Embed Size (px)
Citation preview

Longneck Data Integration an open source data quality tool
MTA SZTAKI
Business Intelligence and Data Warehousing Group
Csaba Sidló [email protected]
http://longneck.sztaki.hu
http://dms.sztaki.hu http://bigdatabi.sztaki.hu
2013. november 6.

MTA SZTAKI Informatics Lab
• from research to applications o data mining, machine learning, search technologies, business
intelligence, data warehousing, social networks, bioinformatics
o „Big Data”:
• Web, social media analytics and search
• smart city, mobility
• sensor data (eg. wind turbines), log data
• dedicated groups: „Momentum – Big Data”, „Big Data Business Intelligence” (partner: SZTAKI EMI)

Longneck history
• our tasks:
o client-centric data warehouse
o Web server + IT infrastructure log analytics
o processing sensor data
• solutions:
o custom scripts 2005
o „Giraffe ETL” 2009
• compiling Java code for processes!
• open source: 2010
o new generation ETL tool
o Longneck: Java data quality tool
• open source: 2013
Gábor Lukács Péter Molnár
András Molnár Péter Neumark Tibor Németh
…
http://longneck.sztaki.hu https://github.com/MTA-SZTAKI/longneck-*

„Yet Another ETL Tool”?
• Own tool?
o needed in many projects
o now: I would choose Longneck
o many years earlier:
• no Longneck, but
• Pentaho Kettle:
o slow (with the simplest test: copying a one-column file)
• commercial tools (eg. IBM Quality Stage, SAP, SAS, …)
o expensive, not flexible enough for us / not available as a standalone tool
• we couldn’t implement our transformations in good quality!
• Free and open source?
o the transformation rules are much more valuable then the framework!
• formulating rules based on domain knowledge must be easy
o can evolve without us
„BI that avoids ETL processes entirely”
“If any of the existing ETL frameworks are
not powerful enough, build your own!”
“Don’t build your own ETL framework”
“STAY AWAY from scripting languages”
„ETL is a methodology, not a tool”

ETL / Data Integration / Quality Tool / …
• heterogeneous, overlapping definitions; problems are hard to generalize
• Gartner „Data Quality Tools Magic Quadrant”, upper right corner („leaders”): o Informatica, SAS/DataFlux, Trillium Software, SAP, IBM o Open Source tools?
• eg.: Talend – they began appearing in reports after complaining
our related tools:
• entity resolution (matching, deduplication)
• job management for ETL and DW maintenance functions
• reporting, analytics, visualization

Data Quality: the problem
• „Data Quality Tool” (Gartner):
o Parsing and standardization
o Generalized cleansing
o Matching
o Profiling
o Monitoring
o Enrichment
• our expectations of a good data quality solution:
o fast, handles large data sets!
o accurate!
o robust!
o easy to develop!
o reusable!
o …
[email protected] empty
[email protected] [email protected] | maik |
szarvnet | hu | Hungary
wwwcsomosmp@hu indicate error: „invalid e-
mail address(es).”
[email protected] ; [email protected]
split to two valid addresses
eg.: email address
o rapid, cost effective projects!
o cheap, reliable support!
o maintainable codes!
o handles data error „well”!
o easy to deploy!
o …

