Embed Size (px)
Citation preview

LREC 2008 AWN 1
Building WordNets:The Arabic case
H. Rodríguez

LREC 2008 AWN 2
Index of the talk
• Introduction• Ontologies• Wordnets• Building wordnets• Arabic WordNet• Semi-automatic extensions of AWN

LREC 2008 AWN 3
Ontologies
• What an ontology is: (Gruber, 1993)
an ontology is an explicit specification of a conceptualization
(Studer et al, 1998)an ontology is a formal explicit specification of
a shared conceptualization

LREC 2008 AWN 4
Ontologies

LREC 2008 AWN 5
Ontologies
• lexico-conceptual ontologies Some authors simply reject this term, an
ontology is by definition conceptual and, thus, language independent (or better, language neutral)
Other authors admit that some conceptualizations are different in different languages, thus leading to different ontologies
(Barbu and Barbu-Mititelu, 2005) classify these differences as accidental, systematic and cultural.
LREC 2008 AWN 6
Ontologies

LREC 2008 AWN 7
Ontologies
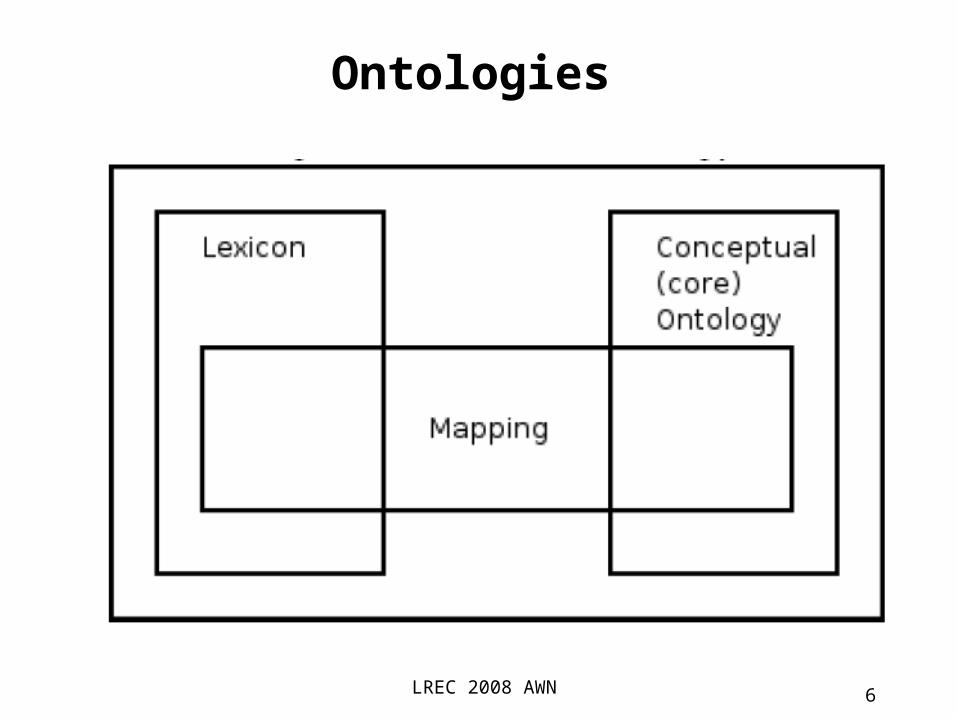
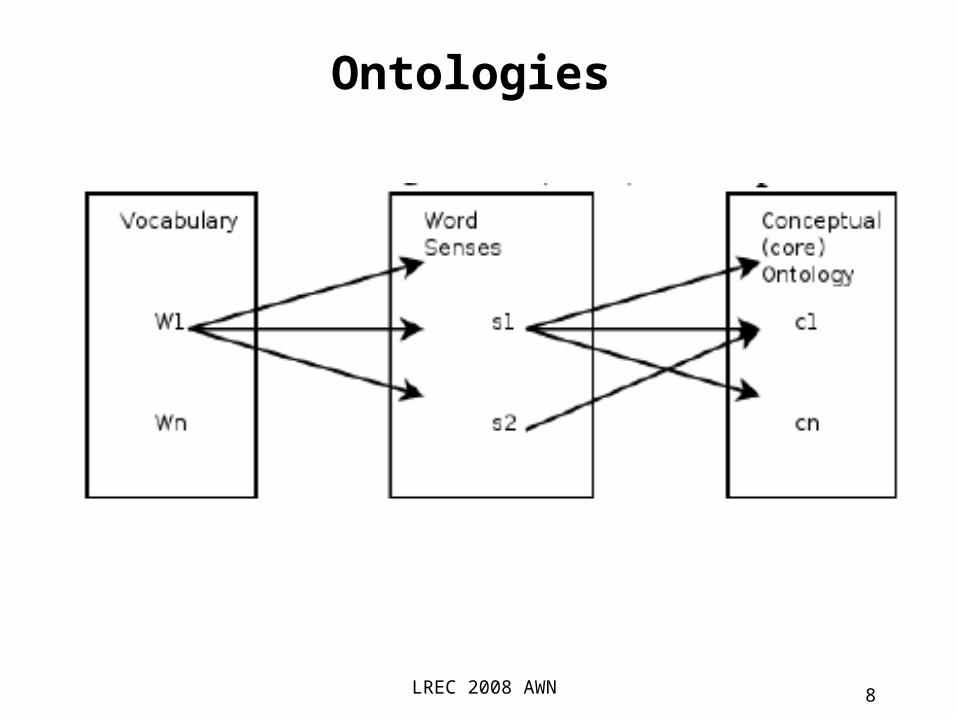
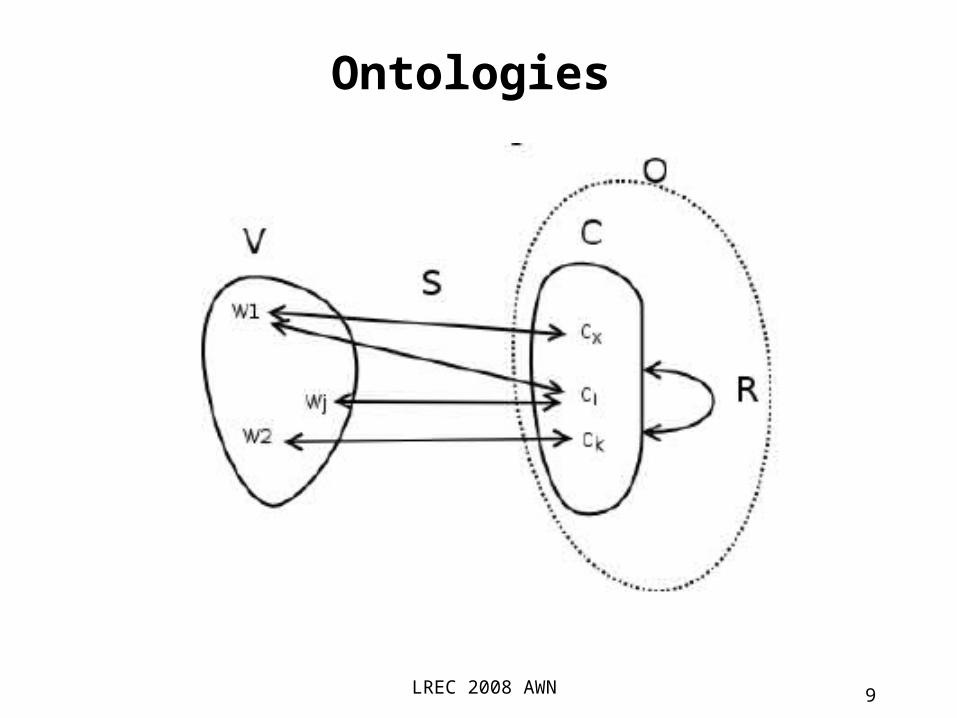
• The mapping between lexical items (words or multiwords) and concepts can be complex. Due to polysemy, most lexical items can be
mapped into more than one concept. Due to synonymy, more than one word can
be mapped to a concept.
• Usually the mapping is splitted into two steps from words into word-senses (i.e. different
word meanings) and from word-senses into concepts.
LREC 2008 AWN 8
Ontologies
LREC 2008 AWN 9
Ontologies
LREC 2008 AWN 10
Ontologies

