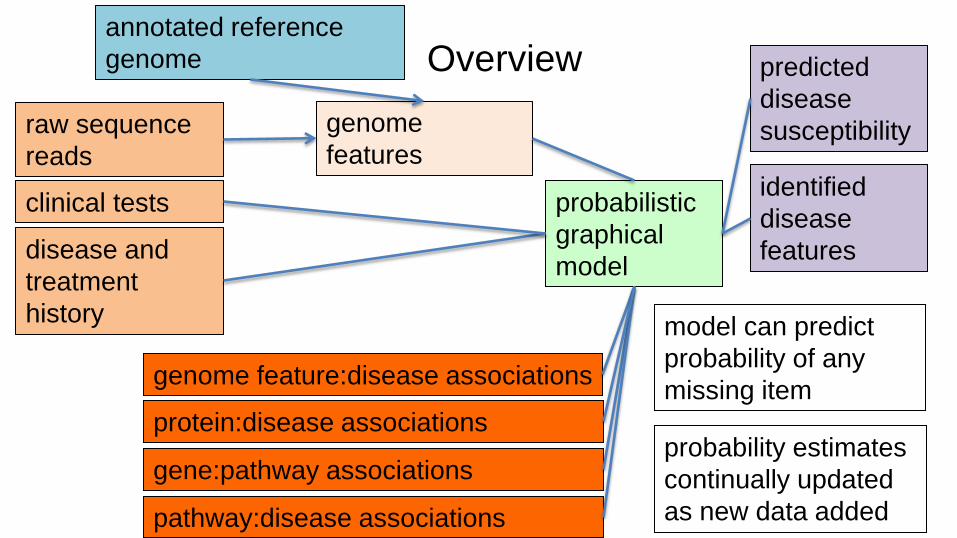
raw sequence
reads
genome
features
disease and
treatment
history
genome feature:disease associations
gene:pathway associations
probabilistic
graphical
model
pathway:disease associations
protein:disease associations
annotated reference
genome
model can predict
probability of any
missing item
probability estimates
continually updated
as new data added
Overview
clinical tests
predicted
disease
susceptibility
identified
disease
features
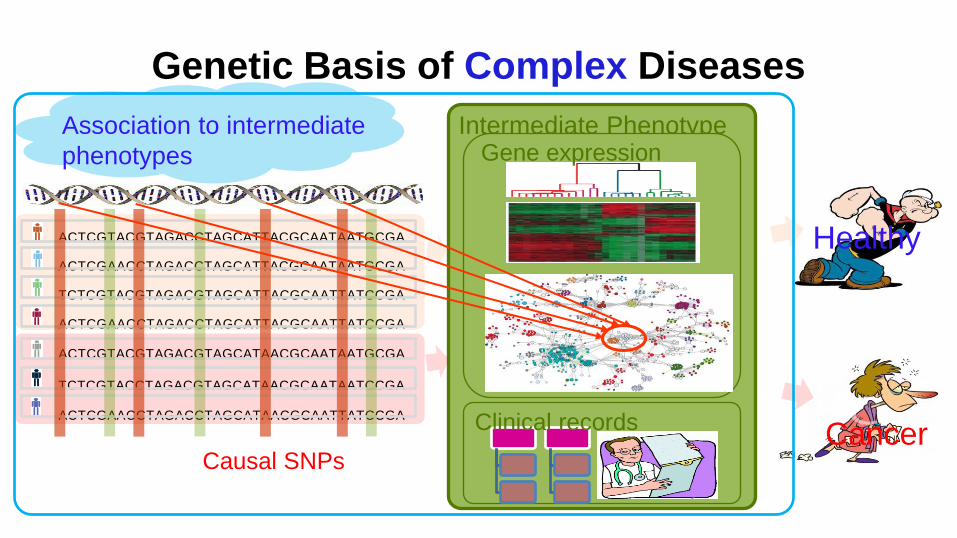
Intermediate Phenotype
Genetic Basis of Complex Diseases
Healthy
Cancer
ACTCGTACGTAGACCTAGCATTACGCAATAATGCGA
ACTCGAACCTAGACCTAGCATTACGCAATAATGCGA
TCTCGTACGTAGACGTAGCATTACGCAATTATCCGA
ACTCGAACCTAGACCTAGCATTACGCAATTATCCGA
ACTCGTACGTAGACGTAGCATAACGCAATAATGCGA
TCTCGTACCTAGACGTAGCATAACGCAATAATCCGA
ACTCGAACCTAGACCTAGCATAACGCAATTATCCGA
Causal SNPs
Clinical records
Gene expression Association to intermediate
phenotypes
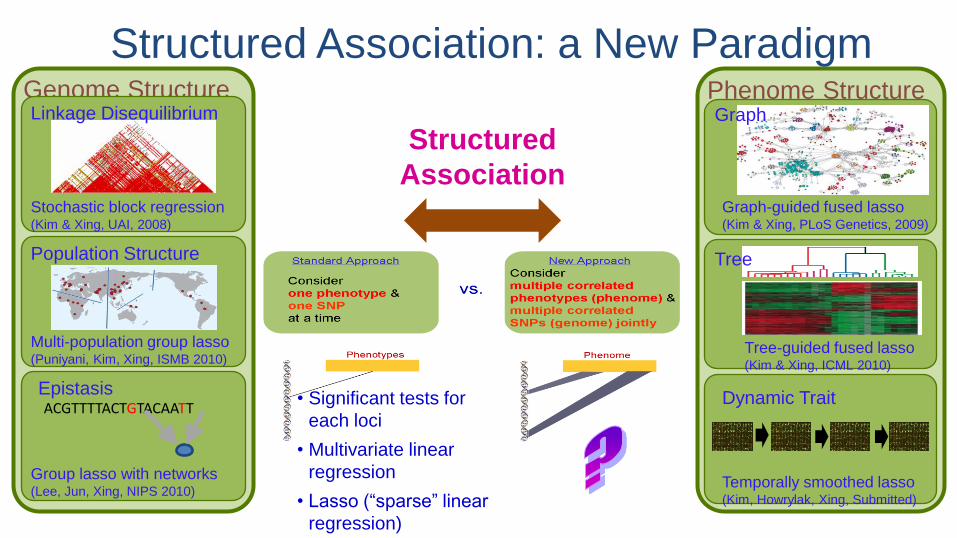
Structured
Association
Phenome Structure
Graph-guided fused lasso (Kim & Xing, PLoS Genetics, 2009)
Graph
Tree-guided fused lasso (Kim & Xing, ICML 2010)
Tree
Temporally smoothed lasso (Kim, Howrylak, Xing, Submitted)
Dynamic Trait
Genome Structure
Stochastic block regression (Kim & Xing, UAI, 2008)
Linkage Disequilibrium
Multi-population group lasso (Puniyani, Kim, Xing, ISMB 2010)
Population Structure
Epistasis ACGTTTTACTGTACAATT
Group lasso with networks (Lee, Jun, Xing, NIPS 2010)
Structured Association: a New Paradigm
• Significant tests for
each loci
• Multivariate linear
regression
• Lasso (“sparse” linear
regression)