Data vs. software quality
• quality of the framework quality of data transformation rules data quality
• properties of a good solution (as a software engineer): o simplicity, size of code,
o reliability, security, information security,
o measurability, traceability,
o reusability, maintainability, modularity, portability
o rich, accessible quality documentation (price of the experts),
o testability
o efficiency, scalability, speed
o …
• Do existing tools fulfill these? For what price?
”all of these tools look pretty nice in a pilot”
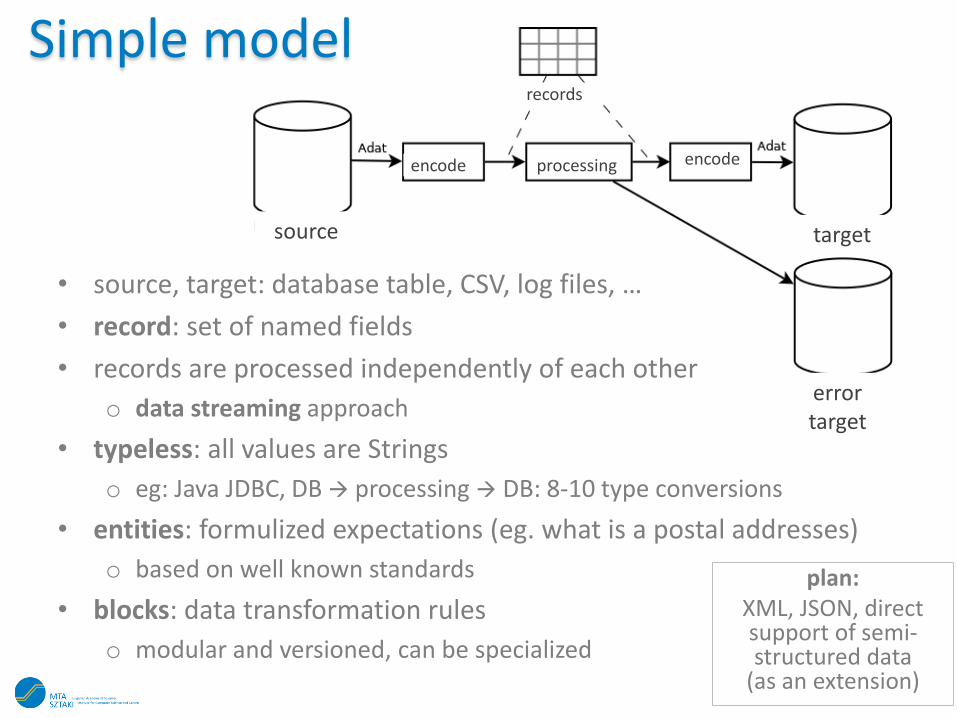
Simple model
• source, target: database table, CSV, log files, …
• record: set of named fields
• records are processed independently of each other
o data streaming approach
• typeless: all values are Strings
o eg: Java JDBC, DB processing DB: 8-10 type conversions
• entities: formulized expectations (eg. what is a postal addresses)
o based on well known standards
• blocks: data transformation rules
o modular and versioned, can be specialized
plan: XML, JSON, direct support of semi-structured data
(as an extension)
processing
source target
error target
records
encode encode

Repository
• eg.: the horror of a broken closed format repository
• Longneck: XML
<process xmlns="urn:hu.sztaki.ilab.longneck:1.0">
<source>
<weblog-file-source name="cli" />
</source>
<target>
<csv-target target="out.csv"/>
</target>
<blocks>
<block-ref id="weblogparser:parse"/>
<if>
<is-null apply-to="virtualServer"/>
<then>
<copy apply-to="virtualServer"
from="requestUrlHost"/>
</then>
</if>
<check summary="virtualServer must not be null.">
<not-null apply-to="virtualServer"/>
</check>
</blocks>
</process>
• versioning: built in + GIT
• supports collaborative work
• reusable, modular:
o embedded blocks
o specializable
o extendible
• subject-oriented
• open standards, coding conventions

Repository 2.
• still a bit too lengthy (in 2013): domain specific language, eg. Groovy
• we will implement this alternative
process {
source {
weblog-file-source "cli"
}
target {
csv-target "out.csv"
}
blocks {
block-ref "weblogparser:parse”
if (is-null „virtualServer") {
copy from: "requestUrlHost" to: "virtualServer"
}
check summary: "virtualServer must not be null." {
not-null "virtualServer"
}
}
}
• Longneck is easy to extend!
• other examples:
o lookup dictionary
o DNS resolver
o GeoIP
o BDB persistence
o log-parser
o identification of unique
o GeoLocation
o …

Operations
• join, sorting, group by: SQL DB, Hadoop stb. o they are good in these!
o unnecessary to build a layer above, eg. SQL is a nice, declarative, efficient language
• control structures: sequence, blocks, if-then, case, …
• replace, match, regexp and other usual string operators
• dictionary-based replacing, checks, …
Existing transformation rule sets • name, company name, tax marking, social security number, sex, … • postal address, geolocation, phone number, email address, … • events and concepts of web analytics; http request, URL, user agent, IP
address, … • events, entities and attributes of application log • sensor data (eg. wind farm, location - smart city)
<source>
<database-source connection-name="client-db" />
<query>
select *
from p1_client c1
join p2_client c2 on (c1.id=c2.id)
</query>
</database-source>
</source>

Robustness, error handling
• Longneck: a survivor! – processes always finish
o data error: local effect
o adjustable levels of detailed logging testing, error detection
target:
error target:
„do not let your ETL layer to corrupt or push wrong data into destination data layer”
name tax_marking address phone
Sidló Csaba Dr 11111111 1111 Bp Kende 13-17 XA (20)39323872
Dr. Sidló Csaba 1111, Budapest, Kende,
utca, 13-17
postal-address 1 Address error. 1111 Bp Kende 13-17 XA
house-number-
unit
2 Address err.: invalid house
number unit.
XA
phone 1 Phone num. err. (20)39323872
phone-number 2 Phone num. err.: invalid number. 39323872