LREC 2008 AWN 11
Ontologies
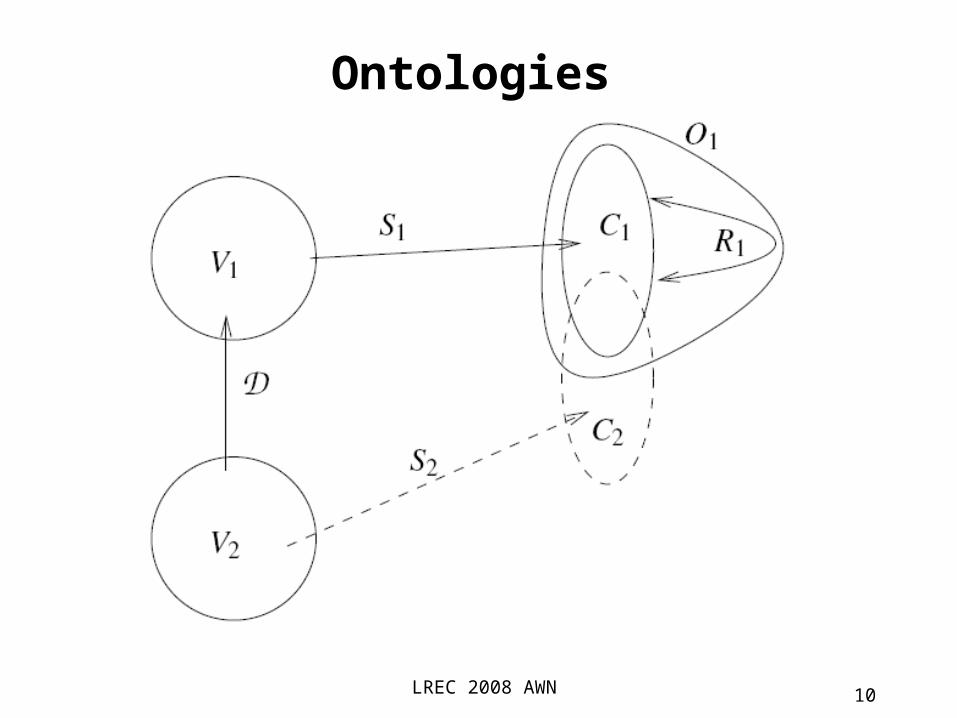
• Building lexico-conceptual ontologies This derivation process is far to be simple. for a LO, the mapping words word-senses
concepts is complex (and controversial)(Kilgarrif, 1997) arguments against the
ontological status of word-senses(Edmonds and Hirst, 2002) reduce a lot the
cases of absolute synonymy and propose, instead, modeling near-synonymy for fine-grained mapping between words and concepts).

LREC 2008 AWN 12
Wordnets
• Princeton's English WordNet (Miller et al, 1990), (Fellbaum, 1998) Semantic Information
more than 123,000 words organised in 117,000 synsets (WN3.0)
more than 235,000 relations between synsets Freely available:
http://wordnet.princeton.edu/