CHALLENGES OF AUTOMATED SYSTEMS FOR BIOMEDICINE

Challenges to society • For all automated systems, as with human systems, errors are
inevitable. For current systems, the consequences of machine error are easily dealt with, whether it is by retrieving misdirected mail, ignoring an uninteresting recommendation, or averaging in some unsuccessful trades with many successful ones. However, as automated decision-making is extended to biomedicine, the consequences of error may be more difficult to address.
• Furthermore, a new question arises: how will people, especially scientists and physicians, react to the existence of systems that understand their fields better than they do?

• Past and Present Students and Postdocs – Justin Newberg (Baylor), Estelle Glory, Arvind Rao (M.D. Anderson),
Armaghan Naik, Josh Kangas
• Funding – NSF, NIH, Commonwealth of Pennsylvania,
Ion Torrent
• Collaborators/Consultants – Mathias Uhlen, Emma Lundberg, Tom Mitchell, Chris Langmead,
Lans Taylor, Jonathan Rothberg, Ziv Bar-Joseph, Seyoung Kim, Kathryn Roeder, Russell Schwartz, Eric Xing
Acknowledgments





![A Century of Discovery · chemistry, brain science, developmental biology, plant science, genomics, immunology, medicine, computer LYONZX[`_L_TZYLW^NTPYNP L]_TNTLWTY_PWWTRPYNP LYO](https://img.pdfslide.us/doc/110x75/5e788acea0d9975da768793d/a-century-of-discovery-chemistry-brain-science-developmental-biology-plant-science.jpg)