Testing, measurement
• size of input and output, number of errors, running time, …
• simple and proven testing methods
o testing processing blocks: should be easy to try with single input values – will have a command line method
GUI • No GUI yet. Do we need one?
• would be good; the business part needs easy to interpret representation
• however, the XML repo cannot be omitted:
o rapid editions, accurate, easy to deploy etc.
o eg.: can be challenging to modify 100 steps of a process using a mouse
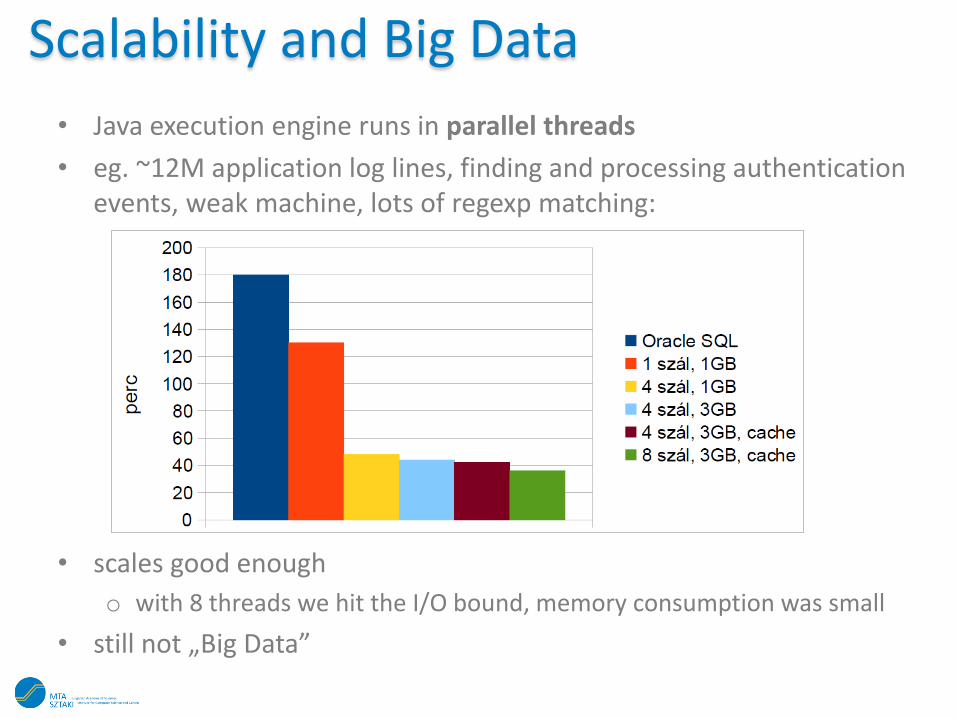
Scalability and Big Data
• Java execution engine runs in parallel threads
• eg. ~12M application log lines, finding and processing authentication events, weak machine, lots of regexp matching:
• scales good enough
o with 8 threads we hit the I/O bound, memory consumption was small
• still not „Big Data”

Longneck-Storm
• Hadoop: batch processing
o easy to implement, but no Longneck execution engine yet
• Storm: real time stream processing
o deploys to clusters automatically
o guaranteed data processing
• Longneck-Storm:
o simple Longneck adaptation to Storm
• eg. Web server log
o 32 old machines
o input: memory
o near-linear!

Entity resolution (deduplication)
• Truly, how many customers do we have?
• duplicates groups of records
• Longneck + entity resolution: very powerful combination
• other tools: up to ~10M records • Hadoop: batch,
Strom: real-time implementations VLDB konf., 2011,
Quality in Databases Workshop

Csaba Sidló
http://longneck.sztaki.hu -- easy to try!
http://dms.sztaki.hu
http://bigdatabi.sztaki.hu
2013. 11. 06 BI Fórum 2013 Open Analytics nap










![DataFlux Expression Language Reference Guide for dfPower ... · ICU License - ICU 1.8.1 and later [used in DataFlux Data Management Platform] ... DataFlux Expression Language Reference](https://img.pdfslide.us/doc/110x75/5b02004f7f8b9a65618e9467/dataflux-expression-language-reference-guide-for-dfpower-license-icu-181.jpg)


