LREC 2008 AWN 13
Wordnets
• Princeton's English WordNet Lexicalised concepts (words, compounds,
multiwords) Synset: synonym set (of words) Large semantic net conecting synsets
synonymy, antonymy, hyperonymy, hyponymy, meronymy, implication, causation ...
StructureNoun hierarchy depth ~12Verb hierarchy depth ~3Adjective/adverb not in hierarchy, but in star
structure
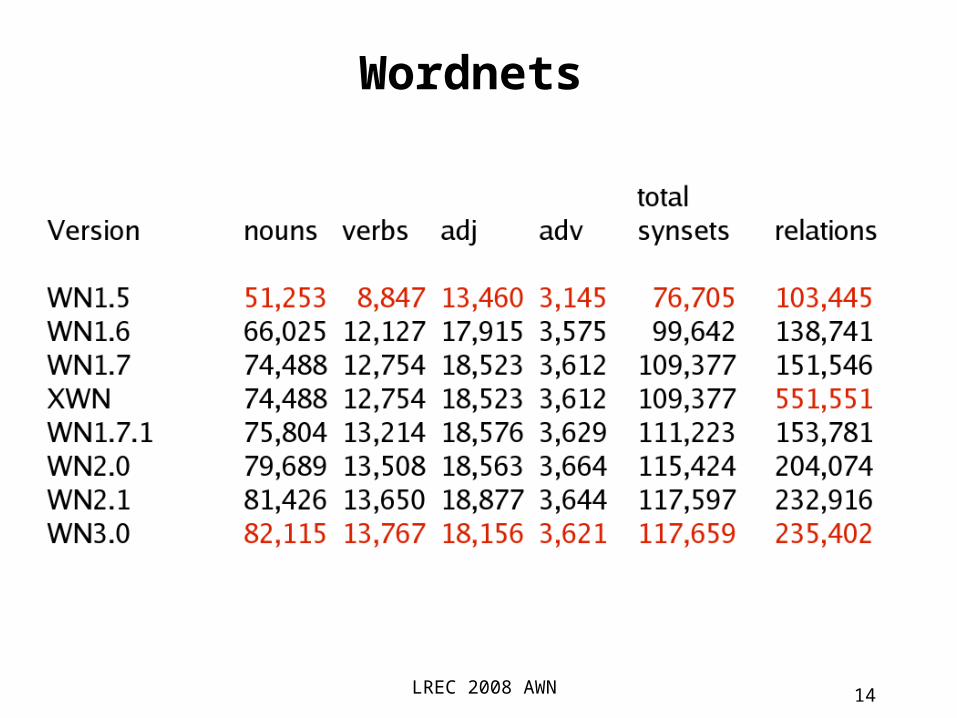
LREC 2008 AWN 14
Wordnets

LREC 2008 AWN 15
Wordnets
• Beyond WN EuroWordNet
(Vossen 98)UE funded project Integrated local wordnets in several languages
English Sheffield Dutch Amsterdam Italian Pisa Spanish UB, UPC, UNED. http://www.hum.uva.nl/~ewn/
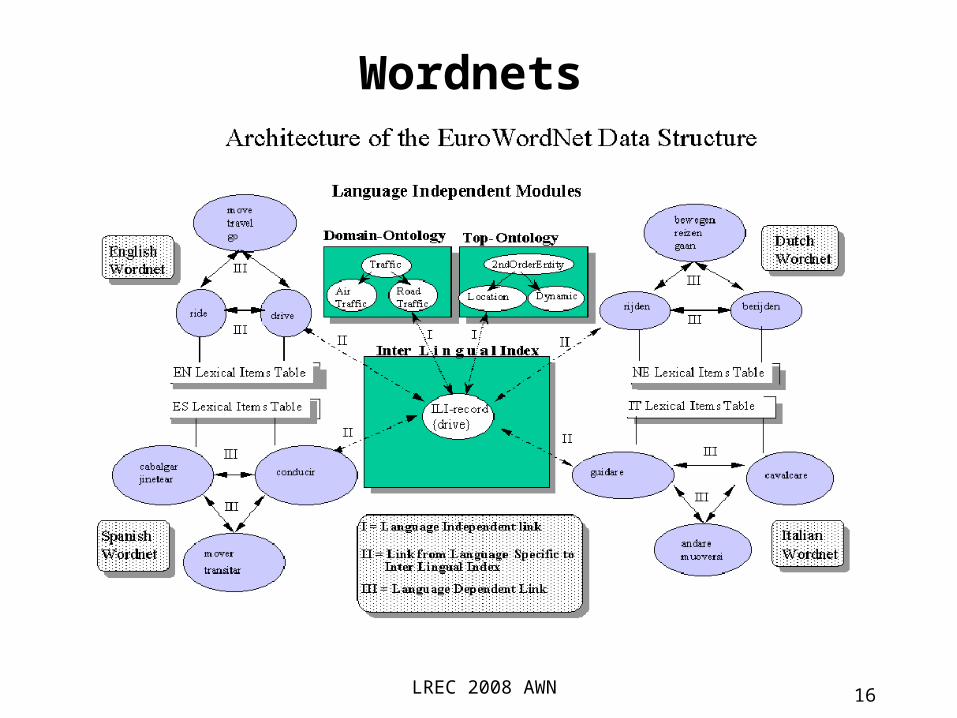
LREC 2008 AWN 16
Wordnets

LREC 2008 AWN 17
Wordnets
• Beyond WN EWN2
German (GermaNet), French, Chec, Swedish, Estonian
ITEM, CRELSpanish, Catalan, Basque (UB, UPC)
EuroTerm, Jur-WordnetExtending EWN in particular domain
BalkanetExtending EWN for the Balkan languages
HownetChinese WN

LREC 2008 AWN 18
Wordnets
• Macro Ontologies based on WN MCR Yago Omega

LREC 2008 AWN 19
Building wordnets
• Merge approach Taxonomy construction: monolingual MRDs Mapping taxonomies: bilingual MRDs
• Expand approach Translation of synsets: bilingual MRDs
• Manual revision

LREC 2008 AWN 20
Building wordnets
• EWN Building Base Concepts (BC)
supposed to be the concepts that play the most important role in different languages.
Two main criteria: A high position in the semantic hierarchy
(abstract) Having many relations to other concepts (hub)
1000 synsets Vertical expansion filling gaps and assuring
good overlapping

LREC 2008 AWN 21
Building wordnets
• EWN Spanish WN
automatic extension with human validationCombination of 17 heuristic methods
1) simple rule 2) pair wise combination 3) Logistic Regression combination
LREC 2008 AWN 22
Building wordnets
LREC 2008 AWN 23
Building wordnets
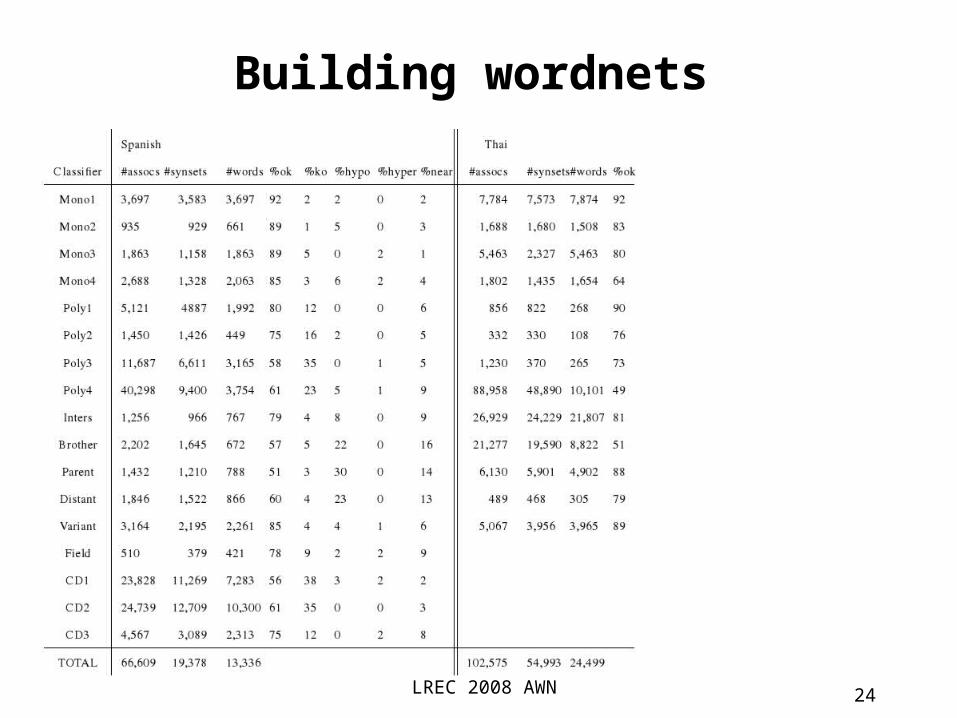
LREC 2008 AWN 24
Building wordnets

LREC 2008 AWN 25
Arabic WordNet
• USA REFLEX program funded (2005-2007) Partners:
Universities Princeton Manchester UPC (Barcelona) UB (Barcelona)
Companies Articulate Software Irion

LREC 2008 AWN 26
Arabic WordNet
• papers Introducing the Arabic WordNet Project
Black et al, 2006 Building a WordNet for Arabic
Elkateb et al, 2006 Arabic WordNet: Current State and Future
ExtensionsRodríguez et al, 2008
Arabic WordNet: Semi-automatic Extensions using Bayesian Inference
Rodríguez et al, 2008

LREC 2008 AWN 27
Arabic WordNet
• Objectives 10,000 synsets including some amount of
domain specific data linked to PWN 2.0
finally to PWN 3.0 linked to SUMO + 1,000 NE manually built (or revised) vowelized entries including root of each entry

LREC 2008 AWN 28
Arabic WordNet
• Approach described in 3rd GWC (Elkateb et al, 2006) Manually built 2 lexicographic interfaces
Manchester, Barcelona guided by automatically generated
suggestions of <Arabic word, English synset> pairs coming from bilingual resources.

LREC 2008 AWN 29
Arabic WordNet
• Approach BCs
Covering of EWN & Balkanet Base Concepts Filling gaps Building Arabic specific synsets Covering domain specific synsets Adding NEs. (Semi) automatic extensions
heuristic basedBayesian networks

LREC 2008 AWN 30
Arabic WordNet
• Resources used LOGOS database of Arabic verbs:
contains 944 fully conjugated Arabic verbs Bilingual (Arabic-English) dictionaries
NMSU bilingual Arabic-English lexicon:SalmonéUniversity of BarcelonaEffel
CorporaArabic GigaWord Corpus (from LDC)UN (2000-2002) bilingual Arabic-English
Corpus (from LDC).

LREC 2008 AWN 31
Arabic WordNet
• Representation database (implemented in MySQL) interchange format (XML) The database structure comprises four
principal entity types: item, word, form and link.

LREC 2008 AWN 32
Arabic WordNet
• Item conceptual entities, including synsets, ontology classes
and instances.• Word
word senses• Form
entity that contains lexical information (not merely inflectional variation)
roots broken plural forms
• Link relates two items, and has a type such as equivalence,
subsuming, etc. interconnect sense items, e.g., a PWN synset to an AWN
synset, a synset to a SUMO concept, etc.

LREC 2008 AWN 33
Arabic WordNet
• Current (Final ?, we hope no!!!) figures up to date statistics:
http://www.lsi.upc.edu/~mbertran/arabic/awn/query/sug_statistics.php.
23496Arabic words
11270Arabic synsets
2538v
110r
7961n
661a
DB contentpos
Named entities:
1656Words in synsets that are named entities
10028Synsets that are not named entities
1142Synsets that are named entities

LREC 2008 AWN 34
Arabic WordNet
• Software Lexicographer's Web Interface
• http://www.lsi.upc.edu/~mbertran/arabic/awn/update/synset_browse.php User's Web Interface
http://www.lsi.upc.edu/~mbertran/arabic/awn/index.html The Arabic Word Spotter
• http://www.lsi.upc.edu/~mbertran/arabic/wwwWn7/ AWN browser
http://sourceforge.net/projects/awnbrowser/ AWN to SUMO mapping including automatic
generation of Arabic paraphrases of SUMO formal axioms

LREC 2008 AWN 35
Arabic WordNet
• Ongoing research (Semi) automatic methods for enriching AWN
Heuristic-based approach GWC 2008
Bayesian Networks LREC 2008
Automatically obtaining & linking NEs using Wikipedia as Knowledge Source

LREC 2008 AWN 36
Arabic WordNet
• (Semi) automatic methods for enriching AWN key idea
In Arabic many words having a common root have related meanings and can be derived from a base verbal form by means of a reduced set of lexical rules

LREC 2008 AWN 37
Semi-automatic Extensions of AWN
• Lexical rules regular verbal derivative forms regular nominal and adjectival derivative
formsmasdar (nominal verb)masculine and feminine active and passive
participles inflected verbal forms

LREC 2008 AWN 38
Semi-automatic Extensions of AWN
• Procedure for generating a set of likely <Arabic word, English synset, score>: produce an initial list of candidate word
forms filter out the less likely candidates from this
list generate an initial list of attachments score the reliability of these candidates manually review the best scored
candidates and include the valid associations in AWN.

LREC 2008 AWN 39
Semi-automatic Extensions of AWN
• Score the reliability of the candidatesbuild a graph representing the words, synsets
and their associations associations synset-synset:
explicit in WN2.0 path-based
apply a set of heuristic rules that use directly the structure of the graph
GWC 2008apply Bayesian inference
LREC 2008
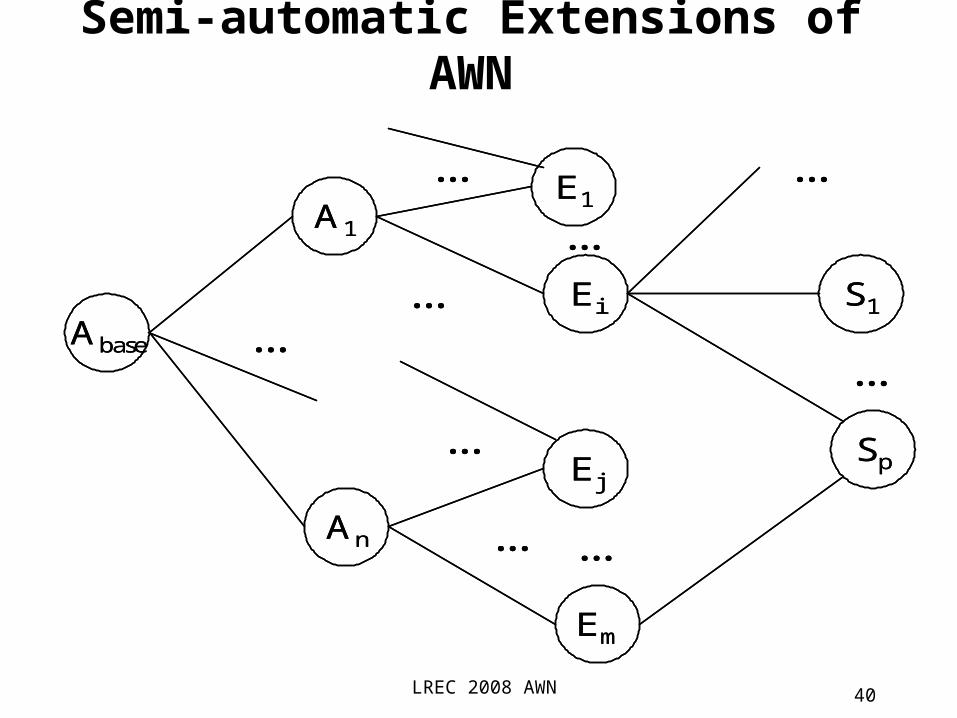
LREC 2008 AWN 40
Semi-automatic Extensions of AWN
Abase
A1
E1
An
Ej
Ei
Em
...
...
...
...
...
...
...
S1
Sp
...
...
Abase
A1
E1
An
Ej
Ei
Em
...
...
...
...
...
...
...
S1
Sp
...
...

LREC 2008 AWN 41
Using Heuristics
•When a unique path A-E-S exists (i.e., A is only translated as E), and E is monosemous (i.e., it is associated with a single synset), then the output tuple <A, S> is tagged as case 1
Using Heuristics, case 1
A E SAbase A E SA E SAbase
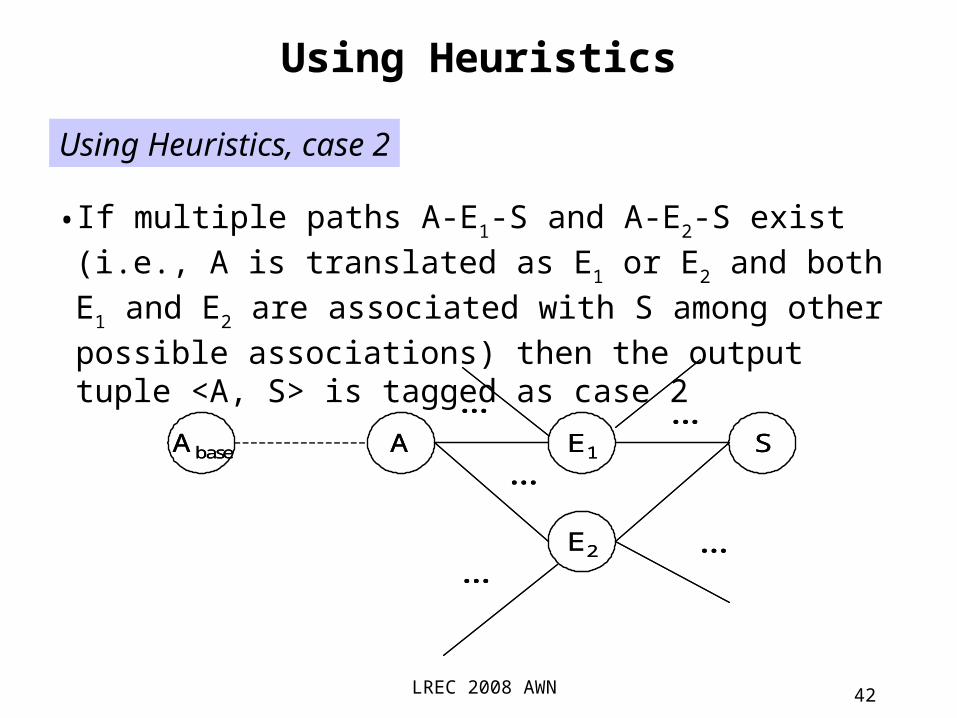
LREC 2008 AWN 42
Using Heuristics
•If multiple paths A-E1-S and A-E2-S exist (i.e., A is translated as E1 or E2 and both E1 and E2 are associated with S among other possible associations) then the output tuple <A, S> is tagged as case 2
Using Heuristics, case 2
A E1 SAbase
E2
...
...
...
...
...
A E1 SAbase
E2
...
...
...
...
...
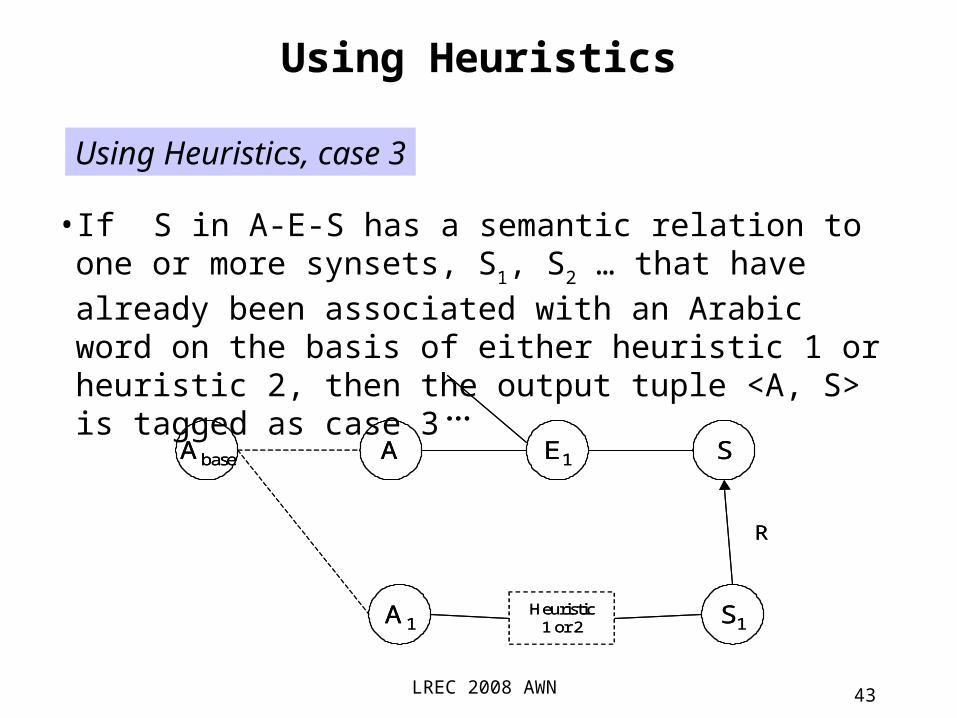
LREC 2008 AWN 43
Using Heuristics
•If S in A-E-S has a semantic relation to one or more synsets, S1, S2 … that have already been associated with an Arabic word on the basis of either heuristic 1 or heuristic 2, then the output tuple <A, S> is tagged as case 3
Using Heuristics, case 3
A E1 SAbase
...
A1 S1
R
Heuristic1 or 2
A E1 SAbase
...
A1 S1
R
Heuristic1 or 2

LREC 2008 AWN 44
Using Heuristics
•If S in A-E-S has some semantic relation with S1, S2 … where S1, S2 … belong to the set of synsets that have already been associated with related Arabic words, then the output tuple <A-S> is tagged as case 4. In this case there is only one translation E of A but more than one synset associated with E. This heuristic can be sub-classified by the number of input edges or supporting semantic relations (1, 2, 3, ...).
Using Heuristics, case 4
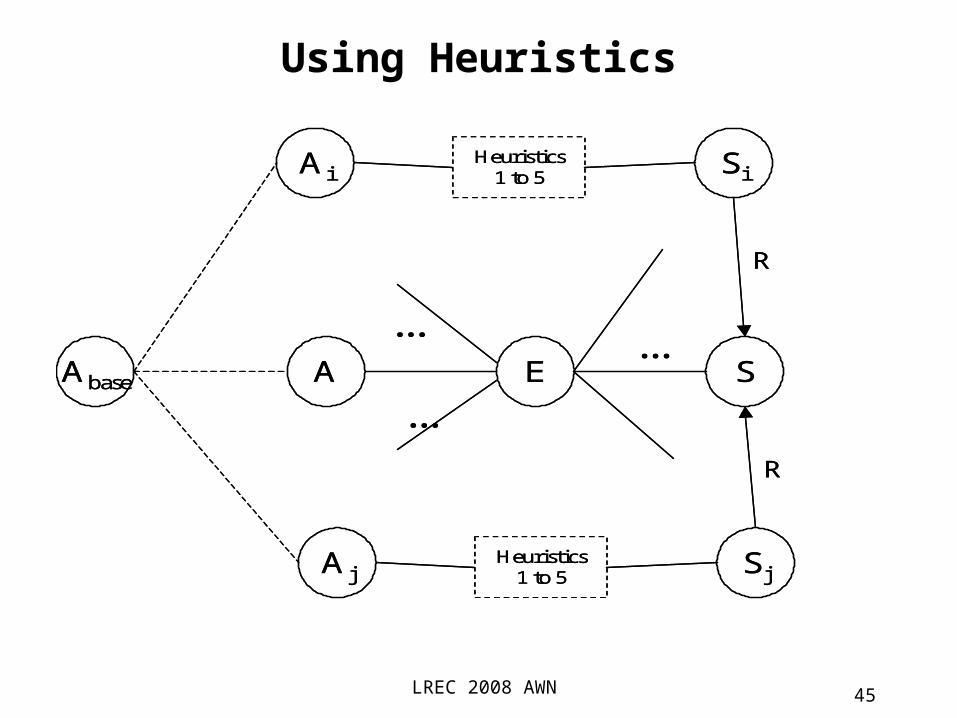
LREC 2008 AWN 45
Using Heuristics
A E SAbase
...
Aj Sj
R
Heuristics1 to 5
Ai Si
R
Heuristics1 to 5
...
...A E SAbase
...
Aj Sj
R
Heuristics1 to 5
Ai Si
R
Heuristics1 to 5
...
...

LREC 2008 AWN 46
Using Heuristics
•Heuristic 5 is the same as heuristic 4 except that there are multiple translations E1, E2, … of A and, for each translation Ei, there are possibly multiple associated synsets Si1, Si2, …. In this case the output tuple <A-S> is tagged as case 5 and again the heuristic can be sub-classified by the number of input edges or supporting semantic relations (1, 2, 3 ...).
Using Heuristics, case 5
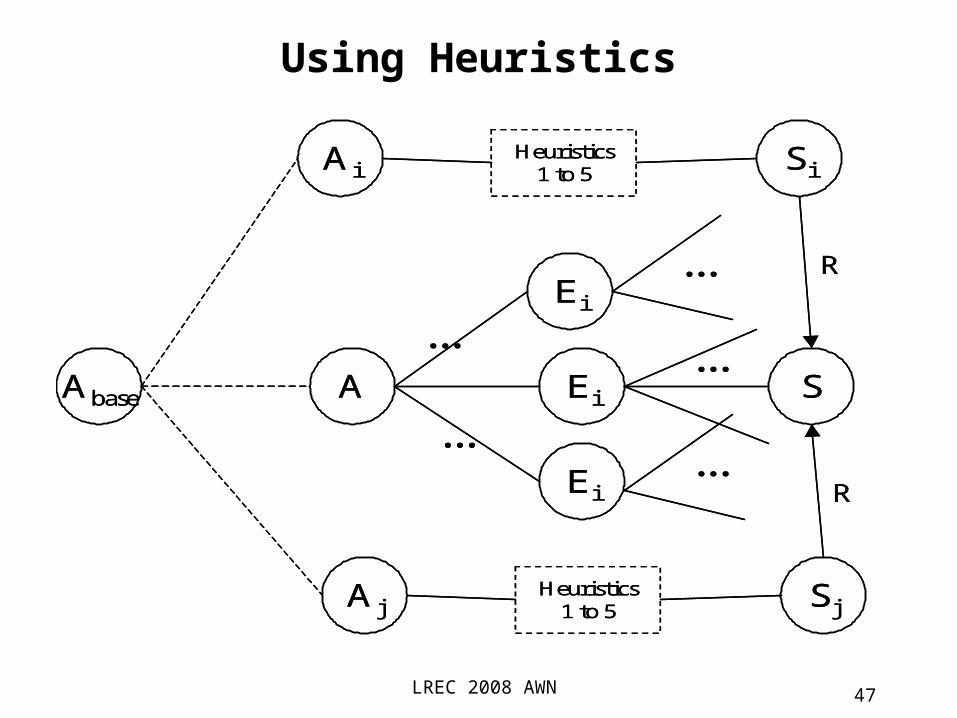
LREC 2008 AWN 47
Using Heuristics
A Ei SAbase
...
Aj Sj
R
Heuristics1 to 5
Ai Si
R
Heuristics1 to 5
...
...
Ei
Ei
...
...
A Ei SAbase
...
Aj Sj
R
Heuristics1 to 5
Ai Si
R
Heuristics1 to 5
...
...
Ei
Ei
...
...
LREC 2008 AWN 48
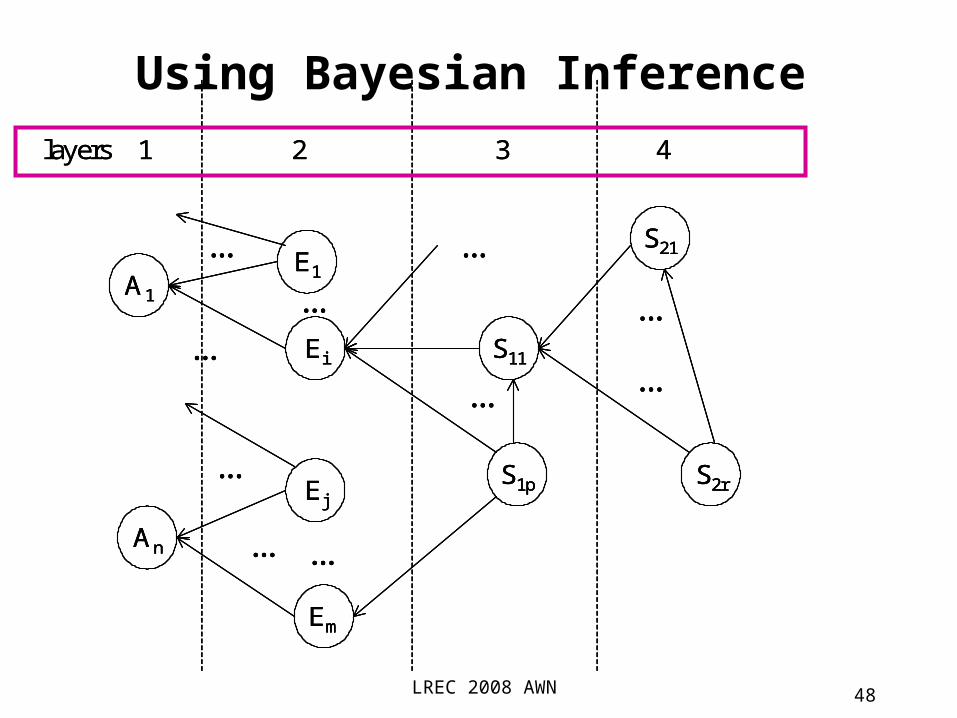
Using Bayesian Inference
A1
E1
An
Ej
Ei
Em
...
...
...
...
...
...
S11
S1p
...
...
S2r
...
...
S21
layers 1 2 3 4
A1
E1
An
Ej
Ei
Em
...
...
...
...
...
...
S11
S1p
...
...
S2r
...
...
S21
A1
E1
An
Ej
Ei
Em
...
...
...
...
...
...
S11
S1p
...
...
S2r
...
...
S21
layers 1 2 3 4

LREC 2008 AWN 49
Using Bayesian Inference
• Building the CPT for each node in the BN edges EW AW
probabilities from statistical translation models built from the UN corpus using GIZA++ (word-word probabilities) filtered to avoid pairs having Arabic expressions with invalid Buckwalter encodings.
all the mass probability is distributed between pairs occurring in the BN
other edges (EW S, S S)linear distribution on priorsnoisy or model

LREC 2008 AWN 50
Using Bayesian Inference
• Performing Bayesian Inference in the BN Assign probability 1 to nodes in layer 1 Infer the probabilities of nodes in layer 3 Select for each word in layer 1 select as
candidates the synsets in layer 3 connected to it and with probability over a threshold
Score the candidate pair with this probability
Select the candidates scored over a threshold

LREC 2008 AWN 51
Empirical Evaluation
• 10 verbs randomly selected from AWN + درس
Arabic verb # English Words # Synsets (S1 S2) ام]ل] 190 107 ع]
ب ]عbق] 77 71 ]أل] ق] 21 31 ص]ب] f ت 102 62 ر]
ر] fخ[ أ 19 9
ر] [ ب bخ[ أ 80 105 ح] fش ر] 40 22
ام]ر] غ] 56 49 ع [ ب bش[ 34 38 أج] ر] bخ[ أ 85 140
س] f51 57 د]ر
LREC 2008 AWN 52
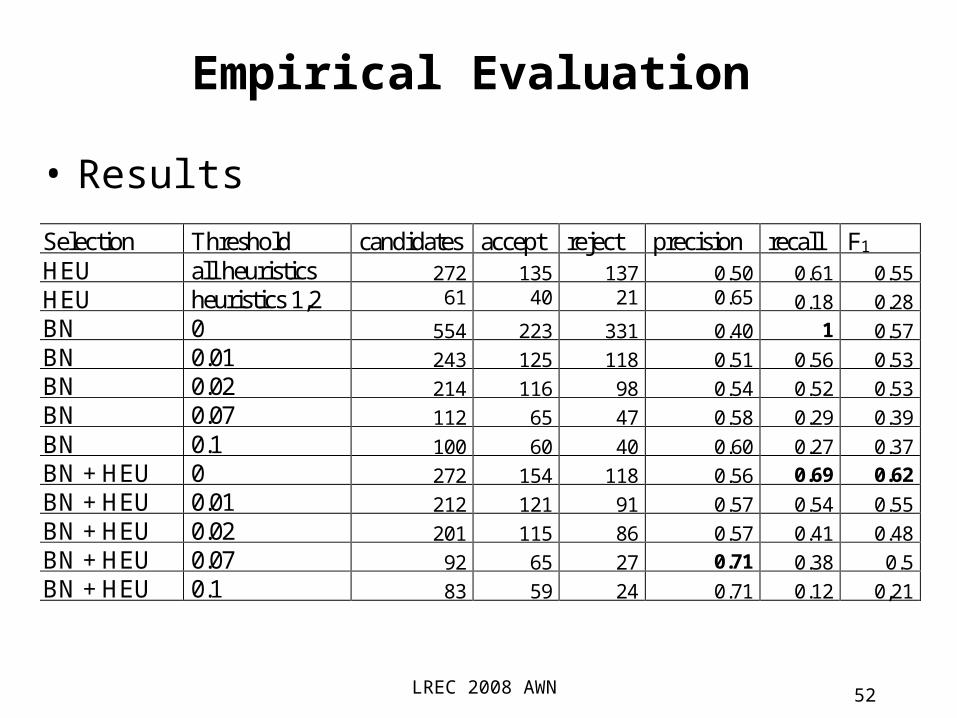
Empirical Evaluation
• ResultsSelection Threshold candidates accept reject precision recall F1 HEU all heuristics 272 135 137 0.50 0.61 0.55 HEU heuristics 1,2 61 40 21 0.65 0.18 0.28 BN 0 554 223 331 0.40 1 0.57 BN 0.01 243 125 118 0.51 0.56 0.53 BN 0.02 214 116 98 0.54 0.52 0.53 BN 0.07 112 65 47 0.58 0.29 0.39 BN 0.1 100 60 40 0.60 0.27 0.37 BN + HEU 0 272 154 118 0.56 0.69 0.62 BN + HEU 0.01 212 121 91 0.57 0.54 0.55 BN + HEU 0.02 201 115 86 0.57 0.41 0.48 BN + HEU 0.07 92 65 27 0.71 0.38 0.5 BN + HEU 0.1 83 59 24 0.71 0.12 0,21

LREC 2008 AWN 53
Results
• Using HEU + BN (threshold 0.07) precision 0.71 65 accepted candidates from 92 proposed
average 65/11 6 extrapolating the results to the set of AWN
verbs (>2,500) lead to 15,000 new synsets from 20,000 candidates

LREC 2008 AWN 54
Conclusions
• the BN approach doubles the number of candidates of the previous HEU approach (554 vs 272).
• The sample is clearly insufficient.• The overlaping of Heu + BN seems to
improve the results• An analysis of the errors shows a
substantial number were due to the lack of the shadda diacritic or the feminine ending form (ta marbuta, ة).

LREC 2008 AWN 55
Future work
• Repeat the entire procedure relying when possible on dictionaries containing diacritics
• Refine the scoring procedure by assigning different weights to the different relations.
• Include additional relations (e.g. path-based)
• Use additional Knowledge Sources for weighting the relations: related entries already included in AWN SUMO Magnini's domain codes

LREC 2008 AWN 56
Thank you for your attention





























